
1. केस स्टडी: इंटेलिजेंट रीटेल
केस स्टडी के लिए, हम तेज़ी से बढ़ते डिजिटल मार्केटप्लेस वाले खुदरा ग्राहक को चुनते हैं. ग्राहक के डेटा का पारंपरिक व्यू सीमित होता है, क्योंकि इसमें यह दिखता है कि लोग क्या खरीदते हैं, लेकिन यह नहीं दिखता कि वे कैसे जुड़े हैं. इस वजह से, धोखाधड़ी के मामले बढ़ते हैं और कई मौके छूट जाते हैं. अब वे नेटवर्क-फ़र्स्ट फ़िलॉसफ़ी पर काम कर रहे हैं. इसके तहत, वे लेन-देन के डेटा के साथ-साथ सोशल और लॉजिस्टिक्स कनेक्शन को भी अहमियत देते हैं.
कारोबार से जुड़ी मुख्य समस्याएं
आपके सामने चार अहम चुनौतियां हैं. इनके लिए, यह समझना ज़रूरी है कि ग्राहक और लॉजिस्टिक्स एक-दूसरे से कैसे जुड़े हैं:
चैलेंज | समस्या | लक्ष्य |
ब्रैंड के असर में अंतर | ब्रॉड विज्ञापन से कम आरओआई मिलता है. फ़िलहाल, असली ट्रेंडसेटर (इन्फ़्लुएंसर) की पहचान करना मुमकिन नहीं है. | इन्फ़्लुएंसर की पहचान करें. ये ऐसे लोग होते हैं जो खरीदारों के कनेक्टेड नेटवर्क में अपने कनेक्शन के ज़रिए, कम्यूनिटी के लिए अहम होते हैं. |
लॉजिस्टिक्स से जुड़ी मुश्किलों से निपटने की क्षमता | सप्लाई चेन में जोखिम हो सकता है, क्योंकि ये अलग-अलग देशों/इलाकों में काम करती हैं. अगर एक की हब काम नहीं करता है, तो पूरे क्षेत्र में प्रॉडक्ट का ऐक्सेस नहीं रहेगा. | गेटकीपर की पहचान करें. ये ऐसे लोग होते हैं जो लॉजिस्टिक्स नेटवर्क को एक साथ जोड़ने के लिए ज़रूरी होते हैं. |
Ghost Networks | धोखाधड़ी करने वाले लोग, चोरी करने और रेटिंग बढ़ाने के लिए फ़र्ज़ी प्रोफ़ाइलों और शेयर किए गए पतों का इस्तेमाल करते हैं. | अलग-थलग पड़े ग्रुप के बारे में जानकारी देना. ये ऐसे ग्रुप होते हैं जो आपस में बहुत ज़्यादा जुड़े होते हैं, लेकिन इनका असली कम्यूनिटी से कोई संबंध नहीं होता. |
ज़्यादा विकल्प होने से फ़ैसले लेने में होने वाली मुश्किल | सुझाव/सिफ़ारिश करने वाला मौजूदा इंजन, सामान्य और बुनियादी है.इसलिए, अक्सर इसे अनदेखा कर दिया जाता है. उदाहरण के लिए, "इस प्रॉडक्ट को खरीदने वाले लोगों ने यह प्रॉडक्ट भी खरीदा ...". | व्यवहार के आधार पर मिलते-जुलते लोगों की पहचान करना; यानी कि शिपिंग के मिलते-जुलते पैटर्न और सोशल सर्कल के आधार पर सुझाव देना. |
बिज़नेस की चुनौतियों को तकनीकी रणनीति से मैप करना (लाइनें → संबंध)
पारंपरिक डेटाबेस में, डेटा को अलग-अलग हिस्सों में सेव किया जाता है: ग्राहकों का डेटा एक टेबल में, लेन-देन का डेटा दूसरी टेबल में, और शिपिंग का डेटा तीसरी टेबल में. एसक्यूएल, "किसने क्या खरीदा?" जैसे सवालों के जवाब देने के लिए सबसे सही है. हालांकि, यह नेटवर्क से जुड़े सवालों के जवाब देने में मुश्किल होती है.
इन चुनौतियों को हल करने के लिए, तकनीकी रणनीति के तहत इस नज़रिए को बदला जाता है:
- रिलेशनल व्यू ("क्या"): इसमें हर ग्राहक को एक अलग लाइन के तौर पर दिखाया जाता है. किसी ग्राहक और उसके दोस्त की खरीदारी के बीच कनेक्शन ढूंढने के लिए, कई जटिल "जॉइन" की ज़रूरत होती है. नेटवर्क बढ़ने पर, ये "जॉइन" बहुत धीमे हो जाते हैं.
- ग्राफ़ व्यू ("कैसे"): इसमें रिश्तों को सबसे ज़्यादा अहमियत दी जाती है. सूचियों में खोजने के बजाय, हम मैप पर नेविगेट करते हैं. हमें तुरंत पता चल जाता है कि ग्राहक A, ग्राहक B से जुड़ा है. ग्राहक B, प्रॉडक्ट को जगह Z पर शिप करता है.
ज़रूरी शर्तों के बारे में ज़्यादा जानकारी
समाधान आर्किटेक्ट इस नतीजे पर पहुंचते हैं कि कारोबार की ज़रूरतों और तकनीकी रणनीति के लिए, मल्टी-मॉडल अप्रोच की ज़रूरत होती है. साथ ही, वे यहां दी गई मुख्य ज़रूरी शर्तों की पहचान करते हैं.
Cloud Spanner, तकनीकी शर्तों को कैसे पूरा करता है
Cloud Spanner को इस ट्रांसफ़ॉर्मेशन के लिए मुख्य डेटाबेस के तौर पर चुना गया है. इससे ग्राहक को अपने डेटा को रिलेशनल फ़ॉर्मैट में बनाए रखने में मदद मिलती है. साथ ही, उसे डीप ग्राफ़ की अहम जानकारी भी मिलती है.
यहां इस बारे में खास जानकारी दी गई है कि Cloud Spanner, तकनीकी ज़रूरी शर्तों और अन्य बातों को कैसे पूरा करता है.
इसके अलावा, Cloud Spanner एक ऐसा तकनीकी आर्किटेक्चर उपलब्ध कराता है जो आने वाले समय में भी काम करता रहेगा
2. डेटा फ़ाउंडेशन सेट अप करना
कारोबार के मामले के बाद, अब हम लागू करने के चरण पर जाते हैं. इस सेक्शन में, हम अपने डेटा आर्किटेक्चर के बारे में बताते हैं. साथ ही, पारंपरिक रिलेशनल मॉडल की सीमाओं के बारे में बताते हैं. इसके अलावा, हम प्रॉपर्टी ग्राफ़ को मुख्य टूल के तौर पर पेश करते हैं, ताकि आपको अहम जानकारी मिल सके.
Cloud Spanner Enterprise इंस्टेंस सेट अप करना
पहला चरण: Cloud Spanner API चालू करना
Google Cloud Console में, बाईं ओर मौजूद नेविगेशन के लिए स्क्रीन पर सबसे ऊपर बाईं ओर मौजूद मेन्यू आइकॉन पर क्लिक करें. नीचे की ओर स्क्रोल करें और "Spanner" चुनें. इसके अलावा, "Spanner" खोजें
अब आपको Cloud Spanner का यूज़र इंटरफ़ेस (यूआई) दिखेगा. अगर आपने ऐसे प्रोजेक्ट का इस्तेमाल किया है जिसमें Cloud Spanner API अब तक चालू नहीं किया गया है, तो आपको एक डायलॉग दिखेगा. इसमें आपको इसे चालू करने के लिए कहा जाएगा. अगर आपने एपीआई पहले ही चालू कर दिया है, तो इस चरण को छोड़ा जा सकता है.
