
۱. مرور کلی
Spanner یک سرویس پایگاه داده توزیعشده جهانی، کاملاً مدیریتشده، مقیاسپذیر افقی و مناسب برای بارهای کاری عملیاتی رابطهای و غیررابطهای است. Spanner فراتر از قابلیتهای اصلی خود، ویژگیهای پیشرفته و قدرتمندی را ارائه میدهد که امکان ساخت برنامههای هوشمند و دادهمحور را فراهم میکند.
این آزمایشگاه کد بر اساس درک بنیادی Spanner بنا شده و با استفاده از یک برنامه بانکداری آنلاین به عنوان پایه، به استفاده از ادغامهای پیشرفته آن برای افزایش پردازش دادهها و قابلیتهای تحلیلی شما میپردازد.
ما بر روی سه ویژگی پیشرفته کلیدی تمرکز خواهیم کرد:
- ادغام هوش مصنوعی ورتکس : نحوه ادغام یکپارچه Spanner با پلتفرم هوش مصنوعی گوگل کلود، Vertex AI، را کشف کنید. شما یاد خواهید گرفت که چگونه مدلهای هوش مصنوعی ورتکس را مستقیماً از درون کوئریهای SQL اسپنر فراخوانی کنید، که امکان تبدیلها و پیشبینیهای قدرتمند درون پایگاه داده را فراهم میکند و به برنامه بانکی ما اجازه میدهد تا به طور خودکار تراکنشها را برای موارد استفاده مانند ردیابی بودجه و تشخیص ناهنجاری دستهبندی کند.
- جستجوی متن کامل : یاد بگیرید که چگونه قابلیت جستجوی متن کامل را در Spanner پیادهسازی کنید. شما با نمایهسازی دادههای متنی و نوشتن پرسوجوهای کارآمد برای انجام جستجوهای مبتنی بر کلمات کلیدی در دادههای عملیاتی خود آشنا خواهید شد و امکان کشف قدرتمند دادهها، مانند یافتن کارآمد مشتریان از طریق آدرس ایمیل در سیستم بانکی ما را فراهم میکنید.
- پرسوجوهای فدرال BigQuery : بررسی کنید که چگونه از قابلیتهای پرسوجوی فدرال Spanner برای پرسوجوی مستقیم از دادههای موجود در BigQuery استفاده کنید. این به شما امکان میدهد دادههای عملیاتی بلادرنگ Spanner را با مجموعه دادههای تحلیلی BigQuery ترکیب کنید تا بینشها و گزارشهای جامعی بدون تکرار دادهها یا فرآیندهای پیچیده ETL داشته باشید و موارد استفاده مختلف را در برنامه بانکی خود مانند کمپینهای بازاریابی هدفمند با ترکیب دادههای بلادرنگ مشتری با روندهای تاریخی گستردهتر از BigQuery تقویت کنید.
آنچه یاد خواهید گرفت
- نحوه تنظیم یک نمونه Spanner.
- نحوه ایجاد پایگاه داده و جداول.
- نحوه بارگذاری دادهها در جداول پایگاه داده Spanner.
- نحوه فراخوانی مدلهای هوش مصنوعی Vertex از Spanner.
- نحوه پرس و جو در پایگاه داده Spanner با استفاده از جستجوی فازی و جستجوی متن کامل.
- نحوه انجام کوئریهای فدرال علیه Spanner از BigQuery.
- چگونه نمونه Spanner خود را حذف کنیم.
آنچه نیاز دارید
۲. تنظیمات و الزامات
ایجاد یک پروژه
اگر از قبل یک پروژه گوگل کلود با قابلیت پرداخت فعال دارید، روی منوی کشویی انتخاب پروژه در سمت چپ بالای کنسول کلیک کنید:

با یک پروژه انتخاب شده، از بخش فعال کردن API های مورد نیاز (Enable the required APIs) صرف نظر کنید.
اگر از قبل حساب گوگل (جیمیل یا برنامههای گوگل) ندارید، باید یکی ایجاد کنید . وارد کنسول پلتفرم ابری گوگل ( console.cloud.google.com ) شوید و یک پروژه جدید ایجاد کنید.
برای ایجاد یک پروژه جدید، روی دکمه "NEW PROJECT" در کادر محاورهای ظاهر شده کلیک کنید:
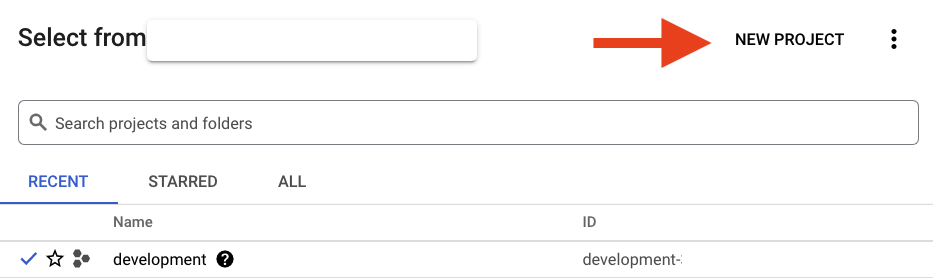
اگر از قبل پروژهای ندارید، باید پنجرهای مانند این را برای ایجاد اولین پروژه خود ببینید:
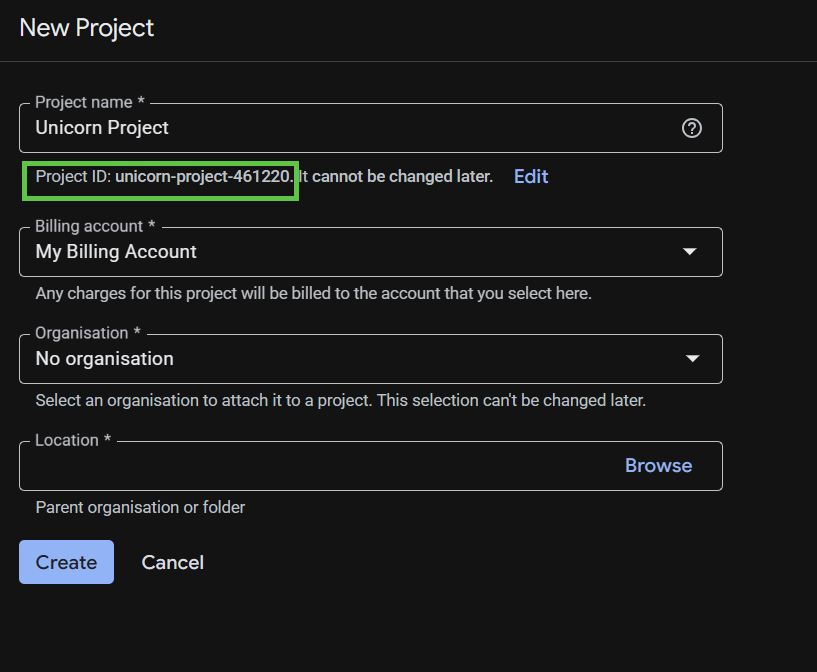
پنجرهی بعدیِ ایجاد پروژه به شما امکان میدهد جزئیات پروژهی جدید خود را وارد کنید.
