
1. Giriş
Bu codelab, mevcut bir perakende veritabanını geliştirmek için Spanner'ın yapay zeka ve grafik özelliklerini kullanma konusunda size yol gösterecektir. Müşterilerinize daha iyi hizmet vermek için Spanner'da makine öğreniminden yararlanmaya yönelik pratik teknikler öğreneceksiniz. Özellikle, her müşterinin ihtiyaçlarına uygun yeni ürünler keşfetmek için k-En Yakın Komşular (kNN) ve Yaklaşık En Yakın Komşular (ANN) algoritmalarını uygulayacağız. Ayrıca, belirli bir ürün önerisinin neden yapıldığına dair net ve doğal dilde açıklamalar sunmak için bir LLM de entegre edeceksiniz.
Önerinin ötesinde, Spanner'ın grafik işlevselliğini inceleyeceğiz. Müşterilerin satın alma geçmişine ve ürün açıklamalarına göre ürünler arasındaki ilişkileri modellemek için grafik sorgularını kullanırsınız. Bu yaklaşım, yakından ilişkili öğelerin keşfedilmesini sağlayarak "Müşteriler ayrıca satın aldı" veya "İlgili öğeler" özelliklerinizin alaka düzeyini ve etkinliğini önemli ölçüde artırır. Bu codelab'in sonunda, tamamen Google Cloud Spanner tarafından desteklenen akıllı, ölçeklenebilir ve duyarlı bir perakende uygulaması oluşturma becerisine sahip olacaksınız.
Senaryo
Elektronik ekipman perakendecisinde çalıştığınızı varsayalım. E-ticaret sitenizde Products, Orders ve OrderItems içeren standart bir Spanner veritabanı var.
Bir müşteri, belirli bir ihtiyacı karşılamak için sitenize geliyor: "Yüksek performanslı bir klavye satın almak istiyorum. Bazen plajda kod yazıyorum, bu nedenle ıslanabilir."
Amacınız, bu isteği akıllıca yanıtlamak için Spanner'ın ileri seviye özelliklerini kullanmaktır:
- Bulma: Vektör aramayı kullanarak, kullanıcının isteğiyle semantik olarak eşleşen açıklamalara sahip ürünleri bulmak için basit anahtar kelime aramasının ötesine geçin.
- Açıklama: En iyi eşleşmeleri analiz etmek ve önerinin neden uygun olduğunu açıklamak için LLM'yi kullanarak müşteri güvenini artırın.
- İlişkilendirme: Müşterilerin bu öneriyle birlikte sıklıkla satın aldığı diğer ürünleri bulmak için grafik sorgularını kullanın.
2. Başlamadan önce
- Proje oluşturma Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Faturalandırmayı etkinleştirin: Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
- Cloud Shell'i etkinleştirin: Konsolda "Cloud Shell'i etkinleştir" düğmesini tıklayarak Cloud Shell'i etkinleştirin. Cloud Shell Terminali ile Düzenleyici arasında geçiş yapabilirsiniz.

- Yetkilendirme ve Projeyi Ayarlama Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, proje kimliğinize ayarlandığını kontrol edin.
gcloud auth list
gcloud config list project
- Projeniz ayarlanmamışsa
<PROJECT_ID>kısmını gerçek proje kimliğinizle değiştirerek projeyi ayarlamak için aşağıdaki komutu kullanın:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Gerekli API'leri Etkinleştirme Spanner, Vertex AI ve Compute Engine API'lerini etkinleştirin. Bu işlem birkaç dakika sürebilir.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Yeniden kullanacağınız birkaç ortam değişkeni ayarlayın.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Henüz bir Spanner örneğiniz yoksa ücretsiz deneme Spanner örneği oluşturun . Veritabanınızı barındırmak için bir Spanner örneğine ihtiyacınız vardır. Yapılandırma olarak
regional-us-central1kullanılacak. İsterseniz bu bilgiyi güncelleyebilirsiniz.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Mimari Genel Bakış
Spanner, Vertex AI'da barındırılan modeller hariç tüm gerekli işlevleri kapsar.
4. 1. adım: Veritabanını ayarlayın ve ilk sorgunuzu gönderin.
Öncelikle veritabanımızı oluşturmamız, örnek perakende verilerimizi yüklememiz ve Spanner'a Vertex AI ile nasıl iletişim kuracağını söylememiz gerekiyor.
Bu bölümde aşağıdaki SQL komut dosyalarını kullanacaksınız.
- Spanner'ın ürün sayfasına gidin.
- Doğru örneği seçin.
