
۱. مطالعه موردی: خردهفروشی هوشمند
برای مطالعه موردی، ما یک مشتری خردهفروشی با یک بازار دیجیتال با رشد سریع را در نظر میگیریم. دیدگاه سنتی مشتری در مورد دادهها محدود است زیرا نشان میدهد مردم چه چیزی میخرند ، اما نحوه ارتباط آنها را نشان نمیدهد . این شکاف منجر به از دست رفتن فرصتها و افزایش کلاهبرداری میشود. اکنون، آنها به فلسفه شبکه-محور روی آوردهاند تا علاوه بر دادههای تراکنشی، به ارتباطات اجتماعی و لجستیکی نیز بها دهند.
چالشهای اصلی کسبوکار که باید به آنها پرداخته شود
شما چهار چالش اساسی دارید که نیاز به درک چگونگی ارتباط مشتریان و لجستیک دارد :
چالش | مشکل | هدف |
شکاف نفوذ | تبلیغات گسترده، بازگشت سرمایه پایینی دارد؛ در حال حاضر شناسایی پیشگامان واقعی (اینفلوئنسرها) امکانپذیر نیست. | اینفلوئنسرهایی را شناسایی کنید که از طریق ارتباطشان در یک شبکه متصل از مشتریان، در جامعه نقش محوری دارند. |
تابآوری لجستیک | زنجیره تأمین میتواند آسیبپذیر باشد (با توجه به اینکه آنها در مناطق جغرافیایی مختلفی فعالیت میکنند). اگر یک مرکز کلیدی از کار بیفتد، کل منطقه میتواند به طور بالقوه دسترسی به محصول را از دست بدهد. | دروازهبانان را شناسایی کنید؛ کسانی که برای ایجاد پل ارتباطی بین شبکههای لجستیک حیاتی هستند. |
شبکههای ارواح | حلقههای کلاهبرداری از پروفایلهای جعلی و آدرسهای مشترک برای هماهنگی سرقت و افزایش رتبهبندیها استفاده میکنند. | جزایر منزوی را افشا کنید؛ گروههایی با ارتباطات بیش از حد که هیچ ارتباطی با جامعه مشروع ندارند. |
پارادوکس انتخاب | موتور پیشنهاد/توصیه فعلی ابتدایی، عمومی و اغلب نادیده گرفته میشود (مثلاً «مشتریانی که این را خریدهاند، ... را نیز خریدهاند» ). | دوقلوهای رفتاری بسازید؛ یعنی توصیههایی بر اساس الگوهای حمل و نقل مشابه و حلقههای اجتماعی. |
ترسیم چالشهای کسبوکار در قالب یک استراتژی فنی (ردیفها → روابط)
در یک پایگاه داده سنتی، دادهها در سیلوهای جداگانه ذخیره میشوند: مشتریان در یک جدول، تراکنشها در جدول دیگر، و ارسالها در جدول سوم. در حالی که SQL برای پاسخ به «چه کسی چه چیزی را خریده است؟» عالی است، برای پاسخ به سوالات مبتنی بر شبکه به مشکل برمیخورد.
برای حل این چالشها، استراتژی فنی تغییر این دیدگاه است:
- دیدگاه رابطهای ("چه"): با هر مشتری به عنوان یک ردیف مجزا رفتار میکند. یافتن ارتباط بین یک مشتری و خرید یک دوست نیازمند چندین "اتصال" پیچیده است که با رشد شبکه به صورت تصاعدی کندتر میشوند.
- نمای نموداری ("چگونگی"): با روابط مانند شهروندان درجه یک رفتار میکند. به جای جستجو در لیستها، ما روی نقشه حرکت میکنیم. میتوانیم فوراً ببینیم که مشتری A به مشتری B متصل است که به مکان Z ارسال میکند.
بررسی عمیق الزامات
معماران راهکار به این نتیجه میرسند که الزامات کسبوکار و استراتژی فنی نیازمند یک رویکرد چندمدلی است و الزامات کلیدی زیر را شناسایی میکنند.
چگونه Cloud Spanner با این الزامات فنی مطابقت دارد
کلود اسپنر به عنوان قلب این تحول انتخاب شده است. این سرویس به مشتری اجازه میدهد تا پایههای رابطهای مستحکم خود را حفظ کند و همزمان بینشهای عمیق نموداری را در اختیار داشته باشد.
در اینجا خلاصهای سریع از نحوهی رسیدگی Cloud Spanner به الزامات فنی و موارد دیگر ارائه شده است.
علاوه بر این، Cloud Spanner یک معماری فنی آیندهنگر ارائه میدهد.
۲. راهاندازی پایگاه داده
پس از طرح توجیهی، اکنون به مرحله پیادهسازی میرسیم. در این بخش، معماری دادههای خود را تعریف میکنیم، محدودیتهای مدل رابطهای سنتی را بررسی میکنیم و نمودار ویژگی را به عنوان ابزار اصلی خود برای کشف بینشهای عمیق معرفی میکنیم.
راهاندازی نمونه سازمانی Cloud Spanner
مرحله ۱: فعال کردن API کلود اسپنر
در کنسول گوگل کلود ، برای پیمایش سمت چپ، روی نماد منو در سمت چپ بالای صفحه کلیک کنید. به پایین بروید و "Spanner" را انتخاب کنید، یا به جای آن "Spanner" را جستجو کنید.
اکنون باید رابط کاربری Cloud Spanner را ببینید، و با فرض اینکه از پروژهای استفاده میکنید که هنوز API Cloud Spanner را فعال نکرده است، پنجرهای را مشاهده خواهید کرد که از شما میخواهد آن را فعال کنید. اگر قبلاً API را فعال کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای ادامه روی « فعال کردن » کلیک کنید:
مرحله 2: ایجاد نمونه Cloud Spanner
ابتدا، یک نمونه Cloud Spanner ایجاد خواهید کرد. در رابط کاربری، برای ایجاد یک نمونه جدید، روی « ایجاد یک نمونه تأمینشده » کلیک کنید.
