
1. Giới thiệu
Lớp học lập trình này sẽ hướng dẫn bạn cách sử dụng các chức năng AI và đồ thị của Spanner để cải thiện cơ sở dữ liệu bán lẻ hiện có. Bạn sẽ tìm hiểu các kỹ thuật thực tế để sử dụng công nghệ học máy trong Spanner nhằm phục vụ khách hàng tốt hơn. Cụ thể, chúng tôi sẽ triển khai k-Nearest Neighbors (kNN) và Approximate Nearest Neighbors (ANN) để khám phá những sản phẩm mới phù hợp với nhu cầu của từng khách hàng. Bạn cũng sẽ tích hợp một LLM để đưa ra lời giải thích rõ ràng bằng ngôn ngữ tự nhiên về lý do một đề xuất cụ thể về sản phẩm được đưa ra.
Ngoài đề xuất, chúng ta sẽ tìm hiểu sâu hơn về chức năng đồ thị của Spanner. Bạn sẽ sử dụng các truy vấn đồ thị để mô hình hoá mối quan hệ giữa các sản phẩm dựa trên nhật ký mua hàng của khách hàng và nội dung mô tả sản phẩm. Phương pháp này giúp khám phá các mặt hàng có liên quan sâu sắc, cải thiện đáng kể mức độ liên quan và hiệu quả của các tính năng "Khách hàng cũng đã mua" hoặc "Mặt hàng có liên quan". Khi kết thúc lớp học lập trình này, bạn sẽ có các kỹ năng để xây dựng một ứng dụng bán lẻ thông minh, có khả năng mở rộng và phản hồi nhanh, hoàn toàn dựa trên Google Cloud Spanner.
Trường hợp
Bạn làm việc cho một nhà bán lẻ thiết bị điện tử. Trang web thương mại điện tử của bạn có một cơ sở dữ liệu Spanner tiêu chuẩn với Products, Orders và OrderItems.
Khách hàng truy cập vào trang web của bạn với một nhu cầu cụ thể: "Tôi muốn mua một bàn phím có hiệu suất cao. Đôi khi tôi viết mã khi đang ở bãi biển nên có thể thiết bị sẽ bị ướt."
Mục tiêu của bạn là sử dụng các tính năng nâng cao của Spanner để trả lời yêu cầu này một cách thông minh:
- Tìm: Không chỉ tìm kiếm bằng từ khoá đơn giản, mà còn tìm những sản phẩm có nội dung mô tả phù hợp về mặt ngữ nghĩa với yêu cầu của người dùng bằng tính năng tìm kiếm vectơ.
- Giải thích: Sử dụng LLM để phân tích các kết quả phù hợp nhất và giải thích lý do đề xuất đó phù hợp, từ đó xây dựng niềm tin của khách hàng.
- Liên quan: Sử dụng truy vấn đồ thị để tìm các sản phẩm khác mà khách hàng thường mua cùng với đề xuất đó.
2. Trước khi bắt đầu
- Tạo dự án trên đám mây Trong bảng điều khiển Cloud, trên trang bộ chọn dự án, hãy chọn hoặc tạo một dự án trên đám mây.
- Bật tính năng thanh toán Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên đám mây. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
- Kích hoạt Cloud Shell Kích hoạt Cloud Shell bằng cách nhấp vào nút "Kích hoạt Cloud Shell" trong bảng điều khiển. Bạn có thể chuyển đổi giữa Cửa sổ dòng lệnh và Trình chỉnh sửa của Cloud Shell.

- Uỷ quyền và đặt dự án Sau khi kết nối với Cloud Shell, hãy kiểm tra để đảm bảo bạn đã được xác thực và dự án được đặt thành mã dự án của bạn.
gcloud auth list
gcloud config list project
- Nếu dự án của bạn chưa được thiết lập, hãy dùng lệnh sau để thiết lập, thay thế
<PROJECT_ID>bằng mã dự án thực tế của bạn:
export PROJECT_ID=<PROJECT_ID>
gcloud config set project $PROJECT_ID
- Bật các API bắt buộc Bật các API Spanner, Vertex AI và Compute Engine. Quá trình này có thể mất vài phút.
gcloud services enable \
spanner.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Đặt một số biến môi trường mà bạn sẽ dùng lại.
export INSTANCE_ID=my-first-spanner
export INSTANCE_CONFIG=regional-us-central1
- Tạo một phiên bản Spanner dùng thử miễn phí nếu bạn chưa có phiên bản Spanner . Bạn sẽ cần một phiên bản Spanner để lưu trữ cơ sở dữ liệu. Chúng ta sẽ sử dụng
regional-us-central1làm cấu hình. Bạn có thể cập nhật thông tin này nếu muốn.
gcloud spanner instances create $INSTANCE_ID \
--instance-type=free-instance --config=$INSTANCE_CONFIG \
--description="Trial Instance"
3. Tổng quan về kiến trúc
Spanner bao bọc tất cả chức năng cần thiết, ngoại trừ các mô hình được lưu trữ trên Vertex AI.
4. Bước 1: Thiết lập Cơ sở dữ liệu và gửi truy vấn đầu tiên.
Trước tiên, chúng ta cần tạo cơ sở dữ liệu, tải dữ liệu bán lẻ mẫu và cho Spanner biết cách giao tiếp với Vertex AI.
