
1. Panoramica
Spanner è un servizio di database completamente gestito, scalabile orizzontalmente e distribuito a livello globale, ideale per carichi di lavoro operativi relazionali e non relazionali. Oltre alle funzionalità di base, Spanner offre potenti funzionalità avanzate che consentono di creare applicazioni intelligenti e basate sui dati.
Questo codelab si basa sulla comprensione di base di Spanner e approfondisce l'utilizzo delle sue integrazioni avanzate per migliorare le funzionalità di analisi ed elaborazione dei dati, utilizzando come base un'applicazione di online banking.
Ci concentreremo su tre funzionalità avanzate chiave:
- Integrazione di Vertex AI: scopri come integrare perfettamente Spanner con Vertex AI, la piattaforma di AI di Google Cloud. Scoprirai come richiamare i modelli Vertex AI direttamente dalle query SQL di Spanner, consentendo trasformazioni e previsioni potenti nel database, in modo che la nostra applicazione bancaria possa classificare automaticamente le transazioni per casi d'uso come il monitoraggio del budget e il rilevamento delle anomalie.
- Ricerca a testo intero: scopri come implementare la funzionalità di ricerca a testo intero in Spanner. Esplorerai l'indicizzazione dei dati di testo e la scrittura di query efficienti per eseguire ricerche basate su parole chiave nei tuoi dati operativi, consentendo una potente scoperta dei dati, ad esempio la ricerca efficiente dei clienti per indirizzo email all'interno del nostro sistema bancario.
- Query federate di BigQuery: scopri come sfruttare le funzionalità di query federate di Spanner per eseguire query direttamente sui dati che si trovano in BigQuery. Ciò ti consente di combinare i dati operativi in tempo reale di Spanner con i set di dati analitici di BigQuery per ottenere approfondimenti e report completi senza duplicazione dei dati o processi ETL complessi, supportando vari casi d'uso nella nostra applicazione bancaria, come campagne di marketing mirate, combinando i dati dei clienti in tempo reale con tendenze storiche più ampie di BigQuery.
Obiettivi didattici
- Come configurare un'istanza di Spanner.
- Come creare un database e delle tabelle.
- Come caricare i dati nelle tabelle del database Spanner.
- Come chiamare i modelli Vertex AI da Spanner.
- Come eseguire query sul database Spanner utilizzando la ricerca approssimativa e la ricerca a testo intero.
- Come eseguire query federate su Spanner da BigQuery.
- Come eliminare l'istanza Spanner.
Che cosa ti serve
2. Configurazione e requisiti
Crea un progetto
Se hai già un progetto cloud Google Cloud con la fatturazione abilitata, fai clic sul menu a discesa di selezione del progetto in alto a sinistra nella console:

Con un progetto selezionato, vai ad Abilitare le API richieste.
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud Platform (console.cloud.google.com) e crea un nuovo progetto.
Fai clic sul pulsante "NUOVO PROGETTO" nella finestra di dialogo risultante per creare un nuovo progetto:
Se non hai ancora un progetto, dovresti visualizzare una finestra di dialogo come questa per creare il primo:
La finestra di dialogo successiva per la creazione del progetto ti consente di inserire i dettagli del nuovo progetto.
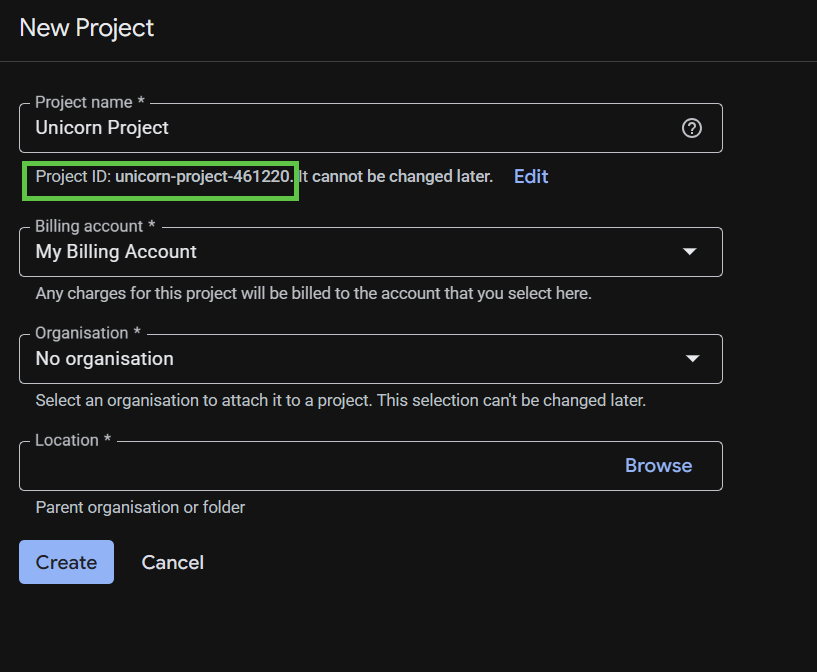
Ricorda l'ID progetto, che è un nome univoco tra tutti i progetti Google Cloud. In questo codelab verrà chiamato PROJECT_ID.
Successivamente, se non l'hai ancora fatto, devi attivare la fatturazione nella console per gli sviluppatori per utilizzare le risorse Google Cloud e attivare l'API Spanner, l'API Vertex AI, l'API BigQuery e l'API BigQuery Connection.
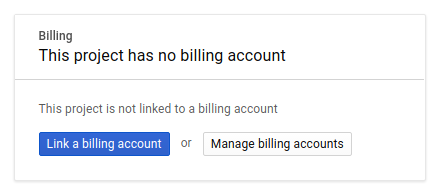
I prezzi di Spanner sono documentati qui. Gli altri costi associati ad altre risorse verranno documentati nelle pagine dei prezzi specifiche.
