
1. Wprowadzenie
Spanner to usługa baz danych w pełni zarządzana, skalowana w poziomie i rozmieszczona globalnie, która doskonale sprawdza się w przypadku relacyjnych i nierelacyjnych obciążeń operacyjnych.
Spanner ma wbudowaną obsługę wyszukiwania wektorowego, co umożliwia przeprowadzanie wyszukiwania podobieństw lub semantycznego oraz wdrażanie generowania rozszerzonego przez wyszukiwanie w zapisanych informacjach (RAG) w aplikacjach GenAI na dużą skalę przy użyciu funkcji dokładnego wyszukiwania K najbliższych sąsiadów (KNN) lub przybliżonego wyszukiwania najbliższych sąsiadów (ANN).
Zapytania dotyczące wyszukiwania wektorowego w Spannerze zwracają aktualne dane w czasie rzeczywistym natychmiast po zatwierdzeniu transakcji, tak samo jak każde inne zapytanie dotyczące danych operacyjnych.
W tym laboratorium dowiesz się, jak skonfigurować podstawowe funkcje wymagane do korzystania ze Spannera w celu przeprowadzania wyszukiwania wektorowego oraz uzyskiwania dostępu do wektorów dystrybucyjnych i modeli LLM z bazy modeli Vertex AI za pomocą SQL.
Architektura wyglądałaby tak:
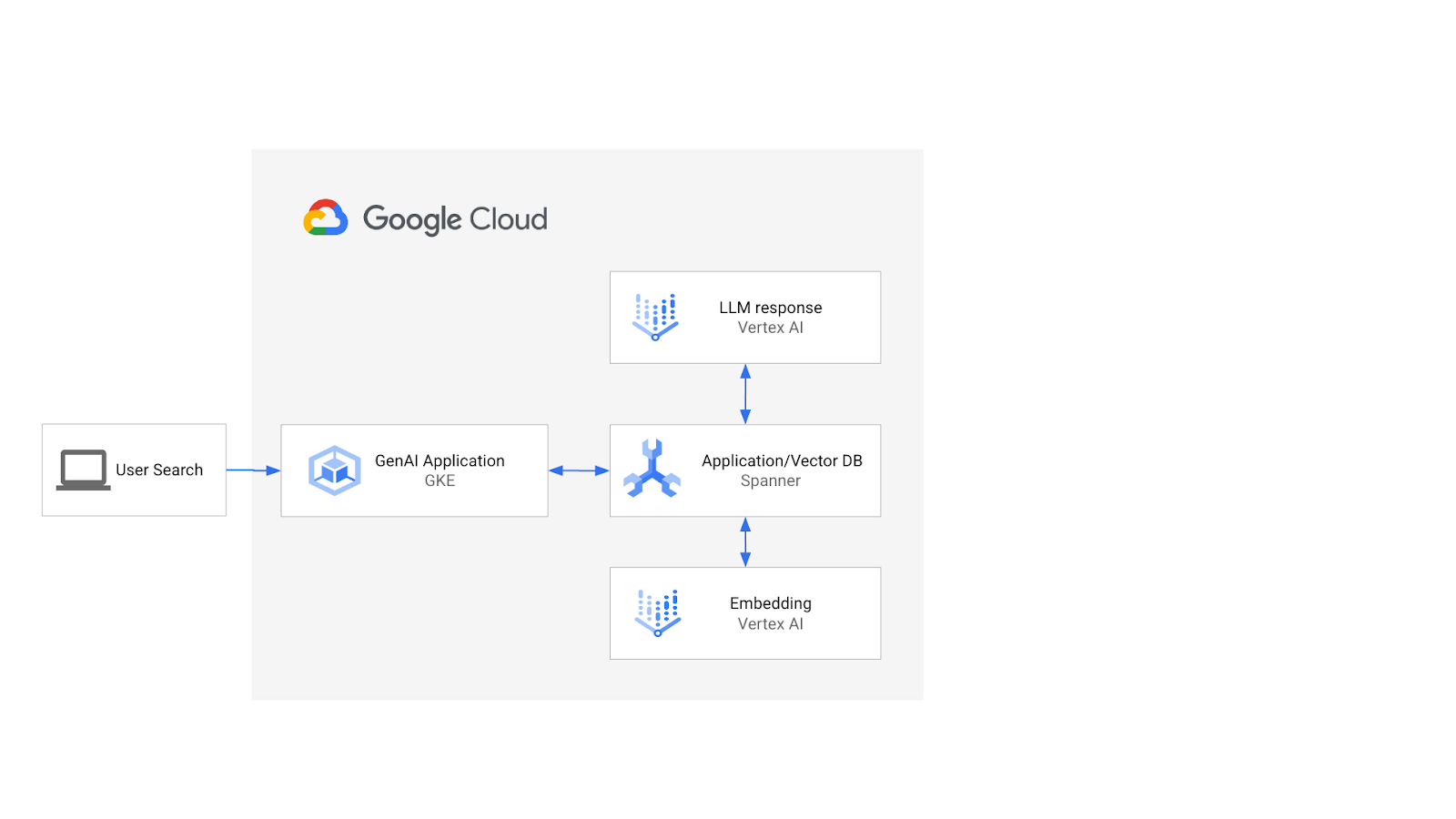
Na tej podstawie dowiesz się, jak utworzyć indeks wektorowy oparty na algorytmie ScaNN, i jak używać funkcji odległości APPROX, gdy Twoje semantyczne zadania wymagają skalowania.
Co utworzysz
W ramach tego laboratorium:
- Tworzenie instancji usługi Spanner
- Konfigurowanie schematu bazy danych Spanner na potrzeby integracji z wektorami dystrybucyjnymi i modelami LLM w Vertex AI
- Wczytywanie zbioru danych o sprzedaży detalicznej
- Wysyłanie do zbioru danych zapytań o podobne problemy
- Przekaż modelowi LLM kontekst, aby generować rekomendacje dotyczące konkretnych produktów.
