
1. กรณีศึกษา: การค้าปลีกอัจฉริยะ
สำหรับกรณีศึกษา เราจะใช้ลูกค้ารายย่อยที่มีตลาดดิจิทัลที่เติบโตอย่างรวดเร็ว มุมมองข้อมูลแบบเดิมของลูกค้ามีข้อจำกัดเนื่องจากแสดงสิ่งที่ผู้คนซื้อ แต่ไม่ได้แสดงวิธีที่ผู้คนเชื่อมต่อกัน ช่องว่างนี้ทำให้พลาดโอกาสและเกิดการฉ้อโกงมากขึ้น ปัจจุบันบริษัทกำลังเปลี่ยนไปใช้ปรัชญาเครือข่ายเป็นอันดับแรกเพื่อประเมินการเชื่อมต่อทางสังคมและการเชื่อมต่อด้านลอจิสติกส์นอกเหนือจากข้อมูลธุรกรรม
ความท้าทายหลักทางธุรกิจที่ต้องแก้ไข
คุณมีปัญหาสำคัญ 4 ประการที่ต้องทำความเข้าใจวิธีที่ลูกค้าและโลจิสติกส์เชื่อมโยงกัน
ภารกิจ | ปัญหา | เป้าหมาย |
ช่องว่างของอิทธิพล | การโฆษณาแบบกว้างให้ ROI ต่ำ ปัจจุบันยังไม่สามารถระบุผู้กำหนดเทรนด์ (อินฟลูเอนเซอร์) ที่แท้จริงได้ | ระบุอินฟลูเอนเซอร์ที่เป็นศูนย์กลางของชุมชนผ่านการเชื่อมต่อในเครือข่ายลูกค้าที่เชื่อมต่อกัน |
ความพร้อมรับมือกับปัญหาด้านโลจิสติกส์ | ซัพพลายเชนอาจมีความเสี่ยง (เนื่องจากมีการดำเนินงานในพื้นที่ทางภูมิศาสตร์ที่แตกต่างกัน) หากฮับคีย์ใดคีย์หนึ่งล้มเหลว ภูมิภาคทั้งหมดอาจเสียสิทธิ์เข้าถึงผลิตภัณฑ์ | ระบุผู้ดูแล ซึ่งเป็นบุคคลสำคัญในการเชื่อมต่อเครือข่ายโลจิสติกส์เข้าด้วยกัน |
เครือข่ายผี | แก๊งฉ้อโกงใช้โปรไฟล์ปลอมและที่อยู่ที่ใช้ร่วมกันเพื่อประสานงานการขโมยและเพิ่มคะแนน | เปิดเผยเกาะที่แยกตัว กลุ่มที่เชื่อมต่อกันอย่างแน่นแฟ้นโดยไม่มีความเกี่ยวข้องกับชุมชนที่ถูกต้อง |
Paradox of Choice | เครื่องมือแนะนำ/แนะนำในปัจจุบันยังไม่ซับซ้อน เป็นแบบทั่วไป และมักถูกมองข้าม (เช่น "ลูกค้าที่ซื้อรายการนี้ยังซื้อ ...") | สร้างกลุ่มเป้าหมายที่คล้ายกันตามพฤติกรรม ซึ่งก็คือคำแนะนำที่อิงตามรูปแบบการจัดส่งและวงสังคมที่คล้ายกัน |
การเชื่อมโยงความท้าทายทางธุรกิจกับกลยุทธ์ทางเทคนิค (แถว → ความสัมพันธ์)
ในฐานข้อมูลแบบดั้งเดิม ข้อมูลจะจัดเก็บไว้ในไซโลที่แยกกัน โดยลูกค้าจะอยู่ในตารางหนึ่ง ธุรกรรมจะอยู่ในอีกตารางหนึ่ง และการจัดส่งจะอยู่ในตารางที่สาม แม้ว่า SQL จะเหมาะอย่างยิ่งสำหรับการตอบคำถามที่ว่า "ใครซื้ออะไร" แต่ก็ตอบคำถามที่อิงตามเครือข่ายได้ยาก
กลยุทธ์ทางเทคนิคในการแก้ปัญหาเหล่านี้คือการเปลี่ยนมุมมองดังนี้
- มุมมองเชิงสัมพันธ์ ("อะไร"): ถือว่าลูกค้าทุกคนเป็นแถวที่แยกกัน การค้นหาความเชื่อมโยงระหว่างลูกค้ากับการซื้อของเพื่อนต้องใช้การ "รวม" ที่ซับซ้อนหลายรายการ ซึ่งจะช้าลงอย่างมากเมื่อเครือข่ายเติบโตขึ้น
- มุมมองกราฟ ("วิธี"): ถือว่าความสัมพันธ์เป็นสิ่งสำคัญอันดับแรก เราจะนำทางในแผนที่แทนที่จะค้นหาในรายการ เราจะเห็นทันทีว่าลูกค้า ก เชื่อมต่อกับลูกค้า ข ซึ่งจัดส่งไปยังสถานที่ตั้ง ง
เจาะลึกข้อกำหนด
สถาปนิกโซลูชันสรุปว่าข้อกำหนดทางธุรกิจและกลยุทธ์ทางเทคนิคต้องใช้แนวทางแบบหลายโมเดล และระบุข้อกำหนดสำคัญต่อไปนี้
Cloud Spanner ตอบโจทย์ข้อกำหนดทางเทคนิคเหล่านั้นได้อย่างไร
เราเลือก Cloud Spanner เป็นหัวใจสำคัญของการเปลี่ยนแปลงนี้ ซึ่งช่วยให้ลูกค้าสามารถรักษาพื้นฐานความสัมพันธ์ที่มั่นคงไว้ได้พร้อมๆ กับการปลดล็อกข้อมูลเชิงลึกของกราฟ
ต่อไปนี้เป็นข้อมูลคร่าวๆ เกี่ยวกับวิธีที่ Cloud Spanner ตอบสนองข้อกำหนดทางเทคนิคและอื่นๆ
นอกจากนี้ Cloud Spanner ยังมีสถาปัตยกรรมทางเทคนิคที่พร้อมรับมือกับอนาคต
2. การสร้างรากฐานข้อมูล
หลังจากพิจารณากรณีการใช้งานทางธุรกิจแล้ว ตอนนี้เราจะเข้าสู่ระยะการติดตั้งใช้งาน ในส่วนนี้ เราจะกำหนดสถาปัตยกรรมข้อมูล สำรวจข้อจำกัดของโมเดลเชิงสัมพันธ์แบบดั้งเดิม และแนะนำกราฟพร็อพเพอร์ตี้เป็นเครื่องมือหลักในการค้นพบข้อมูลเชิงลึก
ตั้งค่าอินสแตนซ์ Cloud Spanner Enterprise
ขั้นตอนที่ 1: เปิดใช้ Cloud Spanner API
ใน คอนโซล Google Cloud ให้คลิกไอคอนเมนูที่ด้านซ้ายบนของหน้าจอเพื่อดูการนำทางด้านซ้าย เลื่อนลงแล้วเลือก "Spanner" หรือค้นหา "Spanner"
ตอนนี้คุณควรเห็น UI ของ Cloud Spanner และหากใช้โปรเจ็กต์ที่ยังไม่ได้เปิดใช้ Cloud Spanner API คุณจะเห็นกล่องโต้ตอบที่ขอให้คุณเปิดใช้ หากเปิดใช้ API แล้ว ให้ข้ามขั้นตอนนี้
คลิก "เปิดใช้" เพื่อดำเนินการต่อ
ขั้นตอนที่ 2: สร้างอินสแตนซ์ Cloud Spanner
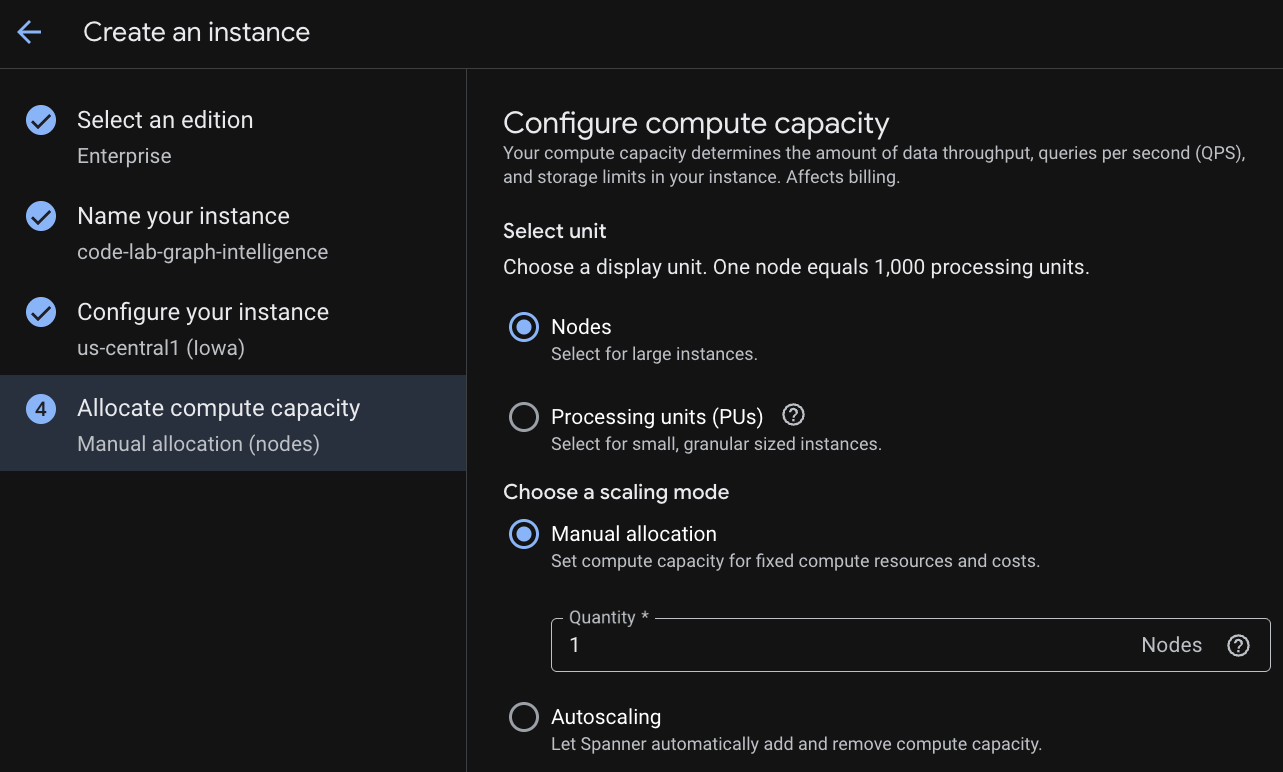
ก่อนอื่น คุณจะต้องสร้างอินสแตนซ์ Cloud Spanner ใน UI ให้คลิก "สร้างอินสแตนซ์ที่จัดสรร" เพื่อสร้างอินสแตนซ์ใหม่
