
1. Estudo de caso: varejo inteligente
Para o estudo de caso, vamos usar um cliente de varejo com um mercado digital em rápido crescimento. A visão tradicional de dados do cliente é limitada porque mostra o que as pessoas compram, mas não como elas estão conectadas. Essa lacuna leva à perda de oportunidades e ao aumento das fraudes. Agora, eles estão mudando para uma filosofia Network-First para valorizar as conexões sociais e de logística, além dos dados de transação.
Principais desafios de negócios a serem enfrentados
Você tem quatro desafios críticos que exigem entender como os clientes e a logística estão interconectados:
Desafio | O problema | O objetivo |
Ausência de influência | A publicidade ampla gera um ROI baixo. No momento, não é possível identificar os verdadeiros criadores de tendências (influenciadores). | Identifique influenciadores que são essenciais para a comunidade por meio da conexão em uma rede conectada de clientes. |
Resiliência logística | A cadeia de suprimentos pode ser vulnerável (considerando que ela opera em diferentes regiões geográficas). Se um hub principal falhar, toda a região poderá perder o acesso ao produto. | Identifique os Gatekeepers , que são essenciais para unir as redes de logística. |
Redes fantasma | As redes de fraude usam perfis falsos e endereços compartilhados para coordenar roubos e aumentar as classificações. | Exponha ilhas isoladas , grupos hiperconectados sem vínculos com a comunidade legítima. |
Paradoxo da escolha | O mecanismo atual de sugestões/recomendações é rudimentar, genérico e muitas vezes ignorado (por exemplo, "Os clientes que compraram isso também compraram..."). | Crie gêmeos comportamentais, ou seja, recomendações com base em padrões de envio e círculos sociais semelhantes. |
Como mapear desafios de negócios para uma estratégia técnica (linhas → relações)
Em um banco de dados tradicional, os dados são armazenados em silos isolados: clientes em uma tabela, transações em outra e envio em uma terceira. O SQL é perfeito para responder a "Quem comprou o quê?", mas tem dificuldade em responder a perguntas baseadas em rede.
Para resolver esses desafios, a estratégia técnica é mudar essa perspectiva:
- A visualização relacional (o "o quê"): trata cada cliente como uma linha isolada. Para encontrar uma conexão entre um cliente e a compra de um amigo, são necessárias várias junções complexas, que ficam exponencialmente mais lentas à medida que a rede cresce.
- A visualização de gráfico (o "Como"): trata relacionamentos como cidadãos de primeira classe. Em vez de pesquisar em listas, navegamos em um mapa. Podemos ver instantaneamente que o cliente A está conectado ao cliente B, que envia para o local Z.
Análise detalhada dos requisitos
Os arquitetos de soluções concluem que os requisitos de negócios e a estratégia técnica exigem uma abordagem de vários modelos e identificam os seguintes requisitos principais.
Como o Cloud Spanner atende a esses requisitos técnicos
O Cloud Spanner é escolhido como o centro dessa transformação. Isso permite que o cliente mantenha a base relacional sólida e, ao mesmo tempo, acesse insights detalhados de gráficos.
Confira um resumo rápido de como o Cloud Spanner atende aos requisitos técnicos e muito mais.
Além disso, o Cloud Spanner oferece uma arquitetura técnica preparada para o futuro.
2. Configurar a base de dados
Depois do caso de negócios, vamos para a fase de implementação. Nesta seção, vamos definir nossa arquitetura de dados, explorar as limitações do modelo relacional tradicional e apresentar o gráfico de propriedades como nossa principal ferramenta para descobrir insights detalhados.
Configurar uma instância do Cloud Spanner Enterprise
Etapa 1: ativar a API Cloud Spanner
No console do Google Cloud, clique no ícone de menu no canto superior esquerdo da tela para abrir a navegação à esquerda. Role a tela para baixo e selecione "Spanner" ou pesquise "Spanner".
Agora você vai ver a interface do Cloud Spanner. Se estiver usando um projeto que ainda não ativou a API Cloud Spanner, uma caixa de diálogo vai pedir que você faça isso. Se você já tiver ativado a API, pule esta etapa.
