
১. কেস-স্টাডি: ইন্টেলিজেন্ট রিটেইল
কেস-স্টাডির জন্য আমরা একটি দ্রুত বর্ধনশীল ডিজিটাল মার্কেটপ্লেসের একজন খুচরা গ্রাহককে বেছে নিয়েছি। গ্রাহকের প্রচলিত ডেটা দৃষ্টিভঙ্গি সীমিত, কারণ এটি দেখায় যে মানুষ কী কেনে , কিন্তু তারা কীভাবে সংযুক্ত তা দেখায় না । এই ঘাটতির ফলে সুযোগ হাতছাড়া হয় এবং জালিয়াতি বৃদ্ধি পায়। এখন, তারা লেনদেন সংক্রান্ত ডেটার পাশাপাশি সামাজিক এবং লজিস্টিক সংযোগগুলোকে গুরুত্ব দিতে একটি 'নেটওয়ার্ক-ফার্স্ট' দর্শনের দিকে ঝুঁকছে।
সমাধান করার জন্য মূল ব্যবসায়িক চ্যালেঞ্জসমূহ
আপনার চারটি গুরুত্বপূর্ণ চ্যালেঞ্জ রয়েছে, যেগুলোর জন্য গ্রাহক এবং সরবরাহ ব্যবস্থার আন্তঃসম্পর্ক বোঝা প্রয়োজন :
চ্যালেঞ্জ | সমস্যাটি | লক্ষ্য |
প্রভাবের ব্যবধান | ব্যাপক বিজ্ঞাপনের মাধ্যমে বিনিয়োগের উপর কম আয় হয়; বর্তমানে প্রকৃত ট্রেন্ডসেটারদের (ইনফ্লুয়েন্সারদের) চিহ্নিত করা সম্ভব নয়। | এমন প্রভাবশালী ব্যক্তিদের চিহ্নিত করুন, যারা গ্রাহকদের একটি সংযুক্ত নেটওয়ার্কের মাধ্যমে সম্প্রদায়ের কেন্দ্রবিন্দুতে রয়েছেন। |
লজিস্টিকস স্থিতিস্থাপকতা | সরবরাহ শৃঙ্খলটি ঝুঁকিপূর্ণ হতে পারে (যেহেতু তারা বিভিন্ন ভৌগোলিক অঞ্চলে কার্যক্রম পরিচালনা করে)। যদি একটি প্রধান কেন্দ্র অকার্যকর হয়ে যায়, তবে পুরো অঞ্চলটি পণ্য সরবরাহ হারাতে পারে। | গেটকিপারদের চিহ্নিত করুন; যারা লজিস্টিকস নেটওয়ার্কগুলোকে একত্রিত করতে অপরিহার্য। |
ঘোস্ট নেটওয়ার্কস | প্রতারক চক্রগুলো চুরি সমন্বয় করতে এবং রেটিং বাড়িয়ে তুলতে ভুয়া প্রোফাইল ও একই ঠিকানা ব্যবহার করে। | বিচ্ছিন্ন দ্বীপপুঞ্জকে উন্মোচন করুন; এমন অতি-সংযুক্ত গোষ্ঠী যাদের বৈধ সম্প্রদায়ের সাথে কোনো সম্পর্ক নেই। |
পছন্দের প্যারাডক্স | বর্তমান পরামর্শ/সুপারিশ ব্যবস্থাটি প্রাথমিক পর্যায়ের, সাধারণ এবং প্রায়শই উপেক্ষিত হয় (যেমন, "যেসব গ্রাহক এটি কিনেছেন, তাঁরা আরও কিনেছেন..." )। | আচরণগত যমজ তৈরি করুন; অর্থাৎ, একই ধরনের শিপিং প্যাটার্ন এবং সামাজিক পরিমণ্ডলের উপর ভিত্তি করে সুপারিশ করুন। |
ব্যবসায়িক প্রতিবন্ধকতাকে প্রযুক্তিগত কৌশলের সাথে সংযুক্ত করা (সারি → সম্পর্ক)
একটি প্রচলিত ডেটাবেসে, ডেটা বিচ্ছিন্নভাবে সংরক্ষিত থাকে: গ্রাহকরা একটি টেবিলে, লেনদেন অন্যটিতে, এবং চালান তৃতীয়টিতে। "কে কী কিনেছে?"—এই ধরনের প্রশ্নের উত্তর দেওয়ার জন্য SQL নিখুঁত হলেও, এটি নেটওয়ার্ক-ভিত্তিক প্রশ্নের উত্তর দিতে হিমশিম খায়।
এই চ্যালেঞ্জগুলো মোকাবেলা করার জন্য, প্রযুক্তিগত কৌশল হলো এই দৃষ্টিভঙ্গি পরিবর্তন করা:
- রিলেশনাল ভিউ (এর মূল বিষয়): এটি প্রতিটি গ্রাহককে একটি বিচ্ছিন্ন সারি হিসেবে বিবেচনা করে। একজন গ্রাহক এবং তার বন্ধুর কেনাকাটার মধ্যে সংযোগ খুঁজে বের করার জন্য একাধিক জটিল 'জয়েন' প্রক্রিয়ার প্রয়োজন হয়, যা নেটওয়ার্ক বড় হওয়ার সাথে সাথে দ্রুতগতিতে ধীর হয়ে যায়।
- গ্রাফ ভিউ (পদ্ধতি): সম্পর্কগুলোকে সর্বোচ্চ গুরুত্ব দেয়। তালিকার মধ্যে খোঁজার পরিবর্তে, আমরা একটি মানচিত্র ব্যবহার করি। আমরা তাৎক্ষণিকভাবে দেখতে পারি যে গ্রাহক A, গ্রাহক B-এর সাথে সংযুক্ত, যিনি Z অবস্থানে পণ্য পাঠান।
প্রয়োজনীয়তাগুলো গভীরভাবে খতিয়ে দেখা
সলিউশন আর্কিটেক্টরা এই সিদ্ধান্তে উপনীত হন যে ব্যবসায়িক চাহিদা এবং প্রযুক্তিগত কৌশলের জন্য একটি বহু-মডেল পদ্ধতির প্রয়োজন, এবং নিম্নলিখিত মূল চাহিদাগুলো চিহ্নিত করেন।
ক্লাউড স্প্যানার কীভাবে সেই প্রযুক্তিগত প্রয়োজনীয়তাগুলো পূরণ করে
এই রূপান্তরের কেন্দ্রবিন্দু হিসেবে ক্লাউড স্প্যানারকে বেছে নেওয়া হয়েছে। এটি গ্রাহককে তার অত্যন্ত শক্তিশালী সম্পর্কগত ভিত্তি বজায় রাখার পাশাপাশি একই সাথে গভীর গ্রাফ অন্তর্দৃষ্টি উন্মোচন করার সুযোগ দেয়।
ক্লাউড স্প্যানার কীভাবে প্রযুক্তিগত প্রয়োজনীয়তা এবং আরও অনেক কিছু পূরণ করে, তার একটি সংক্ষিপ্ত বিবরণ এখানে দেওয়া হলো।
এর পাশাপাশি ক্লাউড স্প্যানার একটি ভবিষ্যৎ-প্রতিরোধী প্রযুক্তিগত কাঠামো প্রদান করে।
২. ডেটার ভিত্তি স্থাপন করা
বিজনেস কেসটির পর আমরা এখন বাস্তবায়ন পর্যায়ে প্রবেশ করছি। এই অংশে, আমরা আমাদের ডেটা আর্কিটেকচার সংজ্ঞায়িত করব, প্রচলিত রিলেশনাল মডেলের সীমাবদ্ধতাগুলো খতিয়ে দেখব এবং গভীর অন্তর্দৃষ্টি উন্মোচনের প্রধান হাতিয়ার হিসেবে প্রপার্টি গ্রাফের সাথে পরিচয় করিয়ে দেব।
ক্লাউড স্প্যানার এন্টারপ্রাইজ ইনস্ট্যান্স সেটআপ করুন
ধাপ ১: ক্লাউড স্প্যানার এপিআই সক্রিয় করুন
গুগল ক্লাউড কনসোলে , বাম দিকের নেভিগেশনের জন্য স্ক্রিনের উপরের বাম দিকে থাকা মেনু আইকনে ক্লিক করুন। নিচে স্ক্রল করে "স্প্যানার" নির্বাচন করুন, অথবা বিকল্পভাবে "স্প্যানার" লিখে অনুসন্ধান করুন।
