
1. Введение
This codelab will guide you through using Spanner's AI and graph capabilities to enhance an existing retail database. You'll learn practical techniques for utilizing machine learning within Spanner to better serve your customers. Specifically, we'll implement k-Nearest Neighbors (kNN) and Approximate Nearest Neighbors (ANN) to discover new products that align with individual customer needs. You will also integrate an LLM to provide clear, natural-language explanations for why a specific product recommendation was made.
Beyond recommendation, we'll dive into Spanner's graph functionality. You'll use graph queries to model relationships between products based on customer purchase history and product descriptions. This approach allows for discovering deeply related items, significantly improving the relevance and effectiveness of your "Customers also bought" or "Related items" features. By the end of this codelab, you will have the skills to build an intelligent, scalable, and responsive retail application powered entirely by Google Cloud Spanner.
Сценарий
Вы работаете в компании, занимающейся розничной продажей электронного оборудования. На вашем сайте электронной коммерции используется стандартная база данных Spanner, содержащая Products , Orders и OrderItems .
Клиент заходит на ваш сайт с конкретной потребностью: «Я хотел бы купить высокопроизводительную клавиатуру. Иногда я занимаюсь программированием на пляже, поэтому она может намокнуть».
Ваша задача — использовать расширенные возможности Spanner для интеллектуального ответа на этот запрос:
- Поиск: Выйдите за рамки простого поиска по ключевым словам и найдите товары, описания которых семантически соответствуют запросу пользователя, используя векторный поиск.
- Объяснение: Используйте LLM для анализа наиболее подходящих вариантов и объясните, почему данная рекомендация является удачной, тем самым укрепляя доверие клиентов.
- Relate: Используйте запросы к графу, чтобы найти другие товары, которые покупатели часто приобретали вместе с этой рекомендацией.
2. Прежде чем начать
- Создание проекта. В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Включите выставление счетов. Убедитесь, что выставление счетов включено для вашего облачного проекта. Узнайте, как проверить, включено ли выставление счетов для проекта .
- Активация Cloud Shell. Активируйте Cloud Shell, нажав кнопку «Активировать Cloud Shell» в консоли. Вы можете переключаться между терминалом Cloud Shell и редактором.

- Авторизация и настройка проекта. После подключения к Cloud Shell убедитесь, что вы прошли аутентификацию и что проект настроен на ваш идентификатор проекта.
gcloud auth list
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки, заменив
<PROJECT_ID>на фактический идентификатор вашего проекта:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Включите необходимые API. Включите API Spanner, Vertex AI и Compute Engine. Это может занять несколько минут.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Установите несколько переменных среды, которые вы будете использовать повторно.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Если у вас еще нет экземпляра Spanner , создайте бесплатную пробную версию . Вам понадобится экземпляр Spanner для размещения базы данных. В качестве конфигурации мы будем использовать
regional-us-central1. При желании вы можете изменить ее.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Архитектурный обзор
Spanner включает в себя весь необходимый функционал, за исключением моделей, которые размещены на платформе Vertex AI.
4. Шаг 1: Настройте базу данных и отправьте свой первый запрос.
Для начала нам нужно создать базу данных, загрузить наши тестовые данные о розничной торговле и указать Spanner, как взаимодействовать с Vertex AI.
Для этого раздела вы будете использовать приведенные ниже SQL-скрипты.
- Перейдите на страницу продукта Spanner.
- Выберите правильный экземпляр.