Clique em Ativar para continuar:
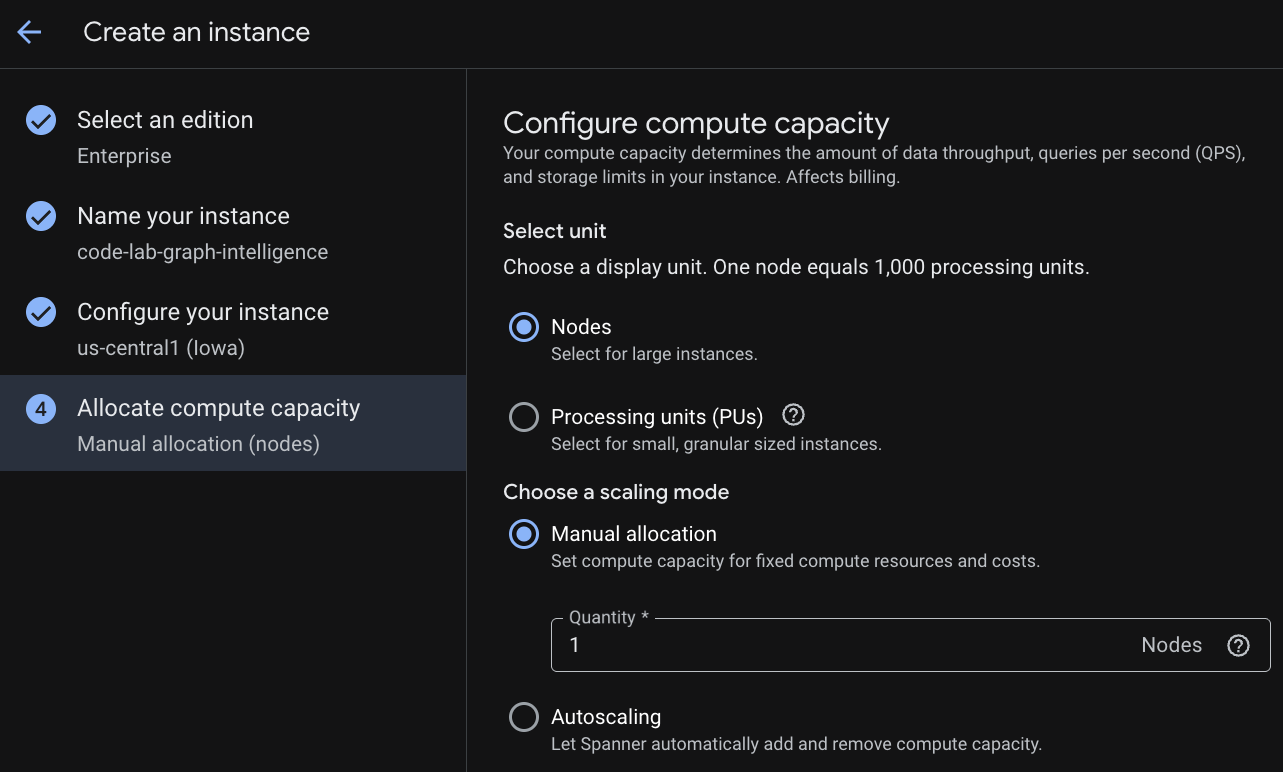
Etapa 2: criar uma instância do Cloud Spanner
Primeiro, crie uma instância do Cloud Spanner. Na interface, clique em Criar uma instância provisionada para criar uma instância.
Na primeira etapa, você precisa selecionar uma edição. Você também pode fazer upgrade da edição depois. Para usar recursos de vários modelos (Spanner Graph), escolha a edição Enterprise.
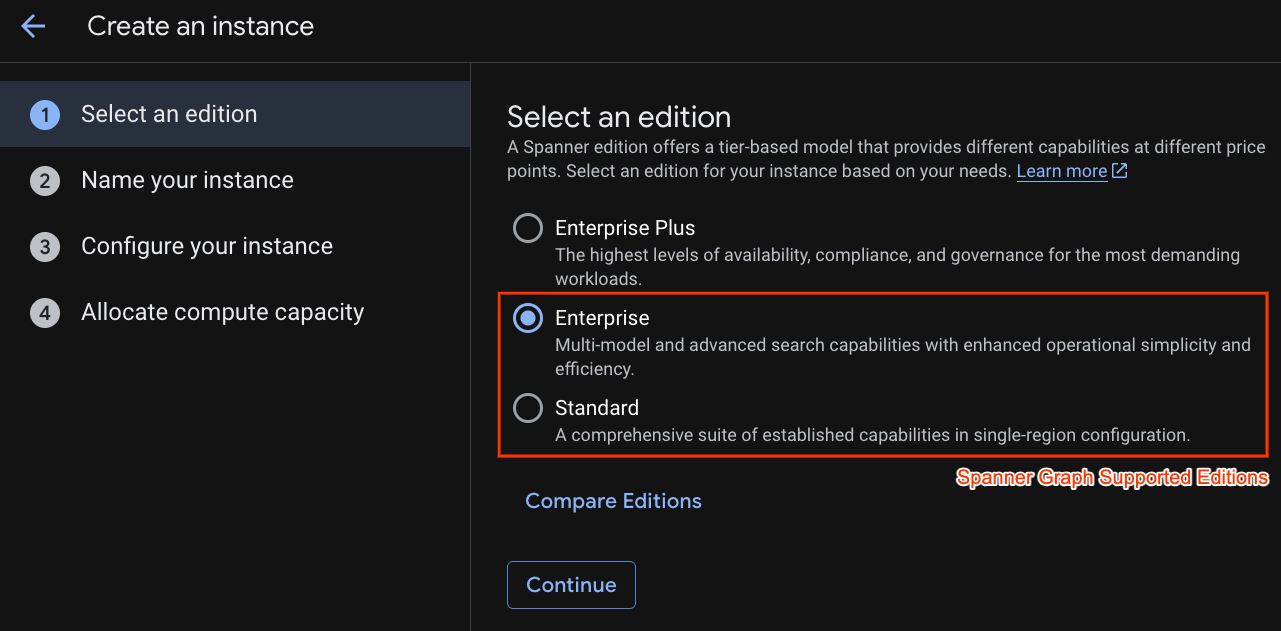
Como nomear sua instância
Selecione uma configuração de implantação e uma região de sua escolha.
