
1. Przegląd
Spanner to usługa baz danych w pełni zarządzana, skalowana w poziomie i rozmieszczona globalnie, która doskonale sprawdza się w przypadku relacyjnych i nierelacyjnych obciążeń operacyjnych. Oprócz podstawowych funkcji Spanner oferuje zaawansowane możliwości, które umożliwiają tworzenie inteligentnych aplikacji opartych na danych.
W tym ćwiczeniu wykorzystamy podstawową wiedzę o Spannerze i zagłębimy się w zaawansowane integracje, aby zwiększyć możliwości przetwarzania danych i analityki. Jako podstawę wykorzystamy aplikację bankowości internetowej.
Skupimy się na 3 kluczowych funkcjach zaawansowanych:
- Integracja z Vertex AI: dowiedz się, jak bezproblemowo zintegrować Spannera z Vertex AI, platformą AI Google Cloud. Dowiesz się, jak wywoływać modele Vertex AI bezpośrednio z zapytań Spanner SQL, co umożliwia zaawansowane przekształcenia i prognozy w bazie danych. Dzięki temu nasza aplikacja bankowa może automatycznie kategoryzować transakcje na potrzeby takich przypadków użycia jak śledzenie budżetu i wykrywanie anomalii.
- Wyszukiwanie pełnotekstowe: dowiedz się, jak wdrożyć w Spannerze funkcję wyszukiwania pełnotekstowego. Poznasz indeksowanie danych tekstowych i pisanie wydajnych zapytań do wyszukiwania na podstawie słów kluczowych w danych operacyjnych, co umożliwi skuteczne odkrywanie danych, np. efektywne wyszukiwanie klientów według adresu e-mail w naszym systemie bankowym.
- Zapytania sfederowane BigQuery: dowiedz się, jak korzystać z funkcji zapytań sfederowanych Spannera, aby bezpośrednio wysyłać zapytania o dane znajdujące się w BigQuery. Umożliwia to łączenie danych operacyjnych w czasie rzeczywistym ze Spannera z analitycznymi zbiorami danych BigQuery w celu uzyskiwania kompleksowych statystyk i raportów bez duplikowania danych ani złożonych procesów ETL. Umożliwia to różne przypadki użycia w naszej aplikacji bankowej, takie jak ukierunkowane kampanie marketingowe, poprzez łączenie danych o klientach w czasie rzeczywistym z szerszymi trendami historycznymi z BigQuery.
Czego się nauczysz
- Jak skonfigurować instancję usługi Spanner.
- Jak utworzyć bazę danych i tabele.
- Jak wczytywać dane do tabel bazy danych Spanner.
- Jak wywoływać modele Vertex AI ze Spannera.
- Jak wysyłać zapytania do bazy danych Spanner za pomocą wyszukiwania przybliżonego i pełnotekstowego.
- Jak wykonywać sfederowane zapytania do Spannera z BigQuery.
- Jak usunąć instancję usługi Spanner.
Czego potrzebujesz
2. Konfiguracja i wymagania
Utwórz projekt
Jeśli masz już projekt w chmurze Google Cloud z włączonymi płatnościami, kliknij menu rozwijane wyboru projektu w lewym górnym rogu konsoli:

Po wybraniu projektu przejdź do sekcji Włączanie wymaganych interfejsów API.
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform (console.cloud.google.com) i utwórz nowy projekt.
W wyświetlonym oknie kliknij przycisk „NOWY PROJEKT”, aby utworzyć nowy projekt:
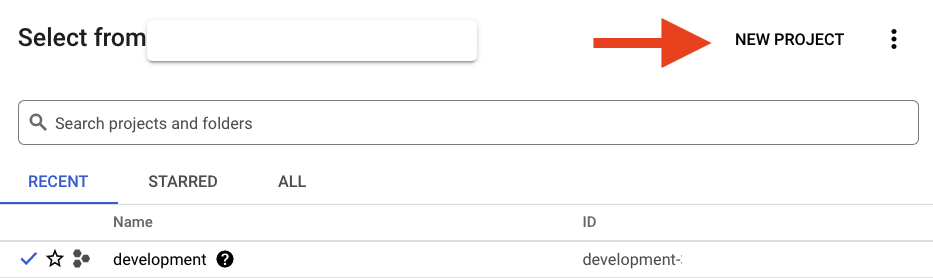
Jeśli nie masz jeszcze projektu, powinien wyświetlić się taki dialog, w którym możesz utworzyć pierwszy projekt:
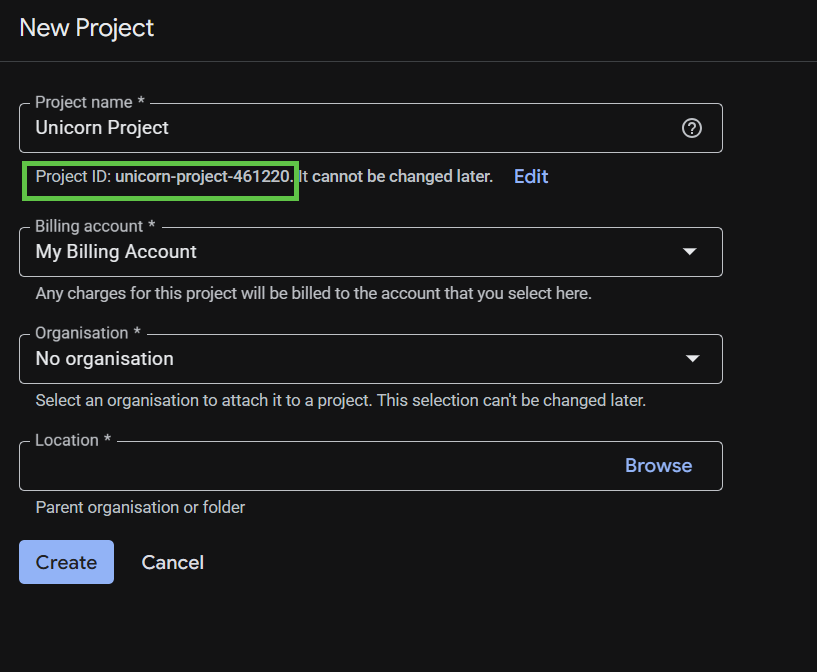
W kolejnym oknie dialogowym tworzenia projektu możesz wpisać szczegóły nowego projektu.
Zapamiętaj identyfikator projektu, który jest unikalną nazwą we wszystkich projektach Google Cloud. W dalszej części tego ćwiczenia będzie on nazywany PROJECT_ID.
