
1. บทนำ
Codelab นี้จะแนะนำวิธีใช้ความสามารถด้าน AI และกราฟของ Spanner เพื่อปรับปรุงฐานข้อมูลการค้าปลีกที่มีอยู่ คุณจะได้เรียนรู้เทคนิคที่นำไปใช้ได้จริงในการใช้แมชชีนเลิร์นนิงภายใน Spanner เพื่อให้บริการลูกค้าได้ดียิ่งขึ้น โดยเฉพาะอย่างยิ่ง เราจะใช้ k-Nearest Neighbors (kNN) และ Approximate Nearest Neighbors (ANN) เพื่อค้นหาผลิตภัณฑ์ใหม่ๆ ที่สอดคล้องกับความต้องการของลูกค้าแต่ละราย นอกจากนี้ คุณยังจะผสานรวม LLM เพื่อให้คำอธิบายที่ชัดเจนในภาษาธรรมชาติเกี่ยวกับเหตุผลที่แนะนำผลิตภัณฑ์หนึ่งๆ ด้วย
นอกจากคำแนะนำแล้ว เราจะเจาะลึกฟังก์ชันกราฟของ Spanner คุณจะใช้การค้นหากราฟเพื่อสร้างความสัมพันธ์ระหว่างผลิตภัณฑ์ตามประวัติการซื้อของลูกค้าและรายละเอียดผลิตภัณฑ์ แนวทางนี้ช่วยให้ค้นพบสินค้าที่เกี่ยวข้องอย่างลึกซึ้ง ซึ่งจะช่วยปรับปรุงความเกี่ยวข้องและประสิทธิภาพของฟีเจอร์ "ลูกค้ายังซื้อ" หรือ "สินค้าที่เกี่ยวข้อง" ได้อย่างมาก เมื่อจบ Codelab นี้ คุณจะมีทักษะในการสร้างแอปพลิเคชันค้าปลีกอัจฉริยะที่ปรับขนาดได้และตอบสนองได้ ซึ่งขับเคลื่อนโดย Google Cloud Spanner ทั้งหมด
สถานการณ์
คุณทำงานให้กับผู้ค้าปลีกอุปกรณ์อิเล็กทรอนิกส์ เว็บไซต์อีคอมเมิร์ซมีฐานข้อมูล Spanner มาตรฐานที่มี Products, Orders และ OrderItems
ลูกค้าเข้าสู่เว็บไซต์ของคุณโดยมีความต้องการที่เฉพาะเจาะจงว่า "ฉันต้องการซื้อคีย์บอร์ดประสิทธิภาพสูง บางครั้งฉันก็เขียนโค้ดตอนอยู่ชายหาด ดังนั้นอุปกรณ์อาจเปียกได้"