شناسه پروژه را به خاطر بسپارید، که یک نام منحصر به فرد در تمام پروژههای Google Cloud است. بعداً در این آزمایشگاه کد به عنوان PROJECT_ID به آن اشاره خواهد شد.
در مرحله بعد، اگر قبلاً این کار را نکردهاید، باید صورتحساب را در کنسول توسعهدهندگان فعال کنید تا بتوانید از منابع Google Cloud استفاده کنید و Spanner API ، Vertex AI API ، BigQuery API و BigQuery Connection API را فعال کنید.
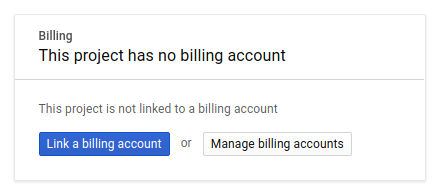
قیمتگذاری آچار فرانسه در اینجا مستند شده است. سایر هزینههای مرتبط با سایر منابع در صفحات قیمتگذاری خاص خود مستند خواهند شد.
کاربران جدید پلتفرم ابری گوگل واجد شرایط دریافت یک دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
راهاندازی پوسته ابری گوگل
در این آزمایشگاه کد، ما از Google Cloud Shell ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهیم کرد.
این ماشین مجازی مبتنی بر دبیان، تمام ابزارهای توسعه مورد نیاز شما را در خود جای داده است. این ماشین مجازی یک دایرکتوری خانگی دائمی ۵ گیگابایتی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. این بدان معناست که تنها چیزی که برای این آزمایشگاه کد نیاز دارید، یک مرورگر است.
برای فعال کردن Cloud Shell از کنسول Cloud، کافیست روی Activate Cloud Shell کلیک کنید. ![]() (فقط چند لحظه طول میکشد تا آماده شود و به محیط متصل شود).
(فقط چند لحظه طول میکشد تا آماده شود و به محیط متصل شود).

پس از اتصال به Cloud Shell، باید ببینید که از قبل احراز هویت شدهاید و پروژه از قبل روی PROJECT_ID شما تنظیم شده است.
gcloud auth list
خروجی مورد انتظار:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
خروجی مورد انتظار:
[core] project = <PROJECT_ID>
اگر به هر دلیلی پروژه تنظیم نشده باشد، دستور زیر را اجرا کنید:
gcloud config set project <PROJECT_ID>
به دنبال PROJECT_ID خود هستید؟ بررسی کنید که در مراحل راهاندازی از چه شناسهای استفاده کردهاید یا آن را در داشبورد Cloud Console جستجو کنید:
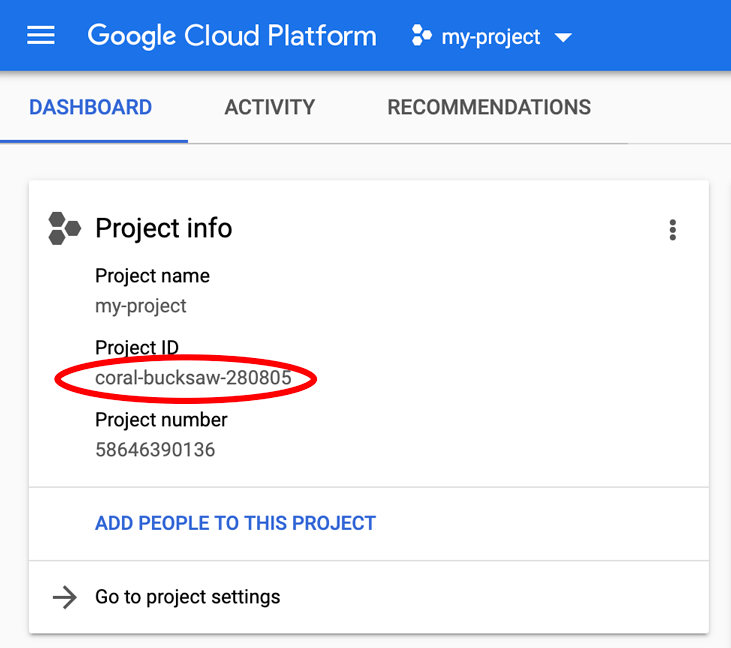
Cloud Shell همچنین برخی از متغیرهای محیطی را به طور پیشفرض تنظیم میکند که ممکن است هنگام اجرای دستورات بعدی مفید باشند.
echo $GOOGLE_CLOUD_PROJECT
خروجی مورد انتظار:
<PROJECT_ID>
فعال کردن API های مورد نیاز
APIهای Spanner، Vertex AI و BigQuery را برای پروژه خود فعال کنید:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
خلاصه
در این مرحله، اگر پروژهای نداشتید، آن را راهاندازی کردهاید، Cloud Shell را فعال کردهاید و APIهای مورد نیاز را فعال کردهاید.
بعدی
در مرحله بعد، نمونه Spanner را تنظیم خواهید کرد.
۳. راهاندازی یک نمونه Spanner
نمونه Spanner را ایجاد کنید
در این مرحله، شما یک نمونه Spanner برای codelab تنظیم خواهید کرد. برای انجام این کار، Cloud Shell را باز کنید و این دستور را اجرا کنید:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
خروجی مورد انتظار:
Creating instance...done.
خلاصه
در این مرحله، شما نمونه Spanner را ایجاد کردهاید.
بعدی
در مرحله بعد، برنامه اولیه را آماده کرده و پایگاه داده و طرحواره را ایجاد خواهید کرد.
۴. ایجاد پایگاه داده و طرحواره
آماده سازی درخواست اولیه
در این مرحله، پایگاه داده و طرحواره را از طریق کد ایجاد خواهید کرد.
ابتدا، با استفاده از Maven یک برنامه جاوا با نام onlinebanking ایجاد کنید:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
فایلهای دادهای که به پایگاه داده اضافه خواهیم کرد را بررسی و کپی کنید (برای مشاهده مخزن کد اینجا را ببینید):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
به پوشه برنامه بروید:
cd onlinebanking
فایل pom.xml مربوط به Maven را باز کنید. بخش مدیریت وابستگیها را اضافه کنید تا بتوانید از Maven BOM برای مدیریت نسخه کتابخانههای Google Cloud استفاده کنید:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
ویرایشگر و فایل به این شکل خواهند بود: 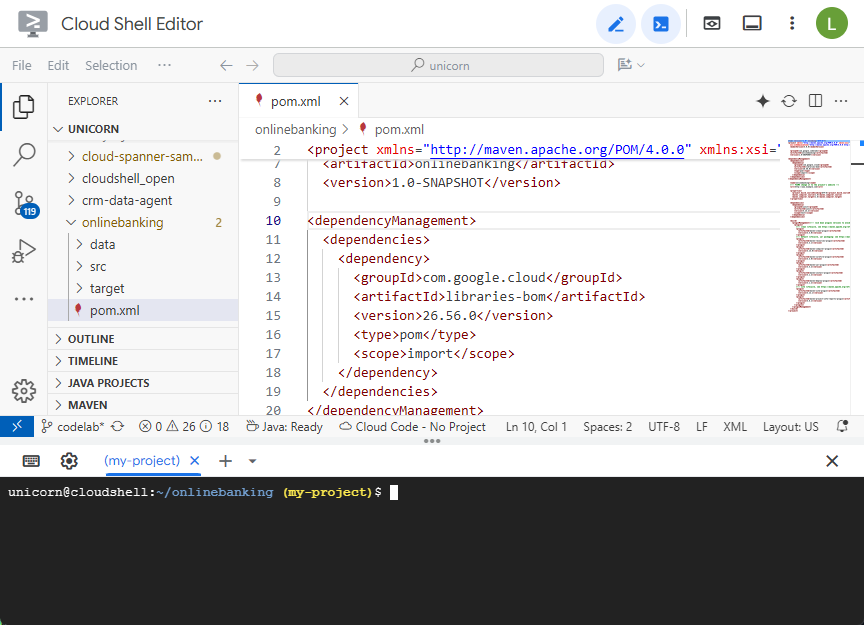
مطمئن شوید که بخش dependencies شامل کتابخانههایی است که برنامه از آنها استفاده خواهد کرد:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
در نهایت، افزونههای ساخت را جایگزین کنید تا برنامه در یک JAR قابل اجرا بستهبندی شود:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
با انتخاب «ذخیره» در منوی «فایل» ویرایشگر Cloud Shell یا با فشار دادن Ctrl+S ، تغییراتی را که در فایل pom.xml ایجاد کردهاید، ذخیره کنید.