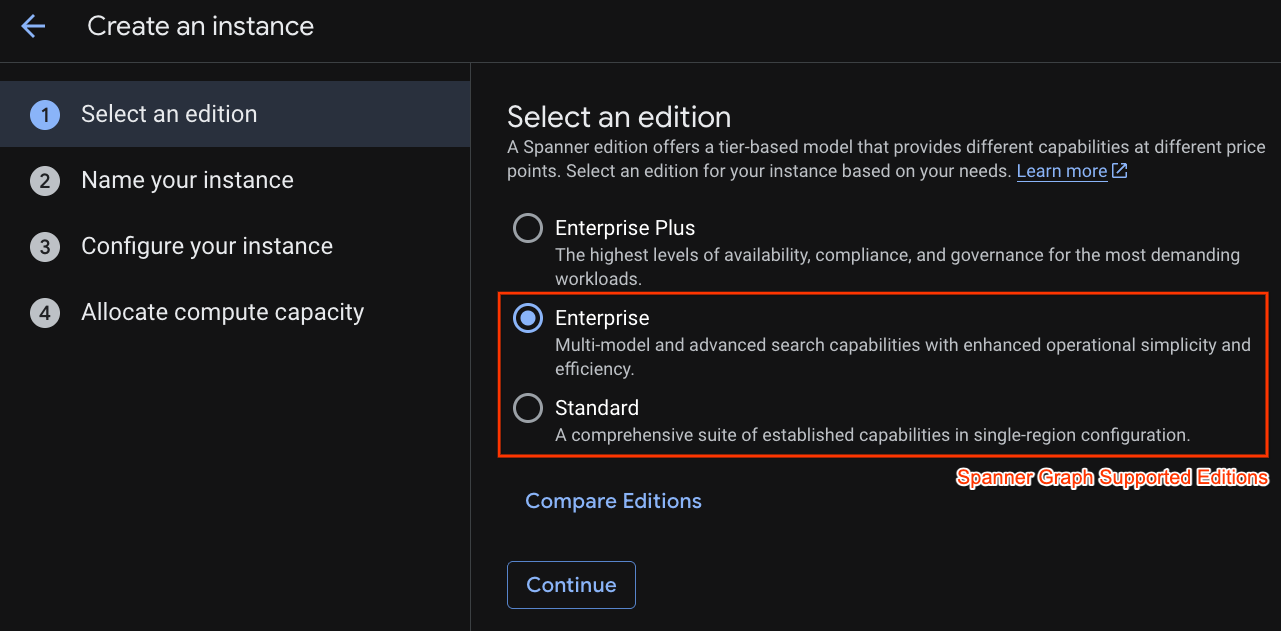
ในขั้นตอนแรก คุณต้องเลือกฉบับ โปรดทราบว่าคุณสามารถอัปเกรดรุ่นได้ในภายหลังด้วย หากต้องการใช้ความสามารถแบบหลายโมเดล (Spanner Graph) เราสามารถใช้รุ่น Enterprise ได้
การตั้งชื่ออินสแตนซ์
เลือกการกำหนดค่าการติดตั้งใช้งานและเลือกภูมิภาคที่ต้องการ
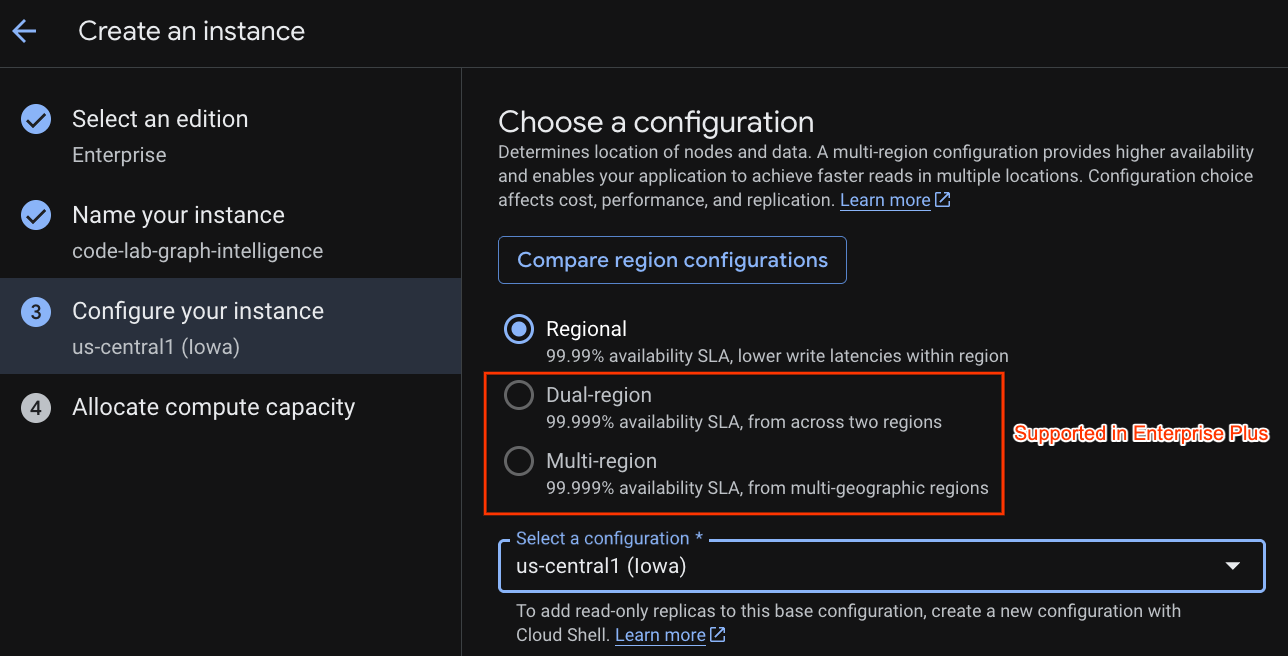
นอกจากนี้ คุณยังเปรียบเทียบตัวเลือกการกำหนดค่าต่างๆ ได้ด้วย เช่น การกำหนดค่าการทำให้ใช้งานได้มีตัวจำลอง R/W อย่างน้อย 3 รายการใน 3 โซนแยกกันของภูมิภาคที่คุณเลือก กล่าวคือ แม้ว่าคุณจะเลือกการทำให้ใช้งานได้แบบโหนดเดียว แต่คุณก็จะมีสำเนา 3 รายการผ่านตัวจำลอง R/W 3 รายการ นอกจากนี้ แม้จะมีการกำหนดค่าการติดตั้งใช้งานระดับภูมิภาค คุณก็ยังขยายการใช้งานได้โดยมีสำเนาแบบอ่านอย่างเดียวเพิ่มเติมในโทโพโลยีการติดตั้งใช้งาน
เมื่อกำหนดค่าความจุแล้ว คุณจะเริ่มต้นที่โหนดแบบเต็มและปรับขนาดอัตโนมัติที่โหนด หรือจะใช้อินสแตนซ์แบบละเอียด (หน่วยประมวลผล 1, 000 PU = 1 โหนด) ก็ได้ นอกจากนี้ คุณยังตั้งเป้าหมายการปรับขนาดอัตโนมัติของอินสแตนซ์ได้ด้วย (ไม่บังคับ) สำหรับภาระงานที่มีเวลาในการตอบสนองต่ำ เราขอแนะนำให้ใช้ 65% สำหรับอินสแตนซ์ระดับภูมิภาค และ 45% สำหรับอินสแตนซ์แบบหลายภูมิภาค
ขั้นตอนที่ 3: สร้างฐานข้อมูล
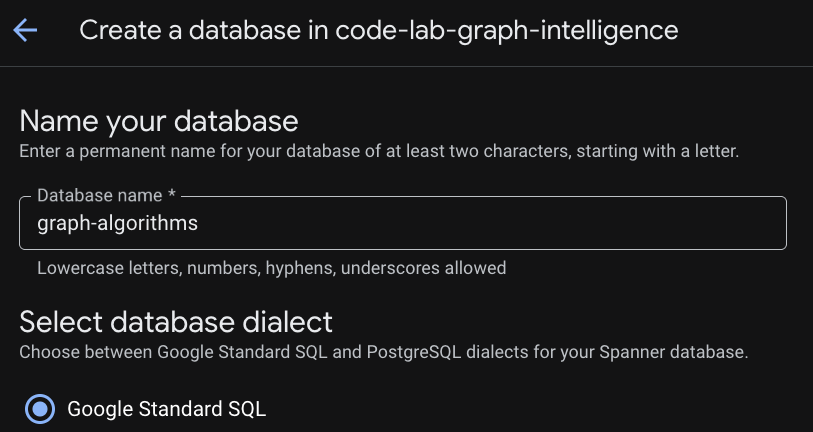
เมื่อจัดสรรอินสแตนซ์แล้ว ให้คลิก "สร้างฐานข้อมูล" เพื่อสร้างฐานข้อมูลสำหรับส่วนที่เหลือของโค้ดแล็บ
การสร้างรากฐานความสัมพันธ์
การเดินทางของเราเริ่มต้นด้วยตารางหลักที่จัดเก็บข้อมูลการดำเนินงาน ใน Cloud Spanner เราใช้การสอดแทรกเพื่อจัดเก็บข้อมูลที่เกี่ยวข้องไว้ด้วยกัน เช่น ความสัมพันธ์และธุรกรรมของลูกค้าจะจัดเก็บไว้กับบันทึกลูกค้าโดยตรง ซึ่งจะช่วยให้มั่นใจได้ว่าการเข้าถึงและสถานที่ตั้งจริงมีประสิทธิภาพสูง
DDL: การสร้างตาราง
คัดลอกและเรียกใช้บล็อกต่อไปนี้เพื่อสร้างสคีมาเชิงสัมพันธ์
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
การเริ่มต้นเครือข่าย
เมื่อตารางพร้อมแล้ว เราต้องป้อนข้อมูลผู้ใช้ ผลิตภัณฑ์ และการเชื่อมต่อที่กำหนดระบบนิเวศของลูกค้า
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
ความท้าทายด้านความสัมพันธ์
ก่อนที่จะแนะนำกราฟ เรามาดูกันว่า SQL แบบดั้งเดิมจัดการกับความท้าทายของลูกค้าอย่างไร เรียกใช้คําค้นหานี้เพื่อค้นหาลูกค้า "นักช็อปโซเชียล" ที่ใช้จ่ายอย่างมากและมีเพื่อนหลายคน
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
ข้อจำกัดของแนวทางเชิงสัมพันธ์
การเอาชนะความท้าทายด้านความสัมพันธ์ผ่านกราฟพร็อพเพอร์ตี้
เราจึงกำหนดกราฟพร็อพเพอร์ตี้เพื่อแก้ปัญหาข้อจำกัดเหล่านี้ ซึ่งจะสร้าง "การซ้อนทับ" ที่ช่วยให้เราถือว่าความสัมพันธ์เป็นสิ่งสำคัญอันดับแรกโดยไม่ต้องย้ายข้อมูลออกจาก Spanner
DDL: การสร้างกราฟพร็อพเพอร์ตี้
DDL นี้กำหนดโหนด (เอนทิตี) และขอบ (ความสัมพันธ์) ในตัวอย่างนี้ เราใช้กราฟที่กำหนดสคีมา แต่ Spanner Graph อนุญาตให้สร้างโมเดลกราฟที่ไม่มีสคีมาเพื่อเปิดใช้การพัฒนาแบบวนซ้ำที่รวดเร็วและยืดหยุ่น รวมถึงจัดการโมเดลข้อมูลที่เปลี่ยนแปลงไปโดยไม่ต้องเปลี่ยนแปลงภาษานิยามข้อมูล (Data Definition Language) อย่างต่อเนื่อง
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
การไปยังส่วนต่างๆ ของกราฟด้วย GQL
เมื่อกำหนดกราฟแล้ว เราจะใช้ Graph Query Language (GQL) เพื่อดำเนินการข้ามหลายฮอปด้วยไวยากรณ์ที่เรียบง่ายและอ่านง่ายได้
การสำรวจที่ 1: การค้นพบร่วมกัน
คําค้นหานี้จะข้ามกราฟเพื่อค้นหาผลิตภัณฑ์ที่เพื่อนของคุณซื้อและทําหน้าที่เป็นพื้นฐานของเครื่องมือแนะนํา
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
การสำรวจ 2: การค้นหาแบบไฮบริด (เชิงสัมพันธ์ + กราฟ)
Spanner ช่วยให้คุณฝังรูปแบบ GQL ไว้ในคําสั่ง FROM ของ SQL มาตรฐานได้โดยใช้ฟังก์ชัน GRAPH_TABLE คําค้นหานี้จะค้นหาลูกค้าที่อาศัยอยู่ในสถานที่เดียวกันกับเพื่อน ซึ่งเป็นการจับคู่รูปแบบ "เพชร"
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
การแสดงภาพการเชื่อมต่อของลูกค้า
สุดท้ายนี้ มาใช้ GQL เพื่อแสดงภาพเครือข่ายกัน คำค้นหาเหล่านี้จะรวมผลลัพธ์เส้นทางไว้ใน SAFE_TO_JSON ซึ่งช่วยให้โปรแกรมแสดงภาพวาดโหนดและเส้นได้
