
1. 우수사례: 지능형 소매
우수사례에서는 빠르게 성장하는 디지털 마켓플레이스를 보유한 소매 고객을 예로 들어 보겠습니다. 고객의 기존 데이터 보기는 사람들이 무엇을 구매하는지는 보여주지만 어떻게 연결되는지는 보여주지 않기 때문에 제한적입니다. 이러한 격차로 인해 기회를 놓치고 사기가 증가합니다. 이제 거래 데이터 외에도 소셜 및 물류 연결을 중시하는 네트워크 우선 철학으로 전환하고 있습니다.
해결해야 할 핵심 비즈니스 과제
고객과 물류가 어떻게 상호 연결되는지 이해해야 하는 네 가지 중요한 과제가 있습니다.
당면 과제 | 문제 | 목표 |
영향 격차 | 광범위한 광고는 ROI가 낮습니다. 현재 실제 트렌드세터 (인플루언서)를 식별할 수 없습니다. | 연결된 고객 네트워크에서 연결을 통해 커뮤니티의 중심이 되는 인플루언서를 식별합니다. |
물류 복원력 | 공급망이 취약할 수 있습니다 (여러 지역에서 운영되는 점을 고려). 하나의 주요 허브가 실패하면 전체 리전에서 제품 액세스 권한이 손실될 수 있습니다. | 물류 네트워크를 연결하는 데 중요한 역할을 하는 게이트키퍼 를 파악합니다. |
Ghost Networks | 사기 조직은 가짜 프로필과 공유 주소를 사용하여 도난을 조장하고 평점을 부풀립니다. | 정상적인 커뮤니티와 연결되지 않은 고립된 섬 , 즉 긴밀하게 연결된 그룹을 노출합니다. |
선택의 역설 | 현재의 추천 엔진은 기본적인 수준이며 일반적이고 무시되는 경우가 많습니다 (예: '이 제품을 구매한 고객은 다음 제품도 구매했습니다'). | 행동 트윈, 즉 유사한 배송 패턴과 소셜 서클을 기반으로 한 추천을 구축합니다. |
비즈니스 과제를 기술 전략에 매핑 (행 → 관계)
기존 데이터베이스에서는 데이터가 격리된 사일로에 저장됩니다. 고객은 한 테이블에, 거래는 다른 테이블에, 배송은 세 번째 테이블에 저장됩니다. SQL은 '누가 무엇을 구매했나요?'라는 질문에 답하는 데 적합하지만 네트워크 기반 질문에 답하는 데는 어려움이 있습니다.
이러한 문제를 해결하기 위한 기술 전략은 다음과 같이 관점을 전환하는 것입니다.
- 관계형 보기('무엇'): 모든 고객을 격리된 행으로 취급합니다. 고객과 친구의 구매 간의 연결을 찾으려면 여러 복잡한 '조인'이 필요하며, 네트워크가 커질수록 속도가 기하급수적으로 느려집니다.
- 그래프 뷰('방법'): 관계를 최우선 요소로 취급합니다. 목록을 검색하는 대신 지도를 탐색합니다. 고객 A가 위치 Z로 배송하는 고객 B에 연결되어 있음을 즉시 확인할 수 있습니다.
요구사항 심층 분석
솔루션 설계자는 비즈니스 요구사항과 기술 전략에 멀티 모델 접근 방식이 필요하다는 결론을 내리고 다음 주요 요구사항을 식별합니다.
Cloud Spanner가 이러한 기술 요구사항을 충족하는 방법
Cloud Spanner가 이 전환의 핵심으로 선택되었습니다. 이를 통해 고객은 견고한 관계형 기반을 유지하면서 동시에 심층적인 그래프 통계를 활용할 수 있습니다.
Cloud Spanner가 기술 요구사항 등을 어떻게 해결하는지 간략하게 살펴보세요.
또한 Cloud Spanner는 미래 지향적인 기술 아키텍처를 제공합니다.
2. 데이터 기반 설정
비즈니스 사례를 검토한 후 구현 단계로 넘어갑니다. 이 섹션에서는 데이터 아키텍처를 정의하고, 기존 관계형 모델의 한계를 살펴보고, 심층적인 통계를 파악하기 위한 기본 도구로 속성 그래프를 소개합니다.
Cloud Spanner Enterprise 인스턴스 설정
1단계: Cloud Spanner API 사용 설정
Google Cloud 콘솔에서 화면 왼쪽 상단의 메뉴 아이콘을 클릭하여 왼쪽 탐색을 표시합니다. 아래로 스크롤하여 '스패너'를 선택하거나 '스패너'를 검색합니다.
이제 Cloud Spanner UI가 표시됩니다. 아직 Cloud Spanner API를 사용 설정하지 않은 프로젝트를 사용하는 경우 사용 설정하라는 대화상자가 표시됩니다. API를 이미 사용 설정한 경우 이 단계를 건너뛰어도 됩니다.
계속하려면 '사용 설정'을 클릭하세요.
2단계: Cloud Spanner 인스턴스 만들기
먼저 Cloud Spanner 인스턴스를 만듭니다. UI에서 '프로비저닝된 인스턴스 만들기'를 클릭하여 새 인스턴스를 만듭니다.
