
1. Studium przypadku: Intelligent Retail
W tym studium przypadku weźmiemy pod uwagę klienta z sektora handlu detalicznego, który ma szybko rozwijający się rynek cyfrowy. Tradycyjny widok danych klienta jest ograniczony, ponieważ pokazuje co kupują użytkownicy, ale nie pokazuje, jak są ze sobą powiązani. Ta luka prowadzi do utraty możliwości i wzrostu liczby oszustw. Obecnie przechodzą na filozofię Network-First, aby oprócz danych transakcyjnych uwzględniać połączenia społecznościowe i logistyczne.
Główne wyzwania biznesowe, na które należy odpowiedzieć
Masz 4 kluczowe wyzwania, które wymagają zrozumienia powiązań między klientami a logistyką:
Wyzwanie | Problem | Cel |
Różnica w wpływie | Reklamy o szerokim zasięgu przynoszą niski zwrot z inwestycji. Obecnie nie można zidentyfikować prawdziwych trendsetterów (influencerów). | Identyfikuj osoby wpływowe, które są kluczowe dla społeczności ze względu na ich powiązania w sieci klientów. |
Odporność logistyki | Łańcuch dostaw może być podatny na zagrożenia (ze względu na to, że firmy działają w różnych regionach geograficznych). Jeśli jedno centrum kluczy ulegnie awarii, cały region może utracić dostęp do produktu. | Określ osoby decyzyjne , które są kluczowe dla połączenia sieci logistycznych. |
Ghost Networks | Grupy oszustów używają fałszywych profili i wspólnych adresów, aby koordynować kradzieże i zawyżać oceny. | Ujawnianie odizolowanych wysp , czyli hiperpołączonych grup bez powiązań z prawdziwą społecznością. |
Paradoks wyboru | Obecny silnik sugestii i rekomendacji jest prosty, ogólny i często ignorowany (np. „Klienci, którzy kupili ten produkt, kupili też…”). | Twórz bliźniaków behawioralnych, czyli rekomendacje oparte na podobnych wzorcach dostawy i kręgach społecznych. |
Dopasowywanie wyzwań biznesowych do strategii technicznej (wiersze → relacje)
W tradycyjnej bazie danych dane są przechowywane w izolowanych silosach: klienci w jednej tabeli, transakcje w innej, a dostawy w jeszcze innej. SQL doskonale sprawdza się w odpowiadaniu na pytanie „Kto co kupił?”, ale ma problemy z odpowiadaniem na pytania dotyczące sieci.
Aby rozwiązać te problemy, strategia techniczna musi zmienić tę perspektywę:
- Widok relacyjny („Co”): traktuje każdego klienta jako osobny wiersz. Znalezienie powiązania między klientem a zakupem znajomego wymaga wielu złożonych „złączeń”, które stają się wykładniczo wolniejsze wraz ze wzrostem sieci.
- Widok grafu („Jak”): traktuje relacje jako elementy najwyższej wagi. Zamiast przeglądać listy, poruszamy się po mapie. Od razu widzimy, że klient A jest połączony z klientem B, który wysyła produkty do lokalizacji Z.
Szczegółowe omówienie wymagań
Architekci rozwiązań dochodzą do wniosku, że wymagania biznesowe i strategia techniczna wymagają podejścia wielomodelowego, i określają te kluczowe wymagania:
Jak Cloud Spanner spełnia te wymagania techniczne
W tym procesie transformacji kluczową rolę odgrywa Cloud Spanner. Umożliwia to Klientowi zachowanie solidnych podstaw relacyjnych przy jednoczesnym uzyskiwaniu szczegółowych informacji z grafu.
Oto krótkie podsumowanie, jak Cloud Spanner spełnia wymagania techniczne i inne.
Cloud Spanner zapewnia też przyszłościową architekturę techniczną.
2. Konfigurowanie podstaw danych
Po opracowaniu uzasadnienia biznesowego przechodzimy do fazy wdrożenia. W tej sekcji definiujemy naszą architekturę danych, omawiamy ograniczenia tradycyjnego modelu relacyjnego i przedstawiamy graf właściwości jako nasze główne narzędzie do odkrywania szczegółowych statystyk.
Konfigurowanie instancji Cloud Spanner Enterprise
Krok 1. Włącz interfejs Cloud Spanner API
W konsoli Google Cloud kliknij ikonę Menu w lewym górnym rogu ekranu, aby otworzyć menu nawigacyjne po lewej stronie. Przewiń w dół i wybierz „Spanner” (Klucz), lub wyszukaj „Spanner” (Klucz).
Powinien wyświetlić się interfejs Cloud Spanner. Jeśli używasz projektu, w którym interfejs Cloud Spanner API nie jest jeszcze włączony, zobaczysz okno z prośbą o jego włączenie. Jeśli interfejs API jest już włączony, możesz pominąć ten krok.
Aby kontynuować, kliknij „Włącz”:
Krok 2. Utwórz instancję Cloud Spanner
Najpierw utworzysz instancję Cloud Spanner. W interfejsie kliknij „Utwórz instancję z zarezerwowaną przepustowością”, aby utworzyć nową instancję.
