
1. Обзор
Spanner — это полностью управляемая, горизонтально масштабируемая, глобально распределенная база данных, отлично подходящая как для реляционных, так и для нереляционных операционных нагрузок. Помимо основных возможностей, Spanner предлагает мощные расширенные функции, позволяющие создавать интеллектуальные и управляемые данными приложения.
Данный практический урок основан на базовых знаниях Spanner и посвящен использованию его расширенных интеграций для повышения эффективности обработки данных и аналитических возможностей, используя в качестве основы приложение для онлайн-банкинга.
Мы сосредоточимся на трех ключевых расширенных функциях:
- Интеграция с Vertex AI : узнайте, как легко интегрировать Spanner с платформой искусственного интеллекта Google Cloud, Vertex AI. Вы научитесь вызывать модели Vertex AI непосредственно из SQL-запросов Spanner, что позволит выполнять мощные преобразования и прогнозирование в базе данных, благодаря чему наше банковское приложение сможет автоматически классифицировать транзакции для таких задач, как отслеживание бюджета и обнаружение аномалий.
- Полнотекстовый поиск : Узнайте, как реализовать функцию полнотекстового поиска в Spanner. Вы изучите индексирование текстовых данных и написание эффективных запросов для выполнения поиска по ключевым словам в ваших операционных данных, что позволит эффективно находить данные, например, быстро находить клиентов по адресу электронной почты в нашей банковской системе.
- Федеративные запросы BigQuery : Узнайте, как использовать возможности федеративных запросов Spanner для прямого запроса данных, хранящихся в BigQuery. Это позволяет объединять оперативные данные Spanner в режиме реального времени с аналитическими наборами данных BigQuery для получения всесторонних аналитических данных и отчетов без дублирования данных или сложных процессов ETL, что позволяет реализовать различные сценарии использования в нашем банковском приложении, например, целевые маркетинговые кампании, путем объединения данных о клиентах в режиме реального времени с более широкими историческими тенденциями из BigQuery.
Что вы узнаете
- Как настроить экземпляр Spanner.
- Как создать базу данных и таблицы.
- Как загрузить данные в таблицы базы данных Spanner.
- Как вызывать модели Vertex AI из Spanner.
- Как выполнять запросы к базе данных Spanner с использованием нечеткого поиска и полнотекстового поиска.
- Как выполнять федеративные запросы к Spanner из BigQuery.
- Как удалить экземпляр Spanner.
Что вам понадобится
2. Настройка и требования
Создать проект
Если у вас уже есть проект Google Cloud с включенной оплатой, щелкните раскрывающееся меню выбора проекта в левом верхнем углу консоли:

Выбрав проект, перейдите к разделу «Включить необходимые API» .
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вам необходимо ее создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект.
Чтобы создать новый проект, нажмите кнопку «СОЗДАТЬ ПРОЕКТ» в появившемся диалоговом окне.
Если у вас ещё нет проекта, вы увидите диалоговое окно, подобное этому, для создания вашего первого проекта:
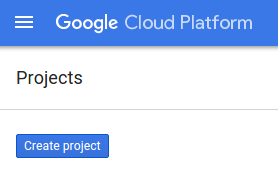
В появившемся диалоговом окне создания проекта вы можете ввести подробные сведения о вашем новом проекте.
Запомните идентификатор проекта (Project ID), который является уникальным именем для всех проектов Google Cloud. В дальнейшем в этом практическом занятии он будет обозначаться как PROJECT_ID .
Далее, если вы еще этого не сделали, вам необходимо включить оплату в консоли разработчика, чтобы использовать ресурсы Google Cloud, а также активировать API Spanner , API Vertex AI , API BigQuery и API подключения BigQuery .
Цены на гаечные ключи указаны здесь . Стоимость других услуг, связанных с использованием других ресурсов, будет указана на страницах с соответствующими ценами.
Новые пользователи Google Cloud Platform могут получить бесплатную пробную версию стоимостью 300 долларов .
Настройка Google Cloud Shell
В этом практическом занятии мы будем использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что для выполнения этого практического задания вам понадобится только браузер.
Для активации Cloud Shell из консоли Cloud Console просто нажмите кнопку «Активировать Cloud Shell». ![]() (Подготовка и подключение к среде займут всего несколько минут).
(Подготовка и подключение к среде займут всего несколько минут).

После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и проект уже настроен на ваш PROJECT_ID .
gcloud auth list
Ожидаемый результат:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Ожидаемый результат:
[core] project = <PROJECT_ID>
Если по какой-либо причине проект не задан, выполните следующую команду:
gcloud config set project <PROJECT_ID>
Ищете свой PROJECT_ID ? Проверьте, какой ID вы использовали на этапах настройки, или найдите его на панели управления Cloud Console :
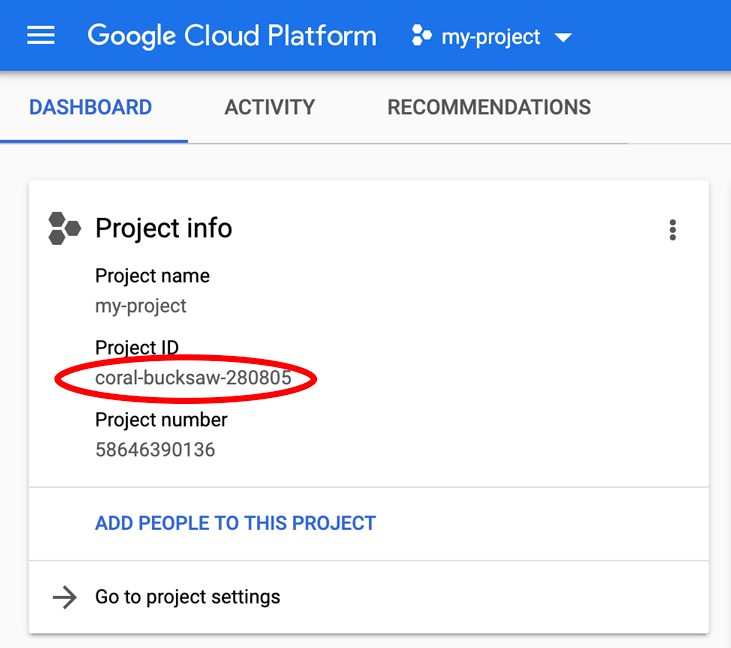
Cloud Shell также по умолчанию устанавливает некоторые переменные среды, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
Ожидаемый результат:
<PROJECT_ID>
Включите необходимые API.
