
1. מקרה לדוגמה: קמעונאות חכמה
במקרה לדוגמה הזה, נשתמש בלקוח קמעונאי עם זירת מסחר דיגיטלית בצמיחה מהירה. תצוגת הנתונים המסורתית של הלקוח מוגבלת כי היא מציגה מה אנשים קונים, אבל לא איך הם קשורים. הפער הזה מוביל להחמצת הזדמנויות ולעלייה בהונאות. עכשיו הם עוברים לפילוסופיה של Network-First כדי להעריך את הקשרים החברתיים והלוגיסטיים בנוסף לנתוני העסקאות.
אתגרים עסקיים מרכזיים לפתרון
יש ארבע בעיות קריטיות שמחייבות להבין איך הלקוחות והלוגיסטיקה קשורים זה לזה:
אתגר | הבעיה | המטרה |
Influence Gap | פרסום רחב היקף מניב החזר נמוך על ההשקעה. בשלב הזה אי אפשר לזהות את מובילי הטרנדים האמיתיים (משפיענים). | זיהוי משפיענים שהם מרכזיים בקהילה באמצעות הקשר שלהם ברשת מחוברת של לקוחות. |
Logistics Resilience | שרשרת האספקה יכולה להיות פגיעה (בהתחשב בכך שהיא פועלת באזורים גיאוגרפיים שונים). אם יש תקלה במרכז מפתחות אחד, יכול להיות שכל האזור יאבד את הגישה למוצר. | זיהוי שומרי סף – אנשים שחשובים לחיבור בין רשתות לוגיסטיות. |
Ghost Networks | חבורות של נוכלים משתמשות בפרופילים מזויפים ובכתובות משותפות כדי לתאם גניבות ולשפר את הדירוגים. | חשיפה של איים מבודדים; קבוצות שמחוברות זו לזו באופן הדוק ללא קשר לקהילה הלגיטימית. |
פרדוקס הבחירה | מנוע ההצעות וההמלצות הנוכחי הוא בסיסי, גנרי ולעתים קרובות מתעלמים ממנו (לדוגמה, "לקוחות שקנו את המוצר הזה קנו גם את..."). | יצירת תאומים התנהגותיים, כלומר המלצות שמבוססות על דפוסי משלוח דומים ועל מעגלים חברתיים דומים. |
מיפוי אתגרים עסקיים לאסטרטגיה טכנית (שורות ← קשרים)
במסד נתונים מסורתי, הנתונים מאוחסנים בסילואים מבודדים: לקוחות בטבלה אחת, עסקאות בטבלה אחרת ומשלוחים בטבלה שלישית. בעוד ש-SQL מושלם למענה על השאלה "מי קנה מה?", הוא מתקשה לענות על שאלות שמבוססות על רשת.
כדי להתמודד עם האתגרים האלה, האסטרטגיה הטכנית היא לשנות את נקודת המבט הזו:
- התצוגה הרלציונית (ה'מה'): כל לקוח מוצג כשורה נפרדת. כדי למצוא קשר בין לקוח לבין רכישה של חבר שלו, צריך לבצע כמה פעולות מורכבות של צירוף נתונים, והמהירות של הפעולות האלה יורדת באופן משמעותי ככל שהרשת גדלה.
- תצוגת הגרף (ה'איך'): מתייחסת לקשרים כאל ישויות חשובות. במקום לחפש ברשימות, אנחנו מנווטים במפה. אנחנו יכולים לראות באופן מיידי שלקוח א' מחובר ללקוח ב', ששולח למיקום ז'.
בדיקה מעמיקה של הדרישות
אדריכלי פתרונות מגיעים למסקנה שהדרישות העסקיות והאסטרטגיה הטכנית מחייבות גישה מרובת מודלים, ומזהים את הדרישות העיקריות הבאות.
איך Cloud Spanner עומד בדרישות הטכניות האלה
Cloud Spanner נבחר כליבת הטרנספורמציה הזו. הוא מאפשר ללקוח לשמור על בסיס נתונים יחסי אמין, ובו-זמנית לקבל תובנות מפורטות מגרף.
הנה סקירה מהירה של האופן שבו Cloud Spanner עונה על הדרישות הטכניות ועוד.
בנוסף, Cloud Spanner מספק ארכיטקטורה טכנית עמידה לעתיד
2. הגדרה של התשתית לנתונים
אחרי שסיימנו את ניתוח המקרה העסקי, אנחנו עוברים לשלב ההטמעה. בקטע הזה נגדיר את ארכיטקטורת הנתונים שלנו, נסביר מהן המגבלות של המודל הרלציוני המסורתי ונציג את גרף הנכסים ככלי העיקרי שלנו לחשיפת תובנות מעמיקות.
הגדרה של מכונת Cloud Spanner Enterprise
שלב 1: הפעלת Cloud Spanner API
ב-מסוף Google Cloud, לוחצים על סמל התפריט בפינה השמאלית העליונה של המסך כדי לפתוח את תפריט הניווט הימני. גוללים למטה ובוחרים באפשרות Spanner, או לחלופין מחפשים את Spanner.
עכשיו אמור להופיע ממשק המשתמש של Cloud Spanner. אם אתם משתמשים בפרויקט שעדיין לא הופעל בו Cloud Spanner API, יופיע דו-שיח עם בקשה להפעיל אותו. אם כבר הפעלתם את ה-API, אתם יכולים לדלג על השלב הזה.