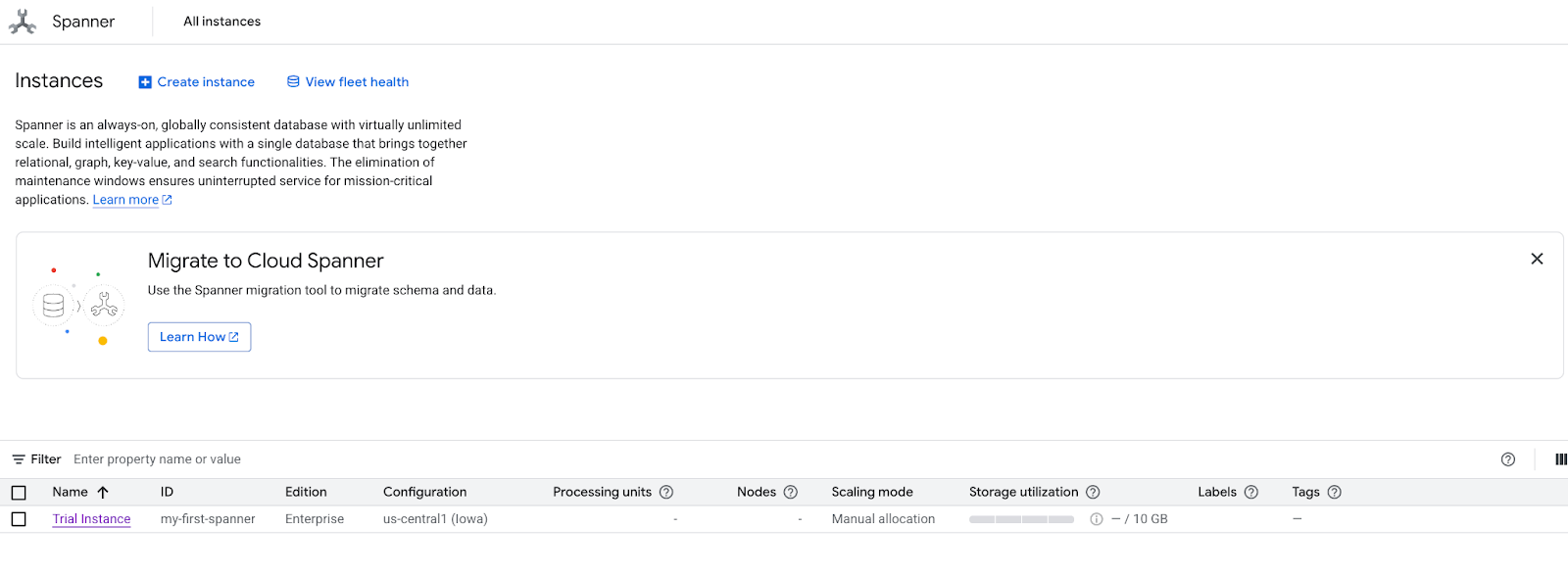
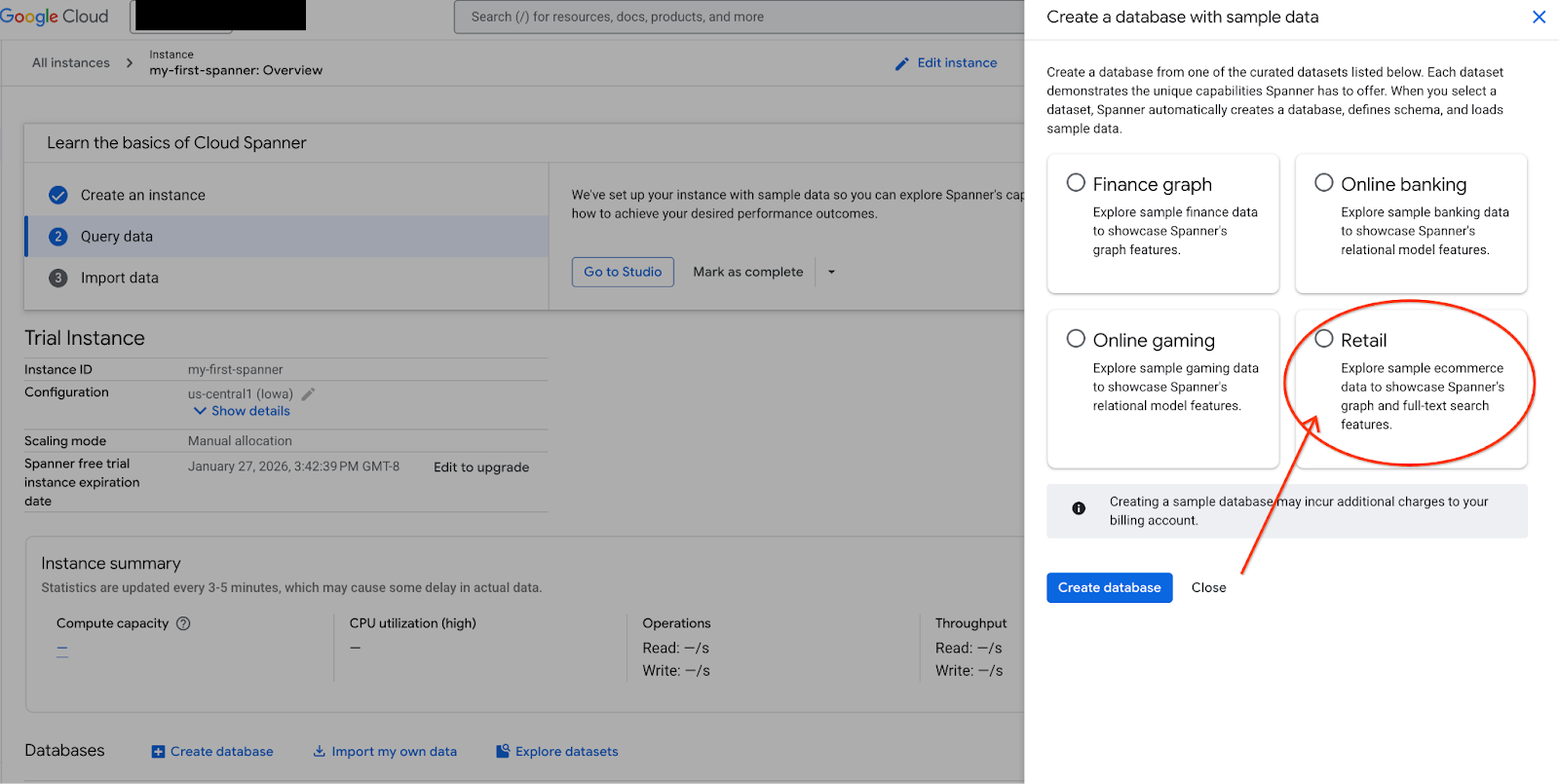
- На экране выберите «Изучить наборы данных». Затем во всплывающем окне выберите пункт «Розничная торговля».
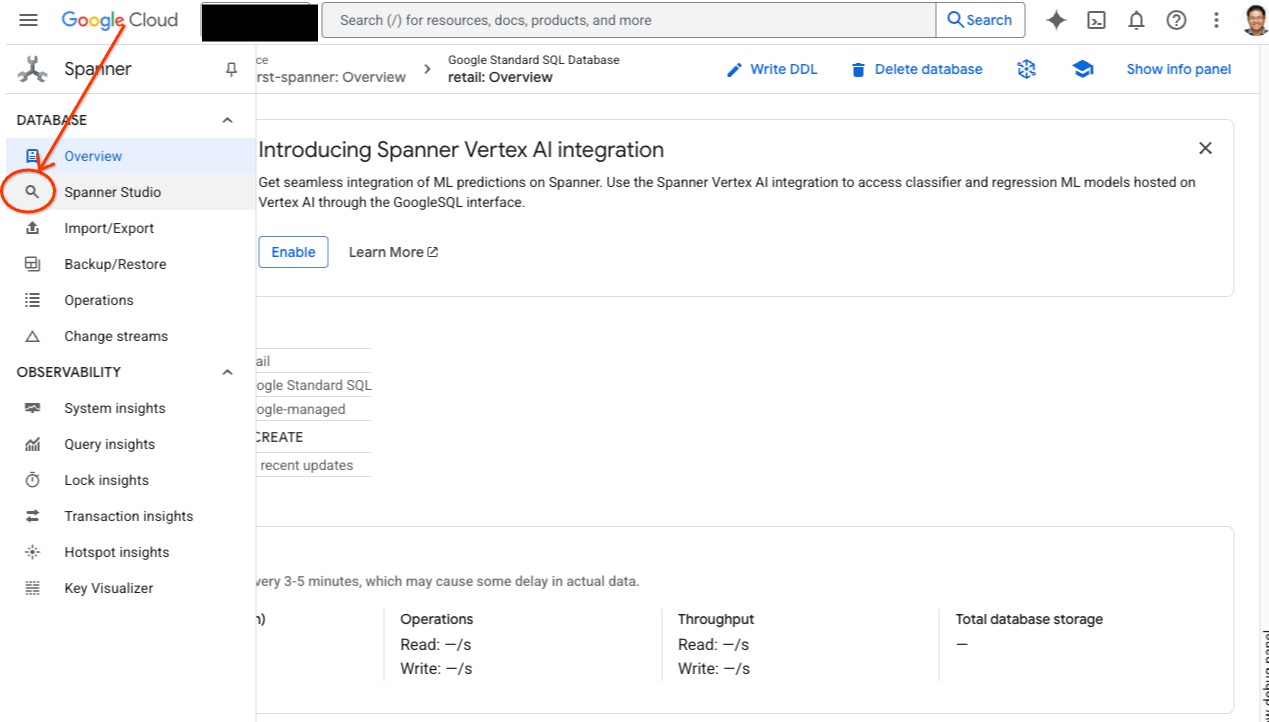
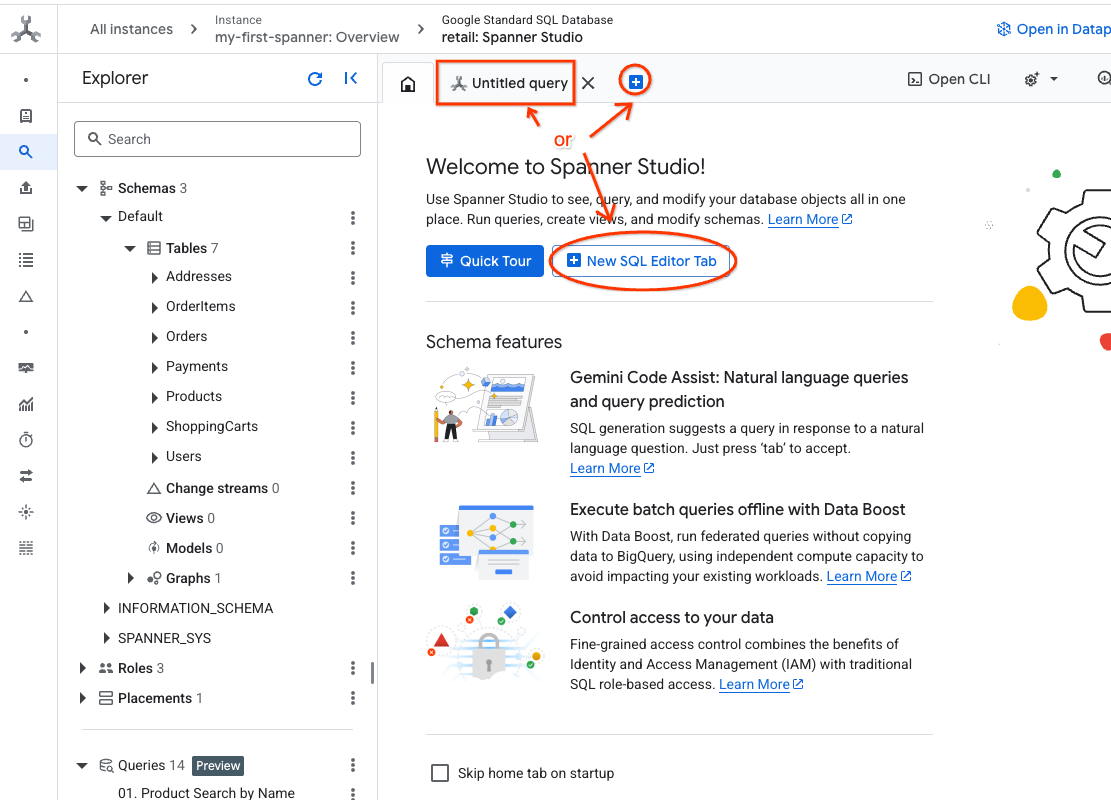
- Перейдите в Spanner Studio. Spanner Studio включает в себя панель «Проводник», которая интегрирована с редактором запросов и таблицей результатов SQL-запросов. Вы можете выполнять операторы DDL, DML и SQL из этого единого интерфейса. Вам нужно будет развернуть меню сбоку, найдите значок лупы.
- Прочитайте таблицу «Продукты». Создайте новую вкладку или воспользуйтесь уже созданной вкладкой «Безымянный запрос».
SELECT *
FROM Products;
5. Шаг 2: Создание моделей ИИ.
Теперь давайте создадим удалённые модели с помощью объектов Spanner. Эти SQL-запросы создают объекты Spanner, которые связываются с конечными точками Vertex AI.