Включите API Spanner, Vertex AI и BigQuery для вашего проекта:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Краткое содержание
На этом этапе вы настроили свой проект, если у вас его еще не было, активировали Cloud Shell и включили необходимые API.
Далее
Далее вам предстоит настроить экземпляр Spanner.
3. Настройте экземпляр Spanner.
Создайте экземпляр Spanner.
На этом шаге вы настроите экземпляр Spanner для выполнения практического задания. Для этого откройте Cloud Shell и выполните следующую команду:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Ожидаемый результат:
Creating instance...done.
Краткое содержание
На этом шаге вы создали экземпляр Spanner.
Далее
Далее вам предстоит подготовить исходное приложение, создать базу данных и схему.
4. Создайте базу данных и схему.
Подготовьте первоначальное заявление.
На этом этапе вы создадите базу данных и схему с помощью кода.
Сначала создайте Java-приложение с именем onlinebanking , используя Maven:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Загрузите и скопируйте файлы данных, которые мы добавим в базу данных (репозиторий с кодом находится здесь ):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Перейдите в папку приложения:
cd onlinebanking
Откройте файл pom.xml Maven. Добавьте раздел управления зависимостями, чтобы использовать Maven BOM для управления версиями библиотек Google Cloud:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Вот как будут выглядеть редактор и файл: 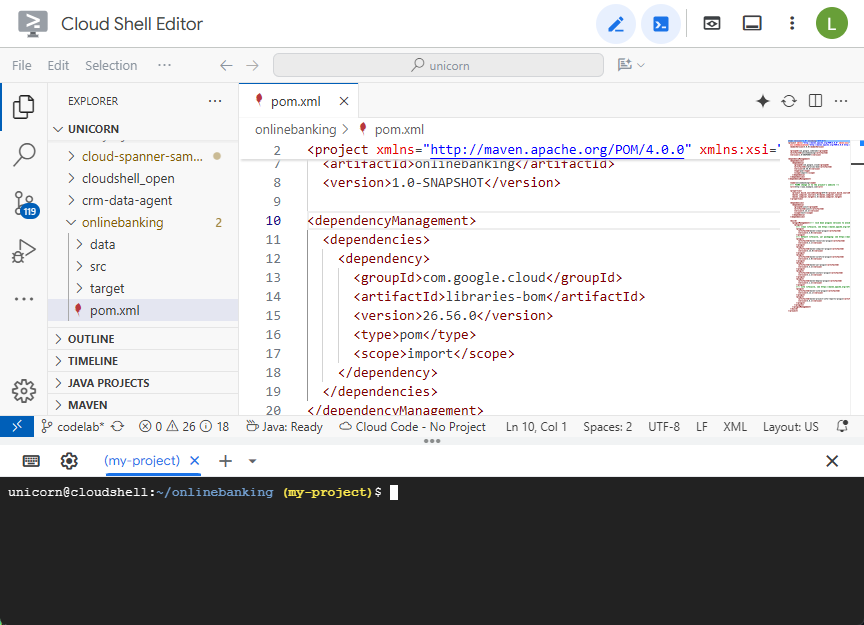
Убедитесь, что в разделе dependencies указаны библиотеки, которые будет использовать приложение:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Наконец, замените плагины сборки, чтобы приложение было упаковано в исполняемый JAR-файл:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Сохраните изменения, внесенные в файл pom.xml , выбрав «Сохранить» в меню «Файл» редактора Cloud Shell или нажав Ctrl+S .
Теперь, когда зависимости готовы, вы добавите код в приложение для создания схемы, нескольких индексов (включая поиск) и модели ИИ, подключенной к удаленной конечной точке. Вы будете развивать эти артефакты и добавлять новые методы в этот класс в ходе выполнения этого практического задания.
Откройте App.java в папке onlinebanking/src/main/java/com/google/codelabs и замените его содержимое следующим кодом:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
Сохраните изменения в файле App.java .
Проанализируйте различные сущности, которые создает ваш код, и соберите JAR-файл приложения:
mvn package
Ожидаемый результат:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Запустите приложение, чтобы просмотреть информацию об использовании:
java -jar target/onlinebanking.jar
Ожидаемый результат:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Создайте базу данных и схему.
Установите необходимые переменные среды приложения:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
Создайте базу данных и схему, выполнив команду create :
java -jar target/onlinebanking.jar create
Ожидаемый результат:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Проверьте схему в Spanner.
В консоли Spanner перейдите к только что созданному экземпляру и базе данных.
Вы должны увидеть все 3 таблицы: Accounts , Customers и TransactionLedger .