เป้าหมายของคุณคือการใช้ฟีเจอร์ขั้นสูงของ Spanner เพื่อตอบคำขอนี้อย่างชาญฉลาด
- ค้นหา: ค้นหาผลิตภัณฑ์ที่มีคำอธิบายที่ตรงกับคำขอของผู้ใช้ในเชิงความหมายโดยใช้การค้นหาเวกเตอร์ นอกเหนือจากการค้นหาคีย์เวิร์ดแบบง่ายๆ
- อธิบาย: ใช้ LLM เพื่อวิเคราะห์การจับคู่ที่ตรงกันมากที่สุดและอธิบายเหตุผลที่คำแนะนำนั้นเหมาะสม เพื่อสร้างความไว้วางใจจากลูกค้า
- เชื่อมโยง: ใช้การค้นหากราฟเพื่อค้นหาผลิตภัณฑ์อื่นๆ ที่ลูกค้าซื้อบ่อยพร้อมกับคำแนะนำนั้น
2. ก่อนเริ่มต้น
- สร้างโปรเจ็กต์ ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- เปิดใช้การเรียกเก็บเงิน ตรวจสอบว่าโปรเจ็กต์ที่อยู่ในระบบคลาวด์เปิดใช้การเรียกเก็บเงินแล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- เปิดใช้งาน Cloud Shell เปิดใช้งาน Cloud Shell โดยคลิกปุ่ม "เปิดใช้งาน Cloud Shell" ในคอนโซล คุณสลับระหว่างเทอร์มินัลและตัวแก้ไขของ Cloud Shell ได้

- ให้สิทธิ์และตั้งค่าโปรเจ็กต์ เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์และตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณ
gcloud auth list
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า โดยแทนที่
<PROJECT_ID>ด้วยรหัสโปรเจ็กต์จริง
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- เปิดใช้ API ที่จำเป็น เปิดใช้ Spanner, Vertex AI และ Compute Engine API การดำเนินการนี้อาจใช้เวลาสักครู่
