
1. Übersicht
Spanner ist ein vollständig verwalteter, horizontal skalierbarer, global verteilter Datenbankdienst, der sich sowohl für relationale als auch für nicht relationale operative Arbeitslasten eignet. Neben den Kernfunktionen bietet Spanner leistungsstarke erweiterte Funktionen, mit denen sich intelligente und datengesteuerte Anwendungen entwickeln lassen.
Dieses Codelab baut auf dem grundlegenden Verständnis von Spanner auf und befasst sich mit der Nutzung der erweiterten Integrationen, um Ihre Datenverarbeitungs- und Analysefunktionen zu verbessern. Als Grundlage dient eine Onlinebanking-Anwendung.
Wir konzentrieren uns auf drei wichtige erweiterte Funktionen:
- Vertex AI-Integration:Hier erfahren Sie, wie Sie Spanner nahtlos in die KI-Plattform von Google Cloud, Vertex AI, einbinden. Sie erfahren, wie Sie Vertex AI-Modelle direkt aus Spanner-SQL-Abfragen aufrufen können. So lassen sich leistungsstarke In-Database-Transformationen und ‑Vorhersagen durchführen, mit denen unsere Banking-Anwendung Transaktionen für Anwendungsfälle wie Budgetverfolgung und Anomalieerkennung automatisch kategorisieren kann.
- Volltextsuche:Hier erfahren Sie, wie Sie die Volltextsuche in Spanner implementieren. Sie lernen, wie Sie Textdaten indexieren und effiziente Abfragen schreiben, um keywordbasierte Suchen in Ihren Betriebsdaten durchzuführen. So können Sie leistungsstarke Datenermittlungen durchführen, z. B. Kunden anhand ihrer E‑Mail-Adresse in unserem Bankensystem effizient finden.
- Föderierte BigQuery-Abfragen:Hier erfahren Sie, wie Sie die Funktionen für föderierte Abfragen von Spanner nutzen können, um Daten, die sich in BigQuery befinden, direkt abzufragen. So können Sie die Echtzeit-Betriebsdaten von Spanner mit den Analysedatasets von BigQuery kombinieren, um umfassende Statistiken und Berichte zu erstellen, ohne dass Daten dupliziert oder komplexe ETL-Prozesse erforderlich sind. Dies ermöglicht verschiedene Anwendungsfälle in unserer Banking-Anwendung, z. B. gezielte Marketingkampagnen, indem Echtzeit-Kundendaten mit umfassenderen historischen Trends aus BigQuery kombiniert werden.
Lerninhalte
- So richten Sie eine Spanner-Instanz ein.
- Datenbank und Tabellen erstellen
- Daten in Ihre Cloud Spanner-Datenbanktabellen laden
- Vertex AI-Modelle aus Spanner aufrufen
- So fragen Sie Ihre Spanner-Datenbank mit Fuzzy-Suche und Volltextsuche ab.
- Föderierte Abfragen aus BigQuery an Spanner senden
- So löschen Sie Ihre Spanner-Instanz.
Voraussetzungen
2. Einrichtung und Anforderungen
Projekt erstellen
Wenn Sie bereits ein Google Cloud-Projekt mit aktivierter Abrechnung haben, klicken Sie oben links in der Console auf das Drop-down-Menü zur Projektauswahl:

Wenn Sie ein Projekt ausgewählt haben, fahren Sie mit Erforderliche APIs aktivieren fort.
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eines erstellen. Melden Sie sich in der Google Cloud Console (console.cloud.google.com) an und erstellen Sie ein neues Projekt.
Klicken Sie im angezeigten Dialogfeld auf die Schaltfläche „NEW PROJECT“ (NEUES PROJEKT), um ein neues Projekt zu erstellen:
Wenn Sie noch kein Projekt haben, wird ein Dialogfeld wie das folgende angezeigt, in dem Sie Ihr erstes Projekt erstellen können:
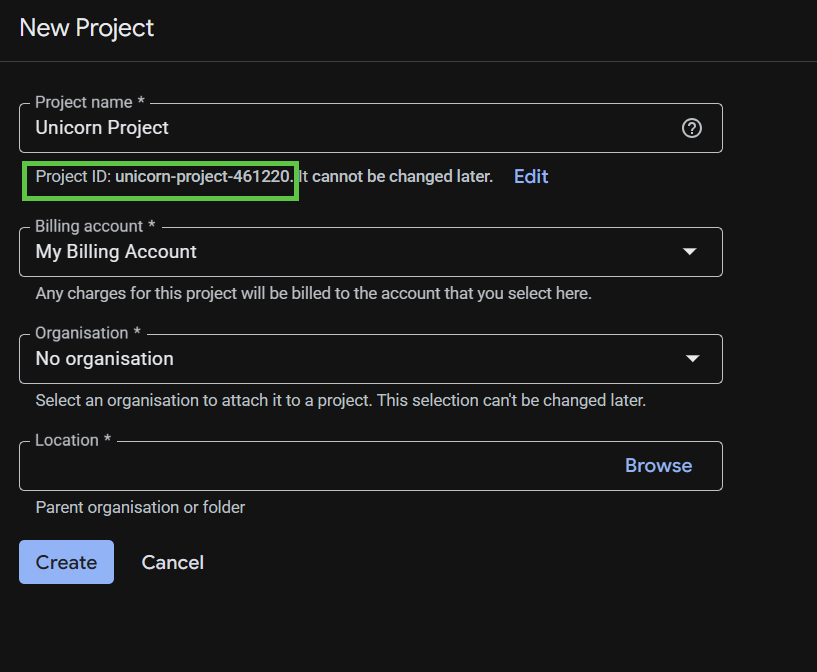
Im nachfolgenden Dialogfeld können Sie die Details Ihres neuen Projekts eingeben.
Merken Sie sich die Projekt-ID, die für alle Google Cloud-Projekte ein eindeutiger Name ist. Sie wird später in diesem Codelab als PROJECT_ID bezeichnet.
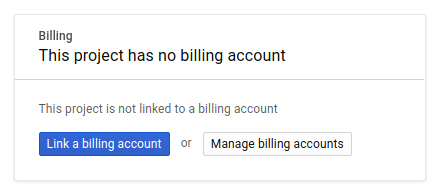
Als Nächstes müssen Sie, falls noch nicht geschehen, die Abrechnung in der Entwicklerkonsole aktivieren, um Google Cloud-Ressourcen zu verwenden und die Spanner API, Vertex AI API, BigQuery API und BigQuery Connection API zu aktivieren.
Die Preise für Spanner sind hier dokumentiert. Andere Kosten, die mit anderen Ressourcen verbunden sind, werden auf den jeweiligen Preisseiten dokumentiert.