כדי להמשיך, לוחצים על הפעלה:
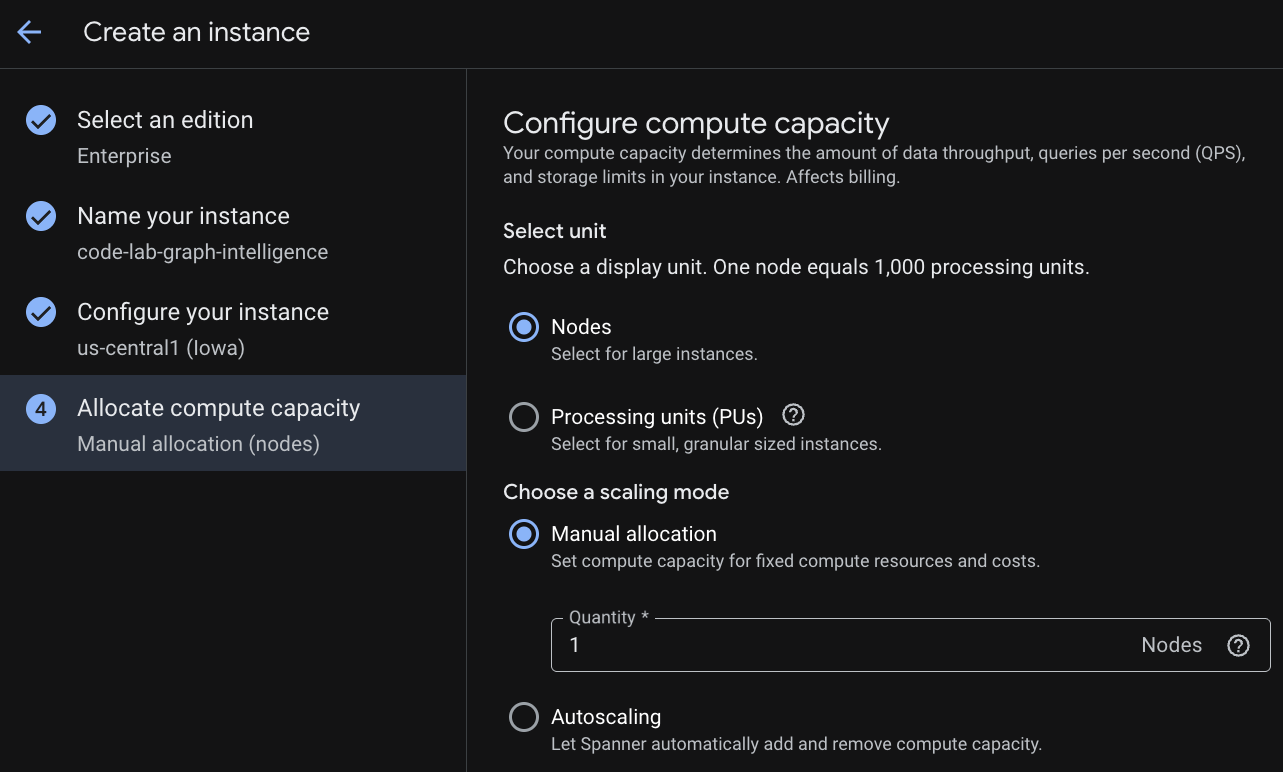
שלב 2: יצירת מופע של Cloud Spanner
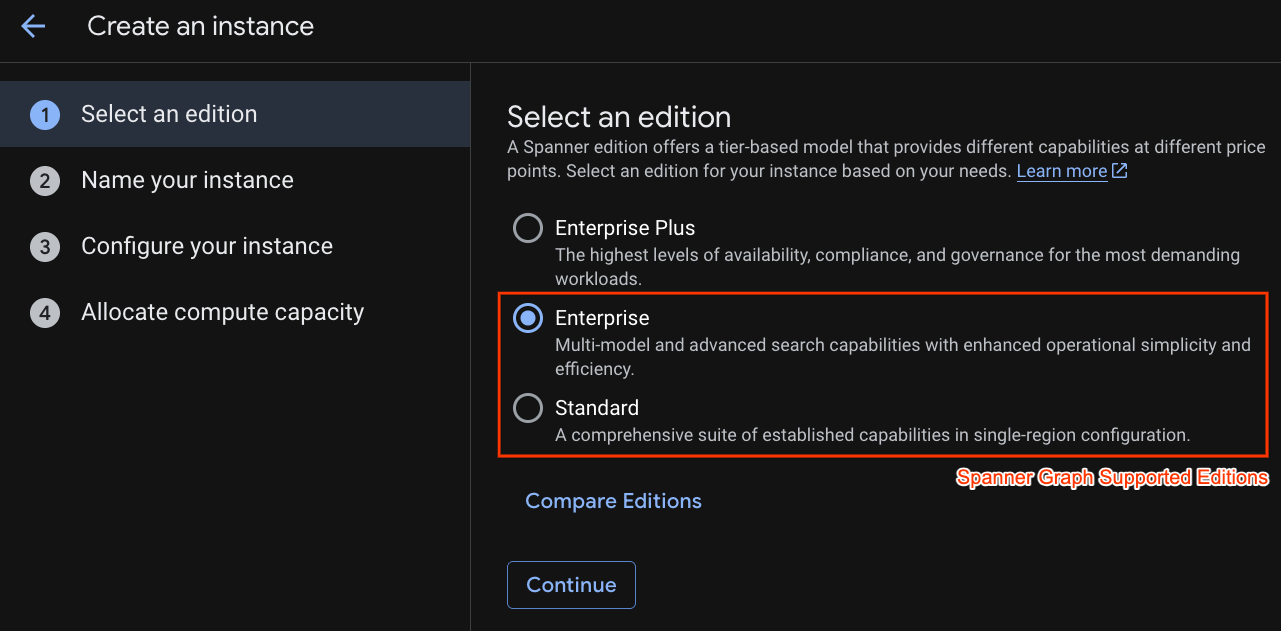
קודם יוצרים מכונת Cloud Spanner. בממשק המשתמש, לוחצים על Create a Provisioned Instance (יצירת מכונה עם הקצאת משאבים) כדי ליצור מכונה חדשה.
בשלב הראשון צריך לבחור מהדורה. שימו לב: אפשר לשדרג את המהדורה גם בשלב מאוחר יותר. כדי להשתמש ביכולות של כמה מודלים (Spanner Graph), אפשר לבחור במהדורת Enterprise.
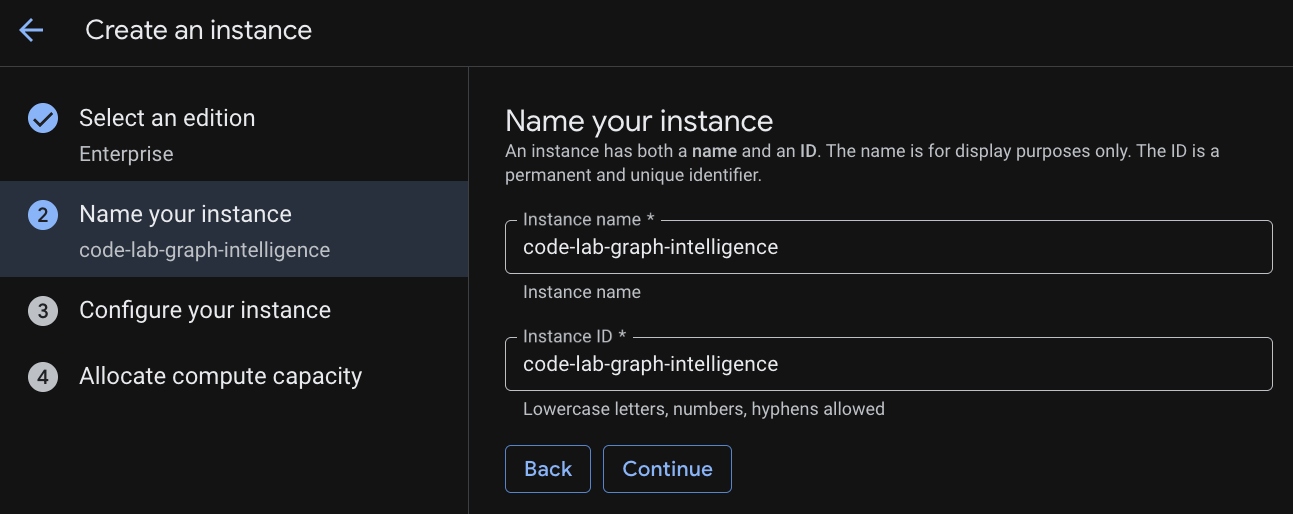
מתן שם למכונה
בוחרים הגדרת פריסה ואזור לבחירה.
