
1. Başarılı örnek: Intelligent Retail
Örnek olay için hızlı büyüyen bir dijital pazar yerine sahip bir perakende müşterisini ele alıyoruz. Müşterinin geleneksel veri görünümü, kullanıcıların ne satın aldığını gösterdiği ancak nasıl bağlantı kurduklarını göstermediği için sınırlıdır. Bu boşluk, fırsatların kaçırılmasına ve sahtekarlığın artmasına neden oluyor. Şimdi ise işlem verilerinin yanı sıra sosyal ve lojistik bağlantılara değer veren bir Network-First (Önce Ağ) felsefesine geçiş yapıyorlar.
Çözülmesi gereken temel iş sorunları
Müşteriler ve lojistik arasındaki bağlantının anlaşılmasını gerektiren dört önemli zorlukla karşı karşıyasınız:
Görev | Sorun | Hedef |
Etki Boşluğu | Geniş kapsamlı reklamcılık düşük yatırım getirisi sağlar. Şu anda gerçek trend belirleyicileri (influencer'lar) belirlemek mümkün değildir. | Müşterilerden oluşan bağlı bir ağdaki bağlantıları aracılığıyla topluluğun merkezinde yer alan influencer'ları belirleyin. |
Lojistik Dayanıklılığı | Tedarik zinciri, farklı coğrafyalarda faaliyet gösterdiği için savunmasız olabilir. Bir anahtar merkezi arızalanırsa tüm bölge ürün erişimini kaybedebilir. | Lojistik ağlarını birbirine bağlamak için kritik öneme sahip olan Gatekeeper'ları belirleyin. |
Hayalet Ağlar | Dolandırıcılık şebekeleri, hırsızlığı koordine etmek ve puanları yükseltmek için sahte profiller ve ortak adresler kullanır. | İzole Adalar : Meşru toplulukla bağlantısı olmayan, aşırı bağlantılı gruplar. |
Seçim paradoksu | Mevcut öneri motoru basit, genel ve genellikle göz ardı ediliyor (ör. "Bunu satın alan müşteriler şunları da satın aldı: ..."). | Davranış ikizleri oluşturun. Örneğin, benzer kargo kalıplarına ve sosyal çevrelere dayalı öneriler. |
İşletme zorluklarını teknik stratejiyle eşleme (satırlar → ilişkiler)
Geleneksel bir veritabanında veriler izole silolarda depolanır: müşteriler bir tabloda, işlemler başka bir tabloda, kargo ise üçüncü bir tabloda. SQL, "Kim ne satın aldı?" sorusunu yanıtlamak için mükemmel olsa da ağ tabanlı soruları yanıtlamakta zorlanır.
Bu zorlukları çözmek için teknik strateji, bu bakış açısını değiştirmektir:
- İlişkisel Görünüm ("Ne"): Her müşteriyi ayrı bir satır olarak ele alır. Bir müşteri ile arkadaşının satın alma işlemi arasında bağlantı kurmak için birden fazla karmaşık "birleştirme" gerekir. Bu birleştirmeler, ağ büyüdükçe katlanarak yavaşlar.
- Grafik Görünümü ("Nasıl"): İlişkileri birinci sınıf vatandaş olarak ele alır. Listelerde arama yapmak yerine haritada geziniriz. A müşterisinin, Z konumuna gönderim yapan B müşterisine bağlı olduğunu anında görebiliriz.
Gereksinimleri ayrıntılı olarak inceleme
Çözüm mimarları, iş gereksinimleri ve teknik stratejinin çok modelli bir yaklaşım gerektirdiği sonucuna varır ve aşağıdaki temel gereksinimleri belirler.
Cloud Spanner bu teknik koşulları nasıl karşılar?
Bu dönüşümün merkezinde Cloud Spanner yer alıyor. Bu sayede Müşteri, kaya gibi sağlam ilişkisel temelini korurken aynı anda derin grafik analizlerinden yararlanabilir.
Cloud Spanner'ın teknik koşulları ve daha fazlasını nasıl karşıladığına dair kısa bir özet aşağıda verilmiştir.
Ayrıca Cloud Spanner, geleceğe hazır bir teknik mimari sunar.
2. Veri temeli oluşturma
İşletme gerekçesini belirledikten sonra uygulama aşamasına geçiyoruz. Bu bölümde, veri mimarimizi tanımlıyor, geleneksel ilişkisel modelin sınırlamalarını inceliyor ve derin analizler elde etmek için birincil aracımız olarak Özellik Grafiği'ni tanıtıyoruz.
Cloud Spanner Enterprise örneğini ayarlama
1. adım: Cloud Spanner API'yi etkinleştirin
Google Cloud Console'da sol gezinme için ekranın sol üst kısmındaki Menü simgesini tıklayın. Aşağı kaydırıp "Spanner"ı seçin veya "Spanner"ı arayın.
Artık Cloud Spanner kullanıcı arayüzünü görmelisiniz. Cloud Spanner API'nin henüz etkinleştirilmediği bir proje kullanıyorsanız etkinleştirmenizi isteyen bir iletişim kutusu gösterilir. API'yi zaten etkinleştirdiyseniz bu adımı atlayabilirsiniz.
Devam etmek için "Etkinleştir"i tıklayın:
2. adım: Cloud Spanner örneği oluşturun
İlk olarak bir Cloud Spanner örneği oluşturacaksınız. Yeni bir örnek oluşturmak için kullanıcı arayüzünde "Sağlanan örnek oluştur"u tıklayın.
