
1. نظرة عامة
Spanner هي خدمة قواعد بيانات موزّعة عالميًا وقابلة للتوسّع أفقيًا ومُدارة بالكامل، وهي مناسبة لمهام العمل التشغيلية العلائقية وغير العلائقية. بالإضافة إلى إمكاناتها الأساسية، يوفّر Spanner ميزات متقدّمة وفعّالة تتيح إنشاء تطبيقات ذكية مستندة إلى البيانات.
يستند هذا الدرس التطبيقي حول الترميز إلى الفهم الأساسي لخدمة Spanner ويتعمّق في الاستفادة من عمليات الدمج المتقدّمة لتحسين إمكانات معالجة البيانات والتحليل، وذلك باستخدام تطبيق للخدمات المصرفية على الإنترنت كأساس.
سنركّز على ثلاث ميزات متقدّمة رئيسية:
- عملية الدمج مع Vertex AI: تعرَّف على كيفية دمج Spanner بسلاسة مع منصة الذكاء الاصطناعي Vertex AI من Google Cloud. ستتعرّف على كيفية استدعاء نماذج Vertex AI مباشرةً من داخل طلبات بحث Spanner SQL، ما يتيح إجراء عمليات تحويل وتوقّعات فعّالة داخل قاعدة البيانات، ويسمح لتطبيقنا المصرفي بتصنيف المعاملات تلقائيًا لحالات استخدام مثل تتبُّع الميزانية ورصد الحالات الشاذة.
- البحث في النص الكامل: تعرَّف على كيفية تنفيذ وظيفة البحث في النص الكامل ضمن Spanner. ستستكشف كيفية فهرسة البيانات النصية وكتابة طلبات بحث فعّالة لإجراء عمليات بحث مستندة إلى الكلمات الرئيسية في بيانات التشغيل، ما يتيح استكشاف البيانات بشكلٍ فعّال، مثل العثور على العملاء بكفاءة من خلال عناوين بريدهم الإلكتروني في نظامنا المصرفي.
- طلبات البحث الموحّدة في BigQuery: يمكنك استكشاف كيفية الاستفادة من إمكانات طلبات البحث الموحّدة في Spanner لطلب البحث مباشرةً عن البيانات المخزّنة في BigQuery. يتيح لك ذلك الجمع بين بيانات التشغيل في الوقت الفعلي من Spanner ومجموعات البيانات التحليلية من BigQuery للحصول على إحصاءات وتقارير شاملة بدون تكرار البيانات أو عمليات استخراج وتحويل وتحميل (ETL) المعقّدة، ما يتيح حالات استخدام مختلفة في تطبيقنا المصرفي، مثل الحملات التسويقية المستهدَفة من خلال الجمع بين بيانات العملاء في الوقت الفعلي والمؤشرات التاريخية الأوسع نطاقًا من BigQuery.
أهداف الدورة التعليمية
- كيفية إعداد مثيل Spanner
- كيفية إنشاء قاعدة بيانات وجداول
- كيفية تحميل البيانات في جداول قاعدة بيانات Spanner
- كيفية استدعاء نماذج Vertex AI من Spanner
- كيفية طلب البحث في قاعدة بيانات Spanner باستخدام البحث التقريبي والبحث عن نص كامل
- كيفية تنفيذ طلبات بحث موحّدة في Spanner من BigQuery
- كيفية حذف مثيل Spanner
المتطلبات
2. الإعداد والمتطلبات
إنشاء مشروع
إذا كان لديك مشروع على السحابة الإلكترونية مفعَّل فيه نظام الفوترة، انقر على القائمة المنسدلة لاختيار المشروع في أعلى يمين وحدة التحكّم:

إذا كان لديك مشروع محدّد، انتقِل إلى تفعيل واجهات برمجة التطبيقات المطلوبة.
إذا لم يكن لديك حساب Google (Gmail أو Google Apps)، عليك إنشاء حساب. سجِّل الدخول إلى وحدة تحكّم Google Cloud Platform (console.cloud.google.com) وأنشِئ مشروعًا جديدًا.
انقر على الزر "مشروع جديد" في مربّع الحوار الناتج لإنشاء مشروع جديد:
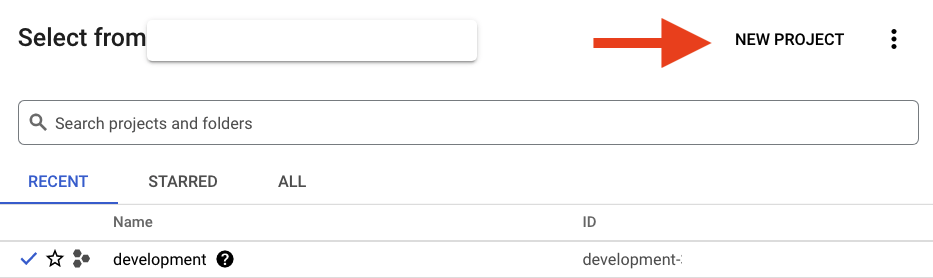
إذا لم يكن لديك مشروع، من المفترض أن يظهر لك مربّع حوار مشابه لما يلي لإنشاء مشروعك الأول:
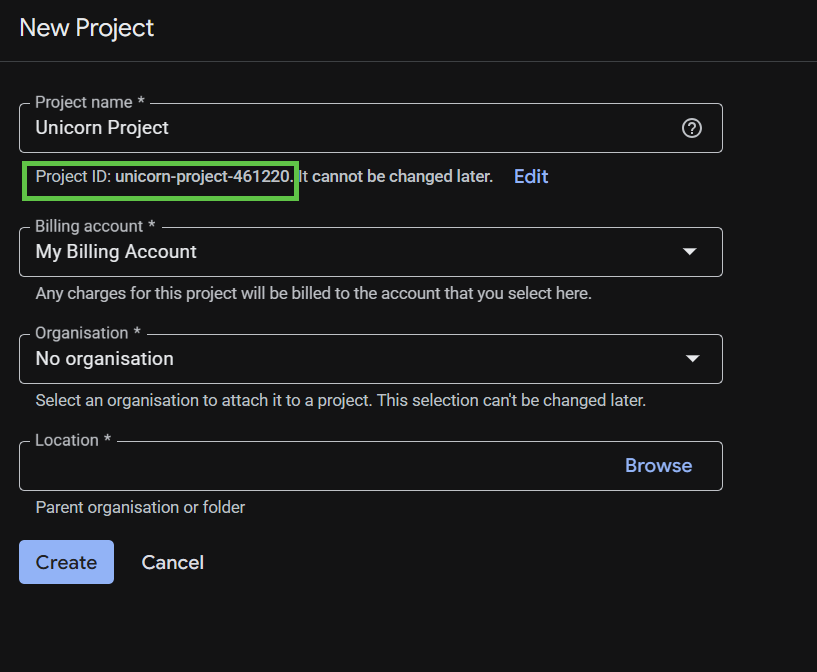
يتيح لك مربّع الحوار التالي لإنشاء المشاريع إدخال تفاصيل مشروعك الجديد.
