
1. Studi kasus: Retail Cerdas
Untuk studi kasus ini, kami mengambil contoh Pelanggan Retail dengan marketplace digital yang berkembang pesat. Tampilan data tradisional pelanggan terbatas karena menampilkan apa yang dibeli orang, tetapi bukan cara mereka terhubung. Kesenjangan ini menyebabkan hilangnya peluang dan meningkatnya penipuan. Sekarang, mereka beralih ke filosofi Network-First untuk menghargai koneksi sosial dan logistik selain data transaksional.
Tantangan Bisnis Utama yang harus diatasi
Anda memiliki empat tantangan penting yang memerlukan pemahaman tentang keterkaitan antara pelanggan dan logistik:
Tantangan | Masalah | Sasaran |
Kesenjangan Pengaruh | Iklan yang luas menghasilkan ROI rendah; saat ini tidak mungkin mengidentifikasi para trendsetter (influencer) yang sebenarnya. | Identifikasi Influencer; yang menjadi pusat komunitas melalui koneksi mereka dalam jaringan pelanggan yang terhubung. |
Ketahanan Logistik | Rantai pasokan dapat rentan (mengingat mereka beroperasi di berbagai wilayah geografis). Jika salah satu hub utama gagal, seluruh wilayah berpotensi kehilangan akses produk. | Identifikasi Penjaga Gerbang; orang-orang yang sangat penting untuk menghubungkan jaringan logistik. |
Jaringan Bayangan (Ghost Networks) | Sindikat penipuan menggunakan profil palsu dan alamat bersama untuk mengoordinasikan pencurian dan memalsukan rating. | Mengekspos Pulau Terpencil; grup yang sangat terhubung tanpa ikatan dengan komunitas yang sah. |
Paradoks Pilihan | Mesin saran/rekomendasi saat ini masih sederhana, generik, dan sering diabaikan (misalnya, "Pelanggan yang membeli ini juga membeli ..."). | Membangun Kembaran Perilaku; yaitu rekomendasi berdasarkan pola pengiriman dan lingkaran sosial yang serupa. |
Memetakan Tantangan Bisnis ke Strategi Teknis (Baris → Hubungan)
Dalam database tradisional, data disimpan dalam silo terpisah: pelanggan dalam satu tabel, transaksi dalam tabel lain, pengiriman dalam tabel ketiga. Meskipun SQL sangat cocok untuk menjawab pertanyaan "Siapa yang membeli apa?", SQL kesulitan menjawab pertanyaan berbasis jaringan.
Untuk mengatasi tantangan ini, strategi teknisnya adalah mengubah perspektif ini:
- Tampilan Relasional ("Apa"): Memperlakukan setiap pelanggan sebagai baris yang terisolasi. Menemukan hubungan antara pelanggan dan pembelian teman memerlukan beberapa "penggabungan" yang kompleks, yang menjadi semakin lambat secara eksponensial seiring pertumbuhan jaringan.
- Tampilan Grafik (Cara): Memperlakukan hubungan sebagai elemen penting. Alih-alih menelusuri daftar, kita menavigasi peta. Kita dapat langsung melihat bahwa Pelanggan A terhubung ke Pelanggan B, yang mengirim ke Lokasi Z.
Mempelajari persyaratan secara mendalam
Arsitek solusi menyimpulkan bahwa persyaratan bisnis dan strategi teknis memerlukan pendekatan multi-model, dan mengidentifikasi persyaratan utama berikut.
Cara Cloud Spanner memenuhi persyaratan teknis tersebut
Cloud Spanner dipilih sebagai inti transformasi ini. Hal ini memungkinkan Pelanggan mempertahankan fondasi relasional yang sangat kuat sekaligus mendapatkan insight grafik yang mendalam.
Berikut ringkasan singkat tentang cara Cloud Spanner memenuhi persyaratan teknis dan lainnya.
Selain itu, Cloud Spanner menyediakan arsitektur teknis yang siap menghadapi masa depan
2. Menyiapkan Fondasi data
Setelah kasus bisnis, kita sekarang beralih ke fase penerapan. Di bagian ini, kita akan menentukan arsitektur data, mempelajari batasan model relasional tradisional, dan memperkenalkan Grafik Properti sebagai alat utama untuk mengungkap insight mendalam.
Menyiapkan Instance Cloud Spanner Enterprise
Langkah 1: Aktifkan Cloud Spanner API
Di Konsol Google Cloud, klik ikon Menu di kiri atas layar untuk navigasi kiri. Scroll ke bawah dan pilih "Spanner", atau telusuri "Spanner"
Sekarang Anda akan melihat UI Cloud Spanner, dan jika Anda menggunakan project yang belum mengaktifkan Cloud Spanner API, Anda akan melihat dialog yang meminta Anda untuk mengaktifkannya. Jika sudah mengaktifkan API, Anda dapat melewati langkah ini.
