
1. Case study: Intelligent Retail
Per il case study prendiamo in esame un cliente del settore retail con un marketplace digitale in rapida crescita. La visualizzazione tradizionale dei dati dei clienti è limitata perché mostra cosa acquistano le persone, ma non come sono connesse. Questo divario porta a perdere opportunità e a un aumento delle frodi. Ora, stanno passando a una filosofia Network-First per valorizzare i collegamenti sociali e logistici, oltre ai dati transazionali.
Sfide aziendali principali da affrontare
Hai quattro sfide fondamentali che richiedono di capire come sono interconnessi clienti e logistica:
Sfida | Il problema | L'obiettivo |
Divario di influenza | La pubblicità generica produce un ROI basso; al momento non è possibile identificare i veri trendsetter (influencer). | Identifica gli influencer, che sono fondamentali per la community grazie al loro collegamento in una rete connessa di clienti. |
Resilienza della logistica | La catena di fornitura può essere vulnerabile (considerando che opera in diverse aree geografiche). Se un hub di chiavi non funziona, l'intera regione potrebbe perdere l'accesso al prodotto. | Identifica i gatekeeper , ovvero le persone fondamentali per collegare le reti logistiche. |
Ghost Networks | Le frodi organizzate utilizzano profili falsi e indirizzi condivisi per coordinare i furti e gonfiare le valutazioni. | Esporre le isole isolate , ovvero gruppi iperconnessi senza legami con la community legittima. |
Paradosso della scelta | L'attuale motore di suggerimenti/consigli è rudimentale, generico e spesso ignorato (ad es. "I clienti che hanno acquistato questo articolo hanno acquistato anche…"). | Crea gemelli comportamentali, ovvero suggerimenti basati su modelli di spedizione e cerchie sociali simili. |
Mappare le sfide aziendali in una strategia tecnica (righe → relazioni)
In un database tradizionale, i dati vengono archiviati in silos isolati: i clienti in una tabella, le transazioni in un'altra e le spedizioni in una terza. SQL è perfetto per rispondere alla domanda "Chi ha acquistato cosa?", ma non è adatto a rispondere a domande basate sulla rete.
Per risolvere queste sfide, la strategia tecnica consiste nel cambiare questa prospettiva:
- La visualizzazione relazionale ("Cosa"): considera ogni cliente come una riga isolata. Per trovare una connessione tra un cliente e l'acquisto di un amico sono necessarie più "join" complesse, che diventano esponenzialmente più lente man mano che la rete cresce.
- La visualizzazione a grafo (il "come"): considera le relazioni come elementi di prima classe. Anziché cercare in elenchi, navighiamo su una mappa. Possiamo vedere immediatamente che il cliente A è collegato al cliente B, che spedisce alla sede Z.
Approfondimento dei requisiti
Gli architetti delle soluzioni giungono alla conclusione che i requisiti aziendali e la strategia tecnica richiedono un approccio multimodello e identificano i seguenti requisiti chiave.
In che modo Cloud Spanner soddisfa questi requisiti tecnici
Cloud Spanner è stato scelto come fulcro di questa trasformazione. Consente al Cliente di mantenere la sua solida base relazionale e allo stesso tempo di ottenere approfondimenti grafici dettagliati.
Ecco un rapido riepilogo di come Cloud Spanner soddisfa i requisiti tecnici e altro ancora.
Inoltre, Cloud Spanner fornisce un'architettura tecnica a prova di futuro.
2. Configurazione di Data Foundation
Dopo aver esaminato il business case, passiamo alla fase di implementazione. In questa sezione definiamo la nostra architettura dei dati, esploriamo i limiti del modello relazionale tradizionale e introduciamo il grafico delle proprietà come strumento principale per scoprire approfondimenti dettagliati.
Configura l'istanza Cloud Spanner Enterprise
Passaggio 1: attiva l'API Cloud Spanner
Nella console Google Cloud, fai clic sull'icona Menu in alto a sinistra dello schermo per la navigazione a sinistra. Scorri verso il basso e seleziona "Chiave" oppure cerca "Chiave".
Ora dovresti vedere la UI di Cloud Spanner e, se utilizzi un progetto in cui l'API Cloud Spanner non è ancora stata abilitata, vedrai una finestra di dialogo che ti chiede di abilitarla. Se hai già abilitato l'API, puoi saltare questo passaggio.
Fai clic su "Attiva" per continuare:
Passaggio 2: crea l'istanza Cloud Spanner
Innanzitutto, creerai un'istanza Cloud Spanner. Nell'interfaccia utente, fai clic su "Crea un'istanza di cui è stato eseguito il provisioning" per creare una nuova istanza.