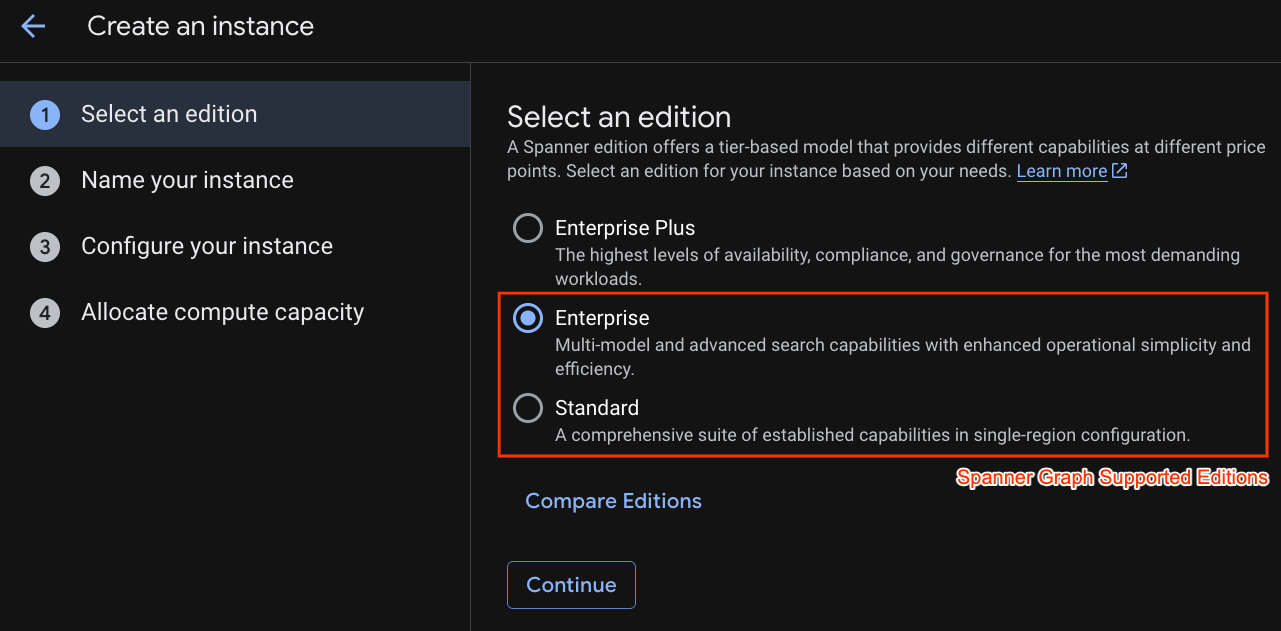
İlk adımda bir sürüm seçmeniz gerekir. Sürümü daha sonra da yükseltebileceğinizi unutmayın. Çok modelli özelliklerden (Spanner Graph) yararlanmak için Enterprise sürümünü kullanabilirsiniz.
Örneğinizi adlandırma
Bir dağıtım yapılandırması ve istediğiniz bir bölgeyi seçin.
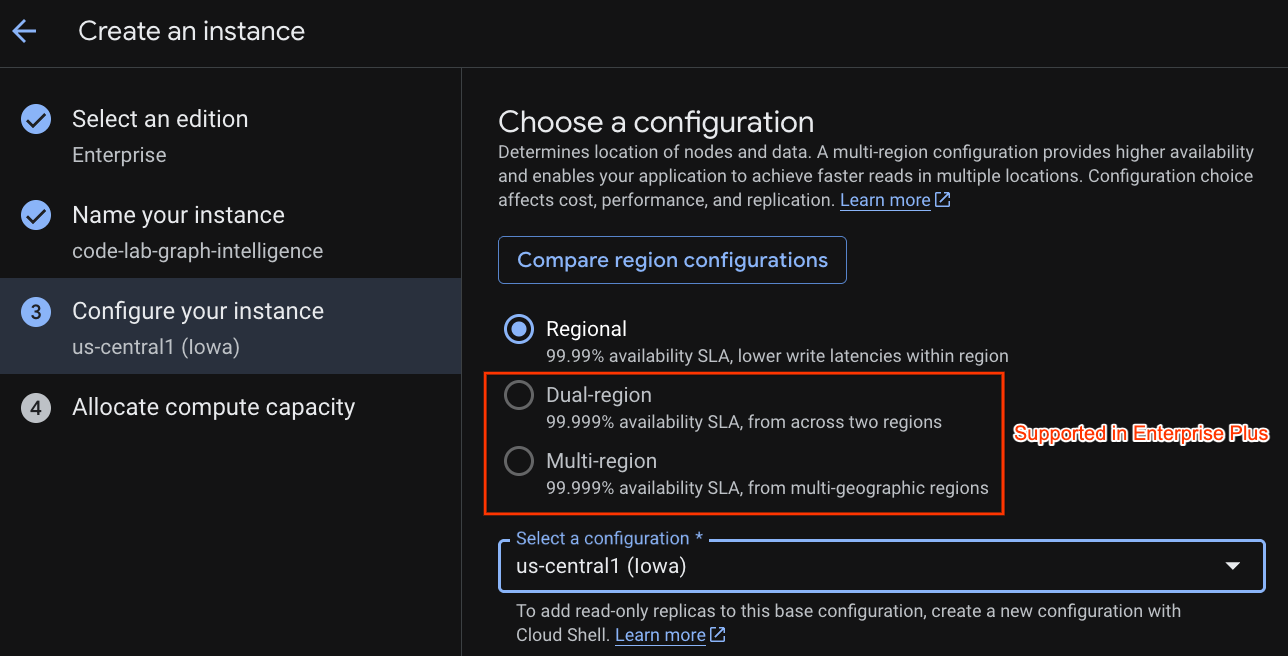
Ayrıca çeşitli yapılandırma seçeneklerini karşılaştırabilirsiniz. Örneğin, dağıtım yapılandırmasında seçtiğiniz bölgenin 3 ayrı bölgesinde en az 3 okuma/yazma replikası bulunur. Yani tek düğümlü bir dağıtım yapsanız bile 3 okuma/yazma replikası aracılığıyla 3 kopya elde edersiniz. Ayrıca, bölgesel dağıtım yapılandırmasıyla bile dağıtım topolojinizde ek salt okunur replikalar bulundurarak kapsamı daha da genişletebilirsiniz.
Kapasiteyi yapılandırdıktan sonra tam düğümle başlayıp düğümlerde otomatik ölçeklendirme yapabilir veya ayrıntılı bir örnek (işleme birimleri; 1.000 işleme birimi = 1 düğüm) kullanabilirsiniz. İsteğe bağlı olarak, örneğin otomatik ölçeklendirme hedeflerini de ayarlayabilirsiniz. Düşük gecikmeli iş yükleri için bölgesel örneklerde% 65, çok bölgeli örneklerde% 45 önerilir.