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
Google Cloud Shell-Einrichtung
In diesem Codelab verwenden wir Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Diese Debian-basierte virtuelle Maschine verfügt über alle Entwicklungstools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Für dieses Codelab benötigen Sie also nur einen Browser.
Klicken Sie zum Aktivieren von Cloud Shell in der Cloud Console einfach auf „Cloud Shell aktivieren“ ![]() . Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
. Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.

Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre PROJECT_ID eingestellt ist.
gcloud auth list
Erwartete Ausgabe:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Erwartete Ausgabe:
[core] project = <PROJECT_ID>
Wenn das Projekt aus irgendeinem Grund nicht festgelegt ist, geben Sie den folgenden Befehl ein:
gcloud config set project <PROJECT_ID>
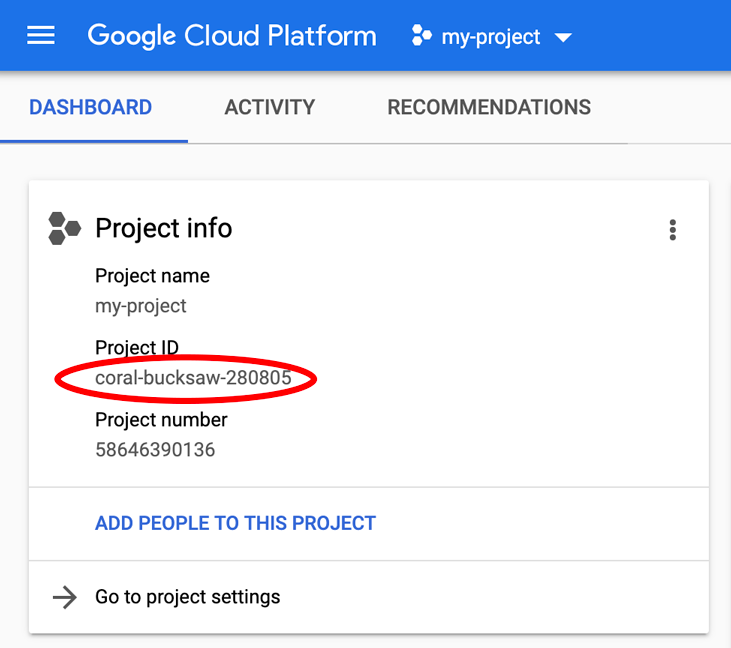
Suchst du nach deinem PROJECT_ID? Prüfen Sie, welche ID Sie in den Einrichtungsschritten verwendet haben, oder suchen Sie sie im Cloud Console-Dashboard:
In Cloud Shell werden auch einige Umgebungsvariablen standardmäßig festgelegt, die für zukünftige Befehle nützlich sein können.
echo $GOOGLE_CLOUD_PROJECT
Erwartete Ausgabe:
<PROJECT_ID>
Erforderliche APIs aktivieren
Aktivieren Sie die Spanner-, Vertex AI- und BigQuery-APIs für Ihr Projekt:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Zusammenfassung
In diesem Schritt haben Sie Ihr Projekt eingerichtet, falls Sie noch keines hatten, Cloud Shell aktiviert und die erforderlichen APIs aktiviert.
Nächster Schritt
Als Nächstes richten Sie die Spanner-Instanz ein.
3. Spanner-Instanz einrichten
Spanner-Instanz erstellen
In diesem Schritt richten Sie eine Spanner-Instanz für das Codelab ein. Öffnen Sie Cloud Shell und führen Sie diesen Befehl aus:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Erwartete Ausgabe:
Creating instance...done.
Zusammenfassung
In diesem Schritt haben Sie die Spanner-Instanz erstellt.
Nächster Schritt
Als Nächstes bereiten Sie die erste Anwendung vor und erstellen die Datenbank und das Schema.
4. Datenbank und Schema erstellen
Erstantrag vorbereiten
In diesem Schritt erstellen Sie die Datenbank und das Schema über den Code.
Erstellen Sie zuerst eine Java-Anwendung mit dem Namen onlinebanking mit Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Checken Sie die Datendateien aus, die wir der Datenbank hinzufügen werden, und kopieren Sie sie (das Code-Repository finden Sie hier):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Rufen Sie den Anwendungsordner auf:
cd onlinebanking
Öffnen Sie die Maven-Datei pom.xml. Fügen Sie den Abschnitt zur Abhängigkeitsverwaltung hinzu, um die Maven-BOM zum Verwalten der Version von Google Cloud-Bibliotheken zu verwenden:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
So sehen der Editor und die Datei aus: 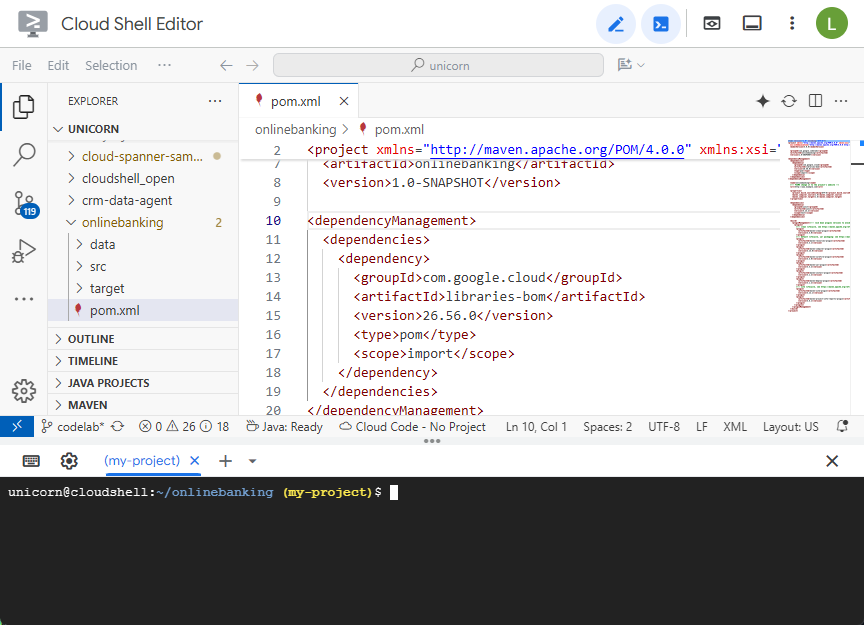
Der Abschnitt dependencies muss die Bibliotheken enthalten, die von der Anwendung verwendet werden:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Ersetzen Sie schließlich die Build-Plug-ins, damit die Anwendung in einer ausführbaren JAR-Datei verpackt wird:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Speichern Sie die Änderungen, die Sie an der Datei pom.xml vorgenommen haben, indem Sie im Cloud Shell-Editor im Menü „Datei“ die Option „Speichern“ auswählen oder Ctrl+S drücken.