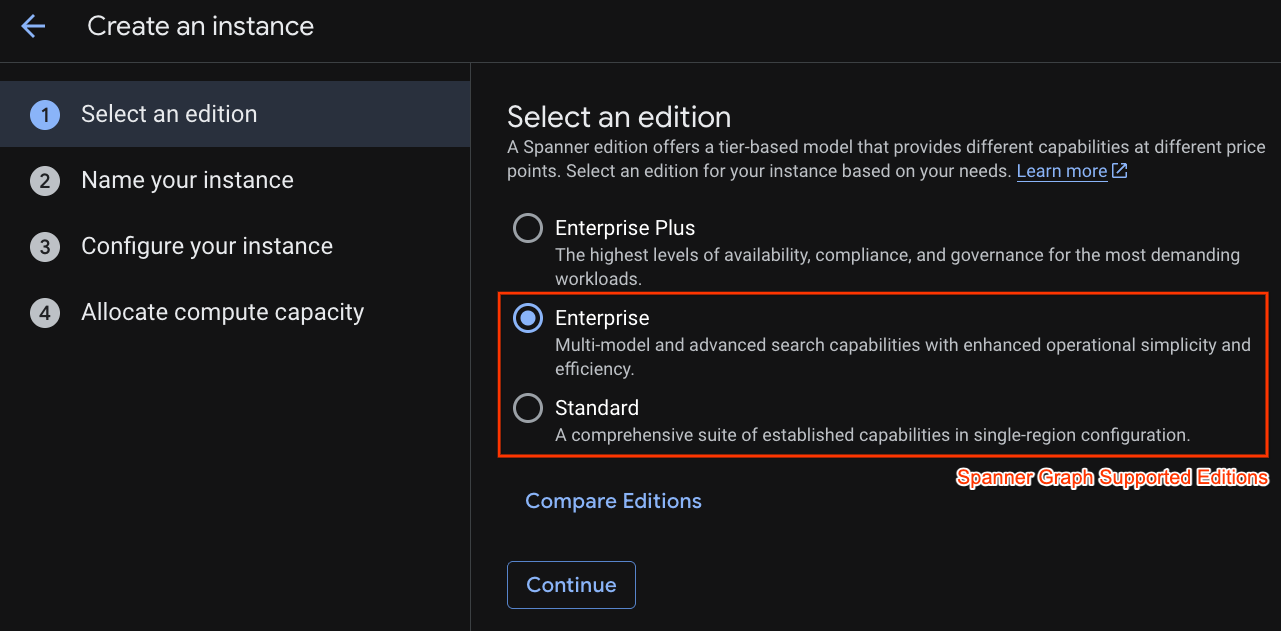
Nel primo passaggio devi selezionare un'edizione. Tieni presente che puoi eseguire l'upgrade della versione anche in un secondo momento. Per utilizzare le funzionalità multimodello (Spanner Graph), possiamo scegliere la versione Enterprise.
Assegnazione del nome all'istanza
Seleziona una configurazione di deployment e una regione di tua scelta.
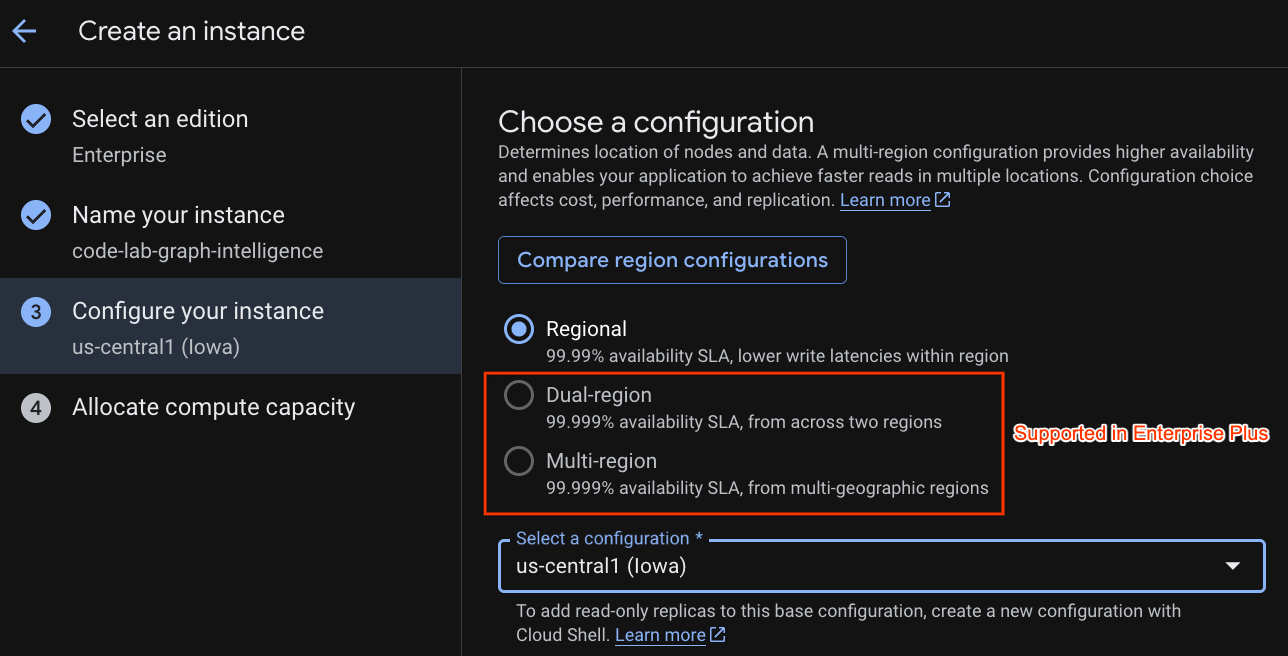
Puoi anche confrontare varie opzioni di configurazione. Ad esempio, la configurazione del deployment ha almeno 3 repliche di lettura/scrittura in 3 zone separate della regione selezionata. Ciò significa che anche se scegli un deployment a un solo nodo, hai 3 copie tramite 3 repliche di lettura/scrittura. Inoltre, anche con la configurazione del deployment regionale, puoi estendere ulteriormente la topologia di deployment aggiungendo repliche di sola lettura aggiuntive.
Una volta configurata la capacità, puoi iniziare con un nodo completo e la scalabilità automatica dei nodi oppure puoi utilizzare un'istanza granulare (unità di elaborazione; 1000 PU = 1 nodo). Facoltativamente, puoi anche impostare i target di scalabilità automatica dell'istanza. Per i workload a bassa latenza, consigliamo il 65% per le istanze regionali e il 45% per le istanze multiregionali.