Klik "Aktifkan" untuk melanjutkan:
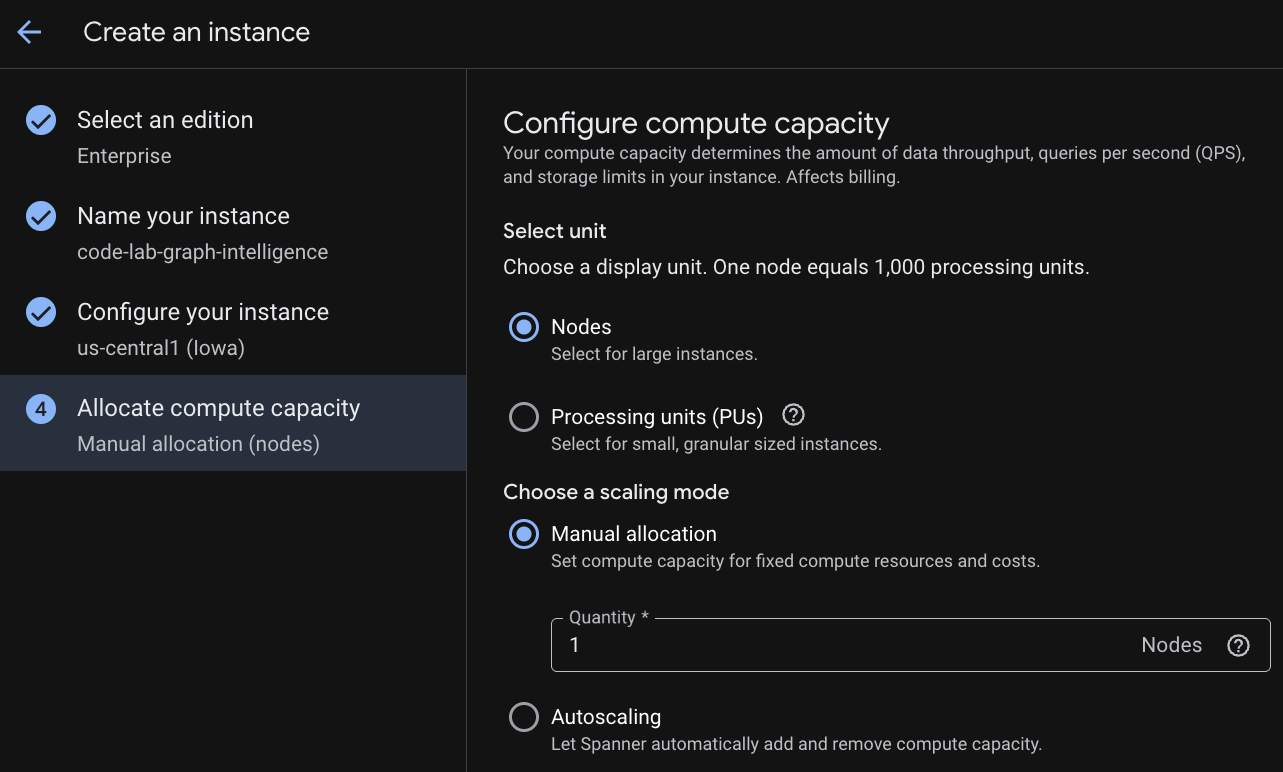
Langkah 2: Buat Instance Cloud Spanner
Pertama, Anda akan membuat instance Cloud Spanner. Di UI, klik "Create a Provisioned Instance" untuk membuat instance baru.
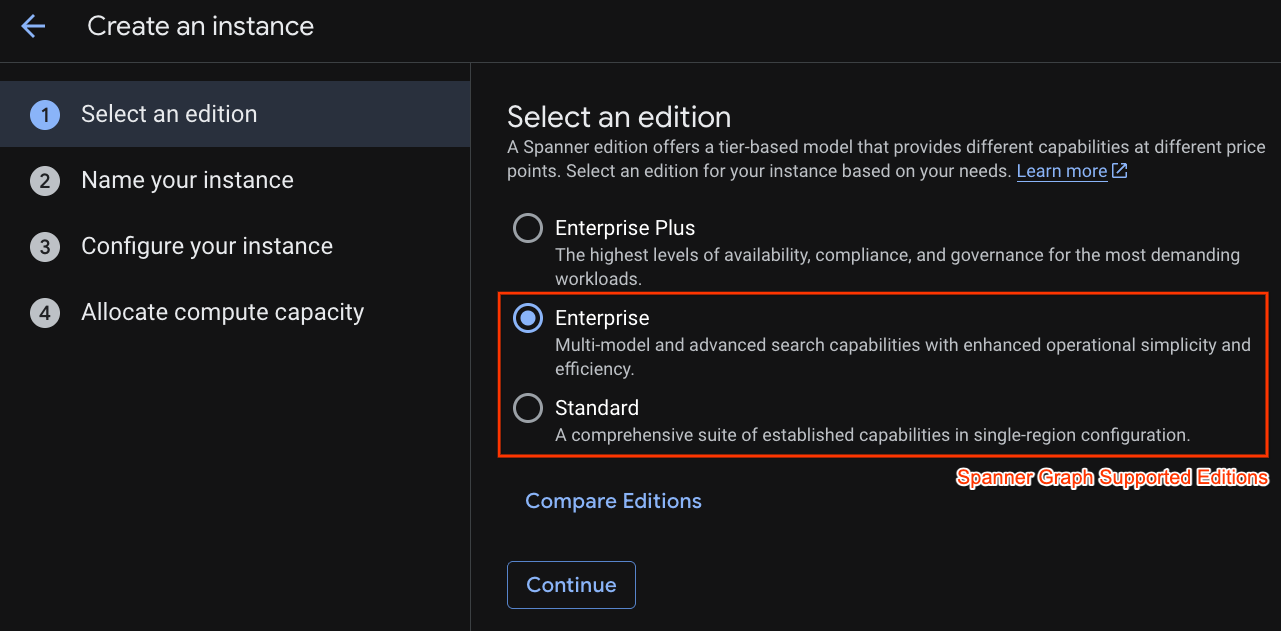
Pada langkah pertama, Anda harus memilih edisi. Perhatikan bahwa Anda juga dapat mengupgrade Edisi setelahnya. Untuk menggunakan kemampuan multi-model (Spanner Graph), kita dapat menggunakan Edisi Enterprise.
Memberi nama instance
Pilih konfigurasi deployment dan pilih region pilihan Anda.