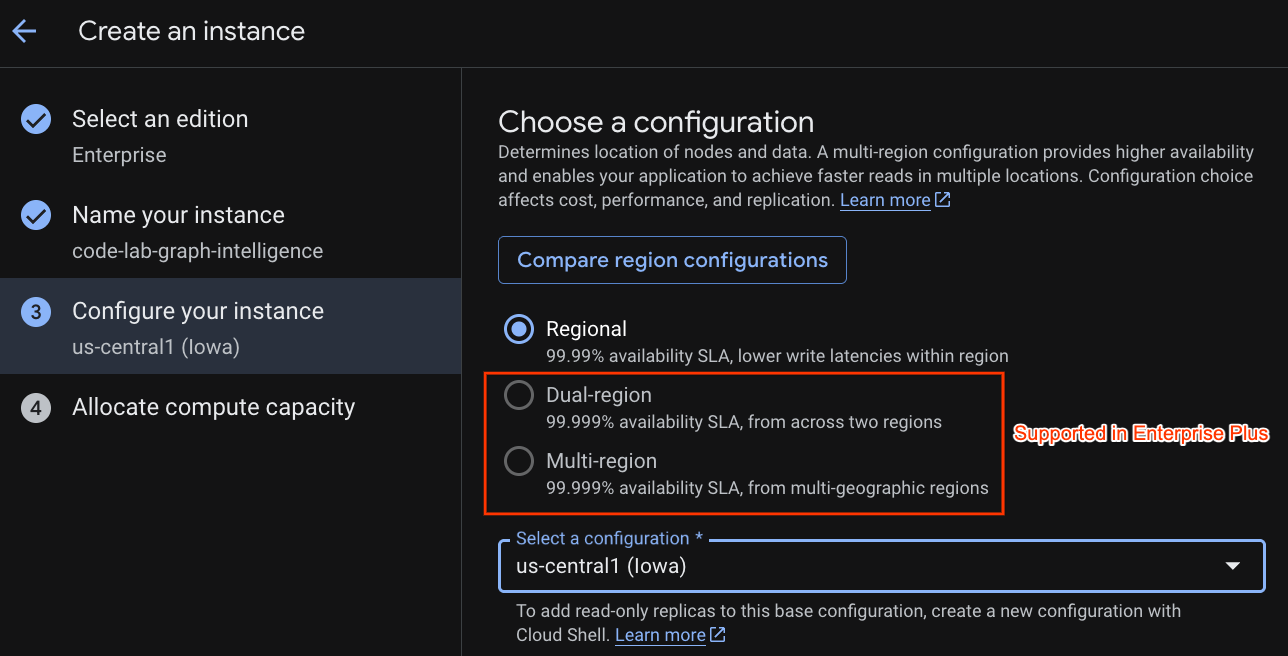
אפשר גם להשוות בין אפשרויות הגדרה שונות. לדוגמה, בהגדרת הפריסה יש לפחות 3 עותקים לקריאה/כתיבה ב-3 אזורים נפרדים באזור שבחרתם. כלומר, גם אם תבחרו בפריסה של צומת יחיד, יהיו לכם 3 עותקים באמצעות 3 עותקים לקריאה/כתיבה. בנוסף, גם בהגדרת פריסה אזורית, אפשר להרחיב את הפריסה על ידי הוספה של עוד עותקים משוכפלים לקריאה בלבד לטופולוגיית הפריסה.
אחרי שמגדירים את הקיבולת, אפשר להתחיל עם צומת מלא והתאמה אוטומטית לעומס בצמתים, או להשתמש במופע גרנולרי (יחידות עיבוד, 1,000 יחידות עיבוד = צומת אחד). אפשר גם להגדיר יעדים של שינוי גודל אוטומטי של מופע. לסביבות עבודה עם השהיה נמוכה, מומלץ להגדיר 65% למופעים אזוריים ו-45% למופעים במספר אזורים.
שלב 3: יצירת מסד נתונים
אחרי שהמופע יוקצה, לוחצים על 'יצירת מסד נתונים' כדי ליצור מסד נתונים לשאר התרגיל.
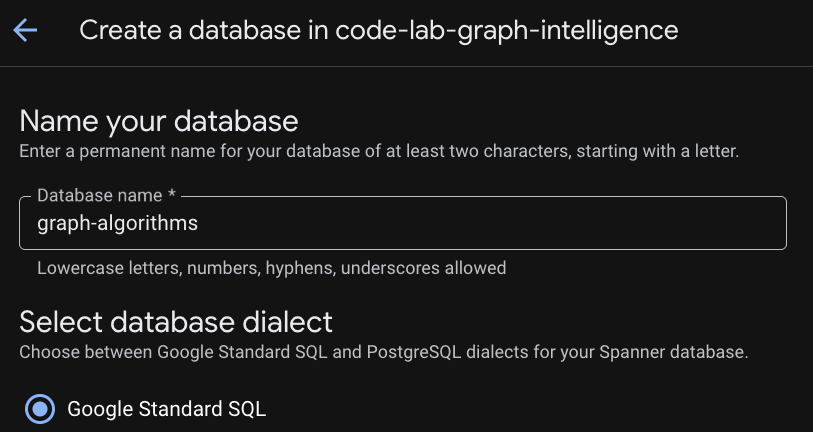
הגדרת בסיס רלציוני
המסע שלנו מתחיל עם טבלאות הליבה שבהן מאוחסנים נתונים תפעוליים. ב-Cloud Spanner, אנחנו משתמשים בשילוב נתונים כדי למקם פיזית נתונים קשורים, כמו חברויות ועסקאות של לקוח, ישירות ברשומת הלקוח. כך מובטחת גישה עם ביצועים גבוהים ומיקום פיזי.
DDL: יצירת הטבלאות
מעתיקים ומריצים את הבלוקים הבאים כדי ליצור את הסכימה הרלציונית:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
שיטת גביע
אחרי שהטבלאות מוכנות, צריך לאכלס אותן עם המשתמשים, המוצרים והקשרים שמגדירים את הסביבה העסקית של הלקוח.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
אתגרים שקשורים למערכות יחסים
לפני שנסביר על הגרף, נראה איך SQL מסורתי מתמודד עם האתגרים של הלקוח. מריצים את השאילתה הזו כדי למצוא לקוחות שהם 'מוציאים כספים על חברים' – לקוחות שמוציאים סכומים משמעותיים ויש להם כמה חברים.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
המגבלות של הגישה הרלציונית
פתרון בעיות שקשורות ליחסים באמצעות גרף נכסים
כדי לעקוף את המגבלות האלה, אנחנו מגדירים גרף נכסים. כך נוצרת שכבת-על שמאפשרת לנו להתייחס לקשרים כאל ישויות חשובות בלי להעביר את הנתונים שלנו מ-Spanner.