تذكَّر رقم تعريف المشروع، وهو اسم فريد في جميع مشاريع Google Cloud. سيتم الإشارة إليه لاحقًا في هذا الدرس التطبيقي حول الترميز باسم PROJECT_ID.
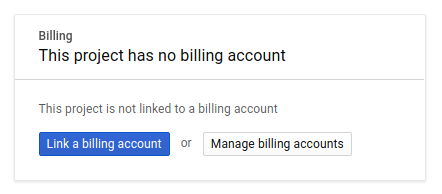
بعد ذلك، إذا لم يسبق لك إجراء ذلك، عليك تفعيل الفوترة في Developers Console من أجل استخدام موارد Google Cloud وتفعيل Spanner API وVertex AI API وBigQuery API وBigQuery Connection API.
يمكنك الاطّلاع هنا على مستندات حول أسعار Spanner. سيتم توثيق التكاليف الأخرى المرتبطة بالمراجع الأخرى في صفحات الأسعار الخاصة بها.
يمكن للمستخدمين الجدد في Google Cloud Platform الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي.
إعداد Google Cloud Shell
في هذا الدرس التطبيقي حول الترميز، سنستخدم Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
يتم تحميل هذا الجهاز الافتراضي المستند إلى Debian بجميع أدوات التطوير التي تحتاج إليها. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. وهذا يعني أنّ كل ما تحتاجه لهذا الدرس التطبيقي حول الترميز هو متصفّح.
لتفعيل Cloud Shell من Cloud Console، ما عليك سوى النقر على "تفعيل Cloud Shell" ![]() (يستغرق توفير البيئة والاتصال بها بضع لحظات فقط).
(يستغرق توفير البيئة والاتصال بها بضع لحظات فقط).

بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تمّت المصادقة عليك وأنّ المشروع تمّ ضبطه مسبقًا على PROJECT_ID.
gcloud auth list
الناتج المتوقّع:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
الناتج المتوقّع:
[core] project = <PROJECT_ID>
إذا لم يتم ضبط المشروع لسبب ما، نفِّذ الأمر التالي:
gcloud config set project <PROJECT_ID>
هل تبحث عن PROJECT_ID؟ تحقَّق من المعرّف الذي استخدمته في خطوات الإعداد أو ابحث عنه في لوحة بيانات Cloud Console:
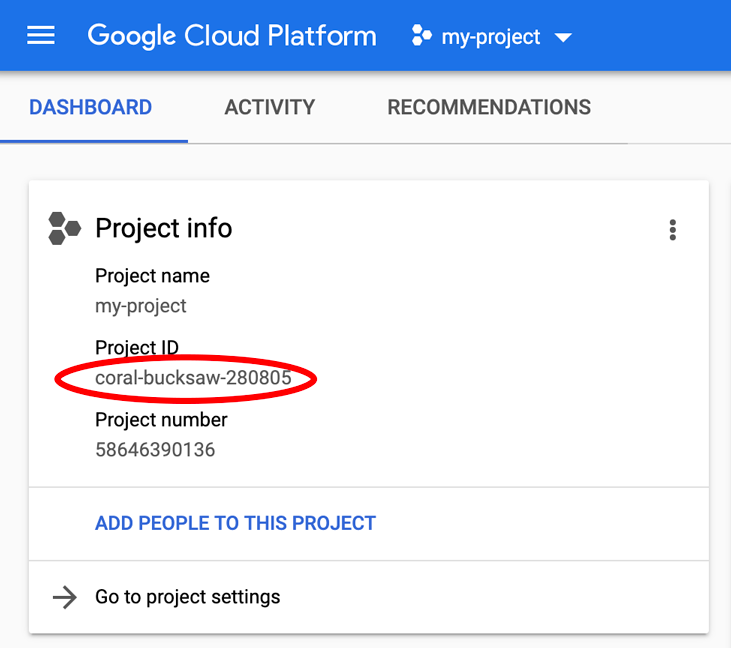
يضبط Cloud Shell أيضًا بعض متغيرات البيئة تلقائيًا، ما قد يكون مفيدًا عند تنفيذ الأوامر المستقبلية.
echo $GOOGLE_CLOUD_PROJECT
الناتج المتوقّع:
<PROJECT_ID>
تفعيل واجهات برمجة التطبيقات المطلوبة
فعِّل واجهات برمجة التطبيقات Spanner وVertex AI وBigQuery لمشروعك:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
ملخّص
في هذه الخطوة، تكون قد أعددت مشروعك إذا لم يكن لديك مشروع من قبل، وفعّلت Cloud Shell، وفعّلت واجهات برمجة التطبيقات المطلوبة.
التالي
بعد ذلك، عليك إعداد مثيل Spanner.
3- إعداد مثيل Spanner
إنشاء مثيل Spanner
في هذه الخطوة، عليك إعداد مثيل Spanner للدرس التطبيقي حول الترميز. لإجراء ذلك، افتح Cloud Shell ونفِّذ الأمر التالي:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
الناتج المتوقّع:
Creating instance...done.
ملخّص
في هذه الخطوة، أنشأت مثيل Spanner.
التالي
بعد ذلك، عليك إعداد التطبيق الأوّلي وإنشاء قاعدة البيانات والمخطط.
4. إنشاء قاعدة بيانات ومخطط
تجهيز الطلب الأوّلي
في هذه الخطوة، ستنشئ قاعدة البيانات والمخطط من خلال الرمز.
أولاً، أنشئ تطبيق Java باسم onlinebanking باستخدام Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
سجِّل الخروج وانسخ ملفات البيانات التي سنضيفها إلى قاعدة البيانات (راجِع هنا لمعرفة مستودع الرموز):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
انتقِل إلى مجلد التطبيق:
cd onlinebanking
افتح ملف Maven pom.xml. أضِف قسم إدارة التبعيات لاستخدام قائمة مواد Maven لإدارة إصدار مكتبات Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
سيظهر المحرّر والملف على النحو التالي: 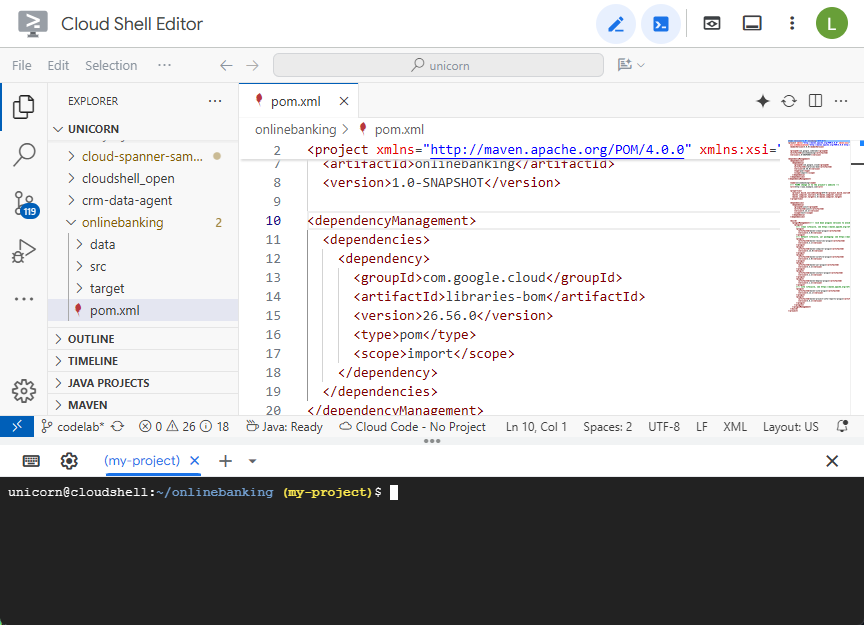
تأكَّد من أنّ القسم dependencies يتضمّن المكتبات التي سيستخدمها التطبيق:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
أخيرًا، استبدِل مكوّنات إنشاء التطبيق الإضافية حتى يتم تجميع التطبيق في ملف JAR قابل للتنفيذ:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
احفظ التغييرات التي أجريتها على ملف pom.xml من خلال النقر على "حفظ" ضمن قائمة "ملف" في "محرّر Cloud Shell" أو من خلال الضغط على Ctrl+S.
