
1. 事例紹介: インテリジェント リテール
この事例紹介では、デジタル マーケットプレイスが急速に成長している小売業のお客様を取り上げます。従来のデータビューでは、ユーザーが何を購入したかはわかりますが、ユーザーがどのようにつながっているかはわからないため、顧客のデータビューは制限されます。このギャップにより、ビジネス チャンスを逃したり、不正行為が増加したりする可能性があります。現在では、トランザクション データに加えてソーシャルやロジスティクスのつながりを重視する「ネットワーク ファースト」の哲学に転換しています。
対処すべきビジネス上の主な課題
お客様とロジスティクスがどのように相互接続されているかを理解することが求められる 4 つの重要な課題があります。
チャレンジ | 問題点 | 目標 |
影響のギャップ | 広範囲の広告は費用対効果が低く、現在のところ、真のトレンドセッター(インフルエンサー)を特定することはできません。 | お客様のネットワーク内のつながりを通じてコミュニティの中心となるインフルエンサーを特定します。 |
ロジスティクスのレジリエンス | サプライ チェーンは脆弱である可能性があります(さまざまな地域で運用されていることを考慮)。1 つのキーハブで障害が発生すると、リージョン全体でプロダクトへのアクセスが失われる可能性があります。 | ロジスティクス ネットワークを繋ぐ上で重要な役割を果たすゲートキーパー を特定します。 |
Ghost Networks | 不正行為グループは、偽のプロフィールと共有住所を使用して、盗難を調整し、評価を不正に高めます。 | 孤立した島 (正当なコミュニティとのつながりがない、過剰に結びついたグループ)を特定します。 |
選択のパラドックス | 現在の提案 / レコメンデーション エンジンは、基本的な汎用的なもので、無視されることがよくあります(「この商品を購入したお客様は、こちらも購入しています」など)。 | 行動ツインを構築します。つまり、類似した配送パターンやソーシャル サークルに基づく推奨事項です。 |
ビジネス上の課題を技術戦略にマッピングする(行 → 関係)
従来のデータベースでは、データは分離されたサイロに保存されます。顧客は 1 つのテーブルに、トランザクションは別のテーブルに、配送は 3 つ目のテーブルに保存されます。SQL は「誰が何を購入したか」という質問に答えるには最適ですが、ネットワークベースの質問に答えるのは苦手です。
こうした課題を解決するために、技術戦略ではこの視点を次のように変えます。
- リレーショナル ビュー(「何」): すべての顧客を個別の行として扱います。顧客と友人の購入の関連性を特定するには、複数の複雑な「結合」が必要になります。ネットワークが拡大するにつれて、この処理は指数関数的に遅くなります。
- グラフビュー(「方法」): 関係を最優先で扱います。リストを検索する代わりに、地図をナビゲートします。顧客 A が顧客 B に接続され、顧客 B が場所 Z に配送していることがすぐにわかります。
要件について詳しく調べる
ソリューション アーキテクトは、ビジネス要件と技術戦略にマルチモデル アプローチが必要であると結論付け、次の主要な要件を特定します。
Cloud Spanner がこれらの技術要件にどのように適合するか
この変革の中心として Cloud Spanner が選ばれました。これにより、お客様は堅牢なリレーショナル基盤を維持しながら、グラフの深い分析情報を同時に活用できます。
Cloud Spanner が技術要件などにどのように対応しているかについて簡単に説明します。
さらに、Cloud Spanner は将来にわたって使い続けられる技術アーキテクチャを提供します。
2. データ基盤の設定
ビジネスケースに沿って、実装フェーズに進みます。このセクションでは、データ アーキテクチャを定義し、従来のリレーショナル モデルの制限事項について説明します。また、詳細な分析情報を明らかにするための主要なツールとして、プロパティ グラフを紹介します。
Cloud Spanner Enterprise インスタンスを設定する
ステップ 1: Cloud Spanner API を有効にする
Google Cloud コンソールで、画面左上のメニュー アイコンをクリックして左側のナビゲーションを開きます。下にスクロールして [Spanner] を選択するか、「Spanner」を検索します。
Cloud Spanner UI が表示されます。Cloud Spanner API がまだ有効になっていないプロジェクトを使用している場合は、有効にするかどうかを尋ねるダイアログが表示されます。すでに API を有効にしている場合は、この手順をスキップできます。
[有効にする] をクリックして続行します。
ステップ 2: Cloud Spanner インスタンスを作成する
まず、Cloud Spanner インスタンスを作成します。UI で [プロビジョニングされたインスタンスを作成] をクリックして、新しいインスタンスを作成します。