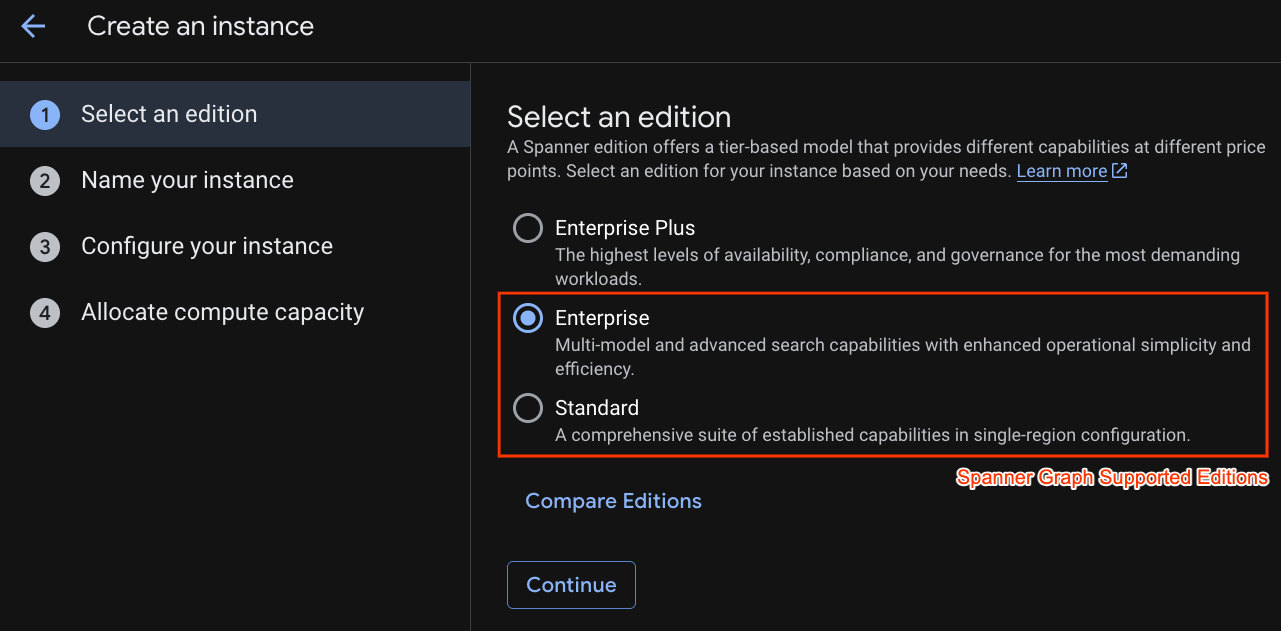
W pierwszym kroku musisz wybrać wersję. Pamiętaj, że możesz później przejść na wyższą wersję. Aby korzystać z funkcji wielu modeli (Spanner Graph), możesz wybrać wersję Enterprise.
Nadawanie nazwy instancji
Wybierz konfigurację wdrożenia i region.
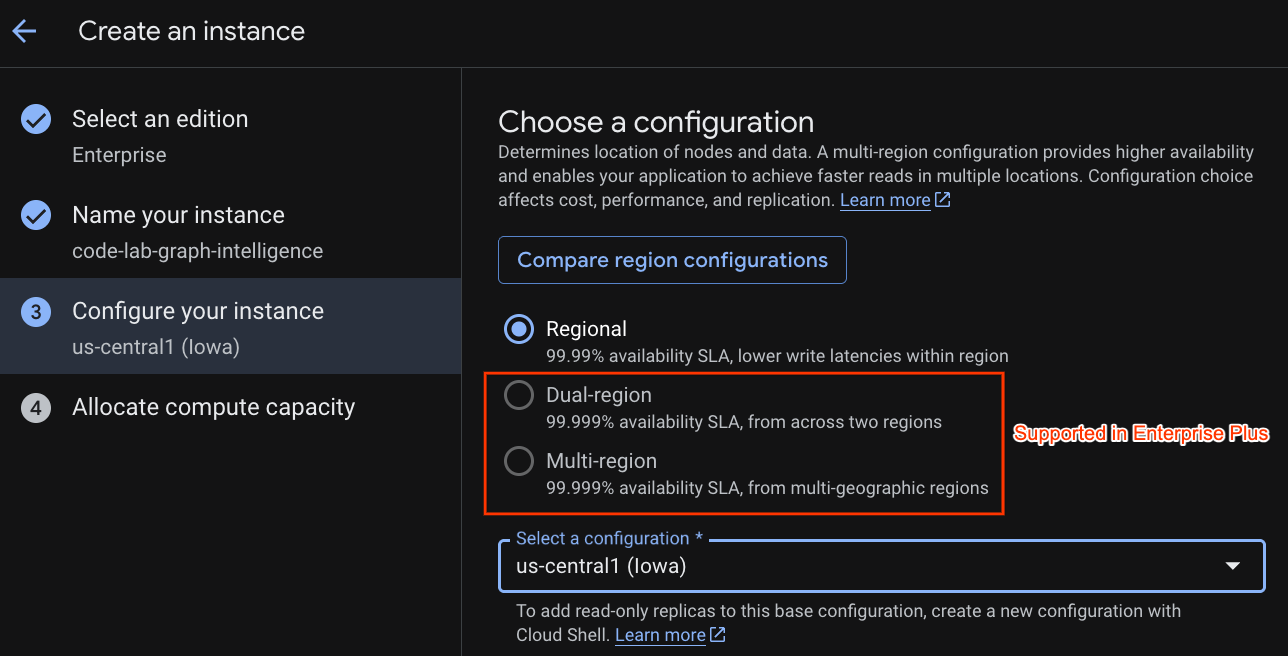
Możesz też porównać różne opcje konfiguracji. Na przykład konfiguracja wdrożenia ma co najmniej 3 repliki odczytu i zapisu w 3 oddzielnych strefach wybranego regionu. Oznacza to, że nawet w przypadku wdrożenia z jednym węzłem masz 3 kopie w 3 replikach odczytu i zapisu. Nawet w przypadku konfiguracji wdrożenia regionalnego możesz rozszerzyć zakres działania, dodając dodatkowe repliki tylko do odczytu w topologii wdrożenia.
Po skonfigurowaniu pojemności możesz zacząć od pełnego węzła i autoskalowania węzłów lub użyć instancji o mniejszej pojemności (jednostki przetwarzania; 1000 jednostek przetwarzania = 1 węzeł). Opcjonalnie możesz też ustawić cele autoskalowania instancji. Dla zbiorów zadań z krótkim czasem oczekiwania zalecamy 65% w przypadku instancji regionalnych i 45% w przypadku instancji w wielu regionach.
