
1. 概要
Spanner は、リレーショナル ワークロードと非リレーショナル ワークロードの両方に適した、フルマネージドで水平スケーリング可能なグローバルに分散されたデータベース サービスです。Spanner は、コア機能に加えて、インテリジェントでデータドリブンなアプリケーションの構築を可能にする高度な機能を提供します。
この Codelab では、Spanner の基本的な理解を基に、オンライン バンキング アプリケーションをベースとして、高度なインテグレーションを活用してデータ処理機能と分析機能を強化する方法を学びます。
ここでは、次の 3 つの上級者向け機能に焦点を当てます。
- Vertex AI との統合: Spanner と Google Cloud の AI プラットフォームである Vertex AI をシームレスに統合する方法について説明します。このセッションでは、Spanner SQL クエリ内から Vertex AI モデルを直接呼び出す方法を学びます。これにより、強力なデータベース内変換と予測が可能になり、予算の追跡や異常検出などのユースケースで、銀行アプリケーションがトランザクションを自動的に分類できるようになります。
- 全文検索: Spanner 内で全文検索機能を実装する方法について説明します。テキストデータのインデックス登録と、オペレーショナル データ全体でキーワード ベースの検索を実行するための効率的なクエリの作成について説明します。これにより、銀行システム内のメールアドレスで顧客を効率的に見つけるなど、強力なデータ検出が可能になります。
- BigQuery 連携クエリ: Spanner の連携クエリ機能を利用して、BigQuery に存在するデータを直接クエリする方法について説明します。これにより、Spanner のリアルタイム オペレーション データと BigQuery の分析データセットを組み合わせて、データの重複や複雑な ETL プロセスなしで包括的な分析情報とレポートを作成できます。また、リアルタイムの顧客データと BigQuery の広範な過去の傾向を組み合わせて、ターゲット マーケティング キャンペーンなどの銀行アプリケーションのさまざまなユースケースを実現できます。
学習内容
- Spanner インスタンスの設定方法。
- データベースとテーブルの作成方法。
- Spanner データベース テーブルにデータを読み込む方法。
- Spanner から Vertex AI モデルを呼び出す方法。
- ファジー検索と全文検索を使用して Spanner データベースをクエリする方法。
- BigQuery から Spanner に対して連携クエリを実行する方法。
- Spanner インスタンスを削除する方法。
必要なもの
2. 設定と要件
プロジェクトを作成する
課金が有効になっている Google Cloud プロジェクトがすでに存在する場合は、コンソールの左上にあるプロジェクト選択プルダウン メニューをクリックします。

プロジェクトが選択されている場合は、必要な API を有効にするに進みます。
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。
表示されたダイアログで [NEW PROJECT] ボタンをクリックして、新しいプロジェクトを作成します。
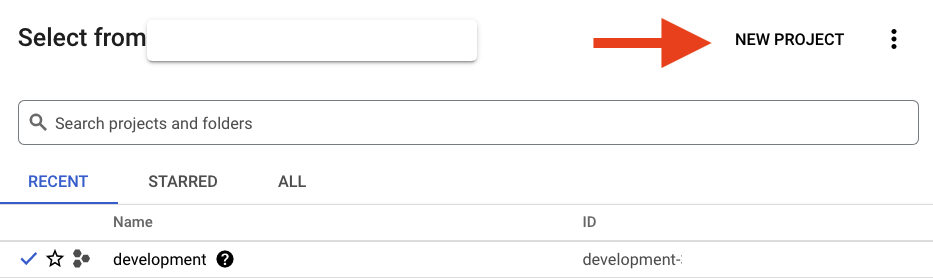
まだプロジェクトが存在しない場合は、次のような最初のプロジェクトを作成するためのダイアログが表示されます。
![[プロジェクト] ダイアログ](https://codelabs.developers.google.com/static/spanner-online-banking-app/img/project-dialog.png?hl=ja)
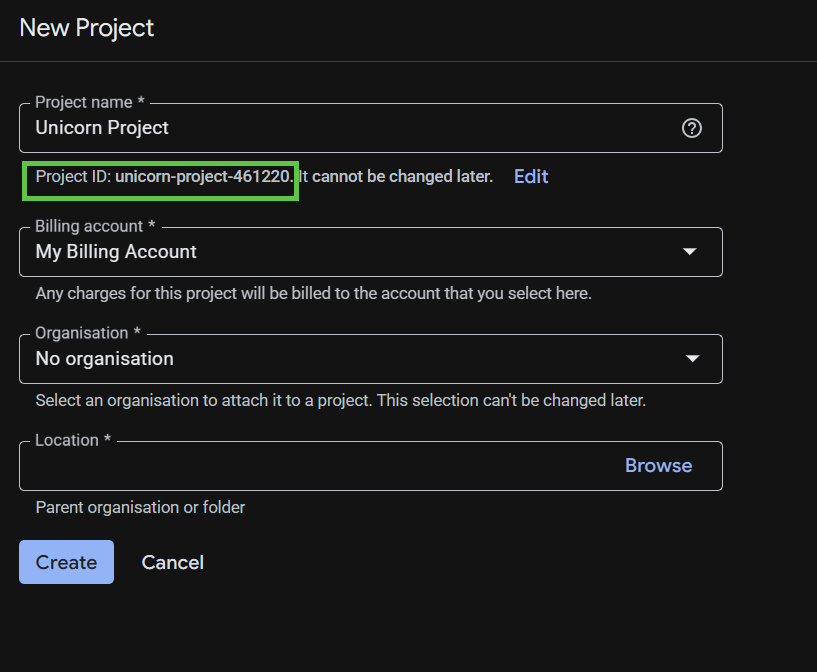
続いて表示されるプロジェクト作成ダイアログでは、新しいプロジェクトの詳細を入力できます。
プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります。以降、このコードラボでは PROJECT_ID と呼びます。