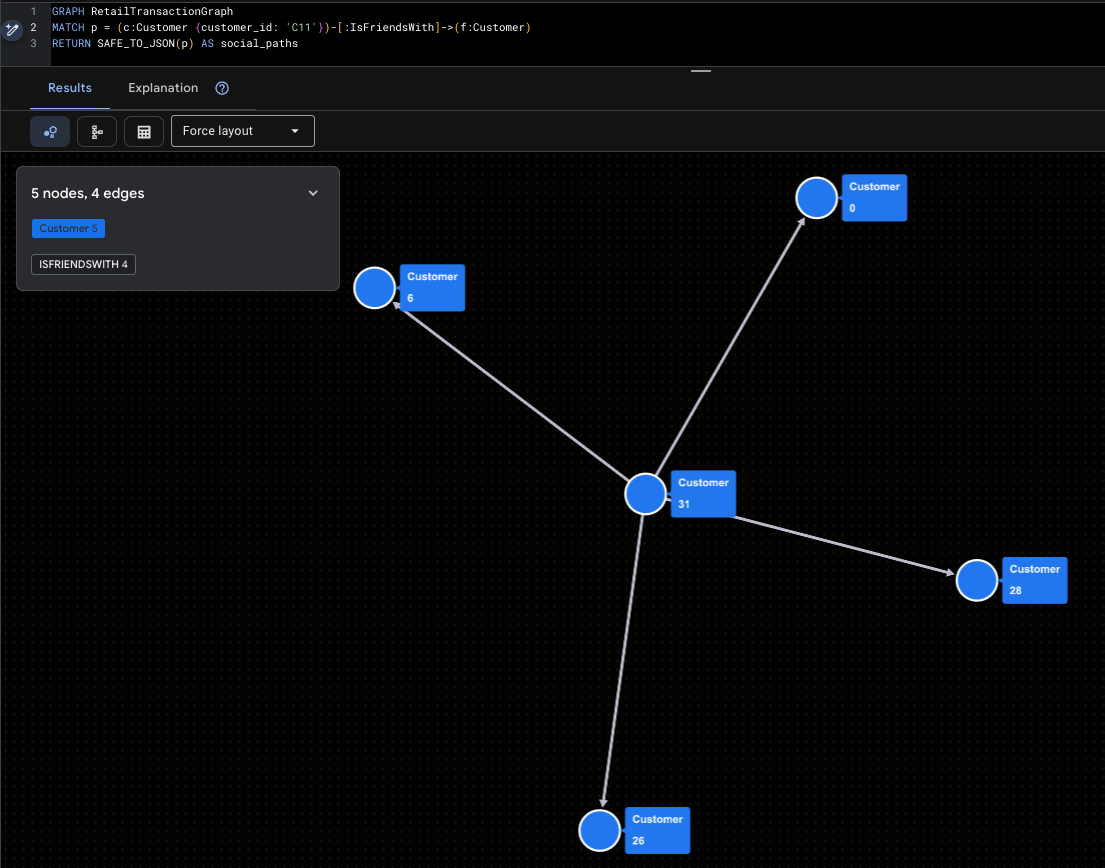
การแสดงภาพ Super-Influencer
ซึ่งไฮไลต์ Mallory (C11) และการเข้าถึงโซเชียลโดยตรงของเธอ
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
การแสดงภาพรูปแบบการฉ้อโกงที่อาจเกิดขึ้น
คำค้นหานี้จะค้นหา "คลัสเตอร์ที่แยกกัน" (Ivan และ Judy) เพื่อดูว่ามีการจัดส่งผลิตภัณฑ์ไปยังที่ใด
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. ข้อมูลเบื้องต้นเกี่ยวกับอัลกอริทึมกราฟ Spanner
ส่วนนี้จะอธิบายสถาปัตยกรรมทางเทคนิคและกฎพื้นฐานของอัลกอริทึมกราฟของ Cloud Spanner เพื่อเตรียมพร้อมสำหรับการเจาะลึกข้อมูลเกี่ยวกับ Graph Intelligence การทำความเข้าใจหลักการเหล่านี้เป็นกุญแจสำคัญในการเปลี่ยนจากการสำรวจแบบง่ายๆ ไปเป็นการวิเคราะห์ความสัมพันธ์ระดับเพตะไบต์
พอร์ตโฟลิโออัลกอริทึม
ปัจจุบัน Cloud Spanner รองรับอัลกอริทึมกราฟมาตรฐานอุตสาหกรรม 14 รายการ ซึ่งจัดหมวดหมู่เป็น 4 กลุ่มฟังก์ชันเพื่อแก้ปัญหาทางธุรกิจที่หลากหลาย ดังนี้
หมวดหมู่ | อัลกอริทึมที่รองรับ | กรณีการใช้งานทางธุรกิจ |
ความเป็นศูนย์กลาง | เพจแรงก์ เพจแรงก์ที่ปรับเปลี่ยนในแบบของคุณ ความเป็นสื่อกลาง ความใกล้ชิด | ระบุอินฟลูเอนเซอร์ ฮับ และคอขวด |
ชุมชน | WCC, การเผยแพร่ป้ายกำกับ, การค้นหากลุ่ม, การจัดกลุ่มความสัมพันธ์ | ตรวจหาเครือข่ายการประพฤติมิชอบ ชุมชนโซเชียล และไซโล |
ความคล้ายคลึง | Jaccard, Cosine, เพื่อนบ้านร่วมกัน, เพื่อนบ้านทั้งหมด | ขับเคลื่อนเครื่องมือแนะนำและการแก้ปัญหาเอนทิตี |
การค้นหาเส้นทาง | เส้นทางที่สั้นที่สุดจากชุดหนึ่งไปยังอีกชุดหนึ่ง ตัวช่วยเส้นทาง GA | เพิ่มประสิทธิภาพด้านโลจิสติกส์และความใกล้เคียงของการเดินทาง |
ข้อควรพิจารณาที่สำคัญเกี่ยวกับสคีมาและการค้นหา
Spanner Graph ต้องปฏิบัติตามกฎต่อไปนี้เพื่อให้มั่นใจว่าอัลกอริทึมกราฟจะทำงานได้อย่างมีประสิทธิภาพ
ข้อกำหนด 1 การจัดวางข้อมูลจริง (การสลับ)
ข้อกำหนดที่สำคัญที่สุดสำหรับการสำรวจกราฟที่มีประสิทธิภาพสูงคือการสลับ ซึ่งจะช่วยให้มั่นใจได้ว่าข้อมูลที่ขอบจะจัดเก็บไว้ในเซิร์ฟเวอร์เดียวกันกับโหนดต้นทาง ซึ่งจะช่วยลดเวลาในการตอบสนองของเครือข่ายระหว่างการเรียกใช้อัลกอริทึม
- กฎ: ตารางขอบต้องสลับกันในตารางโหนดต้นทาง
- การข้ามไปข้างหน้า: การแทรกตารางขอบลงในตารางโหนดต้นทางจะช่วยให้มั่นใจได้ว่าแคชจะอยู่ใกล้กับลิงก์ขาออก
- การย้อนกลับ: ใช้คีย์นอกเพื่อสร้างดัชนีสนับสนุนโดยอัตโนมัติ หรือสร้างดัชนีรองที่สอดแทรกในตารางปลายทาง เพื่อการวิเคราะห์ลิงก์ "ขาเข้า" ที่มีประสิทธิภาพ
ข้อกำหนดที่ 2 ข้อกำหนดในการติดป้ายกำกับที่ไม่ซ้ำกัน
ทุกตารางที่เข้าร่วมในกราฟพร็อพเพอร์ตี้ต้องมีข้อมูลประจำตัวที่ไม่ซ้ำกัน อัลกอริทึมใช้ป้ายกำกับเหล่านี้เพื่อระบุและโหลดกราฟย่อยที่จำเป็นต่อการวิเคราะห์ได้อย่างถูกต้อง
- กฎ: ตารางอินพุตแต่ละตารางต้องมีป้ายกำกับที่ระบุตัวตนที่ไม่ซ้ำกันภายในกราฟพร็อพเพอร์ตี้
- ข้อขัดแย้ง: คุณไม่สามารถแมปป้ายกำกับเดียวกับหลายตารางได้หากต้องการเรียกใช้อัลกอริทึมในตารางเหล่านั้น
ตรรกะ | ตัวอย่าง | ผลลัพธ์ |
❌ ไม่ดี | ตารางโหนด (เอนทิตีป้ายกำกับบุคคล, เอนทิตีป้ายกำกับบัญชี) | ไม่ถูกต้อง: อัลกอริทึมแยกความแตกต่างระหว่างบุคคลกับบัญชีไม่ได้ |
✅ ดี | ตารางโหนด (ป้ายกำกับบุคคล ลูกค้า, ป้ายกำกับบัญชี บัญชี) | ถูกต้อง: แต่ละเอนทิตีมีป้ายกำกับที่ไม่ซ้ำกัน |
ข้อกำหนดที่ 3 โครงสร้างการค้นหาอัลกอริทึม (อนุประโยค MATCH)
เมื่อเรียกใช้อัลกอริทึม อนุประโยค MATCH จะปฏิบัติตามกฎที่เข้มงวดกว่าคำค้นหา GQL มาตรฐานเพื่อให้มั่นใจว่าเครื่องมือการดำเนินการจะเพิ่มประสิทธิภาพไปป์ไลน์การวิเคราะห์ได้
- รูปแบบ 1 รูปแบบต่อการจับคู่ 1 ครั้ง: แต่ละคำสั่ง MATCH จะตั้งชื่อตัวแปรได้เพียง 1 ตัว
- ไม่มีรูปแบบหลายโหนด: คุณไม่สามารถกำหนดรูปแบบความสัมพันธ์ (เช่น (a)-[e]->(b)) โดยตรงภายในส่วนคำสั่ง MATCH ที่มีไว้สำหรับการเรียกอัลกอริทึม
- ตัวกรองตามตัวอักษรเท่านั้น: แม้ว่าคุณจะใช้คําสั่ง WHERE เพื่อกรองโหนดได้ (เช่น WHERE a.id > 400) แต่ระบบไม่รองรับพารามิเตอร์การค้นหา (@param) ในการค้นหาอัลกอริทึมกราฟในขณะนี้
ข้อกำหนดที่ 4 The RETURN Clause (Scalars Only)