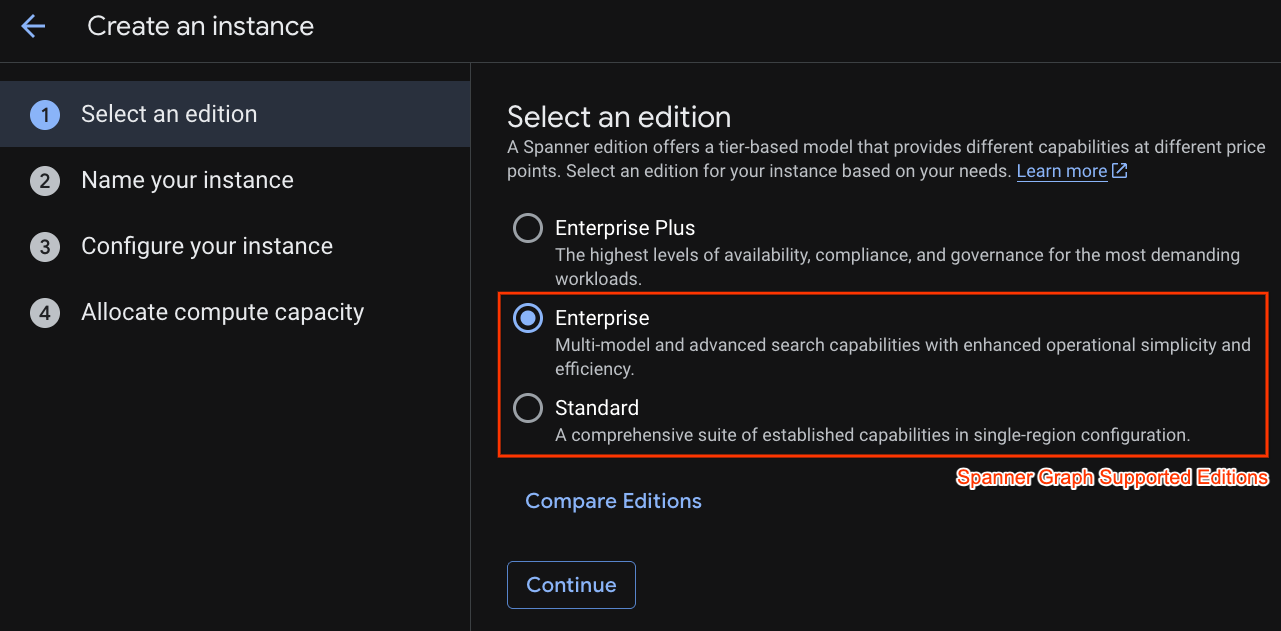
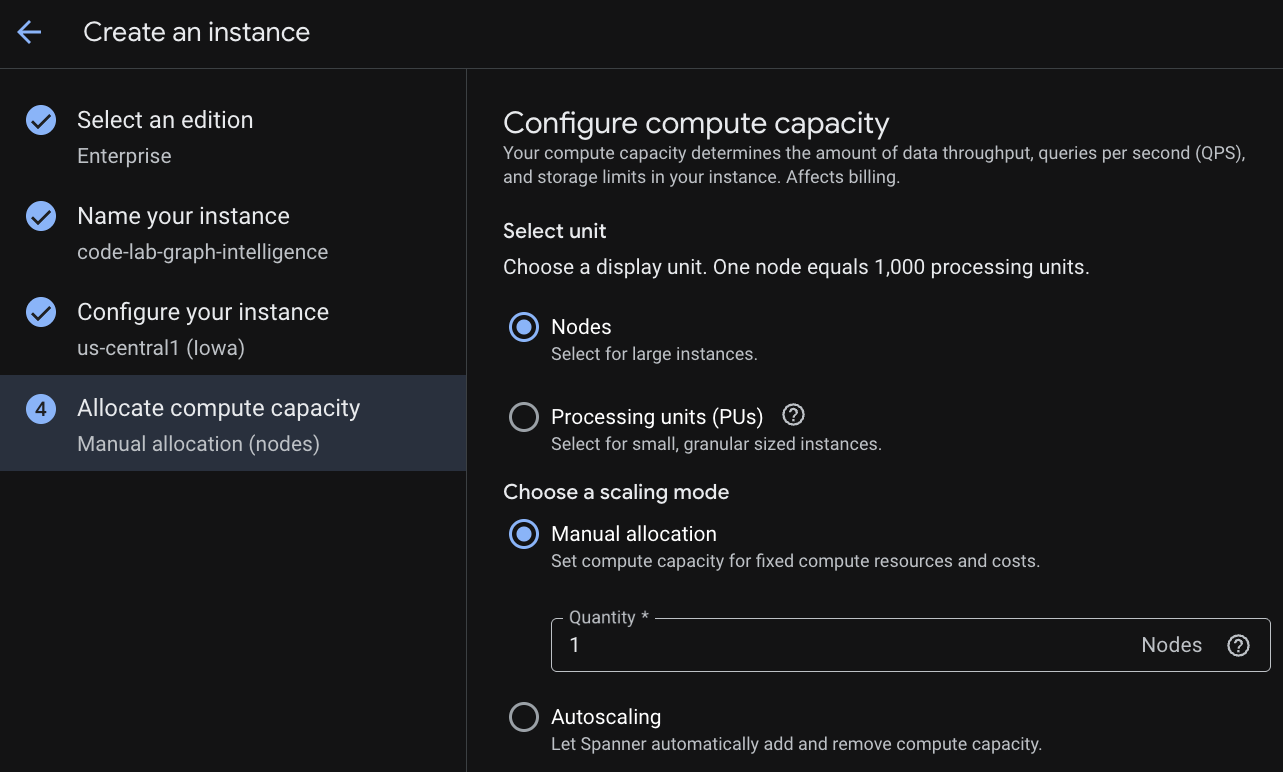
最初のステップでは、エディションを選択する必要があります。エディションは後からアップグレードすることもできます。マルチモデル機能(Spanner Graph)を使用するには、Enterprise エディションを選択します。
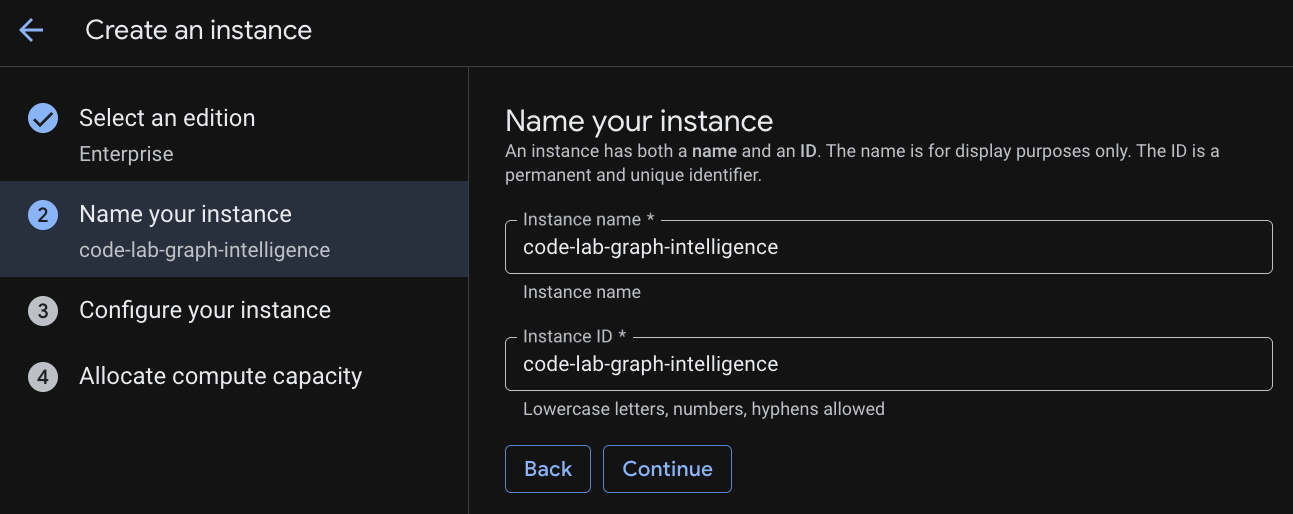
インスタンスに名前を付ける
デプロイ構成を選択し、任意のリージョンを選択します。
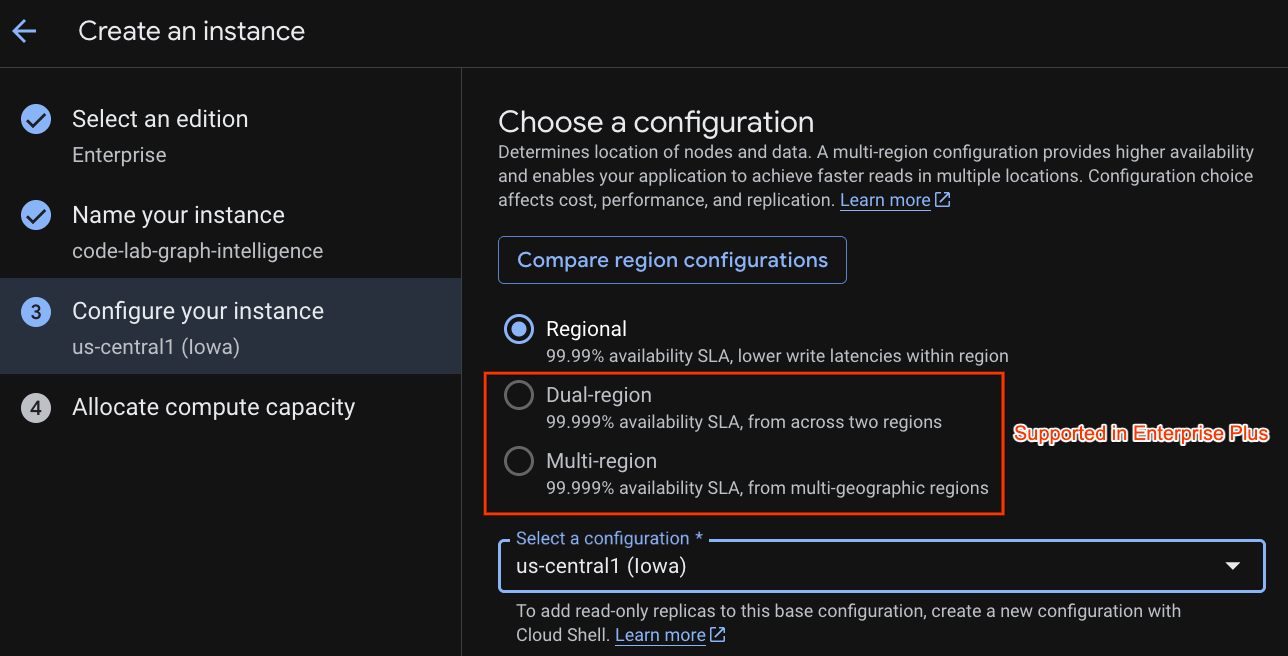
さまざまな構成オプションを比較することもできます。たとえば、デプロイ構成には、選択したリージョンの 3 つの別々のゾーンに少なくとも 3 つの R/W レプリカがあります。つまり、単一ノードのデプロイを選択した場合でも、3 つの R/W レプリカを通じて 3 つのコピーが作成されます。リージョン デプロイ構成でも、デプロイ トポロジに追加の R/O レプリカを配置することで、さらに拡張できます。
容量を構成する際は、フルノードから開始してノードで自動スケーリングを行うか、粒度の細かいインスタンス(処理ユニット。1, 000 PU = 1 ノード)を使用できます。必要に応じて、インスタンスの自動スケーリング ターゲットを設定することもできます。低レイテンシのワークロードの場合、リージョン インスタンスには 65% 、マルチリージョン インスタンスには 45% をおすすめします。
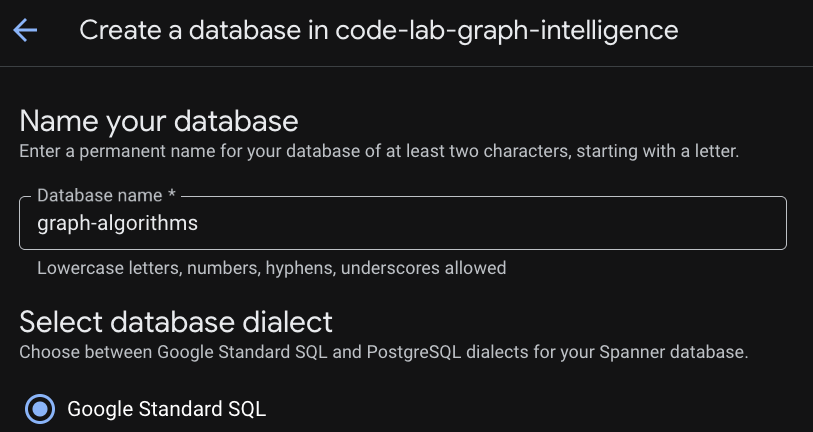
ステップ 3: データベースを作成する
インスタンスがプロビジョニングされたら、[データベースの作成] をクリックして、残りの Codelab で使用するデータベースを作成します。
リレーショナル基盤の設定
ジャーニーは、運用データを保存するコアテーブルから始まります。Cloud Spanner では、インターリーブを使用して、顧客の友情や取引などの関連データを顧客レコードと直接物理的に同じ場所に配置します。これにより、高パフォーマンスのアクセスと物理的なローカリティが確保されます。
DDL: テーブルの作成
次のブロックをコピーして実行し、リレーショナル スキーマを確立します。
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
ネットワークのシード
テーブルの準備ができたら、顧客のエコシステムを定義するユーザー、プロダクト、接続をテーブルに入力する必要があります。
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
リレーショナルに関するチャレンジ
グラフを紹介する前に、従来の SQL がお客様の課題にどのように対応しているかを見てみましょう。このクエリを実行して、支出が多く、友だちが多い「ソーシャル スペンダー」の顧客を検索します。
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
リレーショナル アプローチの制限事項
プロパティ グラフによるリレーショナル チャレンジの克服
これらの制限を克服するために、プロパティ グラフを定義します。これにより、「オーバーレイ」が作成され、データを Spanner から移動することなく、関係をファーストクラスの市民として扱うことができます。
DDL: プロパティ グラフの作成
この DDL は、ノード(エンティティ)とエッジ(関係)を定義します。この例ではスキーマ化されたグラフを使用していますが、Spanner Graph ではスキーマレス グラフをモデル化して、柔軟で迅速な反復型開発を可能にし、DDL(データ定義言語)を常に変更することなく進化するデータモデルを処理できます。
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
GQL を使用してグラフをナビゲートする
グラフが定義されたので、Graph Query Language(GQL)を使用して、シンプルで読みやすい構文でマルチホップ トラバーサルを実行できます。
探索 1: 共同調査
このクエリは、グラフをトラバースして友人が購入した商品を見つけ、レコメンデーション エンジンの基盤として機能します。
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
探索 2: ハイブリッド クエリ(リレーショナル + グラフ)
Spanner では、GRAPH_TABLE 関数を使用して、標準 SQL の FROM 句内に GQL パターンを埋め込むことができます。このクエリは、友人と「ひし形」パターン一致で同じ場所に住んでいる顧客を検索します。
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