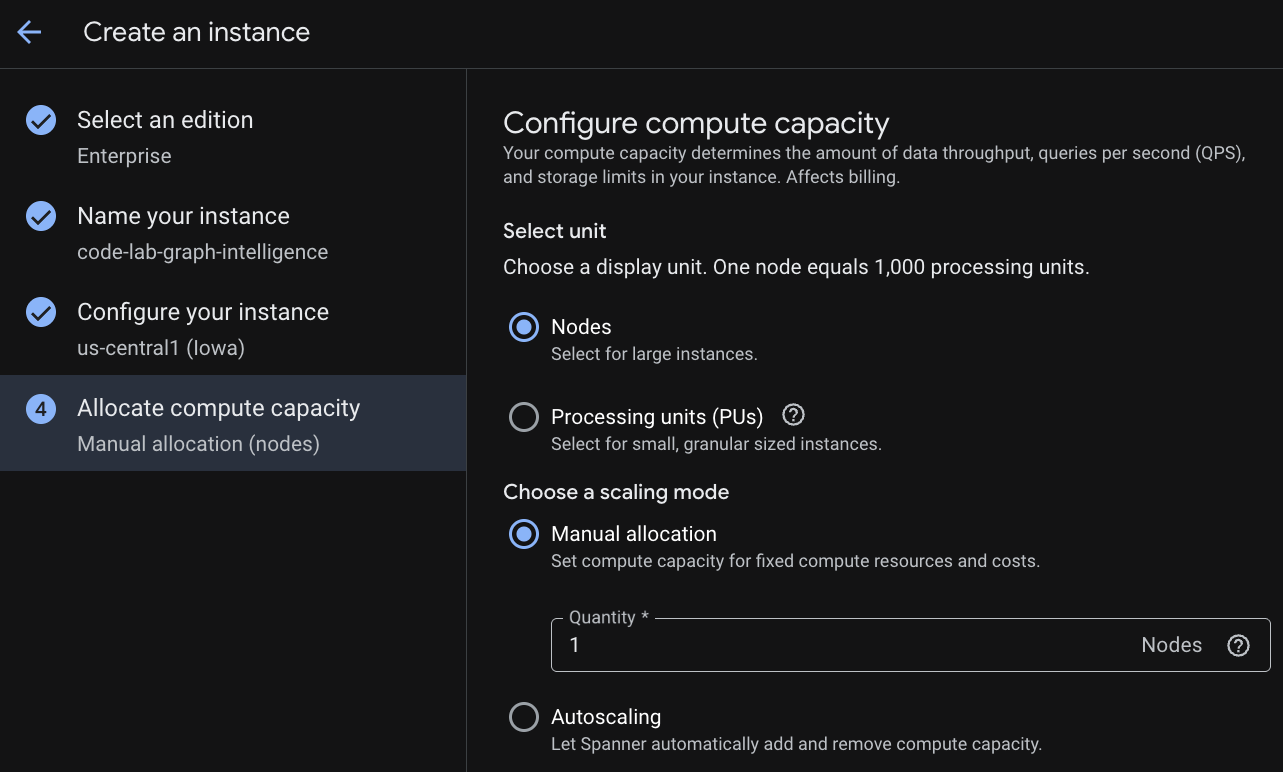
Krok 3. Utwórz bazę danych
Po udostępnieniu instancji kliknij „Utwórz bazę danych”, aby utworzyć bazę danych na potrzeby pozostałej części tego samouczka.
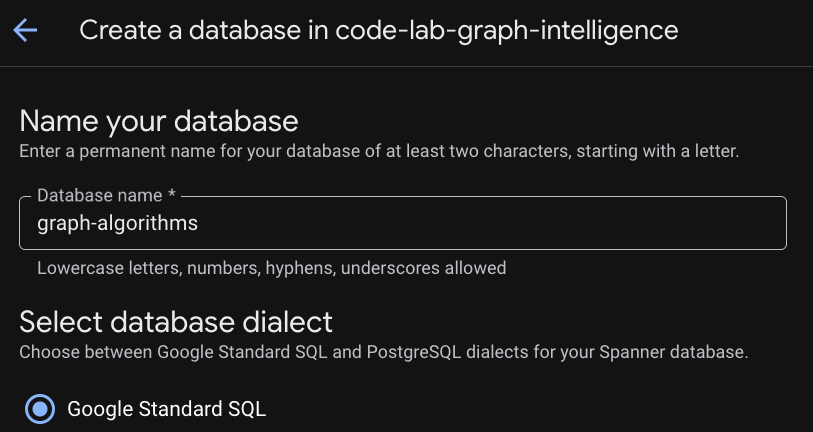
Tworzenie relacyjnej bazy danych
Zaczynamy od podstawowych tabel, w których przechowywane są dane operacyjne. W Cloud Spanner używamy przeplatania, aby fizycznie umieszczać powiązane dane, takie jak znajomości i transakcje klienta, bezpośrednio w jego rekordzie. Zapewnia to dostęp o wysokiej wydajności i fizyczną lokalizację.
DDL: tworzenie tabel
Aby utworzyć schemat relacyjny, skopiuj i uruchom te bloki:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Zasilanie sieci
Gdy tabele są gotowe, musimy wypełnić je użytkownikami, produktami i połączeniami, które definiują ekosystem klienta.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Relational Challenge
Zanim przedstawimy wykres, zobaczmy, jak tradycyjny język SQL radzi sobie z wyzwaniami klienta. Uruchom to zapytanie, aby znaleźć klientów z segmentu „Wydatki w mediach społecznościowych”, którzy dużo wydają i mają wielu znajomych.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Ograniczenia podejścia relacyjnego
Pokonywanie wyzwań związanych z relacjami za pomocą wykresu właściwości
Aby pokonać te ograniczenia, definiujemy wykres właściwości. Tworzy to „nakładkę”, która umożliwia traktowanie relacji jako elementów najwyższej wagi bez przenoszenia danych ze Spannera.
DDL: tworzenie wykresu właściwości
Ten język DDL definiuje nasze węzły (encje) i krawędzie (relacje). W tym przykładzie korzystamy ze schematycznego wykresu, ale Spanner Graph umożliwia modelowanie grafów bez schematu, co pozwala na elastyczne, szybkie i iteracyjne tworzenie aplikacji oraz obsługę rozwijających się modeli danych bez ciągłych zmian w języku definiowania danych (DDL).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Nawigacja po grafie za pomocą języka GQL
Po zdefiniowaniu grafu możemy użyć Graph Query Language (GQL) do wykonywania wieloetapowych przejść za pomocą prostej i czytelnej składni.
Eksploracja 1. Wspólne odkrywanie
To zapytanie przeszukuje graf, aby znaleźć produkty kupione przez Twoich znajomych, i stanowi podstawę silnika rekomendacji.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Eksploracja 2: zapytanie hybrydowe (relacyjne + grafowe)
Spanner umożliwia osadzanie wzorców GQL w standardowej wersji klauzuli FROM SQL za pomocą funkcji GRAPH_TABLE. To zapytanie znajduje klientów, którzy mieszkają w tej samej lokalizacji co ich znajomi – dopasowanie w formie „diamentu”.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Wizualizacja połączeń klienta
Na koniec użyjemy GQL do wizualizacji naszej sieci. Te zapytania otaczają wyniki ścieżki funkcją SAFE_TO_JSON, co umożliwia wizualizatorom rysowanie węzłów i linii.
