
1. Zanim zaczniesz
To ćwiczenie jest kontynuacją wyniku poprzedniego ćwiczenia z tej serii, w którym pokazujemy, jak wykrywać spam w komentarzach przy użyciu TensorFlow.js.
W ostatnim ćwiczeniu utworzyliśmy w pełni funkcjonalną stronę internetową dla fikcyjnego bloga wideo. Komentarze można było filtrować pod kątem spamu, zanim zostały wysłane na serwer w celu przechowywania lub do innych połączonych klientów. W tym celu używaliśmy wstępnie wytrenowanego modelu wykrywania spamu w komentarzach opartego na TensorFlow.js w przeglądarce.
Poniżej znajdziesz efekt końcowy tego samouczka:
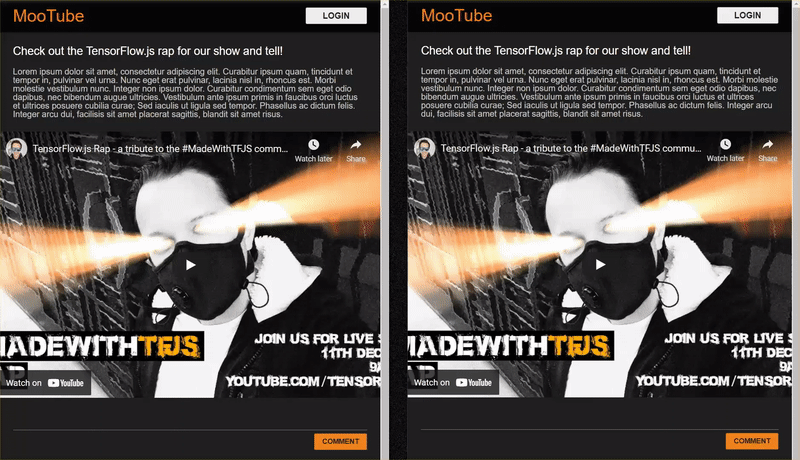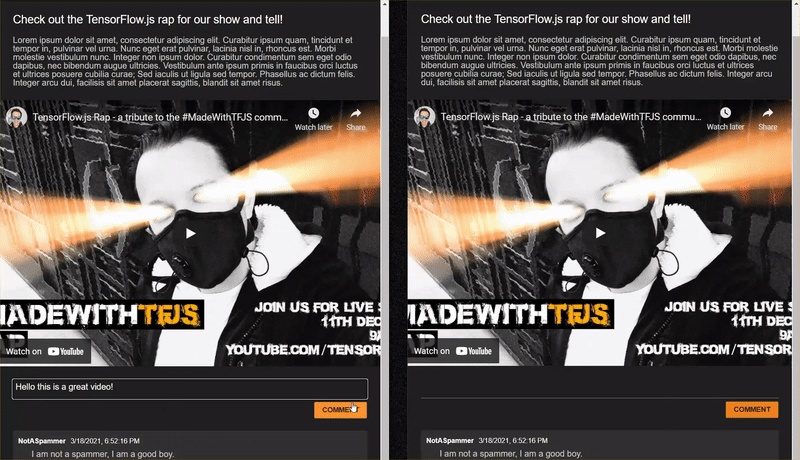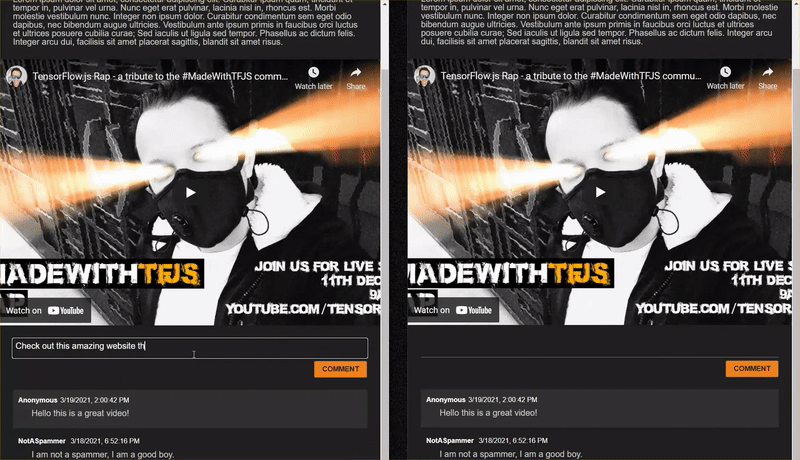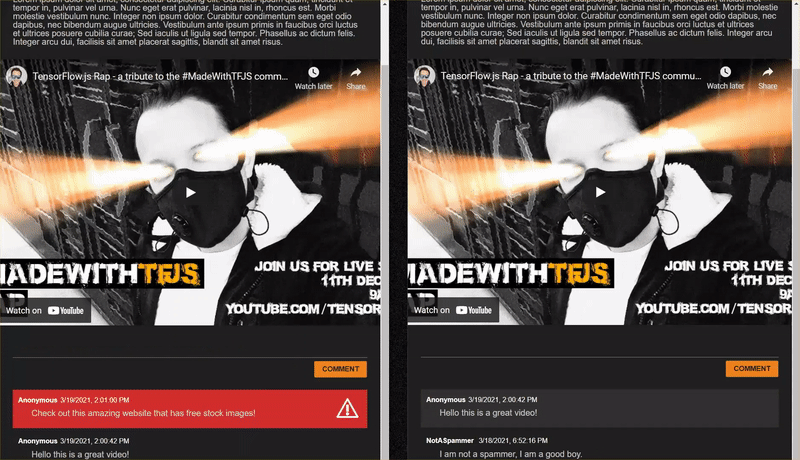
Chociaż to rozwiązanie działało bardzo dobrze, istniały przypadki graniczne, których nie było w stanie wykryć. Możesz ponownie wytrenować model, aby uwzględnić sytuacje, z którymi nie radził sobie wcześniej.