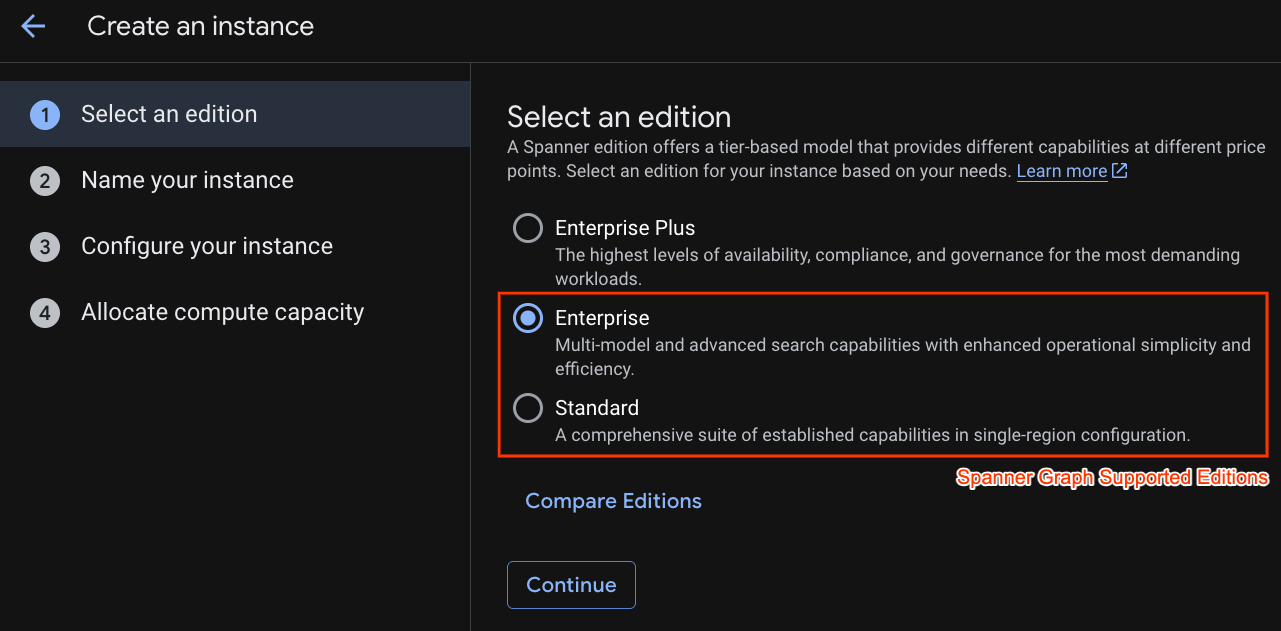
در مرحله اول باید یک نسخه را انتخاب کنید. لطفاً توجه داشته باشید که میتوانید نسخه را بعداً نیز ارتقا دهید. برای استفاده از قابلیتهای چند مدلی (Spanner Graph)، میتوانیم نسخه Enterprise را انتخاب کنیم.
نامگذاری نمونه شما
یک پیکربندی استقرار انتخاب کنید و منطقه مورد نظر خود را انتخاب کنید.
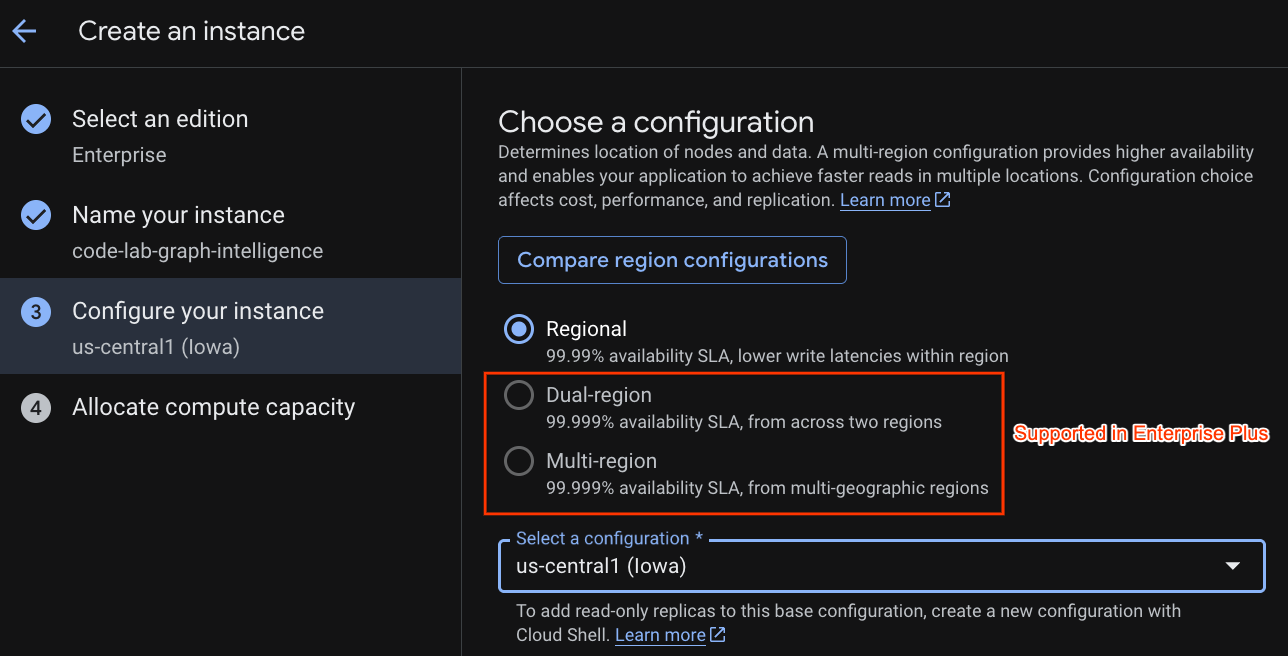
همچنین میتوانید گزینههای مختلف پیکربندی را با هم مقایسه کنید. برای مثال، پیکربندی استقرار حداقل ۳ کپی R/W در ۳ منطقه جداگانه از منطقه انتخابی شما دارد. یعنی حتی اگر با استقرار یک گره واحد پیش بروید، ۳ کپی از طریق ۳ کپی R/W خواهید داشت. علاوه بر این، حتی با پیکربندی استقرار منطقهای میتوانید با داشتن کپیهای R/O اضافی در توپولوژی استقرار خود ، آن را بیشتر گسترش دهید.
پس از پیکربندی ظرفیت، میتوانید از گره کامل شروع کنید و مقیاسبندی خودکار را در گرهها انجام دهید؛ یا میتوانید از یک نمونه جزئی (واحدهای پردازشی؛ ۱۰۰۰ PU = ۱ گره ) استفاده کنید. به صورت اختیاری میتوانید اهداف مقیاسبندی خودکار نمونه را نیز تنظیم کنید. برای بارهای کاری با تأخیر کم، ۶۵٪ را برای نمونههای منطقهای و ۴۵٪ را برای نمونههای چند منطقهای توصیه میکنیم.
