
1. סקירה כללית
Spanner הוא שירות מנוהל של מסד נתונים שניתן להרחבה אופקית ומבוזר גלובלית. הוא מתאים לעומסי עבודה תפעוליים רלציוניים ולא רלציוניים. בנוסף ליכולות הליבה שלו, Spanner מציע תכונות מתקדמות ועוצמתיות שמאפשרות לפתח אפליקציות חכמות שמבוססות על נתונים.
ב-Codelab הזה נשתמש בידע הבסיסי על Spanner כדי להסביר איך אפשר להשתמש בשילובים המתקדמים שלו כדי לשפר את יכולות עיבוד הנתונים וניתוח הנתונים, על סמך אפליקציה לבנקאות דיגיטלית.
נתמקד בשלוש תכונות מתקדמות מרכזיות:
- שילוב עם Vertex AI: איך משלבים את Spanner עם פלטפורמת ה-AI של Google Cloud, Vertex AI. תלמדו איך להפעיל מודלים של Vertex AI ישירות מתוך שאילתות Spanner SQL, כדי לבצע טרנספורמציות ותחזיות עוצמתיות במסד הנתונים. כך אפשר לאפליקציה הבנקאית שלנו לסווג אוטומטית עסקאות לתרחישי שימוש כמו מעקב אחר תקציב וזיהוי אנומליות.
- חיפוש טקסט מלא: איך מטמיעים את הפונקציונליות של חיפוש טקסט מלא ב-Spanner. תלמדו איך לבצע אינדוקס של נתוני טקסט ולכתוב שאילתות יעילות כדי לבצע חיפושים מבוססי מילות מפתח בנתונים התפעוליים שלכם. כך תוכלו לגלות נתונים חשובים, למשל למצוא ביעילות לקוחות לפי כתובת אימייל במערכת הבנקאית שלנו.
- שאילתות לכמה מסדי נתונים ב-BigQuery: הסבר על האופן שבו אפשר להשתמש ביכולות של Spanner להרצת שאילתות לכמה מסדי נתונים כדי להריץ שאילתות ישירות על נתונים שנמצאים ב-BigQuery. כך תוכלו לשלב את הנתונים התפעוליים בזמן אמת של Spanner עם מערכי הנתונים האנליטיים של BigQuery כדי לקבל תובנות מקיפות ולדווח בלי לשכפל נתונים או להשתמש בתהליכי ETL מורכבים. השילוב הזה מאפשר לכם להשתמש בנתונים במגוון תרחישים באפליקציית הבנקאות שלנו, כמו הפעלת קמפיינים שיווקיים ממוקדים על ידי שילוב נתוני לקוחות בזמן אמת עם מגמות היסטוריות רחבות יותר מ-BigQuery.
מה תלמדו
- איך מגדירים מופע Spanner.
- איך יוצרים מסד נתונים וטבלאות.
- איך טוענים נתונים לטבלאות במסד הנתונים של Spanner.
- איך קוראים למודלים של Vertex AI מ-Spanner.
- איך שולחים שאילתות למסד הנתונים של Spanner באמצעות חיפוש משוער וחיפוש טקסט מלא.
- איך לבצע שאילתות מאוחדות ב-Spanner מ-BigQuery.
- איך מוחקים את מכונת Spanner.
הדרישות
2. הגדרה ודרישות
יצירת פרויקט
אם כבר יש לכם פרויקט ב-Google Cloud עם חיוב מופעל, לוחצים על התפריט הנפתח לבחירת פרויקט בפינה הימנית העליונה של המסוף:

אם בחרתם פרויקט, דלגו אל הפעלת ממשקי ה-API הנדרשים.
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים אל Google Cloud Platform Console (console.cloud.google.com) ויוצרים פרויקט חדש.
בתיבת הדו-שיח שמופיעה, לוחצים על הלחצן 'פרויקט חדש' כדי ליצור פרויקט חדש:
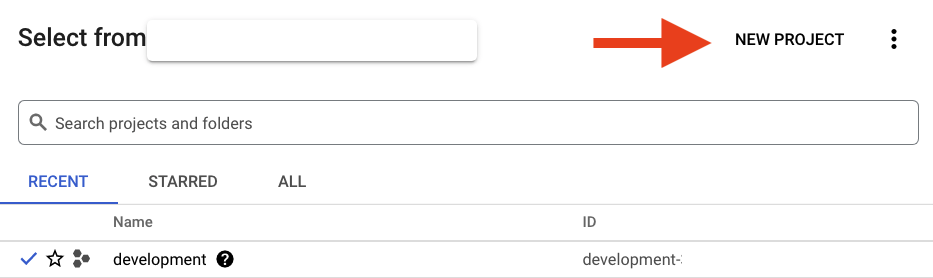
אם עדיין אין לכם פרויקט, תופיע תיבת דו-שיח כמו זו שבהמשך כדי ליצור את הפרויקט הראשון:
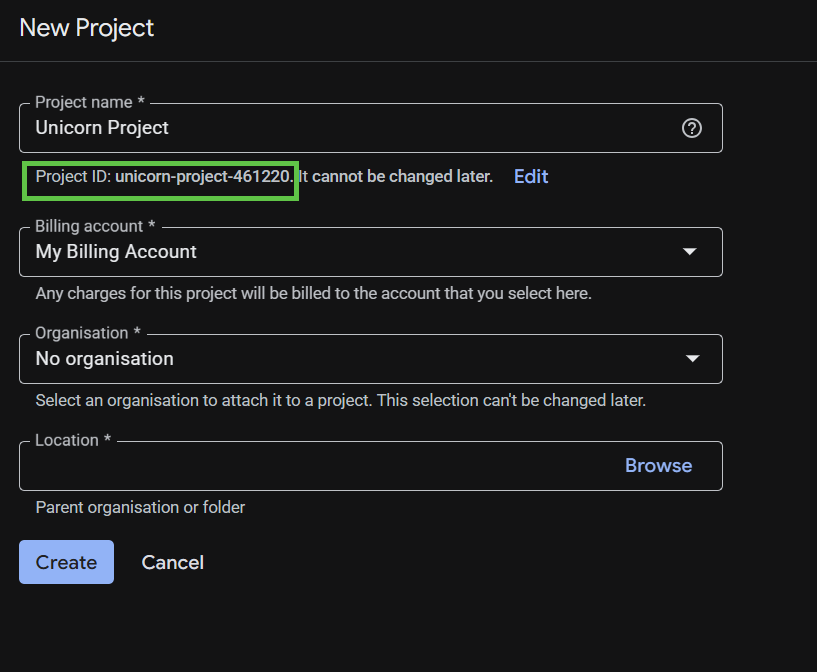
בתיבת הדו-שיח הבאה ליצירת פרויקט, מזינים את הפרטים של הפרויקט החדש.
