
1. Caso de éxito: Intelligent Retail
Para el caso de estudio, tomamos un cliente minorista con un mercado digital de rápido crecimiento. La vista de datos tradicional del cliente es limitada porque muestra lo que compran las personas, pero no cómo se conectan. Esta brecha genera oportunidades perdidas y un aumento del fraude. Ahora, están adoptando una filosofía Network-First para valorar las conexiones sociales y logísticas, además de los datos transaccionales.
Desafíos comerciales principales que se deben abordar
Tienes cuatro desafíos críticos que requieren comprender cómo se interconectan los clientes y la logística:
Desafío | El problema | El objetivo |
Brecha de influencia | La publicidad general genera un ROI bajo. Actualmente, no es posible identificar a los verdaderos creadores de tendencias (influencers). | Identifica a los influencers que son fundamentales para la comunidad a través de su conexión en una red conectada de clientes. |
Resiliencia logística | La cadena de suministro puede ser vulnerable (teniendo en cuenta que opera en diferentes ubicaciones geográficas). Si falla un centro de claves, es posible que toda la región pierda el acceso al producto. | Identifica a los Gatekeepers , es decir, a las personas que son fundamentales para conectar las redes de logística. |
Ghost Networks | Los círculos de fraude usan perfiles falsos y direcciones compartidas para coordinar robos y aumentar las calificaciones. | Exponer islas aisladas , es decir, grupos hiperconectados sin vínculos con la comunidad legítima |
La paradoja de la elección | El motor de sugerencias y recomendaciones actual es rudimentario, genérico y, a menudo, se ignora (p. ej., "Los clientes que compraron este artículo también compraron…"). | Crea gemelos de comportamiento, es decir, recomendaciones basadas en patrones de envío y círculos sociales similares. |
Cómo correlacionar los desafíos comerciales con una estrategia técnica (filas → relaciones)
En una base de datos tradicional, los datos se almacenan en silos aislados: los clientes en una tabla, las transacciones en otra y los envíos en una tercera. Si bien SQL es perfecto para responder la pregunta "¿Quién compró qué?", tiene dificultades para responder preguntas basadas en la red.
Para resolver estos desafíos, la estrategia técnica consiste en cambiar esta perspectiva:
- La vista relacional (el "qué"): Trata a cada cliente como una fila aislada. Encontrar una conexión entre un cliente y la compra de un amigo requiere varias "uniones" complejas, que se vuelven exponencialmente más lentas a medida que crece la red.
- La vista de gráfico (el "cómo"): Considera las relaciones como elementos de primera clase. En lugar de buscar en listas, navegamos por un mapa. Podemos ver al instante que el cliente A está conectado con el cliente B, que realiza envíos a la ubicación Z.
Análisis detallado de los requisitos
Los arquitectos de soluciones llegan a la conclusión de que los requisitos comerciales y la estrategia técnica requieren un enfoque de varios modelos, y, luego, identifican los siguientes requisitos clave.
Cómo Cloud Spanner cumple con esos requisitos técnicos
Cloud Spanner se eligió como el centro de esta transformación. Permite que el Cliente conserve su sólida base relacional y, al mismo tiempo, desbloquee estadísticas detalladas basadas en gráficos.
A continuación, se incluye un resumen de cómo Cloud Spanner aborda los requisitos técnicos y mucho más.
Además, Cloud Spanner proporciona una arquitectura técnica preparada para el futuro
2. Configuración de la base de datos
Después de analizar el caso de negocio, pasamos a la fase de implementación. En esta sección, definimos nuestra arquitectura de datos, exploramos las limitaciones del modelo relacional tradicional y presentamos el grafo de propiedades como nuestra herramienta principal para descubrir estadísticas detalladas.
Configura una instancia de Cloud Spanner Enterprise
Paso 1: Habilita la API de Cloud Spanner
En la consola de Google Cloud, haz clic en el ícono de menú en la parte superior izquierda de la pantalla para ver la navegación de la izquierda. Desplázate hacia abajo y selecciona "Spanner", o bien busca "Spanner".
Ahora deberías ver la IU de Cloud Spanner y, si usas un proyecto en el que aún no se habilitó la API de Cloud Spanner, verás un diálogo en el que se te pedirá que la habilites. Si ya habilitaste la API, puedes omitir este paso.
Haz clic en "Habilitar" para continuar:
Paso 2: Crea una instancia de Cloud Spanner
Primero, crearás una instancia de Cloud Spanner. En la IU, haz clic en "Crear una instancia aprovisionada" para crear una instancia nueva.