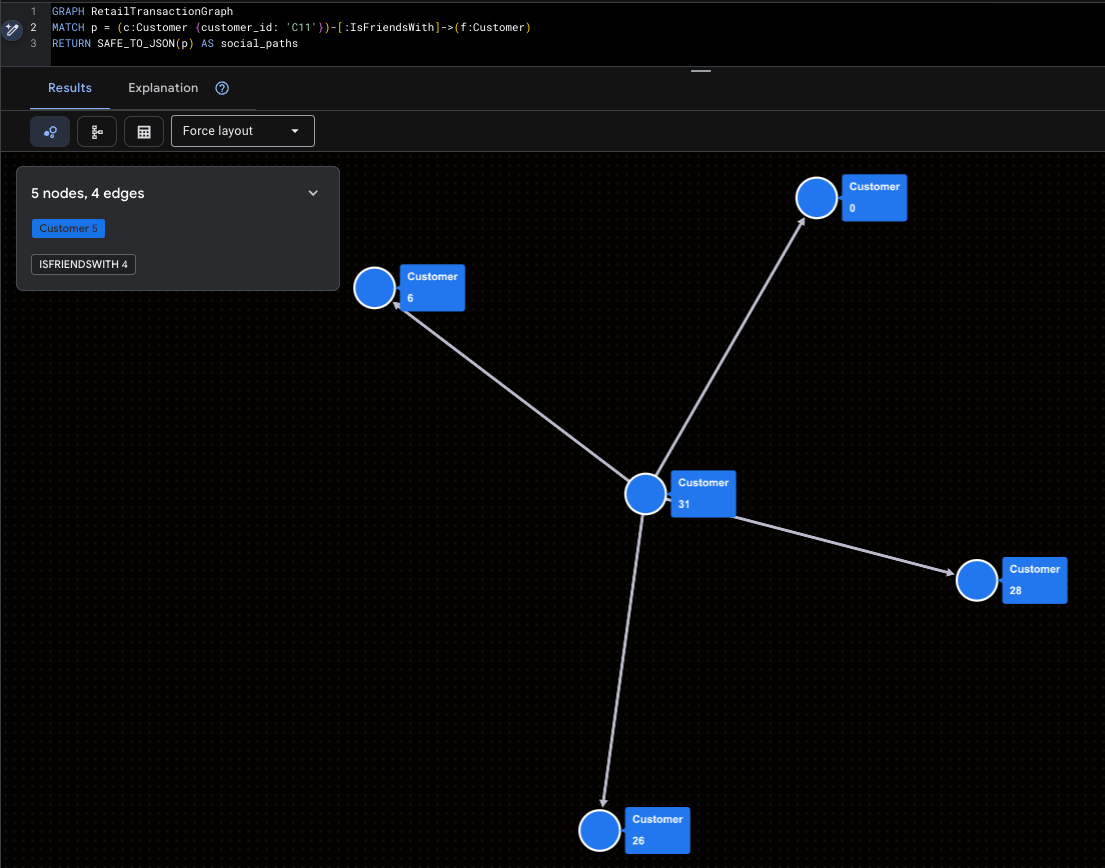
Wizualizacja superinfluencera
Podkreśla to zasięg Mallory (C11) w mediach społecznościowych.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Wizualizacja potencjalnych wzorców oszustw
To zapytanie wyodrębnia „Odizolowany klaster” (Iwan i Judy), aby sprawdzić, gdzie wysyłane są ich produkty.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Wprowadzenie do algorytmów grafowych Spannera
Aby przygotować się do szczegółowego omówienia Graph Intelligence, w tej sekcji przedstawiamy architekturę techniczną i podstawowe reguły algorytmów grafów Cloud Spanner. Zrozumienie tych zasad jest kluczem do przejścia od prostych przeszukiwań do analizy relacji na skalę petabajtów.
The Algorithm Portfolio
Cloud Spanner obsługuje obecnie 14 standardowych algorytmów grafowych, podzielonych na 4 grupy funkcjonalne, które pomagają rozwiązywać różnorodne problemy biznesowe:
Kategoria | Obsługiwane algorytmy | Zastosowanie biznesowe |
Centralność | PageRank, spersonalizowany PageRank, pośredniość, bliskość | Określ osoby wpływowe, centra i wąskie gardła. |
Społeczność | WCC, propagacja etykiet, wyszukiwanie klik, klastrowanie korelacyjne | Wykrywanie grup oszustów, społeczności i izolowanych grup. |
Podobieństwo | Jaccard, Cosine, Common Neighbors, Total Neighbors | wspomaganie systemów rekomendacji i rozwiązywanie problemów z encjami. |
Wyznaczanie ścieżki | Najkrótsza ścieżka od zbioru do zbioru, pomocnicy ścieżki GA | Optymalizuj logistykę i bliskość przejść. |
Najważniejsze kwestie dotyczące schematu i zapytań
Aby zapewnić wydajne wykonywanie algorytmów grafu, Spanner Graph musi przestrzegać tych reguł:
Wymaganie 1. Fizyczna lokalizacja danych (przeplatanie)
Najważniejszym wymaganiem w przypadku przechodzenia po grafie o wysokiej wydajności jest przeplatanie. Dzięki temu dane krawędziowe są fizycznie przechowywane w tym samym podziale serwera co węzeł źródłowy, co minimalizuje opóźnienie sieci podczas wykonywania algorytmu.
- Reguła: tabele krawędzi MUSZĄ być przeplatane w tabelach węzłów źródłowych.
- Przechodzenie do przodu: Przeplatanie tabeli krawędzi z tabelą węzłów źródłowych zapewnia lokalność pamięci podręcznej w przypadku linków wychodzących.
- Odwrotne przemierzanie: aby skutecznie analizować linki „przychodzące”, użyj kluczy obcych do automatycznego tworzenia indeksów wspierających lub utwórz indeks dodatkowy przeplatany w tabeli docelowej.
Wymaganie 2. Wymagania dotyczące unikalnego etykietowania
Każda tabela uczestnicząca w grafie właściwości musi mieć unikalną tożsamość. Algorytmy korzystają z tych etykiet, aby prawidłowo identyfikować i wczytywać podgrafy, które muszą przeanalizować.
- Reguła: każda tabela wejściowa musi mieć w grafie właściwości unikalną etykietę identyfikacyjną.
- Problem: jeśli chcesz uruchamiać algorytmy w wielu tabelach, nie możesz przypisać do nich jednej etykiety.
