
1. Nghiên cứu điển hình: Intelligent Retail
Đối với nghiên cứu điển hình này, chúng ta sẽ lấy một Khách hàng bán lẻ có một trang web thương mại kỹ thuật số đang phát triển nhanh chóng. Chế độ xem dữ liệu truyền thống của khách hàng bị hạn chế vì chế độ này cho biết những gì mọi người mua, nhưng không cho biết cách họ kết nối. Khoảng trống này dẫn đến việc bỏ lỡ cơ hội và gia tăng hành vi gian lận. Giờ đây, họ đang chuyển sang triết lý Ưu tiên mạng lưới để coi trọng các mối quan hệ xã hội và hậu cần, ngoài dữ liệu giao dịch.
Những thách thức cốt lõi về hoạt động kinh doanh cần giải quyết
Bạn có 4 thách thức quan trọng đòi hỏi bạn phải hiểu rõ mối liên kết giữa khách hàng và hoạt động hậu cần:
Thử thách | Vấn đề | Mục tiêu |
Khoảng cách ảnh hưởng | Quảng cáo trên diện rộng mang lại lợi tức đầu tư thấp; hiện tại, bạn không thể xác định những người tạo xu hướng (người có ảnh hưởng) thực sự. | Xác định Người có tầm ảnh hưởng: Những người có vai trò quan trọng trong cộng đồng thông qua mối quan hệ của họ trong mạng lưới khách hàng có kết nối. |
Khả năng phục hồi của hoạt động kho vận | Chuỗi cung ứng có thể dễ bị tổn thương (xét đến việc các công ty này hoạt động ở nhiều khu vực địa lý). Nếu một trung tâm khoá gặp sự cố, toàn bộ khu vực có thể mất quyền truy cập vào sản phẩm. | Xác định Người gác cổng : những người đóng vai trò quan trọng trong việc kết nối các mạng lưới hậu cần với nhau. |
Ghost Networks | Các băng nhóm lừa đảo sử dụng hồ sơ giả và địa chỉ dùng chung để phối hợp hành vi trộm cắp và tăng điểm đánh giá. | Vạch trần Các nhóm biệt lập : Các nhóm có mối liên kết chặt chẽ với nhau nhưng không có mối liên hệ nào với cộng đồng hợp pháp. |
Nghịch lý của sự lựa chọn | Công cụ đề xuất/gợi ý hiện tại còn sơ khai, chung chung và thường bị bỏ qua (ví dụ: "Những khách hàng đã mua sản phẩm này cũng mua ..."). | Xây dựng Hành vi tương tự; tức là đề xuất dựa trên các mẫu vận chuyển và vòng kết nối xã hội tương tự. |
Liên kết các thách thức về kinh doanh với chiến lược kỹ thuật (Hàng → Mối quan hệ)
Trong cơ sở dữ liệu truyền thống, dữ liệu được lưu trữ trong các kho dữ liệu riêng biệt: khách hàng trong một bảng, giao dịch trong một bảng khác, thông tin vận chuyển trong bảng thứ ba. Mặc dù SQL rất phù hợp để trả lời câu hỏi "Ai đã mua sản phẩm nào?", nhưng lại khó trả lời các câu hỏi dựa trên mạng.
Để giải quyết những thách thức này, chiến lược kỹ thuật là thay đổi quan điểm này:
- Chế độ xem mối quan hệ ("What"): Coi mỗi khách hàng là một hàng riêng biệt. Để tìm ra mối liên hệ giữa một khách hàng và giao dịch mua của bạn bè, bạn cần thực hiện nhiều thao tác "kết hợp" phức tạp, và các thao tác này sẽ chậm đi theo cấp số nhân khi mạng lưới phát triển.
- Chế độ xem biểu đồ ("Cách thức"): Coi các mối quan hệ là yếu tố quan trọng hàng đầu. Thay vì tìm kiếm trong danh sách, chúng ta sẽ di chuyển trên bản đồ. Chúng ta có thể thấy ngay rằng Khách hàng A được kết nối với Khách hàng B, người vận chuyển đến Vị trí Z.
Tìm hiểu kỹ các yêu cầu
Các kiến trúc sư giải pháp kết luận rằng yêu cầu kinh doanh và chiến lược kỹ thuật đòi hỏi một phương pháp đa mô hình và xác định các yêu cầu chính sau đây.
Cách Cloud Spanner đáp ứng những yêu cầu kỹ thuật đó
Cloud Spanner được chọn làm cốt lõi của quá trình chuyển đổi này. Nhờ đó, Khách hàng có thể duy trì nền tảng quan hệ vững chắc, đồng thời khai thác thông tin chi tiết chuyên sâu về biểu đồ.
Sau đây là thông tin tóm tắt nhanh về cách Cloud Spanner đáp ứng các yêu cầu kỹ thuật và nhiều yêu cầu khác.
Ngoài ra, Cloud Spanner còn cung cấp một Cấu trúc kỹ thuật có khả năng thích ứng với tương lai
2. Thiết lập nền tảng dữ liệu
Sau đề án kinh doanh, chúng ta sẽ chuyển sang giai đoạn triển khai. Trong phần này, chúng ta sẽ xác định cấu trúc dữ liệu, khám phá những hạn chế của mô hình quan hệ truyền thống và giới thiệu Đồ thị thuộc tính làm công cụ chính để khám phá thông tin chi tiết chuyên sâu.
Thiết lập phiên bản Cloud Spanner Enterprise
Bước 1: Bật Cloud Spanner API
Trong Google Cloud Console, hãy nhấp vào biểu tượng Trình đơn ở trên cùng bên trái màn hình để mở trình đơn điều hướng bên trái. Di chuyển xuống rồi chọn "Spanner" hoặc tìm kiếm "Spanner"
Bây giờ, bạn sẽ thấy giao diện người dùng Cloud Spanner. Giả sử bạn đang sử dụng một dự án chưa bật API Cloud Spanner, bạn sẽ thấy một hộp thoại yêu cầu bạn bật API này. Nếu đã bật API, bạn có thể bỏ qua bước này.
Nhấp vào "Bật" để tiếp tục:
Bước 2: Tạo phiên bản Cloud Spanner
Trước tiên, bạn sẽ tạo một phiên bản Cloud Spanner. Trong giao diện người dùng, hãy nhấp vào "Tạo một phiên bản được cấp phép" để tạo một phiên bản mới.