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי לכל הפרויקטים ב-Google Cloud. בהמשך ה-codelab הזה נתייחס אליו כאל PROJECT_ID.
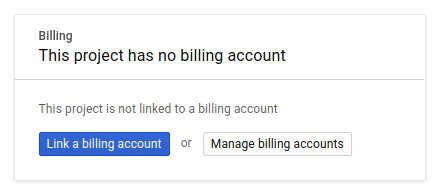
לאחר מכן, אם עדיין לא עשיתם זאת, תצטרכו להפעיל את החיוב במסוף המפתחים כדי להשתמש במשאבי Google Cloud ולהפעיל את Spanner API, Vertex AI API, BigQuery API ו-BigQuery Connection API.
התמחור של Spanner מתועד כאן. עלויות אחרות שקשורות למשאבים אחרים מתועדות בדפי התמחור הספציפיים שלהם.
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$.
הגדרה של Google Cloud Shell
ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות של הרשת. כלומר, כל מה שצריך בשביל ה-codelab הזה הוא דפדפן.
כדי להפעיל את Cloud Shell ממסוף Cloud, פשוט לוחצים על 'הפעלת Cloud Shell' ![]() (הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
(הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).

אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע, ושהפרויקט כבר הוגדר ל-PROJECT_ID.
gcloud auth list
הפלט אמור להיראות כך:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
הפלט אמור להיראות כך:
[core] project = <PROJECT_ID>
אם הפרויקט לא מוגדר מסיבה כלשהי, מריצים את הפקודה הבאה:
gcloud config set project <PROJECT_ID>
מחפש את PROJECT_ID? בודקים את המזהה שבו השתמשתם בשלבי ההגדרה או מחפשים אותו בלוח הבקרה של Cloud Console:
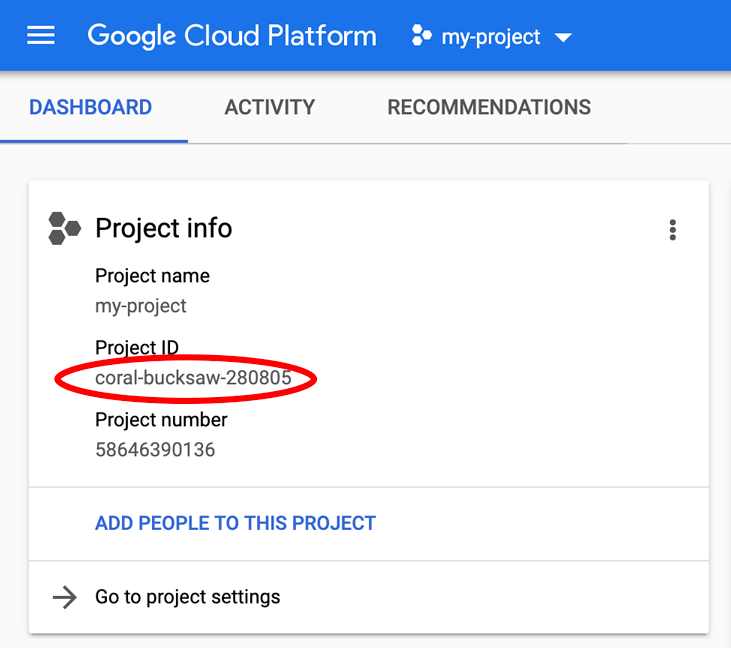
ב-Cloud Shell מוגדרים גם כמה משתני סביבה כברירת מחדל, שיכולים להיות שימושיים כשמריצים פקודות בעתיד.
echo $GOOGLE_CLOUD_PROJECT
הפלט אמור להיראות כך:
<PROJECT_ID>
הפעלת ממשקי ה-API הנדרשים
מפעילים את ממשקי ה-API של Spanner, Vertex AI ו-BigQuery בפרויקט:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
סיכום
בשלב הזה, הגדרתם את הפרויקט אם עדיין לא היה לכם פרויקט, הפעלתם את Cloud Shell והפעלתם את ממשקי ה-API הנדרשים.
הבא בתור
בשלב הבא, תגדירו את מופע Spanner.
3. הגדרת מכונת Spanner
יצירת מכונת Spanner
בשלב הזה תגדירו מופע Spanner בשביל ה-codelab. כדי לעשות זאת, פותחים את Cloud Shell ומריצים את הפקודה הבאה:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
הפלט אמור להיראות כך:
Creating instance...done.
סיכום
בשלב הזה יצרתם את מופע Spanner.
הבא בתור
בשלב הבא, תכינו את האפליקציה הראשונית ותיצרו את מסד הנתונים והסכימה.
4. יצירה של מסד נתונים וסכימה
הכנת הבקשה הראשונית
בשלב הזה תיצרו את מסד הנתונים ואת הסכימה באמצעות הקוד.
קודם כל, יוצרים אפליקציית Java בשם onlinebanking באמצעות Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
מבצעים Checkout ומעתיקים את קובצי הנתונים שנוסיף למסד הנתונים (כאן אפשר לראות את מאגר הקוד):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
עוברים לתיקיית האפליקציה:
cd onlinebanking
פותחים את קובץ Maven pom.xml. כדי להשתמש ב-Maven BOM לניהול הגרסה של ספריות Google Cloud, מוסיפים את הקטע dependency management:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
כך ייראו העורך והקובץ: 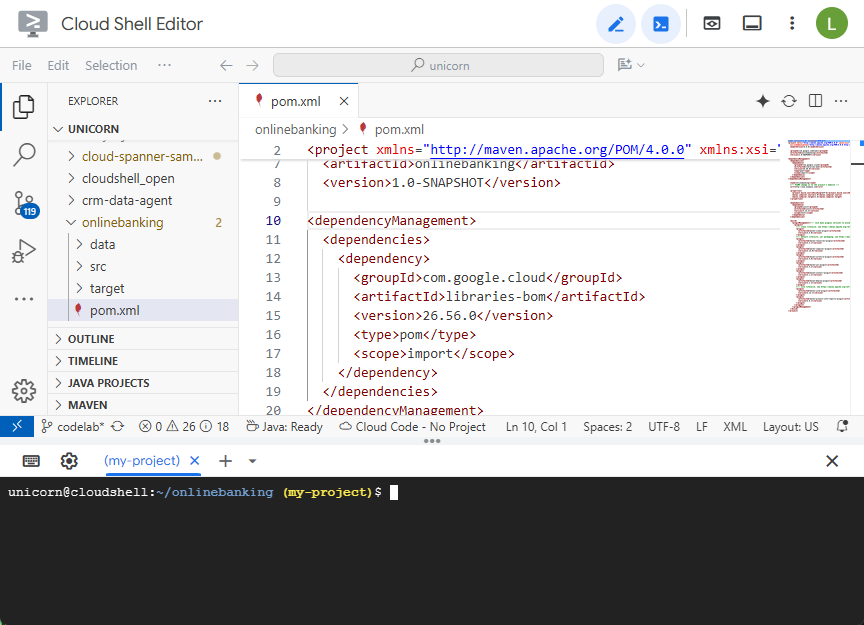
מוודאים שהקטע dependencies כולל את הספריות שבהן האפליקציה תשתמש:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
לבסוף, מחליפים את תוספי ה-build כדי שהאפליקציה תיארז כקובץ JAR שניתן להפעלה:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
שומרים את השינויים שביצעתם בקובץ pom.xml על ידי בחירה באפשרות 'שמירה' בתפריט 'קובץ' של Cloud Shell Editor או על ידי הקשה על Ctrl+S.