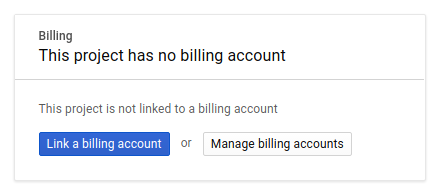
Następnie, jeśli jeszcze tego nie zrobisz, musisz włączyć płatności w Konsoli deweloperów, aby korzystać z zasobów Google Cloud i włączyć interfejsy Spanner API, Vertex AI API, BigQuery API i BigQuery Connection API.
Cennik Spannera znajdziesz tutaj. Inne koszty związane z innymi zasobami są udokumentowane na ich stronach z cennikiem.
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Konfiguracja Google Cloud Shell
W tym ćwiczeniu będziemy używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Oznacza to, że do ukończenia tego ćwiczenia potrzebujesz tylko przeglądarki.
Aby aktywować Cloud Shell w konsoli Cloud, kliknij Aktywuj Cloud Shell ![]() (udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
(udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).

Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu PROJECT_ID.
gcloud auth list
Oczekiwane dane wyjściowe:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Oczekiwane dane wyjściowe:
[core] project = <PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest ustawiony, wydaj to polecenie:
gcloud config set project <PROJECT_ID>
Szukasz urządzenia PROJECT_ID? Sprawdź, jakiego identyfikatora użyto w krokach konfiguracji, lub wyszukaj go w panelu Cloud Console:
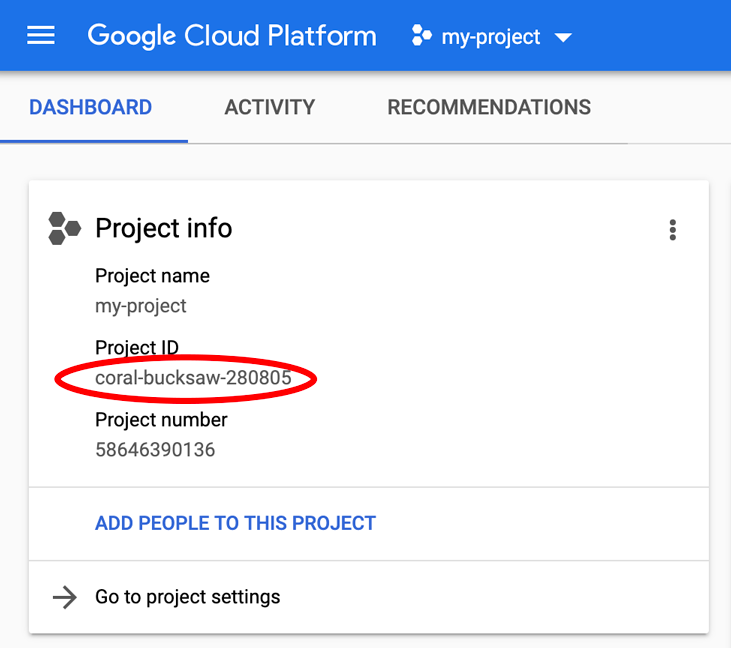
Cloud Shell domyślnie ustawia też niektóre zmienne środowiskowe, które mogą być przydatne podczas wykonywania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Oczekiwane dane wyjściowe:
<PROJECT_ID>
Włączanie wymaganych interfejsów API
Włącz interfejsy Spanner API, Vertex AI API i BigQuery API w projekcie:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Podsumowanie
W tym kroku skonfigurowano projekt (jeśli nie był jeszcze utworzony), aktywowano Cloud Shell i włączono wymagane interfejsy API.
Następny krok
Następnie skonfigurujesz instancję Spannera.
3. Konfigurowanie instancji usługi Spanner
Tworzenie instancji usługi Spanner
W tym kroku skonfigurujesz instancję Spannera na potrzeby tego ćwiczenia. Aby to zrobić, otwórz Cloud Shell i uruchom to polecenie:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Oczekiwane dane wyjściowe:
Creating instance...done.
Podsumowanie
W tym kroku utworzyliśmy instancję usługi Spanner.
Następny krok
Następnie przygotujesz aplikację początkową oraz utworzysz bazę danych i schemat.
4. Tworzenie bazy danych i schematu
Przygotowywanie wstępnego wniosku
W tym kroku utworzysz bazę danych i schemat za pomocą kodu.
Najpierw utwórz aplikację w języku Java o nazwie onlinebanking za pomocą Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Sprawdź i skopiuj pliki danych, które dodamy do bazy danych (repozytorium kodu znajdziesz tutaj):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Przejdź do folderu aplikacji:
cd onlinebanking
Otwórz plik Maven pom.xml. Dodaj sekcję zarządzania zależnościami, aby używać Maven BOM do zarządzania wersją bibliotek Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Edytor i plik będą wyglądać tak: 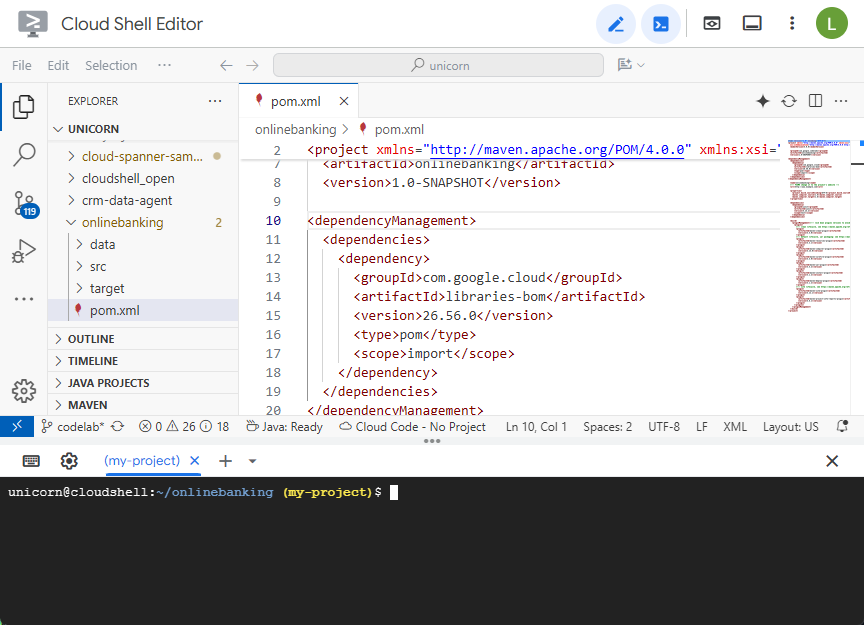
Sprawdź, czy sekcja dependencies zawiera biblioteki, których będzie używać aplikacja:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Na koniec zastąp wtyczki kompilacji, aby aplikacja została spakowana do uruchamialnego pliku JAR:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Zapisz zmiany wprowadzone w pliku pom.xml, wybierając „Zapisz” w menu „Plik” edytora Cloud Shell lub naciskając Ctrl+S.
