
1. Введение
Spanner — это полностью управляемая, горизонтально масштабируемая, глобально распределенная база данных, отлично подходящая как для реляционных, так и для нереляционных операционных нагрузок.
Spanner имеет встроенную поддержку векторного поиска, позволяющую выполнять поиск по сходству или семантический поиск, а также реализовывать расширенную генерацию поиска (RAG) в масштабируемых приложениях GenAI, используя либо точный поиск k-ближайших соседей (KNN), либо приблизительный поиск ближайших соседей (ANN).
Векторные поисковые запросы Spanner возвращают актуальные данные в режиме реального времени сразу после подтверждения транзакций, как и любые другие запросы к вашим операционным данным.
В этой лабораторной работе вы пошагово настроите основные функции, необходимые для использования Spanner для выполнения векторного поиска, а также получите доступ к моделям встраивания и LLM из модельного сада VertexAI с помощью SQL.
Архитектура будет выглядеть примерно так:
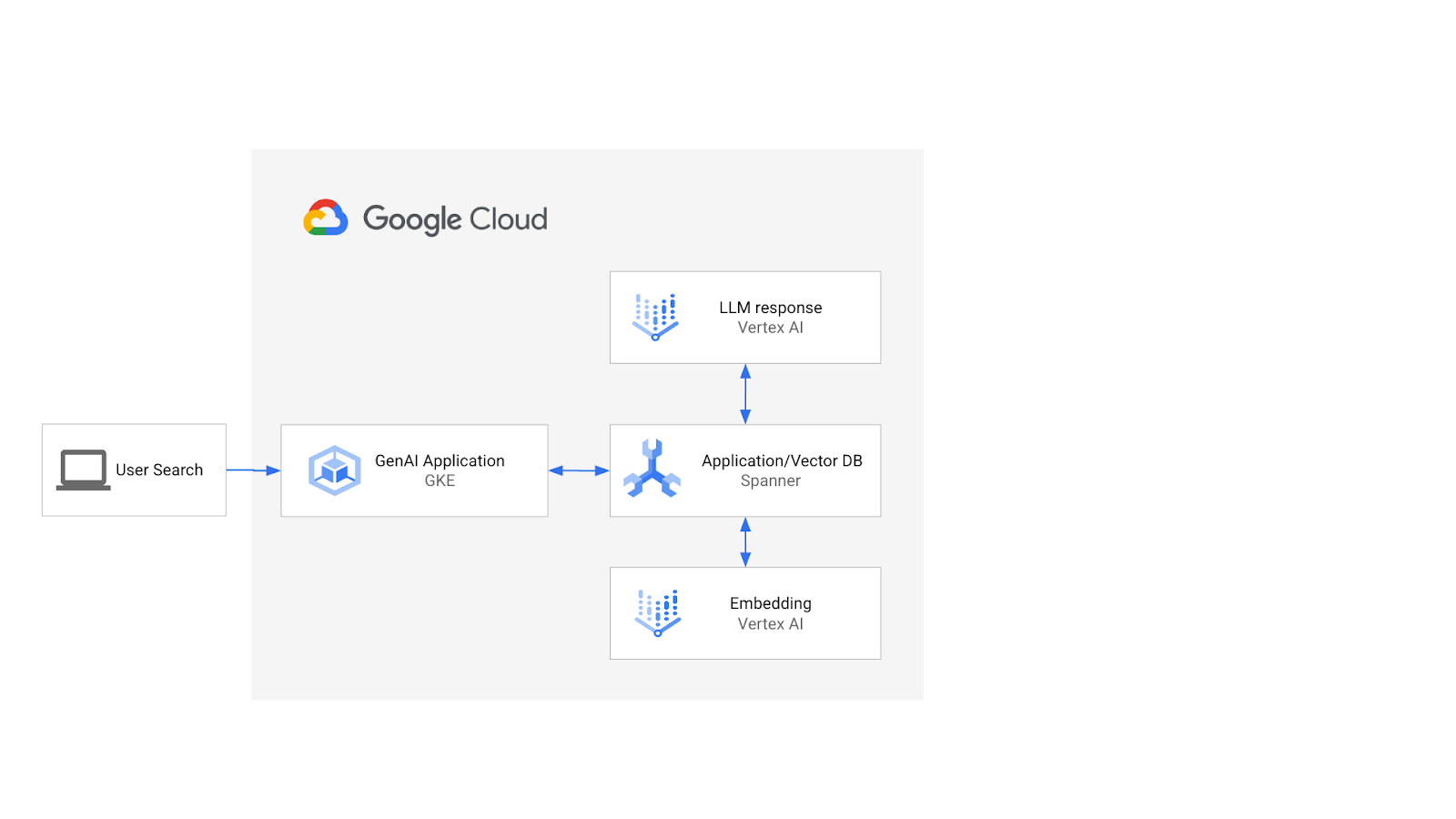
Опираясь на эти знания, вы научитесь создавать векторные индексы с использованием алгоритма ScaNN и применять функции расстояния APPROX, когда ваши семантические рабочие нагрузки должны масштабироваться.