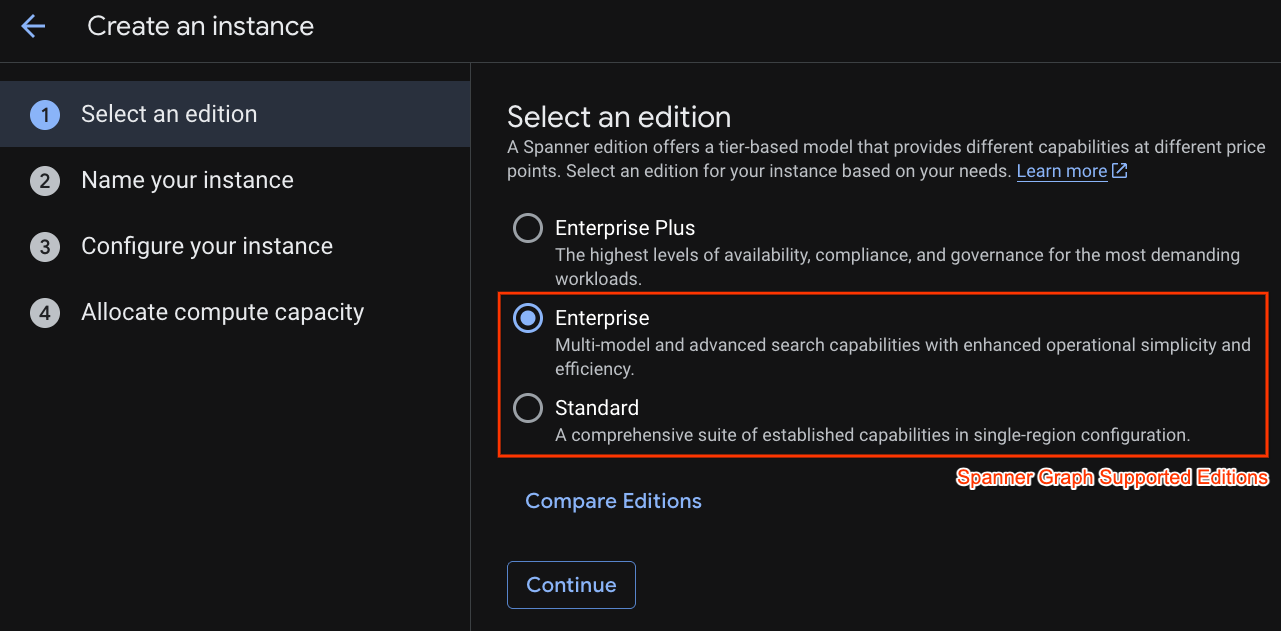
Ở bước đầu tiên, bạn phải chọn một phiên bản. Xin lưu ý rằng bạn cũng có thể nâng cấp Phiên bản sau này. Để sử dụng các chức năng đa mô hình (Spanner Graph), chúng ta có thể sử dụng phiên bản Enterprise.
Đặt tên cho phiên bản
Chọn một cấu hình triển khai và chọn một khu vực mà bạn muốn.
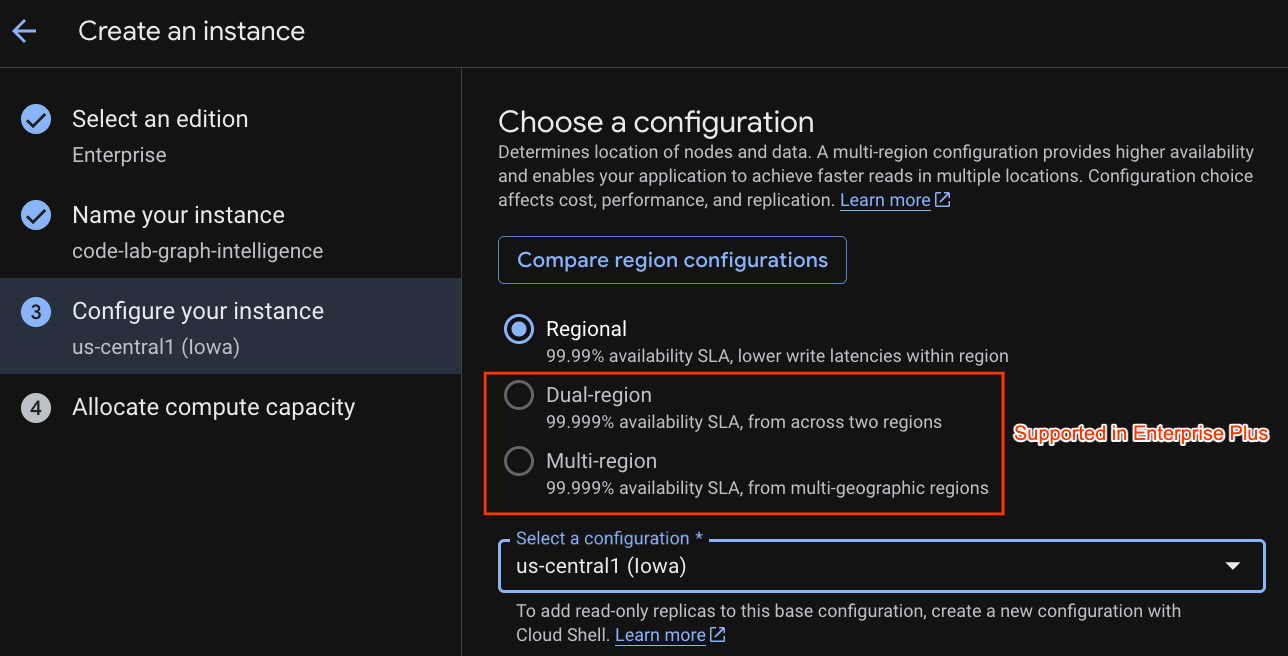
Bạn cũng có thể so sánh nhiều lựa chọn cấu hình. Ví dụ: cấu hình triển khai có tối thiểu 3 bản sao R/W trong 3 vùng riêng biệt của khu vực bạn đã chọn. Tức là ngay cả khi bạn sử dụng một chế độ triển khai một nút, bạn vẫn có 3 bản sao thông qua 3 bản sao R/W. Ngoài ra, ngay cả khi có cấu hình triển khai theo khu vực, bạn vẫn có thể mở rộng hơn nữa bằng cách có các bản sao chỉ đọc bổ sung trong cấu trúc liên kết triển khai.
Sau khi định cấu hình dung lượng, bạn có thể bắt đầu ở chế độ nút đầy đủ và tự động mở rộng quy mô ở các nút; hoặc bạn có thể sử dụng một thực thể chi tiết (Đơn vị xử lý; 1.000 PU = 1 nút). Bạn cũng có thể tuỳ ý đặt mục tiêu điều chỉnh quy mô tự động cho phiên bản. Đối với các tải công việc có độ trễ thấp, bạn nên sử dụng 65% cho các phiên bản theo khu vực và 45% cho các phiên bản trên nhiều khu vực.
