
1. Fallstudie: Intelligent Retail
In der Fallstudie betrachten wir einen Einzelhandelskunden mit einem schnell wachsenden digitalen Marktplatz. Die herkömmliche Datenansicht eines Kunden ist begrenzt, da sie zeigt, was Nutzer kaufen, aber nicht, wie sie miteinander verbunden sind. Diese Lücke führt zu verpassten Chancen und zunehmendem Betrug. Jetzt setzen sie auf eine Network-First-Philosophie, um neben Transaktionsdaten auch soziale und logistische Verbindungen zu berücksichtigen.
Wichtige geschäftliche Herausforderungen
Sie stehen vor vier wichtigen Herausforderungen, die es erfordern, wie Kunden und Logistik miteinander verbunden sind:
Challenge | Das Problem | Das Ziel |
Lücke bei der Beeinflussung | Breit gefächerte Werbung führt zu einem niedrigen ROI. Derzeit ist es nicht möglich, die echten Trendsetter (Influencer) zu identifizieren. | Influencer identifizieren, die durch ihre Verbindung in einem vernetzten Netzwerk von Kunden eine zentrale Rolle in der Community spielen. |
Logistische Resilienz | Die Lieferkette kann anfällig sein, da sie in verschiedenen geografischen Einheiten tätig ist. Wenn ein wichtiger Hub ausfällt, kann es sein, dass in der gesamten Region der Produktzugriff verloren geht. | Identifizieren Sie Gatekeeper , die für die Verbindung der Logistiknetzwerke unerlässlich sind. |
Ghost Networks | Betrügerische Gruppen verwenden gefälschte Profile und gemeinsame Adressen, um Diebstähle zu koordinieren und Bewertungen zu manipulieren. | Isolierte Inseln aufdecken: Das sind hypervernetzte Gruppen ohne Verbindungen zur legitimen Community. |
Paradox of Choice | Die aktuelle Empfehlungs-Engine ist rudimentär, generisch und wird oft ignoriert (z. B. „Kunden, die diesen Artikel gekauft haben, kauften auch…“). | Verhaltenszwillinge erstellen, d.h. Empfehlungen basierend auf ähnlichen Versandmustern und sozialen Kreisen. |
Geschäftliche Herausforderungen einer technischen Strategie zuordnen (Zeilen → Beziehungen)
In einer herkömmlichen Datenbank werden Daten in isolierten Silos gespeichert: Kunden in einer Tabelle, Transaktionen in einer anderen und Versand in einer dritten. SQL eignet sich zwar hervorragend, um die Frage „Wer hat was gekauft?“ zu beantworten, ist aber weniger gut geeignet für Fragen, die auf dem Netzwerk basieren.
Um diese Herausforderungen zu meistern, muss die technische Strategie diese Perspektive ändern:
- Die relationale Ansicht („Was“): Hier wird jeder Kunde als separate Zeile behandelt. Um eine Verbindung zwischen einem Kunden und dem Kauf eines Freundes herzustellen, sind mehrere komplexe Joins erforderlich, die mit zunehmender Größe des Netzwerks exponentiell langsamer werden.
- Graph View (Das „Wie“): Hier werden Beziehungen als gleichberechtigte Elemente behandelt. Anstatt Listen zu durchsuchen, navigieren wir auf einer Karte. Wir sehen sofort, dass Kunde A mit Kunde B verbunden ist, der an Standort Z liefert.
Anforderungen im Detail
Lösungsarchitekten kommen zu dem Schluss, dass die Geschäftsanforderungen und die technische Strategie einen Multi-Modell-Ansatz erfordern, und identifizieren die folgenden wichtigen Anforderungen.
So erfüllt Cloud Spanner diese technischen Anforderungen
Cloud Spanner wurde als Herzstück dieser Transformation ausgewählt. So kann der Kunde seine solide relationale Grundlage beibehalten und gleichzeitig detaillierte Grafikeinblicke gewinnen.
Hier finden Sie einen kurzen Überblick darüber, wie Cloud Spanner technische Anforderungen und mehr erfüllt.
Darüber hinaus bietet Cloud Spanner eine zukunftssichere technische Architektur.
2. Datengrundlage einrichten
Nach dem Business Case folgt nun die Implementierungsphase. In diesem Abschnitt definieren wir unsere Datenarchitektur, untersuchen die Einschränkungen des herkömmlichen relationalen Modells und stellen den Property Graph als unser primäres Tool vor, um tiefgreifende Erkenntnisse zu gewinnen.
Cloud Spanner Enterprise-Instanz einrichten
Schritt 1: Cloud Spanner API aktivieren
Klicken Sie in der Google Cloud Console oben links auf das Menüsymbol, um die linke Navigationsleiste aufzurufen. Scrollen Sie nach unten und wählen Sie „Schraubenschlüssel“ aus oder suchen Sie nach „Schraubenschlüssel“.
Sie sollten jetzt die Cloud Spanner-Benutzeroberfläche sehen. Wenn Sie ein Projekt verwenden, für das die Cloud Spanner API noch nicht aktiviert ist, werden Sie in einem Dialogfeld aufgefordert, sie zu aktivieren. Wenn Sie die API bereits aktiviert haben, können Sie diesen Schritt überspringen.