Đối với phần này, bạn sẽ sử dụng các tập lệnh SQL bên dưới.
- Chuyển đến trang sản phẩm của Spanner.
- Chọn phiên bản chính xác.
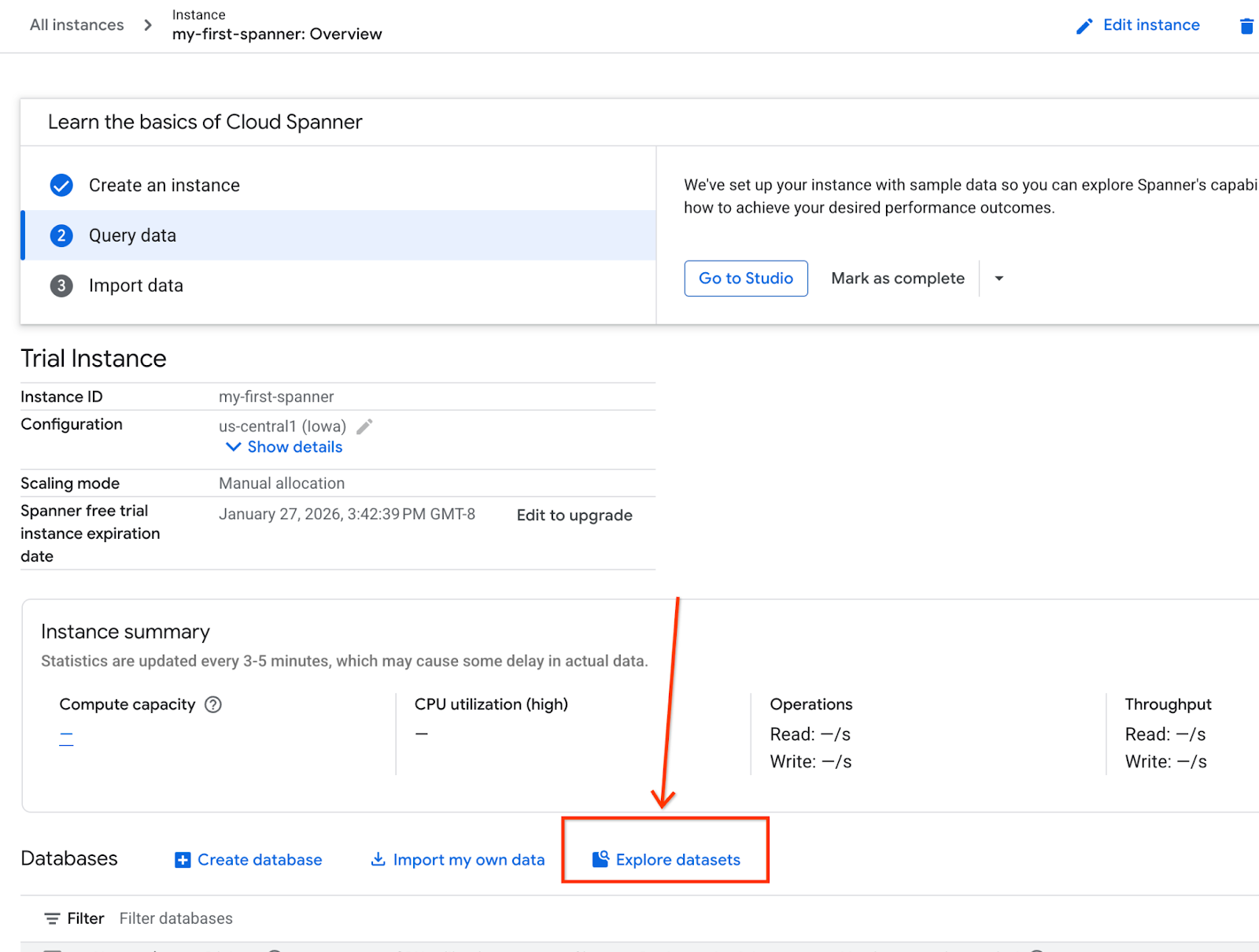
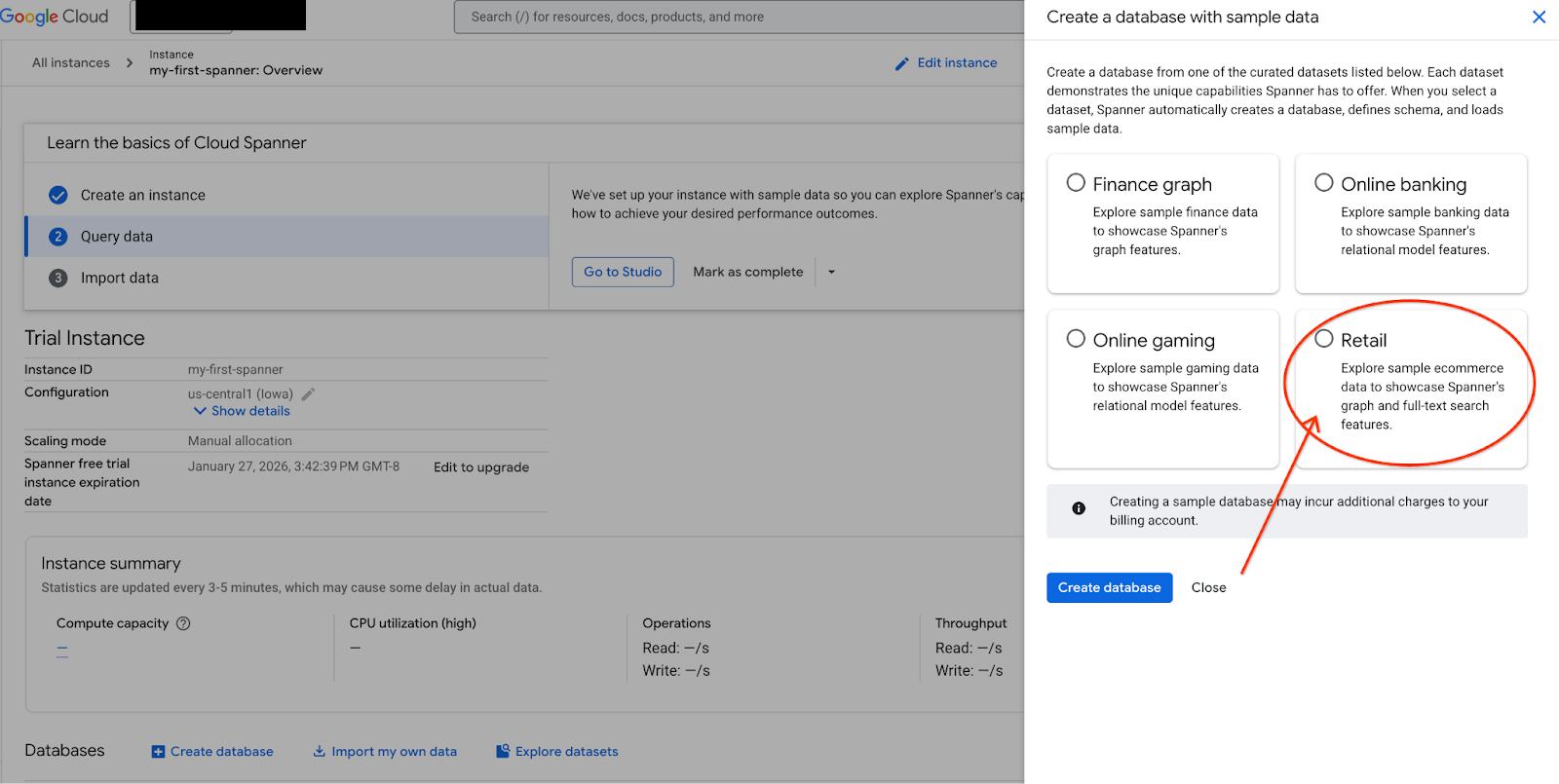
- Trên màn hình, hãy chọn Khám phá tập dữ liệu. Sau đó, trong cửa sổ bật lên, hãy chọn "Bán lẻ".