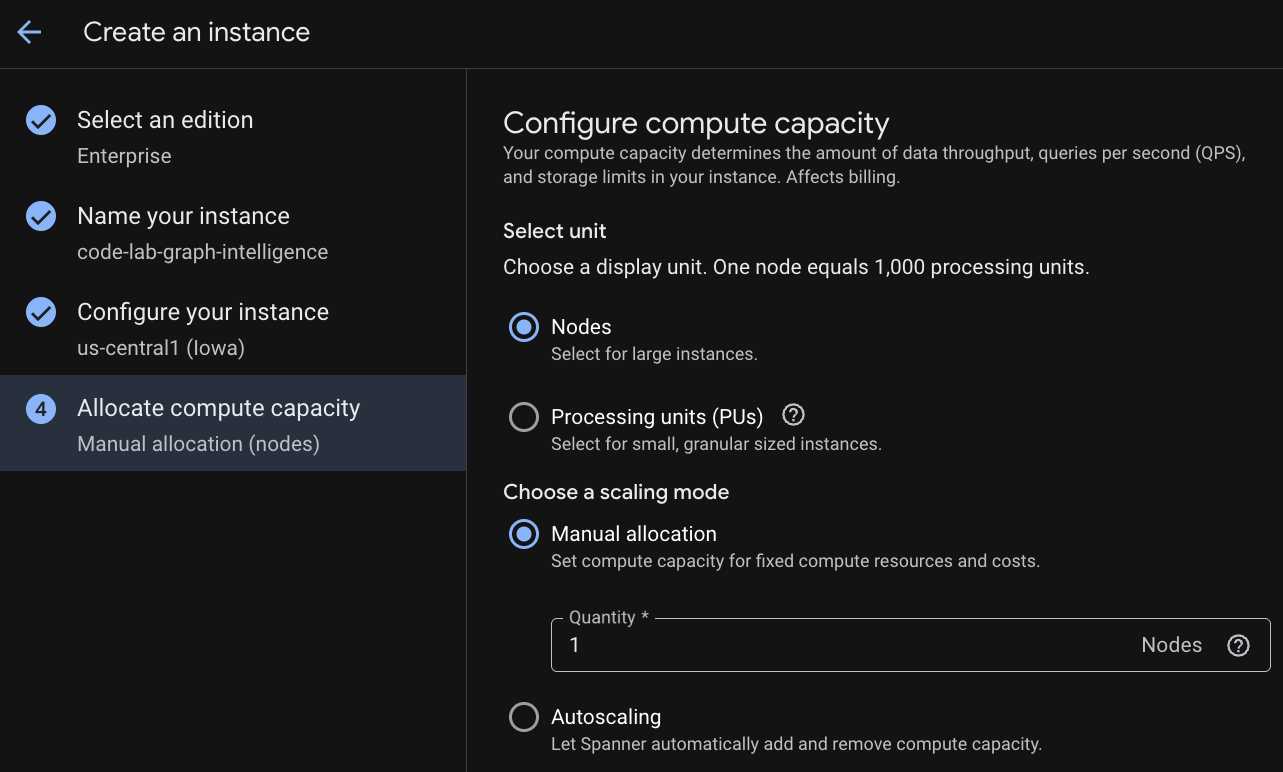
Bước 3: Tạo cơ sở dữ liệu
Sau khi phiên bản của bạn được cung cấp, hãy nhấp vào "Tạo cơ sở dữ liệu" để tạo cơ sở dữ liệu cho phần còn lại của lớp học lập trình.
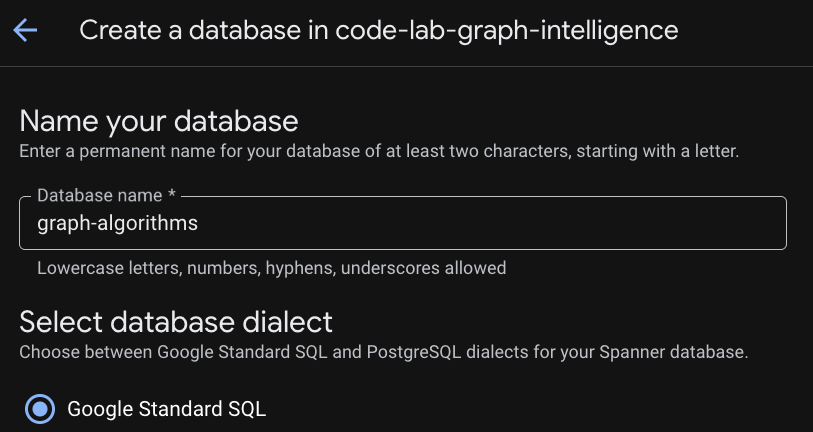
Thiết lập nền tảng mối quan hệ
Hành trình của chúng ta bắt đầu với các bảng cốt lõi lưu trữ dữ liệu hoạt động. Trong Cloud Spanner, chúng tôi sử dụng tính năng Xếp chồng để đồng định vị dữ liệu liên quan về mặt vật lý, chẳng hạn như tình bạn và giao dịch của khách hàng ngay trong hồ sơ khách hàng. Điều này đảm bảo khả năng truy cập hiệu suất cao và vị trí thực tế.
DDL: Tạo bảng
Sao chép và thực thi các khối sau để thiết lập giản đồ quan hệ:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Gieo hạt cho mạng
Sau khi chuẩn bị xong các bảng, chúng ta phải điền thông tin về người dùng, sản phẩm và mối kết nối để xác định hệ sinh thái của Khách hàng.
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
Thử thách về mối quan hệ
Trước khi giới thiệu biểu đồ, hãy xem SQL truyền thống xử lý các thách thức của Khách hàng như thế nào. Chạy truy vấn này để tìm những khách hàng "Chi tiêu trên mạng xã hội", tức là những khách hàng chi tiêu đáng kể và có nhiều bạn bè.
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
Các hạn chế của phương pháp tiếp cận dựa trên mối quan hệ
Vượt qua các thách thức về mối quan hệ thông qua biểu đồ tài sản
Để khắc phục những giới hạn này, chúng ta sẽ xác định một Biểu đồ thuộc tính. Điều này tạo ra một "lớp phủ" cho phép chúng ta coi các mối quan hệ là những thành phần quan trọng mà không cần di chuyển dữ liệu ra khỏi Spanner.
DDL: Tạo biểu đồ tài sản
DDL này xác định Các nút (Thực thể) và Các cạnh (Mối quan hệ) của chúng ta. Trong ví dụ này, chúng ta đang tuân theo một biểu đồ được sơ đồ hoá. Tuy nhiên, Spanner Graph cho phép lập mô hình biểu đồ không có lược đồ để cho phép phát triển linh hoạt, lặp lại nhanh chóng và xử lý các mô hình dữ liệu đang phát triển mà không cần thay đổi DDL (Ngôn ngữ định nghĩa dữ liệu) liên tục.
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
Điều hướng biểu đồ bằng GQL
Bây giờ, khi đã xác định đồ thị, chúng ta có thể sử dụng Ngôn ngữ truy vấn đồ thị (GQL) để thực hiện các hoạt động duyệt qua nhiều bước nhảy bằng một cú pháp đơn giản và dễ đọc.
Khám phá 1: Khám phá dựa trên sự cộng tác
Truy vấn này duyệt qua biểu đồ để tìm các sản phẩm mà bạn bè của bạn đã mua và đóng vai trò là nền tảng của một công cụ đề xuất.
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
Khám phá 2: Truy vấn kết hợp (Quan hệ + Đồ thị)
Spanner cho phép bạn nhúng các mẫu GQL vào bên trong một mệnh đề FROM SQL tiêu chuẩn bằng cách sử dụng hàm GRAPH_TABLE. Truy vấn này tìm những khách hàng sống ở cùng một vị trí với bạn bè của họ, tức là một mẫu khớp "hình kim cương".
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
Trực quan hoá các mối kết nối của khách hàng
Cuối cùng, hãy sử dụng GQL để trực quan hoá mạng của chúng ta. Các truy vấn này bao bọc kết quả đường dẫn trong SAFE_TO_JSON, cho phép trình trực quan hoá vẽ các nút và đường kẻ.