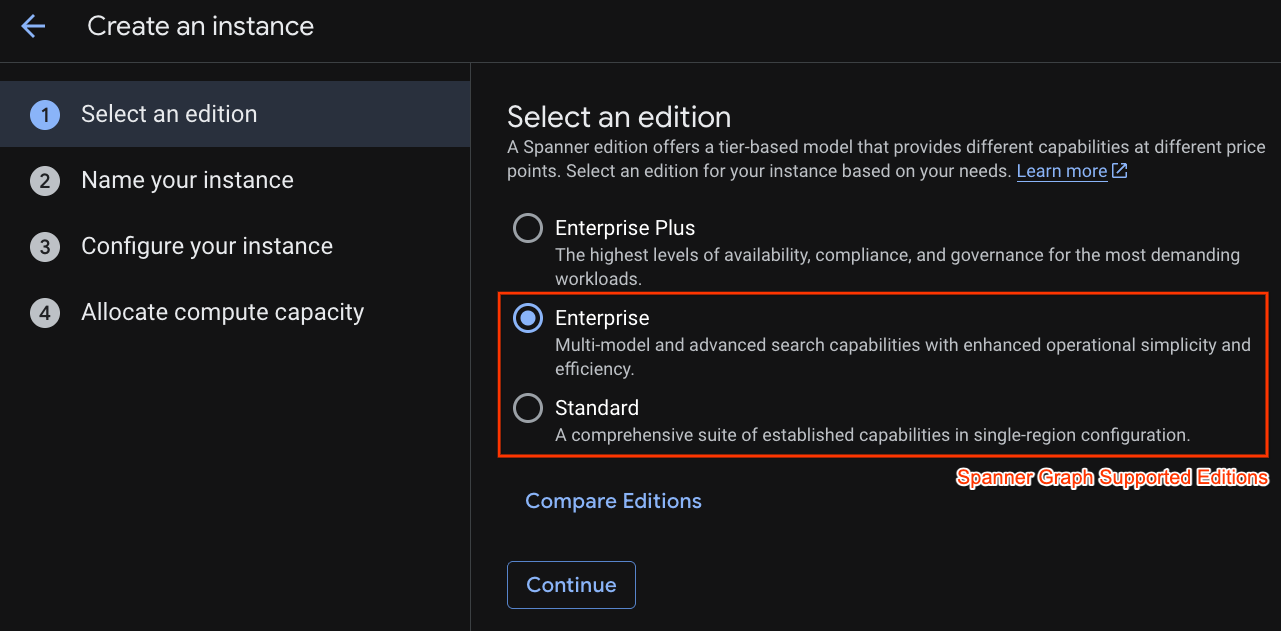
첫 번째 단계에서 버전을 선택해야 합니다. 나중에 Edition을 업그레이드할 수도 있습니다. 멀티 모델 기능 (Spanner Graph)을 사용하려면 Enterprise 버전을 선택하면 됩니다.
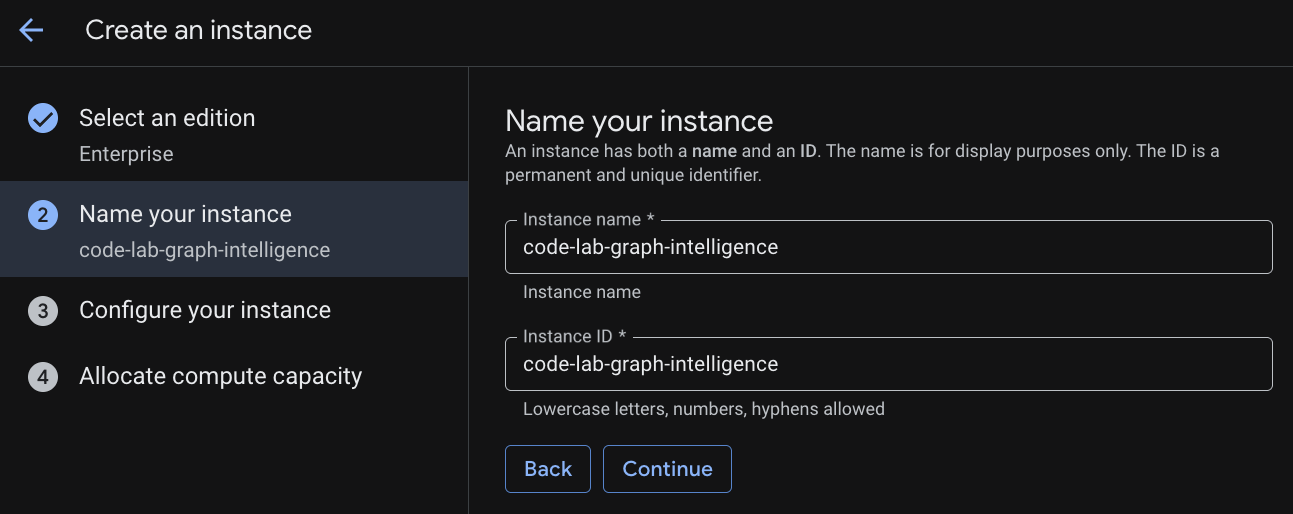
인스턴스 이름 지정
배포 구성을 선택하고 원하는 리전을 선택합니다.
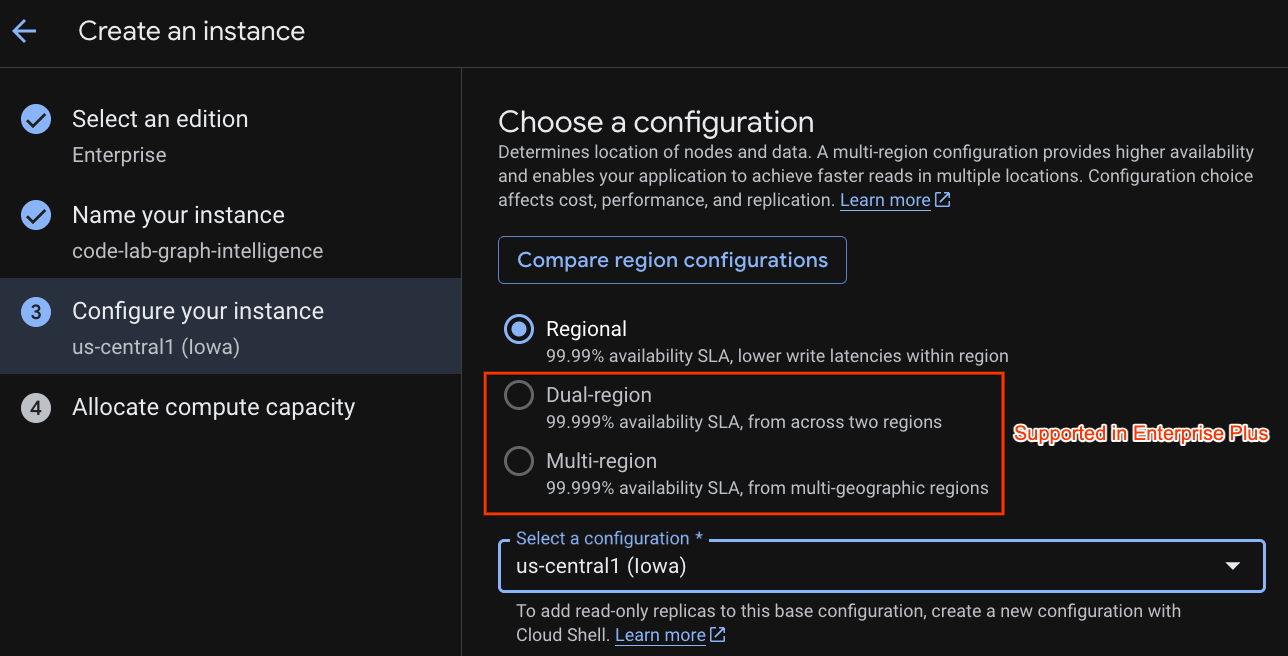
다양한 구성 옵션을 비교할 수도 있습니다. 예를 들어 배포 구성에는 선택한 리전의 3개의 별도 영역에 최소 3개의 읽기/쓰기 복제본이 있습니다. 즉, 단일 노드 배포를 사용하는 경우에도 3개의 읽기/쓰기 복제본을 통해 3개의 복사본이 있습니다. 리전 배포 구성의 경우에도 배포 토폴로지에 추가 R/O 복제본을 포함하여 추가로 확장할 수 있습니다.