এখন আপনি ক্লাউড স্প্যানার UI দেখতে পাবেন, এবং যদি আপনি এমন একটি প্রজেক্ট ব্যবহার করেন যেখানে এখনও ক্লাউড স্প্যানার API চালু করা হয়নি, তাহলে এটি চালু করার জন্য আপনাকে একটি ডায়ালগ বক্স দেখানো হবে। যদি আপনি ইতিমধ্যেই API চালু করে থাকেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
চালিয়ে যেতে " সক্ষম করুন "-এ ক্লিক করুন:
ধাপ ২: ক্লাউড স্প্যানার ইনস্ট্যান্স তৈরি করুন
প্রথমে, আপনাকে একটি ক্লাউড স্প্যানার ইনস্ট্যান্স তৈরি করতে হবে। UI-তে, একটি নতুন ইনস্ট্যান্স তৈরি করার জন্য " Create a Provisioned Instance "-এ ক্লিক করুন।
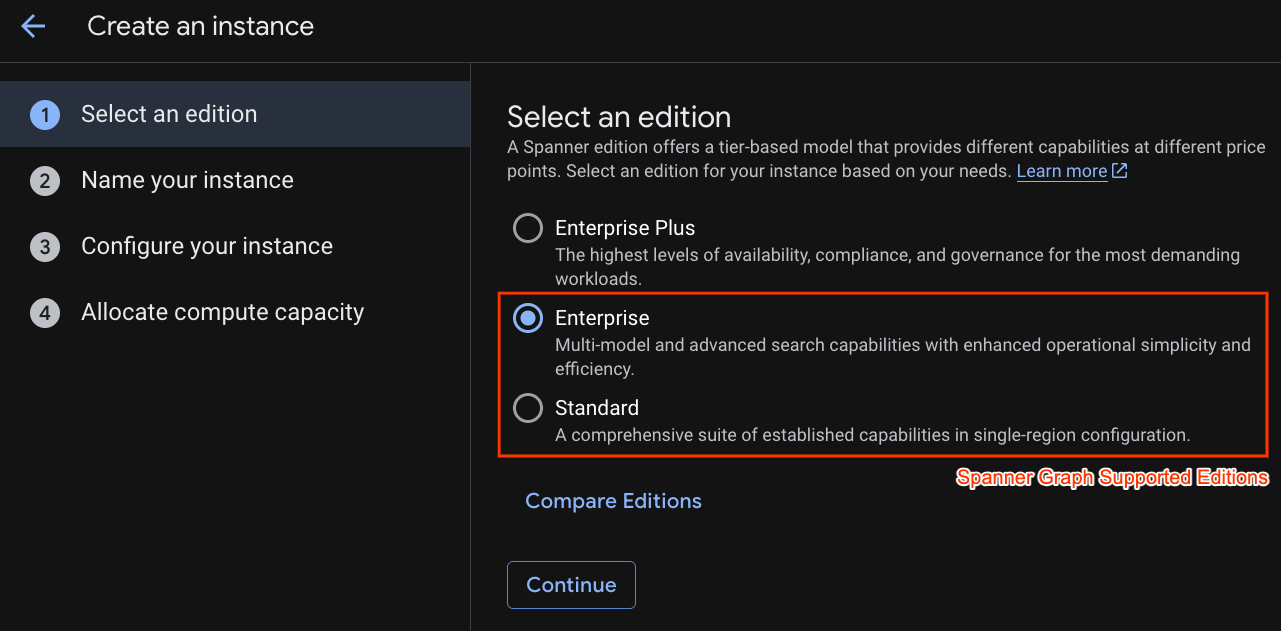
প্রথম ধাপে আপনাকে একটি সংস্করণ নির্বাচন করতে হবে। অনুগ্রহ করে মনে রাখবেন যে আপনি পরবর্তীতেও সংস্করণ আপগ্রেড করতে পারবেন। মাল্টি-মডেল সক্ষমতা (স্প্যানার গ্রাফ) ব্যবহার করার জন্য আমরা এন্টারপ্রাইজ সংস্করণটি বেছে নিতে পারি।
আপনার ইনস্ট্যান্সের নামকরণ
একটি ডেপ্লয়মেন্ট কনফিগারেশন এবং আপনার পছন্দের একটি অঞ্চল নির্বাচন করুন।
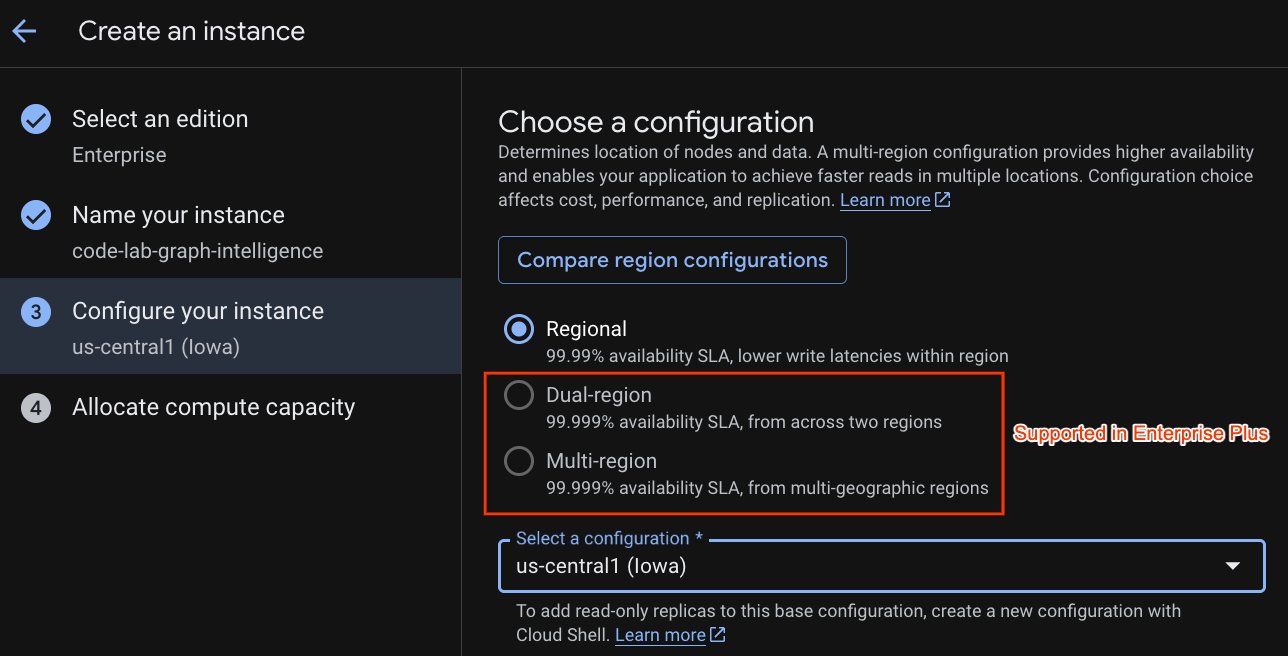
আপনি বিভিন্ন কনফিগারেশন বিকল্পও তুলনা করতে পারেন। উদাহরণস্বরূপ, ডেপ্লয়মেন্ট কনফিগারেশনে আপনার নির্বাচিত অঞ্চলের ৩টি পৃথক জোনে ন্যূনতম ৩টি রিড/রাইট (R/W) রেপ্লিকা থাকে। অর্থাৎ, আপনি যদি একটি সিঙ্গেল নোড ডেপ্লয়মেন্টও বেছে নেন, তাহলেও ৩টি রিড/রাইট (R/W) রেপ্লিকার মাধ্যমে আপনার ৩টি কপি থাকবে। এছাড়াও, রিজিওনাল ডেপ্লয়মেন্ট কনফিগারেশনের মাধ্যমেও আপনি আপনার ডেপ্লয়মেন্ট টপোলজিতে অতিরিক্ত রিড/আউট (R/O) রেপ্লিকা যুক্ত করে এটিকে আরও প্রসারিত করতে পারেন।
ক্যাপাসিটি কনফিগার করার সময়, আপনি হয় ফুল-নোড থেকে শুরু করে নোডগুলোতে অটোস্কেলিং করতে পারেন; অথবা একটি গ্র্যানুলার ইনস্ট্যান্স (প্রসেসিং ইউনিট; ১০০০ পিইউ = ১ নোড ) ব্যবহার করতে পারেন। ঐচ্ছিকভাবে আপনি ইনস্ট্যান্সের অটোস্কেলিং টার্গেটও সেট করতে পারেন। কম ল্যাটেন্সির ওয়ার্কলোডের জন্য, আমরা রিজিওনাল ইনস্ট্যান্সের ক্ষেত্রে ৬৫% এবং মাল্টি-রিজিওন ইনস্ট্যান্সের ক্ষেত্রে ৪৫% সুপারিশ করি।
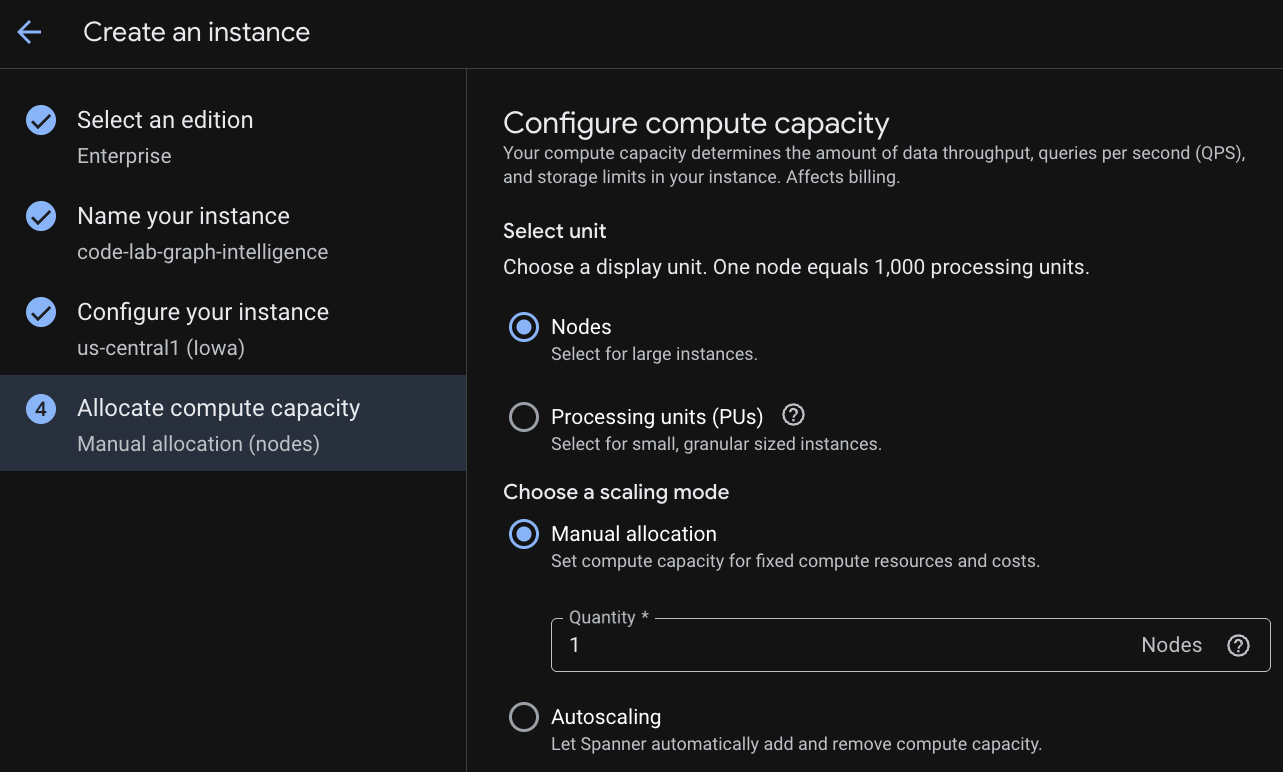
ধাপ ৩: একটি ডাটাবেস তৈরি করুন
আপনার ইনস্ট্যান্সটি প্রোভিশন করা হয়ে গেলে, আপনার কোডল্যাবের বাকি অংশের জন্য একটি ডেটাবেস তৈরি করতে "Create Database"-এ ক্লিক করুন।
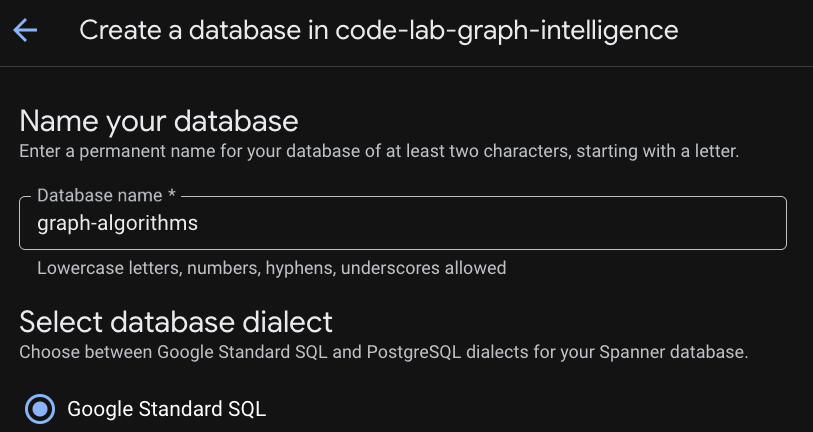
সম্পর্কীয় ভিত্তি স্থাপন
আমাদের যাত্রা শুরু হয় মূল টেবিলগুলো দিয়ে, যেগুলোতে অপারেশনাল ডেটা সংরক্ষিত থাকে। ক্লাউড স্প্যানারে, আমরা ইন্টারলিভিং ব্যবহার করে গ্রাহকের বন্ধুত্ব এবং লেনদেনের মতো সম্পর্কিত ডেটাকে সরাসরি গ্রাহক রেকর্ডের সাথে ভৌতভাবে একই স্থানে রাখি। এটি উচ্চ-পারফরম্যান্স অ্যাক্সেস এবং ভৌত অবস্থান নিশ্চিত করে।
ডিডিএল: টেবিল তৈরি করা
আপনার রিলেশনাল স্কিমা স্থাপন করতে নিম্নলিখিত ব্লকগুলি অনুলিপি করে কার্যকর করুন:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
নেটওয়ার্কে বীজ বপন
আমাদের টেবিলগুলো প্রস্তুত হয়ে গেলে, সেগুলোকে অবশ্যই সেইসব ব্যবহারকারী, পণ্য এবং সংযোগ দিয়ে পূরণ করতে হবে যা গ্রাহকের ইকোসিস্টেমকে সংজ্ঞায়িত করে।
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
সম্পর্কগত চ্যালেঞ্জ
গ্রাফটি দেখানোর আগে, চলুন দেখি প্রচলিত SQL কীভাবে গ্রাহকের চ্যালেঞ্জগুলো মোকাবেলা করে। "সোশ্যাল স্পেন্ডার্স" অর্থাৎ সেইসব গ্রাহকদের খুঁজে বের করতে এই কোয়েরিটি চালান, যারা উল্লেখযোগ্যভাবে খরচ করেন এবং যাদের একাধিক বন্ধু রয়েছে।
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
সম্পর্কভিত্তিক পদ্ধতির সীমাবদ্ধতা
প্রপার্টি গ্রাফের মাধ্যমে সম্পর্কগত প্রতিবন্ধকতা কাটিয়ে ওঠা
এই সীমাবদ্ধতাগুলো কাটিয়ে উঠতে, আমরা একটি প্রপার্টি গ্রাফ সংজ্ঞায়িত করি। এটি একটি 'ওভারলে' তৈরি করে, যা আমাদের ডেটা স্প্যানারের বাইরে না সরিয়েই সম্পর্কগুলোকে প্রথম শ্রেণীর উপাদান হিসেবে বিবেচনা করার সুযোগ দেয়।
ডিডিএল: প্রপার্টি গ্রাফ তৈরি করা
এই DDL আমাদের নোড (সত্তা) এবং এজ (সম্পর্ক) সংজ্ঞায়িত করে। এই উদাহরণে আমরা একটি পরিকল্পিত গ্রাফ অনুসরণ করছি, তবে স্প্যানার গ্রাফ নমনীয়, দ্রুত পুনরাবৃত্তিমূলক উন্নয়ন সক্ষম করতে এবং ক্রমাগত DDL (ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ) পরিবর্তন ছাড়াই পরিবর্তনশীল ডেটা মডেল পরিচালনা করার জন্য স্কিমাবিহীন গ্রাফ মডেলিংয়ের সুযোগ দেয়।