W tym ćwiczeniu skupimy się na wykorzystaniu przetwarzania języka naturalnego (czyli sztuki rozumienia języka ludzkiego przez komputer) i pokażemy, jak zmodyfikować utworzoną przez Ciebie aplikację internetową (zalecamy wykonanie ćwiczeń w odpowiedniej kolejności), aby rozwiązać bardzo realny problem spamu w komentarzach, z którym wielu programistów internetowych z pewnością się spotka, pracując nad jedną z coraz popularniejszych aplikacji internetowych.
W tym laboratorium kodowym zrobisz kolejny krok i ponownie wytrenujesz model ML, aby uwzględnić zmiany w treści wiadomości spamowych, które mogą zachodzić z czasem w zależności od aktualnych trendów lub popularnych tematów dyskusji. Dzięki temu model będzie zawsze aktualny i będzie uwzględniać takie zmiany.
Wymagania wstępne
- ukończyć pierwsze ćwiczenie z tej serii;
- Podstawowa znajomość technologii internetowych, w tym HTML, CSS i JavaScript.
Co utworzysz
Ponownie wykorzystasz utworzoną wcześniej witrynę fikcyjnego bloga wideo z sekcją komentarzy w czasie rzeczywistym i ulepszysz ją, aby wczytywała niestandardową wytrenowaną wersję modelu wykrywania spamu za pomocą TensorFlow.js. Dzięki temu będzie on lepiej radzić sobie w przypadkach granicznych, w których wcześniej zawodził. Jako deweloperzy i inżynierowie stron internetowych możecie oczywiście zmienić ten hipotetyczny UX, aby używać go ponownie w dowolnej witrynie, nad którą pracujecie na co dzień, i dostosować rozwiązanie do każdego przypadku użycia klienta – może to być blog, forum lub jakaś forma systemu zarządzania treścią, np. Drupal.
Zaczynamy hakowanie…
Czego się nauczysz
W ramach ćwiczenia:
- Określ przypadki brzegowe, w których wstępnie wytrenowany model nie działał prawidłowo.
- Ponownie wytrenuj model klasyfikacji spamu utworzony za pomocą narzędzia Model Maker.
- Wyeksportuj ten model oparty na Pythonie do formatu TensorFlow.js, aby używać go w przeglądarkach.
- Zaktualizuj hostowany model i jego słownik za pomocą nowo wytrenowanego modelu i sprawdź wyniki.
W tym laboratorium zakłada się znajomość języków HTML5, CSS i JavaScript. Uruchomisz też kod w Pythonie w notatniku „co lab”, aby ponownie wytrenować model utworzony za pomocą Model Maker. Nie musisz jednak znać języka Python, aby to zrobić.
2. Przygotowanie do kodowania
Do hostowania i modyfikowania aplikacji internetowej ponownie użyjesz Glitch.com. Jeśli nie masz jeszcze za sobą wymaganego ćwiczenia, możesz sklonować tutaj jego końcowy efekt jako punkt początkowy. Jeśli masz pytania dotyczące działania kodu, przed kontynuowaniem wykonaj poprzednie ćwiczenie, w którym pokazaliśmy, jak utworzyć działającą aplikację internetową.
W Glitch wystarczy kliknąć przycisk remix this, aby rozwidlić projekt i utworzyć nowy zestaw plików, które możesz edytować.
3. Odkrywanie przypadków brzegowych w poprzednim rozwiązaniu
Jeśli otworzysz sklonowaną witrynę i spróbujesz wpisać komentarze, zauważysz, że w większości przypadków działa ona zgodnie z przeznaczeniem, blokując komentarze, które wyglądają na spam, i przepuszczając wiarygodne odpowiedzi.
Jeśli jednak spróbujesz przechytrzyć model i sformułować prompt w taki sposób, aby go oszukać, prawdopodobnie w pewnym momencie Ci się to uda. Metodą prób i błędów możesz ręcznie utworzyć przykłady podobne do tych, które widzisz poniżej. Spróbuj wkleić te teksty do istniejącej aplikacji internetowej, sprawdź konsolę i zobacz, jakie prawdopodobieństwo zostanie zwrócone w przypadku, gdy komentarz jest spamem:
Prawidłowe komentarze opublikowane bez problemów (prawdziwie negatywne):
- „Wow, uwielbiam ten film, świetna robota”. Prawdopodobieństwo spamu: 47,91854%
- „Bardzo podobały mi się te prezentacje. Czy masz więcej szczegółów? Prawdopodobieństwo spamu: 47,15898%
- „Na jakiej stronie mogę dowiedzieć się więcej?” Prawdopodobieństwo spamu: 15,32495%
To świetnie. Prawdopodobieństwa dla wszystkich powyższych przypadków są dość niskie i przechodzą przez domyślny próg SPAM_THRESHOLD 75% minimalnego prawdopodobieństwa, zanim zostaną podjęte działania (zdefiniowane w script.js kodzie z poprzednich zajęć).
Teraz spróbujmy napisać bardziej kontrowersyjne komentarze, które zostaną oznaczone jako spam, mimo że nim nie są…
Prawdziwe komentarze oznaczane jako spam (fałszywie pozytywne):
- „Czy ktoś może podać link do strony internetowej z maską, którą ma na sobie ten mężczyzna?” Prawdopodobieństwo spamu: 98,46466%
- „Czy mogę kupić ten utwór w Spotify? Dajcie mi znać! Prawdopodobieństwo, że to spam: 94,40953%
- „Czy ktoś może się ze mną skontaktować i przekazać szczegółowe informacje o tym, jak pobrać TensorFlow.js?” Prawdopodobieństwo spamu: 83,20084%
O nie! Wygląda na to, że te prawidłowe komentarze są oznaczane jako spam, mimo że powinny być dozwolone. Jak możesz to naprawić?