אחרי שהתלות מוכנה, מוסיפים קוד לאפליקציה כדי ליצור סכימה, כמה אינדקסים (כולל חיפוש) ומודל AI שמחובר לנקודת קצה מרוחקת. במהלך ה-Codelab הזה, תשתמשו בארטיפקטים האלה ותוסיפו עוד שיטות למחלקה הזו.
פותחים את App.java בקטע onlinebanking/src/main/java/com/google/codelabs ומחליפים את התוכן בקוד הבא:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
שומרים את השינויים שבוצעו בקובץ App.java.
בודקים את הישויות השונות שהקוד יוצר ובוחרים את קובץ ה-JAR של האפליקציה:
mvn package
הפלט אמור להיראות כך:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
מריצים את האפליקציה כדי לראות את פרטי השימוש:
java -jar target/onlinebanking.jar
הפלט אמור להיראות כך:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
יצירת מסד הנתונים והסכימה
מגדירים את משתני הסביבה הנדרשים של האפליקציה:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
מריצים את הפקודה create כדי ליצור את מסד הנתונים והסכימה:
java -jar target/onlinebanking.jar create
הפלט אמור להיראות כך:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
בדיקת הסכימה ב-Spanner
במסוף Spanner, עוברים למכונה ולמסד הנתונים שנוצרו.
אמורות להופיע כל 3 הטבלאות – Accounts, Customers ו-TransactionLedger.
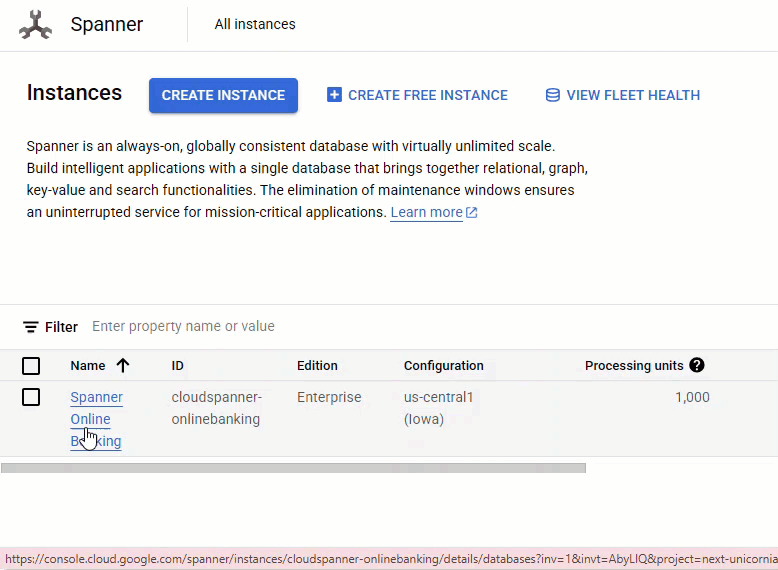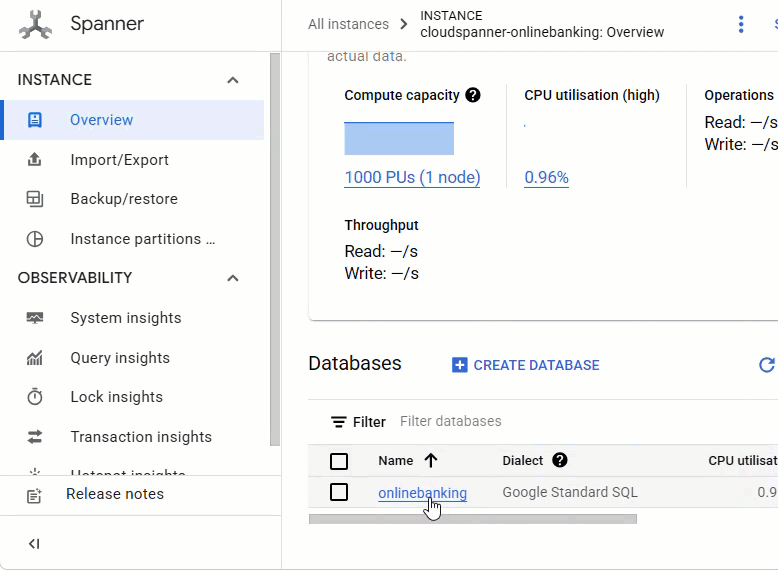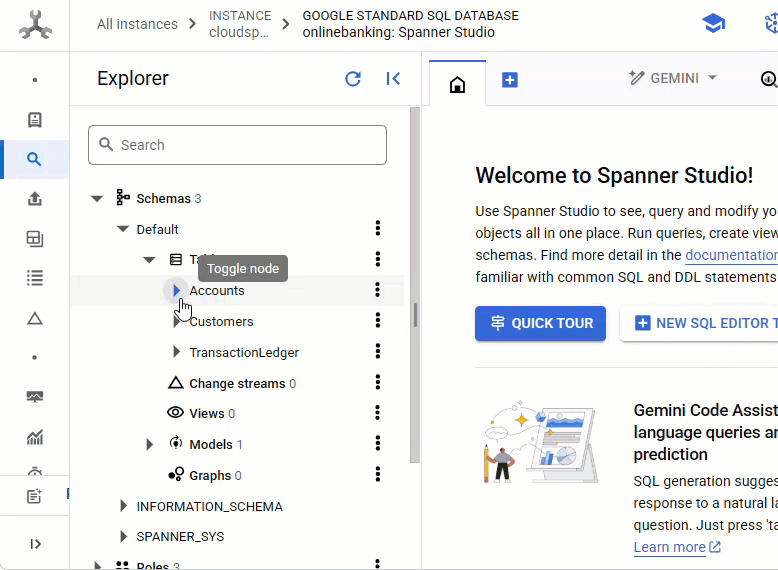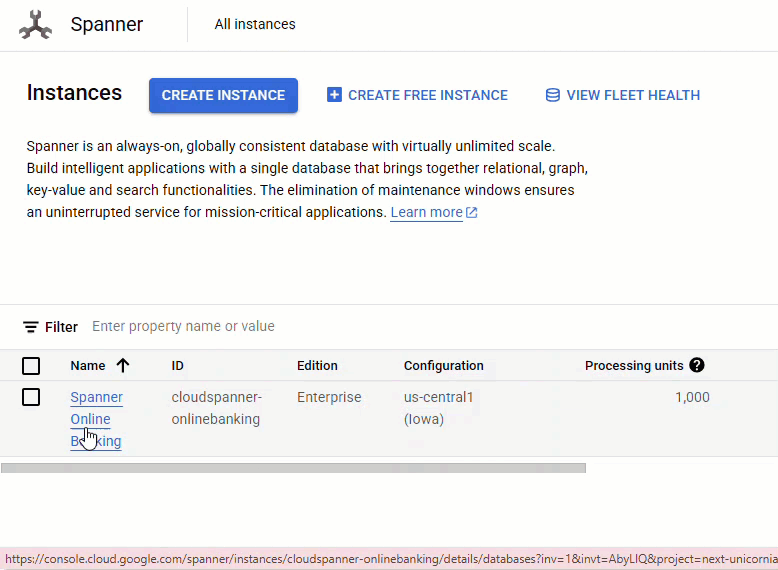
הפעולה הזו יוצרת את סכימת מסד הנתונים, כולל הטבלאות Accounts, Customers ו-TransactionLedger, וגם אינדקסים משניים לאחזור נתונים אופטימלי והפניה למודל Vertex AI.