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- ตั้งค่าตัวแปรสภาพแวดล้อม 2-3 รายการที่คุณจะนำกลับมาใช้ซ้ำ
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- สร้างอินสแตนซ์ Spanner แบบทดลองใช้ฟรี หากยังไม่มีอินสแตนซ์ Spanner คุณจะต้องมีอินสแตนซ์ Spanner เพื่อโฮสต์ฐานข้อมูล เราจะใช้
regional-us-central1เป็นการกำหนดค่า คุณอัปเดตข้อมูลนี้ได้หากต้องการ
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. ภาพรวมสถาปัตยกรรม
Spanner จะห่อหุ้มฟังก์ชันการทำงานที่จำเป็นทั้งหมด ยกเว้นโมเดลที่โฮสต์ใน Vertex AI
4. ขั้นตอนที่ 1: ตั้งค่าฐานข้อมูลและส่งคำค้นหาแรก
ก่อนอื่น เราต้องสร้างฐานข้อมูล โหลดข้อมูลการขายปลีกตัวอย่าง และบอก Spanner วิธีสื่อสารกับ Vertex AI
สำหรับส่วนนี้ คุณจะต้องใช้สคริปต์ SQL ด้านล่าง
- ไปที่หน้าสินค้าของ Spanner
- เลือกอินสแตนซ์ที่ถูกต้อง
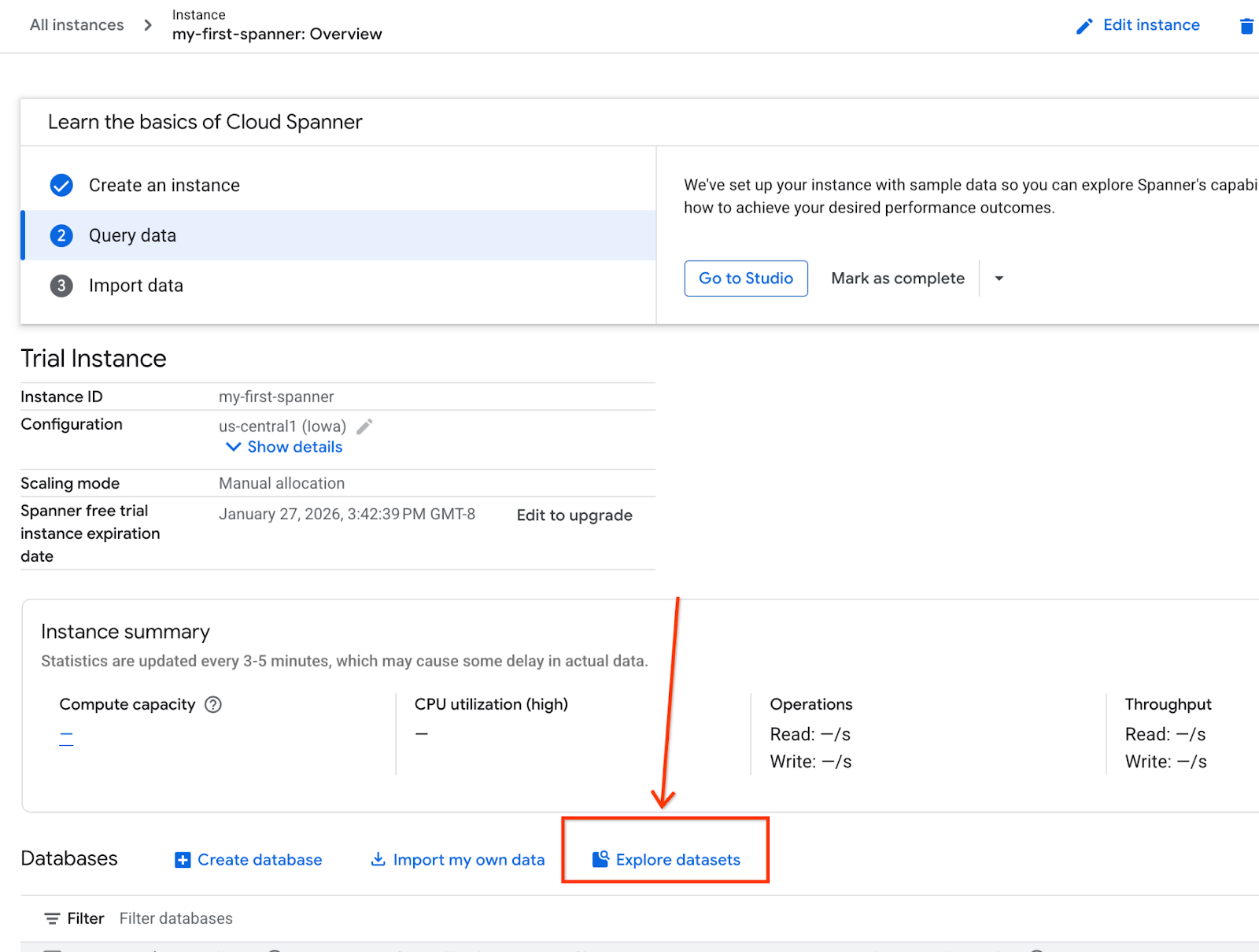
- เลือกสำรวจชุดข้อมูลบนหน้าจอ จากนั้นเลือกตัวเลือก "ค้าปลีก" ในป๊อปอัป
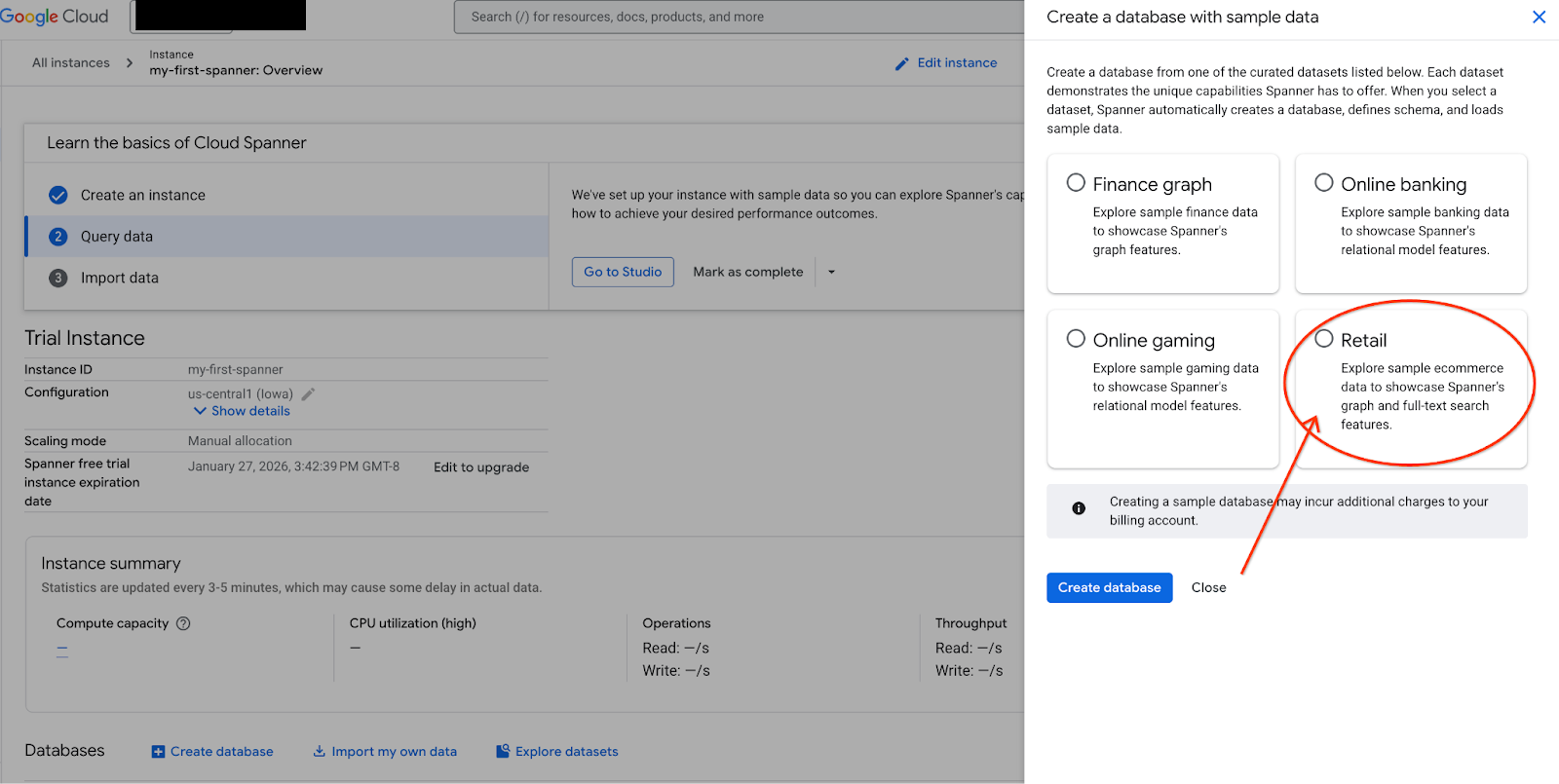
- ไปที่ Spanner Studio Spanner Studio มีแผง Explorer ที่ผสานรวมกับเครื่องมือแก้ไขการค้นหาและตารางผลการค้นหา SQL คุณเรียกใช้คำสั่ง DDL, DML และ SQL ได้จากอินเทอร์เฟซเดียวนี้ คุณจะต้องขยายเมนูที่ด้านข้างและมองหาแว่นขยาย
- อ่านตารางผลิตภัณฑ์ สร้างแท็บใหม่หรือใช้แท็บ "คำค้นหาที่ไม่มีชื่อ" ที่สร้างไว้แล้ว