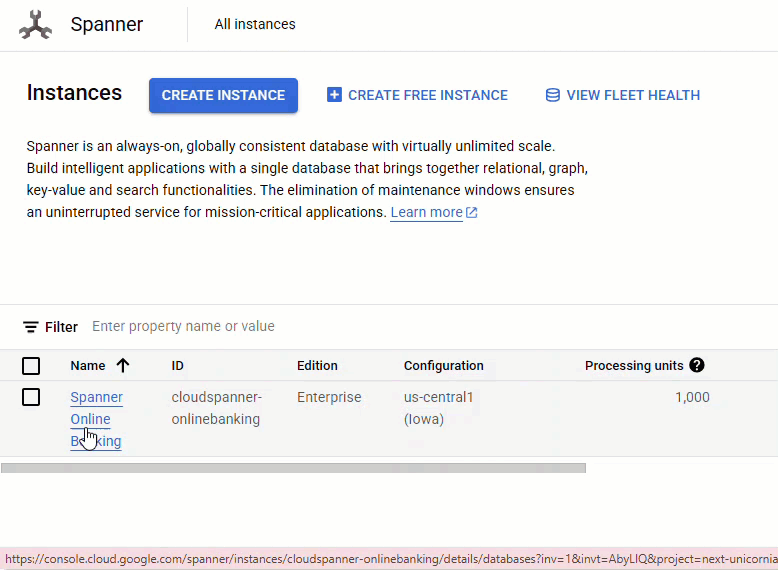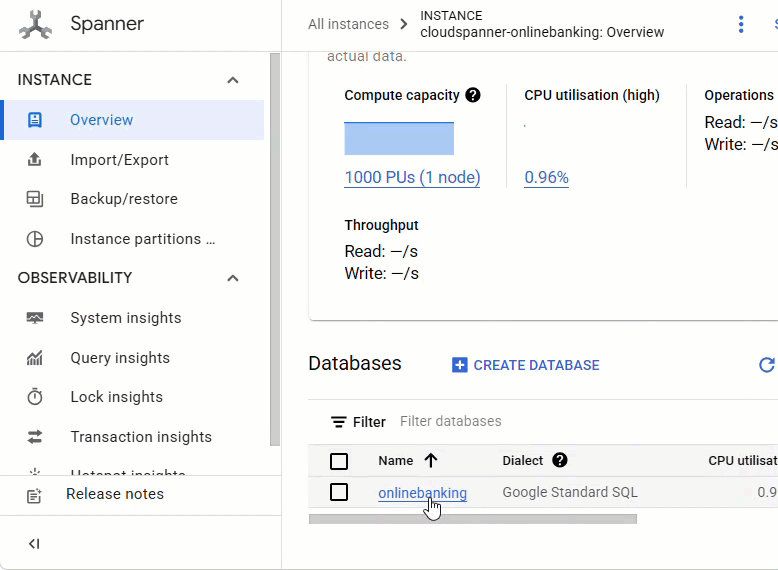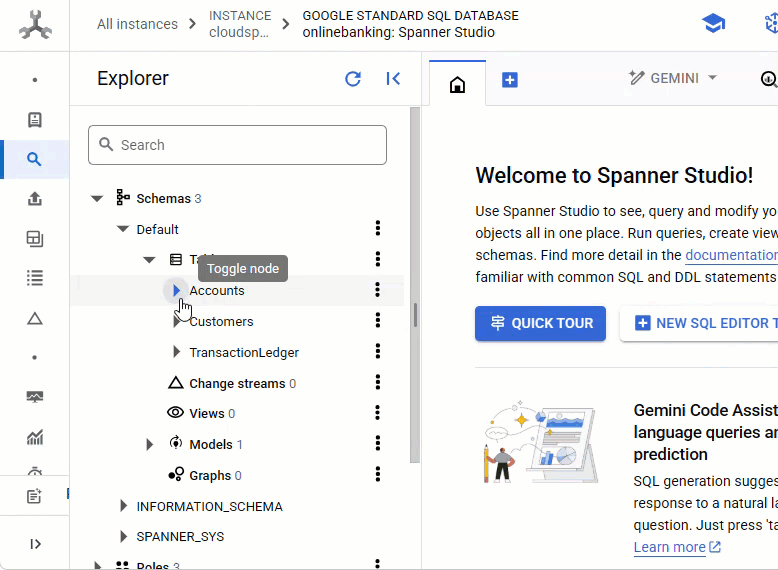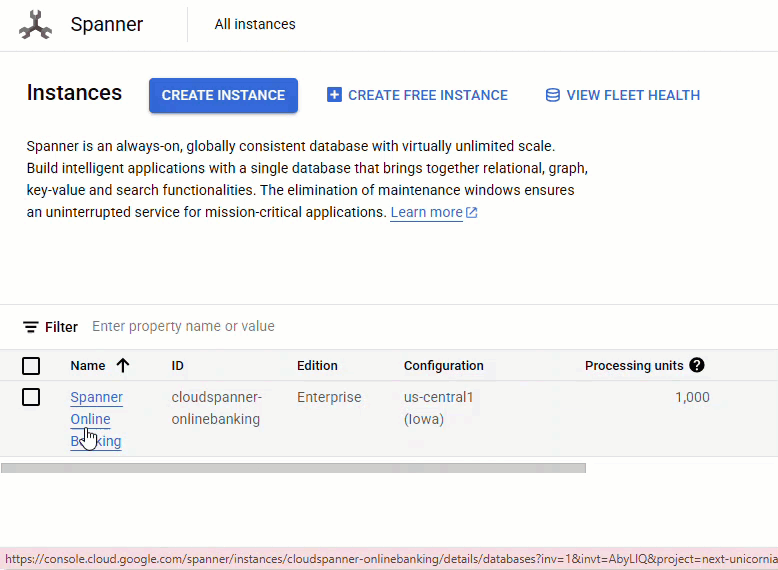
В результате этой операции создается схема базы данных, включая таблицы Accounts , Customers и TransactionLedger , а также вторичные индексы для оптимизированного извлечения данных и ссылку на модель Vertex AI.