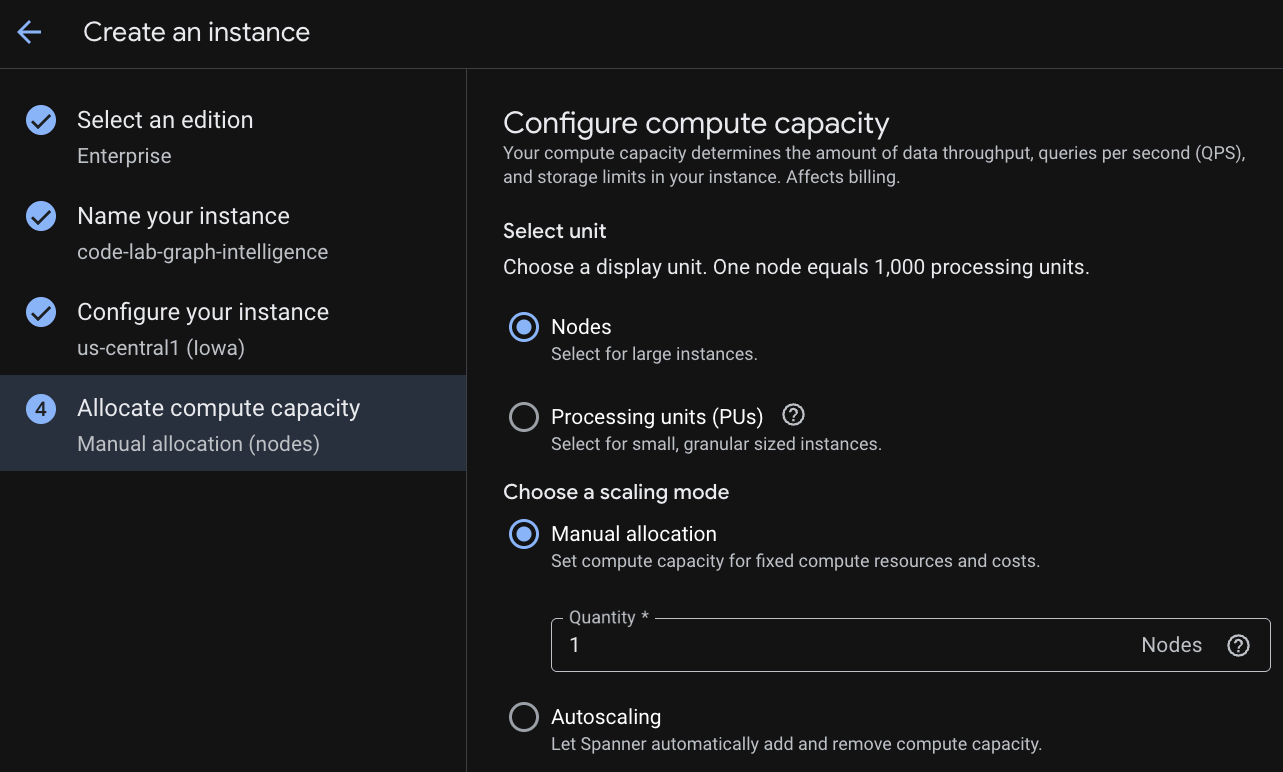
مرحله ۳: ایجاد پایگاه داده
پس از آمادهسازی نمونه، روی «ایجاد پایگاه داده» کلیک کنید تا یک پایگاه داده برای بقیه آزمایشگاه کد خود ایجاد کنید.
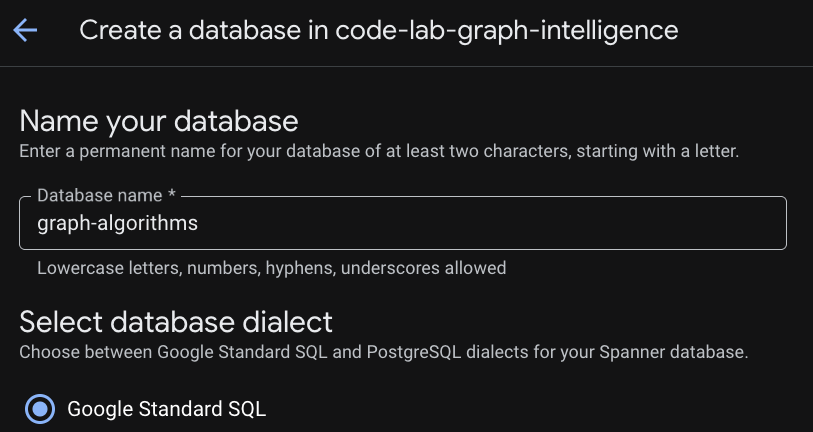
ایجاد یک بنیاد رابطهای
سفر ما با جداول اصلی که دادههای عملیاتی را ذخیره میکنند آغاز میشود. در Cloud Spanner، ما از Interleaving برای مکانیابی فیزیکی دادههای مرتبط، مانند دوستیها و تراکنشهای مشتری، مستقیماً با رکورد مشتری استفاده میکنیم. این امر دسترسی با کارایی بالا و موقعیت فیزیکی را تضمین میکند.
DDL: ایجاد جداول
برای ایجاد طرحواره رابطهای خود، بلوکهای زیر را کپی و اجرا کنید:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
راهاندازی شبکه
با آماده شدن جداول، باید آنها را با کاربران، محصولات و ارتباطاتی که اکوسیستم مشتری را تعریف میکنند، پر کنیم.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
چالش رابطهای
قبل از اینکه نمودار را معرفی کنیم، بیایید ببینیم SQL سنتی چگونه چالشهای مشتری را مدیریت میکند. این کوئری را اجرا کنید تا مشتریان "Social Spenders" را که به طور قابل توجهی خرج میکنند و چندین دوست دارند، پیدا کنید.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
محدودیتهای رویکرد رابطهای
غلبه بر چالشهای رابطهای از طریق نمودار ویژگی
برای غلبه بر این محدودیتها، ما یک نمودار ویژگی (Property Graph ) تعریف میکنیم. این یک «پوشش» (overlay) ایجاد میکند که به ما امکان میدهد بدون انتقال دادههایمان از Spanner، روابط را مانند شهروندان درجه یک در نظر بگیریم.
DDL: ایجاد نمودار ویژگی
این DDL گرهها (موجودیتها) و لبهها (روابط) ما را تعریف میکند. در این مثال، ما یک گراف شماتیک را دنبال میکنیم، با این حال، Spanner Graph امکان مدلسازی گرافهای بدون طرح را فراهم میکند تا توسعه تکراری انعطافپذیر و سریع را امکانپذیر سازد و مدلهای داده در حال تکامل را بدون تغییرات مداوم DDL (زبان تعریف داده) مدیریت کند.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
پیمایش نمودار با GQL
اکنون که گراف ما تعریف شده است، میتوانیم از زبان پرسوجوی گراف (GQL) برای انجام پیمایشهای چندگامی با یک سینتکس ساده و خوانا استفاده کنیم.
اکتشاف ۱: کشف مشارکتی
این کوئری نمودار را طی میکند تا محصولاتی را که توسط دوستانتان خریداری شده است پیدا کند و به عنوان پایه و اساس یک موتور توصیه عمل میکند.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
کاوش ۲: پرسوجوی ترکیبی (رابطهای + گراف)
Spanner به شما امکان میدهد الگوهای GQL را با استفاده از تابع GRAPH_TABLE درون یک عبارت استاندارد SQL FROM جاسازی کنید. این پرسوجو مشتریانی را پیدا میکند که در همان مکان دوستانشان زندگی میکنند. یک الگوی "الماس" مطابق.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
تجسم ارتباطات مشتری
در نهایت، بیایید از GQL برای تجسم شبکه خود استفاده کنیم. این کوئریها نتایج مسیر را در SAFE_TO_JSON قرار میدهند و به تصویرسازها اجازه میدهند گرهها و خطوط را ترسیم کنند.