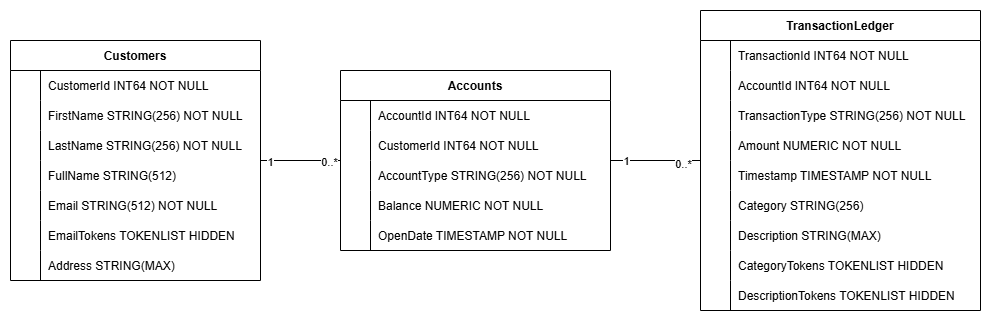
הטבלה TransactionLedger משולבת בטבלה Accounts כדי לשפר את ביצועי השאילתות של טרנזקציות ספציפיות לחשבון באמצעות שיפור הלוקאליות של הנתונים.
הטמענו אינדקסים משניים (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) כדי לבצע אופטימיזציה של דפוסי גישה נפוצים לנתונים שמשמשים ב-Codelab הזה, כמו חיפושים של לקוחות לפי כתובת אימייל מדויקת או משוערת, אחזור חשבונות לפי לקוח ושליחת שאילתות וחיפושים יעילים של נתוני עסקאות.
ה-TransactionCategoryModel משתמש ב-Vertex AI כדי לאפשר קריאות SQL ישירות למודל LLM, שמשמש לסיווג דינמי של עסקאות ב-Codelab הזה.
סיכום
בשלב הזה יצרתם את מסד הנתונים ואת הסכימה ב-Spanner.
הבא בתור
בשלב הבא, טוענים את נתוני האפליקציה לדוגמה.
5. טען נתונים
עכשיו תוסיפו פונקציונליות לטעינת נתונים לדוגמה מקובצי CSV למסד הנתונים.
פותחים את App.java ומתחילים בהחלפת הייבוא:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