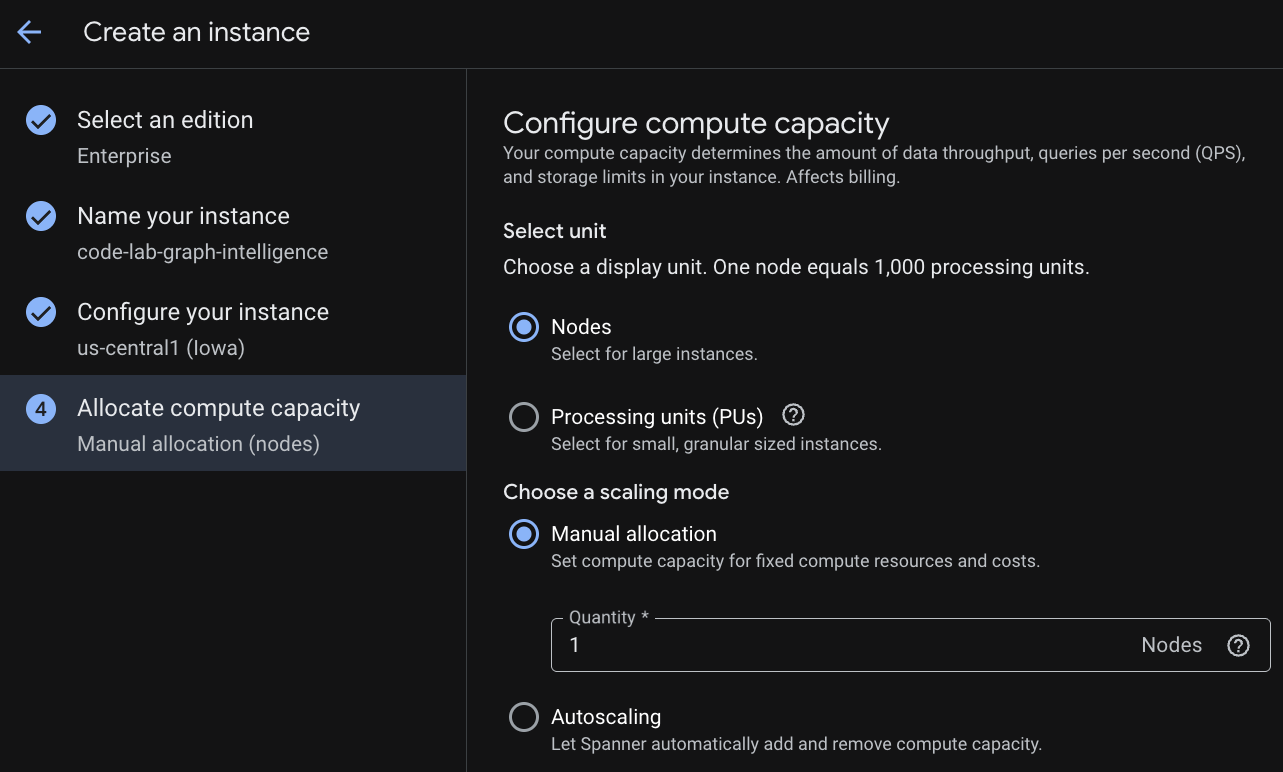
Passaggio 3: crea un database
Una volta eseguito il provisioning dell'istanza, fai clic su "Crea database" per creare un database per il resto del codelab.
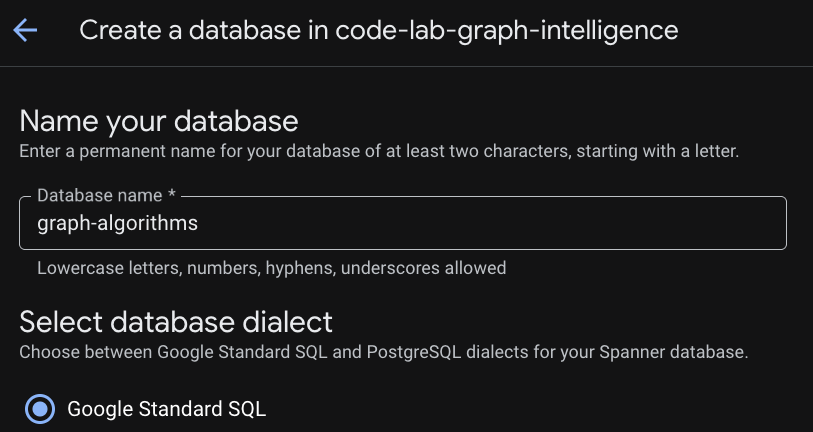
Setting-up a Relational Foundation
Il nostro percorso inizia con le tabelle principali che archiviano i dati operativi. In Cloud Spanner, utilizziamo l'interleaving per collocare fisicamente i dati correlati, ad esempio le amicizie e le transazioni di un cliente, direttamente con il record del cliente. Ciò garantisce accesso ad alte prestazioni e località fisica.
DDL: creazione delle tabelle
Copia ed esegui i seguenti blocchi per stabilire lo schema relazionale:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Creazione della rete
Ora che le tabelle sono pronte, dobbiamo popolarle con gli utenti, i prodotti e le connessioni che definiscono l'ecosistema del cliente.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Relational Challenge
Prima di introdurre il grafico, vediamo come SQL tradizionale gestisce le sfide del cliente. Esegui questa query per trovare i clienti "Social Spenders", ovvero quelli che spendono cifre significative e hanno molti amici.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
I limiti dell'approccio relazionale
Superare le sfide relazionali tramite un grafico delle proprietà
Per superare questi limiti, definiamo un grafico delle proprietà. In questo modo viene creato un "overlay" che ci consente di trattare le relazioni come cittadini di prima classe senza spostare i dati da Spanner.
DDL: creazione del grafico delle proprietà
Questo DDL definisce i nostri nodi (entità) e i nostri archi (relazioni). In questo esempio seguiamo un grafico schematizzato, ma Spanner Graph consente di modellare grafici senza schema per consentire uno sviluppo iterativo flessibile e rapido e per gestire modelli di dati in evoluzione senza modifiche costanti del linguaggio DDL (Data Definition Language).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Navigare nel grafico con GQL
Ora che il grafico è definito, possiamo utilizzare Graph Query Language (GQL) per eseguire attraversamenti multihop con una sintassi semplice e leggibile.