- Zmodyfikuj schemat i utwórz indeks wektorowy.
- Zmień zapytania, aby korzystać z nowo utworzonego indeksu wektorowego.
Czego się nauczysz
- Konfigurowanie instancji usługi Spanner
- Integracja z Vertex AI
- Jak używać usługi Spanner do wyszukiwania wektorowego w celu znajdowania podobnych produktów w zbiorze danych dotyczących handlu detalicznego
- Jak przygotować bazę danych do skalowania obciążeń związanych z wyszukiwaniem wektorowym za pomocą wyszukiwania ANN.
Czego potrzebujesz
2. Konfiguracja i wymagania
Utwórz projekt
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform ( console.cloud.google.com) i utwórz nowy projekt.
Jeśli masz już projekt, kliknij menu wyboru projektu w lewym górnym rogu konsoli:

i w wyświetlonym oknie kliknij przycisk „NOWY PROJEKT”, aby utworzyć nowy projekt:
Jeśli nie masz jeszcze projektu, powinien wyświetlić się taki dialog, w którym możesz utworzyć pierwszy projekt:
W kolejnym oknie dialogowym tworzenia projektu możesz wpisać szczegóły nowego projektu:
Zapamiętaj identyfikator projektu, który jest unikalną nazwą we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tych ćwiczeń z programowania będzie on nazywany PROJECT_ID.
Następnie, jeśli jeszcze tego nie zrobisz, musisz włączyć płatności w Konsoli deweloperów, aby korzystać z zasobów Google Cloud i włączyć interfejs Spanner API.
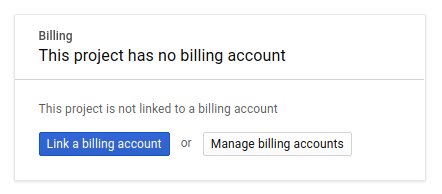
Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu). Ceny Google Cloud Spanner są opisane tutaj.
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD, co powinno sprawić, że to ćwiczenie w Codelabs będzie całkowicie bezpłatne.
Konfiguracja Google Cloud Shell
Z Google Cloud i Spannerem można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjemy Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Oznacza to, że do ukończenia tego ćwiczenia potrzebujesz tylko przeglądarki (działa ona na Chromebooku).
- Aby aktywować Cloud Shell w konsoli Cloud, kliknij Aktywuj Cloud Shell
 (udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
(udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
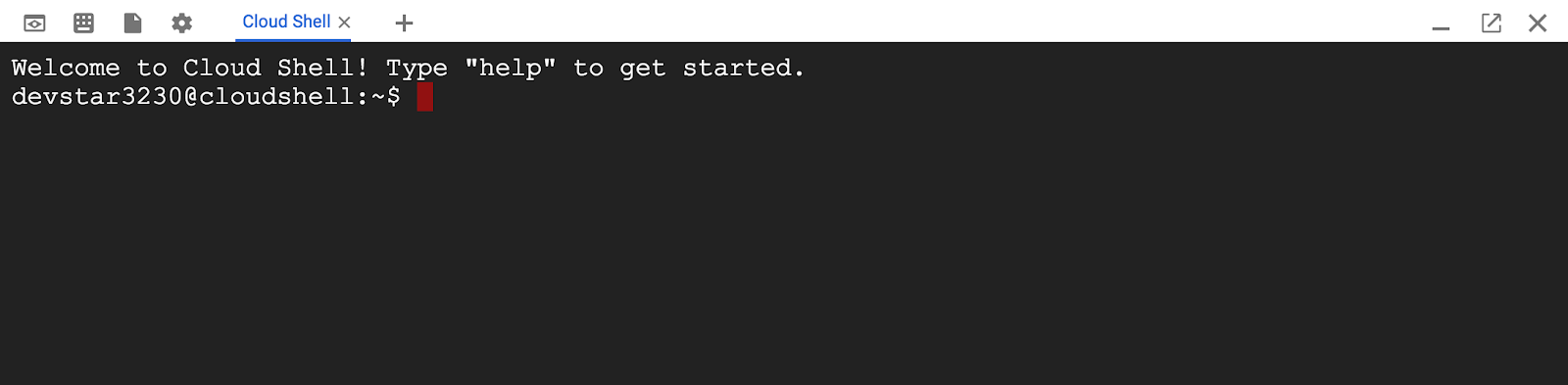
Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator PROJECT_ID.