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
GQL ব্যবহার করে গ্রাফ নেভিগেট করা
এখন যেহেতু আমাদের গ্রাফটি সংজ্ঞায়িত করা হয়েছে, আমরা একটি সহজ ও পাঠযোগ্য সিনট্যাক্স ব্যবহার করে গ্রাফ কোয়েরি ল্যাঙ্গুয়েজ (GQL) দিয়ে মাল্টি-হপ ট্রাভার্সাল সম্পাদন করতে পারি।
অনুসন্ধান ১: সহযোগিতামূলক আবিষ্কার
এই কোয়েরিটি আপনার বন্ধুদের কেনা পণ্যগুলো খুঁজে বের করার জন্য গ্রাফটি পরিভ্রমণ করে এবং এটি একটি সুপারিশ ইঞ্জিনের ভিত্তি হিসেবে কাজ করে।
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
অন্বেষণ ২: হাইব্রিড কোয়েরি (রিলেশনাল + গ্রাফ)
স্প্যানার আপনাকে GRAPH_TABLE ফাংশন ব্যবহার করে একটি স্ট্যান্ডার্ড SQL FROM ক্লজের ভিতরে GQL প্যাটার্ন এম্বেড করার সুযোগ দেয়। এই কোয়েরিটি সেইসব গ্রাহকদের খুঁজে বের করে যারা তাদের বন্ধুদের মতো একই ঠিকানায় বাস করে—এটি একটি 'ডায়মন্ড' প্যাটার্ন ম্যাচ।
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
গ্রাহকের সংযোগগুলোকে দৃশ্যমান করা
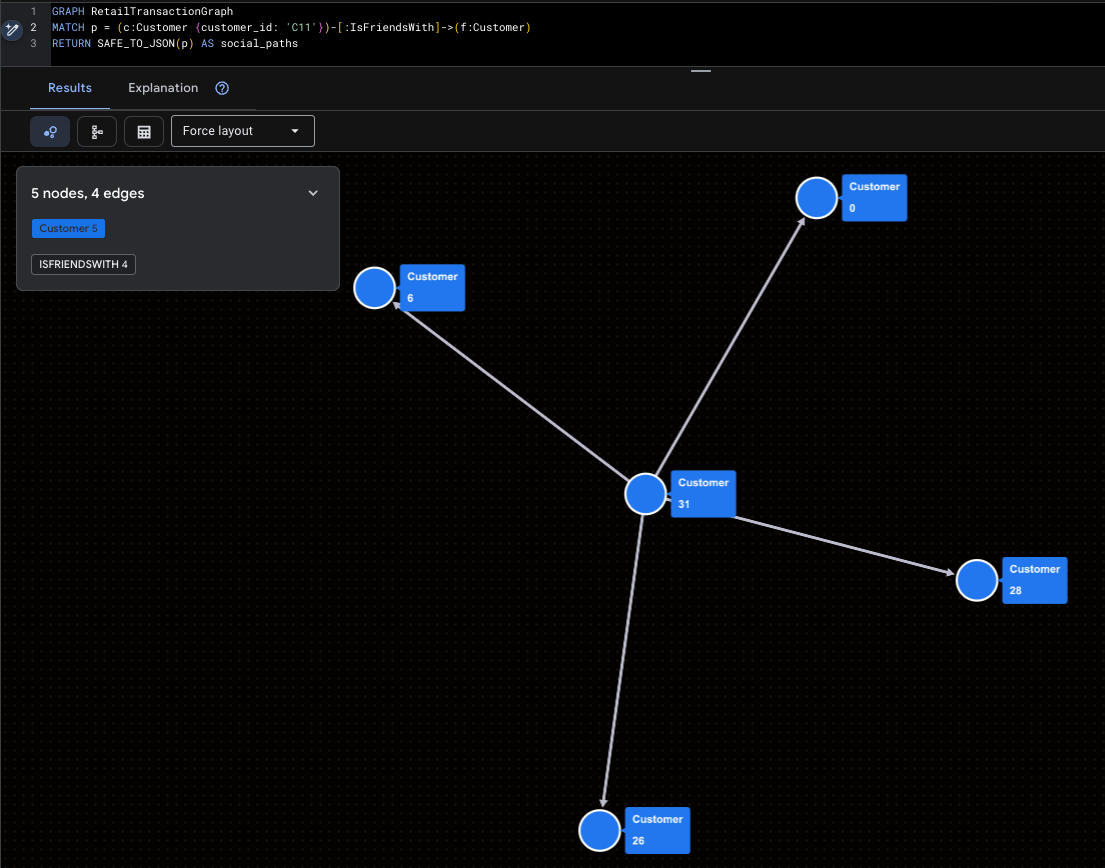
অবশেষে, চলুন আমাদের নেটওয়ার্কটি ভিজ্যুয়ালাইজ করতে GQL ব্যবহার করি। এই কোয়েরিগুলো পাথের ফলাফলগুলোকে SAFE_TO_JSON-এ মোড়কজাত করে, যা ভিজ্যুয়ালাইজারগুলোকে নোড এবং লাইনগুলো আঁকতে সাহায্য করে।
সুপার-ইনফ্লুয়েন্সারকে কল্পনা করা
এটি ম্যালরি (সি১১) এবং তার সরাসরি সামাজিক প্রভাবকে তুলে ধরে।
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
সম্ভাব্য জালিয়াতির ধরণ কল্পনা করা
এই অনুসন্ধানটি "বিচ্ছিন্ন ক্লাস্টার" (ইভান ও জুডি)-কে খুঁজে বের করে, তাদের পণ্যগুলো কোথায় পাঠানো হচ্ছে তা দেখার জন্য।
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
৩. স্প্যানার গ্রাফ অ্যালগরিদমের পরিচিতি
গ্রাফ ইন্টেলিজেন্স বিষয়ে আমাদের গভীর আলোচনার প্রস্তুতির জন্য, এই বিভাগে ক্লাউড স্প্যানার গ্রাফ অ্যালগরিদম -এর প্রযুক্তিগত স্থাপত্য এবং মৌলিক নিয়মাবলীর রূপরেখা দেওয়া হয়েছে। সাধারণ ট্র্যাভার্সাল থেকে পেটাবাইট-স্কেল সম্পর্ক বিশ্লেষণে অগ্রসর হওয়ার জন্য এই নীতিগুলি বোঝা অত্যন্ত গুরুত্বপূর্ণ।
অ্যালগরিদম পোর্টফোলিও
ক্লাউড স্প্যানার বর্তমানে ১৪টি ইন্ডাস্ট্রি-স্ট্যান্ডার্ড গ্রাফ অ্যালগরিদম সমর্থন করে, যেগুলোকে বিভিন্ন ব্যবসায়িক সমস্যা সমাধানের জন্য চারটি কার্যকরী গ্রুপে শ্রেণীবদ্ধ করা হয়েছে:
বিভাগ | সমর্থিত অ্যালগরিদম | ব্যবসায়িক ব্যবহারের ক্ষেত্র |
কেন্দ্রীয়তা | পেজর্যাঙ্ক, ব্যক্তিগতকৃত পেজর্যাঙ্ক, বেটুইননেস, ক্লোজনেস | প্রভাবক, কেন্দ্র এবং প্রতিবন্ধকতা চিহ্নিত করুন। |
সম্প্রদায় | WCC, লেবেল প্রোপাগেশন, ক্লিক ফাইন্ডিং, কোরিলেশন ক্লাস্টারিং | প্রতারণা চক্র, সামাজিক গোষ্ঠী এবং বিচ্ছিন্নতা শনাক্ত করুন। |
সাদৃশ্য | জ্যাকার্ড, কোসাইন, সাধারণ প্রতিবেশী, মোট প্রতিবেশী | শক্তিশালী সুপারিশ ইঞ্জিন এবং সত্তা সমাধান। |
পথ খোঁজা | সেট-টু-সেট সংক্ষিপ্ততম পথ, GA পাথ সহায়ক | সরবরাহ ব্যবস্থা এবং যাতায়াতের নৈকট্যকে সর্বোত্তম করুন। |
গুরুত্বপূর্ণ স্কিমা ও কোয়েরি বিবেচ্য বিষয়সমূহ
গ্রাফ অ্যালগরিদমগুলোর কার্যকর সম্পাদন নিশ্চিত করার জন্য, স্প্যানার গ্রাফকে এই নিয়মগুলো মেনে চলতে হবে:
আবশ্যকতা ১. ভৌত ডেটা স্থানীয়তা (ইন্টারলিভিং)
উচ্চ-পারফরম্যান্স গ্রাফ ট্র্যাভার্সালের জন্য সবচেয়ে গুরুত্বপূর্ণ পূর্বশর্ত হলো ইন্টারলিভিং । এটি নিশ্চিত করে যে এজ ডেটা ভৌতভাবে সোর্স নোডের মতো একই সার্ভার স্প্লিটে সংরক্ষিত থাকে, যা অ্যালগরিদম নির্বাহের সময় নেটওয়ার্ক লেটেন্সি কমিয়ে আনে।
- নিয়ম: এজ টেবিলগুলোকে অবশ্যই তাদের সোর্স নোড টেবিলের সাথে ইন্টারলিভ করতে হবে।
- ফরওয়ার্ড ট্র্যাভার্সাল: সোর্স নোড টেবিলের মধ্যে এজ টেবিলকে অন্তর্ভুক্ত করা বহির্গামী লিঙ্কগুলির জন্য ক্যাশে লোকালিটি নিশ্চিত করে।
- রিভার্স ট্র্যাভার্সাল: কার্যকর "ইনকামিং" লিঙ্ক বিশ্লেষণের জন্য, স্বয়ংক্রিয়ভাবে ব্যাকিং ইনডেক্স তৈরি করতে ফরেন কী ব্যবহার করুন, অথবা ডেস্টিনেশন টেবিলে একটি ইন্টারলিভড সেকেন্ডারি ইনডেক্স তৈরি করুন।
আবশ্যকতা ২. অনন্য লেবেলিং আবশ্যকতা
প্রপার্টি গ্রাফে অংশগ্রহণকারী প্রতিটি টেবিলের একটি অনন্য পরিচয় থাকতে হবে। অ্যালগরিদমগুলো তাদের বিশ্লেষণের জন্য প্রয়োজনীয় সাবগ্রাফগুলোকে সঠিকভাবে শনাক্ত ও লোড করতে এই লেবেলগুলোর ওপর নির্ভর করে।
- নিয়ম: প্রপার্টি গ্রাফের মধ্যে প্রতিটি ইনপুট টেবিলের একটি অনন্য শনাক্তকারী লেবেল থাকতে হবে।
