
1. Étude de cas : Intelligent Retail
Pour l'étude de cas, nous prenons un client du secteur de la vente au détail avec une place de marché numérique en pleine croissance. La vue traditionnelle des données client est limitée, car elle indique ce que les utilisateurs achètent, mais pas comment ils sont connectés. Ce manque à gagner entraîne une perte d'opportunités et une augmentation de la fraude. Ils adoptent désormais une philosophie Network-First pour valoriser les connexions sociales et logistiques en plus des données transactionnelles.
Principaux défis commerciaux à relever
Vous devez relever quatre défis essentiels qui nécessitent de comprendre comment les clients et la logistique sont interconnectés :
Défi | Le problème | Objectif |
Écart d'influence | La publicité à large diffusion génère un faible ROI. Il est actuellement impossible d'identifier les véritables influenceurs. | Identifiez les influenceurs qui sont au centre de la communauté grâce à leur connexion dans un réseau de clients connectés. |
Résilience logistique | La chaîne d'approvisionnement peut être vulnérable (étant donné qu'elle opère dans différentes zones géographiques). Si un hub de clés échoue, l'ensemble de la région peut potentiellement perdre l'accès aux produits. | Identifiez les gatekeepers , c'est-à-dire les personnes essentielles pour relier les réseaux logistiques. |
Ghost Networks | Les réseaux de fraudeurs utilisent de faux profils et des adresses partagées pour coordonner les vols et gonfler les notes. | Exposer les îles isolées : groupes hyperconnectés sans lien avec la communauté légitime. |
Paradoxe du choix | Le moteur de suggestions/recommandations actuel est rudimentaire, générique et souvent ignoré (par exemple, "Les clients qui ont acheté cet article ont également acheté…"). | Créez des jumeaux comportementaux, c'est-à-dire des recommandations basées sur des habitudes de livraison et des cercles sociaux similaires. |
Mappez les défis commerciaux à une stratégie technique (lignes → relations).
Dans une base de données traditionnelle, les données sont stockées dans des silos isolés : les clients dans une table, les transactions dans une autre et les livraisons dans une troisième. Si SQL est idéal pour répondre à la question "Qui a acheté quoi ?", il a du mal à répondre aux questions basées sur le réseau.
Pour relever ces défis, la stratégie technique consiste à changer de perspective :
- Vue relationnelle (le "quoi") : chaque client est traité comme une ligne isolée. Pour établir un lien entre un client et l'achat d'un ami, il faut effectuer plusieurs "jointures" complexes, qui deviennent exponentiellement plus lentes à mesure que le réseau se développe.
- Vue Graphique (le "comment") : les relations sont traitées comme des éléments de première classe. Au lieu de parcourir des listes, nous naviguons sur une carte. Nous pouvons voir instantanément que le client A est associé au client B, qui livre à l'adresse Z.
Examen détaillé des exigences
Les architectes de solutions concluent que les exigences commerciales et la stratégie technique nécessitent une approche multimodèle, et identifient les exigences clés suivantes.
Comment Cloud Spanner répond à ces exigences techniques
Cloud Spanner est choisi comme cœur de cette transformation. Il permet au Client de conserver sa base relationnelle solide tout en débloquant des insights graphiques détaillés.
Voici un bref aperçu de la façon dont Cloud Spanner répond aux exigences techniques et plus encore.
De plus, Cloud Spanner fournit une architecture technique évolutive.
2. Configurer l'infrastructure de données
Après l'analyse de rentabilité, nous passons à la phase d'implémentation. Dans cette section, nous définissons notre architecture de données, explorons les limites du modèle relationnel traditionnel et présentons le graphique de propriétés comme outil principal pour découvrir des insights approfondis.
Configurer une instance Cloud Spanner Enterprise
Étape 1 : Activez l'API Cloud Spanner
Dans la console Google Cloud, cliquez sur l'icône de menu en haut à gauche de l'écran pour afficher le menu de navigation de gauche. Faites défiler la page vers le bas et sélectionnez "Spanner", ou recherchez "Spanner".
L'interface utilisateur Cloud Spanner devrait maintenant s'afficher. Si vous utilisez un projet pour lequel l'API Cloud Spanner n'est pas encore activée, une boîte de dialogue vous demandant de l'activer s'affiche. Si vous avez déjà activé l'API, vous pouvez ignorer cette étape.
Cliquez sur Activer pour continuer :
Étape 2 : Créer une instance Cloud Spanner
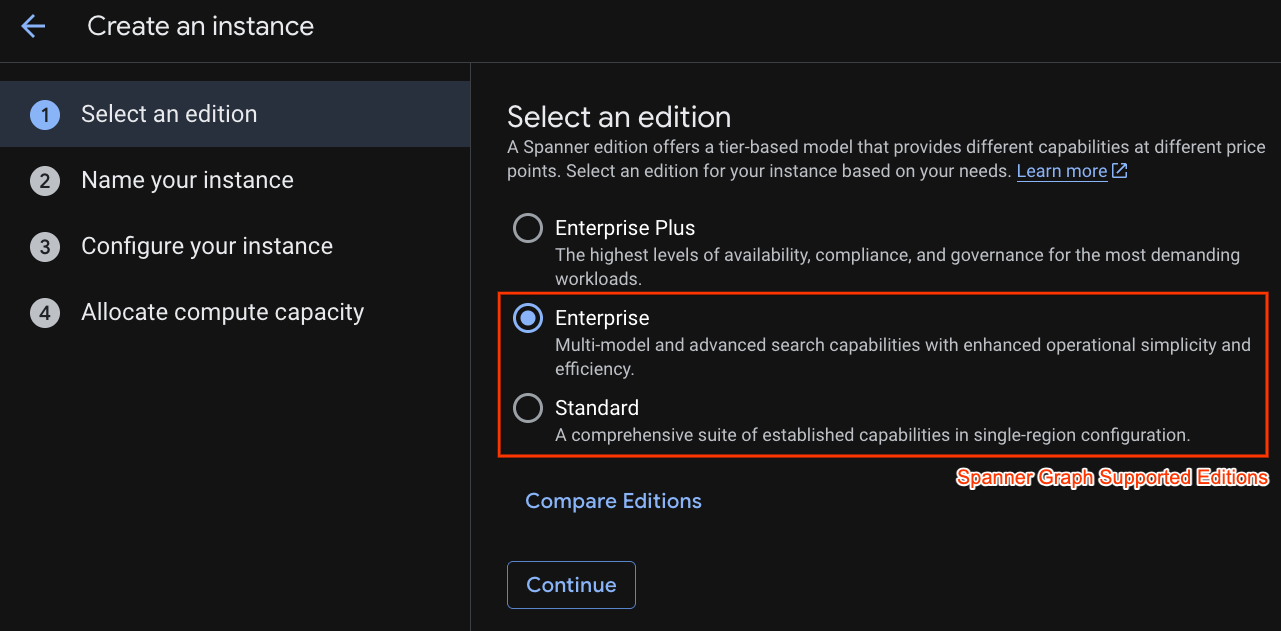
Vous allez d'abord créer une instance Cloud Spanner. Dans l'UI, cliquez sur Créer une instance provisionnée pour créer une instance.