जारी रखने के लिए, "चालू करें" पर क्लिक करें:
दूसरा चरण: Cloud Spanner इंस्टेंस बनाना
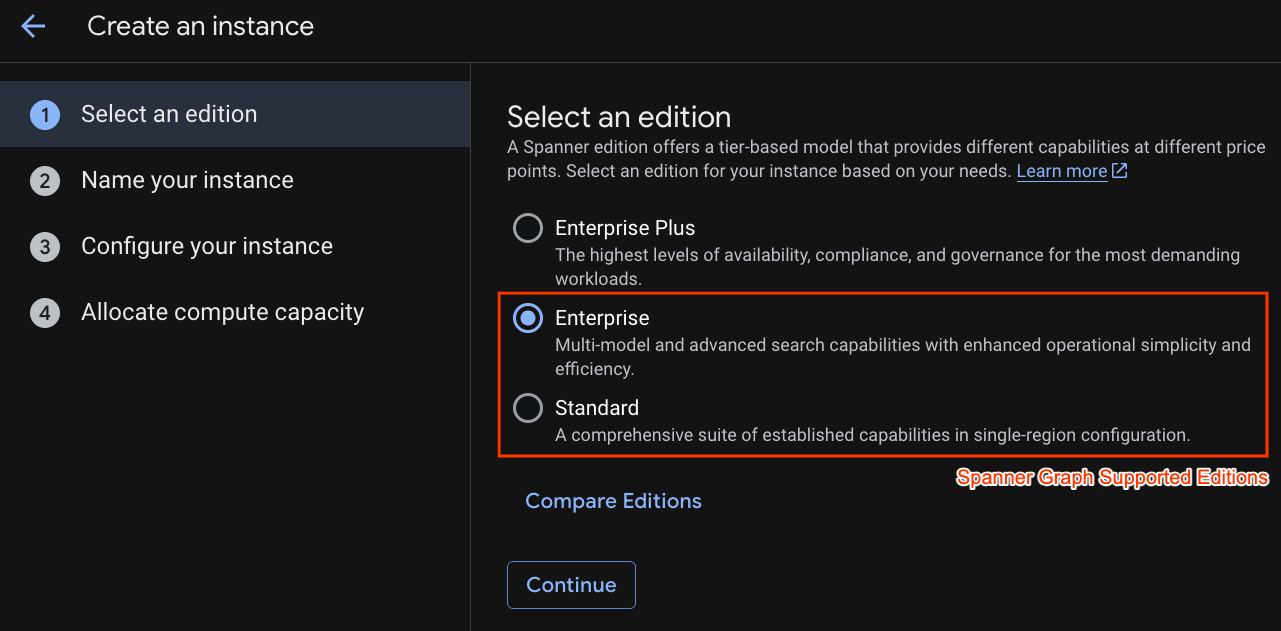
सबसे पहले, आपको Cloud Spanner इंस्टेंस बनाना होगा. नया इंस्टेंस बनाने के लिए, यूज़र इंटरफ़ेस (यूआई) में "प्रोविज़न किया गया इंस्टेंस बनाएं" पर क्लिक करें.
पहले चरण में, आपको कोई एडिशन चुनना होगा. कृपया ध्यान दें कि बाद में भी वर्शन को अपग्रेड किया जा सकता है. मल्टी-मॉडल की सुविधाओं (Spanner Graph) का इस्तेमाल करने के लिए, Enterprise वर्शन का इस्तेमाल किया जा सकता है.
अपने इंस्टेंस का नाम देना
डिप्लॉयमेंट का कॉन्फ़िगरेशन चुनें और अपनी पसंद का क्षेत्र चुनें.
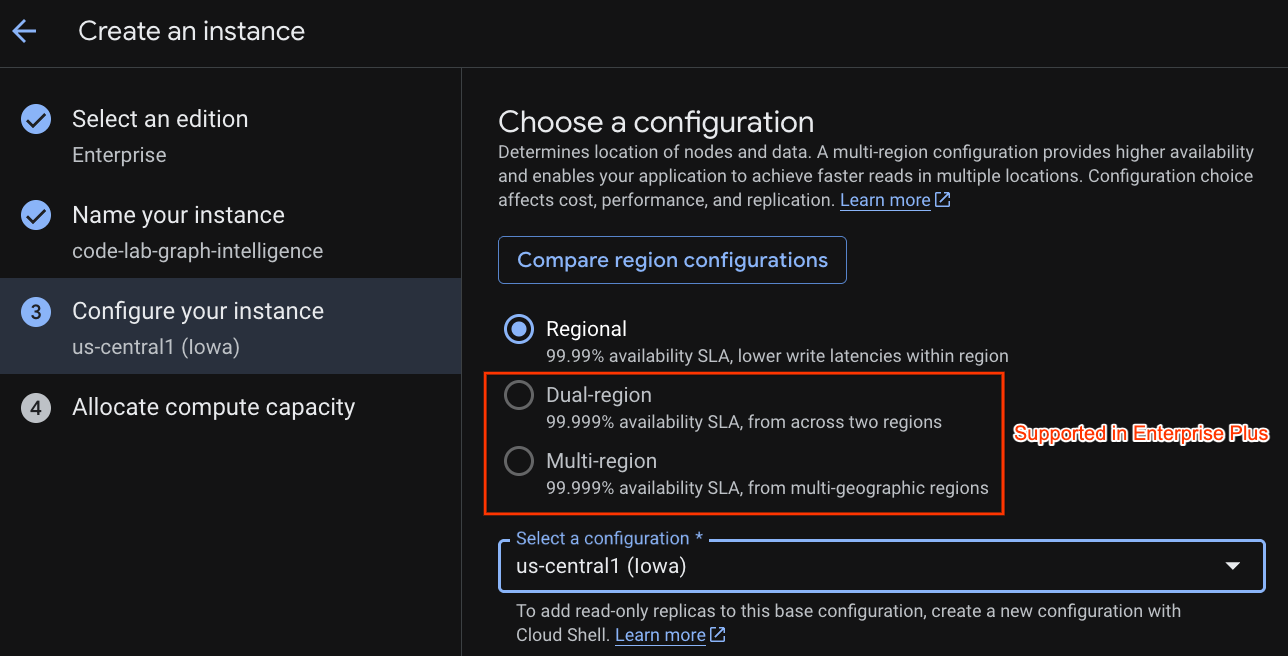
आपके पास अलग-अलग कॉन्फ़िगरेशन विकल्पों की तुलना करने का विकल्प भी होता है. उदाहरण के लिए, डिप्लॉयमेंट कॉन्फ़िगरेशन में, चुने गए क्षेत्र के तीन अलग-अलग ज़ोन में कम से कम तीन R/W रेप्लिका होते हैं. इसका मतलब है कि अगर आपने एक नोड डिप्लॉयमेंट चुना है, तो आपके पास तीन R/W रेप्लिका के ज़रिए तीन कॉपी होंगी. इसके अलावा, रीजनल डिप्लॉयमेंट कॉन्फ़िगरेशन के साथ भी, डिप्लॉयमेंट टोपोलॉजी में अतिरिक्त R/O रेप्लिका जोड़कर, इसे और बढ़ाया जा सकता है.
क्षमता को कॉन्फ़िगर करने के बाद, आपके पास दो विकल्प होते हैं: या तो पूरे नोड से शुरू करें और नोड पर अपने-आप स्केलिंग की सुविधा चालू करें या ग्रेन्यूलर इंस्टेंस (प्रोसेसिंग यूनिट; 1000 पीयू = 1 नोड) का इस्तेमाल करें. आपके पास इंस्टेंस के लिए, अपने-आप स्केल होने के टारगेट सेट करने का विकल्प भी होता है. कम समय में होने वाले वर्कलोड के लिए, हमारा सुझाव है कि रीजनल इंस्टेंस के लिए 65% और एक से ज़्यादा रीजन वाले इंस्टेंस के लिए 45% का इस्तेमाल करें.