Nachdem die Abhängigkeiten eingerichtet sind, fügen Sie der App Code hinzu, um ein Schema, einige Indexe (einschließlich der Suche) und ein KI-Modell zu erstellen, das mit einem Remote-Endpunkt verbunden ist. In diesem Codelab werden Sie auf diesen Artefakten aufbauen und dieser Klasse weitere Methoden hinzufügen.
Öffnen Sie App.java unter onlinebanking/src/main/java/com/google/codelabs und ersetzen Sie den Inhalt durch den folgenden Code:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Speichern Sie die Änderungen in App.java.
Sehen Sie sich die verschiedenen Entitäten an, die von Ihrem Code erstellt werden, und erstellen Sie das Anwendungs-JAR:
mvn package
Erwartete Ausgabe:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Führen Sie die Anwendung aus, um die Nutzungsinformationen aufzurufen:
java -jar target/onlinebanking.jar
Erwartete Ausgabe:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Datenbank und Schema erstellen
Legen Sie die erforderlichen Umgebungsvariablen für die Anwendung fest:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Erstellen Sie die Datenbank und das Schema, indem Sie den Befehl create ausführen:
java -jar target/onlinebanking.jar create
Erwartete Ausgabe:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Schema in Spanner prüfen
Rufen Sie in der Spanner-Konsole die gerade erstellte Instanz und Datenbank auf.
Sie sollten alle drei Tabellen sehen: Accounts, Customers und TransactionLedger.
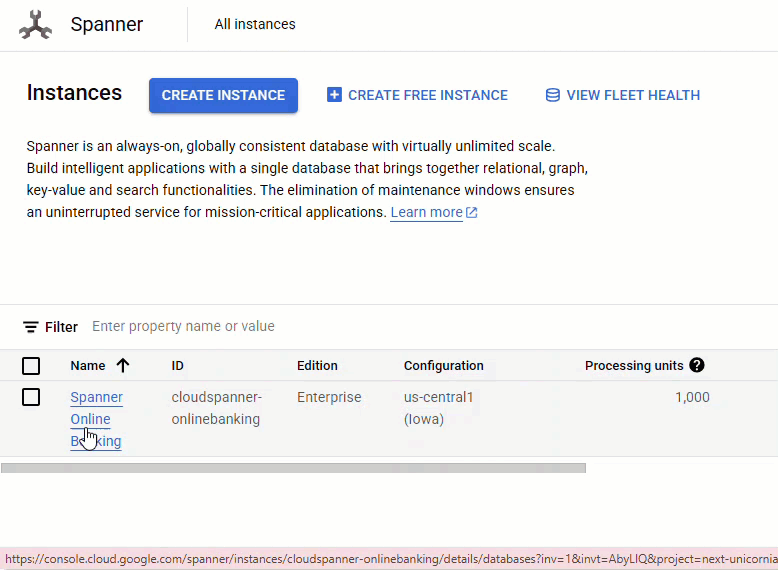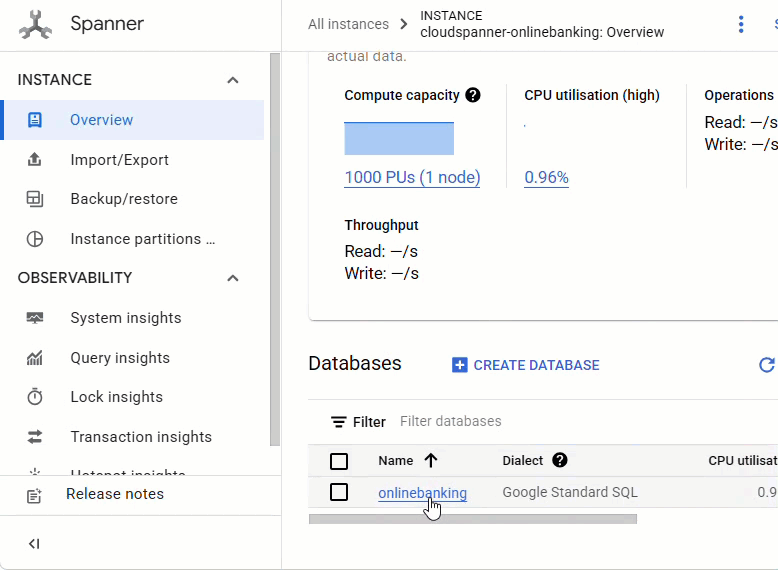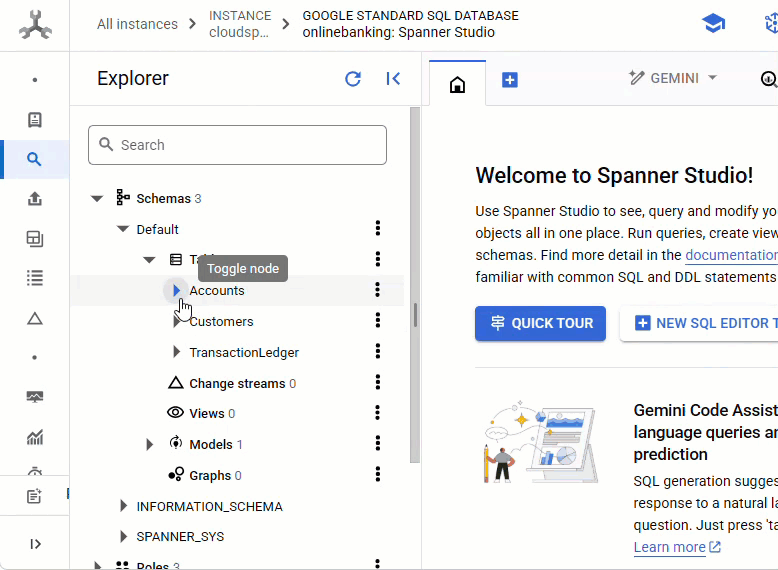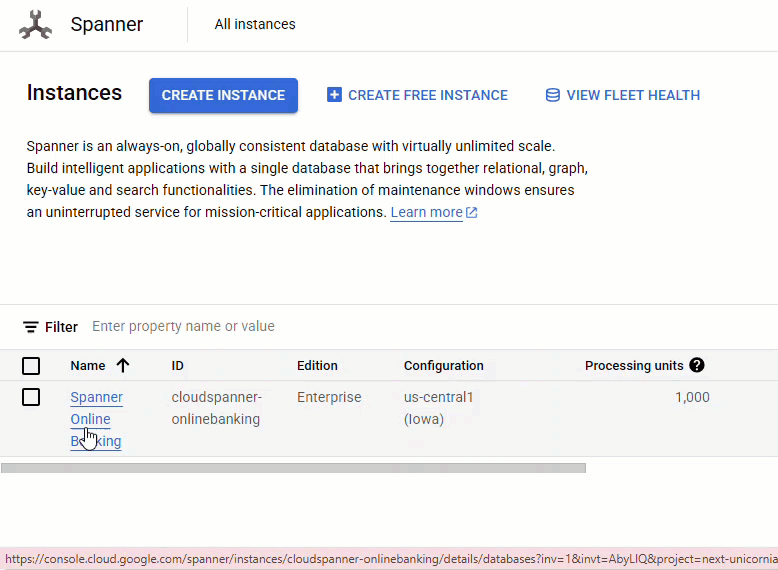
Mit dieser Aktion wird das Datenbankschema erstellt, einschließlich der Tabellen Accounts, Customers und TransactionLedger, zusammen mit sekundären Indexen für einen optimierten Datenabruf und einer Vertex AI-Modellreferenz.