顧客のつながりを可視化する
最後に、GQL を使用してネットワークを可視化しましょう。これらのクエリは、パスの結果を SAFE_TO_JSON でラップし、可視化ツールがノードと線を描画できるようにします。
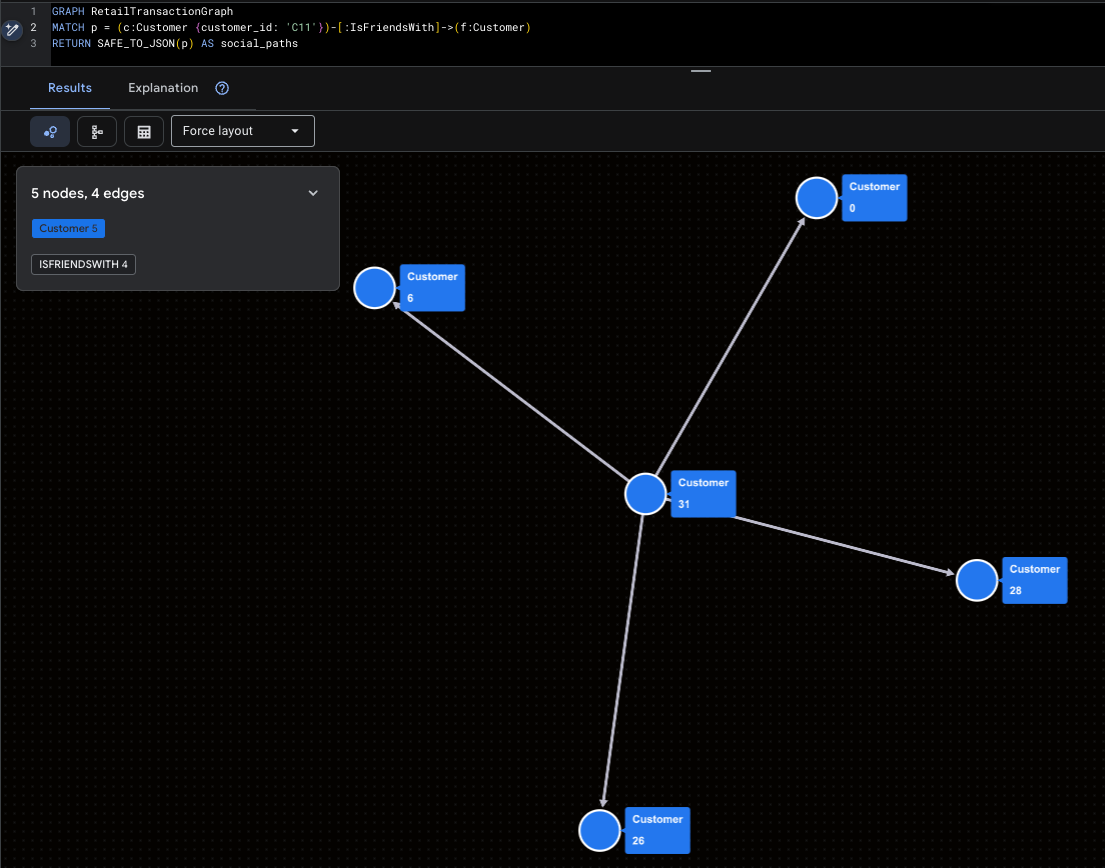
スーパー インフルエンサーを可視化する
これは、Mallory(C11)とその直接的なソーシャルリーチをハイライト表示したものです。
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
不正行為の可能性のあるパターンを可視化する
このクエリは、「Isolated Cluster」(Ivan と Judy)を特定し、その商品がどこに発送されているかを確認します。
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Spanner Graph アルゴリズムの概要
グラフ インテリジェンスの詳細な説明に入る前に、このセクションでは、Cloud Spanner Graph Algorithmsの技術アーキテクチャと基本ルールについて説明します。これらの原則を理解することは、単純なトラバーサルからペタバイト規模の関係分析に移行するための鍵となります。
アルゴリズム ポートフォリオ
Cloud Spanner は現在、14 個の業界標準のグラフ アルゴリズムをサポートしています。これらのアルゴリズムは、さまざまなビジネス上の問題を解決するために、4 つの機能グループに分類されています。
カテゴリ | サポートされているアルゴリズム | ビジネス ユースケース |
Centrality | PageRank、パーソナライズされた PageRank、Betweenness、Closeness | インフルエンサー、ハブ、ボトルネックを特定します。 |
コミュニティ | WCC、ラベル伝播、クリーク検出、相関クラスタリング | 不正行為グループ、ソーシャル コミュニティ、サイロを検出します。 |
類似度 | Jaccard、Cosine、Common Neighbors、Total Neighbors | レコメンデーション エンジンとエンティティ解決を強化します。 |
経路検索 | Set-to-set Shortest Path、GA Path ヘルパー | ロジスティクスとトラバーサルの近接性を最適化します。 |
スキーマとクエリに関する重要な考慮事項
グラフ アルゴリズムを効率的に実行するには、Spanner Graph が次のルールに準拠する必要があります。
要件 1. 物理データの局所性(インターリーブ)
高パフォーマンスのグラフ トラバーサルの最も重要な要件は、インターリーブです。これにより、エッジデータがソースノードと同じサーバー分割に物理的に保存されるため、アルゴリズム実行中のネットワーク レイテンシが最小限に抑えられます。
- ルール: エッジテーブルは、ソースノード テーブルにインターリーブしなければなりません。
- フォワード トラバーサル: エッジテーブルをソースノード テーブルにインターリーブすると、アウトバウンド リンクのキャッシュの局所性が確保されます。
- 逆方向の走査: 効率的な「インバウンド」リンク分析を行うには、外部キーを使用してバックアップ インデックスを自動的に作成するか、宛先テーブルにインターリーブされたセカンダリ インデックスを作成します。
要件 2. 固有のラベル付け要件
プロパティ グラフに参加するすべてのテーブルには、一意の ID が必要です。アルゴリズムは、これらのラベルを使用して、分析に必要なサブグラフを正しく識別して読み込みます。
- ルール: 各入力テーブルには、プロパティ グラフ内で一意に識別できるラベルが必要です。
- 競合: 複数のテーブルでアルゴリズムを実行する場合は、1 つのラベルを複数のテーブルにマッピングすることはできません。
ロジック | 例 | 結果 |
❌ 悪い | NODE TABLES(Person LABEL エンティティ、Account LABEL エンティティ) | 無効: アルゴリズムで Person と Account を区別できません。 |
✅ 良い | NODE TABLES (Person LABEL Customer, Account LABEL Account) | 有効: 各エンティティに個別の固有ラベルが付けられています。 |
要件 3. アルゴリズム クエリの構造(MATCH 句)
アルゴリズムを呼び出す場合、実行エンジンが分析パイプラインを最適化できるように、MATCH 句は標準の GQL クエリよりも厳しいルールに従います。
- MATCH ごとに 1 つのパターン: 各 MATCH ステートメントで指定できる変数は 1 つのみです。
- マルチノード パターンなし: アルゴリズム呼び出し用の MATCH 句内で、関係パターン((a)-[e]->(b) など)を直接定義することはできません。