Что вы построите
В рамках этой лабораторной работы вы:
- Создайте экземпляр Spanner.
- Настройте схему базы данных Spanner для интеграции с моделями встраивания и LLM в VertexAI.
- Загрузите набор данных о розничной торговле.
- Выполните поисковые запросы на выявление сходства в наборе данных.
- Для формирования рекомендаций, специфичных для конкретного продукта, необходимо предоставить контекст для модели LLM.
- Измените схему и создайте векторный индекс.
- Измените запросы, чтобы использовать вновь созданный векторный индекс.
Что вы узнаете
- Как настроить экземпляр Spanner
- Как интегрироваться с VertexAI
- Как использовать Spanner для выполнения векторного поиска похожих товаров в наборе данных о розничной торговле
- Как подготовить базу данных к масштабированию рабочих нагрузок векторного поиска с использованием поиска на основе искусственных нейронных сетей.
Что вам понадобится
2. Настройка и требования
Создать проект
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вам необходимо ее создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект.
Если у вас уже есть проект, щелкните раскрывающееся меню выбора проекта в левом верхнем углу консоли:

и нажмите кнопку «СОЗДАТЬ ПРОЕКТ» в появившемся диалоговом окне, чтобы создать новый проект:
Если у вас ещё нет проекта, вы увидите диалоговое окно, подобное этому, для создания вашего первого проекта:
В появившемся диалоговом окне создания проекта вы можете ввести подробные сведения о вашем новом проекте:
Запомните идентификатор проекта (Project ID), который является уникальным именем для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!). В дальнейшем в этом практическом занятии он будет обозначаться как PROJECT_ID.
Далее, если вы еще этого не сделали, вам необходимо включить оплату в консоли разработчика, чтобы использовать ресурсы Google Cloud и активировать API Spanner .
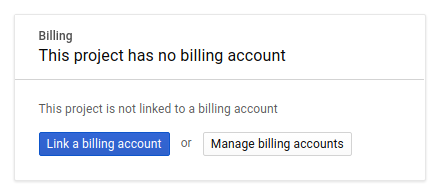
Выполнение этого практического задания не должно обойтись вам дороже нескольких долларов, но может стоить больше, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «очистка» в конце этого документа). Информация о ценах на Google Cloud Spanner приведена здесь .
Новые пользователи Google Cloud Platform могут воспользоваться бесплатной пробной версией стоимостью 300 долларов , что сделает этот практический семинар совершенно бесплатным.
Настройка Google Cloud Shell
Хотя Google Cloud и Spanner можно запускать удаленно с ноутбука, в этом практическом занятии мы будем использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что для выполнения этого практического задания вам понадобится только браузер (да, он работает и на Chromebook).
- Для активации Cloud Shell из консоли Cloud Console просто нажмите «Активировать Cloud Shell».
 (На подготовку и подключение к среде должно уйти всего несколько минут).
(На подготовку и подключение к среде должно уйти всего несколько минут).
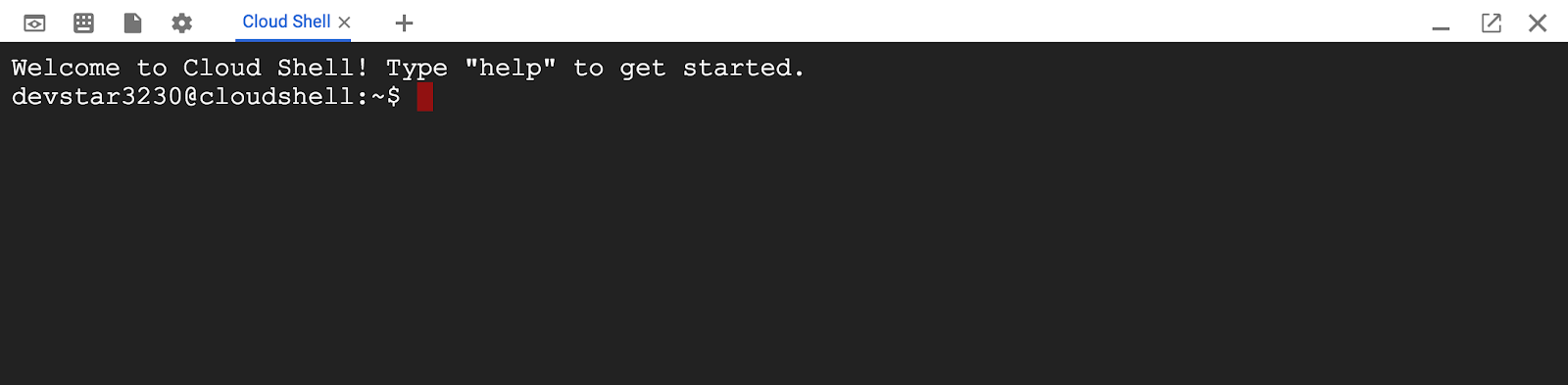
После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и проект уже настроен на ваш PROJECT_ID.
