
1. 案例研究:智能零售
在此案例研究中,我们以一家数字市场快速增长的零售客户为例。客户的传统数据视图存在局限性,因为它只显示人们购买了什么,但不显示他们之间的关联。这种差距会导致错失商机,并导致欺诈行为日益增多。现在,他们正转向网络优先理念,除了交易数据外,还重视社交和物流联系。
需要解决的核心业务挑战
您面临着四项关键挑战,需要了解客户与物流之间的关联:
挑战 | 问题 | 目标 |
影响差距 | 广泛投放广告的投资回报率较低;目前无法识别真正的引领者(网红)。 | 找出有影响力的人;他们通过在互联的客户网络中的联系成为社区的核心。 |
物流弹性 | 供应链可能存在漏洞(考虑到它们在不同的地理位置运营)。如果一个密钥中心发生故障,整个区域可能会失去产品访问权限。 | 确定守门员 ;这些人员对于将物流网络连接在一起至关重要。 |
Ghost Networks | 欺诈团伙会使用虚假商家资料和共享地址来协调盗窃行为并虚增评分。 | 揭露孤立岛屿 :与合法社区没有任何联系的高度互联群体。 |
选择悖论 | 当前的建议/推荐引擎比较初级、通用,并且经常被忽略(例如“购买此商品的客户还购买了…”)。 | 构建行为孪生体;即根据相似的配送模式和社交圈提供建议。 |
将业务挑战与技术策略相关联(行 → 关系)
在传统数据库中,数据存储在孤立的数据孤岛中:客户数据在一个表中,交易数据在另一个表中,配送数据在第三个表中。虽然 SQL 非常适合回答“谁买了什么?”这样的问题,但却难以回答基于网络的问题。
为应对这些挑战,技术策略是转变这一视角:
- 关系视图(“是什么”):将每位客户视为一个孤立的行。要找到客户与好友购买行为之间的关联,需要进行多次复杂的“联接”,而随着网络规模的扩大,这种联接的速度会呈指数级下降。
- 图视图(“如何”):将关系视为一等公民。我们不再需要搜索列表,而是直接在地图上导航。我们可以立即看到,客户 A 与客户 B 相关联,而客户 B 的送货地址为 Z。
深入了解要求
解决方案架构师得出结论,业务需求和技术策略需要采用多模型方法,并确定了以下关键要求。
Cloud Spanner 如何满足这些技术要求
Cloud Spanner 被选为本次转型的核心。这样,客户既可以保留坚实的关系型基础,同时还可以发掘深层的图表洞见。
下面简要介绍一下 Cloud Spanner 如何满足技术要求及其他方面。
此外,Cloud Spanner 还提供可应对未来变化的先进技术架构
2. 设置数据基础
在确定业务用例后,我们现在进入实施阶段。在本部分中,我们将定义数据架构,探讨传统关系模型的局限性,并介绍属性图,将其作为我们发掘深层数据洞见的工具。
设置 Cloud Spanner 企业版实例
第 1 步:启用 Cloud Spanner API
在 Google Cloud 控制台中,点击屏幕左上角的“菜单”图标,打开左侧导航栏。向下滚动并选择“Spanner”,或者搜索“Spanner”
您现在应该会看到 Cloud Spanner 界面,并且假设您使用的是尚未启用 Cloud Spanner API 的项目,您会看到一个对话框,要求您启用该 API。如果您已启用该 API,则可以跳过此步骤。
点击“启用”以继续:
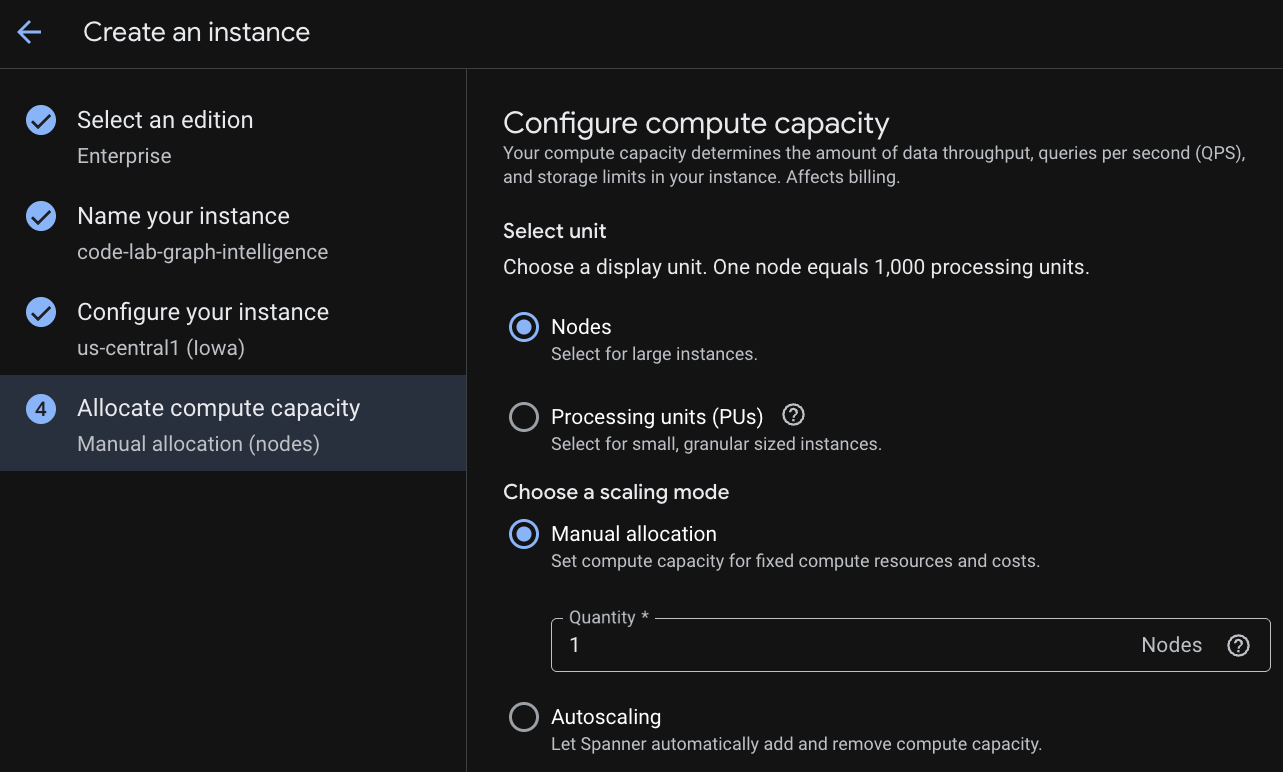
第 2 步:创建 Cloud Spanner 实例
首先,您将创建一个 Cloud Spanner 实例。在界面中,点击“创建预配置实例”以创建新实例。
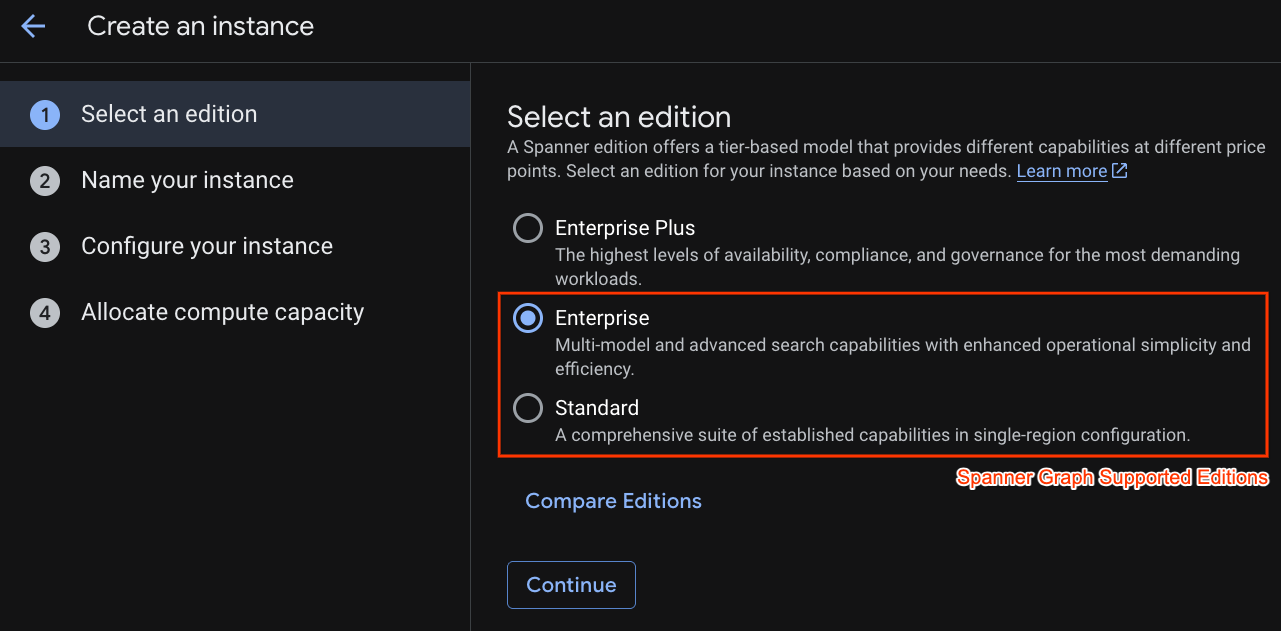
在第一步中,您必须选择一个版本。请注意,您也可以稍后升级版本。如需使用多模型功能 (Spanner Graph),我们可以选择企业版。
为实例命名
选择部署配置,然后选择您所需的区域。
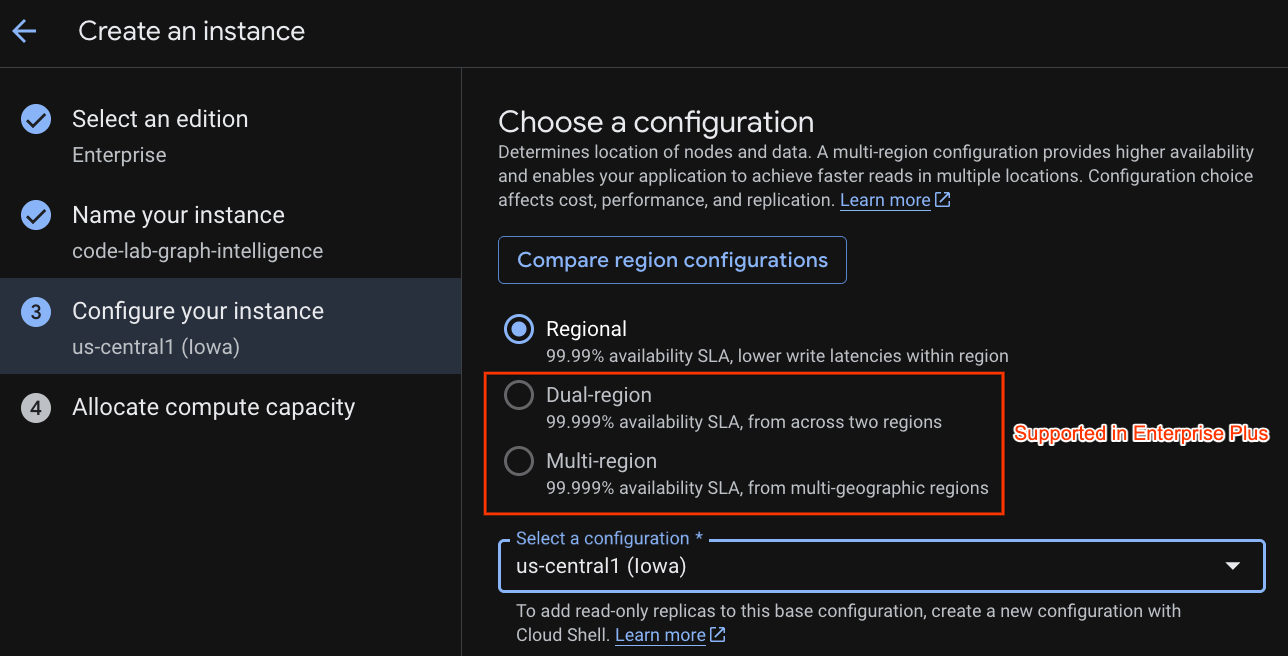
您还可以比较各种配置选项。例如,部署配置在所选区域的 3 个不同可用区中至少有 3 个读/写副本。也就是说,即使您选择单节点部署,也会通过 3 个读/写副本获得 3 个副本。此外,即使采用区域部署配置,您也可以通过在部署拓扑中添加额外的只读副本来进一步扩展。
配置容量后,您可以从完整节点开始,并以节点为单位进行自动扩缩;也可以使用精细实例(处理单元;1, 000 个处理单元 = 1 个节点)。(可选)您还可以设置实例的自动扩缩目标。对于低延迟工作负载,我们建议将区域实例设置为 65% ,而将多区域实例设置为 45% 。
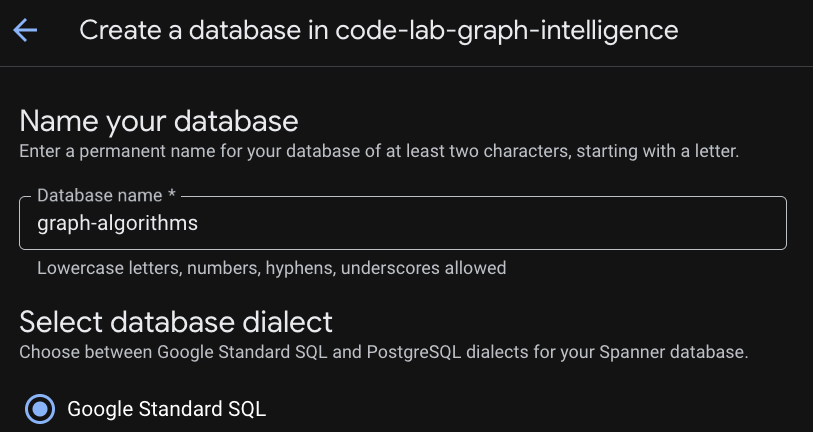
第 3 步:创建数据库
实例预配完成后,点击“创建数据库”,为其余的 Codelab 创建数据库。
设置关系型基础
我们的旅程从存储运营数据的核心表开始。在 Cloud Spanner 中,我们使用交错放置来将相关数据(例如客户的友谊和事务)与客户记录直接放在一起。这可确保高性能访问和物理位置。
DDL:创建表
复制并执行以下代码块,以建立关系型架构:
-- NODE: Customer (Parent)
CREATE TABLE Customer (
customer_id STRING(60) NOT NULL,
customer_email STRING(32),
-- Placeholder fields for Algorithm results
pagerank_score FLOAT64,
centrality_score FLOAT64,
community_id INT64
) PRIMARY KEY(customer_id);
-- EDGE: CustomerFriendship (Interleaved in Customer)
CREATE TABLE CustomerFriendship (
customer_id STRING(60) NOT NULL,
friend_id STRING(60) NOT NULL,
friendship_strength FLOAT64,
created_at TIMESTAMP,