Logika | Przykład | Wynik |
❌ Nieprawidłowo | TABELE WĘZŁÓW (podmiot z etykietą Person, podmiot z etykietą Account) | Nieprawidłowe: algorytm nie może odróżnić osoby od konta. |
✅ Dobra | TABELE WĘZŁÓW (etykieta Osoba: Klient, etykieta Konto: Konto) | Prawidłowe: każda jednostka ma odrębną, niepowtarzalną etykietę. |
Wymaganie 3. Struktura zapytania o algorytm (klauzula MATCH)
Podczas wywoływania algorytmu klauzula MATCH podlega bardziej restrykcyjnym regułom niż standardowe zapytania GQL, aby silnik wykonawczy mógł zoptymalizować potok analityczny.
- Jeden wzorzec na dopasowanie: każda instrukcja MATCH może zawierać tylko jedną zmienną.
- Brak wzorców wielowęzłowych: nie możesz zdefiniować wzorca relacji (np. (a)-[e]->(b)) bezpośrednio w klauzuli MATCH przeznaczonej do wywołania algorytmu.
- Tylko filtry literałów: możesz używać klauzul WHERE do filtrowania węzłów (np. WHERE a.id > 400), ale parametry zapytania (@param) nie są obecnie obsługiwane w zapytaniach dotyczących algorytmów grafów.
Wymaganie 4. Klauzula RETURN (tylko skalary)
Klauzula RETURN w zapytaniu algorytmu działa jako pomost między światem grafów a światem relacyjnym. Funkcja ta jest ściśle ograniczona do zwracania skalarów i stałych.
- Zasada: nie możesz zwracać „elementu wykresu” (surowego obiektu węzła lub krawędzi).
- Brak przekształceń: nie możesz wykonywać działań matematycznych ani stosować funkcji do właściwości zwracanych w instrukcji RETURN.
Ograniczenia klauzuli RETURN
✅ Obsługiwane | ❌ Nieobsługiwane |
RETURN node.id, score | Węzeł RETURN, wynik (nie można zwrócić elementu wykresu) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (Brak operacji na właściwościach) |
ZWROT node.name | RETURN JSON_OBJECT(node.id, score) (bez funkcji) |
Wymaganie 5. Integralność danych: eliminowanie niepołączonych krawędzi
„Wisząca krawędź” występuje, gdy krawędź wskazuje węzeł docelowy, który nie istnieje na wykresie. W rezultacie wykonanie algorytmu kończy się niepowodzeniem, ponieważ struktura wykresu jest niespójna.
- Rozwiązanie: użyj ograniczeń referencyjnych (kluczy obcych) i ON DELETE CASCADE, aby zachować integralność wykresu.
- Bezpieczeństwo zapytań: podczas wywoływania algorytmu musisz zadbać o to, aby wszystkie węzły, do których odwołują się wybrane krawędzie, były też uwzględnione w argumencie node_labels.
Trwałe dane wyjściowe: opcje EKSPORTUJ DANE
Algorytmy grafowe są wymagające pod względem obliczeniowym, dlatego są wykonywane w trybie skalowania w górę za pomocą instrukcji EXPORT DATA. Wykorzystuje to Data Boost, czyli niezależne bezserwerowe zasoby obliczeniowe, aby zapobiec opóźnieniom w transakcjach produkcyjnych.
Opcja 1. Zapisz dane z powrotem w Cloud Spanner
Aby przesyłać wyniki bezpośrednio z powrotem do tabel (np. zapisywać wynik PageRank), użyj formatu „CLOUD_SPANNER”.
update_ignore_all: aktualizuje tylko wiersze dla kluczy, które już istnieją w tabeli docelowej.upsert_ignore_all: aktualizuje istniejące wiersze lub wstawia nowe, jeśli brakuje kluczy.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Opcja 2. Zapisywanie wyników w Google Cloud Storage (GCS)
W przypadku analizy offline na dużą skalę możesz wyeksportować dane do GCS w formatach CSV, Avro lub Parquet.
- Symbole wieloznaczne: użyj
uri => 'gs://bucket/file_*.csv', aby włączyć podzielone dane wyjściowe, co umożliwi Spannerowi równoległe zapisywanie danych w wielu plikach w przypadku dużych zbiorów danych. - Kompresja: obsługuje formaty GZIP, SNAPPY i ZSTD, co pozwala optymalizować koszty miejsca na dane.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Wyzwanie 1. Różnica w wpływie (PageRank)
W tej sekcji zajmiemy się pierwszą przeszkodą biznesową klienta, czyli „luką wpływu”. Przejdziemy od podstawowego „konkursu popularności” do opartej na matematyce mapy prawdziwych wpływów społecznych.
Opis problemu: zespół marketingowy klienta ma problem. Wydają miliony na szeroko zakrojoną reklamę, która przynosi coraz mniejsze zyski, ponieważ nie potrafią zidentyfikować „gwiazd mediów społecznościowych”, czyli rzadkich osób, których rekomendacje rozchodzą się po całej sieci.
Aby to zrobić, musimy uszeregować klientów według wpływu.
Rozwiązanie relacyjne (centralność stopnia)
W standardowej bazie danych najłatwiejszym sposobem na znalezienie influencera jest po prostu policzenie jego obserwujących (dane znane jako stopień centralności).
Uruchom to zapytanie, aby znaleźć najbardziej „popularnych” użytkowników:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Inteligencja grafów (PageRank)
Aby znaleźć prawdziwych liderów, używamy PageRank. Jest to ten sam algorytm, który był używany w początkach wyszukiwania w internecie. Mierzy on znaczenie węzła na podstawie liczby I JAKOŚCI linków przychodzących.
- Model losowego surfera: PageRank symuluje użytkownika poruszającego się po grafie. Współczynnik tłumienia (domyślnie 0,85) określa prawdopodobieństwo, że użytkownik będzie nadal klikać.W przeciwnym razie „teleportuje się” do losowego węzła .
- Siła powiązań: link od wpływowej osoby (np. Mallory) jest znacznie bardziej wartościowy niż link od osoby, która nie ma innych powiązań.