Klicken Sie auf Aktivieren, um fortzufahren:
Schritt 2: Cloud Spanner-Instanz erstellen
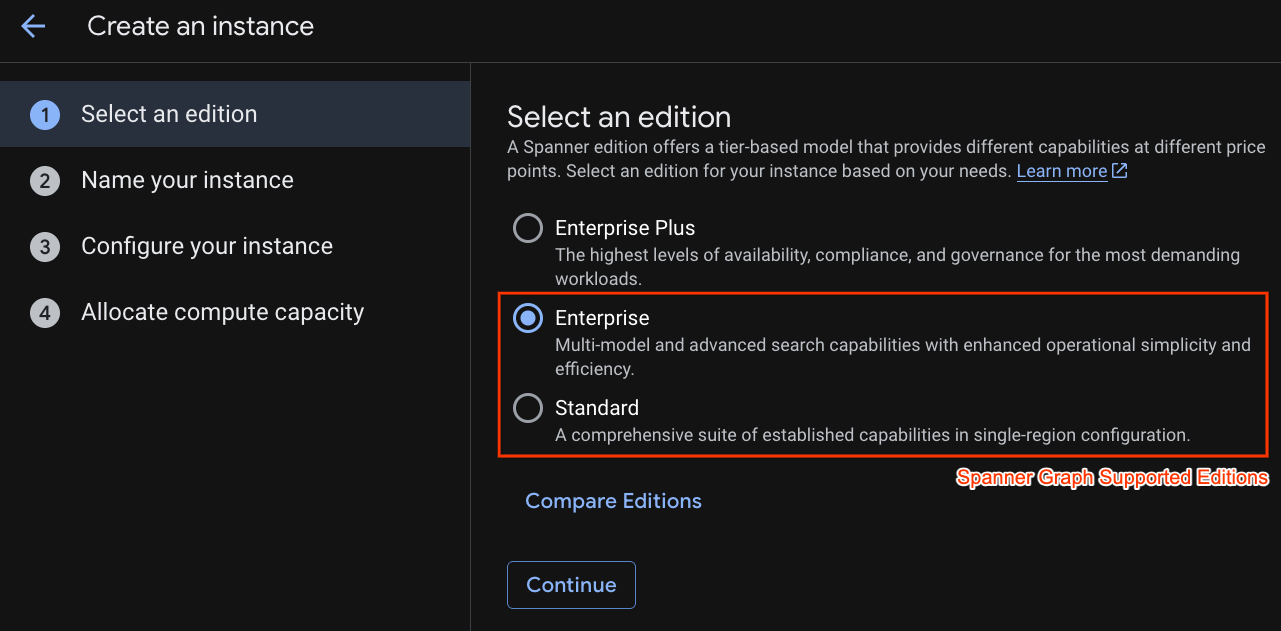
Zuerst erstellen Sie eine Cloud Spanner-Instanz. Klicken Sie in der Benutzeroberfläche auf Bereitgestellte Instanz erstellen, um eine neue Instanz zu erstellen.
Im ersten Schritt müssen Sie eine Version auswählen. Sie können die Edition auch später upgraden. Wenn Sie die Funktionen für mehrere Modelle (Spanner Graph) nutzen möchten, können Sie die Enterprise-Version verwenden.
Instanz benennen
Wählen Sie eine Bereitstellungskonfiguration und eine Region Ihrer Wahl aus.
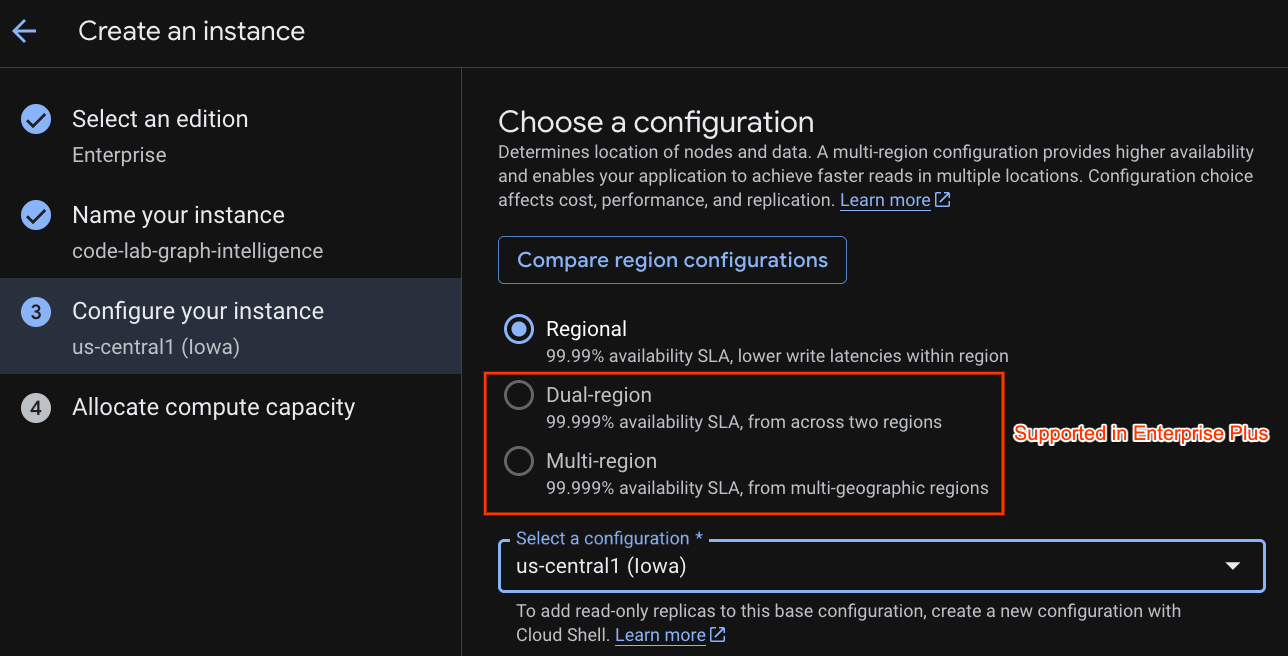
Sie können auch verschiedene Konfigurationsoptionen vergleichen. Die Bereitstellungskonfiguration hat beispielsweise mindestens 3 Lese-/Schreibreplikate in 3 separaten Zonen der ausgewählten Region. Das bedeutet, dass Sie auch bei einer Bereitstellung mit einem einzelnen Knoten 3 Kopien über 3 Lese-/Schreibreplikate haben. Auch bei der Konfiguration für die regionale Bereitstellung können Sie die Bereitstellungstopologie durch zusätzliche schreibgeschützte Replikate erweitern.
Nach der Konfiguration der Kapazität können Sie entweder mit einem Full-Node und Autoscaling bei Knoten beginnen oder eine granulare Instanz (Verarbeitungseinheiten; 1.000 VE = 1 Knoten) verwenden. Optional können Sie auch Autoscaling-Ziele für die Instanz festlegen. Bei Arbeitslasten mit niedriger Latenz empfehlen wir 65% für regionale Instanzen und 45% für multiregionale Instanzen.