Esplorazione 1: scoperta collaborativa
Questa query attraversa il grafico per trovare i prodotti acquistati dai tuoi amici e funge da base per un motore di consigli.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Esplorazione 2: la query ibrida (relazionale + grafico)
Spanner consente di incorporare pattern GQL all'interno di una clausola FROM SQL standard utilizzando la funzione GRAPH_TABLE. Questa query trova i clienti che vivono nella stessa località dei loro amici, una corrispondenza a "diamante".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Visualizzare le connessioni del cliente
Infine, utilizziamo GQL per visualizzare la nostra rete. Queste query racchiudono i risultati del percorso in SAFE_TO_JSON, consentendo ai visualizzatori di disegnare i nodi e le linee.
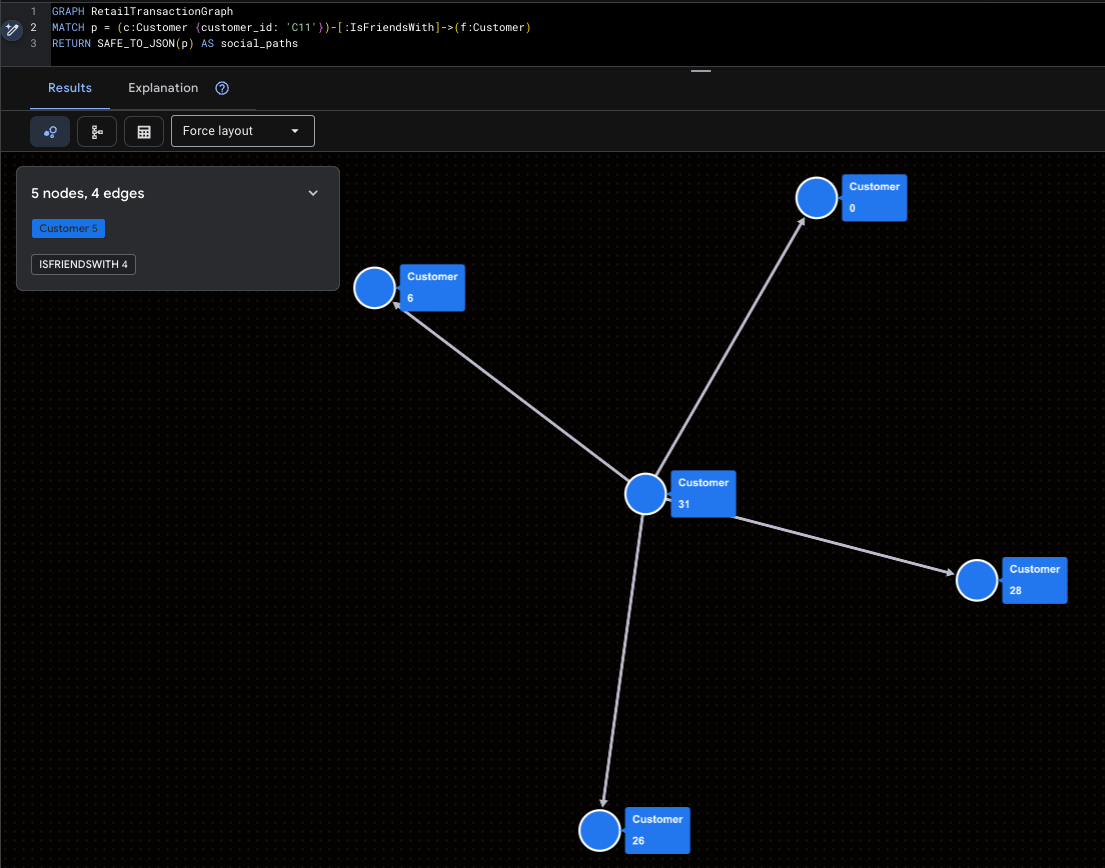
Visualizzare il super influencer
In questo modo vengono evidenziati Mallory (C11) e la sua portata sui social.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Visualizzare potenziali schemi di frode
Questa query individua il "Cluster isolato" (Ivan e Judy) per vedere dove vengono spediti i loro prodotti.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Introduzione agli algoritmi di Spanner Graph
Per prepararti al nostro approfondimento su Graph Intelligence, questa sezione descrive l'architettura tecnica e le regole fondamentali degli algoritmi di Cloud Spanner Graph. Comprendere questi principi è fondamentale per passare da semplici attraversamenti all'analisi delle relazioni su scala di petabyte.
Il portafoglio di algoritmi
Cloud Spanner attualmente supporta 14 algoritmi grafici standard del settore, suddivisi in quattro gruppi funzionali per risolvere diversi problemi aziendali:
Categoria | Algoritmi supportati | Caso d'uso aziendale |
Centralità | PageRank, PageRank personalizzato, centralità di intermediazione, centralità di vicinanza | Identifica influencer, hub e colli di bottiglia. |
Community | WCC, propagazione delle etichette, ricerca di cricche, clustering di correlazione | Rileva frodi organizzate, community social e silos. |
Similarità | Jaccard, Cosine, Vicini comuni, Vicini totali | Potenzia i motori per suggerimenti e la risoluzione delle entità. |
Ricerca del percorso | Set-to-set Shortest Path, GA Path helpers | Ottimizza la logistica e la prossimità di attraversamento. |
Considerazioni importanti su schema e query
Per garantire un'esecuzione efficiente degli algoritmi del grafico, Spanner Graph deve rispettare queste regole:
Requisito 1. Località fisica dei dati (interleaving)
Il requisito più importante per l'attraversamento di grafi ad alte prestazioni è l'interleaving. In questo modo, i dati perimetrali vengono archiviati fisicamente sullo stesso server suddiviso del nodo di origine, riducendo al minimo la latenza di rete durante l'esecuzione dell'algoritmo.
- La regola:le tabelle degli archi DEVONO essere intercalate nelle tabelle dei nodi di origine.
