
1. Présentation
Spanner est un service de base de données entièrement géré, distribué à l'échelle mondiale et à évolutivité horizontale, idéal pour les charges de travail opérationnelles relationnelles et non relationnelles. Au-delà de ses fonctionnalités de base, Spanner propose des fonctionnalités avancées puissantes qui permettent de créer des applications intelligentes et axées sur les données.
Cet atelier de programmation s'appuie sur les connaissances de base de Spanner et explore l'utilisation de ses intégrations avancées pour améliorer vos capacités de traitement et d'analyse des données, en utilisant une application bancaire en ligne comme base.
Nous allons nous concentrer sur trois fonctionnalités avancées clés :
- Intégration de Vertex AI : découvrez comment intégrer Spanner à Vertex AI, la plate-forme d'IA de Google Cloud, de manière fluide. Vous apprendrez à appeler des modèles Vertex AI directement à partir de requêtes Spanner SQL, ce qui permet d'effectuer des transformations et des prédictions puissantes dans la base de données. Notre application bancaire pourra ainsi catégoriser automatiquement les transactions pour des cas d'utilisation tels que le suivi du budget et la détection des anomalies.
- Recherche en texte intégral : découvrez comment implémenter la fonctionnalité de recherche en texte intégral dans Spanner. Vous apprendrez à indexer des données textuelles et à écrire des requêtes efficaces pour effectuer des recherches par mots clés dans vos données opérationnelles. Vous pourrez ainsi découvrir des données puissantes, par exemple en trouvant efficacement des clients par adresse e-mail dans notre système bancaire.
- Requêtes fédérées BigQuery : découvrez comment exploiter les fonctionnalités de requêtes fédérées de Spanner pour interroger directement les données résidant dans BigQuery. Cela vous permet de combiner les données opérationnelles en temps réel de Spanner avec les ensembles de données analytiques de BigQuery pour obtenir des insights et des rapports complets sans duplication de données ni processus ETL complexes. Vous pouvez ainsi alimenter divers cas d'utilisation dans notre application bancaire, comme des campagnes marketing ciblées en combinant les données client en temps réel avec les tendances historiques plus larges de BigQuery.
Points abordés
- Comment configurer une instance Spanner.
- Comment créer une base de données et des tables.
- Comment charger des données dans les tables de votre base de données Spanner.
- Appeler des modèles Vertex AI depuis Spanner
- Comment interroger votre base de données Spanner à l'aide de la recherche approximative et de la recherche en texte intégral.
- Comment effectuer des requêtes fédérées sur Spanner à partir de BigQuery.
- Comment supprimer une instance Spanner.
Prérequis
2. Préparation
Créer un projet
Si vous avez déjà un projet Google Cloud avec la facturation activée, cliquez sur le menu déroulant de sélection du projet en haut à gauche de la console :

Si vous avez déjà sélectionné un projet, passez à Activer les API requises.
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet.
Cliquez ensuite sur le bouton "NEW PROJECT" (NOUVEAU PROJET) dans la boîte de dialogue qui s'affiche pour créer un projet :
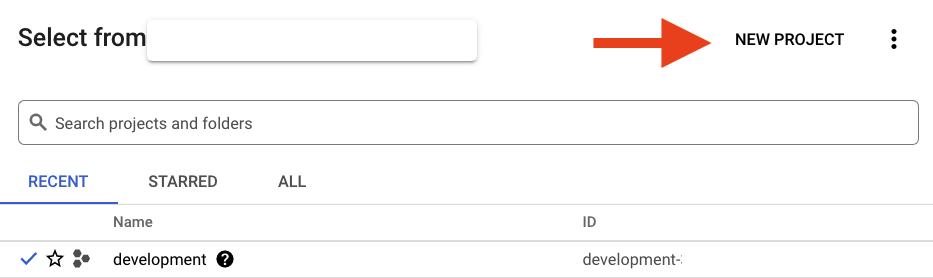
Si vous n'avez pas encore de projet, une boîte de dialogue semblable à celle-ci apparaîtra pour vous permettre d'en créer un :
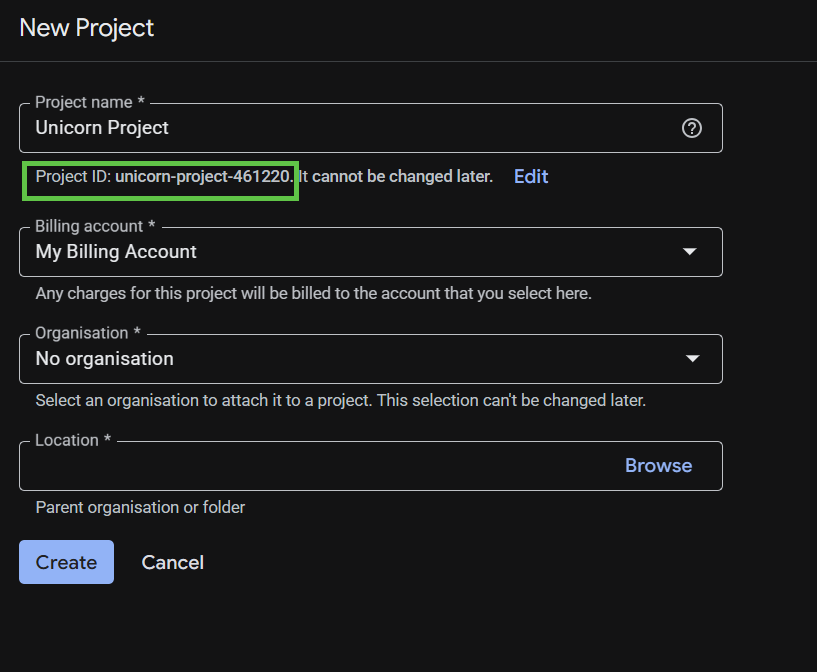
La boîte de dialogue de création de projet suivante vous permet de saisir les détails de votre nouveau projet.
Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud. Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
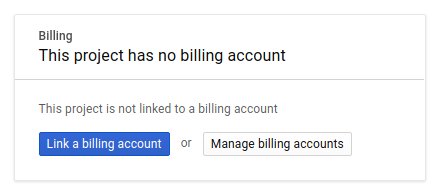
Ensuite, si ce n'est pas déjà fait, vous devez activer la facturation dans la console Developers afin de pouvoir utiliser les ressources Google Cloud et activer les API Spanner, Vertex AI, BigQuery et BigQuery Connection.