Prostym rozwiązaniem jest zwiększenie SPAM_THRESHOLD, aby mieć pewność na poziomie ponad 98,5%. W takim przypadku błędnie zaklasyfikowane komentarze zostaną opublikowane. Mając to na uwadze, przejdźmy do innych możliwych wyników poniżej…
Spam w komentarzach oznaczony jako spam (prawdziwie pozytywne):
- „To fajne, ale sprawdź linki do pobierania na mojej stronie, które są lepsze”. Prawdopodobieństwo spamu: 99,77873%
- „Znam osoby, które mogą Ci załatwić leki. Szczegóły znajdziesz w moim pr0filu”. Prawdopodobieństwo spamu: 98,46955%
- „Zobacz mój profil, aby pobrać jeszcze więcej niesamowitych filmów, które są jeszcze lepsze! http://example.com” Prawdopodobieństwo spamu: 96,26383%
OK, przy pierwotnym progu 75% działa to zgodnie z oczekiwaniami, ale biorąc pod uwagę, że w poprzednim kroku zmieniliśmy wartość SPAM_THRESHOLD na ponad 98,5%, oznacza to, że w tym przypadku przepuszczone zostałyby 2 przykłady, więc próg może być zbyt wysoki. Może 96% będzie lepsze? Jeśli to zrobisz, jeden z komentarzy z poprzedniej sekcji (fałszywie pozytywny) zostanie oznaczony jako spam, mimo że jest prawidłowy, ponieważ jego ocena wynosi 98,46466%.
W takim przypadku najlepiej jest przechwycić wszystkie te prawdziwe komentarze spamowe i po prostu ponownie wytrenować model na podstawie powyższych błędów. Ustawienie progu na 96% nadal pozwala wychwytywać wszystkie wyniki prawdziwie pozytywne i eliminować 2 wyniki fałszywie pozytywne. To całkiem niezły wynik, biorąc pod uwagę, że zmieniliśmy tylko jedną liczbę.
Kontynuujmy…
Spamowe komentarze, które zostały opublikowane (fałszywie negatywne):
- „Zobacz mój profil, aby pobrać jeszcze więcej niesamowitych filmów, które są jeszcze lepsze!” Prawdopodobieństwo spamu: 7,54926%
- „Skorzystaj ze zniżki na nasze zajęcia na siłowni. Zobacz profil!” Prawdopodobieństwo spamu: 17,49849%
- „omg GOOG stock just shot right up! Skorzystaj z niej, zanim będzie za późno”. Prawdopodobieństwo spamu: 20,42894%
W przypadku tych komentarzy nie możesz nic zrobić, zmieniając dalej wartość SPAM_THRESHOLD. Obniżenie progu spamu z 96% do ok. 9% spowoduje, że prawdziwe komentarze będą oznaczane jako spam. Jeden z nich ma ocenę 58%, mimo że jest wiarygodny. Jedynym sposobem radzenia sobie z takimi komentarzami jest ponowne wytrenowanie modelu z uwzględnieniem takich przypadków granicznych w danych treningowych, aby nauczył się dostosowywać swoje postrzeganie świata pod kątem tego, co jest spamem, a co nie.
Obecnie jedyną opcją jest ponowne trenowanie modelu, ale wiesz już, jak dostosować próg, przy którym uznajesz coś za spam, aby zwiększyć skuteczność. Dla człowieka 75% to dość wysoki poziom pewności, ale w przypadku tego modelu, aby był on bardziej skuteczny w przypadku przykładowych danych wejściowych, należało zwiększyć ten poziom do około 81,5%.
Nie ma jednej magicznej wartości, która sprawdza się w przypadku różnych modeli. Wartość progową należy ustawiać indywidualnie dla każdego modelu po przeprowadzeniu eksperymentów z danymi z rzeczywistego świata, aby sprawdzić, co działa dobrze.
W niektórych sytuacjach fałszywie pozytywny (lub negatywny) wynik może mieć poważne konsekwencje (np. w branży medycznej), dlatego możesz ustawić bardzo wysoki próg i poprosić o ręczne sprawdzenie treści, które go nie spełniają. To zależy od Ciebie jako dewelopera i wymaga przeprowadzenia eksperymentów.
4. Ponowne trenowanie modelu do wykrywania spamu w komentarzach
W poprzedniej sekcji zidentyfikowano kilka przypadków brzegowych, w których model nie działał prawidłowo. Jedynym rozwiązaniem było ponowne wytrenowanie modelu, aby uwzględnić te sytuacje. W systemie produkcyjnym można je znaleźć z czasem, gdy użytkownicy ręcznie oznaczają komentarze jako spam, a moderatorzy sprawdzający zgłoszone komentarze stwierdzają, że niektóre z nich nie są spamem i mogą oznaczyć takie komentarze do ponownego trenowania. Załóżmy, że udało Ci się zebrać sporo nowych danych dotyczących tych przypadków brzegowych (aby uzyskać najlepsze wyniki, warto mieć kilka wariantów tych nowych zdań). Teraz pokażemy Ci, jak ponownie wytrenować model z uwzględnieniem tych przypadków.
Gotowe podsumowanie modelu
Użyty przez Ciebie gotowy model został utworzony przez firmę zewnętrzną za pomocą narzędzia Model Maker, które do działania wykorzystuje model „średniego osadzania słów”.
Model został utworzony za pomocą Model Maker, więc musisz na chwilę przełączyć się na Pythona, aby ponownie wytrenować model, a następnie wyeksportować go do formatu TensorFlow.js, aby móc używać go w przeglądarce. Dzięki Model Maker korzystanie z modeli jest bardzo proste, więc nie powinno być problemu z wykonaniem tych czynności. Przeprowadzimy Cię przez cały proces, więc nie martw się, jeśli nigdy wcześniej nie używałeś(-aś) Pythona.
Colabs
W tym ćwiczeniu nie musisz konfigurować serwera Linux z zainstalowanymi różnymi narzędziami Pythona. Możesz po prostu uruchamiać kod w przeglądarce internetowej za pomocą „notatnika Colab”. Te notatniki mogą łączyć się z „backendem”, czyli serwerem z preinstalowanymi komponentami, na którym możesz wykonywać dowolny kod w przeglądarce i wyświetlać wyniki. Jest to bardzo przydatne w przypadku szybkiego tworzenia prototypów lub w samouczkach takich jak ten.