- Attraversamento in avanti:l'interleaving della tabella degli archi nella tabella dei nodi di origine garantisce la località della cache per i link in uscita.
- Attraversamento inverso:per un'analisi efficiente dei link "in entrata", utilizza le chiavi esterne per creare automaticamente indici di supporto oppure crea un indice secondario intercalato nella tabella di destinazione.
Requisito 2. Requisiti di etichettatura univoca
Ogni tabella che partecipa al grafico delle proprietà deve avere un'identità univoca. Gli algoritmi si basano su queste etichette per identificare e caricare correttamente i sottografi che devono analizzare.
- La regola: ogni tabella di input deve avere un'etichetta di identificazione univoca all'interno del grafico delle proprietà.
- Il conflitto:non puoi mappare una singola etichetta a più tabelle se intendi eseguire algoritmi su di esse.
Logic | Esempio | Risultato |
❌ Scadente | TABELLE DEI NODI (entità Etichetta persona, entità Etichetta account) | Non valido: l'algoritmo non riesce a distinguere tra una persona e un account. |
✅ Buono | NODE TABLES (Person LABEL Customer, Account LABEL Account) | Valido: ogni entità ha un'etichetta distinta e univoca. |
Requisito 3. Struttura della query con algoritmo (clausola MATCH)
Quando viene chiamato un algoritmo, la clausola MATCH segue regole più restrittive rispetto alle query GQL standard per garantire che il motore di esecuzione possa ottimizzare la pipeline analitica.
- Un pattern per MATCH:ogni istruzione MATCH può specificare un solo pattern.
- Nessun pattern multi-nodo:non puoi definire un pattern di relazione (ad es. (a)-[e]->(b)) direttamente all'interno di una clausola MATCH destinata a una chiamata di algoritmo.
- Solo filtri letterali:anche se puoi utilizzare le clausole WHERE per filtrare i nodi (ad es. WHERE a.id > 400), i parametri di query (@param) non sono attualmente supportati nelle query dell'algoritmo del grafico.
Requisito 4. Clausola RETURN (solo scalari)
La clausola RETURN in una query dell'algoritmo funge da ponte tra il mondo dei grafi e quello relazionale. È strettamente limitato alla restituzione di scalari e costanti.
- La regola: non puoi restituire un "elemento grafico" (il nodo o l'oggetto arco non elaborato).
- Nessuna trasformazione:non puoi eseguire operazioni matematiche o applicare funzioni alle proprietà restituite all'interno dell'istruzione RETURN.
Limitazioni della clausola di reso
✅ Supportato | ❌ Non supportato |
RETURN node.id, score | Nodo RETURN, punteggio (non è possibile restituire l'elemento del grafico) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (No operations on properties) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (nessuna funzione) |
Requisito 5. Integrità dei dati: eliminazione dei bordi sospesi
Un "arco pendente" si verifica quando un arco punta a un nodo di destinazione che non esiste nel grafico. Di conseguenza, l'esecuzione dell'algoritmo non riesce perché la struttura del grafico non è coerente.
- La soluzione: utilizza i vincoli referenziali (chiavi esterne) e ON DELETE CASCADE per mantenere l'integrità del grafico.
- Sicurezza delle query:quando chiami un algoritmo, devi assicurarti che tutti i nodi a cui fanno riferimento gli archi selezionati siano inclusi anche nell'argomento node_labels.
Output persistente: opzioni EXPORT DATA
Poiché gli algoritmi grafici richiedono molte risorse di calcolo, vengono eseguiti in modalità di esecuzione di scalabilità verticale utilizzando l'istruzione EXPORT DATA. Sfrutta Data Boost, utilizzando risorse di serverless computing indipendenti per evitare ritardi nelle transazioni di produzione.
Opzione 1: persistenza in Cloud Spanner
Per inserire i risultati direttamente nelle tabelle (ad es. per salvare un punteggio PageRank), utilizza format = "CLOUD_SPANNER".
update_ignore_all: aggiorna solo le righe per le chiavi già esistenti nella tabella di destinazione.upsert_ignore_all: aggiorna le righe esistenti o inserisce nuove righe se le chiavi non sono presenti.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Opzione 2: salva i risultati in Google Cloud Storage (GCS)
Per analisi offline su larga scala, puoi esportare in GCS nei formati CSV, Avro o Parquet.
- Caratteri jolly:utilizza
uri => 'gs://bucket/file_*.csv'per attivare l'output suddiviso, consentendo a Spanner di scrivere in più file in parallelo per set di dati di grandi dimensioni. - Compressione:supporta GZIP, SNAPPY e ZSTD per ottimizzare i costi di archiviazione.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Sfida 1: divario di influenza (PageRank)
In questa sezione, affrontiamo il primo ostacolo aziendale del cliente: il "gap di influenza". Passeremo da un semplice "concorso di popolarità" a una mappa dell'influenza sociale reale basata su calcoli matematici.
Dichiarazione del problema:il team di marketing del cliente ha un problema. Spendono milioni in pubblicità generica con rendimenti in calo perché non riescono a identificare le "superstar dei social", ovvero quelle rare persone le cui approvazioni si ripercuotono sull'intera rete.
Per risolvere il problema, dobbiamo classificare i nostri clienti in base all'influenza.
Soluzione relazionale (centralità del grado)
In un database standard, il modo più semplice per trovare un influencer è contare i suoi follower (una metrica nota come centralità di grado).
Esegui questa query per trovare gli utenti più "popolari":
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Graph Intelligence (PageRank)
Per trovare i veri leader, utilizziamo il PageRank. Si tratta dello stesso algoritmo che ha reso possibile la prima ricerca web: misura l'importanza di un nodo in base alla quantità E alla qualità dei link in entrata .
- Modello del navigatore casuale:PageRank simula un utente che si sposta nel grafico. Il fattore di smorzamento (valore predefinito 0,85) rappresenta la probabilità che l'utente continui a fare clic; in caso contrario, si "teletrasporta" a un nodo casuale.