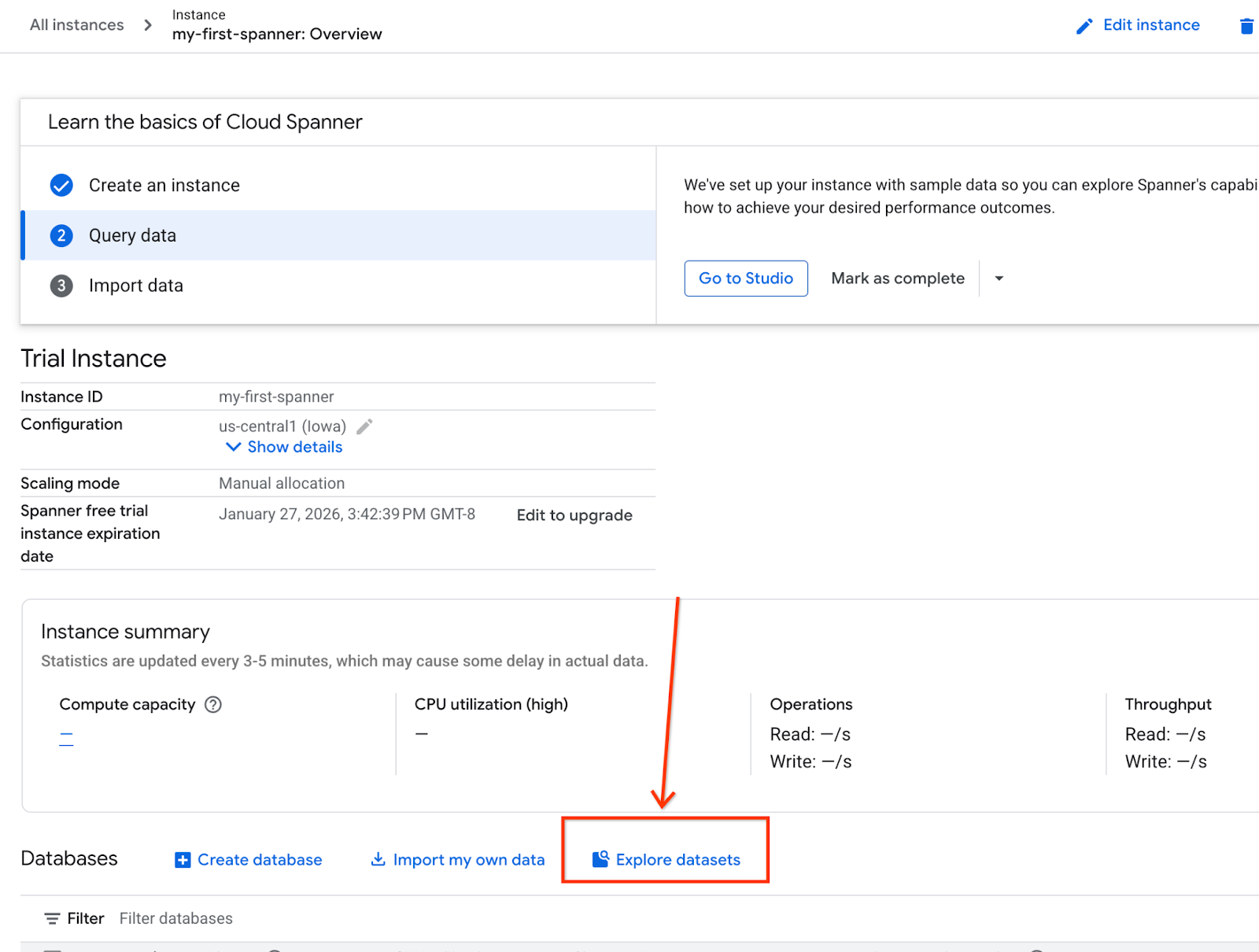
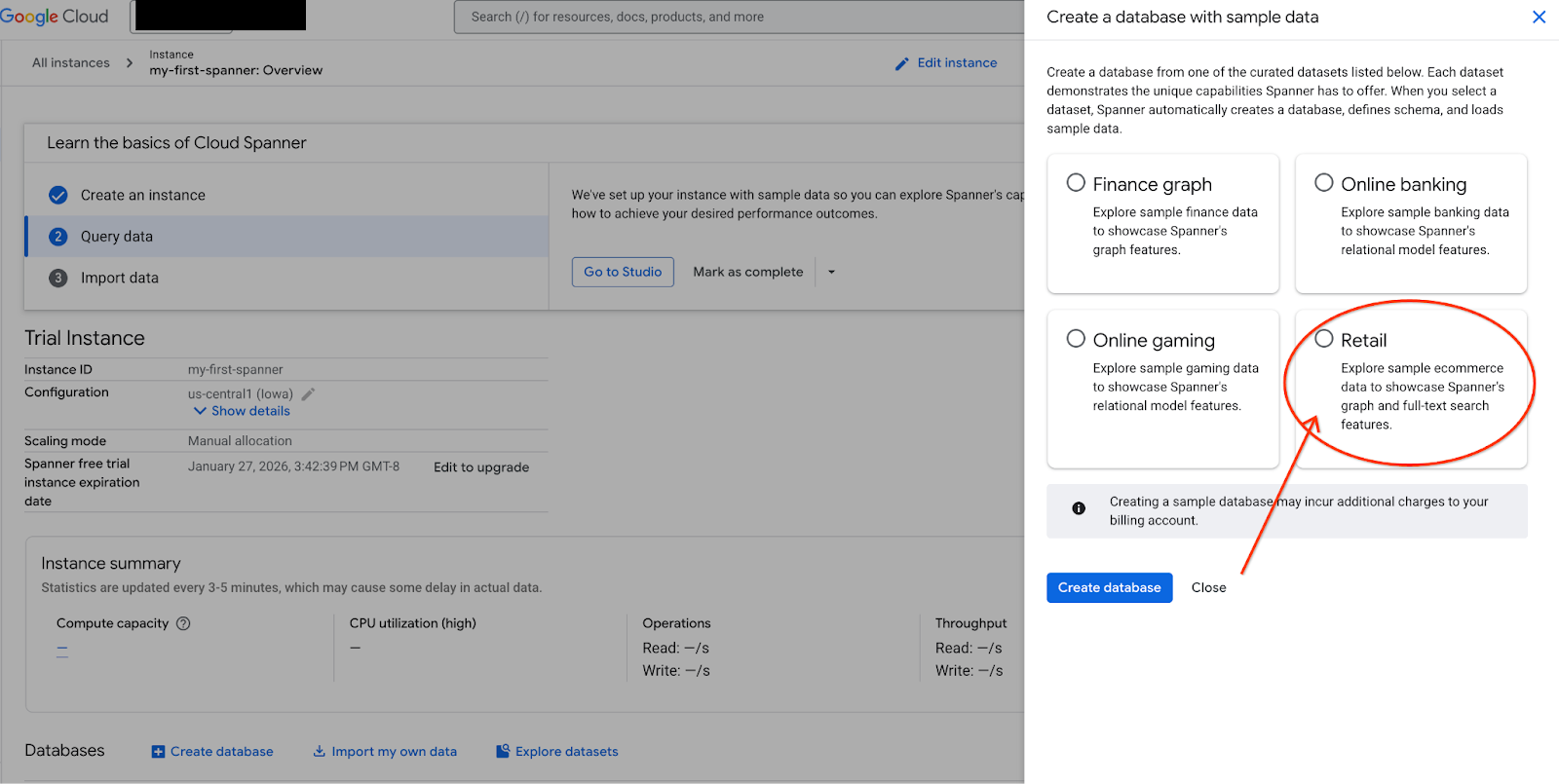
- Ekranda Veri Kümelerini Keşfet'i seçin. Ardından, pop-up'ta "Perakende" seçeneğini belirleyin.