CONSTRAINT FK_Friend FOREIGN KEY(friend_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, friend_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
-- NODE: Product
CREATE TABLE Product (
product_id STRING(60) NOT NULL,
product_name STRING(32),
unit_price FLOAT64,
pagerank_score FLOAT64
) PRIMARY KEY(product_id);
-- NODE: Shipping
CREATE TABLE Shipping (
shipping_id STRING(60) NOT NULL,
city STRING(32),
country STRING(32)
) PRIMARY KEY(shipping_id);
-- EDGE: Transactions (Interleaved in Customer)
CREATE TABLE Transactions (
customer_id STRING(60) NOT NULL,
row_id STRING(36) DEFAULT (GENERATE_UUID()),
product_id STRING(60) NOT NULL,
shipping_id STRING(60) NOT NULL,
transaction_date TIMESTAMP,
amount FLOAT64,
CONSTRAINT FK_Prod FOREIGN KEY(product_id) REFERENCES Product(product_id),
CONSTRAINT FK_Ship FOREIGN KEY(shipping_id) REFERENCES Shipping(shipping_id)
) PRIMARY KEY(customer_id, row_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
为网络提供初始数据
准备好表格后,我们必须在其中填充定义客户生态系统的用户、产品和连接。
-- Populate Products & Shipping
INSERT INTO Product (product_id, product_name, unit_price) VALUES
('P1', 'Smartphone Pro', 999.00), ('P2', 'Wireless Earbuds', 150.00),
('P3', 'USB-C Cable', 25.00), ('P4', '4K Monitor', 450.00),
('P5', 'Ergonomic Chair', 300.00), ('P6', 'Desk Lamp', 45.00);
INSERT INTO Shipping (shipping_id, city, country) VALUES
('S1', 'New York', 'USA'), ('S2', 'London', 'UK'), ('S3', 'Tokyo', 'Japan'),
('S4', 'San Francisco', 'USA'), ('S5', 'Berlin', 'Germany');
-- Populate Customers
INSERT INTO Customer (customer_id, customer_email) VALUES
('C1', 'alice@example.com'), ('C2', 'bob@example.com'), ('C3', 'charlie@example.com'),
('C4', 'david@example.com'), ('C5', 'eve@example.com'), ('C6', 'frank@example.com'),
('C7', 'grace@example.com'), ('C8', 'heidi@example.com'), ('C9', 'ivan@example.com'),
('C10', 'judy@example.com'), ('C11', 'mallory@example.com'), ('C12', 'trent@example.com');
-- Populate Friendships
INSERT INTO CustomerFriendship (customer_id, friend_id, friendship_strength, created_at) VALUES
('C1', 'C2', 1.0, CURRENT_TIMESTAMP()), ('C1', 'C3', 1.0, CURRENT_TIMESTAMP()),
('C2', 'C1', 0.8, CURRENT_TIMESTAMP()), ('C3', 'C1', 0.9, CURRENT_TIMESTAMP()),
('C3', 'C4', 0.5, CURRENT_TIMESTAMP()), ('C4', 'C5', 0.5, CURRENT_TIMESTAMP()),
('C5', 'C6', 1.0, CURRENT_TIMESTAMP()), ('C5', 'C7', 0.8, CURRENT_TIMESTAMP()),
('C7', 'C8', 0.7, CURRENT_TIMESTAMP()), ('C8', 'C5', 0.6, CURRENT_TIMESTAMP()),
('C11', 'C1', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C5', 1.0, CURRENT_TIMESTAMP()),
('C11', 'C7', 1.0, CURRENT_TIMESTAMP()), ('C11', 'C12', 0.5, CURRENT_TIMESTAMP()),