Lors de la première étape, vous devez sélectionner une édition. Notez que vous pourrez également passer à une édition supérieure ultérieurement. Pour utiliser les fonctionnalités multimodes (Spanner Graph), vous pouvez choisir l'édition Enterprise.
Nommer votre instance
Sélectionnez une configuration de déploiement et une région de votre choix.
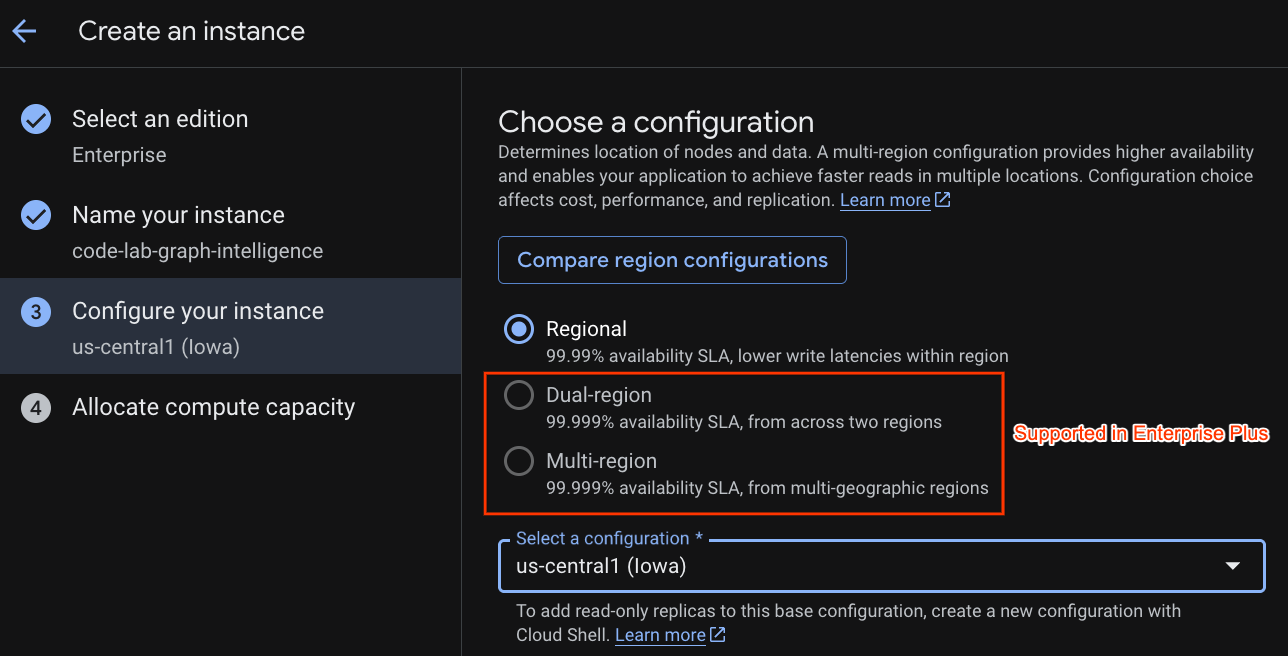
Vous pouvez également comparer différentes options de configuration. Par exemple, la configuration du déploiement comporte au minimum 3 réplicas en lecture/écriture dans 3 zones distinctes de la région sélectionnée. Autrement dit, même si vous optez pour un déploiement à nœud unique, vous disposez de 3 copies grâce aux 3 réplicas en lecture/écriture. De plus, même avec une configuration de déploiement régional, vous pouvez étendre davantage votre déploiement en ajoutant des répliques en lecture seule supplémentaires à votre topologie de déploiement.
Une fois la capacité configurée, vous pouvez commencer par un nœud complet et un autoscaling au niveau des nœuds, ou utiliser une instance précise (unités de traitement ; 1 000 UT = 1 nœud). Vous pouvez également définir des cibles d'autoscaling pour les instances. Pour les charges de travail à faible latence, nous recommandons 65% pour les instances régionales et 45% pour les instances multirégionales.