용량을 구성할 때 전체 노드에서 시작하여 노드에서 자동 확장하거나 세부 인스턴스 (처리 단위, 1,000PU = 1노드)를 사용할 수 있습니다. 원하는 경우 인스턴스의 자동 확장 타겟을 설정할 수도 있습니다. 지연 시간이 짧은 워크로드의 경우 리전 인스턴스에는 65% , 멀티 리전 인스턴스에는 45% 가 권장됩니다.
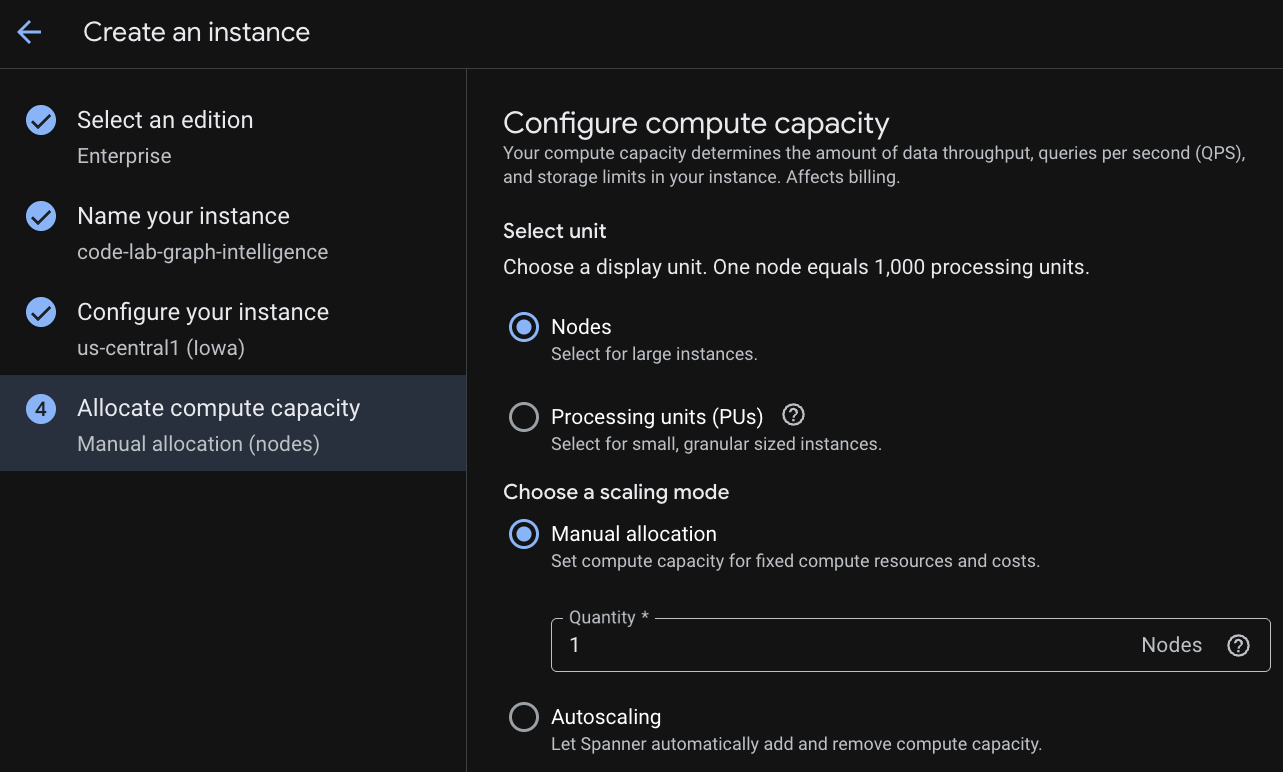
3단계: 데이터베이스 만들기
인스턴스가 프로비저닝되면 '데이터베이스 만들기'를 클릭하여 나머지 Codelab의 데이터베이스를 만듭니다.
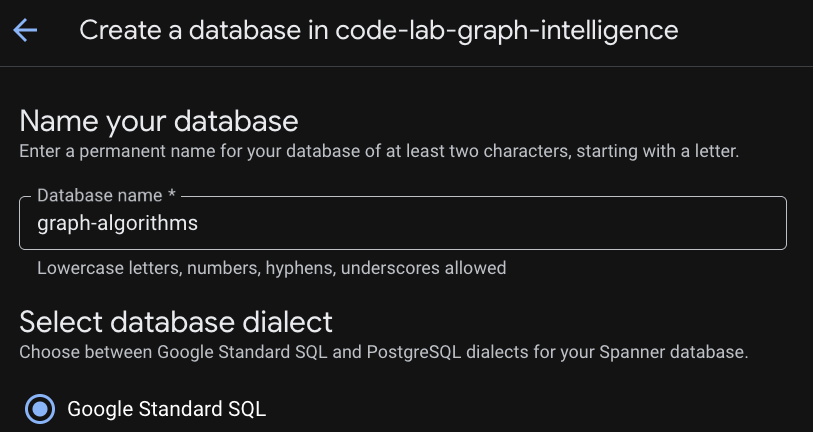
관계형 기반 설정
여정은 운영 데이터를 저장하는 핵심 테이블로 시작됩니다. Cloud Spanner에서는 인터리빙을 사용하여 고객의 친구 관계 및 거래와 같은 관련 데이터를 고객 기록과 직접 물리적으로 공동 배치합니다. 이렇게 하면 고성능 액세스와 물리적 위치가 보장됩니다.