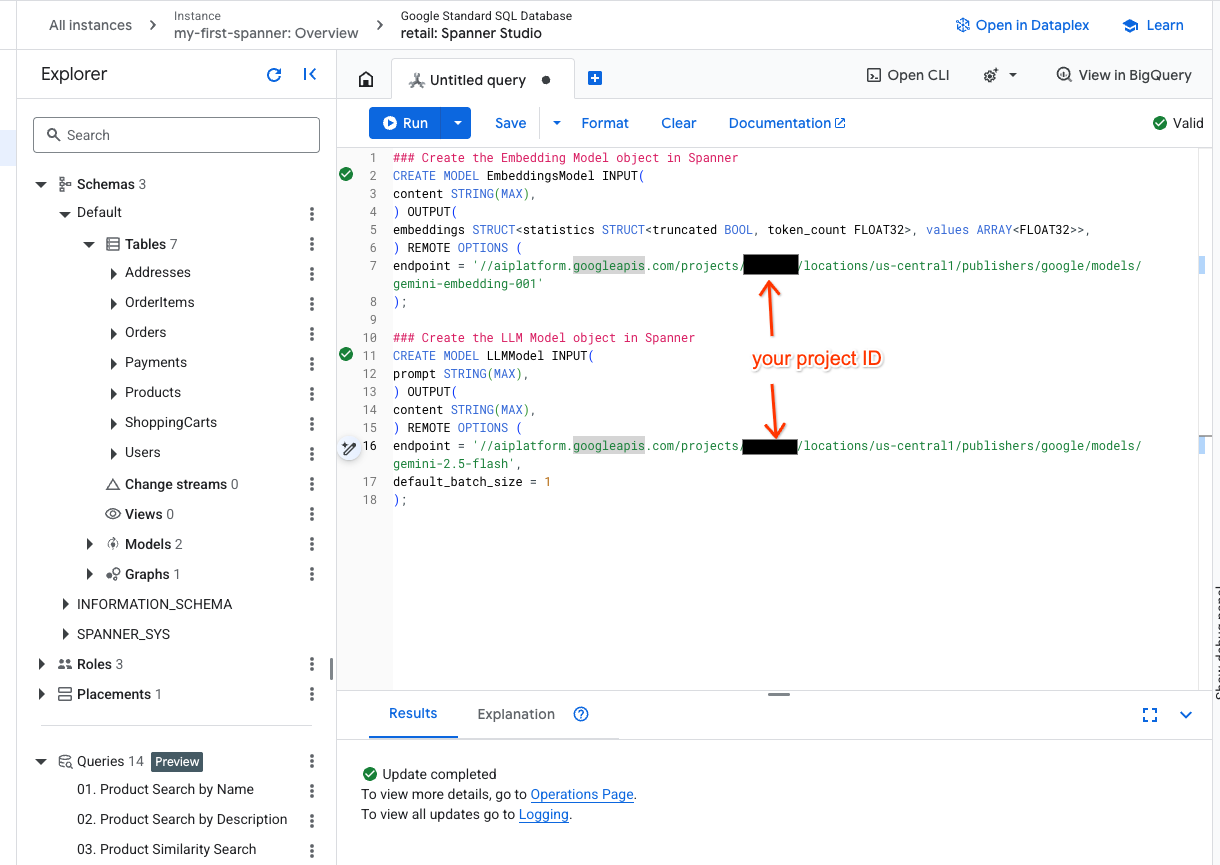
- Откройте новую вкладку в Spanner Studio и создайте две модели. Первая — EmbeddingsModel, которая позволит вам генерировать эмбеддинги. Вторая — LLMModel, которая позволит вам взаимодействовать с LLM (в нашем примере это gemini-2.5-flash). Убедитесь, что вы обновили <PROJECT_ID>, указав идентификатор вашего проекта.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Примечание: Не забудьте заменить
PROJECT_IDна ваш фактический$PROJECT_ID.