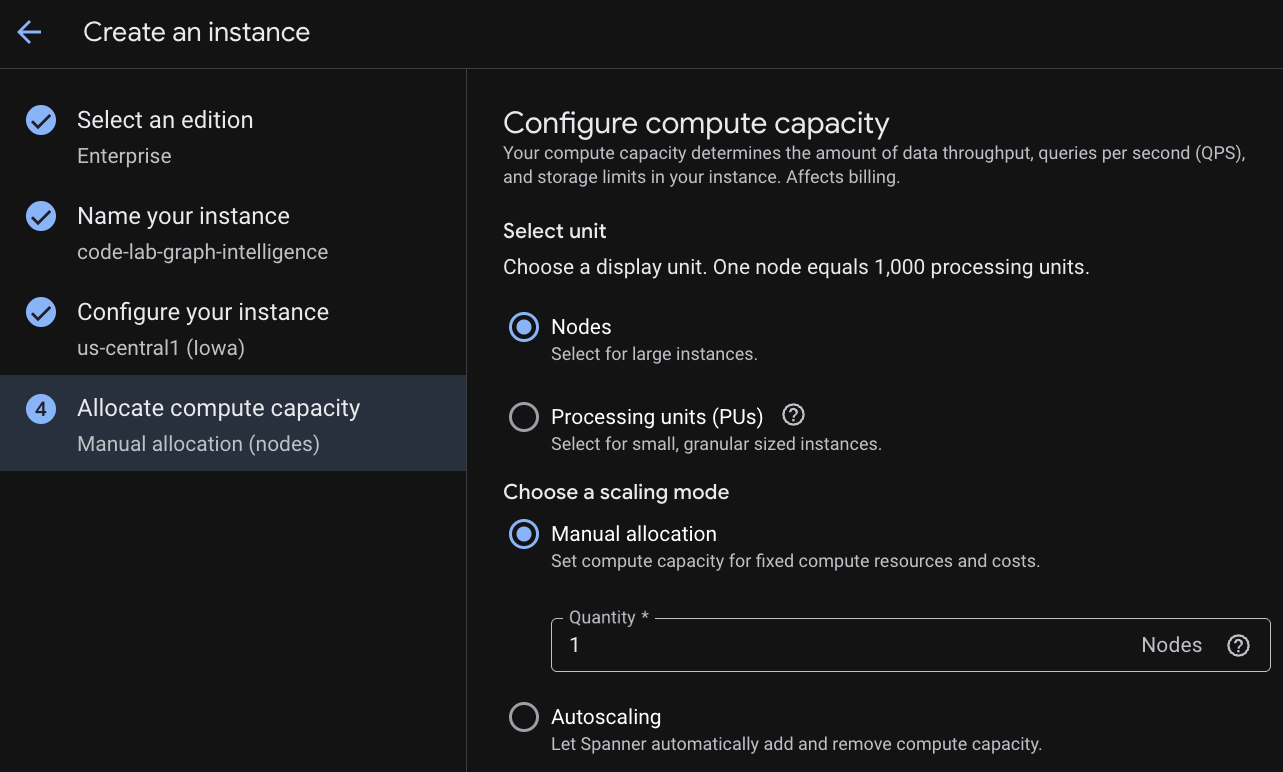
3. adım: Veritabanı oluşturun
Örneğiniz sağlandıktan sonra, codelab'inizin geri kalanı için bir veritabanı oluşturmak üzere "Veritabanı Oluştur"u tıklayın.
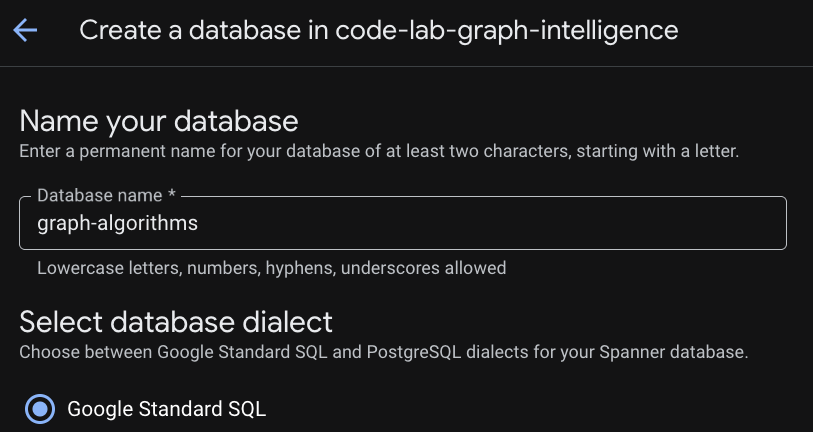
İlişkisel Temel Oluşturma
Yolculuğumuz, operasyonel verileri depolayan temel tablolarla başlar. Cloud Spanner'da, bir müşterinin arkadaşlıkları ve işlemleri gibi ilgili verileri doğrudan müşteri kaydıyla fiziksel olarak aynı yerde bulundurmak için Interleaving'i kullanırız. Bu sayede yüksek performanslı erişim ve fiziksel yerellik sağlanır.
DDL: Tabloları Oluşturma
İlişkisel şemanızı oluşturmak için aşağıdaki blokları kopyalayıp çalıştırın:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Ağı besleme
Tablolarımız hazır olduğunda, bunları Müşteri'nin ekosistemini tanımlayan kullanıcılar, ürünler ve bağlantılarla doldurmamız gerekir.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
İlişkisel Zorluk (Relational Challenge)
Grafiği tanıtmadan önce, geleneksel SQL'in müşterinin zorluklarıyla nasıl başa çıktığına bakalım. Bu sorguyu çalıştırarak önemli miktarda harcama yapan ve çok sayıda arkadaşı olan "Sosyal Harcama Yapanlar" müşterilerini bulun.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
İlişkisel Yaklaşımın Sınırlamaları
Özellik grafiğiyle ilişkisel zorlukların üstesinden gelme
Bu sınırları aşmak için Tesis Grafiği tanımlarız. Bu, verilerimizi Spanner'dan çıkarmadan ilişkileri birinci sınıf vatandaşlar olarak ele almamıza olanak tanıyan bir "kaplama" oluşturur.
DDL: Mülk grafiği oluşturma
Bu DDL, Düğümlerimizi (Varlıklar) ve Kenarlarımızı (İlişkiler) tanımlar. Bu örnekte şemalandırılmış bir grafiği takip ediyoruz. Ancak Spanner Graph, esnek ve hızlı yinelemeli geliştirmeyi etkinleştirmek ve sürekli DDL (Veri Tanımlama Dili) değişiklikleri olmadan gelişen veri modellerini işlemek için şemasız grafiklerin modellenmesine olanak tanır.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
GQL ile grafikte gezinme
Grafiğimiz tanımlandığına göre, basit ve okunabilir bir söz dizimiyle çok adımlı geçişler gerçekleştirmek için Grafik Sorgu Dili'ni (GQL) kullanabiliriz.
1. Keşif: Ortak Keşif
Bu sorgu, arkadaşlarınızın satın aldığı ürünleri bulmak için grafikte gezinir ve bir öneri motorunun temelini oluşturur.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
2. Keşif: Karma Sorgu (İlişkisel + Grafik)
Spanner, GRAPH_TABLE işlevini kullanarak standart bir SQL FROM ifadesine GQL kalıpları yerleştirmenize olanak tanır. Bu sorgu, arkadaşlarıyla aynı konumda yaşayan müşterileri bulur. Bu, "elmas" desen eşleşmesidir.
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Müşterinin Bağlantılarını Görselleştirme
Son olarak, ağımızı görselleştirmek için GQL'yi kullanalım. Bu sorgular, yol sonuçlarını SAFE_TO_JSON ile sarmalayarak görselleştiricilerin düğümleri ve çizgileri çizmesine olanak tanır.