Teraz, gdy zależności są gotowe, dodasz do aplikacji kod, który utworzy schemat, kilka indeksów (w tym indeks wyszukiwania) i model AI połączony ze zdalnym punktem końcowym. W tym ćwiczeniu w Codelabs będziesz rozwijać te artefakty i dodawać do tej klasy kolejne metody.
Otwórz plik App.java w folderze onlinebanking/src/main/java/com/google/codelabs i zastąp jego zawartość tym kodem:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Zapisz zmiany w pliku App.java.
Sprawdź różne encje, które tworzy Twój kod, i utwórz plik JAR aplikacji:
mvn package
Oczekiwane dane wyjściowe:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Uruchom aplikację, aby wyświetlić informacje o korzystaniu:
java -jar target/onlinebanking.jar
Oczekiwane dane wyjściowe:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Tworzenie bazy danych i schematu
Ustaw wymagane zmienne środowiskowe aplikacji:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Utwórz bazę danych i schemat, uruchamiając polecenie create:
java -jar target/onlinebanking.jar create
Oczekiwane dane wyjściowe:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Sprawdzanie schematu w usłudze Spanner
W konsoli Spanner otwórz instancję i bazę danych, które zostały właśnie utworzone.
Powinny być widoczne wszystkie 3 tabele: Accounts, Customers i TransactionLedger.
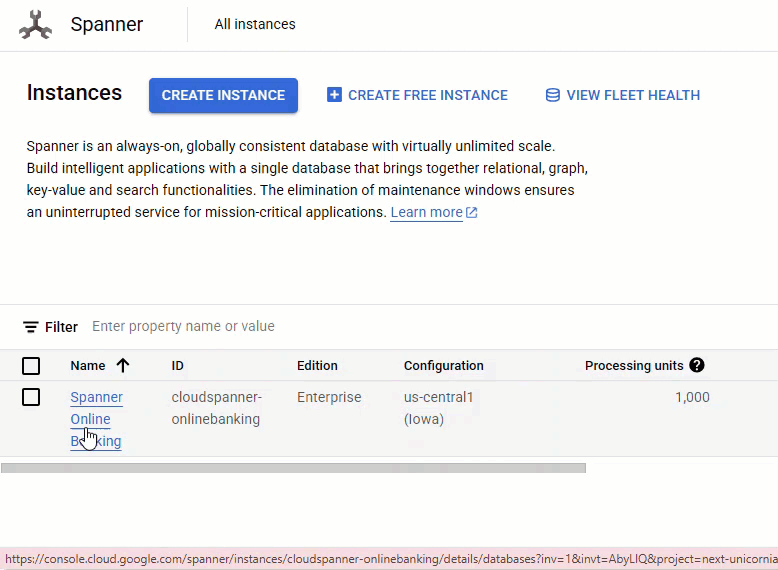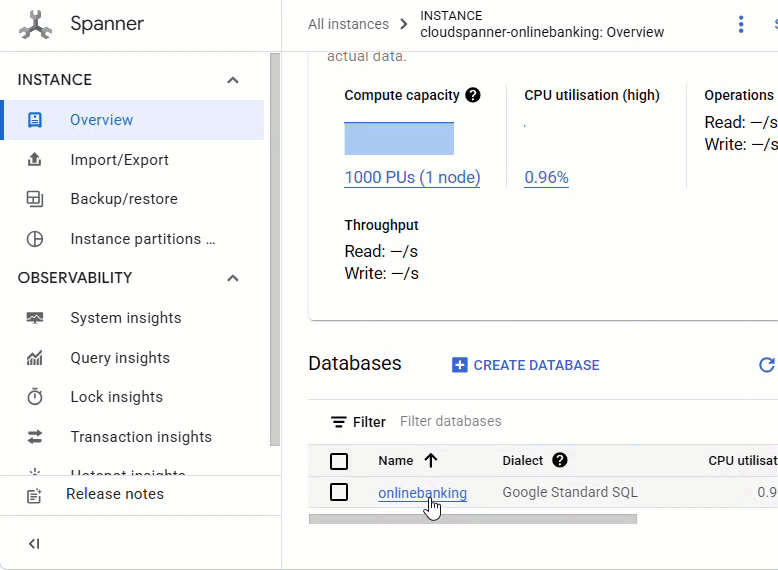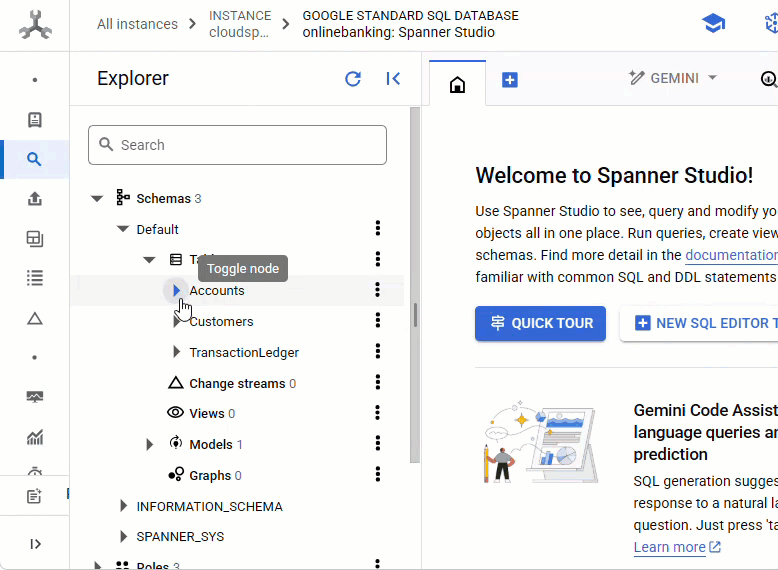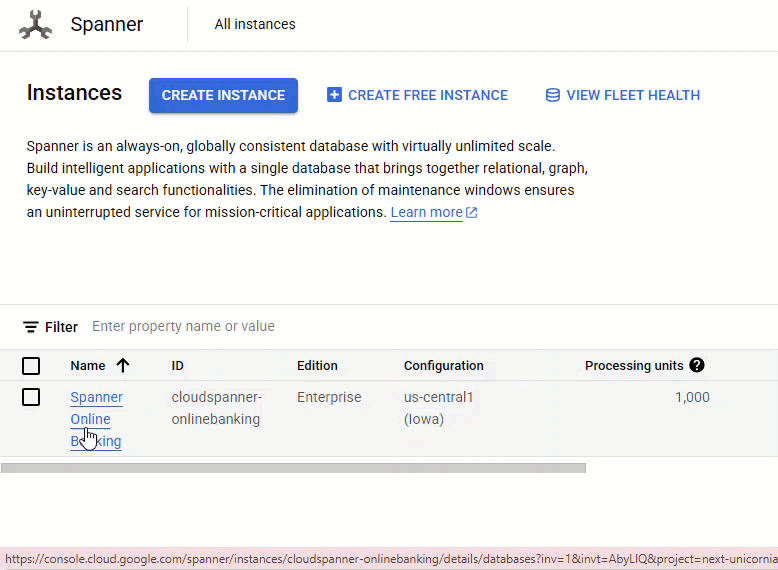
Ta czynność powoduje utworzenie schematu bazy danych, w tym tabel Accounts, Customers i TransactionLedger, a także indeksów dodatkowych do optymalnego pobierania danych oraz odwołania do modelu Vertex AI.
