
1. Пример из практики: Интеллектуальная розничная торговля
В качестве примера рассмотрим розничного клиента с быстрорастущей цифровой торговой площадкой. Традиционное представление данных о клиенте ограничено, поскольку оно показывает , что люди покупают , но не то, как они связаны друг с другом . Этот пробел приводит к упущенным возможностям и росту мошенничества. Теперь они переходят к философии «Сеть прежде всего» , чтобы ценить социальные и логистические связи в дополнение к данным о транзакциях.
Основные бизнес-задачи, которые необходимо решить.
Перед вами стоят четыре важнейшие задачи, требующие понимания взаимосвязи между клиентами и логистикой :
Испытание | Проблема | Цель |
Разрыв во влиянии | Масштабная реклама приносит низкую окупаемость инвестиций; в настоящее время невозможно определить настоящих законодателей моды (инфлюенсеров). | Выявите влиятельных лиц, играющих центральную роль в сообществе благодаря своим связям в разветвленной сети клиентов. |
Устойчивость логистики | Цепочка поставок может быть уязвимой (учитывая, что они работают в разных географических регионах). Если один из ключевых узлов выйдет из строя, весь регион может потенциально потерять доступ к продукции. | Определите ключевых звеньев, которые играют решающую роль в объединении логистических сетей. |
Призрачные сети | Мошеннические группировки используют поддельные профили и общие адреса для координации краж и завышения рейтингов. | Разоблачение изолированных островных сообществ; групп, имеющих сверхтесные связи и не имеющих отношения к законному сообществу. |
Парадокс выбора | Существующая система подсказок/рекомендаций примитивна, универсальна и часто игнорируется (например, "Покупатели, купившие этот товар, также купили..." ). | Создавайте поведенческие модели-близнецы, то есть рекомендации, основанные на схожих моделях доставки и социальных кругах. |
Сопоставление бизнес-задач с технической стратегией (Строки → Связи)
В традиционной базе данных данные хранятся в изолированных хранилищах: клиенты — в одной таблице, транзакции — в другой, доставка — в третьей. Хотя SQL идеально подходит для ответа на вопрос «Кто что купил?» , он с трудом справляется с задачами, связанными с сетевыми данными.
Для решения этих задач техническая стратегия заключается в изменении этой перспективы:
- Реляционное представление («Что»): рассматривает каждого клиента как изолированную строку. Для установления связи между клиентом и покупкой друга требуется множество сложных «соединений», которые становятся экспоненциально медленнее по мере роста сети.
- Графический подход (как это работает): рассматривает отношения как первоклассные элементы. Вместо поиска по спискам мы перемещаемся по карте. Мы можем мгновенно увидеть, что клиент А связан с клиентом Б, который осуществляет доставку в местоположение Z.
Глубокий анализ требований
Архитекторы решений приходят к выводу, что для определения бизнес-требований и технической стратегии необходим многомодельный подход, и выделяют следующие ключевые требования.
Как Cloud Spanner соответствует этим техническим требованиям
В качестве основы для этой трансформации выбран Cloud Spanner. Он позволяет клиенту сохранить свою надежную реляционную базу, одновременно получая доступ к глубокому анализу графов.
Вот краткий обзор того, как Cloud Spanner решает технические задачи и многое другое.
Кроме того, Cloud Spanner обеспечивает перспективную техническую архитектуру.
2. Создание основы данных
После обоснования целесообразности проекта мы переходим к этапу реализации. В этом разделе мы определяем нашу архитектуру данных, рассматриваем ограничения традиционной реляционной модели и представляем граф свойств как наш основной инструмент для выявления глубоких аналитических выводов.
Настройка экземпляра Cloud Spanner Enterprise
Шаг 1: Включите API Cloud Spanner
В консоли Google Cloud нажмите на значок меню в левом верхнем углу экрана для навигации. Прокрутите вниз и выберите «Spanner» или выполните поиск по запросу «Spanner».
Теперь вы должны увидеть пользовательский интерфейс Cloud Spanner, и, если вы используете проект, в котором еще не включен API Cloud Spanner, вы увидите диалоговое окно с запросом на его включение. Если API уже включен, вы можете пропустить этот шаг.
Нажмите « Включить », чтобы продолжить:
Шаг 2: Создание экземпляра Cloud Spanner
Сначала вам нужно создать экземпляр Cloud Spanner. В пользовательском интерфейсе нажмите « Создать выделенный экземпляр », чтобы создать новый экземпляр.
На первом этапе необходимо выбрать версию. Обратите внимание, что впоследствии вы также можете обновить версию. Для использования возможностей работы с несколькими моделями (Spanner Graph) можно выбрать версию Enterprise Edition.