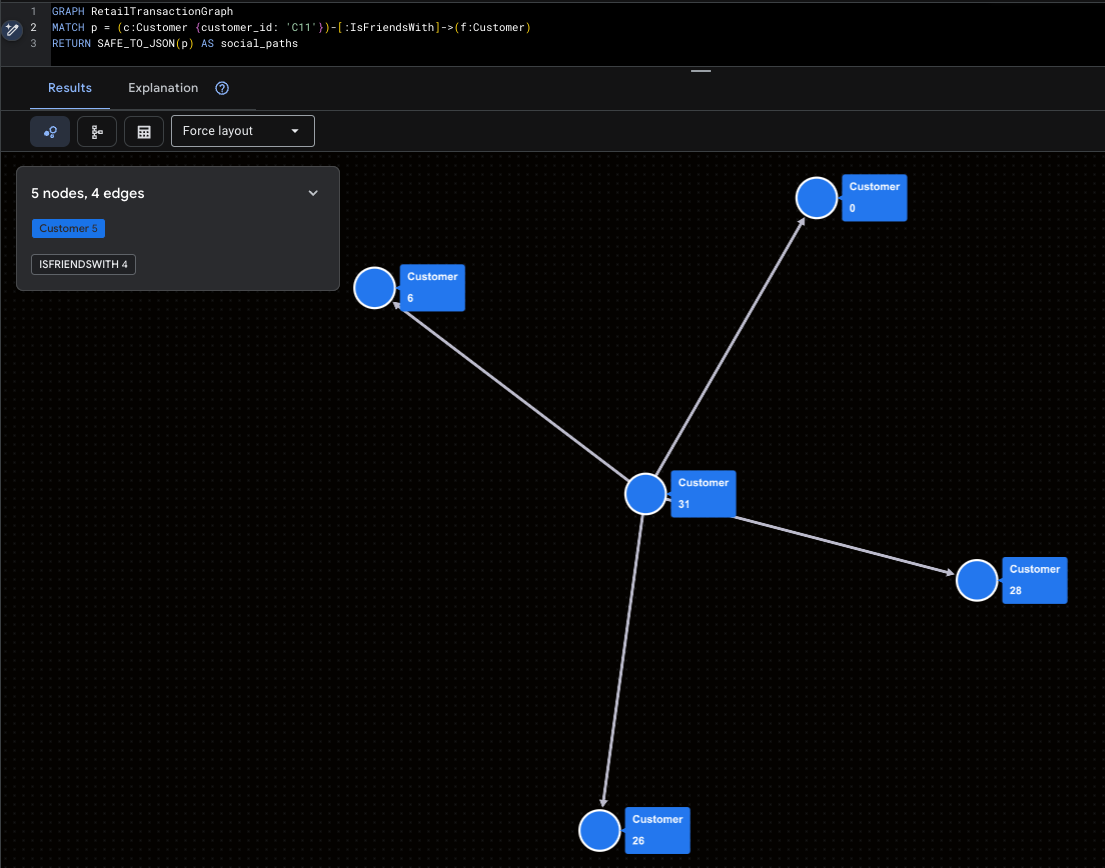
Süper etkileyicinin görselleştirilmesi
Bu örnekte Mallory (C11) ve doğrudan sosyal medya erişimi vurgulanıyor.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Olası sahtekarlık kalıplarını görselleştirme
Bu sorgu, ürünlerinin nereye gönderildiğini görmek için "Yalıtılmış Küme"yi (Ivan ve Judy) tespit eder.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Spanner Graph Algoritmalarına Giriş
Grafik Zekası'na ayrıntılı inceleme yapmaya hazırlanmak için bu bölümde Cloud Spanner Grafik Algoritmaları'nın teknik mimarisi ve temel kuralları özetlenmektedir. Bu ilkeleri anlamak, basit geçişlerden petabayt ölçeğinde ilişki analizine geçiş yapmanın anahtarıdır.
Algoritma Portföyü
Cloud Spanner şu anda 14 endüstri standardı grafik algoritmasını desteklemektedir. Bu algoritmalar, çeşitli iş sorunlarını çözmek için dört işlevsel grupta sınıflandırılmıştır:
Kategori | Desteklenen Algoritmalar | İşletme Kullanım Alanı |
Merkezilik (Centrality) | PageRank, Kişiselleştirilmiş PageRank, Arada Olma, Yakınlık | Etkileyicileri, merkezleri ve darboğazları belirleyin. |
Topluluk | WCC, Etiket Yayma, Clique Finding, Correlation Clustering | Sahtekarlık çetelerini, sosyal toplulukları ve bilgi silolarını tespit edin. |
Benzerlik (Similarity) | Jaccard, Kosinüs, Ortak Komşular, Toplam Komşu Sayısı | Öneri motorlarını ve varlık çözümlemesini destekleyin. |
Yol Bulma | Setten sete en kısa yol, GA yolu yardımcıları | Lojistiği ve geçiş yakınlığını optimize edin. |
Şema ve Sorguyla İlgili Önemli Hususlar
Grafik algoritmalarının verimli bir şekilde yürütülmesini sağlamak için Spanner Graph'in aşağıdaki kurallara uyması gerekir:
1. şart: Fiziksel Veri Yerelliği (İç içe geçirme)
Yüksek performanslı grafik geçişi için en kritik gereksinim Interleaving'dir. Bu, uç verilerin fiziksel olarak kaynak düğümle aynı sunucu bölümünde depolanmasını sağlayarak algoritma yürütme sırasında ağ gecikmesini en aza indirir.
- Kural: Kenar tabloları, kaynak düğüm tablolarında kesinlikle serpiştirilmelidir.
- İleri Geçiş: Kenar tablosunun kaynak düğüm tablosuna yerleştirilmesi, giden bağlantılar için önbellek yerelliğini sağlar.
- Ters Geçiş: "Gelen" bağlantıların verimli bir şekilde analiz edilmesi için destekleyici dizinleri otomatik olarak oluşturmak üzere yabancı anahtarları kullanın veya hedef tabloda araya yerleştirilmiş ikincil bir dizin oluşturun.
2. Şart Benzersiz Etiketleme Şartları
Mülk grafiğine katılan her tablonun benzersiz bir kimliği olmalıdır. Algoritmalar, analiz etmeleri gereken alt grafikleri doğru şekilde tanımlamak ve yüklemek için bu etiketleri kullanır.
- Kural: Her giriş tablosu, özellik grafiğinde benzersiz bir tanımlama etiketine sahip olmalıdır.
- Çakışma: Üzerlerinde algoritma çalıştırmak istiyorsanız tek bir etiketi birden fazla tabloyla eşleyemezsiniz.
