
1. Descripción general
Spanner es un servicio de base de datos distribuido a nivel global, escalable horizontalmente y completamente administrado que es ideal para cargas de trabajo operativas relacionales y no relacionales. Además de sus capacidades principales, Spanner ofrece potentes funciones avanzadas que permiten crear aplicaciones inteligentes basadas en datos.
En este codelab, se profundiza en la comprensión fundamental de Spanner y se explora cómo aprovechar sus integraciones avanzadas para mejorar tus capacidades de procesamiento y análisis de datos, utilizando una aplicación de banca en línea como base.
Nos enfocaremos en tres funciones avanzadas clave:
- Integración en Vertex AI: Descubre cómo integrar Spanner sin problemas en Vertex AI, la plataforma de IA de Google Cloud. Aprenderás a invocar modelos de Vertex AI directamente desde las consultas en SQL de Spanner, lo que permite realizar transformaciones y predicciones potentes en la base de datos, y permite que nuestra aplicación bancaria categorice automáticamente las transacciones para casos de uso como el seguimiento del presupuesto y la detección de anomalías.
- Búsqueda en el texto completo: Aprende a implementar la funcionalidad de búsqueda en el texto completo en Spanner. Explorarás la indexación de datos de texto y la escritura de consultas eficientes para realizar búsquedas basadas en palabras clave en tus datos operativos, lo que permitirá un potente descubrimiento de datos, como encontrar clientes de manera eficiente por dirección de correo electrónico en nuestro sistema bancario.
- Consultas federadas de BigQuery: Explora cómo aprovechar las capacidades de consultas federadas de Spanner para consultar directamente los datos que residen en BigQuery. Esto te permite combinar los datos operativos en tiempo real de Spanner con los conjuntos de datos analíticos de BigQuery para obtener estadísticas y generar informes integrales sin duplicar datos ni realizar procesos de ETL complejos, lo que potencia varios casos de uso en nuestra aplicación bancaria, como las campañas de marketing segmentadas, combinando los datos de los clientes en tiempo real con las tendencias históricas más amplias de BigQuery.
Qué aprenderás
- Cómo configurar una instancia de Spanner
- Cómo crear una base de datos y tablas.
- Cómo cargar datos en las tablas de tu base de datos de Spanner
- Cómo llamar a modelos de Vertex AI desde Spanner
- Cómo consultar tu base de datos de Spanner con la búsqueda parcial y la búsqueda en el texto completo
- Cómo realizar consultas federadas en Spanner desde BigQuery
- Cómo borrar tu instancia de Spanner
Requisitos
2. Configuración y requisitos
Crea un proyecto
Si ya tienes un proyecto de Google Cloud con la facturación habilitada, haz clic en el menú desplegable de selección de proyectos en la parte superior izquierda de la consola:

Con un proyecto seleccionado, ve a Habilita las APIs requeridas.
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console (console.cloud.google.com) y crea un proyecto nuevo.
Haz clic en el botón “PROYECTO NUEVO” en el diálogo resultante para crear un proyecto nuevo:
Si aún no tienes un proyecto, deberías ver un cuadro de diálogo como este para crear el primero:
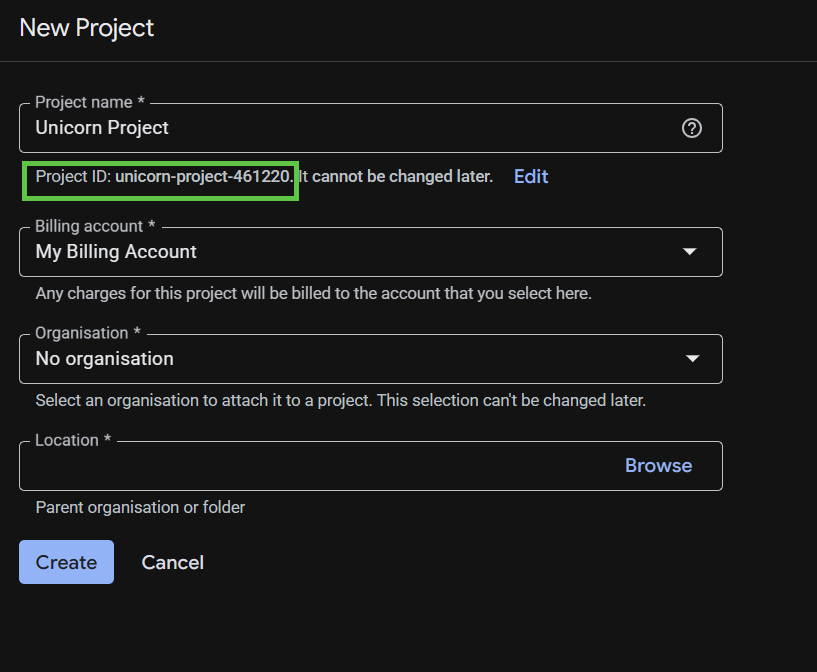
El cuadro de diálogo de creación posterior del proyecto te permite ingresar los detalles de tu proyecto nuevo.
Recuerda el ID del proyecto, que es un nombre único en todos los proyectos de Google Cloud. Se mencionará más adelante en este codelab como PROJECT_ID.
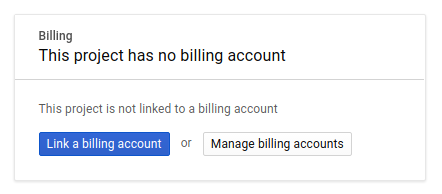
A continuación, si aún no lo has hecho, deberás habilitar la facturación en Developers Console para usar los recursos de Google Cloud y habilitar la API de Spanner, la API de Vertex AI, la API de BigQuery y la API de BigQuery Connection.
Los precios de Spanner se documentan aquí. Otros costos asociados con otros recursos se documentarán en sus páginas de precios específicas.
Los usuarios nuevos de Google Cloud Platform son aptos para obtener una prueba gratuita de USD 300.
Configuración de Google Cloud Shell
En este codelab, usaremos Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Esto significa que todo lo que necesitarás para este codelab es un navegador.