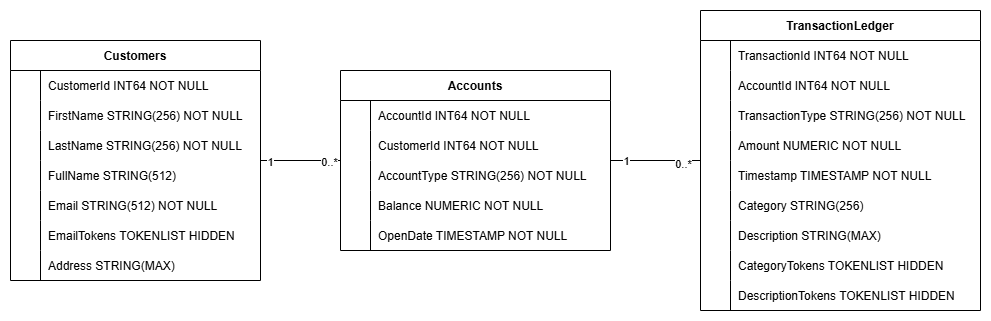
Die Tabelle TransactionLedger ist in Konten verschachtelt, um die Abfrageleistung für kontospezifische Transaktionen durch eine verbesserte Datenlokalität zu steigern.
Sekundärindexe (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) wurden implementiert, um gängige Datenzugriffsmuster zu optimieren, die in diesem Codelab verwendet werden, z. B. Kundensuchen nach genauer und unscharfer E-Mail-Adresse, Abrufen von Konten nach Kunde und effizientes Abfragen und Suchen von Transaktionsdaten.
Die TransactionCategoryModel nutzt Vertex AI, um direkte SQL-Aufrufe an ein LLM zu ermöglichen, das in diesem Codelab für die dynamische Transaktionskategorisierung verwendet wird.
Zusammenfassung
In diesem Schritt haben Sie die Spanner-Datenbank und das Schema erstellt.
Nächster Schritt
Als Nächstes laden Sie die Beispielanwendungsdaten.
5. Daten laden
Als Nächstes fügen Sie Funktionen hinzu, um Beispieldaten aus CSV-Dateien in die Datenbank zu laden.
Öffnen Sie App.java und ersetzen Sie zuerst die Importe:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Fügen Sie dann die Einfügemethoden der Klasse App hinzu:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Fügen Sie in der Methode main eine weitere case-Anweisung für das Einfügen in switch (command) hinzu:
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Fügen Sie schließlich hinzu, wie Sie „insert“ für die Methode printUsageAndExit verwenden:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Speichern Sie die Änderungen, die Sie an App.java vorgenommen haben.
Erstellen Sie die Anwendung neu:
mvn package
Fügen Sie die Beispieldaten ein, indem Sie den Befehl insert ausführen:
java -jar target/onlinebanking.jar insert
Erwartete Ausgabe:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
Kehren Sie in der Spanner Console zu Spanner Studio für Ihre Instanz und Datenbank zurück. Wählen Sie dann die Tabelle TransactionLedger aus und klicken Sie in der Seitenleiste auf „Daten“, um zu prüfen, ob die Daten geladen wurden. Die Tabelle sollte 200 Zeilen enthalten.
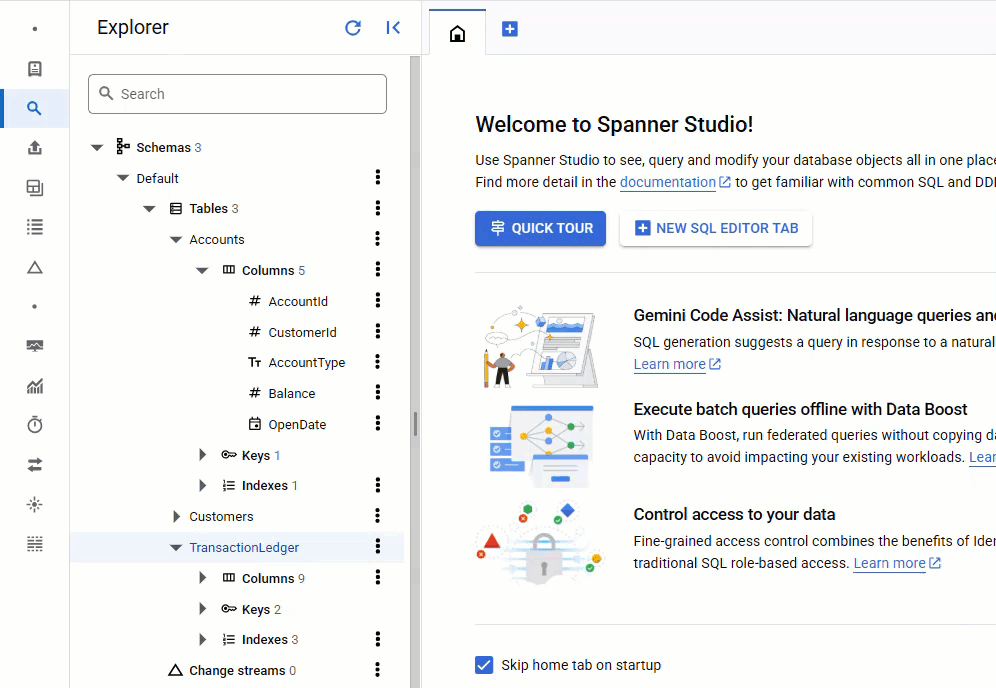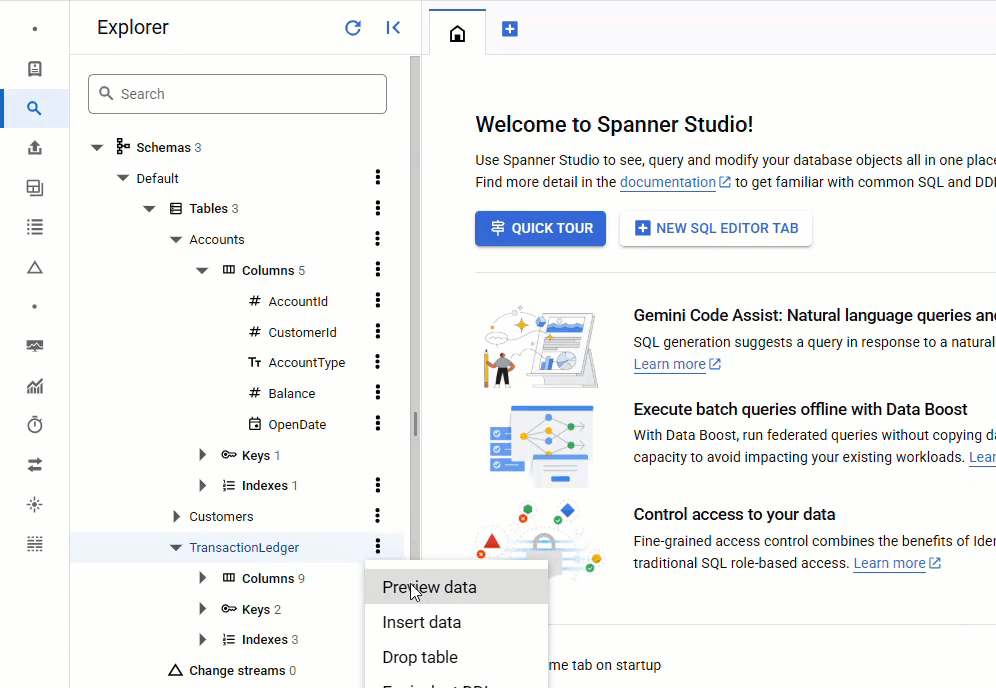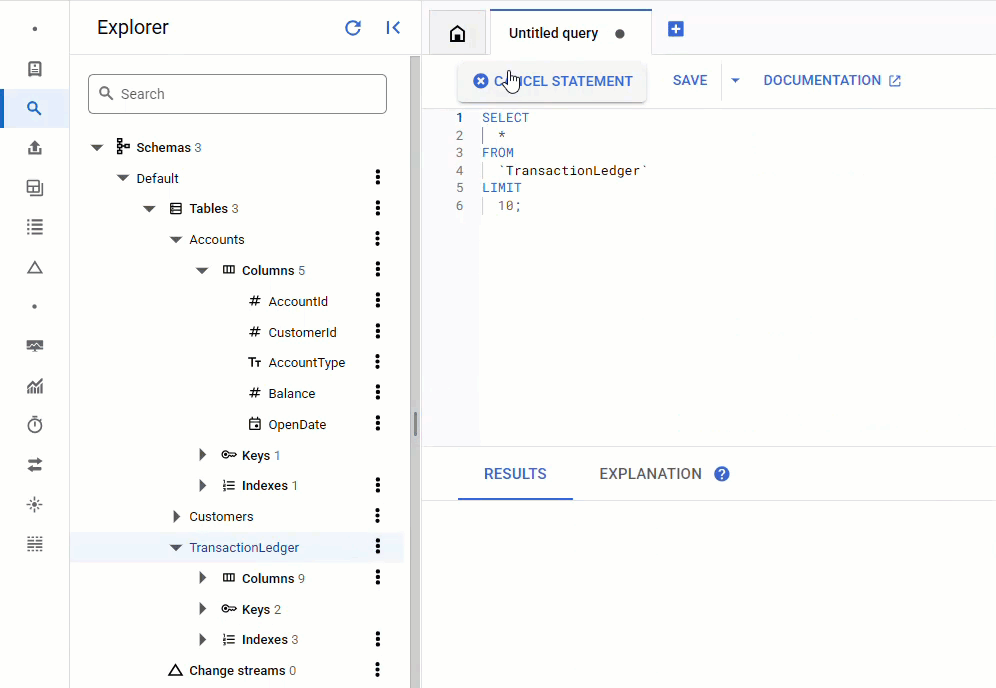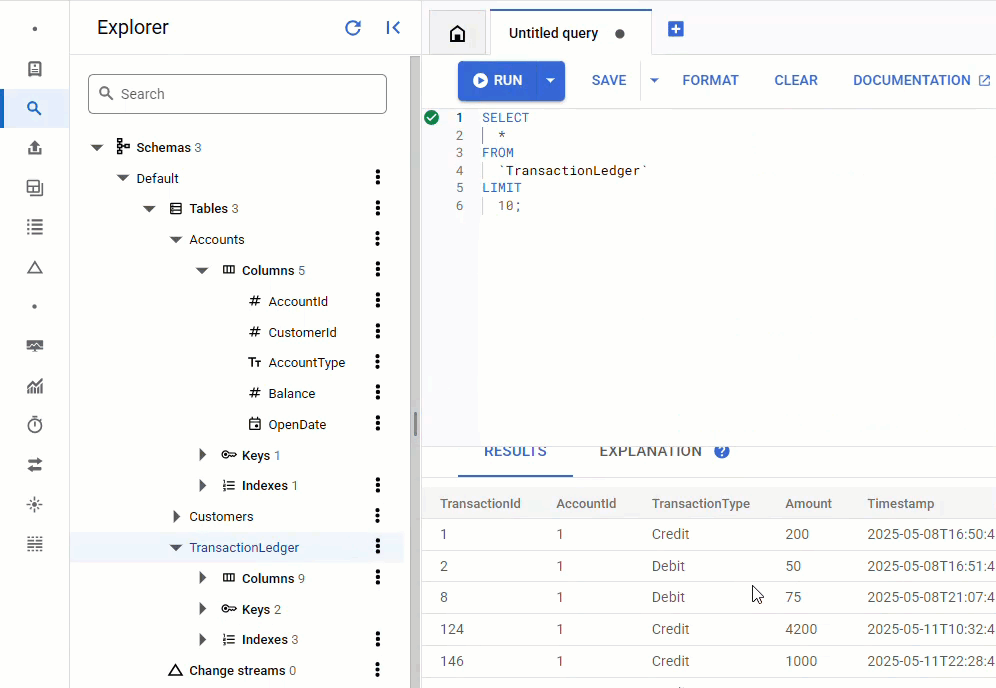
Zusammenfassung
In diesem Schritt haben Sie die Beispieldaten in die Datenbank eingefügt.
Nächster Schritt
Als Nächstes nutzen Sie die Vertex AI-Integration, um Banktransaktionen automatisch direkt in Spanner SQL zu kategorisieren.