Otwórz stronę colab.research.google.com. Zobaczysz ekran powitalny jak na ilustracji:
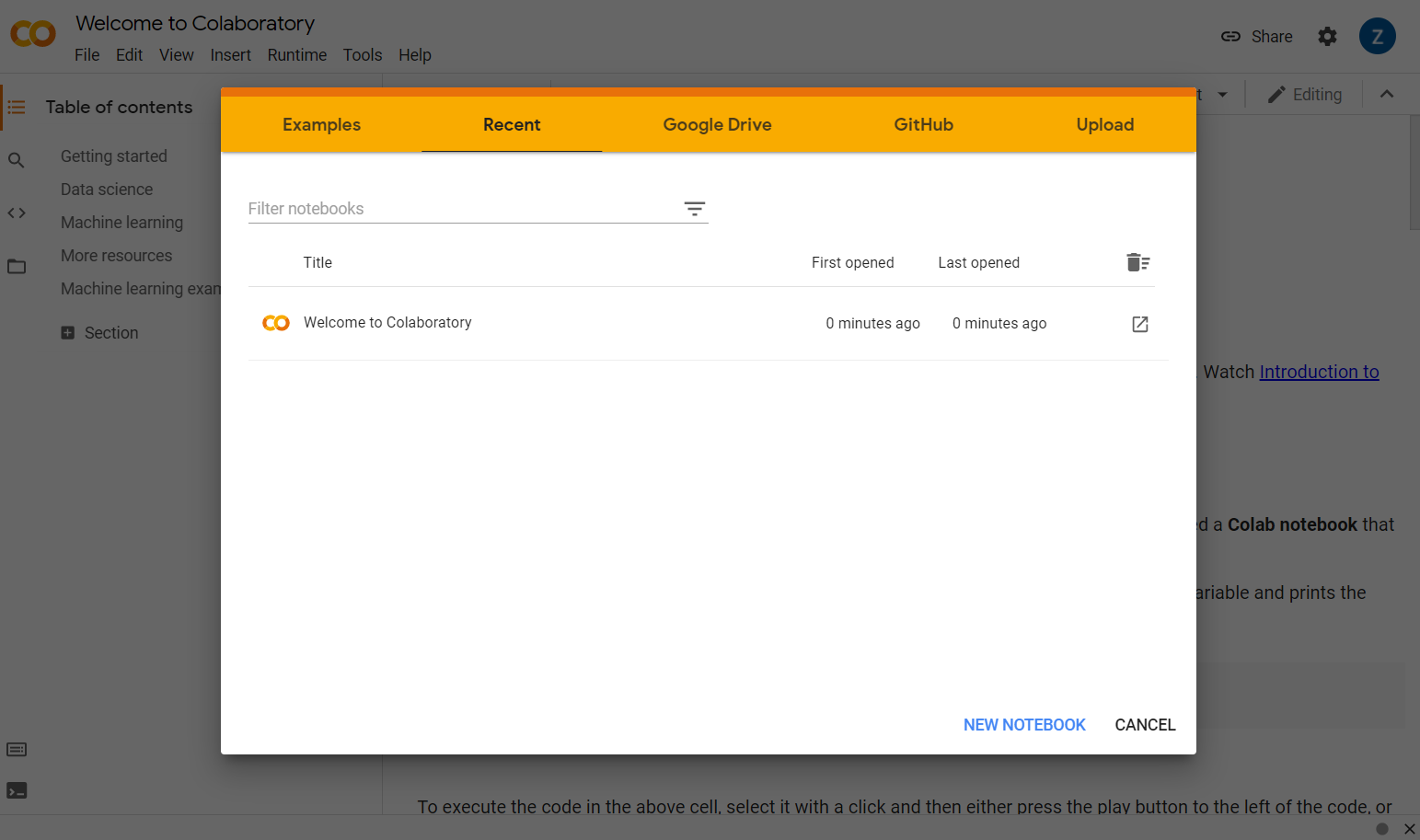
Teraz w prawym dolnym rogu wyskakującego okienka kliknij przycisk Nowy notatnik. Powinien pojawić się pusty notatnik Colab, taki jak ten:
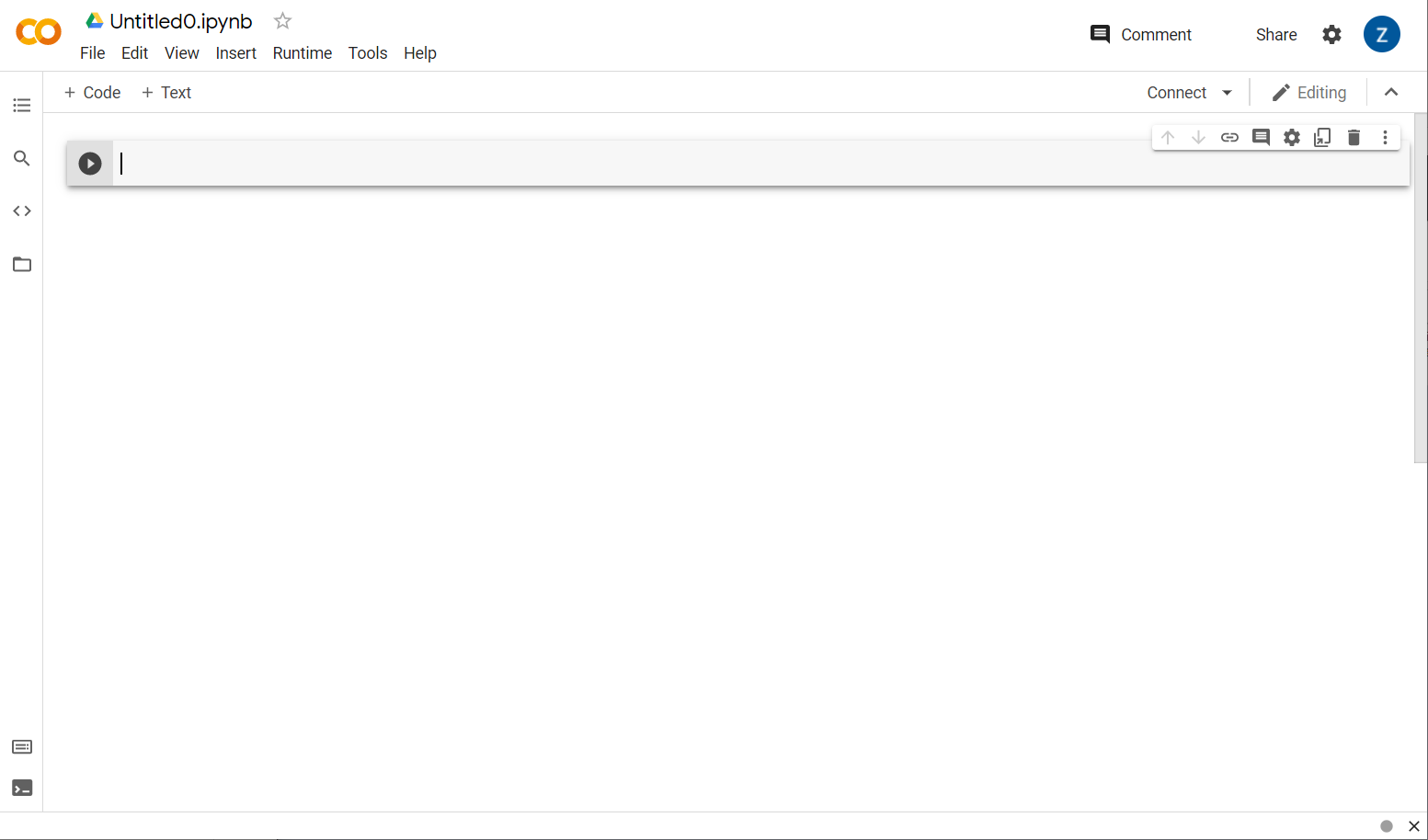
Świetnie. Następnym krokiem jest połączenie frontendu Colab z serwerem backendu, aby można było uruchamiać pisany kod w języku Python. W tym celu kliknij Połącz w prawym górnym rogu i wybierz Połącz z hostowanym środowiskiem wykonawczym.