Mantık (Logic) | Örnek | Sonuç |
❌ Kötü | NODE TABLES (Person LABEL Entity, Account LABEL Entity) | Geçersiz: Algoritma, Kişi ile Hesap arasında ayrım yapamıyor. |
✅ İyi | NODE TABLES (Person LABEL Customer, Account LABEL Account) | Geçerli: Her varlığın farklı ve benzersiz bir etiketi vardır. |
3. Şart Algoritma Sorgu Yapısı (MATCH Clause)
Bir algoritma çağrılırken, yürütme motorunun analitik işlem hattını optimize edebilmesi için MATCH ifadesi standart GQL sorgularından daha kısıtlayıcı kurallara uyar.
- MATCH başına bir kalıp: Her MATCH ifadesi yalnızca bir değişken adlandırabilir.
- Çok düğümlü kalıplar yok: Bir algoritma çağrısı için tasarlanan bir MATCH ifadesinin içinde doğrudan bir ilişki kalıbı (ör. (a)-[e]->(b)) tanımlayamazsınız.
- Yalnızca Değişmez Filtreler: WHERE yan tümcelerini kullanarak düğümleri filtreleyebilirsiniz (ör. WHERE a.id > 400) ancak sorgu parametreleri (@param) şu anda grafik algoritması sorgularında desteklenmemektedir.
4. Şart RETURN ifadesi (yalnızca skalerler)
Bir algoritma sorgusundaki RETURN ifadesi, grafik dünyası ile ilişkisel dünya arasında köprü görevi görür. Yalnızca skaler ve sabit değerler döndürülür.
- Kural: "Grafik Öğesi" (ham düğüm veya kenar nesnesi) döndüremezsiniz.
- Dönüşüm Yok: RETURN ifadesinin kendisinde döndürülen özelliklere matematik işlemleri uygulayamaz veya işlevler kullanamazsınız.
RETURN Clause Restrictions (RETURN Deyimi Kısıtlamaları)
✅ Destekleniyor | ❌ Desteklenmiyor |
RETURN node.id, score | RETURN düğümü, puan (Grafik Öğesi döndürülemiyor) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (Özellikler üzerinde işlem yok) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (İşlev yok) |
5. Şart Veri Bütünlüğü: Boşta Kalan Kenarları Ortadan Kaldırma
Bir uç, grafikte bulunmayan bir hedef düğüme işaret ettiğinde "Dangling Edge" (Boşta Kalan Uç) oluşur. Bu durum, grafik yapısı tutarsız olduğundan algoritma yürütülmesinin başarısız olmasına neden olur.
- Çözüm: Grafik bütünlüğünü korumak için referans kısıtlamaları (yabancı anahtarlar) ve ON DELETE CASCADE kullanın.
- Sorgu Güvenliği: Bir algoritmayı çağırırken seçilen kenarların referans verdiği tüm düğümlerin node_labels bağımsız değişkenine de dahil edildiğinden emin olmanız gerekir.
Kalıcı Çıkış: VERİ DIŞA AKTARMA Seçenekleri
Grafik algoritmaları hesaplama açısından yoğun olduğundan EXPORT DATA ifadesi kullanılarak ölçeklendirme yürütme modunda yürütülür. Bu özellik, üretim işlemlerinizde gecikmeyi önlemek için bağımsız sunucusuz bilgi işlem kaynaklarını kullanan Data Boost'tan yararlanır.
1. seçenek: Cloud Spanner'a geri kalıcı hale getirme
Sonuçları doğrudan tablolarınıza geri göndermek için (ör. PageRank puanı kaydetme) format = "CLOUD_SPANNER" değerini kullanın.
update_ignore_all: Yalnızca hedef tabloda zaten bulunan anahtarlara ait satırları günceller.upsert_ignore_all: Mevcut satırları günceller veya anahtarlar eksikse yeni satırlar ekler.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
2. seçenek: Sonuçları Google Cloud Storage'da (GCS) kalıcı hale getirme
Büyük ölçekli çevrimdışı analiz için CSV, Avro veya Parquet biçimlerinde GCS'ye aktarabilirsiniz.
- Joker karakterler:
uri => 'gs://bucket/file_*.csv'kullanarak parçalanmış çıkışı etkinleştirin. Bu sayede Spanner, büyük veri kümeleri için paralel olarak birden fazla dosyaya yazabilir. - Sıkıştırma: Depolama maliyetlerini optimize etmek için GZIP, SNAPPY ve ZSTD'yi destekler.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. 1. Zorluk: Etki Boşluğu (PageRank)
Bu bölümde, Müşteri'nin ilk iş engeli olan "Etki Boşluğu" konusunu ele alıyoruz. Basit bir "popülerlik yarışmasından" gerçek sosyal etkiyi gösteren matematiksel bir haritaya geçeceğiz.
Sorun açıklaması: Müşterinin pazarlama ekibi bir sorunla karşı karşıya. "Sosyal Süperstarlar"ı (onayları tüm ağda yankı uyandıran nadir kişiler) belirleyemedikleri için, daralan getirilerle birlikte geniş kapsamlı reklamcılığa milyonlarca dolar harcıyorlar.
Bu sorunu çözmek için müşterilerimizi Etki'ye göre sıralamamız gerekir.
İlişkisel Çözüm (Merkezilik Derecesi)
Standart bir veritabanında, bir influencer'ı bulmanın en kolay yolu takipçilerini saymaktır (Merkezilik Derecesi olarak bilinen bir metrik).
En "popüler" kullanıcıları bulmak için bu sorguyu çalıştırın:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Grafik Zekası (PageRank)
Gerçek liderleri bulmak için PageRank'i kullanırız. Bu, ilk web aramasını destekleyen algoritmayla aynıdır. Bir düğümün önemini, gelen bağlantıların hem miktarına hem de kalitesine göre ölçer.
- Rastgele Gezgin Modeli: PageRank, grafikte hareket eden bir kullanıcıyı simüle eder. Sönümleme faktörü (varsayılan 0,85), kullanıcının tıklamaya devam etme olasılığını gösterir.Aksi takdirde, kullanıcı rastgele bir düğüme "ışınlanır".
- İlişkilendirme Gücü: Etkili bir kişiden (ör. Mallory) gelen bağlantı, başka bağlantısı olmayan birinden gelen bağlantıdan çok daha değerlidir.
PageRank algoritmasını çalıştırıp sonuçları doğrudan pagerank_score sütunumuza kaydetmek için EXPORT DATA komutunu kullanacağız .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
PageRank'i kullanan "Etki" kontrol paneli
Puanlar kalıcı hale geldiğine göre şimdi "Önce" (takipçi sayısı) ve "Sonra" (PageRank puanı) değerlerimizi karşılaştıralım.