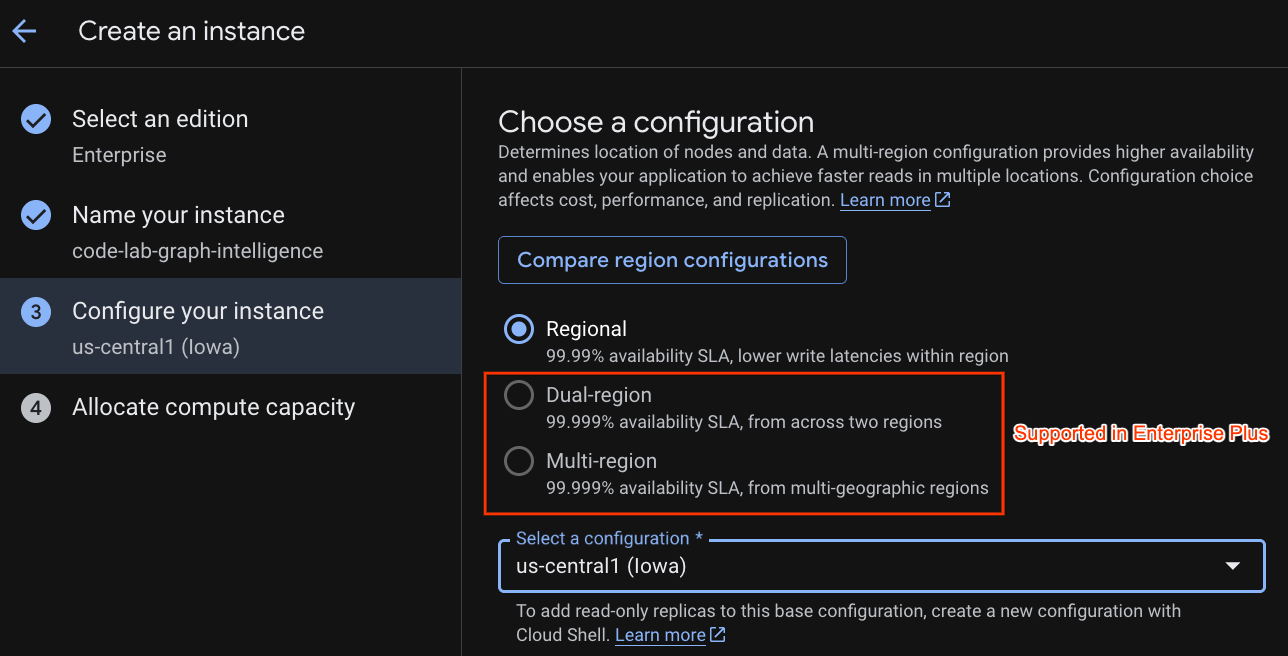
Anda juga dapat membandingkan berbagai opsi konfigurasi. Misalnya, konfigurasi deployment memiliki minimal 3 replika R/W di 3 zona terpisah di region yang Anda pilih. Artinya, meskipun Anda menggunakan deployment satu node, Anda memiliki 3 salinan melalui 3 replika R/W. Selain itu, bahkan dengan konfigurasi deployment Regional, Anda dapat memperluas lebih lanjut dengan memiliki replika R/O tambahan dalam topologi deployment.
Setelah mengonfigurasi kapasitas, Anda dapat memulai dengan node lengkap dan penskalaan otomatis di node; atau Anda dapat menggunakan instance terperinci (Unit Pemrosesan; 1.000 PU = 1 node). Secara opsional, Anda juga dapat menetapkan target penskalaan otomatis instance. Untuk workload latensi rendah, sebaiknya gunakan 65% untuk instance regional dan 45% untuk instance multi-region.
Langkah 3: Buat Database
Setelah instance Anda disediakan, klik "Create Database" untuk membuat database untuk codelab Anda selanjutnya.
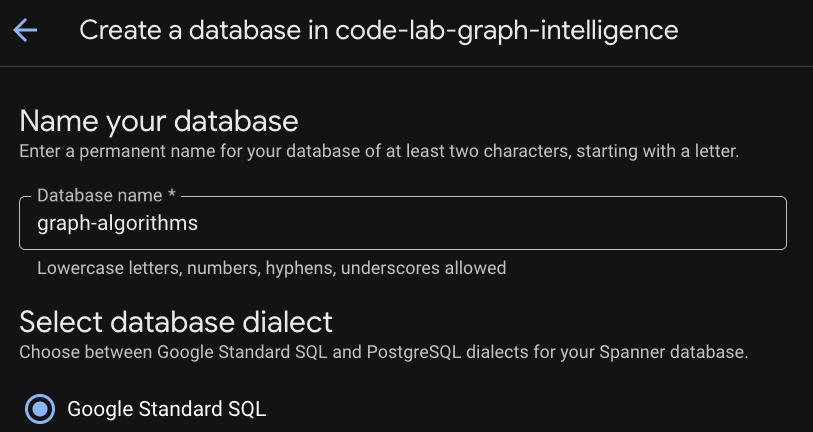
Menyiapkan Fondasi Relasional
Perjalanan kita dimulai dengan tabel inti yang menyimpan data operasional. Di Cloud Spanner, kami menggunakan Interleaving untuk menempatkan data terkait secara fisik, seperti persahabatan dan transaksi pelanggan langsung dengan catatan pelanggan. Hal ini memastikan akses berperforma tinggi dan lokalitas fisik.
DDL: Membuat Tabel
Salin dan jalankan blok berikut untuk membuat skema relasional Anda:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Menyebarkan Jaringan
Setelah tabel siap, kita harus mengisinya dengan pengguna, produk, dan koneksi yang menentukan ekosistem Pelanggan.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Tantangan Relasional (Relational Challenge)
Sebelum memperkenalkan grafik, mari kita lihat cara SQL tradisional menangani tantangan The Customer. Jalankan kueri ini untuk menemukan pelanggan "Pembelanja Sosial" yang berbelanja dalam jumlah besar dan memiliki banyak teman.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Batasan Pendekatan Relasional
Mengatasi Tantangan Relasional melalui Grafik Properti
Untuk mengatasi batasan ini, kami menentukan Grafik Properti. Hal ini akan membuat "overlay" yang memungkinkan kita memperlakukan hubungan sebagai elemen penting tanpa memindahkan data kita dari Spanner.
DDL: Membuat Grafik Properti
DDL ini mendefinisikan Node (Entitas) dan Edge (Hubungan) kami. Dalam contoh ini, kita mengikuti grafik skematis, tetapi Spanner Graph memungkinkan pemodelan grafik tanpa skema untuk memungkinkan pengembangan iteratif yang fleksibel dan cepat serta menangani model data yang terus berkembang tanpa perubahan DDL (Data Definition Language) yang konstan.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Menavigasi Grafik dengan GQL
Setelah grafik ditentukan, kita dapat menggunakan Graph Query Language (GQL) untuk melakukan penelusuran multi-hop dengan sintaksis yang sederhana dan mudah dibaca.