gcloud auth list
вывод команды
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
вывод команды
[core]
project = <PROJECT_ID>
Если по какой-либо причине проект не создан, просто выполните следующую команду:
gcloud config set project <PROJECT_ID>
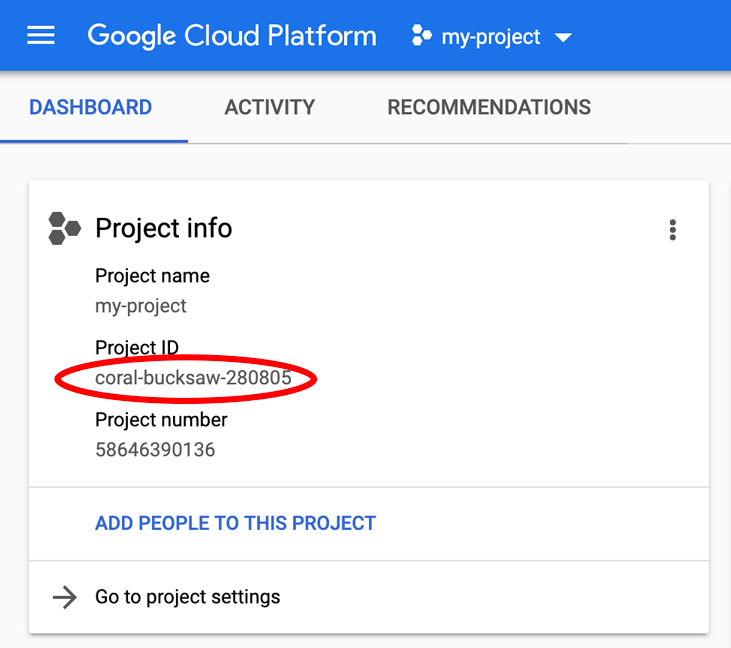
Ищете свой PROJECT_ID ? Проверьте, какой ID вы использовали на этапах настройки, или найдите его на панели управления Cloud Console:
Cloud Shell также по умолчанию устанавливает некоторые переменные среды, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
вывод команды
<PROJECT_ID>
Включите API Spanner и API VertexAI.
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
Проверьте политику IAM :
Для корректной работы векторного поиска в экземпляре Spanner в политике IAM необходимо лишь предоставить права доступа к сервису service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com в качестве агента службы Cloud Spanner API. Щелкните значок с тремя полосками в верхнем левом углу, как показано ниже.
Там вы увидите политику IAM:
Проверить настройки IAM можно в разделе «Разрешения», как показано ниже.
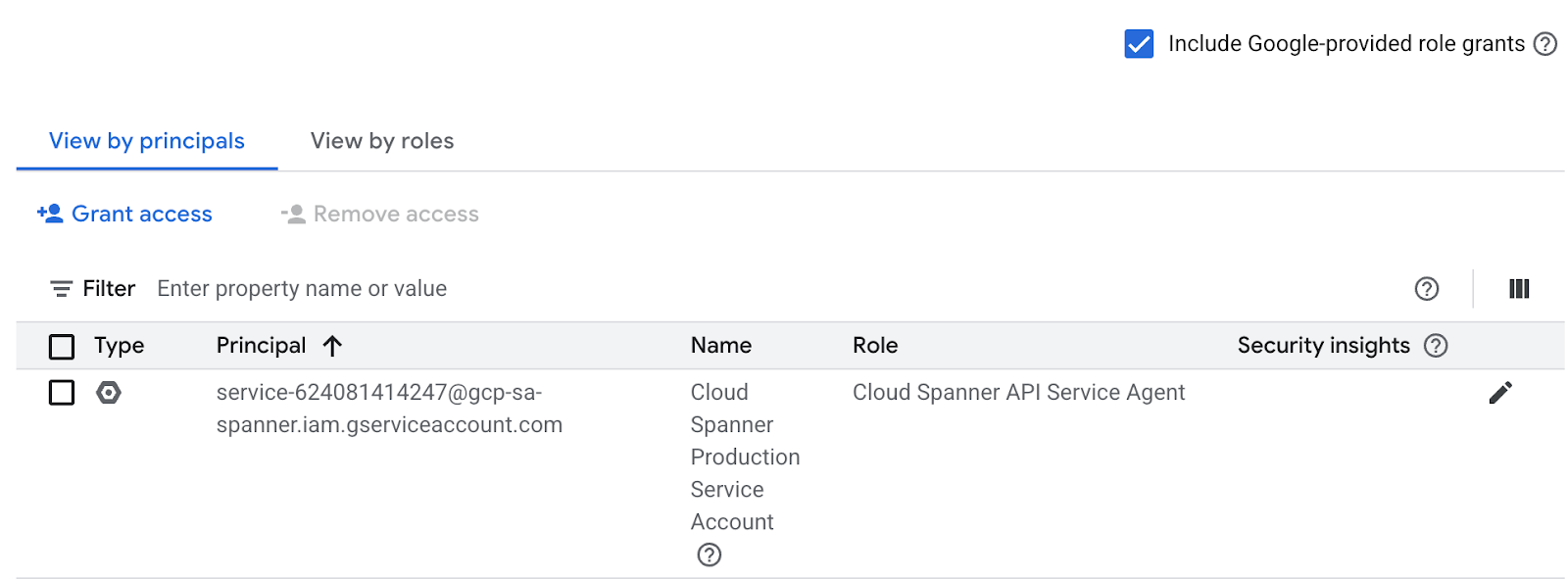
Если Cloud Spanner API Service Agent отсутствует, используйте команду ниже, чтобы предоставить ему права доступа. Дополнительные инструкции можно найти здесь .