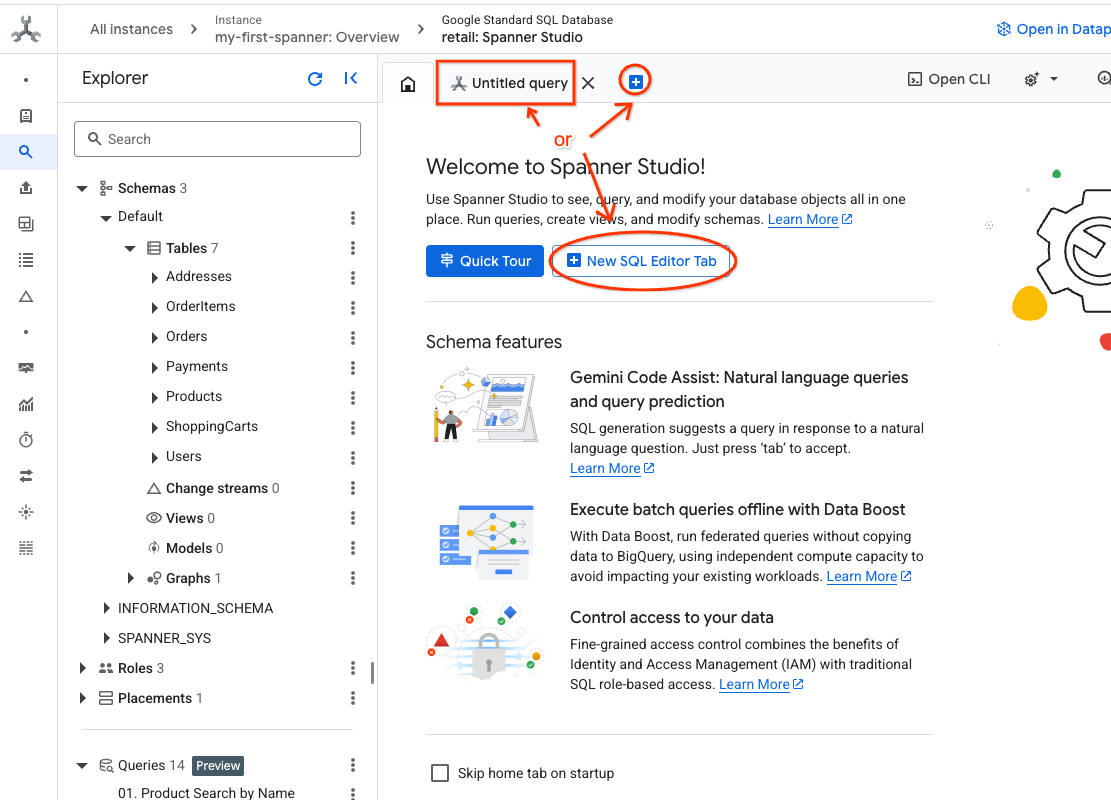
SELECT *
FROM Products;
5. ขั้นตอนที่ 2: สร้างโมเดล AI
ตอนนี้มาสร้างโมเดลระยะไกลด้วยออบเจ็กต์ Spanner กัน คำสั่ง SQL เหล่านี้จะสร้างออบเจ็กต์ Spanner ที่ลิงก์กับปลายทาง Vertex AI
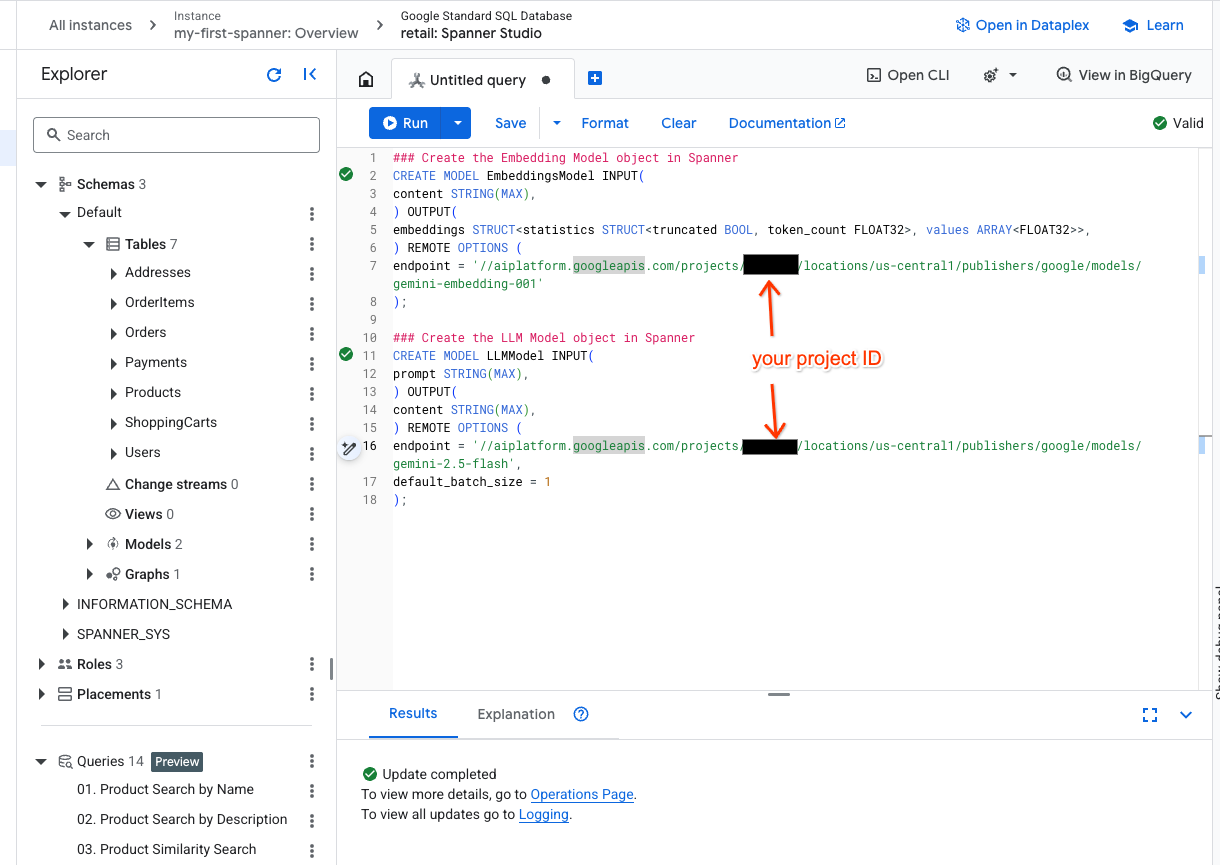
- เปิดแท็บใหม่ใน Spanner Studio แล้วสร้างโมเดล 2 รายการ อย่างแรกคือ EmbeddingsModel ซึ่งจะช่วยให้คุณสร้างการฝังได้ ส่วนที่ 2 คือ LLMModel ซึ่งจะช่วยให้คุณโต้ตอบกับ LLM ได้ (ในตัวอย่างของเราคือ gemini-2.5-flash) ตรวจสอบว่าคุณได้อัปเดต <PROJECT_ID> ด้วยรหัสโปรเจ็กต์แล้ว
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- หมายเหตุ: อย่าลืมแทนที่
PROJECT_IDด้วย$PROJECT_IDจริง
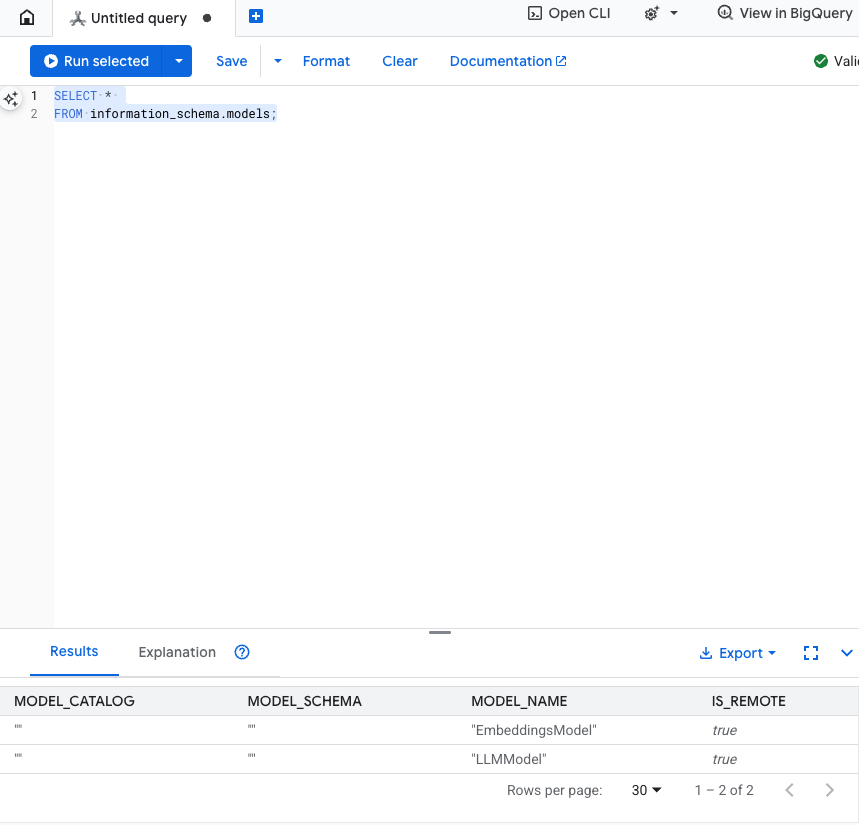
ทดสอบขั้นตอนนี้: คุณตรวจสอบว่าสร้างโมเดลแล้วได้โดยเรียกใช้คำสั่งต่อไปนี้ใน SQL Editor
SELECT *
FROM information_schema.models;
6. ขั้นตอนที่ 3: สร้างและจัดเก็บการฝังเวกเตอร์
ตารางผลิตภัณฑ์ของเรามีคำอธิบายเป็นข้อความ แต่โมเดล AI เข้าใจเวกเตอร์ (อาร์เรย์ของตัวเลข) เราต้องเพิ่มคอลัมน์ใหม่เพื่อจัดเก็บเวกเตอร์เหล่านี้ จากนั้นจึงป้อนข้อมูลโดยเรียกใช้คำอธิบายผลิตภัณฑ์ทั้งหมดผ่าน EmbeddingsModel
- สร้างตารางใหม่เพื่อรองรับการฝัง ก่อนอื่นให้สร้างตารางที่รองรับการฝัง เราใช้โมเดลการฝังที่แตกต่างจากตัวอย่างการฝังของตารางผลิตภัณฑ์ คุณต้องตรวจสอบว่าการฝังสร้างขึ้นจากโมเดลเดียวกันเพื่อให้การค้นหาเวกเตอร์ทํางานได้อย่างถูกต้อง