Eksplorasi 1: Penemuan Kolaboratif
Kueri ini melintasi grafik untuk menemukan produk yang dibeli oleh teman Anda dan berfungsi sebagai dasar mesin rekomendasi.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Eksplorasi 2: Kueri Hybrid (Relasional + Grafik)
Spanner memungkinkan Anda menyematkan pola GQL di dalam klausa FROM SQL standar menggunakan fungsi GRAPH_TABLE. Kueri ini menemukan pelanggan yang tinggal di lokasi yang sama dengan teman mereka, yaitu kecocokan pola "berlian".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Memvisualisasikan Koneksi Pelanggan
Terakhir, mari kita gunakan GQL untuk memvisualisasikan jaringan kita. Kueri ini menggabungkan hasil jalur dalam SAFE_TO_JSON, sehingga visualizer dapat menggambar node dan garis.
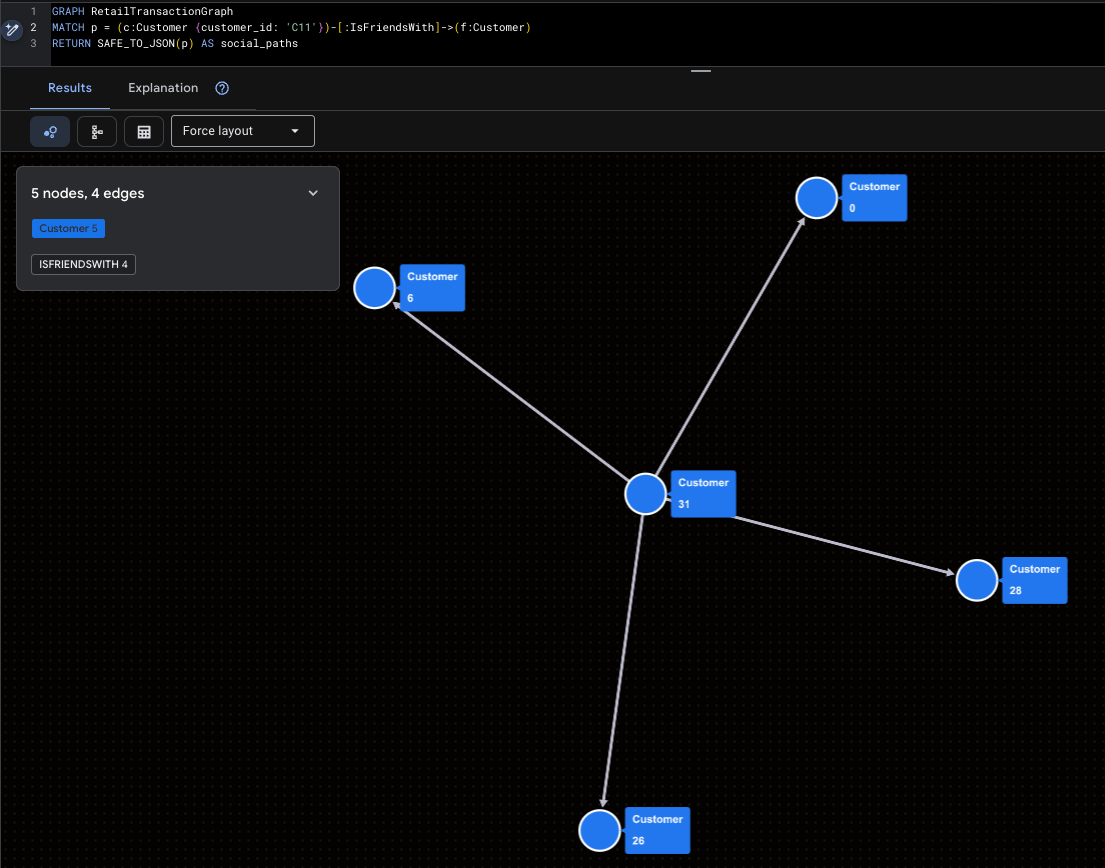
Memvisualisasi Super-Influencer
Hal ini menyoroti Mallory (C11) dan jangkauan sosial langsungnya.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Memvisualisasikan Potensi Pola Penipuan
Kueri ini akan menemukan "Grup Terisolasi" (Ivan & Judy) untuk melihat ke mana produk mereka dikirim.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Pengantar Algoritma Grafik Spanner
Untuk mempersiapkan pembahasan mendalam tentang Kecerdasan Grafik, bagian ini menguraikan arsitektur teknis dan aturan dasar Algoritma Grafik Cloud Spanner. Memahami prinsip-prinsip ini adalah kunci untuk beralih dari penelusuran sederhana ke analisis hubungan skala petabyte.
Portofolio Algoritma
Cloud Spanner saat ini mendukung 14 algoritma grafik standar industri, yang dikategorikan ke dalam empat grup fungsional untuk memecahkan beragam masalah bisnis:
Kategori | Algoritma yang Didukung | Kasus Penggunaan Bisnis |
Sentralitas (Centrality) | PageRank, PageRank yang Dipersonalisasi, Antara, Kedekatan | Mengidentifikasi influencer, pusat, dan hambatan. |
Komunitas | WCC, Penyebaran Label, Penemuan Klik, Pengelompokan Korelasi | Mendeteksi jaringan penipuan, komunitas sosial, dan silo. |
Kesamaan | Jaccard, Cosine, Tetangga Umum, Total Tetangga | Mendukung mesin pemberi saran dan penyelesaian entitas. |
Penemuan Jalur | Jalur Terpendek Set-ke-Set, helper Jalur GA | Mengoptimalkan logistik dan kedekatan penjelajahan. |
Pertimbangan Skema & Kueri Penting
Untuk memastikan eksekusi algoritma Grafik yang efisien, Spanner Graph harus mematuhi aturan berikut:
Persyaratan 1. Lokalitas Data Fisik (Interleaving)
Persyaratan paling penting untuk penelusuran grafik berperforma tinggi adalah Penyisipan. Hal ini memastikan bahwa data edge disimpan secara fisik di pemisahan server yang sama dengan node sumber, sehingga meminimalkan latensi jaringan selama eksekusi algoritma.
- Aturan: Tabel tepi HARUS disisipkan dalam tabel node sumbernya.
- Penelusuran Maju: Menyisipkan tabel tepi ke dalam tabel node sumber memastikan lokalitas cache untuk link keluar.
- Traversal Terbalik: Untuk analisis link "masuk" yang efisien, gunakan Kunci Asing untuk membuat indeks pendukung secara otomatis, atau buat indeks sekunder yang disisipkan dalam tabel tujuan.