โดยในคำค้นหาอัลกอริทึม อนุประโยค RETURN จะทำหน้าที่เป็นตัวเชื่อมระหว่างโลกของกราฟกับโลกของความสัมพันธ์ โดยจะจำกัดไว้เฉพาะการคืนค่าสเกลาร์และค่าคงที่เท่านั้น
- กฎ: คุณไม่สามารถส่งคืน "องค์ประกอบกราฟ" (ออบเจ็กต์โหนดหรือขอบดิบ)
- ไม่มีการแปลง: คุณไม่สามารถดำเนินการทางคณิตศาสตร์หรือใช้ฟังก์ชันกับพร็อพเพอร์ตี้ที่ส่งคืนภายในคำสั่ง RETURN เองได้
ข้อจำกัดของข้อกำหนดการคืนสินค้า
✅ รองรับ | ❌ ไม่รองรับ |
RETURN node.id, score | โหนด RETURN, คะแนน (ไม่สามารถคืนค่าองค์ประกอบกราฟ) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (ไม่มีการดำเนินการในพร็อพเพอร์ตี้) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (ไม่มีฟังก์ชัน) |
ข้อกำหนด 5 ความสมบูรณ์ของข้อมูล: การกำจัดขอบที่ค้างอยู่
"ขอบที่ค้าง" จะเกิดขึ้นเมื่อขอบชี้ไปยังโหนดปลายทางที่ไม่มีอยู่ในกราฟ ซึ่งจะทำให้การเรียกใช้อัลกอริทึมล้มเหลวเนื่องจากโครงสร้างกราฟไม่สอดคล้องกัน
- วิธีแก้ปัญหา: ใช้ข้อจำกัดอ้างอิง (คีย์นอก) และ ON DELETE CASCADE เพื่อรักษาความสมบูรณ์ของกราฟ
- ความปลอดภัยของคําค้นหา: เมื่อเรียกใช้อัลกอริทึม คุณต้องตรวจสอบว่าโหนดทั้งหมดที่ขอบที่เลือกอ้างอิงรวมอยู่ในอาร์กิวเมนต์ node_labels ด้วย
เอาต์พุตแบบถาวร: ตัวเลือกการส่งออกข้อมูล
เนื่องจากอัลกอริทึมกราฟต้องใช้การคำนวณจำนวนมาก จึงจะดำเนินการในโหมดการดำเนินการแบบเพิ่มขนาดโดยใช้คำสั่ง EXPORT DATA ซึ่งใช้ประโยชน์จาก Data Boost โดยใช้ทรัพยากรการประมวลผลแบบไร้เซิร์ฟเวอร์อิสระเพื่อป้องกันไม่ให้เกิดความล่าช้าในธุรกรรมการผลิต
ตัวเลือกที่ 1: คงข้อมูลกลับไปยัง Cloud Spanner
หากต้องการส่งผลลัพธ์กลับไปยังตารางโดยตรง (เช่น บันทึกคะแนนเพจแรงก์) ให้ใช้ format = ‘CLOUD_SPANNER'
update_ignore_all: อัปเดตเฉพาะแถวสำหรับคีย์ที่มีอยู่ในตารางเป้าหมายอยู่แล้วupsert_ignore_all: อัปเดตแถวที่มีอยู่หรือแทรกแถวใหม่หากไม่มีคีย์
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
ตัวเลือกที่ 2: จัดเก็บผลลัพธ์ไว้ใน Google Cloud Storage (GCS)
สำหรับการวิเคราะห์แบบออฟไลน์ในวงกว้าง คุณสามารถส่งออกไปยัง GCS ในรูปแบบ CSV, Avro หรือ Parquet ได้
- ไวลด์การ์ด: ใช้
uri => 'gs://bucket/file_*.csv'เพื่อเปิดใช้เอาต์พุตที่แยกส่วน ซึ่งจะช่วยให้ Spanner เขียนไปยังหลายไฟล์พร้อมกันสำหรับชุดข้อมูลขนาดใหญ่ได้ - การบีบอัด: รองรับ GZIP, SNAPPY และ ZSTD เพื่อเพิ่มประสิทธิภาพต้นทุนในการจัดเก็บข้อมูล
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. ความท้าทายที่ 1: ช่องว่างของอิทธิพล (PageRank)
ในส่วนนี้ เราจะมาพูดถึงอุปสรรคทางธุรกิจแรกของลูกค้า นั่นคือ "ช่องว่างของอิทธิพล" เราจะเปลี่ยนจากการ "ประกวดความนิยม" ขั้นพื้นฐานไปเป็นแผนที่อิทธิพลทางสังคมที่แท้จริงซึ่งขับเคลื่อนด้วยคณิตศาสตร์
คำชี้แจงปัญหา: ทีมการตลาดของลูกค้ามีปัญหา โดยใช้เงินหลายล้านไปกับการโฆษณาแบบกว้างๆ ที่ให้ผลตอบแทนลดลงเนื่องจากไม่สามารถระบุ "ซูเปอร์สตาร์โซเชียล" ซึ่งเป็นบุคคลหายากที่การรับรองของบุคคลนั้นๆ ส่งผลต่อทั้งเครือข่าย
หากต้องการแก้ปัญหานี้ เราต้องจัดอันดับลูกค้าตามอิทธิพล
โซลูชันเชิงสัมพันธ์ (Degree Centrality)
ในฐานข้อมูลมาตรฐาน วิธีที่ง่ายที่สุดในการค้นหาอินฟลูเอนเซอร์คือการนับผู้ติดตาม (เมตริกที่เรียกว่าDegree Centrality)
เรียกใช้การค้นหานี้เพื่อค้นหาผู้ใช้ที่ "ได้รับความนิยม" มากที่สุด
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
ข้อมูลวิเคราะห์กราฟ (PageRank)
เราใช้ PageRank เพื่อค้นหาผู้นำที่แท้จริง อัลกอริทึมนี้เป็นอัลกอริทึมเดียวกับที่ใช้ในการค้นเว็บในช่วงแรก โดยจะวัดความสำคัญของโหนดตามปริมาณและคุณภาพของลิงก์ขาเข้า
- โมเดลการท่องเว็บแบบสุ่ม: PageRank จำลองผู้ใช้ที่เคลื่อนที่ผ่านกราฟ ปัจจัยการลดทอน (ค่าเริ่มต้นคือ 0.85) แสดงถึงความน่าจะเป็นที่ผู้ใช้จะคลิกต่อไป มิเช่นนั้นผู้ใช้จะ "เทเลพอร์ต" ไปยังโหนดแบบสุ่ม
- พลังแห่งการเชื่อมโยง: ลิงก์จากผู้มีอิทธิพล (เช่น Mallory) มีค่ามากกว่าลิงก์จากผู้ที่ไม่มีการเชื่อมต่ออื่นๆ อย่างมาก
เราจะเรียกใช้อัลกอริทึม PageRank และใช้ EXPORT DATA เพื่อบันทึกผลลัพธ์ลงในคอลัมน์ pagerank_score โดยตรง
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