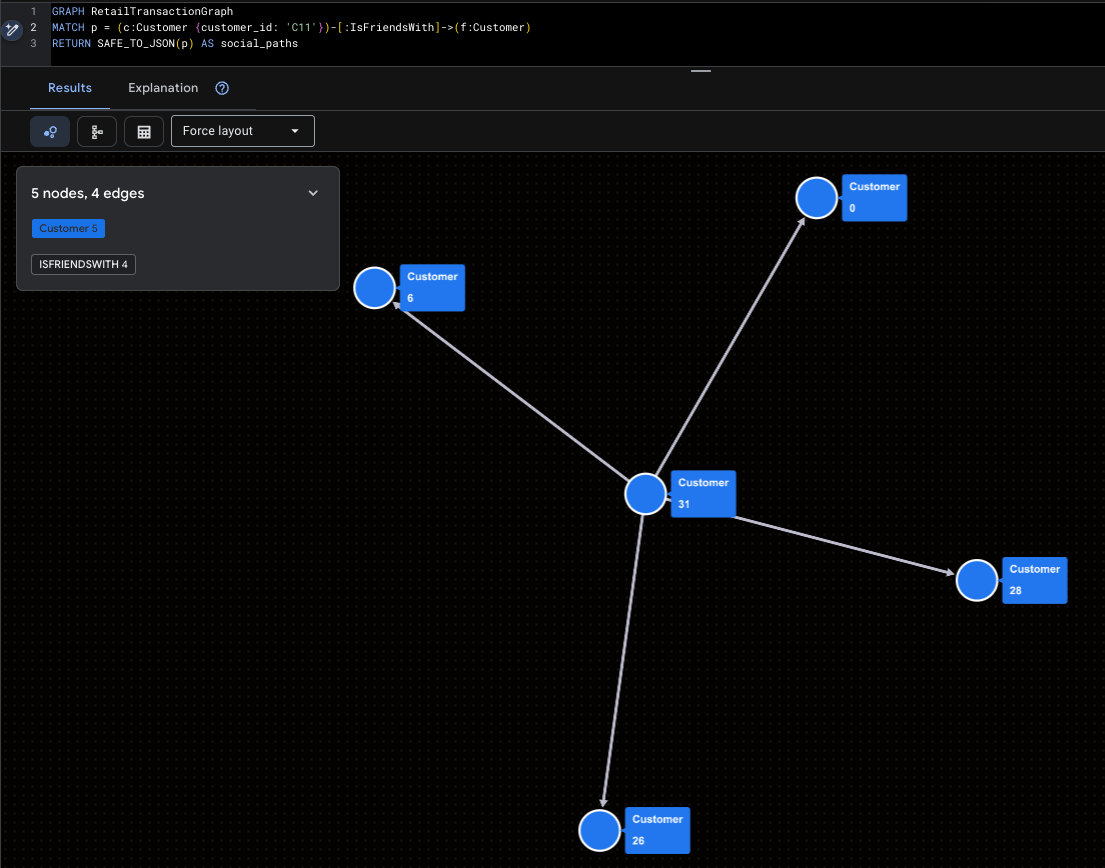
Trực quan hoá Siêu người có ảnh hưởng
Điều này làm nổi bật Mallory (C11) và phạm vi tiếp cận trực tiếp của cô trên mạng xã hội.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
Trực quan hoá các mẫu lừa đảo tiềm ẩn
Truy vấn này sẽ tìm ra "Cụm biệt lập" (Ivan và Judy) để xem sản phẩm của họ đang được vận chuyển đến đâu.
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Giới thiệu về các thuật toán đồ thị Spanner
Để chuẩn bị cho phần nghiên cứu chuyên sâu về Graph Intelligence, phần này trình bày kiến trúc kỹ thuật và các quy tắc cơ bản của Thuật toán đồ thị Cloud Spanner. Việc nắm vững những nguyên tắc này là chìa khoá để chuyển từ việc duyệt qua đơn giản sang phân tích mối quan hệ ở quy mô petabyte.
Danh mục đầu tư Thuật toán
Cloud Spanner hiện hỗ trợ 14 thuật toán đồ thị theo tiêu chuẩn ngành, được phân loại thành 4 nhóm chức năng để giải quyết nhiều vấn đề kinh doanh:
Danh mục | Các thuật toán được hỗ trợ | Trường hợp sử dụng cho doanh nghiệp |
Tính tập trung | PageRank, PageRank được cá nhân hoá, Betweenness, Closeness | Xác định những người có tầm ảnh hưởng, trung tâm và điểm tắc nghẽn. |
Cộng đồng | WCC, Lan truyền nhãn, Tìm nhóm, Phân cụ tương quan | Phát hiện các nhóm gian lận, cộng đồng xã hội và các nhóm riêng biệt. |
Mức độ tương đồng | Jaccard, Cosine, Common Neighbors, Total Neighbors | Cung cấp công cụ đề xuất và giải pháp phân giải thực thể. |
Tìm đường đi | Đường đi ngắn nhất giữa các tập hợp, Trợ lý đường đi GA | Tối ưu hoá hoạt động hậu cần và khoảng cách di chuyển. |
Những điều cần cân nhắc về lược đồ và truy vấn quan trọng
Để đảm bảo việc thực thi hiệu quả các thuật toán Đồ thị, Đồ thị Spanner cần tuân thủ các quy tắc sau:
Yêu cầu 1. Tính cục bộ của dữ liệu thực tế (Xen kẽ)
Yêu cầu quan trọng nhất đối với việc duyệt qua biểu đồ hiệu suất cao là Xen kẽ. Điều này đảm bảo rằng dữ liệu cạnh được lưu trữ thực tế trên cùng một phân chia máy chủ như nút nguồn, giảm thiểu độ trễ mạng trong quá trình thực thi thuật toán.
- Quy tắc: Các bảng cạnh PHẢI được xen kẽ trong các bảng nút nguồn.
- Duyệt theo hướng chuyển tiếp: Việc xen kẽ bảng cạnh vào bảng nút nguồn đảm bảo tính cục bộ của bộ nhớ đệm cho các đường liên kết đi.
- Truyền tải ngược: Để phân tích hiệu quả các đường liên kết "đến", hãy sử dụng Khoá ngoài để tự động tạo chỉ mục sao lưu hoặc tạo chỉ mục phụ xen kẽ trong bảng đích.
Yêu cầu 2. Yêu cầu về việc gắn nhãn riêng biệt
Mỗi bảng tham gia vào biểu đồ tài sản phải có một danh tính riêng biệt. Các thuật toán dựa vào những nhãn này để xác định và tải chính xác các đồ thị con mà chúng cần phân tích.
- Quy tắc: Mỗi bảng đầu vào phải có một nhãn nhận dạng duy nhất trong biểu đồ thuộc tính.
- Xung đột: Bạn không thể liên kết một nhãn duy nhất với nhiều bảng nếu muốn chạy các thuật toán trên những bảng đó.
Logic | Ví dụ | Kết quả |
❌ Kém | BẢNG NÚT (Thực thể NHÃN Người, Thực thể NHÃN Tài khoản) | Không hợp lệ: Thuật toán không phân biệt được giữa Người và Tài khoản. |
✅ Tốt | BẢNG NÚT (Khách hàng có NHÃN là Người, Tài khoản có NHÃN là Tài khoản) | Hợp lệ: Mỗi thực thể có một nhãn riêng biệt và duy nhất. |
Yêu cầu 3. Cấu trúc truy vấn thuật toán (Mệnh đề MATCH)
Khi gọi một thuật toán, mệnh đề MATCH tuân theo các quy tắc hạn chế hơn so với các truy vấn GQL tiêu chuẩn để đảm bảo công cụ thực thi có thể tối ưu hoá quy trình phân tích.
- Một mẫu cho mỗi câu lệnh MATCH: Mỗi câu lệnh MATCH chỉ có thể đặt tên cho một biến.
- Không có mẫu nhiều nút: Bạn không thể xác định mẫu mối quan hệ (ví dụ: (a)-[e]->(b)) ngay bên trong mệnh đề MATCH dành cho lệnh gọi thuật toán.