$ gcloud beta services identity create --service=spanner.googleapis.com --project=<PROJECT_ID>
$ gcloud projects add-iam-policy-binding <PROJECT_NUMBER> --member=serviceAccount:service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com --role=roles/spanner.serviceAgent --condition=None
Краткое содержание
На этом шаге вы настроили свой проект, если у вас его еще не было, активировали Cloud Shell и включили необходимые API.
Далее
Далее вам предстоит настроить экземпляр Spanner и базу данных.
3. Создайте экземпляр Spanner и базу данных.
Создайте экземпляр Spanner.
На этом этапе мы настраиваем экземпляр Spanner для выполнения практического задания. Для этого откройте Cloud Shell и выполните следующую команду:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--edition=ENTERPRISE \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
Самая простая версия — ENTERPRISE . В версии STANDARD отсутствует функция векторного поиска.
Вывод команды:
$ Creating instance...done.
Создайте базу данных
После запуска экземпляра вы можете создать базу данных. Spanner позволяет использовать несколько баз данных на одном экземпляре.
В базе данных вы определяете свою схему. Вы также можете контролировать доступ к базе данных, настраивать пользовательское шифрование, конфигурировать оптимизатор и устанавливать период хранения.
Для создания базы данных снова воспользуйтесь инструментом командной строки gcloud:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
Вывод команды:
$ Creating database...done.
Краткое содержание
На этом шаге вы создали экземпляр Spanner и базу данных.
Далее
Далее вам предстоит настроить схему и данные Spanner.
4. Загрузка схемы и данных тарелок.
Создайте схему тарелок.
Для настройки схемы перейдите в Spanner Studio:
Схема состоит из двух частей. Во-первых, вам нужно добавить таблицу products . Скопируйте и вставьте это выражение в пустую вкладку.
Для схемы скопируйте и вставьте этот DDL-скрипт в поле:
CREATE TABLE products(
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL
OPTIONS (
allow_commit_timestamp = TRUE),
inventoryCount INT64 NOT NULL,
priceInCents INT64,)
PRIMARY KEY(categoryId, productId);
Затем нажмите кнопку run и подождите несколько секунд, пока будет создана ваша схема.
Далее вам предстоит создать две модели и настроить их для работы с конечными точками моделей VertexAI.
Первая модель — это модель встраивания, используемая для генерации векторных представлений из текста, а вторая — это модель LLM, используемая для генерации ответов на основе данных из Spanner.
Вставьте следующую схему в новую вкладку в Spanner Studio:
CREATE OR REPLACE MODEL EmbeddingsModel
INPUT(content STRING(MAX)) OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004');
CREATE OR REPLACE MODEL LLMModel
INPUT(prompt STRING(MAX)) OUTPUT(content STRING(MAX)) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.0-flash-001',
default_batch_size = 1);
Затем нажмите кнопку run и подождите несколько секунд, пока ваши модели будут созданы.
В левой панели Spanner Studio вы должны увидеть следующие таблицы и модели:
Загрузите данные
Теперь вам нужно будет добавить несколько товаров в вашу базу данных. Откройте новую вкладку в Spanner Studio, затем скопируйте и вставьте следующие операторы вставки:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
Нажмите кнопку run , чтобы вставить данные.
Краткое содержание
На этом этапе вы создали схему и загрузили некоторые основные данные в базу данных cymbal-bikes .
Далее
Далее вы интегрируетесь с моделью Embedding для генерации векторных представлений описаний товаров, а также для преобразования текстового поискового запроса в векторное представление для поиска релевантных товаров.
5. Работа с эмбеддингами
Создание векторных представлений для описаний товаров.
Для корректной работы поиска по сходству товаров необходимо сгенерировать векторные представления для описаний товаров.
После создания EmbeddingsModel в схеме, это простая инструкция DML типа UPDATE .
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content))
)
WHERE categoryId = 1;
Нажмите кнопку « run , чтобы обновить описания товаров.