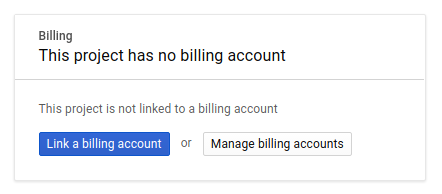
次に、Google Cloud リソースを使用し、Spanner API、Vertex AI API、BigQuery API、BigQuery Connection API を有効にするために、Developers Console で課金を有効にする必要があります。
Spanner の料金については、こちらをご覧ください。他のリソースに関連するその他の費用については、それぞれの料金ページに記載されています。
Google Cloud Platform の新規ユーザーは、300 ドル分の無料トライアルをご利用いただけます。
Google Cloud Shell の設定
この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
この Debian ベースの仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。つまり、この Codelab に必要なのはブラウザだけです。
Cloud Console から Cloud Shell を有効にするには、[Cloud Shell をアクティブにする] ![]() をクリックします(環境のプロビジョニングと接続に若干時間を要します)。
をクリックします(環境のプロビジョニングと接続に若干時間を要します)。

Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自の PROJECT_ID が設定されていることがわかります。
gcloud auth list
予想される出力:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
予想される出力:
[core] project = <PROJECT_ID>
なんらかの理由でプロジェクトが設定されていない場合は、次のコマンドを実行します。
gcloud config set project <PROJECT_ID>
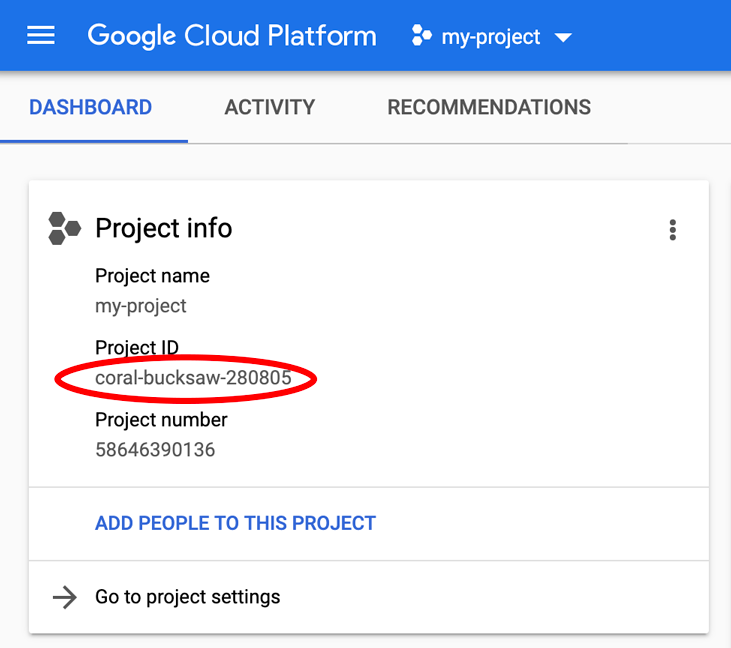
PROJECT_ID が見つからない場合は、設定手順で使用した ID を確認するか、Cloud Console ダッシュボードで検索します。
Cloud Shell では、デフォルトで環境変数もいくつか設定されます。これらの変数は、以降のコマンドを実行する際に有用なものです。
echo $GOOGLE_CLOUD_PROJECT
予想される出力:
<PROJECT_ID>
必要な API を有効にする
プロジェクトで Spanner API、Vertex AI API、BigQuery API を有効にします。
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
概要
このステップでは、プロジェクトがまだない場合はプロジェクトを設定し、Cloud Shell を有効にして、必要な API を有効にしました。
次のステップ
次に、Spanner インスタンスを設定します。
3. Spanner インスタンスを設定する
Spanner インスタンスを作成する
このステップでは、Codelab 用に Spanner インスタンスを設定します。これを行うには、Cloud Shell を開いて次のコマンドを実行します。
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
予想される出力:
Creating instance...done.
概要
このステップでは、Spanner インスタンスを作成しました。
次のステップ
次に、初期アプリケーションを準備し、データベースとスキーマを作成します。
4. データベースとスキーマを作成する
最初のアプリケーションを準備する
このステップでは、コードを使用してデータベースとスキーマを作成します。
まず、Maven を使用して onlinebanking という名前の Java アプリケーションを作成します。