- Potere dell'associazione:un link di una persona influente (come Mallory) vale molto di più di un link di una persona senza altre connessioni.
Eseguiamo l'algoritmo PageRank e utilizziamo EXPORT DATA per salvare i risultati direttamente nella colonna pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Dashboard"Influenza" utilizzando PageRank
Ora che i punteggi sono persistenti, confrontiamo il valore "Prima" (Conteggio follower) con il valore "Dopo" (Punteggio PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0,158392489 |
C10 | judy@example.com | 1 | 0,1093561724 |
C9 | ivan@example.com | 1 | 0,1093561724 |
C1 | alice@example.com | 3 | 0,1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0,09466411918 |
C7 | grace@example.com | 2 | 0,08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bruno@example.com | 1 | 0,0547891818 |
C3 | charlie@example.com | 1 | 0,0547891818 |
C12 | trent@example.com | 1 | 0,04029225558 |
C4 | david@example.com | 1 | 0,04028172791 |
Analisi: chi sono le vere superstar?
Analizzando l'output, ora puoi fare tre scoperte di marketing fondamentali:
Punti chiave per le aziende
Invece di inviare email a tutti gli utenti con più di cinque follower, il team di marketing di The Customer ora può concentrarsi esclusivamente su quelli con il pagerank_score più alto. Questi individui sono le vere "superstar dei social" in grado di generare viralità sistemica in tutto il marketplace.
Ora proviamo a identificare i Gatekeeper che mantengono in funzione la rete logistica del cliente.
5. Sfida 2: resilienza logistica (BetweennessCentrality)
In questa sezione, ci occupiamo di resilienza logistica. Non ci limiteremo a misurare il successo in base al "volume", ma identificheremo i "gatekeeper" vitali che mantengono la rete connessa.
Soluzione relazionale (analisi basata sul volume)
In una configurazione relazionale standard, un hub di spedizione "critico" viene in genere definito come quello che elabora il maggior numero di ordini o genera il maggior numero di entrate.
Esegui questa query per identificare gli hub "principali" in base al conteggio delle transazioni:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
New York | USA | 4 | 3996 |
Berlino | Germania | 2 | 345 |
San Francisco | USA | 2 | 750 |
Per risolvere la mancata corrispondenza, utilizzeremo sia i bordi IsFriendsWith che LivesAt. In questo modo, la nostra analisi non si limita più a un hub di transazioni, ma include anche il controllo sociale.
Graph Intelligence (centralità di intermediazione)
Per trovare i veri colli di bottiglia, utilizziamo la centralità di intermediazione. Questo algoritmo quantifica la frequenza con cui un nodo funge da "ponte" lungo i percorsi più brevi tra tutte le altre coppie di nodi nel grafico. I punteggi elevati identificano i veri gatekeeper che controllano il flusso di beni o informazioni.
Esecuzione e persistenza della centralità di intermediazione
Eseguiamo l'algoritmo utilizzando EXPORT DATA e salviamo i punteggi nella colonna centrality_score. Utilizziamo Data Boost per garantire che questo calcolo complesso del "percorso più breve" abbia un impatto quasi nullo sulle operazioni live del cliente.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analisi: identificazione dei "colli di bottiglia nascosti"
Ora confrontiamo il nostro rischio strutturale (centrality_score) con il nostro volume transazionale (order_count) per trovare i nodi che la leadership del cliente dovrebbe prendere in considerazione.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bruno@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Analizzando questi risultati, il cliente fa tre scoperte sorprendenti:
Business Takeaway
Ora il cliente può dare la priorità ai protocolli di ridondanza e sicurezza della logistica in base al rischio strutturale multimodale. Mallory, Alice ed Eve sono i gatekeeper che devono essere protetti per garantire la stabilità della rete logistica.
Ora proviamo a isolare le isole di frode.
6. Sfida 3: reti fantasma (WCC)
In questa sezione affrontiamo il terzo ostacolo aziendale: le "reti fantasma". Passeremo dal semplice rilevamento di "hotspot" alla scoperta di sofisticate frodi isolate utilizzando il rilevamento della community. La difficoltà sta nel fatto che i malintenzionati creano profili falsi che condividono indirizzi di spedizione o interagiscono in circuiti chiusi per coordinare i furti e gonfiare le valutazioni dei prodotti. ma spesso sono completamente isolati dalla community legittima di The Customer.
Per risolvere questo problema, dobbiamo esporre queste "isole isolate".
Soluzione relazionale (ricerca con identificatore condiviso)
Senza gli algoritmi grafici, il modo standard per rilevare le frodi è cercare "punti caldi" di dati condivisi, ad esempio più clienti che spediscono allo stesso indirizzo .
Esegui questa query per trovare i clienti collegati da una sede di spedizione condivisa:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Per trovare le reti di frode, dobbiamo comprendere la raggiungibilità transitiva.
Graph Intelligence (Weakly Connected Components)
Per trovare l'estensione completa di questi anelli, utilizziamo i componenti debolmente connessi (WCC). WCC è un algoritmo di clustering che identifica insiemi di nodi in cui esiste un percorso tra due nodi qualsiasi, indipendentemente dalla direzione degli archi.
- Zone di raggiungibilità:suddivide il grafico in "isole" o "zone di raggiungibilità".
- Visualizzazione unificata delle entità:analizzando contemporaneamente i legami sociali (IsFriendsWith) e logistici (LivesAt), possiamo raggruppare i profili frammentati in un unico "cluster di impatto" unificato.
Esecuzione e persistenza di WCC
Eseguiamo l'algoritmo WCC e salviamo i risultati nella colonna community_id. Utilizziamo Data Boost per garantire che questa analisi della raggiungibilità approfondita venga eseguita su risorse di computing indipendenti.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analisi: reti di frode
Ora eseguiamo una query di convalida per visualizzare le nostre community isolate. Gli utenti legittimi in genere appartengono alla "terraferma", mentre i frodatori spesso si trovano su piccole "isole".