gcloud auth list
Wynik polecenia
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Wynik polecenia
[core]
project = <PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest ustawiony, po prostu wydaj to polecenie:
gcloud config set project <PROJECT_ID>
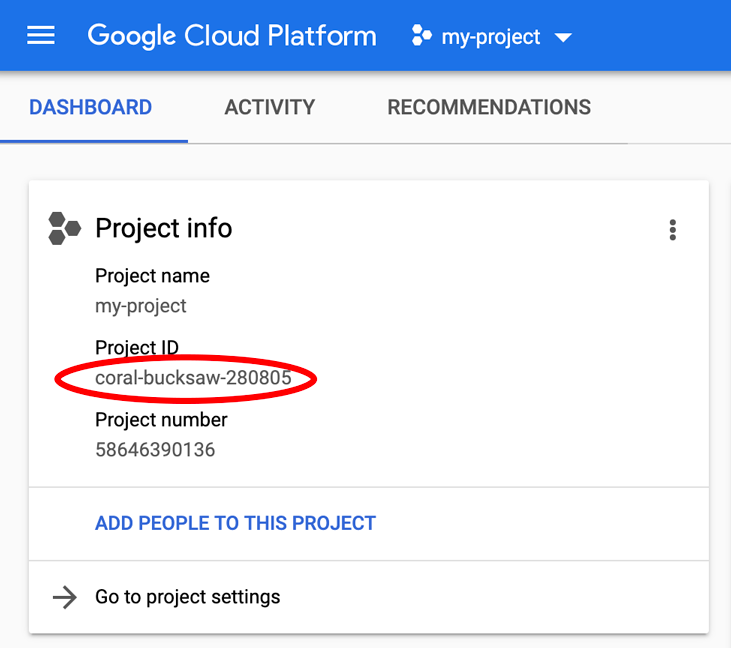
Szukasz urządzenia PROJECT_ID? Sprawdź, jakiego identyfikatora użyto w krokach konfiguracji, lub wyszukaj go w panelu konsoli Cloud:
Cloud Shell domyślnie ustawia też niektóre zmienne środowiskowe, które mogą być przydatne podczas wykonywania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Wynik polecenia
<PROJECT_ID>
Włącz interfejsy Spanner API i Vertex AI API
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
Sprawdź uprawnienia:
Jedyną rzeczą, która jest potrzebna w zasadach uprawnień, aby wyszukiwanie wektorowe działało w instancji Spannera, jest przyznanie kontu service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com roli Agent usługi Cloud Spanner API. W lewym górnym rogu kliknij ikonę z 3 paskami, jak poniżej:
Wyświetlą się uprawnienia:
Ustawienie IAM możesz sprawdzić w sekcji Uprawnienia, jak poniżej.
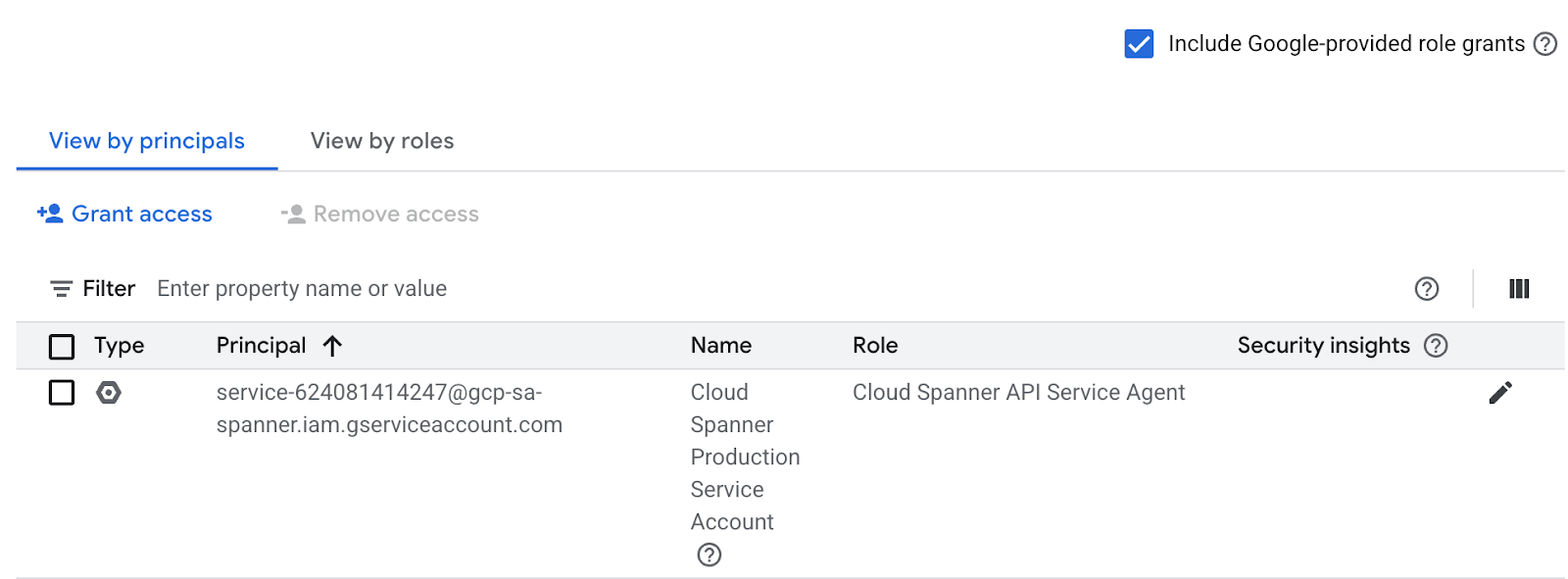
Jeśli nie ma tam Cloud Spanner API Service Agent, użyj poniższego polecenia, aby przyznać to uprawnienie. Więcej instrukcji znajdziesz tutaj.
$ gcloud beta services identity create --service=spanner.googleapis.com --project=<PROJECT_ID>
$ gcloud projects add-iam-policy-binding <PROJECT_NUMBER> --member=serviceAccount:service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com --role=roles/spanner.serviceAgent --condition=None
Podsumowanie
W tym kroku skonfigurowaliśmy projekt (jeśli nie był jeszcze utworzony), aktywowaliśmy Cloud Shell i włączyliśmy wymagane interfejsy API.
Następny krok
Następnie skonfigurujesz instancję i bazę danych Spanner.
3. Tworzenie instancji i bazy danych Spanner
Tworzenie instancji usługi Spanner
W tym kroku skonfigurujemy instancję Spannera na potrzeby ćwiczeń z programowania. Aby to zrobić, otwórz Cloud Shell i uruchom to polecenie:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--edition=ENTERPRISE \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
Najniższa wersja powinna być ENTERPRISE. Wersja STANDARD nie ma funkcji wyszukiwania wektorowego.
Wynik polecenia:
$ Creating instance...done.
Tworzenie bazy danych
Gdy instancja będzie działać, możesz utworzyć bazę danych. Spanner umożliwia korzystanie z wielu baz danych w jednej instancji.