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
データベースに追加するデータファイルをチェックアウトしてコピーします(コード リポジトリについてはこちらをご覧ください)。
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
アプリケーション フォルダに移動します。
cd onlinebanking
Maven の pom.xml ファイルを開きます。依存関係管理セクションを追加して、Maven BOM を使用して Google Cloud ライブラリのバージョンを管理します。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
エディタとファイルは次のようになります。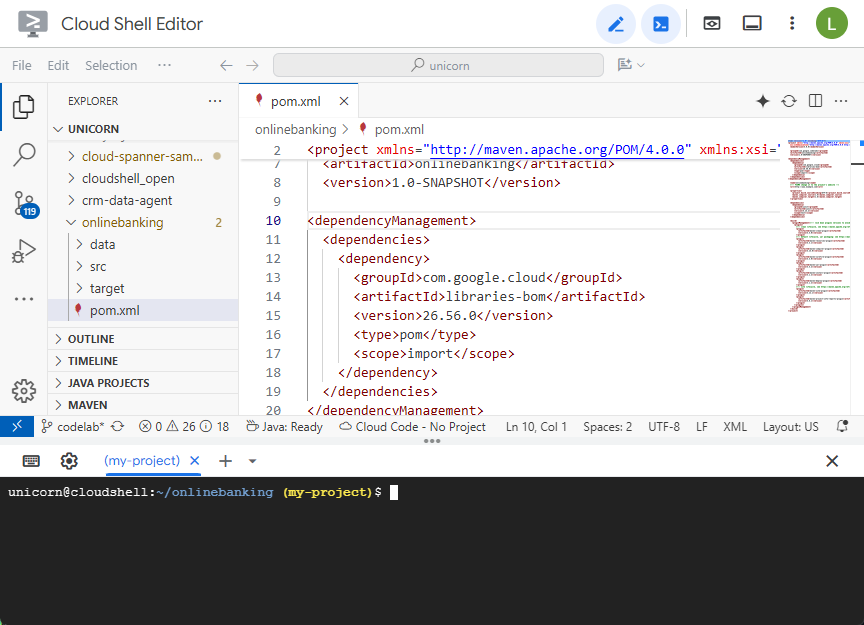
dependencies セクションに、アプリケーションで使用するライブラリが含まれていることを確認します。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
最後に、アプリケーションが実行可能な JAR にパッケージ化されるように、ビルド プラグインを置き換えます。
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Cloud Shell エディタの [File] メニューで [Save] を選択するか、Ctrl+S を押して、pom.xml ファイルに加えた変更を保存します。
依存関係の準備が整ったので、スキーマ、いくつかのインデックス(検索を含む)、リモート エンドポイントに接続された AI モデルを作成するコードをアプリに追加します。この Codelab では、これらのアーティファクトをベースに、このクラスにメソッドを追加していきます。
onlinebanking/src/main/java/com/google/codelabs の App.java を開き、内容を次のコードに置き換えます。
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
変更を App.java に保存します。
コードが作成するさまざまなエンティティを確認し、アプリケーション JAR をビルドします。
mvn package
予想される出力:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
アプリケーションを実行して使用状況情報を確認します。
java -jar target/onlinebanking.jar
予想される出力:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
データベースとスキーマを作成する
必要なアプリケーション環境変数を設定します。
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
create コマンドを実行して、データベースとスキーマを作成します。
java -jar target/onlinebanking.jar create
予想される出力:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Spanner でスキーマを確認する
Spanner コンソールで、作成したインスタンスとデータベースに移動します。
Accounts、Customers、TransactionLedger の 3 つのテーブルがすべて表示されます。
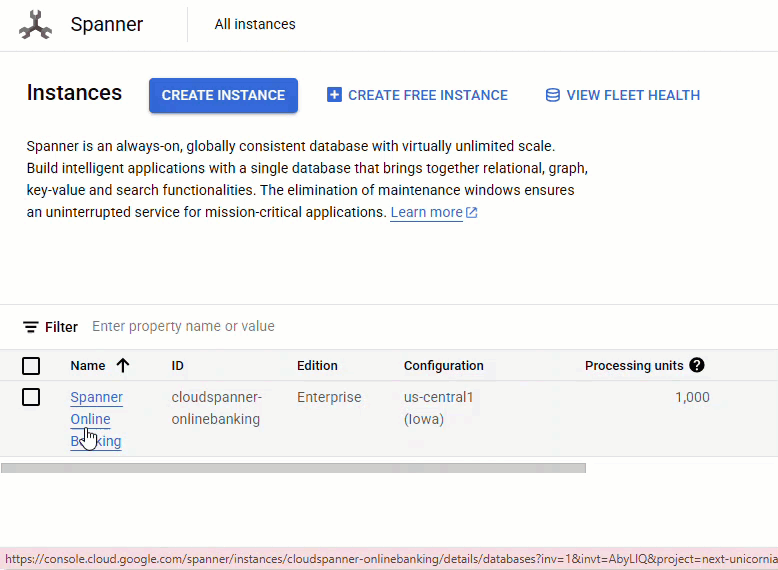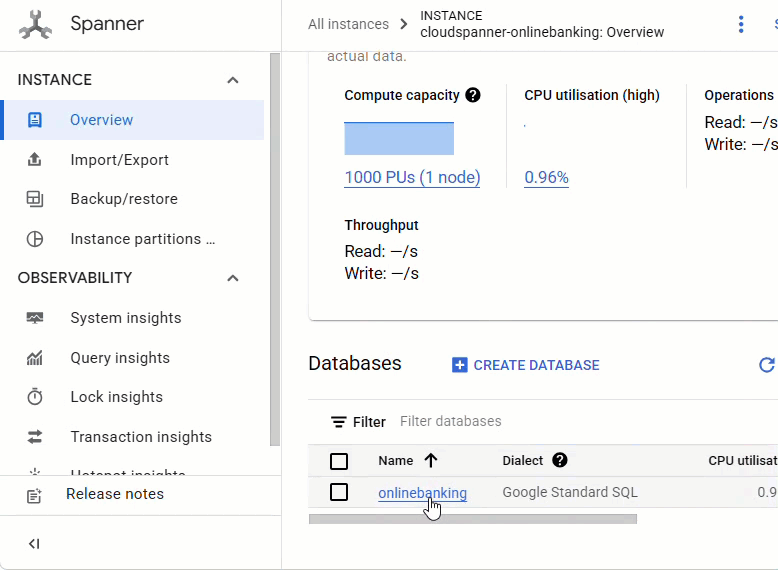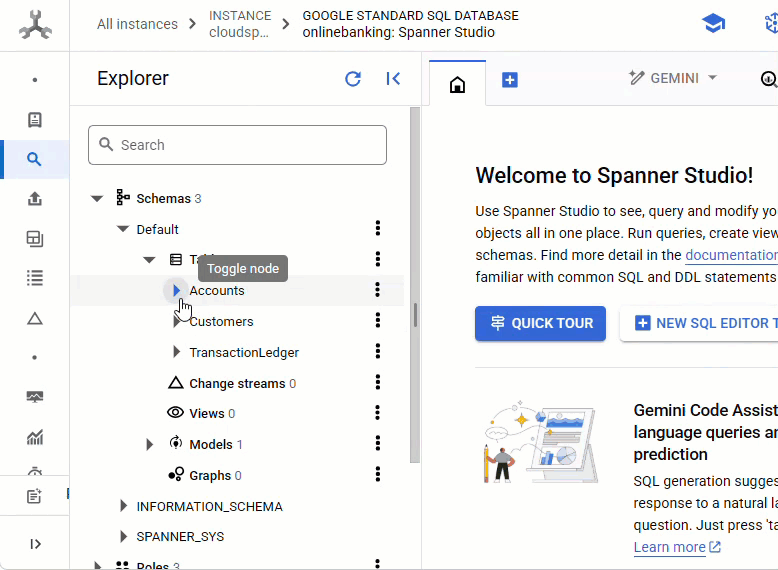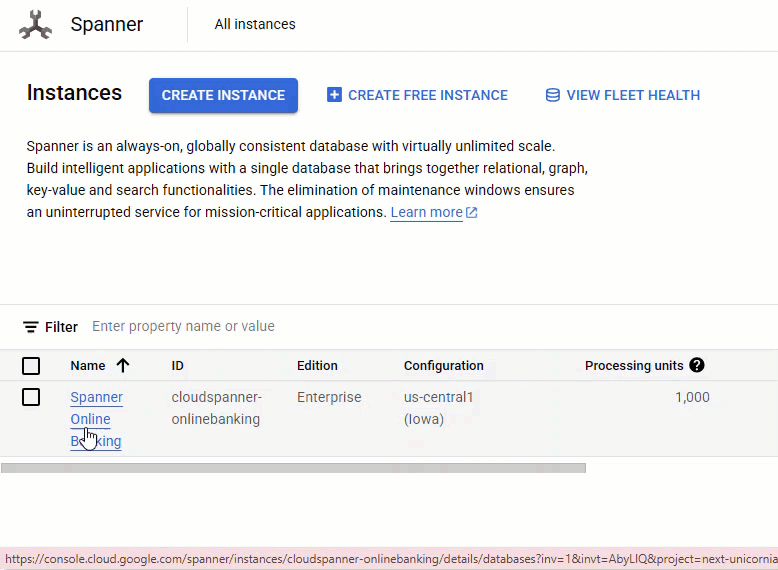
このアクションにより、Accounts、Customers、TransactionLedger テーブルを含むデータベース スキーマが作成されます。また、最適化されたデータ取得のためのセカンダリ インデックスと Vertex AI モデル リファレンスも作成されます。