6. Daten mit Vertex AI kategorisieren
In diesem Schritt nutzen Sie die Leistungsfähigkeit von Vertex AI, um Ihre Finanztransaktionen direkt in Spanner SQL automatisch zu kategorisieren. Mit Vertex AI können Sie ein vorhandenes vortrainiertes Modell auswählen oder Ihr eigenes trainieren und bereitstellen. Die verfügbaren Modelle finden Sie im Vertex AI Model Garden.
In diesem Codelab verwenden wir eines der Gemini-Modelle, nämlich Gemini Flash Lite. Diese Version von Gemini ist kostengünstig und kann dennoch die meisten täglichen Arbeitslasten bewältigen.
Derzeit haben wir eine Reihe von Finanztransaktionen, die wir je nach Beschreibung kategorisieren möchten (groceries, transportation usw.). Dazu registrieren wir ein Modell in Spanner und rufen dann mit ML.PREDICT das KI-Modell auf.
In unserer Banking-Anwendung möchten wir möglicherweise Transaktionen kategorisieren, um mehr Einblicke in das Kundenverhalten zu erhalten. So können wir Dienste personalisieren, Anomalien effektiver erkennen oder dem Kunden die Möglichkeit geben, sein Budget monatlich zu verfolgen.
Der erste Schritt wurde bereits beim Erstellen der Datenbank und des Schemas ausgeführt. Dabei wurde ein Modell wie dieses erstellt:
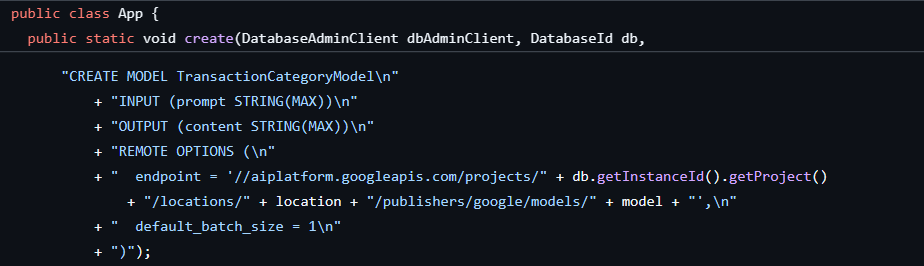
Als Nächstes fügen wir der Anwendung eine Methode hinzu, um ML.PREDICT aufzurufen.
Öffnen Sie App.java und fügen Sie die Methode categorize hinzu:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Fügen Sie in der Methode main eine weitere case-Anweisung für „categorize“ hinzu:
case "categorize":
categorize(dbClient);
break;
Fügen Sie schließlich hinzu, wie „categorize“ für die printUsageAndExit-Methode verwendet wird:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Speichern Sie die Änderungen, die Sie an App.java vorgenommen haben.
Erstellen Sie die Anwendung neu:
mvn package
Kategorisieren Sie die Transaktionen in der Datenbank, indem Sie den Befehl categorize ausführen:
java -jar target/onlinebanking.jar categorize
Erwartete Ausgabe:
Categorizing transactions... Completed categorizing transactions
Führen Sie in Spanner Studio die Anweisung Preview Data für die Tabelle TransactionLedger aus. Die Spalte Category sollte jetzt für alle Zeilen ausgefüllt sein.
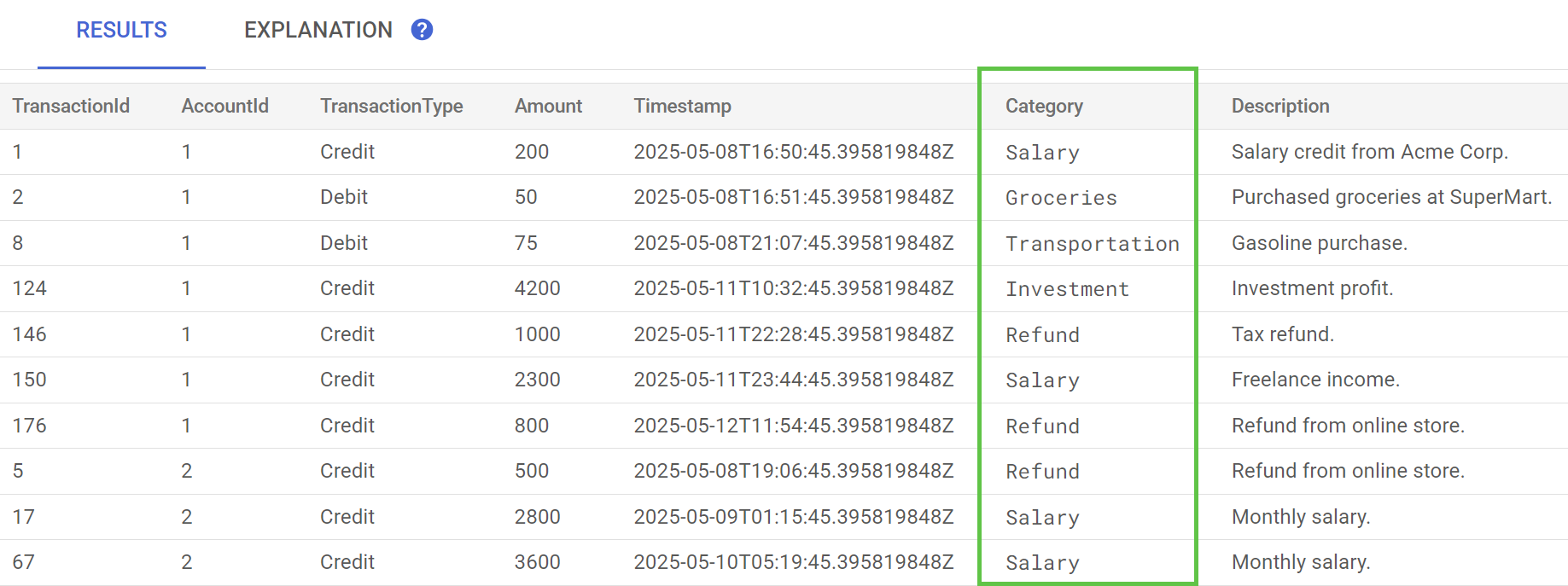
Nachdem wir die Transaktionen kategorisiert haben, können wir diese Informationen für interne oder kundenbezogene Anfragen verwenden. Im nächsten Schritt sehen wir uns an, wie viel ein bestimmter Kunde im Laufe des Monats in einer Kategorie ausgibt.
Zusammenfassung
In diesem Schritt haben Sie ein vortrainiertes Modell verwendet, um Ihre Daten KI-basiert zu kategorisieren.