- দ্বন্দ্ব: যদি আপনি একাধিক টেবিলের উপর অ্যালগরিদম চালাতে চান, তবে একটিমাত্র লেবেলকে সেগুলোর সাথে যুক্ত করতে পারবেন না।
যুক্তি | উদাহরণ | ফলাফল |
❌ খারাপ | নোড টেবিল (ব্যক্তি লেবেল সত্তা, অ্যাকাউন্ট লেবেল সত্তা) | অবৈধ : অ্যালগরিদমটি একজন ব্যক্তি এবং একটি অ্যাকাউন্টের মধ্যে পার্থক্য করতে পারে না। |
✅ ভালো | নোড টেবিল (ব্যক্তি লেবেল গ্রাহক, অ্যাকাউন্ট লেবেল অ্যাকাউন্ট) | বৈধ : প্রতিটি সত্তার একটি স্বতন্ত্র, অনন্য লেবেল রয়েছে। |
আবশ্যকতা ৩. অ্যালগরিদম কোয়েরির গঠন (MATCH ক্লজ)
কোনো অ্যালগরিদম কল করার সময়, এক্সিকিউশন ইঞ্জিন যাতে অ্যানালিটিক্যাল পাইপলাইনকে অপ্টিমাইজ করতে পারে, তা নিশ্চিত করার জন্য MATCH ক্লজটি স্ট্যান্ডার্ড GQL কোয়েরির চেয়ে আরও কঠোর নিয়ম অনুসরণ করে।
- প্রতিটি MATCH স্টেটমেন্টে শুধুমাত্র একটি ভেরিয়েবলের নাম উল্লেখ করা যাবে।
- একাধিক নোড প্যাটার্ন ব্যবহার করা যাবে না: অ্যালগরিদম কলের জন্য ব্যবহৃত MATCH ক্লজের ভিতরে আপনি সরাসরি কোনো রিলেশনশিপ প্যাটার্ন (যেমন, (a)-[e]->(b)) সংজ্ঞায়িত করতে পারবেন না।
- শুধুমাত্র আক্ষরিক ফিল্টার: যদিও আপনি নোড ফিল্টার করার জন্য WHERE ক্লজ ব্যবহার করতে পারেন (যেমন, WHERE a.id > 400), গ্রাফ অ্যালগরিদম কোয়েরিতে বর্তমানে কোয়েরি প্যারামিটার (@param) সমর্থিত নয় ।
আবশ্যকতা ৪। ফেরত সংক্রান্ত ধারা (শুধুমাত্র স্কেলারদের জন্য)
একটি অ্যালগরিদম কোয়েরির RETURN ক্লজটি গ্রাফ জগৎ এবং রিলেশনাল জগতের মধ্যে সেতুবন্ধন হিসেবে কাজ করে। এটি শুধুমাত্র স্কেলার এবং ধ্রুবক রিটার্ন করার মধ্যেই কঠোরভাবে সীমাবদ্ধ।
- নিয়ম: আপনি কোনো "গ্রাফ এলিমেন্ট" (মূল নোড বা এজ অবজেক্ট) রিটার্ন করতে পারবেন না।
- কোনো রূপান্তর নয়: RETURN স্টেটমেন্টের মধ্যেই আপনি ফেরত আসা প্রোপার্টিগুলোর উপর গাণিতিক অপারেশন বা ফাংশন প্রয়োগ করতে পারবেন না।
ফেরত ধারার সীমাবদ্ধতা
✅ সমর্থিত | ❌ সমর্থিত নয় |
নোড.আইডি, স্কোর ফেরত দিন | নোড ও স্কোর ফেরত দিন (গ্রাফ এলিমেন্ট ফেরত দেওয়া যাবে না) |
রিটার্ন পাথ_লেংথ(পি) | নোড.আইডি + ১, স্কোর ফেরত দিন (প্রপার্টির উপর কোনো অপারেশন করা যাবে না) |
নোড.নাম ফেরত দিন | RETURN JSON_OBJECT(node.id, score) (কোনো ফাংশন নেই) |
আবশ্যকতা ৫. ডেটার অখণ্ডতা: ড্যাংলিং এজ অপসারণ
যখন কোনো এজ এমন একটি গন্তব্য নোডের দিকে নির্দেশ করে যা গ্রাফে বিদ্যমান নেই, তখন তাকে 'ড্যাংলিং এজ' বলা হয়। এর ফলে অ্যালগরিদম কার্যকর হওয়া ব্যর্থ হয়, কারণ গ্রাফের কাঠামোটি অসামঞ্জস্যপূর্ণ হয়ে পড়ে।
- সমাধান: গ্রাফের অখণ্ডতা বজায় রাখতে রেফারেনশিয়াল কনস্ট্রেইন্ট (ফরেন কী) এবং অন ডিলিট ক্যাসকেড ব্যবহার করুন।
- কোয়েরি নিরাপত্তা: কোনো অ্যালগরিদম কল করার সময়, আপনাকে অবশ্যই নিশ্চিত করতে হবে যে নির্বাচিত এজগুলো দ্বারা নির্দেশিত সমস্ত নোডও `node_labels` আর্গুমেন্টে অন্তর্ভুক্ত রয়েছে।
স্থায়ী আউটপুট: ডেটা রপ্তানির বিকল্পসমূহ
যেহেতু গ্রাফ অ্যালগরিদমগুলো প্রচুর গণনা-নির্ভর, তাই এগুলো EXPORT DATA স্টেটমেন্ট ব্যবহার করে স্কেল-আপ এক্সিকিউশন মোডে চালানো হয়। এটি ডেটা বুস্ট-এর সুবিধা গ্রহণ করে, যা স্বাধীন সার্ভারলেস কম্পিউট রিসোর্স ব্যবহার করে আপনার প্রোডাকশন ট্রানজ্যাকশনগুলোতে কোনো ধরনের ল্যাগ বা বিলম্ব প্রতিরোধ করে।
বিকল্প ১: ক্লাউড স্প্যানারে ফিরে যান
ফলাফল সরাসরি আপনার টেবিলে ফেরত পাঠাতে (যেমন, পেজর্যাঙ্ক স্কোর সংরক্ষণ করতে), `format = 'CLOUD_SPANNER'` ব্যবহার করুন।
-
update_ignore_all: শুধুমাত্র সেইসব কী-এর সারি আপডেট করে যা টার্গেট টেবিলে আগে থেকেই বিদ্যমান। -
upsert_ignore_all: বিদ্যমান সারিগুলো আপডেট করে অথবা কী (key) অনুপস্থিত থাকলে নতুন সারি যোগ করে।
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
বিকল্প ২: ফলাফল গুগল ক্লাউড স্টোরেজ (GCS)-এ সংরক্ষণ করুন
বৃহৎ পরিসরে অফলাইন বিশ্লেষণের জন্য, আপনি CSV, Avro, বা Parquet ফরম্যাটে GCS-এ এক্সপোর্ট করতে পারেন।
- ওয়াইল্ডকার্ড: শার্ডেড আউটপুট চালু করতে
uri => 'gs://bucket/file_*.csv'ব্যবহার করুন, যা স্প্যানারকে বিশাল ডেটাসেটের জন্য সমান্তরালভাবে একাধিক ফাইলে লেখার সুযোগ দেয়। - কম্প্রেশন: স্টোরেজ খরচ অপ্টিমাইজ করতে GZIP, SNAPPY, এবং ZSTD সাপোর্ট করে।
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
৪. চ্যালেঞ্জ ১: প্রভাবের ব্যবধান (পেজর্যাঙ্ক)
এই অংশে, আমরা গ্রাহকের প্রথম ব্যবসায়িক বাধা— ‘প্রভাবের ব্যবধান’—নিয়ে আলোচনা করব। আমরা একটি সাধারণ ‘জনপ্রিয়তার প্রতিযোগিতা’ থেকে সরে এসে প্রকৃত সামাজিক প্রভাবের একটি গাণিতিকভাবে চালিত মানচিত্রের দিকে অগ্রসর হব।