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0,1093561724 |
C9 | ivan@example.com | 1 | 0,1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0,09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0,0547891818 |
C3 | charlie@example.com | 1 | 0,0547891818 |
C12 | trent@example.com | 1 | 0,04029225558 |
C4 | david@example.com | 1 | 0,04028172791 |
Analiz: Gerçek Süperstarlar Kimler?
Çıktıyı analiz ederek artık üç önemli pazarlama keşfi yapabilirsiniz:
İşletmeyle İlgili Önemli Bilgiler
Müşterinin pazarlama ekibi, beşten fazla takipçisi olan herkese e-posta göndermek yerine artık yalnızca en yüksek pagerank_score değerine sahip olanlara odaklanabiliyor. Bu kişiler, tüm pazar yerinde sistemik olarak viral içerikler oluşturabilen gerçek "Sosyal Süperstarlar"dır.
Şimdi Müşteri'nin lojistik ağının çalışmasını sağlayan bekçileri belirlemeye çalışalım.
5. 2. Görev: Lojistik Esneklik (BetweennessCentrality)
Bu bölümde Lojistik Esnekliği ele alınmaktadır. Başarıyı "hacim" ile ölçmenin ötesine geçerek ağı bağlı tutan önemli "kapı bekçilerini" belirleyeceğiz.
İlişkisel Çözüm (Hacme Dayalı Analiz)
Standart bir ilişkisel kurulumda, "kritik" bir kargo merkezi genellikle en çok siparişi işleyen veya en çok geliri elde eden merkez olarak tanımlanır.
İşlem sayısına göre "en iyi" merkezleri belirlemek için bu sorguyu çalıştırın:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
New York | ABD | 4 | 3996 |
Berlin | Almanya | 2 | 345 |
San Francisco | ABD | 2 | 750 |
Uyuşmazlığı gidermek için hem IsFriendsWith hem de LivesAt kenarlarını kullanacağız. Bu sayede analizimiz, sosyal medya kontrolünü de içerecek şekilde bir işlem merkezine dönüşür.
Grafik Zekası (Aracılık Merkeziyet Ölçüsü)
Gerçek darboğazları bulmak için Aracılık Merkeziyeti'ni kullanırız. Bu algoritma, bir düğümün grafikteki diğer tüm düğüm çiftleri arasındaki en kısa yollarda ne sıklıkta "köprü" görevi gördüğünü ölçer. Yüksek puanlar, ürün veya bilgi akışını kontrol eden gerçek bekçileri gösterir.
Aracılık Merkeziyetini Çalıştırma ve Kalıcı Hale Getirme
EXPORT DATA kullanarak algoritmayı çalıştıracak ve puanları centrality_score sütununa kaydedeceğiz. Bu yoğun "en kısa yol" hesaplamasının müşterinin canlı işlemleri üzerinde neredeyse sıfır etkisi olmasını sağlamak için Veri Artırma'yı kullanırız.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Analiz: "Gizli darboğazları" belirleme
Şimdi, Müşteri'nin yöneticilerinin endişelenmesi gereken düğümleri bulmak için yapısal riskimizi (centrality_score) işlem hacmimizle (order_count) karşılaştırıyoruz.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Müşteri bu sonuçları analiz ederek üç şaşırtıcı keşifte bulunur:
İşletmeler İçin Önemli Noktalar
Müşteri artık lojistik yedekliliğine ve güvenlik protokollerine çok modlu yapısal riske göre öncelik verebilir. Lojistik ağının istikrarını sağlamak için korunması gereken kapı bekçileri Mallory, Alice ve Eve'dir.
Şimdi de sahtekarlık adalarını izole etmeyi deneyelim.
6. 3. Zorluk: Hayalet Ağlar (WCC)
Bu bölümde, üçüncü işletme engelini ele alıyoruz: "Hayalet Ağlar". Basit "hotspot" algılamadan, topluluk algılama özelliğini kullanarak gelişmiş ve izole edilmiş sahtekarlık şebekelerini ortaya çıkarmaya geçeceğiz. Buradaki sorun, kötü niyetli kişilerin sahte profiller oluşturarak hırsızlıkları koordine etmek ve ürün puanlarını yükseltmek için kapalı döngülerde etkileşimde bulunmasıdır. Ancak bu kişiler genellikle meşru Müşteri topluluğundan tamamen izole edilir.
Bu sorunu çözmek için bu "izole adaları" ortaya çıkarmamız gerekiyor.
İlişkisel Çözüm (Paylaşılan Tanımlayıcı Arama)
Grafik algoritmaları olmadan, sahtekarlığı tespit etmenin standart yolu, paylaşılan verilerin "yoğun noktalarını" aramaktır. Örneğin, birden fazla müşterinin tam olarak aynı adrese gönderim yapması.
Ortak bir kargo konumuyla bağlantılı müşterileri bulmak için bu sorguyu çalıştırın:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
E5 | 2 | ["C7","C8"] |
Sahtekarlık ağlarını bulmak için geçişli erişilebilirliği anlamamız gerekir.
Grafik Zekası (Zayıf Bağlantılı Bileşenler)
Bu halkaların tamamını bulmak için Zayıf Bağlantılı Bileşenler (WCC) kullanırız. WCC, kenarların yönünden bağımsız olarak herhangi iki düğüm arasında bir yolun bulunduğu düğüm kümelerini tanımlayan bir kümeleme algoritmasıdır.
- Erişilebilirlik Bölgeleri: Grafiği etkili bir şekilde "adalar" veya "erişilebilirlik bölgeleri" olarak ayırır.
- Birleştirilmiş Varlık Görünümü: Hem sosyal bağları (IsFriendsWith) hem de lojistik bağları (LivesAt) aynı anda analiz ederek parçalanmış profilleri tek bir birleştirilmiş "Etki Kümesi" içinde gruplandırabiliriz.
WCC'yi çalıştırma ve kalıcı hale getirme
WCC algoritmasını çalıştırıp sonuçları community_id sütununa kaydedeceğiz. Bu ayrıntılı erişilebilirlik analizinin bağımsız bilgi işlem kaynaklarında gerçekleşmesini sağlamak için Veri Artırma'yı kullanırız.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Analiz: Sahtekarlık Çeteleri
Şimdi, izole edilmiş topluluklarımızı görmek için bir doğrulama sorgusu çalıştıralım. Gerçek kullanıcılar genellikle "Anakara"ya aitken sahtekarlar genellikle küçük "Adalar"da mahsur kalır.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | members |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Bu topluluk algılamayı çalıştırarak önemli bir anormalliği belirleyebilirsiniz:
İşletmeler İçin Önemli Noktalar
Müşteri artık güvenlik yanıtlarını otomatikleştirebilir. Tek tek hesapları manuel olarak takip etmek yerine basit bir kural yazabilirler: "Bir community_id'de üçten az üye varsa grubun tamamını manuel KYC (Müşterinizi Tanıyın) incelemesi için işaretle"
.