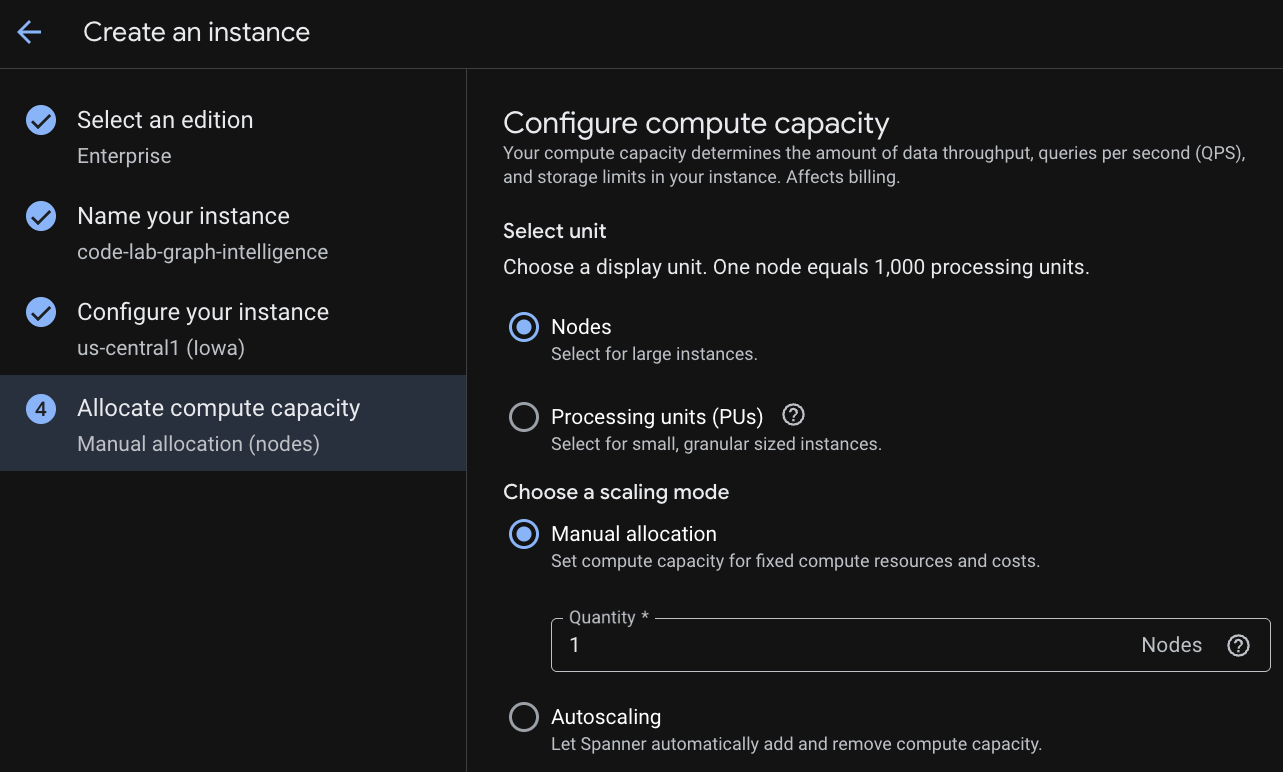
Schritt 3: Datenbank erstellen
Klicken Sie nach der Bereitstellung Ihrer Instanz auf „Datenbank erstellen“, um eine Datenbank für den Rest des Codelabs zu erstellen.
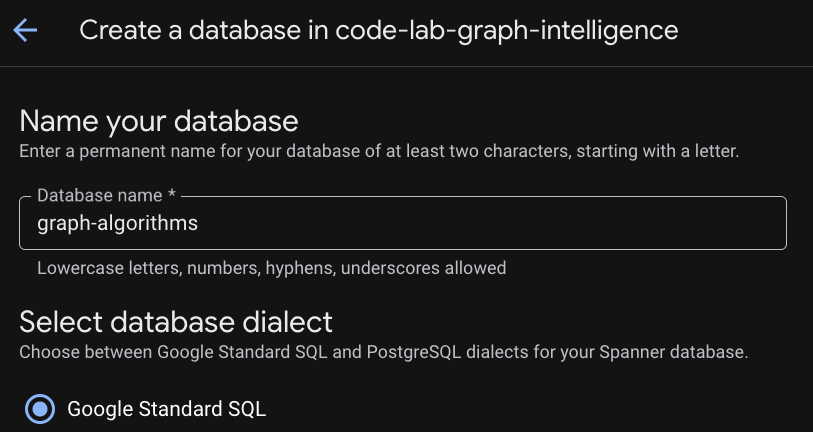
Relationale Grundlage schaffen
Wir beginnen mit den Haupttabellen, in denen Betriebsdaten gespeichert werden. In Cloud Spanner verwenden wir Interleaving, um zusammengehörige Daten wie die Freundschaften und Transaktionen eines Kunden physisch direkt mit dem Kundendatensatz zu platzieren. So wird ein leistungsstarker Zugriff und eine physische Nähe gewährleistet.
DDL: Tabellen erstellen
Kopieren Sie die folgenden Blöcke und führen Sie sie aus, um Ihr relationales Schema zu erstellen:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Netzwerk aufbauen
Nachdem wir die Tabellen erstellt haben, müssen wir sie mit den Nutzern, Produkten und Verbindungen füllen, die das Ökosystem des Kunden definieren.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Relational Challenge
Bevor wir das Diagramm vorstellen, sehen wir uns an, wie herkömmliches SQL die Herausforderungen des Kunden bewältigt. Führen Sie diese Abfrage aus, um Kunden zu finden, die viel Geld ausgeben und viele Freunde haben.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Einschränkungen des relationalen Ansatzes
Beziehungsprobleme mit einem Property Graph lösen
Um diese Einschränkungen zu umgehen, definieren wir einen Attributgraph. Dadurch wird ein „Overlay“ erstellt, mit dem wir Beziehungen als gleichberechtigte Elemente behandeln können, ohne unsere Daten aus Spanner zu verschieben.
DDL: Property Graph erstellen
Diese DDL definiert unsere Knoten (Entitäten) und Kanten (Beziehungen). In diesem Beispiel folgen wir einem schematisierten Diagramm. Mit Spanner Graph können jedoch auch schemalose Graphen modelliert werden, um eine flexible, schnelle iterative Entwicklung zu ermöglichen und sich ändernde Datenmodelle ohne ständige Datendefinitionssprache-Änderungen (DDL) zu verarbeiten.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Mit GQL im Diagramm navigieren
Nachdem wir unseren Graphen definiert haben, können wir Graph Query Language (GQL) verwenden, um Multi-Hop-Traversierungen mit einer einfachen, lesbaren Syntax durchzuführen.
Exploration 1: Gemeinsame Suche
Bei dieser Abfrage wird der Graph durchlaufen, um Produkte zu finden, die von Ihren Freunden gekauft wurden. Sie dient als Grundlage für ein Empfehlungssystem.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Exploration 2: Die Hybridabfrage (relational + Graph)
Mit Spanner können Sie GQL-Muster mithilfe der Funktion GRAPH_TABLE in eine Standard-SQL-FROM-Klausel einbetten. Mit dieser Abfrage werden Kunden gefunden, die am selben Ort wie ihre Freunde wohnen – eine „Diamant“-Musterübereinstimmung.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Verbindungen des Kunden visualisieren
Zum Schluss verwenden wir GQL, um unser Netzwerk zu visualisieren. Bei diesen Abfragen werden die Pfadergebnisse in SAFE_TO_JSON eingeschlossen, sodass die Visualisierungstools die Knoten und Linien zeichnen können.
