
1. 概览
Spanner 是一款全托管式、可横向扩缩的全球分布式数据库服务,非常适合关系型和非关系型运营工作负载。除了核心功能之外,Spanner 还提供强大的高级功能,可用于构建智能型数据驱动的应用。
此 Codelab 在对 Spanner 有了一定了解的基础上,深入了解如何利用其高级集成来增强数据处理和分析功能,并以网上银行应用为基础。
我们将重点介绍以下三项关键的高级功能:
- Vertex AI 集成:了解如何将 Spanner 与 Google Cloud 的 AI 平台 Vertex AI 无缝集成。您将学习如何直接从 Spanner SQL 查询中调用 Vertex AI 模型,从而实现强大的数据库内转换和预测,使我们的银行应用能够自动对交易进行分类,以用于预算跟踪和异常检测等应用场景。
- 全文搜索:了解如何在 Spanner 中实现全文搜索功能。您将探索如何为文本数据编制索引,以及如何编写高效的查询来对运营数据执行基于关键字的搜索,从而实现强大的数据发现功能,例如在银行系统中按电子邮件地址高效查找客户。
- BigQuery 联合查询:了解如何利用 Spanner 的联合查询功能直接查询 BigQuery 中的数据。这样一来,您就可以将 Spanner 的实时运营数据与 BigQuery 的分析数据集相结合,从而获得全面的数据分析洞见和报告,而无需进行数据复制或复杂的 ETL 流程。这有助于在我们的银行应用中实现各种使用情形,例如通过将实时客户数据与 BigQuery 中更广泛的历史趋势相结合,开展有针对性的营销活动。
学习内容
- 如何设置 Spanner 实例。
- 如何创建数据库和表。
- 如何将数据加载到 Spanner 数据库表中。
- 如何从 Spanner 调用 Vertex AI 模型。
- 如何使用模糊搜索和全文搜索查询 Spanner 数据库。
- 如何从 BigQuery 对 Spanner 执行联合查询。
- 如何删除 Spanner 实例。
所需条件
2. 设置和要求
创建项目
如果您已经有一个启用了结算功能的 Google Cloud 云项目,请点击控制台左上方的项目选择下拉菜单:

如果已选择项目,请跳至启用所需的 API。
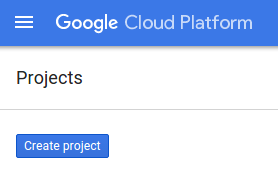
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须创建一个。登录 Google Cloud Platform Console (console.cloud.google.com) 并创建一个新项目。
在出现的对话框中点击“新建项目”按钮以创建一个新项目:
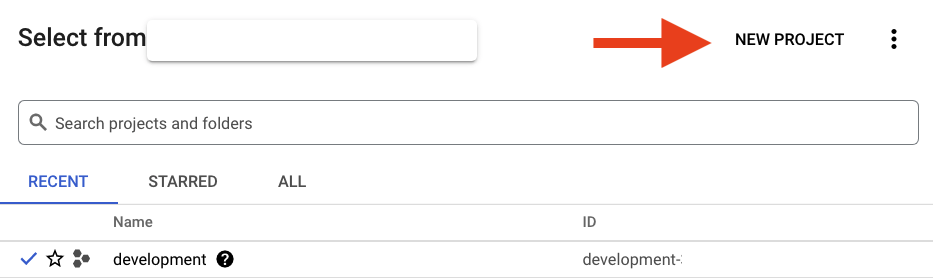
如果您还没有项目,则应该看到一个类似这样的对话框来创建您的第一个项目:
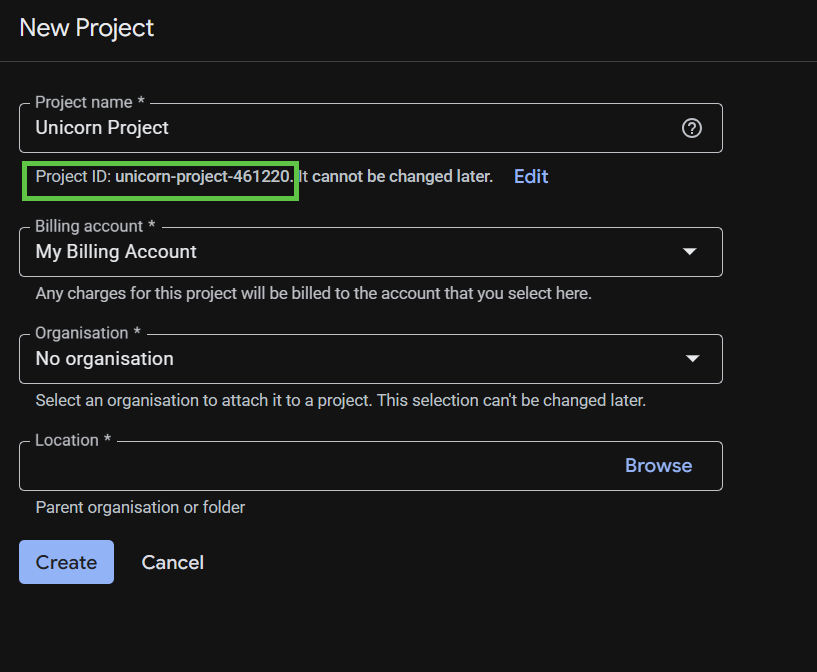
随后的项目创建对话框可让您输入新项目的详细信息。
请记住项目 ID,它是所有 Google Cloud 项目中的唯一名称。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,如果尚未执行此操作,则需要在开发者控制台中启用结算功能,以便使用 Google Cloud 资源并启用 Spanner API、Vertex AI API、BigQuery API 和 BigQuery Connection API。