('C1', 'C11', 0.9, CURRENT_TIMESTAMP()), ('C5', 'C11', 0.9, CURRENT_TIMESTAMP()),
('C9', 'C10', 1.0, CURRENT_TIMESTAMP()), ('C10', 'C9', 1.0, CURRENT_TIMESTAMP());
-- Populate Transactions
INSERT INTO Transactions (customer_id, product_id, shipping_id, amount, transaction_date) VALUES
('C1', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C2', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()),
('C11', 'P4', 'S4', 450.00, CURRENT_TIMESTAMP()), ('C11', 'P5', 'S4', 300.00, CURRENT_TIMESTAMP()),
('C7', 'P5', 'S5', 300.00, CURRENT_TIMESTAMP()), ('C8', 'P6', 'S5', 45.00, CURRENT_TIMESTAMP()),
('C9', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP()), ('C10', 'P1', 'S1', 999.00, CURRENT_TIMESTAMP());
关系挑战
在介绍图之前,我们先来看看传统 SQL 如何应对客户的挑战。运行此查询可找到“社交型消费者”,即消费金额高且好友数量多的客户。
SELECT
c.customer_id,
c.customer_email,
SUM(t.amount) AS total_spent,
COUNT(DISTINCT f.friend_id) AS friend_count
FROM Customer AS c
LEFT JOIN Transactions AS t ON c.customer_id = t.customer_id
LEFT JOIN CustomerFriendship AS f ON c.customer_id = f.customer_id
GROUP BY c.customer_id, c.customer_email
HAVING total_spent > 500
ORDER BY total_spent DESC;
关系型方法的局限性
通过属性图克服关系型挑战
为了克服这些限制,我们定义了属性图。这样一来,我们便可以创建“叠加层”,从而将关系视为一等公民,而无需将数据移出 Spanner。
DDL:创建属性图表
此 DDL 定义了我们的节点(实体)和边(关系)。在此示例中,我们遵循的是架构化图,但 Spanner Graph 允许对无架构图进行建模,以实现灵活、快速的迭代开发,并处理不断发展的数据模型,而无需不断更改 DDL(数据定义语言)。
CREATE OR REPLACE PROPERTY GRAPH RetailTransactionGraph
NODE TABLES (
Customer KEY (customer_id),
Product KEY (product_id),
Shipping KEY (shipping_id)
)
EDGE TABLES (
CustomerFriendship AS IsFriendsWith
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (friend_id) REFERENCES Customer (customer_id)
LABEL IsFriendsWith,
Transactions AS Purchased
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (product_id) REFERENCES Product (product_id)
LABEL Purchased,
Transactions AS LivesAt
SOURCE KEY (customer_id) REFERENCES Customer (customer_id)
DESTINATION KEY (shipping_id) REFERENCES Shipping (shipping_id)
LABEL LivesAt
);
使用 GQL 浏览图
现在,我们已经定义了图,可以使用 Graph Query Language (GQL) 以简单易懂的语法执行多跳遍历。
探索 1:协作发现
此查询会遍历图表,以查找您的好友购买的商品,并作为推荐引擎的基础。
GRAPH RetailTransactionGraph
MATCH (me:Customer)-[:IsFriendsWith]->(friend:Customer)-[:Purchased]->(p:Product)
WHERE me.customer_id = 'C1'
RETURN
me.customer_id AS my_id,
friend.customer_id AS friend_id,
p.product_name AS recommendation
探索 2:混合查询(关系型 + 图)
Spanner 允许您使用 GRAPH_TABLE 函数将 GQL 模式嵌入到标准 SQL FROM 子句中。此查询会查找居住在与朋友相同位置的客户,即“菱形”模式匹配。
SELECT *
FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (a:Customer)-[:IsFriendsWith]-(b:Customer),
(a)-[:LivesAt]->(loc:Shipping),
(b)-[:LivesAt]->(loc)
RETURN a.customer_id AS user_A, b.customer_id AS user_B, loc.city