Uruchomimy algorytm PageRank i użyjemy polecenia EXPORT DATA, aby zapisać wyniki bezpośrednio w kolumnie pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Panel „Wpływ” z użyciem PageRank
Wyniki są już zapisane, więc porównajmy wartości „Przed” (liczba obserwujących) z wartościami „Po” (wynik PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0,158392489 |
C10 | judy@example.com | 1 | 0,1093561724 |
C9 | ivan@example.com | 1 | 0,1093561724 |
C1 | alice@example.com | 3 | 0,1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0,09466411918 |
C7 | grace@example.com | 2 | 0,08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0,0547891818 |
C3 | charlie@example.com | 1 | 0,0547891818 |
C12 | trent@example.com | 1 | 0,04029225558 |
C4 | david@example.com | 1 | 0,04028172791 |
Analiza: kim są prawdziwe supergwiazdy?
Analizując dane wyjściowe, możesz teraz dokonać 3 kluczowych odkryć marketingowych:
Wnioski biznesowe
Zamiast wysyłać e-maile do wszystkich osób, które mają więcej niż 5 obserwujących, zespół marketingowy klienta może teraz skupić się wyłącznie na tych, które mają najwyższy pagerank_score. Te osoby to prawdziwe „gwiazdy mediów społecznościowych”, które mogą wywołać wirusowe rozprzestrzenianie się informacji na całym rynku.
Teraz spróbujmy zidentyfikować osoby decyzyjne, które utrzymują sieć logistyczną klienta.
5. Wyzwanie 2. Odporność logistyczna (BetweennessCentrality)
W tej sekcji zajmiemy się odpornością logistyki. Zamiast mierzyć sukces na podstawie „liczby” połączeń, będziemy identyfikować kluczowych „strażników dostępu”, którzy utrzymują połączenie sieciowe.
Rozwiązanie relacyjne (analiza oparta na wolumenie)
W standardowej konfiguracji relacyjnej „krytyczny” węzeł dostawy jest zwykle definiowany jako ten, który przetwarza najwięcej zamówień lub generuje największe przychody.
Uruchom to zapytanie, aby zidentyfikować „najpopularniejsze” centra według liczby transakcji:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
Nowy Jork | USA | 4 | 3996 |
Berlin | Niemcy | 2 | 345 |
San Francisco | USA | 2 | 750 |
Aby rozwiązać ten problem, użyjemy krawędzi IsFriendsWith i LivesAt. Dzięki temu nasza analiza będzie obejmować nie tylko centrum transakcji, ale też weryfikację w mediach społecznościowych.
Inteligencja grafu (centralność pośrednictwa)
Aby znaleźć prawdziwe wąskie gardła, używamy miary pośrednictwa. Ten algorytm określa, jak często węzeł pełni rolę „mostu” na najkrótszych ścieżkach między wszystkimi innymi parami węzłów na wykresie. Wysokie wyniki wskazują prawdziwych strażników, którzy kontrolują przepływ towarów lub informacji.
Obliczanie i utrwalanie miary pośrednictwa
Uruchomimy algorytm za pomocą polecenia EXPORT DATA i zapiszemy wyniki w kolumnie centrality_score. Używamy Data Boost, aby zapewnić, że to wymagające obliczenie „najkrótszej ścieżki” ma niemal zerowy wpływ na bieżące operacje klienta.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analiza: identyfikowanie „ukrytych wąskich gardeł”
Teraz porównujemy nasze ryzyko strukturalne (centrality_score) z naszym wolumenem transakcji (order_count), aby znaleźć węzły, które powinny niepokoić kierownictwo klienta.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Analizując te wyniki, klient dokonuje 3 zaskakujących odkryć:
Wnioski dla firm
Klient może teraz ustalać priorytety dotyczące redundancji logistycznej i protokołów bezpieczeństwa na podstawie wielomodalnego ryzyka strukturalnego. Mallory, Alice i Eve to osoby, które muszą być chronione, aby zapewnić stabilność sieci logistycznej.
Teraz spróbujmy wyodrębnić wyspy oszustw.
6. Wyzwanie 3. Sieci widmowe (WCC)
W tej sekcji zajmiemy się trzecią przeszkodą biznesową: „sieciami widmowymi”. Z prostego wykrywania „hotspotów” przejdziemy do wykrywania zaawansowanych, odizolowanych grup oszustów za pomocą wykrywania społeczności. Problem polega na tym, że nieuczciwe podmioty tworzą fałszywe profile, które udostępniają adresy dostawy lub wchodzą w interakcje w zamkniętych pętlach, aby koordynować kradzieże i zawyżać oceny produktów. Często są jednak całkowicie odizolowane od prawdziwej społeczności The Customer.
Aby rozwiązać ten problem, musimy ujawnić te „odizolowane wyspy”.
Rozwiązanie relacyjne (wyszukiwanie według wspólnego identyfikatora)
Bez algorytmów grafowych standardowym sposobem wykrywania oszustw jest szukanie „hotspotów” udostępnionych danych, np. wielu klientów wysyłających produkty pod ten sam adres.
Aby znaleźć klientów połączonych wspólną lokalizacją dostawy, uruchom to zapytanie:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Aby znaleźć sieci oszustów, musimy zrozumieć przechodnią osiągalność.
Graph Intelligence (Weakly Connected Components)
Aby określić pełny zakres tych pierścieni, używamy słabo połączonych komponentów (WCC). WCC to algorytm klastrowania, który identyfikuje zbiory węzłów, w których istnieje ścieżka między dowolnymi 2 węzłami, niezależnie od kierunku krawędzi.
- Strefy osiągalności: skutecznie dzieli graf na „wyspy” lub „strefy osiągalności”.
- Ujednolicony widok encji: analizując jednocześnie powiązania społeczne (IsFriendsWith) i logistyczne (LivesAt), możemy grupować rozproszone profile w jeden ujednolicony „klaster wpływu”.
Uruchamianie i utrzymywanie WCC
Uruchomimy algorytm WCC i zapiszemy wyniki w kolumnie community_id. Używamy Data Boost, aby zapewnić, że ta szczegółowa analiza osiągalności będzie przeprowadzana na niezależnych zasobach obliczeniowych.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analiza: grupy oszustów
Teraz uruchomimy zapytanie weryfikacyjne, aby zobaczyć wyodrębnione społeczności. Prawdziwi użytkownicy zwykle należą do „Kontynentu”, a oszuści często znajdują się na małych „Wyspach”.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | członków |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Dzięki uruchomieniu wykrywania społeczności możesz zidentyfikować krytyczną anomalię:
Wnioski dla firm
Klient może teraz zautomatyzować reakcje na zagrożenia. Zamiast ręcznie śledzić poszczególne konta, mogą napisać prostą regułę: „Jeśli identyfikator społeczności ma mniej niż 3 członków, oznacz całą grupę do ręcznej weryfikacji KYC (Know Your Customer)”.