Nächster Schritt
Als Nächstes verwenden Sie die Tokenisierung, um Fuzzy- und Volltextsuchen durchzuführen.
7. Abfrage mit Volltextsuche
Abfragecode hinzufügen
Spanner bietet viele Volltextsuchanfragen. In diesem Schritt führen Sie eine Suche nach exakten Treffern, eine unscharfe Suche und eine Volltextsuche durch.
Öffnen Sie App.java und ersetzen Sie zuerst die Importe:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Fügen Sie dann die Abfragemethoden hinzu:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Fügen Sie eine weitere case-Anweisung in die main-Methode für die Abfrage ein:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Fügen Sie schließlich hinzu, wie die Abfragebefehle an die printUsageAndExit-Methode angehängt werden:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Speichern Sie die Änderungen, die Sie an App.java vorgenommen haben.
Erstellen Sie die Anwendung neu:
mvn package
Nach genau passenden Treffern für Kundenkontostände suchen
Bei einer Suche nach genau passenden Treffern wird nach übereinstimmenden Zeilen gesucht, die genau mit einem Begriff übereinstimmen.
Um die Leistung zu verbessern, wurde beim Erstellen der Datenbank und des Schemas bereits ein Index hinzugefügt:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
Bei der Methode getBalance wird dieser Index implizit verwendet, um Kunden zu finden, die der angegebenen „customerId“ entsprechen. Außerdem werden Konten verknüpft, die zu diesem Kunden gehören.
So sieht die Abfrage aus, wenn sie direkt in Spanner Studio ausgeführt wird: 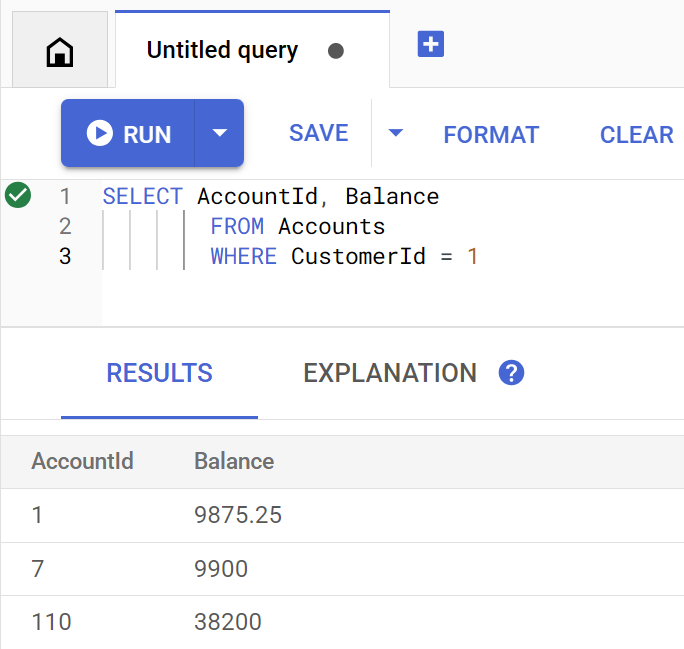
Führen Sie den folgenden Befehl aus, um die Kontostände des Kunden 1 aufzulisten:
java -jar target/onlinebanking.jar query balance 1
Erwartete Ausgabe:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Es gibt 100 Kunden. Sie können also auch die Kontostände anderer Kunden abfragen, indem Sie eine andere Kunden-ID angeben:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Ungefähre Suche in Kunden-E-Mails durchführen
Mit der Fuzzy-Suche können Sie ungefähre Übereinstimmungen für Suchbegriffe finden, einschließlich Rechtschreibvarianten und Tippfehlern.
Beim Erstellen der Datenbank und des Schemas wurde bereits ein N-Gramm-Index hinzugefügt:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
Bei der findCustomers-Methode werden SEARCH_NGRAMS und SCORE_NGRAMS verwendet, um diesen Index abzufragen und Kunden anhand ihrer E-Mail-Adresse zu finden. Da die Spalte „E-Mail“ als N-Gramm-Tokenisiert wurde, kann diese Abfrage Rechtschreibfehler enthalten und trotzdem eine korrekte Antwort zurückgeben. Die Ergebnisse werden nach der besten Übereinstimmung sortiert.
Führen Sie den folgenden Befehl aus, um übereinstimmende Kunden-E-Mail-Adressen zu finden, die madi enthalten:
java -jar target/onlinebanking.jar query email madi
Erwartete Ausgabe:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Diese Antwort zeigt die besten Übereinstimmungen, die madi oder einen ähnlichen String enthalten, in absteigender Reihenfolge.
So sieht die Abfrage aus, wenn sie direkt in Spanner Studio ausgeführt wird: 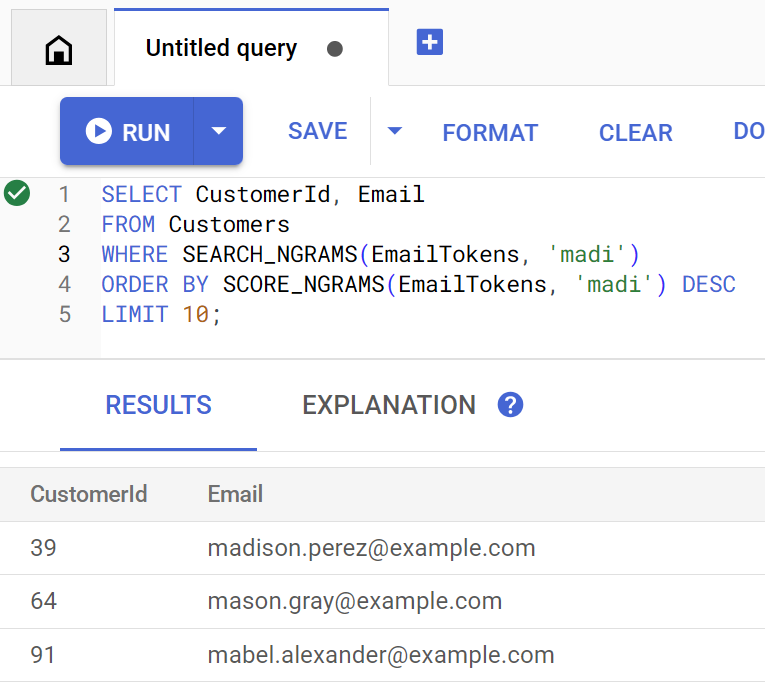
Die Fuzzy-Suche kann auch bei Rechtschreibfehlern wie Falschschreibungen von emily helfen:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Erwartete Ausgabe:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
In jedem Fall wird die erwartete Kunden-E-Mail-Adresse als Top-Ergebnis zurückgegeben.