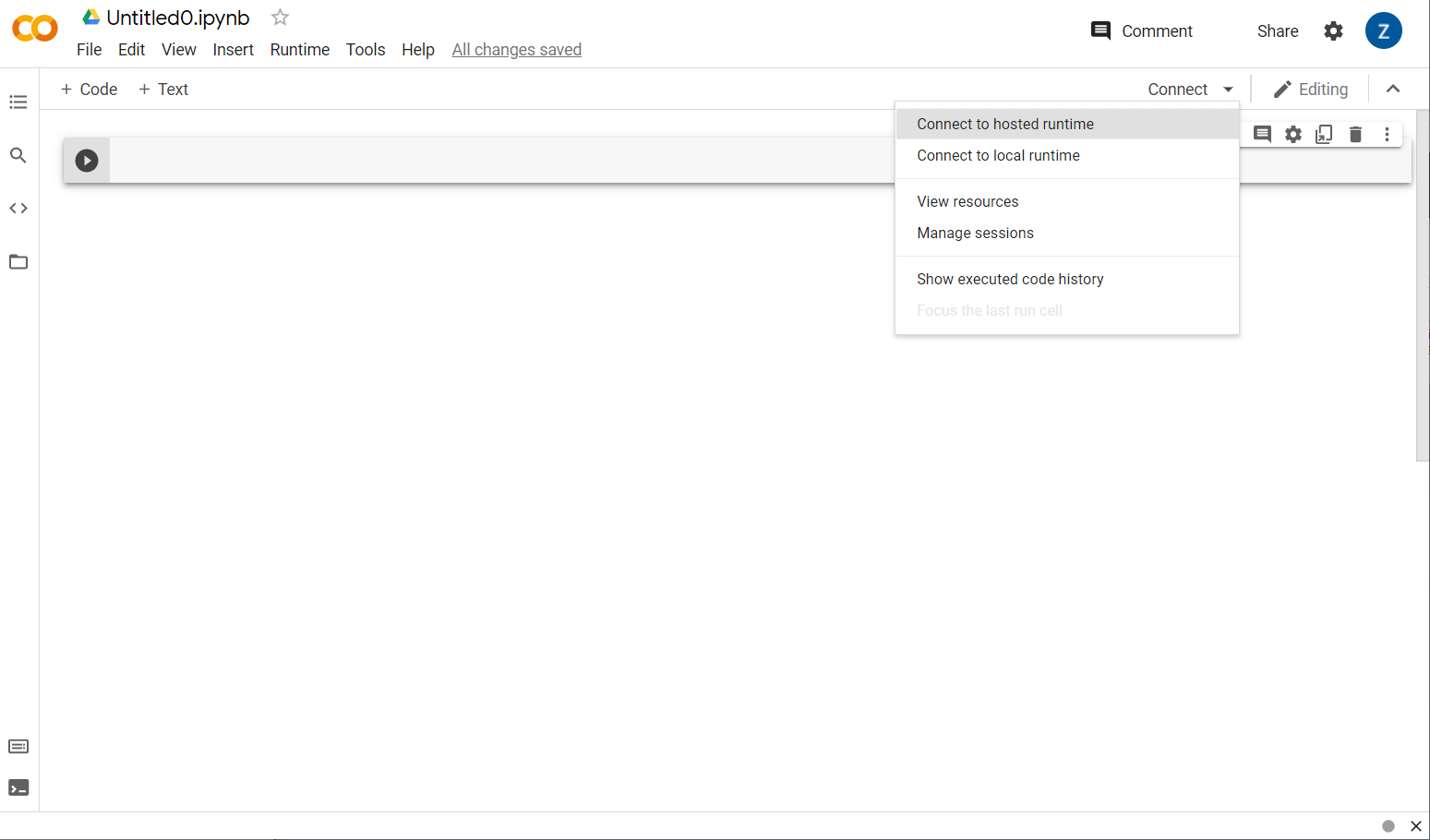
Po połączeniu w tym miejscu powinny się pojawić ikony pamięci RAM i dysku, jak na tym przykładzie:
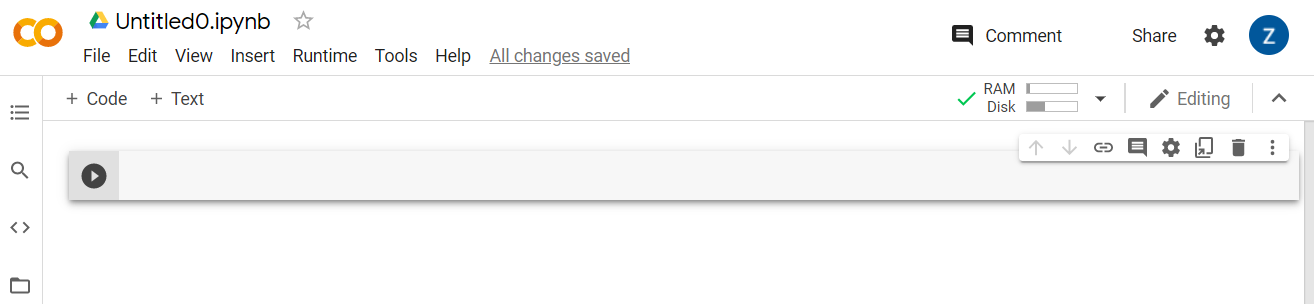
Dobra robota! Możesz teraz zacząć pisać kod w Pythonie, aby ponownie wytrenować model Model Maker. Należy wykonać poniższe instrukcje.