اکنون که وابستگیها آماده هستند، کدی را به برنامه اضافه خواهید کرد تا یک طرحواره، برخی از شاخصها (از جمله جستجو) و یک مدل هوش مصنوعی متصل به یک نقطه پایانی از راه دور ایجاد کنید. شما بر اساس این مصنوعات، متدهای بیشتری را در طول این آزمایشگاه کد به این کلاس اضافه خواهید کرد.
App.java در مسیر onlinebanking/src/main/java/com/google/codelabs باز کنید و محتویات آن را با کد زیر جایگزین کنید:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
تغییرات را در App.java ذخیره کنید.
به موجودیتهای مختلفی که کد شما ایجاد میکند نگاهی بیندازید و JAR برنامه را بسازید:
mvn package
خروجی مورد انتظار:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
برای مشاهده اطلاعات مصرف، برنامه را اجرا کنید:
java -jar target/onlinebanking.jar
خروجی مورد انتظار:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
ایجاد پایگاه داده و طرحواره
متغیرهای محیطی مورد نیاز برنامه را تنظیم کنید:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
با اجرای دستور create پایگاه داده و طرحواره را ایجاد کنید:
java -jar target/onlinebanking.jar create
خروجی مورد انتظار:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
طرحواره را در Spanner بررسی کنید
در کنسول Spanner ، به نمونه و پایگاه دادهای که تازه ایجاد کردهاید بروید.
شما باید هر 3 جدول - Accounts ، Customers و TransactionLedger را ببینید.
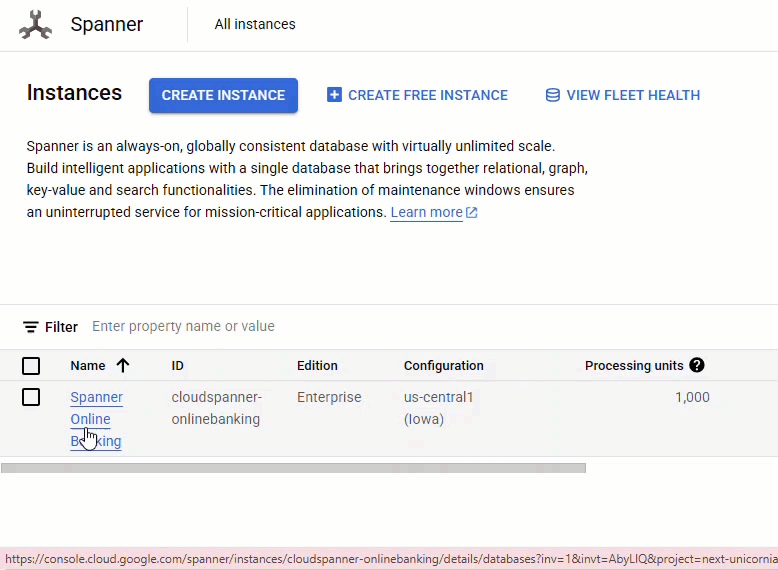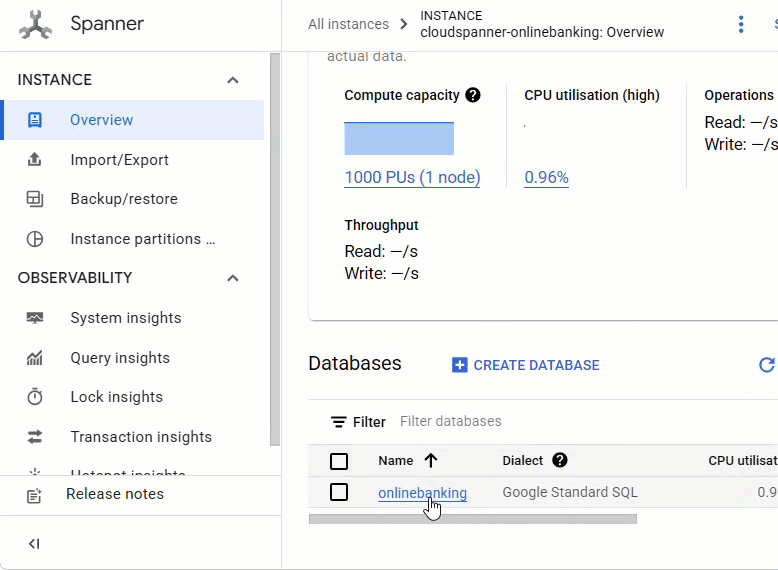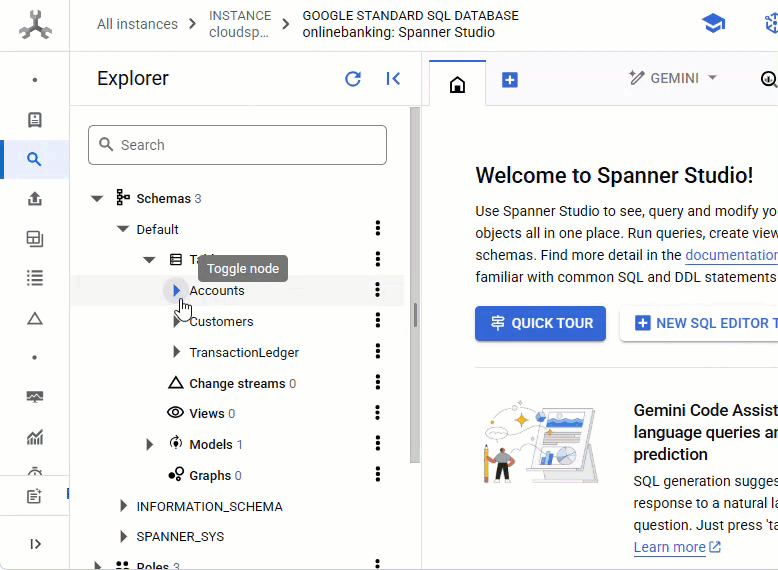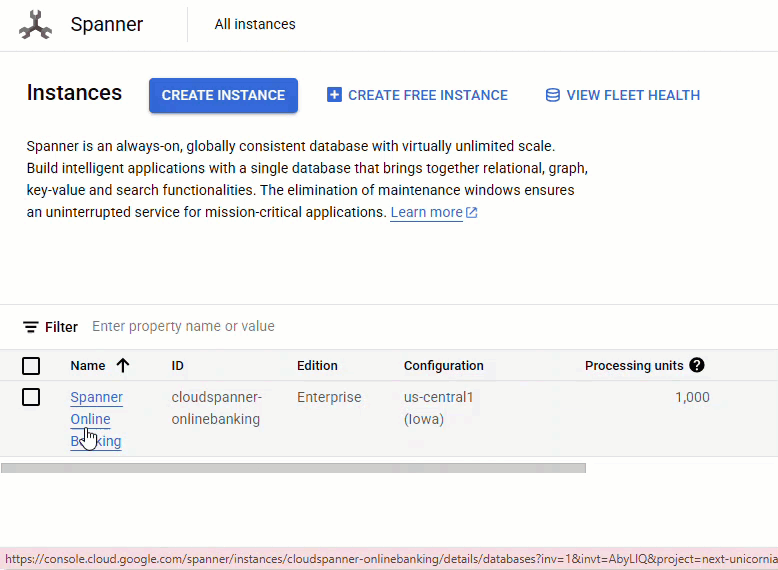
این اقدام، طرحواره پایگاه داده، شامل جداول Accounts ، Customers و TransactionLedger ، به همراه شاخصهای ثانویه برای بازیابی بهینه دادهها و یک مرجع مدل Vertex AI را ایجاد میکند.