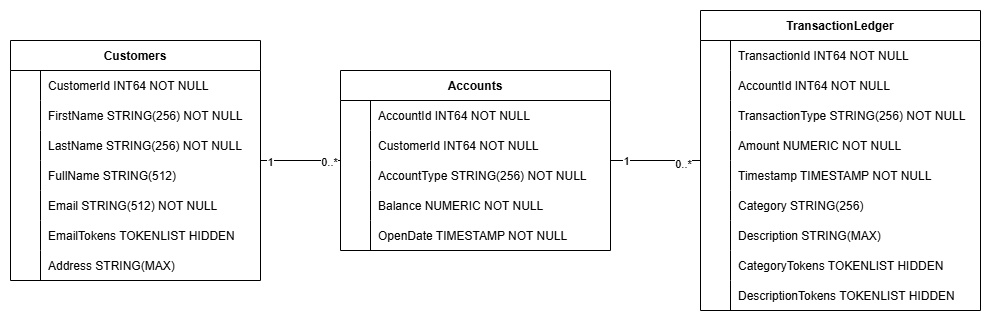
Tabela TransactionLedger jest przeplatana w tabeli Accounts, aby zwiększyć wydajność zapytań dotyczących transakcji na koncie dzięki lepszej lokalizacji danych.
Wdrożyliśmy indeksy dodatkowe (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch), aby zoptymalizować typowe wzorce dostępu do danych używane w tym ćwiczeniu w Codelabs, takie jak wyszukiwanie klientów według dokładnego i przybliżonego adresu e-mail, pobieranie kont według klienta oraz wydajne wykonywanie zapytań i przeszukiwanie danych transakcji.
TransactionCategoryModel korzysta z Vertex AI, aby umożliwić bezpośrednie wywoływanie języka SQL w dużym modelu językowym, który jest używany w tym ćwiczeniu do dynamicznego kategoryzowania transakcji.
Podsumowanie
W tym kroku utworzyliśmy bazę danych i schemat usługi Spanner.
Następny krok
Następnie wczytaj przykładowe dane aplikacji.
5. Wczytaj dane
Teraz dodasz funkcję wczytywania przykładowych danych z plików CSV do bazy danych.