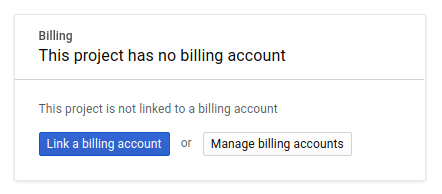
如需了解 Spanner 价格,请参阅此处。与其他资源相关的其他费用将在其各自的价格页面中说明。
Google Cloud Platform 的新用户有资格获享 $300 免费试用。
Google Cloud Shell 设置
在此 Codelab 中,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
基于 Debian 的这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。这意味着在本 Codelab 中,您只需要一个浏览器。
如需从 Cloud 控制台激活 Cloud Shell,只需点击“激活 Cloud Shell”图标 ![]() (预配和连接到环境仅需花费一些时间)。
(预配和连接到环境仅需花费一些时间)。

在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID。
gcloud auth list
预期输出:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
预期输出:
[core] project = <PROJECT_ID>
如果出于某种原因未设置项目,请发出以下命令:
gcloud config set project <PROJECT_ID>
正在查找您的 PROJECT_ID?检查您在设置步骤中使用的 ID,或在 Cloud 控制台信息中心查找该 ID:
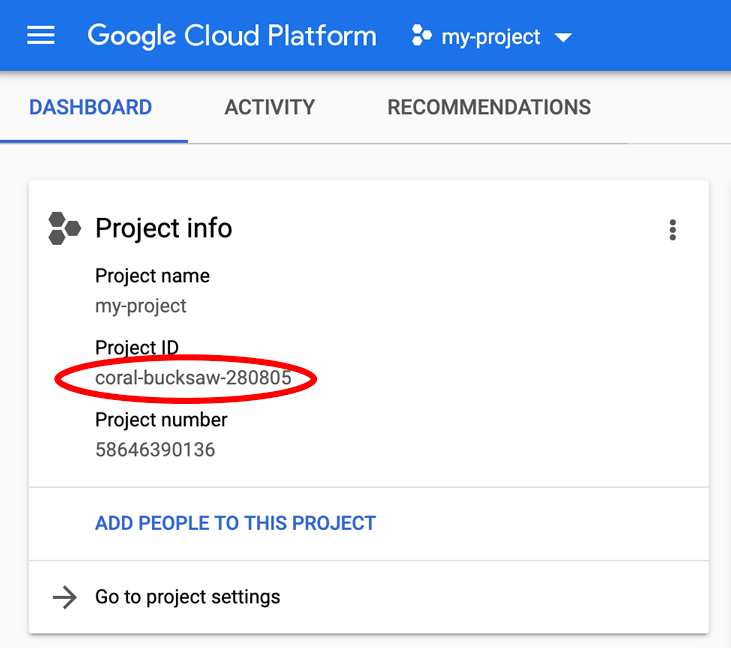
默认情况下,Cloud Shell 还会设置一些环境变量,这对您日后运行命令可能会很有用。
echo $GOOGLE_CLOUD_PROJECT
预期输出:
<PROJECT_ID>
启用所需的 API
为您的项目启用 Spanner、Vertex AI 和 BigQuery API:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
摘要
在此步骤中,您已设置项目(如果您还没有项目)、激活 Cloud Shell 并启用所需的 API。
后续步骤
接下来,您将设置 Spanner 实例。
3. 设置 Spanner 实例
创建 Spanner 实例
在此步骤中,您将为此 Codelab 设置一个 Spanner 实例。为此,请打开 Cloud Shell 并运行以下命令:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
预期输出:
Creating instance...done.
摘要
在此步骤中,您已创建 Spanner 实例。
后续步骤
接下来,您将准备初始应用并创建数据库和架构。
4. 创建数据库和架构
准备初始应用
在此步骤中,您将通过代码创建数据库和架构。
首先,使用 Maven 创建一个名为 onlinebanking 的 Java 应用:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
签出并复制我们将添加到数据库中的数据文件(如需查看代码库,请点击此处):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