- リテラル フィルタのみ: WHERE 句を使用してノードをフィルタできます(例: WHERE a.id > 400)。ただし、グラフ アルゴリズム クエリでは、現在クエリ パラメータ(@param)はサポートされていません。
要件 4. RETURN 句(スカラーのみ)
アルゴリズム クエリの RETURN 句は、グラフの世界とリレーショナルな世界を結ぶブリッジとして機能します。スカラーと定数の戻り値に厳密に制限されます。
- ルール: 「グラフ要素」(未加工のノードまたはエッジ オブジェクト)を返すことはできません。
- 変換なし: RETURN ステートメント自体の中で、返されるプロパティに対して数学演算を実行したり、関数を適用したりすることはできません。
RETURN 句の制限
✅ サポート対象 | ❌ サポート対象外 |
RETURN node.id, score | RETURN ノード、スコア(グラフ要素を返すことはできません) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score(プロパティに対するオペレーションなし) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score)(関数なし) |
要件 5. データの整合性: ぶら下がりエッジの排除
「ダングリング エッジ」は、エッジがグラフに存在しない宛先ノードを指している場合に発生します。グラフ構造に一貫性がないため、アルゴリズムの実行が失敗します。
- 解決策: 参照制約(外部キー)と ON DELETE CASCADE を使用して、グラフの完全性を維持します。
- クエリの安全性: アルゴリズムを呼び出すときは、選択したエッジで参照されるすべてのノードが node_labels 引数にも含まれていることを確認する必要があります。
永続出力: EXPORT DATA オプション
グラフ アルゴリズムは計算負荷が高いため、EXPORT DATA ステートメントを使用してスケールアップ実行モードで実行されます。これにより、Data Boost が活用され、独立したサーバーレス コンピューティング リソースを使用して、本番環境のトランザクションの遅延を防ぐことができます。
オプション 1: Cloud Spanner に保存する
結果をテーブルに直接プッシュバックするには(PageRank スコアの保存など)、format = ‘CLOUD_SPANNER’ を使用します。
update_ignore_all: ターゲット テーブルにすでに存在するキーの行のみを更新します。upsert_ignore_all: キーがない場合は、既存の行を更新するか、新しい行を挿入します。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
オプション 2: 結果を Google Cloud Storage(GCS)に保持する
大規模なオフライン分析を行う場合は、CSV、Avro、Parquet 形式で GCS にエクスポートできます。
- ワイルドカード:
uri => 'gs://bucket/file_*.csv'を使用して分割出力を有効にすると、Spanner は大規模なデータセットに対して複数のファイルに並行して書き込むことができます。 - 圧縮: ストレージ費用を最適化するために、GZIP、SNAPPY、ZSTD をサポートします。
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. 課題 1: 影響力のギャップ(PageRank)
このセクションでは、お客様の最初のビジネス上のハードルである「影響力のギャップ」について説明します。基本的な「人気投票」から、真の社会的影響力を数学的に表すマップへと移行します。
問題文: お客様のマーケティング チームに問題があります。彼らは、ネットワーク全体に影響を与える「ソーシャル スーパースター」を特定できないため、収益が減少しているにもかかわらず、広範囲の広告に数百万ドルを費やしています。
この問題を解決するには、お客様を影響力でランク付けする必要があります。
リレーショナル ソリューション(次数中心性)
標準的なデータベースでは、インフルエンサーを見つける最も簡単な方法は、フォロワー数を数えることです(これは次数中心性と呼ばれる指標です)。
このクエリを実行して、最も「人気のある」ユーザーを見つけます。
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
グラフ インテリジェンス(PageRank)
実際のリーダーを見つけるために、PageRank を使用します。これは初期のウェブ検索を支えたアルゴリズムと同じもので、ノードの重要度を、そのノードへのリンクの量と質に基づいて測定します。
- ランダム サーファー モデル: PageRank は、グラフ内を移動するユーザーをシミュレートします。減衰係数(デフォルトは 0.85)は、ユーザーがクリックを続ける確率を表します。それ以外の場合、ユーザーはランダムなノードに「テレポート」します。