Sahtekarlık şebekelerimiz açığa çıktığında "Davranışsal İkiz" sorununu çözebiliriz.
7. 4. Zorluk: Davranışsal İkiz (JaccardSimilarity)
Bu son zorlukta, dördüncü engeli ele alıyoruz: "Seçim Paradoksu"/"Davranışsal İkiz". Genel "birlikte sıkça satın alınanlar" listelerinden, davranışsal "parmak izlerine" dayalı son derece kişiselleştirilmiş önerilere geçeceğiz.
Müşterinin mevcut ürün önerileri çok genel. Her müşteriye popüler bir USB kablosu önermek güvenlidir ancak kişisel değildir. Müşteri, yüksek hassasiyetli eşleşme sağlayan ürünler önermek için benzersiz kargo kalıpları ve sosyal çevreleri olan müşterileri belirleyen "Davranışsal İkiz" önerileri oluşturmak istiyor.
Bu sorunu çözmek için kullanıcılar arasındaki "Yakınlık" değerini hesaplamamız gerekir.
İlişkisel Çözüm (Mutlak Çakışma)
Standart bir ilişkisel kurulumda, Alice (C1) gibi bir referans kullanıcıyla aynı konumlara gönderim yapan kullanıcıları arayabilirsiniz.
Ayşe'nin coğrafi komşularını bulmak için şu sorguyu çalıştırın:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence (Jaccard Benzerliği)
Gerçek davranış ikizlerini bulmak için Jaccard benzerliği kullanırız. Bu algoritma, paylaşılan komşu sayısını (kesişim) benzersiz komşuların toplam sayısına (birleşim) bölerek normalleştirilmiş bir puan (0,0-1,0) hesaplar.
Burada "davranış ikizi", yalnızca paylaşılan bir kargo adresinden daha fazlasıyla tanımlanır. Fiziksel ayak izlerinin (LivesAt) ve sosyal ekosistemlerin (IsFriendsWith) kesişimini analiz ederek aynı yaşam tarzına ve topluluk etkisine sahip kullanıcıları belirleyebiliriz. Bu sayede çok daha doğru ürün önerileri sunabiliriz.
Önce bir eşleme tablosu oluşturun
Benzerlik çiftler halinde bir ilişki olduğundan (A müşterisi B müşterisine benzer), bu eşlemeleri depolamak için Customer ile iç içe yerleştirilmiş özel bir tablo oluştururuz.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Şimdi Jaccard Benzerliği'ni Çalıştırın
Şimdi algoritmayı çalıştıracağız. Not: Bu sorgu, ortak bir "Guardrail" dersi içerir. Yalnızca Müşteri düğümlerini seçip LivesAt kenarını (Kargo düğümlerini gösterir) kullanırsanız sorgu, "Dangling Edge" (Sarkan Kenar) hatası vererek başarısız olur . Bu sorunu düzeltmek için her iki düğüm etiketini de eklememiz gerekir.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Analiz: "Davranışsal İkiz" Kontrolü
Analiz işi tamamlandıktan sonra bir doğrulama sorgusu çalıştırırız. Yeni eşleme tablomuzu (CustomerSimilarity) orijinal Customer meta verilerimizle birleştirerek Ayşe'nin "davranış ikizlerinin" kimler olduğunu tam olarak görebiliriz.
Alice'in benzerlik sıralamalarını incelemek için bu sorguyu çalıştırın:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0,1093561724 |
bob@example.com | 0.200000003 | 0 | 0,0547891818 |
ivan@example.com | 0.200000003 | 1 | 0,1093561724 |
eve@example.com | 0,1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0,09466411918 |
trent@example.com | 0 | 0 | 0,04029225558 |
charlie@example.com | 0 | 0 | 0,0547891818 |
david@example.com | 0 | 0 | 0,04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Sonuçlarda dikkat edilecek noktalar:
Şimdi de son bir Birleşik İstihbarat görünümü oluşturmayı deneyelim.
8. Birleşik Zeka
Şimdi de bireysel teknik görevlerden Birleşik Zeka'ya geçiyoruz. Burada, net ve uygulanabilir analizler sağlamak için işlem verilerini dört grafik algoritmasıyla birleştiriyoruz.
1. rapor: Birleşik analizler
Spanner gibi çok modelli bir veritabanının gücü, ilişkisel harcama verilerini tek bir istekte grafiklerden elde edilen etki, risk ve benzerlik puanlarıyla birleştirme yeteneğidir. Bu sorgu, her müşteriyi belirli bir işletme karakterine göre sınıflandırır.
Eksiksiz ekosistemi görmek için Birleşik İstihbarat sorgusunu çalıştırın:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | harcama | etki | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0,09466411918 | 44,5 | 0 | 🔵 KRİTİK: Ağ Köprüsü |
C5 | eve@example.com | 0 | 0.158392489 | 35,5 | 0 | 🔵 KRİTİK: Ağ Köprüsü |
C1 | alice@example.com | 999 | 0.1000888124 | 35,5 | 0 | 🔵 KRİTİK: Ağ Köprüsü |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 SOSYAL: Yüksek erişimli influencer |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 SOSYAL: Yüksek erişimli influencer |
C3 | charlie@example.com | 0 | 0,0547891818 | 6 | 0 | 🟢 STANDART: Etkin Müşteri |
C4 | david@example.com | 0 | 0,04028172791 | 3,5 | 0 | 🟢 STANDART: Etkin Müşteri |
C10 | judy@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 YÜKSEK RİSK: İzole Dolandırıcılık Çetesi |
C9 | ivan@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 YÜKSEK RİSK: İzole Dolandırıcılık Çetesi |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 STANDART: Etkin Müşteri |
C2 | bob@example.com | 999 | 0,0547891818 | 0 | 0 | 🟢 STANDART: Etkin Müşteri |
C12 | trent@example.com | 0 | 0,04029225558 | 0 | 0 | 🟢 STANDART: Etkin Müşteri |
Bu matematiksel yaklaşımları birleştirerek "en çok kim harcadı?" sorusundan "en önemli kim?" sorusuna geçiyoruz. Birleştirilmiş kontrol paneli, ekosisteminizi üç net ve uygulanabilir kişiye göre sınıflandırmak için ilişkisel işlem verilerini çok formatlı grafik zekasıyla entegre eder.
"Kritik Ağ Köprüleri" (Esneklik)
Mallory (C11), Eve (C5) ve Alice (C1) gibi düğümlerin bottleneck_risk (aracılık merkeziyeti) değeri >25 olduğundan bu düğümler işaretlenir.