前往应用文件夹:
cd onlinebanking
打开 Maven pom.xml 文件。添加依赖项管理部分,以使用 Maven BOM 管理 Google Cloud 库的版本:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
编辑器和文件将如下所示: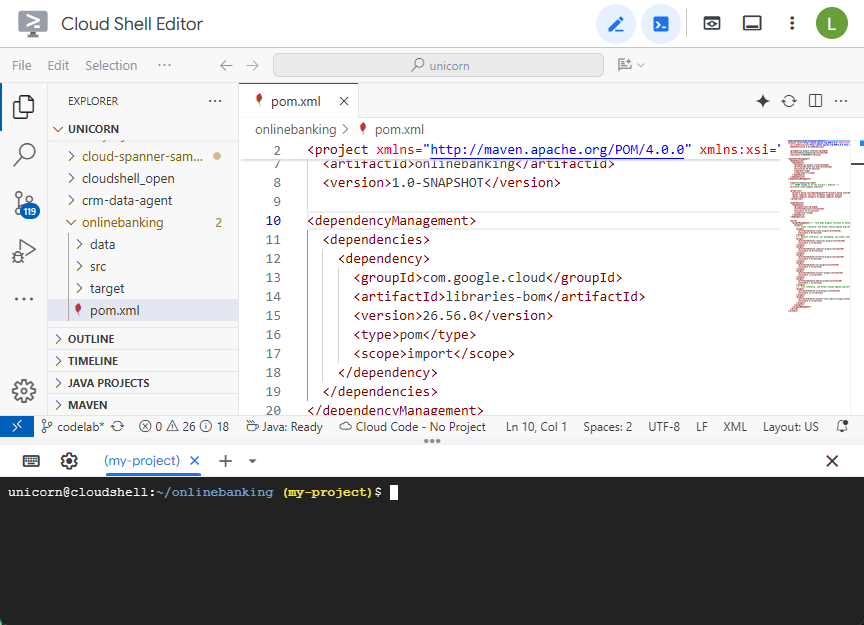
确保 dependencies 部分包含应用将使用的库:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
最后,替换 build 插件,以便将应用打包为可运行的 JAR:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
在 Cloud Shell Editor 的“文件”菜单下选择“保存”,或按 Ctrl+S,保存您对 pom.xml 文件所做的更改。
现在,依赖项已准备就绪,接下来您将向应用添加代码,以创建架构、一些索引(包括搜索)以及连接到远程端点的 AI 模型。在本 Codelab 中,您将基于这些制品并向此类添加更多方法。
打开 onlinebanking/src/main/java/com/google/codelabs 下的 App.java,并将内容替换为以下代码:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
将更改保存到 App.java。
查看代码正在创建的不同实体,并构建应用 JAR:
mvn package
预期输出:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
运行应用以查看使用情况信息:
java -jar target/onlinebanking.jar
预期输出:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
创建数据库和架构
设置必需的应用环境变量:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
运行 create 命令创建数据库和架构:
java -jar target/onlinebanking.jar create
预期输出:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
检查 Spanner 中的架构
在 Spanner 控制台中,前往刚刚创建的实例和数据库。
您应该会看到所有 3 个表 - Accounts、Customers 和 TransactionLedger。
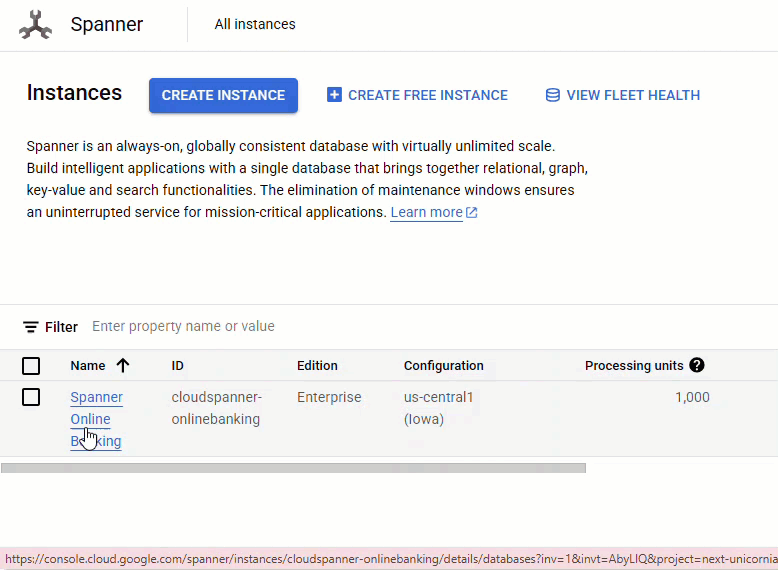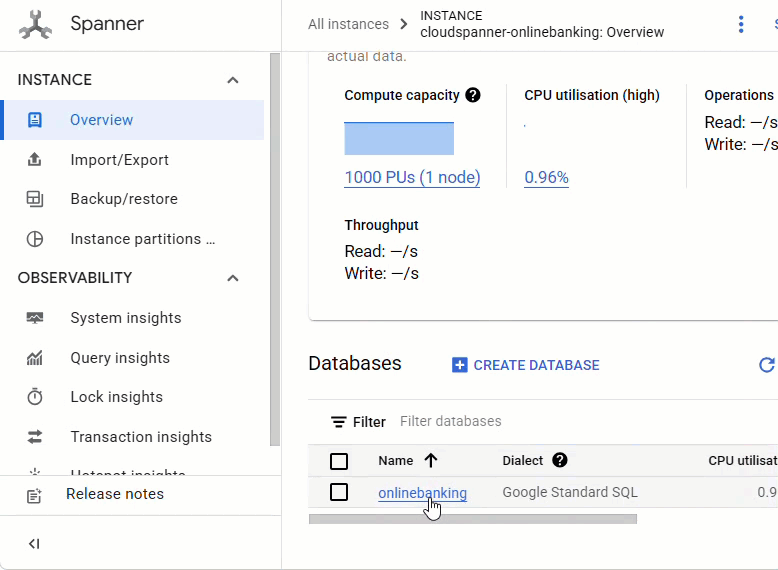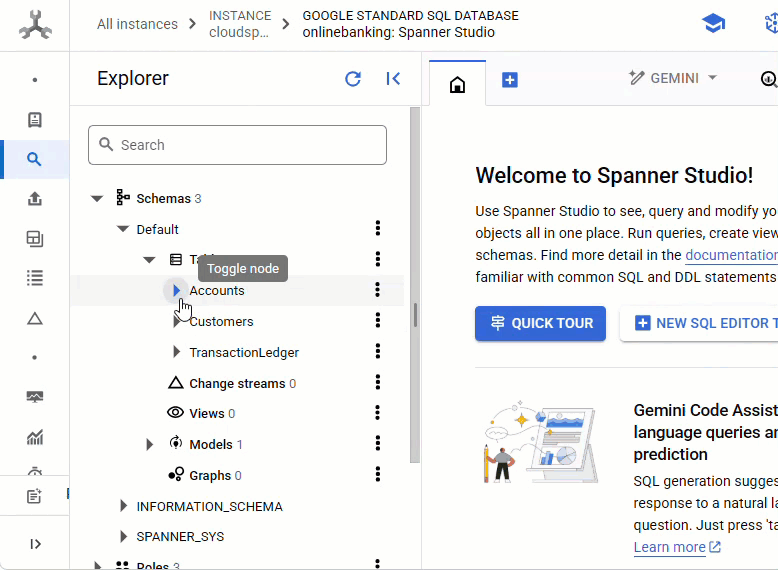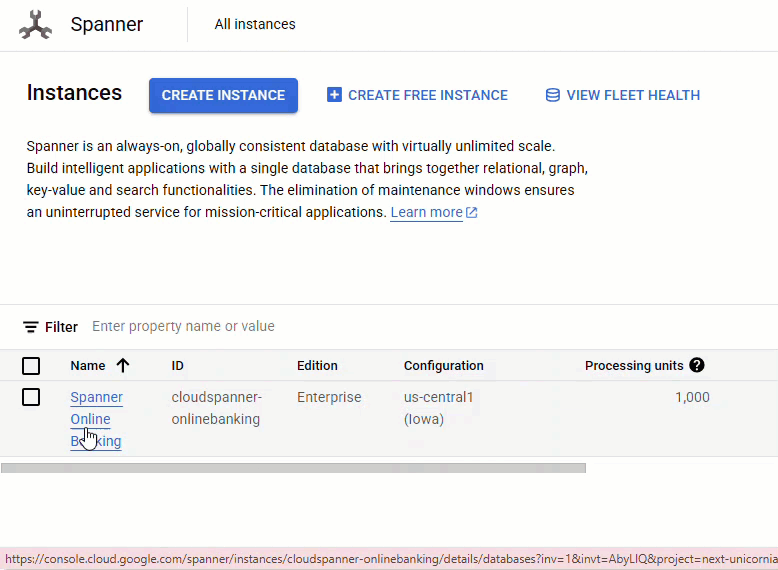
此操作会创建数据库架构,包括 Accounts、Customers 和 TransactionLedger 表,以及用于优化数据检索的辅助索引和 Vertex AI 模型参考。
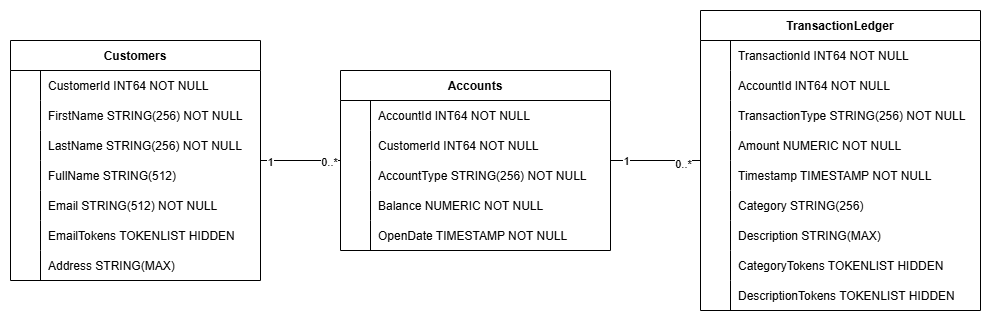