- Chỉ bộ lọc theo nghĩa đen: Mặc dù bạn có thể dùng mệnh đề WHERE để lọc các nút (ví dụ: WHERE a.id > 400), nhưng các tham số truy vấn (@param) hiện không được hỗ trợ trong các truy vấn thuật toán đồ thị.
Yêu cầu 4. Mệnh đề RETURN (Chỉ có giá trị vô hướng)
Mệnh đề RETURN trong truy vấn thuật toán đóng vai trò là cầu nối giữa thế giới đồ thị và thế giới quan hệ. Thao tác này chỉ được phép trả về các đại lượng vô hướng và hằng số.
- Quy tắc: Bạn không thể trả về "Phần tử đồ thị" (nút hoặc đối tượng cạnh thô).
- Không có phép biến đổi: Bạn không thể thực hiện các phép toán hoặc áp dụng các hàm cho những thuộc tính được trả về trong chính câu lệnh RETURN.
Các quy định hạn chế đối với mệnh đề RETURN
✅ Được hỗ trợ | ❌ Không được hỗ trợ |
RETURN node.id, score | Nút RETURN, điểm số (Không thể trả về Phần tử đồ thị) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score (Không có thao tác nào trên các thuộc tính) |
RETURN node.name | RETURN JSON_OBJECT(node.id, score) (Không có hàm) |
Yêu cầu 5. Tính toàn vẹn của dữ liệu: Loại bỏ các cạnh không liên kết
"Cạnh rời" xảy ra khi một cạnh trỏ đến một nút đích không tồn tại trong biểu đồ. Điều này khiến quá trình thực thi thuật toán không thành công vì cấu trúc đồ thị không nhất quán.
- Giải pháp: Sử dụng các ràng buộc tham chiếu (Khoá ngoài) và ON DELETE CASCADE để duy trì tính toàn vẹn của biểu đồ.
- Độ an toàn của truy vấn: Khi gọi một thuật toán, bạn phải đảm bảo rằng tất cả các nút được tham chiếu bởi các cạnh đã chọn cũng được đưa vào đối số node_labels.
Đầu ra liên tục: Các lựa chọn EXPORT DATA
Vì các thuật toán đồ thị có mức sử dụng tài nguyên tính toán cao, nên chúng được thực thi ở Chế độ thực thi mở rộng quy mô bằng cách sử dụng câu lệnh EXPORT DATA. Tính năng này tận dụng Data Boost, sử dụng các tài nguyên điện toán độc lập, không máy chủ để ngăn chặn mọi độ trễ trong các giao dịch sản xuất của bạn.
Cách 1: Duy trì trở lại Cloud Spanner
Để đẩy kết quả trực tiếp trở lại bảng (ví dụ: lưu điểm PageRank), hãy sử dụng định dạng = "CLOUD_SPANNER".
update_ignore_all: Chỉ cập nhật các hàng cho những khoá đã có trong bảng đích.upsert_ignore_all: Cập nhật các hàng hiện có hoặc chèn các hàng mới nếu thiếu khoá.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
Lựa chọn 2: Lưu trữ kết quả vào Google Cloud Storage (GCS)
Để phân tích ngoại tuyến trên quy mô lớn, bạn có thể xuất sang GCS ở định dạng CSV, Avro hoặc Parquet.
- Ký tự đại diện: Sử dụng
uri => 'gs://bucket/file_*.csv'để bật đầu ra phân mảnh, cho phép Spanner ghi vào nhiều tệp song song cho các tập dữ liệu lớn. - Nén: Hỗ trợ GZIP, SNAPPY và ZSTD để tối ưu hoá chi phí lưu trữ.
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. Thử thách 1: Khoảng cách ảnh hưởng (PageRank)
Trong phần này, chúng ta sẽ giải quyết Trở ngại kinh doanh đầu tiên của Khách hàng: "Khoảng trống ảnh hưởng". Chúng tôi sẽ chuyển từ một "cuộc thi phổ biến" cơ bản sang một bản đồ dựa trên toán học về sức ảnh hưởng thực sự trên mạng xã hội.
Tuyên bố về vấn đề: Nhóm tiếp thị của Khách hàng gặp phải một vấn đề. Họ đang chi hàng triệu đô la cho quảng cáo trên diện rộng nhưng lợi nhuận ngày càng giảm vì họ không thể xác định được "Siêu sao mạng xã hội", tức là những cá nhân hiếm hoi có sức ảnh hưởng lan toả khắp mạng lưới.
Để giải quyết vấn đề này, chúng ta cần xếp hạng khách hàng theo Mức độ ảnh hưởng.
Giải pháp quan hệ (Mức độ tập trung)
Trong một cơ sở dữ liệu tiêu chuẩn, cách dễ nhất để tìm ra một người có ảnh hưởng là chỉ cần đếm số người theo dõi của họ (một chỉ số được gọi là Mức độ tập trung).
Chạy truy vấn này để tìm những người dùng "phổ biến" nhất:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
Thông tin chi tiết về biểu đồ (PageRank)
Để tìm ra những nhà lãnh đạo thực sự, chúng tôi sử dụng PageRank. Đây là thuật toán tương tự như thuật toán hỗ trợ tính năng tìm kiếm trên web từ những ngày đầu; thuật toán này đo lường mức độ quan trọng của một nút dựa trên số lượng VÀ chất lượng của các đường liên kết đến .
- Mô hình người dùng truy cập ngẫu nhiên: PageRank mô phỏng một người dùng di chuyển qua biểu đồ. Hệ số giảm chấn (mặc định là 0,85) biểu thị xác suất họ tiếp tục nhấp vào; nếu không, họ sẽ "dịch chuyển tức thời" đến một nút ngẫu nhiên.
- Sức mạnh của mối liên kết: Đường liên kết của một người có tầm ảnh hưởng (như Mallory) có giá trị hơn đáng kể so với đường liên kết của một người không có mối liên hệ nào khác.
Chúng ta sẽ thực thi Thuật toán PageRank và sử dụng EXPORT DATA để lưu kết quả trực tiếp vào cột pagerank_score .
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
Trang tổng quan"Mức độ ảnh hưởng" bằng PageRank
Bây giờ, khi các điểm số đã được duy trì, hãy so sánh "Trước" (Số người theo dõi) với "Sau" (Điểm PageRank).
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0,158392489 |
C10 | judy@example.com | 1 | 0,1093561724 |
C9 | ivan@example.com | 1 | 0,1093561724 |
C1 | alice@example.com | 3 | 0,1000888124 |
C8 | heidi@example.com | 1 | 0,09759821743 |
C11 | mallory@example.com | 2 | 0,09466411918 |
C7 | grace@example.com | 2 | 0,08016719669 |
C6 | frank@example.com | 1 | 0,06022448093 |
C2 | bob@example.com | 1 | 0,0547891818 |
C3 | charlie@example.com | 1 | 0,0547891818 |
C12 | trent@example.com | 1 | 0,04029225558 |
C4 | david@example.com | 1 | 0,04028172791 |
Phân tích: Ai là siêu sao thực sự?
Bằng cách phân tích kết quả, giờ đây, bạn có thể khám phá 3 thông tin quan trọng về hoạt động tiếp thị:
Điểm cần nhớ cho doanh nghiệp
Thay vì gửi email cho tất cả những người có hơn 5 người theo dõi một cách mù quáng, giờ đây, nhóm tiếp thị của Khách hàng có thể chỉ tập trung vào những người có pagerank_score cao nhất. Những cá nhân này là "Siêu sao mạng xã hội" thực thụ, có khả năng tạo ra hiệu ứng lan truyền trên toàn bộ trang web thương mại.