DDL: 테이블 만들기
다음 블록을 복사하여 실행하여 관계형 스키마를 설정합니다.
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
네트워크 시딩
표가 준비되었으므로 고객의 생태계를 정의하는 사용자, 제품, 연결로 표를 채워야 합니다.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
관계형 문제
그래프를 소개하기 전에 기존 SQL이 고객의 문제를 어떻게 처리하는지 살펴보겠습니다. 이 쿼리를 실행하여 지출이 많고 친구가 많은 '소셜 지출자' 고객을 찾습니다.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
관계형 접근 방식의 한계
속성 그래프를 통한 관계형 문제 극복
이러한 제한을 극복하기 위해 속성 그래프를 정의합니다. 이렇게 하면 Spanner에서 데이터를 이동하지 않고도 관계를 최상위 객체로 취급할 수 있는 '오버레이'가 생성됩니다.
DDL: 속성 그래프 만들기
이 DDL은 노드 (엔티티)와 에지 (관계)를 정의합니다. 이 예에서는 스키마가 적용된 그래프를 따르지만 Spanner Graph를 사용하면 스키마가 없는 그래프를 모델링하여 유연하고 신속한 반복 개발을 지원하고 지속적인 DDL (데이터 정의 언어) 변경 없이 진화하는 데이터 모델을 처리할 수 있습니다.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
GQL로 그래프 탐색하기
이제 그래프가 정의되었으므로 Graph Query Language (GQL)을 사용하여 간단하고 읽기 쉬운 구문으로 멀티 홉 순회를 실행할 수 있습니다.
탐색 1: 공동 탐색
이 쿼리는 그래프를 순회하여 친구가 구매한 제품을 찾고 추천 엔진의 기반으로 사용됩니다.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
탐색 2: 하이브리드 쿼리 (관계형 + 그래프)
Spanner에서는 GRAPH_TABLE 함수를 사용하여 표준 SQL FROM 절 내에 GQL 패턴을 삽입할 수 있습니다. 이 쿼리는 친구와 동일한 위치에 거주하는 고객을 '다이아몬드' 패턴 일치로 찾습니다.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
고객의 연결 시각화
마지막으로 GQL을 사용하여 네트워크를 시각화해 보겠습니다. 이러한 쿼리는 시각화 도구가 노드와 선을 그릴 수 있도록 경로 결과를 SAFE_TO_JSON으로 래핑합니다.
슈퍼 인플루언서 시각화
이 예시에서는 Mallory (C11)와 그녀의 직접적인 소셜 도달범위를 강조합니다.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
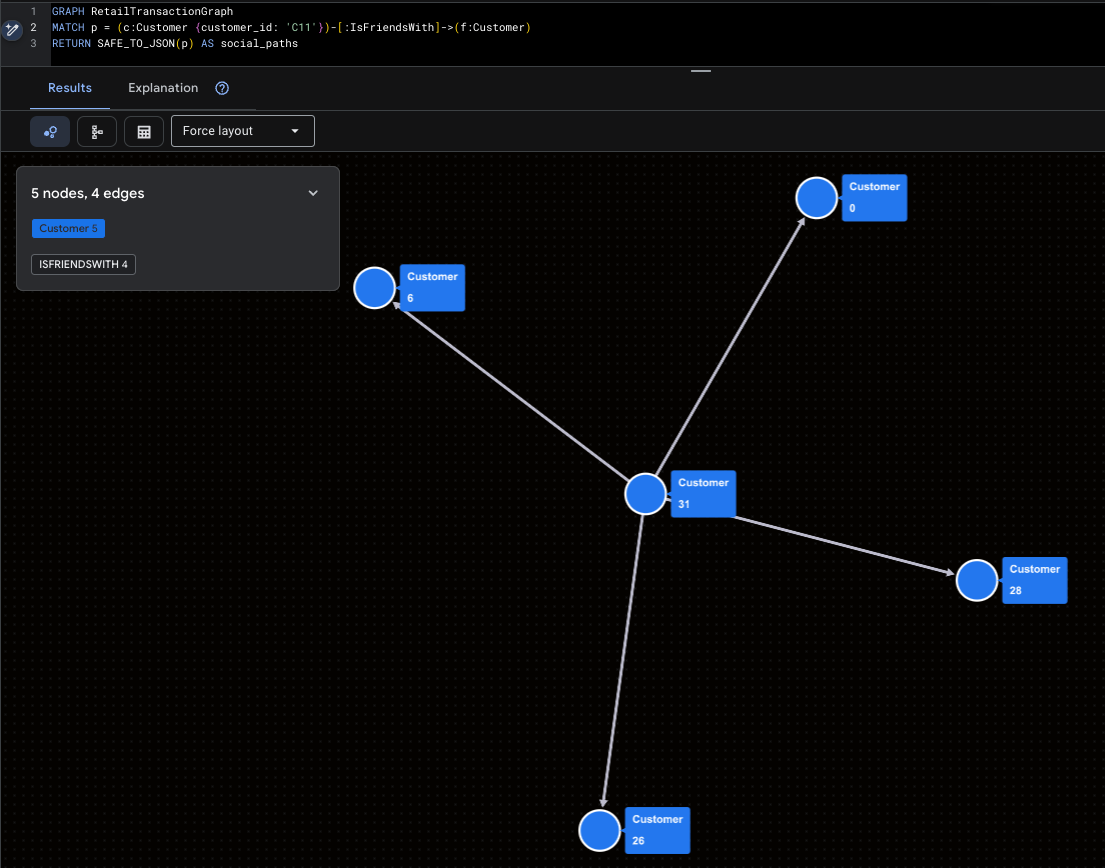
잠재적 사기 패턴 시각화
이 쿼리는 '고립된 클러스터' (Ivan 및 Judy)를 찾아 제품이 배송되는 위치를 확인합니다.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Spanner Graph 알고리즘 소개
그래프 인텔리전스에 대해 자세히 알아보기 위해 이 섹션에서는 Cloud Spanner 그래프 알고리즘의 기술 아키텍처와 기본 규칙을 간략하게 설명합니다. 이러한 원칙을 이해하는 것은 간단한 순회에서 페타바이트 규모의 관계 분석으로 전환하는 데 중요합니다.
알고리즘 포트폴리오
Cloud Spanner는 현재 다양한 비즈니스 문제를 해결하기 위해 네 가지 기능 그룹으로 분류된 14개의 업계 표준 그래프 알고리즘을 지원합니다.