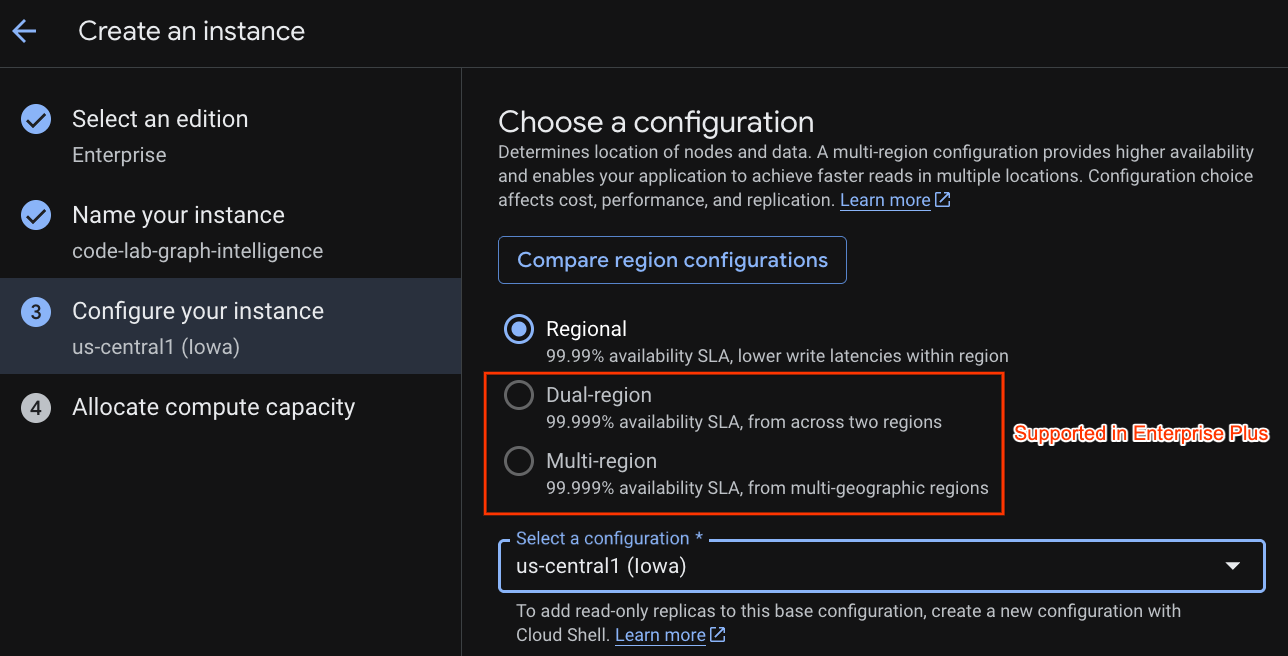
Você também pode comparar várias opções de configuração. Por exemplo, a configuração de implantação tem no mínimo três réplicas de leitura/gravação em três zonas separadas da região selecionada. Ou seja, mesmo que você use uma implantação de nó único, terá três cópias em três réplicas de leitura/gravação. Além disso, mesmo com a configuração de implantação regional, é possível estender ainda mais a implantação com réplicas de leitura/gravação adicionais na topologia de implantação.
Após a configuração da capacidade, você pode começar com o nó completo e o escalonamento automático nos nós ou usar uma instância granular (unidades de processamento; 1.000 PUs = 1 nó). Também é possível definir metas de escalonamento automático da instância. Para cargas de trabalho de baixa latência, recomendamos 65% para instâncias regionais e 45% para instâncias multirregionais.
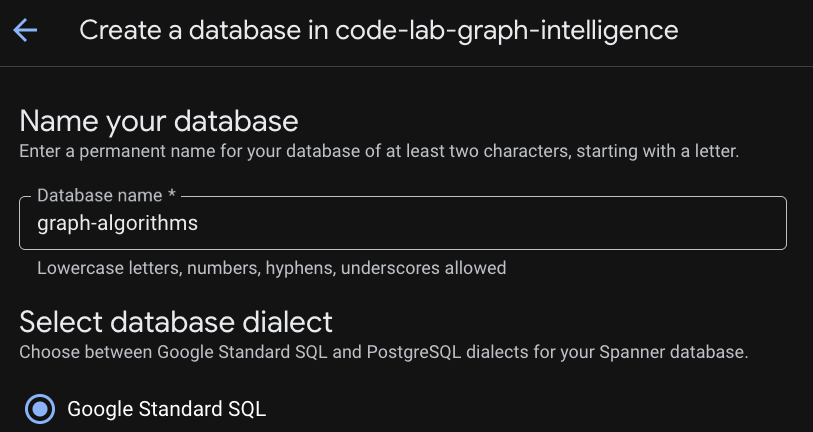
Etapa 3: criar um banco de dados
Depois que a instância for provisionada, clique em "Criar banco de dados" para criar um banco de dados para o restante do codelab.
Como configurar uma base relacional
Nossa jornada começa com as tabelas principais que armazenam dados operacionais. No Cloud Spanner, usamos o intercalamento para alocar fisicamente dados relacionados, como amizades e transações de um cliente, diretamente com o registro dele. Isso garante acesso de alta performance e localidade física.
DDL: como criar as tabelas
Copie e execute os blocos a seguir para estabelecer seu esquema relacional:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Iniciando a rede
Com as tabelas prontas, precisamos preenchê-las com os usuários, produtos e conexões que definem o ecossistema do cliente.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Desafio relacional
Antes de apresentar o gráfico, vamos ver como o SQL tradicional lida com os desafios do cliente. Execute esta consulta para encontrar clientes "Gastadores sociais", que gastam muito e têm vários amigos.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
As limitações da abordagem relacional
Como superar desafios relacionais com um gráfico de propriedades
Para superar esses limites, definimos um gráfico de propriedades. Isso cria uma "sobreposição" que nos permite tratar as relações como cidadãos de primeira classe sem mover nossos dados do Spanner.