แดชบอร์ด"อิทธิพล" โดยใช้ PageRank
ตอนนี้เราได้บันทึกคะแนนไว้แล้ว มาเปรียบเทียบ "ก่อน" (จำนวนผู้ติดตาม) กับ "หลัง" (คะแนนเพจแรงก์) กัน
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
การวิเคราะห์: ใครคือซูเปอร์สตาร์ตัวจริง
การวิเคราะห์ผลลัพธ์จะช่วยให้คุณค้นพบข้อมูลทางการตลาดที่สำคัญ 3 อย่างต่อไปนี้
สิ่งที่ธุรกิจควรทราบ
ตอนนี้ทีมการตลาดของลูกค้าสามารถมุ่งเน้นเฉพาะผู้ที่มี pagerank_score สูงสุดได้แล้ว แทนที่จะส่งอีเมลถึงทุกคนที่มีผู้ติดตามมากกว่า 5 คนโดยไม่เลือก บุคคลเหล่านี้คือ "ซูเปอร์สตาร์โซเชียล" ตัวจริงที่สามารถขับเคลื่อนการแชร์แบบไวรัลในระบบทั่วทั้งมาร์เก็ตเพลส
ตอนนี้เรามาลองระบุผู้ดูแลที่ทำให้เครือข่ายโลจิสติกส์ของลูกค้าทำงานต่อไปได้
5. ความท้าทายที่ 2: ความยืดหยุ่นด้านโลจิสติกส์ (BetweennessCentrality)
ในส่วนนี้ เราจะพูดถึงความยืดหยุ่นด้านโลจิสติกส์ เราจะก้าวข้ามการวัดความสำเร็จด้วย "ปริมาณ" ไปสู่การระบุ "ผู้ดูแล" ที่สำคัญซึ่งทำให้เครือข่ายเชื่อมต่อกันอยู่
โซลูชันเชิงสัมพันธ์ (การวิเคราะห์ตามปริมาณ)
ในการตั้งค่าเชิงสัมพันธ์มาตรฐาน โดยทั่วไปแล้วฮับการจัดส่งที่ "สำคัญ" จะกำหนดเป็นฮับที่ประมวลผลคำสั่งซื้อมากที่สุดหรือสร้างรายได้มากที่สุด
เรียกใช้การค้นหานี้เพื่อระบุฮับ "ยอดนิยม" ตามจำนวนธุรกรรม
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
นิวยอร์ก | USA | 4 | 3996 |
เบอร์ลิน | เยอรมนี | 2 | 345 |
ซานฟรานซิสโก | USA | 2 | 750 |
เราจะใช้ทั้งขอบ IsFriendsWith และ LivesAt เพื่อแก้ไขความไม่ตรงกัน ซึ่งจะเปลี่ยนการวิเคราะห์ของเราจากฮับธุรกรรมให้รวมถึงการตรวจสอบทางสังคมด้วย
ข้อมูลวิเคราะห์กราฟ (Centrality ระหว่าง)
เราใช้ค่าความเป็นศูนย์กลางระหว่างเพื่อค้นหาคอขวดที่แท้จริง อัลกอริทึมนี้จะวัดปริมาณความถี่ที่โหนดทำหน้าที่เป็น "สะพาน" ตามเส้นทางที่สั้นที่สุดระหว่างคู่โหนดอื่นๆ ทั้งหมดในกราฟ คะแนนสูงจะระบุผู้ดูแลที่แท้จริงซึ่งควบคุมการไหลเวียนของสินค้าหรือข้อมูล
การเรียกใช้และการคงค่า Betweenness Centrality
เราจะเรียกใช้อัลกอริทึมโดยใช้ EXPORT DATA และบันทึกคะแนนลงในคอลัมน์ centrality_score เราใช้ Data Boost เพื่อให้มั่นใจว่าการคำนวณ "เส้นทางที่สั้นที่สุด" ที่ซับซ้อนนี้จะแทบไม่มีผลกระทบต่อการดำเนินงานจริงของลูกค้า
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
การวิเคราะห์: การระบุ "คอขวดที่ซ่อนอยู่"
ตอนนี้เราจะเปรียบเทียบความเสี่ยงเชิงโครงสร้าง (centrality_score) กับปริมาณธุรกรรม (order_count) เพื่อค้นหาโหนดที่ผู้นำของลูกค้าควรเป็นกังวล
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
จากการวิเคราะห์ผลลัพธ์เหล่านี้ ลูกค้าได้ค้นพบสิ่งที่น่าตกใจ 3 อย่าง
ข้อคิดทางธุรกิจ
ตอนนี้ลูกค้าสามารถจัดลำดับความสำคัญของโปรโตคอลความซ้ำซ้อนด้านลอจิสติกส์และความปลอดภัยตามความเสี่ยงเชิงโครงสร้างแบบหลายรูปแบบได้แล้ว Mallory, Alice และ Eve เป็นผู้ดูแลประตูที่ต้องได้รับการปกป้องเพื่อให้มั่นใจถึงความเสถียรของเครือข่ายลอจิสติกส์
ตอนนี้เรามาลองแยกเกาะการฉ้อโกงกัน
6. ความท้าทายที่ 3: เครือข่ายผี (WCC)
ในส่วนนี้ เราจะมาจัดการกับอุปสรรคทางธุรกิจที่ 3 นั่นคือ "เครือข่ายผี" เราจะเปลี่ยนจากการตรวจหา "ฮอตสปอต" แบบง่ายๆ ไปเป็นการค้นหาเครือข่ายการฉ้อโกงที่ซับซ้อนและแยกกันโดยใช้การตรวจหาชุมชน ความท้าทายในที่นี้คือผู้ไม่ประสงค์ดีสร้างโปรไฟล์ปลอมที่แชร์ที่อยู่สำหรับจัดส่งหรือโต้ตอบในวงปิดเพื่อประสานงานการลักขโมยและเพิ่มการให้คะแนนสินค้า แต่โดยทั่วไปแล้วมิจฉาชีพเหล่านี้มักจะแยกตัวออกจากชุมชน The Customer ที่ถูกต้องโดยสิ้นเชิง
เราต้องเปิดเผย "เกาะที่แยกตัว" เหล่านี้เพื่อแก้ปัญหานี้
โซลูชันเชิงสัมพันธ์ (การค้นหาตัวระบุที่แชร์)
หากไม่มีอัลกอริทึมกราฟ วิธีมาตรฐานในการตรวจหาการฉ้อโกงคือการมองหา "ฮอตสปอต" ของข้อมูลที่แชร์ เช่น ลูกค้าหลายรายจัดส่งไปยังที่อยู่เดียวกัน
เรียกใช้การค้นหานี้เพื่อค้นหาลูกค้าที่ลิงก์ด้วยสถานที่จัดส่งที่ใช้ร่วมกัน
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
หากต้องการค้นหาเครือข่ายการประพฤติมิชอบ เราต้องทำความเข้าใจการเข้าถึงแบบทรานซิทีฟ
Graph Intelligence (Weakly Connected Components)