بعد أن أصبحت التبعيات جاهزة، ستضيف رمزًا برمجيًا إلى التطبيق لإنشاء مخطط وبعض الفهارس (بما في ذلك البحث) ونموذج ذكاء اصطناعي مرتبط بنقطة نهاية بعيدة. ستعتمد على هذه العناصر وتضيف المزيد من الطرق إلى هذه الفئة خلال هذا الدرس التطبيقي حول الترميز.
افتح App.java ضمن onlinebanking/src/main/java/com/google/codelabs واستبدِل المحتوى بالرمز التالي:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
احفظ التغييرات في App.java.
ألقِ نظرة على العناصر المختلفة التي ينشئها الرمز البرمجي وأنشئ ملف JAR للتطبيق:
mvn package
الناتج المتوقّع:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
شغِّل التطبيق للاطّلاع على معلومات الاستخدام:
java -jar target/onlinebanking.jar
الناتج المتوقّع:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
إنشاء قاعدة البيانات والمخطّط
اضبط متغيّرات بيئة التطبيق المطلوبة:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
أنشئ قاعدة البيانات والمخطط من خلال تنفيذ الأمر create:
java -jar target/onlinebanking.jar create
الناتج المتوقّع:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
التحقّق من المخطط في Spanner
في وحدة تحكّم Spanner، انتقِل إلى المثيل وقاعدة البيانات اللذين تم إنشاؤهما للتو.
يجب أن تظهر لك جميع الجداول الثلاثة: Accounts وCustomers وTransactionLedger.
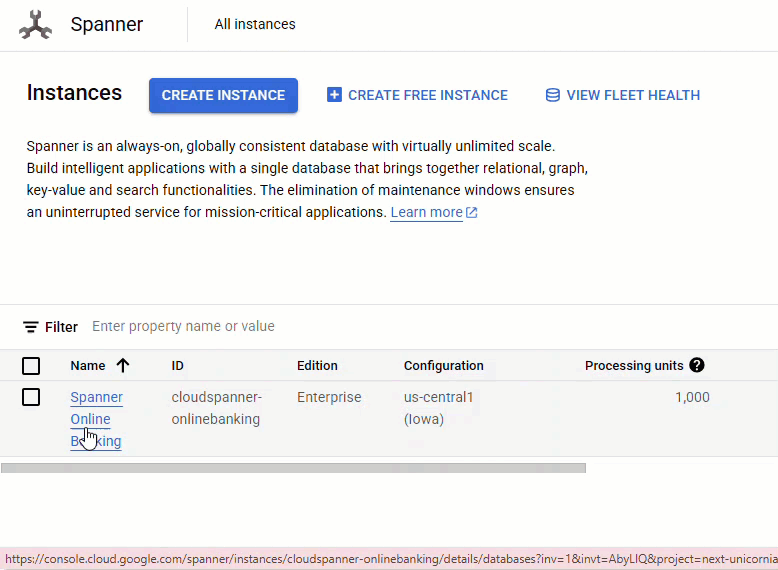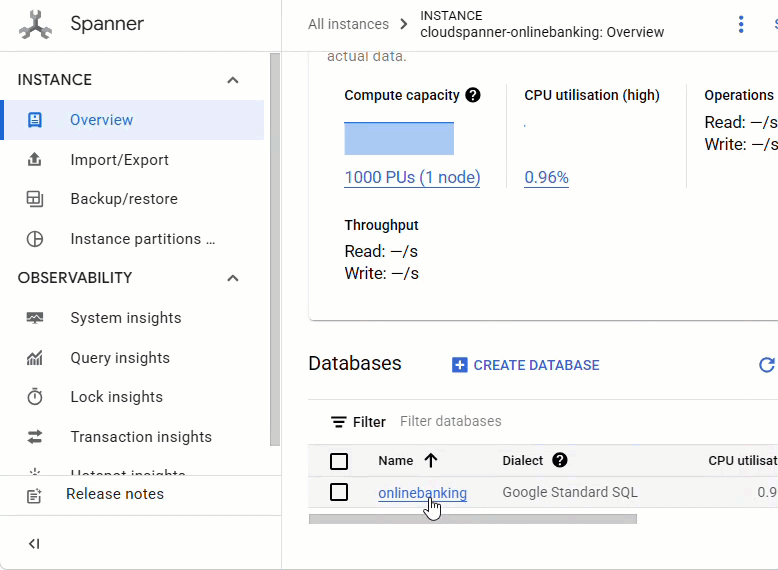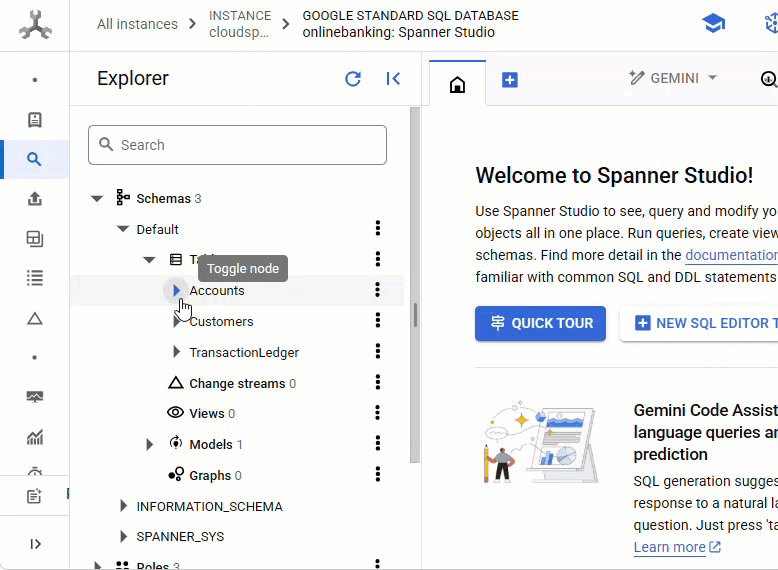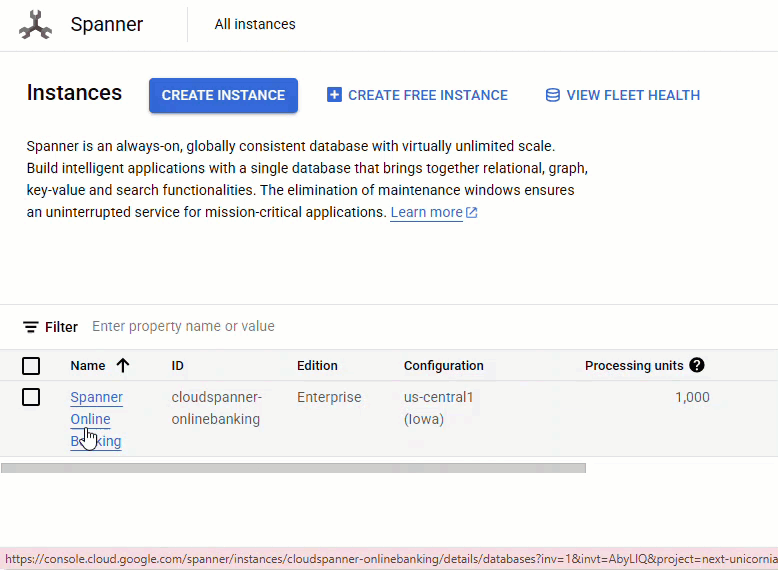
يؤدي هذا الإجراء إلى إنشاء مخطط قاعدة البيانات، بما في ذلك الجداول Accounts وCustomers وTransactionLedger، بالإضافة إلى الفهارس الثانوية لاسترداد البيانات على النحو الأمثل، ومرجع نموذج Vertex AI.