Transaktionen mit der Volltextsuche durchsuchen
Mit der Volltextsuche von Cloud Spanner können Datensätze anhand von Keywords oder Wortgruppen abgerufen werden. Es kann Rechtschreibfehler korrigieren oder nach Synonymen suchen.
Beim Erstellen der Datenbank und des Schemas wurde bereits ein Volltextsuchindex hinzugefügt:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
Bei der getSpending-Methode wird die Volltextsuchfunktion SEARCH verwendet, um den Index abzugleichen. Es wird nach allen Ausgaben (Belastungen) der letzten 30 Tage für die angegebene Kunden-ID gesucht.
Mit dem folgenden Befehl können Sie die Gesamtausgaben für den Kunden 1 in der Kategorie groceries im letzten Monat abrufen:
java -jar target/onlinebanking.jar query spending 1 groceries
Erwartete Ausgabe:
Total spending for customer 1 under category groceries: 50
Sie können auch Ausgaben in anderen Kategorien (die wir in einem vorherigen Schritt kategorisiert haben) aufrufen oder eine andere Kunden-ID verwenden:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Zusammenfassung
In diesem Schritt haben Sie sowohl genau passende Abfragen als auch Fuzzy- und Volltextsuchen durchgeführt.
Nächster Schritt
Als Nächstes binden Sie Spanner in Google BigQuery ein, um föderierte Abfragen auszuführen. So können Sie Ihre Spanner-Echtzeitdaten mit BigQuery-Daten kombinieren.
8. Föderierte Abfragen mit BigQuery ausführen
BigQuery-Dataset erstellen
In diesem Schritt führen Sie BigQuery- und Spanner-Daten mithilfe von föderierten Abfragen zusammen.
Erstellen Sie dazu zuerst ein MarketingCampaigns-Dataset in der Cloud Shell-Befehlszeile:
bq mk --location=us-central1 MarketingCampaigns
Erwartete Ausgabe:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
Und eine CustomerSegments-Tabelle im Dataset:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Erwartete Ausgabe:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Stellen Sie als Nächstes eine Verbindung von BigQuery zu Spanner her:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Erwartete Ausgabe:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Fügen Sie der BigQuery-Tabelle einige Kunden hinzu, die mit unseren Spanner-Daten verknüpft werden können:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Erwartete Ausgabe:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Sie können prüfen, ob die Daten verfügbar sind, indem Sie BigQuery abfragen:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Erwartete Ausgabe:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Diese Daten in BigQuery stellen Daten dar, die über verschiedene Bank-Workflows hinzugefügt wurden. Das kann beispielsweise die Liste der Kunden sein, die vor Kurzem Konten eröffnet oder sich für eine Marketingaktion registriert haben. Um die Liste der Kunden zu ermitteln, die wir in unserer Marketingkampagne ansprechen möchten, müssen wir sowohl diese Daten in BigQuery als auch die Echtzeitdaten in Spanner abfragen. Mit einer föderierten Abfrage ist dies in einer einzigen Abfrage möglich.
Föderierte Abfrage mit BigQuery ausführen
Als Nächstes fügen wir der Anwendung eine Methode hinzu, mit der EXTERNAL_QUERY aufgerufen wird, um die föderierte Abfrage auszuführen. So können Kundendaten in BigQuery und Spanner zusammengeführt und analysiert werden. Beispielsweise lässt sich ermitteln, welche Kunden aufgrund ihrer letzten Ausgaben die Kriterien für unsere Marketingkampagne erfüllen.
Öffnen Sie App.java und ersetzen Sie zuerst die Importe:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Fügen Sie dann die Methode campaign hinzu:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Fügen Sie der main-Methode für die Kampagne eine weitere case-Anweisung hinzu:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Fügen Sie schließlich hinzu, wie die Kampagne verwendet werden soll, und zwar mit der Methode printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Speichern Sie die Änderungen, die Sie an App.java vorgenommen haben.
Erstellen Sie die Anwendung neu:
mvn package
Führen Sie eine föderierte Abfrage aus, um Kunden zu ermitteln, die in die Marketingkampagne aufgenommen werden sollen (campaign1), wenn sie in den letzten drei Monaten mindestens $5000 ausgegeben haben. Verwenden Sie dazu den Befehl campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
Erwartete Ausgabe:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Wir können diese Kunden jetzt mit exklusiven Angeboten oder Prämien ansprechen.
Alternativ können wir nach einer größeren Anzahl von Kunden suchen, die in den letzten drei Monaten einen niedrigeren Ausgabenschwellenwert erreicht haben:
java -jar target/onlinebanking.jar campaign campaign1 2500
Erwartete Ausgabe:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Zusammenfassung
In diesem Schritt haben Sie erfolgreich föderierte Abfragen aus BigQuery ausgeführt, mit denen Spanner-Echtzeitdaten abgerufen wurden.
Nächster Schritt
Als Nächstes können Sie die für dieses Codelab erstellten Ressourcen bereinigen, um Gebühren zu vermeiden.
9. Bereinigen (optional)
Dieser Schritt ist optional. Wenn Sie weiterhin mit Ihrer Spanner-Instanz experimentieren möchten, müssen Sie sie jetzt nicht bereinigen. Für das von Ihnen verwendete Projekt werden jedoch weiterhin Kosten für die Instanz berechnet. Wenn Sie diese Instanz nicht mehr benötigen, sollten Sie sie jetzt löschen, um diese Gebühren zu vermeiden. Zusätzlich zur Spanner-Instanz wurden in diesem Codelab auch ein BigQuery-Dataset und eine BigQuery-Verbindung erstellt, die bereinigt werden sollten, wenn sie nicht mehr benötigt werden.
Löschen Sie die Spanner-Instanz:
gcloud spanner instances delete cloudspanner-onlinebanking
Bestätigen Sie, dass Sie fortfahren möchten (geben Sie Y ein):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
BigQuery-Verbindung und ‑Dataset löschen:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Bestätigen Sie das Löschen des BigQuery-Datasets, indem Sie Y eingeben:
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Glückwunsch
🚀 Sie haben eine neue Cloud Spanner-Instanz und eine leere Datenbank erstellt, Beispieldaten geladen, erweiterte Vorgänge und Abfragen ausgeführt und (optional) die Cloud Spanner-Instanz gelöscht.
Behandelte Themen
- So richten Sie eine Spanner-Instanz ein.
- Datenbank und Tabellen erstellen
- Daten in Ihre Cloud Spanner-Datenbanktabellen laden
- Vertex AI-Modelle aus Spanner aufrufen
- So fragen Sie Ihre Spanner-Datenbank mit Fuzzy-Suche und Volltextsuche ab.
- Föderierte Abfragen aus BigQuery an Spanner senden
- So löschen Sie Ihre Spanner-Instanz.