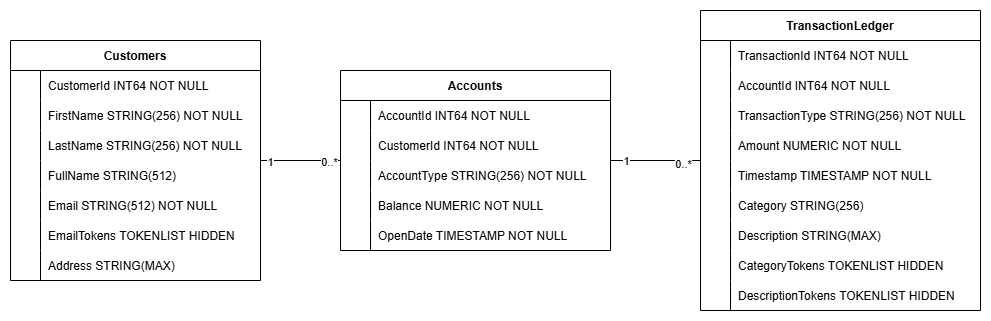
جدول TransactionLedger در داخل Accounts قرار گرفته است تا از طریق بهبود موقعیت مکانی دادهها، عملکرد پرسوجو برای تراکنشهای مختص حساب را افزایش دهد.
شاخصهای ثانویه ( CustomersByEmail ، CustomersFuzzyEmail ، AccountsByCustomer ، TransactionLedgerByAccountType ، TransactionLedgerByCategory ، TransactionLedgerTextSearch ) برای بهینهسازی الگوهای دسترسی به دادههای رایج مورد استفاده در این آزمایشگاه کد، مانند جستجوی مشتری از طریق ایمیل دقیق و فازی، بازیابی حسابها بر اساس مشتری و پرسوجو و جستجوی کارآمد دادههای تراکنش، پیادهسازی شدند.
TransactionCategoryModel از هوش مصنوعی ورتکس (Vertex AI) برای فعال کردن فراخوانیهای مستقیم SQL به یک LLM استفاده میکند که برای دستهبندی پویای تراکنشها در این آزمایشگاه کد استفاده میشود.
خلاصه
در این مرحله، پایگاه داده و طرحواره Spanner را ایجاد کردهاید.
بعدی
در مرحله بعد، دادههای برنامه نمونه را بارگذاری خواهید کرد.
۵. بارگذاری دادهها
اکنون، قابلیتی را برای بارگذاری دادههای نمونه از فایلهای CSV در پایگاه داده اضافه خواهید کرد.