Les tarifs de Spanner sont décrits sur cette page. Les autres coûts associés à d'autres ressources seront indiqués sur les pages de tarification spécifiques.
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits.
Configuration de Google Cloud Shell
Dans cet atelier de programmation, nous allons utiliser Google Cloud Shell, un environnement de ligne de commande exécuté dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur.
Pour activer Cloud Shell à partir de la console Cloud, cliquez simplement sur Activer Cloud Shell ![]() (l'opération de provisionnement et la connexion à l'environnement ne devraient prendre que quelques minutes).
(l'opération de provisionnement et la connexion à l'environnement ne devraient prendre que quelques minutes).

Une fois connecté à Cloud Shell, vous êtes normalement déjà authentifié et le projet PROJECT_ID est sélectionné :
gcloud auth list
Résultat attendu :
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Résultat attendu :
[core] project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez la commande suivante :
gcloud config set project <PROJECT_ID>
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
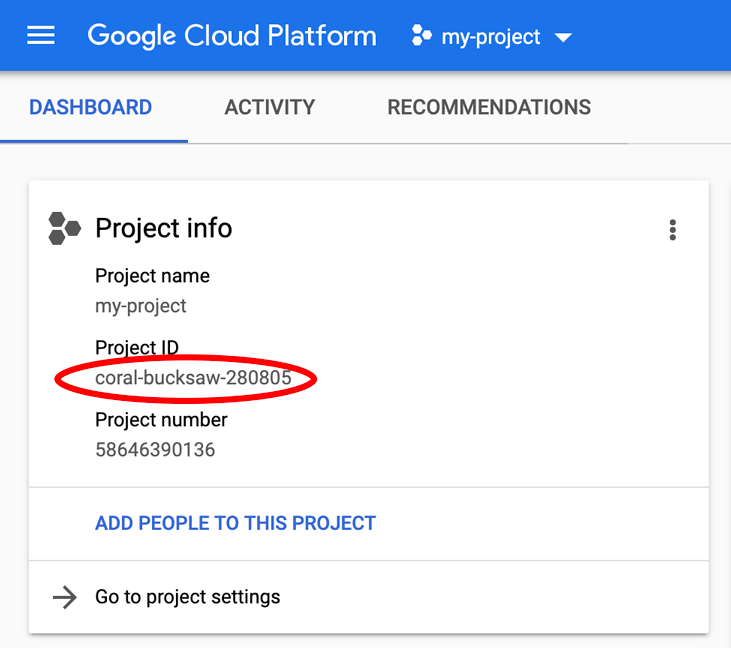
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat attendu :
<PROJECT_ID>
Activer les API requises
Activez les API Spanner, Vertex AI et BigQuery pour votre projet :
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Résumé
Au cours de cette étape, vous avez configuré votre projet si vous n'en aviez pas déjà un, activé Cloud Shell et activé les API requises.
Étape suivante
Vous allez ensuite configurer l'instance Spanner.
3. Configurer une instance Spanner
Créer l'instance Spanner
Dans cette étape, vous allez configurer une instance Spanner pour l'atelier de programmation. Pour ce faire, ouvrez Cloud Shell et exécutez la commande suivante :
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Résultat attendu :
Creating instance...done.
Résumé
Lors de cette étape, vous avez créé l'instance Spanner.
Étape suivante
Vous allez ensuite préparer l'application initiale, puis créer la base de données et le schéma.
4. Créer une base de données et un schéma
Préparer la demande initiale
Dans cette étape, vous allez créer la base de données et le schéma à l'aide du code.
Pour commencer, créez une application Java nommée onlinebanking à l'aide de Maven :
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Extrayez et copiez les fichiers de données que nous ajouterons à la base de données (consultez ici pour accéder au dépôt de code) :
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Accédez au dossier de l'application :
cd onlinebanking
Ouvrez le fichier Maven pom.xml. Ajoutez la section de gestion des dépendances pour utiliser Maven BOM afin de gérer la version des bibliothèques Google Cloud :
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Voici à quoi ressemblent l'éditeur et le fichier : 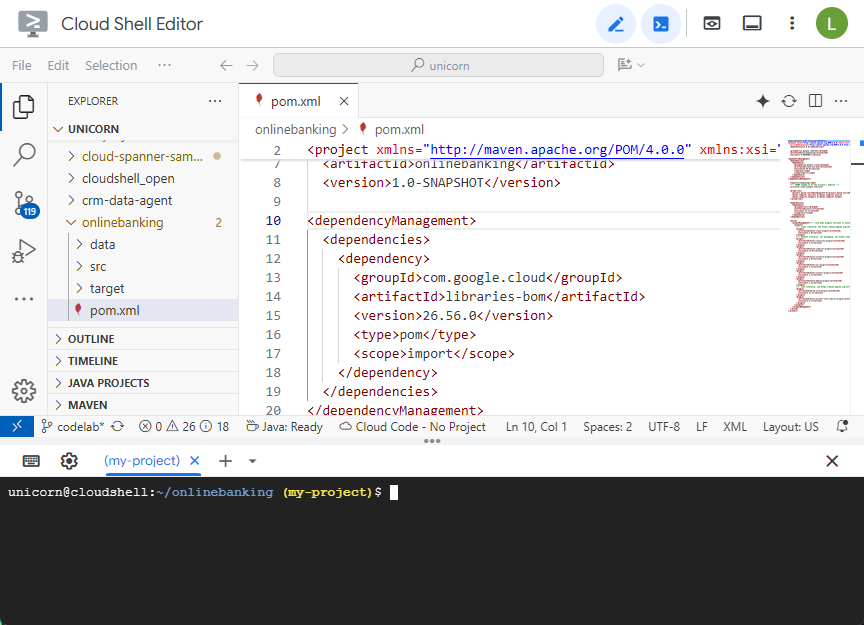
Assurez-vous que la section dependencies inclut les bibliothèques que l'application utilisera :
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Enfin, remplacez les plug-ins de compilation afin que l'application soit empaquetée dans un fichier JAR exécutable :
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Enregistrez les modifications apportées au fichier pom.xml en sélectionnant "Enregistrer" dans le menu "Fichier " de l'éditeur Cloud Shell ou en appuyant sur Ctrl+S.