Otwórz plik App.java i zacznij od zastąpienia instrukcji importu:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Następnie dodaj do klasy App metody wstawiania:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Dodaj kolejną instrukcję case w metodzie main, aby wstawić ją w switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Na koniec dodaj do metody printUsageAndExit sposób użycia wstawiania:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Zapisz zmiany wprowadzone w pliku App.java.
Przebuduj aplikację:
mvn package
Wstaw przykładowe dane, wykonując polecenie insert:
java -jar target/onlinebanking.jar insert
Oczekiwane dane wyjściowe:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
W konsoli Spanner wróć do Spanner Studio dla swojej instancji i bazy danych. Następnie wybierz tabelę TransactionLedger i kliknij „Dane” na pasku bocznym, aby sprawdzić, czy dane zostały wczytane. Tabela powinna zawierać 200 wierszy.
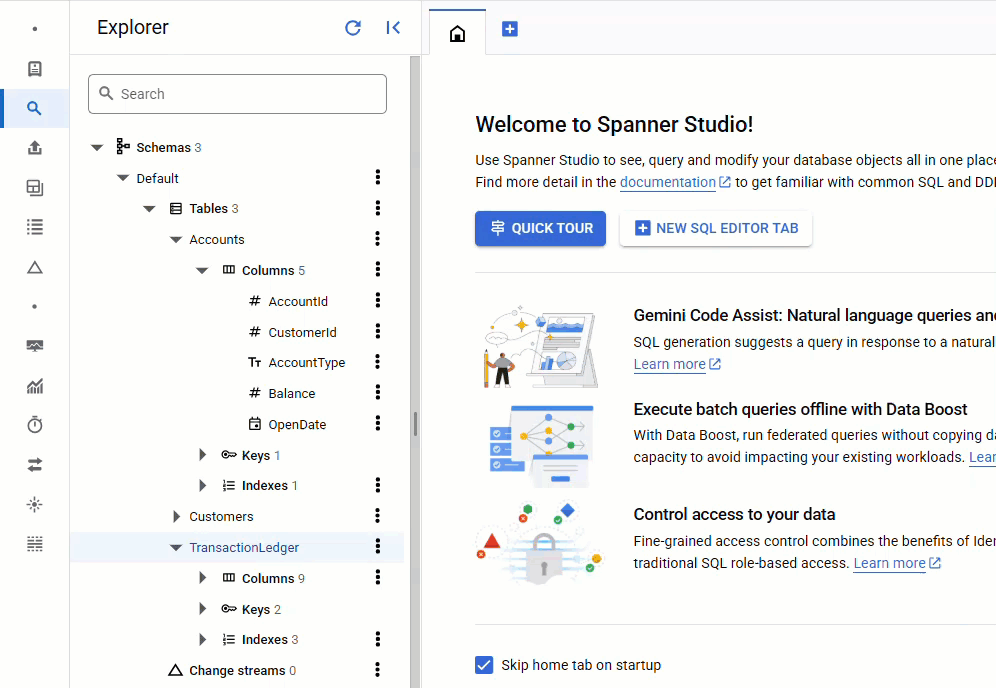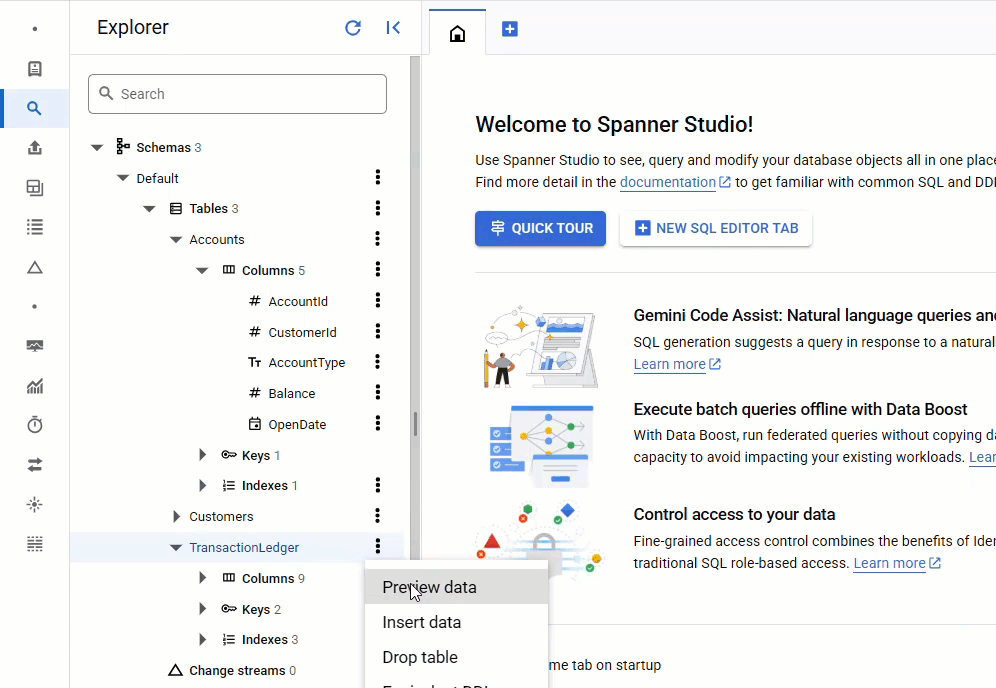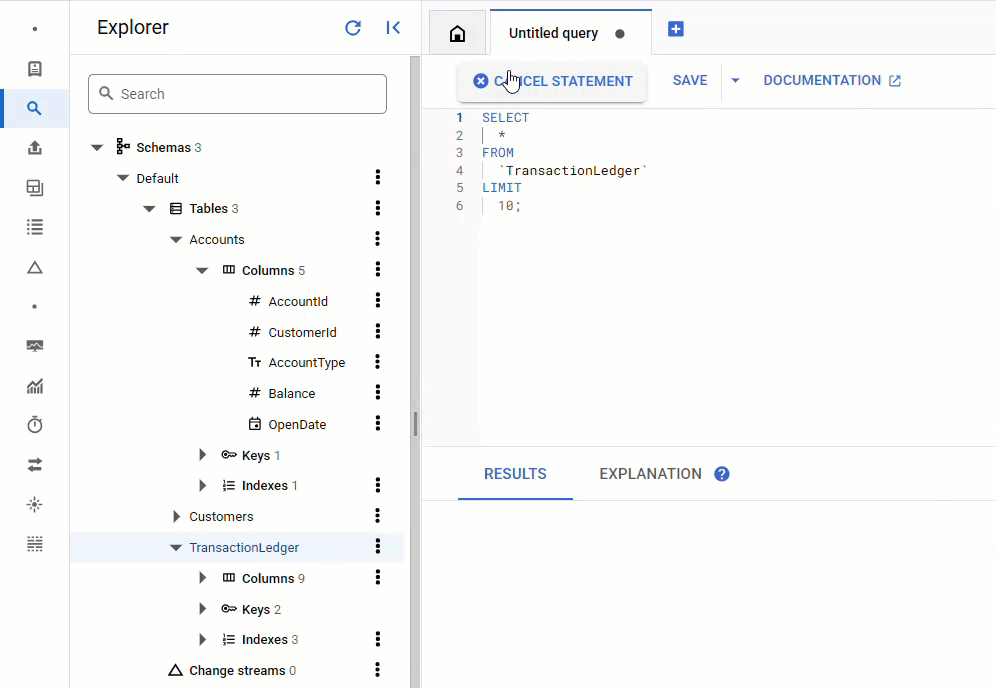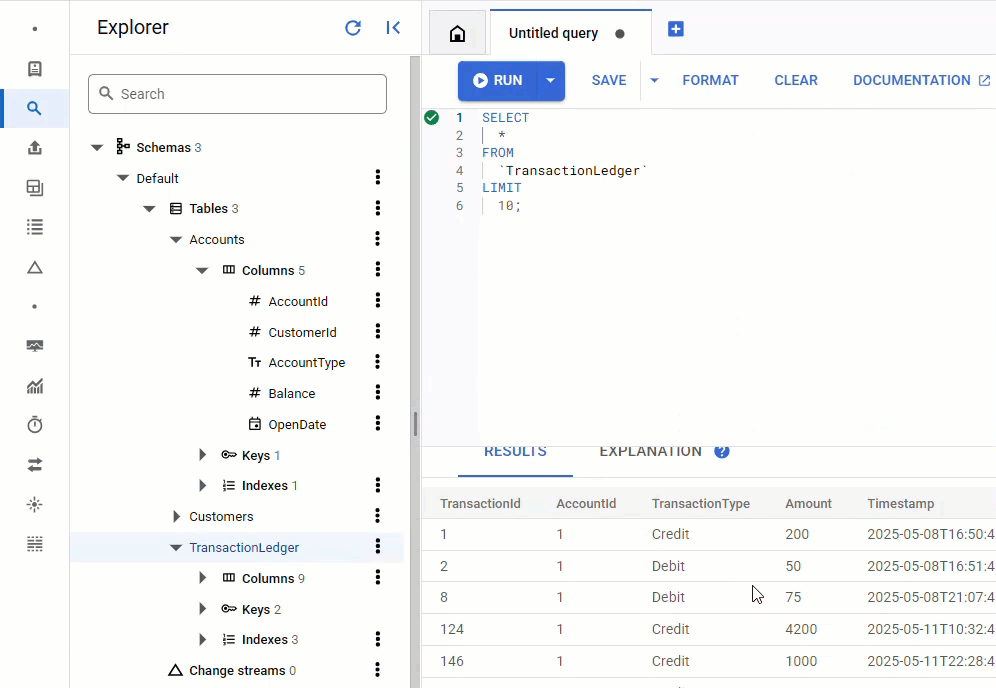
Podsumowanie
W tym kroku wstawisz przykładowe dane do bazy danych.