DDL: como criar o gráfico de propriedades
Essa DDL define nossos nós (entidades) e arestas (relacionamentos). Neste exemplo, estamos seguindo um gráfico esquematizado. No entanto, o Spanner Graph permite modelar gráficos sem esquema para permitir um desenvolvimento iterativo flexível e rápido e lidar com modelos de dados em evolução sem mudanças constantes na DDL (linguagem de definição de dados).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Como navegar no gráfico com GQL
Agora que o gráfico está definido, podemos usar a linguagem de consulta de gráficos (GQL) para fazer travessias de vários saltos com uma sintaxe simples e legível.
Análise detalhada 1: descoberta colaborativa
Essa consulta percorre o gráfico para encontrar produtos comprados pelos seus amigos e serve como base para um mecanismo de recomendação.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Análise detalhada 2: a consulta híbrida (relacional + grafo)
O Spanner permite incorporar padrões de GQL em uma cláusula FROM do SQL padrão usando a função GRAPH_TABLE. Essa consulta encontra clientes que moram no mesmo local que os amigos, uma correspondência de padrão "diamante".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Visualizar as conexões do cliente
Por fim, vamos usar o GQL para visualizar nossa rede. Essas consultas envolvem os resultados do caminho em SAFE_TO_JSON, permitindo que os visualizadores desenhem os nós e as linhas.
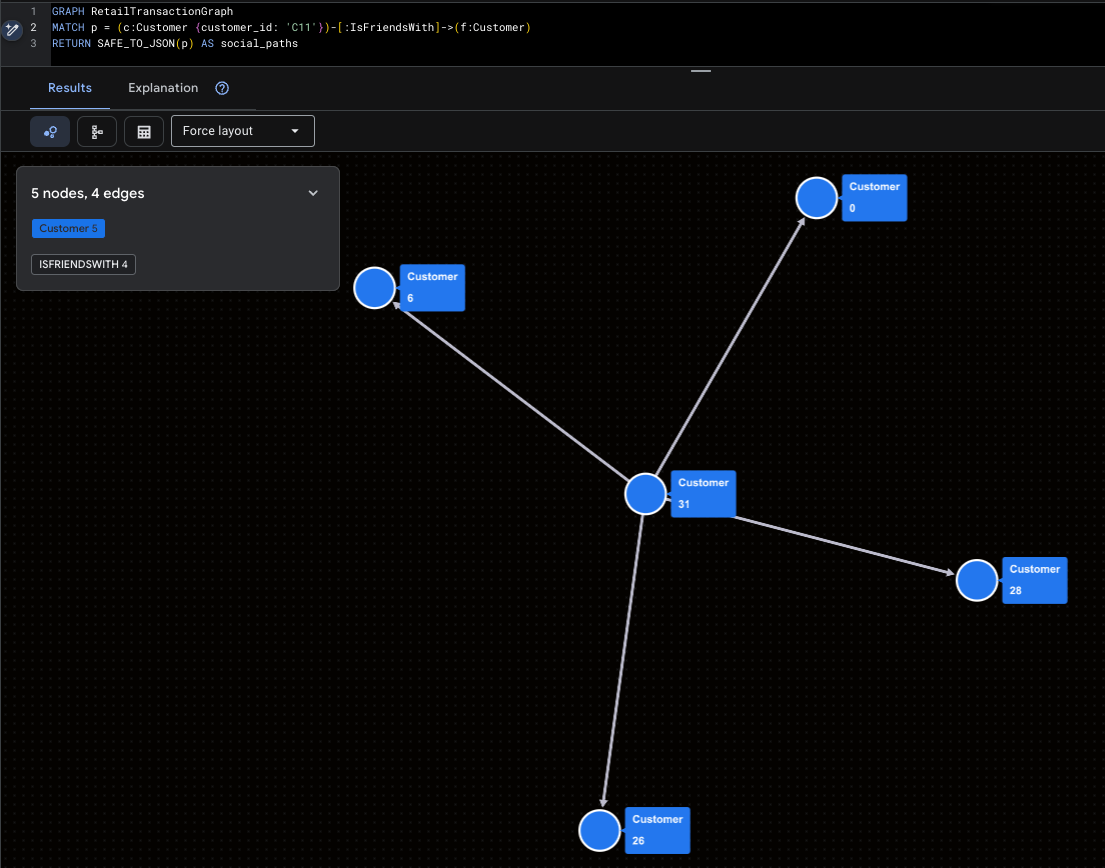
Visualizar o superinfluenciador
Isso destaca Mallory (C11) e o alcance social direto dela.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Visualizar possíveis padrões de fraude
Essa consulta elimina o "Cluster isolado" (Ivan e Judy) para ver onde os produtos deles estão sendo enviados.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Introdução aos algoritmos do Spanner Graph
Para se preparar para o estudo detalhado da inteligência de grafos, esta seção descreve a arquitetura técnica e as regras básicas dos algoritmos do Spanner Graph do Cloud Spanner. Entender esses princípios é fundamental para passar de travessias simples para análises de relacionamento na escala de petabytes.