Para activar Cloud Shell desde la consola de Cloud, solo haz clic en Activar Cloud Shell ![]() (el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).
(el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).

Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu PROJECT_ID:
gcloud auth list
Resultado esperado:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Resultado esperado:
[core] project = <PROJECT_ID>
Si, por algún motivo, el proyecto no está configurado, emite el siguiente comando:
gcloud config set project <PROJECT_ID>
Si no conoce su PROJECT_ID, Observa el ID que usaste en los pasos de configuración o búscalo en el panel de la consola de Cloud:
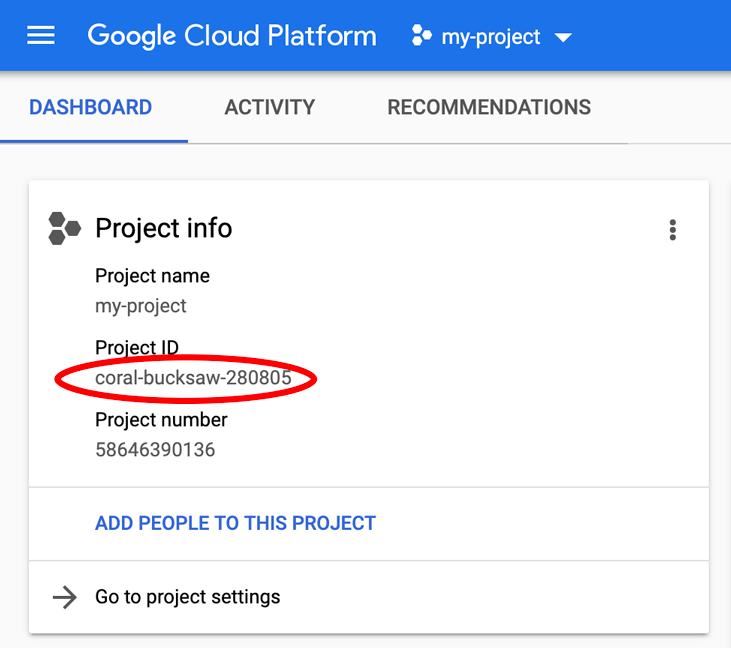
Cloud Shell también configura algunas variables de entorno de forma predeterminada, lo que puede resultar útil cuando ejecutas comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resultado esperado:
<PROJECT_ID>
Habilite las API necesarias
Habilita las APIs de Spanner, Vertex AI y BigQuery para tu proyecto:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Resumen
En este paso, configuraste tu proyecto si aún no tenías uno, activaste Cloud Shell y habilitaste las APIs requeridas.
Cuál es el próximo paso
A continuación, configurarás la instancia de Spanner.
3. Configura una instancia de Spanner
Crea la instancia de Spanner
En este paso, configurarás una instancia de Spanner para el codelab. Para ello, abre Cloud Shell y ejecuta este comando:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Resultado esperado:
Creating instance...done.
Resumen
En este paso, creaste la instancia de Spanner.
Cuál es el próximo paso
A continuación, prepararás la aplicación inicial y crearás la base de datos y el esquema.
4. Crea una base de datos y un esquema
Prepara la aplicación inicial
En este paso, crearás la base de datos y el esquema a través del código.
Primero, crea una aplicación Java llamada onlinebanking con Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Extrae y copia los archivos de datos que agregaremos a la base de datos (consulta aquí el repositorio de código):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Navega a la carpeta de la aplicación:
cd onlinebanking
Abre el archivo pom.xml de Maven. Agrega la sección de administración de dependencias para usar la BOM de Maven y administrar la versión de las bibliotecas de Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Así se verán el editor y el archivo: 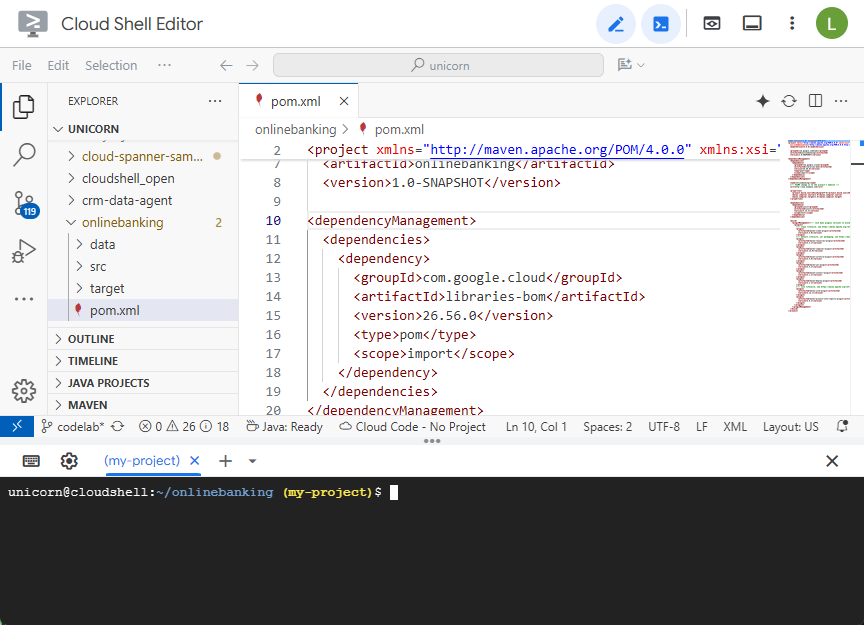
Asegúrate de que la sección dependencies incluya las bibliotecas que usará la aplicación:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Por último, reemplaza los complementos de compilación para que la aplicación se empaquete en un archivo JAR ejecutable:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Para guardar los cambios realizados en el archivo pom.xml, selecciona “Guardar” en el menú “Archivo” del editor de Cloud Shell o presiona Ctrl+S.
Ahora que las dependencias están listas, agregarás código a la app para crear un esquema, algunos índices (incluida la búsqueda) y un modelo de IA conectado a un extremo remoto. A lo largo de este codelab, compilarás estos artefactos y agregarás más métodos a esta clase.