לאחר מכן מוסיפים את שיטות ההוספה למחלקה App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
מוסיפים עוד משפט case בשיטה main להוספה בתוך switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
לבסוף, מוסיפים את אופן השימוש בפונקציה insert לשיטה printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
שומרים את השינויים שביצעתם בקובץ App.java.
בונים מחדש את האפליקציה:
mvn package
מריצים את הפקודה insert כדי להוסיף את הנתונים לדוגמה:
java -jar target/onlinebanking.jar insert
הפלט אמור להיראות כך:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
במסוף Spanner, חוזרים אל Spanner Studio עבור המופע ומסד הנתונים. לאחר מכן בוחרים את הטבלה TransactionLedger ולוחצים על 'נתונים' בסרגל הצד כדי לוודא שהנתונים נטענו. צריכות להיות 200 שורות בטבלה.
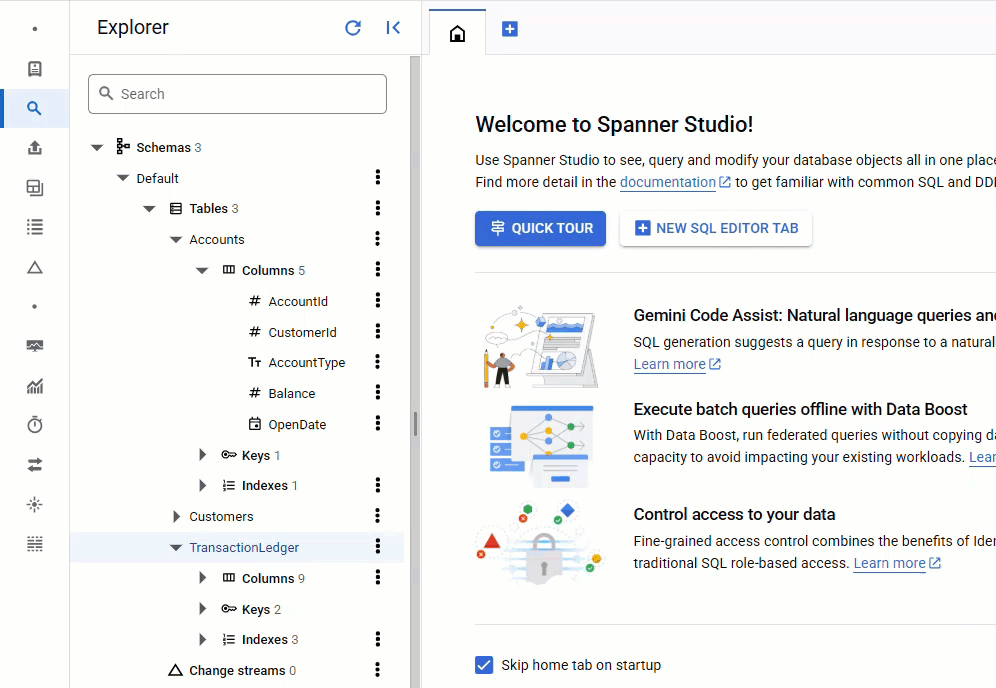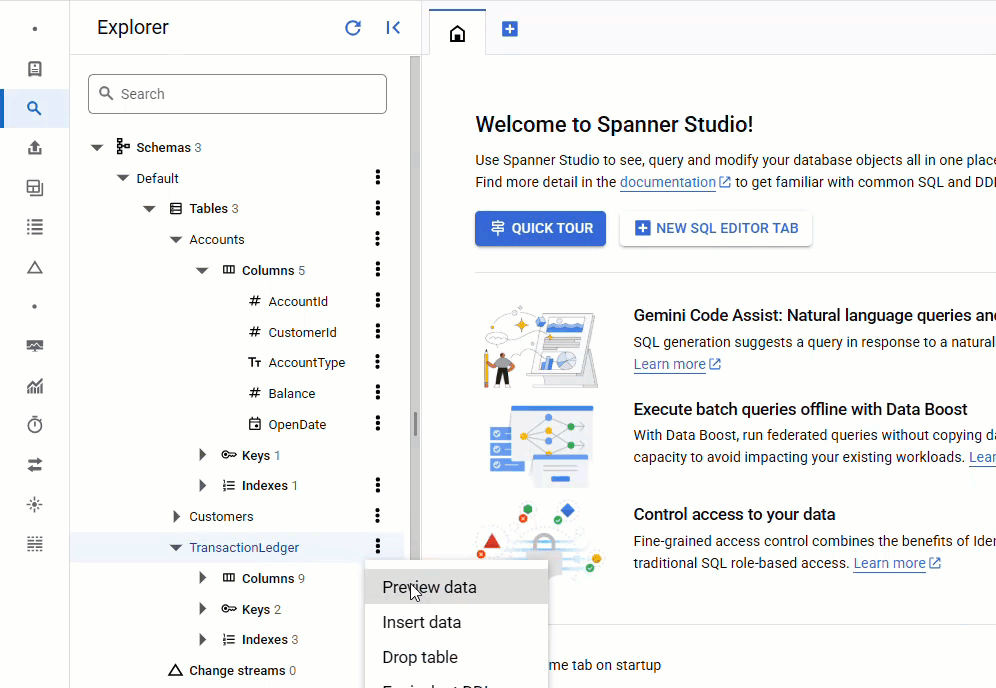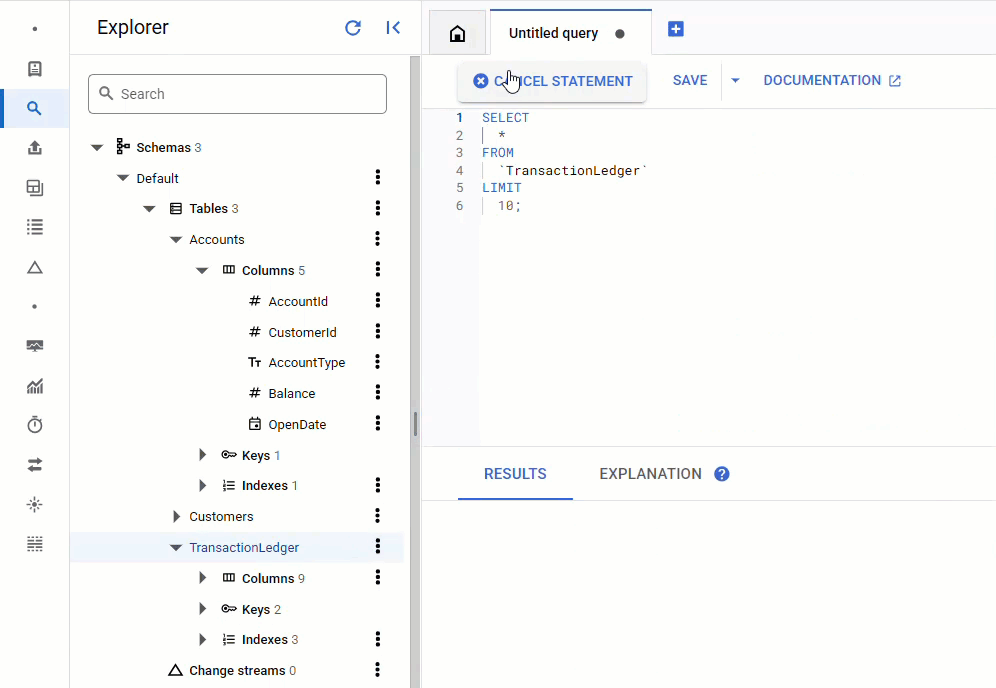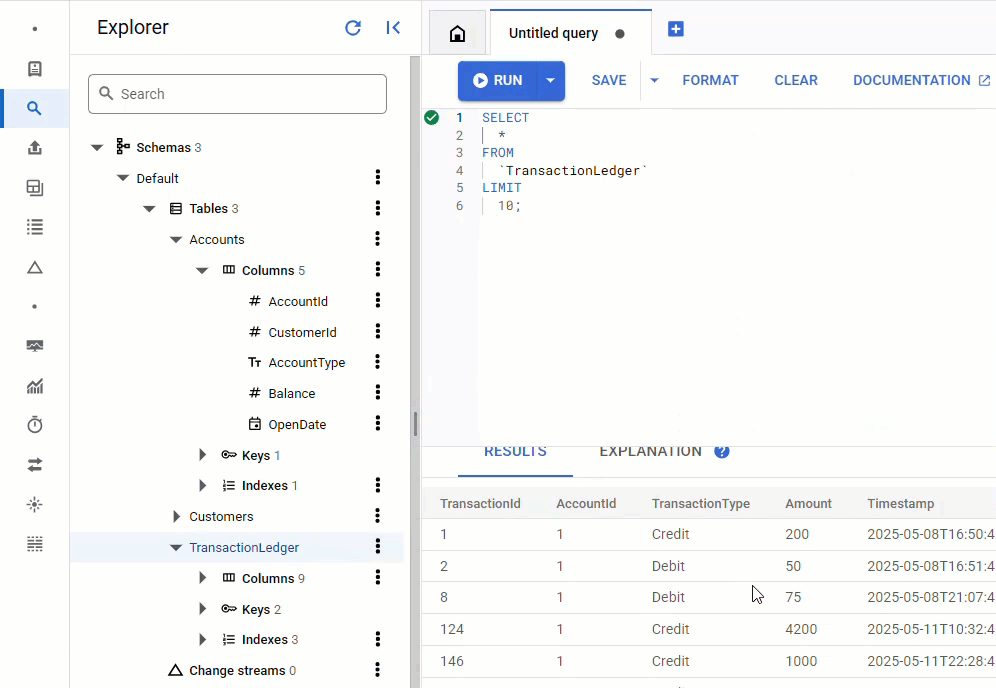
סיכום
בשלב הזה, הוספתם את הנתונים לדוגמה למסד הנתונים.