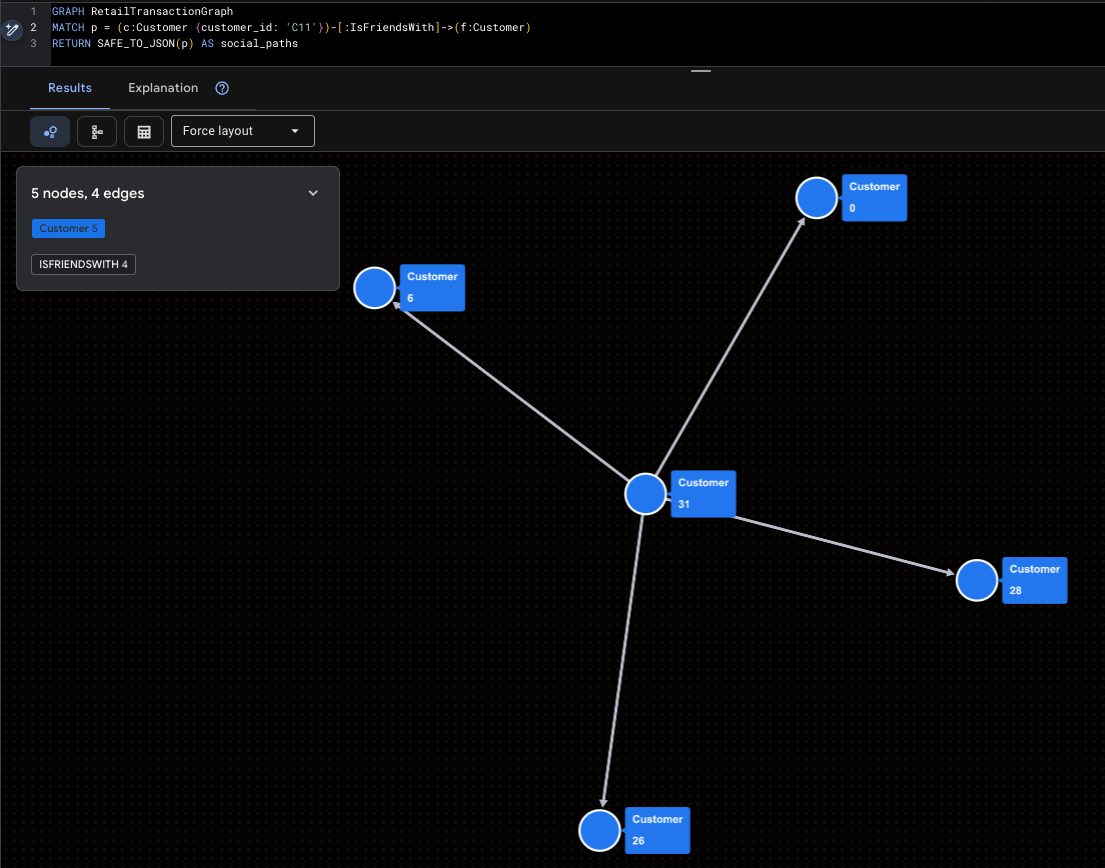
تجسم ابراینفلوئنسر
این موضوع، مالوری (C11) و دسترسی مستقیم اجتماعی او را برجسته میکند.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
تجسم الگوهای کلاهبرداری بالقوه
این کوئری «خوشه ایزوله» (ایوان و جودی) را ریشهیابی میکند تا ببیند محصولاتشان به کجا ارسال میشوند.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
۳. مقدمهای بر الگوریتمهای گراف اسپنر
برای آماده شدن برای بررسی عمیق هوش گراف، این بخش معماری فنی و قوانین بنیادی الگوریتمهای گراف Cloud Spanner را تشریح میکند. درک این اصول، کلید حرکت از پیمایشهای ساده به تحلیل روابط در مقیاس پتابایت است.
نمونه کارهای الگوریتم
Cloud Spanner در حال حاضر از ۱۴ الگوریتم گراف استاندارد صنعتی پشتیبانی میکند که در چهار گروه کاربردی برای حل مشکلات متنوع تجاری طبقهبندی شدهاند:
دسته بندی | الگوریتمهای پشتیبانیشده | مورد استفاده تجاری |
مرکزیت | رتبه صفحه، رتبه صفحه شخصیسازیشده، بینابینی، نزدیکی | افراد تأثیرگذار، مراکز و گلوگاهها را شناسایی کنید. |
جامعه | WCC، انتشار برچسب، یافتن دسته، خوشهبندی همبستگی | حلقههای کلاهبرداری، جوامع اجتماعی و سیلوها را شناسایی کنید. |
شباهت | جاکارد، کسینوس، همسایههای مشترک، مجموع همسایهها | موتورهای توصیهگر قدرتمند و تفکیکپذیری موجودیتها. |
مسیر یابی | کوتاهترین مسیر تنظیمشده، دستیاران مسیر GA | بهینهسازی لجستیک و نزدیکی پیمایش. |
ملاحظات مهم طرحواره و پرس و جو
برای اطمینان از اجرای کارآمد الگوریتمهای گراف، Spanner Graph باید به این قوانین پایبند باشد:
الزام ۱. محل فیزیکی دادهها (جایگذاری)
مهمترین الزام برای پیمایش گراف با کارایی بالا، میانچینی (Interleaving) است. این امر تضمین میکند که دادههای لبه به صورت فیزیکی در همان سروری که گره منبع در آن قرار دارد، ذخیره شوند و تأخیر شبکه را در طول اجرای الگوریتم به حداقل برسانند.
- قانون: جداول لبه باید در جداول گره منبع خود به صورت لایه لایه قرار گیرند.
- پیمایش رو به جلو: قرار دادن جدول لبه در جدول گره منبع، محلی بودن حافظه پنهان را برای لینکهای خروجی تضمین میکند.
- پیمایش معکوس: برای تحلیل کارآمد لینکهای «ورودی»، از کلیدهای خارجی برای ایجاد خودکار شاخصهای پشتیبان استفاده کنید، یا یک شاخص ثانویه ایجاد کنید که در جدول مقصد قرار گرفته باشد.
الزام ۲. الزامات برچسبگذاری منحصر به فرد
هر جدولی که در نمودار ویژگیها شرکت میکند باید یک هویت منحصر به فرد داشته باشد. الگوریتمها برای شناسایی و بارگذاری صحیح زیرگرافهایی که باید تجزیه و تحلیل کنند، به این برچسبها متکی هستند.
- قانون: هر جدول ورودی باید یک برچسب منحصر به فرد در نمودار ویژگی داشته باشد.
- تضاد: اگر قصد دارید الگوریتمهایی را روی چندین جدول اجرا کنید، نمیتوانید یک برچسب واحد را به آنها نگاشت کنید.