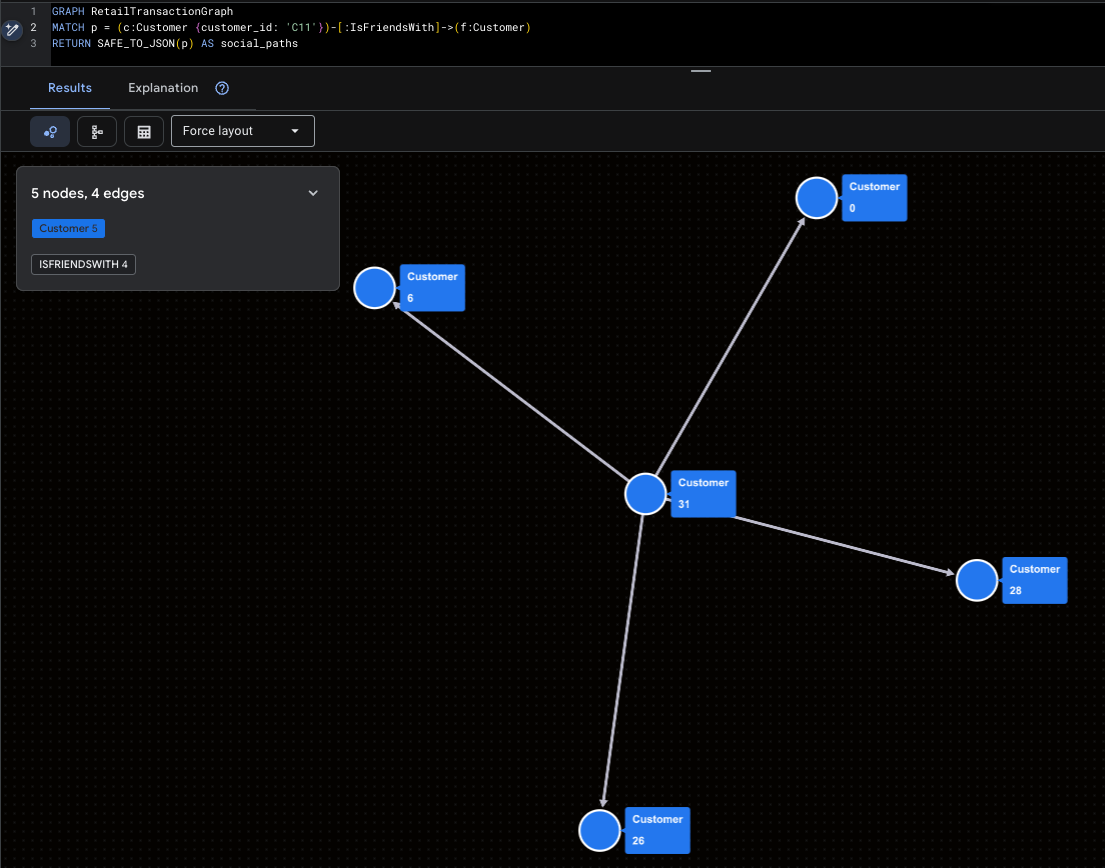
Super-Influencer visualisieren
Hier sehen Sie Mallory (C11) und ihre direkte Reichweite in den sozialen Medien.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Mögliche Betrugsmuster visualisieren
Mit dieser Abfrage wird der „Isolated Cluster“ (Ivan und Judy) herausgefiltert, um zu sehen, wohin ihre Produkte versendet werden.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Einführung in Spanner Graph-Algorithmen
Zur Vorbereitung auf die detaillierte Beschreibung von Graph Intelligence werden in diesem Abschnitt die technische Architektur und die grundlegenden Regeln von Cloud Spanner Graph Algorithms erläutert. Wenn Sie diese Prinzipien verstehen, können Sie von einfachen Traversierungen zu Analysen von Beziehungen im Petabyte-Bereich übergehen.
Das Algorithmusportfolio
Cloud Spanner unterstützt derzeit 14 Standard-Graphenalgorithmen, die in vier Funktionsgruppen kategorisiert sind, um verschiedene geschäftliche Probleme zu lösen:
Kategorie | Unterstützte Algorithmen | Geschäftsanwendungsfall |
Zentralität | PageRank, personalisierter PageRank, Betweenness, Closeness | Identifizieren Sie Influencer, Hubs und Engpässe. |
Community | WCC, Label Propagation, Clique Finding, Correlation Clustering | Betrugsringe, soziale Communities und Silos erkennen. |
Ähnlichkeit | Jaccard, Cosinus, gemeinsame Nachbarn, Gesamtzahl der Nachbarn | Empfehlungssysteme und die Auflösung von Entitäten unterstützen. |
Pfadsuche | Kürzester Pfad von Set zu Set, GA-Pfad-Helfer | Logistik und Nähe zum Einsatzort optimieren |
Wichtige Schema- und Abfrageüberlegungen
Damit Graph-Algorithmen effizient ausgeführt werden können, müssen in Spanner Graph die folgenden Regeln eingehalten werden:
Anforderung 1: Physische Datenlokalität (Interleaving)
Die wichtigste Anforderung für das Durchlaufen von Graphen mit hoher Leistung ist Interleaving. So wird sichergestellt, dass Edge-Daten physisch im selben Server-Split wie der Quellknoten gespeichert werden, wodurch die Netzwerklatenz während der Algorithmusausführung minimiert wird.
- Regel:Edge-Tabellen MÜSSEN in ihre Quellknotentabellen verschachtelt werden.
- Vorwärts-Traversal:Durch die Verschachtelung der Edge-Tabelle in die Quellknoten-Tabelle wird die Cache-Lokalität für ausgehende Links sichergestellt.
- Rückwärts-Traversal:Für eine effiziente Analyse eingehender Links können Sie mit Fremdschlüsseln automatisch Sicherungsindizes erstellen oder einen sekundären Index erstellen, der in die Zieltabelle eingefügt wird.
Anforderung 2: Eindeutige Anforderungen an die Kennzeichnung
Jede Tabelle, die am Property Graph beteiligt ist, muss eine eindeutige Identität haben. Algorithmen sind auf diese Labels angewiesen, um die Untergraphen, die sie analysieren müssen, richtig zu identifizieren und zu laden.
- Regel:Jede Eingabetabelle muss im Property-Graphen ein eindeutiges Label haben.
- Konflikt:Sie können ein einzelnes Label nicht mehreren Tabellen zuordnen, wenn Sie Algorithmen darauf ausführen möchten.