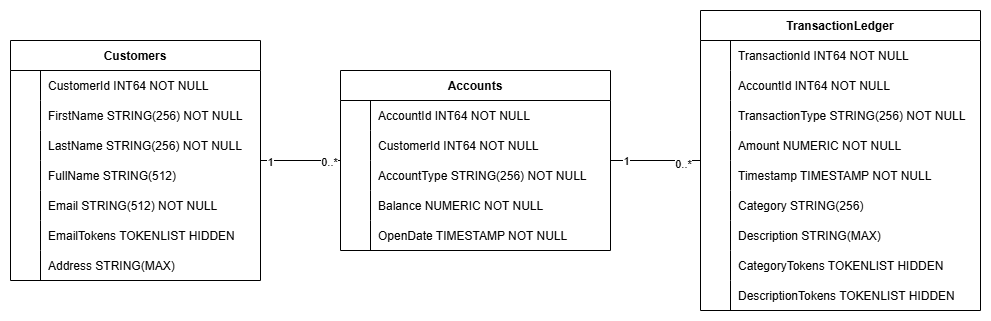
يتم دمج جدول TransactionLedger ضمن "الحسابات" لتحسين أداء طلبات البحث الخاصة بالمعاملات على مستوى الحساب من خلال تحسين موضع البيانات.
تم تنفيذ الفهارس الثانوية (CustomersByEmail وCustomersFuzzyEmail وAccountsByCustomer وTransactionLedgerByAccountType وTransactionLedgerByCategory وTransactionLedgerTextSearch) لتحسين أنماط الوصول الشائعة إلى البيانات المستخدَمة في هذا الدرس التطبيقي حول الترميز، مثل عمليات البحث عن العملاء باستخدام البريد الإلكتروني المطابق تمامًا أو المشابه، واسترداد الحسابات حسب العميل، والاستعلام عن بيانات المعاملات والبحث فيها بكفاءة.
تستفيد أداة TransactionCategoryModel من Vertex AI لتفعيل طلبات SQL مباشرةً إلى نموذج لغوي كبير، ويتم استخدامها لتصنيف المعاملات الديناميكية في هذا الدرس التطبيقي حول الترميز.
ملخّص
في هذه الخطوة، أنشأت قاعدة بيانات ومخطط Spanner.
التالي
بعد ذلك، ستحمّل بيانات التطبيق النموذجية.
5- تحميل البيانات
الآن، ستضيف وظيفة لتحميل عيّنة من البيانات من ملفات CSV إلى قاعدة البيانات.
افتح App.java وابدأ باستبدال عمليات الاستيراد:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
بعد ذلك، أضِف طرق الإدراج إلى الفئة App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
أضِف عبارة case أخرى في طريقة main للإدراج ضمن switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
أخيرًا، أضِف طريقة استخدام الإضافة إلى طريقة printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
احفظ التغييرات التي أجريتها على App.java.
أعِد إنشاء التطبيق:
mvn package
أدرِج نموذج البيانات من خلال تنفيذ الأمر insert:
java -jar target/onlinebanking.jar insert
الناتج المتوقّع:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
في Spanner Console، ارجع إلى Spanner Studio للمثيل وقاعدة البيانات. بعد ذلك، اختَر جدول TransactionLedger، وانقر على "البيانات" في الشريط الجانبي للتأكّد من تحميل البيانات. يجب أن يتضمّن الجدول 200 صف.