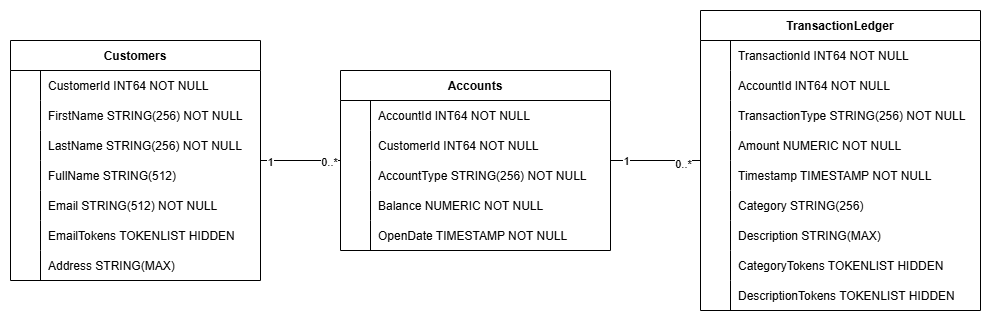
Таблица TransactionLedger интегрирована в таблицу Accounts для повышения производительности запросов к транзакциям, специфичным для каждой учетной записи, за счет улучшения локализации данных.
Для оптимизации распространенных шаблонов доступа TransactionLedgerByCategory данным AccountsByCustomer используемых в этом практическом занятии, таких как поиск клиентов по точному и TransactionLedgerByAccountType адресу электронной почты, получение учетных TransactionLedgerTextSearch по клиентам, а также эффективный запрос и поиск данных о транзакциях, были внедрены вторичные индексы ( CustomersByEmail , CustomersFuzzyEmail , AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch).
TransactionCategoryModel использует Vertex AI для обеспечения прямых SQL-запросов к LLM, которая применяется для динамической категоризации транзакций в этом практическом задании.
Краткое содержание
На этом шаге вы создали базу данных и схему Spanner.
Далее
Далее вам нужно будет загрузить данные тестового приложения.
5. Загрузка данных
Теперь вам предстоит добавить функциональность для загрузки примеров данных из CSV-файлов в базу данных.
Откройте App.java и начните с замены импортов:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Затем добавьте методы вставки в класс App :