Logik | Beispiel | Ergebnis |
❌ Schlecht | KNOTENTABELLEN (Person LABEL Entity, Account LABEL Entity) | Ungültig: Der Algorithmus kann nicht zwischen einer Person und einem Konto unterscheiden. |
✅ Gut | KNOTENTABELLEN (Person LABEL Customer, Account LABEL Account) | Gültig: Jede Entität hat ein eindeutiges Label. |
Anforderung 3. Struktur von Algorithmusabfragen (MATCH-Klausel)
Beim Aufrufen eines Algorithmus unterliegt die MATCH-Anweisung restriktiveren Regeln als Standard-GQL-Abfragen, damit die Ausführungs-Engine die Analysepipeline optimieren kann.
- Ein Muster pro MATCH-Anweisung:In jeder MATCH-Anweisung kann nur eine Variable angegeben werden.
- Keine Muster mit mehreren Knoten:Sie können kein Beziehungsmuster (z.B. (a)-[e]->(b)) direkt in einer MATCH-Klausel definieren, die für einen Algorithmusaufruf vorgesehen ist.
- Nur Literalfilter:Sie können zwar WHERE-Klauseln verwenden, um Knoten zu filtern (z.B. WHERE a.id > 400), aber Abfrageparameter (@param) werden derzeit nicht in Graphalgorithmusabfragen unterstützt.
Anforderung 4: Die RETURN-Klausel (nur Skalare)
Die RETURN-Klausel in einer Algorithmusabfrage fungiert als Brücke zwischen der Graphen- und der relationalen Welt. Es ist streng darauf beschränkt, Skalare und Konstanten zurückzugeben.
- Die Regel:Sie können kein „Graphelement“ (das Rohknoten- oder ‑kantenobjekt) zurückgeben.
- Keine Transformationen:Sie können keine mathematischen Operationen ausführen oder Funktionen auf die Eigenschaften anwenden, die in der RETURN-Anweisung zurückgegeben werden.
Einschränkungen für die RETURN-Klausel
✅ Unterstützt | ❌ Nicht unterstützt |
RETURN node.id, score | RETURN-Knoten, Score (Graph-Element kann nicht zurückgegeben werden) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (Keine Operationen für Eigenschaften) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (Keine Funktionen) |
Anforderung 5. Datenintegrität: Lose Enden eliminieren
Eine „Dangling Edge“ (freihängende Kante) tritt auf, wenn eine Kante auf einen Zielknoten verweist, der im Diagramm nicht vorhanden ist. Dadurch schlägt die Ausführung des Algorithmus fehl, da die Diagrammstruktur inkonsistent ist.
- Lösung:Verwenden Sie referenzielle Einschränkungen (Fremdschlüssel) und ON DELETE CASCADE, um die Integrität des Diagramms aufrechtzuerhalten.
- Abfragesicherheit:Wenn Sie einen Algorithmus aufrufen, müssen Sie dafür sorgen, dass alle Knoten, auf die sich die ausgewählten Kanten beziehen, auch im Argument „node_labels“ enthalten sind.
Dauerhafte Ausgabe: EXPORT DATA-Optionen
Da Graphalgorithmen rechenintensiv sind, werden sie im Scale-up-Ausführungsmodus mit der EXPORT DATA-Anweisung ausgeführt. Dabei wird Data Boost genutzt, wobei unabhängige serverlose Rechenressourcen verwendet werden, um Verzögerungen bei Ihren Produktionsvorgängen zu vermeiden.
Option 1: Daten in Cloud Spanner speichern
Wenn Sie Ergebnisse direkt in Ihre Tabellen übertragen möchten, z.B. um einen PageRank-Wert zu speichern, verwenden Sie format = ‘CLOUD_SPANNER‘.
update_ignore_all: Es werden nur Zeilen für Schlüssel aktualisiert, die bereits in der Zieltabelle vorhanden sind.upsert_ignore_all: Aktualisiert vorhandene Zeilen oder fügt neue Zeilen ein, wenn die Schlüssel fehlen.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Option 2: Ergebnisse in Google Cloud Storage (GCS) speichern
Für umfangreiche Offlineanalysen können Sie Daten in den Formaten CSV, Avro oder Parquet in GCS exportieren.
- Platzhalter:Verwenden Sie
uri => 'gs://bucket/file_*.csv', um die fragmentierte Ausgabe zu aktivieren. So kann Spanner bei großen Datasets parallel in mehrere Dateien schreiben. - Komprimierung:Unterstützt GZIP, SNAPPY und ZSTD zur Optimierung der Speicherkosten.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Herausforderung 1: Einflusslücke (PageRank)
In diesem Abschnitt gehen wir auf die erste geschäftliche Hürde von The Customer ein: die Lücke bei der Einflussnahme. Wir werden von einem einfachen „Beliebtheitswettbewerb“ zu einer mathematisch fundierten Karte des tatsächlichen sozialen Einflusses übergehen.
Problembeschreibung:Das Marketingteam des Kunden hat ein Problem. Sie geben Millionen für breit angelegte Werbung aus, die immer weniger Rendite bringt, weil sie die „Social Superstars“ nicht identifizieren können – die wenigen Personen, deren Empfehlungen sich im gesamten Netzwerk auswirken.
Um das Problem zu lösen, müssen wir unsere Kunden nach Einfluss einstufen.
Relationale Lösung (Degree Centrality)
In einer Standarddatenbank ist die einfachste Möglichkeit, einen Influencer zu finden, die Anzahl seiner Follower zu zählen (ein Messwert, der als Degree Centrality bezeichnet wird).
Mit dieser Abfrage können Sie die „beliebtesten“ Nutzer ermitteln:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Graph Intelligence (PageRank)
Um die tatsächlichen Marktführer zu ermitteln, verwenden wir PageRank. Dieser Algorithmus wurde auch für die frühe Websuche verwendet. Er misst die Wichtigkeit eines Knotens anhand der Anzahl UND Qualität der eingehenden Links.
- Random Surfer Model:Bei PageRank wird simuliert, wie ein Nutzer sich durch den Graphen bewegt. Der Dämpfungsfaktor (Standardwert: 0,85) gibt die Wahrscheinlichkeit an, dass Nutzer weiterhin klicken.Andernfalls werden sie zu einem zufälligen Knoten „teleportiert“.
- Power of Association:Ein Link von einer einflussreichen Person (wie Mallory) ist viel mehr wert als ein Link von jemandem ohne andere Verbindungen.
Wir führen den PageRank-Algorithmus aus und speichern die Ergebnisse mit EXPORT DATA direkt in der Spalte „pagerank_score“.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Dashboard „Einfluss“ mit PageRank
Nachdem die Werte gespeichert wurden, vergleichen wir nun „Vorher“ (Anzahl der Follower) mit „Nachher“ (PageRank-Score).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0,158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
Analyse: Wer sind die echten Superstars?