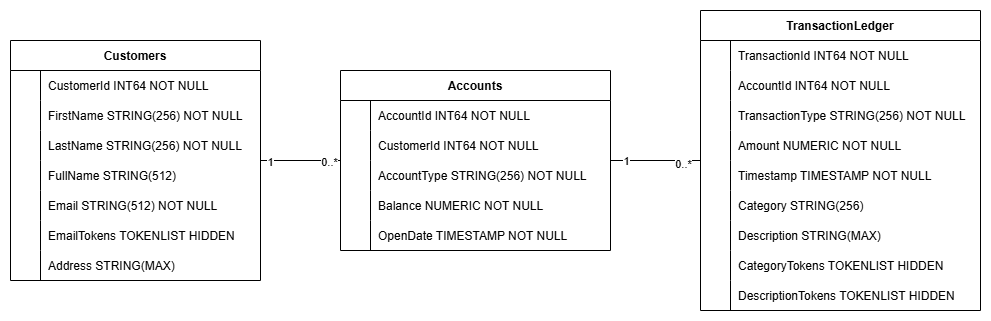
TransactionLedger テーブルは Accounts 内にインターリーブされ、データ局所性の向上によりアカウント固有のトランザクションのクエリ パフォーマンスが向上します。
セカンダリ インデックス(CustomersByEmail、CustomersFuzzyEmail、AccountsByCustomer、TransactionLedgerByAccountType、TransactionLedgerByCategory、TransactionLedgerTextSearch)は、この Codelab で使用される一般的なデータアクセス パターン(メールの完全一致とファジー一致による顧客の検索、顧客によるアカウントの取得、トランザクション データの効率的なクエリと検索など)を最適化するために実装されました。
TransactionCategoryModel は Vertex AI を活用して LLM への直接 SQL 呼び出しを可能にします。この Codelab では、動的トランザクションの分類に使用されます。
概要
このステップでは、Spanner データベースとスキーマを作成しました。
次のステップ
次に、サンプル アプリケーションのデータを読み込みます。
5. データを読み込む
次に、CSV ファイルからデータベースにサンプルデータを読み込む機能を追加します。
App.java を開き、まずインポートを置き換えます。
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
次に、挿入メソッドをクラス App に追加します。
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
switch (command) 内の挿入用に main メソッドに別の case ステートメントを追加します。
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
最後に、挿入の使用方法を printUsageAndExit メソッドに付加します。
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
App.java に加えた変更を保存します。
アプリケーションを再ビルドします。
mvn package
insert コマンドを実行して、サンプルデータを挿入します。
java -jar target/onlinebanking.jar insert
予想される出力:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
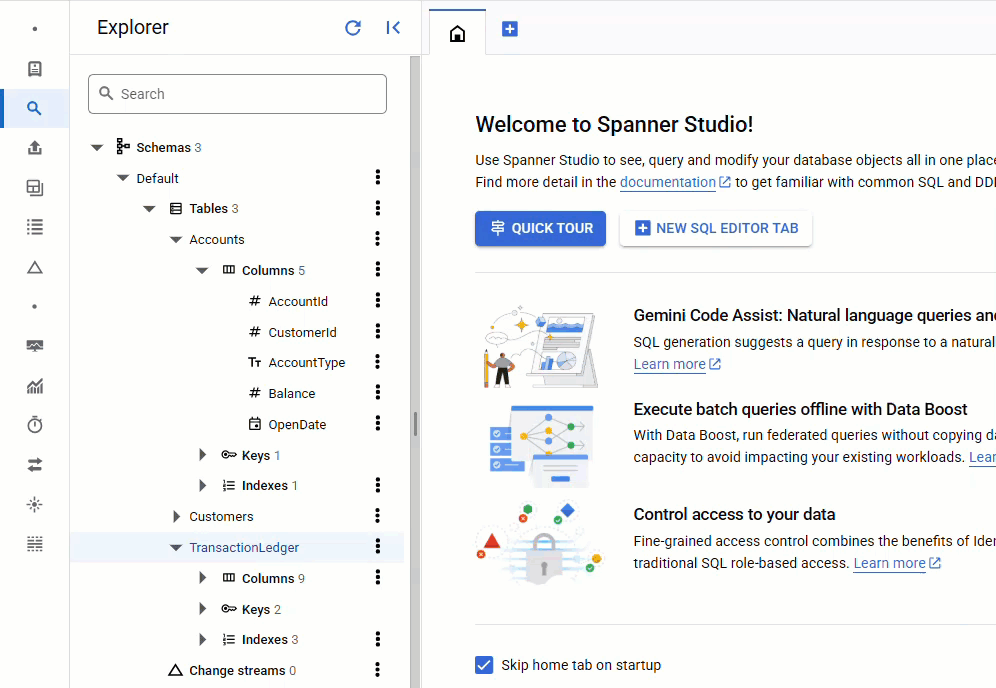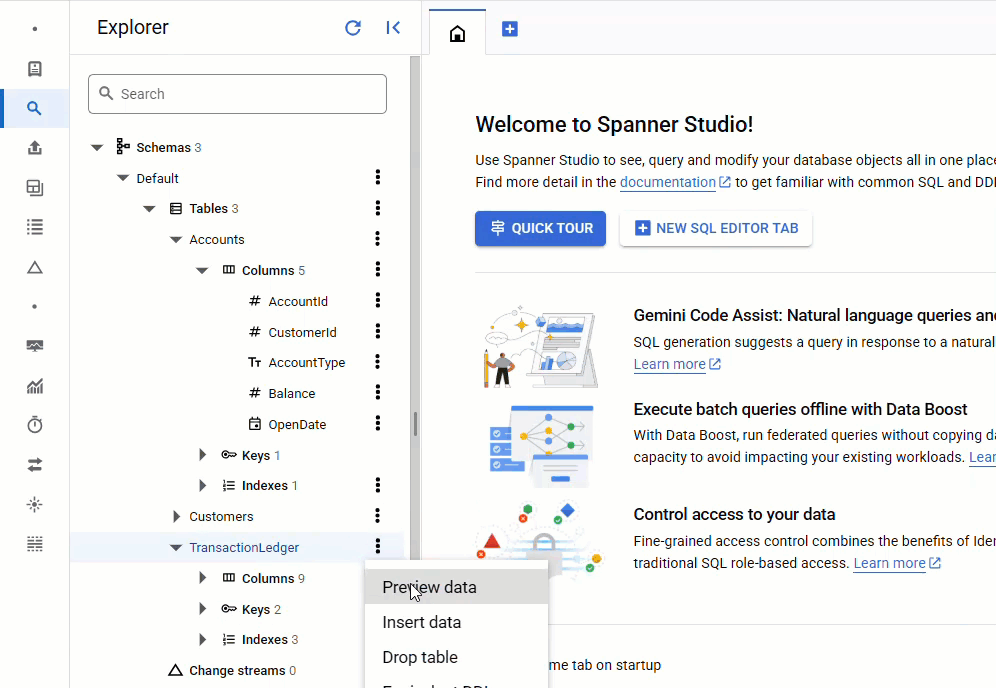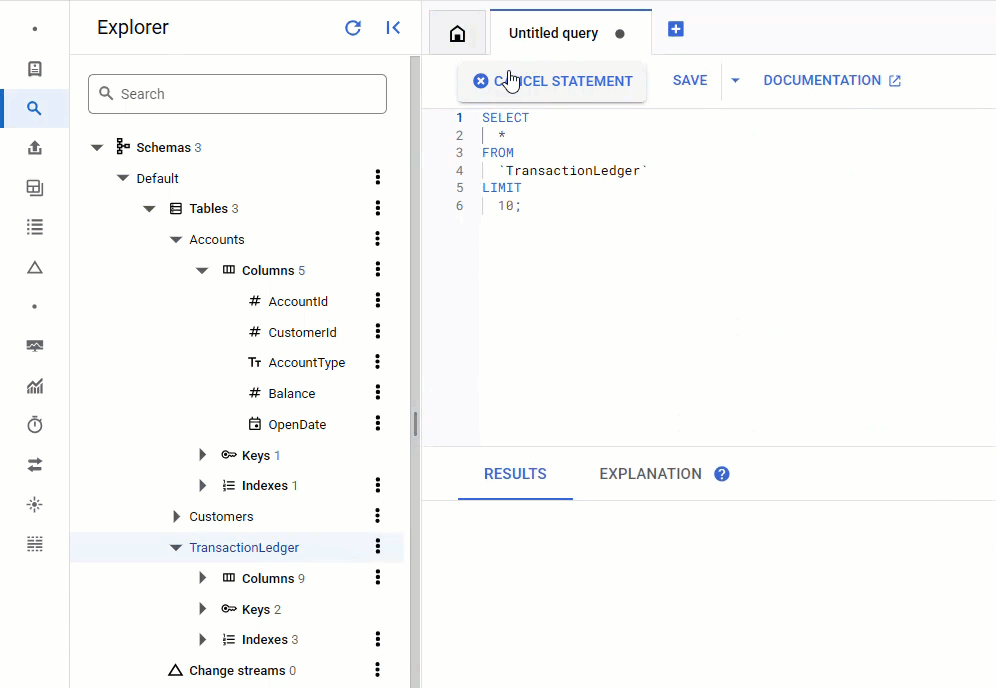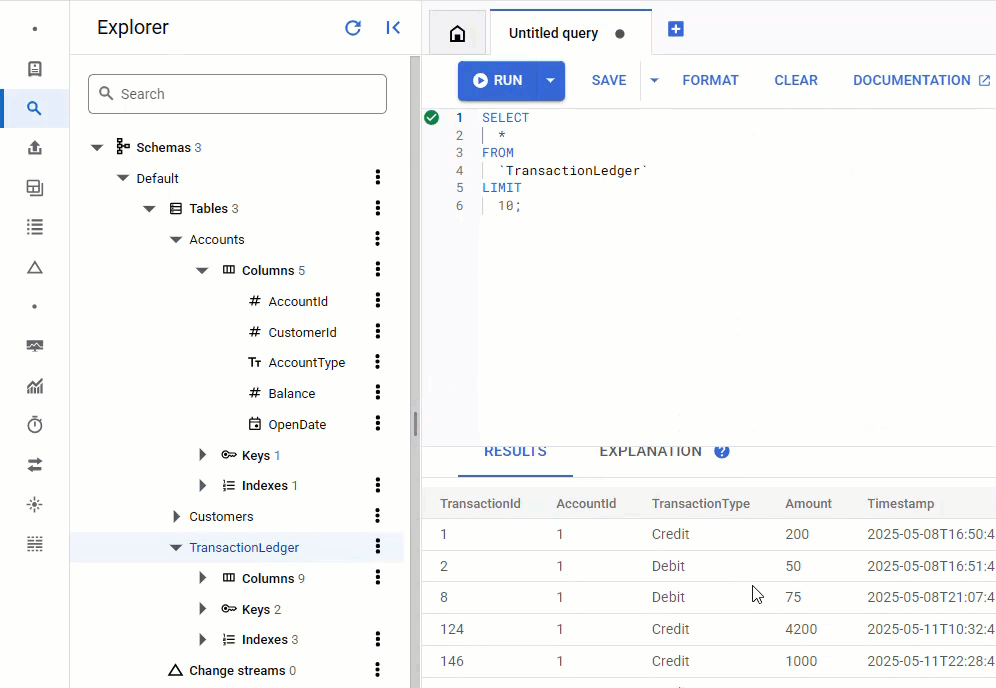
Spanner コンソールで、インスタンスとデータベースの Spanner Studio に戻ります。次に、TransactionLedger テーブルを選択し、サイドバーの [データ] をクリックして、データが読み込まれたことを確認します。テーブルの行数は 200 であるはずです。
概要
このステップでは、データベースにサンプルデータを挿入しました。
次のステップ
次に、Vertex AI インテグレーションを活用して、Spanner SQL 内で銀行取引を自動的に分類します。
6. Vertex AI でデータを分類する
このステップでは、Vertex AI の機能を活用して、Spanner SQL 内で財務取引を自動的に分類します。Vertex AI では、既存の事前トレーニング済みモデルを選択するか、独自のモデルをトレーニングしてデプロイできます。使用可能なモデルについては、Vertex AI Model Garden をご覧ください。