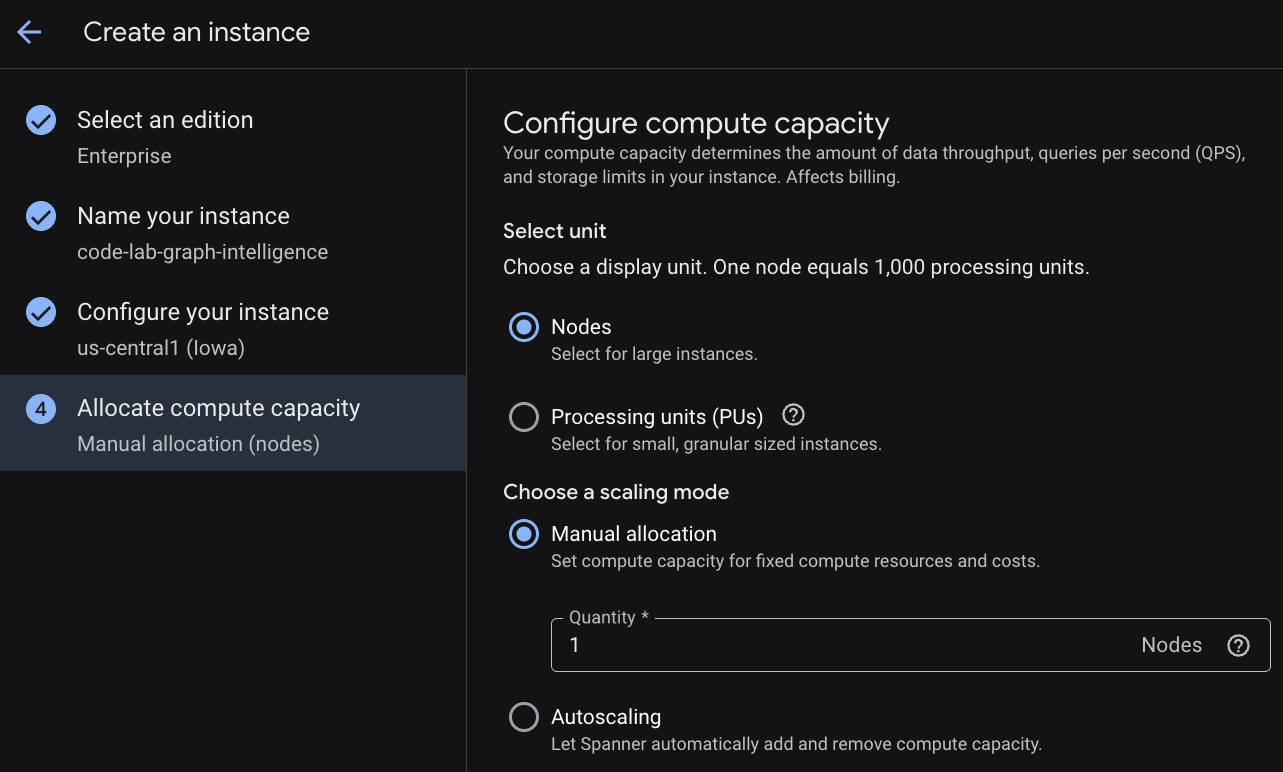
Étape 3 : Créez une base de données
Une fois votre instance provisionnée, cliquez sur "Create Database" (Créer une base de données) pour créer une base de données pour le reste de votre atelier de programmation.
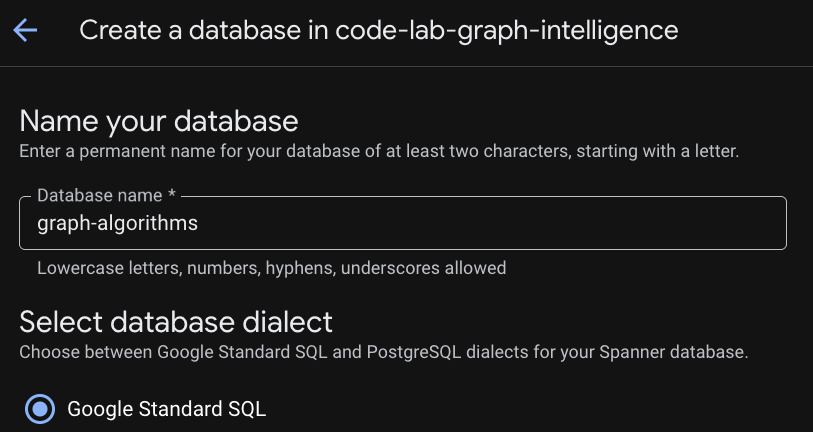
Configurer une base relationnelle
Notre parcours commence avec les tables principales qui stockent les données opérationnelles. Dans Cloud Spanner, nous utilisons l'entrelacement pour colocaliser physiquement les données associées, comme les amitiés et les transactions d'un client, directement avec l'enregistrement du client. Cela garantit un accès hautes performances et une proximité physique.
LDD : créer les tables
Copiez et exécutez les blocs suivants pour établir votre schéma relationnel :
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Lancement du réseau
Une fois nos tables prêtes, nous devons les remplir avec les utilisateurs, les produits et les connexions qui définissent l'écosystème du client.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Défi relationnel
Avant de présenter le graphique, voyons comment le SQL traditionnel gère les défis du client. Exécutez cette requête pour trouver les clients "Dépensiers sociaux", qui dépensent beaucoup et ont plusieurs amis.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Limites de l'approche relationnelle
Surmonter les difficultés relationnelles grâce à un graphique de propriétés
Pour surmonter ces limites, nous définissons un graphique de propriété. Cela crée une "couche" qui nous permet de traiter les relations comme des éléments à part entière sans déplacer nos données hors de Spanner.
LDD : créer le Property Graph
Ce DDL définit nos nœuds (entités) et nos arêtes (relations). Dans cet exemple, nous suivons un graphique schématisé. Toutefois, Spanner Graph permet de modéliser des graphiques sans schéma pour permettre un développement itératif flexible et rapide, et pour gérer les modèles de données évolutifs sans modifications constantes du LDD (langage de définition de données).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Parcourir le graphique avec GQL
Maintenant que notre graphique est défini, nous pouvons utiliser le Graph Query Language (GQL) pour effectuer des traversées multi-sauts avec une syntaxe simple et lisible.