)
直观呈现客户的关联
最后,我们使用 GQL 可视化网络。这些查询会将路径结果封装在 SAFE_TO_JSON 中,以便可视化工具绘制节点和线条。
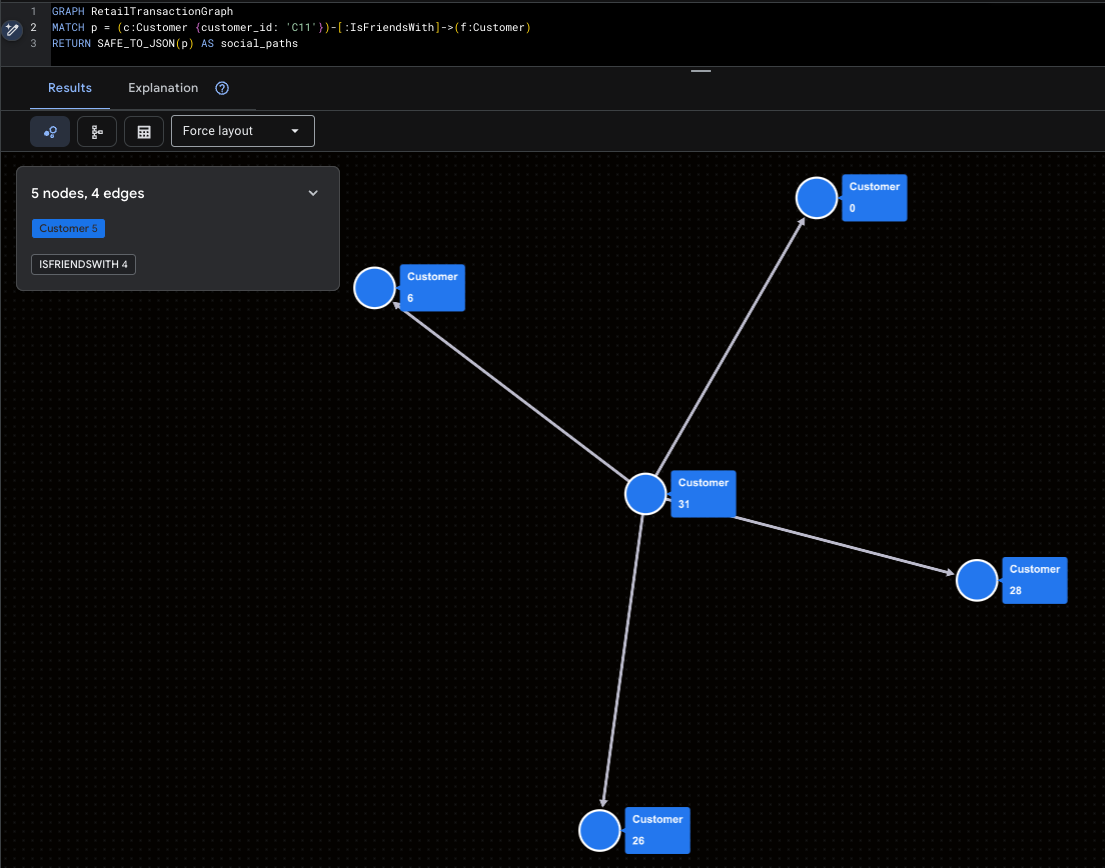
直观呈现超级网红
此图突出了 Mallory (C11) 及其直接社交覆盖面。
GRAPH RetailTransactionGraph
MATCH p = (c:Customer {customer_id: 'C11'})-[:IsFriendsWith]->(f:Customer)
RETURN SAFE_TO_JSON(p) AS social_paths
直观呈现潜在的欺诈模式
此查询会找出“孤立的集群”(Ivan 和 Judy),以查看其产品运往何处。
GRAPH RetailTransactionGraph
MATCH p = (c:Customer)-[:Purchased]->(prod:Product),
q = (c)-[:LivesAt]->(loc:Shipping)
WHERE c.customer_id IN ('C9', 'C10')
RETURN SAFE_TO_JSON(p) AS purchase_path, SAFE_TO_JSON(q) AS shipping_path
3. Spanner Graph 算法简介
为了让您为深入了解图分析智能做好准备,本部分将概述 Cloud Spanner 图算法的技术架构和基本规则。了解这些原则是实现从简单遍历到 PB 级关系分析的关键。
算法投资组合
Cloud Spanner 目前支持 14 种行业标准图算法,这些算法分为四个功能组,可用于解决各种业务问题:
类别 | 支持的算法 | 业务应用场景 |
中心性 | PageRank、个性化 PageRank、介数、紧密度 | 识别影响者、中心和瓶颈。 |
社区 | WCC、标签传播、团查找、相关性聚类 | 检测欺诈团伙、社交社区和信息孤岛。 |
相似性 | Jaccard、余弦、共同邻居、邻居总数 | 为推荐引擎和实体解析提供支持。 |
路径查找 | 集合到集合的最短路径、GA 路径辅助函数 | 优化物流和遍历邻近度。 |
重要的架构和查询注意事项
为了确保高效执行图算法,Spanner Graph 需要遵循以下规则:
要求 1:物理数据局部性(交织)
高性能图遍历的最关键要求是交错。这样可确保边缘数据与源节点在物理上存储在同一服务器拆分上,从而最大限度地减少算法执行期间的网络延迟。
- 规则:边缘表必须交织到其源节点表中。
- 正向遍历:将边缘表交织到来源节点表中可确保传出链接的缓存局部性。
- 反向遍历:为了高效分析“入站”链接,请使用外键自动创建支持性索引,或在目标表中创建交错式二级索引。
要求 2:独特的标签要求
参与属性图的每个表都必须具有唯一的身份。算法依靠这些标签来正确识别和加载需要分析的子图。
- 规则:每个输入表都必须在属性图中具有唯一的标识标签。
- 冲突:如果您打算对多个表运行算法,则无法将单个标签映射到多个表。
逻辑 | 示例 | 结果 |
❌ 较差 | 节点表(Person LABEL 实体、Account LABEL 实体) | 无效:该算法无法区分“Person”和“Account”。 |
✅ 良好 | 节点表(Person 标签 Customer,Account 标签 Account) | 有效:每个实体都有一个不同的唯一标签。 |
要求 3. 算法查询结构(MATCH 子句)
调用算法时,MATCH 子句遵循比标准 GQL 查询更严格的规则,以确保执行引擎可以优化分析流水线。
- 每个 MATCH 语句只能有一个模式:每个 MATCH 语句只能命名一个变量。
- 无多节点模式:您无法在旨在用于算法调用的 MATCH 子句中直接定义关系模式(例如,(a)-[e]->(b))。
- 仅限字面量过滤条件:虽然您可以使用 WHERE 子句来过滤节点(例如,WHERE a.id > 400),但图算法查询目前不支持查询参数 (@param)。
要求 4。RETURN 子句(仅限标量)
算法查询中的 RETURN 子句充当图世界与关系世界之间的桥梁。严格限制为仅返回标量和常量。
- 规则:您无法返回“图元素”(原始节点或边对象)。
- 无转换:您无法在 RETURN 语句本身中对返回的属性执行数学运算或应用函数。
RETURN 子句限制
✅ 支持 | ❌ 不支持 |
RETURN node.id, score | 返回节点、得分(无法返回图表元素) |
RETURN PATH_LENGTH(p) | RETURN node.id + 1, score(不对属性执行任何操作) |
返回 node.name | RETURN JSON_OBJECT(node.id, score)(无函数) |
要求 5. 数据完整性:消除悬空边
当某条边指向图中不存在的目标节点时,就会出现“悬空边”。这会导致算法执行失败,因为图结构不一致。
- 解决方案:使用参照完整性约束(外键)和 ON DELETE CASCADE 来维护图的完整性。
- 查询安全性:调用算法时,您必须确保所选边所引用的所有节点也包含在 node_labels 实参中。
持久性输出:EXPORT DATA 选项
由于图算法属于计算密集型算法,因此它们会使用 EXPORT DATA 语句以纵向扩缩执行模式执行。此功能利用 Data Boost,使用独立的无服务器计算资源来防止生产交易出现任何延迟。
方法 1:持久保存回 Cloud Spanner
如需将结果直接推送到您的表格中(例如,保存 PageRank 分数),请使用 format = ‘CLOUD_SPANNER’。
update_ignore_all:仅更新目标表中已存在的键对应的行。upsert_ignore_all:更新现有行,或在键缺失时插入新行。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
方法 2:将结果持久保存到 Google Cloud Storage (GCS)