O portfólio de algoritmos
No momento, o Cloud Spanner é compatível com 14 algoritmos de grafos padrão do setor, categorizados em quatro grupos funcionais para resolver diversos problemas de negócios:
Categorias | Algoritmos compatíveis | Caso de uso comercial |
Centralidade | PageRank, PageRank personalizado, intermediária, proximidade | Identifique influenciadores, hubs e gargalos. |
Community | WCC, propagação de rótulos, descoberta de cliques, agrupamento por correlação | Detecte redes de fraude, comunidades sociais e silos. |
Semelhança | Jaccard, cosseno, vizinhos comuns, total de vizinhos | Potencialize mecanismos de recomendação e resolução de entidades. |
Descoberta de caminhos | Caminho mais curto de conjunto para conjunto, helpers de caminho do GA | Otimize a logística e a proximidade de travessia. |
Considerações importantes sobre esquema e consultas
Para garantir a execução eficiente dos algoritmos de grafo, o Spanner Graph precisa obedecer a estas regras:
Requisito 1: Localidade física dos dados (intercalação)
O requisito mais importante para a travessia de gráficos de alto desempenho é o intercalamento. Isso garante que os dados de borda sejam armazenados fisicamente na mesma divisão de servidor que o nó de origem, minimizando a latência de rede durante a execução do algoritmo.
- A regra:as tabelas de arestas PRECISAM ser intercaladas nas tabelas de nós de origem.
- Transversal direta:a intercalação da tabela de arestas na tabela de nós de origem garante a localidade do cache para links de saída.
- Transversal inversa:para uma análise eficiente de links "de entrada", use chaves estrangeiras para criar automaticamente índices de suporte ou crie um índice secundário intercalado na tabela de destino.
Requisito 2. Requisitos de rotulagem exclusivos
Cada tabela que participa do gráfico de propriedades precisa ter uma identidade exclusiva. Os algoritmos dependem desses rótulos para identificar e carregar corretamente os subgrafos que precisam analisar.
- A regra:cada tabela de entrada precisa ter um rótulo de identificação exclusivo no gráfico de propriedades.
- O conflito:não é possível mapear um único rótulo para várias tabelas se você pretende executar algoritmos nelas.
Lógica | Exemplo | Result |
❌ Ruim | TABELAS DE NÓS (entidade de RÓTULO de pessoa, entidade de RÓTULO de conta) | Inválido: o algoritmo não consegue distinguir entre uma pessoa e uma conta. |
✅ Bom | NODE TABLES (Person LABEL Customer, Account LABEL Account) | Válido: cada entidade tem um rótulo distinto e exclusivo. |
Requisito 3. Estrutura de consulta de algoritmo (cláusula MATCH)
Ao chamar um algoritmo, a cláusula MATCH segue regras mais restritivas do que as consultas GQL padrão para garantir que o mecanismo de execução possa otimizar o pipeline analítico.
- Um padrão por MATCH:cada instrução MATCH só pode nomear uma variável.
- Sem padrões de vários nós:não é possível definir um padrão de relacionamento (por exemplo, (a)-[e]->(b)) diretamente em uma cláusula MATCH destinada a uma chamada de algoritmo.
- Somente filtros literais:embora seja possível usar cláusulas WHERE para filtrar nós (por exemplo, WHERE a.id > 400), os parâmetros de consulta (@param) não são compatíveis com consultas de algoritmo de grafo no momento.
Requisito 4. A cláusula RETURN (somente escalares)
A cláusula RETURN em uma consulta de algoritmo atua como a ponte entre o mundo dos gráficos e o mundo relacional. Ele é estritamente limitado a retornar escalares e constantes.
- A regra:não é possível retornar um "elemento de gráfico" (o nó bruto ou o objeto de aresta).
- Sem transformações:não é possível realizar operações matemáticas nem aplicar funções às propriedades retornadas na própria instrução RETURN.
Restrições da cláusula RETURN
✅ Compatível | ❌ Não aceito |
RETURN node.id, score | NÓ RETURN, pontuação (não é possível retornar o elemento do gráfico) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (No operations on properties) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (sem funções) |
Requisito 5. Integridade de dados: como eliminar arestas pendentes
Uma "aresta pendente" ocorre quando uma aresta aponta para um nó de destino que não existe no gráfico. Isso faz com que a execução do algoritmo falhe porque a estrutura do gráfico é inconsistente.
- A solução:use restrições referenciais (chaves externas) e ON DELETE CASCADE para manter a integridade do gráfico.
- Segurança da consulta:ao chamar um algoritmo, verifique se todos os nós referidos pelas arestas selecionadas também estão incluídos no argumento "node_labels".
Saída permanente: opções de EXPORT DATA
Como os algoritmos de grafos exigem muito poder de computação, eles são executados no modo de execução de escalonamento vertical usando a instrução EXPORT DATA. Isso aproveita o Data Boost, usando recursos de computação sem servidor independentes para evitar atrasos nas transações de produção.
Opção 1: manter no Cloud Spanner
Para enviar resultados diretamente de volta às suas tabelas (por exemplo, salvar uma pontuação de PageRank), use format = "CLOUD_SPANNER".
update_ignore_all: atualiza apenas as linhas de chaves que já existem na tabela de destino.upsert_ignore_all: atualiza as linhas existentes ou insere novas linhas se as chaves estiverem faltando.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Opção 2: manter os resultados no Google Cloud Storage (GCS)
Para análises off-line em grande escala, é possível exportar para o GCS nos formatos CSV, Avro ou Parquet.
- Caracteres curinga:use
uri => 'gs://bucket/file_*.csv'para ativar a saída fragmentada, permitindo que o Spanner grave em vários arquivos em paralelo para conjuntos de dados grandes. - Compactação:oferece suporte a GZIP, SNAPPY e ZSTD para otimizar os custos de armazenamento.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Desafio 1: lacuna de influência (PageRank)
Nesta seção, vamos abordar o primeiro obstáculo comercial do cliente: a lacuna de influência. Vamos passar de um simples "concurso de popularidade" para um mapa matematicamente orientado de influência social real.