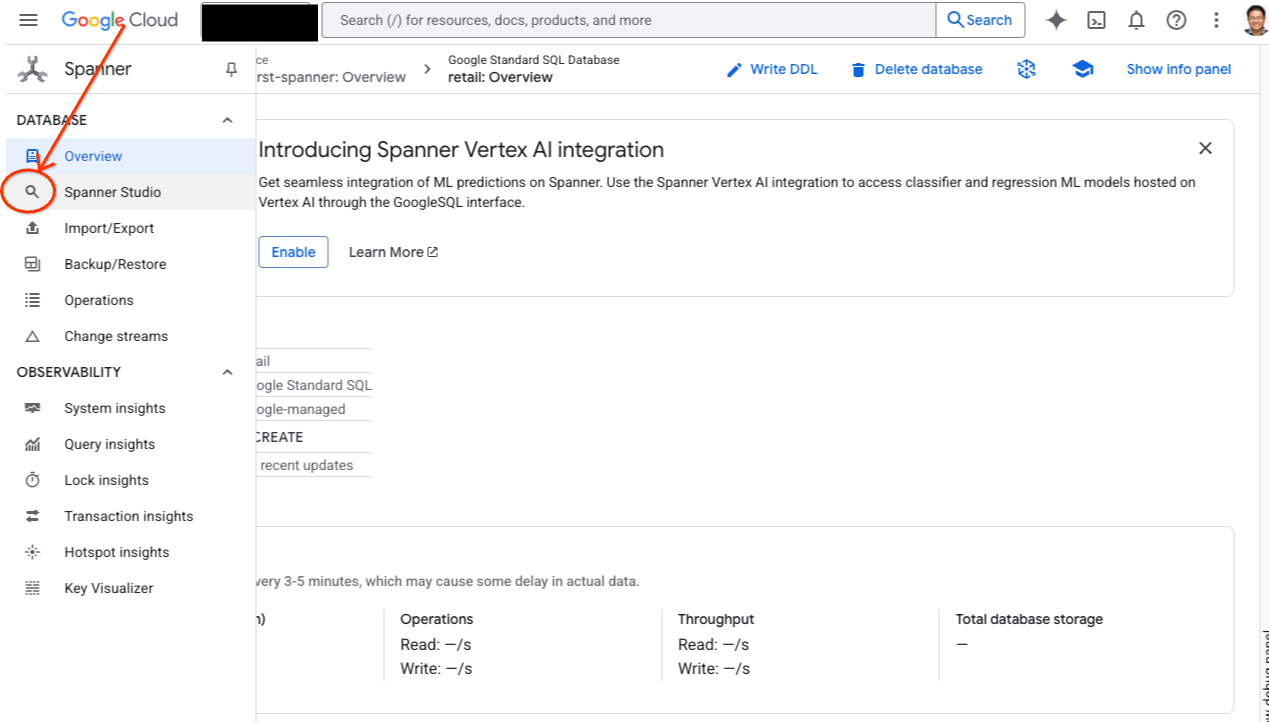
- Chuyển đến Spanner Studio. Spanner Studio có một ngăn Trình khám phá tích hợp với trình chỉnh sửa truy vấn và bảng kết quả truy vấn SQL. Bạn có thể chạy các câu lệnh DDL, DML và SQL từ một giao diện này. Bạn sẽ cần mở rộng trình đơn ở bên cạnh, tìm biểu tượng kính lúp.