TransactionLedger 表交织在 Accounts 中,通过改进数据局部性来提升账号特定交易的查询性能。
我们实现了二级索引(CustomersByEmail、CustomersFuzzyEmail、AccountsByCustomer、TransactionLedgerByAccountType、TransactionLedgerByCategory、TransactionLedgerTextSearch),以优化此 Codelab 中使用的常见数据访问模式,例如按确切电子邮件地址和模糊电子邮件地址查找客户、按客户检索账号,以及高效查询和搜索交易数据。
TransactionCategoryModel 利用 Vertex AI 实现对 LLM 的直接 SQL 调用,在此 Codelab 中用于动态交易分类。
摘要
在此步骤中,您已创建 Spanner 数据库和架构。
后续步骤
接下来,您将加载示例应用数据。
5. 加载数据
现在,您将添加相应功能,以将 CSV 文件中的示例数据加载到数据库中。
打开 App.java,首先替换导入项:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
然后,将插入方法添加到类 App:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
在 main 方法中添加另一个用于在 switch (command) 内插入的 case 语句:
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
最后,将如何使用插入附加到 printUsageAndExit 方法:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
保存您对 App.java 所做的更改。
重新构建应用:
mvn package
运行 insert 命令插入示例数据:
java -jar target/onlinebanking.jar insert
预期输出:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
在 Spanner 控制台中,返回到相应实例和数据库的 Spanner Studio。然后选择 TransactionLedger 表,并点击边栏中的“数据”,验证数据是否已加载。表格中应有 200 行。
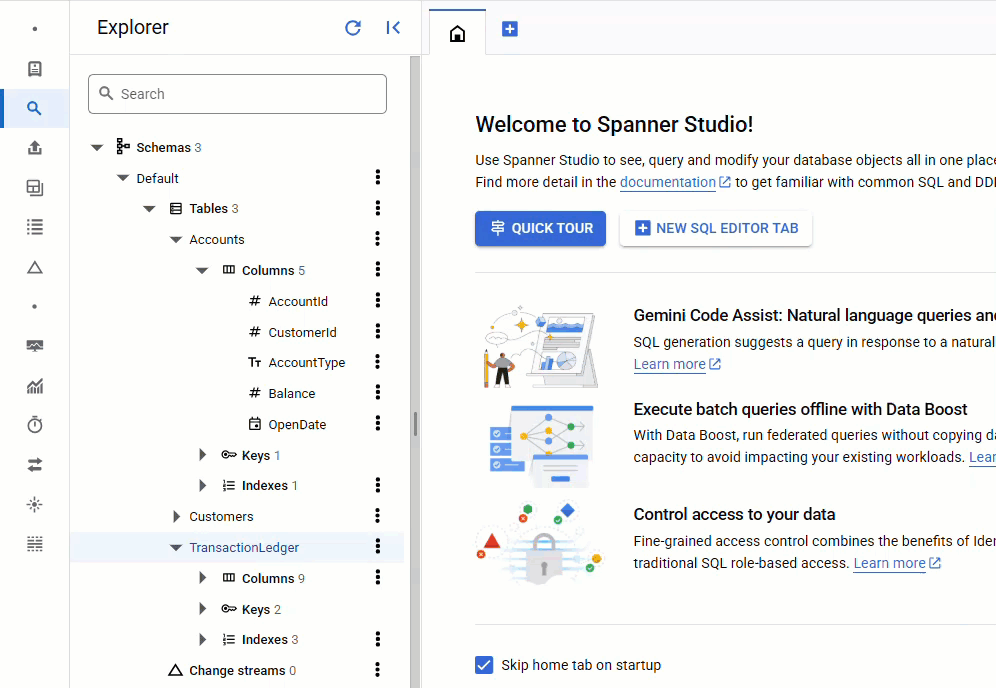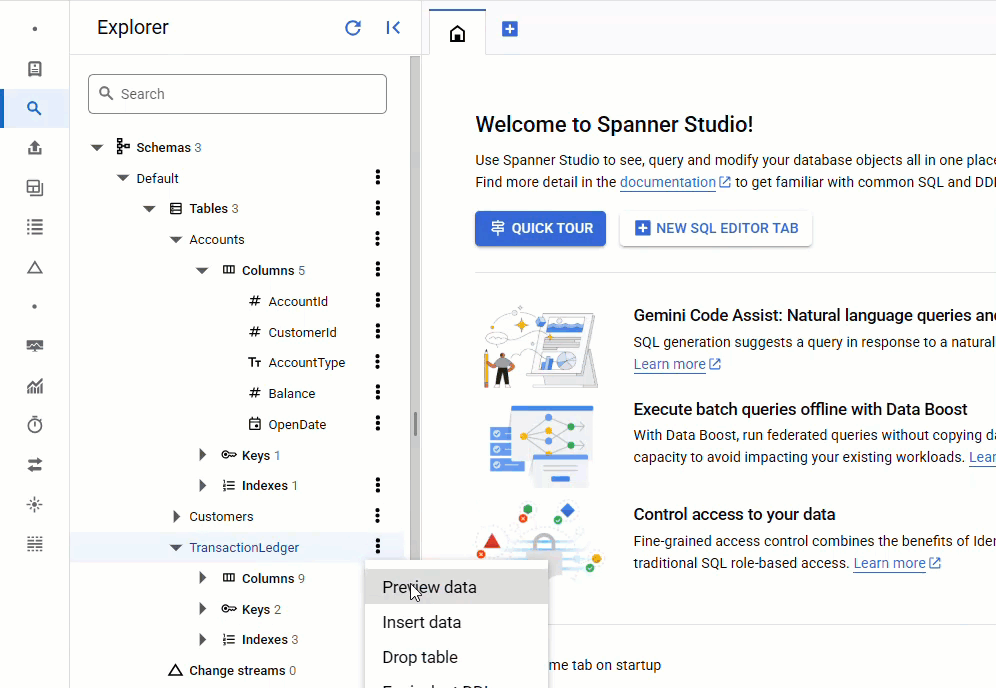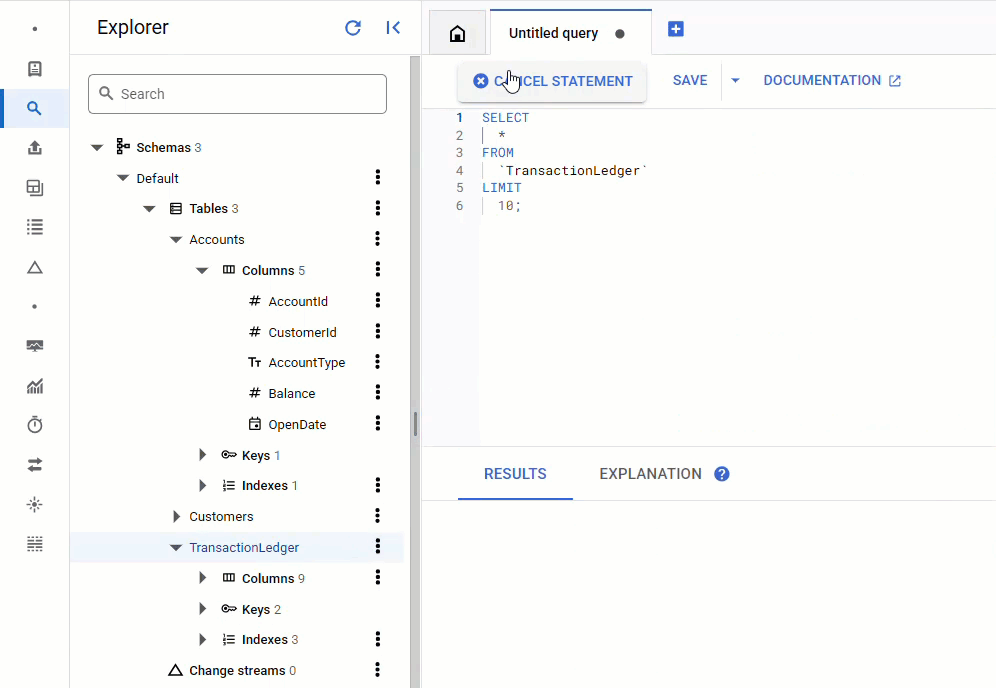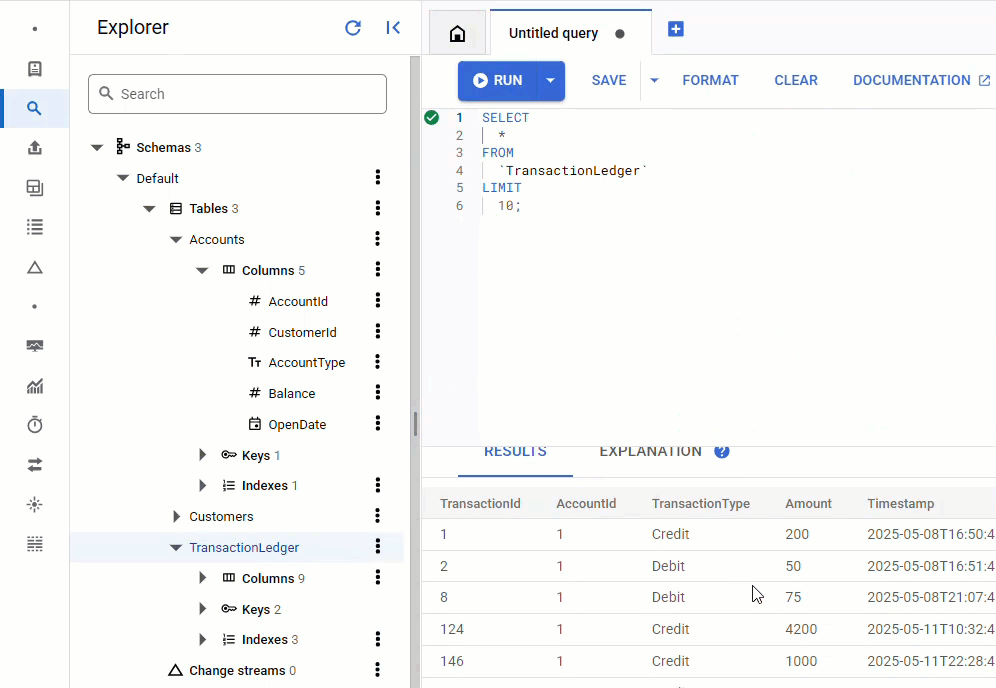
摘要
在此步骤中,您已将示例数据插入数据库。
后续步骤
接下来,您将利用 Vertex AI 集成功能,直接在 Spanner SQL 中自动对银行交易进行分类。
6. 使用 Vertex AI 对数据进行分类
在此步骤中,您将利用 Vertex AI 的强大功能,直接在 Spanner SQL 中自动对财务交易进行分类。借助 Vertex AI,您可以选择现有的预训练模型,也可以训练和部署自己的模型。查看 Vertex AI Model Garden 中的可用模型。