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
Configurazione di Google Cloud Shell
In questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che per questo codelab ti servirà solo un browser.
Per attivare Cloud Shell dalla console Cloud, fai clic su Attiva Cloud Shell ![]() (bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
(bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).

Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
gcloud auth list
Output previsto:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Output previsto:
[core] project = <PROJECT_ID>
Se per qualche motivo il progetto non è impostato, esegui questo comando:
gcloud config set project <PROJECT_ID>
Stai cercando il tuo PROJECT_ID? Controlla l'ID che hai utilizzato nei passaggi di configurazione o cercalo nella dashboard di Cloud Console:
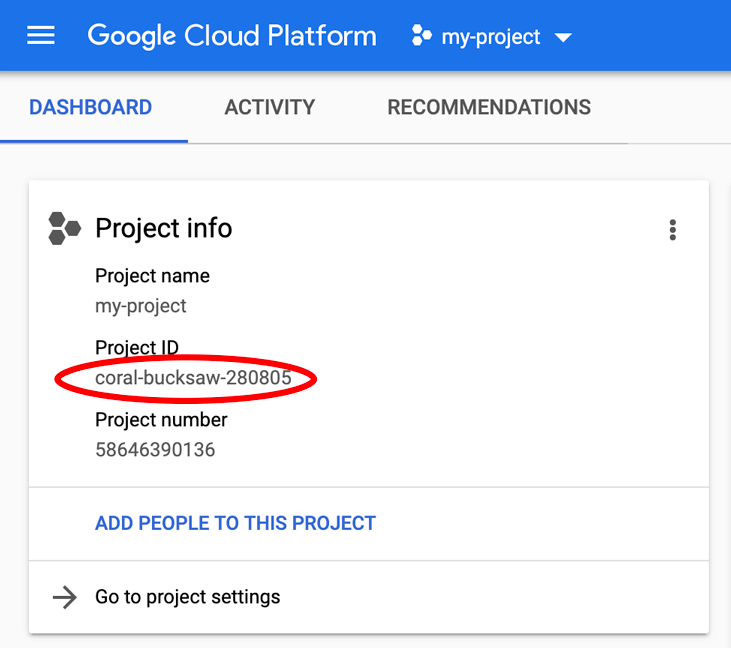
Cloud Shell imposta anche alcune variabili di ambiente per impostazione predefinita, che potrebbero essere utili quando esegui i comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output previsto:
<PROJECT_ID>
Abilita le API richieste
Abilita le API Spanner, Vertex AI e BigQuery per il tuo progetto:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Riepilogo
In questo passaggio, hai configurato il progetto se non ne avevi già uno, hai attivato Cloud Shell e hai abilitato le API richieste.
Prossimo
Il passaggio successivo consiste nel configurare l'istanza Spanner.
3. Configura un'istanza di Spanner
Crea l'istanza Spanner
In questo passaggio configurerai un'istanza Spanner per il codelab. Per farlo, apri Cloud Shell ed esegui questo comando:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Output previsto:
Creating instance...done.
Riepilogo
In questo passaggio hai creato l'istanza Spanner.
Prossimo
A questo punto, preparerai l'applicazione iniziale e creerai il database e lo schema.
4. Crea un database e uno schema
Prepara la richiesta iniziale
In questo passaggio creerai il database e lo schema tramite il codice.
Innanzitutto, crea un'applicazione Java denominata onlinebanking utilizzando Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Estrai e copia i file di dati che aggiungeremo al database (vedi qui per il repository di codice):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Vai alla cartella dell'applicazione:
cd onlinebanking
Apri il file Maven pom.xml. Aggiungi la sezione di gestione delle dipendenze per utilizzare la distinta materiali Maven per gestire la versione delle librerie Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Ecco l'aspetto dell'editor e del file: 
Assicurati che la sezione dependencies includa le librerie che l'applicazione utilizzerà:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Infine, sostituisci i plug-in di build in modo che l'applicazione venga pacchettizzata in un file JAR eseguibile:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Salva le modifiche apportate al file pom.xml selezionando "Salva" nel menu "File " dell'editor di Cloud Shell o premendo Ctrl+S.
Ora che le dipendenze sono pronte, aggiungerai codice all'app per creare uno schema, alcuni indici (inclusa la ricerca) e un modello di AI connesso a un endpoint remoto. In questo codelab, creerai questi artefatti e aggiungerai altri metodi a questa classe.
Apri App.java in onlinebanking/src/main/java/com/google/codelabs e sostituisci i contenuti con il seguente codice:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Salva le modifiche apportate a App.java.
Dai un'occhiata alle diverse entità che il tuo codice sta creando e crea il file JAR dell'applicazione:
mvn package
Output previsto:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Esegui l'applicazione per visualizzare le informazioni sull'utilizzo:
java -jar target/onlinebanking.jar
Output previsto:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Crea il database e lo schema
Imposta le variabili di ambiente dell'applicazione richieste:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Crea il database e lo schema eseguendo il comando create:
java -jar target/onlinebanking.jar create
Output previsto:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Controlla lo schema in Spanner
Nella console Spanner, vai all'istanza e al database appena creati.
Dovresti vedere tutte e tre le tabelle: Accounts, Customers e TransactionLedger.