- 関連性の力: 影響力のある人物(Mallory など)からのリンクは、他のつながりのない人物からのリンクよりもはるかに価値があります。
PageRank アルゴリズムを実行し、EXPORT DATA を使用して結果を pagerank_score 列に直接保存します。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
PageRank を使用した「影響力」ダッシュボード
スコアが永続化されたので、「前」(フォロワー数)と「後」(PageRank スコア)を比較してみましょう。
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
分析: 誰が真のスターか?
出力を分析することで、次の 3 つの重要なマーケティング上の発見が得られます。
ビジネス上のポイント
マーケティング チームは、フォロワーが 5 人以上いるすべてのユーザーに無差別にメールを送信するのではなく、pagerank_score が最も高いユーザーにのみ焦点を当てることができます。これらのユーザーは、マーケットプレイス全体で体系的なバイラル効果を生み出すことができる真の「ソーシャル スーパースター」です。
次に、顧客のロジスティクス ネットワークを維持しているゲートキーパーを特定してみましょう。
5. チャレンジ 2: ロジスティックの回復力(BetweennessCentrality)
このセクションでは、ロジスティクスの復元力について説明します。「量」で成功を測定するだけでなく、ネットワークの接続を維持する重要な「ゲートキーパー」を特定します。
リレーショナル ソリューション(ボリュームベースの分析)
標準的なリレーショナル設定では、「重要な」配送ハブは通常、最も多くの注文を処理するか、最も多くの収益を生み出すハブとして定義されます。
このクエリを実行して、トランザクション数で「上位」ハブを特定します。
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
ニューヨーク | 米国 | 4 | 3996 |
ベルリン | ドイツ | 2 | 345 |
サンフランシスコ | 米国 | 2 | 750 |
この不一致に対処するために、IsFriendsWith エッジと LivesAt エッジの両方を使用します。これにより、取引ハブからソーシャル チェックも含む分析に変換されます。
グラフ インテリジェンス(仲介中心性)
実際のボトルネックを見つけるには、中心性介在度を使用します。このアルゴリズムは、グラフ内の他のすべてのノードペア間の最短パスに沿って、ノードが「ブリッジ」として機能する頻度を定量化します。スコアが高いほど、商品や情報の流れを制御する真のゲートキーパーを特定できます。
媒介中心性の実行と永続化
EXPORT DATA を使用してアルゴリズムを実行し、中心性スコアを centrality_score 列に保存します。この重い「最短経路」の計算がお客様のライブ オペレーションに与える影響をほぼゼロにするために、Data Boost を使用します。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
分析: 「隠れたボトルネック」を特定する
次に、構造リスク(centrality_score)とトランザクション量(order_count)を比較して、顧客のリーダーシップが懸念すべきノードを見つけます。
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
この結果を分析したところ、お客様は 3 つの驚くべき発見をしました。
ビジネスのポイント
お客様は、マルチモーダル構造リスクに基づいて、ロジスティクス冗長性とセキュリティ プロトコルに優先順位を付けることができるようになりました。Mallory、Alice、Eve は、ロジスティクス ネットワークの安定性を確保するために保護する必要があるゲートキーパーです。
次に、不正行為の島を特定してみましょう。
6. 課題 3: ゴースト ネットワーク(WCC)
このセクションでは、3 つ目のビジネス上のハードルである「ゴースト ネットワーク」について説明します。シンプルな「ホットスポット」の検出から、コミュニティ検出を使用して複雑で孤立した不正行為グループを特定する方法に移行します。問題は、悪意のあるユーザーが配送先住所を共有したり、閉じたループ内でやり取りしたりして、盗難を調整し、商品の評価を不正に高める偽のプロフィールを作成することです。しかし、多くの場合、正規の The Customer コミュニティから完全に分離されています。
この問題を解決するには、これらの「孤立した島」を公開する必要があります。
リレーショナル ソリューション(共有 ID 検索)
グラフ アルゴリズムを使用しない場合、不正行為を見つける標準的な方法は、複数の顧客がまったく同じ住所に配送しているなど、共有データの「ホットスポット」を探すことです。