เราใช้คอมโพเนนต์ที่เชื่อมต่ออย่างหลวมๆ (WCC) เพื่อค้นหาขอบเขตทั้งหมดของวงแหวนเหล่านี้ WCC เป็นอัลกอริทึมการจัดกลุ่มที่ระบุชุดโหนดที่มีเส้นทางระหว่างโหนด 2 โหนดใดๆ โดยไม่คำนึงถึงทิศทางของขอบ
- โซนที่เข้าถึงได้: โซนนี้จะแบ่งกราฟออกเป็น "เกาะ" หรือ "โซนที่เข้าถึงได้"
- มุมมองเอนทิตีแบบรวม: การวิเคราะห์ทั้งความสัมพันธ์ทางสังคม (IsFriendsWith) และความสัมพันธ์ด้านโลจิสติกส์ (LivesAt) พร้อมกันช่วยให้เราจัดกลุ่มโปรไฟล์ที่กระจัดกระจายเป็น "คลัสเตอร์อิทธิพล" เดียวแบบรวมได้
การเรียกใช้และการคงอยู่ของ WCC
เราจะเรียกใช้อัลกอริทึม WCC และบันทึกผลลัพธ์ลงในคอลัมน์ community_id เราใช้การเพิ่มข้อมูลเพื่อให้มั่นใจว่าการวิเคราะห์การเข้าถึงเชิงลึกนี้เกิดขึ้นในทรัพยากรการประมวลผลอิสระ
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
การวิเคราะห์: เครือข่ายการประพฤติมิชอบ
ตอนนี้มาเรียกใช้การค้นหาการตรวจสอบเพื่อดูชุมชนที่แยกกัน โดยปกติแล้วผู้ใช้ที่ถูกต้องจะอยู่ใน "แผ่นดินใหญ่" ในขณะที่ผู้ฉ้อโกงมักจะติดอยู่บน "เกาะ" เล็กๆ
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | สมาชิก |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
การเรียกใช้การตรวจหาชุมชนนี้จะช่วยให้คุณระบุความผิดปกติที่สำคัญได้
ข้อคิดทางธุรกิจ
ตอนนี้ลูกค้าสามารถทำให้การตอบสนองด้านความปลอดภัยเป็นแบบอัตโนมัติได้แล้ว แทนที่จะต้องติดตามบัญชีแต่ละบัญชีด้วยตนเอง พวกเขาสามารถเขียนกฎง่ายๆ ได้ว่า "หาก community_id มีสมาชิกน้อยกว่า 3 คน ให้แจ้งกลุ่มทั้งหมดเพื่อรับการตรวจสอบ KYC (Know Your Customer) ด้วยตนเอง"
เมื่อระบุเครือข่ายการประพฤติมิชอบได้แล้ว เราจะแก้ปัญหา "พฤติกรรมที่คล้ายกัน" ได้
7. ความท้าทายที่ 4: Behavioral Twin (JaccardSimilarity)
ในความท้าทายสุดท้ายนี้ เราจะมาพูดถึงอุปสรรคที่ 4 นั่นคือ "Paradox of Choice"/"Behavioral Twin" เราจะเปลี่ยนจากรายการ "ซื้อร่วมกัน" ทั่วไปเป็นคำแนะนำที่ปรับเปลี่ยนในแบบของคุณอย่างยิ่งตาม "ลายนิ้วมือ" ด้านพฤติกรรม
คำแนะนำผลิตภัณฑ์ปัจจุบันของลูกค้าทั่วไปเกินไป การแนะนำสาย USB ที่ได้รับความนิยมให้แก่ลูกค้าทุกคนเป็นเรื่องที่ปลอดภัย แต่ก็ไม่ได้เป็นการแนะนำเฉพาะบุคคล ลูกค้าต้องการสร้างคำแนะนำ "Behavioral Twin" เพื่อระบุลูกค้าที่มีรูปแบบการจัดส่งและวงสังคมที่ไม่เหมือนใคร เพื่อแนะนำผลิตภัณฑ์ที่มีการจับคู่ที่มีความแม่นยำสูง
หากต้องการแก้ปัญหานี้ เราต้องคำนวณ"ความใกล้เคียง"ระหว่างผู้ใช้
โซลูชันเชิงสัมพันธ์ (การทับซ้อนกันโดยสมบูรณ์)
ในการตั้งค่าเชิงสัมพันธ์มาตรฐาน คุณอาจมองหาผู้ที่จัดส่งไปยังสถานที่เดียวกันกับผู้ใช้ที่อ้างอิง เช่น Alice (C1)
เรียกใช้คำค้นหานี้เพื่อค้นหาเพื่อนบ้านทางภูมิศาสตร์ของอลิซ
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (ความคล้ายคลึงของ Jaccard)
เราใช้ความคล้ายคลึงแบบ Jaccard เพื่อค้นหาพฤติกรรมที่เหมือนกันอย่างแท้จริง อัลกอริทึมนี้จะคํานวณคะแนนที่ปรับให้เป็นมาตรฐาน (0.0 ถึง 1.0) โดยการหารจํานวนเพื่อนบ้านที่แชร์ (Intersection) ด้วยจํานวนเพื่อนบ้านที่ไม่ซ้ำกันทั้งหมด (Union)
ในที่นี้ "คู่แฝดเชิงพฤติกรรม" ไม่ได้กำหนดจากที่อยู่สำหรับจัดส่งที่ใช้ร่วมกันเท่านั้น การวิเคราะห์จุดตัดของร่องรอยทางกายภาพ (LivesAt) และระบบนิเวศทางสังคม (IsFriendsWith) ช่วยให้เราสามารถระบุผู้ใช้ที่มีไลฟ์สไตล์และอิทธิพลในชุมชนเดียวกัน ซึ่งนำไปสู่คำแนะนำผลิตภัณฑ์ที่แม่นยำยิ่งขึ้น
ก่อนอื่นให้สร้างตารางการแมป
เนื่องจากความคล้ายคลึงกันเป็นความสัมพันธ์แบบคู่ (ลูกค้า ก. คล้ายกับลูกค้า ข.) เราจึงสร้างตารางเฉพาะที่สอดแทรกใน Customer เพื่อจัดเก็บการแมปเหล่านี้
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
เรียกใช้ความคล้ายคลึงของ Jaccard
ตอนนี้เราจะรันอัลกอริทึม หมายเหตุ: คำถามนี้มีบทเรียน "แนวทาง" ทั่วไป หากคุณเลือกเฉพาะโหนดลูกค้าแต่ใช้ขอบ LivesAt (ซึ่งชี้ไปยังโหนดการจัดส่ง) การค้นหาจะล้มเหลวโดยอ้างถึง"ขอบที่ค้างอยู่" หากต้องการแก้ไขปัญหานี้ เราต้องใส่ป้ายกำกับโหนดทั้ง 2 รายการ
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
การวิเคราะห์: ตรวจสอบ "กลุ่มเป้าหมายตามพฤติกรรม"
เมื่องานวิเคราะห์เสร็จสมบูรณ์แล้ว เราจะเรียกใช้การค้นหาการตรวจสอบ การรวมตารางการแมปใหม่ (CustomerSimilarity) กับข้อมูลเมตา Customer เดิมของเราจะช่วยให้เราเห็นได้อย่างชัดเจนว่าใครคือ "ฝาแฝดด้านพฤติกรรม" ของอลิซ