הבא בתור
בשלב הבא, תשתמשו בשילוב של Vertex AI כדי לסווג באופן אוטומטי עסקאות בנקאיות ישירות ב-Spanner SQL.
6. סיווג נתונים באמצעות Vertex AI
בשלב הזה, תשתמשו ביכולות של Vertex AI כדי לסווג אוטומטית את העסקאות הפיננסיות ישירות ב-Spanner SQL. באמצעות Vertex AI אפשר לבחור מודל קיים שעבר אימון מראש, או לאמן ולפרוס מודל משלכם. אפשר לראות את המודלים הזמינים ב-Vertex AI Model Garden.
ב-Codelab הזה נשתמש באחד מהמודלים של Gemini, Gemini Flash Lite. הגרסה הזו של Gemini חסכונית אבל עדיין יכולה להתמודד עם רוב עומסי העבודה היומיים.
כרגע יש לנו מספר עסקאות פיננסיות שאנחנו רוצים לסווג (groceries, transportation וכו') בהתאם לתיאור. כדי לעשות את זה, צריך לרשום מודל ב-Spanner ואז להשתמש ב-ML.PREDICT כדי לקרוא למודל ה-AI.
באפליקציית בנקאות, יכול להיות שנרצה לסווג עסקאות כדי לקבל תובנות מעמיקות יותר לגבי התנהגות הלקוחות, וכך להתאים אישית את השירותים, לזהות חריגות בצורה יעילה יותר או לספק ללקוחות את האפשרות לעקוב אחרי התקציב שלהם מחודש לחודש.
השלב הראשון כבר בוצע כשבנינו את מסד הנתונים ואת הסכימה, וכך נוצר מודל כזה:
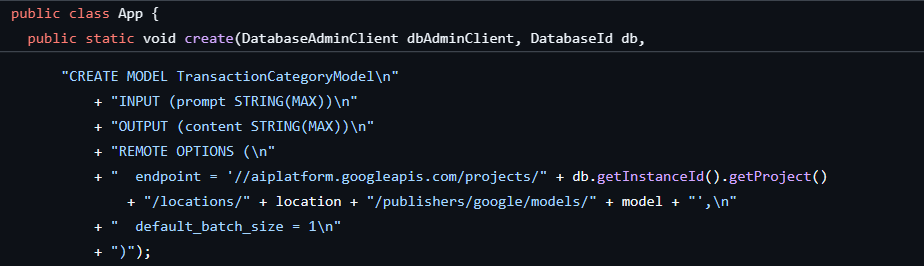
בשלב הבא, נוסיף לאפליקציה שיטה לקריאה ל-ML.PREDICT.
פותחים את App.java ומוסיפים את השיטה categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
מוסיפים עוד משפט case בשיטה main לסיווג:
case "categorize":
categorize(dbClient);
break;
לבסוף, מוסיפים את ההוראות לשימוש בשיטת printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
שומרים את השינויים שביצעתם בקובץ App.java.
בונים מחדש את האפליקציה:
mvn package
כדי לסווג את הטרנזקציות במסד הנתונים, מריצים את הפקודה categorize:
java -jar target/onlinebanking.jar categorize
הפלט אמור להיראות כך:
Categorizing transactions... Completed categorizing transactions
ב-Spanner Studio, מריצים את ההצהרה Preview Data עבור הטבלה TransactionLedger. עכשיו העמודה Category אמורה להתמלא בכל השורות.
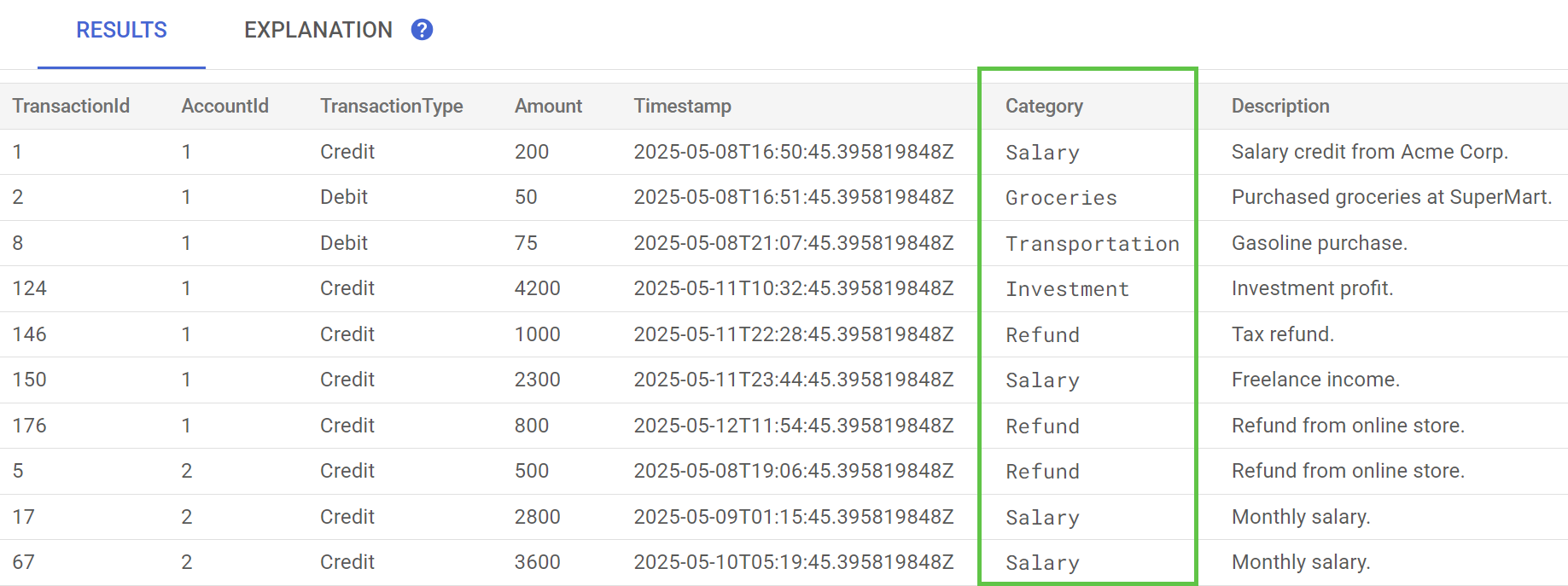
אחרי שסיווגנו את העסקאות, אנחנו יכולים להשתמש במידע הזה לשאילתות פנימיות או לשאילתות שמוצגות ללקוחות. בשלב הבא נראה איך אפשר לגלות כמה לקוח מסוים מוציא בקטגוריה מסוימת במהלך החודש.