Abre App.java en onlinebanking/src/main/java/com/google/codelabs y reemplaza el contenido por el siguiente código:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Guarda los cambios en App.java.
Echa un vistazo a las diferentes entidades que crea tu código y compila el archivo JAR de la aplicación:
mvn package
Resultado esperado:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Ejecuta la aplicación para ver la información de uso:
java -jar target/onlinebanking.jar
Resultado esperado:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Crea la base de datos y el esquema
Configura las variables de entorno de la aplicación necesarias:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Para crear la base de datos y el esquema, ejecuta el comando create:
java -jar target/onlinebanking.jar create
Resultado esperado:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Verifica el esquema en Spanner
En la consola de Spanner, navega a la instancia y la base de datos que acabas de crear.
Deberías ver las 3 tablas: Accounts, Customers y TransactionLedger.
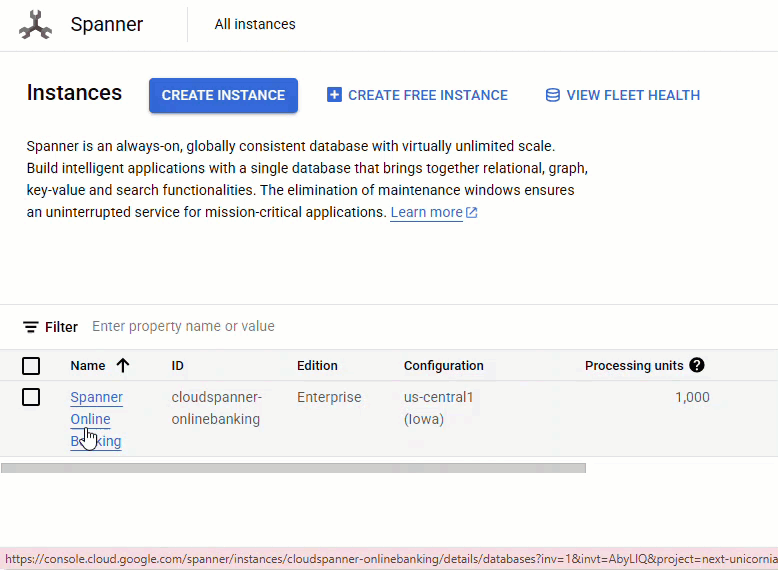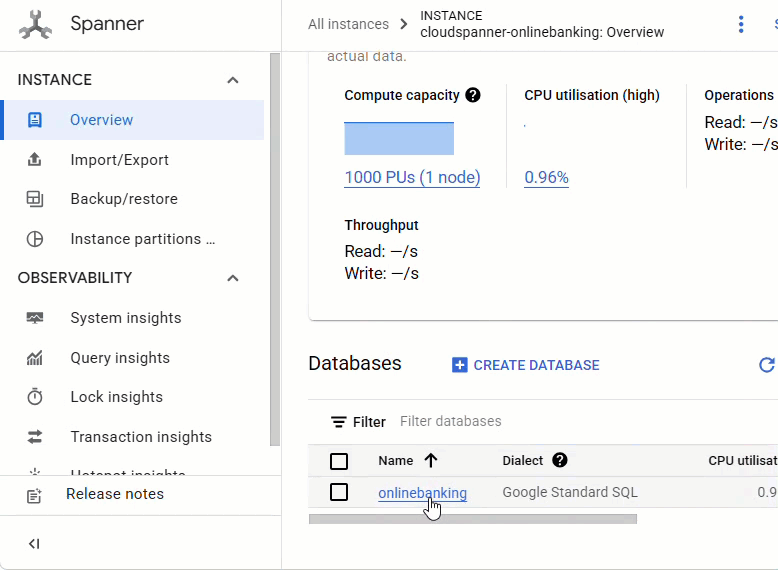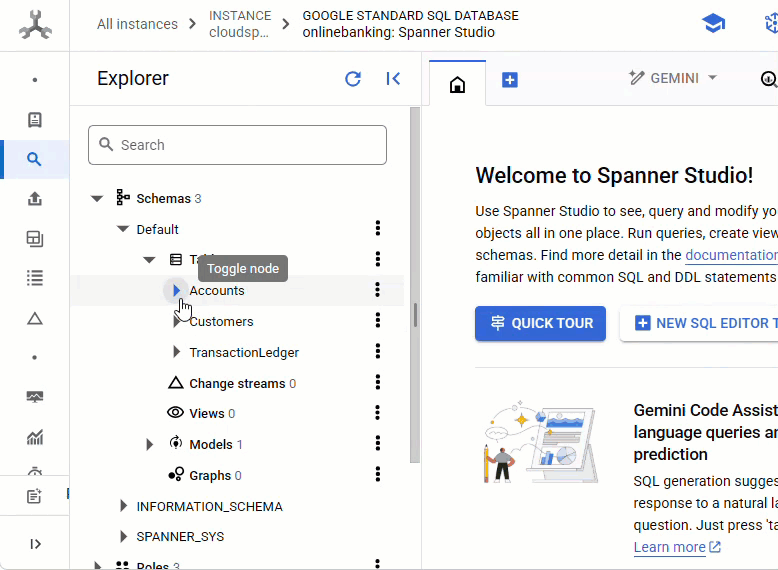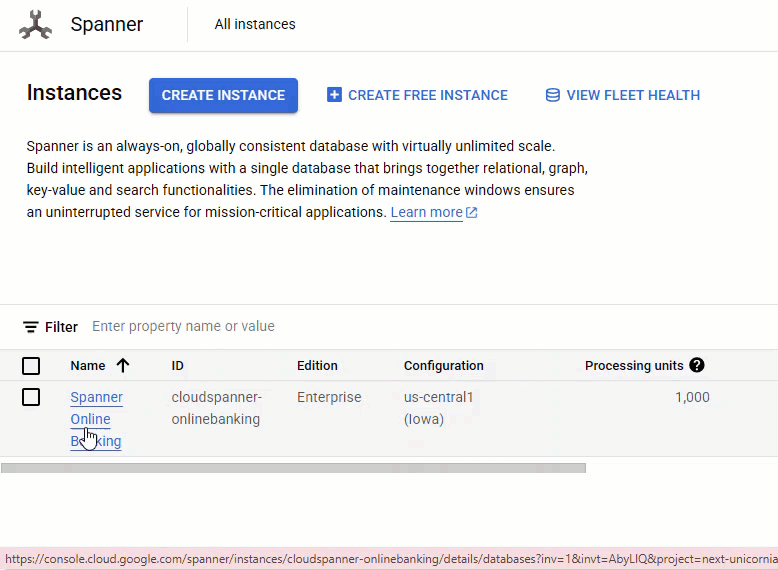
Esta acción crea el esquema de la base de datos, incluidas las tablas Accounts, Customers y TransactionLedger, junto con índices secundarios para la recuperación optimizada de datos y una referencia del modelo de Vertex AI.