W bazie danych definiujesz schemat. Możesz też kontrolować, kto ma dostęp do bazy danych, konfigurować niestandardowe szyfrowanie i optymalizator oraz ustawiać okres przechowywania.
Aby utworzyć bazę danych, ponownie użyj narzędzia wiersza poleceń gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Wynik polecenia:
$ Creating database...done.
Podsumowanie
W tym kroku utworzyliśmy instancję i bazę danych Spanner.
Następny krok
Następnie skonfigurujesz schemat i dane Spanner.
4. Wczytywanie schematu i danych Cymbal
Tworzenie schematu Cymbal
Aby skonfigurować schemat, otwórz Spanner Studio:
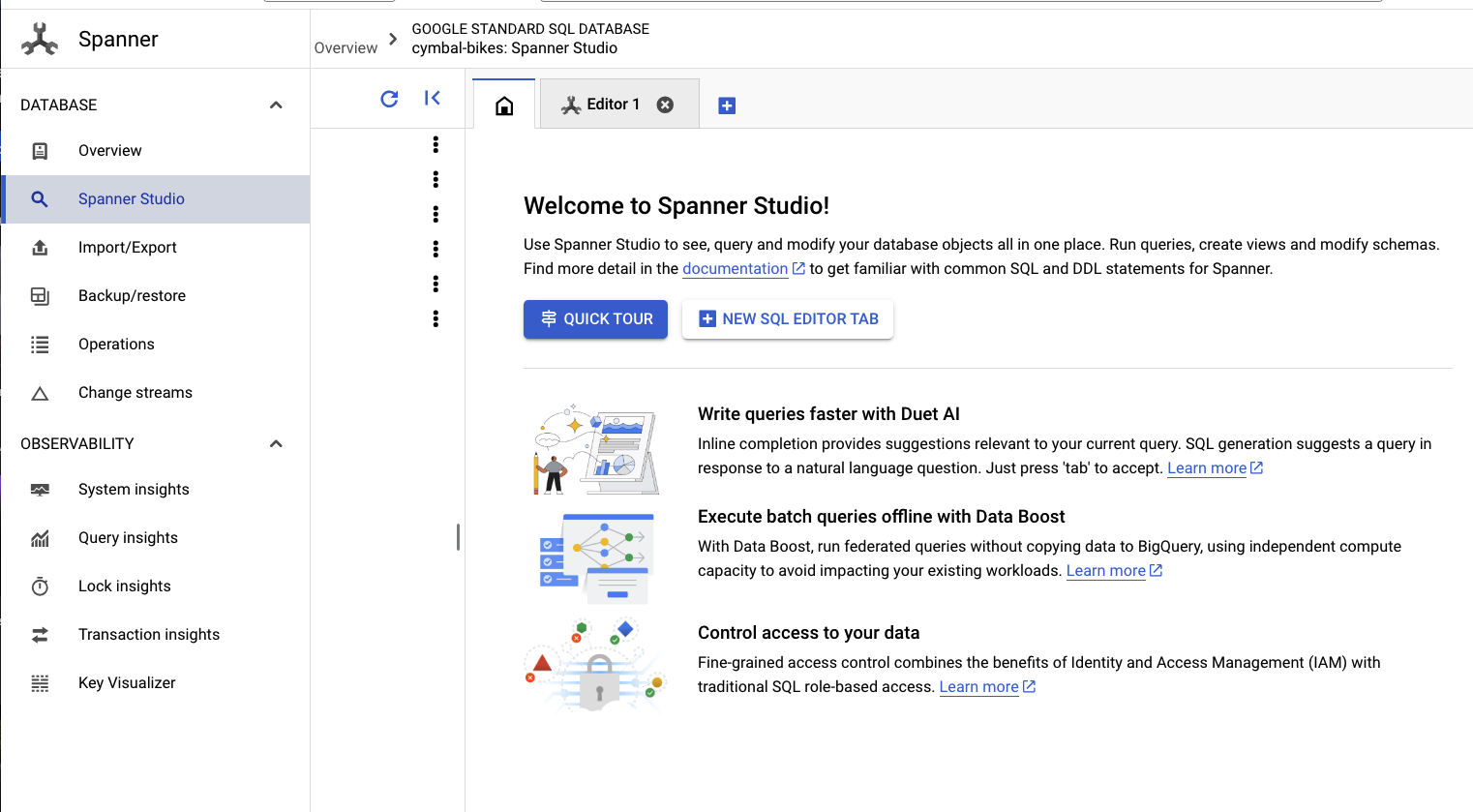
Schemat składa się z 2 części. Najpierw dodaj tabelę products. Skopiuj to oświadczenie i wklej je w pustej karcie.
W przypadku schematu skopiuj i wklej ten DDL w polu:
CREATE TABLE products(
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL
OPTIONS (
allow_commit_timestamp = TRUE),
inventoryCount INT64 NOT NULL,
priceInCents INT64,)
PRIMARY KEY(categoryId, productId);
Następnie kliknij przycisk run i poczekaj kilka sekund na utworzenie schematu.
Następnie utworzysz 2 modele i skonfigurujesz je w punktach końcowych modelu Vertex AI.
Pierwszy model to model osadzania, który służy do generowania osadzeń z tekstu, a drugi to model LLM, który służy do generowania odpowiedzi na podstawie danych w Spannerze.
Wklej ten schemat do nowej karty w Spanner Studio:
CREATE OR REPLACE MODEL EmbeddingsModel
INPUT(content STRING(MAX)) OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004');
CREATE OR REPLACE MODEL LLMModel
INPUT(prompt STRING(MAX)) OUTPUT(content STRING(MAX)) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.0-flash-001',
default_batch_size = 1);
Następnie kliknij przycisk run i poczekaj kilka sekund na utworzenie modeli.