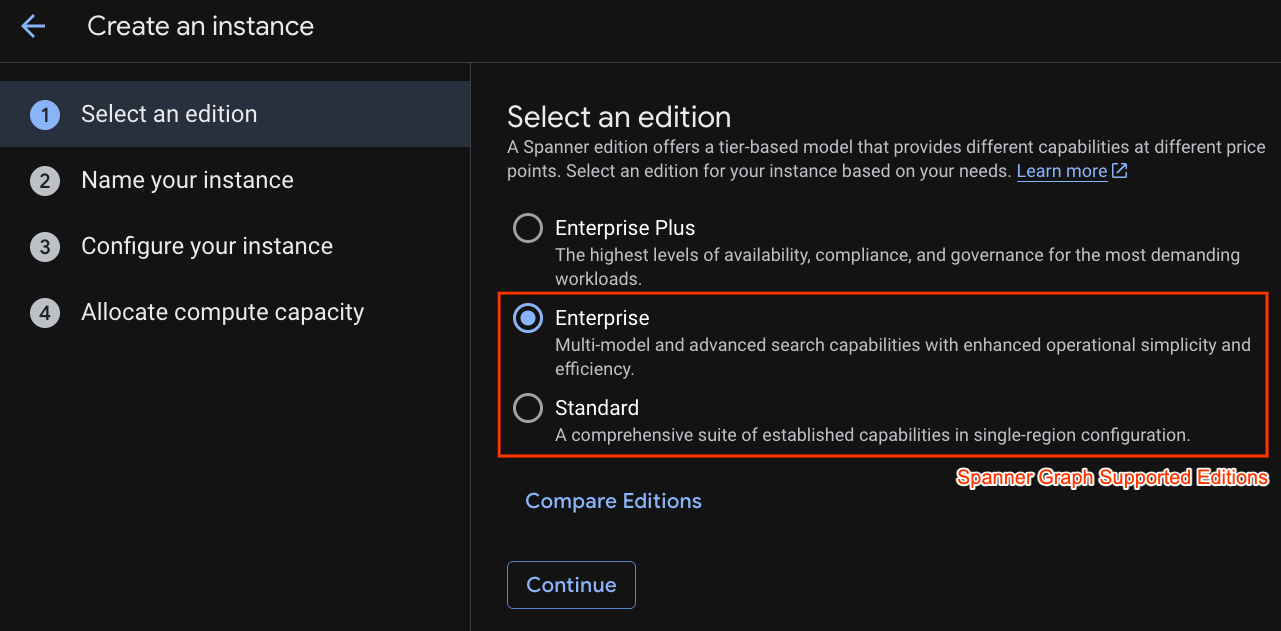
Присвоение имени вашему экземпляру
Выберите конфигурацию развертывания и регион по своему усмотрению.
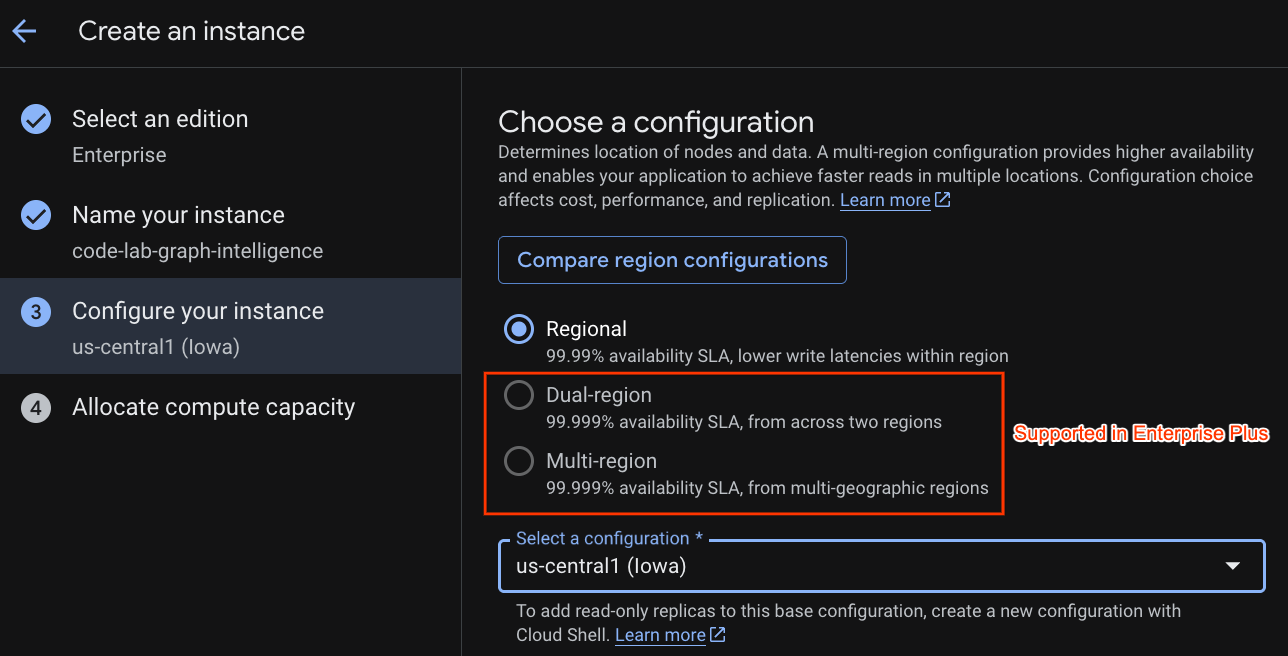
Вы также можете сравнить различные варианты конфигурации. Например, конфигурация развертывания включает как минимум 3 реплики чтения/записи в 3 отдельных зонах выбранного региона. То есть, даже если вы используете развертывание на одном узле, у вас будет 3 копии через 3 реплики чтения/записи. Кроме того, даже при региональной конфигурации развертывания вы можете дополнительно расширить систему, добавив реплики чтения/записи в топологию развертывания .
При настройке мощности вы можете либо начать с полного узла и автоматически масштабировать его по узлам, либо использовать гранулированный экземпляр (процессорные единицы; 1000 ПУ = 1 узел ). При желании вы также можете установить целевые значения автоматического масштабирования экземпляра. Для рабочих нагрузок с низкой задержкой мы рекомендуем 65% для региональных экземпляров и 45% для многорегиональных экземпляров .