この Codelab では、Gemini モデルの 1 つである Gemini Flash Lite を使用します。このバージョンの Gemini は、費用対効果に優れながら、ほとんどの日常的なワークロードを処理できます。
現在、説明に基づいて分類(groceries、transportation など)したい金融取引が多数あります。これを行うには、Spanner にモデルを登録し、ML.PREDICT を使用して AI モデルを呼び出します。
銀行のアプリケーションでは、トランザクションを分類して顧客行動に関する詳細な分析情報を取得し、サービスをパーソナライズしたり、異常をより効果的に検出したり、顧客が予算を月ごとに追跡できるようにしたりすることが必要になる場合があります。
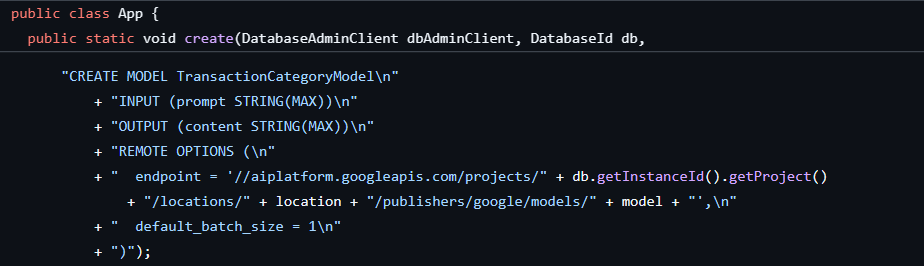
最初のステップは、データベースとスキーマを作成したときにすでに完了しています。これにより、次のようなモデルが作成されました。
次に、ML.PREDICT を呼び出すメソッドをアプリケーションに追加します。
App.java を開き、categorize メソッドを追加します。
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
main メソッドに、分類用の別の case ステートメントを追加します。
case "categorize":
categorize(dbClient);
break;
最後に、categorize の使用方法を printUsageAndExit メソッドに付加します。
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
App.java に加えた変更を保存します。
アプリケーションを再ビルドします。
mvn package
categorize コマンドを実行して、データベース内のトランザクションを分類します。
java -jar target/onlinebanking.jar categorize
予想される出力:
Categorizing transactions... Completed categorizing transactions
Spanner Studio で、TransactionLedger テーブルの Preview Data ステートメントを実行します。これで、すべての行の Category 列に値が入力されます。
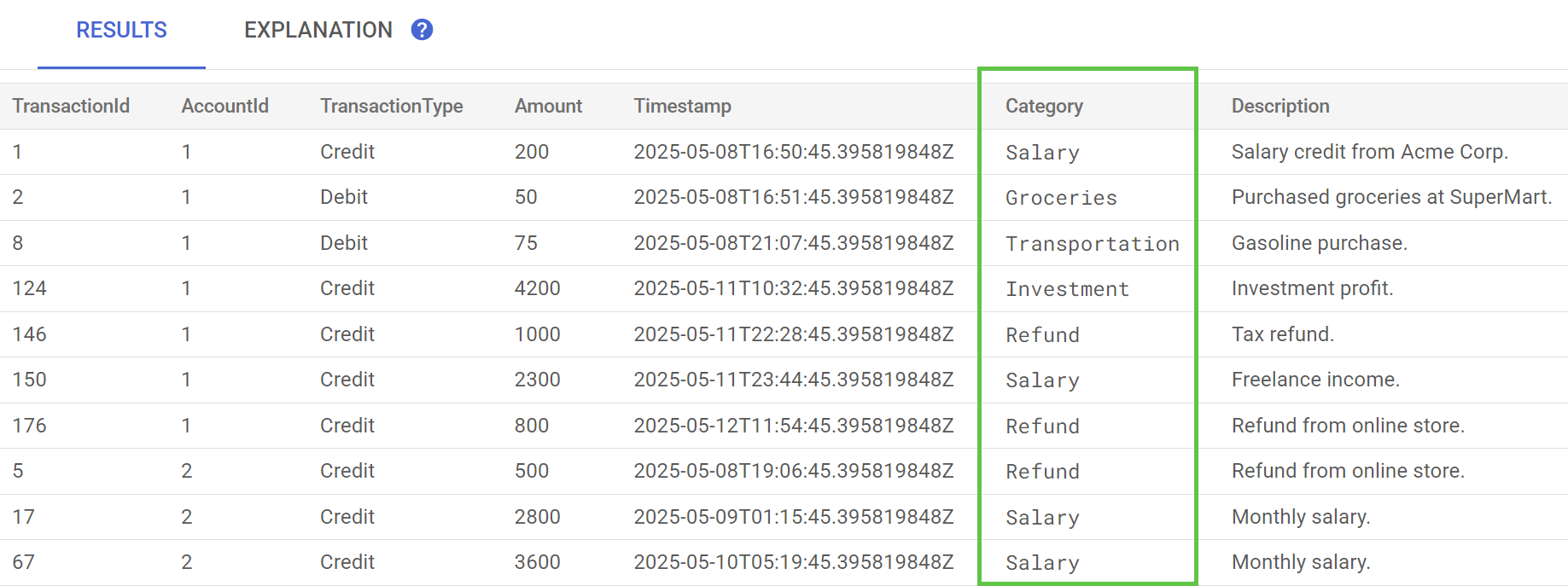
取引を分類したので、この情報を内部または顧客向けのクエリに使用できます。次のステップでは、特定の顧客が 1 か月間に特定のカテゴリでどれくらいの金額を費やしているかを確認する方法について説明します。
概要
このステップでは、事前トレーニング済みのモデルを使用して、AI を活用したデータの分類を行いました。
次のステップ
次に、トークン化を利用してファジー検索と全文検索を行います。
7. 全文検索を使用したクエリ
クエリコードを追加する
Spanner には、多くの全文検索クエリが用意されています。このステップでは、完全一致検索を実行してから、ファジー検索と全文検索を実行します。
App.java を開き、まずインポートを置き換えます。
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
次に、クエリメソッドを追加します。
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
クエリの main メソッドに別の case ステートメントを追加します。
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
最後に、クエリ コマンドの使用方法を printUsageAndExit メソッドに付加します。
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
App.java に加えた変更を保存します。