DDL: יצירת גרף הנכסים
ה-DDL הזה מגדיר את הצמתים (יחידות) והקשתות (קשרים) שלנו. בדוגמה הזו אנחנו עוקבים אחרי תרשים עם סכימה, אבל Spanner Graph מאפשר גם יצירת מודלים של תרשימים ללא סכימה כדי לאפשר פיתוח גמיש ומהיר של איטרציות, ולטפל במודלים של נתונים שמתפתחים בלי שינויים קבועים ב-DDL (שפת הגדרת נתונים).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
ניווט בתרשים באמצעות GQL
אחרי שהגדרנו את הגרף, אנחנו יכולים להשתמש ב-Graph Query Language (GQL) כדי לבצע מעברים בין צמתים מרובים באמצעות תחביר פשוט וקריא.
ניתוח 1: גילוי משותף
השאילתה הזו עוברת על הגרף כדי למצוא מוצרים שנרכשו על ידי החברים שלכם, והיא משמשת כבסיס למערכת המלצות.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
ניתוח 2: שאילתה היברידית (רלציונית + גרף)
Spanner מאפשר להטמיע תבניות GQL בתוך פסוקית FROM של SQL סטנדרטי באמצעות הפונקציה GRAPH_TABLE. השאילתה הזו מוצאת לקוחות שגרים באותו מיקום כמו החברים שלהם – התאמה של תבנית 'יהלום'.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
הדמיה של הקשרים עם הלקוחות
לבסוף, נשתמש ב-GQL כדי להציג את הרשת שלנו באופן חזותי. השאילתות האלה עוטפות את תוצאות הנתיב ב-SAFE_TO_JSON, וכך מאפשרות לכלים להמחשה לצייר את הצמתים והקווים.
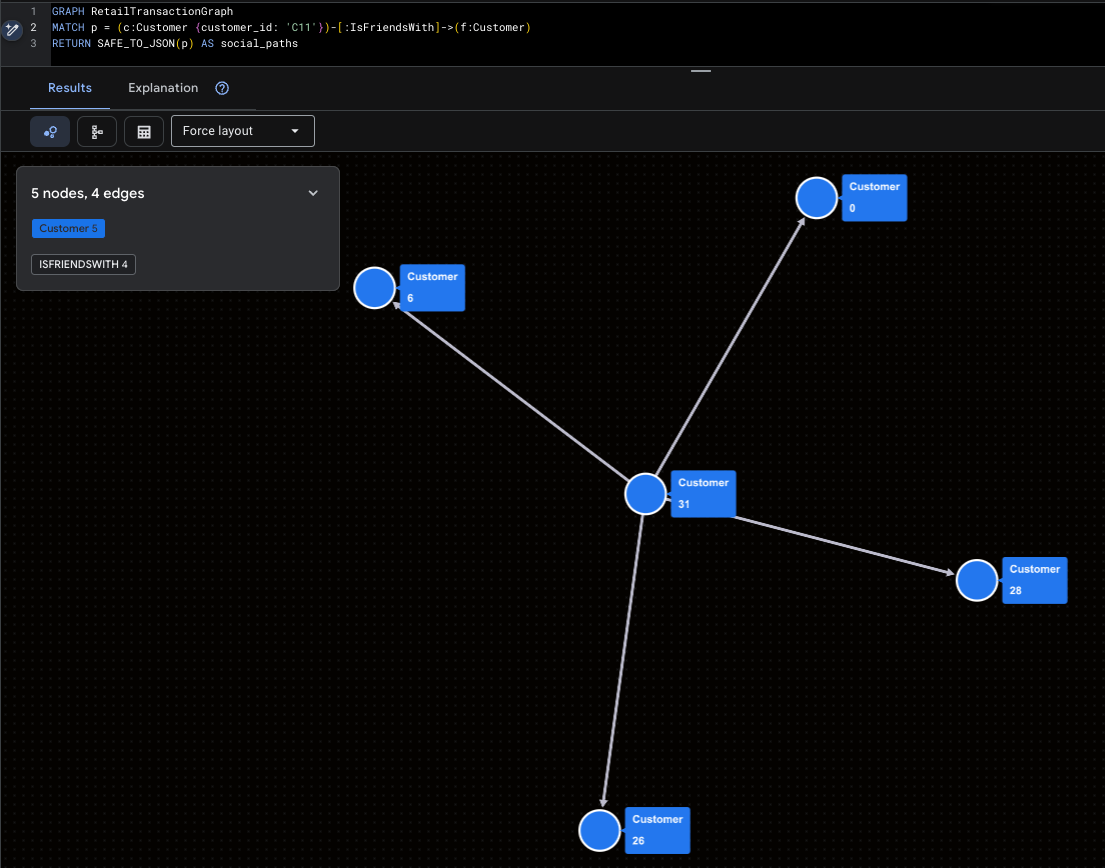
הדמיה של משפיעני-על
הנתון הזה מדגיש את מאלורי (C11) ואת טווח ההגעה הישיר שלה ברשתות החברתיות.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
המחשה של דפוסי הונאה פוטנציאליים
השאילתה הזו מאתרת את 'האשכול המבודד' (Ivan & Judy) כדי לראות לאן המוצרים שלהם נשלחים.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. מבוא לאלגוריתמים של Spanner Graph
כדי להתכונן לסקירה המעמיקה של Graph Intelligence, בקטע הזה נסביר על הארכיטקטורה הטכנית ועל הכללים הבסיסיים של אלגוריתמים של גרפים ב-Cloud Spanner. הבנת העקרונות האלה היא המפתח למעבר ממעברים פשוטים לניתוח קשרים בקנה מידה של פטה-בייט.
האלגוריתמים של שיטות הבידינג הכוללות
בשלב הזה, Cloud Spanner תומך ב-14 אלגוריתמים של גרפים לפי תקנים בתעשייה, שמסווגים לארבע קבוצות פונקציונליות לפתרון בעיות עסקיות מגוונות:
קטגוריה | אלגוריתמים נתמכים | תרחיש שימוש עסקי |
מרכזיות | דירוג דף, דירוג דף בהתאמה אישית, מרכזיות, קרבה | זיהוי משפיענים, מרכזים וצווארי בקבוק. |
קהילה | WCC, Label Propagation, Clique Finding, Correlation Clustering | זיהוי של רשתות הונאה, קהילות ברשתות החברתיות וסילו. |
דמיון | Jaccard, Cosine, Common Neighbors, Total Neighbors | הפעלת מערכות המלצות וזיהוי ישויות. |
חיפוש נתיבים | הנתיב הקצר ביותר בין קבוצות, כלי עזר לניתוח נתיבים ב-GA | אופטימיזציה של הלוגיסטיקה והמרחק בין נקודות המעבר. |
שיקולים חשובים לגבי סכימה ושאילתות
כדי להבטיח הרצה יעילה של אלגוריתמים של גרפים, Spanner Graph צריך לעמוד בכללים הבאים:
דרישה 1. מיקום פיזי של נתונים (שילוב)
הדרישה הקריטית ביותר לחיפוש יעיל בגרף היא שילוב. כך מובטח שהנתונים של קצה הרשת מאוחסנים פיזית באותו פיצול של השרת כמו צומת המקור, וכך מצטמצם זמן האחזור ברשת במהלך הפעלת האלגוריתם.