Maintenant que les dépendances sont prêtes, vous allez ajouter du code à l'application pour créer un schéma, des index (y compris la recherche) et un modèle d'IA connecté à un point de terminaison distant. Vous vous appuierez sur ces artefacts et ajouterez d'autres méthodes à cette classe tout au long de cet atelier de programmation.
Ouvrez App.java sous onlinebanking/src/main/java/com/google/codelabs et remplacez le contenu par le code suivant :
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Enregistrez les modifications apportées à App.java.
Examinez les différentes entités que votre code crée et compilez le fichier JAR de l'application :
mvn package
Résultat attendu :
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Exécutez l'application pour afficher les informations d'utilisation :
java -jar target/onlinebanking.jar
Résultat attendu :
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Créer la base de données et le schéma
Définissez les variables d'environnement requises pour l'application :
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Créez la base de données et le schéma en exécutant la commande create :
java -jar target/onlinebanking.jar create
Résultat attendu :
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Vérifier le schéma dans Spanner
Dans la console Spanner, accédez à l'instance et à la base de données que vous venez de créer.
Vous devriez voir les trois tables : Accounts, Customers et TransactionLedger.
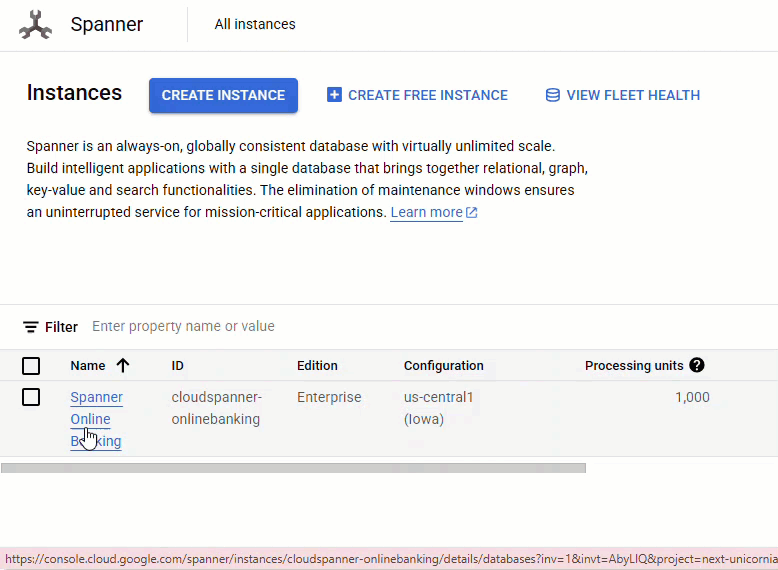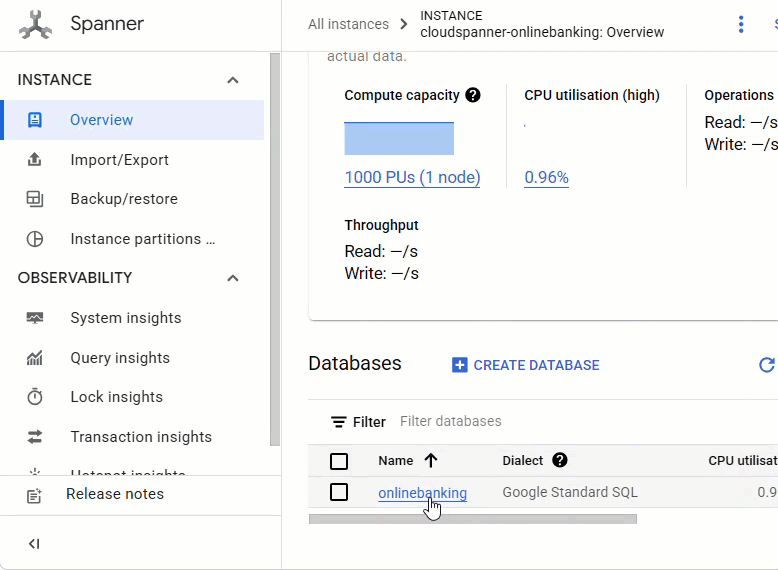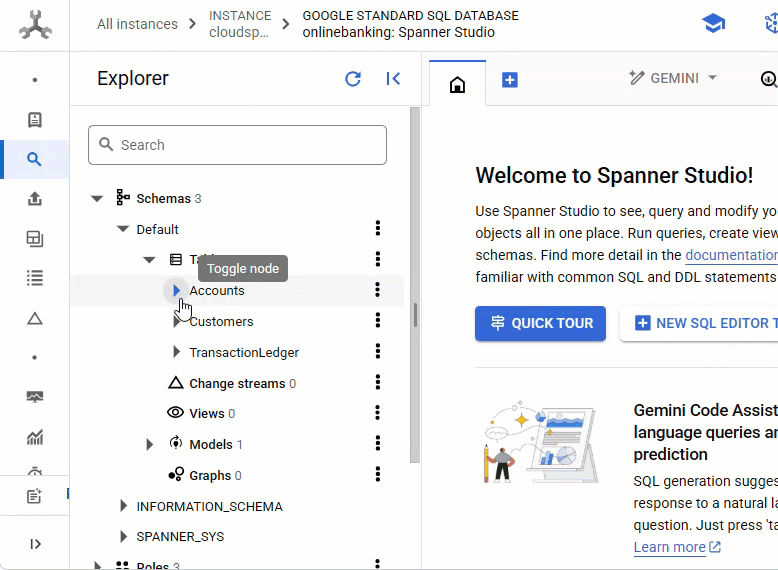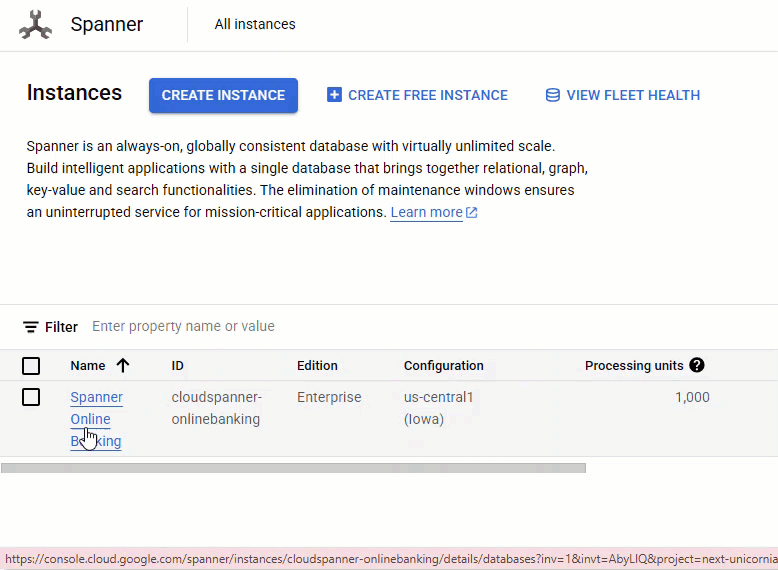
Cette action crée le schéma de base de données, y compris les tables Accounts, Customers et TransactionLedger, ainsi que des index secondaires pour optimiser la récupération des données et une référence de modèle Vertex AI.