Persyaratan 2. Persyaratan Pelabelan Unik
Setiap tabel yang berpartisipasi dalam grafik properti harus memiliki identitas unik. Algoritma mengandalkan label ini untuk mengidentifikasi dan memuat subgraf yang perlu dianalisis dengan benar.
- Aturan: Setiap tabel input harus memiliki label identifikasi unik dalam grafik properti.
- Konflik: Anda tidak dapat memetakan satu label ke beberapa tabel jika Anda ingin menjalankan algoritma di tabel tersebut.
Logika | Contoh | Hasil |
❌ Buruk | TABEL NODE (Entitas LABEL Orang, Entitas LABEL Akun) | Tidak valid: Algoritma tidak dapat membedakan antara Orang dan Akun. |
✅ Baik | TABEL NODE (LABEL Pelanggan ORANG, LABEL Akun AKUN) | Valid: Setiap entity memiliki label yang berbeda dan unik. |
Persyaratan 3. Struktur Kueri Algoritma (Klausul MATCH)
Saat memanggil algoritma, klausa MATCH mengikuti aturan yang lebih ketat daripada kueri GQL standar untuk memastikan mesin eksekusi dapat mengoptimalkan pipeline analitis.
- Satu Pola Per MATCH: Setiap pernyataan MATCH hanya dapat menyebutkan satu variabel.
- Tidak Ada Pola Multi-Node: Anda tidak dapat menentukan pola hubungan (misalnya, (a)-[e]->(b)) secara langsung di dalam klausa MATCH yang ditujukan untuk panggilan algoritma.
- Hanya Filter Literal: Meskipun Anda dapat menggunakan klausa WHERE untuk memfilter node (misalnya, WHERE a.id > 400), parameter kueri (@param) saat ini tidak didukung dalam kueri algoritma grafik.
Persyaratan 4. Klausul RETURN (Khusus Skalar)
Klausul RETURN dalam kueri algoritma bertindak sebagai jembatan antara dunia grafik dan dunia relasional. Fungsi ini sangat terbatas untuk menampilkan skalar dan konstanta.
- Aturan: Anda tidak dapat menampilkan "Elemen Grafik" (objek node atau edge mentah).
- Tanpa Transformasi: Anda tidak dapat melakukan operasi matematika atau menerapkan fungsi ke properti yang ditampilkan dalam pernyataan RETURN itu sendiri.
Pembatasan Klausa RETURN
✅ Didukung | ❌ Tidak Didukung |
RETURN node.id, skor | Simpul RETURN, skor (Tidak dapat menampilkan Elemen Grafik) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, skor (Tidak ada operasi pada properti) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (Tanpa fungsi) |
Persyaratan 5. Integritas Data: Menghilangkan Tepi yang Tergantung
"Edge yang Tidak Terhubung" terjadi saat edge mengarah ke node tujuan yang tidak ada dalam grafik. Hal ini menyebabkan eksekusi algoritma gagal karena struktur grafik tidak konsisten.
- Solusi: Gunakan batasan referensial (Kunci Asing) dan ON DELETE CASCADE untuk menjaga integritas grafik.
- Keamanan Kueri: Saat memanggil algoritma, Anda harus memastikan bahwa semua node yang dirujuk oleh tepi yang dipilih juga disertakan dalam argumen node_labels.
Output Persisten: Opsi EKSPOR DATA
Karena algoritma grafik memerlukan banyak komputasi, algoritma tersebut dieksekusi dalam mode eksekusi Peningkatan skala menggunakan pernyataan EXPORT DATA. Hal ini memanfaatkan Data Boost, menggunakan resource komputasi serverless independen untuk mencegah jeda pada transaksi produksi Anda.
Opsi 1: Persist kembali ke Cloud Spanner
Untuk mengirimkan hasil langsung kembali ke tabel Anda (misalnya, menyimpan skor PageRank), gunakan format = ‘CLOUD_SPANNER'.
update_ignore_all: Hanya memperbarui baris untuk kunci yang sudah ada di tabel target.upsert_ignore_all: Memperbarui baris yang ada atau menyisipkan baris baru jika kunci tidak ada.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Opsi 2: Mempertahankan hasil ke Google Cloud Storage (GCS)
Untuk analisis offline skala besar, Anda dapat mengekspor ke GCS dalam format CSV, Avro, atau Parquet.
- Karakter pengganti: Gunakan
uri => 'gs://bucket/file_*.csv'untuk mengaktifkan output terpisah-pisah, sehingga Spanner dapat menulis ke beberapa file secara paralel untuk set data yang sangat besar. - Kompresi: Mendukung GZIP, SNAPPY, dan ZSTD untuk mengoptimalkan biaya penyimpanan.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Tantangan 1: Kesenjangan Pengaruh (PageRank)
Di bagian ini, kita akan membahas hambatan bisnis pertama Pelanggan: "Kesenjangan Pengaruh". Kita akan beralih dari "kontes popularitas" dasar ke peta pengaruh sosial yang sebenarnya dan didorong secara matematis.
Pernyataan Masalah: Tim pemasaran Pelanggan mengalami masalah. Mereka membelanjakan jutaan dolar untuk iklan luas dengan laba yang terus menurun karena tidak dapat mengidentifikasi "Bintang Media Sosial", yaitu individu langka yang dukungan mereka berdampak besar di seluruh jaringan.
Untuk mengatasinya, kita perlu memberi peringkat pelanggan berdasarkan Pengaruh.
Solusi Relasional (Sentralitas Derajat)
Dalam database standar, cara termudah untuk menemukan influencer adalah dengan menghitung pengikutnya (metrik yang dikenal sebagai Degree Centrality).
Jalankan kueri ini untuk menemukan pengguna yang paling "populer":
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Graph Intelligence (PageRank)
Untuk menemukan pemimpin yang sebenarnya, kami menggunakan PageRank. Algoritma ini sama dengan algoritma yang mendukung penelusuran web awal; algoritma ini mengukur pentingnya sebuah node berdasarkan kuantitas DAN kualitas link masuk .
- Model Peselancar Acak: PageRank menyimulasikan pengguna yang berpindah-pindah dalam grafik. Faktor Peredaman (default 0,85) menunjukkan probabilitas mereka terus mengklik; jika tidak, mereka akan "berpindah" ke node acak.