App.java باز کنید و با جایگزینی importها شروع کنید:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
سپس متدهای درج را به کلاس App اضافه کنید:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
یک دستور case دیگر در متد main برای درج درون switch (command) اضافه کنید:
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
در نهایت، نحوهی استفاده از insert را به متد printUsageAndExit اضافه کنید:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
تغییراتی که در App.java ایجاد کردید را ذخیره کنید.
بازسازی برنامه:
mvn package
با اجرای دستور insert ، دادههای نمونه را وارد کنید:
java -jar target/onlinebanking.jar insert
خروجی مورد انتظار:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
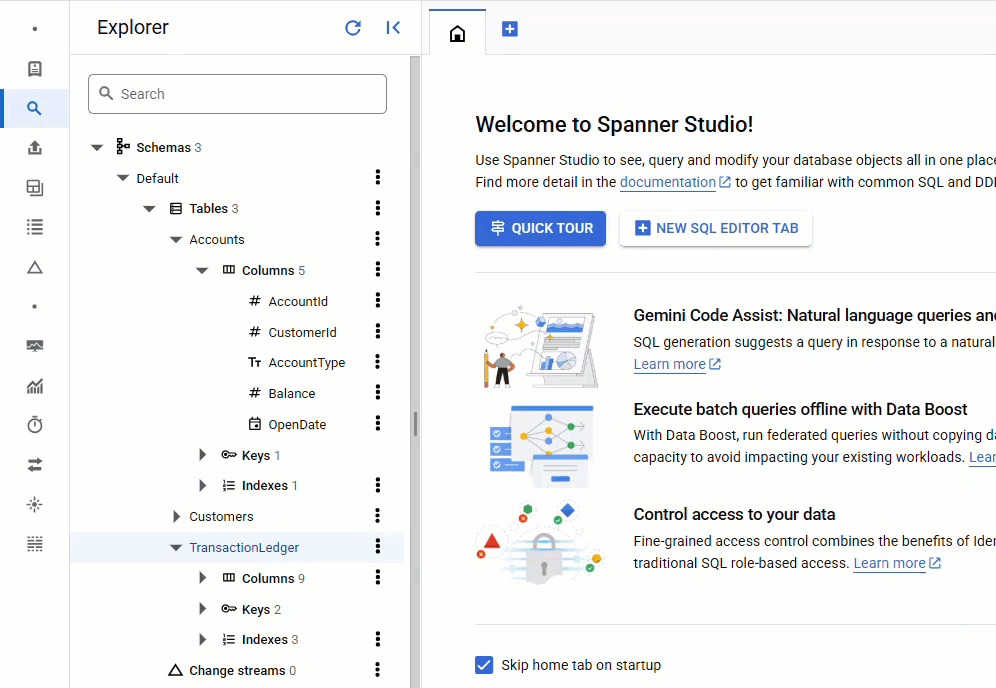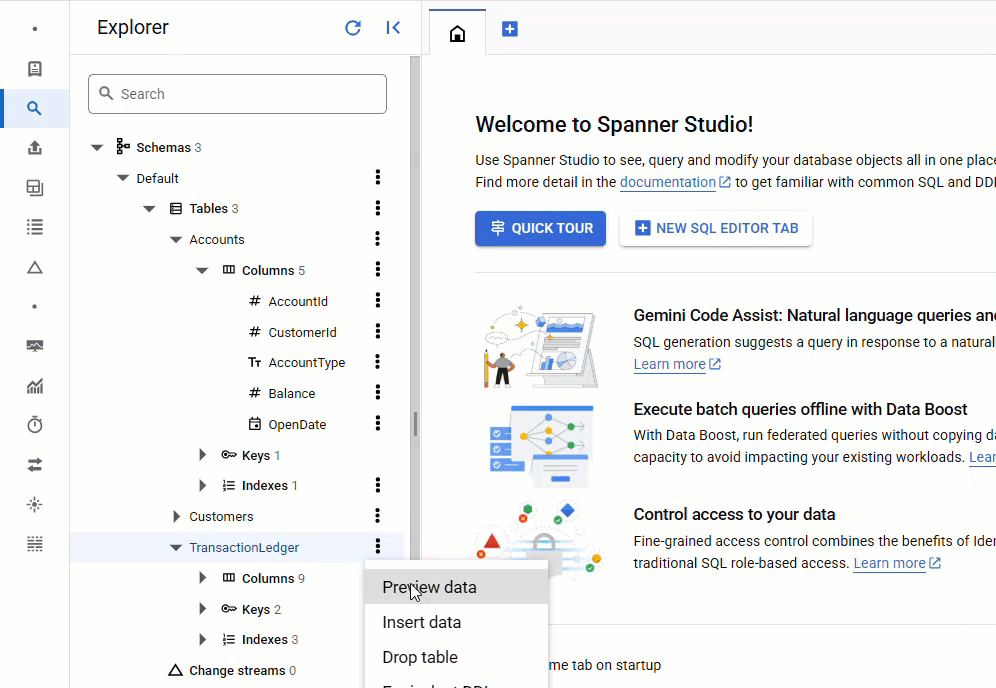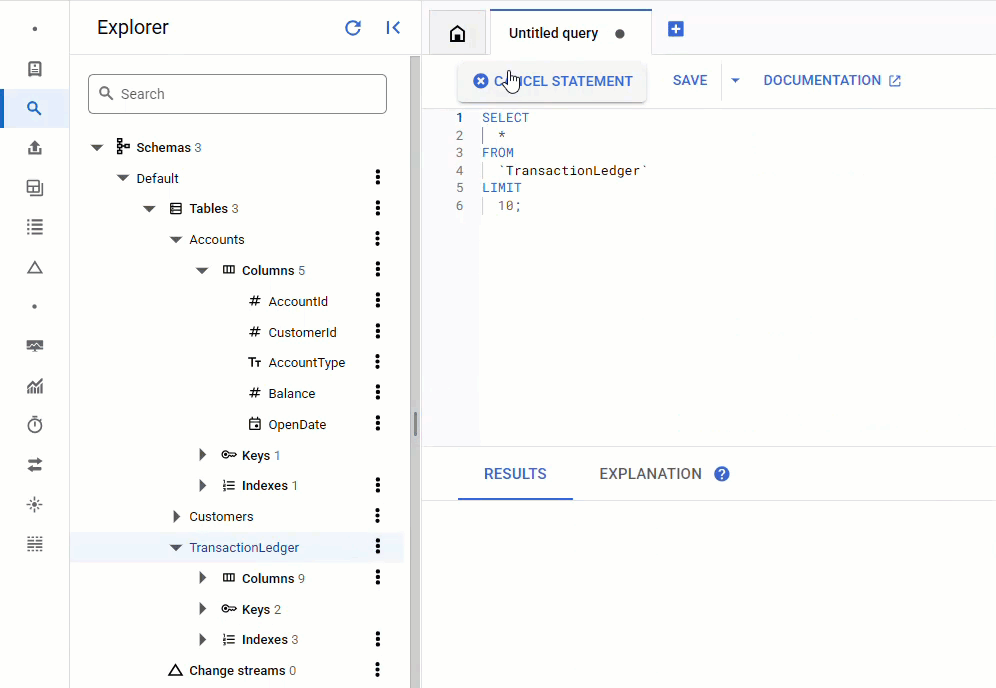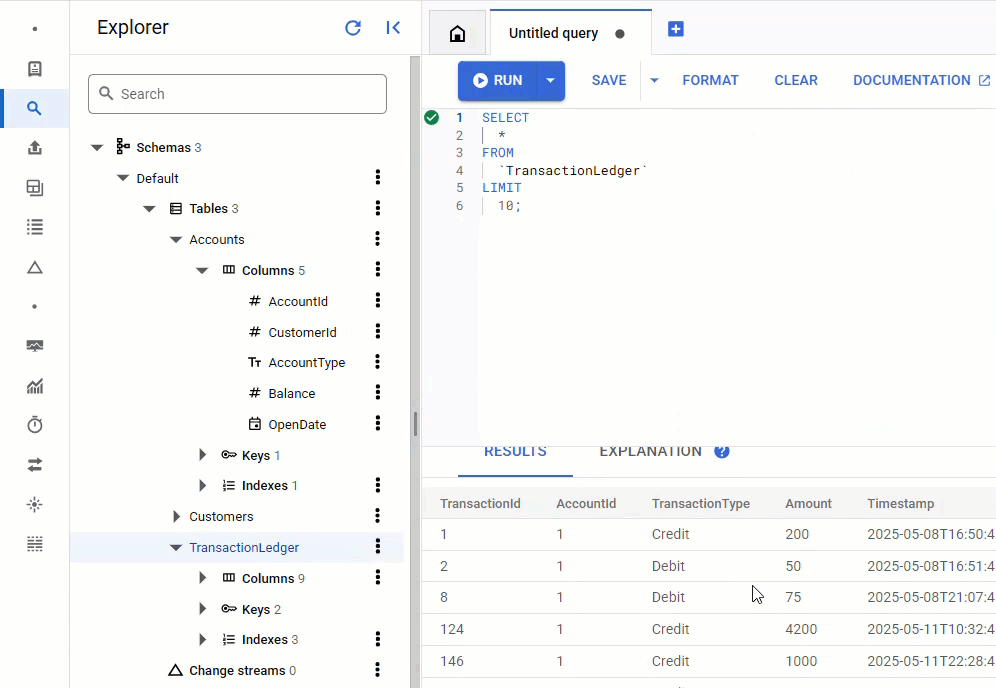
در کنسول Spanner ، به Spanner Studio برای نمونه و پایگاه داده خود برگردید. سپس جدول TransactionLedger را انتخاب کنید و برای تأیید بارگذاری دادهها، روی «دادهها» در نوار کناری کلیک کنید. باید ۲۰۰ ردیف در جدول وجود داشته باشد.