סיכום
בשלב הזה השתמשתם במודל שעבר אימון מראש כדי לבצע סיווג של הנתונים באמצעות AI.
הבא בתור
בשלב הבא, תשתמשו בטוקניזציה כדי לבצע חיפושים משוערים וחיפושים בטקסט מלא.
7. שאילתה באמצעות חיפוש טקסט מלא
הוספת קוד השאילתה
Spanner מספק הרבה שאילתות חיפוש של טקסט מלא. בשלב הזה תבצעו חיפוש של התאמה מדויקת, ואז חיפוש משוער וחיפוש טקסט מלא.
פותחים את App.java ומתחילים בהחלפת הייבוא:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
לאחר מכן מוסיפים את שיטות השאילתה:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
מוסיפים עוד הצהרה של case בשיטה main לשאילתה:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
לבסוף, מוסיפים את ההוראות לשימוש בפקודות השאילתה לשיטה printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
שומרים את השינויים שביצעתם בקובץ App.java.
בונים מחדש את האפליקציה:
mvn package
ביצוע חיפוש בהתאמה מדויקת של יתרות בחשבונות לקוחות
שאילתה בהתאמה מדויקת מחפשת שורות תואמות שזהות למונח מסוים.
כדי לשפר את הביצועים, נוסף כבר אינדקס כשיוצרים את מסד הנתונים ואת הסכימה:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
השיטה getBalance משתמשת באינדקס הזה באופן מרומז כדי למצוא לקוחות שתואמים ל-customerId שצוין, וגם מצטרפת לחשבונות ששייכים ללקוח הזה.
כך נראית השאילתה כשהיא מופעלת ישירות ב-Spanner Studio: 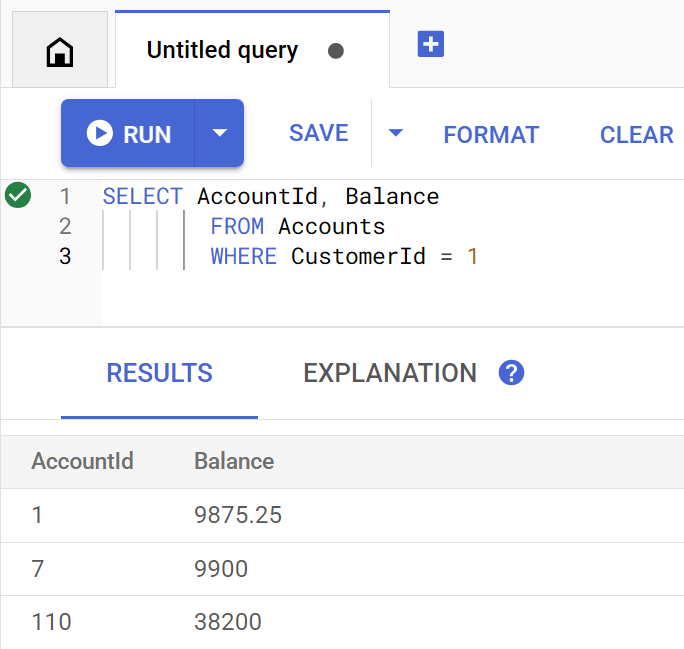
כדי להציג את יתרות החשבון של הלקוח 1, מריצים את הפקודה:
java -jar target/onlinebanking.jar query balance 1
הפלט אמור להיראות כך:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
יש 100 לקוחות, כך שאפשר גם לשלוח שאילתה לגבי יתרות של חשבונות לקוחות אחרים על ידי ציון מספר לקוח אחר:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
ביצוע חיפוש משוער של כתובות אימייל של לקוחות
חיפושים משוערים מאפשרים למצוא התאמות משוערות למונחי חיפוש, כולל גרסאות איות ושגיאות הקלדה.
אינדקס n-gram כבר נוסף כשיוצרים את מסד הנתונים ואת הסכימה:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
השיטה findCustomers משתמשת ב-SEARCH_NGRAMS וב-SCORE_NGRAMS כדי לשלוח שאילתות לאינדקס הזה ולמצוא לקוחות לפי כתובת אימייל. מכיוון שהטור של האימייל עבר טוקניזציה של n-gram, השאילתה הזו יכולה להכיל שגיאות איות ועדיין להחזיר תשובה נכונה. התוצאות מסודרות לפי ההתאמה הטובה ביותר.
כדי למצוא כתובות אימייל תואמות של לקוחות שמכילות madi, מריצים את הפקודה:
java -jar target/onlinebanking.jar query email madi
הפלט אמור להיראות כך:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
בתשובה הזו מוצגות ההתאמות הכי קרובות שכוללות את המחרוזת madi או מחרוזת דומה, בסדר מדורג.
כך נראית השאילתה אם היא מופעלת ישירות ב-Spanner Studio: 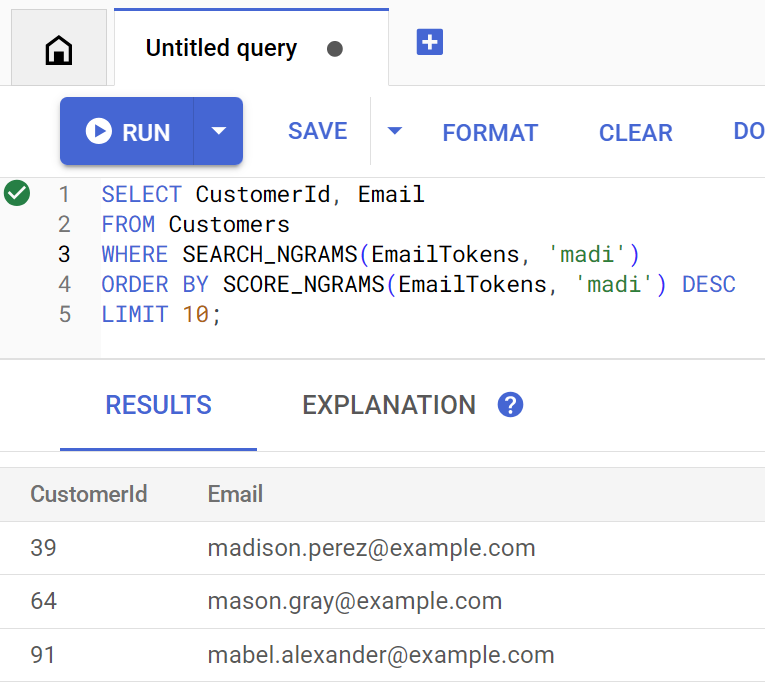
חיפוש משוער יכול לעזור גם בשגיאות איות, כמו איות שגוי של emily:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
הפלט אמור להיראות כך:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
בכל מקרה, כתובת האימייל הצפויה של הלקוח מוחזרת כתוצאה הראשונה.