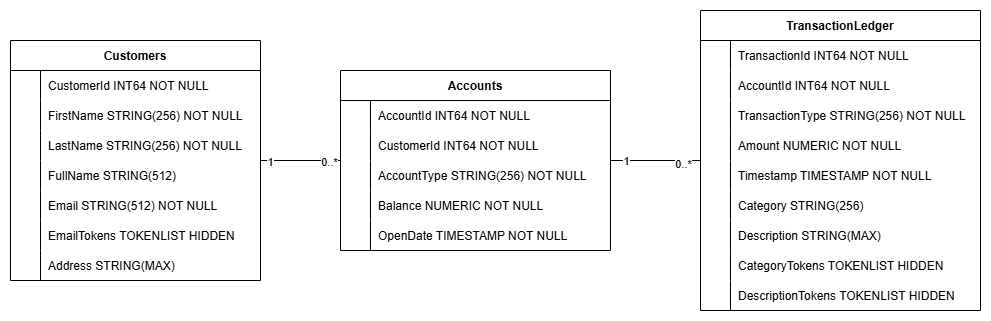
La tabla TransactionLedger se entrelaza dentro de Accounts para mejorar el rendimiento de las consultas de transacciones específicas de la cuenta a través de una mejor localidad de los datos.
Se implementaron índices secundarios (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) para optimizar los patrones de acceso a datos comunes que se usan en este codelab, como las búsquedas de clientes por correo electrónico exacto y aproximado, la recuperación de cuentas por cliente y la consulta y búsqueda eficientes de datos de transacciones.
TransactionCategoryModel aprovecha Vertex AI para permitir llamadas SQL directas a un LLM, que se usa para la categorización dinámica de transacciones en este codelab.
Resumen
En este paso, creaste la base de datos y el esquema de Spanner.
Cuál es el próximo paso
A continuación, cargarás los datos de la aplicación de ejemplo.
5. Cargar datos
Ahora, agregarás la funcionalidad para cargar datos de muestra desde archivos CSV en la base de datos.