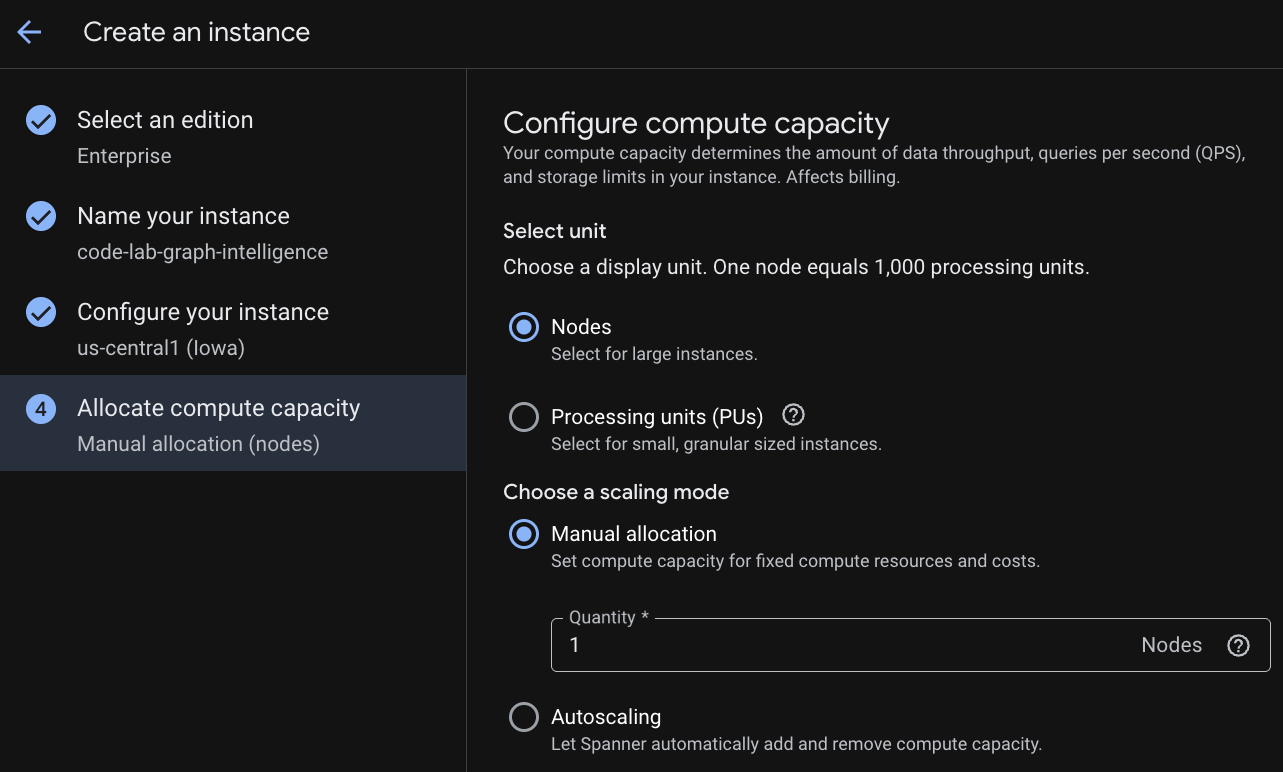
Шаг 3: Создание базы данных
После завершения настройки экземпляра нажмите «Создать базу данных», чтобы создать базу данных для остальной части вашей практической работы.
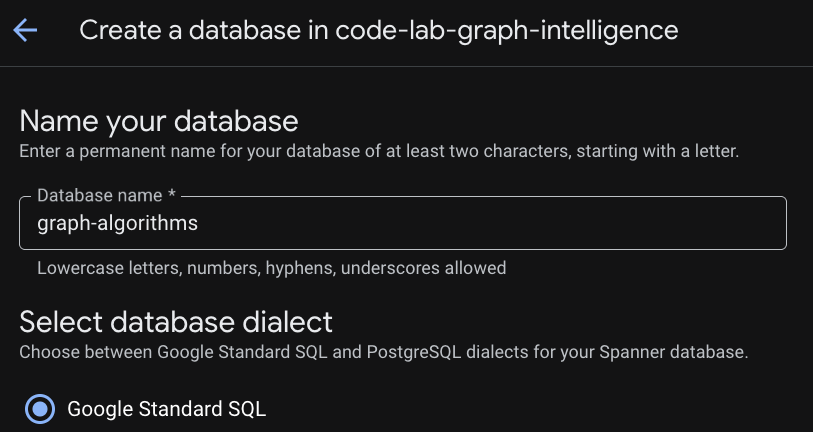
Создание реляционной основы
Наш путь начинается с основных таблиц, хранящих оперативные данные. В Cloud Spanner мы используем технологию Interleaving для физического размещения связанных данных, таких как дружеские связи и транзакции клиента, непосредственно в записи о клиенте. Это обеспечивает высокопроизводительный доступ и физическую локализацию.
DDL: Создание таблиц
Скопируйте и выполните следующие блоки, чтобы создать свою реляционную схему:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Зарождение сети
Подготовив таблицы, мы должны заполнить их данными о пользователях, продуктах и связях, которые определяют экосистему клиента.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Реляционная проблема
Прежде чем представить граф, давайте посмотрим, как традиционный SQL обрабатывает задачи, стоящие перед клиентами. Выполните этот запрос, чтобы найти клиентов, которые тратят значительные суммы и имеют несколько друзей.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Ограничения реляционного подхода
Преодоление проблем, связанных с межличностными отношениями, с помощью графа свойств.