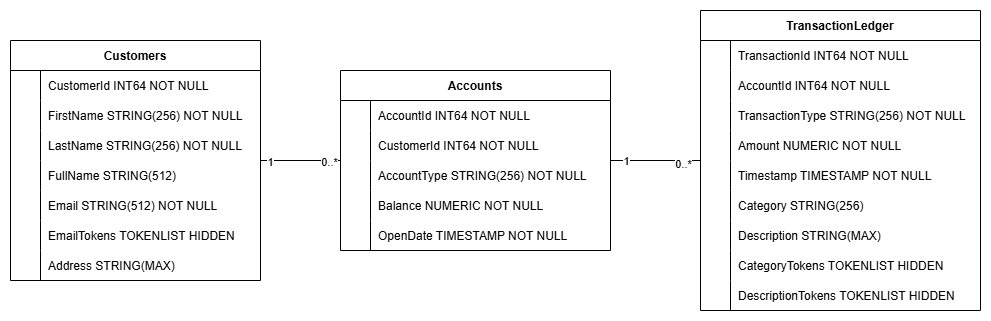
La table TransactionLedger est entrelacée dans les comptes pour améliorer les performances des requêtes pour les transactions spécifiques à un compte grâce à une meilleure localité des données.
Des index secondaires (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) ont été implémentés pour optimiser les modèles d'accès aux données courants utilisés dans cet atelier de programmation, tels que les recherches de clients par e-mail exact et approximatif, la récupération de comptes par client, et l'interrogation et la recherche efficaces de données de transaction.
TransactionCategoryModel utilise Vertex AI pour permettre les appels SQL directs à un LLM, qui est utilisé pour la catégorisation dynamique des transactions dans cet atelier de programmation.
Résumé
Lors de cette étape, vous avez créé la base de données et le schéma Spanner.
Étape suivante
Vous allez ensuite charger les exemples de données de l'application.
5. Charger les données
Vous allez maintenant ajouter une fonctionnalité permettant de charger des exemples de données à partir de fichiers CSV dans la base de données.
Ouvrez App.java et commencez par remplacer les importations :
