
1. Genel Bakış
Spanner, hem ilişkisel hem de ilişkisel olmayan operasyonel iş yükleri için ideal olan, tümüyle yönetilen, yatay olarak ölçeklenebilir ve küresel olarak dağıtılmış bir veritabanı hizmetidir. Spanner, temel özelliklerinin yanı sıra akıllı ve veriye dayalı uygulamalar oluşturmayı sağlayan güçlü ileri seviye özellikler sunar.
Bu codelab'de, Spanner'ın temel işleyişi hakkında bilgi verilir ve bir internet bankacılığı uygulamasını temel alarak veri işleme ve analiz özelliklerinizi geliştirmek için gelişmiş entegrasyonlarından yararlanma konusu ele alınır.
Üç temel ileri seviye özelliğe odaklanacağız:
- Vertex AI entegrasyonu: Spanner'ı Google Cloud'un yapay zeka platformu Vertex AI ile sorunsuz bir şekilde nasıl entegre edeceğinizi öğrenin. Spanner SQL sorgularından doğrudan Vertex AI modellerini nasıl çağıracağınızı öğreneceksiniz. Bu sayede, veritabanı içinde güçlü dönüşümler ve tahminler yapabilir, bankacılık uygulamamızın bütçe takibi ve anomali tespiti gibi kullanım alanları için işlemleri otomatik olarak kategorize etmesini sağlayabilirsiniz.
- Tam metin arama: Spanner'da tam metin arama işlevini nasıl uygulayacağınızı öğrenin. Metin verilerini dizine ekleme ve operasyonel verilerinizde anahtar kelime tabanlı aramalar yapmak için verimli sorgular yazma konularını ele alacaksınız. Bu sayede, bankacılık sistemimizde müşterileri e-posta adresine göre verimli bir şekilde bulma gibi güçlü veri keşifleri yapabileceksiniz.
- BigQuery birleşik sorguları: Spanner'ın birleşik sorgu özelliklerinden yararlanarak BigQuery'de bulunan verileri doğrudan sorgulama hakkında bilgi edinin. Bu sayede, Spanner'ın gerçek zamanlı operasyonel verilerini BigQuery'nin analitik veri kümeleriyle birleştirerek veri tekilleştirme veya karmaşık ETL süreçleri olmadan kapsamlı analizler ve raporlar elde edebilirsiniz. Ayrıca, gerçek zamanlı müşteri verilerini BigQuery'deki daha geniş kapsamlı geçmiş trendlerle birleştirerek bankacılık uygulamamızdaki çeşitli kullanım alanlarını (ör. hedeflenmiş pazarlama kampanyaları) destekleyebilirsiniz.
Neler öğreneceksiniz?
- Spanner örneği oluşturma
- Veritabanı ve tablolar oluşturma
- Spanner veritabanı tablolarınıza nasıl veri yükleneceği.
- Vertex AI modellerini Spanner'dan çağırma
- Yaklaşık arama ve tam metin aramayı kullanarak Spanner veritabanınızı sorgulama
- BigQuery'den Spanner'a karşı birleşik sorgular gerçekleştirme
- Spanner örneğinizi silme
İhtiyacınız olanlar
2. Kurulum ve şartlar
Proje oluşturma
Faturalandırmanın etkin olduğu bir Google Cloud projeniz varsa konsolun sol üst kısmındaki proje seçimi açılır menüsünü tıklayın:

Bir proje seçiliyken Gerekli API'leri etkinleştirme bölümüne geçin.
Henüz bir Google Hesabınız (Gmail veya Google Apps) yoksa oluşturmanız gerekir. Google Cloud Platform Console'da (console.cloud.google.com) oturum açın ve yeni bir proje oluşturun.
Yeni bir proje oluşturmak için açılan iletişim kutusunda "YENİ PROJE" düğmesini tıklayın:
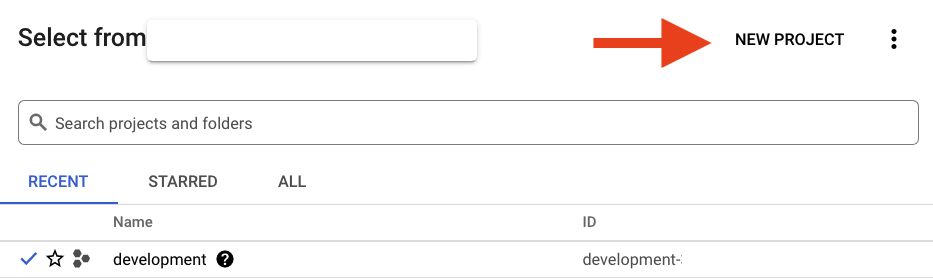
Henüz bir projeniz yoksa ilk projenizi oluşturmak için aşağıdaki gibi bir iletişim kutusu görürsünüz:
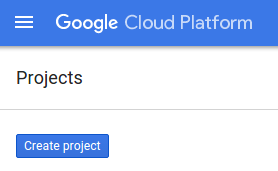
Sonraki proje oluşturma iletişim kutusunda yeni projenizin ayrıntılarını girebilirsiniz.
Tüm Google Cloud projelerinde benzersiz bir ad olan proje kimliğini unutmayın. Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
Ardından, henüz yapmadıysanız Google Cloud kaynaklarını kullanmak ve Spanner API, Vertex AI API, BigQuery API ve BigQuery Connection API'yi etkinleştirmek için Geliştirici Konsolu'nda faturalandırmayı etkinleştirmeniz gerekir.
Spanner fiyatlandırması burada belgelenmiştir. Diğer kaynaklarla ilişkili diğer maliyetler, ilgili fiyatlandırma sayfalarında belgelenir.
Google Cloud Platform'un yeni kullanıcıları 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Google Cloud Shell Kurulumu
Bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacağız.
Bu Debian tabanlı sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin bulunur ve Google Cloud'da çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu nedenle, bu codelab için ihtiyacınız olan tek şey bir tarayıcıdır.
Cloud Shell'i Cloud Console'dan etkinleştirmek için Cloud Shell'i Etkinleştir'i ![]() tıklamanız yeterlidir (ortamın sağlanması ve bağlantının kurulması yalnızca birkaç saniye sürer).
tıklamanız yeterlidir (ortamın sağlanması ve bağlantının kurulması yalnızca birkaç saniye sürer).

Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, PROJECT_ID'nize ayarlandığını görürsünüz.
gcloud auth list
Beklenen çıktı:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
Beklenen çıktı:
[core] project = <PROJECT_ID>
Herhangi bir nedenle proje ayarlanmamışsa aşağıdaki komutu verin:
gcloud config set project <PROJECT_ID>
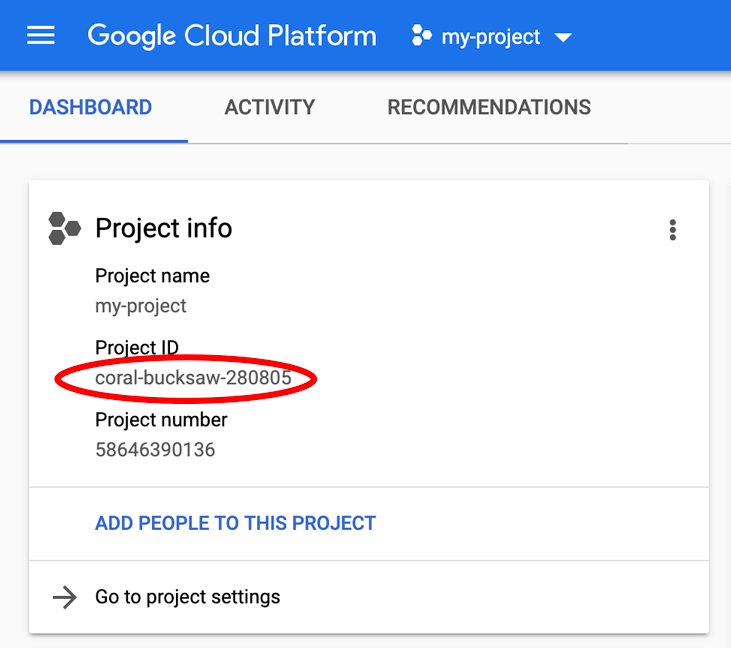
PROJECT_ID cihazınızı mı arıyorsunuz? Kurulum adımlarında hangi kimliği kullandığınızı kontrol edin veya Cloud Console kontrol panelinde arayın:
Cloud Shell, gelecekteki komutları çalıştırırken faydalı olabilecek bazı ortam değişkenlerini de varsayılan olarak ayarlar.
echo $GOOGLE_CLOUD_PROJECT
Beklenen çıktı:
<PROJECT_ID>
Gerekli API'leri etkinleştirme
Projeniz için Spanner, Vertex AI ve BigQuery API'lerini etkinleştirin:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
Özet
Bu adımda, projeniz yoksa proje oluşturup Cloud Shell'i etkinleştirdiniz ve gerekli API'leri etkinleştirdiniz.
Sıradaki
Ardından, Spanner örneğini ayarlayacaksınız.
3. Spanner örneği ayarlama
Spanner örneğini oluşturma
Bu adımda, codelab için bir Spanner örneği oluşturacaksınız. Bunu yapmak için Cloud Shell'i açıp şu komutu çalıştırın:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
Beklenen çıktı:
Creating instance...done.
Özet
Bu adımda Spanner örneğini oluşturdunuz.
Sıradaki
Ardından, ilk uygulamayı hazırlayacak, veritabanını ve şemayı oluşturacaksınız.
4. Veritabanı ve şema oluşturma
İlk başvuruyu hazırlama
Bu adımda, kod aracılığıyla veritabanını ve şemayı oluşturacaksınız.
İlk olarak, Maven'ı kullanarak onlinebanking adlı bir Java uygulaması oluşturun:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
Veritabanına ekleyeceğimiz veri dosyalarını kontrol edip kopyalayın (kod deposu için buraya bakın):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
Uygulama klasörüne gidin:
cd onlinebanking
Maven pom.xml dosyasını açın. Google Cloud kitaplıklarının sürümünü yönetmek için Maven BOM'u kullanmak üzere bağımlılık yönetimi bölümünü ekleyin:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Düzenleyici ve dosya şu şekilde görünür: 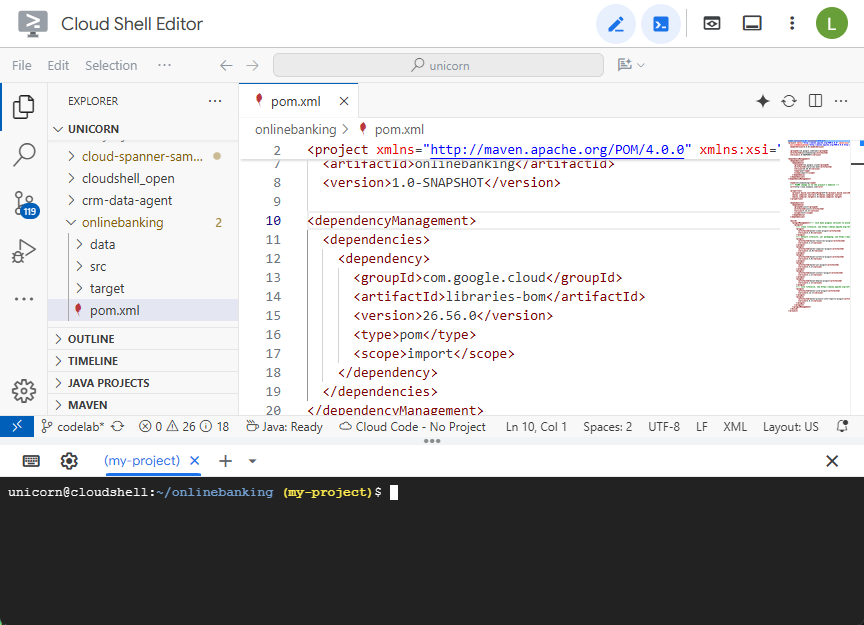
dependencies bölümünde uygulamanın kullanacağı kitaplıkların yer aldığından emin olun:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
Son olarak, uygulamayı çalıştırılabilir bir JAR dosyası olarak paketlemek için derleme eklentilerini değiştirin:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Cloud Shell Düzenleyici'nin"Dosya" menüsünde "Kaydet"i seçerek veya Ctrl+S tuşuna basarak pom.xml dosyasında yaptığınız değişiklikleri kaydedin.
Bağımlılıklar hazır olduğuna göre, şema, bazı dizinler (arama dahil) ve uzak bir uç noktaya bağlı bir yapay zeka modeli oluşturmak için uygulamaya kod ekleyeceksiniz. Bu yapıtları temel alarak bu Codelab boyunca bu sınıfa daha fazla yöntem ekleyeceksiniz.
onlinebanking/src/main/java/com/google/codelabs bölümünde App.java bağlantısını açın ve içeriği aşağıdaki kodla değiştirin:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
App.java dosyasında yapılan değişiklikleri kaydedin.