- הכלל: טבלאות קצה חייבות להיות משולבות בטבלאות של צומת המקור שלהן.
- מעבר קדימה: שילוב של טבלת הקצוות בטבלת צמתי המקור מבטיח לוקאליות של מטמון לקישורים יוצאים.
- מעבר הפוך: כדי לבצע ניתוח יעיל של קישורים נכנסים, משתמשים במפתחות זרים כדי ליצור באופן אוטומטי אינדקסים תומכים, או יוצרים אינדקס משני שמשולב בטבלת היעד.
דרישה 2. דרישות ייחודיות לתוויות
לכל טבלה שמשתתפת בגרף המאפיינים צריך להיות מזהה ייחודי. האלגוריתמים מסתמכים על התוויות האלה כדי לזהות ולטעון בצורה נכונה את תתי-הגרפים שהם צריכים לנתח.
- הכלל: לכל טבלת קלט צריכה להיות תווית ייחודית לזיהוי בגרף הנכס.
- הבעיה: אי אפשר למפות תווית אחת לכמה טבלאות אם רוצים להפעיל עליהן אלגוריתמים.
Logic | דוגמה | תוצאה |
❌ גרועה | טבלאות צמתים (ישות עם התווית Person, ישות עם התווית Account) | לא תקין: האלגוריתם לא יכול להבחין בין אדם לבין חשבון. |
✅ טוב | טבלאות צמתים (לקוח עם התווית Person, חשבון עם התווית Account) | תקין: לכל ישות יש תווית ייחודית. |
דרישה 3. מבנה שאילתת אלגוריתם (המשפט MATCH)
כשקוראים לאלגוריתם, סעיף MATCH פועל לפי כללים מחמירים יותר מאשר שאילתות GQL רגילות, כדי להבטיח שמנוע ההפעלה יוכל לבצע אופטימיזציה של צינור הניתוח.
- דפוס אחד לכל התאמה: כל הצהרת MATCH יכולה לציין רק משתנה אחד.
- אין דפוסי צמתים מרובים: אי אפשר להגדיר דפוס של קשר (למשל, (a)-[e]->(b)) ישירות בתוך פסקה של MATCH שמיועדת לקריאה לאלגוריתם.
- מסננים מילוליים בלבד: אפשר להשתמש בסעיפי WHERE כדי לסנן צמתים (לדוגמה, WHERE a.id > 400), אבל פרמטרים של שאילתות (@param) לא נתמכים כרגע בשאילתות של אלגוריתמים לגרפים.
דרישה 4. הסעיף RETURN (סקלרים בלבד)
הסעיף RETURN בשאילתת אלגוריתם משמש כגשר בין עולם הגרפים לעולם היחסים. הפונקציה מוגבלת להחזרת ערכים סקלריים וקבועים.
- הכלל: אי אפשר להחזיר Graph Element (האובייקט הגולמי של הצומת או הקצה).
- ללא שינויים: אי אפשר לבצע פעולות מתמטיות או להחיל פונקציות על המאפיינים שמוחזרים בהצהרת RETURN עצמה.
הגבלות על סעיף RETURN
✅ נתמך | ❌ לא נתמך |
RETURN node.id, score | צומת RETURN, ציון (לא ניתן להחזיר רכיב גרף) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (No operations on properties) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (ללא פונקציות) |
דרישה 5. תקינות נתונים: ביטול קצוות חופשיים
התופעה 'קצה תלוי' מתרחשת כשקצה מצביע לצומת יעד שלא קיים בתרשים. הסיבה לכך היא שמבנה הגרף לא עקבי, ולכן הפעלת האלגוריתם נכשלת.
- הפתרון: משתמשים באילוצי הפניה (מפתחות זרים) וב-ON DELETE CASCADE כדי לשמור על שלמות הגרף.
- בטיחות שאילתות: כשמפעילים אלגוריתם, צריך לוודא שכל הצמתים שאליהם מתייחסים הקצוות שנבחרו כלולים גם בארגומנט node_labels.
פלט קבוע: אפשרויות של EXPORT DATA
אלגוריתמים של גרפים דורשים הרבה משאבי מחשוב, ולכן הם מופעלים במצב הרצה של הגדלת הקיבולת באמצעות ההצהרה EXPORT DATA. הפתרון הזה מתבסס על Data Boost, ומשתמש במשאבי מחשוב עצמאיים ללא שרת כדי למנוע השהיה בעסקאות הייצור.
אפשרות 1: שמירה חזרה ב-Cloud Spanner
כדי להחזיר תוצאות ישירות לטבלאות (למשל, כדי לשמור ציון PageRank), משתמשים בפורמט = 'CLOUD_SPANNER'.
-
update_ignore_all: עדכון רק של שורות עבור מפתחות שכבר קיימים בטבלת היעד. -
upsert_ignore_all: מעדכן שורות קיימות או מוסיף שורות חדשות אם המפתחות חסרים.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
אפשרות 2: שמירת התוצאות ב-Google Cloud Storage (GCS)
לניתוח אופליין בקנה מידה גדול, אפשר לייצא ל-GCS בפורמטים CSV, Avro או Parquet.
- תווים כלליים לחיפוש: אפשר להשתמש בתווים
uri => 'gs://bucket/file_*.csv'כדי להפעיל פלט מחולק, וכך לאפשר ל-Spanner לכתוב לכמה קבצים במקביל עבור מערכי נתונים גדולים. - דחיסה: תמיכה ב-GZIP, SNAPPY ו-ZSTD כדי לבצע אופטימיזציה של עלויות האחסון.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. אתגר 1: פער ההשפעה (דירוג דף)
בקטע הזה נתייחס למכשול העסקי הראשון של הלקוח: הפער בהשפעה. נעבור מ "תחרות פופולריות" בסיסית למפה מבוססת-מתמטיקה של השפעה חברתית אמיתית.
תיאור הבעיה: לצוות השיווק של הלקוח יש בעיה. הם מוציאים מיליוני דולרים על פרסום רחב היקף עם תשואות הולכות ופוחתות, כי הם לא מצליחים לזהות את "כוכבי הרשת" – אותם אנשים נדירים שההמלצות שלהם משפיעות על כל הרשת.