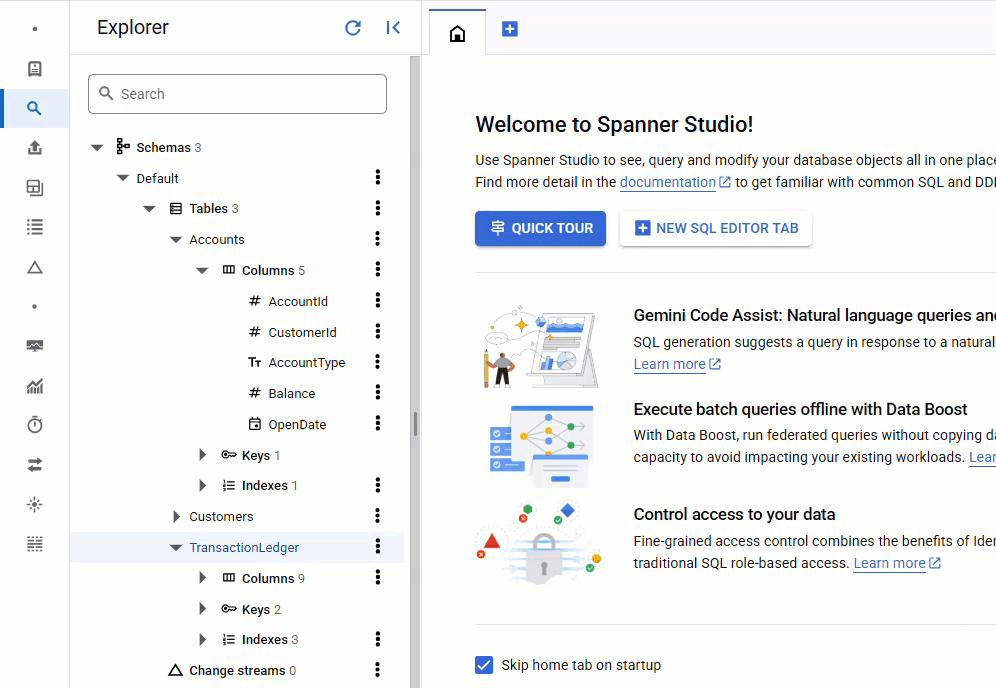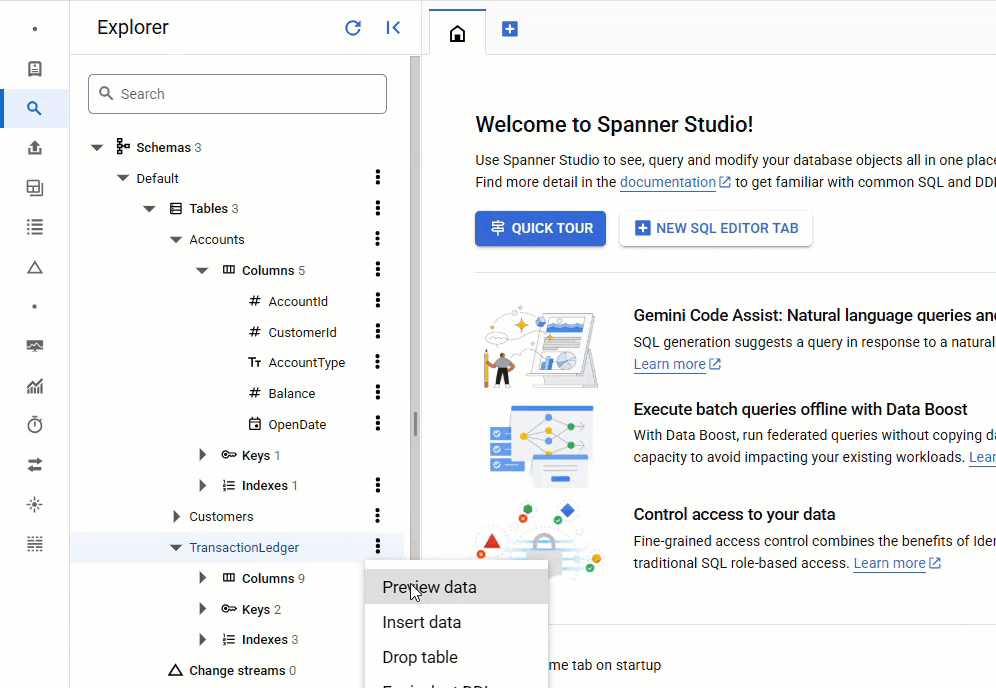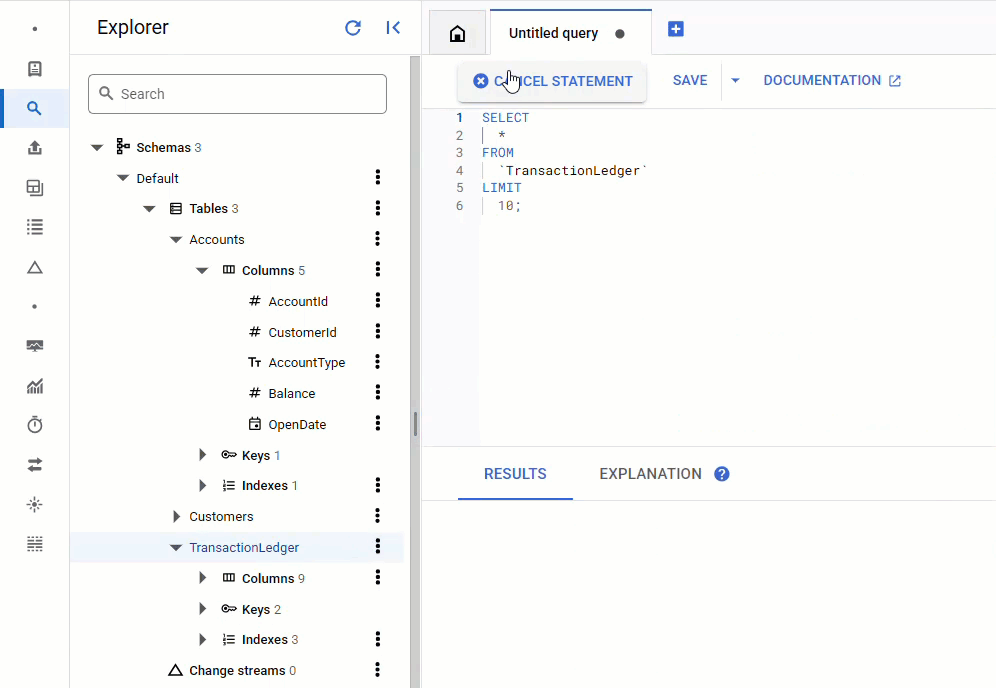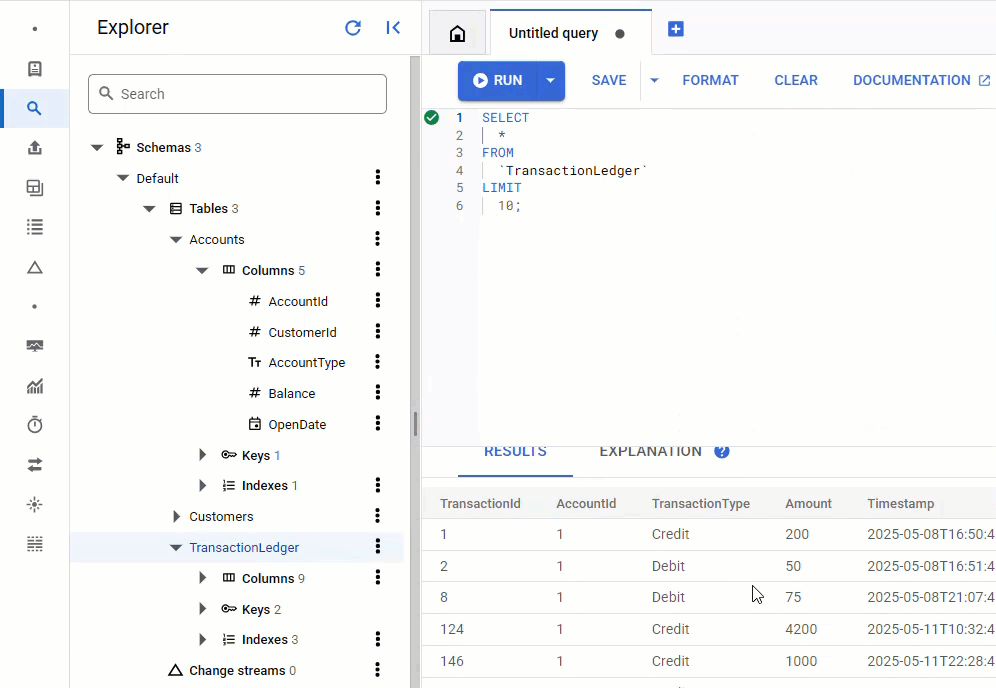
ملخّص
في هذه الخطوة، أدرجت البيانات النموذجية في قاعدة البيانات.
