
1. Visão geral
O Spanner é um serviço de banco de dados totalmente gerenciado, escalonável horizontalmente e distribuído globalmente, ideal para cargas de trabalho operacionais relacionais e não relacionais. Além dos recursos principais, o Spanner oferece recursos avançados e poderosos que permitem criar aplicativos inteligentes e orientados por dados.
Este codelab se baseia no entendimento fundamental do Spanner e se aprofunda no uso das integrações avançadas para melhorar o processamento de dados e os recursos analíticos, usando um aplicativo de banco on-line como base.
Vamos nos concentrar em três recursos avançados principais:
- Integração com a Vertex AI:saiba como integrar o Spanner à plataforma de IA do Google Cloud, a Vertex AI. Você vai aprender a invocar modelos da Vertex AI diretamente de consultas SQL do Spanner, permitindo transformações e previsões eficientes no banco de dados. Assim, nosso aplicativo bancário pode categorizar transações automaticamente para casos de uso como acompanhamento de orçamento e detecção de anomalias.
- Pesquisa de texto completo:saiba como implementar a funcionalidade de pesquisa de texto completo no Spanner. Você vai explorar a indexação de dados de texto e escrever consultas eficientes para realizar pesquisas baseadas em palavras-chave nos seus dados operacionais, permitindo uma descoberta de dados eficiente, como encontrar clientes por endereço de e-mail no nosso sistema bancário.
- Consultas federadas do BigQuery:saiba como aproveitar os recursos de consulta federada do Spanner para consultar diretamente dados no BigQuery. Isso permite combinar os dados operacionais em tempo real do Spanner com os conjuntos de dados analíticos do BigQuery para insights e relatórios abrangentes sem duplicação de dados ou processos complexos de ETL, impulsionando vários casos de uso no nosso aplicativo bancário, como campanhas de marketing segmentadas, combinando dados do cliente em tempo real com tendências históricas mais amplas do BigQuery.
O que você vai aprender
- Como configurar uma instância do Spanner.
- Como criar um banco de dados e tabelas.
- Como carregar dados nas tabelas do banco de dados do Spanner.
- Como chamar modelos da Vertex AI no Spanner.
- Como consultar seu banco de dados do Spanner usando pesquisa aproximada e pesquisa de texto completo.
- Como executar consultas federadas no Spanner do BigQuery.
- Como excluir uma instância do Spanner.
O que é necessário
2. Configuração e requisitos
Criar um projeto
Se você já tiver um projeto na nuvem do Google Cloud com o faturamento ativado, clique no menu suspenso de seleção no canto superior esquerdo do console:

Com um projeto selecionado, pule para Ativar as APIs necessárias.
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), crie uma. Faça login no Console do Google Cloud Platform (console.cloud.google.com) e crie um projeto.
Clique no botão "NEW PROJECT" na caixa de diálogo exibida para criar um novo projeto:
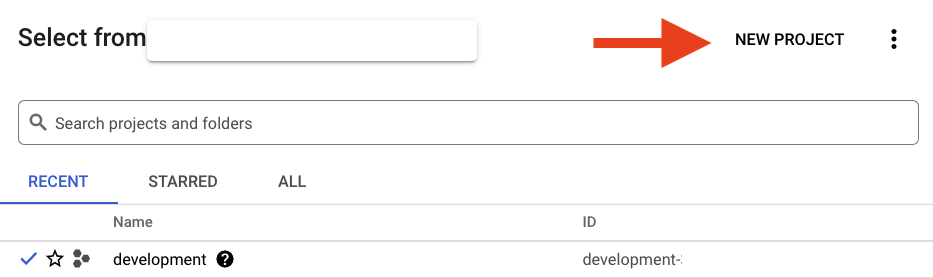
Se você ainda não tiver um projeto, uma caixa de diálogo como esta será exibida para criar seu primeiro:
A caixa de diálogo de criação de projeto subsequente permite que você insira os detalhes do novo projeto.
Lembre-se do ID do projeto, um nome exclusivo em todos os projetos do Google Cloud. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
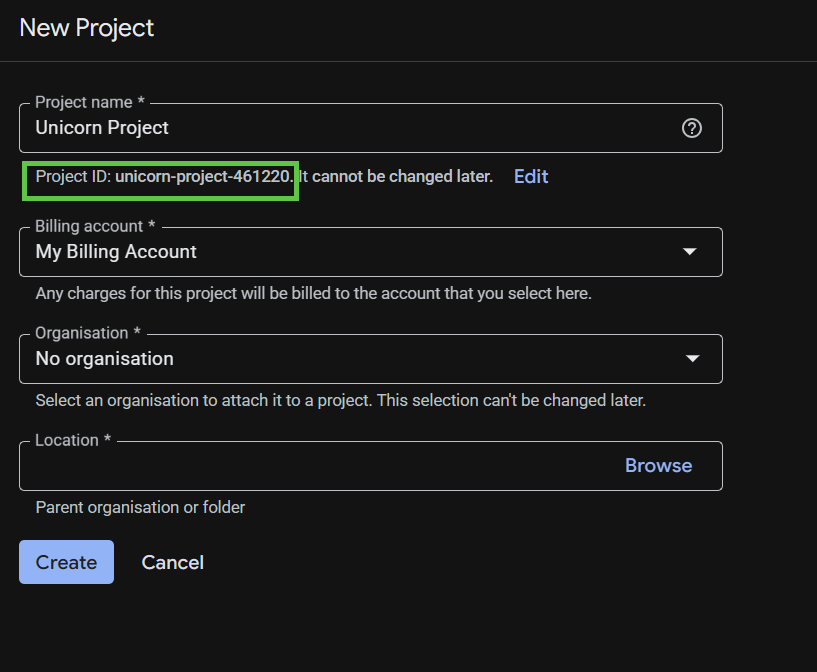
Em seguida, se ainda não tiver feito isso, ative o faturamento no Developers Console para usar os recursos do Google Cloud e ative a API Spanner, a API Vertex AI, a API BigQuery e a API BigQuery Connection.