如需进行大规模离线分析,您可以导出为 CSV、Avro 或 Parquet 格式。
- 通配符:使用
uri => 'gs://bucket/file_*.csv'可启用分片输出,从而允许 Spanner 并行写入多个文件,以处理海量数据集。 - 压缩:支持 GZIP、SNAPPY 和 ZSTD,以优化存储费用。
EXPORT DATA OPTIONS (
uri = 'gs://bucket/pagerank_*.csv',
format = 'CSV',
overwrite = true
) AS
GRAPH RetailTransactionGraph
CALL PageRank(...)
RETURN node.customer_id, score;
4. 挑战 1:影响力差距 (PageRank)
在本部分中,我们将探讨客户面临的第一个业务障碍:影响力差距。我们将从基本的“人气竞赛”转变为由数学驱动的真实社会影响力地图。
问题陈述:客户的营销团队遇到了问题。他们花费数百万美元进行广泛的广告宣传,但回报却在不断减少,因为他们无法找到“社交超级明星”,即那些代言能影响整个网络的稀有个人。
为了解决这个问题,我们需要按影响力对客户进行排名。
关系型解决方案(度中心性)
在标准数据库中,查找网红的最简单方法是直接统计其粉丝数量(一种称为度中心性的指标)。
运行以下查询可找出最“受欢迎”的用户:
SELECT
friend_id AS customer_id,
COUNT(*) AS follower_count
FROM CustomerFriendship
GROUP BY friend_id
ORDER BY follower_count DESC;
customer_id | follower_count |
C1 | 3 |
C5 | 3 |
C11 | 2 |
C7 | 2 |
C10 | 1 |
C12 | 1 |
C2 | 1 |
C3 | 1 |
C4 | 1 |
C6 | 1 |
C8 | 1 |
C9 | 1 |
图智能(PageRank)
为了找到真正的领导者,我们使用了 PageRank。这是早期网页搜索所采用的算法;它根据入站链接的数量和质量来衡量节点的重要性。
- 随机冲浪者模型:PageRank 会模拟用户在图中的移动。阻尼系数(默认值为 0.85)表示用户继续点击的概率;否则,他们会“传送”到随机节点。
- 关联的力量:来自有影响力的人(例如 Mallory)的链接比来自没有其他关联的人的链接更有价值。
我们将执行 PageRank 算法,并使用 EXPORT DATA 将结果直接保存到 pagerank_score 列中。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all' -- Updates existing rows
) AS
GRAPH RetailTransactionGraph
CALL PageRank(
node_labels => ['Customer'], -- Target our Customer nodes
edge_labels => ['IsFriendsWith'], -- Analyze the social ties
damping_factor => 0.85, -- Standard decay
max_iterations => 10 -- Higher iterations for better precision
)
YIELD node, score
RETURN node.customer_id, score as pagerank_score;
使用 PageRank 的“影响力”信息中心
现在,得分已持久保存,接下来我们来比较“之前”(关注者数量)和“之后”(PageRank 得分)。
-- Note that Higher PageRank score means more influential
SELECT
c.customer_id,
c.customer_email,
count_query.follower_count,
c.pagerank_score
FROM Customer c
JOIN (
SELECT friend_id, COUNT(*) AS follower_count
FROM CustomerFriendship GROUP BY friend_id
) AS count_query ON c.customer_id = count_query.friend_id
ORDER BY c.pagerank_score DESC;
customer_id | customer_email | follower_count | pagerank_score |
C5 | eve@example.com | 3 | 0.158392489 |
C10 | judy@example.com | 1 | 0.1093561724 |
C9 | ivan@example.com | 1 | 0.1093561724 |
C1 | alice@example.com | 3 | 0.1000888124 |
C8 | heidi@example.com | 1 | 0.09759821743 |
C11 | mallory@example.com | 2 | 0.09466411918 |
C7 | grace@example.com | 2 | 0.08016719669 |
C6 | frank@example.com | 1 | 0.06022448093 |
C2 | bob@example.com | 1 | 0.0547891818 |
C3 | charlie@example.com | 1 | 0.0547891818 |
C12 | trent@example.com | 1 | 0.04029225558 |
C4 | david@example.com | 1 | 0.04028172791 |
分析:谁是真正的超级巨星?