카테고리 | 지원되는 알고리즘 | 비즈니스 사용 사례 |
중심성 | PageRank, Personalized PageRank, Betweenness, Closeness | 영향력 있는 사용자, 허브, 병목 현상을 식별합니다. |
커뮤니티 | WCC, 라벨 전파, 클리크 찾기, 상관관계 클러스터링 | 사기 조직, 소셜 커뮤니티, 사일로를 감지합니다. |
유사성 | Jaccard, Cosine, Common Neighbors, Total Neighbors | 추천 엔진 및 엔티티 해결 지원 |
경로 찾기 | 세트 간 최단 경로, GA 경로 도우미 | 물류 및 순회 근접성을 최적화합니다. |
중요한 스키마 및 쿼리 고려사항
효율적인 그래프 알고리즘 실행을 보장하려면 Spanner Graph가 다음 규칙을 준수해야 합니다.
요구사항 1. 물리적 데이터 위치 (인터리빙)
고성능 그래프 순회의 가장 중요한 요구사항은 인터리빙입니다. 이렇게 하면 알고리즘 실행 중에 네트워크 지연 시간이 최소화되도록 에지 데이터가 소스 노드와 동일한 서버 분할에 물리적으로 저장됩니다.
- 규칙: 에지 테이블은 소스 노드 테이블에 인터리브 처리해야 합니다(MUST).
- 정방향 순회: 에지 테이블을 소스 노드 테이블에 인터리브 처리하면 발신 링크의 캐시 지역성이 보장됩니다.
- 역방향 순회: 효율적인 '수신' 링크 분석을 위해 외래 키를 사용하여 지원 색인을 자동으로 만들거나 대상 테이블에 인터리브된 보조 색인을 만듭니다.
요구사항 2. 고유 라벨링 요구사항
속성 그래프에 참여하는 모든 테이블에는 고유한 ID가 있어야 합니다. 알고리즘은 이러한 라벨을 사용하여 분석해야 하는 하위 그래프를 올바르게 식별하고 로드합니다.
- 규칙: 각 입력 테이블에는 속성 그래프 내에서 고유하게 식별하는 라벨이 있어야 합니다.
- 충돌: 여러 테이블에서 알고리즘을 실행하려는 경우 단일 라벨을 여러 테이블에 매핑할 수 없습니다.
논리 | 예 | 결과 |
❌ 잘못됨 | 노드 테이블 (Person LABEL Entity, Account LABEL Entity) | 잘못됨: 알고리즘이 사람과 계정을 구분할 수 없습니다. |
✅ 좋음 | 노드 테이블 (Person 라벨 Customer, Account 라벨 Account) | 유효: 각 항목에 고유한 라벨이 있습니다. |
요구사항 3. 알고리즘 쿼리 구조 (MATCH 절)
알고리즘을 호출할 때 실행 엔진이 분석 파이프라인을 최적화할 수 있도록 MATCH 절은 표준 GQL 쿼리보다 더 엄격한 규칙을 따릅니다.
- MATCH당 하나의 패턴: 각 MATCH 문은 하나의 변수만 지정할 수 있습니다.
- 다중 노드 패턴 없음: 알고리즘 호출을 위한 MATCH 절 내에서 관계 패턴 (예: (a)-[e]->(b))을 직접 정의할 수 없습니다.
- 리터럴 필터만 해당: WHERE 절을 사용하여 노드를 필터링할 수 있지만 (예: WHERE a.id > 400) 그래프 알고리즘 쿼리에서는 현재 쿼리 매개변수 (@param)가 지원되지 않습니다.
요구사항 4. RETURN 절 (스칼라만 해당)
알고리즘 쿼리의 RETURN 절은 그래프 세계와 관계형 세계 사이의 다리 역할을 합니다. 스칼라 및 상수 반환으로 엄격하게 제한됩니다.
- 규칙: '그래프 요소' (원시 노드 또는 에지 객체)를 반환할 수 없습니다.
- 변환 없음: RETURN 문 자체 내에서 반환되는 속성에 수학 연산을 실행하거나 함수를 적용할 수 없습니다.
RETURN 절 제한사항
✅ 지원됨 | ❌ 지원되지 않음 |
RETURN node.id, score | RETURN 노드, 점수 (그래프 요소를 반환할 수 없음) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (속성에 대한 작업 없음) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (함수 없음) |
요구사항 5. 데이터 무결성: 연결되지 않은 가장자리 제거
'댕글링 에지'는 에지가 그래프에 없는 대상 노드를 가리킬 때 발생합니다. 그래프 구조가 일관되지 않으므로 알고리즘 실행이 실패합니다.
- 해결 방법: 참조 제약 조건 (외래 키)과 ON DELETE CASCADE를 사용하여 그래프 무결성을 유지합니다.
- 쿼리 안전성: 알고리즘을 호출할 때는 선택한 가장자리에서 참조하는 모든 노드가 node_labels 인수에도 포함되어야 합니다.
영구 출력: EXPORT DATA 옵션
그래프 알고리즘은 컴퓨팅 집약적이므로 EXPORT DATA 문을 사용하여 스케일업 실행 모드에서 실행됩니다. 이를 통해 독립적인 서버리스 컴퓨팅 리소스를 사용하여 프로덕션 트랜잭션의 지연을 방지하는 Data Boost를 활용할 수 있습니다.
옵션 1: Cloud Spanner에 다시 유지
결과를 테이블에 직접 다시 푸시하려면 (예: PageRank 점수 저장) format = 'CLOUD_SPANNER'를 사용하세요.
update_ignore_all: 대상 테이블에 이미 있는 키의 행만 업데이트합니다.upsert_ignore_all: 기존 행을 업데이트하거나 키가 누락된 경우 새 행을 삽입합니다.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
옵션 2: Google Cloud Storage (GCS)에 결과 유지
대규모 오프라인 분석을 위해 CSV, Avro 또는 Parquet 형식으로 GCS에 내보낼 수 있습니다.
- 와일드 카드:
uri => 'gs://bucket/file_*.csv'를 사용하여 샤딩된 출력을 사용 설정하면 Spanner가 대규모 데이터 세트에 대해 여러 파일에 동시에 쓸 수 있습니다. - 압축: 스토리지 비용을 최적화하기 위해 GZIP, SNAPPY, ZSTD를 지원합니다.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. 문제 1: 영향력 격차 (PageRank)
이 섹션에서는 고객의 첫 번째 비즈니스 장애물인 '영향력 격차'를 다룹니다. 기본적인 '인기 경쟁'에서 수학적으로 도출된 진정한 소셜 영향력 지도로 전환할 것입니다.