Abre App.java y comienza por reemplazar las importaciones:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Luego, agrega los métodos de inserción a la clase App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Agrega otra instrucción case en el método main para la inserción dentro de switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Por último, agrega cómo usar la inserción al método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Guarda los cambios que realizaste en App.java.
Vuelve a compilar la aplicación:
mvn package
Para insertar los datos de muestra, ejecuta el comando insert:
java -jar target/onlinebanking.jar insert
Resultado esperado:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
En la consola de Spanner, vuelve a Spanner Studio para tu instancia y base de datos. Luego, selecciona la tabla TransactionLedger y haz clic en "Datos" en la barra lateral para verificar que se hayan cargado los datos. Debería haber 200 filas en la tabla.
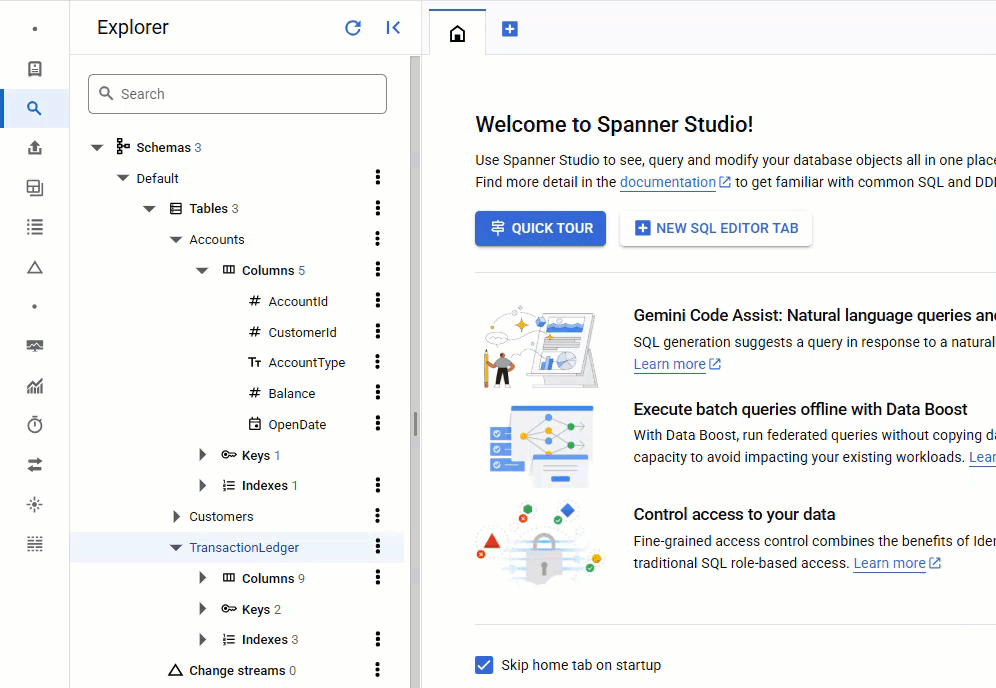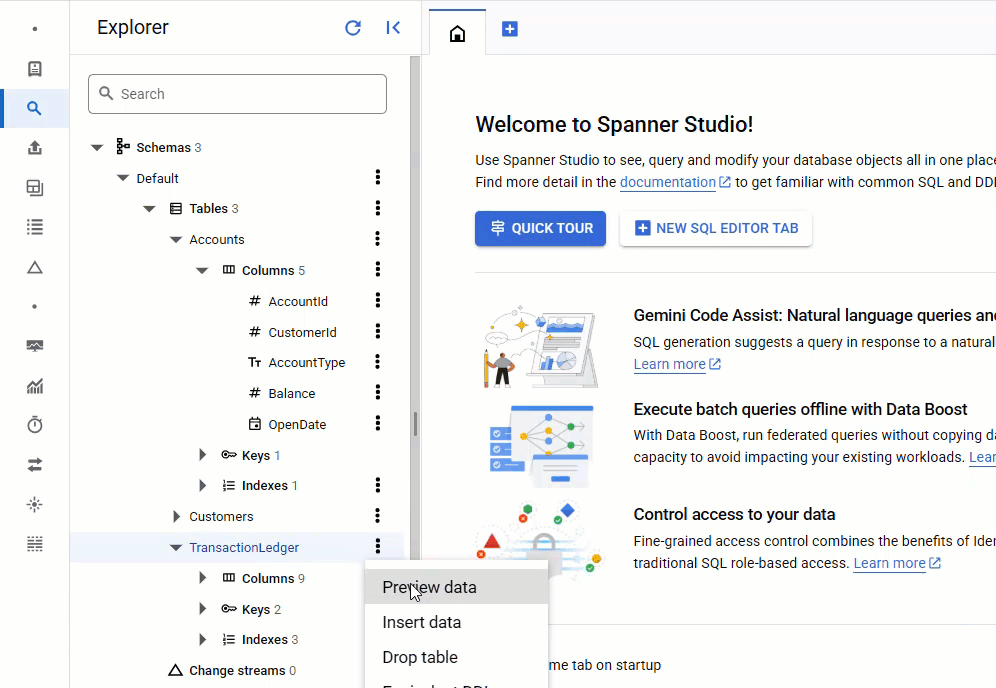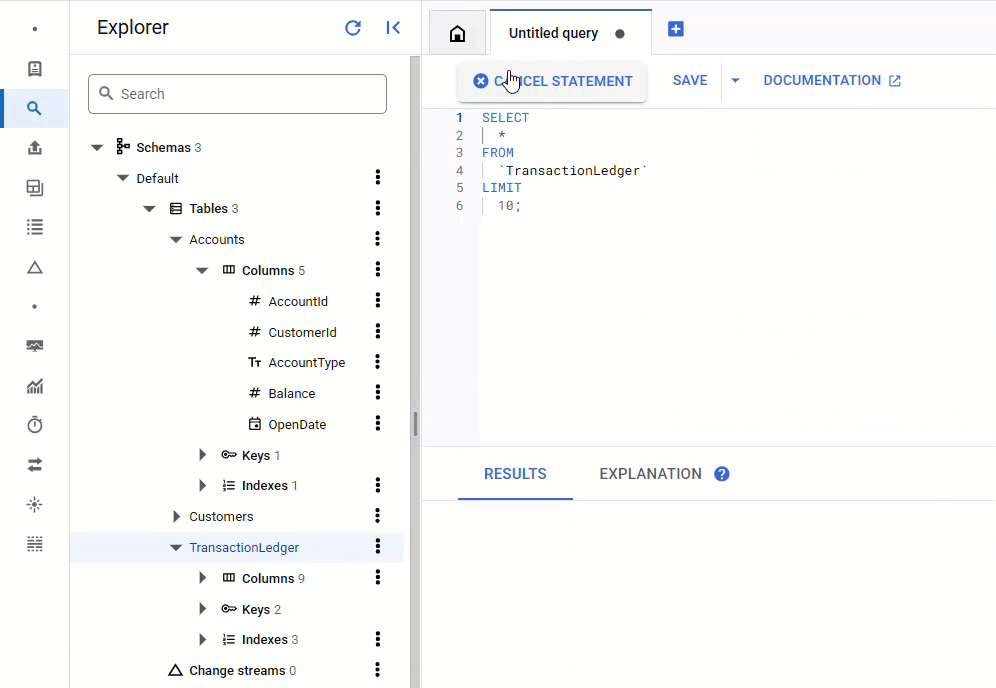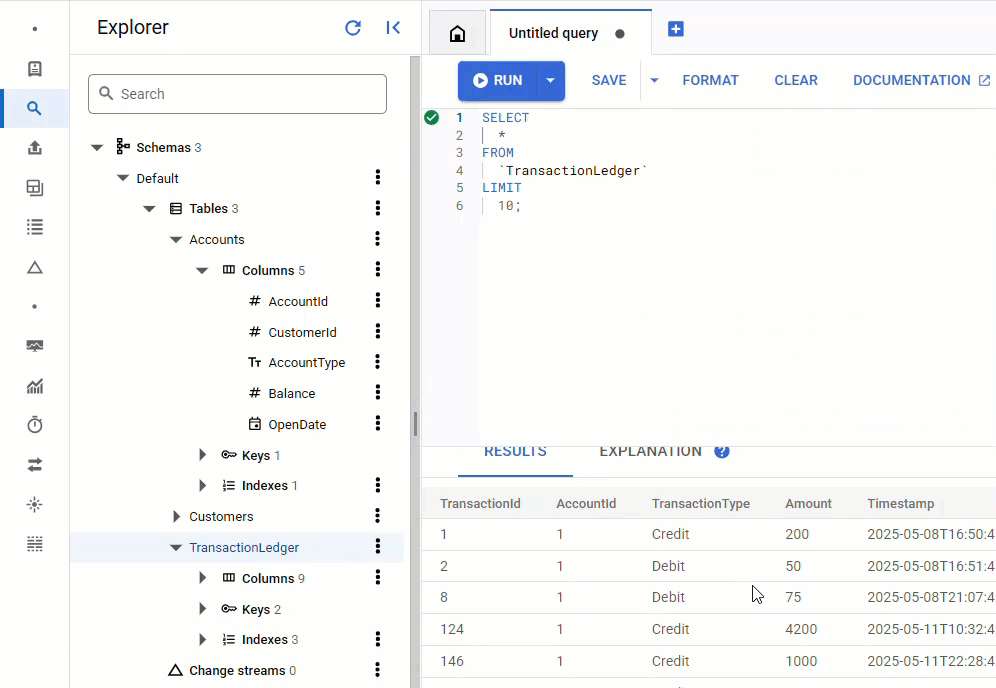
Resumen
En este paso, insertaste los datos de muestra en la base de datos.