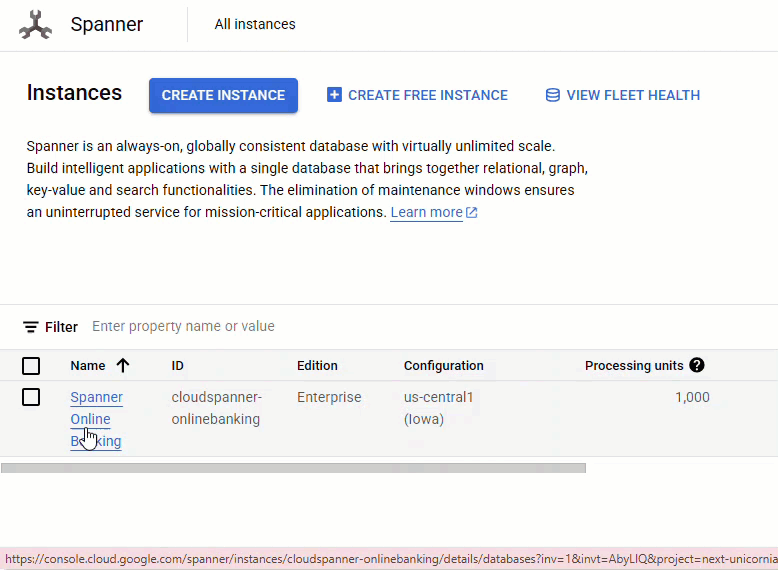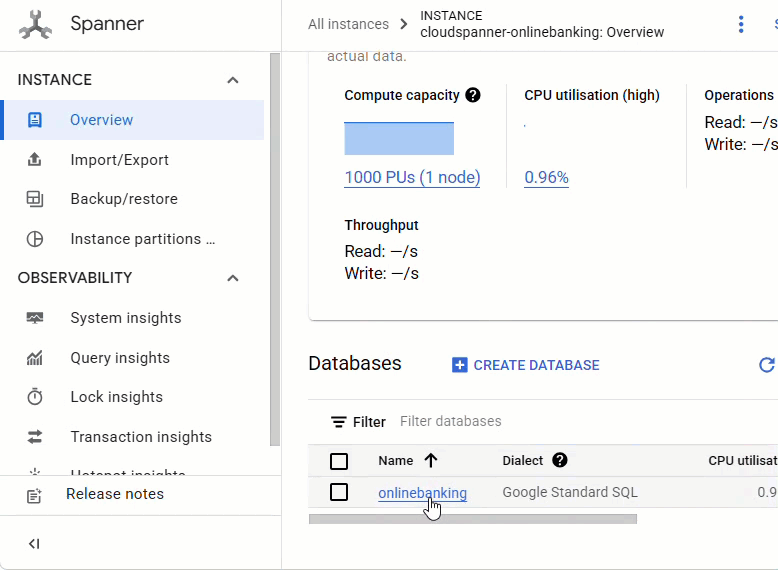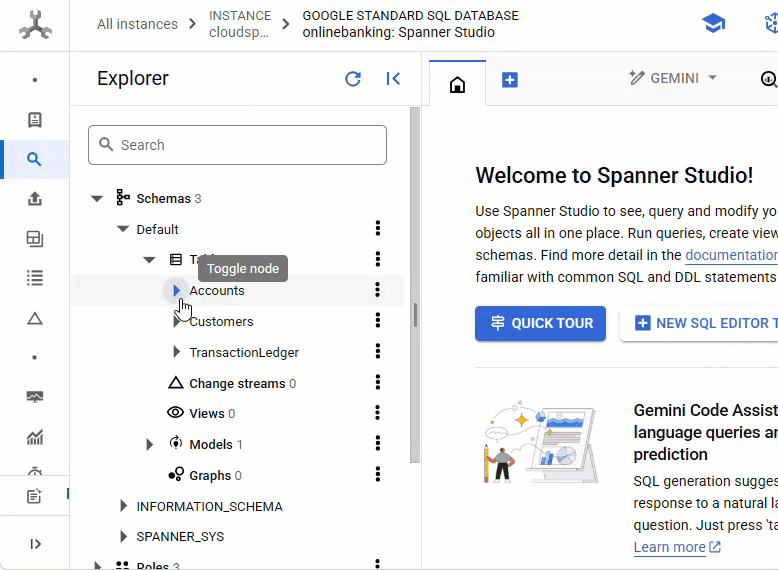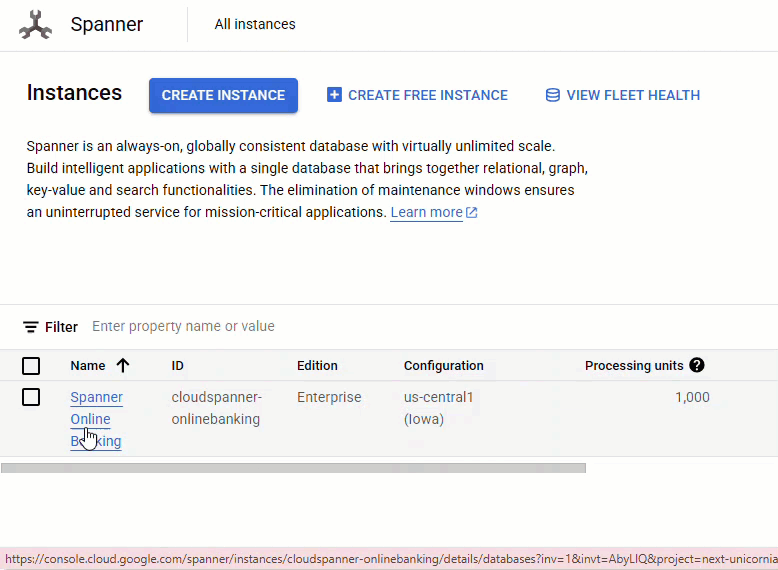
Questa azione crea lo schema del database, incluse le tabelle Accounts, Customers e TransactionLedger, insieme agli indici secondari per il recupero ottimizzato dei dati e a un riferimento al modello Vertex AI.