منطق | مثال | نتیجه |
❌ بد | جداول گره (شخص با برچسب موجودیت، حساب با برچسب موجودیت) | نامعتبر : الگوریتم نمیتواند بین یک شخص و یک حساب تمایز قائل شود. |
✅ خوب | جداول گره (برچسب شخص، برچسب مشتری، برچسب حساب، حساب) | معتبر : هر موجودیت یک برچسب متمایز و منحصر به فرد دارد. |
الزام ۳. ساختار پرسوجوی الگوریتم (عبارت MATCH)
هنگام فراخوانی یک الگوریتم، عبارت MATCH از قوانین محدودکنندهتری نسبت به پرسوجوهای استاندارد GQL پیروی میکند تا اطمینان حاصل شود که موتور اجرا میتواند خط لوله تحلیلی را بهینه کند.
- یک الگو برای هر MATCH: هر دستور MATCH فقط میتواند یک متغیر را نامگذاری کند.
- الگوهای چند گرهای ممنوع: شما نمیتوانید یک الگوی رابطه (مثلاً (a)-[e]->(b)) را مستقیماً درون یک عبارت MATCH که برای فراخوانی الگوریتم در نظر گرفته شده است، تعریف کنید.
- فقط فیلترهای تحتاللفظی: در حالی که میتوانید از عبارات WHERE برای فیلتر کردن گرهها استفاده کنید (مثلاً WHERE a.id > 400)، پارامترهای پرسوجو (@param) در حال حاضر در پرسوجوهای الگوریتم گراف پشتیبانی نمیشوند .
الزام ۴. بند RETURN (فقط اسکالرها)
عبارت RETURN در یک پرسوجوی الگوریتمی به عنوان پلی بین دنیای گراف و دنیای رابطه عمل میکند. این عبارت صرفاً به برگرداندن مقادیر اسکالر و ثابتها محدود است.
- قانون: شما نمیتوانید یک «عنصر گراف» (گره خام یا شیء لبه) را برگردانید.
- بدون تبدیل: شما نمیتوانید عملیات ریاضی انجام دهید یا توابع را روی ویژگیهایی که در داخل خود دستور RETURN برگردانده میشوند، اعمال کنید.
محدودیتهای بند بازگشت
✅ پشتیبانی شده | ❌ پشتیبانی نمیشود |
بازگرداندن node.id، امتیاز | گره، امتیاز را برمیگرداند (عنصر گراف را نمیتوان برگرداند) |
طول مسیر (p) را برمیگرداند | تابع ()return node.id + 1, score را برمیگرداند (هیچ عملیاتی روی ویژگیها انجام نمیشود) |
نام گره را برگردانید | تابع JSON_OBJECT(node.id, score) را برمیگرداند (بدون تابع) |
الزام ۵. یکپارچگی دادهها: حذف لبههای معلق
«لبه آویزان» زمانی رخ میدهد که یک لبه به گره مقصدی اشاره میکند که در گراف وجود ندارد. این امر باعث میشود اجرای الگوریتم با شکست مواجه شود زیرا ساختار گراف ناسازگار است.
- راه حل: از محدودیتهای ارجاعی (کلیدهای خارجی) و ON DELETE CASCADE برای حفظ یکپارچگی گراف استفاده کنید.
- ایمنی پرسوجو: هنگام فراخوانی یک الگوریتم، باید مطمئن شوید که تمام گرههای ارجاعشده توسط لبههای انتخابشده نیز در آرگومان node_labels گنجانده شدهاند.
خروجی دائمی: گزینههای خروجی داده
از آنجا که الگوریتمهای گراف به محاسبات فشرده نیاز دارند، در حالت اجرای Scale-up با استفاده از دستور EXPORT DATA اجرا میشوند. این امر از Data Boost بهره میبرد و با استفاده از منابع محاسباتی مستقل بدون سرور، از هرگونه تاخیر در تراکنشهای تولیدی شما جلوگیری میکند.
گزینه ۱: بازگشت به Cloud Spanner
برای اینکه نتایج مستقیماً به جداول شما بازگردانده شوند (مثلاً ذخیره امتیاز PageRank)، از format = 'CLOUD_SPANNER' استفاده کنید.
-
update_ignore_all: فقط ردیفهایی را بهروزرسانی میکند که کلیدهایی از قبل در جدول هدف وجود دارند. -
upsert_ignore_all: ردیفهای موجود را بهروزرسانی میکند یا در صورت فقدان کلیدها، ردیفهای جدید درج میکند.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
گزینه ۲: ذخیره نتایج در فضای ابری گوگل (GCS)
برای تجزیه و تحلیل آفلاین در مقیاس بزرگ، میتوانید دادهها را در قالبهای CSV، Avro یا Parquet به GCS صادر کنید.
- کاراکترهای جایگزین: از
uri => 'gs://bucket/file_*.csv'برای فعال کردن خروجی خرد شده استفاده کنید، که به Spanner اجازه میدهد برای مجموعه دادههای عظیم، به صورت موازی در چندین فایل بنویسد. - فشردهسازی: از GZIP، SNAPPY و ZSTD برای بهینهسازی هزینههای ذخیرهسازی پشتیبانی میکند.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
۴. چالش ۱: شکاف نفوذ (رتبه صفحه)
در این بخش، به اولین مانع تجاری مشتری میپردازیم: «شکاف نفوذ». ما از یک «مسابقه محبوبیت» ساده به یک نقشه ریاضیمحور از نفوذ اجتماعی واقعی حرکت خواهیم کرد.
صورت مسئله: تیم بازاریابی مشتری با مشکلی مواجه است. آنها میلیونها دلار صرف تبلیغات گسترده با بازدهی رو به کاهش میکنند، زیرا نمیتوانند «سوپراستارهای اجتماعی» را شناسایی کنند، افراد نادری که حمایتهایشان در کل شبکه پخش میشود.
برای حل این مشکل، باید مشتریان خود را بر اساس میزان نفوذشان رتبهبندی کنیم.
راهحل رابطهای (مرکزیت درجه)
در یک پایگاه داده استاندارد، سادهترین راه برای پیدا کردن یک اینفلوئنسر، شمارش دنبالکنندگان اوست (معیاری که به عنوان مرکزیت درجه شناخته میشود).
برای یافتن محبوبترین کاربران، این کوئری را اجرا کنید:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
شناسه مشتری | تعداد دنبالکنندگان |
سی۱ | ۳ |
سی5 | ۳ |
سی۱۱ | ۲ |
سی۷ | ۲ |
سی10 | ۱ |
سی۱۲ | ۱ |
سی۲ | ۱ |
سی3 | ۱ |
سی۴ | ۱ |
سی6 | ۱ |
سی۸ | ۱ |
سی9 | ۱ |
هوش گراف (رتبه صفحه)
برای یافتن رهبران واقعی، ما از PageRank استفاده میکنیم. این همان الگوریتمی است که جستجوی اولیه وب را پشتیبانی میکرد؛ این الگوریتم اهمیت یک گره را بر اساس کمیت و کیفیت لینکهای ورودی اندازهگیری میکند.
- مدل پیمایش تصادفی: رتبهبندی صفحه، حرکت کاربر در نمودار را شبیهسازی میکند. ضریب میرایی (پیشفرض ۰.۸۵) نشان دهنده احتمال ادامه کلیک کردن آنهاست؛ در غیر این صورت، آنها به یک گره تصادفی "تله پورت" میشوند.