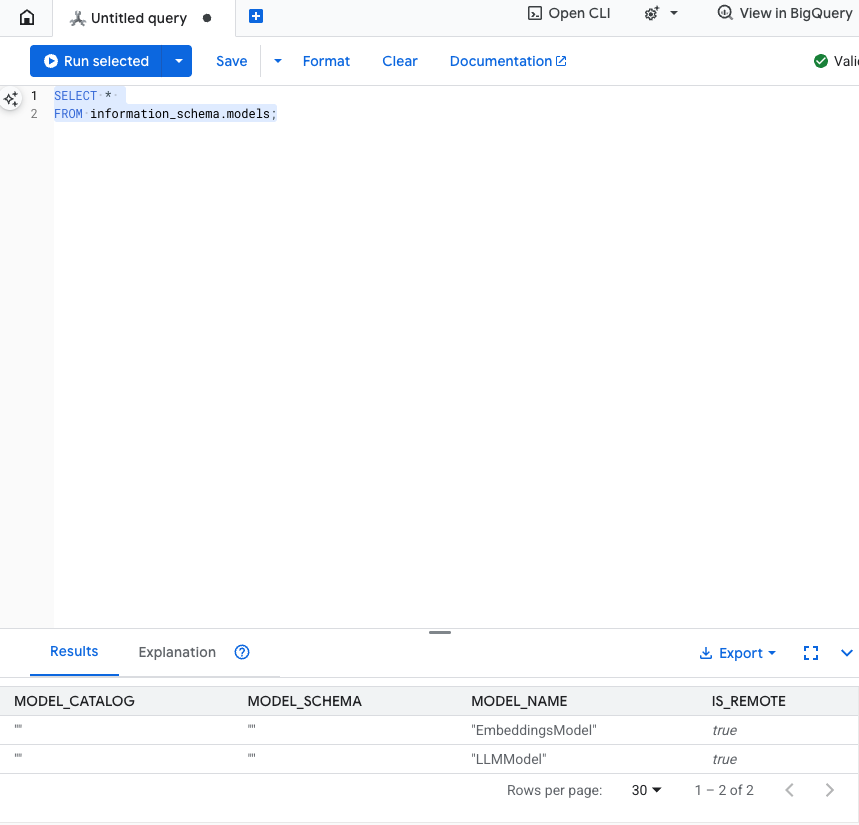
Проверьте этот шаг: Вы можете убедиться в создании моделей, выполнив следующую команду в редакторе SQL.
SELECT *
FROM information_schema.models;
6. Шаг 3: Создание и сохранение векторных представлений
В нашей таблице товаров содержатся текстовые описания, но модель ИИ понимает векторы (массивы чисел). Нам нужно добавить новый столбец для хранения этих векторов, а затем заполнить его, обработав все описания товаров с помощью модели EmbeddingsModel.
- Создайте новую таблицу для поддержки векторных представлений. Сначала создайте таблицу, которая может поддерживать векторные представления. Мы используем другую модель векторных представлений, отличную от модели векторных представлений в примере таблицы продуктов. Необходимо убедиться, что векторные представления были сгенерированы из одной и той же модели, чтобы векторный поиск работал корректно.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Заполните новую таблицу эмбеддингами, сгенерированными моделью. Для простоты мы используем оператор INSERT INTO. Это позволит записать результаты запроса в только что созданную таблицу.
SQL-запрос сначала извлекает и объединяет все соответствующие текстовые столбцы, для которых мы хотим создать векторные представления. Затем мы возвращаем необходимую информацию, включая использованный текст. Обычно это не обязательно, но мы включаем это для наглядности результатов.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
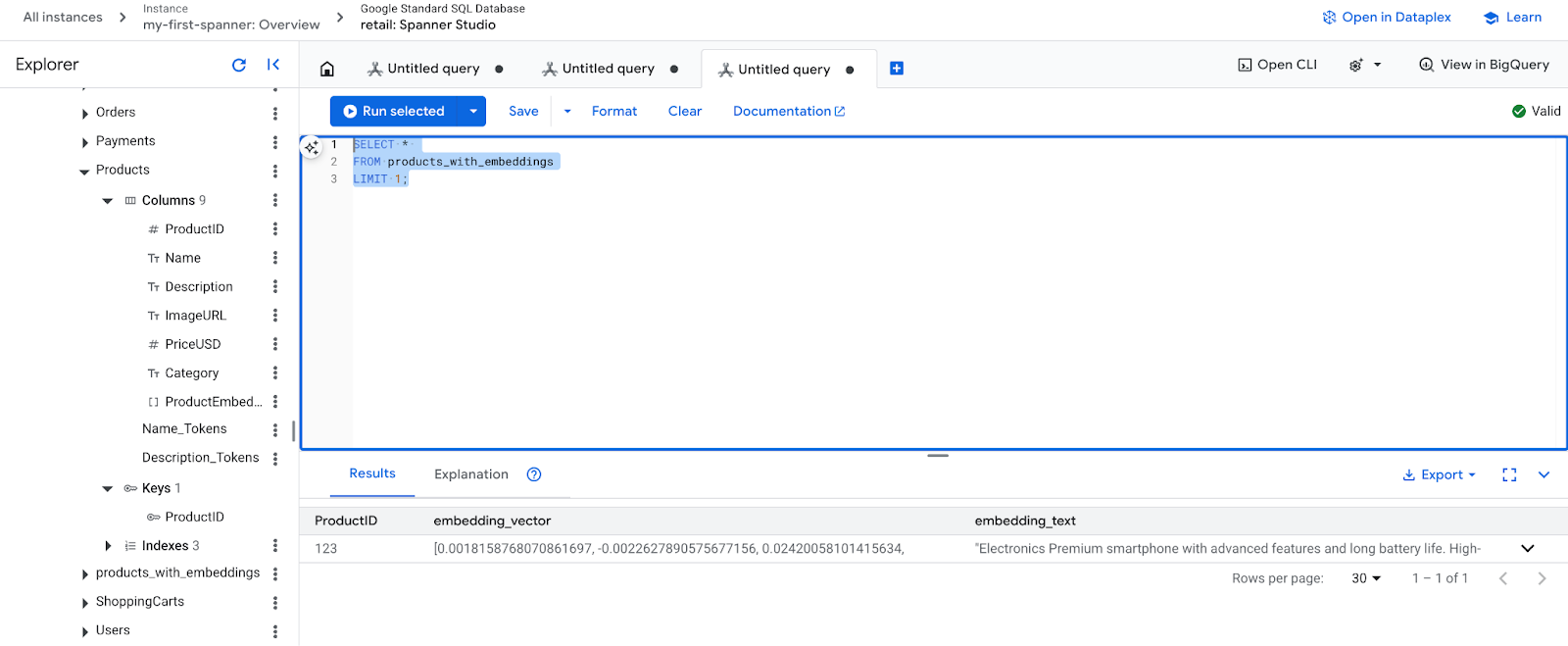
- Проверьте полученные эмбеддинги. Теперь вы должны увидеть сгенерированные эмбеддинги.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Шаг 4: Создание векторного индекса для поиска в ИНС.
Для мгновенного поиска по миллионам векторов нам необходим индекс. Этот индекс позволяет использовать алгоритм приблизительного поиска N ближайших N соседей (ANN), который невероятно быстр и масштабируется по горизонтали.
- Выполните следующий DDL-запрос для создания индекса. В качестве метрики расстояния мы указываем
COSINE, что отлично подходит для семантического поиска текста. Обратите внимание, что предложение WHERE на самом деле необходимо, поскольку Spanner сделает его обязательным для запроса.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Проверьте статус создания индекса на вкладке «Операции».