Если возникнет ошибка, попробуйте выполнить команду SQL в терминале с помощью команды gcloud, чтобы получить более подробное сообщение об ошибке, например:
gcloud spanner databases execute-sql <YOUR_DATA_BASE> --instance=<YOUR_INSTANCE> --sql 'UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;'
Использование векторного поиска
В этом примере вы предоставите поисковый запрос на естественном языке в виде SQL-запроса. Этот запрос преобразует поисковый запрос в векторное представление (embedding), а затем выполнит поиск похожих результатов на основе сохраненных векторных представлений описаний продуктов, сгенерированных на предыдущем шаге.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Нажмите кнопку run , чтобы найти похожие товары. Результаты должны выглядеть примерно так:
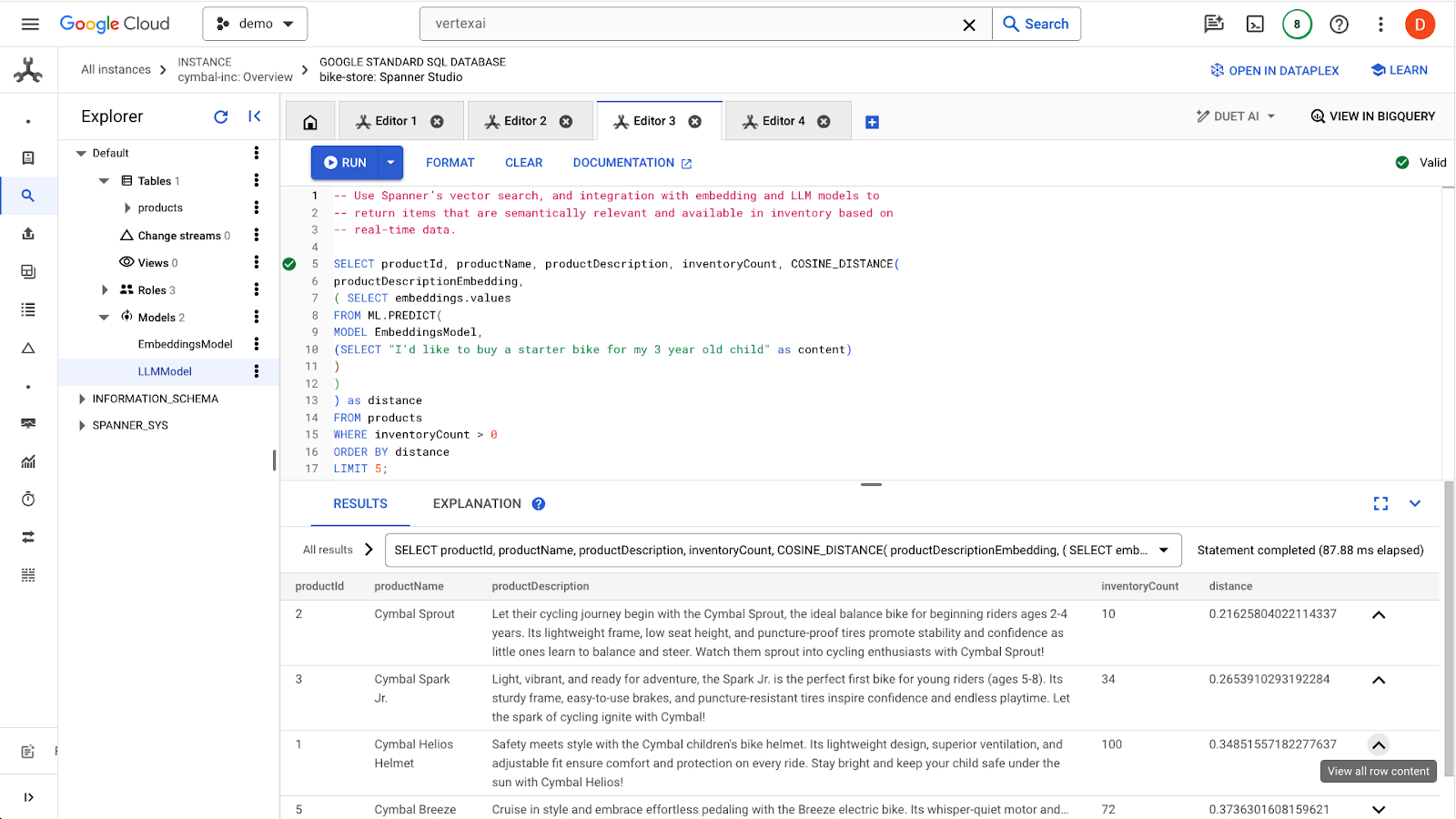
Обратите внимание, что в запросе используются дополнительные фильтры, например, интересуются только товары, имеющиеся в наличии ( inventoryCount > 0 ).
Краткое содержание
На этом этапе вы создали векторные представления описания товаров и векторное представление поискового запроса с использованием SQL, задействовав интеграцию Spanner с моделями VertexAI. Вы также выполнили векторный поиск для нахождения похожих товаров, соответствующих поисковому запросу.
Следующие шаги
Далее, давайте используем результаты поиска для передачи в LLM-модель, чтобы сгенерировать индивидуальный ответ для каждого продукта.
6. Работайте с магистрантом права (LLM).