Kodunuzun oluşturduğu farklı varlıklara göz atın ve uygulama JAR'ını oluşturun:
mvn package
Beklenen çıktı:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Kullanım bilgilerini görmek için uygulamayı çalıştırın:
java -jar target/onlinebanking.jar
Beklenen çıktı:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
Veritabanı ve şema oluşturma
Gerekli uygulama ortamı değişkenlerini ayarlayın:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
create komutunu çalıştırarak veritabanını ve şemayı oluşturun:
java -jar target/onlinebanking.jar create
Beklenen çıktı:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
Spanner'daki şemayı kontrol etme
Spanner konsolunda, yeni oluşturulan örneğinize ve veritabanınıza gidin.
Accounts, Customers ve TransactionLedger olmak üzere 3 tabloyu da görmeniz gerekir.
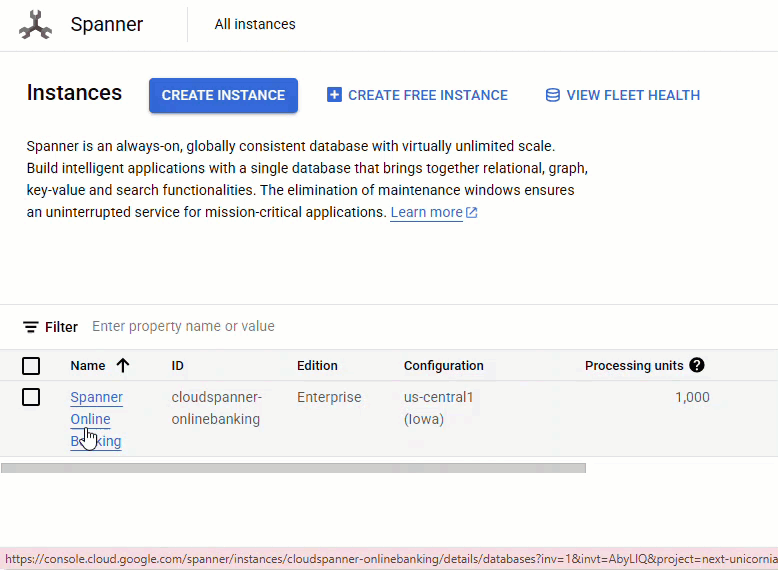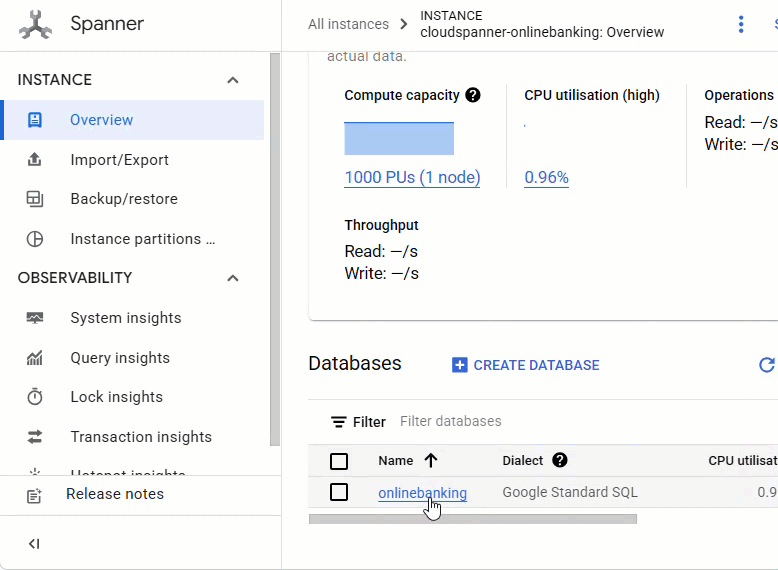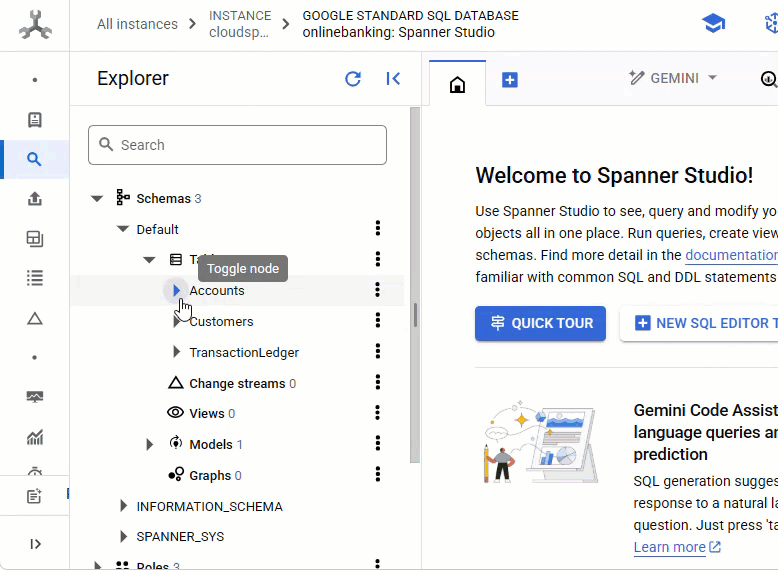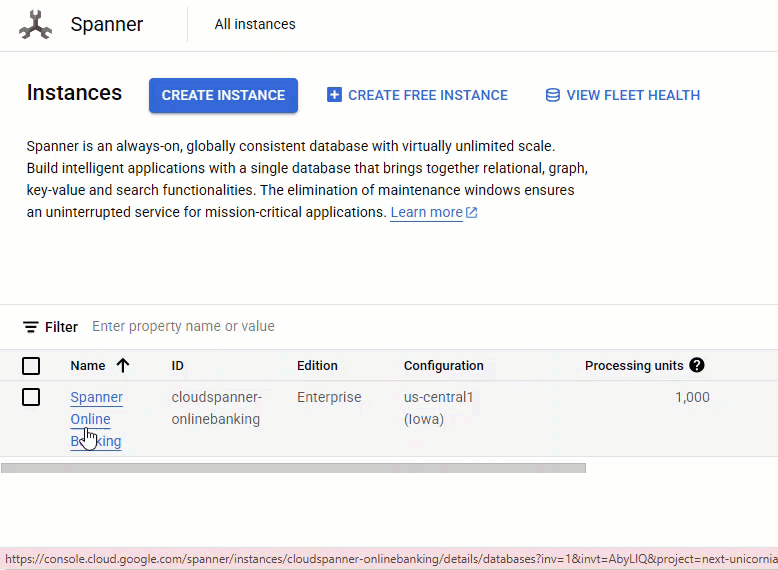
Bu işlem, Accounts, Customers ve TransactionLedger tabloları da dahil olmak üzere veritabanı şemasını, optimize edilmiş veri alma için ikincil dizinleri ve bir Vertex AI modeli referansını oluşturur.