Następny krok
Następnie wykorzystasz integrację z Vertex AI, aby automatycznie kategoryzować transakcje bankowe bezpośrednio w Spanner SQL.
6. Kategoryzowanie danych za pomocą Vertex AI
W tym kroku wykorzystasz możliwości Vertex AI, aby automatycznie kategoryzować transakcje finansowe bezpośrednio w Spanner SQL. W Vertex AI możesz wybrać gotowy wytrenowany model lub wytrenować i wdrożyć własny. Zobacz dostępne modele w bazie modeli Vertex AI.
W tym ćwiczeniu użyjemy jednego z modeli Gemini, Gemini Flash Lite. Ta wersja Gemini jest niedroga, ale nadal może obsługiwać większość codziennych zadań.
Obecnie mamy kilka transakcji finansowych, które chcemy sklasyfikować (groceries, transportation itp.) na podstawie opisu. Możemy to zrobić, rejestrując model w Spannerze, a następnie używając funkcji ML.PREDICT do wywoływania modelu AI.
W aplikacji bankowej możemy chcieć kategoryzować transakcje, aby lepiej poznać zachowania klientów i dostosowywać do nich usługi, skuteczniej wykrywać anomalie lub umożliwić klientowi śledzenie budżetu z miesiąca na miesiąc.
Pierwszy krok został już wykonany podczas tworzenia bazy danych i schematu, co spowodowało utworzenie modelu takiego jak ten:
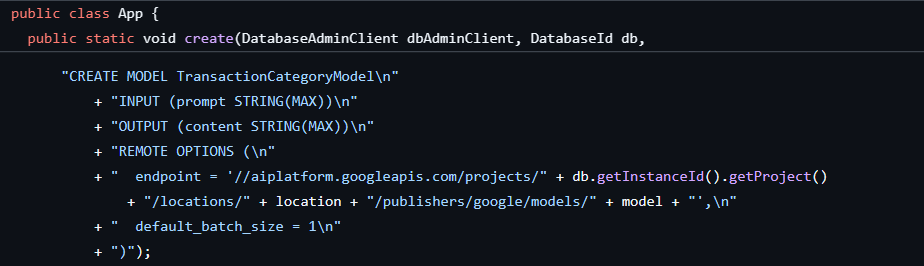
Następnie dodamy do aplikacji metodę wywoływania funkcji ML.PREDICT.
Otwórz App.java i dodaj metodę categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Dodaj kolejną instrukcję case w metodzie main dla funkcji categorize:
case "categorize":
categorize(dbClient);
break;
Na koniec dodaj do metody printUsageAndExit informację o tym, jak używać funkcji categorize:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Zapisz zmiany wprowadzone w pliku App.java.
Przebuduj aplikację:
mvn package
Skategoryzuj transakcje w bazie danych, uruchamiając polecenie categorize:
java -jar target/onlinebanking.jar categorize
Oczekiwane dane wyjściowe:
Categorizing transactions... Completed categorizing transactions
W Spanner Studio wykonaj instrukcję Preview Data (Podgląd danych) dla tabeli TransactionLedger. Kolumna Category powinna być teraz wypełniona we wszystkich wierszach.
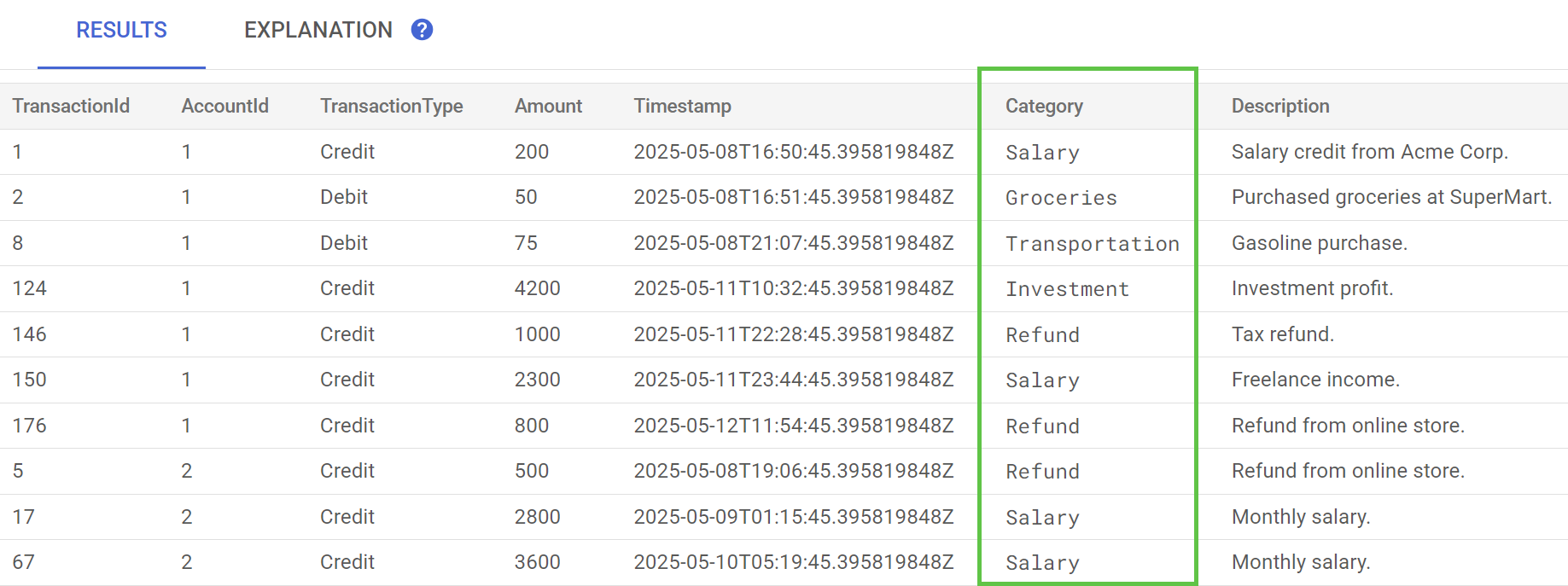
Teraz, gdy mamy już skategoryzowane transakcje, możemy używać tych informacji w zapytaniach wewnętrznych lub zapytaniach klientów. W następnym kroku sprawdzimy, jak dowiedzieć się, ile dany klient wydaje w danej kategorii w ciągu miesiąca.