アプリケーションを再ビルドします。
mvn package
顧客アカウントの残高を完全一致で検索する
完全一致クエリは、用語と完全に一致する一致する行を探します。
パフォーマンスを向上させるため、データベースとスキーマの作成時にインデックスが追加されています。
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
getBalance メソッドは、このインデックスを暗黙的に使用して、指定された customerId に一致する顧客を検索し、その顧客に属するアカウントを結合します。
Spanner Studio で直接実行されたクエリは次のようになります。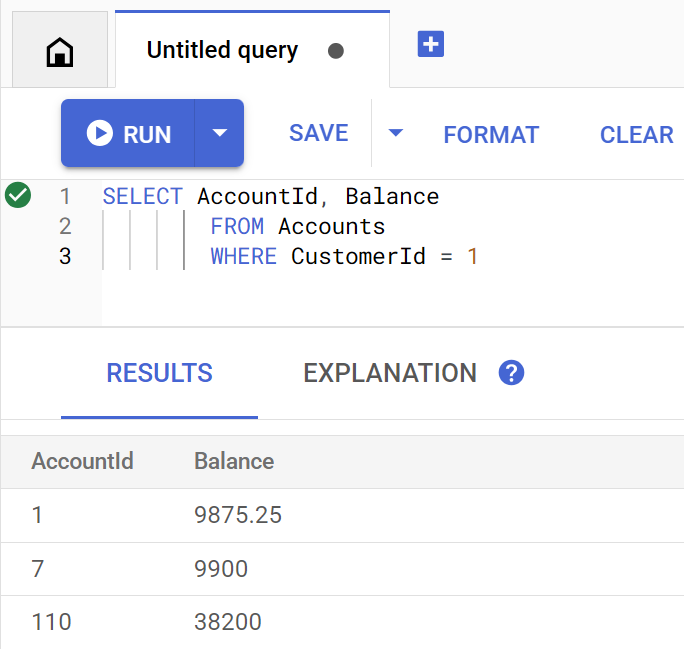
次のコマンドを実行して、お客様の 1 のアカウント残高を表示します。
java -jar target/onlinebanking.jar query balance 1
予想される出力:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
顧客は 100 人いるため、別の顧客 ID を指定して、他の顧客アカウントの残高をクエリすることもできます。
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
顧客のメールに対してファジー検索を実行する
ファジー検索では、スペルのバリエーションやタイプミスなど、検索語句の近似一致を見つけることができます。
データベースとスキーマの作成時に、n グラム インデックスがすでに追加されています。
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
findCustomers メソッドは、SEARCH_NGRAMS と SCORE_NGRAMS を使用してこのインデックスに対してクエリを実行し、メールアドレスで顧客を検索します。メール列は n グラム トークン化されているため、このクエリにはスペルミスが含まれていても、正しい回答が返されます。結果は、最も一致するものに基づいて並べ替えられます。
次のコマンドを実行して、madi を含む一致するお客様のメールアドレスを見つけます。
java -jar target/onlinebanking.jar query email madi
予想される出力:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
このレスポンスには、madi などの文字列を含む最も近い一致がランク順で表示されます。
Spanner Studio で直接実行した場合のクエリは次のようになります。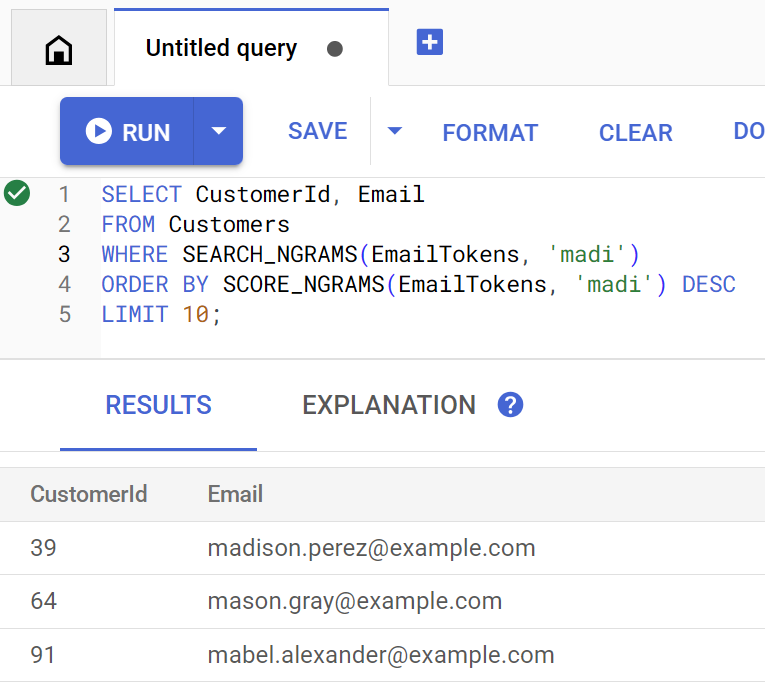
ファジー検索は、emily のスペルミスなどのスペルミスにも役立ちます。
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
予想される出力:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
いずれの場合も、お客様のメールが上位の結果として返されます。
全文検索で取引を検索する
Spanner の全文検索機能は、キーワードやフレーズに基づいてレコードを取得するために使用されます。スペルミスを修正したり、類義語を検索したりする機能があります。
データベースとスキーマを作成したときに、全文検索インデックスがすでに作成されています。
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
getSpending メソッドは、SEARCH 全文検索関数を使用して、そのインデックスと照合します。指定されたお客様 ID の過去 30 日間のすべての費用(引き落とし)を検索します。
次のコマンドを実行して、groceries カテゴリの顧客 1 の過去 1 か月間の合計費用を取得します。
java -jar target/onlinebanking.jar query spending 1 groceries