Exploration 1 : Découverte collaborative
Cette requête parcourt le graphique pour trouver les produits achetés par vos amis et sert de base à un moteur de recommandation.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Exploration 2 : Requête hybride (relationnelle + graphique)
Spanner vous permet d'intégrer des modèles GQL dans une clause FROM SQL standard à l'aide de la fonction GRAPH_TABLE. Cette requête trouve les clients qui vivent au même endroit que leurs amis (correspondance de modèle "diamant").
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Visualiser les connexions des clients
Enfin, utilisons GQL pour visualiser notre réseau. Ces requêtes encapsulent les résultats du chemin dans SAFE_TO_JSON, ce qui permet aux outils de visualisation de dessiner les nœuds et les lignes.
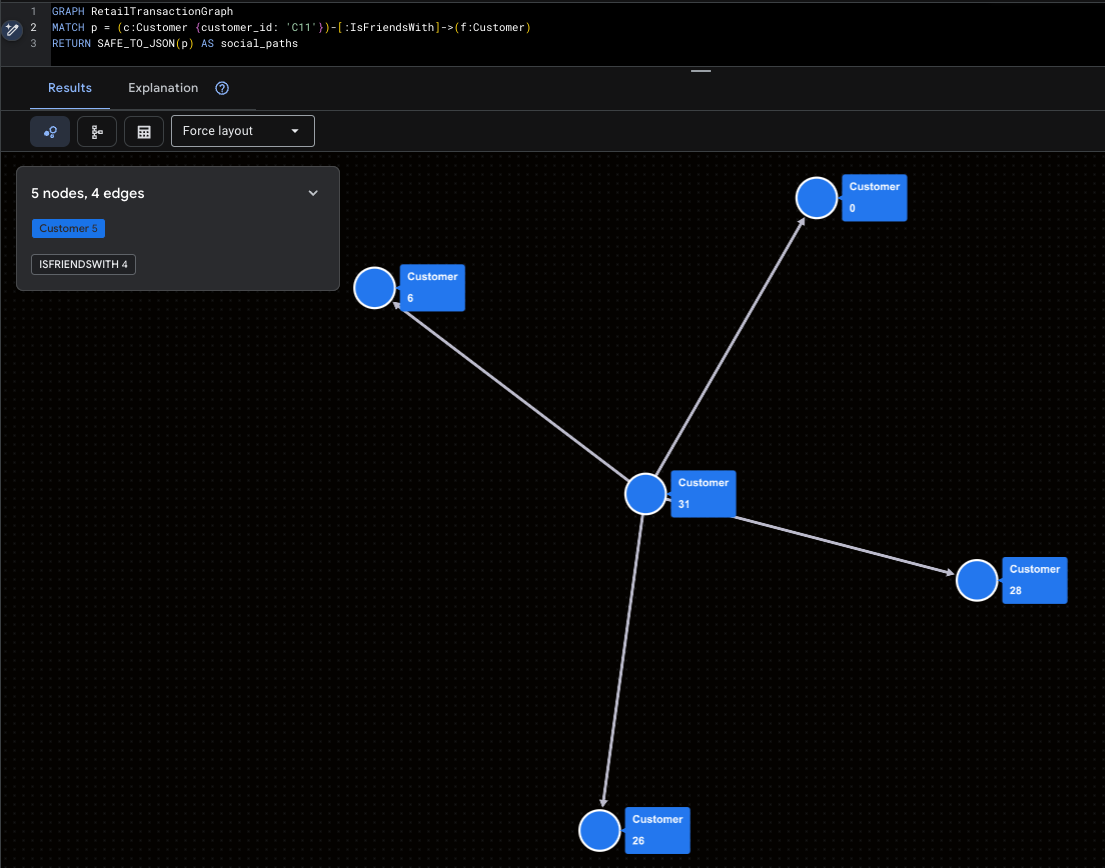
Visualiser le super-influenceur
Cette image met en avant Mallory (C11) et sa couverture directe sur les réseaux sociaux.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Visualiser les schémas de fraude potentiels
Cette requête permet de trouver le cluster isolé (Ivan et Judy) pour voir où leurs produits sont expédiés.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Présentation des algorithmes Spanner Graph
Pour vous préparer à notre présentation détaillée de l'intelligence des graphes, cette section décrit l'architecture technique et les règles de base des algorithmes Spanner Graph Cloud. Comprendre ces principes est essentiel pour passer de simples traversées à l'analyse de relations à l'échelle du pétaoctet.
Portefeuille d'algorithmes
Cloud Spanner est actuellement compatible avec 14 algorithmes de graphes standards, classés en quatre groupes fonctionnels pour résoudre divers problèmes commerciaux :
Catégorie | Algorithmes compatibles | Cas d'utilisation pour les entreprises |
Centralité | PageRank, PageRank personnalisé, Betweenness, Closeness | Identifiez les influenceurs, les hubs et les goulots d'étranglement. |
Communauté | WCC, propagation des libellés, recherche de cliques, clustering par corrélation | Détectez les réseaux de fraude, les communautés sociales et les silos. |
Similarité | Jaccard, Cosinus, Voisins communs, Nombre total de voisins | Alimentez les moteurs de recommandations et la résolution d'entités. |
Recherche de chemin | Chemin le plus court d'un ensemble à un autre, assistants de chemin GA | Optimisez la logistique et la proximité de traversée. |
Points essentiels à prendre en compte concernant le schéma et les requêtes
Pour garantir l'exécution efficace des algorithmes de graphiques, Spanner Graph doit respecter les règles suivantes :
Exigence 1. Localité physique des données (entrelacement)
L'exigence la plus critique pour le parcours de graphe hautes performances est l'entrelacement. Cela garantit que les données de périphérie sont physiquement stockées sur la même partition de serveur que le nœud source, ce qui minimise la latence du réseau lors de l'exécution de l'algorithme.