문제 설명: 고객의 마케팅팀에 문제가 있습니다. '소셜 슈퍼스타'를 식별할 수 없기 때문에 수익이 줄어드는 광범위한 광고에 수백만 달러를 지출하고 있습니다. 소셜 슈퍼스타는 추천이 전체 네트워크에 파급되는 드문 개인입니다.
이 문제를 해결하려면 영향력을 기준으로 고객의 순위를 매겨야 합니다.
관계형 솔루션 (연결 중심성)
표준 데이터베이스에서 인플루언서를 찾는 가장 쉬운 방법은 팔로워 수를 세는 것입니다 (중심성이라는 측정항목).
다음 쿼리를 실행하여 가장 '인기 있는' 사용자를 찾습니다.
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
그래프 인텔리전스 (PageRank)
실제 리더를 찾기 위해 Google에서는 PageRank를 사용합니다. 이는 초기 웹 검색을 지원한 것과 동일한 알고리즘으로, 수신 링크의 수와 품질을 기반으로 노드의 중요도를 측정합니다 .
- 무작위 서퍼 모델: PageRank는 그래프를 이동하는 사용자를 시뮬레이션합니다. 감쇠 계수 (기본값 0.85)는 사용자가 계속 클릭할 확률을 나타냅니다. 그렇지 않으면 무작위 노드로 '순간 이동'합니다.
- 연관성의 힘: 영향력 있는 사람 (예: Mallory)의 링크는 다른 연결이 없는 사람의 링크보다 훨씬 더 가치가 있습니다.
PageRank 알고리즘을 실행하고 EXPORT DATA를 사용하여 결과를 pagerank_score 열에 직접 저장합니다 .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
PageRank를 사용하는 '영향력' 대시보드
이제 점수가 유지되었으므로 '이전' (팔로워 수)과 '이후' (PageRank 점수)를 비교해 보겠습니다.
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
분석: 누가 진정한 슈퍼스타인가요?
이제 출력을 분석하여 다음과 같은 세 가지 중요한 마케팅 정보를 파악할 수 있습니다.
비즈니스 요점
이제 고객의 마케팅팀은 팔로워가 5명 이상인 모든 사용자에게 무작위로 이메일을 보내는 대신 pagerank_score가 가장 높은 사용자에게만 집중할 수 있습니다. 이러한 사용자는 전체 마켓플레이스에서 시스템적 바이럴을 유도할 수 있는 진정한 '소셜 슈퍼스타'입니다.
이제 고객의 물류 네트워크를 운영하는 게이트키퍼를 식별해 보겠습니다.
5. 챌린지 2: 물류 복원력 (BetweennessCentrality)
이 섹션에서는 물류 복원력을 다룹니다. '볼륨'으로 성공을 측정하는 것을 넘어 네트워크를 연결된 상태로 유지하는 중요한 '게이트키퍼'를 식별할 것입니다.
관계형 솔루션 (볼륨 기반 분석)
표준 관계형 설정에서 '중요' 배송 허브는 일반적으로 가장 많은 주문을 처리하거나 가장 많은 수익을 창출하는 허브로 정의됩니다.
다음 쿼리를 실행하여 거래 수별 '상위' 허브를 식별합니다.
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
뉴욕 | 미국 | 4 | 3996 |
베를린 | 독일 | 2 | 345 |
샌프란시스코 | 미국 | 2 | 750 |
불일치를 해결하기 위해 IsFriendsWith 및 LivesAt 가장자리를 모두 사용합니다. 이렇게 하면 거래 허브에서 소셜 확인도 포함하는 분석으로 전환됩니다.
그래프 인텔리전스 (중심성)
실제 병목 현상을 찾기 위해 Betweenness Centrality를 사용합니다. 이 알고리즘은 그래프에 있는 다른 모든 노드 쌍 간의 최단 경로에서 노드가 '브리지' 역할을 하는 빈도를 정량화합니다. 높은 점수는 상품 또는 정보의 흐름을 관리하는 진정한 게이트키퍼를 정확히 파악합니다.
중심성 실행 및 유지
EXPORT DATA를 사용하여 알고리즘을 실행하고 점수를 centrality_score 열에 저장합니다. Google에서는 Data Boost를 사용하여 이 대규모 '최단 경로' 계산이 고객의 실시간 운영에 미치는 영향을 거의 제로로 유지합니다.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
분석: '숨겨진 병목 현상' 식별
이제 구조적 위험 (centrality_score)을 거래량 (order_count)과 비교하여 고객의 경영진이 우려해야 하는 노드를 찾습니다.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
이러한 결과를 분석한 고객은 다음과 같은 세 가지 놀라운 사실을 발견합니다.
비즈니스 핵심 내용
이제 고객은 멀티모달 구조적 위험에 따라 물류 중복 및 보안 프로토콜의 우선순위를 지정할 수 있습니다. 말로리, 앨리스, 이브는 물류 네트워크의 안정성을 보장하기 위해 보호해야 하는 관리자입니다.
이제 사기 아일랜드를 분리해 보겠습니다.
6. 챌린지 3: 유령 네트워크 (WCC)
이 섹션에서는 세 번째 비즈니스 장애물인 '유령 네트워크'를 해결합니다. 단순한 '핫스팟' 감지에서 커뮤니티 감지를 사용하여 정교하고 고립된 사기 조직을 찾아내는 방식으로 전환됩니다. 여기서 문제는 악성 사용자가 배송지 주소를 공유하거나 폐쇄형 루프에서 상호작용하여 도난을 조장하고 제품 평가를 부풀리는 가짜 프로필을 만든다는 것입니다. 하지만 합법적인 고객 커뮤니티와 완전히 격리되는 경우가 많습니다.
이 문제를 해결하려면 이러한 '고립된 섬'을 노출해야 합니다.
관계형 솔루션 (공유 식별자 검색)
그래프 알고리즘이 없으면 사기를 찾는 표준적인 방법은 여러 고객이 정확히 동일한 주소로 배송하는 등 공유 데이터의 '핫스팟'을 찾는 것입니다 .
다음 쿼리를 실행하여 공유 배송 위치로 연결된 고객을 찾습니다.