W panelu po lewej stronie Spanner Studio powinny być widoczne te tabele i modele:
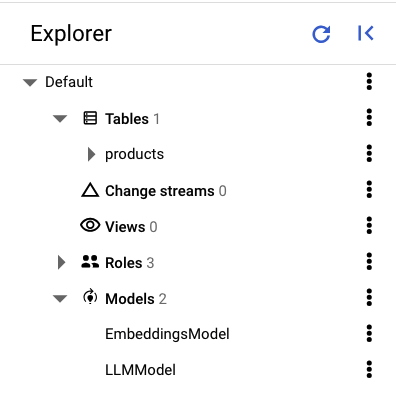
Wczytywanie danych
Teraz musisz wstawić do bazy danych kilka produktów. Otwórz nową kartę w Spanner Studio, a następnie skopiuj i wklej te instrukcje wstawiania:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Kliknij przycisk run, aby wstawić dane.
Podsumowanie
W tym kroku utworzyliśmy schemat i załadowaliśmy do bazy danych cymbal-bikes podstawowe dane.
Następny krok
Następnie zintegrujesz model wektorów dystrybucyjnych, aby generować wektory dystrybucyjne dla opisów produktów, a także przekształcać tekstowe żądanie wyszukiwania w wektor dystrybucyjny, aby wyszukiwać odpowiednie produkty.
5. Praca z wektorami dystrybucyjnymi
Generowanie wektorów dystrybucyjnych dla opisów produktów
Aby wyszukiwanie podobieństwa działało w przypadku produktów, musisz wygenerować wektory dystrybucyjne dla opisów produktów.
W przypadku EmbeddingsModel utworzonego w schemacie jest to prosta instrukcja UPDATE DML.
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content))
)
WHERE categoryId = 1;
Kliknij przycisk run, aby zaktualizować opisy produktów.
Jeśli napotkasz błąd, spróbuj wykonać polecenie SQL w terminalu za pomocą polecenia gcloud, aby uzyskać bardziej szczegółowy komunikat o błędzie, np.:
gcloud spanner databases execute-sql <YOUR_DATA_BASE> --instance=<YOUR_INSTANCE> --sql 'UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;'
Korzystanie z wyszukiwania wektorowego
W tym przykładzie podasz żądanie wyszukiwania w języku naturalnym za pomocą zapytania SQL. To zapytanie przekształci żądanie wyszukiwania w wektor dystrybucyjny, a następnie wyszuka podobne wyniki na podstawie zapisanych wektorów dystrybucyjnych opisów produktów wygenerowanych w poprzednim kroku.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Aby znaleźć podobne produkty, kliknij przycisk run. Wyniki powinny wyglądać tak:
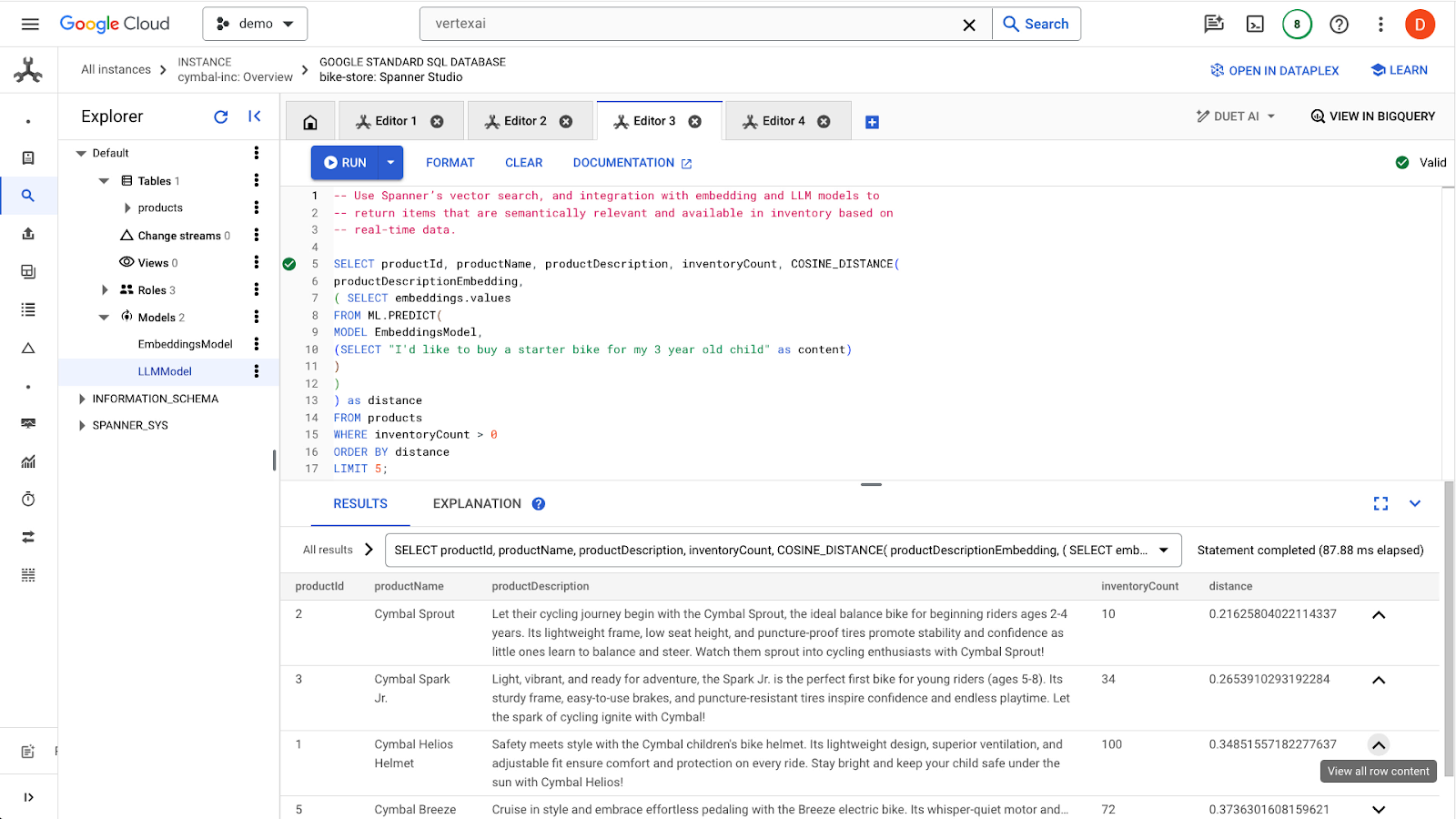
Zwróć uwagę, że w zapytaniu używane są dodatkowe filtry, np. tylko produkty dostępne w magazynie (inventoryCount > 0).