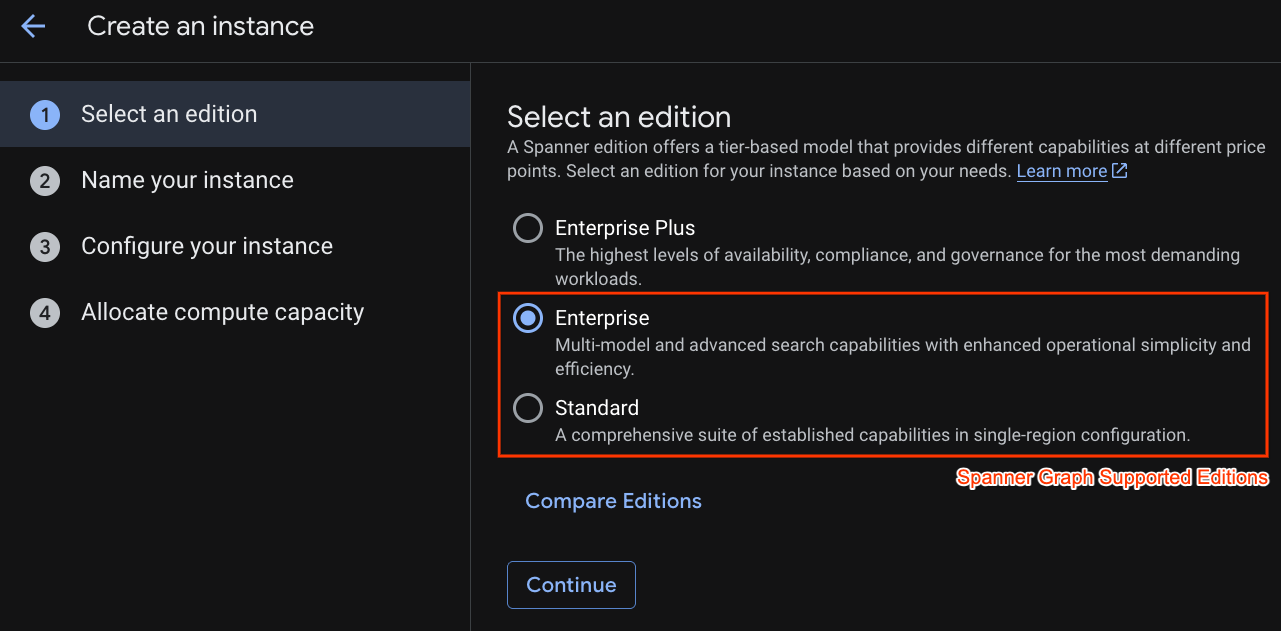
En el primer paso, debes seleccionar una edición. Ten en cuenta que también puedes actualizar la edición más adelante. Para usar las capacidades de varios modelos (Spanner Graph), podemos elegir la edición Enterprise.
Asigna un nombre a tu instancia
Selecciona una configuración de implementación y una región de tu elección.
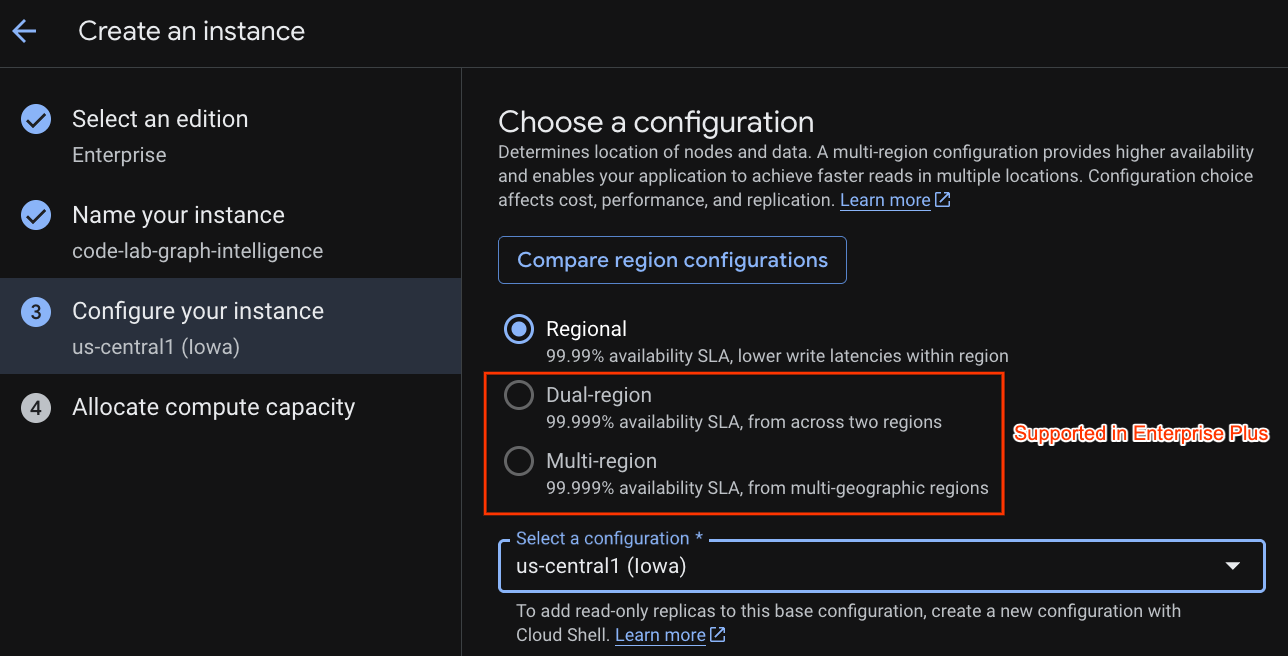
También puedes comparar varias opciones de configuración. Por ejemplo, la configuración de implementación tiene, como mínimo, 3 réplicas de lectura/escritura en 3 zonas separadas de la región seleccionada. Es decir, incluso si eliges una implementación de un solo nodo, tendrás 3 copias a través de 3 réplicas de lectura/escritura. Además, incluso con la configuración de implementación regional, puedes extender aún más tu topología de implementación con réplicas adicionales de solo lectura.