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
사기 네트워크를 찾으려면 전이적 연결 가능성을 이해해야 합니다.
그래프 인텔리전스 (약한 연결 요소)
이러한 고리의 전체 범위를 파악하기 위해 Google에서는 약하게 연결된 구성요소 (WCC)를 사용합니다. WCC는 에지의 방향과 관계없이 두 노드 사이에 경로가 있는 노드 집합을 식별하는 클러스터링 알고리즘입니다.
- 도달 가능성 영역: 그래프를 '섬' 또는 '도달 가능성 영역'으로 효과적으로 구분합니다.
- 통합 항목 보기: 소셜 관계 (IsFriendsWith)와 물류 관계 (LivesAt)를 동시에 분석하여 분산된 프로필을 단일 통합 '영향 클러스터'로 그룹화할 수 있습니다.
WCC 실행 및 유지
WCC 알고리즘을 실행하고 결과를 community_id 열에 저장합니다. Google은 Data Boost를 사용하여 이러한 심층 도달 범위 분석이 독립적인 컴퓨팅 리소스에서 이루어지도록 합니다.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
분석: 사기 조직
이제 유효성 검사 쿼리를 실행하여 격리된 커뮤니티를 확인해 보겠습니다. 일반적으로 합법적인 사용자는 '본토'에 속하는 반면 사기범은 종종 작은 '섬'에 고립됩니다.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | 구성원 |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
이 커뮤니티 감지를 실행하면 다음과 같은 심각한 이상치를 식별할 수 있습니다.
비즈니스 핵심 내용
이제 고객이 보안 대응을 자동화할 수 있습니다. 개별 계정을 수동으로 추적하는 대신 간단한 규칙을 작성할 수 있습니다. 'community_id에 속한 구성원 수가 3명 미만이면 전체 그룹에 수동 KYC (고객 알기) 검토를 위한 플래그를 지정합니다.'
.
사기 조직이 노출되면 '행동 트윈'을 해결할 수 있습니다.
7. 챌린지 4: 행동 트윈 (JaccardSimilarity)
이 마지막 도전과제에서는 네 번째 장애물인 선택의 역설/행동 트윈을 다룹니다. 일반적인 '자주 함께 구매하는 항목' 목록에서 행동 '지문'을 기반으로 한 고도로 맞춤화된 추천으로 전환됩니다.
고객의 현재 제품 추천이 너무 일반적입니다. 모든 고객에게 인기 있는 USB 케이블을 추천하는 것은 안전하지만 개인화되지는 않습니다. 고객은 고유한 배송 패턴과 소셜 네트워크를 공유하는 고객을 식별하여 정밀도가 높은 일치 제품을 추천하는 '행동 트윈' 추천을 구축하려고 합니다.
이 문제를 해결하려면 사용자 간의 '근접성'을 계산해야 합니다.
관계형 솔루션 (절대 중복)
표준 관계형 설정에서는 Alice (C1)와 같은 참조 사용자와 동일한 위치로 배송하는 사용자를 찾을 수 있습니다.
다음 쿼리를 실행하여 Alice의 지리적 이웃을 찾습니다.
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
그래프 인텔리전스 (자카드 유사도)
진정한 행동 트윈을 찾기 위해 Jaccard 유사도를 사용합니다. 이 알고리즘은 공유된 이웃 수 (교집합)를 고유한 이웃의 총수 (합집합)로 나누어 정규화된 점수 (0.0~1.0)를 계산합니다.
여기서 '행동 트윈'은 공유 배송지 주소 이상의 요소로 정의됩니다. 오프라인 활동 (LivesAt)과 소셜 생태계 (IsFriendsWith)의 교차점을 분석하면 동일한 라이프스타일과 커뮤니티 영향력을 공유하는 사용자를 식별할 수 있으므로 훨씬 정확한 제품 추천이 가능합니다.
먼저 매핑 테이블 만들기
유사성은 쌍별 관계 (고객 A는 고객 B와 유사함)이므로 이러한 매핑을 저장하기 위해 Customer에 인터리브 처리된 전용 테이블을 만듭니다.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
이제 Jaccard 유사성 실행
이제 알고리즘을 실행합니다. 참고: 이 쿼리에는 일반적인 '가이드라인' 학습이 포함되어 있습니다. 고객 노드만 선택했지만 LivesAt 에지 (배송 노드를 가리킴)를 사용하면 '매달린 에지'를 인용하며 쿼리가 실패합니다 . 이 문제를 해결하려면 두 노드 라벨을 모두 포함해야 합니다.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
분석: '행동 트윈' 확인
이제 분석 작업이 완료되었으므로 유효성 검사 쿼리를 실행합니다. 새 매핑 테이블 (CustomerSimilarity)을 원래 Customer 메타데이터와 결합하면 앨리스의 '행동 쌍둥이'가 누구인지 정확히 알 수 있습니다.
이 쿼리를 실행하여 Alice의 유사성 순위를 검사합니다.
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
결과에서 확인해야 할 사항:
이제 최종 통합 인텔리전스 뷰를 빌드해 보겠습니다.
8. 통합 인텔리전스
이제 개별 기술 작업에서 통합 인텔리전스로 넘어갑니다. 여기서는 거래 데이터를 4가지 그래프 알고리즘과 결합하여 명확하고 실행 가능한 통계를 제공합니다.
보고서 1: 통합 인텔리전스
Spanner와 같은 멀티 모델 데이터베이스의 장점은 단일 요청에서 관계형 지출 데이터와 그래프에서 파생된 영향력, 위험, 유사성 점수를 결합할 수 있다는 것입니다. 이 쿼리는 모든 고객을 특정 비즈니스 페르소나로 분류합니다.
통합 인텔리전스 쿼리를 실행하여 전체 생태계를 확인합니다.
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | 지출 | 영향 | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 중요: 네트워크 브리지 |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 중요: 네트워크 브리지 |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 중요: 네트워크 브리지 |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 소셜: 도달범위가 높은 인플루언서 |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 소셜: 도달범위가 높은 인플루언서 |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: 활성 고객 |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD: 활성 고객 |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 위험도 높음: 고립된 사기 조직 |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 위험도 높음: 고립된 사기 조직 |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: 활성 고객 |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: 활성 고객 |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: 활성 고객 |
이러한 수학적 관점을 결합하면 '가장 많이 지출한 사용자'에서 '가장 중요한 사용자'로 전환할 수 있습니다. 통합 대시보드는 관계형 거래 데이터를 멀티모달 그래프 인텔리전스와 통합하여 생태계를 명확하고 실행 가능한 세 가지 페르소나로 분류합니다.