通过分析输出内容,您现在可以发现三个关键的营销信息:
业务要点
现在,客户的营销团队可以专注于那些 pagerank_score 最高的用户,而无需盲目地向所有粉丝数超过 5 的用户发送电子邮件。这些用户是真正的“社交明星”,能够推动整个市场实现系统性病毒式传播。
现在,让我们尝试找出维持客户物流网络正常运行的守门员。
5. 挑战 2:物流弹性(中介中心性)
在本部分中,我们将介绍物流韧性。我们将不再只通过“数量”来衡量成功,而是要找出维持网络连接的关键“把关人”。
关系型解决方案(基于交易量的分析)
在标准关系型设置中,“关键”配送中心通常是指处理订单最多或创收最高的配送中心。
运行以下查询,按交易次数找出“热门”枢纽:
-- Identify "Critical" hubs by transaction volume
SELECT
s.city,
s.country,
COUNT(t.row_id) AS transaction_count,
SUM(t.amount) AS total_revenue
FROM Shipping s
JOIN Transactions t ON s.shipping_id = t.shipping_id
GROUP BY s.city, s.country
ORDER BY transaction_count DESC;
city | country | transaction_count | total_revenue |
纽约 | USA | 4 | 3996 |
柏林 | 德国 | 2 | 345 |
旧金山 | USA | 2 | 750 |
为了解决这种不匹配问题,我们将同时使用 IsFriendsWith 和 LivesAt 边。这使我们的分析从交易中心转变为还包括社交检查。
图谱智能(中介中心性)
为了找到真正的瓶颈,我们使用了中介中心性。此算法可量化某个节点在图表中所有其他节点对之间的最短路径中充当“桥梁”的频率。高分可精准识别控制商品或信息流动的真正把关人。
运行和持久化介数中心性
我们将使用 EXPORT DATA 执行该算法,并将得分保存到 centrality_score 列中。我们使用 Data Boost 来确保这种繁重的“最短路径”计算对客户的实时运营几乎没有影响。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL BetweennessCentrality(
-- We include both Customer and Shipping nodes for a full ecosystem view
node_labels => ['Customer', 'Shipping'],
-- We factor in social ties AND physical shipping locations
edge_labels => ['IsFriendsWith', 'LivesAt'],
num_source_nodes => 100
)
YIELD node, score
-- We only persist scores for Customers; Shipping node results are safely ignored
RETURN node.customer_id, score as centrality_score;
分析:找出“隐藏的瓶颈”
现在,我们将结构性风险 (centrality_score) 与交易量 (order_count) 进行比较,以找出客户领导层应关注的节点。
SELECT
c.customer_id,
c.customer_email,
c.centrality_score,
count_query.order_count
FROM Customer c
LEFT JOIN (
SELECT customer_id, COUNT(*) AS order_count
FROM Transactions GROUP BY customer_id
) AS count_query ON c.customer_id = count_query.customer_id
ORDER BY c.centrality_score DESC;
customer_id | customer_email | centrality_score | order_count | |
C11 | mallory@example.com | 44.5 | 2 | |
C1 | alice@example.com | 35.5 | 1 | |
C5 | eve@example.com | 35.5 | ||
C7 | grace@example.com | 12 | 1 | |
C8 | heidi@example.com | 10 | 1 | |
C3 | charlie@example.com | 6 | ||
C4 | david@example.com | 3.5 | ||
C10 | judy@example.com | 0 | 1 | |
C12 | trent@example.com | 0 | ||
C2 | bob@example.com | 0 | 1 | |
C6 | frank@example.com | 0 | ||
C9 | ivan@example.com | 0 | 1 | |
通过分析这些结果,客户发现了三个令人震惊的事实:
业务要点
客户现在可以根据多模态结构风险来确定物流冗余和安全协议的优先级。Mallory、Alice 和 Eve 是必须受到保护的门卫,以确保物流网络的稳定性。
现在,我们来尝试隔离欺诈岛。
6. 挑战 3:幽灵网络 (WCC)
在本部分中,我们将解决第三个业务障碍:“幽灵网络”。我们将从简单的“热点”检测转向使用社区检测来发现复杂且孤立的欺诈团伙。问题在于,作恶方会创建共享送货地址或在闭环中互动的虚假个人资料,以协调盗窃行为并虚增商品评分。但它们通常与合法的“The Customer”社区完全隔离。
为了解决这个问题,我们需要揭示这些“孤立岛屿”。
关系型解决方案(共享标识符搜索)
如果没有图算法,查找欺诈行为的标准方法是查找共享数据的“热点”,例如多个客户的送货地址完全相同。
运行此查询可查找通过共享送货地址关联的客户:
SELECT
shipping_id,
COUNT(DISTINCT customer_id) AS customer_count,
ARRAY_AGG(customer_id) AS linked_customers
FROM Transactions
GROUP BY shipping_id
HAVING customer_count > 1;
shipping_id | customer_count | linked_customers |
S1 | 4 | ["C1","C10","C2","C9"] |
S5 | 2 | ["C7","C8"] |
为了找到欺诈网络,我们需要了解传递可达性。
图谱智能(弱连通组件)
为了找到这些环的完整范围,我们使用了弱连通分量 (WCC)。WCC 是一种聚类算法,用于识别任意两个节点之间都存在路径的节点集,而无论边的方向如何。
- 可达性区域:它有效地将图划分为“岛屿”或“可达性区域”。
- 统一实体视图:通过同时分析社交关系 (IsFriendsWith) 和物流关系 (LivesAt),我们可以将分散的个人资料分组到一个统一的“影响集群”中。
运行和持久化 WCC
我们将执行 WCC 算法,并将结果保存到 community_id 列中。我们使用 Data Boost 来确保此深度可达性分析在独立的计算资源上进行。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'Customer',
write_mode = 'update_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL WeaklyConnectedComponents(
node_labels => ['Customer', 'Shipping'],
edge_labels => ['IsFriendsWith', 'LivesAt']
)
YIELD node, cluster
-- node.customer_id will be NULL for Shipping nodes;
-- EXPORT DATA will safely ignore those rows.