- Đọc bảng Sản phẩm. Tạo một thẻ mới hoặc sử dụng thẻ "Truy vấn chưa có tiêu đề" đã tạo.
SELECT *
FROM Products;
5. Bước 2: Tạo mô hình AI.
Bây giờ, hãy tạo các mô hình từ xa bằng các đối tượng Spanner. Các câu lệnh SQL này tạo ra các đối tượng Spanner liên kết đến các điểm cuối Vertex AI.
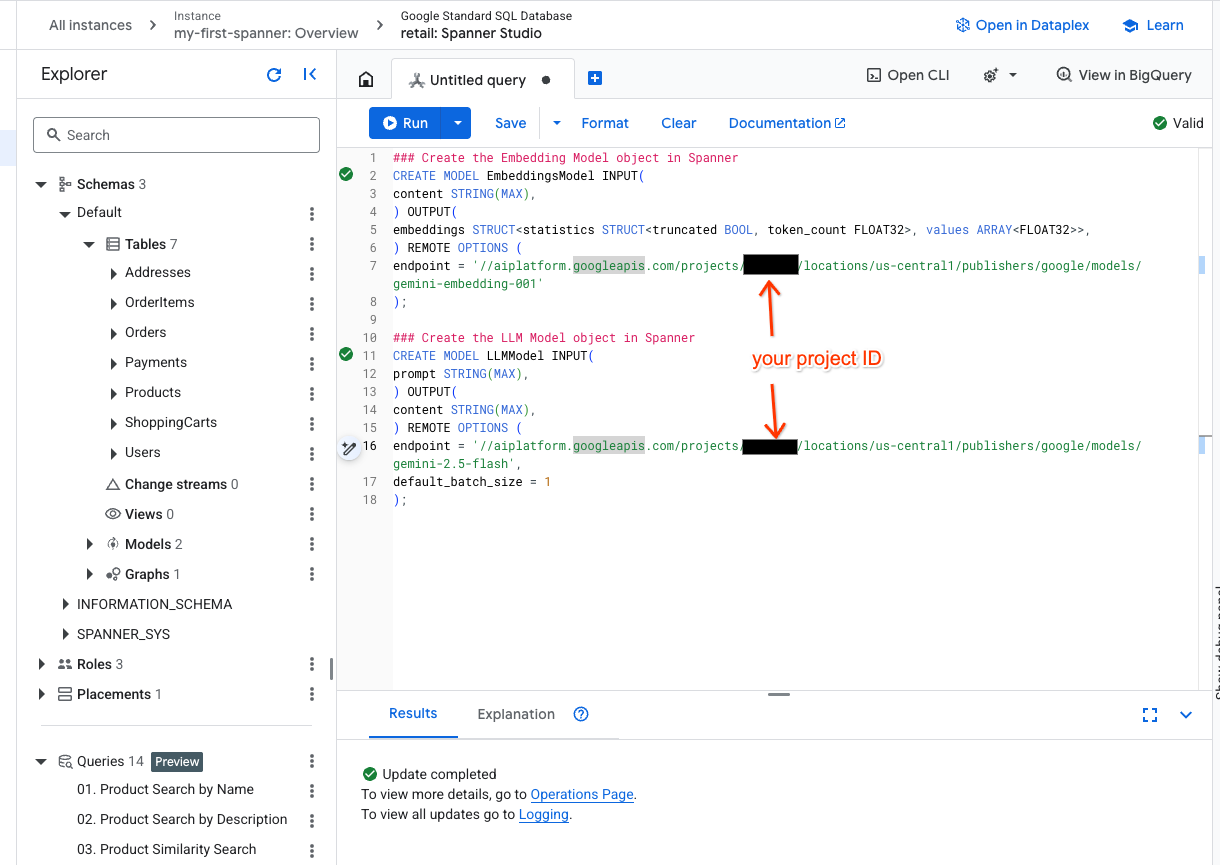
- Mở một thẻ mới trong Spanner Studio rồi tạo hai mô hình. Đầu tiên là EmbeddingsModel, cho phép bạn tạo các mục nhúng. Thứ hai là LLMModel, cho phép bạn tương tác với một LLM (trong ví dụ của chúng tôi, đó là gemini-2.5-flash). Đảm bảo bạn đã cập nhật <PROJECT_ID> bằng mã dự án của mình.