Bây giờ, hãy thử xác định những người kiểm soát giúp mạng lưới hậu cần của Khách hàng hoạt động.
5. Thử thách 2: Khả năng phục hồi về hậu cần (BetweennessCentrality)
Trong phần này, chúng ta sẽ đề cập đến Khả năng phục hồi về hậu cần. Chúng tôi sẽ không chỉ đo lường mức độ thành công dựa trên "số lượng" mà còn xác định những "người gác cổng" quan trọng giúp duy trì kết nối mạng.
Giải pháp quan hệ (Phân tích dựa trên số lượng)
Trong chế độ thiết lập quan hệ tiêu chuẩn, một trung tâm vận chuyển "quan trọng" thường được xác định là trung tâm xử lý nhiều đơn đặt hàng nhất hoặc tạo ra doanh thu cao nhất.
Chạy truy vấn này để xác định các trung tâm "hàng đầu" theo số lượng giao dịch:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
New York | USA | 4 | 3996 |
Berlin | Đức | 2 | 345 |
San Francisco | USA | 2 | 750 |
Để giải quyết vấn đề không khớp này, chúng ta sẽ sử dụng cả các cạnh IsFriendsWith và LivesAt. Điều này giúp chúng tôi chuyển đổi hoạt động phân tích từ một trung tâm giao dịch sang cả hoạt động kiểm tra trên mạng xã hội.
Thông tin tình báo đồ thị (Độ đo trung gian)
Để tìm ra những điểm tắc nghẽn thực sự, chúng tôi sử dụng Độ tập trung trung gian. Thuật toán này định lượng tần suất một nút đóng vai trò là "cầu nối" dọc theo các đường dẫn ngắn nhất giữa tất cả các cặp nút khác trong biểu đồ. Điểm số cao cho biết những người kiểm soát thực sự, những người kiểm soát dòng chảy của hàng hoá hoặc thông tin.
Chạy và duy trì độ đo mức độ tập trung trung gian
Chúng ta sẽ thực thi thuật toán bằng cách sử dụng EXPORT DATA và lưu điểm số vào cột centrality_score. Chúng tôi sử dụng Data Boost để đảm bảo việc tính toán "đường đi ngắn nhất" này không ảnh hưởng đến hoạt động trực tiếp của Khách hàng.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
Phân tích: Xác định "Nút thắt cổ chai ẩn"
Giờ đây, chúng ta so sánh rủi ro về cấu trúc (centrality_score) với khối lượng giao dịch (order_count) để tìm ra những nút mà ban lãnh đạo của Khách hàng nên lo ngại.
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44,5 | 2 | |
C1 | alice@example.com | 35,5 | 1 | |
C5 | eve@example.com | 35,5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3,5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
Khi phân tích những kết quả này, Khách hàng đã phát hiện ra 3 điều đáng kinh ngạc:
Điểm chính cần ghi nhớ về doanh nghiệp
Giờ đây, Khách hàng có thể ưu tiên các giao thức dự phòng và bảo mật về hoạt động hậu cần dựa trên rủi ro về cấu trúc đa phương thức. Mallory, Alice và Eve là những người kiểm soát mà bạn phải bảo vệ để đảm bảo tính ổn định của mạng lưới hậu cần.
Bây giờ, hãy thử xác định các đảo giả mạo.
6. Thử thách 3: Mạng ảo (WCC)
Trong phần này, chúng ta sẽ giải quyết trở ngại thứ ba trong kinh doanh: "Mạng lưới ma". Chúng tôi sẽ chuyển từ việc phát hiện "điểm nóng" đơn giản sang phát hiện các nhóm lừa đảo tinh vi, riêng lẻ bằng cách sử dụng tính năng phát hiện cộng đồng. Thách thức ở đây là những đối tượng xấu tạo hồ sơ giả mạo, chia sẻ địa chỉ giao hàng hoặc tương tác trong các nhóm kín để phối hợp hành vi trộm cắp và tăng điểm xếp hạng sản phẩm. Nhưng họ thường hoàn toàn tách biệt với cộng đồng The Customer hợp pháp.
Để giải quyết vấn đề này, chúng ta cần phải khám phá những "Đảo biệt lập" này.
Giải pháp quan hệ (Tìm kiếm mã nhận dạng dùng chung)
Nếu không có thuật toán đồ thị, cách tiêu chuẩn để phát hiện hành vi gian lận là tìm kiếm "điểm nóng" của dữ liệu được chia sẻ, chẳng hạn như nhiều khách hàng vận chuyển đến cùng một địa chỉ .
Chạy truy vấn này để tìm những khách hàng được liên kết bằng một vị trí vận chuyển chung:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
Để tìm ra các mạng lưới lừa đảo, chúng ta cần hiểu rõ khả năng tiếp cận bắc cầu.
Thông tin đồ thị (Thành phần kết nối yếu)
Để tìm ra phạm vi đầy đủ của các vòng này, chúng tôi sử dụng Thành phần kết nối yếu (WCC). WCC là một thuật toán phân cụm xác định các tập hợp nút mà trong đó có một đường dẫn giữa hai nút bất kỳ, bất kể hướng của các cạnh.
- Vùng có thể tiếp cận: Vùng này phân chia biểu đồ thành các "đảo" hoặc "vùng có thể tiếp cận" một cách hiệu quả.
- Chế độ xem thực thể hợp nhất: Bằng cách phân tích đồng thời cả mối quan hệ xã hội (IsFriendsWith) và mối quan hệ về hậu cần (LivesAt), chúng ta có thể nhóm các hồ sơ rời rạc thành một "Cụm tác động" hợp nhất duy nhất.
Chạy và duy trì WCC
Chúng tôi sẽ thực thi thuật toán WCC và lưu kết quả vào cột community_id. Chúng tôi sử dụng tính năng Data Boost để đảm bảo quá trình phân tích khả năng tiếp cận sâu này diễn ra trên các tài nguyên điện toán độc lập.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
Phân tích: Nhóm lừa đảo
Bây giờ, hãy chạy một truy vấn xác thực để xem các cộng đồng riêng biệt của chúng ta. Người dùng hợp pháp thường thuộc "Lục địa", trong khi kẻ gian thường bị mắc kẹt trên các "Đảo" nhỏ.
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | thành viên |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
Bằng cách chạy tính năng phát hiện cộng đồng này, bạn có thể xác định một điểm bất thường quan trọng:
Điểm chính cần ghi nhớ về doanh nghiệp
Giờ đây, Khách hàng có thể tự động hoá các phản hồi bảo mật. Thay vì phải theo dõi từng tài khoản theo cách thủ công, họ có thể viết một quy tắc đơn giản: "Nếu một community_id có ít hơn 3 thành viên, hãy gắn cờ toàn bộ nhóm để xem xét KYC (Quy trình nhận biết khách hàng) theo cách thủ công"
.
Khi phát hiện các nhóm lừa đảo, chúng ta có thể giải quyết vấn đề "Hành vi tương tự".
7. Thử thách 4: Bản sao hành vi (JaccardSimilarity)
Trong thử thách cuối cùng này, chúng ta sẽ giải quyết trở ngại thứ tư: "Nghịch lý của sự lựa chọn"/"Hành vi tương tự". Chúng tôi sẽ chuyển từ danh sách "thường mua cùng nhau" chung chung sang các đề xuất siêu cá nhân hoá dựa trên "dấu vân tay" hành vi.