RETURN node.customer_id, cluster AS community_id;
分析:欺诈团伙
现在,我们运行验证查询,看看隔离的社区。合法用户通常属于“大陆”,而欺诈者往往滞留在小“岛屿”上。
SELECT
community_id,
COUNT(*) AS member_count,
ARRAY_AGG(customer_email) AS members
FROM Customer
GROUP BY community_id
ORDER BY member_count ASC;
community_id | member_count | 会员 |
1 | 2 | ["judy@example.com","ivan@example.com"] |
0 | 10 | ["alice@example.com","mallory@example.com","trent@example.com","bob@example.com","charlie@example.com","david@example.com","eve@example.com","frank@example.com","grace@example.com","heidi@example.com"] |
通过运行此社区检测,您可以发现一个严重异常:
业务要点
客户现在可以自动执行安全响应。他们可以编写一条简单的规则,而不是手动追踪各个账号:“如果 community_id 的成员少于 3 个,则标记整个群组以进行人工 KYC(了解客户)审核”
。
随着我们揭露欺诈团伙,我们能够解决“行为孪生”问题。
7. 挑战 4:行为孪生(JaccardSimilarity)
在最后一项挑战中,我们将解决第四个障碍:“选择悖论”/“行为孪生”。我们将从通用的“经常一起购买”列表转向基于行为“指纹”的高度个性化推荐。
客户当前的产品建议过于宽泛。向每位客户推荐一款热门 USB 线是安全的,但不够个性化。客户希望构建“行为孪生”推荐系统,识别具有独特配送模式和社交圈的客户,以便推荐高度匹配的产品。
为解决此问题,我们需要计算用户之间的邻近度。
关系型解决方案(绝对重叠)
在标准关系设置中,您可能会寻找与参考用户(例如 Alice [C1])发货地址相同的用户。
运行以下查询可查找 Alice 的地理位置邻居:
SELECT
t2.customer_id AS similar_customer,
COUNT(DISTINCT t1.shipping_id) AS shared_locations
FROM Transactions t1
JOIN Transactions t2 ON t1.shipping_id = t2.shipping_id
WHERE t1.customer_id = 'C1' AND t2.customer_id != 'C1'
GROUP BY similar_customer
ORDER BY shared_locations DESC;
similar_customer | shared_locations |
C2 | 1 |
C10 | 1 |
C9 | 1 |
Graph Intelligence(Jaccard 相似度)
为了找到真正的行为双胞,我们使用了 Jaccard 相似度。此算法通过将共享邻居数(交集)除以唯一邻居总数(并集)来计算归一化得分(0.0 到 1.0)。
这里的“行为孪生”不仅仅是指共享送货地址。通过分析实体足迹 (LivesAt) 和社交生态系统 (IsFriendsWith) 的交集,我们可以识别出具有相同生活方式和社区影响力的用户,从而提供更准确的商品推荐。
首先,创建映射表
由于相似性是一种成对关系(客户 A 与客户 B 相似),因此我们创建了一个交织在 Customer 中的专用表来存储这些映射。
CREATE TABLE CustomerSimilarity (
customer_id STRING(60) NOT NULL, -- Renamed from source_id to match Parent PK
target_id STRING(60) NOT NULL,
similarity_score FLOAT64,
CONSTRAINT FK_SourceCustomer FOREIGN KEY(customer_id) REFERENCES Customer(customer_id),
CONSTRAINT FK_TargetCustomer FOREIGN KEY(target_id) REFERENCES Customer(customer_id)
) PRIMARY KEY(customer_id, target_id),
INTERLEAVE IN PARENT Customer ON DELETE CASCADE;
现在运行 Jaccard 相似度
现在,我们将执行该算法。注意:此查询包含一个常见的“安全护栏”课程。如果您仅选择“客户”节点,但使用指向“送货”节点的“居住在”边,查询将失败并显示“悬空边”。如需解决此问题,我们必须同时包含这两个节点标签。
EXPORT DATA OPTIONS (
format = 'CLOUD_SPANNER',
table = 'CustomerSimilarity',
write_mode = 'upsert_ignore_all'
) AS
GRAPH RetailTransactionGraph
CALL JaccardSimilarity(
node_labels => ['Customer', 'Shipping'], -- Added Shipping to avoid dangling edges
edge_labels => ['LivesAt', 'IsFriendsWith'], -- Use both logistics and social edges for holistic similarity
source_nodes => ARRAY(
SELECT s FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (s:Customer {customer_id: 'C1'})
RETURN s)
),
target_nodes => ARRAY(
SELECT t FROM GRAPH_TABLE(RetailTransactionGraph
MATCH (t:Customer)
WHERE t.customer_id != 'C1'
RETURN t)
)
)
YIELD source_node, target_node, similarity
RETURN
source_node.customer_id AS customer_id,
target_node.customer_id AS target_id,
similarity AS similarity_score;
分析:“行为孪生”检查
现在,分析作业已完成,我们运行验证查询。通过将新的映射表 (CustomerSimilarity) 与原始的 Customer 元数据联接,我们可以准确了解 Alice 的“行为孪生”是谁。
运行以下查询,检查 Alice 的相似度排名:
SELECT
c.customer_email AS peer_email,
s.similarity_score,
c.community_id,
c.pagerank_score
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1'
ORDER BY s.similarity_score DESC;
peer_email | similarity_score | community_id | pagerank_score |
judy@example.com | 0.200000003 | 1 | 0.1093561724 |
bob@example.com | 0.200000003 | 0 | 0.0547891818 |
ivan@example.com | 0.200000003 | 1 | 0.1093561724 |
eve@example.com | 0.1666666716 | 0 | 0.158392489 |
mallory@example.com | 0 | 0 | 0.09466411918 |
trent@example.com | 0 | 0 | 0.04029225558 |
charlie@example.com | 0 | 0 | 0.0547891818 |
david@example.com | 0 | 0 | 0.04028172791 |
frank@example.com | 0 | 0 | 0.06022448093 |
grace@example.com | 0 | 0 | 0.08016719669 |
heidi@example.com | 0 | 0 | 0.09759821743 |
结果中应包含的内容:
现在,我们来尝试构建最终的统一智能视图。
8. 统一智能
现在,我们从单个技术任务转向统一智能。在此示例中,我们将交易数据与所有四种图算法相结合,以提供清晰且切实可行的分析洞见。
报告 1:统一情报
Spanner 等多模型数据库的强大之处在于,能够通过单个请求将关系型支出数据与图表得出的影响力、风险和相似度得分联接起来。此查询会将每位客户归类到特定的业务角色。
运行统一智能查询以查看完整生态系统:
SELECT
c.customer_id,
c.customer_email,
-- Transactional Data (Relational)
COALESCE(t.total_spend, 0) AS spend,
-- Graph Intelligence Data (Algorithms)
c.pagerank_score AS influence,
c.centrality_score AS bottleneck_risk,
c.community_id,