予想される出力:
Total spending for customer 1 under category groceries: 50
他のカテゴリ(前のステップで分類したカテゴリ)の費用を確認したり、別の顧客 ID を使用したりすることもできます。
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
概要
このステップでは、完全一致クエリとファジー検索、全文検索を実行しました。
次のステップ
次に、Spanner を Google BigQuery と統合して連携クエリを実行し、リアルタイムの Spanner データと BigQuery データを組み合わせます。
8. BigQuery で連携クエリを実行する
BigQuery データセットを作成する
このステップでは、連携クエリを使用して BigQuery と Spanner のデータを統合します。
これを行うには、Cloud Shell コマンドラインで、まず MarketingCampaigns データセットを作成します。
bq mk --location=us-central1 MarketingCampaigns
予想される出力:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
データセット内の CustomerSegments テーブル:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
予想される出力:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
次に、BigQuery から Spanner への接続を作成します。
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
予想される出力:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
最後に、Spanner データと結合できる顧客を BigQuery テーブルに追加します。
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
予想される出力:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
BigQuery をクエリして、データが利用可能であることを確認できます。
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
予想される出力:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
BigQuery のこのデータは、さまざまな銀行のワークフローを通じて追加されたデータを表します。たとえば、最近アカウントを開設した顧客や、マーケティング プロモーションに登録した顧客のリストなどです。マーケティング キャンペーンのターゲットとする顧客のリストを特定するには、BigQuery のこのデータと Spanner のリアルタイム データの両方にクエリを実行する必要があります。連携クエリを使用すると、これを 1 つのクエリで実行できます。
BigQuery で連携クエリを実行する
次に、連携クエリを実行するために EXTERNAL_QUERY を呼び出すメソッドをアプリケーションに追加します。これにより、BigQuery と Spanner で顧客データを結合して分析できます。たとえば、最近の支出に基づいてマーケティング キャンペーンの条件を満たす顧客を特定できます。
App.java を開き、まずインポートを置き換えます。
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
次に、campaign メソッドを追加します。
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
キャンペーンの main メソッドに別の case ステートメントを追加します。