Podsumowanie
W tym kroku utworzyliśmy wektory dystrybucyjne opisów produktów i wektor dystrybucyjny żądania wyszukiwania za pomocą SQL, wykorzystując integrację Spannera z modelami w Vertex AI. Przeprowadziliśmy też wyszukiwanie wektorowe, aby znaleźć podobne produkty pasujące do żądania wyszukiwania.
Następne kroki
Następnie wykorzystajmy wyniki wyszukiwania, aby przekazać je do LLM i wygenerować spersonalizowaną odpowiedź dla każdego produktu.
6. Praca z LLM
Spanner ułatwia integrację z modelami LLM udostępnianymi z Vertex AI. Dzięki temu deweloperzy mogą używać SQL do bezpośredniej interakcji z LLM, zamiast wymagać od aplikacji wykonywania logiki.
Na przykład mamy wyniki poprzedniego zapytania SQL od użytkownika "I'd like to buy a starter bike for my 3 year old child".
Deweloper chce podać odpowiedź dla każdego wyniku, aby określić, czy produkt jest odpowiedni dla użytkownika. W tym celu używa tego prompta:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Oto zapytanie, którego możesz użyć:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM
ML.PREDICT(
MODEL LLMModel,
(
SELECT
FORMAT(
"""Answer with Yes or No and explain why: Is this a good fit for me?
I would like to buy a starter bike for my 3 year old child \n Product Name: %s\nProduct Description: %s""", productName,productDescription) AS prompt,
-- Pass through columns.
inventoryCount,
productName,
productDescription,
FROM products
WHERE inventoryCount > 0
ORDER BY
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
))
LIMIT 5
));
Aby wysłać zapytanie, kliknij przycisk run. Wyniki powinny wyglądać tak:
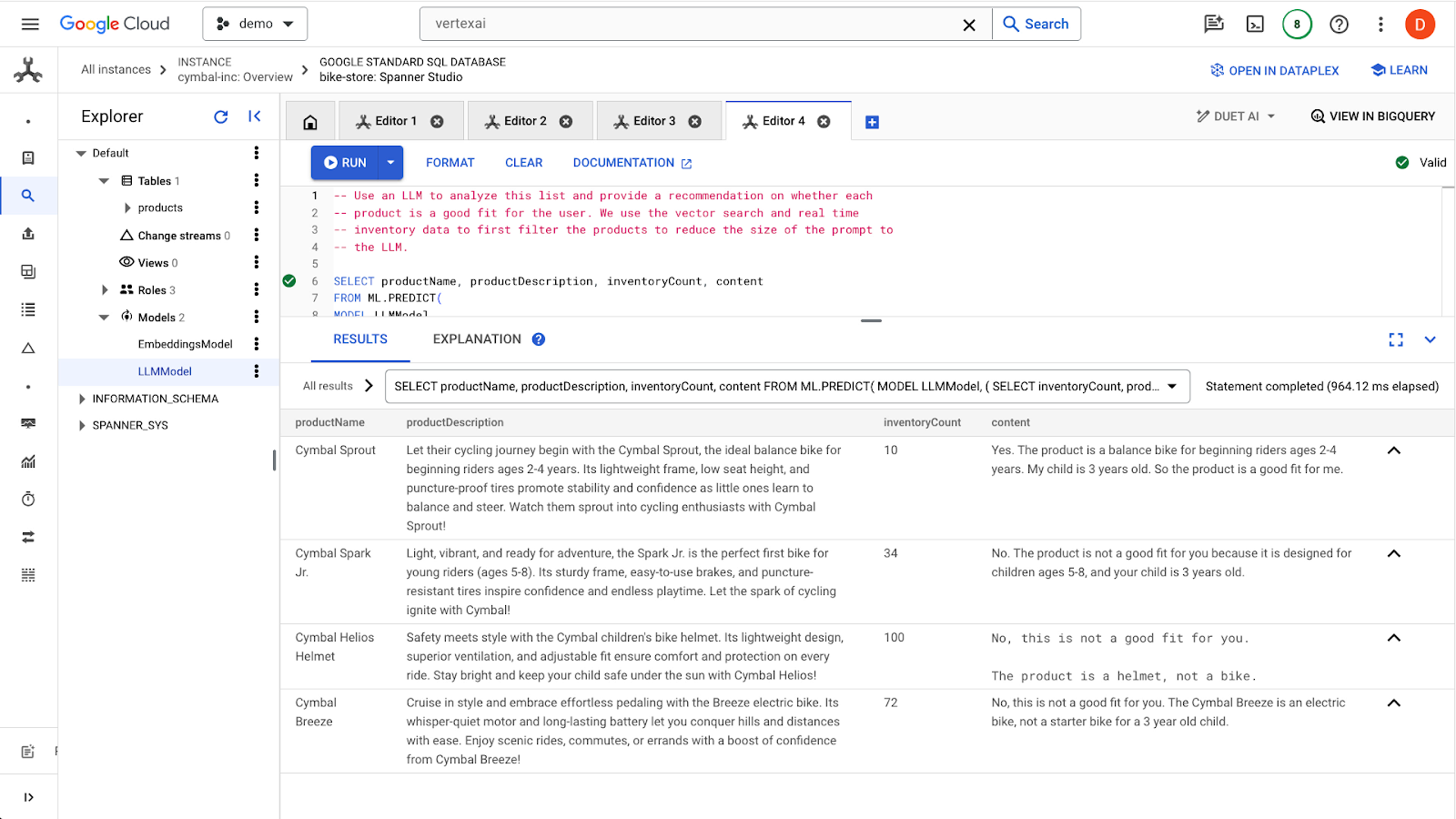
Pierwszy produkt jest odpowiedni dla 3-latka ze względu na przedział wiekowy podany w opisie produktu (2–4 lata). Pozostałe produkty nie są odpowiednie.