- قدرت ارتباط: لینکی از یک فرد بانفوذ (مانند مالوری) به طور قابل توجهی بیشتر از لینکی از کسی که هیچ ارتباط دیگری ندارد، ارزش دارد.
ما الگوریتم PageRank را اجرا خواهیم کرد و از EXPORT DATA برای ذخیره مستقیم نتایج در ستون pagerank_score خود استفاده خواهیم کرد.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
داشبورد «تأثیرگذاری» با استفاده از رتبه صفحه
حالا که امتیازها ثبت شدهاند، بیایید «قبل» (تعداد دنبالکنندگان) را با «بعد» (امتیاز رتبه صفحه) مقایسه کنیم.
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
شناسه مشتری | ایمیل مشتری | تعداد دنبالکنندگان | امتیاز_صفحه |
سی5 | eve@example.com | ۳ | ۰.۱۵۸۳۹۲۴۸۹ |
سی10 | judy@example.com | ۱ | ۰.۱۰۹۳۵۶۱۷۲۴ |
سی9 | ivan@example.com | ۱ | ۰.۱۰۹۳۵۶۱۷۲۴ |
سی۱ | alice@example.com | ۳ | ۰.۱۰۰۰۸۸۸۱۲۴ |
سی۸ | heidi@example.com | ۱ | ۰.۰۹۷۵۹۸۲۱۷۴۳ |
سی۱۱ | mallory@example.com | ۲ | ۰.۰۹۴۶۶۴۱۱۹۱۸ |
سی۷ | grace@example.com | ۲ | ۰.۰۸۰۱۶۷۱۹۶۶۹ |
سی6 | frank@example.com | ۱ | ۰.۰۶۰۲۲۴۴۸۰۹۳ |
سی۲ | bob@example.com | ۱ | ۰.۰۵۴۷۸۹۱۸۱۸ |
سی3 | charlie@example.com | ۱ | ۰.۰۵۴۷۸۹۱۸۱۸ |
سی۱۲ | trent@example.com | ۱ | ۰.۰۴۰۲۹۲۲۵۵۵۸ |
سی۴ | david@example.com | ۱ | ۰.۰۴۰۲۸۱۷۲۷۹۱ |
تحلیل: سوپراستارهای واقعی چه کسانی هستند؟
با تجزیه و تحلیل خروجی، اکنون میتوانید به سه کشف مهم در بازاریابی دست یابید:
غذای آماده کسب و کار
به جای ارسال کورکورانه ایمیل به همه کسانی که بیش از پنج دنبالکننده دارند، تیم بازاریابی مشتری اکنون میتواند منحصراً روی افرادی که بالاترین امتیاز پیج رنک را دارند تمرکز کند. این افراد «سوپراستارهای اجتماعی» واقعی هستند که میتوانند ویروسی شدن سیستمی را در کل بازار هدایت کنند.
حالا بیایید سعی کنیم دروازهبانانی را که شبکه لجستیک مشتری را فعال نگه میدارند، شناسایی کنیم.
۵. چالش ۲: تابآوری لجستیکی (میانمحوری)
در این بخش، به تابآوری لجستیک میپردازیم. ما فراتر از سنجش موفقیت بر اساس «حجم» به شناسایی «دروازهبانان» حیاتی که شبکه را متصل نگه میدارند، خواهیم پرداخت.
راهکار رابطهای (تحلیل مبتنی بر حجم)
در یک ساختار رابطهای استاندارد، یک مرکز حمل و نقل «حیاتی» معمولاً به عنوان مرکزی تعریف میشود که بیشترین سفارشات را پردازش میکند یا بیشترین درآمد را ایجاد میکند.
این کوئری را برای شناسایی هابهای «برتر» بر اساس تعداد تراکنشها اجرا کنید:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
شهر | کشور | تعداد تراکنش | درآمد کل |
نیویورک | ایالات متحده آمریکا | ۴ | ۳۹۹۶ عدد |
برلین | آلمان | ۲ | ۳۴۵ |
سانفرانسیسکو | ایالات متحده آمریکا | ۲ | ۷۵۰ |
برای رفع این عدم تطابق، ما از هر دو لبه IsFriendsWith و LivesAt استفاده خواهیم کرد. این امر تحلیل ما را از یک مرکز تراکنش به بررسی اجتماعی نیز تبدیل میکند.
هوش گراف (مرکزیت بینابینی)
برای یافتن گلوگاههای واقعی، از مرکزیت بینابینی استفاده میکنیم. این الگوریتم میزان نقش یک گره به عنوان "پل" در کوتاهترین مسیرها بین تمام جفت گرههای دیگر در گراف را کمّی میکند. نمرات بالا، دروازهبانان واقعی را که جریان کالا یا اطلاعات را کنترل میکنند، مشخص میکند.
مرکزیت بینابینیِ در حال اجرا و تداوم
ما الگوریتم را با استفاده از EXPORT DATA اجرا خواهیم کرد و امتیازها را در ستون centrality_score ذخیره خواهیم کرد. ما از Data Boost استفاده میکنیم تا اطمینان حاصل کنیم که این محاسبه سنگین "کوتاهترین مسیر" تأثیر تقریباً صفر بر عملیات جاری مشتری دارد.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
تحلیل: شناسایی «گلوگاههای پنهان»
اکنون، ریسک ساختاری ( centrality_score ) خود را با حجم تراکنشها ( order_count ) مقایسه میکنیم تا گرههایی را که رهبری مشتری باید نگران آنها باشد، پیدا کنیم.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
شناسه مشتری | ایمیل مشتری | امتیاز مرکزیت | تعداد_سفارش | |
سی۱۱ | mallory@example.com | ۴۴.۵ | ۲ | |
سی۱ | alice@example.com | ۳۵.۵ | ۱ | |
سی5 | eve@example.com | ۳۵.۵ | ||
سی۷ | grace@example.com | ۱۲ | ۱ | |
سی۸ | heidi@example.com | ۱۰ | ۱ | |
سی3 | charlie@example.com | ۶ | ||
سی۴ | david@example.com | ۳.۵ | ||
سی10 | judy@example.com | 0 | ۱ | |
سی۱۲ | trent@example.com | 0 | ||
سی۲ | bob@example.com | 0 | ۱ | |
سی6 | frank@example.com | 0 | ||
سی9 | ivan@example.com | 0 | ۱ | |
با تجزیه و تحلیل این نتایج، مشتری به سه کشف شگفتانگیز دست مییابد:
غذای آماده کسب و کار
اکنون مشتری میتواند افزونگی لجستیک و پروتکلهای امنیتی خود را بر اساس ریسک ساختاری چندوجهی اولویتبندی کند. مالوری، آلیس و ایو دروازهبانانی هستند که باید برای تضمین ثبات شبکه لجستیکی محافظت شوند.
حالا بیایید سعی کنیم جزایر کلاهبرداری را جدا کنیم.