8. Шаг 5: Поиск рекомендаций с помощью метода k-ближайших соседей (KNN).
А теперь самое интересное! Давайте найдем товары, соответствующие запросу нашего клиента: «Я хотел бы купить высокопроизводительную клавиатуру. Иногда я программирую на пляже, поэтому она может намокнуть».
Начнём с поиска K - N ближайших N соседей (KNN). Это точный поиск, который сравнивает наш вектор запроса с каждым отдельным вектором-произведением. Он точен, но может быть медленным на очень больших наборах данных (поэтому мы создали индекс ANN для шага 5).
Этот запрос выполняет две задачи:
- В подзапросе используется функция ML.PREDICT для получения вектора встраивания для запроса нашего клиента.
- Внешний запрос использует COSINE_DISTANCE для вычисления «расстояния» между вектором запроса и вектором встраивания каждого продукта. Меньшее расстояние означает лучшее совпадение.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Вы должны увидеть список товаров, причем водостойкие клавиатуры будут находиться в самом верху.
9. Шаг 6: Поиск рекомендаций с помощью приблизительного поиска (ANN).
KNN — отличный инструмент, но для производственной системы с миллионами товаров и тысячами запросов в секунду нам нужна скорость нашего индекса на основе искусственной нейронной сети.
Для использования индекса необходимо указать функцию APPROX_COSINE_DISTANCE.
- Получите векторное представление вашего текста, как вы это делали выше. Мы объединим результаты с записями в таблице products_with_embeddings, чтобы вы могли использовать их в своей функции APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Ожидаемый результат: Результаты должны быть идентичны или очень похожи на результаты запроса KNN, но выполняться гораздо эффективнее за счет использования индекса. В примере это может быть незаметно.
10. Шаг 7: Используйте LLM для объяснения рекомендаций.
Просто показать список товаров — это хорошо, но объяснить, почему тот или иной товар подходит или нет, — это замечательно. Для этого мы можем использовать нашу модель LLMModel (Gemini).