Definição do problema:a equipe de marketing do cliente tem um problema. Eles gastam milhões em publicidade ampla com retornos cada vez menores porque não conseguem identificar os "Superstars sociais", aqueles indivíduos raros cujos endossos se espalham por toda a rede.
Para resolver isso, precisamos classificar nossos clientes por Influência.
Solução relacional (centralidade de grau)
Em um banco de dados padrão, a maneira mais fácil de encontrar um influenciador é simplesmente contar os seguidores dele (uma métrica conhecida como centralidade de grau).
Execute esta consulta para encontrar os usuários mais "populares":
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Inteligência de gráficos (PageRank)
Para encontrar os verdadeiros líderes, usamos o PageRank. É o mesmo algoritmo que impulsionou a pesquisa na Web no início. Ele mede a importância de um nó com base na quantidade E na qualidade dos links recebidos.
- Modelo de navegante aleatório:o PageRank simula um usuário navegando pelo gráfico. O fator de amortecimento (padrão 0,85) representa a probabilidade de que eles continuem clicando.Caso contrário, eles "se teletransportam" para um nó aleatório .
- Poder da associação:um link de uma pessoa influente (como Mallory) vale muito mais do que um link de alguém sem outras conexões.
Vamos executar o algoritmo PageRank e usar EXPORT DATA para salvar os resultados diretamente na coluna pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Painel"Influência" usando o PageRank
Agora que as pontuações foram mantidas, vamos comparar o "Antes" (contagem de seguidores) com o "Depois" (pontuação do PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0,158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0,1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0,08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
Análise: quem são os verdadeiros superstars?
Ao analisar a saída, você pode fazer três descobertas importantes de marketing:
Aprendizado para empresas
Em vez de enviar e-mails para todos os usuários com mais de cinco seguidores, a equipe de marketing do cliente agora pode se concentrar exclusivamente naqueles com a maior pagerank_score. Essas pessoas são as verdadeiras "superestrelas sociais" capazes de impulsionar a viralidade sistêmica em todo o mercado.
Agora vamos tentar identificar os Gatekeepers que mantêm a rede de logística do cliente funcionando.
5. Desafio 2: resiliência logística (BetweennessCentrality)
Nesta seção, abordamos a resiliência logística. Vamos além da medição do sucesso por "volume" para identificar os "gatekeepers" vitais que mantêm a rede conectada.
Solução relacional (análise baseada em volume)
Em uma configuração relacional padrão, um hub de envio "crítico" é normalmente definido como aquele que processa mais pedidos ou gera mais receita.
Execute esta consulta para identificar os hubs "principais" por contagem de transações:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
Nova York | EUA | 4 | 3996 |
Berlim | Alemanha | 2 | 345 |
São Francisco | EUA | 2 | 750 |
Para resolver a incompatibilidade, vamos usar as bordas IsFriendsWith e LivesAt. Isso transforma nossa análise de um hub de transações para incluir também a verificação social.
Inteligência de gráficos (centralidade de intermediário)
Para encontrar os gargalos reais, usamos a centralidade de intermediária. Esse algoritmo quantifica a frequência com que um nó atua como uma "ponte" nos caminhos mais curtos entre todos os outros pares de nós no gráfico. As pontuações altas identificam os verdadeiros gatekeepers que controlam o fluxo de produtos ou informações.
Executar e manter a centralidade de intermediária
Vamos executar o algoritmo usando EXPORT DATA e salvar as pontuações na coluna "centrality_score". Usamos o Data Boost para garantir que esse cálculo pesado de "caminho mais curto" tenha impacto quase zero nas operações ativas do cliente.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Análise: identificação dos "Gargalos ocultos"
Agora, comparamos nosso risco estrutural (centrality_score) com nosso volume de transações (order_count) para encontrar os nós que a liderança do cliente precisa monitorar.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Ao analisar esses resultados, o cliente faz três descobertas surpreendentes:
Aprendizado para empresas
Agora, o cliente pode priorizar a redundância logística e os protocolos de segurança com base no risco estrutural multimodal. Mallory, Alice e Eve são os guardiões que precisam ser protegidos para garantir a estabilidade da rede logística.
Agora vamos tentar isolar as ilhas de fraude.
6. Desafio 3: redes fantasmas (WCC)
Nesta seção, vamos abordar o terceiro obstáculo comercial: as "redes fantasmas". Vamos passar da detecção simples de "pontos de acesso" para a descoberta de redes de fraude sofisticadas e isoladas usando a detecção de comunidades. O desafio aqui é que usuários de má-fé criam perfis falsos que compartilham endereços de entrega ou interagem em loops fechados para coordenar roubos e aumentar as classificações dos produtos. mas geralmente são completamente isoladas da comunidade legítima do The Customer.
Para resolver isso, precisamos expor essas "Ilhas isoladas".
Solução relacional (pesquisa de identificador compartilhado)
Sem algoritmos de grafos, a maneira padrão de encontrar fraudes é procurar "pontos críticos" de dados pessoais compartilhados, como vários clientes enviando para o mesmo endereço .
Execute esta consulta para encontrar clientes vinculados por um local de entrega compartilhado:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Para encontrar as redes de fraude, precisamos entender a acessibilidade transitiva.
Inteligência de gráficos (componentes fracamente conectados)
Para encontrar a extensão total desses anéis, usamos Componentes fracamente conectados (WCC, na sigla em inglês). O WCC é um algoritmo de clusterização que identifica conjuntos de nós em que há um caminho entre dois nós, independente da direção das arestas.
- Zonas de capacidade de alcance:dividem o gráfico em "ilhas" ou "zonas de capacidade de alcance".