- Kekuatan Asosiasi: Link dari orang yang berpengaruh (seperti Mallory) jauh lebih berharga daripada link dari seseorang yang tidak memiliki koneksi lain.
Kita akan menjalankan Algoritma PageRank dan menggunakan EXPORT DATA untuk menyimpan hasilnya langsung ke kolom pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Dasbor"Pengaruh" menggunakan PageRank
Setelah skor dipertahankan, mari kita bandingkan "Sebelum" (Jumlah Pengikut) dengan "Setelah" (Skor PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
Analisis: Siapa Bintang Super yang Sebenarnya?
Dengan menganalisis output, Anda kini dapat membuat tiga penemuan pemasaran penting:
Poin Penting Bisnis
Daripada mengirim email secara membabi buta kepada semua orang yang memiliki lebih dari lima pengikut, tim pemasaran The Customer kini dapat berfokus secara eksklusif pada orang-orang yang memiliki pagerank_score tertinggi. Individu ini adalah "Bintang Media Sosial" sejati yang mampu mendorong viralitas sistemik di seluruh marketplace.
Sekarang, mari kita coba mengidentifikasi Penjaga Gerbang yang menjaga agar jaringan logistik Pelanggan tetap berjalan.
5. Tantangan 2: Ketahanan Logistik (BetweennessCentrality)
Di bagian ini, kita akan membahas Ketahanan Logistik. Kami akan melampaui pengukuran kesuksesan berdasarkan "volume" untuk mengidentifikasi "penjaga gerbang" penting yang menjaga jaringan tetap terhubung.
Solusi Relasional (Analisis Berbasis Volume)
Dalam penyiapan relasional standar, hub pengiriman "kritis" biasanya ditentukan sebagai hub yang memproses pesanan terbanyak atau menghasilkan pendapatan terbanyak.
Jalankan kueri ini untuk mengidentifikasi hub "teratas" berdasarkan jumlah transaksi:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
kota | country | transaction_count | total_revenue |
New York | AS | 4 | 3996 |
Berlin | Jerman | 2 | 345 |
San Francisco | AS | 2 | 750 |
Untuk mengatasi ketidakcocokan, kita akan menggunakan tepi IsFriendsWith dan LivesAt. Hal ini mengubah analisis kami dari hub transaksi menjadi juga mencakup pemeriksaan sosial.
Graph Intelligence (Betweenness Centrality)
Untuk menemukan hambatan yang sebenarnya, kita menggunakan Betweenness Centrality. Algoritma ini mengukur seberapa sering sebuah node bertindak sebagai "jembatan" di sepanjang jalur terpendek antara semua pasangan node lainnya dalam grafik. Skor tinggi menunjukkan penjaga gerbang yang sebenarnya yang mengontrol aliran barang atau informasi.
Menjalankan & Mempertahankan Centrality Antara
Kita akan menjalankan algoritma menggunakan EKSPOR DATA dan menyimpan skor ke dalam kolom centrality_score. Kami menggunakan Peningkatan Data untuk memastikan perhitungan "jalur terpendek" yang berat ini hampir tidak berdampak pada operasi live Pelanggan.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analisis: Mengidentifikasi "Hambatan Tersembunyi"
Sekarang, kita membandingkan risiko struktural (centrality_score) dengan volume transaksi (order_count) untuk menemukan node yang harus dikhawatirkan oleh kepemimpinan Pelanggan.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Dengan menganalisis hasil ini, Pelanggan membuat tiga penemuan yang mengejutkan:
Poin Penting Bisnis
Pelanggan kini dapat memprioritaskan protokol keamanan dan redundansi logistiknya berdasarkan risiko struktural multimodal. Mallory, Alice, dan Eve adalah penjaga gerbang yang harus dilindungi untuk memastikan stabilitas jaringan logistik.
Sekarang, mari kita coba mengisolasi pulau penipuan.
6. Tantangan 3: Jaringan Hantu (WCC)
Di bagian ini, kita akan mengatasi hambatan bisnis ketiga: "Jaringan Hantu". Kami akan beralih dari deteksi "hotspot" sederhana ke mengungkap jaringan penipuan canggih dan terisolasi menggunakan deteksi komunitas. Tantangannya adalah pelaku kejahatan membuat profil palsu yang membagikan alamat pengiriman atau berinteraksi dalam loop tertutup untuk mengoordinasikan pencurian dan memalsukan rating produk. Namun, mereka sering kali benar-benar terisolasi dari komunitas Pelanggan yang sah.
Untuk mengatasinya, kita perlu mengekspos "Pulau Terpencil" ini.
Solusi Relasional (Penelusuran ID Bersama)
Tanpa algoritma grafik, cara standar untuk menemukan penipuan adalah dengan mencari "hotspot" data bersama, seperti beberapa pelanggan yang mengirimkan barang ke alamat yang sama persis .
Jalankan kueri ini untuk menemukan pelanggan yang ditautkan berdasarkan lokasi pengiriman bersama:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Untuk menemukan jaringan penipuan, kita perlu memahami keterjangkauan transitif.
Graph Intelligence (Weakly Connected Components)
Untuk menemukan cakupan penuh cincin ini, kita menggunakan Weakly Connected Components (WCC). WCC adalah algoritma pengelompokan yang mengidentifikasi sekumpulan node yang memiliki jalur di antara dua node mana pun, terlepas dari arah tepi.
- Zona Keterjangkauan: Secara efektif, algoritma ini membagi grafik menjadi "pulau" atau "zona keterjangkauan".
- Tampilan Entitas Terpadu: Dengan menganalisis ikatan sosial (IsFriendsWith) dan ikatan logistik (LivesAt) secara bersamaan, kita dapat mengelompokkan profil yang terfragmentasi ke dalam satu "Grup Dampak" yang terpadu.