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- ป้อนข้อมูลลงในตารางใหม่ด้วยการฝังที่สร้างจากโมเดล เราใช้คำสั่ง INSERT INTO เพื่อความสะดวกที่นี่ ซึ่งจะส่งผลการค้นหาไปยังตารางที่คุณเพิ่งสร้าง
คำสั่ง SQL จะดึงและต่อกันคอลัมน์ข้อความที่เกี่ยวข้องทั้งหมดที่เราต้องการสร้างการฝังก่อน จากนั้นเราจะแสดงข้อมูลที่เกี่ยวข้อง รวมถึงข้อความที่เราใช้ โดยปกติแล้วคุณไม่จำเป็นต้องทำเช่นนี้ แต่เราใส่ไว้เพื่อให้คุณเห็นภาพผลลัพธ์
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
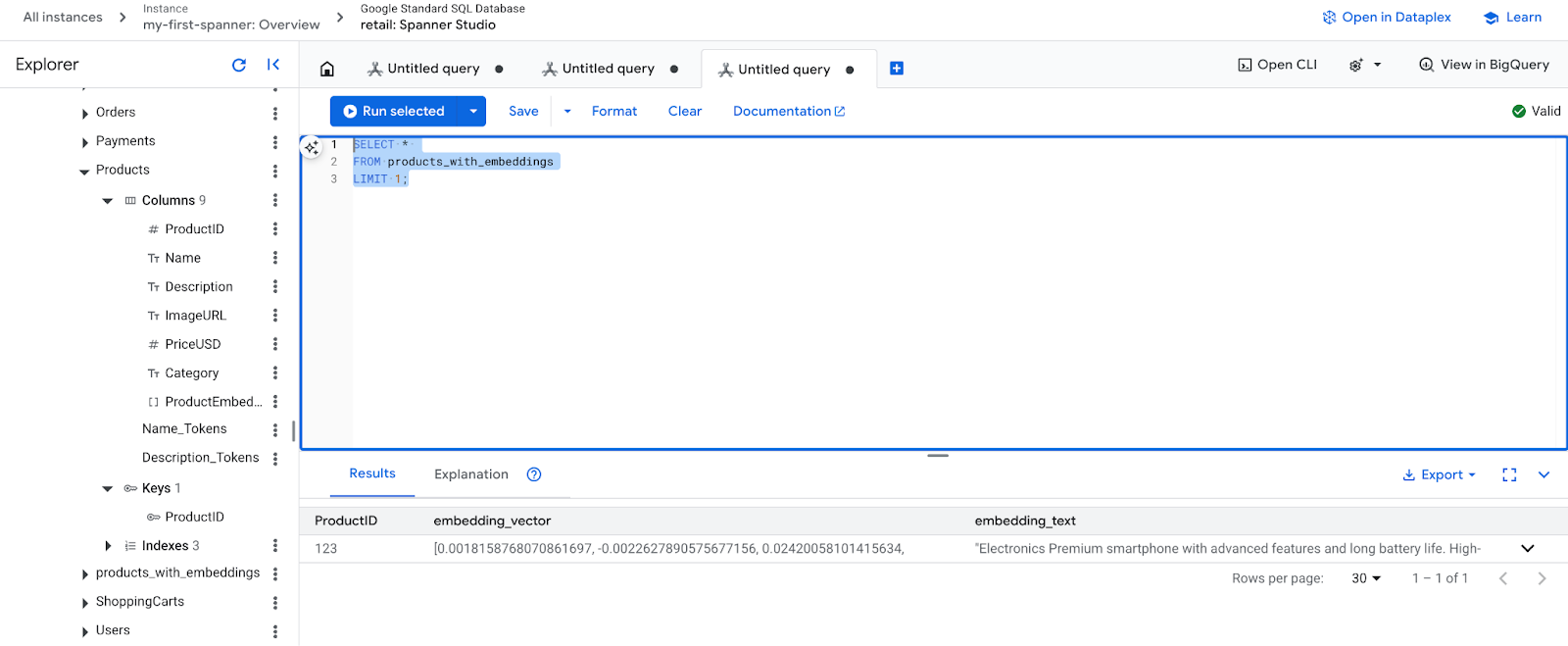
- ตรวจสอบการฝังใหม่ ตอนนี้คุณควรเห็นการฝังที่สร้างขึ้น
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. ขั้นตอนที่ 4: สร้างดัชนีเวกเตอร์สำหรับการค้นหา ANN
เราต้องมีดัชนีเพื่อค้นหาเวกเตอร์นับล้านได้ทันที ดัชนีนี้ช่วยให้การค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ (ANN) ทำงานได้อย่างรวดเร็วและปรับขนาดในแนวนอนได้
- เรียกใช้การค้นหา DDL ต่อไปนี้เพื่อสร้างดัชนี เราระบุ
COSINEเป็นเมตริกของระยะทาง ซึ่งเหมาะอย่างยิ่งสำหรับการค้นหาข้อความเชิงความหมาย โปรดทราบว่าจริงๆ แล้วต้องมีคําสั่ง WHERE เนื่องจาก Spanner จะกำหนดให้ต้องมีในคำค้นหา
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- ตรวจสอบสถานะการสร้างดัชนีในแท็บการดำเนินการ