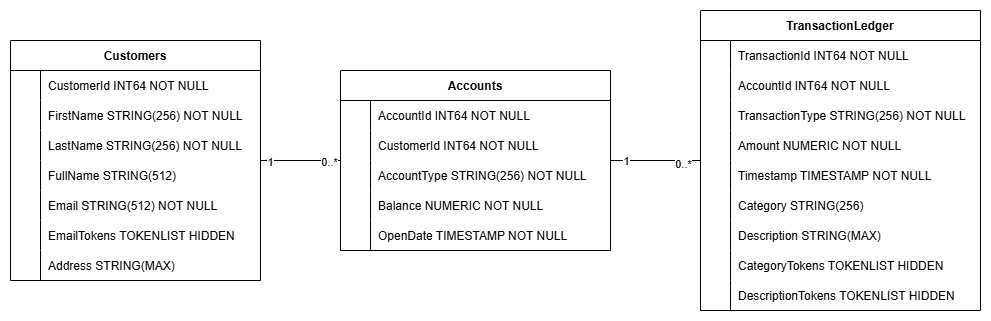
TransactionLedger tablosu, veri yerelliğini iyileştirerek hesaba özel işlemlerin sorgu performansını artırmak için Hesaplar'a yerleştirilmiştir.
Bu kod laboratuvarında kullanılan yaygın veri erişim kalıplarını (ör. müşterileri tam ve yaklaşık e-posta adresine göre arama, hesapları müşteriye göre alma, işlem verilerini verimli bir şekilde sorgulama ve arama) optimize etmek için ikincil dizinler (CustomersByEmail, CustomersFuzzyEmail, AccountsByCustomer, TransactionLedgerByAccountType, TransactionLedgerByCategory, TransactionLedgerTextSearch) uygulandı.
TransactionCategoryModel, bu codelab'de dinamik işlem sınıflandırması için kullanılan bir LLM'ye doğrudan SQL çağrıları yapılmasına olanak tanımak üzere Vertex AI'dan yararlanır.
Özet
Bu adımda Spanner veritabanını ve şemasını oluşturdunuz.
Sıradaki
Ardından, örnek uygulama verilerini yükleyeceksiniz.
5. Verileri yükle
Şimdi, CSV dosyalarındaki örnek verileri veritabanına yükleme işlevini ekleyeceksiniz.
App.java dosyasını açın ve içe aktarma işlemlerini değiştirerek başlayın:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ardından, ekleme yöntemlerini App sınıfına ekleyin:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
switch (command) içine eklemek için main yöntemine başka bir büyük/küçük harf ifadesi ekleyin:
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