সমস্যা বিবরণ: গ্রাহকের বিপণন দলের একটি সমস্যা রয়েছে। তারা ব্যাপক বিজ্ঞাপনে লক্ষ লক্ষ টাকা খরচ করছে, কিন্তু তার থেকে প্রাপ্ত আয় ক্রমশ কমছে, কারণ তারা ‘সোশ্যাল সুপারস্টার’দের চিহ্নিত করতে পারছে না; এই বিরল ব্যক্তিরা হলেন তারা, যাদের সমর্থন পুরো নেটওয়ার্ক জুড়ে ছড়িয়ে পড়ে।
এর সমাধান করতে, আমাদের গ্রাহকদের প্রভাব অনুসারে ক্রম নির্ধারণ করতে হবে।
সম্পর্কীয় সমাধান (ডিগ্রি কেন্দ্রিকতা)
একটি স্ট্যান্ডার্ড ডেটাবেসে, কোনো ইনফ্লুয়েন্সারকে খুঁজে বের করার সবচেয়ে সহজ উপায় হলো তার ফলোয়ার সংখ্যা গণনা করা (এই মেট্রিকটি ডিগ্রি সেন্ট্রালিটি নামে পরিচিত)।
সবচেয়ে 'জনপ্রিয়' ব্যবহারকারীদের খুঁজে পেতে এই কোয়েরিটি চালান:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
গ্রাহক_আইডি | অনুসারীর সংখ্যা |
সি১ | ৩ |
সি৫ | ৩ |
সি১১ | ২ |
সি৭ | ২ |
সি১০ | ১ |
সি১২ | ১ |
সি২ | ১ |
সি৩ | ১ |
সি৪ | ১ |
সি৬ | ১ |
সি৮ | ১ |
সি৯ | ১ |
গ্রাফ ইন্টেলিজেন্স (পেজর্যাঙ্ক)
প্রকৃত অগ্রগামীদের খুঁজে বের করতে আমরা পেজর্যাঙ্ক (PageRank ) ব্যবহার করি। এটি সেই একই অ্যালগরিদম যা প্রাথমিক ওয়েব সার্চকে চালিত করেছিল; এটি আগত লিঙ্কের পরিমাণ এবং গুণমান উভয়ের উপর ভিত্তি করে একটি নোডের গুরুত্ব পরিমাপ করে।
- র্যান্ডম সার্ফার মডেল: পেজর্যাঙ্ক একজন ব্যবহারকারীর গ্রাফের মধ্য দিয়ে চলাচলের অনুকরণ করে। ড্যাম্পিং ফ্যাক্টর (ডিফল্ট ০.৮৫) ব্যবহারকারীর ক্লিক চালিয়ে যাওয়ার সম্ভাবনাকে নির্দেশ করে; অন্যথায়, তারা একটি র্যান্ডম নোডে "টেলিপোর্ট" হয়ে যায়।
- সংযোগের শক্তি: ম্যালোরির মতো একজন প্রভাবশালী ব্যক্তির দেওয়া লিঙ্কের মূল্য, অন্য কোনো সংযোগ নেই এমন কারো দেওয়া লিঙ্কের চেয়ে অনেক বেশি।
আমরা পেজর্যাঙ্ক অ্যালগরিদম চালাব এবং ফলাফলগুলো সরাসরি আমাদের pagerank_score কলামে সংরক্ষণ করতে EXPORT DATA ব্যবহার করব।
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
পেজর্যাঙ্ক ব্যবহার করে "প্রভাব" ড্যাশবোর্ড
এখন যেহেতু স্কোরগুলো সংরক্ষিত হয়েছে, চলুন আমাদের 'আগের' (অনুসারীর সংখ্যা) অবস্থার সাথে 'পরের' (পেজর্যাঙ্ক স্কোর) অবস্থার তুলনা করা যাক।
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
গ্রাহক_আইডি | গ্রাহকের ইমেল | অনুসারীর সংখ্যা | পেজর্যাঙ্ক_স্কোর |
সি৫ | eve@example.com | ৩ | ০.১৫৮৩৯২৪৮৯ |
সি১০ | judy@example.com | ১ | ০.১০৯৩৫৬১৭২৪ |
সি৯ | ivan@example.com | ১ | ০.১০৯৩৫৬১৭২৪ |
সি১ | alice@example.com | ৩ | ০.১০০০০৮৮৮১২৪ |
সি৮ | heidi@example.com | ১ | ০.০৯৭৫৯৮২১৭৪৩ |
সি১১ | mallory@example.com | ২ | ০.০৯৪৬৬৪১১৯১৮ |
সি৭ | grace@example.com | ২ | ০.০৮০১৬৭১৯৬৬৯ |
সি৬ | frank@example.com | ১ | ০.০৬০২২৪৪৮০৯৩ |
সি২ | bob@example.com | ১ | ০.০৫৪৭৮৯১৮১৮ |
সি৩ | charlie@example.com | ১ | ০.০৫৪৭৮৯১৮১৮ |
সি১২ | trent@example.com | ১ | ০.০৪০২৯২২৫৫৫৮ |
সি৪ | david@example.com | ১ | ০.০৪০২৮১৭২৭৯১ |
বিশ্লেষণ: আসল সুপারস্টার কারা?
আউটপুট বিশ্লেষণ করে, আপনি এখন বিপণন সংক্রান্ত তিনটি গুরুত্বপূর্ণ বিষয় আবিষ্কার করতে পারেন:
ব্যবসায়িক শিক্ষা
পাঁচজনের বেশি ফলোয়ার আছে এমন প্রত্যেককে নির্বিচারে ইমেল করার পরিবর্তে, গ্রাহকের মার্কেটিং টিম এখন শুধুমাত্র সর্বোচ্চ পেজর্যাঙ্ক_স্কোর (pagerank_score) সম্পন্ন ব্যক্তিদের উপর মনোযোগ দিতে পারে। এই ব্যক্তিরাই হলেন প্রকৃত "সোশ্যাল সুপারস্টার", যারা সমগ্র মার্কেটপ্লেস জুড়ে পদ্ধতিগত ভাইরালিটি (simple virality) চালনা করতে সক্ষম।
এখন আসুন সেই গেটকিপারদের চিহ্নিত করার চেষ্টা করি যারা গ্রাহকের লজিস্টিকস নেটওয়ার্ক সচল রাখে।
৫. চ্যালেঞ্জ ২: লজিস্টিক স্থিতিস্থাপকতা (মধ্যবর্তী কেন্দ্রিকতা)
এই অংশে আমরা লজিস্টিকস স্থিতিস্থাপকতা নিয়ে আলোচনা করব। আমরা কেবল পরিমাণের ভিত্তিতে সাফল্য পরিমাপের ধারণা থেকে সরে এসে সেইসব গুরুত্বপূর্ণ ‘গেটকিপার’ বা নিয়ন্ত্রকদের চিহ্নিত করব, যারা নেটওয়ার্কটিকে সংযুক্ত রাখে।
সম্পর্কীয় সমাধান (আয়তন-ভিত্তিক বিশ্লেষণ)
একটি আদর্শ রিলেশনাল সেটআপে, একটি 'গুরুত্বপূর্ণ' শিপিং হাবকে সাধারণত সেটি হিসাবে সংজ্ঞায়িত করা হয় যা সর্বাধিক অর্ডার প্রসেস করে বা সর্বাধিক রাজস্ব তৈরি করে।
লেনদেনের সংখ্যা অনুসারে 'শীর্ষ' হাবগুলি শনাক্ত করতে এই কোয়েরিটি চালান:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
শহর | দেশ | লেনদেনের সংখ্যা | মোট_রাজস্ব |
নিউ ইয়র্ক | মার্কিন যুক্তরাষ্ট্র | ৪ | ৩৯৯৬ |
বার্লিন | জার্মানি | ২ | ৩৪৫ |