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ajoutez ensuite les méthodes d'insertion à la classe App :
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Ajoutez une autre instruction case dans la méthode main pour l'insertion dans switch (command) :
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Enfin, ajoutez la façon d'utiliser l'insertion à la méthode printUsageAndExit :
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Enregistrez les modifications apportées à App.java.
Recompilez l'application :
mvn package
Insérez les exemples de données en exécutant la commande insert :
java -jar target/onlinebanking.jar insert
Résultat attendu :
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
Dans la console Spanner, revenez à Spanner Studio pour votre instance et votre base de données. Sélectionnez ensuite la table TransactionLedger, puis cliquez sur "Données" dans la barre latérale pour vérifier que les données ont été chargées. Le tableau doit comporter 200 lignes.
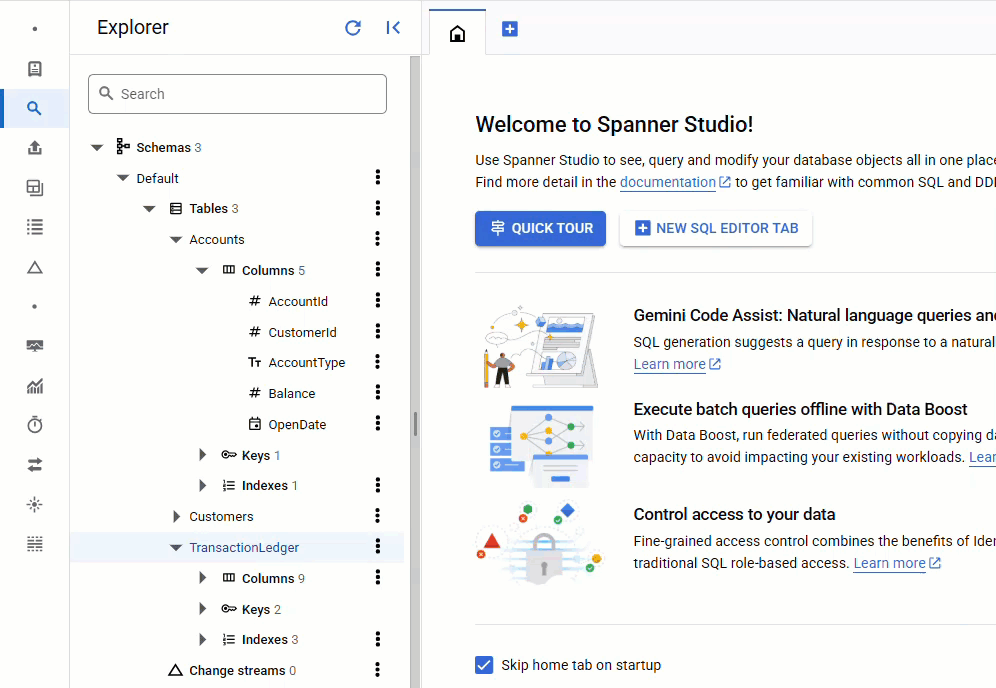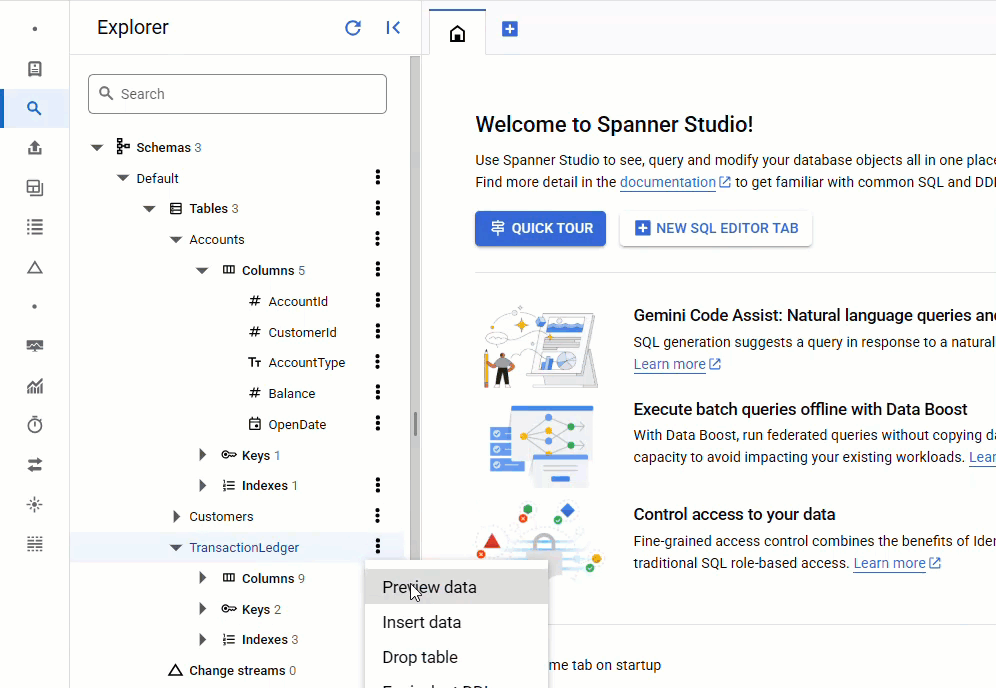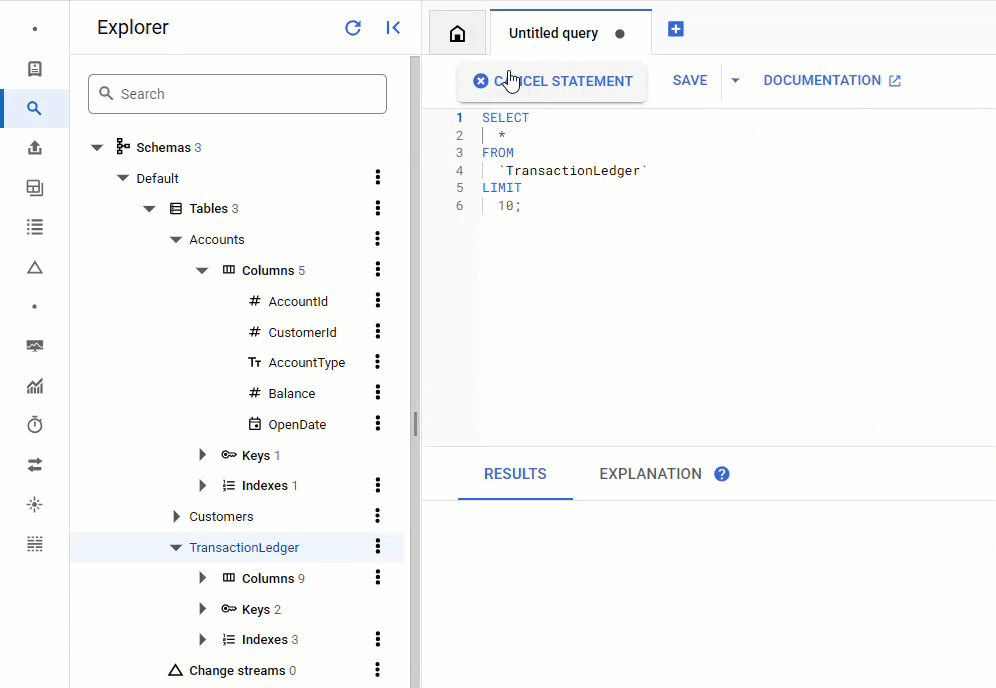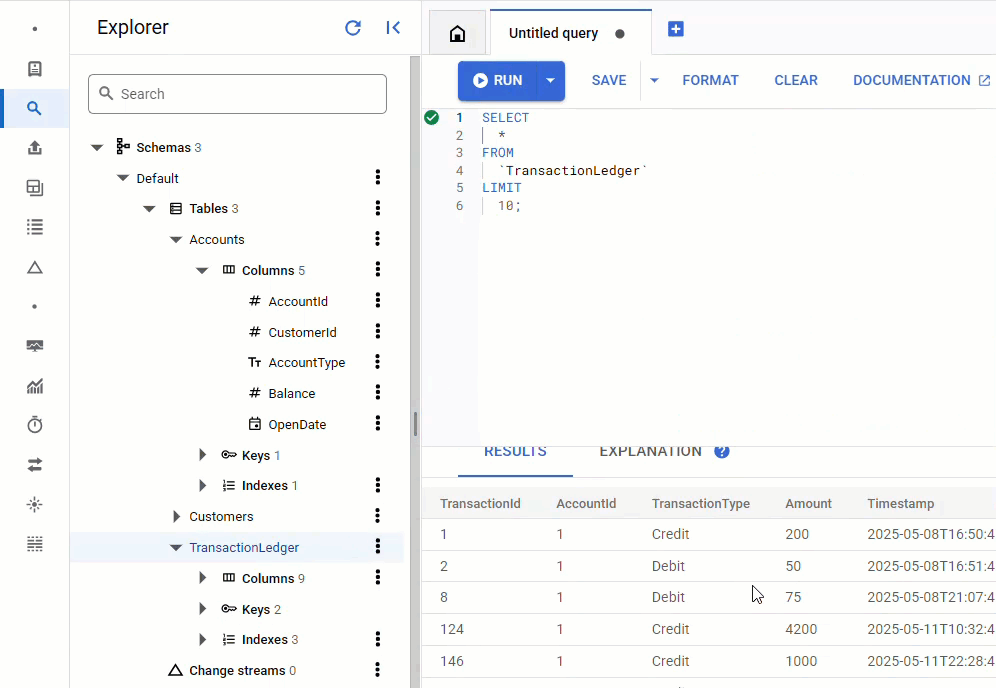
Résumé
Dans cette étape, vous avez inséré les exemples de données dans la base de données.