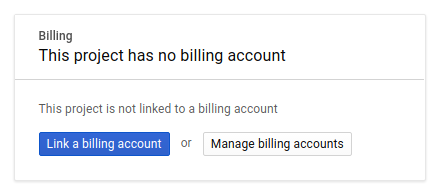
Os preços do Spanner estão documentados aqui. Outros custos associados a outros recursos serão documentados nas páginas de preços específicas.
Novos usuários do Google Cloud Platform têm direito a uma avaliação sem custo financeiro de US$300.
Configuração do Google Cloud Shell
Neste codelab, vamos usar o Google Cloud Shell, um ambiente de linha de comando executado na nuvem.
O Cloud Shell é uma máquina virtual com base em Debian que contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Isso significa que tudo que você precisa para este codelab é um navegador.
Para ativar o Cloud Shell no Console do Cloud, basta clicar em Ativar o Cloud Shell ![]() . Leva apenas alguns instantes para provisionar e se conectar ao ambiente.
. Leva apenas alguns instantes para provisionar e se conectar ao ambiente.

Depois de se conectar ao Cloud Shell, você já estará autenticado e o projeto estará configurado com seu PROJECT_ID.
gcloud auth list
Saída esperada:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Saída esperada:
[core] project = <PROJECT_ID>
Se, por algum motivo, o projeto não estiver definido, execute o seguinte comando:
gcloud config set project <PROJECT_ID>
Quer encontrar seu PROJECT_ID? Confira qual ID você usou nas etapas de configuração ou procure-o no painel do Console do Cloud:
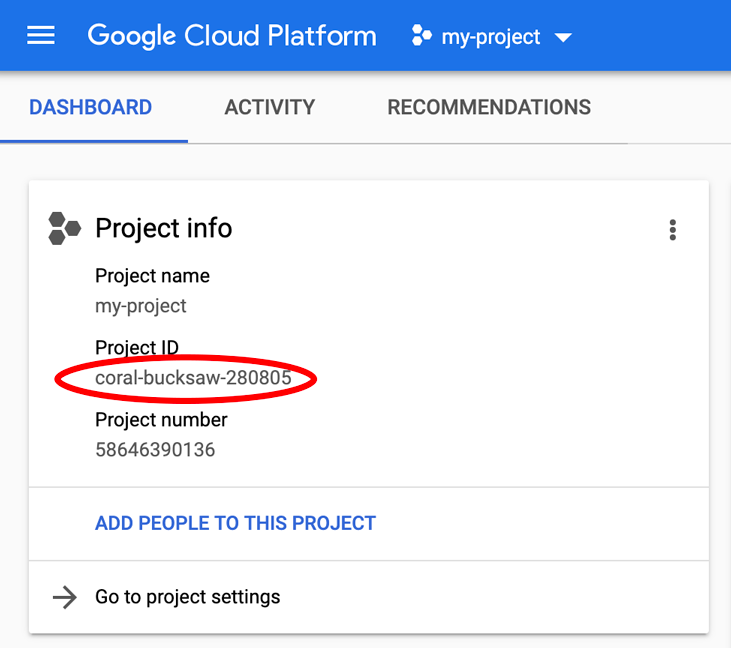
O Cloud Shell também define algumas variáveis de ambiente por padrão, o que pode ser útil ao executar comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Saída esperada:
<PROJECT_ID>
Ative as APIs necessárias
Ative as APIs Spanner, Vertex AI e BigQuery para seu projeto:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Resumo
Nesta etapa, você configurou seu projeto, caso ainda não tivesse um, ativou o Cloud Shell e as APIs necessárias.
A seguir
Em seguida, configure a instância do Spanner.
3. Configurar uma instância do Spanner
Criar a instância do Spanner
Nesta etapa, você vai configurar uma instância do Spanner para o codelab. Para fazer isso, abra o Cloud Shell e execute este comando:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Saída esperada:
Creating instance...done.
Resumo
Nesta etapa, você criou a instância do Spanner.
A seguir
Em seguida, você vai preparar o aplicativo inicial e criar o banco de dados e o esquema.
4. Criar um banco de dados e um esquema
Preparar a inscrição inicial
Nesta etapa, você vai criar o banco de dados e o esquema usando o código.
Primeiro, crie um aplicativo Java chamado onlinebanking usando o Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Faça o checkout e copie os arquivos de dados que vamos adicionar ao banco de dados. Consulte aqui para acessar o repositório de código:
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Navegue até a pasta do aplicativo:
cd onlinebanking
Abra o arquivo pom.xml do Maven. Adicione a seção de gerenciamento de dependências para usar a BOM do Maven e gerenciar a versão das bibliotecas do Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Esta é a aparência do editor e do arquivo: 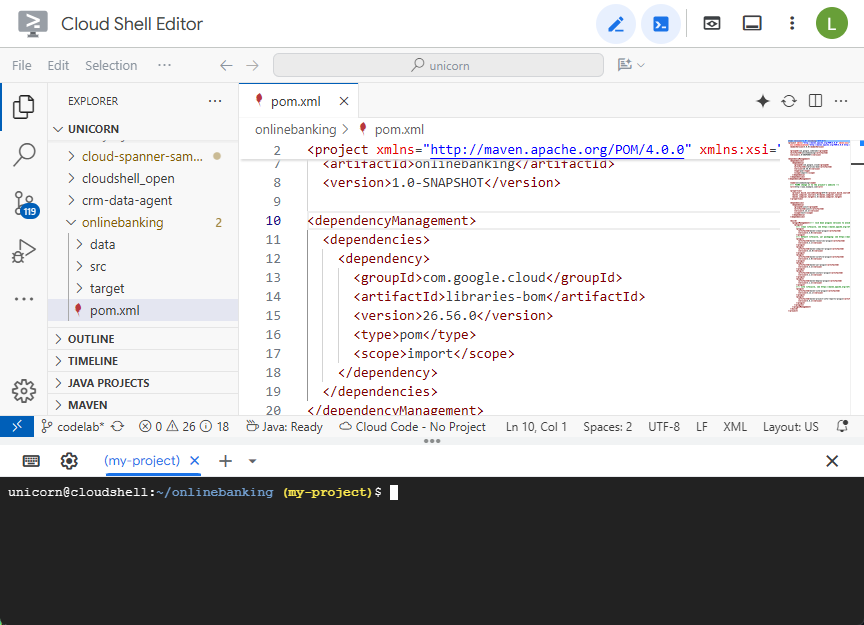
Verifique se a seção dependencies inclui as bibliotecas que o aplicativo vai usar:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Por fim, substitua os plug-ins de build para que o aplicativo seja empacotado em um JAR executável:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Salve as mudanças feitas no arquivo pom.xml selecionando "Salvar" no menu "Arquivo" do editor do Cloud Shell ou pressionando Ctrl+S.