在此 Codelab 中,我们将使用 Gemini 模型之一,即 Gemini Flash Lite。此版本的 Gemini 经济实惠,但仍能处理大多数日常工作负载。
目前,我们有许多金融交易需要根据说明进行分类(groceries、transportation 等)。为此,我们可以在 Spanner 中注册模型,然后使用 ML.PREDICT 调用 AI 模型。
在银行应用中,我们可能需要对交易进行分类,以便更深入地了解客户行为,从而实现服务个性化、更有效地检测异常情况,或让客户能够按月跟踪预算。
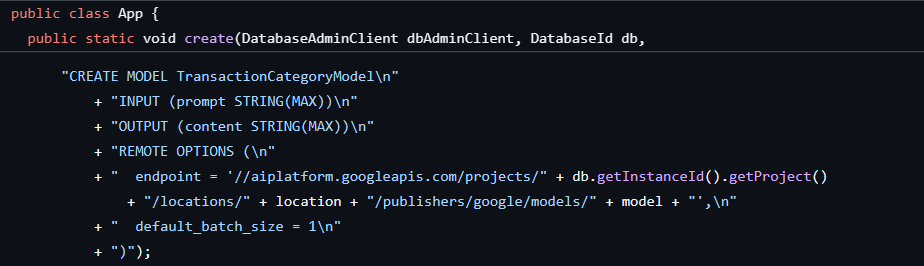
创建数据库和架构时,我们已经完成了第一步,创建了一个如下所示的模型:
接下来,我们将向应用添加一个方法来调用 ML.PREDICT。
打开 App.java 并添加 categorize 方法:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
在 main 方法中为分类添加另一个 case 语句:
case "categorize":
categorize(dbClient);
break;
最后,将如何使用分类功能附加到 printUsageAndExit 方法:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
保存您对 App.java 所做的更改。
重新构建应用:
mvn package
运行 categorize 命令,对数据库中的交易进行分类:
java -jar target/onlinebanking.jar categorize
预期输出:
Categorizing transactions... Completed categorizing transactions
在 Spanner Studio 中,针对 TransactionLedger 表运行 Preview Data 语句。现在,所有行的 Category 列都应已填充。
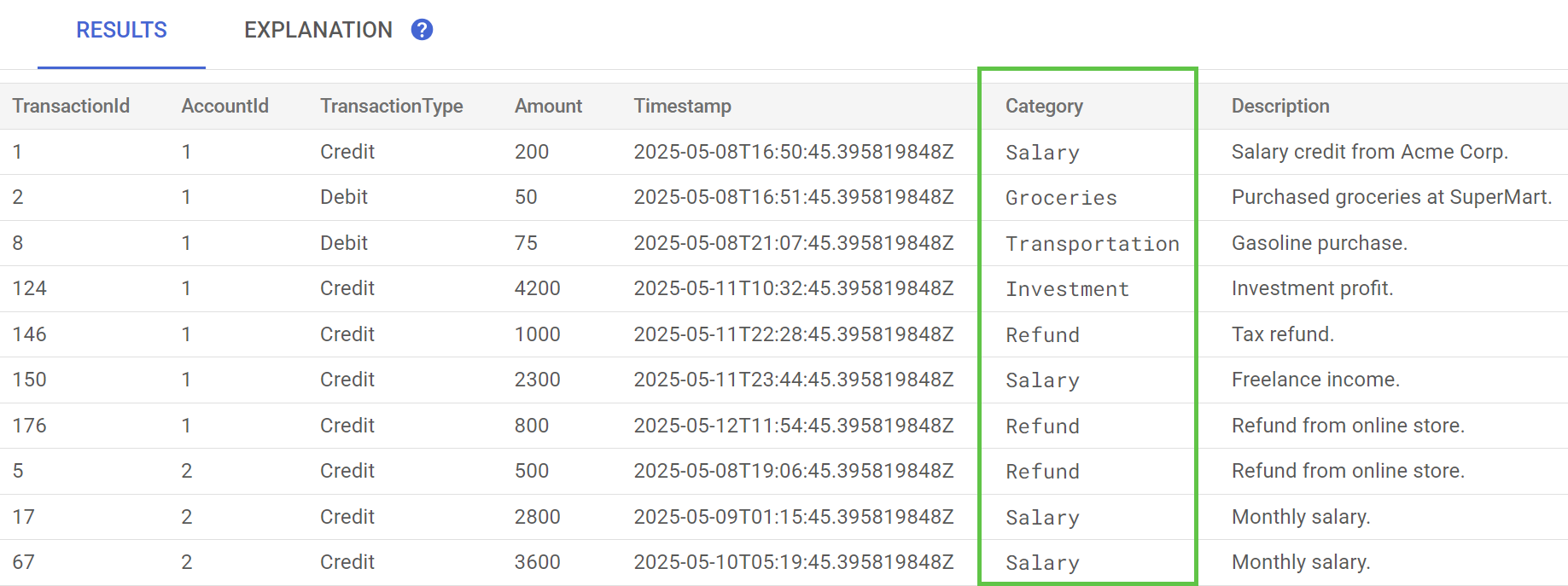
现在,我们已经对交易进行了分类,接下来,我们将了解如何查找特定客户在某个月份中在某个类别上的支出金额。
摘要
在此步骤中,您利用预训练模型对数据执行了 AI 赋能的分类。
后续步骤
接下来,您将利用词元化来执行模糊搜索和全文搜索。
7. 使用全文搜索进行查询
添加查询代码
Spanner 提供了许多全文搜索查询。在此步骤中,您将执行完全匹配搜索,然后执行模糊搜索和全文搜索。
打开 App.java,首先替换导入项:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
然后,添加查询方法:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
在 main 方法中添加另一个 case 语句以进行查询:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
最后,将有关如何使用查询命令的信息附加到 printUsageAndExit 方法:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
保存您对 App.java 所做的更改。
重新构建应用:
mvn package