Son olarak, ekleme yönteminin nasıl kullanılacağını printUsageAndExit yöntemine ekleyin:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
App.java dosyasında yaptığınız değişiklikleri kaydedin.
Uygulamayı yeniden oluşturun:
mvn package
insert komutunu çalıştırarak örnek verileri ekleyin:
java -jar target/onlinebanking.jar insert
Beklenen çıktı:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
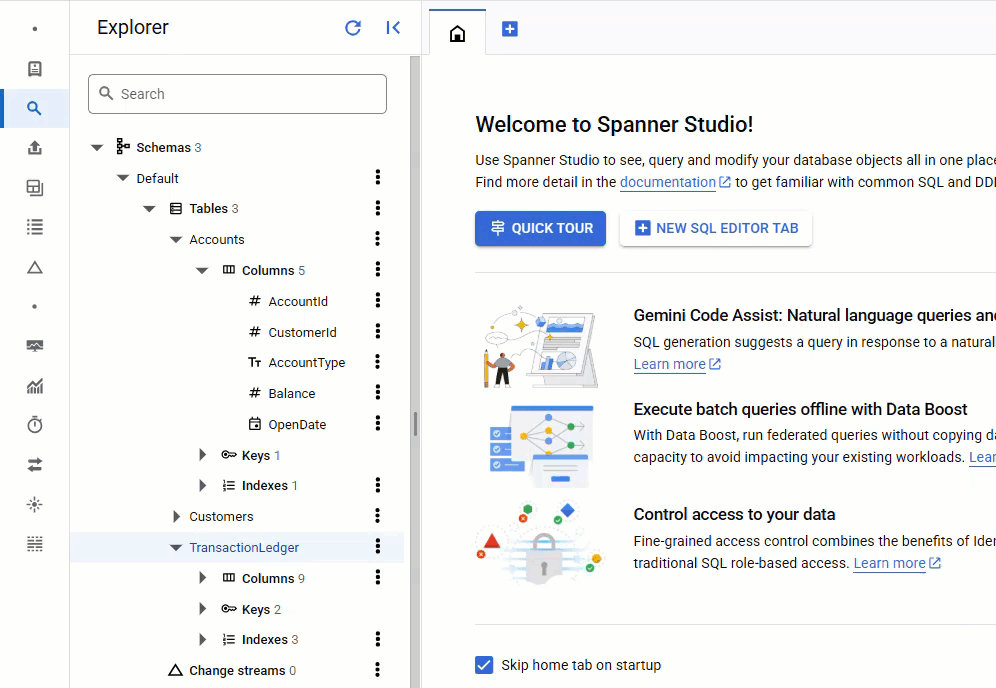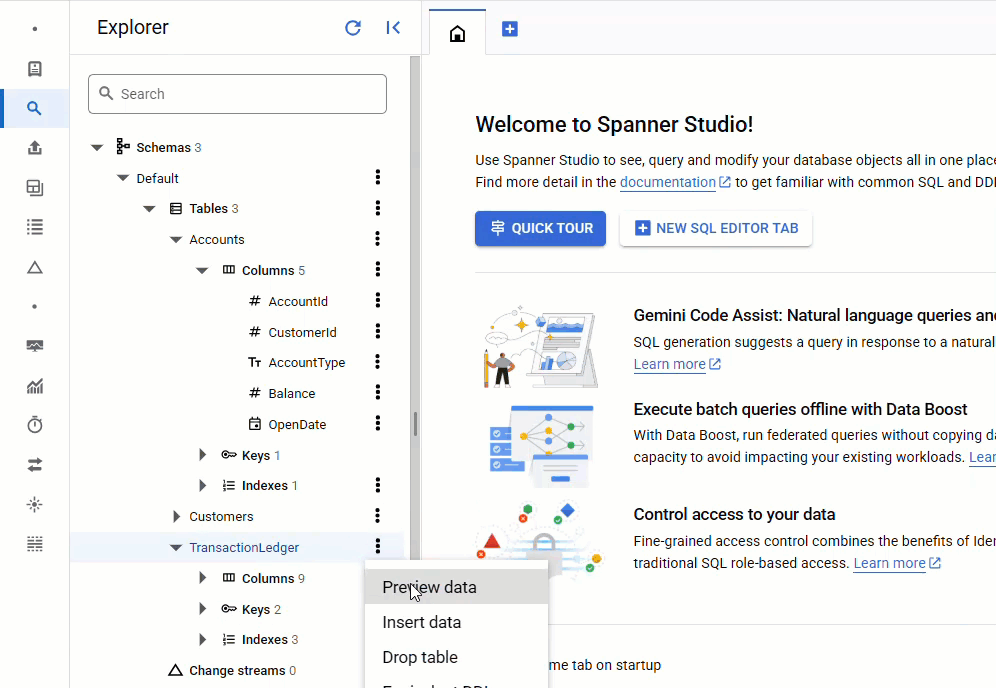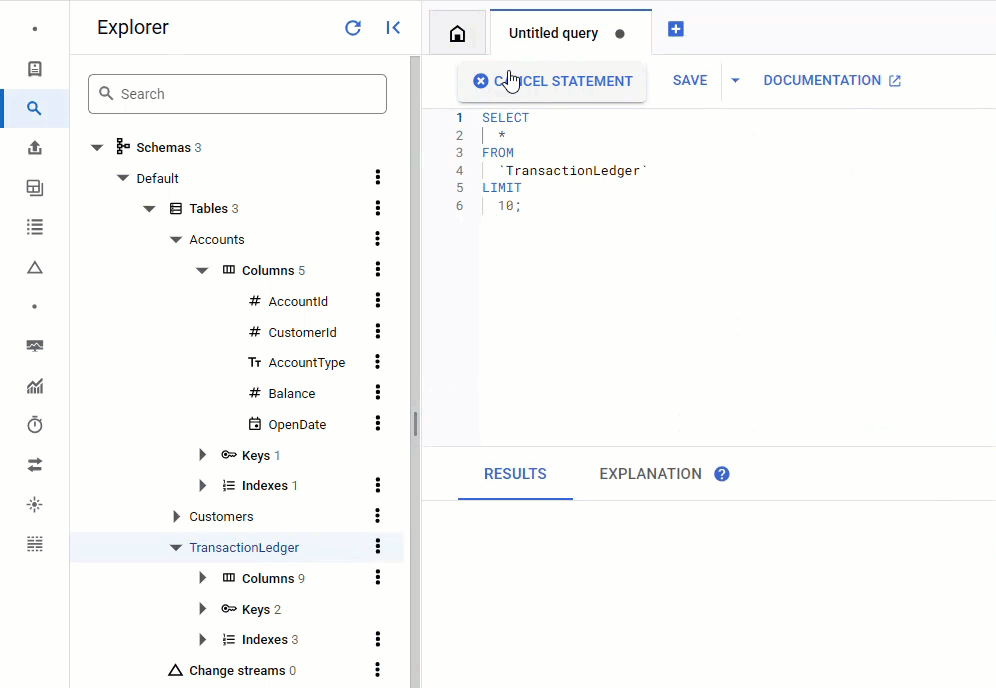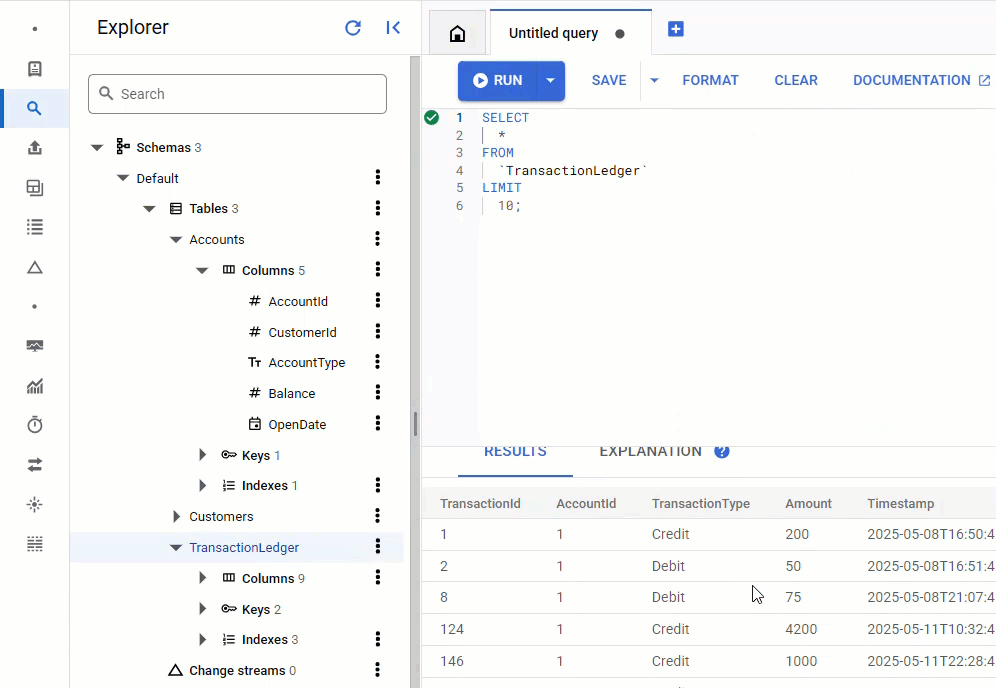
Spanner Console'da, örneğiniz ve veritabanınız için Spanner Studio'ya geri dönün. Ardından TransactionLedger tablosunu seçin ve verilerin yüklendiğini doğrulamak için kenar çubuğunda "Veriler"i tıklayın. Tabloda 200 satır olmalıdır.
Özet
Bu adımda, örnek verileri veritabanına eklediniz.
Sıradaki
Ardından, bankacılık işlemlerini doğrudan Spanner SQL'de otomatik olarak sınıflandırmak için Vertex AI entegrasyonundan yararlanacaksınız.
6. Vertex AI ile verileri kategorilere ayırma
Bu adımda, finansal işlemlerinizi doğrudan Spanner SQL'de otomatik olarak kategorize etmek için Vertex AI'ın gücünden yararlanacaksınız. Vertex AI ile mevcut önceden eğitilmiş bir modeli seçebilir veya kendi modelinizi eğitip dağıtabilirsiniz. Vertex AI Model Garden'daki mevcut modellere göz atın.