Menjalankan & Mempertahankan WCC
Kita akan menjalankan algoritma WCC dan menyimpan hasilnya ke dalam kolom community_id. Kami menggunakan Data Boost untuk memastikan analisis kemampuan jangkauan yang mendalam ini terjadi pada resource komputasi independen.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analisis: Sindikat Penipuan
Sekarang, jalankan kueri validasi untuk melihat komunitas terisolasi kita. Pengguna yang sah biasanya termasuk dalam "Daratan", sedangkan penipu sering kali terdampar di "Pulau" kecil.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | anggota |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Dengan menjalankan deteksi komunitas ini, Anda dapat mengidentifikasi anomali penting:
Poin Penting Bisnis
Pelanggan kini dapat mengotomatiskan respons keamanannya. Daripada mengejar akun satu per satu secara manual, mereka dapat menulis aturan sederhana: "Jika community_id memiliki kurang dari tiga anggota, tandai seluruh grup untuk peninjauan KYC (Kenali Pelanggan Anda) secara manual"
.
Dengan terungkapnya jaringan penipuan kami, kami dapat menyelesaikan "Kembaran Perilaku".
7. Tantangan 4: Kembaran Perilaku (JaccardSimilarity)
Dalam tantangan terakhir ini, kita akan mengatasi hambatan keempat: "Paradoks Pilihan"/"Kembaran Perilaku". Kami akan beralih dari daftar "sering dibeli bersama" umum ke rekomendasi yang sangat dipersonalisasi berdasarkan "sidik jari" perilaku.
Saran produk saat ini untuk Pelanggan terlalu umum. Merekomendasikan kabel USB populer kepada setiap pelanggan memang aman, tetapi tidak bersifat pribadi. Pelanggan ingin membuat rekomendasi "Kembaran Perilaku" yang mengidentifikasi pelanggan yang memiliki pola pengiriman dan lingkaran sosial yang unik untuk menyarankan produk dengan pencocokan presisi tinggi.
Untuk menyelesaikannya, kita perlu menghitung "Kedekatan" antar-pengguna.
Solusi Relasional (Tumpang-Tindih Mutlak)
Dalam penyiapan relasional standar, Anda dapat mencari orang yang mengirim ke lokasi yang sama dengan pengguna referensi, seperti Alice (C1).
Jalankan kueri ini untuk menemukan tetangga geografis Alice:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (Kesamaan Jaccard)
Untuk menemukan kembaran perilaku yang sebenarnya, kami menggunakan Kesamaan Jaccard. Algoritma ini menghitung skor yang dinormalisasi (0,0 hingga 1,0) dengan membagi jumlah tetangga yang sama (Persimpangan) dengan jumlah total tetangga unik (Gabungan).
Di sini, "Kembaran Perilaku" ditentukan oleh lebih dari sekadar alamat pengiriman yang sama. Dengan menganalisis persimpangan jejak fisik (LivesAt) dan ekosistem sosial (IsFriendsWith), kita dapat mengidentifikasi pengguna yang memiliki gaya hidup dan pengaruh komunitas yang sama, sehingga menghasilkan rekomendasi produk yang jauh lebih akurat.
Pertama, buat Tabel Pemetaan
Karena kemiripan adalah hubungan berpasangan (Pelanggan A mirip dengan Pelanggan B), kami membuat tabel khusus yang disisipkan di Customer untuk menyimpan pemetaan ini.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Sekarang Jalankan Jaccard Similarity
Sekarang kita akan menjalankan algoritma. Catatan: Kueri ini mencakup pelajaran "Pembatas" umum. Jika Anda hanya memilih node Pelanggan, tetapi menggunakan edge LivesAt (yang mengarah ke node Pengiriman), kueri akan gagal dengan mengutip "Dangling Edge" . Untuk memperbaikinya, kita harus menyertakan kedua label node.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analisis: Pemeriksaan "Kembaran Perilaku"
Setelah tugas analisis selesai, kita menjalankan kueri validasi. Dengan menggabungkan tabel pemetaan baru (CustomerSimilarity) dengan metadata Customer asli, kita dapat melihat dengan tepat siapa "Kembaran Perilaku" Alice.
Jalankan kueri ini untuk memeriksa peringkat kemiripan Alice:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Yang harus diidentifikasi dalam hasil:
Sekarang, mari kita coba membuat tampilan Kecerdasan Terpadu akhir.
8. Unified Intelligence
Sekarang kita beralih dari tugas teknis individual ke Unified Intelligence. Di sini, kami menggabungkan data transaksi dengan keempat algoritma grafik untuk memberikan insight yang jelas dan dapat ditindaklanjuti.
Laporan 1: Intelijensi Terpadu
Keunggulan database multi-model seperti Spanner adalah kemampuannya untuk menggabungkan data pembelanjaan relasional dengan skor pengaruh, risiko, dan kesamaan yang berasal dari grafik dalam satu permintaan. Kueri ini mengategorikan setiap pelanggan ke dalam persona bisnis tertentu.
Jalankan kueri Unified Intelligence untuk melihat ekosistem lengkap:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | pembelanjaan | pengaruh | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44,5 | 0 | 🔵 KRITIS: Jembatan Jaringan |
C5 | eve@example.com | 0 | 0.158392489 | 35,5 | 0 | 🔵 KRITIS: Jembatan Jaringan |
C1 | alice@example.com | 999 | 0.1000888124 | 35,5 | 0 | 🔵 KRITIS: Jembatan Jaringan |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 SOSIAL: Influencer dengan Jangkauan Tinggi |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 SOSIAL: Influencer dengan Jangkauan Tinggi |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDAR: Pelanggan Aktif |
C4 | david@example.com | 0 | 0.04028172791 | 3,5 | 0 | 🟢 STANDAR: Pelanggan Aktif |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RISIKO TINGGI: Ring Penipuan Terisolasi |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 RISIKO TINGGI: Ring Penipuan Terisolasi |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDAR: Pelanggan Aktif |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDAR: Pelanggan Aktif |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDAR: Pelanggan Aktif |
Dengan menggabungkan perspektif matematika ini, kita dapat melampaui "siapa yang paling banyak membelanjakan" menjadi "siapa yang paling penting". Dasbor terpadu mengintegrasikan data transaksi relasional dengan kecerdasan grafik multi-modal untuk mengategorikan ekosistem Anda ke dalam tiga persona yang jelas dan dapat ditindaklanjuti.
"Jembatan Jaringan Kritis" (Ketahanan)
Node seperti Mallory (C11), Eve (C5), dan Alice (C1) ditandai karena bottleneck_risk (Betweenness Centrality) mereka adalah >25.
- Anchor Struktural: Mallory memiliki skor risiko tertinggi, yaitu 44,5, yang menjadikannya sebagai gateway utama untuk seluruh jaringan.