Durch die Analyse der Ausgabe können Sie nun drei wichtige Marketing-Erkenntnisse gewinnen:
Wichtige Erkenntnisse für Unternehmen
Anstatt blind E‑Mails an alle mit mehr als fünf Followern zu senden, kann sich das Marketingteam des Kunden jetzt ausschließlich auf diejenigen mit dem höchsten pagerank_score konzentrieren. Diese Personen sind die wahren „Social Superstars“, die in der Lage sind, eine systemische Viralität auf dem gesamten Marktplatz zu fördern.
Versuchen wir nun, die Gatekeeper zu identifizieren, die das Logistiknetzwerk des Kunden am Laufen halten.
5. Herausforderung 2: Logistische Resilienz (BetweennessCentrality)
In diesem Abschnitt geht es um Logistics Resilience (Resilienz der Logistik). Wir werden nicht mehr nur den Erfolg anhand des „Volumens“ messen, sondern auch die wichtigen „Gatekeeper“ identifizieren, die das Netzwerk verbunden halten.
Relationale Lösung (volumenbasierte Analyse)
In einer standardmäßigen relationalen Einrichtung wird ein „kritischer“ Versandknotenpunkt in der Regel als derjenige definiert, der die meisten Bestellungen verarbeitet oder den größten Umsatz generiert.
Führen Sie diese Abfrage aus, um die „Top“-Hubs nach Anzahl der Transaktionen zu ermitteln:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
Ort | Land | transaction_count | total_revenue |
New York | USA | 4 | 3996 |
Berlin | Deutschland | 2 | 345 |
San Francisco | USA | 2 | 750 |
Um die Diskrepanz zu beheben, verwenden wir sowohl IsFriendsWith- als auch LivesAt-Kanten. Dadurch wird unsere Analyse von einem Transaktionshub zu einem Hub, der auch soziale Checks umfasst.
Graph Intelligence (Betweenness Centrality)
Um die tatsächlichen Engpässe zu finden, verwenden wir die Betweenness Centrality. Dieser Algorithmus quantifiziert, wie oft ein Knoten als „Brücke“ entlang der kürzesten Pfade zwischen allen anderen Knotenpaaren im Diagramm fungiert. Hohe Werte weisen auf die wahren Gatekeeper hin, die den Fluss von Waren oder Informationen kontrollieren.
Betweenness Centrality ausführen und beibehalten
Wir führen den Algorithmus mit EXPORT DATA aus und speichern die Werte in der Spalte „centrality_score“. Wir verwenden Data Boost, um sicherzustellen, dass diese aufwendige Berechnung des „kürzesten Pfads“ sich praktisch nicht auf die Live-Vorgänge des Kunden auswirkt.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analyse: „Verborgene Engpässe“ identifizieren
Nun vergleichen wir unser strukturelles Risiko (centrality_score) mit unserem Transaktionsvolumen (order_count), um die Knoten zu finden, die die Führungsebene des Kunden im Blick behalten sollte.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Durch die Analyse dieser Ergebnisse macht The Customer drei überraschende Entdeckungen:
Wichtige Erkenntnisse für Unternehmen
Der Kunde kann seine Logistikredundanz und Sicherheitsprotokolle jetzt auf Grundlage des multimodalen strukturellen Risikos priorisieren. Mallory, Alice und Eve sind die Gatekeeper, die geschützt werden müssen, um die Stabilität des Logistiknetzwerks zu gewährleisten.
Versuchen wir nun, Betrugsinseln zu isolieren.
6. Herausforderung 3: Ghost Networks (WCC)
In diesem Abschnitt gehen wir auf die dritte geschäftliche Hürde ein: Die „Ghost Networks“. Wir werden von der einfachen Hotspot-Erkennung zur Aufdeckung komplexer, isolierter Betrugsringe mithilfe der Community-Erkennung übergehen. Das Problem besteht darin, dass Betrüger gefälschte Profile erstellen, die Versandadressen gemeinsam nutzen oder in geschlossenen Kreisen interagieren, um Diebstähle zu koordinieren und Produktbewertungen zu manipulieren. Sie sind jedoch oft vollständig von der legitimen The Customer-Community isoliert.
Um das Problem zu beheben, müssen wir diese „isolierten Inseln“ aufdecken.
Relationale Lösung (Suche nach gemeinsamer Kennung)
Ohne Graphalgorithmen besteht die Standardmethode zur Erkennung von Betrug darin, nach „Hotspots“ mit weitergegebenen Daten zu suchen, z. B. wenn mehrere Kunden an dieselbe Adresse liefern lassen.
Führen Sie diese Abfrage aus, um Kunden zu finden, die über einen gemeinsamen Versandort verknüpft sind:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Um die Betrugsnetzwerke zu finden, müssen wir die transitive Erreichbarkeit verstehen.
Graph Intelligence (Weakly Connected Components)
Um die volle Ausdehnung dieser Ringe zu ermitteln, verwenden wir Weakly Connected Components (WCC). WCC ist ein Clustering-Algorithmus, der Knotengruppen identifiziert, in denen es unabhängig von der Richtung der Kanten einen Pfad zwischen zwei beliebigen Knoten gibt.
- Erreichbarkeitszonen:Der Graph wird in „Inseln“ oder „Erreichbarkeitszonen“ unterteilt.
- Einheitliche Ansicht von Entitäten:Durch die gleichzeitige Analyse von sozialen Beziehungen („IsFriendsWith“) und logistischen Beziehungen („LivesAt“) können wir fragmentierte Profile in einem einzigen, einheitlichen „Impact Cluster“ gruppieren.
WCC ausführen und beibehalten
Wir führen den WCC-Algorithmus aus und speichern die Ergebnisse in der Spalte „community_id“. Wir verwenden Data Boost, um sicherzustellen, dass diese Analyse der Erreichbarkeit auf unabhängigen Rechenressourcen erfolgt.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analyse: Betrugsringe
Führen wir nun eine Validierungsabfrage aus, um unsere isolierten Communities zu sehen. Legitime Nutzer gehören in der Regel zum „Festland“, während Betrüger oft auf kleinen „Inseln“ stranden.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | Mitglieder |
1 | 2 | ["judy@beispiel.de","ivan@beispiel.de"] |
0 | 10 | ["alice@beispiel.de","mallory@beispiel.de","trent@beispiel.de","bob@beispiel.de","charlie@beispiel.de","david@beispiel.de","eve@beispiel.de","frank@beispiel.de","grace@beispiel.de","heidi@beispiel.de"] |
Wenn Sie diese Community-Erkennung ausführen, können Sie eine kritische Anomalie identifizieren:
Wichtige Erkenntnisse für Unternehmen
Der Kunde kann seine Sicherheitsreaktionen jetzt automatisieren. Statt einzelne Konten manuell zu überprüfen, können sie eine einfache Regel schreiben: Wenn eine community_id weniger als drei Mitglieder hat, kennzeichnen Sie die gesamte Gruppe für die manuelle KYC-Überprüfung (Know Your Customer).