- Yapısal Bağlantılar: Mallory, 44,5 ile en yüksek risk puanına sahip olduğundan tüm ağ için birincil ağ geçidi olarak işaretlenir.
- Sıfır Harcama Paradoksu: Elif (C5), sıfır sipariş sayısına sahip olmasına rağmen 35,5 risk puanıyla yapısal olarak vazgeçilmezdir. Standart SQL onu tamamen göz ardı ederdi ancak Graph Intelligence, onun bir alt topluluğun tamamı için hayati bir köprü olduğunu ortaya çıkarıyor.
- Yüksek Değerli Ağ Geçidi: Ayşe (M1), 35,5 ile Elif ile eşit puan aldı ve yüksek harcama yapanların da önemli yapısal bağlantılar olabileceğini kanıtladı.
"Sosyal Medya Süperstarları" (Erişim)
Heidi (C8) ve Grace (C7), PageRank puanları nedeniyle yüksek erişimli influencer'lar olarak tanımlanıyor .
"İzole Dolandırıcılık Şebekesi" (Anormallikler)
Judy (C10) ve Ivan (C9), izole edilmiş community_id 1'e ait oldukları için işaretlenir.
İşletme içgörüsünden stratejik işlemlere
Persona | Anahtar Metrik | Business Insight | Stratejik İşlem |
🔵 Ağ Köprüleri | Yüksek Merkeziyet (High Centrality) | Yapısal Sabitleyiciler: Eve (C5) ve Mallory (C11), ağı bir arada tutar. | Elde tutma: Topluluğun parçalanmasını önlemek için bu kişileri koruyun. |
📱 Sosyal Medya Süperstarları | Yüksek PageRank | Viral Motorlar: Heidi (C8) gibi kullanıcılar çevrelerinde en yüksek erişime sahiptir. | Pazarlama: Yüksek etkili tavsiye ve marka elçisi programları için kullanın. |
🔴 Sahtekarlık Riskleri | Yalıtılmış WCC | Hayalet Ağlar: Judy (C10) ve Ivan (C9) yüksek harcama yapan müşterilerdir ancak "adalar"da yaşamaktadır. | Güvenlik: Anında manuel KYC incelemesi; bunlar klasik sahtekarlık imzalarıdır. |
🟢 Standart Kullanıcılar | Dengeli puanlar | Sağlıklı Çekirdek: David (C4) gibi "yerel" köprüler de dahil olmak üzere ağın büyük bir kısmı. | Büyüme: Standart kişiselleştirilmiş reklamları ve "davranışsal benzer" önerilerini uygulayın. |
2. Rapor: Kimlik Anormalliği Raporu
Şimdi de dolandırıcıların yasal hesapları "taklit edip etmediğini" öğrenmeniz gerekiyor. % 100 davranış benzerliğine sahip ancak sosyal bağlantısı olmayan kullanıcıları bularak bu sorunu çözebiliriz.
Olası "Kimlik Anomalilerini" işaretlemek için bu sorguyu çalıştırın:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Anormallik Belirleme Raporu önemli bilgiler sağlar. Gerçek müşteriler gibi davranan ancak sosyal bağları olmayan kullanıcıları izole ederek tahminden matematiksel kesinliğe geçiş yapıyoruz .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
Sonuçların Analizi
Benzerlik (Jaccard) ile Topluluk Algılama (WCC)'yı birleştirerek geleneksel işlem verilerinin göremediği gizli riskleri ortaya çıkarıyoruz.
- "Davranışsal İkizler" (Yakınlık): Judy (C10) ve Ivan (C9) gibi düğümler, Alice (C1) ile ilgili olarak 0,20 Jaccard benzerliği puanını paylaştıkları için işaretlenir.
- İzolasyon Davranışı: Judy (C10) ve Ivan (C9) izole edilmiş community_id 1'de gruplandırılırken Alice sosyal "Anakara"ya (Topluluk 0) aittir.
- Sahtekarlık İşaretleri: Raporda, davranışları büyük oranda örtüşen (>0,9) ve birincil ağdan sosyal olarak bağlantısı kesilmiş kullanıcılar tanımlanır.
9. Tebrikler ve Özet
Bu laboratuvarda, Cloud Spanner'ın ilişkisel bir veritabanını nasıl çok modelli bir güç merkezine dönüştürdüğü gösterilmektedir. Grafik zekasını Müşteri'ye uygulayarak statik verilerden uygulanabilir iş stratejisine geçtik.
Spanner Multi-Model'in avantajları
- Birleşik Mimari: Spanner, ETL'nin riskleri ve gecikmeleri olmadan, ilişki madenciliği için anında bir özellik grafiği "yerleştirirken" kaya gibi sağlam bir ilişkisel temel oluşturmanıza olanak tanır.
- Kutu Dışı Analitik Yalıtım: Data Boost'tan yararlanarak PageRank veya WCC gibi bellek yoğun algoritmaları bağımsız ve sunucusuz bilgi işlem kaynaklarında çalıştırabilir, böylece üretim ödeme performansınızın etkilenmemesini sağlayabilirsiniz.
- İç içe yerleştirilmiş performans: Spanner'ın benzersiz iç içe yerleştirme özelliği, düğümlerin ve ilişkilerinin fiziksel olarak aynı yerde bulunmasını sağlayarak karmaşık küresel geçişleri yüksek hızlı yerel aramalara dönüştürür.
"Gizli Hazineleri" ve Anormallikleri Ortaya Çıkarma
- Yapısal Değeri Belirleme: Betweenness Centrality gibi grafik algoritmaları, sıfır harcama ile "Gizli Köprüler"i ortaya çıkardı. Bu köprüler, ağın esnekliği açısından en çok harcama yapan müşterilerden daha önemli olabilir.
- Davranışsal Taklitçiliği Ortaya Çıkarma: Jaccard Benzerliği ve Zayıf Bağlantılı Bileşenler'i birleştirerek "Sosyal Yabancıları" belirledik. Bu hesaplar meşru müşteriler gibi görünse de matematiksel olarak izole edilmiş sahtekarlık çeteleri olduğu kanıtlanmıştır.
- Küresel ve Yerel Gerçek: Manuel SQL analizi köprüleri ortaya çıkarabilirken küresel algoritmalar ağın önemli bekçilerini ortaya çıkarabilir.
Verileri Akıllı ve İşlem Yapılabilir Hale Getirme
- Karakter odaklı strateji: Satırlarımızı başarıyla ilişkiye dönüştürdük ve algoritmalar çalıştırarak dört iş sorununu (Ağ Köprüleri, Sosyal Medya Süperstarları, Sahtekarlık Riskleri ve Standart Kullanıcılar) ele alabiliyoruz.