חיפוש עסקאות באמצעות חיפוש טקסט מלא
התכונה של חיפוש טקסט מלא ב-Spanner משמשת לאחזור רשומות על סמך מילות מפתח או ביטויים. הוא יכול לתקן שגיאות איות או לחפש מילים נרדפות.
אינדקס חיפוש טקסט מלא כבר נוסף כשיוצרים את מסד הנתונים והסכימה:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
השיטה getSpending משתמשת בפונקציית החיפוש SEARCH בטקסט מלא כדי להתאים לאינדקס הזה. הכלי מחפש את כל ההוצאות (חיובים) ב-30 הימים האחרונים לפי מספר הלקוח שצוין.
כדי לקבל את סך ההוצאות בחודש האחרון של לקוח 1 בקטגוריה groceries, מריצים את הפקודה:
java -jar target/onlinebanking.jar query spending 1 groceries
הפלט אמור להיראות כך:
Total spending for customer 1 under category groceries: 50
אפשר גם לראות את ההוצאות בקטגוריות אחרות (שסווגו בשלב הקודם), או להשתמש במספר לקוח אחר:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
סיכום
בשלב הזה, ביצעתם שאילתות בהתאמה מדויקת וגם חיפושים לא מדויקים וחיפושים בטקסט מלא.
הבא בתור
בשלב הבא, תשולב מערכת Spanner עם Google BigQuery כדי להריץ שאילתות מאוחדות, שיאפשרו לכם לשלב את נתוני Spanner בזמן אמת עם נתוני BigQuery.
8. הרצת שאילתות מאוחדות באמצעות BigQuery
יצירת מערך הנתונים ב-BigQuery
בשלב הזה, תשלבו נתונים מ-BigQuery ומ-Spanner באמצעות שאילתות מאוחדות.
כדי לעשות את זה, בשורת הפקודה של Cloud Shell, יוצרים קודם מערך נתונים MarketingCampaigns:
bq mk --location=us-central1 MarketingCampaigns
הפלט אמור להיראות כך:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
וטבלה CustomerSegments במערך הנתונים:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
הפלט אמור להיראות כך:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
לאחר מכן, יוצרים חיבור מ-BigQuery ל-Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
הפלט אמור להיראות כך:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
לבסוף, מוסיפים כמה לקוחות לטבלה ב-BigQuery שאפשר לצרף לנתוני Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
הפלט אמור להיראות כך:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
כדי לוודא שהנתונים זמינים, אפשר להריץ שאילתה ב-BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
הפלט אמור להיראות כך:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
הנתונים האלה ב-BigQuery מייצגים נתונים שנוספו באמצעות תהליכי עבודה שונים של הבנק. לדוגמה, רשימת הלקוחות שפתחו לאחרונה חשבונות או נרשמו למבצע שיווקי. כדי לקבוע את רשימת הלקוחות שאליהם אנחנו רוצים לפנות בקמפיין שיווק, אנחנו צריכים לשלוח שאילתה על הנתונים האלה ב-BigQuery וגם על הנתונים בזמן אמת ב-Spanner. שאילתה לכמה מסדי נתונים מאפשרת לנו לעשות את זה בשאילתה אחת.
הרצת שאילתה לכמה מסדי נתונים באמצעות BigQuery
בשלב הבא, נוסיף שיטה לאפליקציה כדי לקרוא ל-EXTERNAL_QUERY ולהריץ את השאילתה המאוחדת. כך תוכלו לאחד ולנתח נתוני לקוחות ב-BigQuery וב-Spanner, למשל לזהות אילו לקוחות עומדים בקריטריונים של קמפיין השיווק שלנו על סמך ההוצאות האחרונות שלהם.
פותחים את App.java ומתחילים בהחלפת הייבוא:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
לאחר מכן מוסיפים את אמצעי התשלום campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
מוסיפים עוד הצהרת case בשיטה main לקמפיין:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
לבסוף, מוסיפים את אופן השימוש בקמפיין לשיטה printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
שומרים את השינויים שביצעתם בקובץ App.java.
בונים מחדש את האפליקציה:
mvn package
מריצים שאילתה לכמה מסדי נתונים כדי לקבוע אילו לקוחות צריכים להיכלל בקמפיין שיווק (campaign1) אם הם הוציאו לפחות $5000 ב-3 החודשים האחרונים, על ידי הרצת הפקודה campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
הפלט אמור להיראות כך:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
עכשיו אפשר לטרגט את הלקוחות האלה עם מבצעים או תמריצים בלעדיים.
לחלופין, אפשר לחפש מספר גדול יותר של לקוחות שהגיעו לסף הוצאות נמוך יותר ב-3 החודשים האחרונים:
java -jar target/onlinebanking.jar campaign campaign1 2500
הפלט אמור להיראות כך:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
סיכום
בשלב הזה, הפעלתם בהצלחה שאילתות מאוחדות מ-BigQuery שהביאו נתונים מ-Spanner בזמן אמת.
הבא בתור
אחרי כן, כדי להימנע מחיובים, אפשר למחוק את המשאבים שנוצרו בסדנת הקוד הזו.
9. ניקוי (אופציונלי)
השלב הזה הוא אופציונלי. אם רוצים להמשיך להתנסות במופע Spanner, אין צורך לנקות אותו בשלב הזה. עם זאת, הפרויקט שבו אתם משתמשים ימשיך להיות מחויב על המופע. אם אין לכם יותר צורך במכונה הזו, כדאי למחוק אותה עכשיו כדי להימנע מהחיובים האלה. בנוסף למופע Spanner, ב-codelab הזה נוצרו גם מערך נתונים וחיבור ל-BigQuery, וצריך לנקות אותם כשאין בהם יותר צורך.
מוחקים את מכונת Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
מאשרים שרוצים להמשיך (מקלידים Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
מוחקים את החיבור ל-BigQuery ואת מערך הנתונים:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
מאשרים את המחיקה של מערך הנתונים ב-BigQuery (מקלידים Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. מזל טוב
🚀 יצרתם מכונה חדשה של Cloud Spanner, יצרתם מסד נתונים ריק, טענתם נתונים לדוגמה, ביצעתם פעולות ושאילתות מתקדמות, ובאופן אופציונלי מחקתם את המכונה של Cloud Spanner.
מה נכלל
- איך מגדירים מופע Spanner.
- איך יוצרים מסד נתונים וטבלאות.
- איך טוענים נתונים לטבלאות במסד הנתונים של Spanner.
- איך קוראים למודלים של Vertex AI מ-Spanner.
- איך שולחים שאילתות למסד הנתונים של Spanner באמצעות חיפוש משוער וחיפוש טקסט מלא.
- איך לבצע שאילתות מאוחדות ב-Spanner מ-BigQuery.
- איך מוחקים את מכונת Spanner.