.
Po wykryciu sieci oszustów możemy rozwiązać problem „bliźniaka behawioralnego”.
7. Wyzwanie 4. Behavioral Twin (JaccardSimilarity)
W tym ostatnim wyzwaniu zajmiemy się czwartą przeszkodą, czyli „paradoksem wyboru”/„bliźniakiem behawioralnym”. Przejdziemy od ogólnych list „często kupowane razem” do hiperspersonalizowanych rekomendacji opartych na „odciskach palców” behawioralnych.
Obecne sugestie dotyczące produktów klienta są zbyt ogólne. Polecanie każdemu klientowi popularnego kabla USB jest bezpieczne, ale nie jest spersonalizowane. Klient chce tworzyć rekomendacje „bliźniaka behawioralnego”, które identyfikują klientów o podobnych wzorcach dostawy i kręgach społecznych, aby sugerować produkty o wysokiej precyzji dopasowania.
Aby to zrobić, musimy obliczyć „bliskość” między użytkownikami.
Relational Solution (Absolute Overlap)
W standardowej konfiguracji relacyjnej możesz szukać osób, które wysyłają produkty do tych samych lokalizacji co użytkownik referencyjny, np. Alicja (C1).
Uruchom to zapytanie, aby znaleźć sąsiadów geograficznych Alicji:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (podobieństwo Jaccarda)
Aby znaleźć prawdziwe bliźniaki behawioralne, używamy podobieństwa Jaccarda. Ten algorytm oblicza znormalizowany wynik (od 0,0 do 1,0), dzieląc liczbę wspólnych sąsiadów (przecięcie) przez łączną liczbę unikalnych sąsiadów (suma).
„Bliźniak behawioralny” to nie tylko osoba, która ma ten sam adres dostawy. Analizując przecięcie śladów fizycznych (LivesAt) i ekosystemów społecznych (IsFriendsWith), możemy identyfikować użytkowników, którzy mają podobny styl życia i wpływ na społeczność, co pozwala nam dostarczać znacznie dokładniejsze rekomendacje produktów.
Najpierw utwórz tabelę mapowania
Podobieństwo jest relacją parową (klient A jest podobny do klienta B), dlatego tworzymy specjalną tabelę przeplataną w Customer, aby przechowywać te mapowania.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Uruchom teraz podobieństwo Jaccarda
Teraz uruchomimy algorytm. Uwaga: to zapytanie zawiera typową lekcję „Guardrail”. Jeśli wybierzesz tylko węzły Customer, ale użyjesz krawędzi LivesAt (która wskazuje węzły Shipping), zapytanie zakończy się niepowodzeniem z powodu „Dangling Edge” . Aby to naprawić, musimy uwzględnić obie etykiety węzłów.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analiza: sprawdzenie „bliźniaka behawioralnego”
Po zakończeniu zadania analitycznego uruchamiamy zapytanie weryfikacyjne. Łącząc naszą nową tabelę mapowania (CustomerSimilarity) z oryginalnymi Customer metadanymi, możemy dokładnie określić, kim są „bliźniacy behawioralni” Alicji.
Uruchom to zapytanie, aby sprawdzić rankingi podobieństwa Alicji:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0,1093561724 |
bob@example.com | 0.200000003 | 0 | 0,0547891818 |
ivan@example.com | 0.200000003 | 1 | 0,1093561724 |
eve@example.com | 0,1666666716 | 0 | 0,158392489 |
mallory@example.com | 0 | 0 | 0,09466411918 |
trent@example.com | 0 | 0 | 0,04029225558 |
charlie@example.com | 0 | 0 | 0,0547891818 |
david@example.com | 0 | 0 | 0,04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0,08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Na co zwrócić uwagę w wynikach:
Teraz spróbujmy utworzyć ostateczny widok Unified Intelligence.
8. Ujednolicona inteligencja
Teraz przechodzimy od poszczególnych zadań technicznych do zintegrowanej inteligencji. Łączymy tu dane transakcyjne ze wszystkimi 4 algorytmami grafów, aby dostarczać jasne i przydatne statystyki.
Raport 1. Ujednolicone statystyki
Zaletą bazy danych z wieloma modelami, takiej jak Spanner, jest możliwość łączenia w jednym żądaniu relacyjnych danych o wydatkach z ocenami wpływu, ryzyka i podobieństwa uzyskanymi na podstawie grafu. To zapytanie przypisuje każdego klienta do określonego profilu biznesowego.
Uruchom zapytanie Unified Intelligence, aby zobaczyć cały ekosystem:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | wydatki | wpływ | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0,09466411918 | 44,5 | 0 | 🔵 KRYTYCZNY: mostek sieciowy |
C5 | eve@example.com | 0 | 0,158392489 | 35,5 | 0 | 🔵 KRYTYCZNY: mostek sieciowy |
C1 | alice@example.com | 999 | 0,1000888124 | 35,5 | 0 | 🔵 KRYTYCZNY: mostek sieciowy |
C7 | grace@example.com | 300 | 0,08016719669 | 12 | 0 | 📱 SOCIAL: High-Reach Influencer |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 SOCIAL: High-Reach Influencer |
C3 | charlie@example.com | 0 | 0,0547891818 | 6 | 0 | 🟢 STANDARD: aktywny klient |
C4 | david@example.com | 0 | 0,04028172791 | 3,5 | 0 | 🟢 STANDARD: aktywny klient |
C10 | judy@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 WYSOKIE RYZYKO: odizolowana grupa oszustów |
C9 | ivan@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 WYSOKIE RYZYKO: odizolowana grupa oszustów |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDARD: aktywny klient |
C2 | bob@example.com | 999 | 0,0547891818 | 0 | 0 | 🟢 STANDARD: aktywny klient |
C12 | trent@example.com | 0 | 0,04029225558 | 0 | 0 | 🟢 STANDARD: aktywny klient |
Łącząc te perspektywy matematyczne, przechodzimy od pytania „kto wydał najwięcej” do pytania „kto ma największe znaczenie”. Ujednolicony panel integruje relacyjne dane o transakcjach z wielomodalną inteligencją grafu, aby podzielić Twój ekosystem na 3 jasne, przydatne w praktyce profile.