خلاصه
در این مرحله، دادههای نمونه را در پایگاه داده وارد کردید.
بعدی
در مرحله بعد، از ادغام Vertex AI برای دستهبندی خودکار تراکنشهای بانکی مستقیماً در Spanner SQL استفاده خواهید کرد.
۶. دستهبندی دادهها با Vertex AI
در این مرحله، شما از قدرت Vertex AI برای دستهبندی خودکار تراکنشهای مالی خود مستقیماً در Spanner SQL استفاده خواهید کرد. با Vertex AI میتوانید یک مدل از پیش آموزشدیده موجود را انتخاب کنید یا مدل خودتان را آموزش داده و مستقر کنید. مدلهای موجود را در Vertex AI Model Garden مشاهده کنید.
برای این آزمایشگاه کد، ما از یکی از مدلهای Gemini، Gemini Flash Lite استفاده خواهیم کرد. این نسخه از Gemini مقرون به صرفه است، اما همچنان میتواند اکثر حجم کارهای روزانه را مدیریت کند.
در حال حاضر، تعدادی تراکنش مالی داریم که میخواهیم بسته به توضیحات، آنها را دستهبندی کنیم ( groceries ، transportation و غیره). میتوانیم این کار را با ثبت یک مدل در Spanner و سپس استفاده از ML.PREDICT برای فراخوانی مدل هوش مصنوعی انجام دهیم.
در برنامه بانکی خود، ممکن است بخواهیم تراکنشها را دستهبندی کنیم تا بینش عمیقتری از رفتار مشتری به دست آوریم تا بتوانیم خدمات را شخصیسازی کنیم، ناهنجاریها را به طور مؤثرتری تشخیص دهیم یا به مشتری این امکان را بدهیم که بودجه خود را ماه به ماه پیگیری کند.
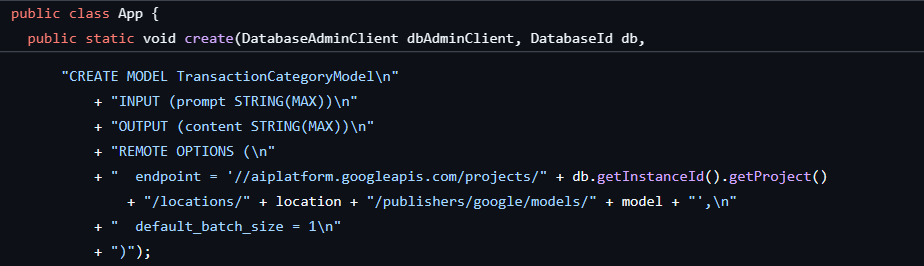
مرحله اول قبلاً انجام شده بود، زمانی که پایگاه داده و طرحواره را ایجاد کردیم، که مدلی مانند این ایجاد کرد:
در مرحله بعد، متدی را به برنامه اضافه خواهیم کرد تا ML.PREDICT فراخوانی کند.
App.java را باز کنید و متد categorize اضافه کنید:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
یک دستور case دیگر در متد main برای categorize اضافه کنید:
case "categorize":
categorize(dbClient);
break;
در نهایت، نحوهی استفاده از categorize را به متد printUsageAndExit اضافه کنید:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
تغییراتی که در App.java ایجاد کردید را ذخیره کنید.
بازسازی برنامه:
mvn package
با اجرای دستور categorize تراکنشهای موجود در پایگاه داده را دستهبندی کنید:
java -jar target/onlinebanking.jar categorize
خروجی مورد انتظار:
Categorizing transactions... Completed categorizing transactions
در Spanner Studio، دستور Preview Data را برای جدول TransactionLedger اجرا کنید. اکنون ستون Category باید برای همه ردیفها پر شده باشد.
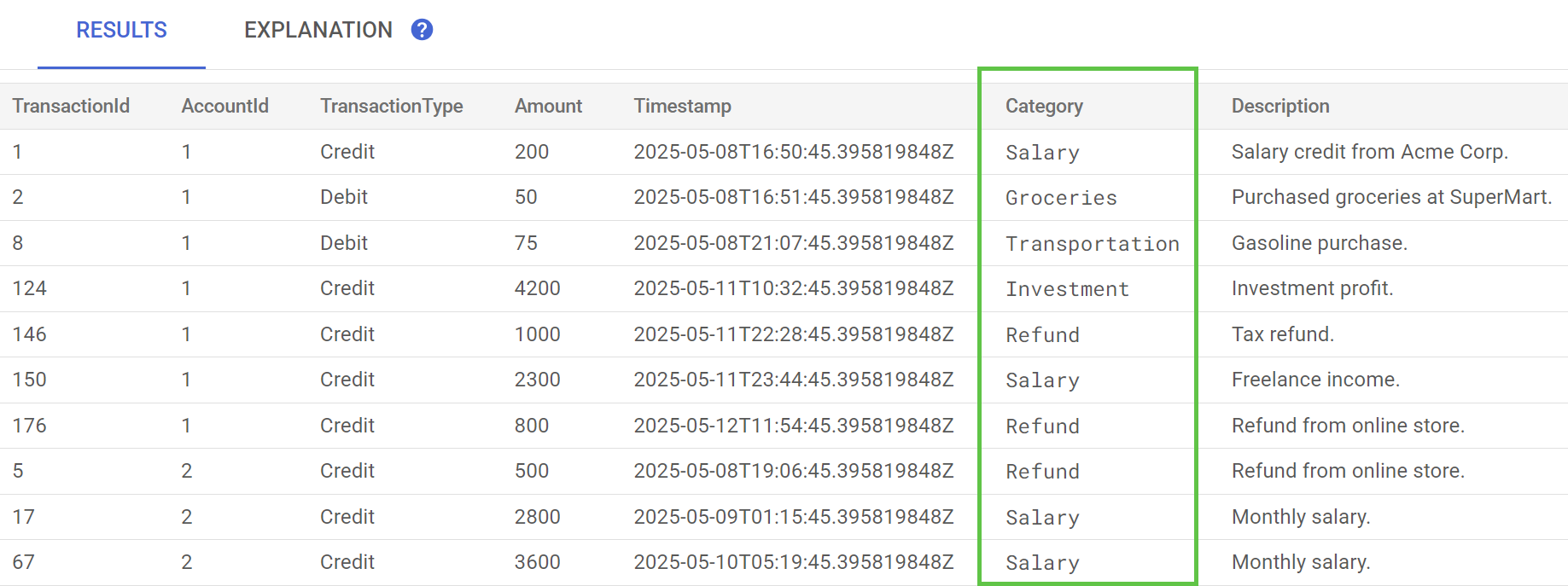
اکنون که تراکنشها را دستهبندی کردهایم، میتوانیم از این اطلاعات برای پرسشهای داخلی یا مربوط به مشتری استفاده کنیم. در مرحله بعد، به نحوهی یافتن میزان هزینهی ماهانهی یک مشتری خاص در یک دستهبندی خواهیم پرداخت.
خلاصه
در این مرحله، شما از یک مدل از پیش آموزشدیده برای انجام طبقهبندی مبتنی بر هوش مصنوعی دادههای خود استفاده کردید.