เรียกใช้การค้นหานี้เพื่อตรวจสอบการจัดอันดับความคล้ายคลึงของอลิซ
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
สิ่งที่ควรดูในผลลัพธ์
ตอนนี้มาลองสร้างมุมมอง Unified Intelligence สุดท้ายกัน
8. Unified Intelligence
ตอนนี้เราจะเปลี่ยนจากงานด้านเทคนิคแต่ละอย่างไปเป็น Unified Intelligence ในที่นี้ เราจะรวมข้อมูลธุรกรรมเข้ากับอัลกอริทึมกราฟทั้ง 4 รายการเพื่อมอบข้อมูลเชิงลึกที่ชัดเจนและนำไปใช้ได้จริง
รายงานที่ 1: ข้อมูลอัจฉริยะแบบรวม
ความสามารถของฐานข้อมูลแบบหลายโมเดลอย่าง Spanner คือความสามารถในการรวมข้อมูลค่าใช้จ่ายเชิงสัมพันธ์กับคะแนนอิทธิพล ความเสี่ยง และความคล้ายคลึงที่ได้จากกราฟในคำขอเดียว คําค้นหานี้จะจัดหมวดหมู่ลูกค้าทุกคนเป็นลักษณะตัวตนทางธุรกิจที่เฉพาะเจาะจง
เรียกใช้การค้นหา Unified Intelligence เพื่อดูระบบนิเวศที่สมบูรณ์
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | ค่าใช้จ่าย | อิทธิพล | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 วิกฤต: Network Bridge |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 วิกฤต: Network Bridge |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 วิกฤต: Network Bridge |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 โซเชียล: อินฟลูเอนเซอร์ที่มีการเข้าถึงสูง |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 โซเชียล: อินฟลูเอนเซอร์ที่มีการเข้าถึงสูง |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 มาตรฐาน: ลูกค้าที่ใช้งานอยู่ |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 มาตรฐาน: ลูกค้าที่ใช้งานอยู่ |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ความเสี่ยงสูง: เครือข่ายการประพฤติมิชอบที่แยกกัน |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 ความเสี่ยงสูง: เครือข่ายการประพฤติมิชอบที่แยกกัน |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 มาตรฐาน: ลูกค้าที่ใช้งานอยู่ |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 มาตรฐาน: ลูกค้าที่ใช้งานอยู่ |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 มาตรฐาน: ลูกค้าที่ใช้งานอยู่ |
การผสมผสานมุมมองทางคณิตศาสตร์เหล่านี้ช่วยให้เราก้าวข้ามคำถามที่ว่า "ใครใช้จ่ายมากที่สุด" ไปสู่คำถามที่ว่า "ใครสำคัญที่สุด" แดชบอร์ดแบบรวมจะผสานรวมข้อมูลธุรกรรมเชิงสัมพันธ์กับข้อมูลเชิงลึกแบบกราฟหลายรูปแบบเพื่อจัดหมวดหมู่ระบบนิเวศของคุณเป็น 3 กลุ่มเป้าหมายที่ชัดเจนและนําไปปฏิบัติได้
"สะพานเครือข่ายที่สำคัญ" (ความยืดหยุ่น)
ระบบจะแจ้งว่าโหนดอย่าง Mallory (C11), Eve (C5) และ Alice (C1) มีความเสี่ยงเนื่องจาก bottleneck_risk (Betweenness Centrality) >25
- แองเคอร์เชิงโครงสร้าง: Mallory มีคะแนนความเสี่ยงสูงสุดที่ 44.5 ซึ่งทำให้เธอเป็นเกตเวย์หลักสำหรับทั้งเครือข่าย
- The Zero-Spend Paradox: Eve (C5) มีจำนวนคำสั่งซื้อเป็น 0 แต่มีความสำคัญในเชิงโครงสร้างโดยมีคะแนนความเสี่ยงอยู่ที่ 35.5 SQL มาตรฐานจะละเลยเธอไปโดยสิ้นเชิง แต่ Graph Intelligence เผยให้เห็นว่าเธอเป็นสะพานสำคัญที่เชื่อมโยงไปยังชุมชนย่อยทั้งหมด
- เกตเวย์ที่มีมูลค่าสูง: อลิซ (C1) มีคะแนนเท่ากับอีฟที่ 35.5 ซึ่งพิสูจน์ให้เห็นว่าผู้ใช้ที่ใช้จ่ายสูงก็เป็นจุดยึดโครงสร้างที่สำคัญได้เช่นกัน
"ซูเปอร์สตาร์โซเชียล" (การเข้าถึง)
Heidi (C8) และ Grace (C7) ได้รับการระบุว่าเป็นอินฟลูเอนเซอร์ที่มีการเข้าถึงสูงเนื่องจากคะแนน PageRank
"วงแหวนการฉ้อโกงที่แยกกัน" (ความผิดปกติ)
ระบบจะแจ้งว่า Judy (C10) และ Ivan (C9) มีความเสี่ยงเนื่องจากอยู่ใน community_id 1 ที่แยกกัน
ข้อมูลเชิงลึกทางธุรกิจเพื่อการดำเนินการเชิงกลยุทธ์
ลักษณะตัวตน | เมตริกหลัก | ข้อมูลเชิงลึกทางธุรกิจ | การดำเนินการเชิงกลยุทธ์ |
🔵 อุปกรณ์เชื่อมโยงเครือข่าย | High Centrality | จุดยึดโครงสร้าง: อีฟ (C5) และมัลลอรี (C11) เป็นตัวยึดเครือข่าย | การรักษา: ปกป้องผู้ดูแลเหล่านี้เพื่อป้องกันไม่ให้ชุมชนแตกแยก |