Krok 1
W pierwszej pustej komórce skopiuj poniższy kod. Zainstaluje on TensorFlow Lite Model Maker za pomocą menedżera pakietów Pythona o nazwie „pip” (jest on podobny do npm, który większość czytelników tego ćwiczenia może znać z ekosystemu JS):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Wklejenie kodu do komórki nie spowoduje jednak jego wykonania. Następnie najedź kursorem myszy na szarą komórkę, do której wklejono powyższy kod. Po lewej stronie komórki pojawi się mała ikona „odtwarzania”, jak pokazano poniżej:
 Kliknij przycisk odtwarzania, aby uruchomić kod wpisany w komórce.
Kliknij przycisk odtwarzania, aby uruchomić kod wpisany w komórce.
Zobaczysz, że instalacja narzędzia do tworzenia modeli jest w toku:
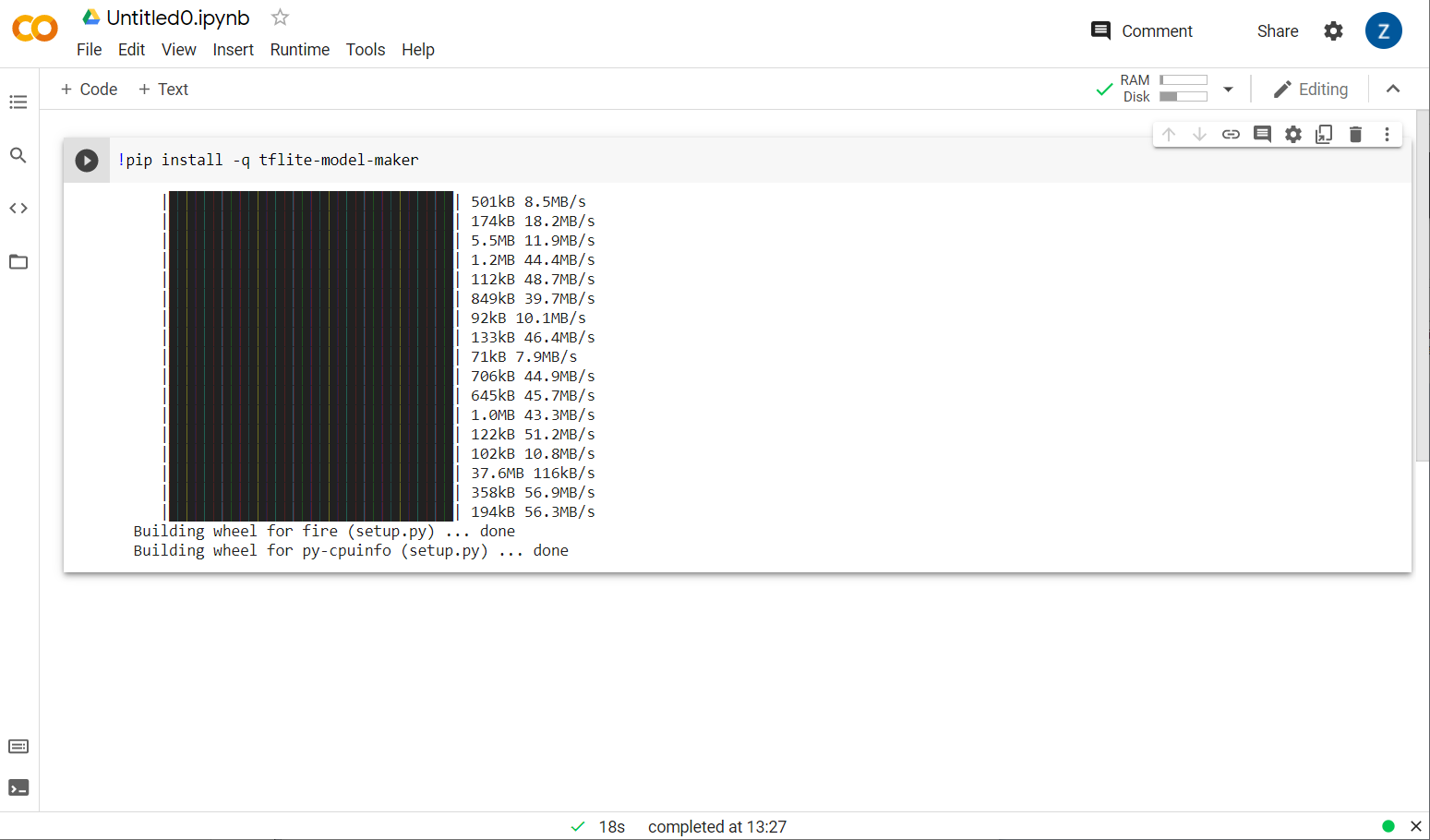
Gdy wykonanie tej komórki zostanie zakończone (jak pokazano), przejdź do następnego kroku poniżej.