针对客户账号余额执行完全匹配搜索
完全匹配查询会查找与字词完全匹配的匹配行。
为了提高性能,在创建数据库和架构时,系统已添加索引:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
getBalance 方法会隐式使用此索引来查找与所提供的 customerId 匹配的客户,还会联接属于该客户的账号。
直接在 Spanner Studio 中执行查询时,查询如下所示: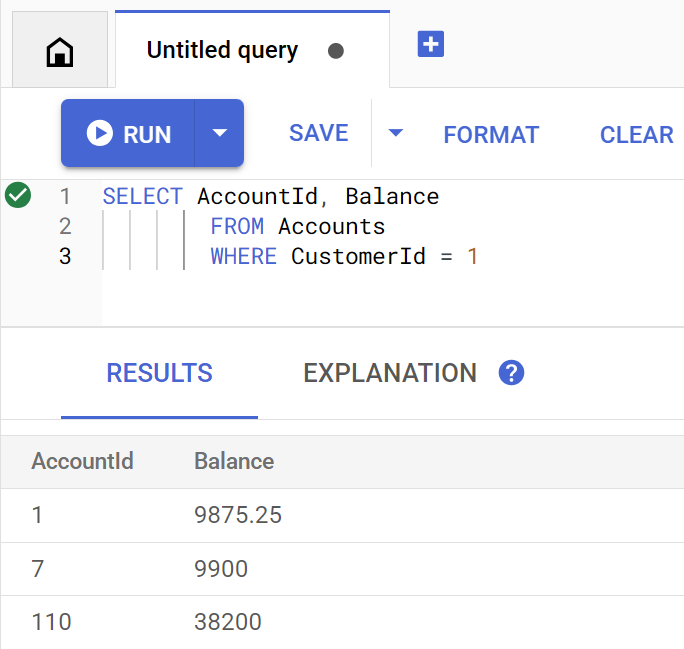
运行以下命令,列出客户 1 的账号余额:
java -jar target/onlinebanking.jar query balance 1
预期输出:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
有 100 位客户,因此您还可以通过指定其他客户 ID 来查询任何其他客户的账号余额:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
针对客户电子邮件执行模糊搜索
模糊搜索可查找搜索字词的近似匹配项,包括拼写变体和拼写错误。
您在创建数据库和架构时已添加 n-gram 索引:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
findCustomers 方法使用 SEARCH_NGRAMS 和 SCORE_NGRAMS 对此索引执行查询,以按电子邮件地址查找客户。由于电子邮件列已进行 N 元语法词元化,因此即使此查询包含拼写错误,仍可返回正确答案。结果会按匹配度从高到低排序。
运行以下命令,查找包含 madi 的匹配客户电子邮件地址:
java -jar target/onlinebanking.jar query email madi
预期输出:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
此响应会按排名顺序显示包含 madi 或类似字符串的最接近的匹配项。
如果直接在 Spanner Studio 中执行,查询如下所示: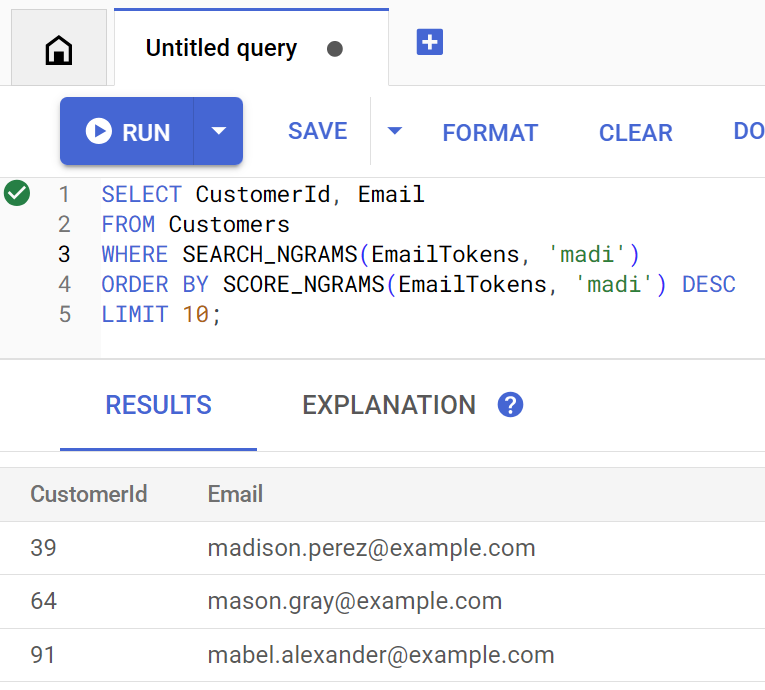
模糊搜索还可以帮助处理拼写错误,例如 emily 的拼写错误:
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
预期输出:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
在每种情况下,系统都会将预期客户电子邮件作为头条命中结果返回。
使用全文搜索功能搜索交易
Spanner 的全文搜索功能用于根据关键字或短语检索记录。它能够更正拼写错误或搜索同义词。
您在创建数据库和架构时已添加全文搜索索引:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
getSpending 方法使用 SEARCH 全文搜索函数来与该索引进行匹配。此查询会查找指定客户 ID 对应的过去 30 天内的所有支出(借记)。
运行以下命令,获取客户 1 在 groceries 类别中上个月的总支出:
java -jar target/onlinebanking.jar query spending 1 groceries
预期输出:
Total spending for customer 1 under category groceries: 50
您还可以查找其他类别(我们在上一步中进行了分类)的支出,或使用其他客户 ID:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
摘要
在此步骤中,您执行了完全匹配查询,以及模糊搜索和全文搜索。
后续步骤
接下来,您将 Spanner 与 Google BigQuery 集成以执行联合查询,从而将实时 Spanner 数据与 BigQuery 数据相结合。
8. 使用 BigQuery 运行联合查询
创建 BigQuery 数据集
在此步骤中,您将使用联合查询将 BigQuery 和 Spanner 数据整合在一起。
为此,请在 Cloud Shell 命令行中,先创建一个 MarketingCampaigns 数据集:
bq mk --location=us-central1 MarketingCampaigns
预期输出:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
以及数据集中的 CustomerSegments 表:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
预期输出:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
接下来,建立从 BigQuery 到 Spanner 的连接:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
预期输出:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
最后,向 BigQuery 表中添加一些可与 Spanner 数据联接的客户:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
预期输出:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
您可以通过查询 BigQuery 来验证数据是否可用:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
预期输出:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
BigQuery 中的这些数据表示通过各种银行工作流程添加的数据。例如,最近开户或注册参加营销促销活动的客户名单。为了确定要在营销活动中定位的客户名单,我们需要查询 BigQuery 中的这些数据以及 Spanner 中的实时数据,而联合查询可让我们通过一次查询完成此操作。
使用 BigQuery 运行联合查询
接下来,我们将向应用添加一个方法,以调用 EXTERNAL_QUERY 来执行联合查询。这样一来,您就可以在 BigQuery 和 Spanner 中联接和分析客户数据,例如根据客户近期的支出情况,确定哪些客户符合营销活动条件。
打开 App.java,首先替换导入项:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
然后添加 campaign 方法:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