সান ফ্রান্সিসকো | মার্কিন যুক্তরাষ্ট্র | ২ | ৭৫০ |
এই অমিলটি নিরসন করতে, আমরা IsFriendsWith এবং LivesAt উভয় এজ ব্যবহার করব। এটি আমাদের বিশ্লেষণকে একটি ট্রানজ্যাকশন হাব থেকে সামাজিক যাচাই অন্তর্ভুক্ত করার পর্যায়ে রূপান্তরিত করে।
গ্রাফ ইন্টেলিজেন্স (মধ্যবর্তী কেন্দ্রীয়তা)
প্রকৃত প্রতিবন্ধকতাগুলো খুঁজে বের করতে আমরা ‘বিটুইননেস সেন্ট্রালিটি’ ব্যবহার করি। এই অ্যালগরিদমটি পরিমাপ করে যে, গ্রাফের অন্য সব জোড়া নোডের মধ্যেকার সংক্ষিপ্ততম পথগুলোতে একটি নোড কত ঘন ঘন 'সেতু' হিসেবে কাজ করে। উচ্চ স্কোরগুলো সেই প্রকৃত নিয়ন্ত্রকদের চিহ্নিত করে, যারা পণ্য বা তথ্যের প্রবাহ নিয়ন্ত্রণ করে।
চলমান এবং স্থায়ী মধ্যবর্তী কেন্দ্রীয়তা
আমরা এক্সপোর্ট ডেটা (EXPORT DATA) ব্যবহার করে অ্যালগরিদমটি চালাব এবং স্কোরগুলো সেন্ট্রালিটি_স্কোর (centrality_score) কলামে সংরক্ষণ করব। আমরা ডেটা বুস্ট (Data Boost) ব্যবহার করি এটা নিশ্চিত করতে যে, এই জটিল 'সংক্ষিপ্ততম পথ' (shortest path) গণনাটি গ্রাহকের চলমান কার্যক্রমে প্রায়-শূন্য প্রভাব ফেলে।
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
বিশ্লেষণ: 'লুকানো প্রতিবন্ধকতা' চিহ্নিতকরণ
এখন, গ্রাহকের নেতৃত্বের কোন নোডগুলো নিয়ে উদ্বিগ্ন হওয়া উচিত তা খুঁজে বের করার জন্য আমরা আমাদের কাঠামোগত ঝুঁকি ( centrality_score ) এবং লেনদেনের পরিমাণ ( order_count ) তুলনা করি।
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
গ্রাহক_আইডি | গ্রাহকের ইমেল | কেন্দ্রীয়তার_স্কোর | অর্ডার_সংখ্যা | |
সি১১ | mallory@example.com | ৪৪.৫ | ২ | |
সি১ | alice@example.com | ৩৫.৫ | ১ | |
সি৫ | eve@example.com | ৩৫.৫ | ||
সি৭ | grace@example.com | ১২ | ১ | |
সি৮ | heidi@example.com | ১০ | ১ | |
সি৩ | charlie@example.com | ৬ | ||
সি৪ | david@example.com | ৩.৫ | ||
সি১০ | judy@example.com | ০ | ১ | |
সি১২ | trent@example.com | ০ | ||
সি২ | bob@example.com | ০ | ১ | |
সি৬ | frank@example.com | ০ | ||
সি৯ | ivan@example.com | ০ | ১ | |
এই ফলাফলগুলো বিশ্লেষণ করে গ্রাহক তিনটি চমকপ্রদ বিষয় আবিষ্কার করেন:
ব্যবসায়িক শিক্ষা
গ্রাহক এখন মাল্টি-মোডাল কাঠামোগত ঝুঁকির উপর ভিত্তি করে তার লজিস্টিকস রিডানডেন্সি এবং নিরাপত্তা প্রোটোকলগুলোকে অগ্রাধিকার দিতে পারে। ম্যালোরি, অ্যালিস এবং ইভ হলো সেই দ্বাররক্ষক, যাদের লজিস্টিকস নেটওয়ার্কের স্থিতিশীলতা নিশ্চিত করার জন্য অবশ্যই সুরক্ষিত রাখতে হবে।
এখন চলুন জালিয়াতির কেন্দ্রগুলো চিহ্নিত করার চেষ্টা করি।
৬. চ্যালেঞ্জ ৩: ভুতুড়ে নেটওয়ার্ক (ডব্লিউসিসি)
এই অংশে, আমরা তৃতীয় ব্যবসায়িক বাধাটি নিয়ে আলোচনা করব: ‘ঘোস্ট নেটওয়ার্ক’। আমরা সাধারণ ‘হটস্পট’ শনাক্তকরণ থেকে সরে এসে কমিউনিটি ডিটেকশন ব্যবহার করে অত্যাধুনিক ও বিচ্ছিন্ন জালিয়াতি চক্র উন্মোচন করব। এখানকার চ্যালেঞ্জটি হলো, দুষ্কৃতকারীরা এমন সব নকল প্রোফাইল তৈরি করে যেগুলো শিপিং অ্যাড্রেস শেয়ার করে অথবা চুরি সমন্বয় করতে এবং পণ্যের রেটিং বাড়িয়ে তুলতে ক্লোজড লুপে যোগাযোগ করে। কিন্তু তারা প্রায়শই বৈধ গ্রাহক কমিউনিটি থেকে সম্পূর্ণ বিচ্ছিন্ন থাকে।
এর সমাধান করতে হলে আমাদের এই 'বিচ্ছিন্ন দ্বীপগুলোকে' উন্মোচন করতে হবে।
সম্পর্কীয় সমাধান (ভাগ করা শনাক্তকারী অনুসন্ধান)
গ্রাফ অ্যালগরিদম ছাড়া, জালিয়াতি শনাক্ত করার প্রচলিত উপায় হলো একই ডেটার ‘হটস্পট’ খোঁজা, যেমন একাধিক গ্রাহক হুবহু একই ঠিকানায় পণ্য পাঠাচ্ছেন।
একই শিপিং লোকেশনের মাধ্যমে সংযুক্ত গ্রাহকদের খুঁজে পেতে এই কোয়েরিটি চালান:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
শিপিং_আইডি | গ্রাহকের সংখ্যা | সংযুক্ত_গ্রাহক |
এস১ | ৪ | ["C1","C10","C2","C9"] |
এস৫ | ২ | ["C7","C8"] |
প্রতারণার নেটওয়ার্কগুলো খুঁজে বের করতে হলে আমাদের ট্রানজিটিভ রিচেবিলিটি বুঝতে হবে।
গ্রাফ ইন্টেলিজেন্স (দুর্বলভাবে সংযুক্ত উপাদান)
এই বলয়গুলোর সম্পূর্ণ বিস্তৃতি নির্ণয় করতে আমরা উইকলি কানেক্টেড কম্পোনেন্টস (WCC) ব্যবহার করি। WCC হলো একটি ক্লাস্টারিং অ্যালগরিদম যা এমন নোডের সেট শনাক্ত করে, যেখানে প্রান্তগুলোর দিক নির্বিশেষে যেকোনো দুটি নোডের মধ্যে একটি পথ বিদ্যমান থাকে।
- পৌঁছানোযোগ্য অঞ্চল: এটি কার্যকরভাবে গ্রাফটিকে 'দ্বীপ' বা 'পৌঁছানোযোগ্য অঞ্চল'-এ বিভক্ত করে।
- একীভূত সত্তা দৃষ্টিভঙ্গি: সামাজিক সম্পর্ক (কার সাথে বন্ধুত্ব আছে) এবং লজিস্টিক সম্পর্ক (কোথায় থাকে) উভয়ই একযোগে বিশ্লেষণ করে, আমরা খণ্ডিত প্রোফাইলগুলোকে একটি একক, একীভূত "প্রভাব ক্লাস্টার"-এ একত্রিত করতে পারি।