Una vez que configures la capacidad, puedes comenzar con un nodo completo y el ajuste de escala automático en los nodos, o bien puedes usar una instancia granular (unidades de procesamiento; 1,000 PU = 1 nodo). De manera opcional, también puedes establecer objetivos de ajuste de escala automático de la instancia. En el caso de las cargas de trabajo de baja latencia, recomendamos un 65% para las instancias regionales y un 45% para las instancias multirregionales.
Paso 3: Crea una base de datos
Una vez que se aprovisione tu instancia, haz clic en "Crear base de datos" para crear una base de datos para el resto del codelab.
Cómo configurar una base relacional
Nuestro recorrido comienza con las tablas principales que almacenan datos operativos. En Cloud Spanner, usamos la intercalación para ubicar físicamente los datos relacionados, como las amistades y las transacciones de un cliente, directamente con el registro del cliente. Esto garantiza un acceso de alto rendimiento y una ubicación física.
DDL: Creación de las tablas
Copia y ejecuta los siguientes bloques para establecer tu esquema relacional:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Seeding the Network (Sembrando la red)
Con nuestras tablas listas, debemos completarlas con los usuarios, los productos y las conexiones que definen el ecosistema del cliente.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Desafío relacional
Antes de presentar el gráfico, veamos cómo el SQL tradicional aborda los desafíos del cliente. Ejecuta esta consulta para encontrar clientes que gastan mucho y tienen varios amigos, es decir, "Social Spenders".
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Las limitaciones del enfoque relacional
Cómo superar los desafíos relacionales con un gráfico de propiedades
Para superar estos límites, definimos un gráfico de propiedades. Esto crea una "superposición" que nos permite tratar las relaciones como elementos de primera clase sin sacar nuestros datos de Spanner.
DDL: Crea el gráfico de propiedades
Este DDL define nuestros nodos (entidades) y aristas (relaciones). En este ejemplo, seguimos un gráfico esquematizado. Sin embargo, Spanner Graph permite modelar gráficos sin esquemas para habilitar un desarrollo iterativo flexible y rápido, y para controlar la evolución de los modelos de datos sin cambios constantes en el DDL (lenguaje de definición de datos).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Cómo navegar por el gráfico con GQL
Ahora que nuestro gráfico está definido, podemos usar Graph Query Language (GQL) para realizar recorridos de varios saltos con una sintaxis simple y legible.
Exploración 1: Descubrimiento colaborativo
Esta consulta recorre el gráfico para encontrar los productos que compraron tus amigos y sirve como base para un motor de recomendaciones.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Exploración 2: La búsqueda híbrida (relacional y de gráfico)
Spanner te permite incorporar patrones de GQL dentro de una cláusula FROM de SQL estándar con la función GRAPH_TABLE. Esta búsqueda encuentra clientes que viven en la misma ubicación que sus amigos, lo que se denomina una coincidencia de patrón "diamante".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Visualización de las conexiones del cliente
Por último, usemos GQL para visualizar nuestra red. Estas consultas envuelven los resultados de la ruta en SAFE_TO_JSON, lo que permite que los visualizadores dibujen los nodos y las líneas.
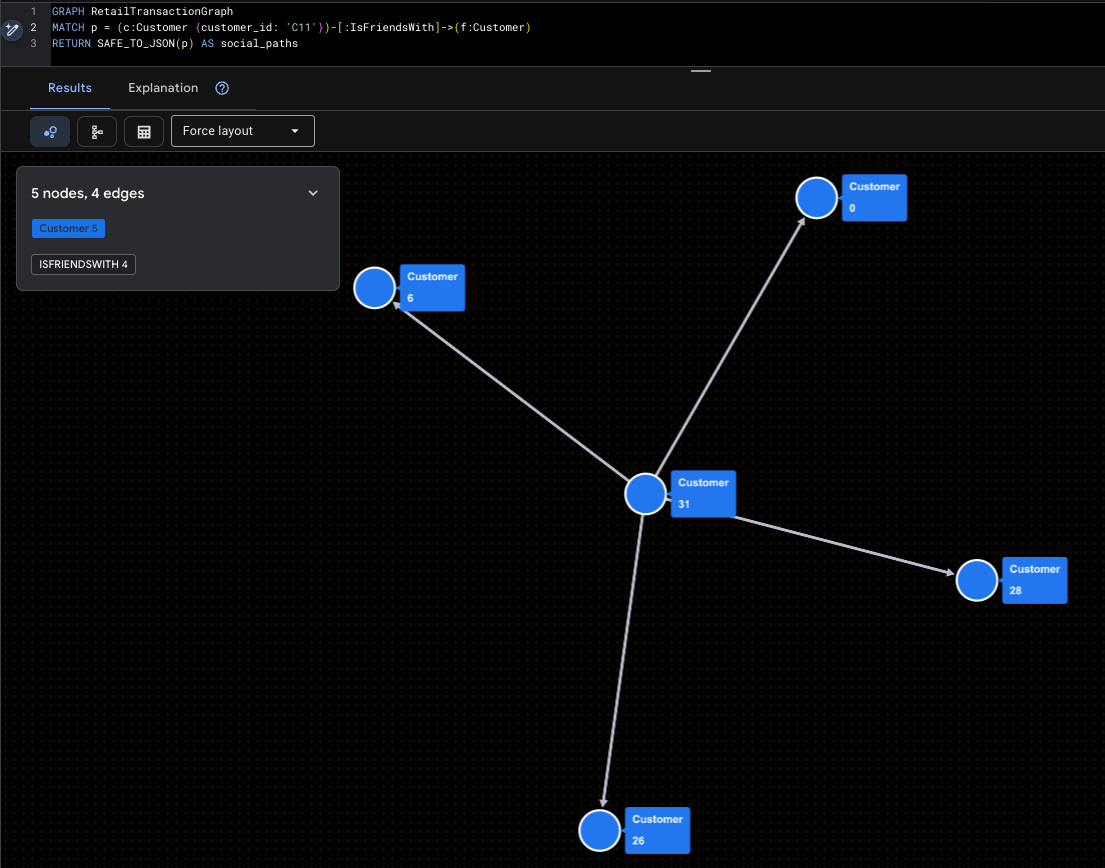
Visualización del superinfluencer