Étape suivante
Ensuite, vous exploiterez l'intégration de Vertex AI pour catégoriser automatiquement les transactions bancaires directement dans SpannerSQL.
6. Catégoriser des données avec Vertex AI
Dans cette étape, vous allez exploiter la puissance de Vertex AI pour catégoriser automatiquement vos transactions financières directement dans Spanner SQL. Avec Vertex AI, vous pouvez choisir un modèle pré-entraîné existant ou entraîner et déployer le vôtre. Consultez les modèles disponibles dans Vertex AI Model Garden.
Pour cet atelier de programmation, nous utiliserons l'un des modèles Gemini, Gemini Flash Lite. Cette version de Gemini est économique, mais peut tout de même gérer la plupart des charges de travail quotidiennes.
Actuellement, nous avons un certain nombre de transactions financières que nous aimerions catégoriser (groceries, transportation, etc.) en fonction de la description. Pour ce faire, nous pouvons enregistrer un modèle dans Spanner, puis utiliser ML.PREDICT pour appeler le modèle d'IA.
Dans notre application bancaire, nous pouvons vouloir catégoriser les transactions pour obtenir des informations plus approfondies sur le comportement des clients. Cela nous permet de personnaliser les services, de détecter plus efficacement les anomalies ou de permettre au client de suivre son budget mois par mois.
La première étape a déjà été effectuée lors de la création de la base de données et du schéma, ce qui a créé un modèle comme celui-ci :
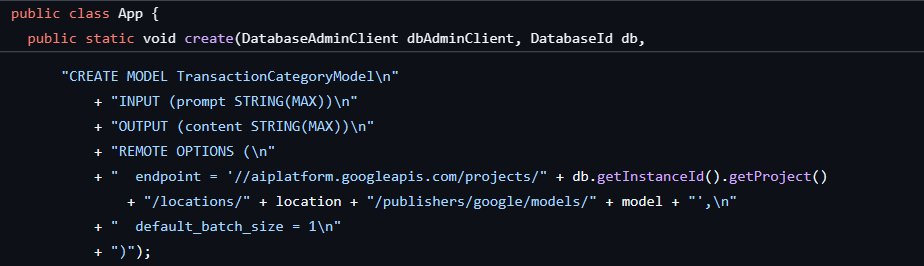
Nous allons ensuite ajouter une méthode à l'application pour appeler ML.PREDICT.
Ouvrez App.java et ajoutez la méthode categorize :
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Ajoutez une autre instruction case dans la méthode main pour la catégorisation :
case "categorize":
categorize(dbClient);
break;
Enfin, ajoutez la façon d'utiliser la catégorisation à la méthode printUsageAndExit :
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Enregistrez les modifications apportées à App.java.
Recompilez l'application :
mvn package
Catégorisez les transactions dans la base de données en exécutant la commande categorize :
java -jar target/onlinebanking.jar categorize
Résultat attendu :
Categorizing transactions... Completed categorizing transactions
Dans Spanner Studio, exécutez l'instruction Preview Data pour la table TransactionLedger. La colonne Category doit maintenant être renseignée pour toutes les lignes.
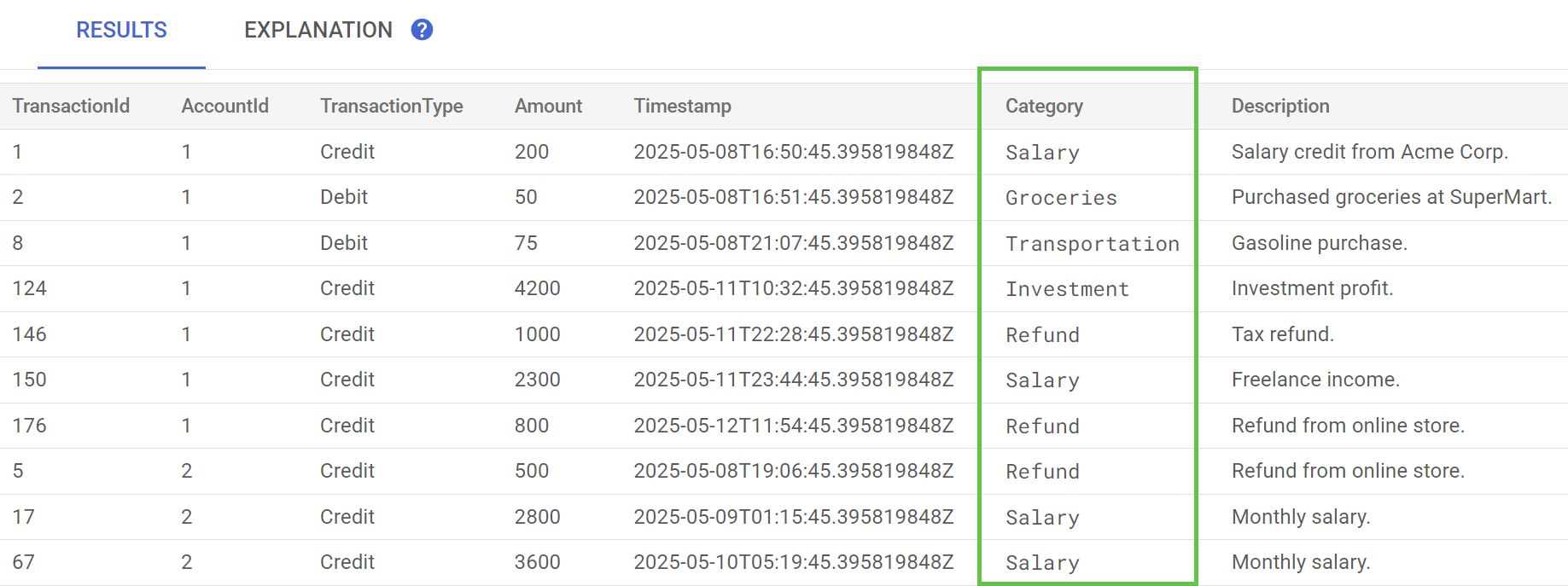
Maintenant que nous avons catégorisé les transactions, nous pouvons utiliser ces informations pour des requêtes internes ou destinées aux clients. Dans une prochaine étape, nous verrons comment déterminer combien un client donné dépense dans une catégorie au cours du mois.