التالي
بعد ذلك، ستستفيد من عملية دمج Vertex AI لتصنيف المعاملات المصرفية تلقائيًا مباشرةً في Spanner SQL.
6. تصنيف البيانات باستخدام Vertex AI
في هذه الخطوة، ستستفيد من إمكانات Vertex AI لتصنيف معاملاتك المالية تلقائيًا مباشرةً في Spanner SQL. باستخدام Vertex AI، يمكنك اختيار نموذج حالي مُدرَّب مسبقًا أو تدريب نموذجك الخاص وتفعيله. اطّلِع على النماذج المتاحة في Model Garden في Vertex AI.
في هذا الدرس التطبيقي حول الترميز، سنستخدم أحد نماذج Gemini، وهو Gemini Flash Lite. هذا الإصدار من Gemini فعّال من حيث التكلفة، ولكنّه لا يزال بإمكانه التعامل مع معظم أحمال العمل اليومية.
لدينا حاليًا عدد من المعاملات المالية التي نريد تصنيفها (groceries وtransportation وما إلى ذلك) حسب الوصف. يمكننا إجراء ذلك من خلال تسجيل نموذج في Spanner ثم استخدام ML.PREDICT لاستدعاء نموذج الذكاء الاصطناعي.
في تطبيقنا المصرفي، قد نريد تصنيف المعاملات للحصول على إحصاءات أعمق حول سلوك العملاء حتى نتمكّن من تخصيص الخدمات أو رصد الحالات الشاذة بفعالية أكبر أو منح العميل القدرة على تتبُّع ميزانيته من شهر إلى آخر.
لقد تمّت الخطوة الأولى عند إنشاء قاعدة البيانات والمخطّط، ما أدّى إلى إنشاء نموذج على النحو التالي:
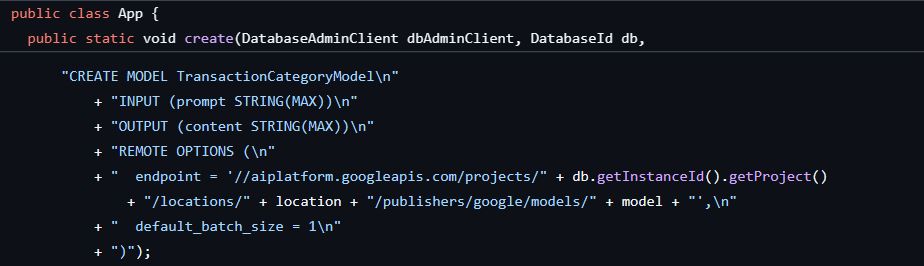
بعد ذلك، سنضيف طريقة إلى التطبيق لاستدعاء ML.PREDICT.
افتح App.java وأضِف طريقة categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
أضِف عبارة case أخرى في طريقة main للتصنيف:
case "categorize":
categorize(dbClient);
break;
أخيرًا، أضِف كيفية استخدام التصنيف إلى الطريقة printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
احفظ التغييرات التي أجريتها على App.java.
أعِد إنشاء التطبيق:
mvn package
صنِّف المعاملات في قاعدة البيانات من خلال تنفيذ الأمر categorize:
java -jar target/onlinebanking.jar categorize
الناتج المتوقّع:
Categorizing transactions... Completed categorizing transactions
في Spanner Studio، شغِّل عبارة معاينة البيانات للجدول TransactionLedger. يجب الآن ملء العمود Category لجميع الصفوف.
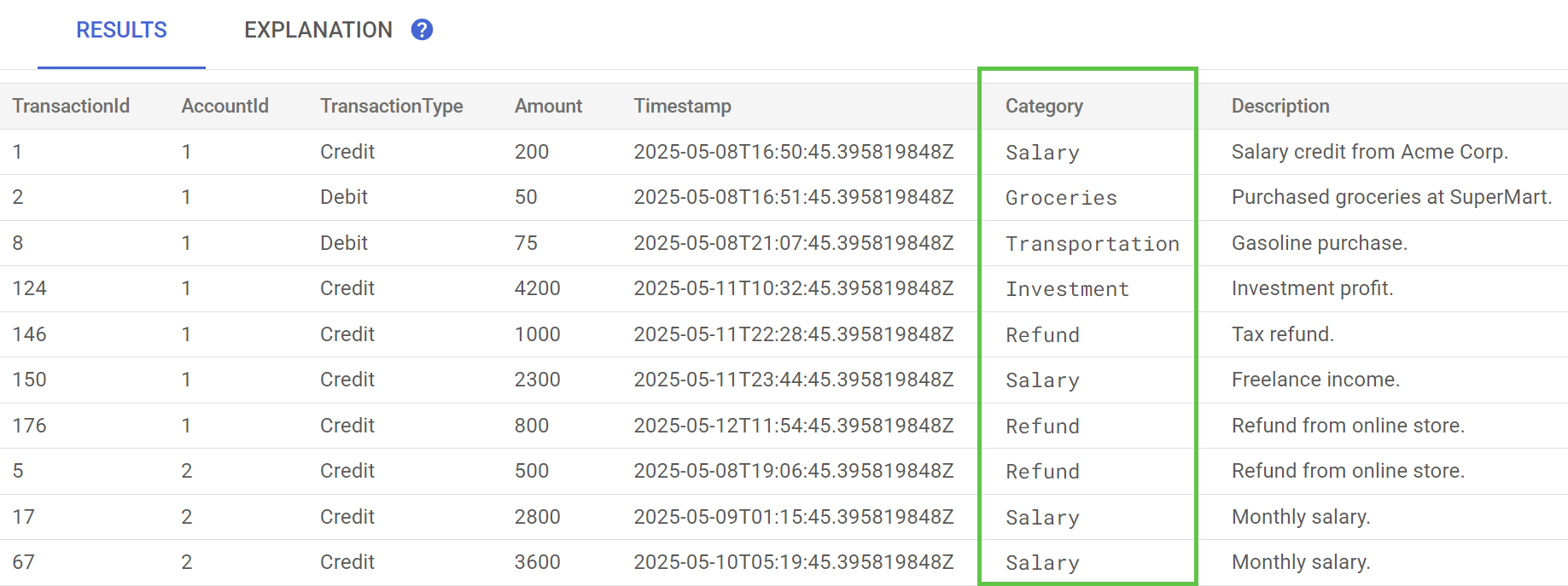
بعد أن صنّفنا المعاملات، يمكننا استخدام هذه المعلومات في طلبات البحث الداخلية أو المخصّصة للعملاء. وفي خطوة لاحقة، سنستعرض كيفية معرفة المبلغ الذي ينفقه عميل معيّن في فئة معيّنة على مدار الشهر.