En esta diapositiva, se destaca a Mallory (C11) y su alcance social directo.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Visualización de posibles patrones de fraude
Esta búsqueda identifica el "clúster aislado" (Iván y Judy) para ver dónde se envían sus productos.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Introducción a los algoritmos de Spanner Graph
Para prepararte para nuestro análisis detallado de Graph Intelligence, en esta sección, se describen la arquitectura técnica y las reglas fundamentales de los algoritmos de Spanner Graph de Cloud Spanner. Comprender estos principios es clave para pasar de los recorridos simples al análisis de relaciones a escala de petabytes.
La cartera de algoritmos
Actualmente, Cloud Spanner admite 14 algoritmos de grafos estándares de la industria, categorizados en cuatro grupos funcionales para resolver diversos problemas comerciales:
Categoría | Algoritmos admitidos | Caso de uso empresarial |
Centralidad | PageRank, PageRank personalizado, intermediación, cercanía | Identifica los influencers, los centros y los cuellos de botella. |
Comunidad | WCC, propagación de etiquetas, búsqueda de clics, agrupamiento por correlación | Detecta redes de fraude, comunidades sociales y silos. |
Similitud | Jaccard, coseno, vecinos comunes, vecinos totales | Potenciar los motores de recomendaciones y la resolución de entidades |
Búsqueda de ruta | Shortest Path de conjunto a conjunto, asistentes de GA Path | Optimiza la logística y la proximidad de los viajes. |
Consideraciones importantes sobre el esquema y las consultas
Para garantizar la ejecución eficiente de los algoritmos de grafos, Spanner Graph debe cumplir con las siguientes reglas:
Requisito 1. Localidad física de los datos (entrelazado)
El requisito más importante para el recorrido de grafos de alto rendimiento es la intercalación. Esto garantiza que los datos de borde se almacenen físicamente en la misma división del servidor que el nodo fuente, lo que minimiza la latencia de la red durante la ejecución del algoritmo.
- La regla: Las tablas de borde DEBEN intercalarse en sus tablas de nodos de origen.
- Recorrido hacia adelante: La intercalación de la tabla de aristas en la tabla de nodos de origen garantiza la localidad de la caché para los vínculos salientes.
- Recorrido inverso: Para un análisis eficiente de los vínculos "entrantes", usa claves externas para crear automáticamente índices de respaldo o crea un índice secundario intercalado en la tabla de destino.
Requisito 2. Requisitos de etiquetado únicos
Cada tabla que participa en el gráfico de propiedades debe tener una identidad única. Los algoritmos se basan en estas etiquetas para identificar y cargar correctamente los subgrafos que necesitan analizar.
- La regla: Cada tabla de entrada debe tener una etiqueta de identificación única dentro del gráfico de propiedades.
- El conflicto: No puedes asignar una sola etiqueta a varias tablas si planeas ejecutar algoritmos en ellas.
Lógica | Ejemplo | Resultado |
❌ Mala | TABLAS DE NODOS (entidad de ETIQUETA de persona, entidad de ETIQUETA de cuenta) | No válido: El algoritmo no puede distinguir entre una persona y una cuenta. |
✅ Bueno | TABLAS DE NODO (Cliente con ETIQUETA Persona, Cuenta con ETIQUETA Cuenta) | Válido: Cada entidad tiene una etiqueta única y distinta. |
Requisito 3. Estructura de la consulta del algoritmo (cláusula MATCH)
Cuando se llama a un algoritmo, la cláusula MATCH sigue reglas más restrictivas que las consultas de GQL estándar para garantizar que el motor de ejecución pueda optimizar la canalización analítica.