### Create the Embedding Model object in Spanner
CREATE MODEL EmbeddingsModel INPUT(
content STRING(MAX),
) OUTPUT(
embeddings STRUCT<statistics STRUCT<truncated BOOL, token_count FLOAT32>, values ARRAY<FLOAT32>>,
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-005'
);
### Create the LLM Model object in Spanner
CREATE MODEL LLMModel INPUT(
prompt STRING(MAX),
) OUTPUT(
content STRING(MAX),
) REMOTE OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.5-flash',
default_batch_size = 1
);
- Lưu ý: Hãy nhớ thay thế
PROJECT_IDbằng$PROJECT_IDthực tế của bạn.
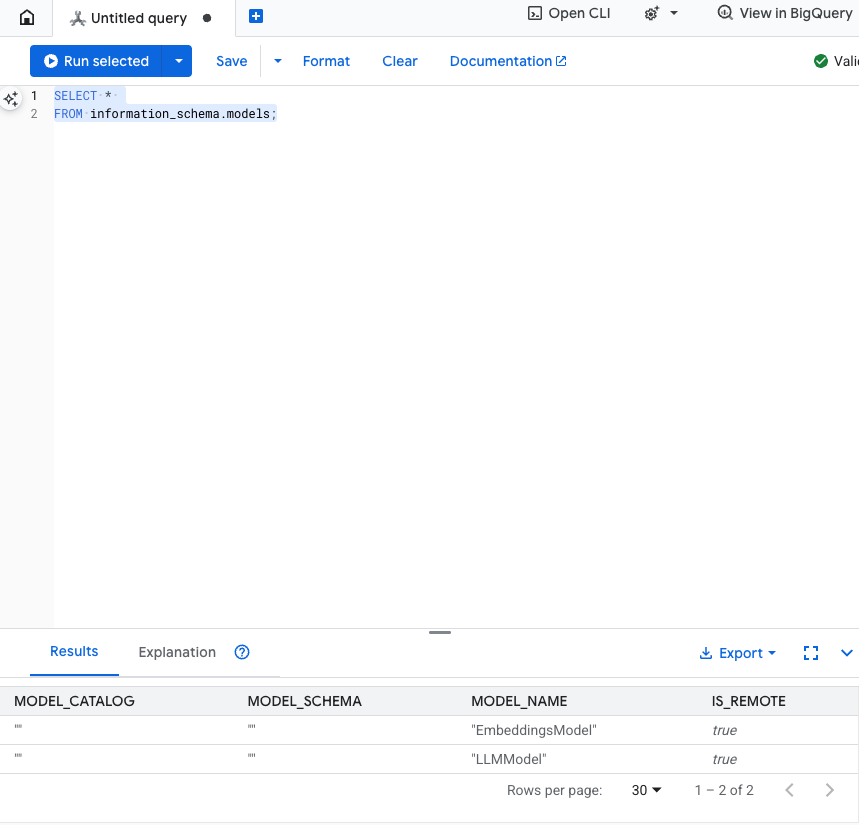
Kiểm thử bước này: Bạn có thể xác minh rằng các mô hình đã được tạo bằng cách chạy nội dung sau trong trình chỉnh sửa SQL.
SELECT *
FROM information_schema.models;
6. Bước 3: Tạo và lưu trữ các vectơ nhúng
Bảng Sản phẩm của chúng tôi có nội dung mô tả bằng văn bản, nhưng mô hình AI hiểu được các vectơ (mảng số). Chúng ta cần thêm một cột mới để lưu trữ các vectơ này, sau đó điền sẵn bằng cách chạy tất cả nội dung mô tả sản phẩm thông qua EmbeddingsModel.
- Tạo một bảng mới để hỗ trợ các mục nhúng. Trước tiên, hãy tạo một bảng có thể hỗ trợ các thành phần nhúng. Chúng tôi đang sử dụng một mô hình nhúng khác với các mục nhúng mẫu trong bảng sản phẩm. Bạn cần đảm bảo rằng các mục nhúng được tạo từ cùng một mô hình để tính năng tìm kiếm vectơ hoạt động đúng cách.
CREATE TABLE products_with_embeddings (
ProductID INT64,
embedding_vector ARRAY<FLOAT32>(vector_length=>768),
embedding_text STRING(MAX)
)
PRIMARY KEY (ProductID);
- Điền vào bảng mới bằng các vectơ nhúng được tạo từ mô hình. Để đơn giản, chúng ta sẽ dùng câu lệnh chèn vào. Thao tác này sẽ đẩy kết quả truy vấn vào bảng mà bạn vừa tạo.
Câu lệnh SQL này trước tiên sẽ lấy và nối tất cả các cột văn bản có liên quan mà chúng ta muốn tạo các vectơ nhúng. Sau đó, chúng tôi sẽ trả về thông tin liên quan, bao gồm cả văn bản mà chúng tôi đã sử dụng. Thông thường, bạn không cần làm việc này nhưng chúng tôi vẫn đưa vào để bạn có thể hình dung kết quả.