- Paradoks Tanpa Pembelanjaan: Eve (C5) memiliki jumlah pesanan nol, tetapi secara struktural sangat diperlukan dengan skor risiko 35,5. SQL standar akan mengabaikannya sepenuhnya, tetapi Kecerdasan Grafik mengungkapkan bahwa dia adalah jembatan penting bagi seluruh sub-komunitas.
- Gerbang Nilai Tinggi: Alice (C1) seri dengan Eve di 35,5, yang membuktikan bahwa pembelanja dengan pembelanjaan tinggi juga dapat menjadi penentu struktural yang penting.
"Bintang Media Sosial" (Jangkauan)
Heidi (C8) dan Grace (C7) diidentifikasi sebagai influencer dengan jangkauan tinggi karena skor PageRank mereka .
"Jaringan Penipuan Terisolasi" (Anomali)
Judy (C10) dan Ivan (C9) ditandai karena mereka termasuk dalam community_id 1 yang terisolasi
Insight Bisnis untuk Tindakan Strategis
Persona | Metrik Utama | Insight Bisnis | Tindakan Strategis |
🔵 Jembatan Jaringan | Sentralitas Tinggi | Anchor Struktural: Eve (C5) dan Mallory (C11) menyatukan jaringan. | Retensi: Lindungi para penjaga gerbang ini untuk mencegah fragmentasi komunitas. |
📱 Bintang Media Sosial | PageRank Tinggi | Mesin Viralnya: Pengguna seperti Heidi (C8) memiliki jangkauan tertinggi dalam lingkaran mereka. | Pemasaran: Gunakan untuk program rujukan dan brand ambassador yang berdampak tinggi. |
🔴 Risiko Penipuan | WCC Terisolasi | Jaringan Hantu (Ghost Networks): Judy (C10) dan Ivan (C9) adalah pembelanja besar, tetapi tinggal di "pulau". | Keamanan: Peninjauan KYC manual segera; ini adalah tanda tangan penipuan klasik. |
🟢 Pengguna Standar | Skor Seimbang | Inti Sehat (Healthy Core): Sebagian besar jaringan, termasuk jembatan "lokal" seperti David (C4). | Pertumbuhan: Terapkan iklan yang dipersonalisasi standar dan rekomendasi "Kembaran Perilaku". |
Laporan 2: Laporan Anomali Identitas
Sekarang Anda perlu mengetahui apakah akun yang sah sedang "ditiru" oleh penipu. Kita dapat menyelesaikannya dengan menemukan pengguna yang memiliki Kemiripan Perilaku 100%, tetapi Koneksi Sosial Nol.
Jalankan kueri ini untuk menandai potensi "Anomali Identitas":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Laporan Identifikasi Anomali memberikan informasi penting. Dengan mengisolasi pengguna yang bertindak seperti pelanggan yang sah, tetapi tidak memiliki ikatan sosial, kita beralih dari menebak-nebak ke kepastian matematis .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Analisis Hasil
Dengan menyatukan Kemiripan (Jaccard) dengan Deteksi Komunitas (WCC), kami mengungkap risiko tersembunyi yang tidak dapat dilihat oleh data transaksi tradisional.
- "Kembaran Perilaku" (Kedekatan): Node seperti Judy (C10) dan Ivan (C9) ditandai karena memiliki skor Kesamaan Jaccard 0,20 relatif terhadap Alice (C1).
- Perilaku Isolasi: Judy (C10) dan Ivan (C9) dikelompokkan ke dalam community_id 1 yang terisolasi, sedangkan Alice termasuk dalam "Mainland" (Komunitas 0) yang sosial.
- Tanda Penipuan: Laporan ini mengidentifikasi pengguna dengan tumpang-tindih perilaku yang tinggi (>0,9) yang tetap tidak terhubung secara sosial dari jaringan utama.
9. Ucapan Selamat dan Ringkasan
Lab ini menunjukkan cara Cloud Spanner mengubah database relasional menjadi database multimodel yang andal. Dengan menerapkan analisis grafik ke Pelanggan, kami beralih dari data statis ke strategi bisnis yang dapat ditindaklanjuti.
Keunggulan Multi-Model Spanner
- Arsitektur Terpadu: Spanner memungkinkan Anda mempertahankan fondasi relasional yang sangat kuat sekaligus "meng-overlay" grafik properti secara instan untuk penambangan hubungan tanpa risiko dan jeda ETL.
- Isolasi Analisis Off-Box: Dengan memanfaatkan Data Boost, Anda dapat menjalankan algoritma yang membutuhkan banyak memori seperti PageRank atau WCC pada resource komputasi serverless yang independen, sehingga memastikan tidak ada dampak pada performa checkout produksi Anda.
- Performa yang Disisipkan: Penyisipan unik Spanner memastikan bahwa node dan hubungannya ditempatkan bersama secara fisik, sehingga mengubah penelusuran global yang kompleks menjadi pencarian lokal berkecepatan tinggi.
Menampilkan "Permata Tersembunyi" & Anomali
- Mengidentifikasi Nilai Struktural: Algoritma grafik seperti Betweenness Centrality mengungkapkan "Jembatan Tersembunyi" dengan pembelanjaan nol yang dapat menjadi lebih penting bagi ketahanan jaringan daripada pelanggan yang paling banyak berbelanja.
- Mengekspos Peniruan Perilaku: Dengan menggabungkan Kemiripan Jaccard dan Komponen yang Terhubung Lemah, kami mengidentifikasi "Orang Asing Sosial". Akun ini terlihat seperti pelanggan yang sah, tetapi secara matematis terbukti merupakan jaringan penipuan yang terisolasi.
- Kebenaran Global vs. Lokal: Meskipun analisis SQL manual dapat memunculkan jembatan, algoritma global dapat memunculkan Penjaga Gerbang utama jaringan.
Membuat Data yang Cerdas dan Dapat Ditindaklanjuti
- Strategi Berbasis Persona: Kami berhasil mengubah baris menjadi hubungan, dan dengan menjalankan algoritma, kami dapat mengatasi empat masalah bisnis, yaitu: Jembatan Jaringan, Bintang Sosial, Risiko Penipuan, dan Pengguna Standar.