8. ขั้นตอนที่ 5: ค้นหาคำแนะนำด้วยการค้นหา K-Nearest Neighbor (KNN)
มาถึงช่วงสนุกๆ กันแล้ว มาค้นหาสินค้าที่ตรงกับคำค้นหาของลูกค้ากัน "ฉันอยากซื้อคีย์บอร์ดประสิทธิภาพสูง บางครั้งฉันก็เขียนโค้ดขณะอยู่ริมหาด ดังนั้นอุปกรณ์อาจเปียกได้"
เราจะเริ่มด้วยการค้นหาK-Nearest Neighbor (KNN) นี่คือการค้นหาที่ตรงกันทุกประการซึ่งจะเปรียบเทียบเวกเตอร์การค้นหากับเวกเตอร์ผลิตภัณฑ์ทุกรายการ มีความแม่นยำ แต่ชุดข้อมูลขนาดใหญ่อาจทำงานช้า (ซึ่งเป็นเหตุผลที่เราสร้างดัชนี ANN สำหรับขั้นตอนที่ 5)
การค้นหานี้จะทำ 2 สิ่งต่อไปนี้
- คําค้นหาย่อยใช้ ML.PREDICT เพื่อรับเวกเตอร์การฝังสําหรับคําค้นหาของลูกค้า
- คิวรีภายนอกใช้ COSINE_DISTANCE เพื่อคำนวณ "ระยะห่าง" ระหว่างเวกเตอร์คำค้นหากับ embedding_vector ของผลิตภัณฑ์ทุกรายการ ระยะทางที่สั้นกว่าหมายถึงการจับคู่ที่ดีกว่า
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
คุณควรเห็นรายการผลิตภัณฑ์ โดยมีคีย์บอร์ดที่กันน้ำอยู่ด้านบนสุด
9. ขั้นตอนที่ 6: ค้นหาคำแนะนำด้วยการค้นหาโดยประมาณ (ANN)
KNN นั้นยอดเยี่ยม แต่สำหรับระบบการใช้งานที่มีผลิตภัณฑ์หลายล้านรายการและจำนวนคำค้นหาหลายพันรายการต่อวินาที เราต้องการความเร็วของดัชนี ANN
การใช้ดัชนีต้องระบุฟังก์ชัน APPROX_COSINE_DISTANCE
- รับการฝังเวกเตอร์ของข้อความตามที่คุณทำด้านบน เราจะทำการครอสจอยน์ผลลัพธ์ดังกล่าวกับระเบียนในตาราง products_with_embeddings เพื่อให้คุณใช้ในฟังก์ชัน APPROX_COSINE_DISTANCE ได้