.
Wenn wir die Betrugsringe aufgedeckt haben, können wir das Problem des „Behavioral Twin“ lösen.
7. Herausforderung 4: Behavioral Twin (JaccardSimilarity)
In dieser letzten Aufgabe geht es um die vierte Hürde: das Paradox of Choice/Behavioral Twin. Wir werden von allgemeinen Listen mit häufig zusammen gekauften Artikeln zu hochgradig personalisierten Empfehlungen auf Grundlage von Verhaltensmustern übergehen.
Die aktuellen Produktvorschläge des Kunden sind zu allgemein. Es ist zwar sicher, jedem Kunden ein beliebtes USB-Kabel zu empfehlen, aber es ist nicht persönlich. Der Kunde möchte Empfehlungen für Verhaltenszwillinge erstellen, um Kunden mit ähnlichen Versandmustern und sozialen Kreisen zu identifizieren und ihnen Produkte mit hoher Präzision vorzuschlagen.
Um dieses Problem zu beheben, müssen wir die Nähe zwischen Nutzern berechnen.
Relationale Lösung (absolute Überschneidung)
In einer standardmäßigen relationalen Einrichtung suchen Sie möglicherweise nach Personen, die an dieselben Orte wie ein Referenznutzer, z. B. Alice (C1), liefern.
Führen Sie diese Abfrage aus, um die geografischen Nachbarn von Alice zu finden:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (Jaccard-Ähnlichkeit)
Um wirklich ähnliche Nutzer zu finden, verwenden wir die Jaccard-Ähnlichkeit. Bei diesem Algorithmus wird eine normalisierte Punktzahl (0,0 bis 1,0) berechnet, indem die Anzahl der gemeinsamen Nachbarn (Schnittmenge) durch die Gesamtzahl der eindeutigen Nachbarn (Vereinigung) geteilt wird.
Ein „Verhaltenszwilling“ wird hier nicht nur durch eine gemeinsame Versandadresse definiert. Durch die Analyse der Überschneidung von physischen Fußabdrücken (LivesAt) und sozialen Ökosystemen (IsFriendsWith) können wir Nutzer identifizieren, die denselben Lebensstil und Community-Einfluss haben. Das führt zu wesentlich genaueren Produktempfehlungen.
Zuerst eine Zuordnungstabelle erstellen
Da Ähnlichkeit eine paarweise Beziehung ist (Kunde A ist ähnlich wie Kunde B), erstellen wir eine spezielle Tabelle, die in Customer verschachtelt ist, um diese Zuordnungen zu speichern.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Jaccard-Ähnlichkeit jetzt ausführen
Wir führen den Algorithmus jetzt aus. Hinweis:Diese Abfrage enthält eine allgemeine „Guardrail“-Lektion. Wenn Sie nur Customer-Knoten auswählen, aber die LivesAt-Kante verwenden, die auf Shipping-Knoten verweist, schlägt die Abfrage mit dem Fehler „Dangling Edge“ fehl . Um das Problem zu beheben, müssen wir beide Knotenlabels einfügen.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analyse: „Behavioral Twin“-Check
Nachdem der Analysejob abgeschlossen ist, führen wir eine Validierungsabfrage aus. Wenn wir unsere neue Zuordnungstabelle (CustomerSimilarity) mit unseren ursprünglichen Customer-Metadaten zusammenführen, können wir genau sehen, wer die „Verhaltenszwillinge“ von Alice sind.
Führen Sie diese Abfrage aus, um die Ähnlichkeitsrankings von Alice zu prüfen:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0,200000003 | 1 | 0.1093561724 |
bob@example.com | 0,200000003 | 0 | 0.0547891818 |
ivan@example.com | 0,200000003 | 1 | 0.1093561724 |
eve@example.com | 0,1666666716 | 0 | 0,158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Worauf Sie bei den Ergebnissen achten sollten:
Jetzt versuchen wir, eine endgültige Unified Intelligence-Ansicht zu erstellen.
8. Unified Intelligence
Als Nächstes befassen wir uns mit Unified Intelligence. Hier werden Transaktionsdaten mit allen vier Diagrammalgorithmen kombiniert, um klare, umsetzbare Erkenntnisse zu liefern.
Bericht 1: Unified Intelligence
Der Vorteil einer Multi-Model-Datenbank wie Spanner besteht darin, dass Sie relationale Ausgabendaten mit aus dem Diagramm abgeleiteten Einfluss-, Risiko- und Ähnlichkeitswerten in einer einzigen Anfrage verknüpfen können. Mit dieser Abfrage wird jeder Kunde einer bestimmten Unternehmensidentität zugeordnet.
Führen Sie die Unified Intelligence-Abfrage aus, um das gesamte Ökosystem zu sehen:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | Ausgaben | Einfluss | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44,5 | 0 | 🔵 KRITISCH: Netzwerkbrücke |
C5 | eve@example.com | 0 | 0,158392489 | 35,5 | 0 | 🔵 KRITISCH: Netzwerkbrücke |
C1 | alice@example.com | 999 | 0.1000888124 | 35,5 | 0 | 🔵 KRITISCH: Netzwerkbrücke |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 SOZIAL: Influencer mit hoher Reichweite |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 SOZIAL: Influencer mit hoher Reichweite |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: Aktiver Kunde |
C4 | david@example.com | 0 | 0.04028172791 | 3,5 | 0 | 🟢 STANDARD: Aktiver Kunde |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 HOHES RISIKO: Isolierter Betrugsring |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 HOHES RISIKO: Isolierter Betrugsring |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: Aktiver Kunde |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: Aktiver Kunde |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: Aktiver Kunde |
Durch die Kombination dieser mathematischen Ansätze können wir über die Frage „Wer hat am meisten ausgegeben?“ hinausgehen und uns stattdessen fragen: „Wer ist am wichtigsten?“ Im einheitlichen Dashboard werden relationale Transaktionsdaten mit multimodaler Graph-Intelligenz kombiniert, um Ihr Ökosystem in drei klare, umsetzbare Personas zu unterteilen.