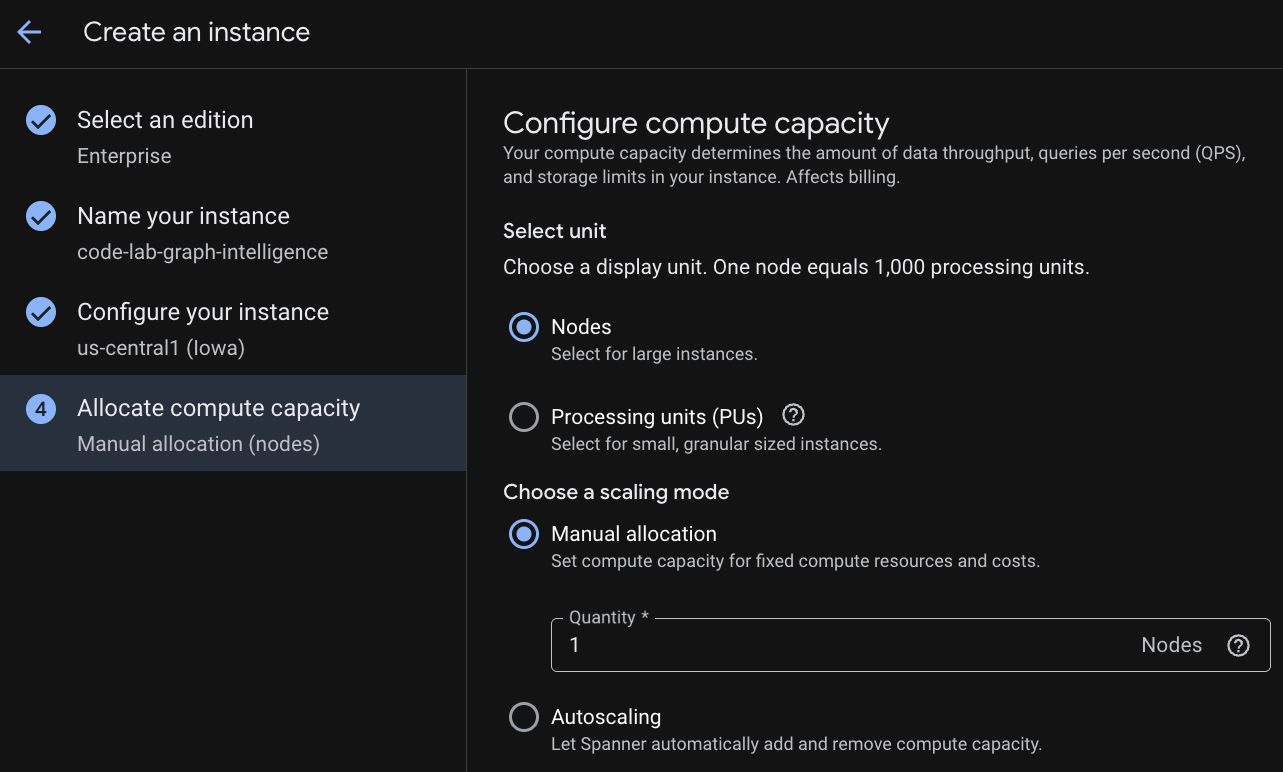
तीसरा चरण: डेटाबेस बनाना
आपका इंस्टेंस तैयार हो जाने के बाद, "डेटाबेस बनाएं" पर क्लिक करें. इससे आपके बाकी कोडलैब के लिए डेटाबेस बन जाएगा.
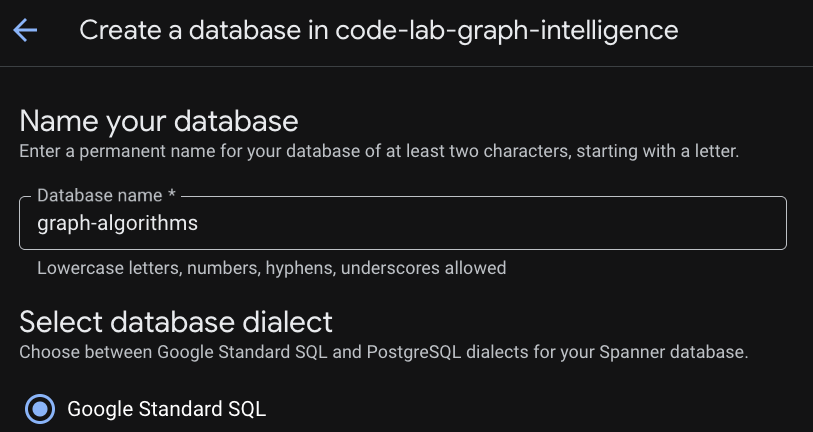
रिलेशनशिप बनाने की शुरुआत करना
हमारी यात्रा, उन मुख्य टेबल से शुरू होती है जिनमें ऑपरेशनल डेटा सेव होता है. Cloud Spanner में, हम इंटरलीविंग का इस्तेमाल करके, एक-दूसरे से जुड़े डेटा को एक साथ रखते हैं. जैसे, किसी ग्राहक की दोस्ती और लेन-देन की जानकारी को सीधे तौर पर ग्राहक के रिकॉर्ड के साथ रखा जाता है. इससे यह पक्का होता है कि आपको बेहतर परफ़ॉर्मेंस और फ़िज़िकल लोकैलिटी का ऐक्सेस मिले.
डीडीएल: टेबल बनाना
रिलेशनल स्कीमा बनाने के लिए, यहां दिए गए ब्लॉक को कॉपी करें और लागू करें:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
नेटवर्क को सीड करना
टेबल तैयार होने के बाद, हमें उनमें उन उपयोगकर्ताओं, प्रॉडक्ट, और कनेक्शन की जानकारी भरनी होगी जो ग्राहक के नेटवर्क को तय करते हैं.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
रिश्ते से जुड़ी समस्या
ग्राफ़ के बारे में बताने से पहले, आइए देखते हैं कि पारंपरिक एसक्यूएल, ग्राहक की चुनौतियों को कैसे मैनेज करता है. ज़्यादा खर्च करने वाले और कई दोस्तों वाले "सोशल स्पेंडर" ग्राहकों को ढूंढने के लिए, यह क्वेरी चलाएं.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
रिलेशनल डेटाबेस की सीमाएं
प्रॉपर्टी ग्राफ़ की मदद से, रिलेशनल डेटा से जुड़ी समस्याओं को हल करना
इन सीमाओं को दूर करने के लिए, हम प्रॉपर्टी ग्राफ़ को तय करते हैं. इससे एक "ओवरले" बनता है. इसकी मदद से, हम अपने डेटा को Spanner से बाहर ले जाए बिना, संबंधों को पहले दर्जे के नागरिक के तौर पर मान सकते हैं.
डीडीएल: प्रॉपर्टी ग्राफ़ बनाना
यह DDL, हमारे नोड (इकाइयों) और एज (संबंधों) के बारे में बताता है. इस उदाहरण में, हम स्कीमा वाले ग्राफ़ का इस्तेमाल कर रहे हैं. हालांकि, Spanner Graph में बिना स्कीमा वाले ग्राफ़ को मॉडल करने की अनुमति होती है. इससे, ज़रूरत के हिसाब से बदलाव करने, तेज़ी से डेवलपमेंट करने, और डेटा मॉडल में लगातार बदलाव किए बिना, DDL (डेटा डेफ़िनिशन लैंग्वेज) में बदलाव करने की सुविधा मिलती है.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
GQL की मदद से ग्राफ़ में नेविगेट करना
ग्राफ़ तय हो जाने के बाद, हम ग्राफ़ क्वेरी लैंग्वेज (GQL) का इस्तेमाल करके, एक से ज़्यादा हॉप वाले ट्रैवर्सल कर सकते हैं. इसके लिए, हमें आसान और पढ़ने में आसान सिंटैक्स का इस्तेमाल करना होगा.
एक्सप्लोरेशन 1: साथ मिलकर खोज करना
यह क्वेरी, ग्राफ़ को ट्रैवर्स करके आपके दोस्तों के खरीदे गए प्रॉडक्ट ढूंढती है. साथ ही, यह सुझाव देने वाले इंजन के तौर पर काम करती है.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
एक्सप्लोरेशन 2: हाइब्रिड क्वेरी (रिलेशनल + ग्राफ़)
Spanner, GRAPH_TABLE फ़ंक्शन का इस्तेमाल करके, स्टैंडर्ड एसक्यूएल के FROM क्लॉज़ में GQL पैटर्न एम्बेड करने की अनुमति देता है. इस क्वेरी से, उन ग्राहकों को खोजा जाता है जो अपने दोस्तों की तरह ही एक ही जगह पर रहते हैं. इसे "डायमंड" पैटर्न मैच कहा जाता है.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
ग्राहक के कनेक्शन को विज़ुअलाइज़ करना
आखिर में, आइए GQL का इस्तेमाल करके अपने नेटवर्क को विज़ुअलाइज़ करें. इन क्वेरी में, पाथ के नतीजों को SAFE_TO_JSON में रैप किया जाता है. इससे विज़ुअलाइज़र, नोड और लाइनें बना पाते हैं.