Bu codelab'de Gemini modellerinden birini (Gemini Flash Lite) kullanacağız. Gemini'ın bu sürümü uygun maliyetlidir ancak günlük iş yüklerinin çoğunu yine de karşılayabilir.
Şu anda, açıklamaya bağlı olarak sınıflandırmak istediğimiz bir dizi finansal işlemimiz var (groceries, transportation vb.). Bunu, Spanner'da bir model kaydedip yapay zeka modelini çağırmak için ML.PREDICT kullanarak yapabiliriz.
Bankacılık uygulamamızda, müşteri davranışları hakkında daha ayrıntılı bilgi edinmek için işlemleri kategorize etmek isteyebiliriz. Böylece hizmetleri kişiselleştirebilir, anormallikleri daha etkili bir şekilde tespit edebilir veya müşteriye bütçesini aylık olarak takip etme olanağı sunabiliriz.
Veritabanını ve şemayı oluşturduğumuzda ilk adım zaten tamamlanmıştı. Bu adımda aşağıdaki gibi bir model oluşturuldu:
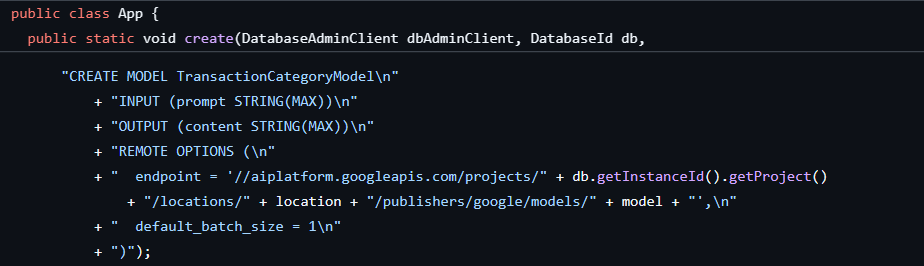
Ardından, ML.PREDICT'ı çağırmak için uygulamaya bir yöntem ekleyeceğiz.
App.java dosyasını açın ve categorize yöntemini ekleyin:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
Kategorilere ayırma için main yöntemine başka bir case ifadesi ekleyin:
case "categorize":
categorize(dbClient);
break;
Son olarak, printUsageAndExit yöntemine nasıl sınıflandırılacağını ekleyin:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
App.java dosyasında yaptığınız değişiklikleri kaydedin.
Uygulamayı yeniden oluşturun:
mvn package
categorize komutunu çalıştırarak veritabanındaki işlemleri kategorilere ayırın:
java -jar target/onlinebanking.jar categorize
Beklenen çıktı:
Categorizing transactions... Completed categorizing transactions
Spanner Studio'da TransactionLedger tablosu için Verileri Önizle ifadesini çalıştırın. Category sütunu artık tüm satırlar için doldurulmuş olmalıdır.
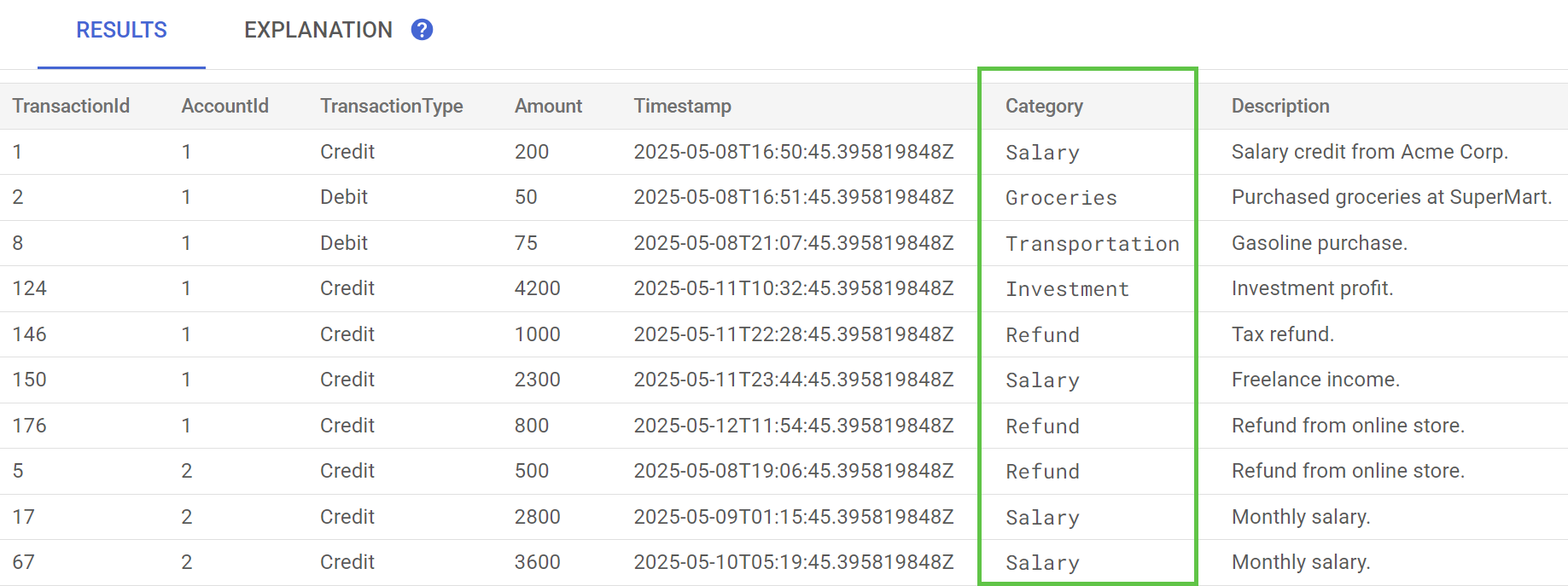
İşlemleri kategorize ettiğimize göre bu bilgileri dahili veya müşteri odaklı sorgular için kullanabiliriz. Bir sonraki adımda, belirli bir müşterinin bir ay boyunca bir kategoride ne kadar harcama yaptığını nasıl bulacağımızı inceleyeceğiz.
Özet
Bu adımda, verilerinizin yapay zeka destekli sınıflandırmasını yapmak için önceden eğitilmiş bir model kullandınız.
Sıradaki
Ardından, yaklaşık ve tam metin aramaları yapmak için belirteçleştirme özelliğini kullanacaksınız.