- Règle : les tables d'arêtes DOIVENT être entrelacées dans leurs tables de nœuds sources.
- Parcours avant : l'entrelacement de la table des arêtes dans la table des nœuds sources assure la localité du cache pour les liens sortants.
- Parcours inverse : pour une analyse efficace des liens "entrants", utilisez des clés étrangères pour créer automatiquement des index de soutien ou créez un index secondaire entrelacé dans la table de destination.
Exigence 2. Exigences uniques concernant les libellés
Chaque table participant au graphique de propriétés doit avoir une identité unique. Les algorithmes s'appuient sur ces libellés pour identifier et charger correctement les sous-graphiques qu'ils doivent analyser.
- Règle : chaque table d'entrée doit comporter un libellé d'identification unique dans le graphique de propriétés.
- Le conflit : vous ne pouvez pas mapper un seul libellé à plusieurs tables si vous prévoyez d'exécuter des algorithmes sur celles-ci.
Logique | Exemple | Résultat |
❌ Mauvaise | TABLES DE NŒUDS (entité LABEL Personne, entité LABEL Compte) | Non valide : l'algorithme ne peut pas faire la différence entre une personne et un compte. |
✅ Bonne | TABLES DE NŒUDS (Person LABEL Customer, Account LABEL Account) | Valide : chaque entité possède un libellé unique et distinct. |
Exigence 3. Structure des requêtes d'algorithme (clause MATCH)
Lorsque vous appelez un algorithme, la clause MATCH suit des règles plus restrictives que les requêtes GQL standards pour s'assurer que le moteur d'exécution peut optimiser le pipeline analytique.
- Un format par MATCH : chaque instruction MATCH ne peut nommer qu'une seule variable.
- Aucun modèle multi-nœuds : vous ne pouvez pas définir de modèle de relation (par exemple, (a)-[e]->(b)) directement dans une clause MATCH destinée à un appel d'algorithme.
- Filtres littéraux uniquement : vous pouvez utiliser des clauses WHERE pour filtrer les nœuds (par exemple, WHERE a.id > 400), mais les paramètres de requête (@param) ne sont pas compatibles avec les requêtes d'algorithme de graphique pour le moment.
Exigence 4 : Clause RETURN (scalaires uniquement)
Dans une requête d'algorithme, la clause RETURN sert de passerelle entre le monde des graphiques et celui des relations. Elle est strictement limitée au renvoi de scalaires et de constantes.
- Règle : vous ne pouvez pas renvoyer un "élément de graphique" (le nœud ou l'objet d'arête bruts).
- Aucune transformation : vous ne pouvez pas effectuer d'opérations mathématiques ni appliquer de fonctions aux propriétés renvoyées dans l'instruction RETURN elle-même.
Restrictions de la clause RETURN
✅ Compatible | ❌ Non compatible |
RETURN node.id, score | Nœud RETURN, score (impossible de renvoyer l'élément Graph) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (No operations on properties) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (aucune fonction) |
Exigence 5. Intégrité des données : éliminer les arêtes isolées
Une "arête orpheline" se produit lorsqu'une arête pointe vers un nœud de destination qui n'existe pas dans le graphique. L'exécution de l'algorithme échoue, car la structure du graphique est incohérente.
- Solution : utilisez des contraintes référentielles (clés étrangères) et ON DELETE CASCADE pour préserver l'intégrité du graphique.
- Sécurité des requêtes : lorsque vous appelez un algorithme, vous devez vous assurer que tous les nœuds auxquels font référence les arêtes sélectionnées sont également inclus dans l'argument "node_labels".
Options d'EXPORT DATA pour la sortie persistante
Étant donné que les algorithmes de graphiques nécessitent beaucoup de calculs, ils sont exécutés en mode d'exécution scale-up à l'aide de l'instruction EXPORT DATA. Cette fonctionnalité utilise Data Boost, qui emploie des ressources de calcul sans serveur indépendantes pour éviter tout décalage dans vos transactions de production.
Option 1 : Faire persister les données dans Cloud Spanner
Pour renvoyer directement les résultats dans vos tables (par exemple, pour enregistrer un score PageRank), utilisez format = "CLOUD_SPANNER".
update_ignore_all: ne met à jour que les lignes dont les clés existent déjà dans la table cible.upsert_ignore_all: met à jour les lignes existantes ou insère de nouvelles lignes si les clés sont manquantes.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Option 2 : Persister les résultats dans Google Cloud Storage (GCS)
Pour une analyse hors connexion à grande échelle, vous pouvez exporter les données vers GCS aux formats CSV, Avro ou Parquet.
- Caractères génériques : utilisez
uri => 'gs://bucket/file_*.csv'pour activer la sortie fragmentée, ce qui permet à Spanner d'écrire dans plusieurs fichiers en parallèle pour les ensembles de données volumineux. - Compression : compatible avec GZIP, SNAPPY et ZSTD pour optimiser les coûts de stockage.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Défi 1 : Écart d'influence (PageRank)
Dans cette section, nous abordons le premier obstacle commercial du client : le manque d'influence. Nous allons passer d'un simple "concours de popularité" à une carte mathématique de la véritable influence sociale.
Énoncé du problème : l'équipe marketing du client rencontre un problème. Ils dépensent des millions dans des campagnes publicitaires à grande échelle dont le retour sur investissement diminue, car ils ne parviennent pas à identifier les "superstars des réseaux sociaux", ces rares personnes dont les recommandations se propagent dans tout le réseau.
Pour résoudre ce problème, nous devons classer nos clients par influence.