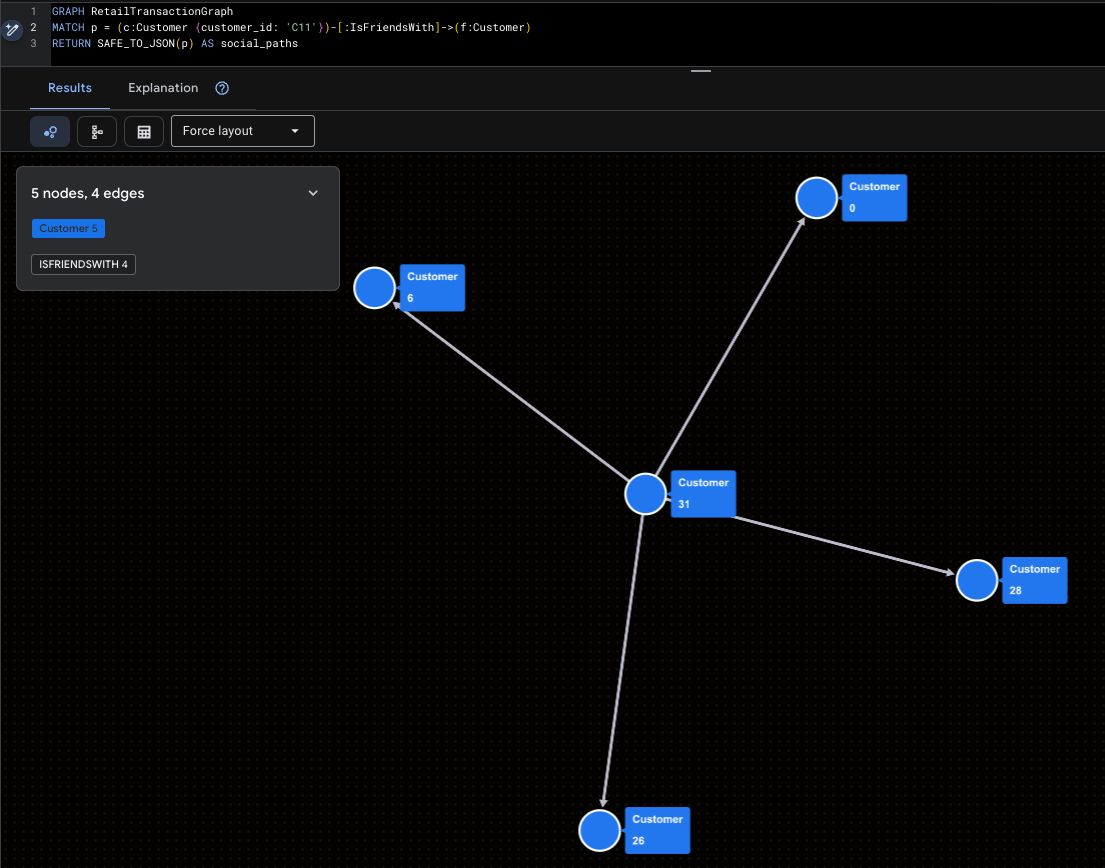
सुपर-इन्फ़्लुएंसर को विज़ुअलाइज़ करना
इससे मैलरी (C11) और उसकी सोशल मीडिया पर सीधी पहुंच के बारे में पता चलता है.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
धोखाधड़ी के संभावित पैटर्न को विज़ुअलाइज़ करना
इस क्वेरी से "आइसोलेटेड क्लस्टर" (इवान और जूडी) का पता चलता है, ताकि यह देखा जा सके कि उनके प्रॉडक्ट कहां शिप किए जा रहे हैं.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Spanner Graph के एल्गोरिदम के बारे में जानकारी
इस सेक्शन में, Cloud Spanner Graph Algorithms के तकनीकी आर्किटेक्चर और बुनियादी नियमों के बारे में बताया गया है. इससे आपको Graph Intelligence के बारे में ज़्यादा जानने में मदद मिलेगी. इन सिद्धांतों को समझना, सामान्य ट्रैवर्सल से लेकर पेटाबाइट-स्केल के संबंध विश्लेषण तक जाने के लिए ज़रूरी है.
एल्गोरिदम पोर्टफ़ोलियो
फ़िलहाल, Cloud Spanner में इंडस्ट्री स्टैंडर्ड वाली 14 ग्राफ़ एल्गोरिदम काम करती हैं. इन्हें चार फ़ंक्शनल ग्रुप में बांटा गया है, ताकि कारोबार से जुड़ी अलग-अलग समस्याओं को हल किया जा सके:
कैटगरी | साथ काम करने वाले एल्गोरिदम | कारोबार के लिए इस्तेमाल का उदाहरण |
सेंट्रेलिटी | PageRank, लोगों के हिसाब से PageRank, बिटवीननेस, क्लोज़नेस | प्रभाव डालने वाले लोगों, हब, और बॉटलनेक की पहचान करें. |
कम्यूनिटी | WCC, लेबल प्रोपगेशन, क्लिक्क फ़ाइंडिंग, कोरिलेशन क्लस्टरिंग | बेईमानी करने वाले ग्रुप, सोशल कम्यूनिटी, और साइलो का पता लगाना. |
मिलती-जुलती जानकारी | जैकार्ड, कोसाइन, कॉमन नेबर, टोटल नेबर | सुझाव देने वाले इंजन और इकाई के रिज़ॉल्यूशन को बेहतर बनाता है. |
पाथ फ़ाइंडिंग | सेट-टू-सेट शॉर्टेस्ट पाथ, GA पाथ हेल्पर | लॉजिस्टिक्स और यात्रा की दूरी को ऑप्टिमाइज़ करें. |
स्कीमा और क्वेरी से जुड़ी ज़रूरी बातें
ग्राफ़ एल्गोरिदम को सही तरीके से लागू करने के लिए, Spanner Graph को इन नियमों का पालन करना होगा:
पहली ज़रूरी शर्त. फ़िजिकल डेटा लोकैलिटी (इंटरलीविंग)
तेज़ी से काम करने वाले ग्राफ़ ट्रैवर्सल के लिए, इंटरलीविंग सबसे ज़रूरी है. इससे यह पक्का होता है कि एज डेटा को उसी सर्वर पर सेव किया गया है जिस पर सोर्स नोड को स्प्लिट किया गया है. इससे एल्गोरिदम को लागू करते समय नेटवर्क की लेटेन्सी कम हो जाती है.
- नियम: एज टेबल को उनके सोर्स नोड टेबल में इंटरलीव किया जाना चाहिए.
- फ़ॉरवर्ड ट्रैवर्सल: सोर्स नोड टेबल में एज टेबल को इंटरलीव करने से, आउटगोइंग लिंक के लिए कैश लोकैलिटी पक्का होती है.
- रिवर्स ट्रैवर्सल: "इनकमिंग" लिंक का बेहतर तरीके से विश्लेषण करने के लिए, फ़ॉरेन की का इस्तेमाल करें. इससे बैकिंग इंडेक्स अपने-आप बन जाते हैं. इसके अलावा, डेस्टिनेशन टेबल में इंटरलीव किया गया सेकंडरी इंडेक्स भी बनाया जा सकता है.
दूसरी ज़रूरी शर्त. यूनिक लेबलिंग से जुड़ी ज़रूरी शर्तें
प्रॉपर्टी ग्राफ़ में शामिल हर टेबल की एक यूनीक आइडेंटिटी होनी चाहिए. एल्गोरिदम इन लेबल पर भरोसा करते हैं, ताकि वे उन सबग्राफ़ की सही पहचान कर सकें और उन्हें लोड कर सकें जिनका उन्हें विश्लेषण करना है.
- नियम: हर इनपुट टेबल में, प्रॉपर्टी ग्राफ़ के अंदर यूनीक आइडेंटिफ़ाइंग लेबल होना चाहिए.
- समस्या: अगर आपको कई टेबल पर एल्गोरिदम चलाने हैं, तो एक लेबल को कई टेबल से मैप नहीं किया जा सकता.
लॉजिक | उदाहरण | नतीजा |
❌ खराब | नोड टेबल (व्यक्ति के तौर पर लेबल की गई इकाई, खाते के तौर पर लेबल की गई इकाई) | अमान्य: एल्गोरिदम, किसी व्यक्ति और खाते के बीच अंतर नहीं कर सकता. |
✅ अच्छी | नोड टेबल (व्यक्ति का लेबल ग्राहक, खाते का लेबल खाता) | मान्य: हर इकाई का एक अलग और यूनीक लेबल है. |
तीसरी ज़रूरी शर्त. Algorithm Query Structure (The MATCH Clause)
किसी एल्गोरिदम को कॉल करते समय, MATCH क्लॉज़, स्टैंडर्ड GQL क्वेरी की तुलना में ज़्यादा पाबंदियों वाले नियमों का पालन करता है. इससे यह पक्का किया जा सकता है कि एक्ज़ीक्यूशन इंजन, विश्लेषण पाइपलाइन को ऑप्टिमाइज़ कर सके.
- हर MATCH के लिए एक पैटर्न: हर MATCH स्टेटमेंट में सिर्फ़ एक वैरिएबल का नाम दिया जा सकता है.
- एक से ज़्यादा नोड वाले पैटर्न नहीं: एल्गोरिदम कॉल के लिए बनाए गए MATCH क्लॉज़ में, सीधे तौर पर किसी संबंध के पैटर्न (जैसे, (a)-[e]->(b)) को तय नहीं किया जा सकता.