在 main 方法中为广告系列添加另一个 case 语句:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
最后,将如何使用广告系列附加到 printUsageAndExit 方法:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
保存您对 App.java 所做的更改。
重新构建应用:
mvn package
运行联合查询,以确定哪些客户应纳入营销活动 (campaign1),前提是这些客户在过去 3 个月内的支出至少达到 $5000,方法是运行 campaign 命令:
java -jar target/onlinebanking.jar campaign campaign1 5000
预期输出:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
现在,我们可以向这些客户提供专属优惠或奖励。
或者,我们可以寻找过去 3 个月内达到较低支出最低限额的更多客户:
java -jar target/onlinebanking.jar campaign campaign1 2500
预期输出:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
摘要
在此步骤中,您已成功从 BigQuery 执行联合查询,从而获取了实时 Spanner 数据。
后续步骤
接下来,您可以清理为本 Codelab 创建的资源,以避免产生费用。
9. 清理(可选)
这是可选步骤。如果您想继续对 Spanner 实例进行实验,则无需立即清理该实例。不过,您使用的项目仍需继续支付实例费用。如果您不再需要此实例,则应立即将其删除,以免产生这些费用。除了 Spanner 实例之外,此 Codelab 还创建了一个 BigQuery 数据集和连接,在不再需要时应将其清理干净。
删除 Spanner 实例:
gcloud spanner instances delete cloudspanner-onlinebanking
确认您要继续(输入 Y):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
删除 BigQuery 连接和数据集:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
确认删除 BigQuery 数据集(输入 Y):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
10. 恭喜
🚀 您已创建新的 Cloud Spanner 实例、创建空数据库、加载示例数据、执行高级操作和查询,并(可选)删除了 Cloud Spanner 实例。
所学内容
- 如何设置 Spanner 实例。
- 如何创建数据库和表。
- 如何将数据加载到 Spanner 数据库表中。
- 如何从 Spanner 调用 Vertex AI 模型。
- 如何使用模糊搜索和全文搜索查询 Spanner 数据库。
- 如何从 BigQuery 对 Spanner 执行联合查询。
- 如何删除 Spanner 实例。
接下来怎么做?
- 详细了解高级 Spanner 功能,包括:
- 请参阅可用的 Spanner 客户端库。