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | membri |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Eseguendo questo rilevamento della community, puoi identificare un'anomalia critica:
Business Takeaway
Il cliente ora può automatizzare le risposte di sicurezza. Invece di inseguire manualmente i singoli account, possono scrivere una semplice regola: "Se un community_id ha meno di tre membri, segnala l'intero gruppo per la revisione manuale KYC (Know Your Customer)"
.
Con le nostre frodi esposte, possiamo risolvere il problema del "gemello comportamentale".
7. Sfida 4: Behavioral Twin (JaccardSimilarity)
In questa sfida finale, affrontiamo il quarto ostacolo: il "paradosso della scelta"/"gemello comportamentale". Passeremo da elenchi generici di "prodotti acquistati spesso insieme" a consigli iper-personalizzati basati sulle "impronte" comportamentali.
I suggerimenti sui prodotti attuali del cliente sono troppo generici. Consigliare un cavo USB popolare a ogni cliente è sicuro, ma non è personalizzato. Il cliente vuole creare consigli basati su "gemelli comportamentali" che identificano i clienti che condividono modelli di spedizione e cerchie sociali unici per suggerire prodotti con una corrispondenza di alta precisione.
Per risolvere il problema, dobbiamo calcolare la "prossimità" tra gli utenti.
Soluzione relazionale (sovrapposizione assoluta)
In una configurazione relazionale standard, potresti cercare persone che effettuano spedizioni nelle stesse località di un utente di riferimento, ad esempio Alice (C1).
Esegui questa query per trovare i vicini geografici di Alice:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (similarità di Jaccard)
Per trovare veri e propri gemelli comportamentali, utilizziamo la similarità di Jaccard. Questo algoritmo calcola un punteggio normalizzato (da 0,0 a 1,0) dividendo il numero di vicini condivisi (intersezione) per il numero totale di vicini unici (unione).
In questo caso, un "gemello comportamentale" è definito da più di un semplice indirizzo di spedizione condiviso. Analizzando l'intersezione tra impronte fisiche (LivesAt) ed ecosistemi sociali (IsFriendsWith), possiamo identificare gli utenti che condividono lo stesso stile di vita e la stessa influenza della community, il che porta a consigli sui prodotti molto più accurati.
Per prima cosa, crea una tabella di mappatura
Poiché la somiglianza è una relazione pairwise (il cliente A è simile al cliente B), creiamo una tabella dedicata intercalata in Customer per archiviare queste mappature.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Esegui ora la similarità di Jaccard
Ora eseguiamo l'algoritmo. Nota:questa query include una lezione comune di "Guardrail". Se selezioni solo i nodi Customer, ma utilizzi il bordo LivesAt (che punta ai nodi Shipping), la query non andrà a buon fine e verrà visualizzato un "Dangling Edge" . Per risolvere il problema, dobbiamo includere entrambe le etichette dei nodi.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analisi: controllo "gemello comportamentale"
Ora che il job di analisi è completato, eseguiamo una query di convalida. Unendo la nostra nuova tabella di mappatura (CustomerSimilarity) ai nostri metadati Customer originali, possiamo vedere esattamente chi sono i "gemelli comportamentali" di Alice.
Esegui questa query per esaminare le classifiche di somiglianza di Alice:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0,200000003 | 1 | 0,1093561724 |
bruno@example.com | 0,200000003 | 0 | 0,0547891818 |
ivan@example.com | 0,200000003 | 1 | 0,1093561724 |
eve@example.com | 0.1666666716 | 0 | 0,158392489 |
mallory@example.com | 0 | 0 | 0,09466411918 |
trent@example.com | 0 | 0 | 0,04029225558 |
charlie@example.com | 0 | 0 | 0,0547891818 |
david@example.com | 0 | 0 | 0,04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0,08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Cosa cercare nei risultati:
Ora proviamo a creare una visualizzazione finale di Unified Intelligence.
8. Unified Intelligence
Ora passiamo dalle singole attività tecniche all'Unified Intelligence. Qui combiniamo i dati transazionali con tutti e quattro gli algoritmi grafici per fornire approfondimenti chiari e fruibili.
Report 1: Unified Intelligence
La potenza di un database multimodello come Spanner è la possibilità di unire i dati di spesa relazionali con i punteggi di influenza, rischio e somiglianza derivati dal grafico in un'unica richiesta. Questa query classifica ogni cliente in un profilo aziendale specifico.
Esegui la query Unified Intelligence per visualizzare l'ecosistema completo:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | spesa | influenza | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0,09466411918 | 44,5 | 0 | 🔵 CRITICO: bridge di rete |
C5 | eve@example.com | 0 | 0,158392489 | 35,5 | 0 | 🔵 CRITICO: bridge di rete |
C1 | alice@example.com | 999 | 0,1000888124 | 35,5 | 0 | 🔵 CRITICO: bridge di rete |
C7 | grace@example.com | 300 | 0,08016719669 | 12 | 0 | 📱 SOCIAL: High-Reach Influencer |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 SOCIAL: High-Reach Influencer |
C3 | charlie@example.com | 0 | 0,0547891818 | 6 | 0 | 🟢 STANDARD: cliente attivo |
C4 | david@example.com | 0 | 0,04028172791 | 3,5 | 0 | 🟢 STANDARD: cliente attivo |
C10 | judy@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 RISCHIO ELEVATO: frode isolata |
C9 | ivan@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 RISCHIO ELEVATO: frode isolata |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDARD: cliente attivo |
C2 | bruno@example.com | 999 | 0,0547891818 | 0 | 0 | 🟢 STANDARD: cliente attivo |
C12 | trent@example.com | 0 | 0,04029225558 | 0 | 0 | 🟢 STANDARD: cliente attivo |
Combinando questi approcci matematici, andiamo oltre la domanda "chi ha speso di più" per rispondere alla domanda "chi conta di più". La dashboard unificata integra i dati transazionali relazionali con l'intelligence dei grafi multimodali per classificare il tuo ecosistema in tre buyer persona chiare e attuabili.