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
Добавьте еще один оператор case в метод main для вставки внутри switch (command) :
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Наконец, добавьте в метод printUsageAndExit информацию о том, как использовать функцию insert:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
Сохраните изменения, внесенные в файл App.java .
Пересоберите приложение:
mvn package
Вставьте примерные данные, выполнив команду insert :
java -jar target/onlinebanking.jar insert
Ожидаемый результат:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
В консоли Spanner вернитесь в Spanner Studio для вашего экземпляра и базы данных. Затем выберите таблицу TransactionLedger и нажмите «Данные» на боковой панели, чтобы убедиться, что данные загружены. В таблице должно быть 200 строк.
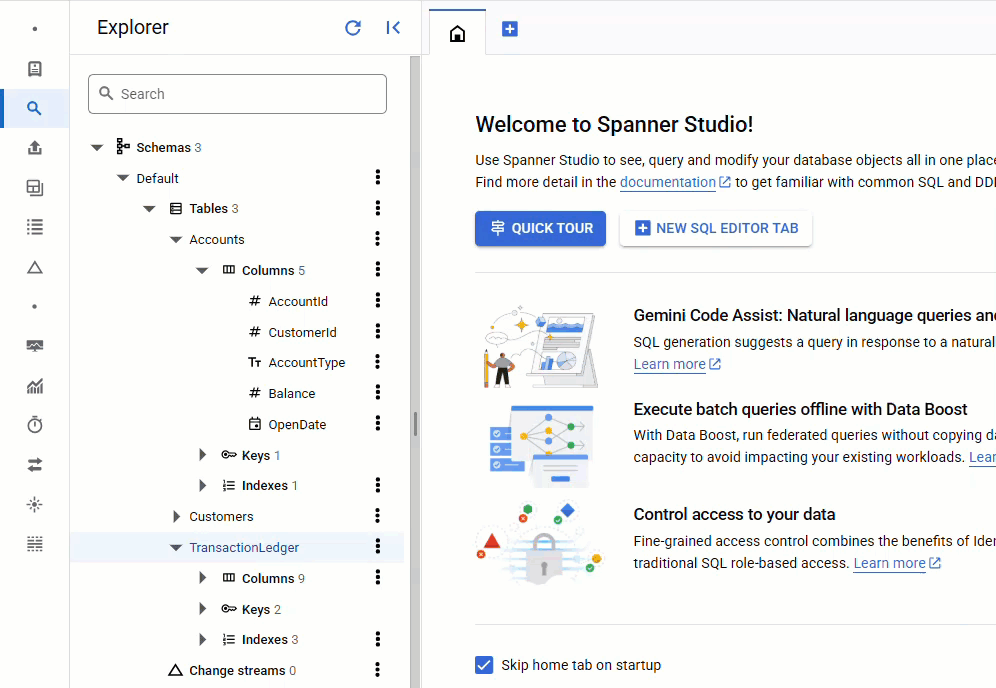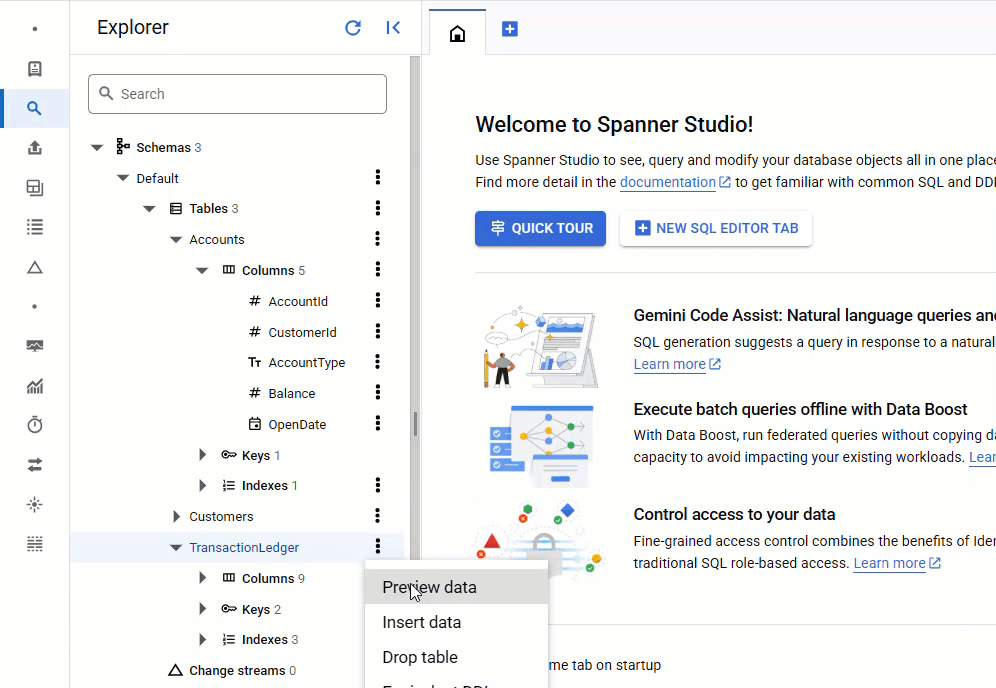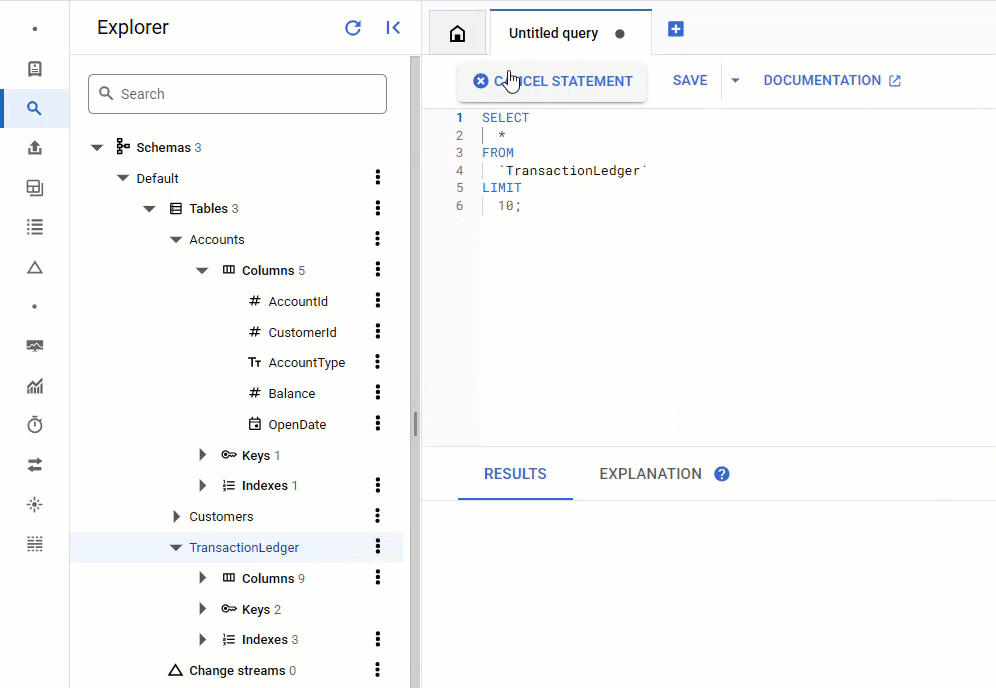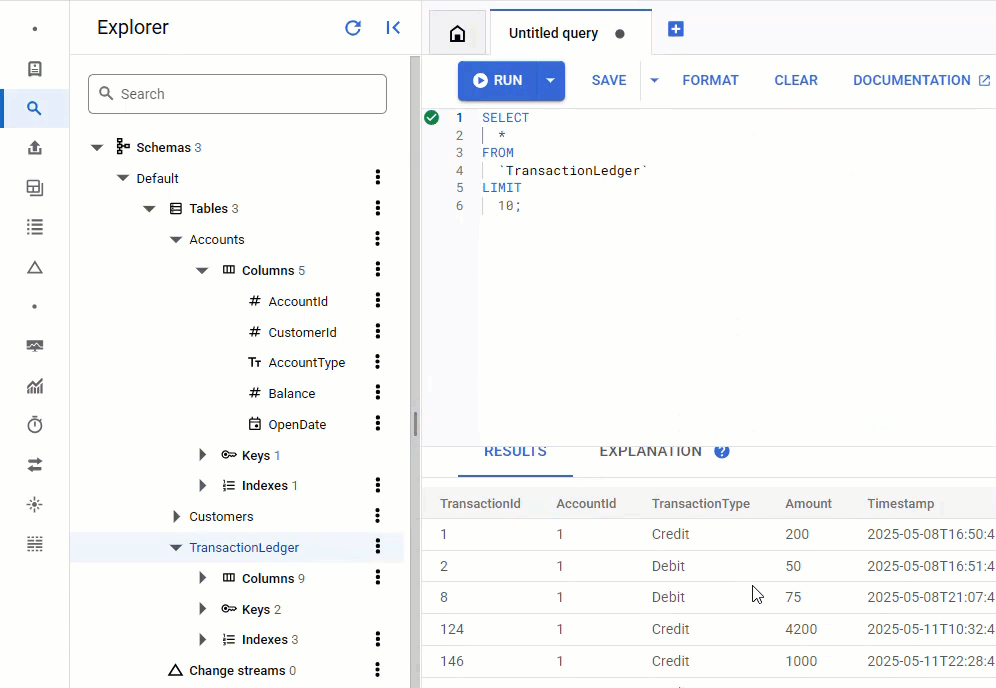
Краткое содержание
На этом этапе вы вставили тестовые данные в базу данных.
Далее
Далее вы воспользуетесь интеграцией Vertex AI для автоматической классификации банковских транзакций непосредственно в Spanner SQL.