כדי לפתור את הבעיה, אנחנו צריכים לדרג את הלקוחות לפי השפעה.
פתרון רלציוני (מרכזיות לפי דרגה)
במסד נתונים רגיל, הדרך הכי קלה למצוא משפיענים היא פשוט לספור את העוקבים שלהם (מדד שנקרא Degree Centrality).
מריצים את השאילתה הבאה כדי למצוא את המשתמשים הכי 'פופולריים':
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Graph Intelligence (PageRank)
כדי למצוא את האתרים המובילים באמת, אנחנו משתמשים ב-PageRank. זהו אותו אלגוריתם שהפעיל את חיפוש האינטרנט המוקדם. הוא מודד את החשיבות של צומת על סמך הכמות וגם האיכות של הקישורים הנכנסים.
- מודל הגולש האקראי: אלגוריתם PageRank מדמה משתמש שעובר בין הצמתים בתרשים. מקדם השיכוך (ברירת מחדל 0.85) מייצג את ההסתברות שהמשתמש ימשיך ללחוץ. אחרת, הוא עובר באופן אקראי לצומת אחר.
- השפעה של שיוך: קישור מאדם משפיע (כמו Mallory) שווה הרבה יותר מקישור מאדם שאין לו קשרים אחרים.
נריץ את אלגוריתם דירוג הדף ונשתמש בפקודה EXPORT DATA כדי לשמור את התוצאות ישירות בעמודה pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
לוח הבקרה 'השפעה' באמצעות PageRank
עכשיו, כשהציונים נשמרים, אפשר להשוות בין הנתונים של 'לפני' (מספר העוקבים) לבין הנתונים של 'אחרי' (ציון PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
ניתוח: מי הם הכוכבים האמיתיים?
ניתוח הפלט מאפשר לכם להסיק שלוש תובנות שיווקיות חשובות:
ייצוא נתונים של העסק
במקום לשלוח אימייל לכל מי שיש לו יותר מחמישה עוקבים, צוות השיווק של הלקוח יכול עכשיו להתמקד רק באנשים עם הציון הכי גבוה של pagerank_score. האנשים האלה הם באמת 'כוכבי רשת' שיכולים ליצור תופעה ויראלית בכל השוק.
עכשיו ננסה לזהות את שומרי הסף שמאפשרים לרשת הלוגיסטית של הלקוח לפעול.
5. אתגר 2: חוסן לוגיסטי (BetweennessCentrality)
בקטע הזה נדון בעמידות לוגיסטית. במקום למדוד את ההצלחה לפי 'נפח', נתמקד בזיהוי 'שומרי הסף' החיוניים ששומרים על הרשת מחוברת.
פתרון רלציוני (ניתוח לפי נפח)
בהגדרה רגילה של קשרים, מרכז משלוחים 'קריטי' מוגדר בדרך כלל כמרכז שמטפל בהכי הרבה הזמנות או שמייצר הכי הרבה הכנסות.
מריצים את השאילתה הזו כדי לזהות את המרכזים ה "מובילים" לפי מספר העסקאות:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
ניו יורק | ארה"ב | 4 | 3996 |
ברלין | גרמניה | 2 | 345 |
סן פרנסיסקו | ארה"ב | 2 | 750 |
כדי לפתור את הבעיה, נשתמש בשני הקצוות IsFriendsWith ו-LivesAt. השינוי הזה הופך את הניתוח שלנו ממרכז עסקאות לניתוח שכולל גם בדיקה חברתית.
Graph Intelligence (Betweenness Centrality)
כדי למצוא את צווארי הבקבוק האמיתיים, אנחנו משתמשים במרכזיות בין. האלגוריתם הזה מחשב את התדירות שבה צומת מסוים משמש כ'גשר' לאורך הנתיבים הקצרים ביותר בין כל זוגות הצמתים האחרים בתרשים. ציונים גבוהים מצביעים על שומרי הסף האמיתיים ששולטים בזרימת הסחורות או המידע.
הפעלה של מדד המרכזיות בין צמתים ושימור שלו
אנחנו נריץ את האלגוריתם באמצעות EXPORT DATA ונשמור את הניקוד בעמודה centrality_score. אנחנו משתמשים בהגדלת נפח הנתונים כדי לוודא שהחישוב המורכב הזה של "הנתיב הקצר ביותר" לא ישפיע כמעט בכלל על הפעולות השוטפות של הלקוח.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
ניתוח: זיהוי 'צווארי בקבוק נסתרים'
עכשיו, אנחנו משווים את הסיכון המבני (centrality_score) לנפח העסקאות (order_count) כדי למצוא את הצמתים שההנהלה של הלקוח צריכה לדאוג לגביהם.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
בעקבות ניתוח התוצאות האלה, הלקוח מגיע לשלוש תובנות מפתיעות:
Business Takeaway
הלקוח יכול עכשיו לתת עדיפות ליתירות הלוגיסטית ולפרוטוקולי האבטחה שלו על סמך סיכון מבני רב-אופני. מאלורי, אליס ואיב הם שומרי הסף שצריך להגן עליהם כדי להבטיח את היציבות של הרשת הלוגיסטית.
עכשיו ננסה לבודד אזורים שבהם מתרחשת הונאה.
6. אתגר 3: רשתות רפאים (WCC)
בקטע הזה נתייחס לאתגר השלישי שעומד בפני העסק: 'רשתות רפאים'. אנחנו נעבור מזיהוי פשוט של נקודות לשיתוף אינטרנט לזיהוי של רשתות הונאה מתוחכמות ומבודדות באמצעות זיהוי קהילתי. הבעיה היא שגורמים זדוניים יוצרים פרופילים מזויפים שמשתפים כתובות למשלוח או יוצרים אינטראקציות במעגלים סגורים כדי לתאם גניבות ולנפח את דירוגי המוצרים. אבל לעיתים קרובות הם מבודדים לחלוטין מהקהילה הלגיטימית של הלקוח.
כדי לפתור את הבעיה, אנחנו צריכים לחשוף את האיים המבודדים האלה.
פתרון רלציוני (חיפוש מזהה משותף)
בלי אלגוריתמים של גרפים, הדרך הרגילה לזיהוי הונאה היא לחפש 'נקודות חמות' של נתונים משותפים, כמו כמה לקוחות ששולחים מוצרים לאותה כתובת בדיוק .
כדי למצוא לקוחות שמקושרים באמצעות מיקום משלוח משותף, מריצים את השאילתה הבאה:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
כדי למצוא את רשתות ההונאה, צריך להבין את המושג נגישות טרנזיטיבית.
Graph Intelligence (Weakly Connected Components)
כדי למצוא את ההיקף המלא של הטבעות האלה, אנחנו משתמשים ברכיבים מחוברים חלשים (WCC). WCC הוא אלגוריתם של אשכולות שמזהה קבוצות של צמתים שקיים ביניהם נתיב, ללא קשר לכיוון הקצוות.