Agora que as dependências estão prontas, você vai adicionar código ao app para criar um esquema, alguns índices (incluindo pesquisa) e um modelo de IA conectado a um endpoint remoto. Você vai criar esses artefatos e adicionar mais métodos a essa classe ao longo deste codelab.
Abra App.java em onlinebanking/src/main/java/com/google/codelabs e substitua o conteúdo pelo seguinte código:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Salve as mudanças em App.java.
Confira as diferentes entidades que seu código está criando e crie o JAR do aplicativo:
mvn package
Saída esperada:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Execute o aplicativo para conferir as informações de uso:
java -jar target/onlinebanking.jar
Saída esperada:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Criar o banco de dados e o esquema
Defina as variáveis de ambiente necessárias do aplicativo:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Execute o comando create para criar o banco de dados e o esquema:
java -jar target/onlinebanking.jar create
Saída esperada:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Verificar o esquema no Spanner
No console do Spanner, acesse a instância e o banco de dados que acabaram de ser criados.
As três tabelas (Accounts, Customers e TransactionLedger) vão aparecer.
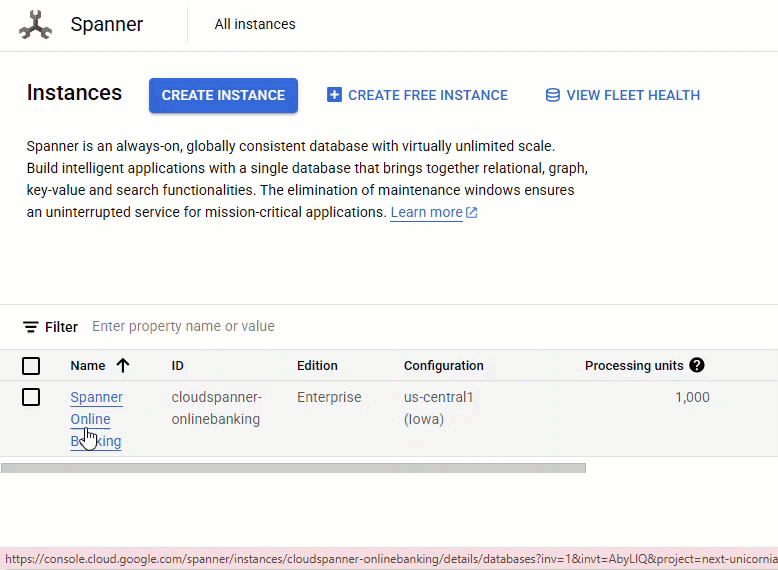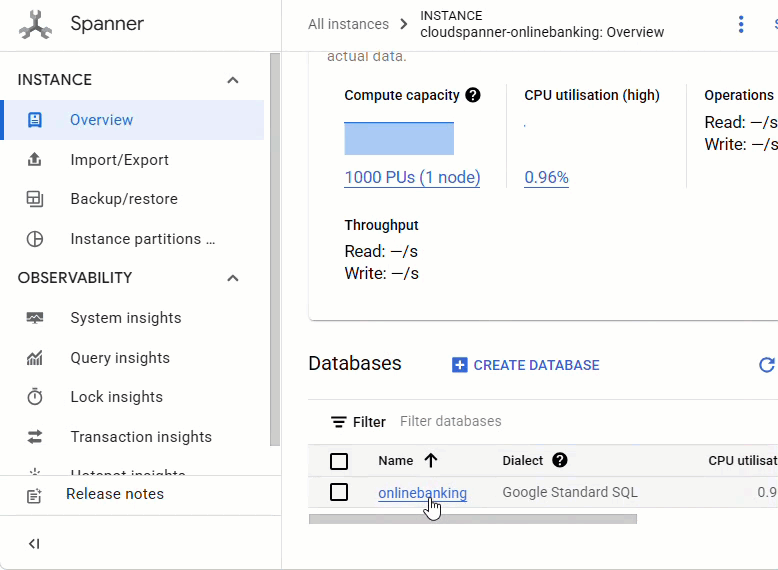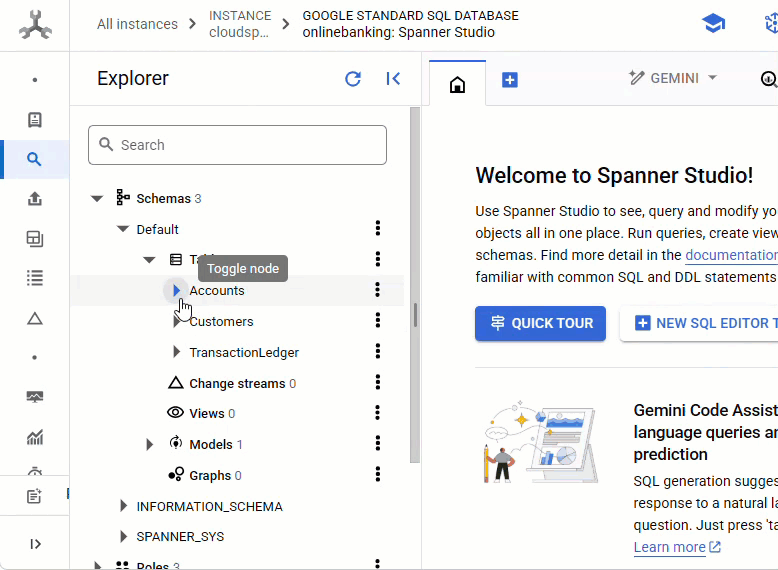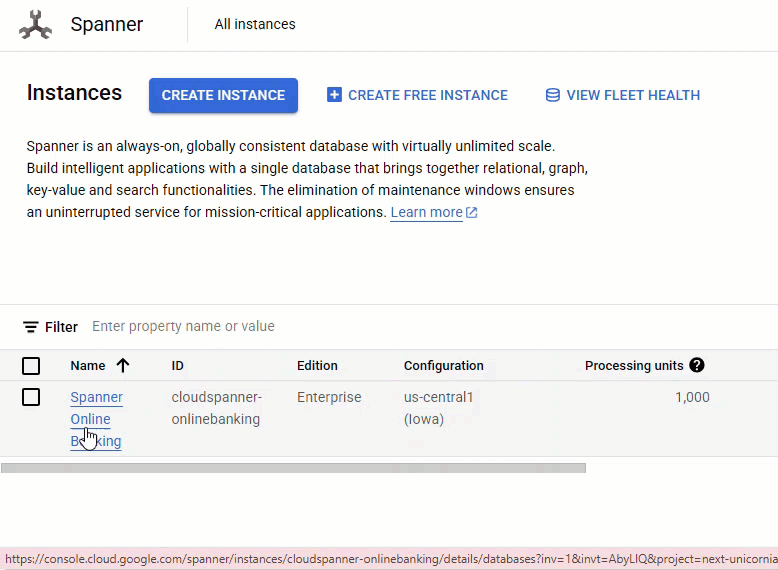
Essa ação cria o esquema do banco de dados, incluindo as tabelas Accounts, Customers e TransactionLedger, além de índices secundários para recuperação otimizada de dados e uma referência de modelo da Vertex AI.