Cuál es el próximo paso
A continuación, aprovecharás la integración de Vertex AI para categorizar automáticamente las transacciones bancarias directamente en Spanner SQL.
6. Categoriza datos con Vertex AI
En este paso, aprovecharás el poder de Vertex AI para categorizar automáticamente tus transacciones financieras directamente en Spanner SQL. Con Vertex AI, puedes elegir un modelo existente previamente entrenado o entrenar e implementar el tuyo. Consulta los modelos disponibles en Vertex AI Model Garden.
En este codelab, usaremos uno de los modelos de Gemini, Gemini Flash Lite. Esta versión de Gemini es rentable y, a la vez, puede manejar la mayoría de las cargas de trabajo diarias.
Actualmente, tenemos varias transacciones financieras que nos gustaría categorizar (groceries, transportation, etc.) según la descripción. Para ello, registraremos un modelo en Spanner y, luego, usaremos ML.PREDICT para llamar al modelo de IA.
En nuestra aplicación bancaria, es posible que deseemos categorizar las transacciones para obtener estadísticas más detalladas sobre el comportamiento de los clientes y, así, poder personalizar los servicios, detectar anomalías de manera más eficaz o brindarles a los clientes la capacidad de hacer un seguimiento de su presupuesto mes a mes.
El primer paso ya se completó cuando creamos la base de datos y el esquema, lo que generó un modelo como este:
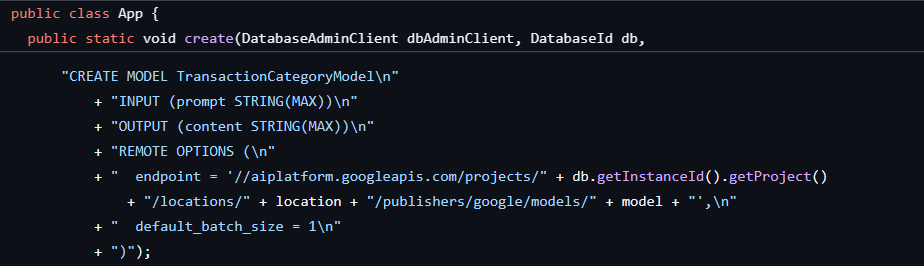
A continuación, agregaremos un método a la aplicación para llamar a ML.PREDICT.
Abre App.java y agrega el método categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Agrega otra instrucción case en el método main para categorizar:
case "categorize":
categorize(dbClient);
break;
Por último, agrega cómo usar la categorización al método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Guarda los cambios que realizaste en App.java.
Vuelve a compilar la aplicación:
mvn package
Para categorizar las transacciones en la base de datos, ejecuta el comando categorize:
java -jar target/onlinebanking.jar categorize
Resultado esperado:
Categorizing transactions... Completed categorizing transactions
En Spanner Studio, ejecuta la instrucción Preview Data para la tabla TransactionLedger. La columna Category ahora debería estar completada para todas las filas.
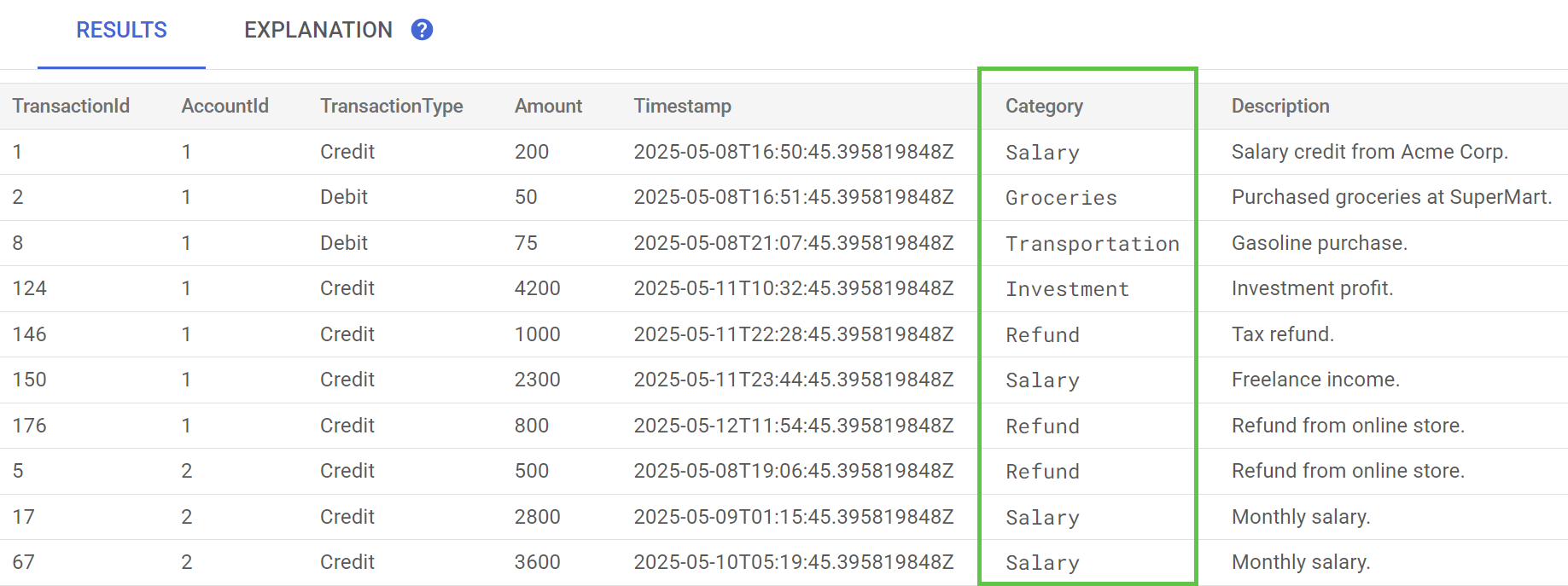
Ahora que categorizamos las transacciones, podemos usar esta información para consultas internas o externas. En el siguiente paso, veremos cómo averiguar cuánto gasta un cliente determinado en una categoría durante el mes.