Для преодоления этих ограничений мы определяем граф свойств . Это создает «наложение», которое позволяет нам рассматривать отношения как первоклассные элементы, не перемещая наши данные за пределы Spanner.
DDL: Создание графа свойств
Этот DDL определяет наши узлы (сущности) и ребра (связи). В этом примере мы используем схематизированный граф, однако Spanner Graph позволяет моделировать графы без схемы , что обеспечивает гибкую и быструю итеративную разработку, а также позволяет обрабатывать изменяющиеся модели данных без постоянных изменений DDL (языка определения данных).
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Навигация по графу с помощью GQL
Теперь, когда наш граф определен, мы можем использовать язык запросов к графам (GQL) для выполнения многошаговых обходов с помощью простого и понятного синтаксиса.
Исследование 1: Совместное исследование
Этот запрос проходит по графу, чтобы найти товары, купленные вашими друзьями, и служит основой для системы рекомендаций.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Исследование 2: Гибридный запрос (реляционный + графовый)
Spanner позволяет встраивать шаблоны GQL в стандартное SQL-запрос FROM с помощью функции GRAPH_TABLE. Этот запрос находит клиентов, проживающих в том же месте, что и их друзья, используя шаблон "ромб".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Визуализация взаимосвязей с клиентом
Наконец, давайте воспользуемся GQL для визуализации нашей сети. Эти запросы заключают результаты поиска путей в формат SAFE_TO_JSON, что позволяет визуализаторам отображать узлы и линии.
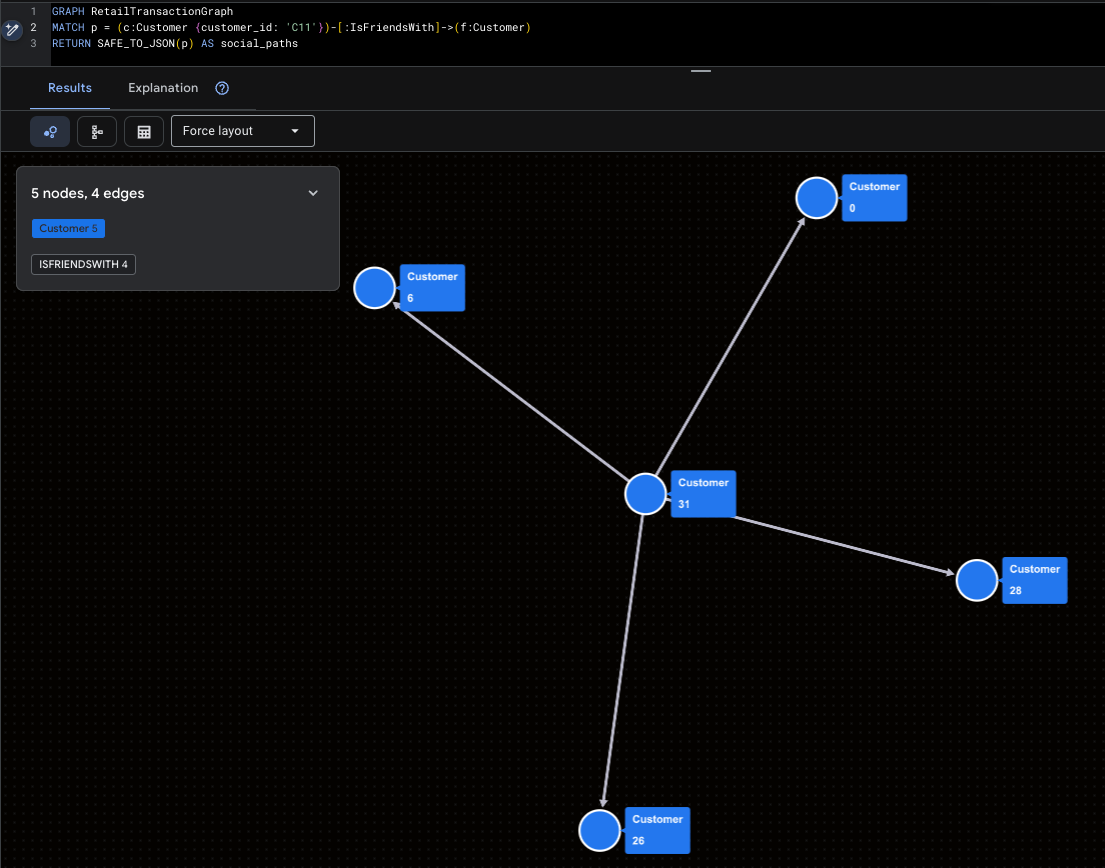
Визуализация супер-инфлюенсера
Это подчеркивает роль Мэллори (C11) и ее непосредственное социальное влияние.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Визуализация потенциальных схем мошенничества
Этот запрос выявляет "изолированный кластер" (Иван и Джуди), чтобы определить, куда отправляется их продукция.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Введение в алгоритмы построения графов-гаек
В рамках подготовки к углублённому изучению интеллектуальных графов, в этом разделе изложена техническая архитектура и основные правила алгоритмов Cloud Spanner для работы с графами . Понимание этих принципов является ключом к переходу от простых обходов к анализу взаимосвязей в петабайтном масштабе.