Spanner упрощает интеграцию с моделями LLM, предоставляемыми VertexAI. Это позволяет разработчикам использовать SQL для прямого взаимодействия с моделями LLM, вместо того чтобы требовать от приложения выполнения соответствующей логики.
Например, у нас есть результаты предыдущего SQL-запроса от пользователя "I'd like to buy a starter bike for my 3 year old child".
Разработчик хотел бы предоставить ответ для каждого результата, указав, подходит ли продукт пользователю, используя следующую подсказку:
"Answer with 'Yes' or 'No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
Вот запрос, который вы можете использовать:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM
ML.PREDICT(
MODEL LLMModel,
(
SELECT
FORMAT(
"""Answer with Yes or No and explain why: Is this a good fit for me?
I would like to buy a starter bike for my 3 year old child \n Product Name: %s\nProduct Description: %s""", productName,productDescription) AS prompt,
-- Pass through columns.
inventoryCount,
productName,
productDescription,
FROM products
WHERE inventoryCount > 0
ORDER BY
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
))
LIMIT 5
));
Нажмите кнопку run , чтобы отправить запрос. Результаты должны выглядеть примерно так:
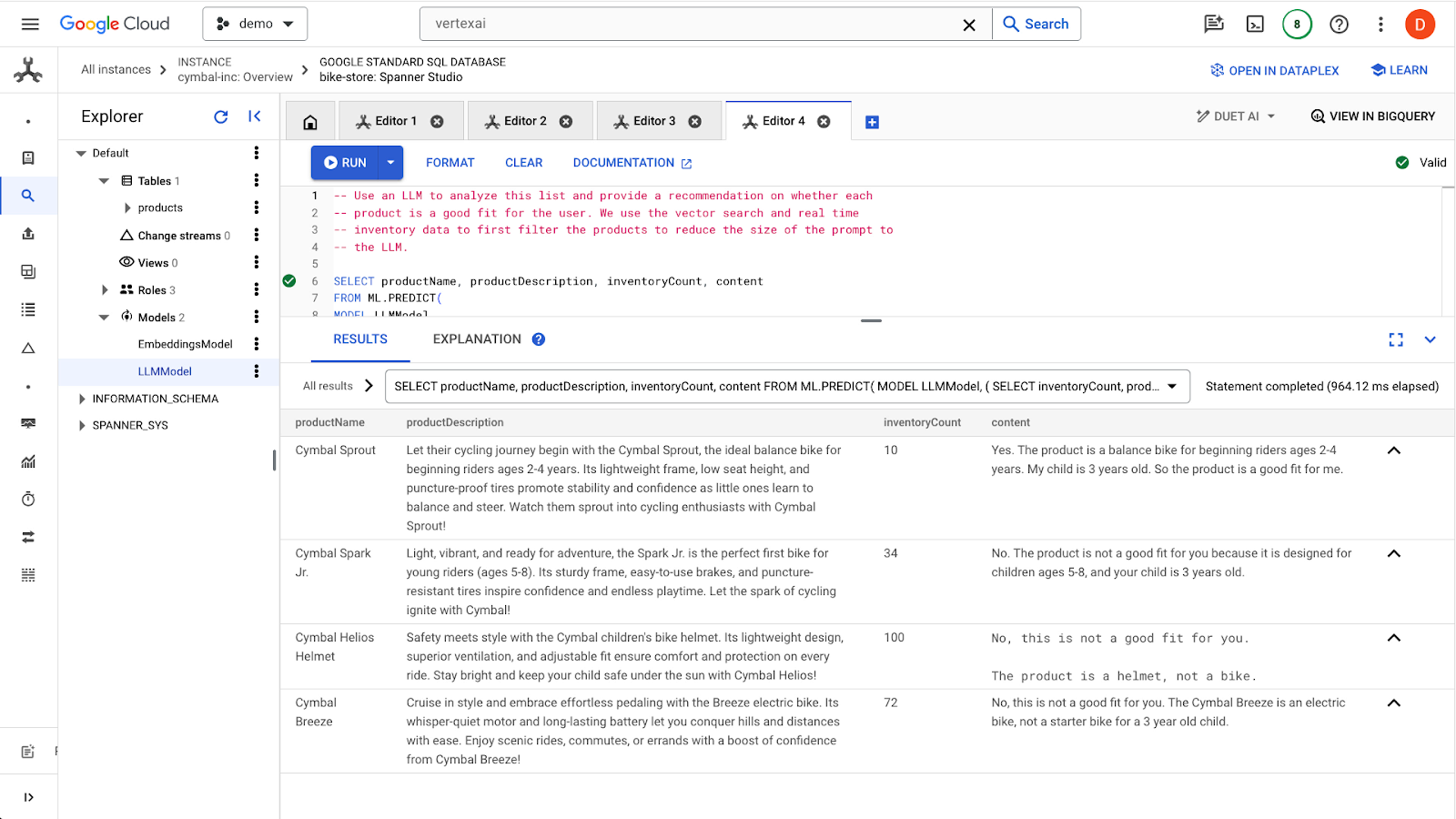
Первый товар подходит для 3-летнего ребенка, поскольку в описании указан возрастной диапазон (от 2 до 4 лет). Остальные товары подходят не очень хорошо.