Resumen
En este paso, usaste un modelo previamente entrenado para categorizar tus datos con tecnología de IA.
Cuál es el próximo paso
A continuación, usarás la tokenización para realizar búsquedas aproximadas y de texto completo.
7. Consulta con la búsqueda en el texto completo
Agrega el código de la consulta
Spanner proporciona muchas consultas de búsqueda en el texto completo. En este paso, realizarás una búsqueda de concordancia exacta, luego una búsqueda aproximada y, por último, una búsqueda de texto completo.
Abre App.java y comienza por reemplazar las importaciones:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Luego, agrega los métodos de consulta:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Agrega otra instrucción case en el método main para la consulta:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Por último, agrega cómo usar los comandos de consulta al método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Guarda los cambios que realizaste en App.java.
Vuelve a compilar la aplicación:
mvn package
Realiza una búsqueda de coincidencia exacta de los saldos de las cuentas de los clientes
Una búsqueda de concordancia exacta busca filas que coincidan exactamente con un término.
Para mejorar el rendimiento, ya se agregó un índice cuando creaste la base de datos y el esquema:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
El método getBalance usa implícitamente este índice para encontrar clientes que coincidan con el customerId proporcionado y también realiza una unión en las cuentas que pertenecen a ese cliente.
Así se ve la consulta cuando se ejecuta directamente en Spanner Studio: 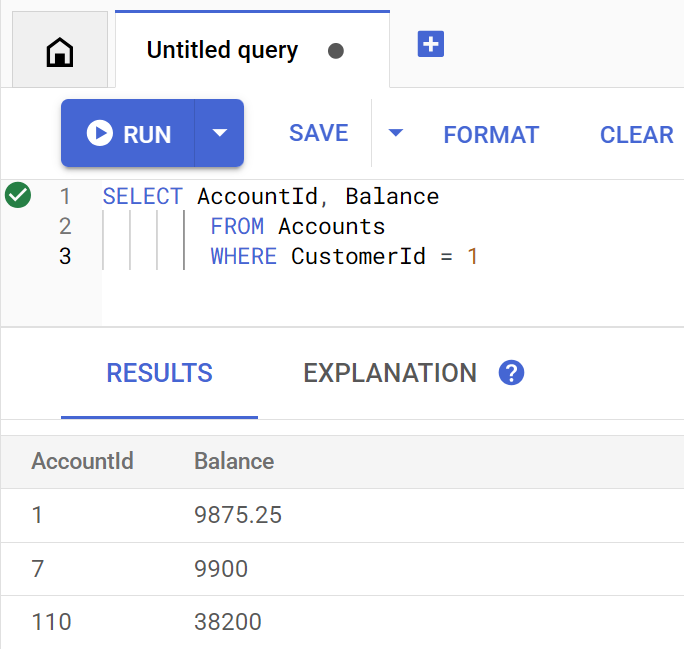
Para obtener una lista de los saldos de la cuenta del cliente 1, ejecuta el siguiente comando:
java -jar target/onlinebanking.jar query balance 1
Resultado esperado:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Hay 100 clientes, por lo que también puedes consultar cualquiera de los otros saldos de las cuentas de los clientes especificando un ID de cliente diferente:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Realiza una búsqueda aproximada en los correos electrónicos de los clientes
Las búsquedas aproximadas permiten encontrar coincidencias aproximadas para los términos de búsqueda, incluidas las variaciones ortográficas y los errores tipográficos.
Ya se agregó un índice de n-gramas cuando creaste la base de datos y el esquema:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
El método findCustomers usa SEARCH_NGRAMS y SCORE_NGRAMS para consultar este índice y encontrar clientes por correo electrónico. Dado que la columna de correo electrónico se tokenizó con n-gramas, esta búsqueda puede contener errores ortográficos y, aun así, devolver una respuesta correcta. Los resultados se ordenan según la mejor coincidencia.
Para encontrar las direcciones de correo electrónico de los clientes que coincidan y que contengan madi, ejecuta el siguiente comando:
java -jar target/onlinebanking.jar query email madi
Resultado esperado:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Esta respuesta muestra las coincidencias más cercanas que incluyen madi o una cadena similar, en orden de clasificación.
Así se ve la consulta si se ejecuta directamente en Spanner Studio: 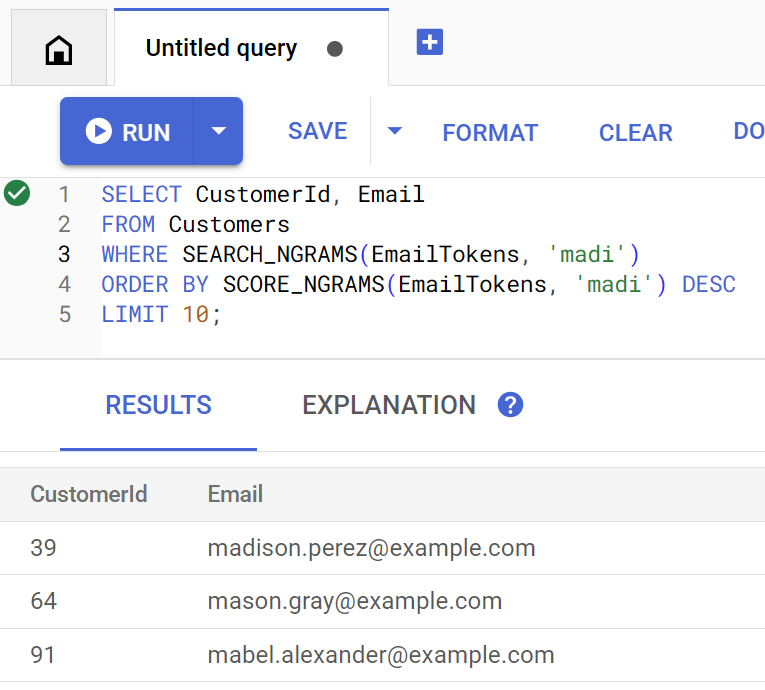
La búsqueda parcial también puede ayudar con errores ortográficos, como la escritura incorrecta de emily:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Resultado esperado:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
En cada caso, el correo electrónico esperado del cliente se devuelve como el resultado principal.