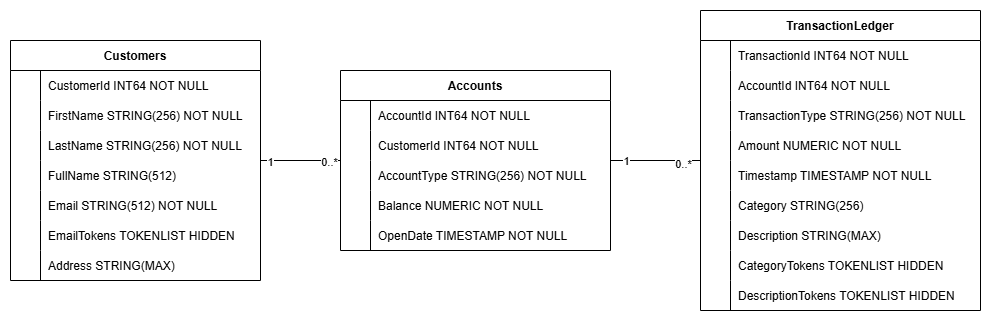
La tabella TransactionLedger è intercalata all'interno degli account per migliorare il rendimento delle query per le transazioni specifiche dell'account grazie a una migliore località dei dati.
Gli indici secondari (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) sono stati implementati per ottimizzare i pattern di accesso ai dati comuni utilizzati in questo codelab, come le ricerche dei clienti per email esatta e approssimativa, il recupero degli account per cliente e l'esecuzione di query e ricerche efficienti sui dati delle transazioni.
TransactionCategoryModel utilizza Vertex AI per consentire chiamate SQL dirette a un LLM, che viene utilizzato per la classificazione dinamica delle transazioni in questo codelab.
Riepilogo
In questo passaggio hai creato il database e lo schema Spanner.
Prossimo
Poi caricherai i dati dell'applicazione di esempio.
5. Carica dati
Ora aggiungerai la funzionalità per caricare i dati di esempio dai file CSV nel database.