Podsumowanie
W tym kroku wykorzystaliśmy wstępnie wytrenowany model do przeprowadzenia klasyfikacji danych opartej na AI.
Następny krok
Następnie użyjesz tokenizacji, aby przeprowadzić wyszukiwanie przybliżone i pełnotekstowe.
7. Wykonywanie zapytań za pomocą wyszukiwania pełnotekstowego
Dodawanie kodu zapytania
Spanner udostępnia wiele zapytań wyszukiwania pełnotekstowego. W tym kroku przeprowadzisz wyszukiwanie dokładne, a potem wyszukiwanie przybliżone i pełnotekstowe.
Otwórz plik App.java i zacznij od zastąpienia instrukcji importu:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Następnie dodaj metody zapytań:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Dodaj kolejne stwierdzenie case w metodzie main dla zapytania:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Na koniec dodaj do metody printUsageAndExit informacje o tym, jak używać poleceń zapytań:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Zapisz zmiany wprowadzone w pliku App.java.
Przebuduj aplikację:
mvn package
Przeprowadzanie wyszukiwania ścisłego dopasowania sald kont klientów
Zapytanie o dopasowanie ścisłe wyszukuje pasujące wiersze, które dokładnie odpowiadają danemu terminowi.
Aby zwiększyć wydajność, indeks został dodany już podczas tworzenia bazy danych i schematu:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
Metoda getBalance niejawnie używa tego indeksu do znajdowania klientów pasujących do podanego identyfikatora klienta, a także łączy konta należące do tego klienta.
Tak wygląda zapytanie po wykonaniu bezpośrednio w Spanner Studio: 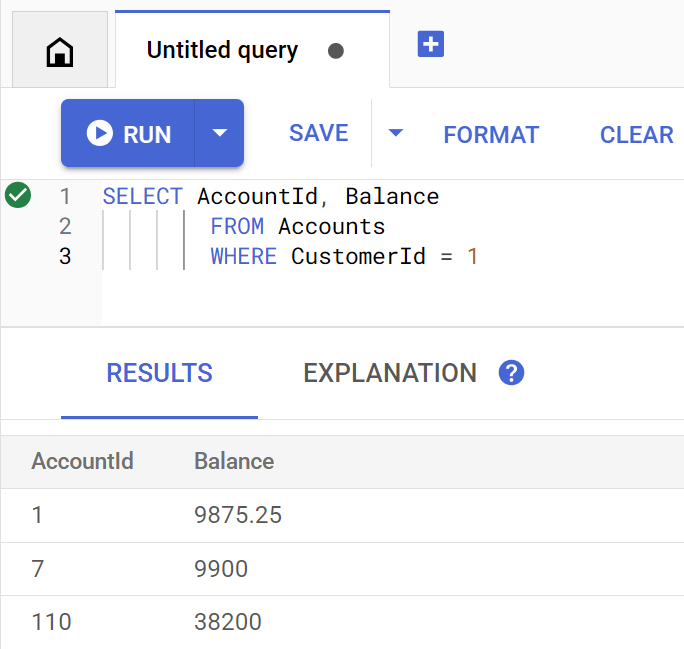
Wyświetl saldo konta klienta 1, uruchamiając to polecenie:
java -jar target/onlinebanking.jar query balance 1
Oczekiwane dane wyjściowe:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Jest 100 klientów, więc możesz też wysłać zapytanie o saldo dowolnego innego konta klienta, podając inny identyfikator klienta:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Przeprowadzanie wyszukiwania przybliżonego w e-mailach klientów
Wyszukiwanie przybliżone umożliwia znajdowanie przybliżonych wyników wyszukiwania, w tym odmian pisowni i literówek.
Indeks n-gramów został już dodany podczas tworzenia bazy danych i schematu:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
Metoda findCustomers używa funkcji SEARCH_NGRAMS i SCORE_NGRAMS do wysyłania zapytań do tego indeksu w celu wyszukiwania klientów według adresu e-mail. Ponieważ kolumna e-mail została podzielona na tokeny n-gramowe, to zapytanie może zawierać błędy ortograficzne, a mimo to zwracać prawidłową odpowiedź. Wyniki są uporządkowane według najlepszego dopasowania.
Aby znaleźć pasujące adresy e-mail klientów zawierające madi, uruchom to polecenie:
java -jar target/onlinebanking.jar query email madi
Oczekiwane dane wyjściowe:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Odpowiedź zawiera najbliższe dopasowania, które zawierają ciąg madi lub podobny, w kolejności od najbardziej do najmniej trafnego.
Tak wygląda zapytanie wykonane bezpośrednio w Spanner Studio: 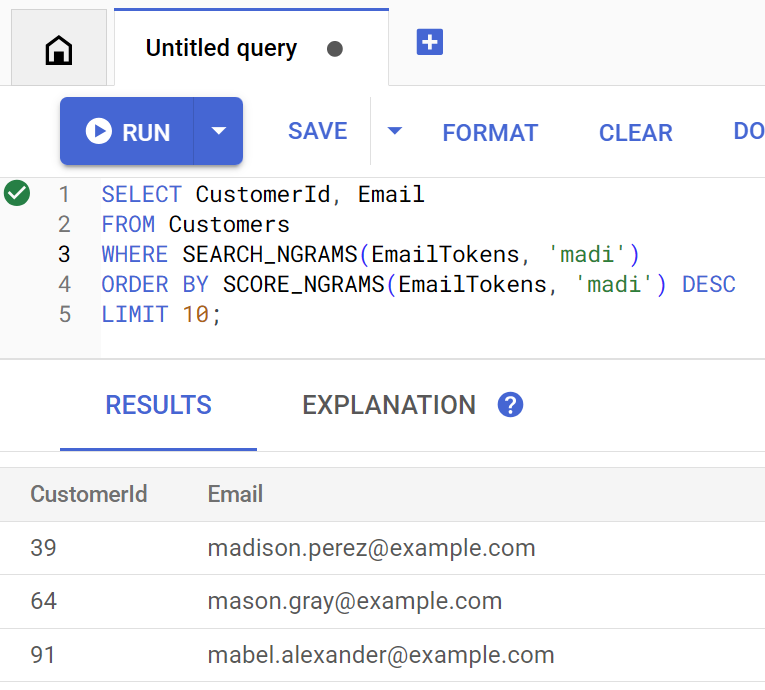
Wyszukiwanie przybliżone może też pomóc w przypadku błędów ortograficznych, np. błędnie napisanych słów: emily.