Cómo buscar transacciones con la búsqueda en el texto completo
La función de búsqueda de texto completo de Spanner se usa para recuperar registros según palabras clave o frases. Tiene la capacidad de corregir errores ortográficos o buscar sinónimos.
Ya se agregó un índice de búsqueda de texto completo cuando creaste la base de datos y el esquema:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
El método getSpending usa la función de búsqueda de texto completo SEARCH para realizar la coincidencia con ese índice. Busca todos los gastos (débitos) de los últimos 30 días para el ID de cliente determinado.
Para obtener la inversión total del último mes del cliente 1 en la categoría groceries, ejecuta el siguiente comando:
java -jar target/onlinebanking.jar query spending 1 groceries
Resultado esperado:
Total spending for customer 1 under category groceries: 50
También puedes consultar la inversión en otras categorías (que clasificamos en un paso anterior) o usar un ID de cliente diferente:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Resumen
En este paso, realizaste consultas de concordancia exacta, así como búsquedas difusas y de texto completo.
Cuál es el próximo paso
A continuación, integrarás Spanner con Google BigQuery para realizar consultas federadas, lo que te permitirá combinar tus datos de Spanner en tiempo real con los datos de BigQuery.
8. Ejecuta consultas federadas con BigQuery
Crea el conjunto de datos de BigQuery
En este paso, combinarás los datos de BigQuery y Spanner con consultas federadas.
Para ello, primero crea un conjunto de datos MarketingCampaigns en la línea de comandos de Cloud Shell:
bq mk --location=us-central1 MarketingCampaigns
Resultado esperado:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
Y una tabla CustomerSegments en el conjunto de datos:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Resultado esperado:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
A continuación, establece una conexión de BigQuery a Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Resultado esperado:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Por último, agrega algunos clientes a la tabla de BigQuery que se pueden unir con nuestros datos de Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Resultado esperado:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Para verificar que los datos estén disponibles, consulta BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Resultado esperado:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Estos datos en BigQuery representan los datos que se agregaron a través de varios flujos de trabajo bancarios. Por ejemplo, puede ser la lista de clientes que abrieron cuentas recientemente o se registraron para recibir una promoción de marketing. Para determinar la lista de clientes a los que queremos segmentar nuestra campaña de marketing, debemos consultar estos datos en BigQuery y los datos en tiempo real en Spanner, y una consulta federada nos permite hacerlo en una sola consulta.
Ejecuta una consulta federada con BigQuery
A continuación, agregaremos un método a la aplicación para llamar a EXTERNAL_QUERY y realizar la consulta federada. Esto permitirá unir y analizar los datos de los clientes en BigQuery y Spanner, por ejemplo, para identificar qué clientes cumplen con los criterios de nuestra campaña de marketing en función de sus gastos recientes.
Abre App.java y comienza por reemplazar las importaciones:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Luego, agrega el método campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Agrega otra instrucción case en el método main para la campaña:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Por último, agrega cómo usar la campaña al método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Guarda los cambios que realizaste en App.java.
Vuelve a compilar la aplicación:
mvn package
Ejecuta una consulta federada para determinar los clientes que se deben incluir en la campaña de marketing (campaign1) si gastaron al menos $5000 en los últimos 3 meses ejecutando el comando campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
Resultado esperado:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Ahora podemos segmentar nuestros anuncios para llegar a estos clientes con ofertas o recompensas exclusivas.
También podemos buscar una mayor cantidad de clientes que hayan alcanzado un umbral de inversión más bajo en los últimos 3 meses:
java -jar target/onlinebanking.jar campaign campaign1 2500
Resultado esperado:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Resumen
En este paso, ejecutaste correctamente consultas federadas desde BigQuery que incorporaron datos de Spanner en tiempo real.
Cuál es el próximo paso
A continuación, puedes limpiar los recursos creados para este codelab y evitar cargos.
9. Limpieza (opcional)
Este paso es opcional. Si deseas seguir experimentando con tu instancia de Spanner, no es necesario que la limpies en este momento. Sin embargo, se le seguirá cobrando al proyecto que uses por la instancia. Si ya no necesitas esta instancia, bórrala ahora para evitar estos cargos. Además de la instancia de Spanner, en este codelab también se crearon un conjunto de datos y una conexión de BigQuery que se deben limpiar cuando ya no sean necesarios.
Borra la instancia de Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
Confirma que deseas continuar (escribe Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Borra la conexión y el conjunto de datos de BigQuery:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Confirma el borrado del conjunto de datos de BigQuery (escribe Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Felicitaciones
🚀 Creaste una instancia nueva de Cloud Spanner, creaste una base de datos vacía, cargaste datos de muestra, realizaste operaciones y consultas avanzadas y, de forma opcional, borraste la instancia de Cloud Spanner.
Temas abordados
- Cómo configurar una instancia de Spanner
- Cómo crear una base de datos y tablas.
- Cómo cargar datos en las tablas de tu base de datos de Spanner
- Cómo llamar a modelos de Vertex AI desde Spanner
- Cómo consultar tu base de datos de Spanner con la búsqueda parcial y la búsqueda en el texto completo
- Cómo realizar consultas federadas en Spanner desde BigQuery
- Cómo borrar tu instancia de Spanner
Próximos pasos
- Obtén más información sobre las funciones avanzadas de Spanner, incluidas las siguientes:
- Consulta las bibliotecas cliente de Spanner disponibles.