このクエリを実行して、配送先住所が共通しているお客様を検索します。
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
不正行為ネットワークを見つけるには、推移的な到達可能性を理解する必要があります。
グラフ インテリジェンス(弱連結成分)
これらのリングの範囲を特定するために、弱連結成分(WCC)を使用します。WCC は、エッジの方向に関係なく、任意の 2 つのノード間にパスが存在するノードのセットを特定するクラスタリング アルゴリズムです。
- 到達可能性ゾーン: グラフを「島」または「到達可能性ゾーン」に効果的に分割します。
- 統合エンティティ ビュー: ソーシャル リンク(IsFriendsWith)とロジスティクス リンク(LivesAt)の両方を同時に分析することで、断片化されたプロファイルを 1 つの統合された「影響クラスタ」にグループ化できます。
WCC の実行と永続化
WCC アルゴリズムを実行し、結果を community_id 列に保存します。Data Boost を使用して、この詳細な到達可能性分析が独立したコンピューティング リソースで行われるようにします。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
分析: 不正行為グループ
次に、検証クエリを実行して、分離されたコミュニティを確認します。正当なユーザーは通常「本土」に属し、不正行為者は「島」に閉じ込められることがよくあります。
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | メンバー |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
このコミュニティ検出を実行すると、重大な異常を特定できます。
ビジネスのポイント
お客様はセキュリティ対応を自動化できるようになりました。個々のアカウントを手動で追跡する代わりに、簡単なルール(「community_id のメンバーが 3 人未満の場合は、グループ全体に手動の KYC(顧客確認)審査のフラグを設定する」)を作成できます。
不正行為グループを特定することで、「行動ツイン」を解決できます。
7. 課題 4: 行動ツイン(JaccardSimilarity)
最後の課題では、4 つ目のハードルである「選択のパラドックス」と「行動の双子」について説明します。一般的な「よく一緒に購入される商品」リストから、行動の「フィンガープリント」に基づく高度にパーソナライズされたおすすめに移行します。
お客様の現在の商品の提案が一般的すぎる。すべてのお客様に人気の USB ケーブルをおすすめするのは安全ですが、パーソナライズされていません。お客様は、独自の配送パターンやソーシャル サークルを共有する顧客を特定し、高精度のマッチングで商品を提案する「行動ツイン」のおすすめを構築したいと考えています。
この問題を解決するには、ユーザー間の「近接性」を計算する必要があります。
リレーショナル ソリューション(絶対重複)
標準のリレーショナル設定では、参照ユーザー(Alice(C1)など)と同じ場所に配送するユーザーを探すことができます。
次のクエリを実行して、Alice の地理的な近隣ユーザーを見つけます。
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
グラフ インテリジェンス(ジャカード類似度)
真の行動ツインを見つけるには、ジャカード類似度を使用します。このアルゴリズムは、共有近傍の数(交差)を固有の近傍の総数(和集合)で割って、正規化されたスコア(0.0 ~ 1.0)を計算します。
ここで「行動ツイン」は、配送先住所が同じであることだけではなく、物理的なフットプリント(LivesAt)とソーシャル エコシステム(IsFriendsWith)の交差点を分析することで、同じライフスタイルとコミュニティの影響を共有するユーザーを特定し、より正確な商品のおすすめにつながります。
まず、マッピング テーブルを作成します
類似性はペアワイズ関係(顧客 A は顧客 B に類似している)であるため、これらのマッピングを保存するために、Customer にインターリーブされた専用のテーブルを作成します。
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
ジャカード類似度を実行する
アルゴリズムを実行します。注釈: このクエリには、一般的な「ガードレール」レッスンが含まれています。顧客ノードのみを選択し、LivesAt エッジ(配送ノードを指す)を使用すると、クエリは「Dangling Edge」を引用して失敗します。この問題を解決するには、両方のノードラベルを含める必要があります。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