Портфель алгоритмов
В настоящее время Cloud Spanner поддерживает 14 стандартных алгоритмов обработки графов , сгруппированных в четыре функциональные группы для решения разнообразных бизнес-задач:
Категория | Поддерживаемые алгоритмы | Вариант использования в бизнесе |
Центральность | PageRank, персонализированный PageRank, центральность по посредничеству, близость | Выявите влиятельных лиц, центры и узкие места. |
Сообщество | WCC, распространение меток, поиск клик, корреляционная кластеризация | Выявляйте мошеннические группировки, социальные сообщества и изолированные структуры. |
Сходство | Жаккар, косинус, общие соседи, полные соседи | Системы рекомендаций по энергопотреблению и разрешение сущностей. |
Поиск пути | Метод кратчайшего пути от набора к набору, вспомогательные функции для построения пути в Google Analytics. | Оптимизация логистики и транспортной доступности. |
Важные аспекты схемы и запросов
Для обеспечения эффективного выполнения алгоритмов обработки графов, Spanner Graph должен соответствовать следующим правилам:
Требование 1. Физическая локальность данных (чередование).
Наиболее важным требованием для высокопроизводительного обхода графа является чередование данных . Это гарантирует, что данные о ребрах физически хранятся на том же сервере, что и исходный узел, минимизируя задержку в сети во время выполнения алгоритма.
- Правило: таблицы ребер ДОЛЖНЫ быть чередованы с таблицами исходных узлов.
- Прямое перемещение: чередование таблицы ребер с таблицей исходного узла обеспечивает локальность кэша для исходящих каналов.
- Обратный обход: Для эффективного анализа входящих ссылок используйте внешние ключи для автоматического создания базовых индексов или создайте вторичный индекс, чередующийся с целевой таблицей.
Требование 2. Требования к уникальной маркировке.
Каждая таблица, участвующая в графе свойств, должна иметь уникальный идентификатор. Алгоритмы используют эти метки для правильной идентификации и загрузки подграфов, необходимых для анализа.
- Правило: Каждая входная таблица должна иметь уникальную идентификационную метку в графе свойств.
- Конфликт: Вы не можете сопоставить одну метку с несколькими таблицами, если планируете применять к ним алгоритмы.
Логика | Пример | Результат |
❌ Плохой | ТАБЛИЦЫ УЗЛОВ (сущность метка "Person", сущность метка "Account") | Неверно : алгоритм не может отличить человека от учетной записи. |
✅ Хорошо | ТАБЛИЦЫ УЗЛОВ (МЕТКА "Person" - "Customer", МЕТКА "Account" - "Account") | Допустимое значение : Каждый объект имеет уникальную метку. |
Требование 3. Структура запроса алгоритма (условие MATCH)
При вызове алгоритма условие MATCH подчиняется более строгим правилам, чем стандартные запросы GQL, чтобы гарантировать, что механизм выполнения сможет оптимизировать аналитический конвейер.
- Один шаблон на один оператор MATCH: каждый оператор MATCH может указывать только на одну переменную.
- Запрещены многоузловые шаблоны: вы не можете определить шаблон связи (например, (a)-[e]->(b)) непосредственно внутри предложения MATCH, предназначенного для вызова алгоритма.
- Только литеральные фильтры: Хотя вы можете использовать предложения WHERE для фильтрации узлов (например, WHERE a.id > 400), параметры запроса (@param) в настоящее время не поддерживаются в запросах алгоритмов графов.
Требование 4. Пункт о возврате (только для скалярных величин)
В алгоритмическом запросе оператор RETURN выступает связующим звеном между миром графов и миром реляционных представлений. Он строго ограничен возвратом скалярных значений и констант .
- Правило: Вы не можете возвращать «элемент графа» (сырой объект узла или ребра).
- Преобразования запрещены: Вы не можете выполнять математические операции или применять функции к возвращаемым свойствам непосредственно в операторе RETURN.
Ограничения, указанные в пункте о возврате
✅ Поддерживается | ❌ Не поддерживается |
RETURN node.id, score | RETURN узел, оценка (Невозможно вернуть элемент графа) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (Операции со свойствами не выполняются) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (Без функций) |
Требование 5. Целостность данных: устранение «висячих» связей.
«Висячее ребро» возникает, когда ребро указывает на целевой узел, которого нет в графе. Это приводит к сбою выполнения алгоритма, поскольку структура графа является непоследовательной.
- Решение: Используйте ссылочные ограничения (внешние ключи) и ON DELETE CASCADE для поддержания целостности графа.
- Безопасность запросов: При вызове алгоритма необходимо убедиться, что все узлы, на которые ссылаются выбранные ребра, также включены в аргумент node_labels.
Постоянный вывод: Параметры экспорта данных
Поскольку алгоритмы обработки графов требуют больших вычислительных ресурсов, они выполняются в режиме масштабируемого выполнения с использованием оператора EXPORT DATA . Это позволяет использовать Data Boost , задействуя независимые бессерверные вычислительные ресурсы, чтобы предотвратить задержки в производственных транзакциях.
Вариант 1: Вернуться в Cloud Spanner
Чтобы напрямую записывать результаты в таблицы (например, сохранять оценку PageRank), используйте параметр format = 'CLOUD_SPANNER'.
-
update_ignore_all: Обновляет только строки с ключами, которые уже существуют в целевой таблице. -
upsert_ignore_all: Обновляет существующие строки или вставляет новые строки, если ключи отсутствуют.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Вариант 2: Сохранение результатов в Google Cloud Storage (GCS)
Для крупномасштабного автономного анализа вы можете экспортировать данные в GCS в форматах CSV, Avro или Parquet .