Résumé
Lors de cette étape, vous avez utilisé un modèle pré-entraîné pour catégoriser vos données à l'aide de l'IA.
Étape suivante
Vous allez ensuite utiliser la tokenisation pour effectuer des recherches approximatives et en texte intégral.
7. Exécuter une requête à l'aide de la recherche en texte intégral
Ajouter le code de requête
Spanner propose de nombreuses requêtes de recherche en texte intégral. Dans cette étape, vous allez effectuer une recherche de correspondance exacte, puis une recherche approximative et une recherche en texte intégral.
Ouvrez App.java et commencez par remplacer les importations :
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ajoutez ensuite les méthodes de requête :
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Ajoutez une autre instruction case dans la méthode main pour la requête :
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Enfin, ajoutez la façon d'utiliser les commandes de requête à la méthode printUsageAndExit :
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Enregistrez les modifications apportées à App.java.
Recompilez l'application :
mvn package
Effectuer une recherche en requête exacte pour les soldes des comptes client
Une requête de correspondance exacte recherche les lignes correspondantes qui correspondent exactement à un terme.
Pour améliorer les performances, un index a déjà été ajouté lorsque vous avez créé la base de données et le schéma :
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
La méthode getBalance utilise implicitement cet index pour trouver les clients correspondant au customerId fourni et effectue également une jointure sur les comptes appartenant à ce client.
Voici à quoi ressemble la requête lorsqu'elle est exécutée directement dans Spanner Studio : 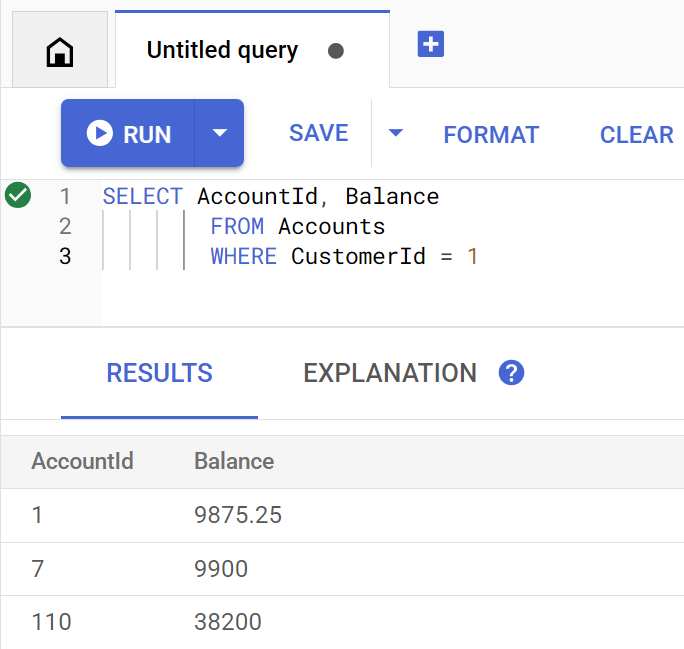
Pour lister le ou les soldes du compte du client 1, exécutez la commande suivante :
java -jar target/onlinebanking.jar query balance 1
Résultat attendu :
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Il y a 100 clients. Vous pouvez également interroger le solde du compte d'un autre client en spécifiant un autre ID client :
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Effectuer une recherche approximative dans les adresses e-mail des clients
Les recherches approximatives permettent de trouver des correspondances approximatives pour les termes de recherche, y compris les variantes orthographiques et les fautes de frappe.
Un index n-gram a déjà été ajouté lorsque vous avez créé la base de données et le schéma :
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
La méthode findCustomers utilise SEARCH_NGRAMS et SCORE_NGRAMS pour interroger cet index et trouver des clients par e-mail. Étant donné que la colonne "Adresse e-mail" a été tokenisée en n-grammes, cette requête peut contenir des fautes d'orthographe et renvoyer quand même une réponse correcte. Les résultats sont triés en fonction de la meilleure correspondance.
Pour trouver les adresses e-mail de clients correspondantes contenant madi, exécutez la commande suivante :
java -jar target/onlinebanking.jar query email madi
Résultat attendu :
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Cette réponse affiche les correspondances les plus proches qui incluent madi ou une chaîne semblable, par ordre de pertinence.
Voici à quoi ressemble la requête si elle est exécutée directement dans Spanner Studio : 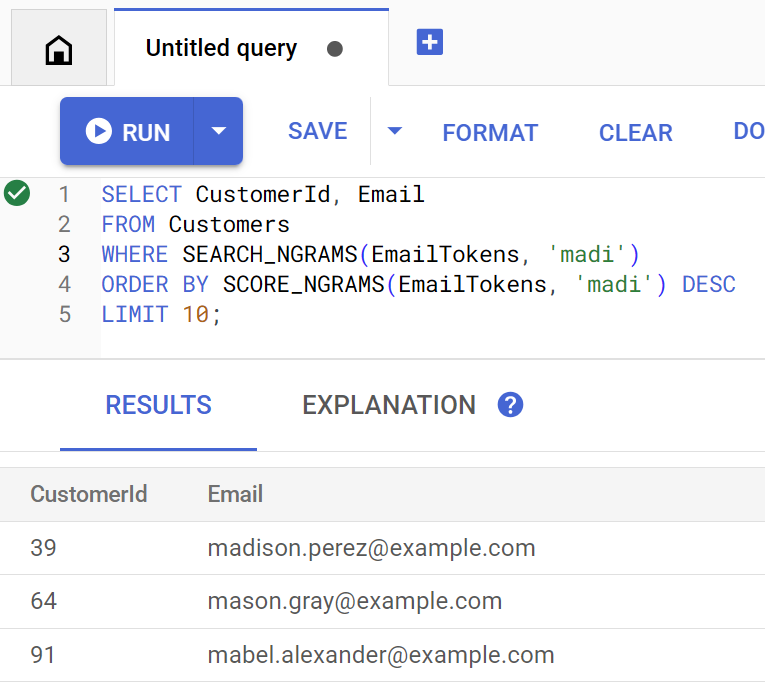
La recherche approximative peut également vous aider à corriger les fautes d'orthographe, par exemple emily :
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Résultat attendu :
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
Dans chaque cas, l'adresse e-mail du client attendue est renvoyée en premier résultat.