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
最後に、キャンペーンの使用方法を printUsageAndExit メソッドに付加します。
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
App.java に加えた変更を保存します。
アプリケーションを再ビルドします。
mvn package
campaign コマンドを実行して、過去 3 か月間に $5000 以上を費やした顧客を特定し、マーケティング キャンペーン(campaign1)に含めるかどうかを判断する連携クエリを実行します。
java -jar target/onlinebanking.jar campaign campaign1 5000
予想される出力:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
これらの顧客を対象に、限定特典やポイント プログラムを提供できるようになりました。
または、過去 3 か月間に少額の費用しきい値を達成した顧客の数をより広範囲に検索することもできます。
java -jar target/onlinebanking.jar campaign campaign1 2500
予想される出力:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
概要
このステップでは、BigQuery から連携クエリを実行して、Spanner のリアルタイム データを取得しました。
次のステップ
次に、この Codelab 用に作成したリソースをクリーンアップして、料金が発生しないようにします。
9. クリーンアップ(省略可)
この手順は省略可能です。Spanner インスタンスのテストを続ける場合は、現時点でクリーンアップする必要はありません。ただし、使用しているプロジェクトには、インスタンスの料金が引き続き請求されます。このインスタンスが不要になった場合は、この時点で削除して、これらの料金が発生しないようにする必要があります。この Codelab では、Spanner インスタンスに加えて、BigQuery データセットと接続も作成しました。これらは不要になったらクリーンアップする必要があります。
Spanner インスタンスを削除します。
gcloud spanner instances delete cloudspanner-onlinebanking
続行することを確認します(「Y」と入力します)。
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
BigQuery 接続とデータセットを削除します。
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
BigQuery データセットの削除を確認します(「Y」と入力します)。
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. 完了
🚀 新しい Cloud Spanner インスタンスを作成し、空のデータベースを作成して、サンプルデータを読み込み、高度なオペレーションとクエリを実行し、Cloud Spanner インスタンスを削除しました(省略可)。
学習した内容
- Spanner インスタンスの設定方法。
- データベースとテーブルの作成方法。
- Spanner データベース テーブルにデータを読み込む方法。
- Spanner から Vertex AI モデルを呼び出す方法。
- ファジー検索と全文検索を使用して Spanner データベースをクエリする方法。
- BigQuery から Spanner に対して連携クエリを実行する方法。
- Spanner インスタンスを削除する方法。
次のステップ
-
以下のような高度な Spanner 機能の詳細を確認する。
- 有効期間(TTL)。
- きめ細かいアクセス制御。
- ベクトル エンベディングと検索。
- JSON 検索インデックス。
- Spanner Graph。
- 使用可能な Spanner クライアント ライブラリをご覧ください。