7. Tam metin araması kullanarak sorgulama
Sorgu kodunu ekleme
Spanner, birçok tam metin arama sorgusu sağlar. Bu adımda, tam eşleşme araması, ardından yaklaşık eşleşme araması ve tam metin araması yapacaksınız.
App.java dosyasını açın ve içe aktarma işlemlerini değiştirerek başlayın:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ardından sorgu yöntemlerini ekleyin:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
Sorgu için main yönteminde başka bir case ifadesi ekleyin:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
Son olarak, sorgu komutlarının nasıl kullanılacağını printUsageAndExit yöntemine ekleyin:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
App.java dosyasında yaptığınız değişiklikleri kaydedin.
Uygulamayı yeniden oluşturun:
mvn package
Müşteri hesabı bakiyeleri için tam eşleşme araması yapma
Tam eşlemeli sorgu, bir terimle tam olarak eşleşen satırları arar.
Performansı artırmak için veritabanını ve şemayı oluşturduğunuzda zaten bir dizin eklenmişti:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
getBalance yöntemi, sağlanan customerId ile eşleşen müşterileri bulmak için bu dizini örtülü olarak kullanır ve bu müşteriye ait hesapları birleştirir.
Sorgu, doğrudan Spanner Studio'da yürütüldüğünde şu şekilde görünür: 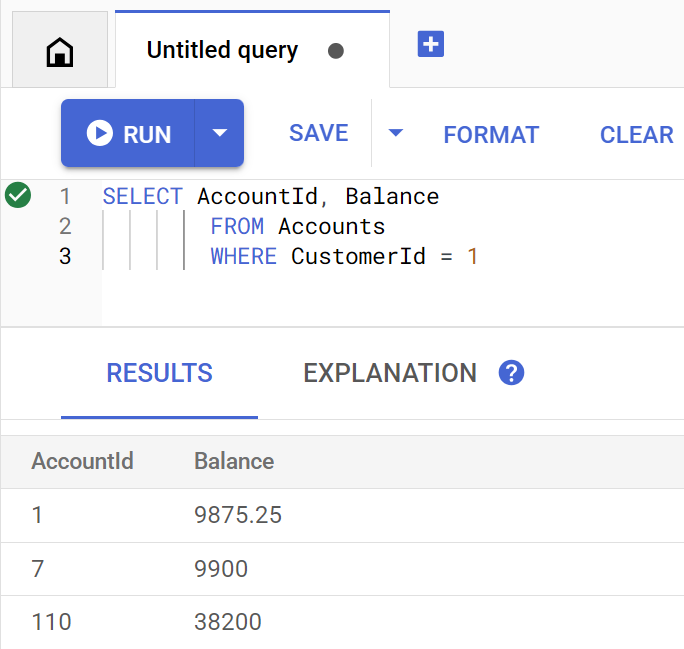
Aşağıdaki komutu çalıştırarak müşteri 1'nın hesap bakiyelerini listeleyin:
java -jar target/onlinebanking.jar query balance 1
Beklenen çıktı:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
100 müşteri olduğundan farklı bir müşteri kimliği belirterek diğer müşteri hesabı bakiyelerini de sorgulayabilirsiniz:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
Müşteri e-postalarında yaklaşık arama yapma
Yaklaşık eşleme aramaları, yazım varyasyonları ve yazım hataları da dahil olmak üzere arama terimlerinin yaklaşık eşleşmelerini bulmanıza olanak tanır.
Veritabanını ve şemayı oluşturduğunuzda n-gram dizini zaten eklenmişti:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
findCustomers yöntemi, e-posta adresine göre müşteri bulmak için bu dizine karşı sorgu oluşturmak üzere SEARCH_NGRAMS ve SCORE_NGRAMS kullanır. E-posta sütunu n-gram olarak belirteçleştirildiği için bu sorgu yazım hataları içerebilir ve yine de doğru yanıt döndürebilir. Sonuçlar, en iyi eşleşmeye göre sıralanır.
Aşağıdaki komutu çalıştırarak madi içeren eşleşen müşteri e-posta adreslerini bulun:
java -jar target/onlinebanking.jar query email madi
Beklenen çıktı:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
Bu yanıtta, madi veya benzer bir dize içeren en yakın eşleşmeler sıralı olarak gösterilir.
Sorgu, doğrudan Spanner Studio'da yürütüldüğünde şu şekilde görünür: 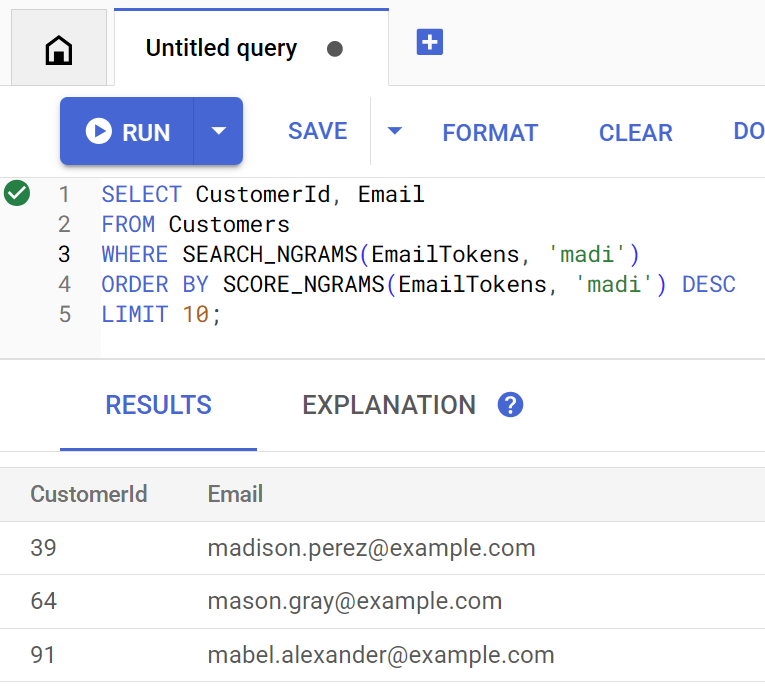
Yaklaşık arama, emily gibi kelimelerin yanlış yazılması gibi yazım hatalarında da yardımcı olabilir:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
Beklenen çıktı:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
Her durumda, beklenen müşteri e-postası en üstteki sonuç olarak döndürülür.
Tam metin aramasıyla işlemleri arama
Spanner'ın tam metin arama özelliği, kayıtları anahtar kelimelere veya ifadelere göre almak için kullanılır. Yazım hatalarını düzeltme veya eş anlamlı kelimeleri arama özelliği vardır.