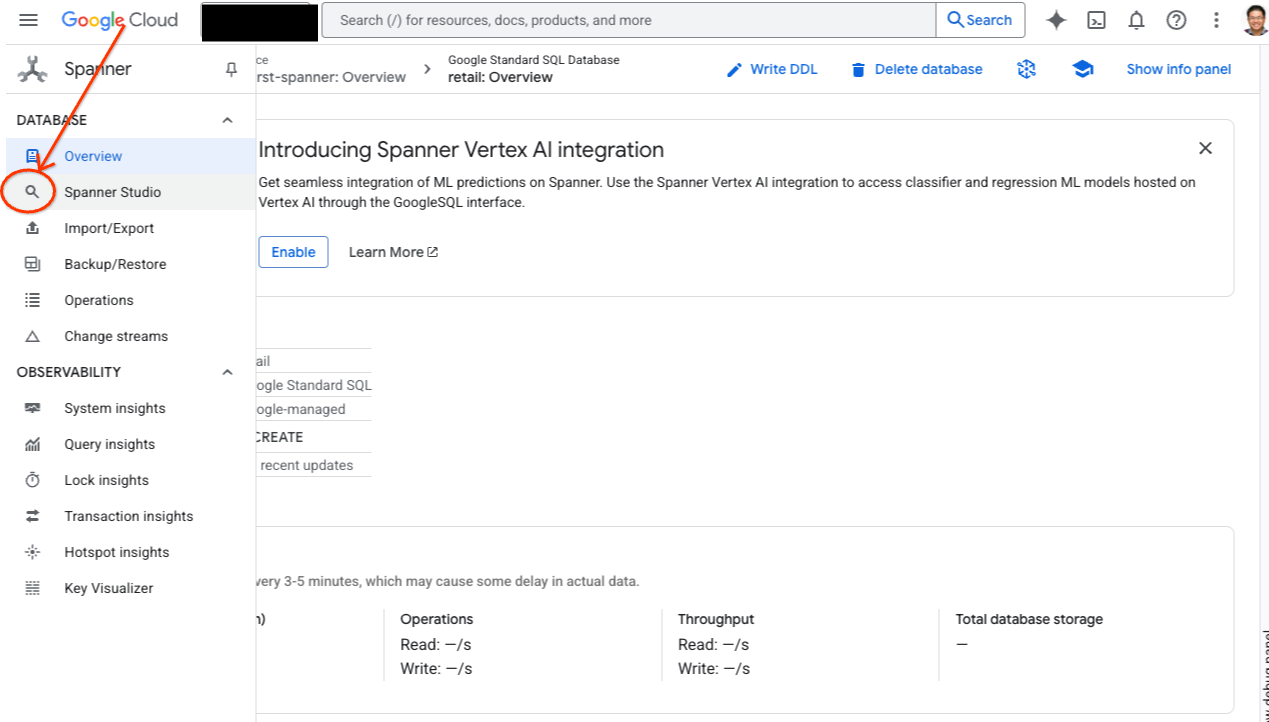
- Spanner Studio'ya gidin. Spanner Studio'da, sorgu düzenleyici ve SQL sorgu sonuçları tablosuyla entegre olan bir Gezgin bölmesi bulunur. Bu tek arayüzden DDL, DML ve SQL ifadelerini çalıştırabilirsiniz. Yandaki menüyü genişletmeniz ve büyüteci bulmanız gerekir.
- Ürünler tablosunu okuyun. Yeni bir sekme oluşturun veya önceden oluşturulmuş "Adsız sorgu" sekmesini kullanın.
SELECT *
FROM Products;
5. 2. adım: Yapay zeka modellerini oluşturun.
Şimdi Spanner nesneleriyle uzak modelleri oluşturalım. Bu SQL ifadeleri, Vertex AI uç noktalarına bağlanan Spanner nesneleri oluşturur.