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
เอาต์พุตที่คาดไว้: ผลลัพธ์ควรเหมือนกันหรือคล้ายกับคำค้นหา KNN มาก แต่จะดำเนินการได้อย่างมีประสิทธิภาพมากขึ้นโดยใช้ดัชนี คุณอาจไม่เห็นสิ่งนี้ในตัวอย่าง
10. ขั้นตอนที่ 7: ใช้ LLM เพื่ออธิบายคำแนะนำ
การแสดงรายการผลิตภัณฑ์เป็นสิ่งที่ดี แต่การอธิบายว่าเหตุใดผลิตภัณฑ์จึงเหมาะหรือไม่เหมาะเป็นสิ่งที่ดีกว่า เราสามารถใช้ LLMModel (Gemini) เพื่อดำเนินการนี้ได้
การค้นหานี้จะซ้อนการค้นหา KNN จากขั้นตอนที่ 4 ไว้ในการเรียกใช้ ML.PREDICT เราใช้ CONCAT เพื่อสร้างพรอมต์สำหรับ LLM โดยให้ข้อมูลต่อไปนี้
- คำสั่งที่ชัดเจน ("ตอบว่า "ใช่" หรือ "ไม่" และอธิบายเหตุผล...")
- คำค้นหาเดิมของลูกค้า
- ชื่อและคำอธิบายของผลิตภัณฑ์ที่ตรงกันมากที่สุดแต่ละรายการ
จากนั้น LLM จะประเมินผลิตภัณฑ์แต่ละรายการเทียบกับคำค้นหาและให้คำตอบเป็นภาษาที่เป็นธรรมชาติ
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
ผลลัพธ์ที่คาดไว้: คุณจะได้รับตารางที่มีคอลัมน์ LLMResponse ใหม่ คำตอบควรเป็นประมาณว่า "ไม่ เหตุผลคือ * "กันน้ำ" ไม่ใช่ "กันน้ำเข้า" แป้นพิมพ์ที่ "กันน้ำ" สามารถรับมือกับน้ำกระเด็น ฝนตกปรอยๆ หรือน้ำหกใส่ได้
11. ขั้นตอนที่ 8: สร้างกราฟพร็อพเพอร์ตี้
มาดูคำแนะนำอีกประเภทหนึ่งกัน นั่นคือ "ลูกค้าที่ซื้อสินค้านี้ยังซื้อ..."