- Un patrón por MATCH: Cada instrucción MATCH solo puede nombrar una variable.
- Sin patrones de varios nodos: No puedes definir un patrón de relación (p.ej., (a)-[e]->(b)) directamente dentro de una cláusula MATCH destinada a una llamada de algoritmo.
- Solo filtros literales: Si bien puedes usar cláusulas WHERE para filtrar nodos (p.ej., WHERE a.id > 400), los parámetros de consulta (@param) no se admiten actualmente en las consultas de algoritmos de grafos.
Requisito 4. La cláusula RETURN (solo para escalares)
La cláusula RETURN en una consulta de algoritmo actúa como puente entre el mundo de los gráficos y el mundo relacional. Se limita estrictamente a devolver escalares y constantes.
- La regla: No puedes devolver un "elemento del gráfico" (el objeto de borde o nodo sin procesar).
- Sin transformaciones: No puedes realizar operaciones matemáticas ni aplicar funciones a las propiedades que se muestran en la propia sentencia RETURN.
Restricciones de la cláusula RETURN
✅ Compatible | ❌ No compatible |
RETURN node.id, score | Nodo RETURN, puntuación (no se puede devolver el elemento de gráfico) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (sin operaciones en las propiedades) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (sin funciones) |
Requisito 5: Integridad de los datos: Eliminación de bordes colgantes
Una "conexión colgante" se produce cuando una conexión apunta a un nodo de destino que no existe en el gráfico. Esto provoca que falle la ejecución del algoritmo porque la estructura del grafo es incoherente.
- La solución: Usa restricciones referenciales (claves externas) y ON DELETE CASCADE para mantener la integridad del gráfico.
- Seguridad de la búsqueda: Cuando llames a un algoritmo, debes asegurarte de que todos los nodos a los que se hace referencia en las aristas seleccionadas también se incluyan en el argumento node_labels.
Salida persistente: Opciones de EXPORT DATA
Debido a que los algoritmos de grafos requieren mucha capacidad de procesamiento, se ejecutan en el modo de ejecución de ampliación con la instrucción EXPORT DATA. Esto aprovecha Data Boost, que usa recursos de procesamiento sin servidores independientes para evitar cualquier retraso en tus transacciones de producción.
Opción 1: Conserva los datos en Cloud Spanner
Para enviar los resultados directamente a tus tablas (p.ej., guardar una puntuación de PageRank), usa format = "CLOUD_SPANNER".
update_ignore_all: Solo actualiza las filas de las claves que ya existen en la tabla de destino.upsert_ignore_all: Actualiza las filas existentes o inserta filas nuevas si faltan las claves.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Opción 2: Persiste los resultados en Google Cloud Storage (GCS)
Para el análisis sin conexión a gran escala, puedes exportar a GCS en formatos CSV, Avro o Parquet.
- Comodines: Usa
uri => 'gs://bucket/file_*.csv'para habilitar la salida fragmentada, lo que permite que Spanner escriba en varios archivos en paralelo para conjuntos de datos masivos. - Compresión: Admite GZIP, SNAPPY y ZSTD para optimizar los costos de almacenamiento.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Desafío 1: Brecha de influencia (PageRank)
En esta sección, abordamos el primer obstáculo comercial de The Customer: la "brecha de influencia". Pasaremos de un "concurso de popularidad" básico a un mapa de la verdadera influencia social basado en cálculos matemáticos.
Declaración del problema: El equipo de marketing del cliente tiene un problema. Invierten millones en publicidad general con retornos cada vez menores porque no pueden identificar a las "superestrellas sociales", esas personas poco comunes cuyos respaldos se propagan por toda la red.
Para resolver este problema, debemos clasificar a nuestros clientes según su influencia.
Solución relacional (centralidad de grado)
En una base de datos estándar, la forma más sencilla de encontrar a un influencer es simplemente contar sus seguidores (una métrica conocida como centralidad de grado).
Ejecuta esta consulta para encontrar a los usuarios más "populares":
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Inteligencia de gráficos (PageRank)
Para encontrar a los verdaderos líderes, usamos PageRank. Este es el mismo algoritmo que impulsó la primera búsqueda web. Mide la importancia de un nodo en función de la cantidad Y la calidad de los vínculos entrantes.
- Modelo de navegante aleatorio: PageRank simula a un usuario que se desplaza por el gráfico. El factor de amortiguación (0.85 de forma predeterminada) representa la probabilidad de que el usuario siga haciendo clics; de lo contrario, se "teletransporta" a un nodo aleatorio .
- Poder de asociación: Un vínculo de una persona influyente (como Mallory) vale mucho más que un vínculo de alguien sin otras conexiones.
Ejecutaremos el algoritmo de PageRank y usaremos EXPORT DATA para guardar los resultados directamente en nuestra columna pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Panel de"Influencia" con PageRank
Ahora que las puntuaciones se conservan, comparemos nuestro "Antes" (recuento de seguidores) con nuestro "Después" (puntuación de PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | roberto@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
Análisis: ¿Quiénes son las verdaderas superestrellas?