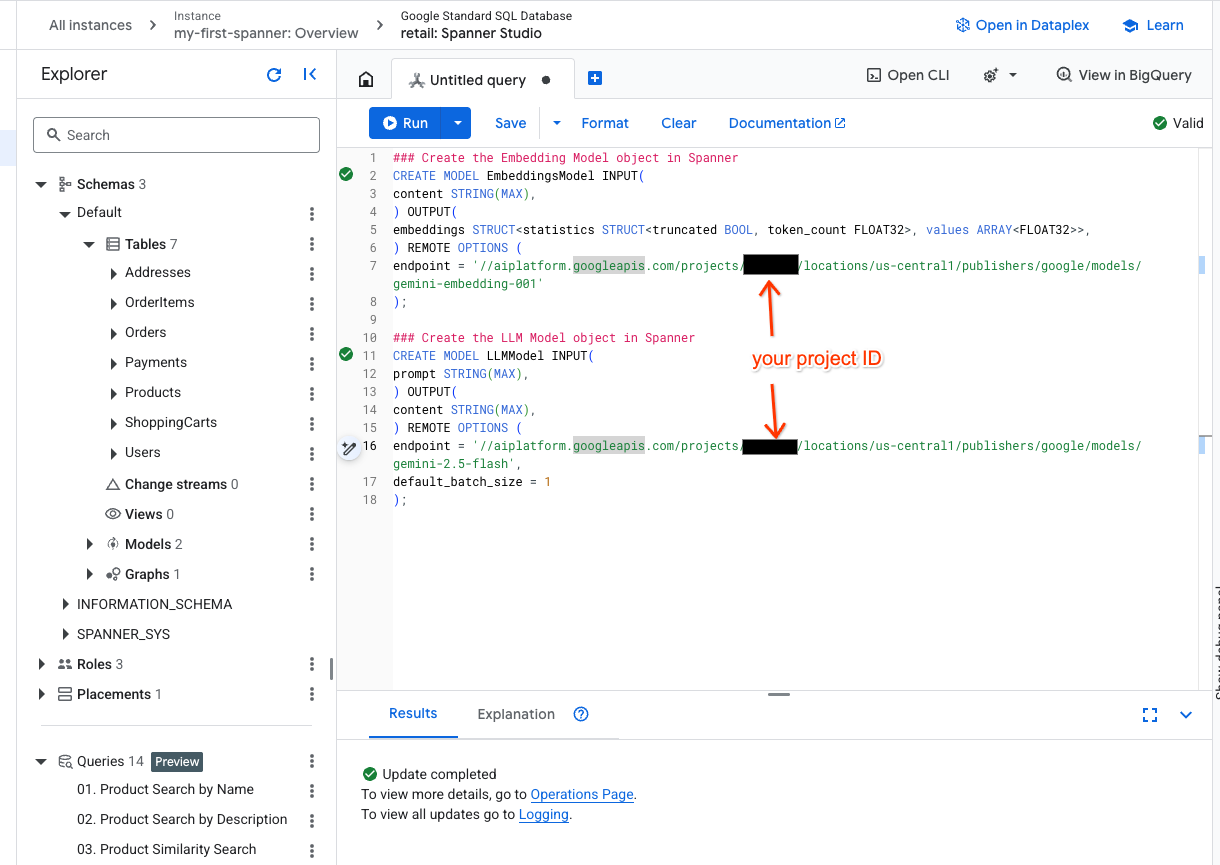
- Spanner Studio'da yeni bir sekme açın ve iki modelinizi oluşturun. Bunlardan ilki, yerleştirmeler oluşturmanıza olanak tanıyan EmbeddingsModel'dir. İkincisi ise LLMModel. Bu model, bir LLM ile (örneğimizde gemini-2.5-flash) etkileşim kurmanıza olanak tanır. <PROJECT_ID> kısmını proje kimliğinizle güncellediğinizden emin olun.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Not:
PROJECT_IDyerine gerçek$PROJECT_IDdeğerinizi girmeyi unutmayın.
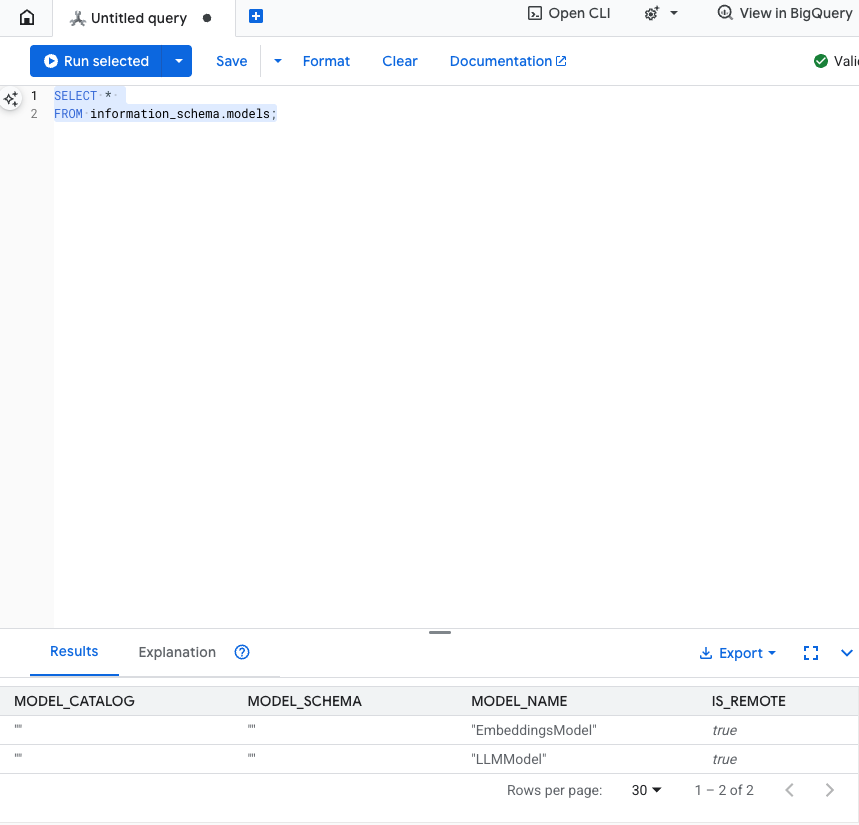
Bu adımı test edin: Modellerin oluşturulduğunu doğrulamak için SQL düzenleyicide aşağıdakileri çalıştırabilirsiniz.