6. Классификация данных с помощью Vertex AI
На этом этапе вы воспользуетесь возможностями Vertex AI для автоматической классификации ваших финансовых транзакций непосредственно в Spanner SQL. С помощью Vertex AI вы можете выбрать существующую предварительно обученную модель или обучить и развернуть свою собственную. Список доступных моделей можно посмотреть в Vertex AI Model Garden .
Для этой практической работы мы будем использовать одну из моделей Gemini — Gemini Flash Lite . Эта версия Gemini экономична, но при этом способна справляться с большинством повседневных задач.
В настоящее время у нас есть ряд финансовых транзакций, которые мы хотели бы классифицировать ( groceries , transportation и т. д.) в зависимости от описания. Мы можем сделать это, зарегистрировав модель в Spanner, а затем используя ML.PREDICT для вызова модели ИИ.
В нашем банковском приложении нам может потребоваться классифицировать транзакции, чтобы получить более глубокое понимание поведения клиентов, персонализировать услуги, более эффективно выявлять аномалии или предоставить клиенту возможность отслеживать свой бюджет по месяцам.
Первый шаг уже был сделан, когда мы создали базу данных и схему, в результате чего получилась модель следующего вида:
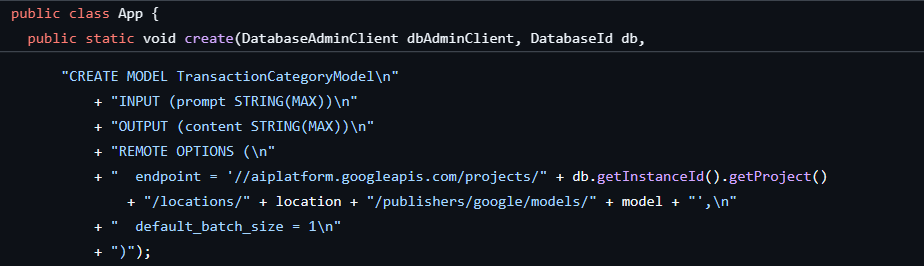
Далее мы добавим в приложение метод для вызова ML.PREDICT .
Откройте файл App.java и добавьте метод categorize :
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Добавьте еще один оператор case в main метод для класса categorize:
case "categorize":
categorize(dbClient);
break;
Наконец, добавьте в метод printUsageAndExit информацию о том, как использовать классификацию:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
Сохраните изменения, внесенные в файл App.java .
Пересоберите приложение:
mvn package
Для классификации транзакций в базе данных выполните команду categorize :
java -jar target/onlinebanking.jar categorize
Ожидаемый результат:
Categorizing transactions... Completed categorizing transactions
В Spanner Studio выполните запрос «Предварительный просмотр данных» для таблицы TransactionLedger . Теперь столбец Category должен быть заполнен для всех строк.
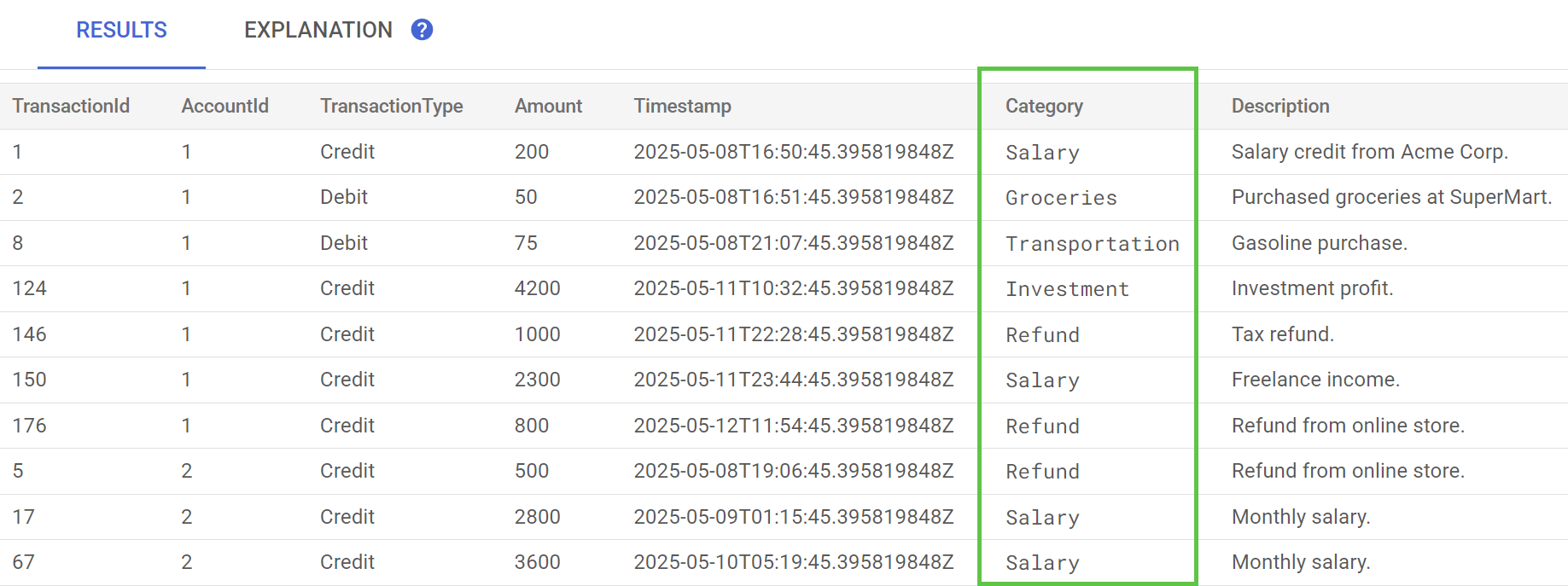
Теперь, когда мы классифицировали транзакции, мы можем использовать эту информацию для внутренних запросов или запросов от клиентов. На следующем этапе мы рассмотрим, как узнать, сколько конкретный клиент тратит в определенной категории за месяц.