Si analizas el resultado, ahora puedes hacer tres descubrimientos de marketing fundamentales:
Conclusión comercial
En lugar de enviar correos electrónicos a ciegas a todas las personas con más de cinco seguidores, el equipo de marketing de The Customer ahora puede enfocarse exclusivamente en quienes tienen la puntuación de pagerank_score más alta. Estas personas son las verdaderas "superestrellas sociales" capaces de generar viralidad sistémica en todo el mercado.
Ahora, intentemos identificar a los guardianes que mantienen en funcionamiento la red logística del cliente.
5. Desafío 2: Resiliencia logística (BetweennessCentrality)
En esta sección, abordaremos la resiliencia logística. Dejaremos de medir el éxito por "volumen" para identificar a los "guardianes" vitales que mantienen la red conectada.
Solución relacional (análisis basado en el volumen)
En una configuración relacional estándar, un centro de envío "crítico" suele definirse como el que procesa la mayor cantidad de pedidos o genera la mayor cantidad de ingresos.
Ejecuta esta consulta para identificar los concentradores de "mayor" actividad por recuento de transacciones:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
Nueva York | Estados Unidos | 4 | 3996 |
Berlín | Alemania | 2 | 345 |
San Francisco | Estados Unidos | 2 | 750 |
Para abordar la falta de coincidencia, usaremos las uniones IsFriendsWith y LivesAt. Esto transforma nuestro análisis de un centro de transacciones para incluir también la verificación social.
Inteligencia de gráficos (centralidad de intermediación)
Para encontrar los cuellos de botella reales, usamos la centralidad de intermediación. Este algoritmo cuantifica la frecuencia con la que un nodo actúa como un "puente" a lo largo de las rutas más cortas entre todos los demás pares de nodos del gráfico. Las puntuaciones altas señalan a los verdaderos guardianes que controlan el flujo de bienes o información.
Cómo ejecutar y conservar la centralidad de intermediación
Ejecutaremos el algoritmo con EXPORT DATA y guardaremos las puntuaciones en la columna centrality_score. Usamos Data Boost para garantizar que este cálculo complejo del "camino más corto" tenga un impacto casi nulo en las operaciones en vivo del cliente.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Análisis: Identificación de los "cuellos de botella ocultos"
Ahora, comparamos nuestro riesgo estructural (centrality_score) con nuestro volumen de transacciones (order_count) para encontrar los nodos que deberían preocupar al liderazgo del cliente.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | roberto@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Al analizar estos resultados, el cliente hace tres descubrimientos sorprendentes:
Conclusión para empresas
Ahora el Cliente puede priorizar sus protocolos de seguridad y redundancia logística en función del riesgo estructural multimodal. Mallory, Alice y Eve son los guardianes que deben protegerse para garantizar la estabilidad de la red logística.
Ahora intentemos aislar las islas de fraude.
6. Desafío 3: Redes fantasma (WCC)
En esta sección, abordamos el tercer obstáculo comercial: las "redes fantasma". Pasaremos de la detección simple de "hotspots" a descubrir sofisticados y aislados anillos de fraude con la detección de comunidades. El desafío aquí es que los infractores crean perfiles falsos que comparten direcciones de envío o interactúan en bucles cerrados para coordinar robos y aumentar las calificaciones de los productos. Sin embargo, a menudo están completamente aislados de la comunidad legítima de The Customer.
Para resolver este problema, debemos exponer estas "islas aisladas".
Solución relacional (búsqueda de identificador compartido)
Sin los algoritmos de grafos, la forma estándar de detectar el fraude es buscar "puntos críticos" de datos compartidos, como varios clientes que envían productos a la misma dirección exacta .
Ejecuta esta consulta para encontrar clientes vinculados por una ubicación de envío compartida:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Para encontrar las redes de fraude, debemos comprender la accesibilidad transitiva.
Graph Intelligence (componentes débilmente conectados)
Para encontrar la extensión completa de estos anillos, usamos los componentes débilmente conectados (WCC). WCC es un algoritmo de agrupamiento en clústeres que identifica conjuntos de nodos en los que existe una ruta entre dos nodos cualesquiera, independientemente de la dirección de las aristas.
- Zonas de accesibilidad: Divide el gráfico de manera eficaz en "islas" o "zonas de accesibilidad".
- Vista de entidad unificada: Al analizar los vínculos sociales (IsFriendsWith) y los vínculos logísticos (LivesAt) de forma simultánea, podemos agrupar los perfiles fragmentados en un solo "clúster de impacto" unificado.
Ejecución y persistencia de WCC
Ejecutaremos el algoritmo de WCC y guardaremos los resultados en la columna community_id. Utilizamos Data Boost para garantizar que este análisis de accesibilidad profunda se realice en recursos de procesamiento independientes.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Análisis: Redes de fraude
Ahora, ejecutemos una consulta de validación para ver nuestras comunidades aisladas. Por lo general, los usuarios legítimos pertenecen a la "Tierra firme", mientras que los defraudadores suelen quedar varados en pequeñas "Islas".
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | miembros |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Si ejecutas esta detección de comunidades, puedes identificar una anomalía crítica:
Conclusión para empresas
Ahora el Cliente puede automatizar sus respuestas de seguridad. En lugar de hacer un seguimiento manual de las cuentas individuales, pueden escribir una regla simple: "Si un community_id tiene menos de tres miembros, marca todo el grupo para que se realice una revisión manual de KYC (Conoce a tu cliente)"
.