SELECT *
FROM information_schema.models;
6. 3. adım: Vektör yerleştirmeleri oluşturun ve saklayın
Ürün tablomuzda metin açıklamaları var ancak yapay zeka modeli vektörleri (sayı dizileri) anlıyor. Bu vektörleri depolamak için yeni bir sütun eklememiz ve ardından tüm ürün açıklamalarımızı EmbeddingsModel üzerinden geçirerek bu sütunu doldurmamız gerekiyor.
- Yerleştirmeleri desteklemek için yeni bir tablo oluşturun. Öncelikle yerleştirmeleri destekleyebilecek bir tablo oluşturun. Ürün tablosu örnek yerleştirmelerinden farklı bir yerleştirme modeli kullanıyoruz. Vektör aramasının düzgün çalışması için yerleştirmelerin aynı modelden oluşturulduğundan emin olmanız gerekir.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Yeni tabloyu, modelden oluşturulan yerleştirmelerle doldurun. Burada basitlik için insert into ifadesini kullanıyoruz. Bu işlem, sorgu sonuçlarını yeni oluşturduğunuz tabloya aktarır.
SQL ifadesi önce yerleştirme oluşturmak istediğimiz tüm alakalı metin sütunlarını alır ve birleştirir. Ardından, kullandığımız metin de dahil olmak üzere ilgili bilgileri döndürürüz. Bu genellikle gerekli değildir ancak sonuçları görselleştirebilmeniz için eklenmiştir.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
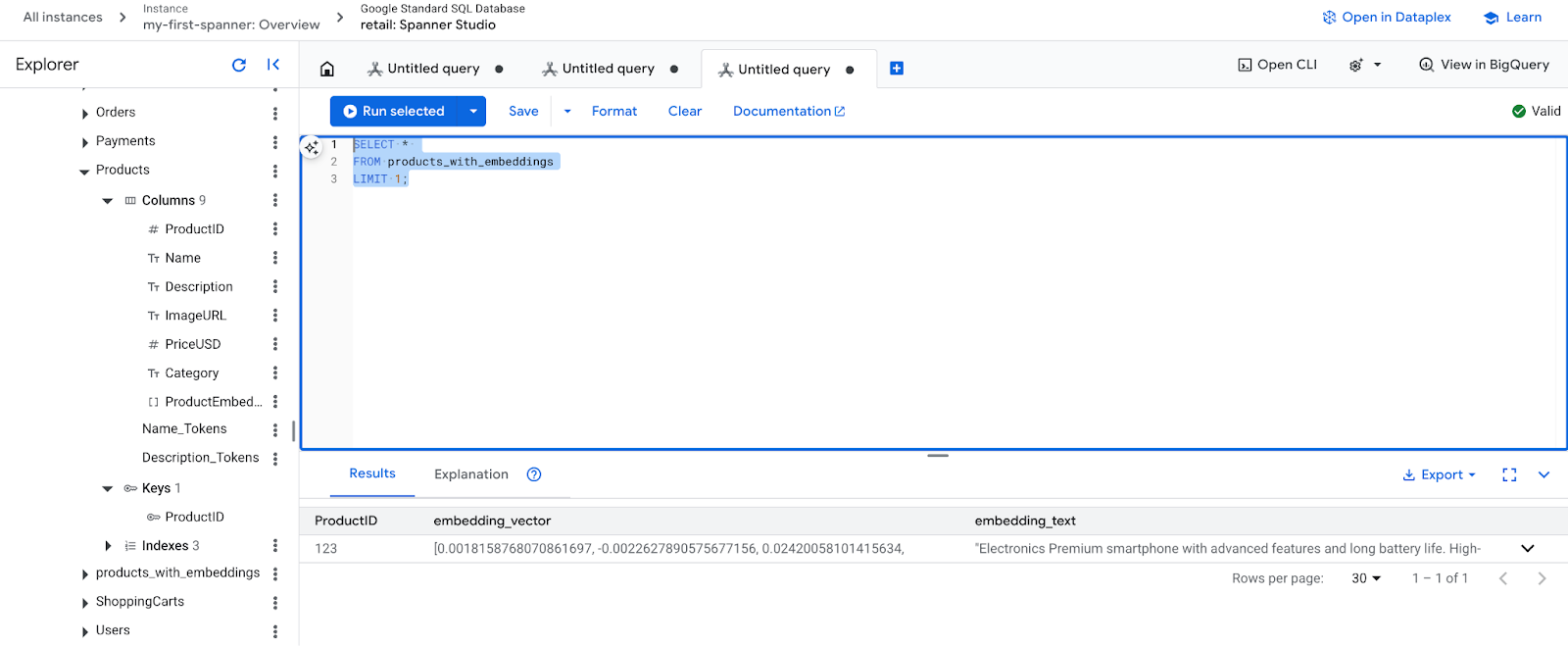
- Yeni yerleştirmelerinizi kontrol edin. Oluşturulan yerleştirmeleri göreceksiniz.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. 4. adım: ANN araması için vektör dizini oluşturun
Milyonlarca vektörde anında arama yapmak için bir dizine ihtiyacımız var. Bu dizin, Yaklaşık En Yakın Komşu (ANN) aramayı mümkün kılar. Bu arama son derece hızlıdır ve yatay olarak ölçeklenebilir.