Krok 2
Następnie dodaj nową komórkę kodu, jak pokazano poniżej, aby wkleić do niej więcej kodu po pierwszej komórce i wykonać go osobno:
W następnej komórce zostaną wykonane importy, których kod w pozostałej części notatnika będzie musiał użyć. Skopiuj i wklej poniższy kod do nowej komórki:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
To dość standardowe działanie, nawet jeśli nie znasz Pythona. Importujesz tylko niektóre narzędzia i funkcje Model Makera potrzebne do klasyfikatora spamu. Sprawdzimy też, czy używasz TensorFlow 2.x, co jest wymagane do korzystania z Model Maker.
Na koniec, tak jak wcześniej, wykonaj komórkę, klikając ikonę „odtwarzania”, która pojawi się po najechaniu na nią kursorem, a potem dodaj nową komórkę kodu, aby przejść do następnego kroku.
Krok 3
Następnie pobierz dane z serwera zdalnego na urządzenie i ustaw zmienną training_data jako ścieżkę do pobranego pliku lokalnego:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker może trenować modele na podstawie prostych plików CSV, takich jak pobrany plik. Wystarczy, że określisz, które kolumny zawierają tekst, a które etykiety. W kroku 5 dowiesz się, jak to zrobić. Jeśli chcesz, możesz pobrać plik CSV i sprawdzić jego zawartość.
Uważni użytkownicy zauważą, że nazwa tego pliku to jm_blog_comments_extras.csv. Jest to po prostu oryginalny zbiór danych treningowych, którego użyliśmy do wygenerowania pierwszego modelu spamu w komentarzach, połączony z nowymi danymi dotyczącymi przypadków granicznych, które udało Ci się znaleźć. Wszystkie dane znajdują się w jednym pliku. Oprócz nowych zdań, na podstawie których chcesz się uczyć, potrzebujesz też oryginalnych danych treningowych użytych do wytrenowania modelu.
Opcjonalnie: jeśli pobierzesz ten plik CSV i sprawdzisz kilka ostatnich wierszy, zobaczysz przykłady przypadków brzegowych, które wcześniej nie działały prawidłowo. Zostały one dodane na końcu istniejących danych treningowych, których gotowy model używał do trenowania.
Wykonaj kod w tej komórce, a gdy to zrobisz, dodaj nową komórkę i przejdź do kroku 4.
Krok 4
Korzystając z Model Maker, nie musisz tworzyć modeli od zera. Zwykle używasz istniejących modeli, które następnie dostosowujesz do swoich potrzeb.
Model Maker udostępnia kilka wstępnie wytrenowanych osadzeń modeli, których możesz używać. Najprostszym i najszybszym sposobem na rozpoczęcie pracy jest average_word_vec, którego używasz w poprzednim ćwiczeniu w Codelabs do tworzenia witryny. Oto kod:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Po wklejeniu kodu do nowej komórki uruchom go.
Interpretowanie
num_words
parameter
Jest to liczba słów, których ma użyć model. Może się wydawać, że im więcej, tym lepiej, ale zwykle istnieje optymalna liczba słów kluczowych, która zależy od częstotliwości używania każdego z nich. Jeśli użyjesz wszystkich słów z całego korpusu, model może próbować nauczyć się i zrównoważyć wagi słów, które są używane tylko raz, co nie jest zbyt przydatne. W każdym korpusie językowym wiele słów jest używanych tylko raz lub dwa, więc zwykle nie warto ich uwzględniać w modelu, ponieważ mają znikomy wpływ na ogólny wydźwięk. Za pomocą parametru num_words możesz dostosować model do liczby słów, których potrzebujesz. Mniejsza liczba w tym miejscu oznacza mniejszy i szybszy model, ale może być on mniej dokładny, ponieważ rozpoznaje mniej słów. Im większa liczba, tym większy i potencjalnie wolniejszy model. Znalezienie optymalnego rozwiązania jest kluczowe i zależy od Ciebie jako inżyniera uczenia maszynowego. Musisz określić, co najlepiej sprawdzi się w Twoim przypadku.
Interpretowanie
wordvec_dim
parameter
Parametr wordvec_dim to liczba wymiarów, których chcesz użyć w przypadku wektora każdego słowa. Wymiary te to różne cechy (utworzone przez algorytm uczenia maszynowego podczas trenowania), według których można mierzyć każde słowo. Program będzie ich używać, aby jak najlepiej kojarzyć słowa, które są w jakiś istotny sposób podobne.
Jeśli np. masz wymiar określający, jak bardzo dane słowo jest „medyczne”, słowo „pigułki” może mieć w tym wymiarze wysoki wynik i być powiązane z innymi słowami o wysokim wyniku, np. „zdjęcie rentgenowskie”, ale słowo „kot” będzie miało w tym wymiarze niski wynik. Może się okazać, że „wymiar medyczny” jest przydatny do wykrywania spamu w połączeniu z innymi potencjalnymi wymiarami, które mogą być istotne.
W przypadku słów, które uzyskują wysokie wyniki w „wymiarze medycznym”, może się okazać, że przydatny jest drugi wymiar, który koreluje słowa z ludzkim ciałem. Słowa takie jak „noga”, „ręka” czy „szyja” mogą uzyskać wysoki wynik w tej kategorii, a także w kategorii medycznej.
Model może używać tych wymiarów do wykrywania słów, które są bardziej prawdopodobnie powiązane ze spamem. Być może spam częściej zawiera słowa, które są zarówno terminami medycznymi, jak i nazwami części ciała.
Z badań wynika, że w przypadku tego parametru dobrze sprawdza się czwarty pierwiastek z liczby słów. Jeśli używam 2000 słów, dobrym punktem początkowym jest 7 wymiarów. Jeśli zmienisz liczbę użytych słów, możesz też zmienić tę wartość.
Interpretowanie
seq_len
parameter
Modele są zwykle bardzo sztywne, jeśli chodzi o wartości wejściowe. W przypadku modelu językowego oznacza to, że może on klasyfikować zdania o określonej, statycznej długości. Określa to parametr seq_len, który oznacza „długość sekwencji”. Gdy przekształcisz słowa w liczby (lub tokeny), zdanie stanie się sekwencją tych tokenów. Model zostanie więc wytrenowany (w tym przypadku) do klasyfikowania i rozpoznawania zdań zawierających 20 tokenów. Jeśli zdanie jest dłuższe, zostanie obcięte. Jeśli jest krótszy, zostanie uzupełniony – tak jak w pierwszym ćwiczeniu z tej serii.