นี่คือคำค้นหาตามความสัมพันธ์ เครื่องมือที่เหมาะที่สุดสำหรับงานนี้คือกราฟพร็อพเพอร์ตี้ Spanner ช่วยให้คุณสร้างกราฟบนตารางที่มีอยู่ได้โดยไม่ต้องทำซ้ำข้อมูล
คำสั่ง DDL นี้กำหนดกราฟของเรา
- โหนด: ตาราง
ProductและUserโหนดคือเอนทิตีที่คุณต้องการหาความสัมพันธ์ คุณต้องการทราบว่าลูกค้าที่ซื้อผลิตภัณฑ์ของคุณซื้อผลิตภัณฑ์ "XYZ" ด้วย - ขอบ: ตาราง
Ordersซึ่งเชื่อมต่อUser(แหล่งที่มา) กับProduct(ปลายทาง) ด้วยป้ายกำกับ "ซื้อ" ขอบจะแสดงความสัมพันธ์ระหว่างผู้ใช้กับสิ่งที่ผู้ใช้ซื้อ
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. ขั้นตอนที่ 9: รวมการค้นหาเวกเตอร์และการค้นหากราฟ
ขั้นตอนนี้มีประสิทธิภาพมากที่สุด เราจะรวมการค้นหาเวกเตอร์ AI และการค้นหากราฟไว้ในคำสั่งเดียวเพื่อค้นหาสินค้าที่เกี่ยวข้อง
การค้นหานี้อ่านได้ 3 ส่วน โดยคั่นด้วย NEXT statement เรามาแบ่งออกเป็นส่วนๆ กัน
- ก่อนอื่น เราจะค้นหาผลลัพธ์ที่ตรงกันมากที่สุดโดยใช้การค้นหาเวกเตอร์
- ML.PREDICT จะสร้างการฝังเวกเตอร์จากคำค้นหาที่เป็นข้อความของผู้ใช้โดยใช้ EmbeddingsModel
- คําค้นหาจะคํานวณ COSINE_DISTANCE ระหว่างการฝังใหม่นี้กับ p.embedding_vector ที่จัดเก็บไว้สําหรับสินค้าทั้งหมด
- โดยจะเลือกและแสดงผลิตภัณฑ์ที่ตรงกันดีที่สุดเพียงรายการเดียวซึ่งมีระยะทางต่ำสุด (ความคล้ายกันเชิงความหมายสูงสุด)
- จากนั้นเราจะสำรวจกราฟเพื่อค้นหาความสัมพันธ์
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- การค้นหาจะย้อนกลับจาก bestMatch ไปยังโหนด Orders ทั่วไป (ผู้ใช้) แล้วส่งต่อไปยังผลิตภัณฑ์อื่นๆ ที่ซื้อด้วยกัน
- โดยจะกรองผลิตภัณฑ์เดิมออกและใช้ GROUP BY และ COUNT(1) เพื่อรวบรวมความถี่ที่มีการซื้อสินค้าพร้อมกัน
- โดยจะแสดงผลิตภัณฑ์ที่ซื้อร่วมกัน 3 อันดับแรก (purchasedWith) ซึ่งเรียงตามความถี่ของการเกิดร่วมกัน
นอกจากนี้ เรายังพบความสัมพันธ์ระหว่างผู้ใช้กับคำสั่งซื้อด้วย
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- ขั้นตอนกลางนี้จะดำเนินการตามรูปแบบการข้ามเพื่อเชื่อมโยงเอนทิตีหลัก ได้แก่ bestMatch, โหนด connecting user:Orders และรายการ purchasedWith
- โดยจะผูกความสัมพันธ์นั้นๆ เป็น "ซื้อ" โดยเฉพาะสำหรับการดึงข้อมูลในขั้นตอนถัดไป
- รูปแบบนี้ช่วยให้มั่นใจได้ว่ามีการสร้างบริบทเพื่อดึงรายละเอียดเฉพาะคำสั่งซื้อและเฉพาะผลิตภัณฑ์
- สุดท้าย เราจะแสดงผลลัพธ์ที่จะส่งคืน เนื่องจากต้องจัดรูปแบบโหนดกราฟก่อนที่จะส่งคืนเป็นผลลัพธ์ SQL
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
ผลลัพธ์ที่คาดไว้: คุณจะเห็นออบเจ็กต์ JSON ที่แสดงถึงสินค้า 3 อันดับแรกที่ซื้อร่วมกัน ซึ่งจะให้คำแนะนำในการขายครอสเซล
13. การล้างข้อมูล
หากไม่ต้องการให้มีการเรียกเก็บเงิน คุณสามารถลบทรัพยากรที่สร้างขึ้นได้
- ลบอินสแตนซ์ Spanner: การลบอินสแตนซ์จะเป็นการลบฐานข้อมูลด้วย
gcloud spanner instances delete my-first-spanner --quiet
- ลบโปรเจ็กต์ Google Cloud: หากคุณสร้างโปรเจ็กต์นี้เพื่อใช้ใน Codelab โดยเฉพาะ การลบโปรเจ็กต์จะเป็นวิธีที่ง่ายที่สุดในการล้างข้อมูล
- ไปที่หน้าจัดการทรัพยากรในคอนโซล Google Cloud
- เลือกโปรเจ็กต์แล้วคลิกลบ
🎉 ยินดีด้วย
คุณสร้างระบบคำแนะนำแบบเรียลไทม์ที่ซับซ้อนได้สำเร็จแล้วโดยใช้ Spanner AI และ Graph
คุณได้เรียนรู้วิธีผสานรวม Spanner กับ Vertex AI เพื่อการฝังและการสร้าง LLM วิธีทำการค้นหาเวกเตอร์ความเร็วสูง (KNN และ ANN) เพื่อค้นหาผลิตภัณฑ์ที่เกี่ยวข้องเชิงความหมาย และวิธีใช้การค้นหากราฟเพื่อค้นหาความสัมพันธ์ของผลิตภัณฑ์ คุณได้สร้างระบบที่ไม่เพียงค้นหาผลิตภัณฑ์ แต่ยังอธิบายคำแนะนำและแนะนำสินค้าที่เกี่ยวข้องได้อีกด้วย ทั้งหมดนี้มาจากฐานข้อมูลเดียวที่ปรับขนาดได้