Đề xuất sản phẩm hiện tại của Khách hàng quá chung chung. Việc đề xuất một cáp USB phổ biến cho mọi khách hàng là an toàn, nhưng không mang tính cá nhân. Khách hàng muốn tạo đề xuất "Bản sao hành vi" để xác định những khách hàng có cùng mẫu vận chuyển và vòng kết nối xã hội riêng biệt nhằm đề xuất sản phẩm có độ chính xác cao.
Để giải quyết vấn đề này, chúng ta cần tính toán "Khoảng cách" giữa người dùng.
Giải pháp tương quan (Hoàn toàn trùng lặp)
Trong một chế độ thiết lập quan hệ tiêu chuẩn, bạn có thể tìm những người giao hàng đến cùng một địa điểm với một người dùng tham chiếu, chẳng hạn như Alice (C1).
Chạy truy vấn này để tìm những người hàng xóm của Alice theo vị trí địa lý:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Thông tin chi tiết về biểu đồ (Độ tương đồng Jaccard)
Để tìm ra những người dùng có hành vi giống hệt nhau, chúng tôi sử dụng Độ tương đồng Jaccard. Thuật toán này tính điểm được chuẩn hoá (từ 0,0 đến 1,0) bằng cách chia số lượng lân cận chung (Giao) cho tổng số lượng lân cận riêng biệt (Hợp).
Ở đây, "Bản sao hành vi" được xác định không chỉ bằng địa chỉ giao hàng dùng chung. Bằng cách phân tích điểm giao nhau giữa dấu vết thực tế (LivesAt) và hệ sinh thái xã hội (IsFriendsWith), chúng tôi có thể xác định những người dùng có cùng lối sống và tầm ảnh hưởng trong cộng đồng, từ đó đưa ra các đề xuất sản phẩm chính xác hơn nhiều.
Trước tiên, hãy tạo một Bảng liên kết
Vì mức độ tương đồng là mối quan hệ theo cặp (Khách hàng A tương tự như Khách hàng B), nên chúng tôi tạo một bảng chuyên dụng được xen kẽ trong Customer để lưu trữ các mối liên kết này.
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
Chạy tính năng So khớp Jaccard ngay
Bây giờ, chúng ta sẽ thực thi thuật toán. Lưu ý: Truy vấn này bao gồm một bài học "Nguyên tắc chung". Nếu bạn chỉ chọn các nút Khách hàng nhưng sử dụng cạnh LivesAt (trỏ đến các nút Vận chuyển), thì truy vấn sẽ không thành công và trích dẫn "Cạnh treo" . Để khắc phục vấn đề này, chúng ta phải thêm cả hai nhãn nút.
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
Phân tích: Kiểm tra "Bản sao hành vi"
Sau khi hoàn tất công việc phân tích, chúng ta sẽ chạy một truy vấn xác thực. Bằng cách kết hợp bảng ánh xạ mới (CustomerSimilarity) với siêu dữ liệu Customer ban đầu, chúng ta có thể biết chính xác "Bản sao hành vi" của Alice là ai.
Chạy truy vấn này để kiểm tra thứ hạng tương đồng của Alice:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0,200000003 | 1 | 0,1093561724 |
bob@example.com | 0,200000003 | 0 | 0,0547891818 |
ivan@example.com | 0,200000003 | 1 | 0,1093561724 |
eve@example.com | 0,1666666716 | 0 | 0,158392489 |
mallory@example.com | 0 | 0 | 0,09466411918 |
trent@example.com | 0 | 0 | 0,04029225558 |
charlie@example.com | 0 | 0 | 0,0547891818 |
david@example.com | 0 | 0 | 0,04028172791 |
frank@example.com | 0 | 0 | 0,06022448093 |
grace@example.com | 0 | 0 | 0,08016719669 |
heidi@example.com | 0 | 0 | 0,09759821743 |
Những điểm cần chú ý trong kết quả:
Bây giờ, hãy thử tạo một chế độ xem cuối cùng về Thông tin tình báo hợp nhất.
8. Thông tin chi tiết hợp nhất
Giờ đây, chúng ta chuyển từ các nhiệm vụ kỹ thuật riêng lẻ sang Trí thông minh hợp nhất. Tại đây, chúng tôi kết hợp dữ liệu giao dịch với cả 4 thuật toán đồ thị để cung cấp thông tin chi tiết rõ ràng và hữu ích.
Báo cáo 1: Thông tin chi tiết hợp nhất
Sức mạnh của cơ sở dữ liệu đa mô hình như Spanner là khả năng kết hợp dữ liệu chi tiêu quan hệ với điểm số ảnh hưởng, rủi ro và mức độ tương đồng có nguồn gốc từ biểu đồ trong một yêu cầu duy nhất. Cụm từ tìm kiếm này phân loại từng khách hàng thành một nhân cách kinh doanh cụ thể.
Chạy truy vấn Unified Intelligence để xem toàn bộ hệ sinh thái:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | chi tiêu | ảnh hưởng | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0,09466411918 | 44,5 | 0 | 🔵 NGHIÊM TRỌNG: Cầu mạng |
C5 | eve@example.com | 0 | 0,158392489 | 35,5 | 0 | 🔵 NGHIÊM TRỌNG: Cầu mạng |
C1 | alice@example.com | 999 | 0,1000888124 | 35,5 | 0 | 🔵 NGHIÊM TRỌNG: Cầu mạng |
C7 | grace@example.com | 300 | 0,08016719669 | 12 | 0 | 📱 MẠNG XÃ HỘI: Người có tầm ảnh hưởng rộng |
C8 | heidi@example.com | 45 | 0,09759821743 | 10 | 0 | 📱 MẠNG XÃ HỘI: Người có tầm ảnh hưởng rộng |
C3 | charlie@example.com | 0 | 0,0547891818 | 6 | 0 | 🟢 CHUẨN: Khách hàng đang hoạt động |
C4 | david@example.com | 0 | 0,04028172791 | 3,5 | 0 | 🟢 CHUẨN: Khách hàng đang hoạt động |
C10 | judy@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 RỦI RO CAO: Nhóm lừa đảo riêng biệt |
C9 | ivan@example.com | 999 | 0,1093561724 | 0 | 1 | 🔴 RỦI RO CAO: Nhóm lừa đảo riêng biệt |
C6 | frank@example.com | 0 | 0,06022448093 | 0 | 0 | 🟢 CHUẨN: Khách hàng đang hoạt động |
C2 | bob@example.com | 999 | 0,0547891818 | 0 | 0 | 🟢 CHUẨN: Khách hàng đang hoạt động |
C12 | trent@example.com | 0 | 0,04029225558 | 0 | 0 | 🟢 CHUẨN: Khách hàng đang hoạt động |
Bằng cách kết hợp những góc nhìn toán học này, chúng ta sẽ không chỉ xem xét "ai chi tiêu nhiều nhất" mà còn biết được "ai quan trọng nhất". Trang tổng quan hợp nhất tích hợp dữ liệu giao dịch quan hệ với thông tin chi tiết về biểu đồ đa phương thức để phân loại hệ sinh thái của bạn thành 3 nhóm đối tượng rõ ràng, có thể hành động.
"Các cầu quan trọng trong mạng" (Khả năng phục hồi)
Các nút như Mallory (C11), Eve (C5) và Alice (C1) được gắn cờ vì bottleneck_risk (Độ đo trung tâm trung gian) của chúng là >25.