Apri App.java e inizia sostituendo le importazioni:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Poi aggiungi i metodi di inserimento alla classe App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Aggiungi un'altra istruzione CASE nel metodo main per l'inserimento in switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Infine, aggiungi come utilizzare insert al metodo printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Salva le modifiche apportate a App.java.
Ricrea l'applicazione:
mvn package
Inserisci i dati di esempio eseguendo il comando insert:
java -jar target/onlinebanking.jar insert
Output previsto:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
Nella console Spanner, torna a Spanner Studio per la tua istanza e il tuo database. Poi seleziona la tabella TransactionLedger e fai clic su "Dati" nella barra laterale per verificare che i dati siano stati caricati. La tabella deve contenere 200 righe.
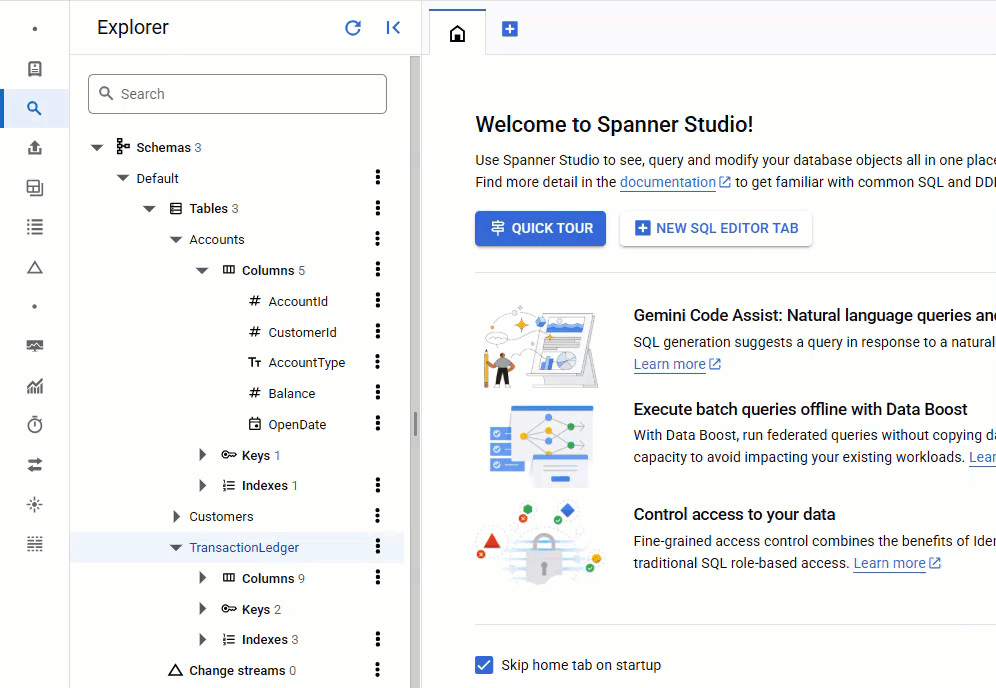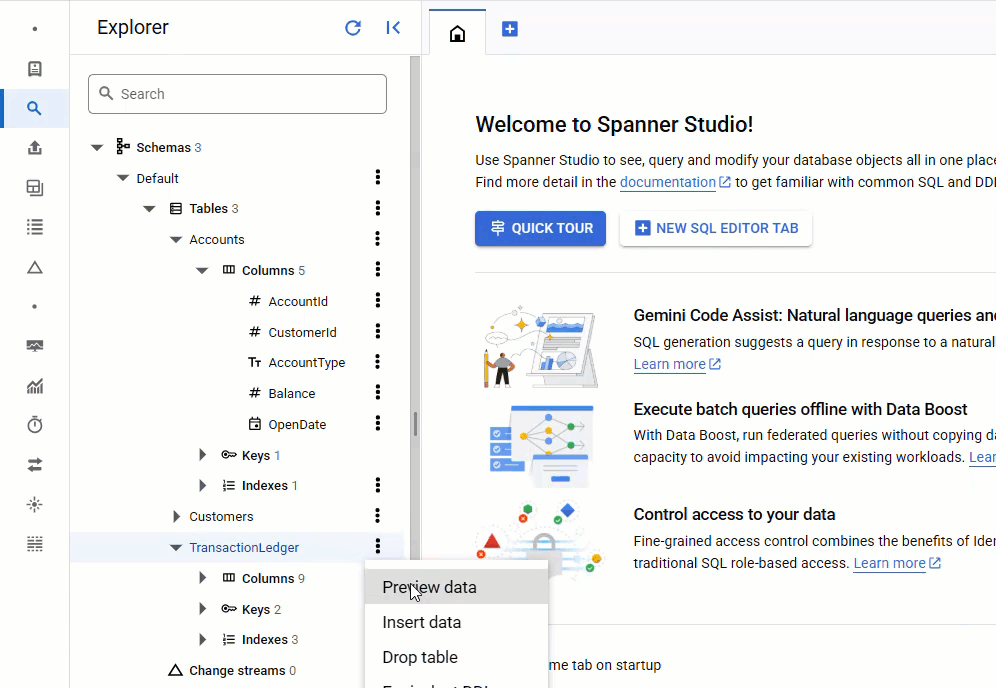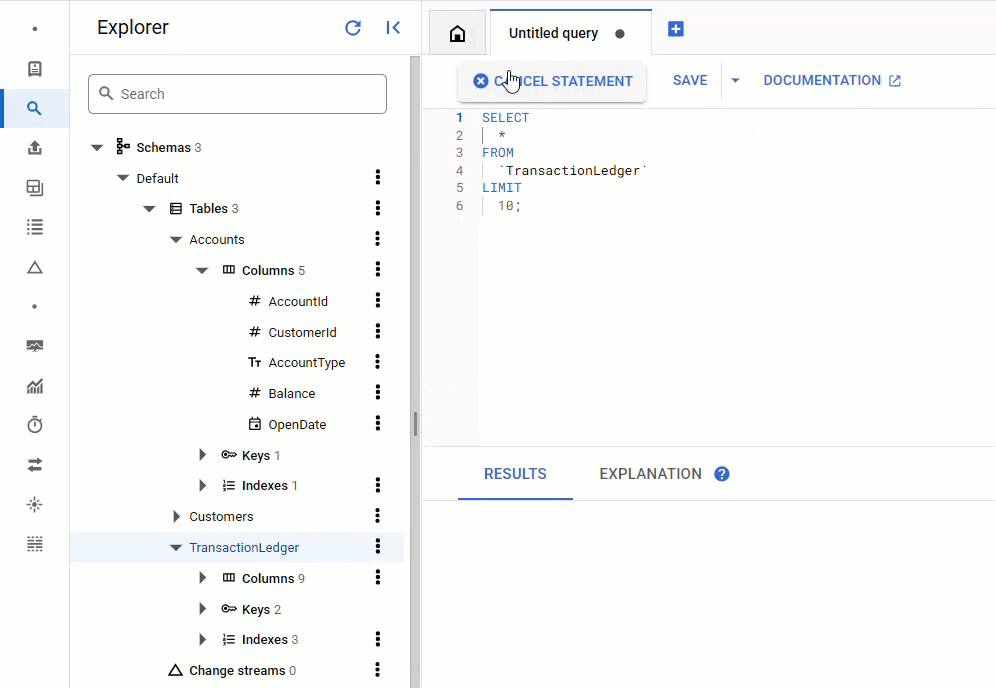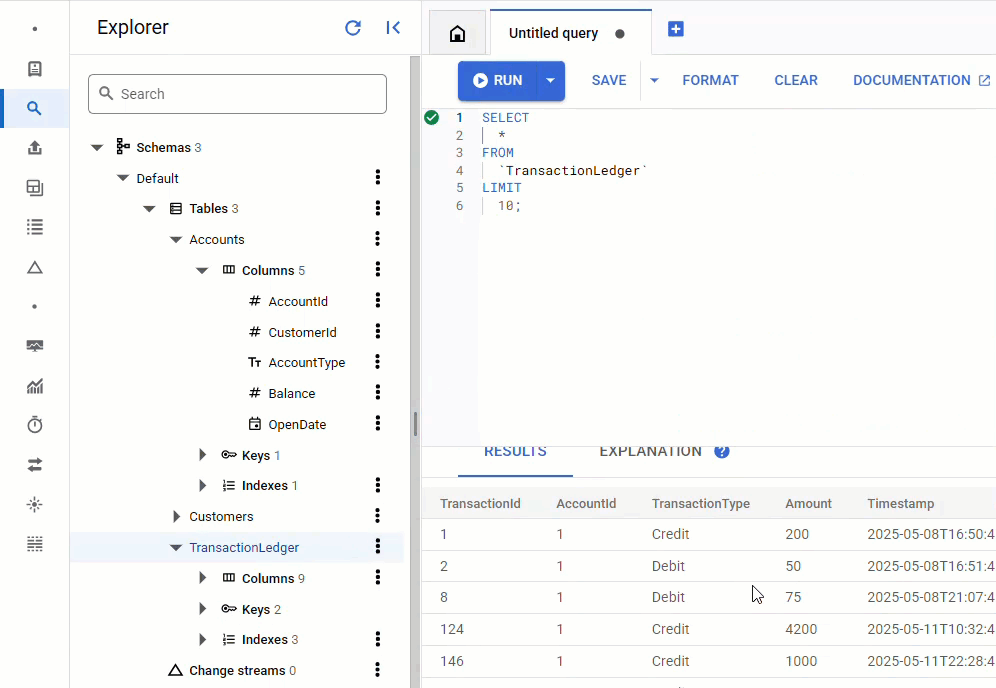
Riepilogo
In questo passaggio, hai inserito i dati di esempio nel database.
Prossimo
Successivamente, sfrutterai l'integrazione di Vertex AI per classificare automaticamente le transazioni bancarie direttamente in Spanner SQL.