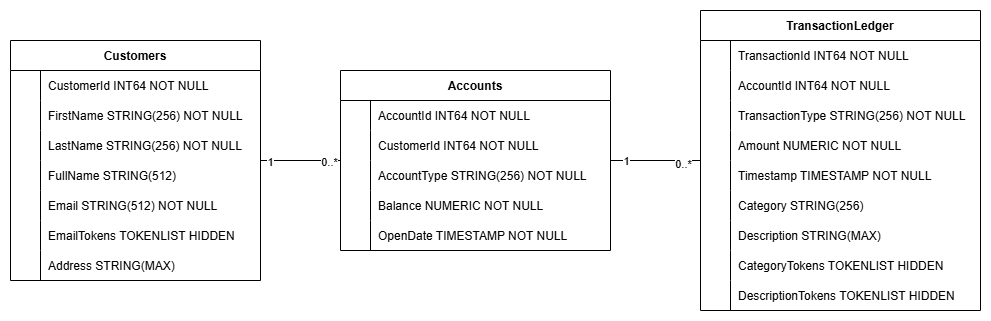
A tabela TransactionLedger é intercalada nas contas para melhorar o desempenho da consulta de transações específicas da conta com uma localidade de dados aprimorada.
Os índices secundários (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) foram implementados para otimizar padrões comuns de acesso aos dados usados neste codelab, como pesquisas de clientes por e-mail exato e aproximado, recuperação de contas por cliente e consulta e pesquisa eficientes de dados de transação.
O TransactionCategoryModel usa a Vertex AI para permitir chamadas SQL diretas a um LLM, que é usado para categorização dinâmica de transações neste codelab.
Resumo
Nesta etapa, você criou o banco de dados e o esquema do Spanner.
A seguir
Em seguida, carregue os dados do aplicativo de amostra.
5. Carregar dados
Agora, você vai adicionar a funcionalidade para carregar dados de amostra de arquivos CSV no banco de dados.
Abra App.java e comece substituindo as importações:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Em seguida, adicione os métodos de inserção à classe App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Adicione outra instrução case no método main para inserção em switch (command):
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Por fim, adicione como usar "insert" ao método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Salve as mudanças feitas em App.java.
Recrie o aplicativo:
mvn package
Insira os dados de amostra executando o comando insert:
java -jar target/onlinebanking.jar insert
Saída esperada:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
No console do Spanner, volte ao Spanner Studio para sua instância e banco de dados. Em seguida, selecione a tabela TransactionLedger e clique em "Dados" na barra lateral para verificar se os dados foram carregados. A tabela precisa ter 200 linhas.