INSERT INTO products_with_embeddings (productId, embedding_text, embedding_vector)
SELECT
ProductID,
content as embedding_text,
embeddings.values as embedding_vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(
SELECT
ProductID,
embedding_text AS content
FROM (
SELECT
ProductID,
CONCAT(
Category,
" ",
Description,
" ",
Name
) AS embedding_text
FROM products)));
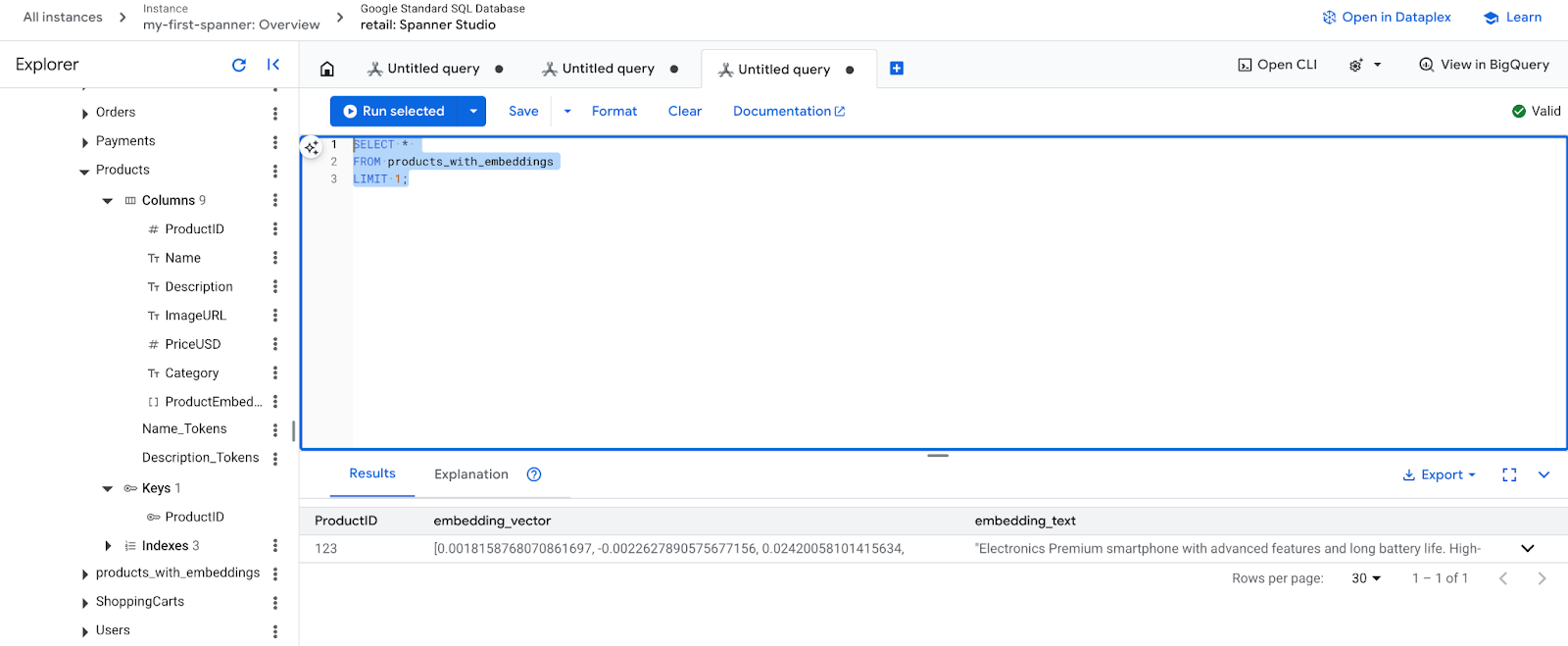
- Kiểm tra các mục nhúng mới. Lúc này, bạn sẽ thấy các mục nhúng đã được tạo.
SELECT *
FROM products_with_embeddings
LIMIT 1;
7. Bước 4: Tạo chỉ mục vectơ cho tìm kiếm ANN
Để tìm kiếm hàng triệu vectơ ngay lập tức, chúng ta cần một chỉ mục. Chỉ mục này cho phép tìm kiếm Người Nhân Nhất Gần Đúng (ANN), có tốc độ cực nhanh và có thể mở rộng theo chiều ngang.
- Chạy truy vấn DDL sau để tạo chỉ mục. Chúng tôi chỉ định
COSINElàm chỉ số khoảng cách, rất phù hợp cho tính năng tìm kiếm văn bản ngữ nghĩa. Xin lưu ý rằng mệnh đề WHERE thực sự cần thiết vì Spanner sẽ yêu cầu truy vấn phải có mệnh đề này.
CREATE VECTOR INDEX DescriptionEmbeddingIndex
ON products_with_embeddings(embedding_vector)
WHERE embedding_vector IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
- Kiểm tra trạng thái tạo chỉ mục trong thẻ thao tác.
8. Bước 5: Tìm đề xuất bằng tính năng tìm kiếm K lân cận gần nhất (KNN)
Giờ đến phần thú vị! Hãy tìm những sản phẩm phù hợp với câu hỏi của khách hàng: "Tôi muốn mua một bàn phím hiệu suất cao. Đôi khi tôi viết mã khi đang ở bãi biển nên có thể thiết bị sẽ bị ướt.".
Chúng ta sẽ bắt đầu với tìm kiếm K-Neighbor (KNN). Đây là một cụm từ tìm kiếm chính xác, so sánh vectơ truy vấn của chúng ta với từng vectơ sản phẩm. Phương pháp này chính xác nhưng có thể chậm đối với các tập dữ liệu rất lớn (đó là lý do chúng tôi tạo chỉ mục ANN cho Bước 5).