Veritabanını ve şemayı oluşturduğunuzda tam metin arama dizini zaten eklenmişti:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
getSpending yöntemi, bu dizinle eşleşmek için SEARCH tam metin arama işlevini kullanır. Belirtilen müşteri kimliği için son 30 gün içindeki tüm harcamaları (borçlar) arar.
groceries kategorisindeki 1 müşterisi için son bir ayda yapılan toplam harcamayı öğrenmek üzere şu komutu çalıştırın:
java -jar target/onlinebanking.jar query spending 1 groceries
Beklenen çıktı:
Total spending for customer 1 under category groceries: 50
Diğer kategorilerdeki harcamaları da (önceki adımda kategorize ettiğimiz) bulabilir veya farklı bir müşteri kimliği kullanabilirsiniz:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
Özet
Bu adımda, tam eşleme sorgularının yanı sıra yaklaşık ve tam metin aramaları gerçekleştirdiniz.
Sıradaki
Ardından, birleştirilmiş sorgular gerçekleştirmek için Spanner'ı Google BigQuery ile entegre edeceksiniz. Bu sayede, gerçek zamanlı Spanner verilerinizi BigQuery verileriyle birleştirebileceksiniz.
8. BigQuery ile birleşik sorgular çalıştırma
BigQuery veri kümesini oluşturma
Bu adımda, birleştirilmiş sorguları kullanarak BigQuery ve Spanner verilerini bir araya getireceksiniz.
Bunu yapmak için Cloud Shell komut satırında önce bir MarketingCampaigns veri kümesi oluşturun:
bq mk --location=us-central1 MarketingCampaigns
Beklenen çıktı:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
Veri kümesinde bir CustomerSegments tablosu:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
Beklenen çıktı:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
Ardından, BigQuery'den Spanner'a bağlantı oluşturun:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
Beklenen çıktı:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
Son olarak, BigQuery tablosuna Spanner verilerimizle birleştirilebilecek bazı müşteriler ekleyin:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
Beklenen çıktı:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
BigQuery'yi sorgulayarak verilerin kullanılabilir olduğunu doğrulayabilirsiniz:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
Beklenen çıktı:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
BigQuery'deki bu veriler, çeşitli banka iş akışları aracılığıyla eklenen verileri temsil eder. Örneğin, bu, yakın zamanda hesap açan veya bir pazarlama promosyonuna kaydolan müşterilerin listesi olabilir. Pazarlama kampanyamızda hedeflemek istediğimiz müşterilerin listesini belirlemek için BigQuery'deki bu verileri ve Spanner'daki gerçek zamanlı verileri sorgulamamız gerekir. Birleştirilmiş sorgu, bunu tek bir sorguda yapmamıza olanak tanır.
BigQuery ile birleşik sorgu çalıştırma
Ardından, birleştirilmiş sorguyu gerçekleştirmek için uygulamaya EXTERNAL_QUERY'ı çağıran bir yöntem ekleyeceğiz. Bu sayede, müşterilerin son harcamalarına göre pazarlama kampanyamızın ölçütlerini karşılayan müşterileri belirleme gibi BigQuery ve Spanner'daki müşteri verileri birleştirilip analiz edilebilir.
App.java dosyasını açın ve içe aktarma işlemlerini değiştirerek başlayın:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
Ardından campaign yöntemini ekleyin:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
Kampanya için main yöntemine başka bir case ifadesi ekleyin:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
Son olarak, kampanyanın nasıl kullanılacağını printUsageAndExit yöntemine ekleyin:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
App.java dosyasında yaptığınız değişiklikleri kaydedin.
Uygulamayı yeniden oluşturun:
mvn package
campaign komutunu çalıştırarak son 3 ayda en az $5000 harcama yapmış müşterileri belirlemek için birleşik sorgu çalıştırarak bu müşterilerin pazarlama kampanyasına (campaign1) dahil edilip edilmeyeceğini belirleyin:
java -jar target/onlinebanking.jar campaign campaign1 5000
Beklenen çıktı:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
Artık bu müşterileri özel teklifler veya ödüllerle hedefleyebiliriz.
Alternatif olarak, son 3 ay içinde daha düşük bir harcama eşiğine ulaşan daha fazla sayıda müşteri arayabiliriz:
java -jar target/onlinebanking.jar campaign campaign1 2500
Beklenen çıktı:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
Özet
Bu adımda, BigQuery'den gerçek zamanlı Spanner verilerini getiren birleştirilmiş sorguları başarıyla yürüttünüz.
Sıradaki
Ardından, ücretlendirilmemek için bu codelab'de oluşturulan kaynakları temizleyebilirsiniz.
9. Temizleme (isteğe bağlı)
Bu adım isteğe bağlıdır. Spanner örneğinizle denemeler yapmaya devam etmek istiyorsanız şu anda temizlemeniz gerekmez. Ancak kullandığınız proje, örnek için ücretlendirilmeye devam eder. Bu örneğe artık ihtiyacınız yoksa bu ücretlerden kaçınmak için örneği hemen silmeniz gerekir. Bu codelab'de Spanner örneğinin yanı sıra bir BigQuery veri kümesi ve bağlantısı da oluşturuldu. Bunlar artık gerekli olmadığında temizlenmelidir.
Spanner örneğini silin:
gcloud spanner instances delete cloudspanner-onlinebanking
Devam etmek istediğinizi onaylayın (Y yazın):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
BigQuery bağlantısını ve veri kümesini silin:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
BigQuery veri kümesinin silinmesini onaylayın (Y yazın):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. Tebrikler
🚀 Yeni bir Cloud Spanner örneği oluşturdunuz, boş bir veritabanı oluşturdunuz, örnek verileri yüklediniz, gelişmiş işlemler ve sorgular gerçekleştirdiniz ve (isteğe bağlı olarak) Cloud Spanner örneğini sildiniz.
İşlediğimiz konular
- Spanner örneği oluşturma
- Veritabanı ve tablolar oluşturma
- Spanner veritabanı tablolarınıza nasıl veri yükleneceği.
- Vertex AI modellerini Spanner'dan çağırma
- Yaklaşık arama ve tam metin aramayı kullanarak Spanner veritabanınızı sorgulama
- BigQuery'den Spanner'a karşı birleşik sorgular gerçekleştirme
- Spanner örneğinizi silme
Sırada ne var?
- Aşağıdakiler de dahil olmak üzere ileri seviye Spanner özellikleri hakkında daha fazla bilgi edinin:
- Mevcut Spanner istemci kitaplıklarına bakın.