分析: 「行動ツイン」チェック
分析ジョブが完了したので、検証クエリを実行します。新しいマッピング テーブル(CustomerSimilarity)を元の Customer メタデータと結合することで、アリスの「行動ツイン」が誰であるかを正確に把握できます。
次のクエリを実行して、Alice の類似性ランキングを調べます。
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
結果で確認すべき点:
では、最終的な Unified Intelligence ビューを作成してみましょう。
8. 統合インテリジェンス
次に、個々の技術タスクから Unified Intelligence に移ります。ここでは、トランザクション データと 4 つのグラフ アルゴリズムを組み合わせて、明確で実用的な分析情報を提供します。
レポート 1: 統合インテリジェンス
Spanner などのマルチモデル データベースの強みは、1 つのリクエストでリレーショナル費用データとグラフから導出された影響度、リスク、類似度スコアを結合できることです。このクエリは、すべての顧客を特定のビジネス ペルソナに分類します。
Unified Intelligence クエリを実行して、エコシステム全体を確認します。
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | 費用 | 影響度 | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 重大: ネットワーク ブリッジ |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 重大: ネットワーク ブリッジ |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 重大: ネットワーク ブリッジ |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 ソーシャル: リーチの広いインフルエンサー |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 ソーシャル: リーチの広いインフルエンサー |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: アクティブな顧客 |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD: アクティブな顧客 |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 リスクが高い: 孤立した不正行為グループ |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 リスクが高い: 孤立した不正行為グループ |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: アクティブな顧客 |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: アクティブな顧客 |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: アクティブな顧客 |
これらの数学的なレンズを組み合わせることで、「誰が最も多く費やしたか」から「誰が最も重要か」へと視点を移すことができます。統合ダッシュボードは、リレーショナル トランザクション データとマルチモーダル グラフ インテリジェンスを統合し、エコシステムを 3 つの明確で実用的なペルソナに分類します。
「クリティカル ネットワーク ブリッジ」(復元性)
Mallory(C11)、Eve(C5)、Alice(C1)などのノードは、bottleneck_risk(Betweenness Centrality)が >25 であるため、フラグが設定されます。
- 構造アンカー: Mallory のリスクスコアは 44.5 で最も高く、ネットワーク全体のプライマリ ゲートウェイとしてマークされています。
- ゼロ支出のパラドックス: Eve(C5)の注文数はゼロですが、リスクスコアが 35.5 であり、構造的に不可欠です。標準 SQL では彼女は完全に無視されますが、グラフ インテリジェンスでは、彼女がサブコミュニティ全体への重要な橋渡し役であることが明らかになります。
- 高価値のゲートウェイ: Alice(C1)は Eve と同率の 35.5 であり、高額消費者が重要な構造的アンカーにもなり得ることを示しています。
「ソーシャル スーパースター」(リーチ)
Heidi(C8)と Grace(C7)は、PageRank スコアに基づいてリーチの大きいインフルエンサーとして識別されます。
「孤立した不正行為グループ」(異常)
Judy(C10)と Ivan(C9)は、分離された community_id 1 に属しているため、フラグが設定されています。