۶. چالش ۳: شبکههای ارواح (WCC)
در این بخش، به سومین مانع تجاری میپردازیم: «شبکههای شبح». ما از تشخیص سادهی «نقاط داغ» به کشف حلقههای کلاهبرداری پیچیده و منزوی با استفاده از تشخیص جامعه خواهیم پرداخت. چالش اینجا این است که بازیگران بد، پروفایلهای جعلی ایجاد میکنند که آدرسهای حمل و نقل را به اشتراک میگذارند یا در حلقههای بسته تعامل میکنند تا سرقتها را هماهنگ کرده و رتبهبندی محصولات را افزایش دهند. اما آنها اغلب کاملاً از جامعهی مشروع مشتریان جدا هستند.
برای حل این مشکل، باید این «جزایر منزوی» را آشکار کنیم.
راهکار رابطهای (جستجوی شناسه مشترک)
بدون الگوریتمهای گراف، روش استاندارد برای یافتن کلاهبرداری، جستجوی «نقاط داغ» دادههای مشترک است، مانند چندین مشتری که دقیقاً به یک آدرس ارسال میکنند.
برای یافتن مشتریانی که از طریق یک مکان ارسال مشترک به هم مرتبط هستند، این کوئری را اجرا کنید:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
شناسه حمل و نقل | تعداد_مشتری | مشتریان مرتبط |
اس۱ | ۴ | ["C1"، "C10"، "C2"، "C9"] |
اس۵ | ۲ | ["C7"، "C8"] |
برای یافتن شبکههای کلاهبرداری، باید مفهوم دسترسیپذیری انتقالی را درک کنیم.
هوش گراف (اجزای اتصال ضعیف)
برای یافتن کل این حلقهها، از «اجزای متصل ضعیف» (Weakly Connected Components) یا به اختصار WCC استفاده میکنیم. WCC یک الگوریتم خوشهبندی است که مجموعهای از گرهها را شناسایی میکند که در آنها مسیری بین هر دو گره وجود دارد، صرف نظر از جهت لبهها.
- مناطق دسترسی: این روش عملاً نمودار را به «جزیرهها» یا «مناطق دسترسی» تقسیم میکند.
- دیدگاه یکپارچه: با تجزیه و تحلیل همزمان پیوندهای اجتماعی (IsFriendsWith) و پیوندهای لجستیکی (LivesAt)، میتوانیم پروفایلهای پراکنده را در یک «خوشه تأثیر» واحد و یکپارچه گروهبندی کنیم.
WCC در حال اجرا و پایدار
ما الگوریتم WCC را اجرا کرده و نتایج را در ستون community_id ذخیره خواهیم کرد. ما از Data Boost برای اطمینان از انجام این تحلیل عمیق دسترسیپذیری روی منابع محاسباتی مستقل استفاده میکنیم.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
تحلیل: حلقههای کلاهبرداری
حالا، بیایید یک کوئری اعتبارسنجی اجرا کنیم تا جوامع ایزولهشدهمان را ببینیم. کاربران قانونی معمولاً متعلق به «سرزمین اصلی» هستند، در حالی که کلاهبرداران اغلب در «جزایر» کوچک گیر افتادهاند.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
شناسه_جامعه | تعداد_عضو | اعضا |
۱ | ۲ | ["judy@example.com","ivan@example.com"] |
0 | ۱۰ | ["alice@example.com"، "mallory@example.com"، "trent@example.com"، "bob@example.com"، "charlie@example.com"، "david@example.com"، "eve@example.com"، "frank@example.com"، "grace@example.com"، "heidi@example.com"] |
با اجرای این تشخیص انجمن، میتوانید یک ناهنجاری بحرانی را شناسایی کنید:
غذای آماده کسب و کار
مشتری اکنون میتواند پاسخهای امنیتی خود را خودکار کند. به جای پیگیری دستی حسابهای کاربری، میتواند یک قانون ساده بنویسد: «اگر یک community_id کمتر از سه عضو دارد، کل گروه را برای بررسی دستی KYC (شناسایی مشتری) علامتگذاری کن.»
.
با افشای حلقههای کلاهبرداریمان، میتوانیم «دوقلوی رفتاری» را حل کنیم.
۷. چالش ۴: دوقلوی رفتاری (شباهت جاکارد)
در این چالش نهایی، به مانع چهارم میپردازیم: «پارادوکس انتخاب»/«دوقلوی رفتاری». ما از فهرستهای کلی «کالاهایی که اغلب با هم خریداری میشوند» به سمت توصیههای فوقالعاده شخصیسازیشده بر اساس «اثر انگشت» رفتاری حرکت خواهیم کرد.
پیشنهادات فعلی مشتری برای محصول بیش از حد کلی است. توصیه یک کابل USB محبوب به هر مشتری ایمن است، اما شخصی نیست. مشتری میخواهد توصیههای «دوقلوی رفتاری» ایجاد کند که مشتریانی را که الگوهای حمل و نقل منحصر به فرد و حلقههای اجتماعی مشترک دارند، شناسایی کند تا محصولاتی با تطابق بالا پیشنهاد دهد.
برای حل این مشکل، باید «نزدیکی» (Proximity) بین کاربران را محاسبه کنیم.
راهحل رابطهای (همپوشانی مطلق)
در یک ساختار رابطهای استاندارد، ممکن است به دنبال افرادی باشید که به همان مکانهایی که کاربر مرجع قرار دارد، ارسال میکنند، مانند آلیس (C1) .
برای یافتن همسایگان جغرافیایی آلیس، این کوئری را اجرا کنید:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
مشتری_مشابه | مکانهای_اشتراکی |
سی۲ | ۱ |
سی10 | ۱ |
سی9 | ۱ |
هوش گراف (شباهت جاکارد)
برای یافتن دوقلوهای رفتاری واقعی، از الگوریتم شباهت جاکارد استفاده میکنیم. این الگوریتم با تقسیم تعداد همسایههای مشترک (تقاطع) بر تعداد کل همسایههای منحصر به فرد (اتحادیه)، یک امتیاز نرمالشده (0.0 تا 1.0) محاسبه میکند.
در اینجا «دوقلوی رفتاری» چیزی بیش از یک آدرس حمل و نقل مشترک تعریف میشود. با تجزیه و تحلیل تقاطع ردپاهای فیزیکی ( LivesAt ) و اکوسیستمهای اجتماعی ( IsFriendsWith )، میتوانیم کاربرانی را که سبک زندگی و نفوذ اجتماعی یکسانی دارند، شناسایی کنیم و به توصیههای محصول بسیار دقیقتری دست یابیم.
ابتدا یک جدول نگاشت ایجاد کنید
از آنجا که شباهت یک رابطهی دو به دو است (مشتری A شبیه مشتری B است)، ما یک جدول اختصاصی ایجاد میکنیم که در Customer قرار گرفته تا این نگاشتها را ذخیره کند.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
حالا تشابه جاکارد را اجرا کنید
We will now execute the algorithm. Note: This query includes a common "Guardrail" lesson. If you only select Customer nodes but use the LivesAt edge (which points to Shipping nodes), the query will fail citing a "Dangling Edge" . To fix this, we must include both node labels.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
تحلیل: بررسی «دوقلوی رفتاری»
Now that the analytical job is complete, we run a validation query. By joining our new mapping table ( CustomerSimilarity ) with our original Customer metadata, we can see exactly who Alice's "Behavioral Twins" are.