Podsumowanie
W tym kroku pracujesz z modelem LLM, aby generować podstawowe odpowiedzi na prompty użytkownika.
Następne kroki
Następnie dowiedz się, jak używać ANN do skalowania wyszukiwania wektorowego.
7. Skalowanie wyszukiwania wektorowego
W poprzednich przykładach wyszukiwania wektorowego używaliśmy dokładnego wyszukiwania wektorowego KNN. Jest to przydatne, gdy możesz wysyłać zapytania do bardzo konkretnych podzbiorów danych Spanner. Takie zapytania są łatwe do podzielenia.
Jeśli nie masz zbiorów zadań, które można łatwo podzielić na partycje, a masz dużą ilość danych, warto użyć wyszukiwania wektorowego ANN z wykorzystaniem algorytmu ScaNN, aby zwiększyć wydajność wyszukiwania.
Aby to zrobić w Spannerze, musisz wykonać 2 czynności:
- Tworzenie indeksu wektorowego
- Zmodyfikuj zapytanie, aby używać funkcji odległości APPROX.
Tworzenie indeksu wektorowego
Aby utworzyć indeks wektorowy w tym zbiorze danych, musimy najpierw zmodyfikować kolumnę productDescriptionEmbeddings, aby określić długość każdego wektora. Aby dodać długość wektora do kolumny, musisz usunąć oryginalną kolumnę i utworzyć ją ponownie.
ALTER TABLE products DROP COLUMN productDescriptionEmbedding;
ALTER TABLE products
ADD COLUMN productDescriptionEmbedding ARRAY<FLOAT32>(vector_length => 768);
Następnie ponownie utwórz wektory z kroku Generate Vector embedding, który został wcześniej wykonany.
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;
Po utworzeniu kolumny utwórz indeks:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Jeśli Cię to interesuje, zapoznaj się z dokumentacją PDML na stronie https://cloud.google.com/spanner/docs/backfill-embeddings. Pojedyncza instrukcja DML to transakcja podlegająca ograniczeniu 80 tys. mutacji, więc nie można aktualizować zbyt wielu wierszy naraz. PDML skutecznie dzieli dane na mniejsze partie.
Korzystanie z nowego indeksu
Aby użyć nowego indeksu wektorowego, musisz nieznacznie zmodyfikować poprzednie zapytanie dotyczące osadzania.
Oto oryginalne zapytanie:
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Musisz wprowadzić te zmiany:
- Użyj wskazówki dotyczącej indeksu w przypadku nowego indeksu wektorowego:
@{force_index=ProductDescriptionEmbeddingIndex} - Zmień wywołanie funkcji
COSINE_DISTANCEnaAPPROX_COSINE_DISTANCE. Pamiętaj, że opcje JSON w ostatecznym zapytaniu poniżej są również wymagane. - Wektory dystrybucyjne generuj osobno za pomocą funkcji ML.PREDICT.
- Skopiuj wyniki osadzania do ostatecznego zapytania.
Wygeneruj i użyj wektorów dystrybucyjnych:
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
);
Zaznacz wyniki zapytania i skopiuj je.
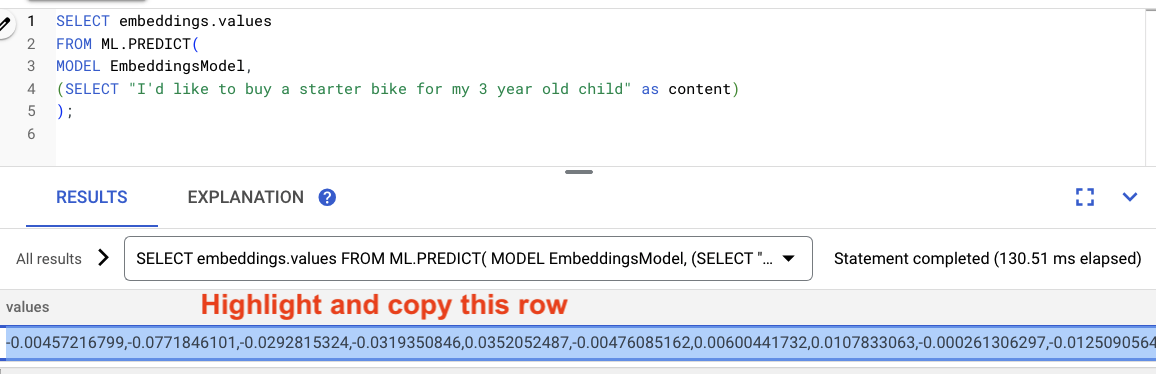
Następnie w tym zapytaniu zastąp <VECTOR>, wklejając skopiowane wektory.