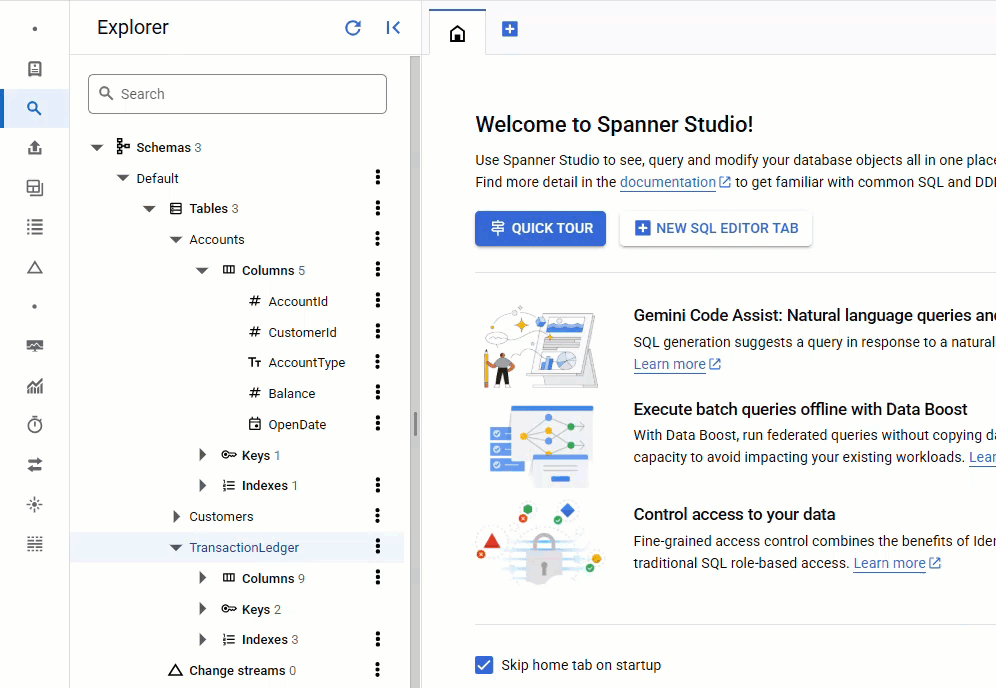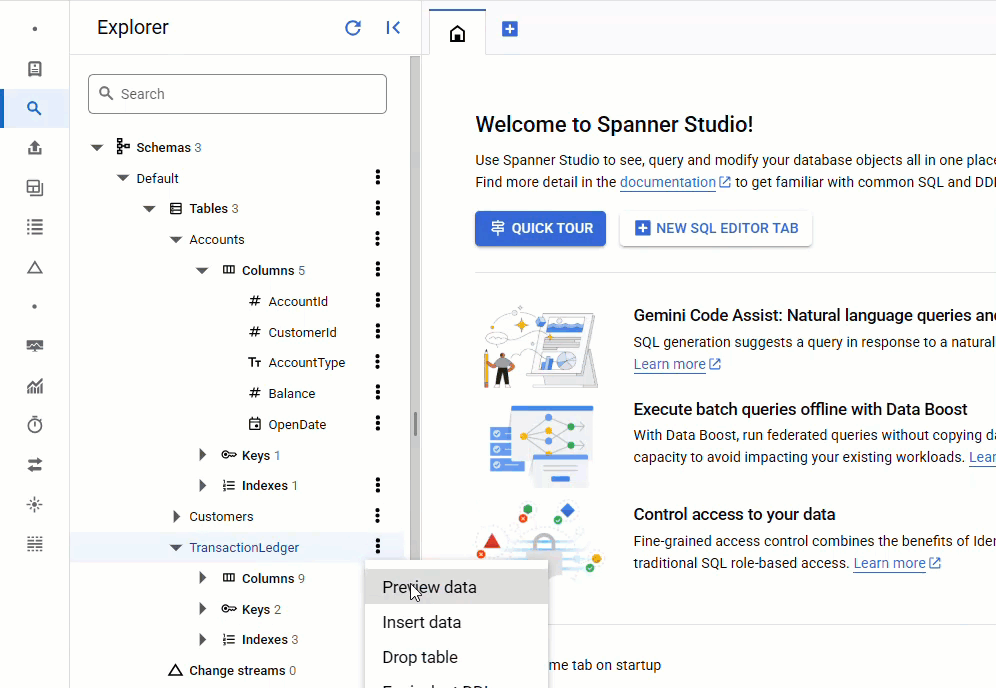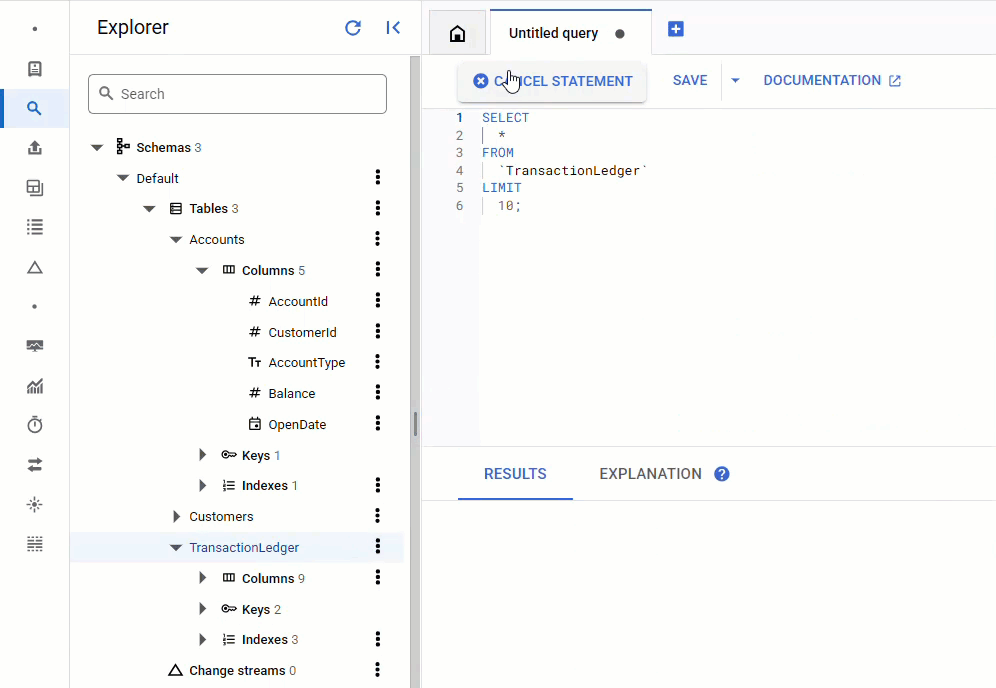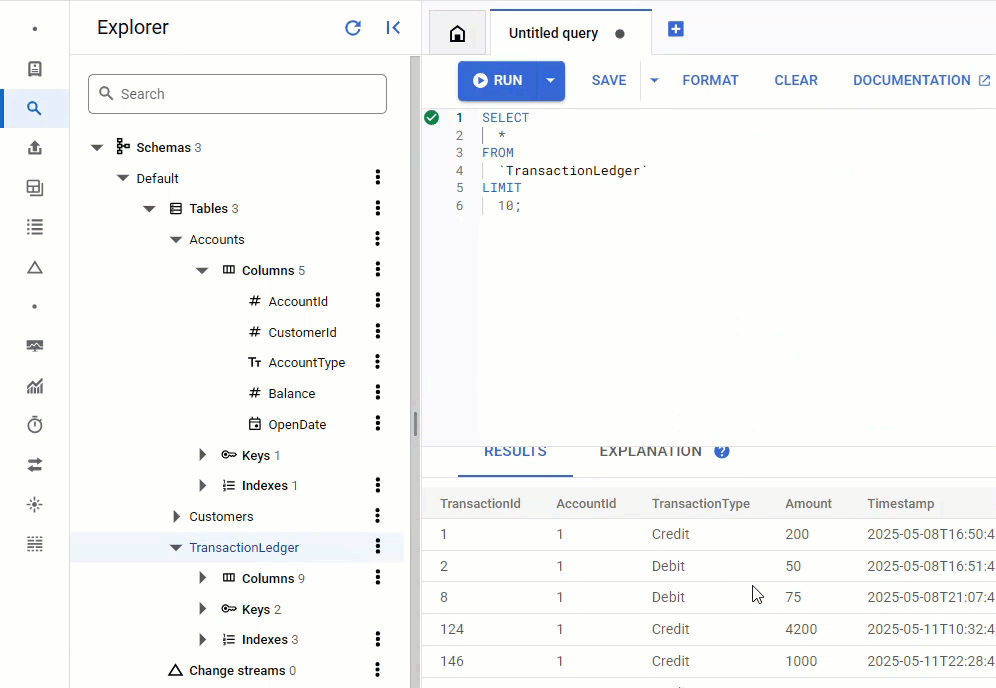
Resumo
Nesta etapa, você inseriu os dados de amostra no banco de dados.