Краткое содержание
На этом этапе вы использовали предварительно обученную модель для выполнения категоризации данных с помощью искусственного интеллекта.
Далее
Далее вы воспользуетесь токенизацией для выполнения нечеткого и полнотекстового поиска.
7. Выполните запрос с использованием полнотекстового поиска.
Добавьте код запроса
Spanner предоставляет множество запросов для полнотекстового поиска . На этом этапе вы выполните поиск с точным совпадением, затем нечеткий поиск и полнотекстовый поиск.
Откройте App.java и начните с замены импортов:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Затем добавьте методы запроса:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Добавьте еще один оператор case в main метод для запроса:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Наконец, добавьте в метод printUsageAndExit инструкцию по использованию команд запроса:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
Сохраните изменения, внесенные в файл App.java .
Пересоберите приложение:
mvn package
Выполните поиск с точным совпадением остатков на счетах клиентов.
Запрос с точным совпадением ищет строки, которые точно соответствуют заданному термину.
Для повышения производительности индекс был добавлен уже при создании базы данных и схемы:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
Метод getBalance неявно использует этот индекс для поиска клиентов, соответствующих предоставленному customerId, а также выполняет объединение таблиц по учетным записям, принадлежащим этому клиенту.
Вот как выглядит запрос при выполнении непосредственно в Spanner Studio: 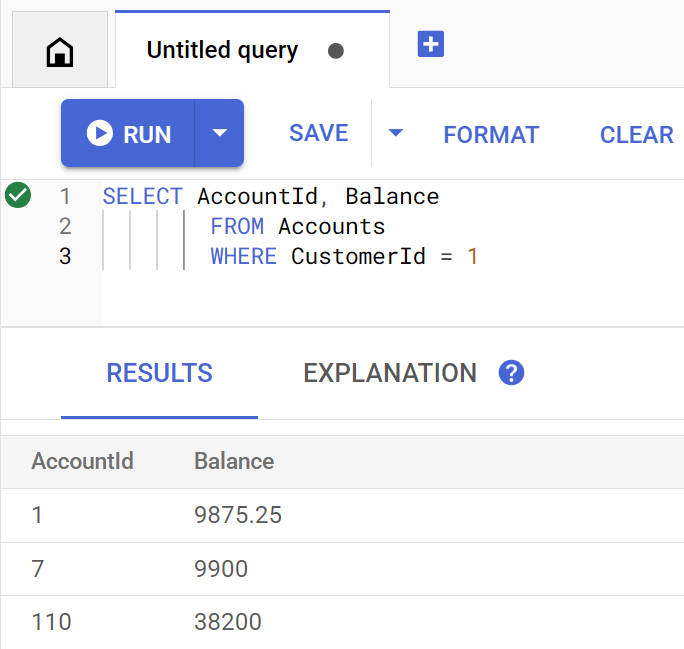
Чтобы просмотреть баланс счета(ов) клиента 1 , выполните следующую команду:
java -jar target/onlinebanking.jar query balance 1
Ожидаемый результат:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
Всего 100 клиентов, поэтому вы также можете запросить балансы счетов других клиентов, указав другой идентификатор клиента:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Выполните нечеткий поиск по электронным адресам клиентов.
Нечеткий поиск позволяет находить приблизительные совпадения поисковых запросов, включая варианты написания и опечатки.
n-граммовый индекс уже был добавлен при создании базы данных и схемы:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
Метод findCustomers использует SEARCH_NGRAMS и SCORE_NGRAMS для выполнения запросов к этому индексу с целью поиска клиентов по электронной почте. Поскольку столбец email был токенизирован с помощью n-грамм, этот запрос может содержать орфографические ошибки и при этом возвращать правильный ответ. Результаты упорядочиваются в зависимости от наилучшего совпадения.
Найдите совпадающие адреса электронной почты клиентов, содержащие madi , выполнив команду:
java -jar target/onlinebanking.jar query email madi
Ожидаемый результат:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
В этом ответе отображаются наиболее близкие совпадения, содержащие madi или аналогичную строку, в порядке убывания значимости.
Вот как выглядит запрос, если его выполнить непосредственно в Spanner Studio: 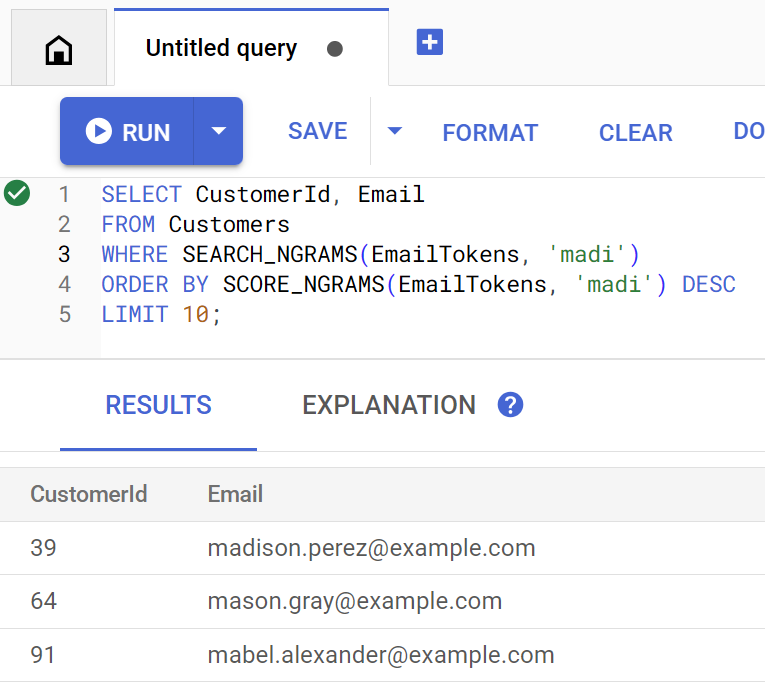
Нечеткий поиск также может помочь исправить орфографические ошибки, например, неправильное написание имени emily :
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Ожидаемый результат:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
В каждом случае ожидаемый адрес электронной почты клиента возвращается в качестве первого результата поиска.