Solution relationnelle (centralité de degré)
Dans une base de données standard, le moyen le plus simple de trouver un influenceur est de compter simplement ses abonnés (une métrique appelée centralité de degré).
Exécutez cette requête pour trouver les utilisateurs les plus "populaires" :
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Intelligence des graphiques (PageRank)
Pour identifier les véritables leaders, nous utilisons le PageRank. Il s'agit du même algorithme qui alimentait les premières recherches sur le Web. Il mesure l'importance d'un nœud en fonction de la quantité ET de la qualité des liens entrants.
- Modèle Random Surfer : PageRank simule un utilisateur se déplaçant dans le graphique. Le facteur d'amortissement (0,85 par défaut) représente la probabilité que l'utilisateur continue de cliquer.Sinon, il est "téléporté" vers un nœud aléatoire .
- Pouvoir d'association : un lien provenant d'une personne influente (comme Mallory) a beaucoup plus de valeur qu'un lien provenant d'une personne sans autre lien.
Nous allons exécuter l'algorithme PageRank et utiliser EXPORT DATA pour enregistrer les résultats directement dans notre colonne "pagerank_score".
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Tableau de bord"Influence" utilisant PageRank
Maintenant que les scores sont conservés, comparons notre "Avant " (nombre d'abonnés) avec notre "Après" (score PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0,0547891818 |
C3 | charlie@example.com | 1 | 0,0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
Analyse : qui sont les vraies superstars ?
En analysant les résultats, vous pouvez désormais faire trois découvertes marketing essentielles :
À retenir pour votre entreprise
Au lieu d'envoyer des e-mails à tous les utilisateurs ayant plus de cinq abonnés, l'équipe marketing de The Customer peut désormais se concentrer exclusivement sur ceux qui ont le pagerank_score le plus élevé. Ces personnes sont de véritables "stars des réseaux sociaux" capables de générer une viralité systémique sur l'ensemble de la place de marché.
Essayons maintenant d'identifier les responsables qui assurent le bon fonctionnement du réseau logistique du client.
5. Défi 2 : Résilience logistique (BetweennessCentrality)
Dans cette section, nous abordons la résilience logistique. Nous ne nous contenterons plus de mesurer le succès en termes de "volume", mais nous identifierons les "gatekeepers" essentiels qui maintiennent le réseau connecté.
Solution relationnelle (analyse basée sur le volume)
Dans une configuration relationnelle standard, un centre de distribution "critique" est généralement défini comme celui qui traite le plus de commandes ou génère le plus de revenus.
Exécutez cette requête pour identifier les hubs "les plus performants" en fonction du nombre de transactions :
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
New York | USA | 4 | 3996 |
Berlin | Allemagne | 2 | 345 |
San Francisco | USA | 2 | 750 |
Pour résoudre cette incohérence, nous allons utiliser les arêtes IsFriendsWith et LivesAt. Cela transforme notre analyse, qui passe d'un hub de transactions à un hub incluant également le contrôle social.
Graph Intelligence (centralité d'intermédiarité)
Pour identifier les véritables goulots d'étranglement, nous utilisons la centralité d'intermédiarité. Cet algorithme quantifie la fréquence à laquelle un nœud sert de "pont" sur les chemins les plus courts entre toutes les autres paires de nœuds du graphique. Les scores élevés identifient les véritables responsables qui contrôlent le flux de marchandises ou d'informations.
Exécuter et conserver la centralité d'intermédiarité
Nous allons exécuter l'algorithme à l'aide de EXPORT DATA et enregistrer les scores dans la colonne "centrality_score". Nous utilisons Data Boost pour nous assurer que ce calcul intensif du "chemin le plus court" n'a quasiment aucun impact sur les opérations en direct du Client.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analyse : identifier les "goulots d'étranglement cachés"
Nous comparons maintenant notre risque structurel (centrality_score) à notre volume transactionnel (order_count) pour identifier les nœuds qui devraient inquiéter la direction de l'entreprise.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
En analysant ces résultats, le client fait trois découvertes surprenantes :
Points à retenir pour votre entreprise
Le client peut désormais hiérarchiser ses protocoles de redondance et de sécurité logistiques en fonction du risque structurel multimodal. Paul, Alice et Ève sont les responsables de l'accès qui doivent être protégés pour assurer la stabilité du réseau logistique.
Essayons maintenant d'isoler les zones de fraude.
6. Problème 3 : Réseaux fantômes (WCC)
Dans cette section, nous abordons le troisième obstacle commercial : les réseaux fantômes. Nous passerons de la simple détection de "points chauds" à la découverte de réseaux de fraude sophistiqués et isolés à l'aide de la détection de communautés. Le problème est que les personnes malintentionnées créent de faux profils qui partagent des adresses de livraison ou interagissent en boucle fermée pour coordonner des vols et gonfler les notes des produits. Mais ils sont souvent complètement isolés de la communauté légitime The Customer.
Pour résoudre ce problème, nous devons exposer ces îles isolées.
Solution relationnelle (recherche par identifiant partagé)
Sans algorithmes de graphiques, la méthode standard pour détecter la fraude consiste à rechercher des "points chauds" de données partagées, par exemple plusieurs clients qui se font livrer à la même adresse exacte .
Exécutez cette requête pour trouver les clients associés par une adresse de livraison commune :
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Pour identifier les réseaux de fraude, nous devons comprendre la transitivité.
Graph Intelligence (composantes faiblement connexes)
Pour trouver l'étendue complète de ces anneaux, nous utilisons les composantes faiblement connexes. WCC est un algorithme de clustering qui identifie les ensembles de nœuds pour lesquels un chemin existe entre deux nœuds, quelle que soit la direction des arêtes.
- Zones de couverture : elles divisent efficacement le graphique en "îles" ou "zones de couverture".