- Visualização unificada de entidades:ao analisar simultaneamente os laços sociais (IsFriendsWith) e logísticos (LivesAt), podemos agrupar perfis fragmentados em um único "Cluster de impacto" unificado.
Executar e manter o WCC
Vamos executar o algoritmo WCC e salvar os resultados na coluna "community_id". Usamos o Data Boost para garantir que essa análise de acessibilidade detalhada seja feita em recursos de computação independentes.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Análise: redes de fraude
Agora, vamos executar uma consulta de validação para ver nossas comunidades isoladas. Os usuários legítimos geralmente pertencem ao "Continente", enquanto os fraudadores costumam ficar isolados em pequenas "Ilhas".
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | membros |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Ao executar essa detecção de comunidade, você pode identificar uma anomalia crítica:
Aprendizado para empresas
O cliente agora pode automatizar as respostas de segurança. Em vez de procurar manualmente contas individuais, eles podem escrever uma regra simples: "Se um community_id tiver menos de três membros, sinalize o grupo inteiro para análise manual de KYC (Conheça seu cliente)"
.
Com as redes de fraude expostas, podemos resolver o "gêmeo comportamental".
7. Desafio 4: gêmeo comportamental (JaccardSimilarity)
Neste desafio final, abordamos o quarto obstáculo: o "Paradoxo da escolha"/"Gêmeo comportamental". Vamos passar de listas genéricas de "comprados juntos com frequência" para recomendações hiperpersonalizadas com base em "impressões digitais" comportamentais.
As sugestões de produtos atuais do cliente são muito genéricas. Recomendar um cabo USB popular para todos os clientes é seguro, mas não é pessoal. O cliente quer criar recomendações de gêmeos comportamentais que identifiquem clientes com padrões de envio e círculos sociais exclusivos para sugerir produtos com correspondência de alta precisão.
Para resolver isso, precisamos calcular a proximidade entre os usuários.
Solução relacional (sobreposição absoluta)
Em uma configuração relacional padrão, você pode procurar pessoas que enviam para os mesmos locais que um usuário de referência, como Alice (C1).
Execute esta consulta para encontrar os vizinhos geográficos de Alice:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Inteligência de gráficos (similaridade de Jaccard)
Para encontrar gêmeos comportamentais verdadeiros, usamos a similaridade de Jaccard. Esse algoritmo calcula uma pontuação normalizada (0,0 a 1,0) dividindo o número de vizinhos compartilhados (interseção) pelo número total de vizinhos únicos (união).
Aqui, um "gêmeo comportamental" é definido por mais do que apenas um endereço de entrega compartilhado. Ao analisar a interseção de pegadas físicas (LivesAt) e ecossistemas sociais (IsFriendsWith), podemos identificar usuários que compartilham o mesmo estilo de vida e influência da comunidade, resultando em recomendações de produtos muito mais precisas.
Primeiro, crie uma tabela de mapeamento
Como a similaridade é uma relação par a par (o cliente A é semelhante ao cliente B), criamos uma tabela intercalada dedicada em Customer para armazenar esses mapeamentos.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Executar a similaridade de Jaccard agora
Agora vamos executar o algoritmo. Observação:esta consulta inclui uma lição comum de "proteção". Se você selecionar apenas nós de cliente, mas usar a aresta"LivesAt" (que aponta para nós de frete), a consulta vai falhar citando uma aresta pendente . Para corrigir isso, inclua os dois rótulos de nós.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Análise: verificação de "gêmeo comportamental"
Agora que o trabalho analítico está concluído, executamos uma consulta de validação. Ao unir nossa nova tabela de mapeamento (CustomerSimilarity) com os metadados originais de Customer, podemos ver exatamente quem são os "gêmeos comportamentais" de Alice.
Execute esta consulta para inspecionar as classificações de similaridade de Alice:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0,200000003 | 1 | 0.1093561724 |
bob@example.com | 0,200000003 | 0 | 0.0547891818 |
ivan@example.com | 0,200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0,158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0,08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
O que procurar nos resultados:
Agora vamos tentar criar uma visualização final do Unified Intelligence.
8. Inteligência unificada
Agora vamos passar de tarefas técnicas individuais para a inteligência unificada. Aqui, combinamos dados de transações com todos os quatro algoritmos de grafo para fornecer insights claros e úteis.
Relatório 1: Unified Intelligence
A capacidade de um banco de dados multimodelo como o Spanner é unir dados de gastos relacionais com pontuações de influência, risco e similaridade derivadas de gráficos em uma única solicitação. Essa consulta categoriza cada cliente em um perfil de negócios específico.
Execute a consulta da Unified Intelligence para ver o ecossistema completo:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | gastos | influenciar | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44,5 | 0 | 🔵 CRÍTICO: ponte de rede |
C5 | eve@example.com | 0 | 0,158392489 | 35,5 | 0 | 🔵 CRÍTICO: ponte de rede |
C1 | alice@example.com | 999 | 0,1000888124 | 35,5 | 0 | 🔵 CRÍTICO: ponte de rede |
C7 | grace@example.com | 300 | 0,08016719669 | 12 | 0 | 📱 REDES SOCIAIS: influenciador com alto alcance |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 REDES SOCIAIS: influenciador com alto alcance |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: cliente ativo |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD: cliente ativo |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ALTO RISCO: rede de fraude isolada |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ALTO RISCO: rede de fraude isolada |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDARD: cliente ativo |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: cliente ativo |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: cliente ativo |
Ao combinar essas lentes matemáticas, vamos além de "quem gastou mais" para "quem é mais importante". O painel unificado integra dados de transações relacionais com inteligência de gráficos multimodais para categorizar seu ecossistema em três personas claras e práticas.