📱 สุดยอดครีเอเตอร์โซเชียล | เพจแรงก์สูง | เครื่องมือที่ทำให้เกิดการแชร์อย่างรวดเร็ว: ผู้ใช้เช่น Heidi (C8) มีการเข้าถึงสูงสุดในวงสังคมของตน | การตลาด: ใช้สำหรับโปรแกรมแนะนำและโปรแกรมแอมบาสเดอร์ที่มีผลลัพธ์สูง |
🔴 ความเสี่ยงในการฉ้อโกง | Isolated WCC | เครือข่ายผี: จูดี้ (C10) และไอแวน (C9) เป็นผู้ใช้ที่ใช้จ่ายสูงแต่ไม่ได้อยู่ในกลุ่มเดียวกัน | ความปลอดภัย: การตรวจสอบ KYC โดยเจ้าหน้าที่ทันที ซึ่งเป็นลายเซ็นการฉ้อโกงแบบคลาสสิก |
🟢 ผู้ใช้ทั่วไป | คะแนนที่สมดุล | Healthy Core: เครือข่ายส่วนใหญ่ รวมถึงบริดจ์ "ท้องถิ่น" เช่น David (C4) | การเติบโต: ใช้โฆษณาที่ปรับตามโปรไฟล์ผู้ใช้มาตรฐานและคำแนะนำ "กลุ่มเป้าหมายที่คล้ายกันตามพฤติกรรม" |
รายงานที่ 2: รายงานความผิดปกติของข้อมูลระบุตัวตน
ตอนนี้คุณต้องทราบว่ามิจฉาชีพกำลัง "เลียนแบบ" บัญชีที่ถูกต้องหรือไม่ เราสามารถแก้ปัญหานี้ได้โดยการค้นหาผู้ใช้ที่มีความคล้ายคลึงกันด้านพฤติกรรม 100% แต่ไม่มีการเชื่อมต่อทางสังคม
เรียกใช้การค้นหานี้เพื่อแจ้ง "ความผิดปกติของข้อมูลประจำตัว" ที่อาจเกิดขึ้น
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
รายงานการระบุความผิดปกติจะให้ข้อมูลที่สำคัญ การแยกผู้ใช้ที่ทำตัวเหมือนลูกค้าที่ถูกต้องแต่ไม่มีความเชื่อมโยงทางสังคมช่วยให้เราเปลี่ยนจากการคาดเดาไปสู่ความแน่นอนทางคณิตศาสตร์ได้
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
การวิเคราะห์ผลลัพธ์
การรวม Similarity (Jaccard) เข้ากับ Community Detection (WCC) ทำให้เราเห็นความเสี่ยงที่ซ่อนอยู่ซึ่งข้อมูลธุรกรรมแบบดั้งเดิมมองไม่เห็น
- "คู่แฝดเชิงพฤติกรรม" (ความใกล้เคียง): ระบบจะแจ้งว่าโหนดอย่าง Judy (C10) และ Ivan (C9) มีความคล้ายคลึงกันเนื่องจากมีคะแนนความคล้ายคลึงของ Jaccard เท่ากับ 0.20 เมื่อเทียบกับ Alice (C1)
- ลักษณะการทำงานแบบแยก: ระบบจะจัดกลุ่ม Judy (C10) และ Ivan (C9) ไว้ใน community_id 1 ที่แยกไว้ ส่วน Alice จะอยู่ใน "Mainland" (ชุมชน 0) ซึ่งเป็นชุมชนโซเชียล
- การแจ้งว่าเป็นการประพฤติมิชอบ: รายงานจะระบุผู้ใช้ที่มีการทับซ้อนกันของพฤติกรรมสูง (>0.9) ซึ่งยังคงไม่ได้เชื่อมต่อกับเครือข่ายหลัก
9. ขอแสดงความยินดีและสรุป
แล็บนี้แสดงให้เห็นว่า Cloud Spanner เปลี่ยนฐานข้อมูลเชิงสัมพันธ์ให้กลายเป็นเครื่องมือแบบหลายโมเดลได้อย่างไร การใช้ความสามารถของกราฟกับลูกค้าทำให้เราเปลี่ยนจากข้อมูลแบบคงที่ไปเป็นกลยุทธ์ทางธุรกิจที่นำไปใช้ได้จริง
ข้อดีของ Spanner Multi-Model
- สถาปัตยกรรมแบบรวม: Spanner ช่วยให้คุณรักษาพื้นฐานเชิงสัมพันธ์ที่มั่นคงได้ในขณะที่ "ซ้อนทับ" กราฟพร็อพเพอร์ตี้เพื่อการค้นหาความสัมพันธ์ได้ทันทีโดยไม่ต้องเสี่ยงและหน่วงเวลา ETL
- การแยกการวิเคราะห์นอกกล่อง: การใช้ประโยชน์จาก Data Boost ช่วยให้คุณเรียกใช้อัลกอริทึมที่ใช้หน่วยความจำสูง เช่น PageRank หรือ WCC ในทรัพยากรการคำนวณแบบไร้เซิร์ฟเวอร์ที่เป็นอิสระได้ ซึ่งจะช่วยให้มั่นใจได้ว่าจะไม่มีผลกระทบต่อประสิทธิภาพการชำระเงินในเวอร์ชันที่ใช้งานจริง
- ประสิทธิภาพแบบ Interleaved: การ Interleaved ที่ไม่เหมือนใครของ Spanner ช่วยให้มั่นใจได้ว่าโหนดและความสัมพันธ์ของโหนดจะอยู่ร่วมกันทางกายภาพ ซึ่งจะเปลี่ยนการข้ามผ่านทั่วโลกที่ซับซ้อนเป็นการค้นหาในเครื่องที่มีความเร็วสูง
การแสดง "อัญมณีที่ซ่อนอยู่" และความผิดปกติ
- การระบุคุณค่าเชิงโครงสร้าง: อัลกอริทึมกราฟ เช่น Betweenness Centrality เผยให้เห็น "สะพานที่ซ่อนอยู่" ซึ่งไม่มีการใช้จ่าย แต่อาจมีความสําคัญต่อความยืดหยุ่นของเครือข่ายมากกว่าลูกค้าที่ใช้จ่ายสูงสุด
- การเปิดเผยการเลียนแบบพฤติกรรม: การรวมความคล้ายคลึงของ Jaccard และคอมโพเนนต์ที่เชื่อมต่ออย่างอ่อนทำให้เราระบุ "คนแปลกหน้าในโซเชียล" ได้ บัญชีเหล่านี้ดูเหมือนลูกค้าที่ถูกต้อง แต่ได้รับการพิสูจน์ทางคณิตศาสตร์แล้วว่าเป็นกลุ่มการประพฤติมิชอบที่แยกกัน
- ความจริงระดับโลกเทียบกับระดับท้องถิ่น: แม้ว่าการวิเคราะห์ SQL ด้วยตนเองจะแสดงบริดจ์ได้ แต่อัลกอริทึมระดับโลกจะแสดงผู้ดูแลหลักของเครือข่ายได้
การทำให้ข้อมูลมีความอัจฉริยะและนำไปใช้ได้จริง
- กลยุทธ์ที่อิงตามลักษณะตัวตน: เราเปลี่ยนแถวให้เป็นความสัมพันธ์ได้สำเร็จ และการเรียกใช้อัลกอริทึมช่วยให้เราแก้ปัญหาทางธุรกิจได้ 4 อย่าง ได้แก่ Network Bridges, Social Superstars, Fraud Risks และ Standard Users