- Vue unifiée des entités : en analysant simultanément les liens sociaux (IsFriendsWith) et logistiques (LivesAt), nous pouvons regrouper les profils fragmentés dans un seul "cluster d'impact" unifié.
Exécuter et conserver WCC
Nous allons exécuter l'algorithme WCC et enregistrer les résultats dans la colonne "community_id". Nous utilisons Data Boost pour nous assurer que cette analyse approfondie de l'accessibilité se produit sur des ressources de calcul indépendantes.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analyse : réseaux de fraude
Exécutons maintenant une requête de validation pour afficher nos communautés isolées. Les utilisateurs légitimes appartiennent généralement à la "Terre ferme", tandis que les fraudeurs sont souvent bloqués sur de petites "Îles".
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | membres |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
En exécutant cette détection de communauté, vous pouvez identifier une anomalie critique :
Points à retenir pour votre entreprise
Le client peut désormais automatiser ses réponses de sécurité. Au lieu de rechercher manuellement les comptes individuels, ils peuvent écrire une règle simple : "Si un community_id compte moins de trois membres, signalez l'ensemble du groupe pour un examen manuel KYC (Know Your Customer)".
.
Maintenant que nous avons identifié les réseaux de fraude, nous pouvons résoudre le problème du "jumeau comportemental".
7. Défi 4 : Jumeau comportemental (JaccardSimilarity)
Dans ce dernier défi, nous abordons le quatrième obstacle : le paradoxe du choix/jumeau comportemental. Nous allons passer de listes génériques "Fréquemment achetés ensemble" à des recommandations ultra-personnalisées basées sur les "empreintes digitales" comportementales.
Les suggestions de produits actuelles du client sont trop génériques. Recommander un câble USB populaire à chaque client est une solution sûre, mais pas personnalisée. Le client souhaite créer des recommandations de jumeaux comportementaux pour identifier les clients qui partagent des habitudes de livraison et des cercles sociaux uniques afin de suggérer des produits avec une correspondance de haute précision.
Pour résoudre ce problème, nous devons calculer la proximité entre les utilisateurs.
Solution relationnelle (chevauchement absolu)
Dans une configuration relationnelle standard, vous pouvez rechercher des personnes qui se font livrer à la même adresse qu'un utilisateur de référence, comme Alice (C1).
Exécutez cette requête pour trouver les voisins géographiques d'Alice :
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (similarité de Jaccard)
Pour trouver de véritables jumeaux comportementaux, nous utilisons la similarité de Jaccard. Cet algorithme calcule un score normalisé (de 0,0 à 1,0) en divisant le nombre de voisins partagés (intersection) par le nombre total de voisins uniques (union).
Ici, un "jumeau comportemental" est défini par plus qu'une simple adresse de livraison partagée. En analysant l'intersection des empreintes physiques (LivesAt) et des écosystèmes sociaux (IsFriendsWith), nous pouvons identifier les utilisateurs qui partagent le même mode de vie et la même influence communautaire, ce qui permet de générer des recommandations de produits beaucoup plus précises.
Créez d'abord une table de mappage.
Étant donné que la similarité est une relation par paire (le client A est similaire au client B), nous créons une table entrelacée dédiée dans Customer pour stocker ces mappages.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Exécuter la similarité de Jaccard
Nous allons maintenant exécuter l'algorithme. Remarque : Cette requête inclut une leçon courante sur les garde-fous. Si vous ne sélectionnez que des nœuds "Customer" (Client), mais que vous utilisez l'arête "LivesAt" (Réside à) (qui pointe vers des nœuds "Shipping" (Livraison)), la requête échouera et affichera un message "Dangling Edge" (Arête isolée). Pour résoudre ce problème, nous devons inclure les deux libellés de nœud.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analyse : vérification des jumeaux comportementaux
Maintenant que le job analytique est terminé, nous exécutons une requête de validation. En associant notre nouvelle table de mappage (CustomerSimilarity) à nos métadonnées Customer d'origine, nous pouvons identifier précisément les "jumeaux comportementaux" d'Alice.
Exécutez cette requête pour inspecter les classements de similarité d'Alice :
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0,0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0,0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Éléments à rechercher dans les résultats :
Essayons maintenant de créer une vue Unified Intelligence finale.
8. Unified Intelligence
Nous allons maintenant passer des tâches techniques individuelles à l'intelligence unifiée. Nous y combinons les données transactionnelles avec les quatre algorithmes de graphiques pour fournir des insights clairs et exploitables.
Rapport 1 : Unified Intelligence
La puissance d'une base de données multimodèle comme Spanner réside dans sa capacité à joindre les données relationnelles sur les dépenses aux scores d'influence, de risque et de similarité dérivés des graphes dans une seule requête. Cette requête classe chaque client dans une persona d'entreprise spécifique.
Exécutez la requête Unified Intelligence pour afficher l'écosystème complet :
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | dépenses | influence | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 CRITIQUE : Pont réseau |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 CRITIQUE : Pont réseau |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 CRITIQUE : Pont réseau |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 RÉSEAUX SOCIAUX : influenceur à forte couverture |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 RÉSEAUX SOCIAUX : influenceur à forte couverture |
C3 | charlie@example.com | 0 | 0,0547891818 | 6 | 0 | 🟢 STANDARD : client actif |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD : client actif |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RISQUE ÉLEVÉ : réseau de fraude isolé |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RISQUE ÉLEVÉ : réseau de fraude isolé |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDARD : client actif |
C2 | bob@example.com | 999 | 0,0547891818 | 0 | 0 | 🟢 STANDARD : client actif |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD : client actif |
En combinant ces perspectives mathématiques, nous passons de "qui a dépensé le plus" à "qui compte le plus". Le tableau de bord unifié intègre des données transactionnelles relationnelles à l'intelligence graphique multimodale pour classer votre écosystème en trois personas clairs et exploitables.