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Oczekiwane dane wyjściowe:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
W każdym przypadku oczekiwany e-mail klienta jest zwracany jako pierwszy wynik.
Wyszukiwanie transakcji za pomocą wyszukiwania pełnotekstowego
Funkcja wyszukiwania pełnotekstowego Spannera służy do pobierania rekordów na podstawie słów kluczowych lub wyrażeń. Może poprawiać błędy pisowni lub wyszukiwać synonimy.
Indeks wyszukiwania pełnotekstowego został już dodany podczas tworzenia bazy danych i schematu:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
Metoda getSpending korzysta z funkcji wyszukiwania pełnotekstowego SEARCH, aby dopasować wyniki do tego indeksu. Wyszukuje wszystkie wydatki (obciążenia) w ciągu ostatnich 30 dni w przypadku danego identyfikatora klienta.
Aby uzyskać łączne wydatki klienta 1 w kategorii groceries w ostatnim miesiącu, uruchom to polecenie:
java -jar target/onlinebanking.jar query spending 1 groceries
Oczekiwane dane wyjściowe:
Total spending for customer 1 under category groceries: 50
Możesz też sprawdzić wydatki w innych kategoriach (które zostały sklasyfikowane w poprzednim kroku) lub użyć innego identyfikatora klienta:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Podsumowanie
W tym kroku wykonano zapytania w dopasowaniu ścisłym, a także wyszukiwania przybliżone i pełnotekstowe.
Następny krok
Następnie zintegrujesz Spanner z Google BigQuery, aby wykonywać sfederowane zapytania, co umożliwi Ci łączenie danych Spanner w czasie rzeczywistym z danymi BigQuery.
8. Uruchamianie zapytań sfederowanych za pomocą BigQuery
Tworzenie zbioru danych BigQuery
W tym kroku połączysz dane BigQuery i Spanner za pomocą zapytań sfederowanych.
Aby to zrobić, w wierszu poleceń Cloud Shell utwórz najpierw zbiór danych MarketingCampaigns:
bq mk --location=us-central1 MarketingCampaigns
Oczekiwane dane wyjściowe:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
oraz tabelę CustomerSegments w zbiorze danych:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Oczekiwane dane wyjściowe:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Następnie utwórz połączenie z BigQuery do Spannera:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Oczekiwane dane wyjściowe:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Na koniec dodaj do tabeli BigQuery klientów, których można połączyć z danymi Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Oczekiwane dane wyjściowe:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Dostępność danych możesz sprawdzić, wysyłając zapytanie do BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Oczekiwane dane wyjściowe:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Te dane w BigQuery reprezentują dane dodane w ramach różnych przepływów pracy banku. Może to być np. lista klientów, którzy niedawno otworzyli konta lub zarejestrowali się w programie promocji marketingowych. Aby określić listę klientów, do których chcemy kierować naszą kampanię marketingową, musimy wysłać zapytanie dotyczące tych danych w BigQuery, a także danych w czasie rzeczywistym w Spannerze. Zapytanie federacyjne umożliwia nam to w ramach jednego zapytania.
Uruchamianie zapytania sfederowanego za pomocą BigQuery
Następnie dodamy do aplikacji metodę wywoływania funkcji EXTERNAL_QUERY w celu wykonania zapytania sfederowanego. Umożliwi to łączenie i analizowanie danych klientów w BigQuery i Spannerze, np. identyfikowanie klientów, którzy spełniają kryteria naszej kampanii marketingowej na podstawie ostatnich wydatków.
Otwórz plik App.java i zacznij od zastąpienia instrukcji importu:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Następnie dodaj metodę campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Dodaj kolejną instrukcję case w metodzie main dla kampanii:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Na koniec dodaj do printUsageAndExit metodę: jak używać kampanii
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Zapisz zmiany wprowadzone w pliku App.java.
Przebuduj aplikację:
mvn package
Uruchom zapytanie sfederowane, aby określić klientów, którzy powinni zostać uwzględnieni w kampanii marketingowej (campaign1), jeśli w ciągu ostatnich 3 miesięcy wydali co najmniej $5000. W tym celu uruchom polecenie campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
Oczekiwane dane wyjściowe:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Możemy teraz kierować do tych klientów ekskluzywne oferty lub nagrody.
Możemy też poszukać większej liczby klientów, którzy w ciągu ostatnich 3 miesięcy osiągnęli niższy próg wydatków:
java -jar target/onlinebanking.jar campaign campaign1 2500
Oczekiwane dane wyjściowe:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Podsumowanie
W tym kroku udało Ci się wykonać sfederowane zapytania z BigQuery, które pobrały dane z Spannera w czasie rzeczywistym.
Następny krok
Następnie możesz zwolnić miejsce zajmowane przez zasoby utworzone na potrzeby tego ćwiczenia z programowania, aby uniknąć opłat.
9. Czyszczenie (opcjonalnie)
Ten krok jest opcjonalny. Jeśli chcesz nadal eksperymentować z instancją Spanner, nie musisz jej teraz czyścić. Jednak projekt, którego używasz, będzie nadal obciążany opłatami za instancję. Jeśli nie potrzebujesz już tej instancji, usuń ją, aby uniknąć tych opłat. Oprócz instancji Spannera w ramach tego samouczka utworzono też zbiór danych i połączenie BigQuery, które należy usunąć, gdy nie będą już potrzebne.
Usuń instancję usługi Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
Potwierdź, że chcesz kontynuować (wpisz Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Usuń połączenie z BigQuery i zbiór danych:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Potwierdź usunięcie zbioru danych BigQuery (wpisz Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Gratulacje
🚀 Utworzono nową instancję Cloud Spanner, utworzono pustą bazę danych, wczytano przykładowe dane, wykonano zaawansowane operacje i zapytania oraz (opcjonalnie) usunięto instancję Cloud Spanner.
Omówione zagadnienia
- Jak skonfigurować instancję usługi Spanner.
- Jak utworzyć bazę danych i tabele.
- Jak wczytywać dane do tabel bazy danych Spanner.
- Jak wywoływać modele Vertex AI ze Spannera.
- Jak wysyłać zapytania do bazy danych Spanner za pomocą wyszukiwania przybliżonego i pełnotekstowego.
- Jak wykonywać sfederowane zapytania do Spannera z BigQuery.
- Jak usunąć instancję usługi Spanner.
Co dalej?
- Dowiedz się więcej o zaawansowanych funkcjach Spannera, w tym:
- Zobacz dostępne biblioteki klienta Spanner.