Die „Critical Network Bridges“ (Resilience)
Knoten wie Mallory (C11), Eve (C5) und Alice (C1) werden gekennzeichnet, weil ihre bottleneck_risk (Betweenness Centrality) >25 ist.
- Die strukturellen Anker: Mallory hat mit 44, 5 den höchsten Risikowert und ist damit das primäre Gateway für das gesamte Netzwerk.
- Das Zero-Spend-Paradoxon: Eve (C5) hat keine Bestellungen, ist aber mit einem Risikoscore von 35,5 strukturell unverzichtbar. In Standard-SQL wäre sie völlig ignoriert worden, aber Graph Intelligence zeigt, dass sie eine wichtige Brücke zu einer ganzen Untergruppe der Community ist.
- Das High-Value-Gateway: Alice (C1) hat mit Eve mit 35,5 gleichgezogen.Das zeigt, dass Nutzer mit hohen Ausgaben auch wichtige strukturelle Anker sein können.
Die „Social Superstars“ (Reichweite)
Heidi (C8) und Grace (C7) werden aufgrund ihrer PageRank-Werte als Influencer mit hoher Reichweite eingestuft .
Der „Isolated Fraud Ring“ (Anomalien)
Judy (C10) und Ivan (C9) werden gekennzeichnet, weil sie zur isolierten community_id 1 gehören.
Geschäftseinblicke in strategische Maßnahmen umwandeln
Identität | Hauptmesswert | Business Insight | Strategische Maßnahme |
🔵 Netzwerkbrücken | Hohe Zentralität | Strukturelle Anker: Eve (C5) und Mallory (C11) halten das Netzwerk zusammen. | Bindung: Schütze diese Gatekeeper, um eine Fragmentierung der Community zu verhindern. |
📱 Social Superstars | Hoher PageRank | Viral Engines: Nutzer wie Heidi (C8) haben die höchste Reichweite in ihren Kreisen. | Marketing: Für wirkungsvolle Empfehlungs- und Botschafterprogramme. |
🔴 Betrugsrisiken | Isolierte WCC | Ghost Networks: Judy (C10) und Ivan (C9) geben viel Geld aus, leben aber auf „Inseln“. | Sicherheit: Sofortige manuelle KYC-Überprüfung; dies sind klassische Betrugssignaturen. |
🟢 Nutzer mit Standardzugriff | Ausgewogene Bewertungen | Gesunder Kern: Der Großteil des Netzwerks, einschließlich „lokaler“ Brücken wie David (C4). | Wachstum: Wenden Sie Standardempfehlungen für personalisierte Anzeigen und „Behavioral Twin“ an. |
Bericht 2: Bericht zu Identitätsanomalien
Jetzt müssen Sie herausfinden, ob betrügerische Konten legitime Konten „nachahmen“. Wir können dieses Problem lösen, indem wir Nutzer finden, die 100% Verhaltensähnlichkeit, aber keine soziale Verbindung haben.
Führen Sie diese Abfrage aus, um potenzielle „Identitätsanomalien“ zu kennzeichnen:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Der Bericht zur Identifizierung von Anomalien enthält wichtige Informationen. Indem wir Nutzer isolieren, die sich wie echte Kunden verhalten, aber keine sozialen Kontakte haben, gehen wir von Vermutungen zu mathematischer Gewissheit über .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0,200000003 | 1 |
C9 | ivan@example.com | 0,200000003 | 1 |
Ergebnisse analysieren
Durch die Vereinheitlichung von Ähnlichkeit (Jaccard) mit Community Detection (WCC) decken wir verborgene Risiken auf, die mit herkömmlichen Transaktionsdaten nicht erkannt werden können.
- Verhaltenszwillinge (Nähe): Knoten wie Judy (C10) und Ivan (C9) werden gekennzeichnet, weil sie einen Jaccard-Ähnlichkeitswert von 0,20 in Bezug auf Alice (C1) haben.
- Isolationsverhalten:Judy (C10) und Ivan (C9) sind in der isolierten community_id 1 gruppiert, während Alice zur sozialen „Mainland“-Community 0 gehört.
- Betrugsmerkmale:Im Bericht werden Nutzer mit einer hohen Verhaltensüberschneidung (>0,9) identifiziert, die sozial nicht mit dem primären Netzwerk verbunden sind.
9. Glückwünsche und Zusammenfassung
In diesem Lab wird gezeigt, wie Cloud Spanner eine relationale Datenbank in ein Multi-Modell-Kraftpaket verwandelt. Durch die Anwendung von Graph Intelligence auf The Customer konnten wir von statischen Daten zu einer umsetzbaren Geschäftsstrategie übergehen.
Vorteile von Spanner Multi-Model
- Einheitliche Architektur:Mit Spanner können Sie eine solide relationale Grundlage beibehalten und gleichzeitig sofort einen Eigenschaftsgraphen für die Beziehungsextraktion überlagern – ohne das Risiko und die Verzögerung von ETL.
- Analytische Isolation außerhalb der Box:Mit Data Boost können Sie speicherintensive Algorithmen wie PageRank oder WCC auf unabhängigen, serverlosen Rechenressourcen ausführen und so sicherstellen, dass die Leistung Ihres Produktions-Checkouts nicht beeinträchtigt wird.
- Verschränkte Leistung:Durch die einzigartige Verschachtelung von Spanner werden Knoten und ihre Beziehungen physisch zusammengefasst. So werden komplexe globale Traversierungen in schnelle lokale Suchvorgänge umgewandelt.
„Hidden Gems“ und Anomalien aufdecken
- Strukturellen Wert ermitteln:Mithilfe von Grafalgorithmen wie Betweenness Centrality wurden „versteckte Brücken“ mit null Ausgaben ermittelt, die für die Widerstandsfähigkeit des Netzwerks wichtiger sein können als Kunden mit den höchsten Ausgaben.
- Aufdecken von Verhaltensnachahmung:Durch die Kombination von Jaccard-Ähnlichkeit und schwach verbundenen Komponenten haben wir „Social Strangers“ identifiziert. Diese Konten sehen aus wie legitime Kunden, sind aber mathematisch nachweislich isolierte Betrugsringe.
- Globale vs. lokale Wahrheit:Bei der manuellen SQL-Analyse können Brücken gefunden werden, mit globalen Algorithmen lassen sich jedoch wichtige Gatekeeper des Netzwerks ermitteln.
Daten intelligent und umsetzbar machen
- Persona-basierte Strategie:Wir haben unsere Zeilen erfolgreich in Beziehungen umgewandelt. Durch die Ausführung von Algorithmen können wir vier geschäftliche Probleme angehen: Network Bridges, Social Superstars, Fraud Risks und Standard Users.