Краткое содержание
На этом этапе вы работали с программой LLM для генерации простых ответов на запросы пользователя.
Следующие шаги
Далее давайте научимся использовать искусственные нейронные сети для масштабирования векторного поиска.
7. Поиск масштабируемых векторов
В предыдущих примерах векторного поиска использовался точный KNN-поиск. Это отлично подходит, когда вы можете запрашивать очень специфические подмножества данных Spanner. Такие запросы считаются легко разделяемыми .
Если у вас нет задач, требующих широкого разделения на разделы, и вы располагаете большим объемом данных, вам следует использовать векторный поиск на основе искусственных нейронных сетей (ИНС) с применением алгоритма ScaNN для повышения эффективности поиска.
Для этого в Spanner вам потребуется сделать две вещи:
- Создать векторный индекс
- Измените свой запрос, чтобы использовать функции приблизительного расстояния (APPROX) .
Создать векторный индекс
Для создания векторного индекса на основе этого набора данных нам сначала потребуется изменить столбец productDescriptionEmbeddings , чтобы определить длину каждого вектора. Чтобы добавить длину вектора к столбцу, необходимо удалить исходный столбец и создать его заново.
ALTER TABLE products DROP COLUMN productDescriptionEmbedding;
ALTER TABLE products
ADD COLUMN productDescriptionEmbedding ARRAY<FLOAT32>(vector_length => 768);
Далее, создайте векторные представления заново, используя шаг Generate Vector embedding который вы выполняли ранее.
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;
После создания столбца создайте индекс:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
Если вас заинтересовал PDML, ознакомьтесь с ним по ссылке https://cloud.google.com/spanner/docs/backfill-embeddings . Одно оператор DML представляет собой транзакцию, ограниченную 80 000 изменений, поэтому вы не можете обновить слишком много строк одновременно. PDML эффективно разбивает операции на более мелкие пакеты.
Воспользуйтесь новым указателем.
Для использования нового векторного индекса вам потребуется немного изменить предыдущий запрос на встраивание.
Вот исходный запрос:
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
Вам потребуется внести следующие изменения:
- Используйте подсказку индекса для нового векторного индекса:
@{force_index=ProductDescriptionEmbeddingIndex} - Измените вызов функции
COSINE_DISTANCEнаAPPROX_COSINE_DISTANCE. Обратите внимание, что параметры JSON в итоговом запросе ниже также обязательны. - Сгенерируйте эмбеддинги из функции ML.PREDICT отдельно.
- Скопируйте результаты эмбеддингов в итоговый запрос.
Сгенерируйте и используйте векторные представления:
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
);
Выделите результаты запроса и скопируйте их.
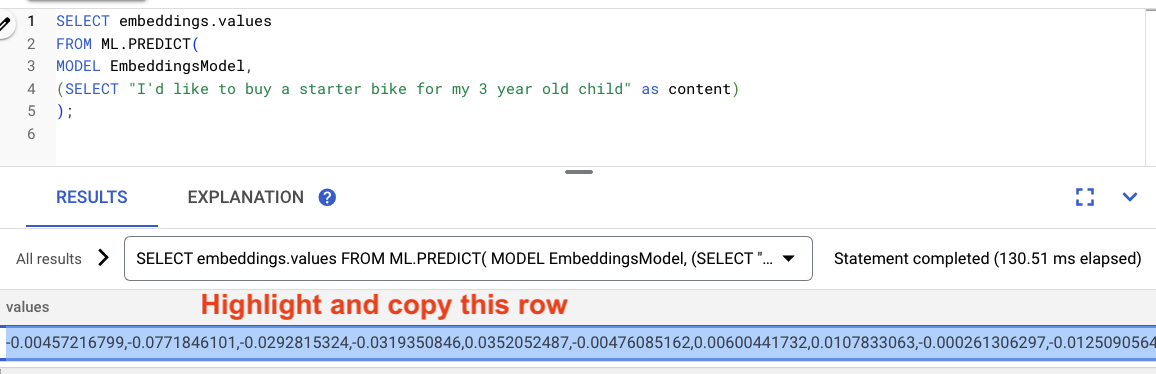
Затем замените <VECTOR> в следующем запросе, вставив скопированные вами векторные представления.