- אזורי נגישות: התכונה הזו מחלקת את הגרף בצורה יעילה ל'איים' או ל'אזורי נגישות'.
- תצוגת ישות מאוחדת: על ידי ניתוח בו-זמני של קשרים חברתיים (IsFriendsWith) וקשרים לוגיסטיים (LivesAt), אנחנו יכולים לקבץ פרופילים מפוצלים לאשכול השפעה מאוחד יחיד.
הפעלה של WCC והמשך הפעולה שלה
אנחנו נריץ את האלגוריתם WCC ונשמור את התוצאות בעמודה community_id. אנחנו משתמשים בData Boost כדי לוודא שהניתוח המעמיק הזה של יכולת הגעה (reachability) מתבצע במשאבי מחשוב עצמאיים.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
ניתוח: רשתות של הונאות
עכשיו נריץ שאילתת אימות כדי לראות את הקהילות המבודדות. משתמשים לגיטימיים בדרך כלל שייכים ל'יבשת', בעוד שרמאים נתקעים לעיתים קרובות ב'איים' קטנים.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | משתמשים |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
אם תפעילו את זיהוי הקהילה הזה, תוכלו לזהות אנומליה קריטית:
Business Takeaway
הלקוח יכול עכשיו להפוך את תגובות האבטחה שלו לאוטומטיות. במקום לרדוף אחרי כל חשבון בנפרד, הם יכולים לכתוב כלל פשוט: "אם יש פחות משלושה חברים בקהילה עם מזהה community_id, צריך לסמן את כל הקבוצה לבדיקת KYC (הכרת הלקוח) ידנית"
.
אחרי שחשפנו את רשתות ההונאה, אנחנו יכולים לפתור את הבעיה של 'תאום התנהגותי'.
7. אתגר 4: תאום התנהגותי (JaccardSimilarity)
באחרון מבין האתגרים האלה, נתייחס למכשול הרביעי: 'פרדוקס הבחירה'/'תאום התנהגותי'. נעבור מרשימות כלליות של מוצרים שנקנים יחד לעיתים קרובות להמלצות בהתאמה אישית על סמך טביעות אצבע התנהגותיות.
ההצעות הנוכחיות למוצרים של הלקוח גנריות מדי. המלצה על כבל USB פופולרי לכל לקוח היא בטוחה, אבל היא לא אישית. הלקוח רוצה ליצור המלצות "תאום התנהגותי" כדי לזהות לקוחות עם דפוסי משלוח ייחודיים ומעגלים חברתיים משותפים, ולהציע להם מוצרים בהתאמה מדויקת.
כדי לפתור את הבעיה, צריך לחשב את הקרבה בין המשתמשים.
פתרון יחסי (חפיפה מוחלטת)
בהגדרה רגילה של מסד נתונים יחסי, יכול להיות שתחפשו אנשים ששולחים מוצרים לאותם מיקומים כמו משתמש לדוגמה, למשל Alice (C1).
מריצים את השאילתה הזו כדי למצוא את השכנים הגיאוגרפיים של אליס:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (Jaccard Similarity)
כדי למצוא תאומים התנהגותיים אמיתיים, אנחנו משתמשים בדמיון ג'קארד. האלגוריתם הזה מחשב ציון מנורמל (0.0 עד 1.0) על ידי חלוקת מספר השכנים המשותפים (הצטלבות) במספר הכולל של שכנים ייחודיים (איחוד).
ההגדרה של 'תאום התנהגותי' כוללת יותר מכתובת משלוח משותפת. ניתוח של נקודות המפגש בין הטביעות הפיזיות (LivesAt) לבין המערכות האקולוגיות החברתיות (IsFriendsWith) מאפשר לנו לזהות משתמשים שחולקים את אותו סגנון חיים ואת אותה השפעה קהילתית, וכך להציע המלצות מדויקות הרבה יותר למוצרים.
קודם יוצרים טבלת מיפוי
מכיוון שהדמיון הוא קשר זוגי (לקוח א' דומה ללקוח ב'), אנחנו יוצרים טבלה ייעודית שמשולבת ב-Customer כדי לאחסן את המיפויים האלה.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
הפעלת דמיון ג'קארד
עכשיו נפעיל את האלגוריתם. הערה: השאילתה הזו כוללת שיעור נפוץ בנושא אמצעי הגנה. אם בוחרים רק בצמתי לקוחות אבל משתמשים בקצה LivesAt (שמפנה לצמתי משלוח), השאילתה תיכשל ותציין "קצה תלוי" . כדי לפתור את הבעיה, צריך לכלול את שתי תוויות הצמתים.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
ניתוח: בדיקת 'תאום התנהגותי'
עכשיו, אחרי שהניתוח הסתיים, אנחנו מריצים שאילתת אימות. אם נצרף את טבלת המיפוי החדשה שלנו (CustomerSimilarity) למטא-נתונים המקוריים שלנו (Customer), נוכל לראות בדיוק מי הם התאומים ההתנהגותיים של אליס.
מריצים את השאילתה הזו כדי לבדוק את דירוגי הדמיון של אליס:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
מה כדאי לחפש בתוצאות:
עכשיו ננסה ליצור תצוגה סופית של Unified Intelligence.
8. Unified Intelligence
עכשיו נעבור ממשימות טכניות פרטניות אל ה-AI המאוחד. כאן אנחנו משלבים נתונים טרנזקציוניים עם כל ארבעת האלגוריתמים של הגרף כדי לספק תובנות ברורות ופרקטיות.
דוח 1: אינטליגנציה מאוחדת
היתרון של מסד נתונים מרובה-מודלים כמו Spanner הוא האפשרות לצרף נתונים יחסיים של הוצאות לנתונים של השפעה, סיכון ודמיון שנגזרים מגרף, בבקשה אחת. השאילתה הזו מסווגת כל לקוח לדמות עסק ספציפית.
מריצים את השאילתה של Unified Intelligence כדי לראות את המערכת האקולוגית המלאה:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | הוצאה | השפעה | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 קריטי: גשר לרשת |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 קריטי: גשר לרשת |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 קריטי: גשר לרשת |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 רשתות חברתיות: משפיע/ה עם היקף חשיפה רחב |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 רשתות חברתיות: משפיע/ה עם היקף חשיפה רחב |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: לקוח פעיל |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD: לקוח פעיל |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 סיכון גבוה: רשת הונאה מבודדת |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 סיכון גבוה: רשת הונאה מבודדת |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: לקוח פעיל |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: לקוח פעיל |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: לקוח פעיל |
השילוב של הגישות המתמטיות האלה מאפשר לנו להבין מי הכי חשוב ולא רק מי הוציא הכי הרבה כסף. לוח הבקרה המאוחד משלב נתוני עסקאות יחסיים עם ניתוח גרפים רב-אופני כדי לסווג את המערכת האקולוגית שלכם לשלוש פרסונות ברורות ופרקטיות.