Поиск транзакций с помощью полнотекстового поиска
Функция полнотекстового поиска в Spanner используется для поиска записей по ключевым словам или фразам. Она позволяет исправлять орфографические ошибки или искать синонимы.
Индекс для полнотекстового поиска был добавлен уже при создании базы данных и схемы:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
Метод getSpending использует функцию полнотекстового поиска SEARCH для сопоставления с указанным индексом. Он ищет все расходы (дебеты) за последние 30 дней для заданного идентификатора клиента.
Чтобы получить общую сумму расходов за последний месяц для клиента 1 в категории groceries , выполните команду:
java -jar target/onlinebanking.jar query spending 1 groceries
Ожидаемый результат:
Total spending for customer 1 under category groceries: 50
Вы также можете найти данные о расходах по другим категориям (которые мы классифицировали на предыдущем шаге) или использовать другой идентификатор клиента:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Краткое содержание
На этом этапе вы выполнили запросы с точным совпадением, а также нечеткий и полнотекстовый поиск.
Далее
Далее вы интегрируете Spanner с Google BigQuery для выполнения федеративных запросов, что позволит вам объединять данные Spanner в режиме реального времени с данными BigQuery.
8. Выполняйте федеративные запросы с помощью BigQuery.
Создайте набор данных BigQuery.
На этом этапе вы объедините данные BigQuery и Spanner с помощью федеративных запросов.
Для этого в командной строке Cloud Shell сначала создайте набор данных MarketingCampaigns :
bq mk --location=us-central1 MarketingCampaigns
Ожидаемый результат:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
А также таблица CustomerSegments в наборе данных:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Ожидаемый результат:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Далее установите соединение между BigQuery и Spanner:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Ожидаемый результат:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Наконец, добавьте в таблицу BigQuery несколько клиентов, которые можно объединить с нашими данными из Spanner:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Ожидаемый результат:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
Проверить доступность данных можно, выполнив запрос к BigQuery:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Ожидаемый результат:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
Эти данные в BigQuery представляют собой информацию, добавленную в результате различных банковских процессов. Например, это может быть список клиентов, которые недавно открыли счета или зарегистрировались для участия в маркетинговой акции. Чтобы определить список клиентов, на которых мы хотим ориентироваться в нашей маркетинговой кампании, нам необходимо запросить как эти данные в BigQuery, так и данные в реальном времени в Spanner, и федеративный запрос позволяет нам сделать это в одном запросе.
Выполните федеративный запрос с помощью BigQuery
Далее мы добавим в приложение метод для вызова EXTERNAL_QUERY для выполнения федеративного запроса. Это позволит объединять и анализировать данные о клиентах из BigQuery и Spanner, например, определять, какие клиенты соответствуют критериям нашей маркетинговой кампании на основе их недавних расходов.
Откройте App.java и начните с замены импортов:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Затем добавьте метод campaign :
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Добавьте еще один оператор case в main метод для кампании:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Наконец, добавьте инструкцию по использованию кампании в метод printUsageAndExit :
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
Сохраните изменения, внесенные в файл App.java .
Пересоберите приложение:
mvn package
Выполните федеративный запрос, чтобы определить клиентов, которых следует включить в маркетинговую кампанию ( campaign1 ), если они потратили не менее $5000 за последние 3 месяца, выполнив команду campaign :
java -jar target/onlinebanking.jar campaign campaign1 5000
Ожидаемый результат:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Теперь мы можем предлагать этим клиентам эксклюзивные предложения или бонусы.
Или же мы можем поискать более широкий круг клиентов, которые за последние 3 месяца достигли меньшего порога расходов:
java -jar target/onlinebanking.jar campaign campaign1 2500
Ожидаемый результат:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Краткое содержание
На этом этапе вы успешно выполнили федеративные запросы из BigQuery, которые получили данные Spanner в режиме реального времени.
Далее
Далее вы можете очистить ресурсы, созданные для этого практического занятия, чтобы избежать дополнительных расходов.
9. Уборка (необязательно)
Этот шаг необязателен. Если вы хотите продолжить экспериментировать с экземпляром Spanner, вам не нужно его удалять в данный момент. Однако проект, который вы используете, будет продолжать оплачивать использование этого экземпляра. Если вам больше не нужен этот экземпляр, то вам следует удалить его сейчас, чтобы избежать этих расходов. В дополнение к экземпляру Spanner, в этом практическом задании также был создан набор данных BigQuery и подключение, которые следует удалить, когда они больше не понадобятся.
Удалите экземпляр Spanner:
gcloud spanner instances delete cloudspanner-onlinebanking
Подтвердите, что хотите продолжить (введите Y ):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
Удалите подключение к BigQuery и набор данных:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
Подтвердите удаление набора данных BigQuery (тип Y ):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Поздравляем!
🚀 Вы создали новый экземпляр Cloud Spanner, создали пустую базу данных, загрузили тестовые данные, выполнили расширенные операции и запросы, а также (при желании) удалили экземпляр Cloud Spanner.
Что мы рассмотрели
- Как настроить экземпляр Spanner.
- Как создать базу данных и таблицы.
- Как загрузить данные в таблицы базы данных Spanner.
- Как вызывать модели Vertex AI из Spanner.
- Как выполнять запросы к базе данных Spanner с использованием нечеткого поиска и полнотекстового поиска.
- Как выполнять федеративные запросы к Spanner из BigQuery.
- Как удалить экземпляр Spanner.
Что дальше?
- Узнайте больше о расширенных функциях Spanner , в том числе:
- Ознакомьтесь с доступными клиентскими библиотеками Spanner .