Truy vấn này thực hiện hai việc:
- Một truy vấn phụ sử dụng ML.PREDICT để lấy vectơ nhúng cho truy vấn của khách hàng.
- Truy vấn bên ngoài sử dụng COSINE_DISTANCE để tính "khoảng cách" giữa vectơ truy vấn và embedding_vector của mỗi sản phẩm. Khoảng cách càng nhỏ thì kết quả càng phù hợp.
SELECT
productid,
embedding_text,
COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
) AS distance
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Bạn sẽ thấy một danh sách sản phẩm, trong đó có bàn phím chịu được nước ở vị trí đầu tiên.
9. Bước 6: Tìm đề xuất bằng tính năng Tìm kiếm tương tự (ANN)
KNN là một lựa chọn tuyệt vời, nhưng đối với một hệ thống sản xuất có hàng triệu sản phẩm và hàng nghìn truy vấn mỗi giây, chúng ta cần tốc độ của chỉ mục ANN.
Để sử dụng chỉ mục, bạn phải chỉ định hàm APPROX_COSINE_DISTANCE.
- Lấy vectơ nhúng của văn bản như bạn đã làm ở trên. Chúng tôi kết hợp các kết quả đó với các bản ghi trong bảng products_with_embeddings để bạn có thể sử dụng kết quả đó trong hàm APPROX_COSINE_DISTANCE.
WITH vector_query as
(
SELECT embeddings.values as vector
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." as content)
)
)
SELECT
ProductID,
embedding_text,
APPROX_COSINE_DISTANCE(embedding_vector, vector, options => JSON '{\"num_leaves_to_search\": 10}') distance
FROM products_with_embeddings @{force_index=DescriptionEmbeddingIndex},
vector_query
WHERE embedding_vector IS NOT NULL
ORDER BY distance
LIMIT 5;
Đầu ra dự kiến: Kết quả phải giống hệt hoặc rất giống với truy vấn KNN, nhưng được thực thi hiệu quả hơn nhiều bằng cách sử dụng chỉ mục. Bạn có thể không nhận thấy điều này trong ví dụ.
10. Bước 7: Sử dụng LLM để giải thích các đề xuất
Chỉ hiển thị danh sách sản phẩm là tốt, nhưng giải thích lý do tại sao sản phẩm đó phù hợp hoặc không phù hợp thì càng tốt. Chúng ta có thể dùng LLMModel (Gemini) để thực hiện việc này.
Truy vấn này lồng truy vấn KNN của chúng ta từ Bước 4 vào bên trong một lệnh gọi ML.PREDICT. Chúng ta sẽ dùng hàm CONCAT để tạo một câu lệnh cho LLM, cung cấp cho LLM:
- Hướng dẫn rõ ràng ("Trả lời bằng "Có" hoặc "Không" và giải thích lý do...").
- Cụm từ tìm kiếm ban đầu của khách hàng.
- Tên và nội dung mô tả của từng sản phẩm phù hợp nhất.
Sau đó, LLM sẽ đánh giá từng sản phẩm dựa trên cụm từ tìm kiếm và đưa ra câu trả lời bằng ngôn ngữ tự nhiên.
SELECT
ProductID,
embedding_text,
content AS LLMResponse
FROM ML.PREDICT(
MODEL LLMModel,
(
SELECT
ProductID,
embedding_text,
CONCAT(
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me?",
"I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet. \n",
"Product Description:", embedding_text
) AS prompt,
FROM products_with_embeddings
WHERE embedding_vector IS NOT NULL
ORDER BY COSINE_DISTANCE(
embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 5
),
STRUCT(1056 AS maxOutputTokens)
);
Kết quả dự kiến: Bạn sẽ nhận được một bảng có cột LLMResponse mới. Câu trả lời nên có dạng như: "Không. Lý do là: * "Chịu được nước" không phải là "hoàn toàn chống nước". Bàn phím "chống nước" có thể chịu được nước bắn, mưa nhẹ hoặc chất lỏng đổ vào"
11. Bước 8: Tạo biểu đồ thuộc tính
Bây giờ, hãy xem một loại đề xuất khác: "những khách hàng đã mua mặt hàng này cũng mua..."
Đây là một truy vấn dựa trên mối quan hệ. Biểu đồ thuộc tính là công cụ hoàn hảo cho việc này. Spanner cho phép bạn tạo một biểu đồ trên các bảng hiện có mà không cần sao chép dữ liệu.
Câu lệnh DDL này xác định biểu đồ của chúng ta:
- Nút: bảng
ProductvàUser. Các nút là những thực thể mà bạn muốn rút ra mối quan hệ, bạn muốn biết những khách hàng đã mua sản phẩm của bạn cũng đã mua sản phẩm "XYZ". - Cạnh: Bảng
Orders, kết nốiUser(Nguồn) vớiProduct(Đích đến) bằng nhãn "Đã mua". Các cạnh cung cấp mối quan hệ giữa người dùng và những gì họ đã mua.