6. Categorizzare i dati con Vertex AI
In questo passaggio, sfrutterai la potenza di Vertex AI per classificare automaticamente le tue transazioni finanziarie direttamente in Spanner SQL. Con Vertex AI puoi scegliere un modello preaddestrato esistente o addestrarne e implementarne uno tuo. Visualizza i modelli disponibili in Vertex AI Model Garden.
Per questo codelab utilizzeremo uno dei modelli Gemini, Gemini Flash Lite. Questa versione di Gemini è conveniente, ma può comunque gestire la maggior parte dei workload quotidiani.
Al momento, abbiamo una serie di transazioni finanziarie che vorremmo classificare (groceries, transportation e così via) in base alla descrizione. Possiamo farlo registrando un modello in Spanner e poi utilizzando ML.PREDICT per chiamare il modello di AI.
Nella nostra applicazione bancaria potremmo voler classificare le transazioni per ottenere informazioni più approfondite sul comportamento dei clienti, in modo da personalizzare i servizi, rilevare le anomalie in modo più efficace o fornire al cliente la possibilità di monitorare il proprio budget di mese in mese.
Il primo passaggio è stato eseguito durante la creazione del database e dello schema, che ha creato un modello simile a questo:
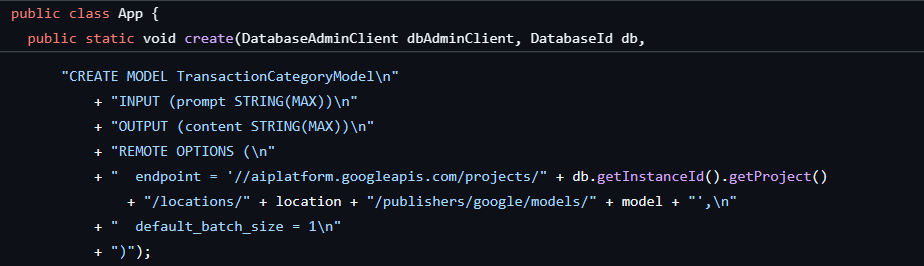
A questo punto, aggiungeremo un metodo all'applicazione per chiamare ML.PREDICT.
Apri App.java e aggiungi il metodo categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Aggiungi un'altra istruzione case nel metodo main per la categorizzazione:
case "categorize":
categorize(dbClient);
break;
Infine, aggiungi come utilizzare la classificazione al metodo printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Salva le modifiche apportate a App.java.
Ricrea l'applicazione:
mvn package
Classifica le transazioni nel database eseguendo il comando categorize:
java -jar target/onlinebanking.jar categorize
Output previsto:
Categorizing transactions... Completed categorizing transactions
In Spanner Studio, esegui l'istruzione Anteprima dati per la tabella TransactionLedger. La colonna Category dovrebbe ora essere compilata per tutte le righe.
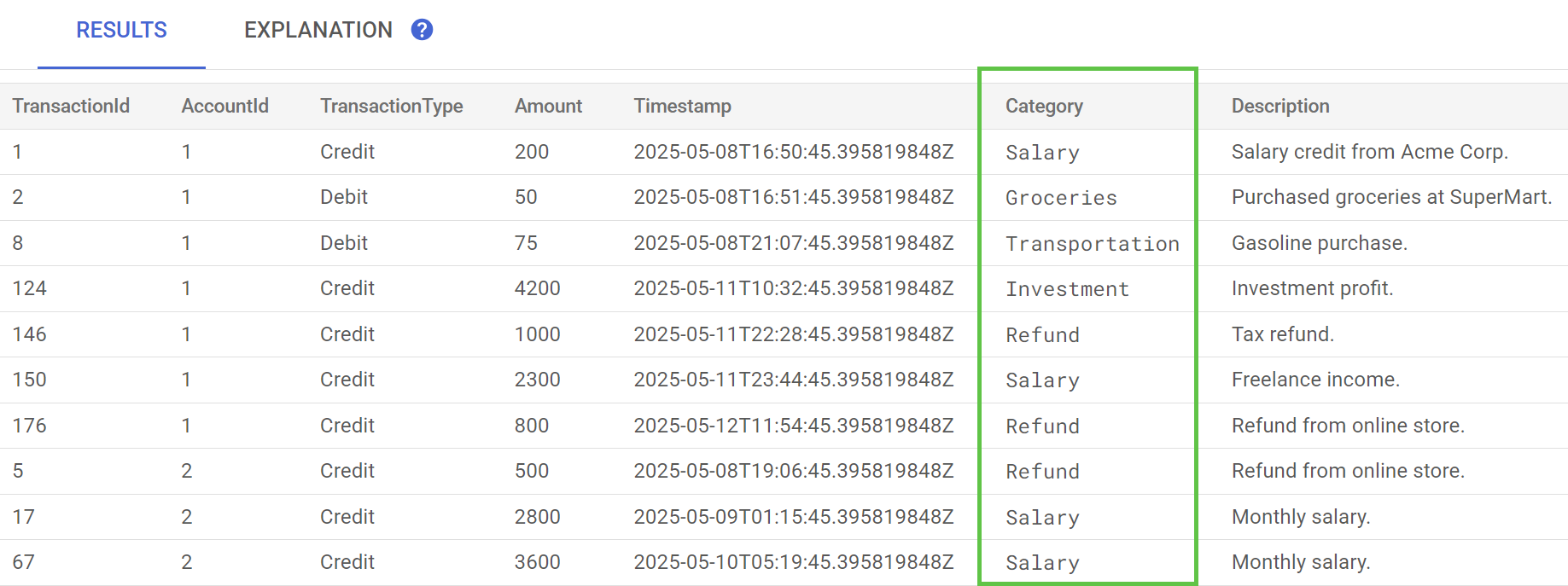
Ora che abbiamo classificato le transazioni, possiamo utilizzare queste informazioni per query interne o rivolte ai clienti. Nel passaggio successivo, vedremo come scoprire quanto spende un determinato cliente in una categoria nel corso del mese.