A seguir
Em seguida, você vai aproveitar a integração da Vertex AI para categorizar automaticamente transações bancárias diretamente no SQL do Spanner.
6. Categorizar dados com a Vertex AI
Nesta etapa, você vai aproveitar o poder da Vertex AI para categorizar automaticamente suas transações financeiras diretamente no Spanner SQL. Com a Vertex AI, é possível escolher um modelo pré-treinado ou treinar e implantar o seu. Confira os modelos disponíveis no Model Garden da Vertex AI.
Neste codelab, vamos usar um dos modelos do Gemini, o Gemini Flash Lite. Essa versão do Gemini tem um bom custo-benefício e ainda pode lidar com a maioria das cargas de trabalho diárias.
No momento, temos várias transações financeiras que gostaríamos de categorizar (groceries, transportation etc.) dependendo da descrição. Para isso, registre um modelo no Spanner e use ML.PREDICT para chamar o modelo de IA.
No nosso aplicativo bancário, podemos categorizar transações para ter insights mais profundos sobre o comportamento do cliente e personalizar serviços, detectar anomalias com mais eficiência ou permitir que o cliente acompanhe o orçamento mês a mês.
A primeira etapa já foi concluída quando criamos o banco de dados e o esquema, o que gerou um modelo como este:
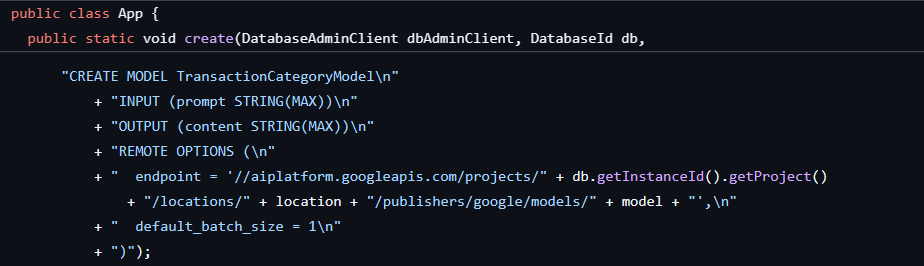
Em seguida, vamos adicionar um método ao aplicativo para chamar ML.PREDICT.
Abra App.java e adicione o método categorize:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Adicione outra instrução case no método main para categorizar:
case "categorize":
categorize(dbClient);
break;
Por fim, adicione como usar "categorize" ao método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Salve as mudanças feitas em App.java.
Recrie o aplicativo:
mvn package
Execute o comando categorize para categorizar as transações no banco de dados:
java -jar target/onlinebanking.jar categorize
Saída esperada:
Categorizing transactions... Completed categorizing transactions
No Spanner Studio, execute a instrução Visualizar dados para a tabela TransactionLedger. A coluna Category agora vai ser preenchida em todas as linhas.
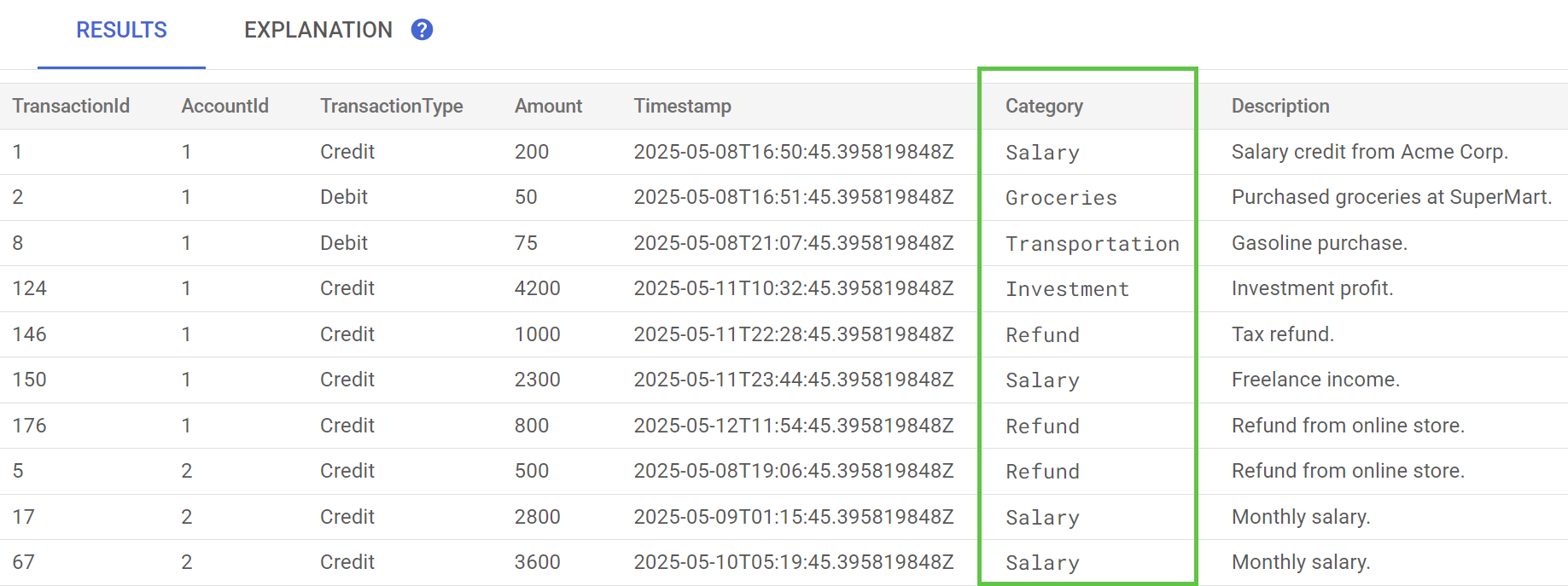
Agora que categorizamos as transações, podemos usar essas informações para consultas internas ou voltadas ao cliente. Na próxima etapa, vamos analisar como descobrir quanto um determinado cliente está gastando em uma categoria ao longo do mês.