- सिर्फ़ लिटरल फ़िल्टर: नोड को फ़िल्टर करने के लिए WHERE क्लॉज़ का इस्तेमाल किया जा सकता है.जैसे, WHERE a.id > 400.हालांकि, फ़िलहाल ग्राफ़ एल्गोरिदम क्वेरी में क्वेरी पैरामीटर (@param) इस्तेमाल नहीं किए जा सकते.
चौथी ज़रूरी शर्त. RETURN क्लॉज़ (सिर्फ़ स्केलर के लिए)
किसी एल्गोरिदम क्वेरी में मौजूद RETURN क्लॉज़, ग्राफ़ वर्ल्ड और रिलेशनल वर्ल्ड के बीच एक पुल की तरह काम करता है. यह सिर्फ़ स्केलर और कॉन्स्टेंट वैल्यू दिखाता है.
- नियम: "ग्राफ़ एलिमेंट" (रॉ नोड या एज ऑब्जेक्ट) को वापस नहीं लाया जा सकता.
- कोई बदलाव नहीं किया जा सकता: RETURN स्टेटमेंट में दिखाई गई प्रॉपर्टी में, गणित से जुड़ी कार्रवाइयां नहीं की जा सकतीं. साथ ही, उन पर फ़ंक्शन भी लागू नहीं किए जा सकते.
RETURN क्लॉज़ से जुड़ी पाबंदियां
✅ काम करता है | ❌ काम नहीं करता |
RETURN node.id, score | RETURN नोड, स्कोर (ग्राफ़ एलिमेंट नहीं दिखाया जा सकता) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (No operations on properties) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (No functions) |
पांचवीं ज़रूरी शर्त. डेटा का रखरखाव: डैंगलिंग एज को हटाना
"डैंगलिंग एज" तब होता है, जब कोई एज ऐसे डेस्टिनेशन नोड की ओर इशारा करता है जो ग्राफ़ में मौजूद नहीं है. इस वजह से, एल्गोरिदम काम नहीं करता, क्योंकि ग्राफ़ का स्ट्रक्चर एक जैसा नहीं होता.
- समाधान: ग्राफ़ की इंटिग्रिटी बनाए रखने के लिए, रेफ़रेंशियल कंस्ट्रेंट (विदेशी कुंजियां) और ON DELETE CASCADE का इस्तेमाल करें.
- क्वेरी की सुरक्षा: किसी एल्गोरिदम को कॉल करते समय, आपको यह पक्का करना होगा कि चुने गए सभी किनारों से जुड़े नोड भी node_labels आर्ग्युमेंट में शामिल हों.
परसिस्टेंट आउटपुट: EXPORT DATA के विकल्प
ग्राफ़ एल्गोरिदम में ज़्यादा कंप्यूटिंग की ज़रूरत होती है. इसलिए, इन्हें EXPORT DATA स्टेटमेंट का इस्तेमाल करके, स्केल-अप एक्ज़ीक्यूशन मोड में एक्ज़ीक्यूट किया जाता है. यह डेटा बूस्ट का इस्तेमाल करता है. इसमें इंडिपेंडेंट सर्वरलेस कंप्यूट रिसॉर्स का इस्तेमाल किया जाता है, ताकि आपके प्रोडक्शन ट्रांज़ैक्शन में कोई रुकावट न आए.
पहला विकल्प: Cloud Spanner में डेटा सेव करना
नतीजों को सीधे अपनी टेबल में वापस भेजने के लिए, format = ‘CLOUD_SPANNER' का इस्तेमाल करें. उदाहरण के लिए, PageRank स्कोर सेव करना.
update_ignore_all: यह सिर्फ़ उन कुंजियों के लिए लाइनों को अपडेट करता है जो टारगेट टेबल में पहले से मौजूद हैं.upsert_ignore_all: इससे मौजूदा पंक्तियां अपडेट होती हैं. अगर कुंजियां मौजूद नहीं हैं, तो नई पंक्तियां जोड़ी जाती हैं.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
दूसरा विकल्प: नतीजों को Google Cloud Storage (GCS) में सेव करना
बड़े पैमाने पर ऑफ़लाइन विश्लेषण के लिए, डेटा को GCS में CSV, Avro या Parquet फ़ॉर्मैट में एक्सपोर्ट किया जा सकता है.
- वाइल्डकार्ड:
uri => 'gs://bucket/file_*.csv'का इस्तेमाल करके, शार्ड किया गया आउटपुट चालू करें. इससे Spanner, बड़े डेटासेट के लिए एक साथ कई फ़ाइलों में डेटा लिख सकता है. - कंप्रेशन: स्टोरेज के खर्च को ऑप्टिमाइज़ करने के लिए, GZIP, SNAPPY, और ZSTD के साथ काम करता है.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. पहली चुनौती: पेज रैंक के आधार पर, कॉन्टेंट को बेहतर तरीके से रैंक करने की सुविधा
इस सेक्शन में, हम ग्राहक की पहली कारोबारी चुनौती के बारे में बात करेंगे: "इन्फ़्लुएंस गैप." हम "लोकप्रियता की प्रतियोगिता" से हटकर, गणित के आधार पर तैयार किए गए ऐसे मैप पर काम करेंगे जिससे सोशल मीडिया पर किसी व्यक्ति की लोकप्रियता का सही आकलन किया जा सकेगा.
समस्या का ब्यौरा: ग्राहक की मार्केटिंग टीम को समस्या आ रही है. वे ब्रॉड विज्ञापन पर लाखों रुपये खर्च कर रहे हैं, लेकिन उन्हें कम फ़ायदा मिल रहा है. इसकी वजह यह है कि वे "सोशल सुपरस्टार" की पहचान नहीं कर पा रहे हैं. ये ऐसे लोग होते हैं जिनके प्रमोशन से पूरे नेटवर्क को फ़ायदा मिलता है.
इस समस्या को हल करने के लिए, हमें अपने ग्राहकों को इन्फ़्लुएंस के हिसाब से रैंक करना होगा.
रिलेशनल सलूशन (डिग्री सेंट्रलिटी)
स्टैंडर्ड डेटाबेस में, किसी इन्फ़्लुएंसर को ढूंढने का सबसे आसान तरीका है कि उसके फ़ॉलोअर की संख्या गिनी जाए. इस मेट्रिक को डिग्री सेंट्रेलिटी कहा जाता है.
सबसे "लोकप्रिय" उपयोगकर्ताओं को ढूंढने के लिए, यह क्वेरी चलाएं:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
ग्राफ़ इंटेलिजेंस (पेज रैंक)
असल लीडर का पता लगाने के लिए, हम PageRank का इस्तेमाल करते हैं. यह वही एल्गोरिदम है जो वेब खोज की शुरुआती सुविधा को बेहतर बनाता है. यह नोड की अहमियत का आकलन, आने वाले लिंक की संख्या और क्वालिटी के आधार पर करता है.
- रैंडम सर्फ़र मॉडल: PageRank, किसी उपयोगकर्ता के ग्राफ़ में घूमने की नकल करता है. डैंपिंग फ़ैक्टर (डिफ़ॉल्ट रूप से 0.85) से पता चलता है कि उपयोगकर्ता के क्लिक जारी रखने की कितनी संभावना है. ऐसा न होने पर, वे किसी रैंडम नोड पर "टेलीपोर्ट" हो जाते हैं .
- अहमियत: किसी प्रभावशाली व्यक्ति (जैसे, मैलरी) से मिला लिंक, किसी ऐसे व्यक्ति से मिले लिंक की तुलना में ज़्यादा अहम होता है जिसके कोई अन्य कनेक्शन नहीं हैं.
हम PageRank एल्गोरिदम को लागू करेंगे और EXPORT DATA का इस्तेमाल करके, नतीजों को सीधे pagerank_score कॉलम में सेव करेंगे .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
PageRank का इस्तेमाल करके"असर" डैशबोर्ड
अब स्कोर सेव हो गए हैं. इसलिए, आइए "पहले" (फ़ॉलोअर की संख्या) और "बाद में" (PageRank स्कोर) की तुलना करें.
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
विश्लेषण: असली सुपरस्टार कौन हैं?
आउटपुट का विश्लेषण करके, अब मार्केटिंग से जुड़ी तीन अहम बातों का पता लगाया जा सकता है:
कारोबार के लिए अहम जानकारी
पांच से ज़्यादा फ़ॉलोअर वाले सभी लोगों को ईमेल भेजने के बजाय, अब ग्राहक की मार्केटिंग टीम सिर्फ़ उन लोगों पर फ़ोकस कर सकती है जिनका pagerank_score सबसे ज़्यादा है. ये लोग "सोशल सुपरस्टार" होते हैं. ये पूरे मार्केटप्लेस में सिस्टमैटिक तरीके से वायरल होने की क्षमता रखते हैं.