ビジネスの分析情報から戦略的なアクションへ
ペルソナ | 主な指標 | ビジネス分析情報 | 戦略的アクション |
🔵 ネットワーク ブリッジ | 中心性が高い | 構造アンカー: Eve(C5)と Mallory(C11)がネットワークを維持します。 | 定着: コミュニティの分断を防ぐため、これらのゲートキーパーを保護します。 |
📱 ソーシャル スーパースター | PageRank が高い | クチコミ エンジン: Heidi(C8)のようなユーザーは、サークル内で最もリーチが大きい。 | マーケティング: 効果の高い紹介プログラムやアンバサダー プログラムに使用します。 |
🔴 不正行為のリスク | 分離された WCC | ゴースト ネットワーク: Judy(C10)と Ivan(C9)は高額購入者ですが、「島」に住んでいます。 | セキュリティ: 手動による KYC 審査が直ちに必要。これは、典型的な不正行為のシグネチャです。 |
🟢 標準ユーザー | バランス スコア | 健全なコア: David(C4)などの「ローカル」ブリッジを含む、ネットワークの大部分。 | 成長: 標準のパーソナライズド広告と「行動ツイン」の最適化案を適用します。 |
レポート 2: ID 異常レポート
次に、正規のアカウントが不正行為者によって「模倣」されているかどうかを確認する必要があります。この問題を解決するには、行動類似度が 100% で、ソーシャル ネットワークのつながりがゼロのユーザーを見つけます。
次のクエリを実行して、潜在的な「ID の異常」にフラグを設定します。
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
異常検出レポートには重要な情報が記載されています。正当な顧客のように振る舞うが、社会的つながりがないユーザーを特定することで、推測から数学的な確実性へと移行します。
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
結果の分析
類似度(ジャカード)とコミュニティ検出(WCC)を統合することで、従来のトランザクション データでは見えない隠れたリスクを明らかにします。
- 「行動の双子」(近接性): Judy(C10)や Ivan(C9)などのノードは、Alice(C1)とのジャカード類似度スコアが 0.20 であるため、フラグが設定されます。
- 分離の動作: Judy(C10)と Ivan(C9)は分離された community_id 1 にグループ化され、Alice はソーシャル「Mainland」(コミュニティ 0)に属しています。
- 不正行為のフラグ: このレポートでは、行動の重複率が高く(>0.9)、メインのネットワークから社会的に切り離されたままのユーザーを特定します。
9. おめでとうございますと概要
このラボでは、Cloud Spanner がリレーショナル データベースをマルチモデルの強力なデータベースに変える方法について説明します。グラフ インテリジェンスを The Customer に適用することで、静的データから実用的なビジネス戦略に移行しました。
Spanner マルチモデルの利点
- 統合アーキテクチャ: Spanner を使用すると、堅牢なリレーショナル基盤を維持しながら、関係マイニング用のプロパティ グラフを即座に「オーバーレイ」できます。ETL のリスクや遅延は発生しません。
- オフボックス分析の分離: Data Boost を活用することで、PageRank や WCC などのメモリ使用量の多いアルゴリズムを独立したサーバーレス コンピューティング リソースで実行し、本番環境の購入手続きのパフォーマンスに影響を与えないようにすることができます。
- インターリーブされたパフォーマンス: Spanner 独自のインターリーブにより、ノードとその関係が物理的に同じ場所に配置され、複雑なグローバル トラバーサルが高速なローカル ルックアップに変換されます。
「隠れた逸品」と異常の検出
- 構造的価値の特定: 中心性などのグラフ アルゴリズムにより、ネットワークの復元力において最も費用を費やしている顧客よりも重要な役割を果たす可能性がある、費用を費やしていない「隠れたブリッジ」が明らかになりました。
- 行動模倣の検出: ジャカード類似度と弱連結成分を組み合わせることで、「ソーシャル ストレンジャー」を特定しました。これらのアカウントは正当な顧客のように見えますが、数学的に孤立した不正行為グループであることが証明されています。
- グローバルな真実とローカルな真実: 手動の SQL 分析ではブリッジを特定できますが、グローバル アルゴリズムではネットワークの主要なゲートキーパーを特定できます。
データをインテリジェントで実用的なものにする
- ペルソナ主導の戦略: 行を関係に変換し、アルゴリズムを実行することで、ネットワーク ブリッジ、ソーシャル スーパースター、不正リスク、標準ユーザーという 4 つのビジネス上の問題に対処できました。