- Các điểm neo cấu trúc: Mallory có điểm rủi ro cao nhất là 44,5, cho thấy cô ấy là cổng chính cho toàn bộ mạng.
- Nghịch lý về việc không chi tiêu: Eve (C5) có số lượng đơn đặt hàng là 0, nhưng cô ấy là người không thể thiếu về mặt cấu trúc với điểm số rủi ro là 35,5. SQL chuẩn sẽ hoàn toàn bỏ qua cô ấy, nhưng Graph Intelligence cho thấy cô ấy là cầu nối quan trọng với toàn bộ cộng đồng nhỏ.
- Cổng có giá trị cao: Alice (C1) có số điểm bằng với Eve là 35,5, cho thấy rằng những người chi tiêu nhiều cũng có thể là những trụ cột quan trọng về cấu trúc.
"Ngôi sao mạng xã hội" (Phạm vi tiếp cận)
Heidi (C8) và Grace (C7) được xác định là những người có tầm ảnh hưởng cao do điểm PageRank của họ .
"Nhóm lừa đảo biệt lập" (Điểm bất thường)
Judy (C10) và Ivan (C9) bị gắn cờ vì họ thuộc community_id 1 riêng biệt
Thông tin chi tiết về hoạt động kinh doanh để đưa ra các hành động chiến lược
Chân dung người dùng | Chỉ số chính | Thông tin chi tiết về doanh nghiệp | Hành động chiến lược |
🔵 Cầu mạng | Mức độ tập trung cao | Structural Anchors (Điểm neo cấu trúc): Eve (C5) và Mallory (C11) là những người giữ vai trò kết nối mạng lưới. | Giữ chân: Bảo vệ những người gác cổng này để ngăn chặn tình trạng phân mảnh cộng đồng. |
📱 Siêu sao mạng xã hội | PageRank cao | Viral Engines (Động cơ lan truyền): Những người dùng như Heidi (C8) có phạm vi tiếp cận cao nhất trong vòng kết nối của họ. | Tiếp thị: Sử dụng cho các chương trình giới thiệu và đại sứ có tác động lớn. |
🔴 Rủi ro gian lận | WCC biệt lập | Mạng lưới ma: Judy (C10) và Ivan (C9) là những người chi tiêu nhiều nhưng sống ở "đảo". | Bảo mật: Xem xét KYC thủ công ngay lập tức; đây là những dấu hiệu gian lận kinh điển. |
🟢 Người dùng tiêu chuẩn | Điểm số cân bằng | Healthy Core (Nhóm cốt lõi lành mạnh): Phần lớn mạng lưới, bao gồm cả những cầu thủ "địa phương" như David (C4). | Tăng trưởng: Áp dụng quảng cáo được cá nhân hoá tiêu chuẩn và đề xuất "Đối tượng tương tự dựa trên hành vi". |
Báo cáo 2: Báo cáo về hoạt động bất thường liên quan đến danh tính
Giờ đây, bạn cần biết liệu những kẻ lừa đảo có đang "bắt chước" các tài khoản hợp pháp hay không. Chúng ta có thể giải quyết vấn đề này bằng cách tìm những người dùng có 100% Mức độ tương đồng về hành vi nhưng không có Mối quan hệ xã hội.
Chạy truy vấn này để gắn cờ "Điểm bất thường về danh tính" tiềm ẩn:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
Báo cáo xác định điểm bất thường cung cấp thông tin quan trọng. Bằng cách tách biệt những người dùng hành động như khách hàng hợp pháp nhưng không có mối quan hệ xã hội, chúng ta chuyển từ việc đoán sang sự chắc chắn về mặt toán học .
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0,200000003 | 1 |
C9 | ivan@example.com | 0,200000003 | 1 |
Phân tích kết quả
Bằng cách hợp nhất Độ tương đồng (Jaccard) với Phát hiện cộng đồng (WCC), chúng tôi phát hiện ra những rủi ro tiềm ẩn mà dữ liệu giao dịch truyền thống không thể thấy được.
- "Bản sao hành vi" (Tương cận): Các nút như Judy (C10) và Ivan (C9) được gắn cờ vì có cùng Điểm tương đồng Jaccard là 0,20 so với Alice (C1).
- Hành vi cô lập: Judy (C10) và Ivan (C9) được nhóm vào community_id 1 riêng biệt, trong khi Alice thuộc về "Lục địa" xã hội (Cộng đồng 0).
- Cờ gian lận: Báo cáo xác định những người dùng có hành vi trùng lặp ở mức cao (>0,9) nhưng vẫn không kết nối với mạng xã hội chính.
9. Lời chúc mừng và phần tóm tắt
Phòng thí nghiệm này cho thấy cách Cloud Spanner biến cơ sở dữ liệu quan hệ thành một cơ sở dữ liệu đa mô hình mạnh mẽ. Bằng cách áp dụng trí tuệ đồ thị cho Khách hàng, chúng tôi đã chuyển từ dữ liệu tĩnh sang chiến lược kinh doanh có thể hành động.
Lợi thế của Spanner Multi-Model
- Kiến trúc hợp nhất: Spanner cho phép bạn duy trì nền tảng quan hệ vững chắc trong khi ngay lập tức "phủ" một biểu đồ thuộc tính để khai thác mối quan hệ mà không gặp phải rủi ro và độ trễ của ETL.
- Phân tích độc lập bên ngoài hộp: Bằng cách tận dụng Data Boost, bạn có thể thực thi các thuật toán sử dụng nhiều bộ nhớ như PageRank hoặc WCC trên các tài nguyên điện toán độc lập, không máy chủ, đảm bảo không ảnh hưởng đến hiệu suất thanh toán trong quá trình sản xuất.
- Hiệu suất xen kẽ: Tính năng xen kẽ độc đáo của Spanner đảm bảo rằng các nút và mối quan hệ của chúng được đặt cùng nhau về mặt vật lý, biến các hoạt động duyệt qua phức tạp trên toàn cầu thành các hoạt động tra cứu cục bộ tốc độ cao.
Làm nổi bật "Ngọc ẩn" và điểm bất thường
- Xác định giá trị cấu trúc: Các thuật toán đồ thị như Độ tập trung trung gian đã tiết lộ "Cầu nối ẩn" với mức chi tiêu bằng 0, những người có thể quan trọng hơn đối với khả năng phục hồi của mạng so với những khách hàng chi tiêu nhiều nhất.
- Phát hiện hành vi bắt chước: Bằng cách kết hợp Độ tương đồng Jaccard và Thành phần kết nối yếu, chúng tôi đã xác định được "Người lạ trên mạng xã hội". Những tài khoản này trông giống như khách hàng hợp pháp nhưng được chứng minh bằng toán học là các nhóm lừa đảo riêng biệt.
- Sự thật toàn cầu so với sự thật cục bộ: Mặc dù việc phân tích SQL theo cách thủ công có thể cho thấy các cầu nối, nhưng các thuật toán toàn cầu có thể cho thấy những Người kiểm soát chính của mạng.
Biến dữ liệu thành thông tin thông minh và hữu ích
- Chiến lược dựa trên vai trò: Chúng tôi đã chuyển đổi thành công các hàng thành mối quan hệ và bằng cách chạy các thuật toán, chúng tôi có thể giải quyết 4 vấn đề kinh doanh, cụ thể là: Cầu nối mạng, Siêu sao mạng xã hội, Rủi ro gian lận và Người dùng tiêu chuẩn.