अब उन गेटकीपर की पहचान करने की कोशिश करते हैं जो ग्राहक के लॉजिस्टिक्स नेटवर्क को चालू रखते हैं.
5. दूसरी चुनौती: लॉजिस्टिक रेज़िलिएंस (बिटवीननेससेंट्रेलिटी)
इस सेक्शन में, हम लॉजिस्टिक्स की मज़बूती के बारे में बात करेंगे. हम "वॉल्यूम" के आधार पर सफलता का आकलन करने के बजाय, उन अहम "गेटकीपर" की पहचान करेंगे जो नेटवर्क को कनेक्ट रखते हैं.
रिलेशनल सलूशन (वॉल्यूम के आधार पर विश्लेषण)
स्टैंडर्ड रिलेशनल सेटअप में, "ज़रूरी" शिपिंग हब को आम तौर पर ऐसे हब के तौर पर तय किया जाता है जो सबसे ज़्यादा ऑर्डर प्रोसेस करता है या सबसे ज़्यादा रेवेन्यू जनरेट करता है.
लेन-देन की संख्या के हिसाब से "टॉप" हब की पहचान करने के लिए, यह क्वेरी चलाएं:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
न्यूयॉर्क | यूएसए | 4 | 3996 |
बर्लिन | जर्मनी | 2 | 345 |
सैन फ़्रांसिस्को | यूएसए | 2 | 750 |
इस अंतर को ठीक करने के लिए, हम IsFriendsWith और LivesAt, दोनों किनारों का इस्तेमाल करेंगे. इससे हमारा विश्लेषण, लेन-देन के हब से बदलकर सोशल चेक में भी शामिल हो जाता है.
ग्राफ़ इंटेलिजेंस (बिटवीननेस सेंट्रलटी)
असली समस्याओं का पता लगाने के लिए, हम बिटवीननेस सेंट्रलटी का इस्तेमाल करते हैं. यह एल्गोरिदम यह तय करता है कि किसी ग्राफ़ में मौजूद नोड के हर जोड़े के बीच सबसे छोटे पाथ में, कोई नोड कितनी बार "ब्रिज" के तौर पर काम करता है. ज़्यादा स्कोर से, उन लोगों की पहचान की जा सकती है जो सामान या जानकारी के फ़्लो को कंट्रोल करते हैं.
बिटवीननेस सेंट्रलटी को लागू करना और बनाए रखना
हम EXPORT DATA का इस्तेमाल करके एल्गोरिदम को लागू करेंगे और स्कोर को centrality_score कॉलम में सेव करेंगे. हम डेटा बूस्ट का इस्तेमाल करते हैं, ताकि "सबसे छोटा रास्ता" कैलकुलेट करने की इस जटिल प्रक्रिया का असर, ग्राहक की लाइव कार्रवाइयों पर न पड़े.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
विश्लेषण: "छिपे हुए बॉटलनेक" की पहचान करना
अब हम स्ट्रक्चरल जोखिम (centrality_score) की तुलना, लेन-देन की संख्या (order_count) से करते हैं. इससे हमें उन नोड का पता चलता है जिनके बारे में ग्राहक की लीडरशिप को चिंता करनी चाहिए.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
इन नतीजों का विश्लेषण करके, ग्राहक को तीन चौंकाने वाली बातें पता चलती हैं:
कारोबार के लिए अहम जानकारी
ग्राहक अब मल्टी-मॉडल स्ट्रक्चरल रिस्क के आधार पर, लॉजिस्टिक्स रिडंडेंसी और सुरक्षा प्रोटोकॉल को प्राथमिकता दे सकता है. मैलरी, एलिस, और ईव, गेटकीपर हैं. लॉजिस्टिकल नेटवर्क को स्थिर रखने के लिए, इन्हें सुरक्षित रखना ज़रूरी है.
अब हम फ़्रॉड आइलैंड को अलग करने की कोशिश करते हैं.
6. तीसरी चुनौती: घोस्ट नेटवर्क (डब्ल्यूसीसी)
इस सेक्शन में, हम कारोबार से जुड़ी तीसरी समस्या के बारे में बात करेंगे: "घोस्ट नेटवर्क". हम "हॉटस्पॉट" का पता लगाने के लिए, कम्यूनिटी का पता लगाने वाली सुविधा का इस्तेमाल करेंगे. इससे हमें धोखाधड़ी करने वाले ऐसे ग्रुप का पता लगाने में मदद मिलेगी जो अलग-अलग जगहों पर काम करते हैं. यहां चुनौती यह है कि बुरे लोग, नकली प्रोफ़ाइलें बनाते हैं. ये प्रोफ़ाइलें, शिपिंग के पते शेयर करती हैं या चोरी को अंजाम देने और प्रॉडक्ट की रेटिंग बढ़ाने के लिए, बंद लूप में इंटरैक्ट करती हैं. हालांकि, ये अक्सर असली ग्राहक समुदाय से पूरी तरह अलग होते हैं.
इस समस्या को हल करने के लिए, हमें इन "आइसोलेटेड आइलैंड" को दिखाना होगा.
रिलेशनल सलूशन (शेयर किए गए आइडेंटिफ़ायर की मदद से खोज करना)
ग्राफ़ एल्गोरिदम के बिना, धोखाधड़ी का पता लगाने का सामान्य तरीका यह है कि शेयर किए गए डेटा के "हॉटस्पॉट" खोजे जाएं. जैसे, एक ही पते पर शिपिंग करने वाले कई ग्राहक.
शिपिंग की जगह की जानकारी शेयर करने वाले खरीदारों को ढूंढने के लिए, यह क्वेरी चलाएं:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
धोखाधड़ी करने वाले नेटवर्क का पता लगाने के लिए, हमें ट्रांज़िटिव रीचेबिलिटी को समझना होगा.
ग्राफ़ इंटेलिजेंस (वीकली कनेक्टेड कॉम्पोनेंट)
इन रिंग की पूरी जानकारी पाने के लिए, हम वीकली कनेक्टेड कॉम्पोनेंट (डब्ल्यूसीसी) का इस्तेमाल करते हैं. डब्ल्यूसीसी, क्लस्टरिंग एल्गोरिदम है. यह नोड के ऐसे सेट की पहचान करता है जिनमें किसी भी दो नोड के बीच पाथ मौजूद होता है. इसमें किनारों की दिशा से कोई फ़र्क़ नहीं पड़ता.
- रीचेबिलिटी ज़ोन: यह ग्राफ़ को "आइलैंड" या "रीचेबिलिटी ज़ोन" में बांटता है.
- एक जैसी इकाइयों को एक साथ देखने की सुविधा: सामाजिक संबंधों (IsFriendsWith) और लॉजिस्टिक्स से जुड़े संबंधों (LivesAt) का एक साथ विश्लेषण करके, हम अलग-अलग प्रोफ़ाइलों को एक ही "इंपैक्ट क्लस्टर" में ग्रुप कर सकते हैं.
WCC को चालू रखना और उसे बनाए रखना
हम WCC एल्गोरिदम को लागू करेंगे और नतीजों को community_id कॉलम में सेव करेंगे. हम डेटा बूस्ट का इस्तेमाल करते हैं, ताकि यह पक्का किया जा सके कि पहुंच से जुड़ी इस बेहतर विश्लेषण को इंडिपेंडेंट कंप्यूट रिसोर्स पर किया जाए.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
विश्लेषण: धोखाधड़ी करने वाले ग्रुप
अब, अलग-अलग कम्यूनिटी देखने के लिए, पुष्टि करने वाली क्वेरी चलाएं. आम तौर पर, असली उपयोगकर्ता "मुख्य भूभाग" से होते हैं, जबकि धोखाधड़ी करने वाले लोग अक्सर छोटे "द्वीप" से होते हैं.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | सदस्य |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
कम्यूनिटी का पता लगाने की सुविधा का इस्तेमाल करके, इस अहम गड़बड़ी का पता लगाया जा सकता है:
कारोबार के लिए अहम जानकारी
अब ग्राहक, सुरक्षा से जुड़े जवाबों को अपने-आप जनरेट होने की सुविधा का इस्तेमाल कर सकता है. अलग-अलग खातों को मैन्युअल तरीके से ट्रैक करने के बजाय, वे एक आसान नियम बना सकते हैं: "अगर किसी community_id में तीन से कम सदस्य हैं, तो पूरे ग्रुप को मैन्युअल तरीके से केवाईसी (अपने ग्राहक को जानें) की समीक्षा के लिए फ़्लैग करें"
.
धोखाधड़ी करने वाले ग्रुप का पता चलने पर, हम "बिहेवियरल ट्विन" की समस्या को हल कर सकते हैं.