Riepilogo
In questo passaggio, hai utilizzato un modello preaddestrato per eseguire la classificazione dei dati basata sull'AI.
Prossimo
Successivamente, utilizzerai la tokenizzazione per eseguire ricerche fuzzy e a testo intero.
7. Esegui query utilizzando la ricerca a testo intero
Aggiungere il codice della query
Spanner fornisce molte query di ricerca full-text. In questo passaggio eseguirai una ricerca per corrispondenza esatta, quindi una ricerca approssimativa e una ricerca full-text.
Apri App.java e inizia sostituendo le importazioni:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Poi aggiungi i metodi di query:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Aggiungi un'altra istruzione case nel metodo main per la query:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Infine, aggiungi le istruzioni su come utilizzare i comandi di query al metodo printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Salva le modifiche apportate a App.java.
Ricrea l'applicazione:
mvn package
Eseguire una ricerca a corrispondenza esatta dei saldi degli account cliente
Una query a corrispondenza esatta cerca righe corrispondenti che corrispondono esattamente a un termine.
Per migliorare le prestazioni, è già stato aggiunto un indice quando hai creato il database e lo schema:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
Il metodo getBalance utilizza implicitamente questo indice per trovare i clienti che corrispondono al customerId fornito e unisce anche gli account appartenenti a quel cliente.
Ecco come appare la query quando viene eseguita direttamente in Spanner Studio: 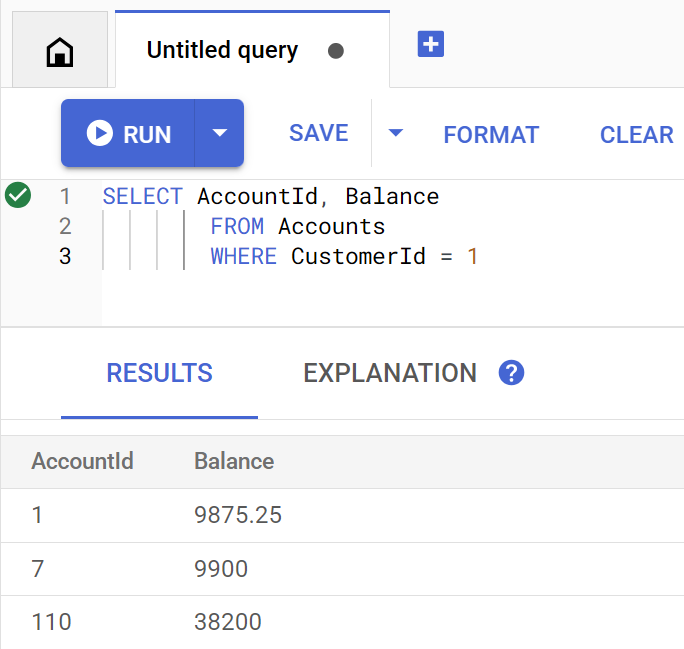
Elenca il saldo o i saldi dell'account del cliente 1 eseguendo il comando:
java -jar target/onlinebanking.jar query balance 1
Output previsto:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Esistono 100 clienti, quindi puoi anche eseguire query su uno qualsiasi degli altri saldi dell'account cliente specificando un ID cliente diverso:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Esegui una ricerca approssimativa nelle email dei clienti
Le ricerche approssimative consentono di trovare corrispondenze approssimative per i termini di ricerca, incluse variazioni ortografiche ed errori di battitura.
Un indice n-grammi è già stato aggiunto quando hai creato il database e lo schema:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
Il metodo findCustomers utilizza SEARCH_NGRAMS e SCORE_NGRAMS per eseguire query su questo indice per trovare i clienti per email. Poiché la colonna email è stata tokenizzata con n-grammi, questa query può contenere errori ortografici e restituire comunque una risposta corretta. I risultati sono ordinati in base alla corrispondenza migliore.
Trova gli indirizzi email dei clienti corrispondenti che contengono madi eseguendo il comando:
java -jar target/onlinebanking.jar query email madi
Output previsto:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Questa risposta mostra le corrispondenze più vicine che includono madi o una stringa simile, in ordine di classificazione.
Ecco come appare la query se eseguita direttamente in Spanner Studio: 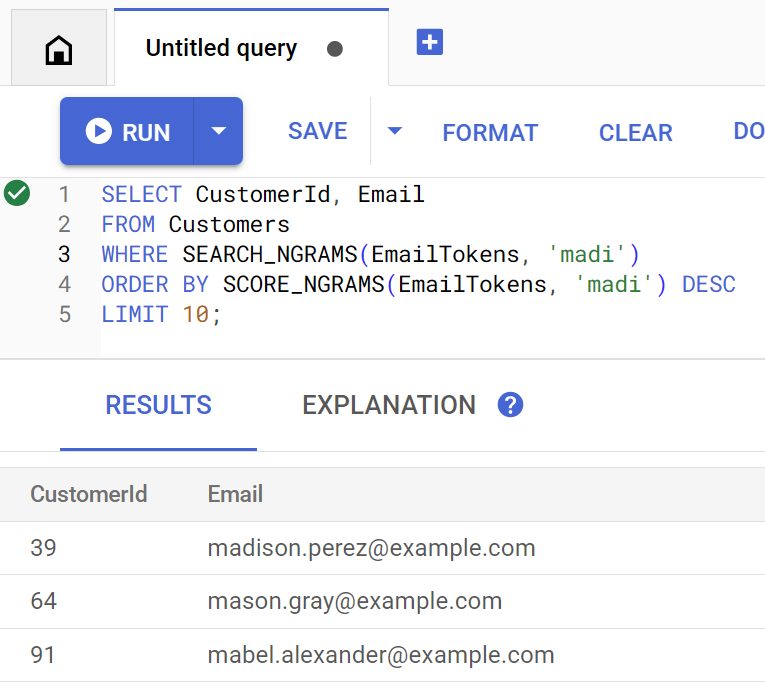
La ricerca approssimativa può anche aiutarti a correggere errori ortografici come quelli di emily:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Output previsto:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
In ogni caso, l'email del cliente prevista viene restituita come primo risultato.