'중요한 네트워크 브리지' (복원력)
Mallory (C11), Eve (C5), Alice (C1)와 같은 노드는 bottleneck_risk (중심성)이 >25이기 때문에 플래그가 지정됩니다.
- 구조적 앵커: Mallory의 위험 점수가 44.5로 가장 높아 전체 네트워크의 기본 게이트웨이로 표시됩니다.
- 지출 제로의 역설: Eve (C5)의 주문 수는 0이지만 위험 점수가 35.5로 구조적으로 필수적입니다. 표준 SQL은 그녀를 완전히 무시했을 테지만 그래프 인텔리전스는 그녀가 전체 하위 커뮤니티로 연결되는 중요한 다리임을 보여줍니다.
- 가치가 높은 게이트웨이: 앨리스 (C1)는 이브와 35.5로 동률을 기록하여 지출이 많은 사용자도 중요한 구조적 앵커가 될 수 있음을 입증했습니다.
'소셜 슈퍼스타' (도달범위)
Heidi (C8)와 Grace (C7)는 PageRank 점수로 인해 도달범위가 높은 인플루언서로 식별됩니다 .
'고립된 사기 조직' (이상치)
Judy (C10)와 Ivan (C9)은 격리된 community_id 1에 속하므로 플래그가 지정됩니다.
비즈니스 통계에서 전략적 행동으로
개성 | 주요 측정항목 | 비즈니스 통계 | 전략적 조치 |
🔵 네트워크 브리지 | 높은 중심성 | 구조적 앵커: Eve (C5)와 Mallory (C11)가 네트워크를 함께 유지합니다. | 유지: 커뮤니티가 분열되지 않도록 이러한 게이트키퍼를 보호합니다. |
📱 소셜 슈퍼스타 | 높은 PageRank | 바이럴 엔진: Heidi (C8)와 같은 사용자는 서클에서 도달범위가 가장 높습니다. | 마케팅: 효과적인 추천 및 홍보대사 프로그램에 사용합니다. |
🔴 사기 위험 | 격리된 WCC | 유령 네트워크: 주디 (C10)와 이반 (C9)은 지출이 많지만 '섬'에 거주합니다. | 보안: 즉각적인 수동 KYC 검토, 이는 전형적인 사기 서명입니다. |
🟢 일반 사용자 | 균형 잡힌 점수 | 건강한 핵심: 데이비드 (C4)와 같은 '지역' 브리지를 포함한 대부분의 네트워크 | 성장: 표준 개인 맞춤 광고 및 '행동 트윈' 추천을 적용합니다. |
보고서 2: 신원 이상 보고서
이제 사기범이 합법적인 계정을 '모방'하고 있는지 확인해야 합니다. 행동 유사성이 100%이지만 소셜 연결이 없는 사용자를 찾아 이 문제를 해결할 수 있습니다.
이 쿼리를 실행하여 잠재적인 'ID 이상'을 표시합니다.
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
이상치 식별 보고서는 중요한 정보를 제공합니다. 정상적인 고객처럼 행동하지만 소셜 관계가 없는 사용자를 격리함으로써 추측에서 수학적 확실성으로 전환할 수 있습니다 .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
결과 분석
유사성 (Jaccard)을 커뮤니티 감지 (WCC)와 통합하여 기존 거래 데이터에서는 볼 수 없는 숨겨진 위험을 노출합니다.
- '행동 쌍둥이' (근접성): 주디 (C10)와 아이반 (C9) 같은 노드는 앨리스 (C1)와 비교하여 자카드 유사도 점수가 0.20이기 때문에 플래그가 지정됩니다.
- 고립 행동: Judy (C10)와 Ivan (C9)은 고립된 community_id 1로 그룹화되고 Alice는 소셜 '본토' (커뮤니티 0)에 속합니다.
- 사기 플래그: 행동 중복이 높고 (>0.9) 기본 네트워크에서 소셜 연결이 끊긴 사용자를 식별합니다.
9. 축하 및 요약
이 실습에서는 Cloud Spanner가 관계형 데이터베이스를 멀티 모델 강자로 전환하는 방법을 보여줍니다. 그래프 인텔리전스를 고객에 적용하여 정적 데이터에서 실행 가능한 비즈니스 전략으로 전환했습니다.
Spanner 멀티 모델의 이점
- 통합 아키텍처: Spanner를 사용하면 ETL의 위험과 지연 없이 관계 마이닝을 위해 속성 그래프를 즉시 '오버레이'하면서 견고한 관계형 기반을 유지할 수 있습니다.
- 오프박스 분석 격리: Data Boost를 활용하면 독립적인 서버리스 컴퓨팅 리소스에서 PageRank 또는 WCC와 같은 메모리 집약적 알고리즘을 실행하여 프로덕션 결제 성능에 미치는 영향을 제로로 유지할 수 있습니다.
- 인터리브 처리 성능: Spanner의 고유한 인터리브 처리를 통해 노드와 관계가 물리적으로 공동 배치되므로 복잡한 전역 순회가 고속 로컬 조회로 전환됩니다.
'숨겨진 보석' 및 이상치 표시
- 구조적 가치 식별: 중심성과 같은 그래프 알고리즘을 통해 지출이 0인 '숨겨진 브리지'를 파악할 수 있습니다. 이들은 지출이 가장 많은 고객보다 네트워크의 복원력에 더 중요할 수 있습니다.
- 행동 모방 노출: Jaccard 유사도와 약하게 연결된 구성요소를 결합하여 '소셜 낯선 사람'을 식별했습니다. 이러한 계정은 합법적인 고객처럼 보이지만 수학적으로 고립된 사기 조직으로 입증되었습니다.
- 글로벌 진실 대 로컬 진실: 수동 SQL 분석을 통해 브리지를 파악할 수 있지만, 글로벌 알고리즘을 통해 네트워크의 주요 게이트키퍼를 파악할 수 있습니다.
데이터를 지능적이고 실행 가능하게 만들기
- 페르소나 기반 전략: 행을 관계로 변환하고 알고리즘을 실행하여 네트워크 브리지, 소셜 슈퍼스타, 사기 위험, 일반 사용자라는 네 가지 비즈니스 문제를 해결할 수 있었습니다.