Con nuestros anillos de fraude expuestos, podemos resolver el "gemelo de comportamiento".
7. Desafío 4: Gemelo de comportamiento (JaccardSimilarity)
En este último desafío, abordamos el cuarto obstáculo: la "paradoja de la elección" o "gemelo conductual". Pasaremos de listas genéricas de "Se suelen comprar juntos" a recomendaciones altamente personalizadas basadas en "huellas" de comportamiento.
Las sugerencias de productos actuales del cliente son demasiado genéricas. Recomendar un cable USB popular a cada cliente es seguro, pero no es personal. El cliente desea crear recomendaciones de "clientes gemelos" que identifiquen a los clientes que comparten patrones de envío y círculos sociales únicos para sugerir productos con una alta precisión de coincidencia.
Para resolver este problema, debemos calcular la "proximidad" entre los usuarios.
Solución relacional (superposición absoluta)
En una configuración relacional estándar, podrías buscar personas que realicen envíos a las mismas ubicaciones que un usuario de referencia, como Alice (C1).
Ejecuta esta consulta para encontrar los vecinos geográficos de Alice:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Inteligencia de gráficos (similitud de Jaccard)
Para encontrar gemelos conductuales verdaderos, usamos la similitud de Jaccard. Este algoritmo calcula una puntuación normalizada (de 0.0 a 1.0) dividiendo la cantidad de vecinos compartidos (intersección) entre la cantidad total de vecinos únicos (unión).
Aquí, un "gemelo de comportamiento" se define por algo más que una dirección de envío compartida. Si analizamos la intersección de las huellas físicas (LivesAt) y los ecosistemas sociales (IsFriendsWith), podemos identificar a los usuarios que comparten el mismo estilo de vida y la misma influencia en la comunidad, lo que genera recomendaciones de productos mucho más precisas.
Primero, crea una tabla de asignación
Dado que la similitud es una relación por pares (el cliente A es similar al cliente B), creamos una tabla intercalada dedicada en Customer para almacenar estas asignaciones.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Now Run Jaccard Similarity
Ahora ejecutaremos el algoritmo. Nota: Esta búsqueda incluye una lección común sobre "protecciones". Si solo seleccionas nodos de Customer, pero usas la arista LivesAt (que apunta a nodos de Shipping), la consulta fallará y se citará una "arista colgante" . Para solucionar este problema, debemos incluir ambas etiquetas de nodo.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Análisis: Verificación de "gemelo de comportamiento"
Ahora que se completó el trabajo analítico, ejecutamos una consulta de validación. Si unimos nuestra nueva tabla de correlación (CustomerSimilarity) con los metadatos originales de Customer, podemos ver exactamente quiénes son los "gemelos de comportamiento" de Alicia.
Ejecuta esta consulta para inspeccionar las clasificaciones de similitud de Alice:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
roberto@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
Qué debes buscar en los resultados:
Ahora intentemos crear una vista final de Inteligencia unificada.
8. Inteligencia unificada
Ahora pasamos de las tareas técnicas individuales a la Inteligencia unificada. Aquí, combinamos los datos de transacciones con los cuatro algoritmos de grafos para proporcionar estadísticas claras y prácticas.
Informe 1: Inteligencia unificada
El poder de una base de datos multimodelo como Spanner radica en la capacidad de unir datos de inversión relacionales con puntuaciones de influencia, riesgo y similitud derivadas de gráficos en una sola solicitud. Esta consulta clasifica a cada cliente en un arquetipo de empresa específico.
Ejecuta la consulta de Inteligencia unificada para ver el ecosistema completo:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | inversión | influencia | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 CRÍTICO: Puente de red |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 CRÍTICO: Puente de red |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 CRÍTICO: Puente de red |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 REDES SOCIALES: Influencer con un alcance alto |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 REDES SOCIALES: Influencer con un alcance alto |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 ESTÁNDAR: Cliente activo |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 ESTÁNDAR: Cliente activo |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RIESGO ALTO: Red de fraude aislada |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RIESGO ALTO: Red de fraude aislada |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 ESTÁNDAR: Cliente activo |
C2 | roberto@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 ESTÁNDAR: Cliente activo |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 ESTÁNDAR: Cliente activo |
Al combinar estos enfoques matemáticos, pasamos de "quién gastó más" a "quién es más importante". El panel unificado integra datos de transacciones relacionales con la inteligencia de gráficos multimodales para categorizar tu ecosistema en tres arquetipos claros y prácticos.
Los "Puentes de red críticos" (resiliencia)
Los nodos como Mallory (C11), Eve (C5) y Alice (C1) se marcan porque su bottleneck_risk (centralidad de intermediación) es >25.
- Los anclajes estructurales: Mallory tiene la puntuación de riesgo más alta, con 44.5, lo que la marca como la puerta de entrada principal para toda la red.