Cercare transazioni con la ricerca a testo intero
La funzionalità di ricerca a testo intero di Spanner viene utilizzata per recuperare i record in base a parole chiave o frasi. Ha la capacità di correggere gli errori ortografici o cercare sinonimi.
Quando hai creato il database e lo schema, è già stato aggiunto un indice di ricerca full-text:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
Il metodo getSpending utilizza la funzione di ricerca a testo intero SEARCH per la corrispondenza con l'indice. Vengono cercate tutte le spese (addebiti) degli ultimi 30 giorni per l'ID cliente specificato.
Per ottenere la spesa totale nell'ultimo mese per il cliente 1 nella categoria groceries, esegui il comando:
java -jar target/onlinebanking.jar query spending 1 groceries
Output previsto:
Total spending for customer 1 under category groceries: 50
Puoi anche trovare la spesa in altre categorie (che abbiamo classificato in un passaggio precedente) o utilizzare un ID cliente diverso:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Riepilogo
In questo passaggio, hai eseguito query a corrispondenza esatta, nonché ricerche approssimative e a testo intero.
Prossimo
Successivamente, integrerai Spanner con Google BigQuery per eseguire query federate, consentendoti di combinare i dati Spanner in tempo reale con i dati BigQuery.
8. Esegui query federate con BigQuery
Crea il set di dati BigQuery
In questo passaggio, combinerai i dati di BigQuery e Spanner utilizzando query federate.
A questo scopo, nella riga di comando di Cloud Shell, crea prima un set di dati MarketingCampaigns:
bq mk --location=us-central1 MarketingCampaigns
Output previsto:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
E una tabella CustomerSegments nel set di dati:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Output previsto:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Successivamente, crea una connessione da BigQuery a Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Output previsto:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Infine, aggiungi alcuni clienti alla tabella BigQuery che possono essere uniti ai nostri dati Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Output previsto:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Puoi verificare che i dati siano disponibili eseguendo una query BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Output previsto:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Questi dati in BigQuery rappresentano i dati aggiunti tramite vari flussi di lavoro bancari. Ad esempio, potrebbe trattarsi dell'elenco dei clienti che hanno aperto di recente degli account o si sono registrati per una promozione di marketing. Per determinare l'elenco dei clienti a cui vogliamo rivolgerci nella nostra campagna di marketing, dobbiamo eseguire query sia su questi dati in BigQuery sia sui dati in tempo reale in Spanner e una query federata ci consente di farlo in un'unica query.
Esegui una query federata con BigQuery
Successivamente, aggiungeremo un metodo all'applicazione per chiamare EXTERNAL_QUERY per eseguire la query federata. Ciò consentirà di unire e analizzare i dati dei clienti in BigQuery e Spanner, ad esempio identificare i clienti che soddisfano i criteri per la nostra campagna di marketing in base alle loro recenti spese.
Apri App.java e inizia sostituendo le importazioni:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Poi aggiungi il metodo campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Aggiungi un'altra istruzione case nel metodo main per la campagna:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Infine, aggiungi come utilizzare la campagna al metodo printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Salva le modifiche apportate a App.java.
Ricrea l'applicazione:
mvn package
Esegui una query federata per determinare i clienti da includere nella campagna di marketing (campaign1) se hanno speso almeno $5000 negli ultimi tre mesi eseguendo il comando campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
Output previsto:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Ora possiamo scegliere come target questi clienti con offerte o premi esclusivi.
In alternativa, possiamo cercare un numero maggiore di clienti che hanno raggiunto una soglia di spesa inferiore negli ultimi 3 mesi:
java -jar target/onlinebanking.jar campaign campaign1 2500
Output previsto:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Riepilogo
In questo passaggio, hai eseguito correttamente query federate da BigQuery che hanno importato dati Spanner in tempo reale.
Prossimo
Successivamente, puoi liberare spazio dalle risorse create per questo codelab per evitare addebiti.
9. Pulizia (facoltativo)
Questo passaggio è facoltativo. Se vuoi continuare a sperimentare con l'istanza Spanner, non devi pulirla in questo momento. Tuttavia, al progetto che utilizzi continuerà a essere addebitato il costo dell'istanza. Se non hai più bisogno di questa istanza, devi eliminarla ora per evitare questi addebiti. Oltre all'istanza Spanner, questo codelab ha creato anche una connessione e un set di dati BigQuery che devono essere puliti quando non sono più necessari.
Elimina l'istanza Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
Conferma di voler continuare (digita Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Elimina la connessione e il set di dati BigQuery:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Conferma l'eliminazione del set di dati BigQuery (digita Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Complimenti
🚀 Hai creato una nuova istanza Cloud Spanner, un database vuoto, caricato dati di esempio, eseguito operazioni e query avanzate e (facoltativamente) eliminato l'istanza Cloud Spanner.
Argomenti trattati
- Come configurare un'istanza di Spanner.
- Come creare un database e delle tabelle.
- Come caricare i dati nelle tabelle del database Spanner.
- Come chiamare i modelli Vertex AI da Spanner.
- Come eseguire query sul database Spanner utilizzando la ricerca approssimativa e la ricerca a testo intero.
- Come eseguire query federate su Spanner da BigQuery.
- Come eliminare l'istanza Spanner.
Passaggi successivi
- Scopri di più sulle funzionalità avanzate di Spanner, tra cui:
- Consulta le librerie client di Spanner disponibili.