- Dizini oluşturmak için aşağıdaki DDL sorgusunu çalıştırın. Uzaklık metriğimiz olarak
COSINEdeğerini belirtiyoruz. Bu değer, semantik metin araması için mükemmeldir. Spanner, sorgu için WHERE ifadesini zorunlu kılacağından bu ifadenin gerekli olduğunu unutmayın.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- İşlemler sekmesinde dizin oluşturma işleminizin durumunu kontrol edin.
8. 5. adım: K-En Yakın Komşu (KNN) aramasıyla önerileri bulma
Şimdi de işin eğlenceli kısmına geçelim. Müşterimizin sorgusuyla eşleşen ürünleri bulalım: "Yüksek performanslı bir klavye satın almak istiyorum. Bazen plajda kod yazıyorum, bu nedenle ıslanabilir.".
K-Nearest Neighbor (KNN) aramasıyla başlayacağız. Bu, sorgu vektörümüzü her bir ürün vektörüyle karşılaştıran tam bir aramadır. Hassas olsa da çok büyük veri kümelerinde yavaş olabilir (bu nedenle 5. adım için bir ANN dizini oluşturduk).
Bu sorgu iki işlem yapar:
- Bir alt sorgu, müşterimizin sorgusu için yerleştirme vektörünü almak üzere ML.PREDICT işlevini kullanır.
- Dış sorgu, sorgu vektörü ile her ürünün embedding_vector'ü arasındaki"uzaklığı" hesaplamak için COSINE_DISTANCE işlevini kullanır. Daha kısa mesafe, daha iyi eşleşme anlamına gelir.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
En üstte suya dayanıklı klavyelerin yer aldığı bir ürün listesi görürsünüz.
9. 6. adım: Yaklaşık (ANN) Arama ile önerileri bulma
KNN harika bir yöntem olsa da milyonlarca ürün ve saniyedeki binlerce sorgu sayısı içeren bir üretim sistemi için ANN dizinimizin hızına ihtiyacımız var.
Dizini kullanmak için APPROX_COSINE_DISTANCE işlevini belirtmeniz gerekir.
- Metninizin vektör yerleştirmesini yukarıda yaptığınız gibi alın. Bu sonuçları, APPROX_COSINE_DISTANCE işlevinizde kullanabilmeniz için products_with_embeddings tablosundaki kayıtlarla çapraz olarak birleştiririz.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Beklenen Çıkış: Sonuçlar, KNN sorgusuyla aynı veya çok benzer olmalıdır ancak dizin kullanılarak çok daha verimli bir şekilde yürütülür. Bu durumu örnekte fark etmeyebilirsiniz.
10. 7. adım: Önerileri açıklamak için LLM kullanın
Yalnızca ürün listesi göstermek iyi olsa da neden iyi veya kötü bir seçim olduğunu açıklamak daha da iyidir. Bunu yapmak için LLMModel'imizi (Gemini) kullanabiliriz.
Bu sorgu, 4. adımda oluşturduğumuz KNN sorgusunu bir ML.PREDICT çağrısının içine yerleştirir. CONCAT işlevini kullanarak LLM için bir istem oluştururuz. Bu istemde LLM'ye şunlar verilir:
- Net bir talimat ("Evet" veya "Hayır" şeklinde yanıtlayın ve nedenini açıklayın).
- Müşterinin orijinal sorgusu.
- En iyi eşleşen her ürünün adı ve açıklaması.
Ardından LLM, her ürünü sorguya göre değerlendirir ve doğal dilde bir yanıt verir.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Beklenen Çıkış: Yeni bir LLMResponse sütunu içeren bir tablo elde edersiniz. Yanıt şu şekilde olmalıdır: "Hayır. Bunun nedeni: * "Suya dayanıklı" ile "su geçirmez" aynı şey değildir. "Suya dayanıklı" bir klavye, sıçramalara, hafif yağmura veya dökülen sıvılara karşı dayanıklıdır.