Resumo
Nesta etapa, você usou um modelo pré-treinado para realizar a categorização dos seus dados com tecnologia de IA.
A seguir
Em seguida, você vai usar a tokenização para realizar pesquisas difusas e de texto completo.
7. Consulta usando a pesquisa de texto completo
Adicionar o código de consulta
O Spanner oferece muitas consultas de pesquisa de texto completo. Nesta etapa, você vai realizar uma pesquisa de correspondência exata, uma pesquisa difusa e uma pesquisa de texto completo.
Abra App.java e comece substituindo as importações:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Em seguida, adicione os métodos de consulta:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Adicione outra instrução case ao método main para consulta:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Por fim, adicione como usar os comandos de consulta ao método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Salve as mudanças feitas em App.java.
Recrie o aplicativo:
mvn package
Fazer uma pesquisa de correspondência exata para saldos de contas de clientes
Uma consulta de correspondência exata procura linhas que correspondem exatamente a um termo.
Para melhorar o desempenho, um índice já foi adicionado quando você criou o banco de dados e o esquema:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
O método getBalance usa implicitamente esse índice para encontrar clientes que correspondem ao customerId fornecido e também faz junções em contas pertencentes a esse cliente.
Esta é a aparência da consulta quando executada diretamente no Spanner Studio: 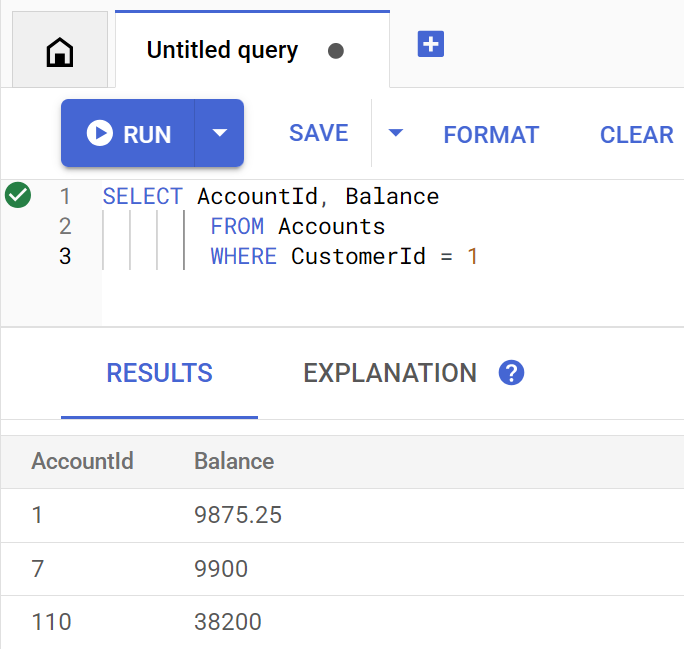
Execute o comando a seguir para listar os saldos da conta do cliente 1:
java -jar target/onlinebanking.jar query balance 1
Saída esperada:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Há 100 clientes, então você também pode consultar qualquer um dos outros saldos de contas de clientes especificando um ID de cliente diferente:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Fazer uma pesquisa difusa nos e-mails dos clientes
As pesquisas aproximadas permitem encontrar correspondências aproximadas para termos de pesquisa, incluindo variações ortográficas e erros de digitação.
Um índice de n-gramas já foi adicionado quando você criou o banco de dados e o esquema:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
O método findCustomers usa SEARCH_NGRAMS e SCORE_NGRAMS para consultar esse índice e encontrar clientes por e-mail. Como a coluna de e-mail foi tokenizada com n-gramas, essa consulta pode conter erros de ortografia e ainda retornar uma resposta correta. Os resultados são ordenados com base na melhor correspondência.
Para encontrar endereços de e-mail de clientes correspondentes que contenham madi, execute o comando:
java -jar target/onlinebanking.jar query email madi
Saída esperada:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Essa resposta mostra as correspondências mais próximas que incluem madi ou uma string semelhante, em ordem de classificação.
Esta é a aparência da consulta se ela for executada diretamente no Spanner Studio: 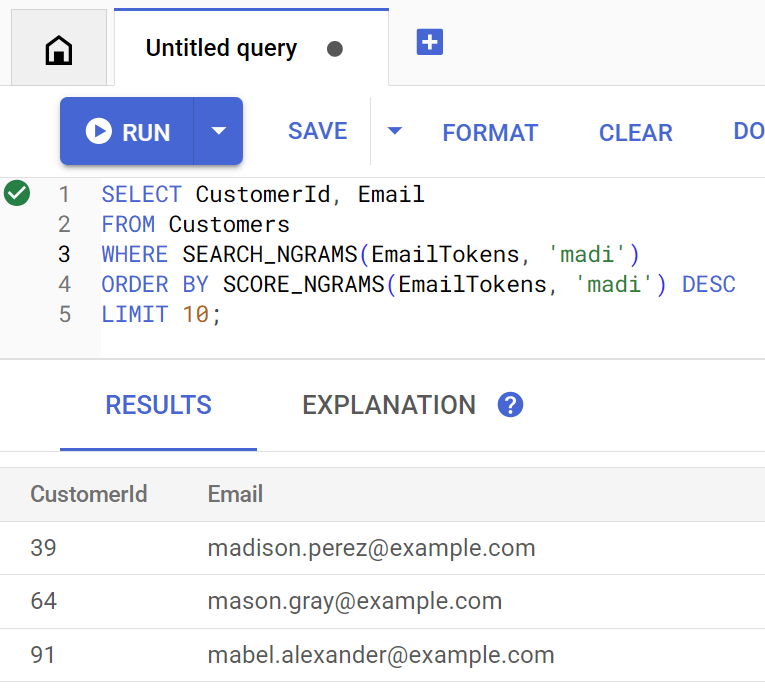
A pesquisa imprecisa também pode ajudar com erros de ortografia, como grafias incorretas de emily:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Saída esperada:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
Em cada caso, o e-mail esperado do cliente é retornado como o principal resultado.