„Krytyczne mosty sieciowe” (odporność)
Węzły takie jak Mallory (C11), Eve (C5) i Alice (C1) są oznaczone, ponieważ ich bottleneck_risk (miara pośrednictwa) jest >25.
- Węzły strukturalne: Mallory ma najwyższy wynik ryzyka – 44,5, co oznacza, że jest główną bramą dla całej sieci.
- Paradoks zerowych wydatków: Eve (C5) ma 0 zamówień, ale jest niezbędna z punktu widzenia struktury i ma wynik ryzyka równy 35,5. Standardowa wersja SQL całkowicie by ją zignorowała, ale Graph Intelligence pokazuje, że jest ona ważnym łącznikiem z całą podspołecznością.
- Brama o wysokiej wartości: Alice (C1) uzyskała 35,5 pkt, czyli tyle samo co Eve, co dowodzi, że osoby wydające duże kwoty mogą być również kluczowymi elementami strukturalnymi.
„Social Superstars” (zasięg)
Heidi (C8) i Grace (C7) są uznawane za influencerki o dużym zasięgu ze względu na ich wyniki PageRank .
„Odizolowany krąg oszustów” (anomalie)
Użytkownicy Judy (C10) i Ivan (C9) są oznaczeni, ponieważ należą do odizolowanej grupy community_id 1.
Od informacji biznesowych do działań strategicznych
Persona | Kluczowe dane | Business Insight | Działanie strategiczne |
🔵 Mostki sieciowe | Wysoka centralność | Kotwice strukturalne: Eve (C5) i Mallory (C11) utrzymują sieć w całości. | Utrzymanie: chroń tych strażników, aby zapobiec fragmentacji społeczności. |
📱 Supergwiazdy mediów społecznościowych | Wysoki PageRank | Viral Engines: użytkownicy tacy jak Heidi (C8) mają największy zasięg w swoich kręgach. | Marketing: używaj go w programach poleceń i ambasadorskich o dużym wpływie. |
🔴 Ryzyko oszustwa | Izolowane WCC | Ghost Networks: Judy (C10) i Ivan (C9) to osoby, które dużo wydają, ale żyją na „wyspach”. | Bezpieczeństwo: natychmiastowa ręczna weryfikacja tożsamości klienta; są to klasyczne oznaki oszustwa. |
🟢 Użytkownicy z dostępem standardowym | Zrównoważone wyniki | Zdrowy rdzeń: większość sieci, w tym „lokalne” mosty, takie jak David (C4). | Wzrost: stosuj standardowe reklamy spersonalizowane i rekomendacje dotyczące „bliźniaka behawioralnego”. |
Raport 2. Raport o anomaliach tożsamości
Teraz musisz sprawdzić, czy oszuści nie „podszywają się” pod legalne konta. Możemy to rozwiązać, znajdując użytkowników, którzy mają 100% podobieństwa behawioralnego, ale nie mają żadnych powiązań społecznościowych.
Uruchom to zapytanie, aby oznaczyć potencjalne „Anomalie tożsamości”:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Kluczowe informacje znajdziesz w raporcie Identyfikowanie anomalii. Dzięki wyodrębnieniu użytkowników, którzy zachowują się jak prawdziwi klienci, ale nie mają powiązań społecznościowych, przechodzimy od zgadywania do pewności matematycznej .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Analiza wyników
Łącząc podobieństwo (Jaccarda) z wykrywaniem społeczności (WCC), ujawniamy ukryte zagrożenia, których nie widać w tradycyjnych danych transakcyjnych.
- „Bliźniacy behawioralni” (bliskość): węzły takie jak Judy (C10) i Ivan (C9) są oznaczone, ponieważ mają wynik podobieństwa Jaccarda wynoszący 0,20 w stosunku do Alice (C1).
- Zachowanie w izolacji: Judy (C10) i Ivan (C9) są zgrupowani w izolowanej społeczności_id 1, a Alice należy do społeczności „Mainland” (społeczność 0).
- Oznaczenia oszustwa: raport identyfikuje użytkowników o wysokim stopniu podobieństwa zachowań (powyżej 0,9), którzy pozostają odłączeni od głównej sieci społecznościowej.
9. Gratulacje i podsumowanie
Z tego modułu dowiesz się, jak Cloud Spanner przekształca relacyjną bazę danych w wielomodelową platformę. Dzięki zastosowaniu analizy grafów do klienta przeszliśmy od statycznych danych do praktycznej strategii biznesowej.
Zalety usługi Spanner Multi-Model
- Ujednolicona architektura: Spanner umożliwia utrzymanie solidnych podstaw relacyjnych, a jednocześnie natychmiastowe „nakładanie” wykresu właściwości w celu eksploracyjnego wydobywania relacji bez ryzyka i opóźnień związanych z procesem ETL.
- Izolacja analityczna poza urządzeniem: dzięki Data Boost możesz wykonywać algorytmy wymagające dużej ilości pamięci, takie jak PageRank czy WCC, na niezależnych, bezserwerowych zasobach obliczeniowych, co zapewnia zerowy wpływ na wydajność procesu płatności w środowisku produkcyjnym.
- Przeplatana wydajność: unikalne przeplatanie w Spannerze zapewnia fizyczne współlokalizowanie węzłów i ich relacji, co przekształca złożone globalne przeszukiwania w szybkie lokalne wyszukiwania.
Wykrywanie „ukrytych perełek” i anomalii
- Określanie wartości strukturalnej: algorytmy grafowe, takie jak miara pośrednictwa, ujawniły „ukryte mosty” o zerowych wydatkach, które mogą mieć większe znaczenie dla odporności sieci niż klienci o najwyższych wydatkach.
- Wykrywanie naśladowania zachowań: łącząc podobieństwo Jaccarda i słabo połączone komponenty, zidentyfikowaliśmy „osoby obce w mediach społecznościowych”. Te konta wyglądają jak konta prawdziwych klientów, ale matematycznie udowodniono, że są odizolowanymi grupami oszustów.
- Prawda globalna a lokalna: ręczna analiza SQL może ujawnić pomosty, ale globalne algorytmy mogą ujawnić kluczowych strażników sieci.
Przekształcanie danych w inteligentne i przydatne informacje
- Strategia oparta na profilach: udało nam się przekształcić wiersze w relacje. Dzięki uruchomieniu algorytmów możemy rozwiązać 4 problemy biznesowe: mosty w sieci, gwiazdy mediów społecznościowych, ryzyko oszustwa i standardowi użytkownicy.