Rechercher des transactions avec la recherche en texte intégral
La fonctionnalité de recherche en texte intégral de Spanner permet de récupérer des enregistrements en fonction de mots clés ou d'expressions. Il peut corriger les fautes d'orthographe ou rechercher des synonymes.
Un index de recherche en texte intégral a déjà été ajouté lorsque vous avez créé la base de données et le schéma :
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
La méthode getSpending utilise la fonction de recherche en texte intégral SEARCH pour établir une correspondance avec cet index. Elle recherche toutes les dépenses (débits) au cours des 30 derniers jours pour l'ID client donné.
Pour obtenir le total des dépenses du mois dernier pour le client 1 dans la catégorie groceries, exécutez la commande suivante :
java -jar target/onlinebanking.jar query spending 1 groceries
Résultat attendu :
Total spending for customer 1 under category groceries: 50
Vous pouvez également consulter les dépenses dans d'autres catégories (que nous avons classées à l'étape précédente) ou utiliser un autre ID client :
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Résumé
Au cours de cette étape, vous avez effectué des requêtes exactes, ainsi que des recherches approximatives et en texte intégral.
Étape suivante
Vous allez ensuite intégrer Spanner à Google BigQuery pour effectuer des requêtes fédérées, ce qui vous permettra de combiner vos données Spanner en temps réel avec les données BigQuery.
8. Exécuter des requêtes fédérées avec BigQuery
Créer l'ensemble de données BigQuery
Dans cette étape, vous allez rassembler les données BigQuery et Spanner à l'aide de requêtes fédérées.
Pour ce faire, dans la ligne de commande Cloud Shell, commencez par créer un ensemble de données MarketingCampaigns :
bq mk --location=us-central1 MarketingCampaigns
Résultat attendu :
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
et une table CustomerSegments dans l'ensemble de données :
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Résultat attendu :
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Ensuite, créez une connexion entre BigQuery et Spanner :
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Résultat attendu :
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Enfin, ajoutez des clients à la table BigQuery qui peuvent être associés à nos données Spanner :
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Résultat attendu :
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Pour vérifier que les données sont disponibles, interrogez BigQuery :
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Résultat attendu :
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Ces données dans BigQuery représentent les données qui ont été ajoutées via différents workflows bancaires. Par exemple, il peut s'agir de la liste des clients qui ont récemment ouvert des comptes ou se sont inscrits à une promotion marketing. Pour déterminer la liste des clients que nous souhaitons cibler dans notre campagne marketing, nous devons interroger à la fois ces données dans BigQuery et les données en temps réel dans Spanner. Une requête fédérée nous permet de le faire en une seule requête.
Exécuter une requête fédérée avec BigQuery
Nous allons ensuite ajouter une méthode à l'application pour appeler EXTERNAL_QUERY afin d'exécuter la requête fédérée. Cela vous permettra de joindre et d'analyser les données client dans BigQuery et Spanner, par exemple pour identifier les clients qui répondent aux critères de notre campagne marketing en fonction de leurs dépenses récentes.
Ouvrez App.java et commencez par remplacer les importations :
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ajoutez ensuite la méthode campaign :
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Ajoutez une autre instruction case dans la méthode main pour la campagne :
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Enfin, ajoutez la façon d'utiliser la campagne à la méthode printUsageAndExit :
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Enregistrez les modifications apportées à App.java.
Recompilez l'application :
mvn package
Exécutez une requête fédérée pour déterminer les clients à inclure dans la campagne marketing (campaign1) s'ils ont dépensé au moins $5000 au cours des trois derniers mois en exécutant la commande campaign :
java -jar target/onlinebanking.jar campaign campaign1 5000
Résultat attendu :
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Nous pouvons désormais cibler ces clients avec des offres ou des récompenses exclusives.
Nous pouvons également rechercher un plus grand nombre de clients ayant atteint un seuil de dépenses plus faible au cours des trois derniers mois :
java -jar target/onlinebanking.jar campaign campaign1 2500
Résultat attendu :
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Résumé
Au cours de cette étape, vous avez exécuté des requêtes fédérées depuis BigQuery qui ont importé des données Spanner en temps réel.
Étape suivante
Ensuite, vous pouvez nettoyer les ressources créées pour cet atelier de programmation afin d'éviter que des frais ne vous soient facturés.
9. Nettoyage (facultatif)
Cette étape est facultative. Si vous souhaitez continuer à tester votre instance Spanner, vous n'avez pas besoin de la nettoyer pour le moment. Toutefois, le projet que vous utilisez continuera à être facturé pour l'instance. Si vous n'avez plus besoin de cette instance, supprimez-la dès maintenant pour éviter ces frais. En plus de l'instance Spanner, cet atelier de programmation a également créé un ensemble de données et une connexion BigQuery qui doivent être nettoyés lorsqu'ils ne sont plus nécessaires.
Supprimez l'instance Spanner :
gcloud spanner instances delete cloudspanner-onlinebanking
Confirmez que vous souhaitez continuer (saisissez Y) :
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Supprimez la connexion et l'ensemble de données BigQuery :
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Confirmez la suppression de l'ensemble de données BigQuery (saisissez Y) :
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Félicitations
🚀 Vous avez créé une instance Cloud Spanner, une base de données vide, chargé des exemples de données, effectué des opérations et des requêtes avancées, et (facultativement) supprimé l'instance Cloud Spanner.
Points abordés
- Comment configurer une instance Spanner.
- Comment créer une base de données et des tables.
- Comment charger des données dans les tables de votre base de données Spanner.
- Appeler des modèles Vertex AI depuis Spanner
- Comment interroger votre base de données Spanner à l'aide de la recherche approximative et de la recherche en texte intégral.
- Comment effectuer des requêtes fédérées sur Spanner à partir de BigQuery.
- Comment supprimer une instance Spanner.
Étape suivante
- Découvrez les fonctionnalités avancées de Spanner, y compris :
- Consultez les bibliothèques clientes Spanner disponibles.