- Использование символов подстановки: используйте
uri => 'gs://bucket/file_*.csv', чтобы включить сегментированный вывод , позволяющий Spanner записывать данные в несколько файлов параллельно для обработки больших наборов данных. - Сжатие: Поддерживает GZIP, SNAPPY и ZSTD для оптимизации затрат на хранение.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Задача 1: Разрыв во влиянии (PageRank)
В этом разделе мы рассмотрим первую бизнес-проблему клиента : «разрыв во влиянии». Мы перейдем от простого «конкурса популярности» к математически обоснованной карте истинного социального влияния.
Постановка проблемы: У маркетинговой команды клиента возникла проблема. Они тратят миллионы на масштабную рекламу, получая при этом всё меньшую отдачу, потому что не могут выявить «социальных суперзвезд» — тех редких людей, чьи рекомендации распространяются по всей сети.
Для решения этой проблемы нам необходимо ранжировать наших клиентов по уровню влияния .
Реляционное решение (центральность по степени)
В стандартной базе данных самый простой способ найти влиятельного человека — это просто подсчитать количество его подписчиков (показатель, известный как центральность степени ).
Выполните этот запрос, чтобы найти самых популярных пользователей:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | количество подписчиков |
С1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
С2 | 1 |
С3 | 1 |
С4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Графовый интеллект (PageRank)
Чтобы найти настоящих лидеров, мы используем PageRank . Это тот же алгоритм, который лежал в основе раннего веб-поиска; он измеряет важность узла на основе количества И качества входящих ссылок.
- Модель случайного перемещения пользователя: PageRank имитирует движение пользователя по графу. Коэффициент затухания (по умолчанию 0,85) представляет вероятность того, что он продолжит кликать; в противном случае он «телепортируется» к случайному узлу.
- Сила связей: ссылка от влиятельного человека (например, от Мэллори) стоит значительно больше, чем ссылка от человека, не имеющего других связей.
Мы выполним алгоритм PageRank и воспользуемся функцией EXPORT DATA для сохранения результатов непосредственно в столбец pagerank_score.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Панель мониторинга «Влияние» с использованием PageRank
Теперь, когда оценки сохранены, давайте сравним наши показатели "До" (количество подписчиков) с показателями "После" (оценка PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | адрес электронной почты клиента | количество подписчиков | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
С1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
С2 | bob@example.com | 1 | 0.0547891818 |
С3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
С4 | david@example.com | 1 | 0.04028172791 |
Анализ: Кто же настоящие суперзвезды?
Проанализировав полученные данные, вы можете сделать три важных маркетинговых открытия:
Выводы для бизнеса
Вместо того чтобы вслепую рассылать электронные письма всем, у кого более пяти подписчиков, маркетинговая команда клиента теперь может сосредоточиться исключительно на тех, у кого самый высокий pagerank_score . Эти люди — настоящие «социальные суперзвезды», способные обеспечить системный вирусный эффект на всем рынке.
Теперь давайте попробуем определить тех «привратников», которые обеспечивают бесперебойную работу логистической сети клиента.
5. Задача 2: Логистическая устойчивость (Центральность по показателю «между сторонами»)
В этом разделе мы рассмотрим устойчивость логистики . Мы перейдем от измерения успеха по «объему» к выявлению важнейших «контролирующих факторов», обеспечивающих бесперебойную работу сети.
Реляционное решение (объемный анализ)
В стандартной реляционной архитектуре «критически важным» центром обработки заказов обычно считается тот, который обрабатывает наибольшее количество заказов или приносит наибольший доход.
Выполните этот запрос, чтобы определить «ведущие» хабы по количеству транзакций:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
город | страна | transaction_count | общий_доход |
Нью-Йорк | США | 4 | 3996 |
Берлин | Германия | 2 | 345 |
Сан-Франциско | США | 2 | 750 |
Для устранения несоответствия мы будем использовать ребра IsFriendsWith и LivesAt . Это преобразует наш анализ из анализа транзакций в анализ, включающий также социальную проверку.
Графовый интеллект (показатель центральности по посредничеству)
Для выявления реальных узких мест мы используем показатель центральности по посредничеству (Betweenness Centrality ). Этот алгоритм количественно определяет, как часто узел выступает в роли «моста» на кратчайших путях между всеми другими парами узлов в графе. Высокие значения указывают на истинных «привратников», контролирующих поток товаров или информации.
Текущая и устойчивая центральность посредничества
Мы выполним алгоритм с помощью команды EXPORT DATA и сохраним результаты в столбце centrality_score. Мы используем Data Boost , чтобы гарантировать, что этот ресурсоемкий расчет «кратчайшего пути» окажет минимальное влияние на работу клиента в режиме реального времени.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Анализ: Выявление «скрытых узких мест»
Теперь мы сравниваем наш структурный риск ( centrality_score ) с объемом транзакций ( order_count ), чтобы определить узлы, которые должны вызывать беспокойство у руководства компании-клиента.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | адрес электронной почты клиента | показатель центральности | количество заказов | |
C11 | mallory@example.com | 44.5 | 2 | |
С1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
С3 | charlie@example.com | 6 | ||
С4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
С2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Проанализировав эти результаты, Клиент делает три поразительных открытия:
Выводы для бизнеса
Теперь Заказчик может расставлять приоритеты в отношении резервирования логистических систем и протоколов безопасности на основе мультимодальных структурных рисков . Мэллори, Алиса и Ева — это привратники, которых необходимо защищать для обеспечения стабильности логистической сети.