ملخّص
في هذه الخطوة، استخدمت نموذجًا مدرَّبًا مسبقًا لتنفيذ عملية تصنيف بياناتك المستندة إلى الذكاء الاصطناعي.
التالي
بعد ذلك، ستستفيد من تقسيم النص إلى رموز مميزة لإجراء عمليات بحث تقريبية وبحث كامل عن النص.
7. طلب البحث باستخدام البحث في النص الكامل
إضافة رمز طلب البحث
توفّر خدمة Spanner العديد من طلبات البحث عن النص الكامل. في هذه الخطوة، ستُجري عملية بحث عن مطابقة تامة، ثم عملية بحث تقريبي وعملية بحث عن نص كامل.
افتح App.java وابدأ باستبدال عمليات الاستيراد:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
بعد ذلك، أضِف طرق الاستعلام:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
أضِف عبارة case أخرى في طريقة main للاستعلام:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
أخيرًا، أضِف كيفية استخدام أوامر البحث إلى الطريقة printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
احفظ التغييرات التي أجريتها على App.java.
أعِد إنشاء التطبيق:
mvn package
إجراء بحث عن مطابقة تامة لأرصدة حسابات العملاء
يبحث طلب البحث عن المطابقة التامة عن الصفوف المطابقة التي تتطابق تمامًا مع عبارة بحث.
لتحسين الأداء، تمت إضافة فهرس عند إنشاء قاعدة البيانات والمخطط:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
تستخدِم الطريقة getBalance هذا الفهرس ضمنيًا للعثور على العملاء الذين يتطابقون مع customerId المقدَّم، كما تنضم إلى الحسابات التي تخصّ هذا العميل.
في ما يلي شكل طلب البحث عند تنفيذه مباشرةً في Spanner Studio: 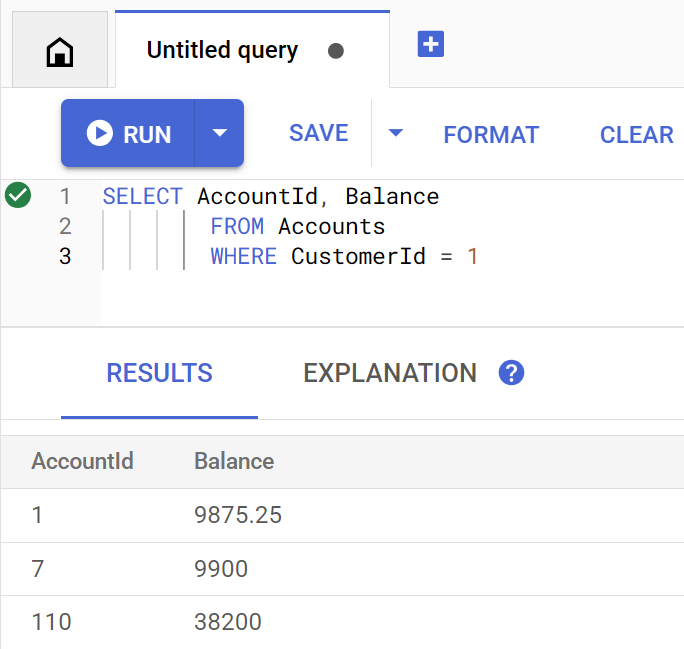
أدرِج أرصدة حساب العميل 1 من خلال تنفيذ الأمر التالي:
java -jar target/onlinebanking.jar query balance 1
الناتج المتوقّع:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
هناك 100 عميل، لذا يمكنك أيضًا طلب أي من أرصدة حسابات العملاء الأخرى عن طريق تحديد رقم تعريف مختلف للعميل:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
إجراء بحث تقريبي عن رسائل البريد الإلكتروني للعملاء
تتيح عمليات البحث التقريبية العثور على نتائج مطابقة تقريبية لعبارات البحث، بما في ذلك الصيغ المختلفة للأحرف والأخطاء الإملائية.
تمت إضافة فهرس n-gram عند إنشاء قاعدة البيانات والمخطط:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
تستخدِم الطريقة findCustomers SEARCH_NGRAMS وSCORE_NGRAMS لطلب البحث في هذا الفهرس للعثور على العملاء حسب البريد الإلكتروني. بما أنّ عمود البريد الإلكتروني تم تقسيمه إلى وحدات n-gram، يمكن أن يحتوي طلب البحث هذا على أخطاء إملائية ويظل يعرض إجابة صحيحة. يتم ترتيب النتائج استنادًا إلى أفضل تطابق.
للعثور على عناوين البريد الإلكتروني المطابقة للعملاء والتي تتضمّن madi، نفِّذ الأمر التالي:
java -jar target/onlinebanking.jar query email madi
الناتج المتوقّع:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
تعرض هذه الاستجابة أقرب النتائج المطابقة التي تتضمّن madi أو سلسلة مشابهة، وذلك بترتيب مُحدّد.
في ما يلي شكل طلب البحث عند تنفيذه مباشرةً في Spanner Studio: 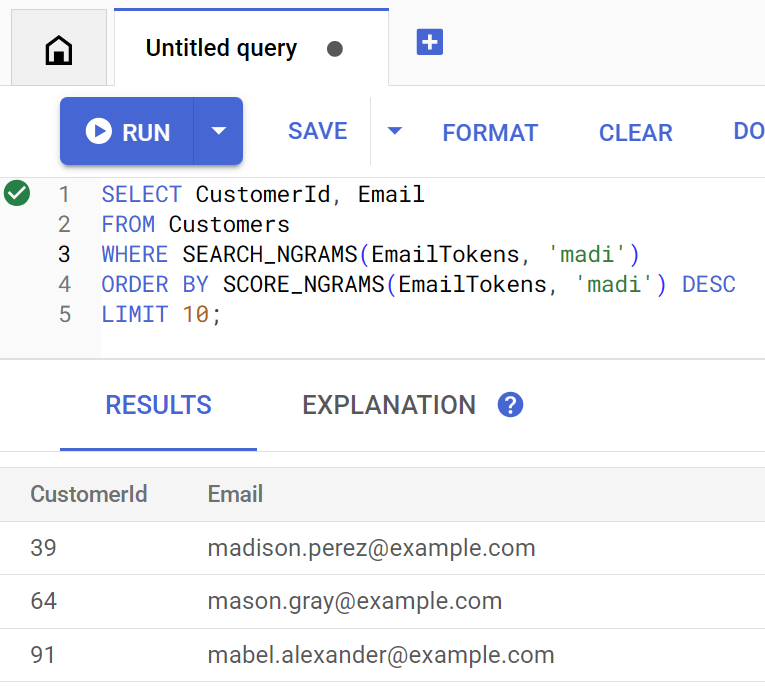
يمكن أن يساعد البحث التقريبي أيضًا في تصحيح الأخطاء الإملائية، مثل الأخطاء الإملائية في emily:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
الناتج المتوقّع:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
في كل حالة، يتم عرض الرسالة الإلكترونية المتوقّعة للعميل كنتيجة أولى.