- La paradoja de la inversión cero: Eve (C5) tiene un recuento de pedidos de cero, pero es estructuralmente indispensable con una puntuación de riesgo de 35.5. El SQL estándar la habría ignorado por completo, pero la Inteligencia de gráficos revela que es un puente vital hacia toda una subcomunidad.
- La puerta de enlace de alto valor: Alice (C1) empató con Eve en 35.5, lo que demuestra que los usuarios con un gasto elevado también pueden ser anclajes estructurales críticos.
Las "superestrellas sociales" (alcance)
Heidi (C8) y Grace (C7) se identifican como influencers de gran alcance debido a sus puntuaciones de PageRank .
El "anillo de fraude aislado" (anomalías)
Judy (C10) e Ivan (C9) se marcan porque pertenecen al community_id aislado 1.
Información comercial para acciones estratégicas
Persona | Métrica clave | Estadísticas de la empresa | Acción estratégica |
🔵 Puentes de red | Centralidad alta | Anclajes estructurales: Eve (C5) y Mallory (C11) mantienen unida la red. | Retención: Protege a estos guardianes para evitar la fragmentación de la comunidad. |
📱 Superestrellas de las redes sociales | PageRank alto | Motores virales: Los usuarios como Heidi (C8) tienen el mayor alcance en sus círculos. | Marketing: Se usa para programas de embajadores y de referencias de alto impacto. |
🔴 Riesgos de fraude | WCC aislado | Redes fantasma: Judy (C10) e Ivan (C9) son clientes con un gasto elevado, pero viven en "islas". | Seguridad: Revisión manual inmediata del KYC; estas son firmas de fraude clásicas. |
🟢 Usuarios estándar | Puntuaciones equilibradas | Núcleo saludable: La mayoría de la red, incluidos los puentes "locales" como David (C4). | Crecimiento: Aplica anuncios personalizados estándar y recomendaciones de "Gemelo de comportamiento". |
Informe 2: Informe de anomalías de identidad
Ahora debes saber si los defraudadores están "imitando" cuentas legítimas. Para resolver este problema, podemos buscar usuarios que tengan un 100% de similitud de comportamiento, pero cero conexión social.
Ejecuta esta consulta para marcar posibles "Anomalías de identidad":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
El Informe de identificación de anomalías proporciona información fundamental. Al aislar a los usuarios que actúan como clientes legítimos, pero que no tienen vínculos sociales, pasamos de la suposición a la certeza matemática .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Análisis de los resultados
Al unificar la similitud (Jaccard) con la detección de comunidades (WCC), exponemos riesgos ocultos que los datos transaccionales tradicionales no pueden ver.
- Los "gemelos de comportamiento" (proximidad): Se marcan nodos como Judy (C10) e Ivan (C9) porque comparten una puntuación de similitud de Jaccard de 0.20 en relación con Alice (C1).
- Comportamiento de aislamiento: Judy (C10) e Ivan (C9) se agrupan en el community_id 1 aislado, mientras que Alice pertenece a la "Tierra firme" social (comunidad 0).
- Indicadores de fraude: El informe identifica a los usuarios con una superposición de comportamiento alta (superior a 0.9) que permanecen desconectados socialmente de la red principal.
9. Felicitaciones y resumen
En este lab, se muestra cómo Cloud Spanner convierte una base de datos relacional en una potencia multimodelos. Al aplicar la inteligencia de grafos a The Customer, pasamos de datos estáticos a una estrategia comercial práctica.
La ventaja del modelo múltiple de Spanner
- Arquitectura unificada: Spanner te permite mantener una base relacional sólida y, al mismo tiempo, "superponer" instantáneamente un gráfico de propiedades para la extracción de relaciones, todo sin el riesgo ni el retraso de la ETL.
- Aislamiento analítico fuera de la caja: Si aprovechas Data Boost, puedes ejecutar algoritmos que consumen mucha memoria, como PageRank o WCC, en recursos de procesamiento independientes y sin servidores, lo que garantiza que no haya ningún impacto en el rendimiento de la confirmación de compra en producción.
- Rendimiento intercalado: La intercalación única de Spanner garantiza que los nodos y sus relaciones se ubiquen físicamente en el mismo lugar, lo que convierte los recorridos globales complejos en búsquedas locales de alta velocidad.
Surgimiento de "Gemas ocultas" y anomalías
- Identificación del valor estructural: Los algoritmos de gráficos, como Betweenness Centrality, revelaron "puentes ocultos" con cero de inversión que pueden ser más importantes para la resiliencia de la red que los clientes con mayor inversión.
- Exposing Behavioral Mimicry: Combinamos la similitud de Jaccard y los componentes débilmente conectados para identificar a los "extraños sociales". Estas cuentas parecen clientes legítimos, pero se demostró matemáticamente que son redes de fraude aisladas.
- Verdad global vs. local: Si bien el análisis manual de SQL puede revelar puentes, los algoritmos globales pueden revelar a los principales guardianes de la red.
Cómo hacer que los datos sean inteligentes y prácticos
- Estrategia basada en arquetipos de usuarios: Transformamos con éxito nuestras filas en relaciones y, con la ejecución de algoritmos, podemos abordar cuatro problemas comerciales: Puentes de redes, Superestrellas sociales, Riesgos de fraude y Usuarios estándar.