הקטע 'גשרים קריטיים ברשת' (חוסן)
הצמתים Mallory (C11), Eve (C5) ו-Alice (C1) מסומנים כי הערך שלהם bottleneck_risk (Betweenness Centrality) הוא >25.
- הנקודות המרכזיות: למאלורי יש את ציון הסיכון הגבוה ביותר, 44.5, ולכן היא מהווה את נקודת הכניסה העיקרית לכל הרשת.
- הפרדוקס של הוצאות אפס: לאווה (C5) יש מספר הזמנות אפס, אבל היא חיונית מבחינה מבנית עם ציון סיכון של 35.5. SQL סטנדרטי היה מתעלם ממנה לחלוטין, אבל Graph Intelligence חושפת שהיא מהווה גשר חיוני לקהילת משנה שלמה.
- השער לערך גבוה: אליס (C1) הגיעה למקום הראשון יחד עם אווה עם ציון של 35.5, מה שמוכיח שגם לקוחות עם הוצאות גבוהות יכולים להיות עוגנים מבניים קריטיים.
המדד 'כוכבי רשת' (היקף החשיפה)
היידי (C8) וגרייס (C7) מזוהות כמשפיעניות עם פוטנציאל חשיפה גבוה בגלל הניקוד שלהן ב-PageRank .
התכונה 'רשת הונאה מבודדת' (אנומליות)
המשתמשים Judy (C10) ו-Ivan (C9) מסומנים בדגל כי הם שייכים לקהילה המבודדת community_id 1
Business Insight to Strategic Actions
Persona | מדד מרכזי | תובנות עסקיות | פעולה אסטרטגית |
🔵 גשרים לרשת | מרכזיות גבוהה | עוגנים מבניים: איב (C5) ומלורי (C11) מחזיקים את הרשת. | שימור: חשוב להגן על שומרי הסף האלה כדי למנוע פיצול של הקהילה. |
📱 כוכבי הרשתות החברתיות | דירוג דף גבוה | מנועי ויראליות: למשתמשים כמו היידי (C8) יש את פוטנציאל החשיפה הגבוה ביותר במעגלים שלהם. | שיווק: אפשר להשתמש בהם לתוכניות הפניה ושגרירים עם השפעה גבוהה. |
🔴 סיכוני הונאה | WCC מבודד | רשתות רפאים: ג'ודי (C10) ואיוון (C9) מוציאים סכומי כסף גדולים אבל גרים ב"איים". | אבטחה: בדיקה ידנית מיידית של תהליך הכרת הלקוח (KYC). אלה חתימות קלאסיות של הונאה. |
🟢 משתמשים רגילים | ציון מאוזן | Healthy Core: רוב הרשת, כולל גשרים 'מקומיים' כמו David (C4). | צמיחה: יישום של המלצות סטנדרטיות להתאמה אישית של מודעות ושל המלצות מסוג 'תאום התנהגותי'. |
דוח 2: דוח האנומליות של הזהות
עכשיו צריך לדעת אם נוכלים מחקים חשבונות לגיטימיים. כדי לפתור את הבעיה הזו, אפשר למצוא משתמשים עם דמיון התנהגותי של 100% אבל אפס קשרים חברתיים.
מריצים את השאילתה הזו כדי לסמן חריגות פוטנציאליות בזהות:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
דוח זיהוי האנומליות מספק מידע קריטי. אנחנו מבודדים משתמשים שמתנהגים כמו לקוחות לגיטימיים אבל אין להם קשרים חברתיים, וכך אנחנו עוברים מניחוש לוודאות מתמטית .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
ניתוח התוצאות
השילוב של דמיון (Jaccard) עם זיהוי קהילות (WCC) מאפשר לנו לחשוף סיכונים נסתרים שלא ניתן לראות בנתוני עסקאות מסורתיים.
- התאומים ההתנהגותיים (קרבה): צמתים כמו Judy (C10) ו-Ivan (C9) מסומנים כי יש להם ציון דמיון לפי ג'קארד של 0.20 ביחס ל-Alice (C1).
- התנהגות מבודדת: ג'ודי (C10) ואיוון (C9) מקובצים בcommunity_id 1 המבודד, בעוד שאליס שייכת ל"יבשת" החברתית (קהילה 0).
- דגלים של הונאה: בדוח מזוהים משתמשים עם חפיפה גבוהה בהתנהגות (מעל 0.9) שלא מקושרים חברתית לרשת הראשית.
9. ברכות וסיכום
בשיעור ה-Lab הזה נסביר איך Cloud Spanner הופך מסד נתונים רלציוני למסד נתונים רב-מודלי רב עוצמה. השימוש ב-graph intelligence בנתוני הלקוחות אפשר לנו לעבור מנתונים סטטיים לאסטרטגיה עסקית שניתן ליישם.
היתרון של Spanner Multi-Model
- ארכיטקטורה מאוחדת: Spanner מאפשר לכם לשמור על בסיס יחסי איתן, ובו-זמנית להוסיף גרף מאפיינים לכריית קשרים, בלי הסיכון וההשהיה של ETL.
- בידוד אנליטי מחוץ לתיבה: באמצעות Data Boost, אתם יכולים להריץ אלגוריתמים עתירי זיכרון כמו PageRank או WCC על משאבי מחשוב עצמאיים ללא שרת, וכך להבטיח שלא תהיה השפעה על ביצועי התשלום בייצור.
- ביצועים משולבים: השילוב הייחודי של Spanner מבטיח שהצמתים והקשרים שלהם יהיו ממוקמים פיזית באותו מקום, וכך הופך מעברים גלובליים מורכבים לחיפושים מקומיים מהירים.
הצגת 'פנינים נסתרות' ואנומליות
- זיהוי ערך מבני: אלגוריתמים של גרפים כמו Betweenness Centrality חשפו 'גשרים נסתרים' עם הוצאות אפסיות שיכולים להיות חשובים יותר לחוסן הרשת מאשר לקוחות עם ההוצאות הכי גבוהות.
- חשיפת חיקוי התנהגותי: באמצעות שילוב של דמיון ג'קארד ורכיבים מחוברים חלש, זיהינו 'זרים חברתיים'. החשבונות האלה נראים כמו לקוחות לגיטימיים, אבל הוכח מתמטית שהם חלק מרשתות הונאה מבודדות.
- אמת גלובלית לעומת אמת מקומית: ניתוח ידני של SQL יכול לחשוף גשרים, אבל אלגוריתמים גלובליים יכולים לחשוף שומרי סף מרכזיים ברשת.
הפיכת נתונים לנתונים חכמים שאפשר לפעול לפיהם
- אסטרטגיה מבוססת-פרסונה: הצלחנו להפוך את השורות שלנו לקשרים, ועל ידי הפעלת אלגוריתמים אנחנו יכולים לטפל בארבע בעיות עסקיות, כלומר: Network Bridges, Social Superstars, Fraud Risks ו-Standard Users.