البحث في المعاملات باستخدام البحث في النص الكامل
تُستخدَم ميزة البحث عن نص كامل في Spanner لاسترداد السجلات استنادًا إلى الكلمات الرئيسية أو العبارات. يمكن لهذه الميزة تصحيح الأخطاء الإملائية أو البحث عن المرادفات.
تمت إضافة فهرس بحث في النص الكامل عند إنشاء قاعدة البيانات والمخطط:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
تستخدِم الطريقة getSpending وظيفة البحث عن النص الكامل SEARCH للمطابقة مع هذا الفهرس. يبحث عن جميع النفقات (الخصومات) خلال آخر 30 يومًا لمعرّف العميل المحدّد.
احصل على إجمالي الإنفاق خلال الشهر الماضي للعميل 1 في فئة groceries من خلال تنفيذ الأمر:
java -jar target/onlinebanking.jar query spending 1 groceries
الناتج المتوقّع:
Total spending for customer 1 under category groceries: 50
يمكنك أيضًا العثور على الإنفاق في فئات أخرى (صنّفناها في خطوة سابقة)، أو استخدام رقم تعريف عميل مختلف:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
ملخّص
في هذه الخطوة، نفّذت طلبات بحث تستخدم المطابقة التامة، بالإضافة إلى عمليات بحث تقريبية وبحث عن نص كامل.
التالي
بعد ذلك، ستدمج Spanner مع Google BigQuery لتنفيذ طلبات بحث موحّدة، ما يتيح لك دمج بيانات Spanner في الوقت الفعلي مع بيانات BigQuery.
8. تنفيذ طلبات بحث موحّدة باستخدام BigQuery
إنشاء مجموعة بيانات BigQuery
في هذه الخطوة، ستجمع بيانات BigQuery وSpanner معًا من خلال استخدام الاستعلامات الموحّدة.
لتنفيذ ذلك، أنشئ أولاً مجموعة بيانات MarketingCampaigns في سطر أوامر Cloud Shell:
bq mk --location=us-central1 MarketingCampaigns
الناتج المتوقّع:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
وCustomerSegments جدول في مجموعة البيانات:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
الناتج المتوقّع:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
بعد ذلك، أنشئ اتصالاً من BigQuery إلى Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
الناتج المتوقّع:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
أخيرًا، أضِف بعض العملاء إلى جدول BigQuery الذي يمكن ربطه ببيانات Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
الناتج المتوقّع:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
يمكنك التأكّد من توفّر البيانات من خلال طلب البحث في BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
الناتج المتوقّع:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
تمثّل هذه البيانات في BigQuery البيانات التي تمت إضافتها من خلال سير عمل مصرفي مختلف. على سبيل المثال، قد تكون هذه قائمة العملاء الذين فتحوا حسابات مؤخرًا أو اشتركوا في عرض ترويجي تسويقي. لتحديد قائمة العملاء الذين نريد استهدافهم في حملتنا التسويقية، نحتاج إلى طلب البحث عن هذه البيانات في BigQuery وكذلك البيانات الفورية في Spanner، ويتيح لنا طلب البحث الموحّد إجراء ذلك في طلب بحث واحد.
تنفيذ طلب بحث موحّد باستخدام BigQuery
بعد ذلك، سنضيف طريقة إلى التطبيق لاستدعاء EXTERNAL_QUERY من أجل تنفيذ الاستعلام الموحّد. سيسمح ذلك بدمج بيانات العملاء وتحليلها في كلّ من BigQuery وSpanner، مثل تحديد العملاء الذين يستوفون معايير حملتنا التسويقية استنادًا إلى إنفاقهم الأخير.
افتح App.java وابدأ باستبدال عمليات الاستيراد:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
بعد ذلك، أضِف طريقة campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
أضِف عبارة حالة أخرى في طريقة main للحملة:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
أخيرًا، أضِف طريقة استخدام الحملة إلى الطريقة printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
احفظ التغييرات التي أجريتها على App.java.
أعِد إنشاء التطبيق:
mvn package
نفِّذ طلب بحث موحّدًا لتحديد العملاء الذين يجب تضمينهم في الحملة التسويقية (campaign1) إذا أنفقوا $5000 على الأقل خلال الأشهر الثلاثة الماضية من خلال تنفيذ الأمر campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
الناتج المتوقّع:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
يمكننا الآن استهداف هؤلاء العملاء بعروض أو مكافآت حصرية.
أو يمكننا البحث عن عدد أكبر من العملاء الذين حقّقوا حدّ إنفاق أقل خلال الأشهر الثلاثة الماضية:
java -jar target/onlinebanking.jar campaign campaign1 2500
الناتج المتوقّع:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
ملخّص
في هذه الخطوة، نفّذت طلبات بحث موحّدة بنجاح من BigQuery جلبت بيانات Spanner في الوقت الفعلي.
التالي
بعد ذلك، يمكنك تنظيف الموارد التي تم إنشاؤها لهذا الدرس البرمجي لتجنُّب تحصيل الرسوم.
9- التنظيف (اختياري)
وهذه الخطوة اختيارية. إذا أردت مواصلة تجربة مثيل Spanner، ليس عليك تنظيفه في الوقت الحالي. ومع ذلك، سيستمر تحصيل رسوم من المشروع الذي تستخدمه مقابل الجهاز الظاهري. إذا لم تعُد بحاجة إلى هذا الجهاز الافتراضي، عليك حذفه في الوقت الحالي لتجنُّب هذه الرسوم. بالإضافة إلى مثيل Spanner، أنشأ هذا الدرس التطبيقي حول الترميز أيضًا مجموعة بيانات وعملية ربط في BigQuery يجب تنظيفها عند عدم الحاجة إليها.
احذف مثيل Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
أكِّد أنّك تريد المتابعة (اكتب Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
احذف اتصال BigQuery ومجموعة البيانات:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
أكِّد حذف مجموعة بيانات BigQuery (اكتب Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. تهانينا
🚀 لقد أنشأت مثيلاً جديدًا من Cloud Spanner، وأنشأت قاعدة بيانات فارغة، وحمّلت نموذج بيانات، ونفّذت عمليات وطلبات بحث متقدّمة، وحذفت مثيل Cloud Spanner (اختياريًا).
المواضيع التي تناولناها
- كيفية إعداد مثيل Spanner
- كيفية إنشاء قاعدة بيانات وجداول
- كيفية تحميل البيانات في جداول قاعدة بيانات Spanner
- كيفية استدعاء نماذج Vertex AI من Spanner
- كيفية طلب البحث في قاعدة بيانات Spanner باستخدام البحث التقريبي والبحث عن نص كامل
- كيفية تنفيذ طلبات بحث موحّدة في Spanner من BigQuery
- كيفية حذف مثيل Spanner
ما هي الخطوات التالية؟
- يمكنك الاطّلاع على مزيد من المعلومات حول ميزات Spanner المتقدّمة، بما في ذلك:
- اطّلِع على مكتبات برامج Spanner المتوفّرة.