-- Generate the embeddings and query them using the vector index
SELECT
productName,
productDescription,
inventoryCount,
APPROX_COSINE_DISTANCE(
productDescriptionEmbedding,
array<float32>[@VECTOR],
options => JSON '{\"num_leaves_to_search\": 10}') AS distance
FROM products @{force_index = ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Powinna wyglądać mniej więcej tak:
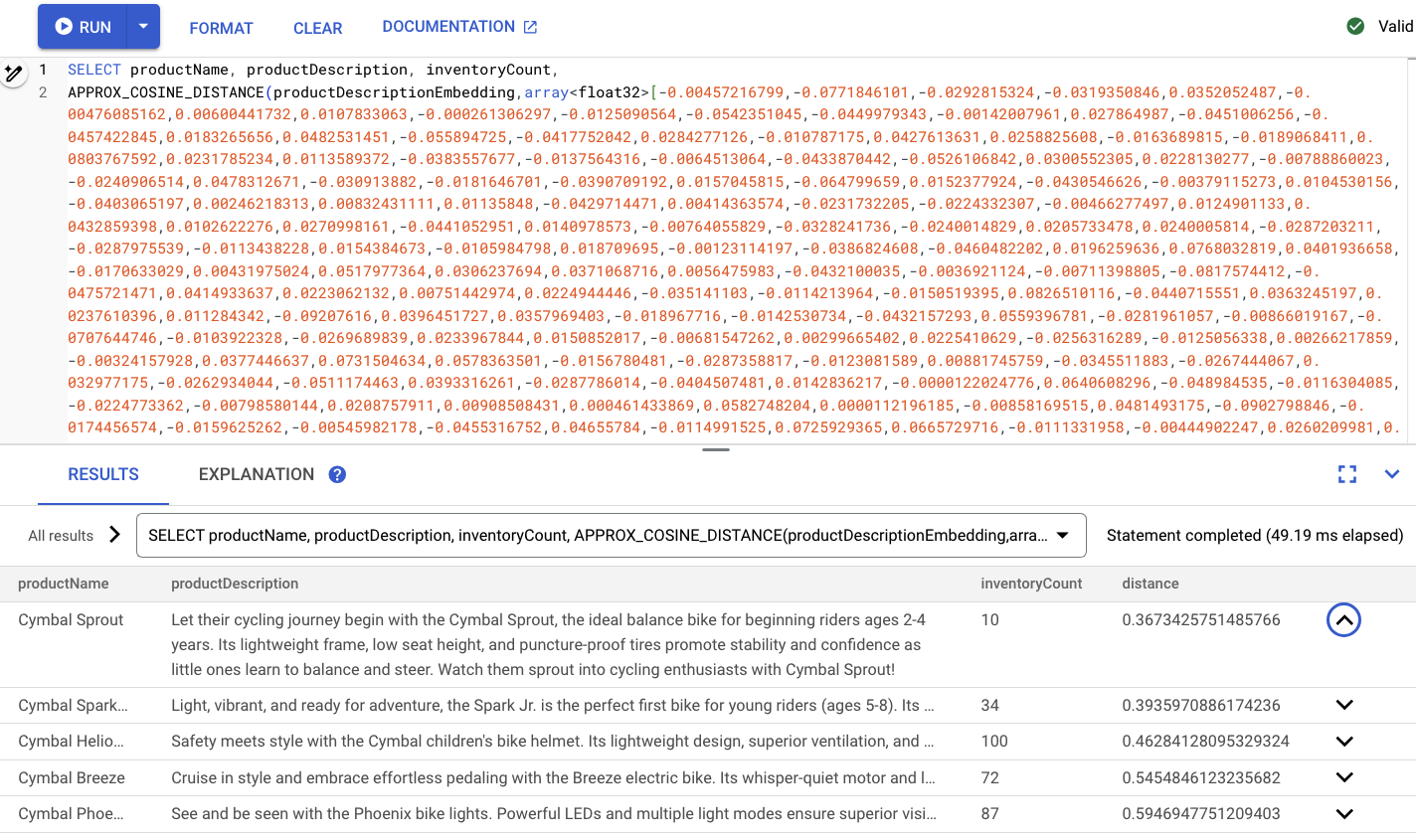
Podsumowanie
W tym kroku przekształcisz schemat, aby utworzyć indeks wektorowy. Następnie zmodyfikowano zapytanie o wektory dystrybucyjne, aby przeprowadzić wyszukiwanie ANN za pomocą indeksu wektorowego. Jest to ważny krok, ponieważ w miarę wzrostu ilości danych będziesz skalować zadania wyszukiwania wektorowego.
Następne kroki
Następnie czas na zwolnienie miejsca!
8. Czyszczenie (opcjonalnie)
Aby zwolnić miejsce, po prostu usuń instancję retail-demo utworzoną w tym ćwiczeniu.
9. Gratulacje!
Gratulujemy! Udało Ci się przeprowadzić wyszukiwanie podobieństwa za pomocą wbudowanej w Spanner wyszukiwarki wektorowej. Pokazaliśmy też, jak łatwo można pracować z modelami wektorów dystrybucyjnych i LLM, aby udostępniać funkcje generatywnej AI bezpośrednio za pomocą SQL.
Na koniec dowiedzieliśmy się, jak przeprowadzać wyszukiwanie ANN oparte na algorytmie ScaNN, aby skalować zadania wyszukiwania wektorowego.
Co dalej?
Więcej informacji o funkcji dokładnego wyszukiwania najbliższych sąsiadów (wyszukiwanie wektorowe KNN) w Spanner znajdziesz tutaj: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Więcej informacji o funkcji przybliżonego wyszukiwania najbliższych sąsiadów (wyszukiwanie wektorowe ANN) w Spanner znajdziesz tutaj: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
Więcej informacji o tym, jak wykonywać prognozy online za pomocą SQL przy użyciu integracji Spannera z Vertex AI, znajdziesz tutaj: https://cloud.google.com/spanner/docs/ml