7. चौथी चुनौती: बिहेवियरल ट्विन (JaccardSimilarity)
इस आखिरी चुनौती में, हम चौथी समस्या के बारे में बात करेंगे: "पसंद का विरोधाभास"/"व्यवहार से मिलते-जुलते". हम "अक्सर साथ में खरीदे जाने वाले प्रॉडक्ट" की सामान्य सूचियों से, व्यवहार के "फ़िंगरप्रिंट" के आधार पर, लोगों की दिलचस्पी के हिसाब से बनाए गए सुझावों पर स्विच करेंगे.
ग्राहक को प्रॉडक्ट के बारे में दिए गए मौजूदा सुझाव बहुत सामान्य हैं. हर ग्राहक को लोकप्रिय यूएसबी केबल का सुझाव देना सुरक्षित है, लेकिन यह निजी नहीं है. ग्राहक को "बिहेवियरल ट्विन" के आधार पर सुझाव देने हैं. इसके लिए, उसे ऐसे खरीदारों की पहचान करनी है जो शिपिंग के लिए एक जैसे पैटर्न और सोशल सर्कल का इस्तेमाल करते हैं. इससे, वह सटीक मैच वाले प्रॉडक्ट के सुझाव दे पाएगा.
इस समस्या को हल करने के लिए, हमें उपयोगकर्ताओं के बीच "निकटता" का हिसाब लगाना होगा.
रिलेशनल सलूशन (पूरी तरह से ओवरलैप)
स्टैंडर्ड रिलेशनल सेटअप में, आपको उन लोगों को ढूंढना पड़ सकता है जो रेफ़रंस उपयोगकर्ता, जैसे कि ऐलिस (C1) की तरह ही जगहों पर शिपिंग करते हैं.
ऐलिस के आस-पास रहने वाले लोगों की भौगोलिक जानकारी ढूंढने के लिए, यह क्वेरी चलाएं:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
ग्राफ़ इंटेलिजेंस (जैकार्ड सिमिलैरिटी)
व्यवहार के आधार पर मिलते-जुलते उपयोगकर्ताओं का पता लगाने के लिए, हम जैकार्ड सिमिलैरिटी का इस्तेमाल करते हैं. यह एल्गोरिदम, सामान्य किए गए स्कोर (0.0 से 1.0) का हिसाब लगाता है. इसके लिए, शेयर किए गए पड़ोसियों (इंटरसेक्शन) की संख्या को, यूनीक पड़ोसियों (यूनियन) की कुल संख्या से भाग दिया जाता है.
यहां "व्यवहार से मिलते-जुलते" लोगों को सिर्फ़ शिपिंग के पते के आधार पर नहीं, बल्कि अन्य आधारों पर भी तय किया जाता है. फ़िज़िकल फ़ुटप्रिंट (LivesAt) और सोशल इकोसिस्टम (IsFriendsWith) के इंटरसेक्शन का विश्लेषण करके, हम उन उपयोगकर्ताओं की पहचान कर सकते हैं जिनका लाइफ़स्टाइल और कम्यूनिटी इन्फ़्लुएंस एक जैसा है. इससे, प्रॉडक्ट के ज़्यादा सटीक सुझाव दिए जा सकते हैं.
सबसे पहले, मैपिंग टेबल बनाएं
समानता एक पेयरवाइज़ संबंध है (ग्राहक A, ग्राहक B के जैसा है). इसलिए, हम इन मैपिंग को सेव करने के लिए, Customer में इंटरलीव की गई एक खास टेबल बनाते हैं.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
अब जैकार्ड सिमिलैरिटी का इस्तेमाल करें
अब हम एल्गोरिदम को लागू करेंगे. ध्यान दें: इस क्वेरी में, "गार्डरेल" का एक सामान्य सबक शामिल है. अगर सिर्फ़ ग्राहक नोड चुने जाते हैं, लेकिन LivesAt एज का इस्तेमाल किया जाता है (जो शिपिंग नोड की ओर इशारा करता है), तो क्वेरी में "डैंगलिंग एज" की वजह से गड़बड़ी होगी . इस समस्या को ठीक करने के लिए, हमें दोनों नोड लेबल शामिल करने होंगे.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
विश्लेषण: "व्यवहार से मिलते-जुलते" चेक
विश्लेषण का काम पूरा होने के बाद, हम पुष्टि करने वाली क्वेरी चलाते हैं. हमारी नई मैपिंग टेबल (CustomerSimilarity) को हमारे ओरिजनल Customer मेटाडेटा के साथ जोड़ने पर, हमें यह पता चल सकता है कि एलिस के "बिहेवियरल ट्विन" कौन हैं.
ऐलिस की मिलती-जुलती रैंकिंग की जांच करने के लिए, यह क्वेरी चलाएं:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
नतीजों में क्या देखें:
अब हम यूनीफ़ाइड इंटेलिजेंस का फ़ाइनल व्यू बनाने की कोशिश करते हैं.
8. यूनिफ़ाइड इंटेलिजेंस
अब हम अलग-अलग तकनीकी टास्क से यूनिफ़ाइड इंटेलिजेंस पर आते हैं. यहां, हम लेन-देन के डेटा को चारों ग्राफ़ एल्गोरिदम के साथ मिलाकर, काम की अहम जानकारी देते हैं.
पहली रिपोर्ट: यूनीफ़ाइड इंटेलिजेंस
Spanner जैसे मल्टी-मॉडल डेटाबेस की सबसे बड़ी खासियत यह है कि यह एक ही अनुरोध में, खर्च से जुड़े डेटा को ग्राफ़ से मिले असर, जोखिम, और समानता के स्कोर के साथ जोड़ सकता है. इस क्वेरी से, हर ग्राहक को किसी खास कारोबारी पर्सोना में कैटगरी में रखा जाता है.
पूरा ईकोसिस्टम देखने के लिए, यूनिफ़ाइड इंटेलिजेंस क्वेरी चलाएं:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | खर्च | प्रभाव | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 ज़रूरी: नेटवर्क ब्रिज |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 ज़रूरी: नेटवर्क ब्रिज |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 ज़रूरी: नेटवर्क ब्रिज |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 सोशल मीडिया: ज़्यादा लोगों तक पहुंचने वाला इन्फ़्लुएंसर |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 सोशल मीडिया: ज़्यादा लोगों तक पहुंचने वाला इन्फ़्लुएंसर |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 स्टैंडर्ड: चालू ग्राहक |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 स्टैंडर्ड: चालू ग्राहक |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ज़्यादा जोखिम: धोखाधड़ी करने वाले लोगों का ग्रुप |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ज़्यादा जोखिम: धोखाधड़ी करने वाले लोगों का ग्रुप |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 स्टैंडर्ड: चालू ग्राहक |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 स्टैंडर्ड: चालू ग्राहक |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 स्टैंडर्ड: चालू ग्राहक |
इन गणितीय लेंस को मिलाकर, हम "किसने सबसे ज़्यादा खर्च किया" से आगे बढ़कर "कौन सबसे ज़्यादा मायने रखता है" पर पहुंचते हैं. यूनिफ़ाइड डैशबोर्ड, रिलेशनल ट्रांज़ैक्शन डेटा को मल्टी-मॉडल ग्राफ़ इंटेलिजेंस के साथ इंटिग्रेट करता है. इससे आपके इकोसिस्टम को तीन कैटगरी में बांटा जा सकता है. ये कैटगरी साफ़ तौर पर दिखती हैं और इनके आधार पर कार्रवाई की जा सकती है.
"ज़रूरी नेटवर्क ब्रिज" (लचीलापन)
Mallory (C11), Eve (C5), और Alice (C1) जैसे नोड को फ़्लैग किया गया है, क्योंकि इनका bottleneck_risk (बिटवीननेस सेंट्रेलिटी) >25 है.
- स्ट्रक्चरल ऐंकर: मैलरी का रिस्क स्कोर सबसे ज़्यादा 44.5 है. इससे पता चलता है कि वह पूरे नेटवर्क के लिए प्राइमरी गेटवे है.
- बिना खर्च किए ज़्यादा फ़ायदा पाने का विरोधाभास: ईव (C5) को कोई ऑर्डर नहीं मिला है. हालांकि, वह स्ट्रक्चर के हिसाब से ज़रूरी है और उसका जोखिम स्कोर 35.5 है. स्टैंडर्ड एसक्यूएल, उसे पूरी तरह से अनदेखा कर देता. हालांकि, ग्राफ़ इंटेलिजेंस से पता चलता है कि वह पूरी सब-कम्यूनिटी के लिए एक अहम कड़ी है.