Pesquisar transações com a pesquisa de texto completo
O recurso de pesquisa de texto completo do Spanner é usado para recuperar registros com base em palavras-chave ou frases. Ele pode corrigir erros de ortografia ou pesquisar sinônimos.
Um índice de pesquisa de texto completo já foi adicionado quando você criou o banco de dados e o esquema:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
O método getSpending usa a função de pesquisa de texto completo SEARCH para fazer a correspondência com esse índice. Ele procura todos os gastos (débitos) nos últimos 30 dias para o ID de cliente especificado.
Para saber o gasto total do cliente 1 na categoria groceries no último mês, execute o comando:
java -jar target/onlinebanking.jar query spending 1 groceries
Saída esperada:
Total spending for customer 1 under category groceries: 50
Você também pode encontrar gastos em outras categorias (que categorizamos em uma etapa anterior) ou usar um ID de cliente diferente:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Resumo
Nesta etapa, você fez consultas de correspondência exata, além de pesquisas difusas e de texto completo.
A seguir
Em seguida, você vai integrar o Spanner ao Google BigQuery para realizar consultas federadas, permitindo combinar seus dados do Spanner em tempo real com os dados do BigQuery.
8. Executar consultas federadas com o BigQuery
Crie o conjunto de dados do BigQuery
Nesta etapa, você vai reunir dados do BigQuery e do Spanner usando consultas federadas.
Para isso, na linha de comando do Cloud Shell, primeiro crie um conjunto de dados MarketingCampaigns:
bq mk --location=us-central1 MarketingCampaigns
Saída esperada:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
e uma tabela CustomerSegments no conjunto de dados:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Saída esperada:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Em seguida, faça uma conexão do BigQuery com o Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Saída esperada:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Por fim, adicione alguns clientes à tabela do BigQuery que podem ser unidos aos dados do Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Saída esperada:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Para verificar se os dados estão disponíveis, consulte o BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Saída esperada:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Esses dados no BigQuery representam dados que foram adicionados por vários fluxos de trabalho bancários. Por exemplo, pode ser a lista de clientes que abriram contas ou se inscreveram em uma promoção de marketing recentemente. Para determinar a lista de clientes que queremos segmentar na nossa campanha de marketing, precisamos consultar esses dados no BigQuery e os dados em tempo real no Spanner. Uma consulta federada permite fazer isso em uma única consulta.
Executar uma consulta federada com o BigQuery
Em seguida, vamos adicionar um método ao aplicativo para chamar EXTERNAL_QUERY e realizar a consulta federada. Isso permite unir e analisar dados do cliente no BigQuery e no Spanner, como identificar quais clientes atendem aos critérios da nossa campanha de marketing com base nos gastos recentes.
Abra App.java e comece substituindo as importações:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Em seguida, adicione o método campaign:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Adicione outra instrução case no método main para a campanha:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Por fim, adicione como usar a campanha ao método printUsageAndExit:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Salve as mudanças feitas em App.java.
Recrie o aplicativo:
mvn package
Execute uma consulta federada para determinar os clientes que devem ser incluídos na campanha de marketing (campaign1) se gastaram pelo menos $5000 nos últimos três meses executando o comando campaign:
java -jar target/onlinebanking.jar campaign campaign1 5000
Saída esperada:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Agora podemos segmentar esses clientes com ofertas ou recompensas exclusivas.
Ou podemos procurar um número maior de clientes que atingiram um limite de gastos menor nos últimos três meses:
java -jar target/onlinebanking.jar campaign campaign1 2500
Saída esperada:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Resumo
Nesta etapa, você executou consultas federadas do BigQuery que trouxeram dados do Spanner em tempo real.
A seguir
Em seguida, libere memória dos recursos criados para este codelab e evite cobranças.
9. Limpeza (opcional)
Esta etapa é opcional. Se você quiser continuar a experimentar com sua instância do Spanner, não é necessário limpá-la agora. No entanto, o projeto que você está usando vai continuar sendo cobrado pela instância. Se você não precisar mais dessa instância, exclua-a agora para evitar essas cobranças. Além da instância do Spanner, este codelab também criou um conjunto de dados e uma conexão do BigQuery, que precisam ser limpos quando não forem mais necessários.
Exclua a instância do Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
Confirme que quer continuar (digite Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Exclua a conexão e o conjunto de dados do BigQuery:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Confirme a exclusão do conjunto de dados do BigQuery (digite Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Parabéns
🚀 Você criou uma instância do Cloud Spanner, um banco de dados vazio, carregou dados de amostra, realizou operações e consultas avançadas e (opcionalmente) excluiu a instância do Cloud Spanner.
O que aprendemos
- Como configurar uma instância do Spanner.
- Como criar um banco de dados e tabelas.
- Como carregar dados nas tabelas do banco de dados do Spanner.
- Como chamar modelos da Vertex AI no Spanner.
- Como consultar seu banco de dados do Spanner usando pesquisa aproximada e pesquisa de texto completo.
- Como executar consultas federadas no Spanner do BigQuery.
- Como excluir uma instância do Spanner.
A seguir
- Saiba mais sobre os recursos avançados do Spanner, incluindo:
- Consulte as bibliotecas de cliente do Spanner disponíveis.