Pontes de rede críticas (resiliência)
Nós como Mallory (C11), Eve (C5) e Alice (C1) são sinalizados porque a bottleneck_risk (centralidade de intermediário) deles é >25.
- Os pontos de ancoragem estruturais:Mallory tem a maior pontuação de risco, 44,5, o que a marca como o gateway principal de toda a rede.
- O paradoxo do gasto zero: Eve (C5) tem uma contagem de pedidos zero, mas é estruturalmente indispensável com uma pontuação de risco de 35,5. O SQL padrão a ignoraria completamente, mas a inteligência de gráficos revela que ela é uma ponte vital para toda uma subcomunidade.
- O gateway de alto valor: Alice (C1) empatou com Eve em 35,5, provando que os grandes gastadores também podem ser âncoras estruturais importantes.
Os "Superstars sociais" (alcance)
Heidi (C8) e Grace (C7) são identificadas como influenciadoras de alto alcance devido às pontuações de PageRank .
O "Isolated Fraud Ring" (Anomalias)
Judy (C10) e Ivan (C9) são sinalizados porque pertencem ao community_id isolado 1.
Insights de negócios para ações estratégicas
Perfil | Métrica principal | Insight de negócios | Ação estratégica |
🔵 Pontes de rede | Centralidade alta | Âncoras estruturais: Eve (C5) e Mallory (C11) mantêm a rede unida. | Retenção: proteja esses gatekeepers para evitar a fragmentação da comunidade. |
📱 Superestrelas das redes sociais | PageRank alto | Mecanismos virais: usuários como Heidi (C8) têm o maior alcance nos círculos deles. | Marketing: use para programas de indicação e embaixadores de alto impacto. |
🔴 Riscos de fraude | WCC isolado | Redes fantasmas: Judy (C10) e Ivan (C9) gastam muito, mas vivem em "ilhas". | Segurança: análise manual imediata de KYC. Essas são assinaturas de fraude clássicas. |
🟢 Usuários padrão | Pontuações equilibradas | Núcleo saudável: a maioria da rede, incluindo pontes "locais" como David (C4). | Crescimento: aplique anúncios personalizados padrão e recomendações de "Gêmeo comportamental". |
Relatório 2: o relatório de anomalia de identidade
Agora você precisa saber se contas legítimas estão sendo "imitadas" por fraudadores. Para resolver isso, encontramos usuários com 100% de similaridade comportamental, mas sem conexão social.
Execute esta consulta para sinalizar possíveis "Anomalias de identidade":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
O relatório de identificação de anomalias fornece informações importantes. Ao isolar usuários que agem como clientes legítimos, mas não têm vínculos sociais, passamos da especulação para a certeza matemática .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0,200000003 | 1 |
C9 | ivan@example.com | 0,200000003 | 1 |
Análise de resultados
Ao unificar a Similaridade (Jaccard) com a Detecção de comunidade (WCC), expomos riscos ocultos que os dados transacionais tradicionais não conseguem identificar.
- Os "gêmeos comportamentais" (proximidade): nós como Judy (C10) e Ivan (C9) são sinalizados porque compartilham uma pontuação de similaridade de Jaccard de 0,20 em relação a Alice (C1).
- Comportamento de isolamento:Judy (C10) e Ivan (C9) são agrupados no community_id 1 isolado, enquanto Alice pertence à "Mainland" social (comunidade 0).
- Flags de fraude:o relatório identifica usuários com alta sobreposição comportamental (>0,9) que permanecem desconectados socialmente da rede principal.
9. Parabéns e resumo
Neste laboratório, mostramos como o Cloud Spanner transforma um banco de dados relacional em um sistema multimodelos eficiente. Ao aplicar a inteligência de grafos ao cliente, passamos de dados estáticos para uma estratégia de negócios prática.
A vantagem multimodelo do Spanner
- Arquitetura unificada:o Spanner permite manter uma base relacional sólida e "sobrepor" instantaneamente um gráfico de propriedades para mineração de relacionamentos, tudo sem o risco e o atraso do ETL.
- Isolamento analítico fora da caixa:ao usar o Data Boost, é possível executar algoritmos que exigem muita memória, como PageRank ou WCC, em recursos de computação independentes e sem servidor, garantindo zero impacto no desempenho do checkout de produção.
- Performance intercalada:a intercalação exclusiva do Spanner garante que os nós e as relações deles estejam fisicamente no mesmo lugar, transformando travessias globais complexas em pesquisas locais de alta velocidade.
Como encontrar "Gems ocultos" e anomalias
- Identificação do valor estrutural:algoritmos de gráficos, como a centralidade de intermediário, revelaram "pontes ocultas" com gasto zero que podem ser mais importantes para a resiliência da rede do que os clientes com maior gasto.
- Expondo a imitação comportamental:ao combinar a similaridade de Jaccard e os componentes fracamente conectados, identificamos os "estranhos sociais". Essas contas parecem ser de clientes legítimos, mas são comprovadamente grupos isolados de fraude.
- Verdade global x local:embora a análise manual de SQL possa identificar pontes, os algoritmos globais podem identificar os principais Gatekeepers da rede.
Como tornar os dados inteligentes e úteis
- Estratégia orientada por personas:transformamos com sucesso nossas linhas em relacionamentos e, ao executar algoritmos, podemos resolver quatro problemas de negócios: pontes de rede, superestrelas sociais, riscos de fraude e usuários padrão.