Run this query to inspect Alice's similarity rankings:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | ۱ | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | ۱ | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
What to look for in results:
Now lets try to build a final Unified Intelligence view.
8. Unified Intelligence
Now we move from individual technical tasks to Unified Intelligence . Here, we blend transactional data with all four graph algorithms to provide clear, actionable insights.
گزارش ۱: اطلاعات یکپارچه
The power of a multi-model database like Spanner is the ability to join relational spend data with graph-derived influence, risk, and similarity scores in a single request. This query categorizes every customer into a specific business persona.
Run the Unified Intelligence query to see complete ecosystem:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | spend | نفوذ | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | ۴۴.۵ | 0 | 🔵 CRITICAL: Network Bridge |
سی5 | eve@example.com | 0 | 0.158392489 | ۳۵.۵ | 0 | 🔵 CRITICAL: Network Bridge |
سی۱ | alice@example.com | ۹۹۹ | 0.1000888124 | ۳۵.۵ | 0 | 🔵 CRITICAL: Network Bridge |
سی۷ | grace@example.com | ۳۰۰ | 0.08016719669 | ۱۲ | 0 | 📱 SOCIAL: High-Reach Influencer |
C8 | heidi@example.com | ۴۵ | 0.09759821743 | ۱۰ | 0 | 📱 SOCIAL: High-Reach Influencer |
سی3 | charlie@example.com | 0 | 0.0547891818 | ۶ | 0 | 🟢 STANDARD: Active Customer |
سی۴ | david@example.com | 0 | 0.04028172791 | ۳.۵ | 0 | 🟢 STANDARD: Active Customer |
C10 | judy@example.com | ۹۹۹ | 0.1093561724 | 0 | ۱ | 🔴 HIGH RISK: Isolated Fraud Ring |
C9 | ivan@example.com | ۹۹۹ | 0.1093561724 | 0 | ۱ | 🔴 HIGH RISK: Isolated Fraud Ring |
سی6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: Active Customer |
سی۲ | bob@example.com | ۹۹۹ | 0.0547891818 | 0 | 0 | 🟢 STANDARD: Active Customer |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: Active Customer |
By blending these mathematical lenses, we move beyond "who spent the most" to "who matters the most." The unified dashboard integrates relational transaction data with multi-modal graph intelligence to categorize your ecosystem into three clear, actionable personas.
The "Critical Network Bridges" (Resilience)
Nodes like Mallory (C11) , Eve (C5) , and Alice (C1) are flagged because their bottleneck_risk (Betweenness Centrality) is >25 .
- The Structural Anchors: Mallory holds the highest risk score at 44.5 , marking her as the primary gateway for the entire network.
- The Zero-Spend Paradox: Eve (C5) has an order count of zero, yet she is structurally indispensable with a risk score of 35.5 . Standard SQL would have ignored her entirely, but Graph Intelligence reveals she is a vital bridge to an entire sub-community.
- The High-Value Gateway: Alice (C1) tied with Eve at 35.5 , proving that high spenders can also be critical structural anchors.
«سوپراستارهای اجتماعی» (ریچ)
Heidi (C8) and Grace (C7) are identified as high-reach influencers due to their PageRank scores .
The "Isolated Fraud Ring" (Anomalies)
Judy (C10) and Ivan (C9) are flagged because they belong to the isolated community_id 1
Business Insight to Strategic Actions
پرسونا | Key Metric | Business Insight | Strategic Action |
🔵 Network Bridges | High Centrality | Structural Anchors : Eve (C5) and Mallory (C11) hold the network together. | Retention : Protect these gatekeepers to prevent community fragmentation. |
📱 Social Superstars | High PageRank | Viral Engines : Users like Heidi (C8) have the highest reach in their circles. | Marketing : Use for high-impact referral and ambassador programs. |
🔴 Fraud Risks | Isolated WCC | Ghost Networks : Judy (C10) and Ivan (C9) are high-spenders but live on "islands." | Security : Immediate manual KYC review; these are classic fraud signatures. |
🟢 Standard Users | Balanced Scores | Healthy Core : The majority of the network, including "local" bridges like David (C4). | Growth : Apply standard personalized ads and "Behavioral Twin" recommendations. |
Report 2: The Identity Anomaly Report
Now you need to know if legitimate accounts are being "mimicked" by fraudsters. We can solve this by finding users who have 100% Behavioral Similarity but Zero Social Connection.
Run this query to flag potential "Identity Anomalies":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
The Identify Anomaly Report provides critical information. By isolating users who act like legitimate customers but lack their social ties, we move from guessing to mathematical certainty .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | ۱ |
C9 | ivan@example.com | 0.200000003 | ۱ |
Analysis of Results
By unifying Similarity (Jaccard) with Community Detection (WCC) , we expose hidden risks that traditional transactional data cannot see.
- The "Behavioral Twins" (Proximity): Nodes like Judy (C10) and Ivan (C9) are flagged because they share a Jaccard Similarity score of 0.20 relative to Alice (C1).
- Isolation Behavior: Judy (C10) and Ivan (C9) are grouped into the isolated community_id 1 , while Alice belongs to the social "Mainland" (Community 0).
- Fraud Flags: The report identifies users with high behavioral overlap (>0.9) who remain socially disconnected from the primary network.
9. Congratulations and Summary
This lab shows how Cloud Spanner turns a relational database into a multi-model powerhouse. By applying graph intelligence to The Customer , we moved from static data to actionable business strategy.
مزیت چند مدلی بودن آچار
- Unified Architecture: Spanner allows you to maintain a rock-solid relational foundation while instantly "overlaying" a property graph for relationship mining all without the risk and lag of ETL.
- Off-Box Analytical Isolation: By leveraging Data Boost , you can execute memory-intensive algorithms like PageRank or WCC on independent, serverless compute resources, ensuring zero impact on your production checkout performance.
- Interleaved Performance: Spanner's unique interleaving ensures that nodes and their relationships are physically co-located, turning complex global traversals into high-speed local lookups.
Surfacing "Hidden Gems" & Anomalies
- Identifying Structural Value: Graph algorithms like Betweenness Centrality revealed "Hidden Bridges" with zero spend who can be more critical to network's resilience than highest-spending customers.
- Exposing Behavioral Mimicry: By combining Jaccard Similarity and Weakly Connected Components , we identified "Social Strangers". These accounts look like legitimate customers but are mathematically proven to be isolated fraud rings.
- Global vs. Local Truth: While manual SQL analysis can surface bridges, global algorithms can surface key Gatekeepers of the network.
Making Data Intelligent and Actionable
- Persona-Driven Strategy: We successfully transformed our rows to relationship, and by running algorithms we can address four business problems, namely: Network Bridges, Social Superstars, Fraud Risks, and Standard Users .