-- Generate the embeddings and query them using the vector index
SELECT
productName,
productDescription,
inventoryCount,
APPROX_COSINE_DISTANCE(
productDescriptionEmbedding,
array<float32>[@VECTOR],
options => JSON '{\"num_leaves_to_search\": 10}') AS distance
FROM products @{force_index = ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
Это должно выглядеть примерно так:
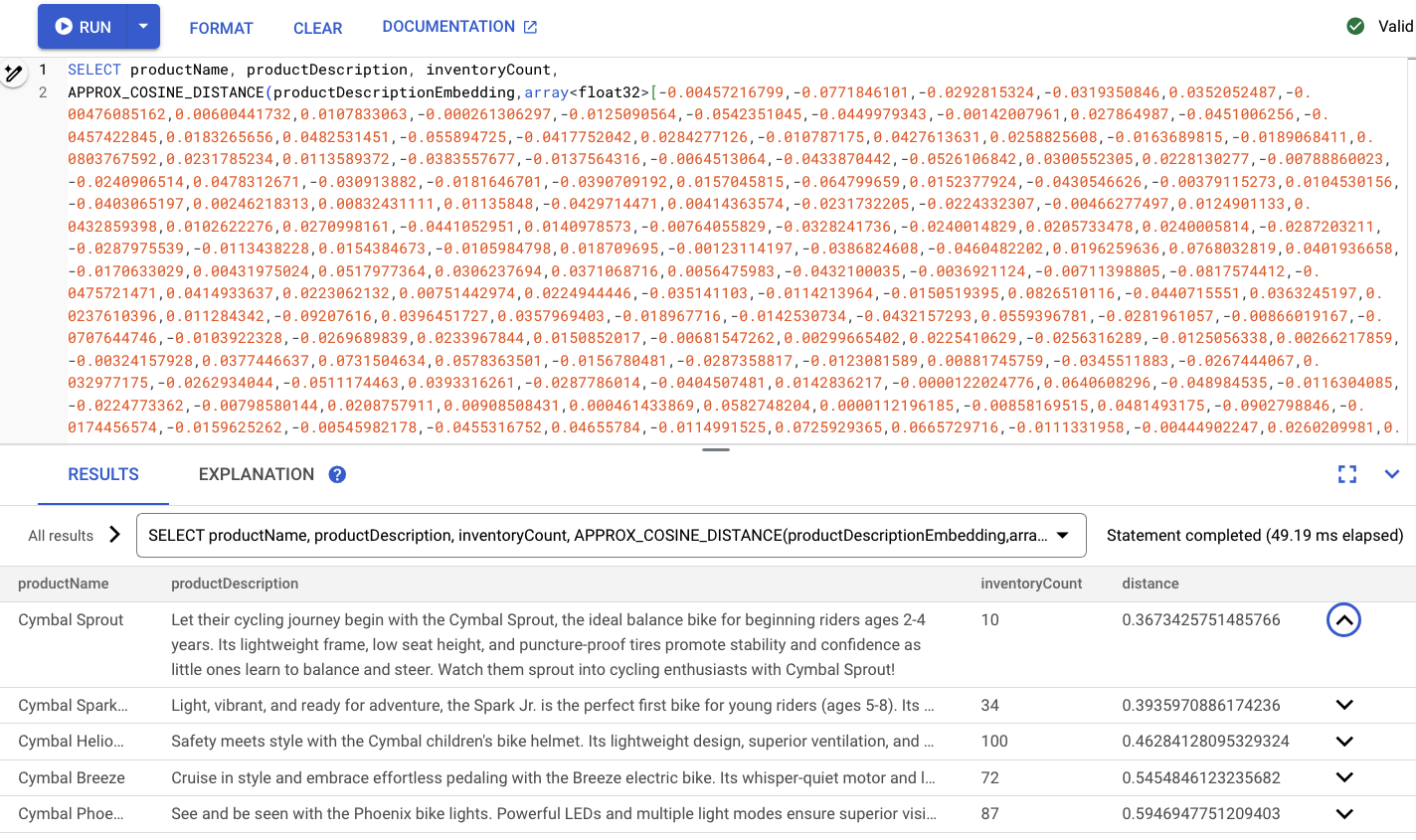
Краткое содержание
На этом этапе вы преобразовали свою схему для создания векторного индекса. Затем вы переписали запрос на встраивание, чтобы выполнить поиск с помощью ИНС, используя этот векторный индекс. Это важный шаг, поскольку ваши данные растут, что приводит к масштабируемости задач векторного поиска.
Следующие шаги
Далее, пришло время уборки!
8. Уборка (необязательно)
Для завершения процесса просто удалите экземпляр ' retail-demo ' , который мы создали в практическом задании.
9. Поздравляем!
Поздравляем, вы успешно выполнили поиск сходства, используя встроенный в Spanner векторный поиск. Кроме того, вы убедились, насколько легко работать с моделями встраивания и LLM для обеспечения функциональности генеративного ИИ непосредственно с помощью SQL.
В итоге вы изучили процесс выполнения поиска с использованием искусственных нейронных сетей (ИНС) на основе алгоритма ScaNN для масштабирования рабочих нагрузок векторного поиска.
Что дальше?
Подробнее о функции поиска ближайших соседей (KNN-векторный поиск) в Spanner можно узнать здесь: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
Подробнее о функции поиска ближайших ближайших соседей (векторный поиск с использованием искусственной нейронной сети) в Spanner можно узнать здесь: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
Вы также можете узнать больше о том, как выполнять онлайн-прогнозирование с помощью SQL, используя интеграцию Spanner с VertexAI, здесь: https://cloud.google.com/spanner/docs/ml