- ज़्यादा कन्वर्ज़न वैल्यू वाला गेटवे: एलिस (C1) ने ईव के साथ 35.5 का स्कोर हासिल किया. इससे पता चलता है कि ज़्यादा खर्च करने वाले खरीदार भी स्ट्रक्चरल ऐंकर के तौर पर अहम भूमिका निभा सकते हैं.
"सोशल मीडिया के स्टार" (पहुंच)
Heidi (C8) और Grace (C7) को उनके PageRank स्कोर की वजह से, ज़्यादा पहुंच वाले इन्फ़्लुएंसर के तौर पर पहचाना गया है .
"अलग-अलग फ़्रॉड रिंग" (असामान्य गतिविधियां)
जूडी (C10) और इवान (C9) को फ़्लैग किया गया है, क्योंकि ये अलग-अलग community_id 1 से जुड़े हैं
कारोबार से जुड़ी अहम जानकारी से लेकर रणनीतिक कार्रवाइयां करने तक
Persona | मुख्य मेट्रिक | कारोबार की अहम जानकारी | रणनीतिक कार्रवाई |
🔵 नेटवर्क ब्रिज | ज़्यादा सेंट्रल होना | स्ट्रक्चरल ऐंकर: ईव (C5) और मैलरी (C11) नेटवर्क को एक साथ रखते हैं. | उपयोगकर्ताओं को बनाए रखना: इन गेटकीपर को सुरक्षित रखें, ताकि कम्यूनिटी को अलग-अलग हिस्सों में बंटने से रोका जा सके. |
📱 सोशल मीडिया के सुपरस्टार | ज़्यादा PageRank | वायरल इंजन: हाइडी (C8) जैसे उपयोगकर्ताओं की पहुंच, उनके सर्कल में सबसे ज़्यादा होती है. | मार्केटिंग: इसका इस्तेमाल, रेफ़रल और ऐंबैसडर प्रोग्राम के लिए करें. |
🔴 धोखाधड़ी के जोखिम | आइसोलेटेड डब्ल्यूसीसी | घोस्ट नेटवर्क: जूडी (C10) और इवान (C9) ज़्यादा खर्च करने वाले लोग हैं, लेकिन वे "आइलैंड" पर रहते हैं. | सुरक्षा: केवाईसी की मैन्युअल तरीके से तुरंत समीक्षा की जाती है. ये धोखाधड़ी के क्लासिक सिग्नेचर हैं. |
🟢 स्टैंडर्ड यूज़र | बैलेंस्ड स्कोर | हेल्दी कोर: नेटवर्क का ज़्यादातर हिस्सा, जिसमें डेविड (C4) जैसे "स्थानीय" ब्रिज शामिल हैं. | कारोबार में बढ़ोतरी: लोगों की दिलचस्पी के हिसाब से दिखाए जाने वाले स्टैंडर्ड विज्ञापन और "व्यवहार से मिलते-जुलते" सुझाव लागू करें. |
दूसरी रिपोर्ट: पहचान से जुड़ी गड़बड़ी की रिपोर्ट
अब आपको यह जानना होगा कि क्या धोखेबाज़, असली खातों की "नकल" कर रहे हैं. हम ऐसे उपयोगकर्ताओं को ढूंढकर इस समस्या को हल कर सकते हैं जिनकी व्यवहार से जुड़ी समानता 100% है, लेकिन सोशल कनेक्शन ज़ीरो है.
"पहचान से जुड़ी अनियमितताओं" का पता लगाने के लिए, यह क्वेरी चलाएं:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
अनियमितता की पहचान करने वाली रिपोर्ट में अहम जानकारी मिलती है. ऐसे उपयोगकर्ताओं को अलग करके जो असली ग्राहकों की तरह व्यवहार करते हैं, लेकिन उनके पास सोशल मीडिया से जुड़ा डेटा नहीं है, हम अनुमान लगाने के बजाय गणितीय संभावनाओं के आधार पर फ़ैसले लेते हैं .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
नतीजों का विश्लेषण
समानता (जैकार्ड) को कम्यूनिटी का पता लगाने (डब्ल्यूसीसी) के साथ मिलाकर, हम छिपे हुए जोखिमों का पता लगाते हैं. लेन-देन के पारंपरिक डेटा से इन जोखिमों का पता नहीं लगाया जा सकता.
- "बिहेवियरल ट्विंस" (समानता): जूडी (C10) और इवान (C9) जैसे नोड को फ़्लैग किया गया है, क्योंकि ऐलिस (C1) के मुकाबले, इनका जैकार्ड सिमिलैरिटी स्कोर 0.20 है.
- अलग-थलग रहने का व्यवहार: जूडी (C10) और इवान (C9) को अलग-थलग community_id 1 में ग्रुप किया गया है, जबकि एलिस सामाजिक "मुख्यभूमि" (कम्यूनिटी 0) से है.
- धोखाधड़ी के फ़्लैग: इस रिपोर्ट में, ऐसे उपयोगकर्ताओं की पहचान की जाती है जिनके व्यवहार में ज़्यादा समानता है (>0.9). साथ ही, जो मुख्य नेटवर्क से सामाजिक रूप से जुड़े नहीं हैं.
9. बधाई हो और खास जानकारी
इस लैब में बताया गया है कि Cloud Spanner, रिलेशनल डेटाबेस को मल्टी-मॉडल पावरहाउस में कैसे बदलता है. ग्राहक से जुड़े डेटा पर ग्राफ़ इंटेलिजेंस लागू करके, हमने स्टैटिक डेटा से कारोबार की रणनीति को बेहतर बनाने के लिए कार्रवाई करने लायक डेटा हासिल किया.
Spanner Multi-Model के फ़ायदे
- यूनीफ़ाइड आर्किटेक्चर: Spanner की मदद से, रिलेशनल डेटाबेस को आसानी से मैनेज किया जा सकता है. साथ ही, ईटीएल के जोखिम और लैग के बिना, रिलेशनशिप माइनिंग के लिए प्रॉपर्टी ग्राफ़ को तुरंत "ओवरले" किया जा सकता है.
- ऑफ-बॉक्स ऐनलिटिकल आइसोलेशन: डेटा बूस्ट का इस्तेमाल करके, मेमोरी का ज़्यादा इस्तेमाल करने वाले एल्गोरिदम (जैसे, PageRank या WCC) को इंडिपेंडेंट, सर्वरलेस कंप्यूट रिसॉर्स पर लागू किया जा सकता है. इससे, प्रोडक्शन चेकआउट की परफ़ॉर्मेंस पर कोई असर नहीं पड़ता.
- इंटरलीविंग की परफ़ॉर्मेंस: Spanner की यूनीक इंटरलीविंग की सुविधा यह पक्का करती है कि नोड और उनके संबंध एक ही जगह पर मौजूद हों. इससे, ग्लोबल डेटा को तेज़ी से ऐक्सेस किया जा सकता है.
"छुपे हुए रत्न" और अनियमितताओं का पता लगाना
- स्ट्रक्चरल वैल्यू की पहचान करना: बिटवीननेस सेंट्रलटी जैसे ग्राफ़ एल्गोरिदम ने बिना किसी खर्च वाले "छिपे हुए ब्रिज" का पता लगाया. ये सबसे ज़्यादा खर्च करने वाले ग्राहकों की तुलना में, नेटवर्क की मज़बूती के लिए ज़्यादा अहम हो सकते हैं.
- व्यवहार की नकल करने वाले खातों का पता लगाना: हमने जैकार्ड सिमिलैरिटी और वीकली कनेक्टेड कॉम्पोनेंट को मिलाकर, "सोशल स्ट्रेंजर" का पता लगाया. ये खाते, असली ग्राहकों की तरह दिखते हैं. हालांकि, गणित के हिसाब से यह साबित हो चुका है कि ये धोखाधड़ी करने वाले अलग-अलग ग्रुप हैं.
- ग्लोबल बनाम लोकल जानकारी: मैन्युअल एसक्यूएल विश्लेषण से, नेटवर्क में शामिल लोगों के बीच बातचीत के बारे में पता चल सकता है. वहीं, ग्लोबल एल्गोरिदम से नेटवर्क के मुख्य गेटकीपर के बारे में पता चल सकता है.
डेटा को स्मार्ट और कार्रवाई करने लायक बनाना
- पर्सोना-ड्रिवन रणनीति: हमने अपनी लाइनों को रिलेशनशिप में बदल दिया है. साथ ही, एल्गोरिदम चलाकर हम कारोबार से जुड़ी चार समस्याओं को हल कर सकते हैं. ये समस्याएं हैं: नेटवर्क ब्रिज, सोशल सुपरस्टार, धोखाधड़ी के जोखिम, और स्टैंडर्ड यूज़र.