Теперь давайте попробуем выделить отдельные очаги мошенничества.
6. Задание 3: Призрачные сети (WCC)
В этом разделе мы рассмотрим третью проблему бизнеса: «призрачные сети». Мы перейдем от простого обнаружения «горячих точек» к выявлению сложных, изолированных мошеннических группировок с помощью обнаружения сообществ. Проблема здесь в том, что злоумышленники создают поддельные профили, которые обмениваются адресами доставки или взаимодействуют в замкнутых циклах для координации краж и завышения рейтингов товаров. Но зачастую они полностью изолированы от законного сообщества клиентов.
Для решения этой проблемы нам необходимо обнажить эти «изолированные острова».
Реляционное решение (поиск по общему идентификатору)
Без использования алгоритмов обработки графов стандартный способ выявления мошенничества заключается в поиске «горячих точек» общих данных, например, когда несколько клиентов отправляют товары по одному и тому же адресу.
Выполните этот запрос, чтобы найти клиентов, связанных общим местом доставки:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | количество клиентов | связанные_клиенты |
С1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Для выявления мошеннических сетей необходимо понимать транзитивную достижимость .
Графовый интеллект (слабосвязные компоненты)
Для определения полного размера этих колец мы используем алгоритм слабосвязных компонентов (WCC) . WCC — это алгоритм кластеризации, который идентифицирует наборы узлов, между любыми двумя узлами которых существует путь, независимо от направления ребер.
- Зоны достижимости: По сути, это разделяет граф на «острова» или «зоны достижимости».
- Единое представление сущностей: анализируя одновременно социальные связи (IsFriendsWith) и логистические связи (LivesAt), мы можем сгруппировать разрозненные профили в единый, целостный «кластер влияния».
Бег и упорство в WCC
Мы выполним алгоритм WCC и сохраним результаты в столбце community_id. Мы используем Data Boost , чтобы гарантировать, что этот углубленный анализ достижимости будет проводиться на независимых вычислительных ресурсах.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Анализ: Мошеннические группировки
Теперь давайте выполним проверочный запрос, чтобы увидеть наши изолированные сообщества. Легитимные пользователи, как правило, находятся на «материковой» территории, в то время как мошенники часто оказываются на небольших «островах».
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | количество участников | члены |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Запустив эту функцию обнаружения сообществ, вы сможете выявить критическую аномалию:
Выводы для бизнеса
Теперь клиент может автоматизировать свои действия по обеспечению безопасности. Вместо того чтобы вручную проверять отдельные учетные записи, он может написать простое правило: «Если у community_id меньше трех участников, пометить всю группу для ручной проверки KYC (Знай своего клиента)».
.
Разоблачение наших мошеннических схем позволит нам решить задачу "поведенческого двойника".
7. Задание 4: Поведенческий близнец (аналогия Жаккара)
В этом заключительном задании мы рассмотрим четвертое препятствие: «парадокс выбора»/«поведенческий двойник». Мы перейдем от общих списков «часто покупаемых вместе» к гиперперсонализированным рекомендациям, основанным на поведенческих «отпечатках».
Предлагаемые клиентом товары слишком общие. Рекомендация популярного USB-кабеля каждому клиенту — это безопасно, но не персонализировано. Клиент хочет создать систему рекомендаций на основе «поведенческих двойников», которая будет выявлять клиентов с уникальными моделями доставки и социальными кругами, чтобы предлагать товары с высокой точностью.
Для решения этой задачи нам необходимо рассчитать «близость» между пользователями.
Реляционное решение (абсолютное перекрытие)
В стандартной реляционной базе данных вы можете искать людей, которые осуществляют доставку в те же места, что и эталонный пользователь, например, Алиса (C1) .
Выполните этот запрос, чтобы найти географических соседей Алисы:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
похожий_клиент | shared_locations |
С2 | 1 |
C10 | 1 |
C9 | 1 |
Графовый интеллект (аналитический коэффициент Жаккара)
Для поиска истинных поведенческих близнецов мы используем коэффициент сходства Жаккара . Этот алгоритм вычисляет нормализованный балл (от 0,0 до 1,0), деля количество общих соседей (пересечение) на общее количество уникальных соседей (объединение).
В данном контексте «поведенческий двойник» определяется не только общим адресом доставки. Анализируя пересечение физических местоположений ( LivesAt ) и социальных экосистем ( IsFriendsWith ), мы можем идентифицировать пользователей, разделяющих тот же образ жизни и оказывающих влияние на сообщество, что приводит к гораздо более точным рекомендациям товаров.
Сначала создайте таблицу сопоставления.
Поскольку сходство представляет собой попарное отношение (клиент А похож на клиента Б), мы создаем отдельную таблицу, интегрированную в Customer , для хранения этих сопоставлений.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Теперь запустите алгоритм сходства Жаккара.
We will now execute the algorithm. Note: This query includes a common "Guardrail" lesson. If you only select Customer nodes but use the LivesAt edge (which points to Shipping nodes), the query will fail citing a "Dangling Edge" . To fix this, we must include both node labels.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analysis: "Behavioral Twin" Check
Now that the analytical job is complete, we run a validation query. By joining our new mapping table ( CustomerSimilarity ) with our original Customer metadata, we can see exactly who Alice's "Behavioral Twins" are.
Run this query to inspect Alice's similarity rankings:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
What to look for in results:
Now lets try to build a final Unified Intelligence view.