WCC চালানো ও চালিয়ে যাওয়া
আমরা WCC অ্যালগরিদমটি চালাব এবং ফলাফলগুলো community_id কলামে সংরক্ষণ করব। এই গভীর রিচেবিলিটি বিশ্লেষণটি যেন স্বাধীন কম্পিউট রিসোর্সে সম্পন্ন হয়, তা নিশ্চিত করতে আমরা ডেটা বুস্ট (Data Boost) ব্যবহার করি।
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
বিশ্লেষণ: জালিয়াতি চক্র
এখন, আমাদের বিচ্ছিন্ন কমিউনিটিগুলো দেখতে একটি ভ্যালিডেশন কোয়েরি চালানো যাক। বৈধ ব্যবহারকারীরা সাধারণত 'মূল ভূখণ্ড'-এর অন্তর্ভুক্ত, আর প্রতারকরা প্রায়শই ছোট ছোট 'দ্বীপ'-এ আটকা পড়ে থাকে।
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
কমিউনিটি_আইডি | সদস্য_সংখ্যা | সদস্যরা |
১ | ২ | ["judy@example.com","ivan@example.com"] |
০ | ১০ | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
এই কমিউনিটি ডিটেকশনটি চালানোর মাধ্যমে, আপনি একটি গুরুতর অসঙ্গতি শনাক্ত করতে পারেন:
ব্যবসায়িক শিক্ষা
গ্রাহক এখন তার নিরাপত্তা সংক্রান্ত প্রতিক্রিয়াগুলো স্বয়ংক্রিয় করতে পারে। প্রতিটি অ্যাকাউন্টের পেছনে ম্যানুয়ালি ছোটাছুটি করার পরিবর্তে, তারা একটি সহজ নিয়ম লিখতে পারে: "যদি কোনো community_id-তে তিনজনের কম সদস্য থাকে, তাহলে ম্যানুয়াল KYC (Know Your Customer) পর্যালোচনার জন্য পুরো গ্রুপটিকে চিহ্নিত করুন।"
.
আমাদের প্রতারণার চক্রগুলো ফাঁস হয়ে যাওয়ায়, আমরা 'আচরণগত যমজ' রহস্যটির সমাধান করতে পারব।
৭. চ্যালেঞ্জ ৪: আচরণগত যমজ (জ্যাকার্ড সাদৃশ্য)
এই চূড়ান্ত চ্যালেঞ্জে, আমরা চতুর্থ বাধাটি মোকাবেলা করব: ‘পছন্দের প্যারাডক্স’/‘আচরণগত যমজ’। আমরা গতানুগতিক ‘প্রায়শই একসাথে কেনা হয়’ এমন তালিকা থেকে সরে এসে আচরণগত ‘ফিঙ্গারপ্রিন্ট’-এর উপর ভিত্তি করে অতি-ব্যক্তিগতকৃত সুপারিশের দিকে অগ্রসর হব।
গ্রাহকের বর্তমান পণ্যের পরামর্শগুলো খুবই সাধারণ। প্রত্যেক গ্রাহককে একটি জনপ্রিয় ইউএসবি কেবলের সুপারিশ করা নিরাপদ, কিন্তু এতে ব্যক্তিগত ছোঁয়া নেই। গ্রাহক এমন 'বিহেভিয়ারাল টুইন' সুপারিশ ব্যবস্থা তৈরি করতে চান, যা অনন্য শিপিং প্যাটার্ন এবং সামাজিক পরিমণ্ডলের গ্রাহকদের শনাক্ত করে অত্যন্ত নিখুঁতভাবে পণ্যের মিল খুঁজে বের করবে।
এটি সমাধান করতে, আমাদের ব্যবহারকারীদের মধ্যে 'নৈকট্য' গণনা করতে হবে।
সম্পর্কীয় সমাধান (পরম ওভারল্যাপ)
একটি সাধারণ রিলেশনাল সেটআপে, আপনি এমন ব্যক্তিদের খুঁজতে পারেন যারা অ্যালিস (C1)- এর মতো একজন রেফারেন্স ব্যবহারকারীর মতোই একই লোকেশনে পণ্য পাঠান।
অ্যালিসের ভৌগোলিক প্রতিবেশীদের খুঁজে পেতে এই কোয়েরিটি চালান:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
অনুরূপ গ্রাহক | ভাগ করা অবস্থানগুলি |
সি২ | ১ |
সি১০ | ১ |
সি৯ | ১ |
গ্রাফ ইন্টেলিজেন্স (জ্যাকার্ড সাদৃশ্য)
প্রকৃত আচরণগত যমজ খুঁজে বের করার জন্য আমরা জ্যাকার্ড সিমিলারিটি ব্যবহার করি। এই অ্যালগরিদমটি অভিন্ন প্রতিবেশীর সংখ্যাকে (ইন্টারসেকশন) মোট অনন্য প্রতিবেশীর সংখ্যা (ইউনিয়ন) দ্বারা ভাগ করে একটি স্বাভাবিককৃত স্কোর (০.০ থেকে ১.০) গণনা করে।
এখানে 'আচরণগত যমজ'-কে শুধুমাত্র একটি অভিন্ন শিপিং ঠিকানার চেয়েও বেশি কিছু দিয়ে সংজ্ঞায়িত করা হয়। ভৌত পদচিহ্ন ( LivesAt ) এবং সামাজিক বাস্তুতন্ত্রের ( IsFriendsWith ) সংযোগস্থল বিশ্লেষণ করে, আমরা এমন ব্যবহারকারীদের শনাক্ত করতে পারি যারা একই জীবনধারা এবং সামাজিক প্রভাব ভাগ করে নেয়, যার ফলে পণ্যের সুপারিশ অনেক বেশি নির্ভুল হয়।
প্রথমে একটি ম্যাপিং টেবিল তৈরি করুন।
যেহেতু সাদৃশ্য একটি জোড়াভিত্তিক সম্পর্ক (যেমন গ্রাহক A, গ্রাহক B-এর অনুরূপ), তাই এই ম্যাপিংগুলো সংরক্ষণ করার জন্য আমরা Customer মধ্যে একটি বিশেষ টেবিল তৈরি করি।
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
এখন জ্যাকার্ড সিমিলারিটি চালান
We will now execute the algorithm. Note: This query includes a common "Guardrail" lesson. If you only select Customer nodes but use the LivesAt edge (which points to Shipping nodes), the query will fail citing a "Dangling Edge" . To fix this, we must include both node labels.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
বিশ্লেষণ: "আচরণগত যমজ" যাচাই
Now that the analytical job is complete, we run a validation query. By joining our new mapping table ( CustomerSimilarity ) with our original Customer metadata, we can see exactly who Alice's "Behavioral Twins" are.