CREATE PROPERTY GRAPH RetailGraph
NODE TABLES (
products_with_embeddings,
Orders
)
EDGE TABLES (
OrderItems
SOURCE KEY (OrderID) REFERENCES Orders
DESTINATION KEY (ProductID) REFERENCES products_with_embeddings
LABEL Purchased
);
12. Bước 9: Kết hợp tính năng Tìm kiếm vectơ và Truy vấn đồ thị
Đây là bước mạnh mẽ nhất. Chúng tôi sẽ kết hợp tính năng tìm kiếm vectơ dựa trên AI và truy vấn đồ thị trong một câu lệnh duy nhất để tìm các sản phẩm có liên quan.
Cụm từ tìm kiếm này được đọc thành 3 phần, phân tách bằng dấu NEXT statement. Hãy chia cụm từ này thành các phần.
- Trước tiên, chúng tôi tìm kết quả phù hợp nhất bằng tính năng tìm kiếm vectơ.
- ML.PREDICT tạo một vectơ nhúng từ truy vấn văn bản của người dùng bằng EmbeddingsModel.
- Truy vấn này tính toán COSINE_DISTANCE giữa vectơ nhúng mới này và p.embedding_vector được lưu trữ cho tất cả sản phẩm.
- Hàm này chọn và trả về một sản phẩm bestMatch duy nhất có khoảng cách tối thiểu (mức độ tương đồng ngữ nghĩa cao nhất).
- Tiếp theo, chúng ta sẽ duyệt qua biểu đồ để tìm mối quan hệ.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
- Truy vấn này truy xuất ngược từ bestMatch đến các nút Orders (user) phổ biến, sau đó chuyển tiếp đến các sản phẩm purchasedWith khác.
- Thao tác này sẽ lọc ra sản phẩm ban đầu và sử dụng GROUP BY và COUNT(1) để tổng hợp tần suất các mặt hàng được mua cùng nhau.
- Hàm này trả về 3 sản phẩm được mua cùng nhau (purchasedWith) hàng đầu, được sắp xếp theo tần suất xuất hiện cùng nhau.
Ngoài ra, chúng tôi còn tìm thấy Mối quan hệ giữa người dùng và đơn đặt hàng.
NEXT MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
- Bước trung gian này thực thi mẫu duyệt qua để liên kết các thực thể chính: bestMatch, nút Orders kết nối người dùng và mặt hàng purchasedWith.
- Thao tác này liên kết mối quan hệ đó dưới dạng đã mua để trích xuất dữ liệu ở bước tiếp theo.
- Mẫu này đảm bảo bối cảnh được thiết lập để tìm nạp thông tin chi tiết cụ thể về đơn đặt hàng và sản phẩm.
- Cuối cùng, chúng ta xuất kết quả được trả về dưới dạng các nút đồ thị phải được định dạng trước khi được trả về dưới dạng kết quả SQL.
GRAPH RetailGraph
MATCH (p:products_with_embeddings)
WHERE p.embedding_vector IS NOT NULL
RETURN p AS bestMatch
ORDER BY COSINE_DISTANCE(
p.embedding_vector,
(
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a high performance keyboard. I sometimes code while I'm at the beach so it may get wet." AS content)
)
)
)
LIMIT 1
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[:Purchased]->(purchasedWith:products_with_embeddings)
FILTER bestMatch.productId <> purchasedWith.productId
RETURN bestMatch, purchasedWith
GROUP BY bestMatch, purchasedWith
ORDER BY COUNT(1) DESC
LIMIT 3
NEXT
MATCH (bestMatch)<-[:Purchased]-(user:Orders)-[purchased:Purchased]->(purchasedWith)
RETURN
TO_JSON(Purchased) AS purchased,
TO_JSON(user.OrderID) AS user,
TO_JSON(purchasedWith.productId) AS purchasedWith;
Đầu ra dự kiến: Bạn sẽ thấy các đối tượng JSON đại diện cho 3 mặt hàng được mua cùng nhau hàng đầu, cung cấp các đề xuất bán kèm.
13. Dọn dẹp
Để không bị tính phí, bạn có thể xoá các tài nguyên mà mình đã tạo.
- Xoá phiên bản Spanner: Khi xoá phiên bản, bạn cũng sẽ xoá cơ sở dữ liệu.
gcloud spanner instances delete my-first-spanner --quiet
- Xoá dự án trên Google Cloud: Nếu bạn tạo dự án này chỉ cho lớp học lập trình, thì việc xoá dự án là cách dễ nhất để dọn dẹp.
- Chuyển đến trang Quản lý tài nguyên trong Google Cloud Console.
- Chọn dự án của bạn rồi nhấp vào Xoá.
🎉 Xin chúc mừng!
Bạn đã tạo thành công một hệ thống đề xuất phức tạp theo thời gian thực bằng Spanner AI và Graph!
Bạn đã học được cách tích hợp Spanner với Vertex AI để tạo các giá trị nhúng và LLM, cách thực hiện tìm kiếm vectơ tốc độ cao (KNN và ANN) để tìm các sản phẩm có liên quan về mặt ngữ nghĩa và cách sử dụng các truy vấn đồ thị để khám phá mối quan hệ giữa các sản phẩm. Bạn đã xây dựng một hệ thống không chỉ có thể tìm sản phẩm mà còn có thể giải thích các đề xuất và đề xuất các mặt hàng có liên quan, tất cả đều từ một cơ sở dữ liệu duy nhất có khả năng mở rộng.