8. Unified Intelligence
Now we move from individual technical tasks to Unified Intelligence . Here, we blend transactional data with all four graph algorithms to provide clear, actionable insights.
Report 1: Unified Intelligence
The power of a multi-model database like Spanner is the ability to join relational spend data with graph-derived influence, risk, and similarity scores in a single request. This query categorizes every customer into a specific business persona.
Run the Unified Intelligence query to see complete ecosystem:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | тратить | влияние | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 CRITICAL: Network Bridge |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 CRITICAL: Network Bridge |
С1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 CRITICAL: Network Bridge |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 SOCIAL: High-Reach Influencer |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 SOCIAL: High-Reach Influencer |
С3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD: Active Customer |
С4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD: Active Customer |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 HIGH RISK: Isolated Fraud Ring |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 HIGH RISK: Isolated Fraud Ring |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD: Active Customer |
С2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD: Active Customer |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD: Active Customer |
By blending these mathematical lenses, we move beyond "who spent the most" to "who matters the most." The unified dashboard integrates relational transaction data with multi-modal graph intelligence to categorize your ecosystem into three clear, actionable personas.
The "Critical Network Bridges" (Resilience)
Nodes like Mallory (C11) , Eve (C5) , and Alice (C1) are flagged because their bottleneck_risk (Betweenness Centrality) is >25 .
- The Structural Anchors: Mallory holds the highest risk score at 44.5 , marking her as the primary gateway for the entire network.
- The Zero-Spend Paradox: Eve (C5) has an order count of zero, yet she is structurally indispensable with a risk score of 35.5 . Standard SQL would have ignored her entirely, but Graph Intelligence reveals she is a vital bridge to an entire sub-community.
- The High-Value Gateway: Alice (C1) tied with Eve at 35.5 , proving that high spenders can also be critical structural anchors.
The "Social Superstars" (Reach)
Heidi (C8) and Grace (C7) are identified as high-reach influencers due to their PageRank scores .
The "Isolated Fraud Ring" (Anomalies)
Judy (C10) and Ivan (C9) are flagged because they belong to the isolated community_id 1
Business Insight to Strategic Actions
Персона | Key Metric | Business Insight | Strategic Action |
🔵 Network Bridges | High Centrality | Structural Anchors : Eve (C5) and Mallory (C11) hold the network together. | Retention : Protect these gatekeepers to prevent community fragmentation. |
📱 Social Superstars | High PageRank | Viral Engines : Users like Heidi (C8) have the highest reach in their circles. | Marketing : Use for high-impact referral and ambassador programs. |
🔴 Fraud Risks | Isolated WCC | Ghost Networks : Judy (C10) and Ivan (C9) are high-spenders but live on "islands." | Security : Immediate manual KYC review; these are classic fraud signatures. |
🟢 Standard Users | Balanced Scores | Healthy Core : The majority of the network, including "local" bridges like David (C4). | Growth : Apply standard personalized ads and "Behavioral Twin" recommendations. |
Report 2: The Identity Anomaly Report
Now you need to know if legitimate accounts are being "mimicked" by fraudsters. We can solve this by finding users who have 100% Behavioral Similarity but Zero Social Connection.
Run this query to flag potential "Identity Anomalies":
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
The Identify Anomaly Report provides critical information. By isolating users who act like legitimate customers but lack their social ties, we move from guessing to mathematical certainty .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Analysis of Results
By unifying Similarity (Jaccard) with Community Detection (WCC) , we expose hidden risks that traditional transactional data cannot see.
- The "Behavioral Twins" (Proximity): Nodes like Judy (C10) and Ivan (C9) are flagged because they share a Jaccard Similarity score of 0.20 relative to Alice (C1).
- Isolation Behavior: Judy (C10) and Ivan (C9) are grouped into the isolated community_id 1 , while Alice belongs to the social "Mainland" (Community 0).
- Fraud Flags: The report identifies users with high behavioral overlap (>0.9) who remain socially disconnected from the primary network.
9. Congratulations and Summary
This lab shows how Cloud Spanner turns a relational database into a multi-model powerhouse. By applying graph intelligence to The Customer , we moved from static data to actionable business strategy.
The Spanner Multi-Model Advantage
- Unified Architecture: Spanner allows you to maintain a rock-solid relational foundation while instantly "overlaying" a property graph for relationship mining all without the risk and lag of ETL.
- Off-Box Analytical Isolation: By leveraging Data Boost , you can execute memory-intensive algorithms like PageRank or WCC on independent, serverless compute resources, ensuring zero impact on your production checkout performance.
- Interleaved Performance: Spanner's unique interleaving ensures that nodes and their relationships are physically co-located, turning complex global traversals into high-speed local lookups.
Surfacing "Hidden Gems" & Anomalies
- Identifying Structural Value: Graph algorithms like Betweenness Centrality revealed "Hidden Bridges" with zero spend who can be more critical to network's resilience than highest-spending customers.
- Exposing Behavioral Mimicry: By combining Jaccard Similarity and Weakly Connected Components , we identified "Social Strangers". These accounts look like legitimate customers but are mathematically proven to be isolated fraud rings.
- Global vs. Local Truth: While manual SQL analysis can surface bridges, global algorithms can surface key Gatekeepers of the network.
Making Data Intelligent and Actionable
- Persona-Driven Strategy: We successfully transformed our rows to relationship, and by running algorithms we can address four business problems, namely: Network Bridges, Social Superstars, Fraud Risks, and Standard Users .