Run this query to inspect Alice's similarity rankings:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | ১ | 0.1093561724 |
bob@example.com | 0.200000003 | ০ | 0.0547891818 |
ivan@example.com | 0.200000003 | ১ | 0.1093561724 |
eve@example.com | 0.1666666716 | ০ | 0.158392489 |
mallory@example.com | ০ | ০ | 0.09466411918 |
trent@example.com | ০ | ০ | 0.04029225558 |
charlie@example.com | ০ | ০ | 0.0547891818 |
david@example.com | ০ | ০ | 0.04028172791 |
frank@example.com | ০ | ০ | 0.06022448093 |
grace@example.com | ০ | ০ | 0.08016719669 |
heidi@example.com | ০ | ০ | 0.09759821743 |
ফলাফলে কী কী দেখতে হবে:
Now lets try to build a final Unified Intelligence view.
8. Unified Intelligence
Now we move from individual technical tasks to Unified Intelligence . Here, we blend transactional data with all four graph algorithms to provide clear, actionable insights.
প্রতিবেদন ১: সমন্বিত গোয়েন্দা তথ্য
The power of a multi-model database like Spanner is the ability to join relational spend data with graph-derived influence, risk, and similarity scores in a single request. This query categorizes every customer into a specific business persona.
Run the Unified Intelligence query to see complete ecosystem:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | ব্যয় | প্রভাব | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | ৭৫০ | 0.09466411918 | 44.5 | ০ | 🔵 CRITICAL: Network Bridge |
সি৫ | eve@example.com | ০ | 0.158392489 | 35.5 | ০ | 🔵 CRITICAL: Network Bridge |
সি১ | alice@example.com | ৯৯৯ | 0.1000888124 | 35.5 | ০ | 🔵 CRITICAL: Network Bridge |
C7 | grace@example.com | ৩০০ | 0.08016719669 | ১২ | ০ | 📱 SOCIAL: High-Reach Influencer |
সি৮ | heidi@example.com | ৪৫ | 0.09759821743 | ১০ | ০ | 📱 SOCIAL: High-Reach Influencer |
সি৩ | charlie@example.com | ০ | 0.0547891818 | ৬ | ০ | 🟢 STANDARD: Active Customer |
সি৪ | david@example.com | ০ | 0.04028172791 | ৩.৫ | ০ | 🟢 STANDARD: Active Customer |
C10 | judy@example.com | ৯৯৯ | 0.1093561724 | ০ | ১ | 🔴 HIGH RISK: Isolated Fraud Ring |
সি৯ | ivan@example.com | ৯৯৯ | 0.1093561724 | ০ | ১ | 🔴 HIGH RISK: Isolated Fraud Ring |
C6 | frank@example.com | ০ | 0.06022448093 | ০ | ০ | 🟢 STANDARD: Active Customer |
সি২ | bob@example.com | ৯৯৯ | 0.0547891818 | ০ | ০ | 🟢 STANDARD: Active Customer |
C12 | trent@example.com | ০ | 0.04029225558 | ০ | ০ | 🟢 STANDARD: Active Customer |
By blending these mathematical lenses, we move beyond "who spent the most" to "who matters the most." The unified dashboard integrates relational transaction data with multi-modal graph intelligence to categorize your ecosystem into three clear, actionable personas.
The "Critical Network Bridges" (Resilience)
Nodes like Mallory (C11) , Eve (C5) , and Alice (C1) are flagged because their bottleneck_risk (Betweenness Centrality) is >25 .
- The Structural Anchors: Mallory holds the highest risk score at 44.5 , marking her as the primary gateway for the entire network.
- The Zero-Spend Paradox: Eve (C5) has an order count of zero, yet she is structurally indispensable with a risk score of 35.5 . Standard SQL would have ignored her entirely, but Graph Intelligence reveals she is a vital bridge to an entire sub-community.
- The High-Value Gateway: Alice (C1) tied with Eve at 35.5 , proving that high spenders can also be critical structural anchors.
The "Social Superstars" (Reach)
Heidi (C8) and Grace (C7) are identified as high-reach influencers due to their PageRank scores .
The "Isolated Fraud Ring" (Anomalies)
Judy (C10) and Ivan (C9) are flagged because they belong to the isolated community_id 1
ব্যবসায়িক অন্তর্দৃষ্টি থেকে কৌশলগত পদক্ষেপ
ব্যক্তিত্ব | Key Metric | Business Insight | Strategic Action |
🔵 Network Bridges | High Centrality | Structural Anchors : Eve (C5) and Mallory (C11) hold the network together. | Retention : Protect these gatekeepers to prevent community fragmentation. |
📱 Social Superstars | High PageRank | Viral Engines : Users like Heidi (C8) have the highest reach in their circles. | Marketing : Use for high-impact referral and ambassador programs. |
🔴 Fraud Risks | Isolated WCC | Ghost Networks : Judy (C10) and Ivan (C9) are high-spenders but live on "islands." | Security : Immediate manual KYC review; these are classic fraud signatures. |
🟢 Standard Users | Balanced Scores | Healthy Core : The majority of the network, including "local" bridges like David (C4). | Growth : Apply standard personalized ads and "Behavioral Twin" recommendations. |
প্রতিবেদন ২: পরিচয় অসঙ্গতি প্রতিবেদন
Now you need to know if legitimate accounts are being "mimicked" by fraudsters. We can solve this by finding users who have 100% Behavioral Similarity but Zero Social Connection.
Run this query to flag potential "Identity Anomalies":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
The Identify Anomaly Report provides critical information. By isolating users who act like legitimate customers but lack their social ties, we move from guessing to mathematical certainty .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | ১ |
সি৯ | ivan@example.com | 0.200000003 | ১ |
ফলাফলের বিশ্লেষণ
By unifying Similarity (Jaccard) with Community Detection (WCC) , we expose hidden risks that traditional transactional data cannot see.
- The "Behavioral Twins" (Proximity): Nodes like Judy (C10) and Ivan (C9) are flagged because they share a Jaccard Similarity score of 0.20 relative to Alice (C1).
- Isolation Behavior: Judy (C10) and Ivan (C9) are grouped into the isolated community_id 1 , while Alice belongs to the social "Mainland" (Community 0).
- Fraud Flags: The report identifies users with high behavioral overlap (>0.9) who remain socially disconnected from the primary network.
9. Congratulations and Summary
This lab shows how Cloud Spanner turns a relational database into a multi-model powerhouse. By applying graph intelligence to The Customer , we moved from static data to actionable business strategy.
স্প্যানার মাল্টি-মডেল সুবিধা
- Unified Architecture: Spanner allows you to maintain a rock-solid relational foundation while instantly "overlaying" a property graph for relationship mining all without the risk and lag of ETL.
- Off-Box Analytical Isolation: By leveraging Data Boost , you can execute memory-intensive algorithms like PageRank or WCC on independent, serverless compute resources, ensuring zero impact on your production checkout performance.
- Interleaved Performance: Spanner's unique interleaving ensures that nodes and their relationships are physically co-located, turning complex global traversals into high-speed local lookups.
Surfacing "Hidden Gems" & Anomalies
- Identifying Structural Value: Graph algorithms like Betweenness Centrality revealed "Hidden Bridges" with zero spend who can be more critical to network's resilience than highest-spending customers.
- Exposing Behavioral Mimicry: By combining Jaccard Similarity and Weakly Connected Components , we identified "Social Strangers". These accounts look like legitimate customers but are mathematically proven to be isolated fraud rings.
- Global vs. Local Truth: While manual SQL analysis can surface bridges, global algorithms can surface key Gatekeepers of the network.
Making Data Intelligent and Actionable
- Persona-Driven Strategy: We successfully transformed our rows to relationship, and by running algorithms we can address four business problems, namely: Network Bridges, Social Superstars, Fraud Risks, and Standard Users .