11. 8. adım: Mülk grafiği oluşturun
Şimdi de farklı bir öneri türüne bakalım: "Bu ürünü satın alan müşteriler şunları da satın aldı..."
Bu, ilişkiye dayalı bir sorgudur. Bu amaç için mükemmel araç özellik grafiğidir. Spanner, verileri kopyalamadan mevcut tablolarınızın üzerinde grafik oluşturmanıza olanak tanır.
Bu DDL ifadesi grafiğimizi tanımlar:
- Düğümler:
ProductveUsertabloları. Düğümler, ilişki oluşturmak istediğiniz öğelerdir. Örneğin, ürününüzü satın alan müşterilerin "XYZ" ürünlerini de satın alıp almadığını öğrenmek isteyebilirsiniz. - Kenarlar: "Satın alındı" etiketiyle bir
User(Kaynak) öğesini birProduct(Hedef) öğesine bağlayanOrderstablosu. Kenarlar, kullanıcı ile satın aldığı ürün arasındaki ilişkiyi gösterir.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. 9. adım: Vector Search ve grafik sorgularını birleştirin
Bu en etkili adımdır. İlgili ürünleri bulmak için yapay zeka Vector Search ve grafik sorgularını tek bir ifadede birleştiririz.
Bu sorgu, NEXT statement ile ayrılmış üç bölüm halinde okunur. Şimdi bunu bölümlere ayıralım.
- Öncelikle vektör arama kullanarak en iyi eşleşmeyi buluruz.
- ML.PREDICT, EmbeddingsModel'i kullanarak kullanıcının metin sorgusundan vektör yerleştirme oluşturur.
- Sorgu, bu yeni yerleştirme ile tüm ürünler için depolanan p.embedding_vector arasındaki COSINE_DISTANCE değerini hesaplar.
- En kısa mesafeye (en yüksek semantik benzerlik) sahip tek bir bestMatch ürününü seçip döndürür.
- Ardından, ilişkileri bulmak için grafikte ilerleriz.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Sorgu, bestMatch'ten ortak Orders düğümlerine (kullanıcı) geri, ardından da purchasedWith ile satın alınan diğer ürünlere doğru izlenir.
- Orijinal ürünü filtreler ve öğelerin birlikte satın alınma sıklığını toplamak için GROUP BY ve COUNT(1) işlevlerini kullanır.
- Birlikte satın alınma sıklığına göre sıralanmış, birlikte satın alınan en popüler 3 ürünü (purchasedWith) döndürür.
Ayrıca, Kullanıcı Sipariş İlişkisi'ni de buluruz.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Bu ara adım, anahtar öğeleri (bestMatch, bağlanan kullanıcı:Siparişler düğümü ve purchasedWith öğesi) bağlamak için geçiş modelini yürütür.
- Bu işlev, özellikle bir sonraki adımda veri ayıklama için ilişkinin kendisini satın alınmış olarak bağlar.
- Bu kalıp, siparişe ve ürüne özel ayrıntıların getirilmesi için bağlamın oluşturulmasını sağlar.
- Son olarak, döndürülecek sonuçları çıkış olarak veriyoruz. Grafik düğümleri olarak döndürülmeden önce SQL sonuçları olarak biçimlendirilmesi gerekir.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Beklenen Çıkış: Çapraz satış önerileri sunan, birlikte satın alınan ilk 3 öğeyi temsil eden JSON nesnelerini görürsünüz.
13. Temizleme
Ücretlendirilmemek için oluşturduğunuz kaynakları silebilirsiniz.
- Spanner örneğini silin: Örneği sildiğinizde veritabanı da silinir.
gcloud spanner instances delete my-first-spanner --quiet
- Google Cloud projesini silme: Bu projeyi yalnızca codelab için oluşturduysanız temizlik yapmanın en kolay yolu projeyi silmektir.
- Google Cloud Console'da Kaynakları yönetin sayfasına gidin.
- Projenizi seçin ve Sil'i tıklayın.
🎉 Tebrikler!
Spanner AI ve Graph'ı kullanarak gelişmiş ve anlık bir öneri sistemi oluşturmayı başardınız.
Yerleştirilmiş öğeler ve LLM oluşturma için Spanner'ı Vertex AI ile entegre etmeyi, semantik olarak alakalı ürünleri bulmak için yüksek hızlı vektör araması (KNN ve ANN) yapmayı ve ürün ilişkilerini keşfetmek için grafik sorgularını kullanmayı öğrendiniz. Tek bir ölçeklenebilir veritabanından ürünleri bulmanın yanı sıra önerileri açıklayabilen ve ilgili öğeleri önerebilen bir sistem oluşturdunuz.