بعدی
در مرحله بعد، از توکنسازی برای انجام جستجوهای فازی و تمام متنی استفاده خواهید کرد.
۷. پرسوجو با استفاده از جستجوی متن کامل
کد استعلام را اضافه کنید
اسپنر کوئریهای جستجوی متن کامل زیادی ارائه میدهد. در این مرحله شما یک جستجوی تطبیق دقیق، سپس یک جستجوی فازی و یک جستجوی متن کامل انجام خواهید داد.
App.java باز کنید و با جایگزینی importها شروع کنید:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
سپس متدهای کوئری را اضافه کنید:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
یک دستور case دیگر در متد main برای کوئری اضافه کنید:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
در نهایت، نحوهی استفاده از دستورات کوئری را به متد printUsageAndExit اضافه کنید:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
تغییراتی که در App.java ایجاد کردید را ذخیره کنید.
بازسازی برنامه:
mvn package
انجام جستجوی دقیق برای موجودی حساب مشتری
یک پرسوجوی تطابق دقیق، ردیفهای منطبقی را جستجو میکند که دقیقاً با یک عبارت مطابقت دارند.
برای بهبود عملکرد، هنگام ایجاد پایگاه داده و طرحواره، یک فهرست از قبل اضافه شده است:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
متد getBalance به طور ضمنی از این شاخص برای یافتن مشتریانی که با customerId ارائه شده مطابقت دارند استفاده میکند و همچنین حسابهای متعلق به آن مشتری را join میکند.
این همان چیزی است که کوئری هنگام اجرای مستقیم در Spanner Studio به نظر میرسد: 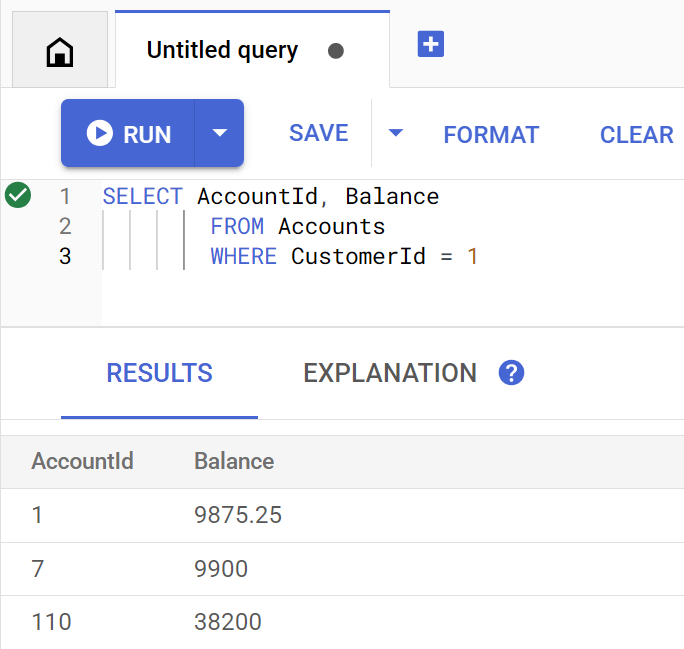
با اجرای دستور زیر، موجودی حساب مشتری 1 را فهرست کنید:
java -jar target/onlinebanking.jar query balance 1
خروجی مورد انتظار:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
۱۰۰ مشتری وجود دارد، بنابراین میتوانید با مشخص کردن یک شناسه مشتری متفاوت، موجودی حساب هر یک از مشتریان دیگر را نیز استعلام کنید:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
انجام جستجوی فازی در ایمیلهای مشتریان
جستجوهای فازی امکان یافتن تطابقهای تقریبی برای عبارات جستجو، از جمله تغییرات املایی و غلطهای املایی را فراهم میکنند.
هنگام ایجاد پایگاه داده و طرحواره، یک شاخص n-gram از قبل اضافه شده است:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
متد findCustomers از SEARCH_NGRAMS و SCORE_NGRAMS برای پرسوجو در برابر این اندیس جهت یافتن مشتریان از طریق ایمیل استفاده میکند. از آنجایی که ستون ایمیل به صورت n-gram توکنسازی شده است، این پرسوجو میتواند حاوی اشتباهات املایی باشد و همچنان پاسخ صحیح را بازگرداند. نتایج بر اساس بهترین تطابق مرتب میشوند.
با اجرای دستور زیر، آدرسهای ایمیل مشتریانی که حاوی madi هستند را پیدا کنید:
java -jar target/onlinebanking.jar query email madi
خروجی مورد انتظار:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
این پاسخ، نزدیکترین تطابقهایی که شامل madi یا رشتهای مشابه هستند را به ترتیب رتبهبندی نشان میدهد.
اگر کوئری مستقیماً در Spanner Studio اجرا شود، به این شکل خواهد بود: 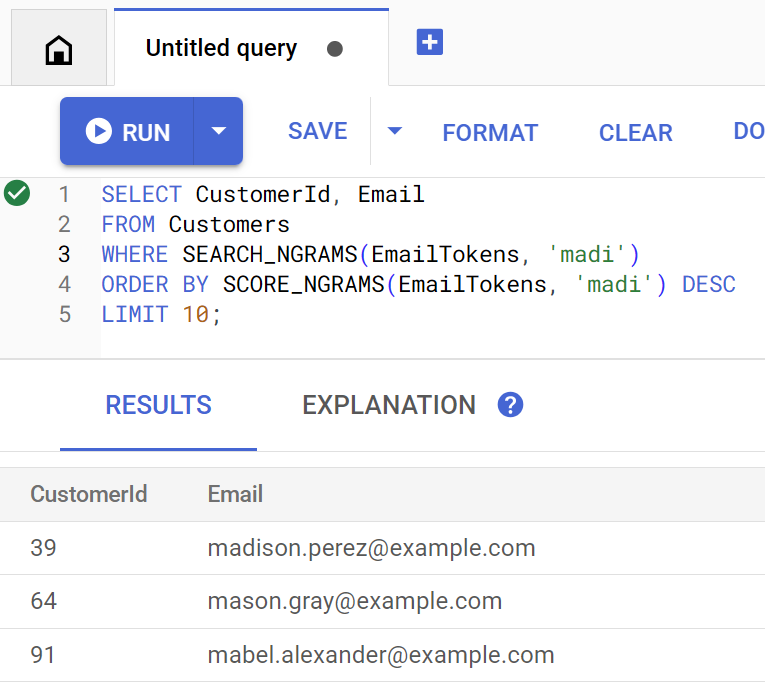
جستجوی فازی همچنین میتواند به اشتباهات املایی مانند غلط املایی emily کمک کند:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
خروجی مورد انتظار:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
در هر مورد، ایمیل مورد انتظار مشتری به عنوان بالاترین نتیجه برگردانده میشود.
جستجوی تراکنشها با جستجوی متن کامل
قابلیت جستجوی متن کامل Spanner برای بازیابی رکوردها بر اساس کلمات کلیدی یا عبارات استفاده میشود. این قابلیت را دارد که اشتباهات املایی را اصلاح کند یا مترادفها را جستجو کند.