"Critical Network Bridges" (Resilienza)
I nodi come Mallory (C11), Eve (C5) e Alice (C1) sono contrassegnati perché la loro bottleneck_risk (centralità di intermediazione) è >25.
- Gli ancoraggi strutturali:Mallory ha il punteggio di rischio più alto, pari a 44,5, il che la rende il gateway principale per l'intera rete.
- Il paradosso della spesa zero: Eve (C5) ha un conteggio ordini pari a zero, ma è strutturalmente indispensabile con un punteggio di rischio di 35,5. SQL standard l'avrebbe ignorata completamente, ma Graph Intelligence rivela che è un ponte fondamentale per un'intera sottocomunità.
- Il gateway di alto valore: Alice (C1) è arrivata a pari merito con Eva a 35,5, dimostrando che gli utenti con una spesa elevata possono anche essere punti di riferimento strutturali fondamentali.
"Superstar dei social" (copertura)
Heidi (C8) e Grace (C7) sono identificate come influencer con un'ampia copertura grazie ai loro punteggi PageRank .
"Isolated Fraud Ring" (Anomalie)
Judy (C10) e Ivan (C9) sono contrassegnati perché appartengono all'ID community isolato 1
Approfondimenti aziendali per azioni strategiche
Persona | Metrica principale | Business Insight | Azione strategica |
🔵 Bridge di rete | Centralità elevata | Ancore strutturali: Eve (C5) e Mallory (C11) tengono insieme la rete. | Fidelizzazione: proteggi questi gatekeeper per evitare la frammentazione della community. |
📱 Superstar dei social | PageRank elevato | Motori virali: utenti come Heidi (C8) hanno la copertura più ampia nelle loro cerchie. | Marketing: utilizza questo tipo di dati per programmi di referral e ambasciatori ad alto impatto. |
🔴 Rischi di frode | Isolated WCC | Reti fantasma: Judy (C10) e Ivan (C9) sono persone che spendono molto, ma vivono in "isole". | Sicurezza: revisione manuale immediata della procedura KYC; si tratta di firme di frode classiche. |
🟢 Utenti standard | Punteggi bilanciati | Healthy Core: la maggior parte della rete, inclusi i ponti "locali" come David (C4). | Crescita: applica annunci personalizzati standard e consigli "Gemello comportamentale". |
Report 2: The Identity Anomaly Report
Ora devi sapere se gli account legittimi vengono "imitati" dai frodatori. Possiamo risolvere il problema trovando utenti con similarità comportamentale del 100%, ma nessuna connessione sociale.
Esegui questa query per segnalare potenziali "anomalie di identità":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Il report Identifica anomalia fornisce informazioni fondamentali. Isolando gli utenti che si comportano come clienti legittimi, ma non hanno legami sociali, passiamo da una supposizione a una certezza matematica .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0,200000003 | 1 |
C9 | ivan@example.com | 0,200000003 | 1 |
Analisi dei risultati
Unificando la similarità (Jaccard) con il rilevamento della community (WCC), mettiamo in luce i rischi nascosti che i dati transazionali tradizionali non possono rilevare.
- I "gemelli comportamentali" (prossimità): i nodi come Judy (C10) e Ivan (C9) sono contrassegnati perché condividono un punteggio di similarità di Jaccard pari a 0,20 rispetto ad Alice (C1).
- Comportamento di isolamento:Judy (C10) e Ivan (C9) sono raggruppati nell'ID community 1 isolato, mentre Alice appartiene alla comunità sociale "Mainland" (community 0).
- Indicatori di frode:il report identifica gli utenti con un'elevata sovrapposizione comportamentale (> 0,9) che rimangono socialmente disconnessi dalla rete principale.
9. Congratulazioni e riepilogo
Questo lab mostra come Cloud Spanner trasforma un database relazionale in una risorsa multi-modello. Applicando l'intelligenza del grafico a Il cliente, siamo passati da dati statici a una strategia aziendale attuabile.
Il vantaggio di Spanner Multi-Model
- Architettura unificata:Spanner ti consente di mantenere una base relazionale solida come una roccia e di "sovrapporre" istantaneamente un grafico delle proprietà per l'estrazione delle relazioni, il tutto senza il rischio e il ritardo dell'ETL.
- Isolamento analitico off-box:sfruttando Data Boost, puoi eseguire algoritmi che richiedono molta memoria, come PageRank o WCC, su risorse di calcolo serverless indipendenti, garantendo un impatto nullo sulle prestazioni di pagamento della produzione.
- Rendimento interleaved: l'interleaving unico di Spanner garantisce che i nodi e le relative relazioni si trovino nella stessa posizione fisica, trasformando attraversamenti globali complessi in ricerche locali ad alta velocità.
Visualizzazione di "tesori nascosti" e anomalie
- Identificazione del valore strutturale:gli algoritmi grafici come Betweenness Centrality hanno rivelato "ponti nascosti" con spesa pari a zero che possono essere più importanti per la resilienza della rete rispetto ai clienti con la spesa più elevata.
- Esposizione della mimesi comportamentale:combinando la similarità di Jaccard e i componenti debolmente connessi, abbiamo identificato gli "estranei sociali". Questi account sembrano clienti legittimi, ma è stato dimostrato matematicamente che si tratta di gruppi di frode isolati.
- Verità globale e locale:mentre l'analisi SQL manuale può rivelare i ponti, gli algoritmi globali possono rivelare i principali Gatekeeper della rete.
Rendere i dati intelligenti e utilizzabili
- Strategia basata sulle buyer persona: abbiamo trasformato con successo le righe in relazioni e, eseguendo algoritmi, possiamo affrontare quattro problemi aziendali, ovvero ponti di rete, superstar dei social,rischi di frode e utenti standard.