-- Persona Categorization Logic
CASE
WHEN c.community_id = 1 THEN '🔴 HIGH RISK: Isolated Fraud Ring'
WHEN c.centrality_score > 25 THEN '🔵 CRITICAL: Network Bridge'
WHEN c.pagerank_score > 0.08 AND t.total_spend > 500 THEN '⭐ VIP: Influential Spender'
WHEN c.pagerank_score > 0.08 THEN '📱 SOCIAL: High-Reach Influencer'
WHEN sim.similarity_to_alice = 1.0 AND c.community_id != 0 THEN '⚠️ WARNING: Identity Anomaly'
ELSE '🟢 STANDARD: Active Customer'
END AS business_persona
FROM Customer c
LEFT JOIN (
-- Aggregate total spend per customer
SELECT customer_id, SUM(amount) AS total_spend
FROM Transactions GROUP BY customer_id
) t ON c.customer_id = t.customer_id
LEFT JOIN (
-- Pull similarity relative to our reference user 'C1'
SELECT target_id, similarity_score AS similarity_to_alice
FROM CustomerSimilarity WHERE customer_id = 'C1'
) sim ON c.customer_id = sim.target_id
ORDER BY c.centrality_score DESC, c.pagerank_score DESC;
customer_id | customer_email | 支出 | 影响 | bottleneck_risk | community_id | business_persona |
C11 | mallory@example.com | 750 | 0.09466411918 | 44.5 | 0 | 🔵 严重:网络桥 |
C5 | eve@example.com | 0 | 0.158392489 | 35.5 | 0 | 🔵 严重:网络桥 |
C1 | alice@example.com | 999 | 0.1000888124 | 35.5 | 0 | 🔵 严重:网络桥 |
C7 | grace@example.com | 300 | 0.08016719669 | 12 | 0 | 📱 社交媒体:高覆盖面网红 |
C8 | heidi@example.com | 45 | 0.09759821743 | 10 | 0 | 📱 社交媒体:高覆盖面网红 |
C3 | charlie@example.com | 0 | 0.0547891818 | 6 | 0 | 🟢 STANDARD:活跃客户 |
C4 | david@example.com | 0 | 0.04028172791 | 3.5 | 0 | 🟢 STANDARD:活跃客户 |
C10 | judy@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 高风险:孤立的欺诈团伙 |
C9 | ivan@example.com | 999 | 0.1093561724 | 0 | 1 | 🔴 高风险:孤立的欺诈团伙 |
C6 | frank@example.com | 0 | 0.06022448093 | 0 | 0 | 🟢 STANDARD:活跃客户 |
C2 | bob@example.com | 999 | 0.0547891818 | 0 | 0 | 🟢 STANDARD:活跃客户 |
C12 | trent@example.com | 0 | 0.04029225558 | 0 | 0 | 🟢 STANDARD:活跃客户 |
通过融合这些数学视角,我们可以从“谁的支出最多”转变为“谁最重要”。统一的信息中心将关系型交易数据与多模态图智能相结合,可将您的生态系统划分为三个清晰且可据以采取行动的用户群。
“关键网络桥接”功能(弹性)
系统会标记 Mallory (C11)、Eve (C5) 和 Alice (C1) 等节点,因为它们的 bottleneck_risk(中介中心性)>25。
- 结构锚点:Mallory 的风险得分最高,为 44.5,这表明她是整个网络的主要网关。
- 零支出悖论:Eve (C5) 的订单数为零,但从结构上来说,她不可或缺,风险得分为 35.5。标准 SQL 会完全忽略她,但图智能会显示她是整个子社区的重要桥梁。
- 高价值网关:Alice (C1) 与 Eve 并列第一,均为 35.5,这证明了高支出者也可以成为关键的结构性锚点。
“社交媒体超级明星”(覆盖面)
Heidi (C8) 和 Grace (C7) 因其 PageRank 得分而被确定为高覆盖面网红。
“孤立的欺诈团伙”(异常值)
Judy (C10) 和 Ivan (C9) 被标记,因为他们属于隔离的 community_id 1
从业务洞见到战略行动
角色 | 关键指标 | Business Insight | 战略行动 |
🔵 网桥 | 高中心性 | 结构锚点:Eve (C5) 和 Mallory (C11) 将网络连接在一起。 | 留存:保护这些守门员,防止社区分裂。 |
📱 社交媒体超级明星 | PageRank 高 | 病毒式传播引擎:像 Heidi (C8) 这样的用户在自己的圈子中具有最高的覆盖面。 | 营销:用于高影响力的推荐计划和品牌大使计划。 |
🔴 欺诈风险 | 孤立的 WCC | 幽灵网络:Judy (C10) 和 Ivan (C9) 是高支出客户,但居住在“孤岛”上。 | 安全性:立即进行人工 KYC 审核;这些是典型的欺诈特征。 |
🟢 标准用户 | 平衡得分 | 健康的核心:网络的大部分,包括像 David (C4) 这样的“本地”桥梁。 | 增长:应用标准个性化广告和“行为相似细分”建议。 |
报告 2:身份异常报告
现在,您需要了解欺诈者是否在“模仿”合法账号。我们可以通过查找行为相似度为 100% 但社交关系为零的用户来解决此问题。
运行以下查询以标记潜在的“身份异常”:
SELECT
s.target_id AS suspect_id,
c.customer_email,
s.similarity_score AS behavioral_overlap,
c.community_id AS social_group
FROM CustomerSimilarity s
JOIN Customer c ON s.target_id = c.customer_id
WHERE s.customer_id = 'C1' -- Reference Alice (Legitimate)
AND s.similarity_score > 0.15
AND c.community_id != 0 -- Filter for social strangers
ORDER BY s.similarity_score DESC;
“识别异常”报告可提供关键信息。通过隔离行为像合法客户但缺乏社交联系的用户,我们从猜测转向了数学上的确定性。
suspect_id | customer_email | behavioral_overlap | social_group |
C10 | judy@example.com | 0.200000003 | 1 |
C9 | ivan@example.com | 0.200000003 | 1 |
结果分析
通过将相似度(Jaccard)与社区检测(WCC)相结合,我们可以发现传统交易数据无法发现的隐藏风险。
- “行为双胞胎”(邻近度):系统会标记 Judy (C10) 和 Ivan (C9) 等节点,因为它们相对于 Alice (C1) 的 Jaccard 相似度得分为 0.20。
- 隔离行为:Judy (C10) 和 Ivan (C9) 被归入隔离的 community_id 1,而 Alice 属于社交“大陆”(社区 0)。
- 欺诈标记:此报告会识别行为重叠度较高(>0.9)但仍与主要社交网络断开连接的用户。
9. 恭喜和总结
本实验展示了 Cloud Spanner 如何将关系型数据库转变为多模型强力数据库。通过将图智能应用于客户,我们从静态数据转向了可行的业务策略。
Spanner 多模型优势
- 统一架构:借助 Spanner,您可以保持坚实的关系基础,同时立即“叠加”属性图,以便挖掘关系,而无需承担 ETL 的风险和延迟。
- 盒外分析隔离:通过利用 Data Boost,您可以在独立的无服务器计算资源上执行 PageRank 或 WCC 等内存密集型算法,确保对生产结账性能没有任何影响。
- 交错性能:Spanner 独特的交错功能可确保节点及其关系在物理上位于同一位置,从而将复杂的全局遍历转换为高速本地查找。
发现“隐藏的宝藏”和异常情况
- 识别结构性价值:通过中介中心性等图算法,我们发现了零支出的“隐藏桥梁”,他们对网络弹性的重要性可能高于支出最高的客户。
- 揭示行为模仿:通过结合 Jaccard 相似度和弱连通分量,我们识别出了“社交陌生人”。这些账号看起来像是合法客户,但从数学角度来看,它们是孤立的欺诈团伙。
- 全局与局部事实:虽然手动 SQL 分析可以发现桥梁,但全局算法可以发现网络中的关键门卫。
让数据变得智能且可据以采取行动
- 以用户角色为导向的策略:我们成功地将行转换为关系,并通过运行算法解决了四个业务问题,即:网络桥梁、社交明星、欺诈风险和标准用户。