"Ponts réseau critiques" (résilience)
Les nœuds tels que Mallory (C11), Ève (C5) et Alice (C1) sont signalés, car leur bottleneck_risk (centralité d'intermédiarité) est > 25.
- Ancres structurelles : Mallory présente le score de risque le plus élevé (44,5), ce qui fait d'elle la principale passerelle pour l'ensemble du réseau.
- Le paradoxe des dépenses nulles : Eve (C5) a un nombre de commandes nul, mais elle est structurellement indispensable avec un score de risque de 35,5. Le SQL standard l'aurait complètement ignorée, mais l'intelligence graphique révèle qu'elle est un lien essentiel vers toute une sous-communauté.
- Le gateway à forte valeur : Alice (C1) a obtenu 35,5, à égalité avec Eve, ce qui prouve que les gros dépensiers peuvent également être des ancres structurelles essentielles.
Superstars des réseaux sociaux (couverture)
Heidi (C8) et Grace (C7) sont identifiées comme des influenceuses à large couverture en raison de leur score PageRank .
"Réseau de fraude isolé" (anomalies)
Judy (C10) et Ivan (C9) sont signalés, car ils appartiennent à la communauté isolée 1.
Transformer les insights commerciaux en actions stratégiques
Personna | Métrique clé | Insight sur l'activité | Action stratégique |
🔵 Ponts réseau | Centralité élevée | Ancres structurelles : Eve (C5) et Mallory (C11) maintiennent le réseau. | Rétention : protégez ces gardiens pour éviter la fragmentation de la communauté. |
📱 Superstars des réseaux sociaux | PageRank élevé | Moteurs viraux : les utilisateurs comme Heidi (C8) ont la plus grande couverture dans leurs cercles. | Marketing : à utiliser pour les programmes de recommandation et d'ambassadeurs à fort impact. |
🔴 Risques de fraude | WCC isolé | Réseaux fantômes : Judy (C10) et Ivan (C9) sont de gros dépensiers, mais vivent sur des "îles". | Sécurité : examen KYC manuel immédiat. Il s'agit de signatures de fraude classiques. |
🟢 Utilisateurs standards | Scores équilibrés | Healthy Core : la majorité du réseau, y compris les ponts "locaux" comme David (C4). | Croissance : appliquez les recommandations standards concernant les annonces personnalisées et les jumeaux comportementaux. |
Rapport 2 : Rapport sur les anomalies d'identité
Vous devez maintenant déterminer si des comptes légitimes sont "imités" par des fraudeurs. Pour résoudre ce problème, nous pouvons rechercher les utilisateurs qui présentent une similarité comportementale de 100%, mais aucune connexion sociale.
Exécutez cette requête pour signaler les potentielles "anomalies d'identité" :
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Le rapport "Identifier les anomalies" fournit des informations essentielles. En isolant les utilisateurs qui agissent comme des clients légitimes, mais qui n'ont pas de liens sociaux, nous passons de la supposition à la certitude mathématique .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Analyse des résultats
En unifiant la similarité (Jaccard) avec la détection de communauté (WCC), nous exposons les risques cachés que les données transactionnelles traditionnelles ne peuvent pas voir.
- Jumeaux comportementaux (proximité) : les nœuds tels que Judy (C10) et Ivan (C9) sont signalés, car ils partagent un score de similarité Jaccard de 0,20 par rapport à Alice (C1).
- Comportement d'isolement : Judy (C10) et Ivan (C9) sont regroupés dans la community_id 1 isolée, tandis qu'Alice appartient à la communauté sociale "Mainland" (communauté 0).
- Indicateurs de fraude : le rapport identifie les utilisateurs présentant un fort chevauchement comportemental (> 0,9) qui restent socialement déconnectés du réseau principal.
9. Félicitations et récapitulatif
Cet atelier montre comment Cloud Spanner transforme une base de données relationnelle en un outil multimode puissant. En appliquant l'intelligence des graphiques à The Customer, nous sommes passés de données statiques à une stratégie commerciale exploitable.
Avantages de Spanner Multi-Model
- Architecture unifiée : Spanner vous permet de conserver une base relationnelle solide tout en "superposant" instantanément un graphique de propriétés pour l'exploration des relations, sans les risques et le décalage de l'ETL.
- Isolation analytique hors boîte : en tirant parti de Data Boost, vous pouvez exécuter des algorithmes gourmands en mémoire tels que PageRank ou WCC sur des ressources de calcul indépendantes et sans serveur, ce qui garantit un impact nul sur les performances de votre processus de paiement en production.
- Performances d'entrelacement : l'entrelacement unique de Spanner garantit que les nœuds et leurs relations sont colocalisés physiquement, ce qui transforme les traversées globales complexes en recherches locales à grande vitesse.
Identifier les "pépites" et les anomalies
- Identifier la valeur structurelle : les algorithmes de graphiques tels que la centralité d'intermédiarité ont révélé des"ponts cachés" avec zéro dépense, qui peuvent être plus essentiels à la résilience du réseau que les clients qui dépensent le plus.
- Exposer l'imitation comportementale : en combinant la similarité de Jaccard et les composantes faiblement connexes, nous avons identifié les "inconnus sociaux". Ces comptes ressemblent à des clients légitimes, mais il est mathématiquement prouvé qu'ils appartiennent à des réseaux de fraude isolés.
- Vérité globale vs vérité locale : si l'analyse SQL manuelle peut révéler des ponts, les algorithmes globaux peuvent identifier les principaux Gatekeepers du réseau.
Rendre les données intelligentes et exploitables
- Stratégie axée sur les personas : nous avons réussi à transformer nos lignes en relations. En exécutant des algorithmes, nous pouvons résoudre quatre problèmes commerciaux, à savoir les ponts de réseau, les superstars sociales, les risques de fraude et les utilisateurs standards.