Этот запрос вкладывает наш KNN-запрос из шага 4 в вызов ML.PREDICT. Мы используем CONCAT для формирования запроса для LLM, предоставляя ему:
- Чёткое указание («Ответьте «Да» или «Нет» и объясните почему...»).
- Первоначальный запрос клиента.
- Название и описание каждого наиболее подходящего товара.
Затем LLM оценивает каждый продукт на соответствие запросу и предоставляет ответ на естественном языке.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Ожидаемый результат: Вы получите таблицу с новым столбцом LLMResponse. Ответ должен выглядеть примерно так: " Нет. Вот почему: * "Водостойкий" не означает "водонепроницаемый". " Водостойкая" клавиатура выдерживает брызги, небольшой дождь или пролитую жидкость."
11. Шаг 8: Создайте график свойств
А теперь рассмотрим другой тип рекомендаций: «покупатели, купившие этот товар, также купили...»
Это запрос, основанный на связях. Идеальным инструментом для этого является граф свойств . Spanner позволяет создать граф на основе существующих таблиц без дублирования данных.
Данное операторное выражение DDL определяет наш граф:
- Узлы: таблицы
ProductиUser. Узлы — это сущности, от которых вы хотите вывести связь: вы хотите знать, что клиенты, купившие ваш продукт, также купили продукты «XYZ». - Ребра: Таблица
Orders, которая связываетUser(Источник) сProduct(Назначение) с меткой «Приобретено». Ребра обеспечивают связь между пользователем и тем, что он приобрел.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Шаг 9: Объединение векторного поиска и запросов к графу.
Это самый мощный шаг. Мы объединим векторный поиск с использованием ИИ и запросы к графам в одном запросе для поиска связанных товаров.
Этот запрос считывается в три части, разделенные NEXT statement , давайте разберем его по разделам.
- Сначала мы находим наилучшее совпадение, используя векторный поиск.
- ML.PREDICT генерирует векторное представление на основе текстового запроса пользователя с помощью EmbeddingsModel.
- Запрос вычисляет COSINE_DISTANCE между этим новым векторным представлением и сохраненным p.embedding_vector для всех продуктов.
- Он выбирает и возвращает единственный продукт bestMatch с минимальным расстоянием (наивысшим семантическим сходством).
- Далее мы будем обходить граф в поисках взаимосвязей.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Запрос отслеживает данные от bestMatch до общих узлов Orders (пользователь), а затем переходит к другим товарам purchasedWith.
- Он отфильтровывает исходный продукт и использует GROUP BY и COUNT(1) для агрегирования частоты совместных покупок товаров.
- Функция возвращает 3 наиболее часто приобретаемых совместно товара (purchasedWith), отсортированных по частоте их совместного использования.
Кроме того, мы обнаруживаем взаимосвязь между заказом и порядком действий пользователя.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- На этом промежуточном этапе выполняется обход шаблона для привязки ключевых сущностей: bestMatch, узла user:Orders, соединяющего элементы, и элемента purchasedWith.
- Это конкретно закрепляет саму связь, приобретенную для извлечения данных на следующем этапе.
- Этот шаблон гарантирует создание контекста для получения информации, относящейся к конкретному заказу и товару.
- Наконец, мы выводим результаты, которые должны быть возвращены в виде графа; узлы графа должны быть отформатированы перед возвратом в виде результатов SQL-запроса.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Ожидаемый результат: Вы увидите JSON-объекты, представляющие 3 наиболее часто приобретаемых товара, с рекомендациями по перекрестным продажам.
13. Уборка
Чтобы избежать дополнительных расходов, вы можете удалить созданные вами ресурсы.
- Удаление экземпляра Spanner: удаление экземпляра приведет к удалению и базы данных.
gcloud spanner instances delete my-first-spanner --quiet
- Удалите проект Google Cloud: если вы создали этот проект только для выполнения практического задания, удаление — самый простой способ навести порядок.
- Перейдите на страницу «Управление ресурсами» в консоли Google Cloud.
- Выберите свой проект и нажмите «Удалить» .
🎉 Поздравляем!
Вы успешно создали сложную систему рекомендаций в режиме реального времени, используя Spanner AI и Graph!
You've learned how to integrate Spanner with Vertex AI for embeddings and LLM generation, how to perform high-speed vector search (KNN and ANN) to find semantically relevant products, and how to use graph queries to discover product relationships. You've built a system that can not only find products but also explain recommendations and suggest related items, all from a single, scalable database.