هنگام ایجاد پایگاه داده و طرحواره، یک فهرست جستجوی متن کامل از قبل اضافه شده است:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
متد getSpending از تابع جستجوی متن کامل SEARCH برای تطبیق با آن شاخص استفاده میکند. این متد به دنبال تمام مخارج (بدهیها) در 30 روز گذشته برای شناسه مشتری داده شده میگردد.
با اجرای دستور زیر، کل هزینههای مشتری 1 در دسته groceries در ماه گذشته را دریافت کنید:
java -jar target/onlinebanking.jar query spending 1 groceries
خروجی مورد انتظار:
Total spending for customer 1 under category groceries: 50
همچنین میتوانید هزینههای مربوط به دستههای دیگر (که در مرحله قبل دستهبندی کردیم) را پیدا کنید، یا از یک شناسه مشتری متفاوت استفاده کنید:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
خلاصه
در این مرحله، شما جستجوهای تطبیق دقیق و همچنین جستجوهای فازی و متن کامل را انجام دادید.
بعدی
در مرحله بعد، Spanner را با Google BigQuery ادغام خواهید کرد تا کوئریهای فدرالی انجام دهید و به شما امکان میدهد دادههای Spanner خود را به صورت بلادرنگ با دادههای BigQuery ترکیب کنید.
۸. اجرای کوئریهای فدرال با BigQuery
ایجاد مجموعه داده BigQuery
در این مرحله، دادههای BigQuery و Spanner را از طریق استفاده از کوئریهای فدرالی (Federated Query) گرد هم خواهید آورد.
برای انجام این کار، در خط فرمان Cloud Shell، ابتدا یک مجموعه داده MarketingCampaigns ایجاد کنید:
bq mk --location=us-central1 MarketingCampaigns
خروجی مورد انتظار:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
و یک جدول CustomerSegments در مجموعه دادهها:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
خروجی مورد انتظار:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
سپس، از BigQuery به Spanner یک اتصال برقرار کنید:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
خروجی مورد انتظار:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
در نهایت، چند مشتری به جدول BigQuery اضافه کنید که بتوان آنها را با دادههای Spanner ما به هم متصل کرد:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
خروجی مورد انتظار:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
میتوانید با پرسوجو از BigQuery، از در دسترس بودن دادهها اطمینان حاصل کنید:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
خروجی مورد انتظار:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
این دادهها در BigQuery نشاندهنده دادههایی هستند که از طریق گردشهای کاری مختلف بانکی اضافه شدهاند. به عنوان مثال، این ممکن است لیست مشتریانی باشد که اخیراً حساب باز کردهاند یا برای یک تبلیغ بازاریابی ثبتنام کردهاند. برای تعیین لیست مشتریانی که میخواهیم در کمپین بازاریابی خود هدف قرار دهیم، باید هم این دادهها را در BigQuery و هم دادههای بلادرنگ را در Spanner جستجو کنیم و یک جستجوی فدرال به ما امکان میدهد این کار را در یک جستجوی واحد انجام دهیم.
اجرای یک کوئری فدرال با BigQuery
در مرحله بعد، متدی را به برنامه اضافه خواهیم کرد تا EXTERNAL_QUERY را برای انجام کوئری فدرال فراخوانی کند. این کار امکان ادغام و تجزیه و تحلیل دادههای مشتری در BigQuery و Spanner را فراهم میکند، مانند شناسایی اینکه کدام مشتریان بر اساس هزینههای اخیرشان، معیارهای کمپین بازاریابی ما را دارند.
App.java باز کنید و با جایگزینی importها شروع کنید:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
سپس متد campaign را اضافه کنید:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
یک دستور case دیگر در متد main برای campaign اضافه کنید:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
در نهایت، نحوه استفاده از campaign را به متد printUsageAndExit اضافه کنید:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
تغییراتی که در App.java ایجاد کردید را ذخیره کنید.
بازسازی برنامه:
mvn package
با اجرای دستور campaign یک کوئری فدرال اجرا کنید تا مشخص شود مشتریانی که باید در کمپین بازاریابی ( campaign1 ) گنجانده شوند، در صورتی که حداقل $5000 در ۳ ماه گذشته هزینه کردهاند:
java -jar target/onlinebanking.jar campaign campaign1 5000
خروجی مورد انتظار:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
اکنون میتوانیم این مشتریان را با پیشنهادات یا پاداشهای انحصاری هدف قرار دهیم.
یا میتوانیم به دنبال تعداد بیشتری از مشتریان باشیم که در طول ۳ ماه گذشته به آستانه خرید کمتری دست یافتهاند:
java -jar target/onlinebanking.jar campaign campaign1 2500
خروجی مورد انتظار:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
خلاصه
در این مرحله، شما با موفقیت کوئریهای فدرالی از BigQuery را اجرا کردید که دادههای Spanner را به صورت بلادرنگ (real-time) به ارمغان میآورد.
بعدی
در مرحله بعد، میتوانید منابع ایجاد شده برای این codelab را پاک کنید تا از هزینههای اضافی جلوگیری شود.
۹. پاکسازی (اختیاری)
این مرحله اختیاری است. اگر میخواهید به آزمایش با نمونه Spanner خود ادامه دهید، در حال حاضر نیازی به پاکسازی آن ندارید. با این حال، پروژهای که استفاده میکنید همچنان برای این نمونه هزینه دریافت خواهد کرد. اگر دیگر نیازی به این نمونه ندارید، باید در حال حاضر آن را حذف کنید تا از این هزینهها جلوگیری شود. علاوه بر نمونه Spanner، این codelab همچنین یک مجموعه داده و اتصال BigQuery ایجاد کرده است که باید وقتی دیگر نیازی به آنها نیست، پاکسازی شوند.
نمونه Spanner را حذف کنید:
gcloud spanner instances delete cloudspanner-onlinebanking
تأیید کنید که میخواهید ادامه دهید ( Y را تایپ کنید):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
اتصال و مجموعه داده BigQuery را حذف کنید:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
حذف مجموعه داده BigQuery را تأیید کنید (نوع Y ):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
۱۰. تبریک
شما یک نمونه جدید از Cloud Spanner ایجاد کردهاید، یک پایگاه داده خالی ساختهاید، دادههای نمونه را بارگذاری کردهاید، عملیات و پرسوجوهای پیشرفته انجام دادهاید و (به صورت اختیاری) نمونه Cloud Spanner را حذف کردهاید.
آنچه ما پوشش دادهایم
- نحوه تنظیم یک نمونه Spanner.
- نحوه ایجاد پایگاه داده و جداول.
- نحوه بارگذاری دادهها در جداول پایگاه داده Spanner.
- نحوه فراخوانی مدلهای هوش مصنوعی Vertex از Spanner.
- نحوه پرس و جو در پایگاه داده Spanner با استفاده از جستجوی فازی و جستجوی متن کامل.
- نحوه انجام کوئریهای فدرال علیه Spanner از BigQuery.
- چگونه نمونه Spanner خود را حذف کنیم.
بعدش چی؟
- درباره ویژگیهای پیشرفته آچار ، از جمله موارد زیر، بیشتر بدانید:
- کتابخانههای کلاینت Spanner موجود را ببینید.