Krok 5. Wczytaj dane treningowe
Wcześniej pobrano plik CSV. Teraz musisz użyć narzędzia do wczytywania danych, aby przekształcić je w dane treningowe, które model będzie mógł rozpoznać.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Jeśli otworzysz plik CSV w edytorze, zobaczysz, że każdy wiersz zawiera tylko 2 wartości, a są one opisane tekstem w pierwszym wierszu pliku. Zwykle każdy wpis jest traktowany jako „kolumna”. Zobaczysz, że opis pierwszej kolumny to commenttext, a pierwszy wpis w każdym wierszu to tekst komentarza.
Podobnie deskryptor drugiej kolumny to spam, a drugi wpis w każdym wierszu to TRUE lub FALSE, co oznacza, czy tekst jest uznawany za spam w komentarzach. Pozostałe właściwości określają specyfikację modelu utworzoną w kroku 4 oraz znak rozdzielający, którym w tym przypadku jest przecinek, ponieważ plik jest rozdzielany przecinkami. Ustawiasz też parametr tasowania, aby losowo zmieniać kolejność danych treningowych. Dzięki temu elementy, które mogły być podobne lub zebrane razem, są losowo rozproszone w zbiorze danych.
Następnie użyjesz data.split(), aby podzielić dane na dane treningowe i testowe. Wartość 0,9 oznacza, że 90% zbioru danych zostanie użyte do trenowania, a pozostałe 10% – do testowania.
Krok 6. Tworzenie modelu
Dodaj kolejną komórkę, w której umieścisz kod do utworzenia modelu:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
W ten sposób utworzysz model klasyfikatora tekstu za pomocą narzędzia Model Maker. Określisz dane treningowe, których chcesz użyć (zdefiniowane w kroku 4), specyfikację modelu (również skonfigurowaną w kroku 4) oraz liczbę epok, w tym przypadku 50.
Podstawową zasadą uczenia maszynowego jest dopasowywanie wzorców. Początkowo wczyta wstępnie wytrenowane wagi słów i spróbuje je pogrupować, przewidując, które z nich po zgrupowaniu wskazują na spam, a które nie. Za pierwszym razem prawdopodobnie będzie to blisko 50:50, ponieważ model dopiero zaczyna działać, jak pokazano poniżej:

Następnie zmierzy wyniki i zmieni wagi modelu, aby dostosować prognozę, po czym spróbuje ponownie. To jest epoka. Jeśli więc określisz epochs=50, pętla zostanie wykonana 50 razy, jak pokazano poniżej:

Dlatego po 50 epokach model będzie wykazywać znacznie wyższy poziom dokładności. W tym przypadku jest to 99,1%.
Krok 7. Eksportowanie modelu
Po zakończeniu trenowania możesz wyeksportować model. TensorFlow trenuje model we własnym formacie, który należy przekonwertować na format TensorFlow.js, aby można go było używać na stronie internetowej. Wklej ten kod do nowej komórki i wykonaj go:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
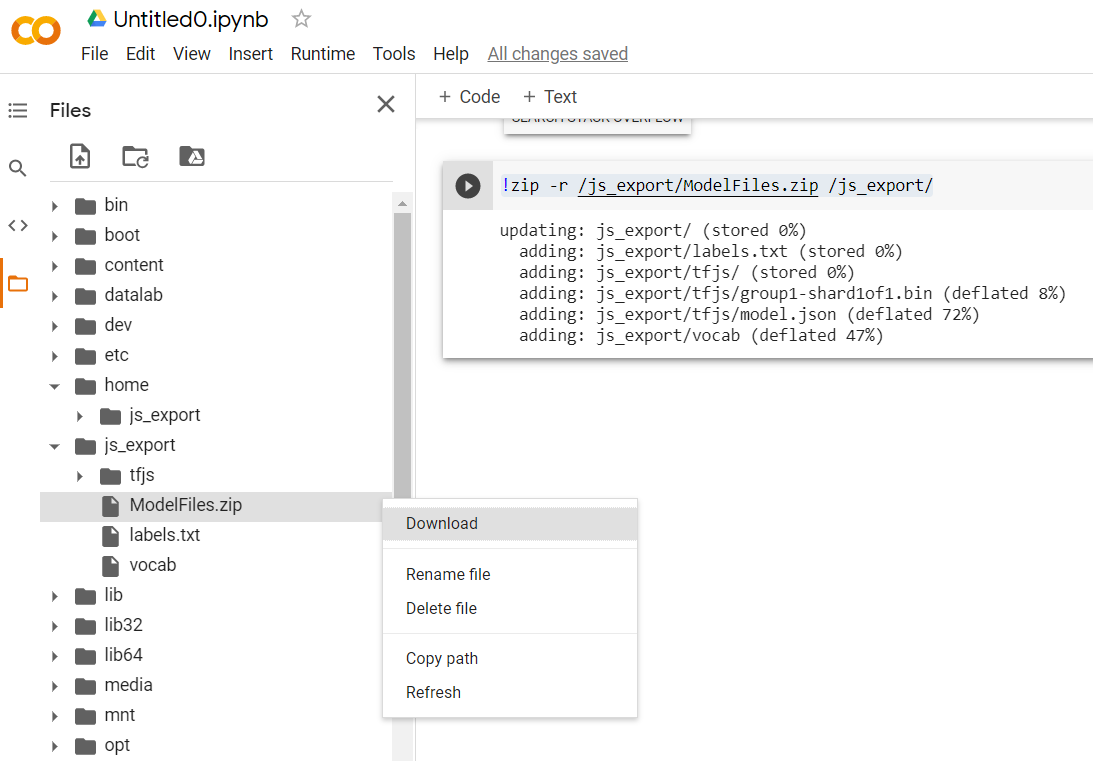
!zip -r /js_export/ModelFiles.zip /js_export/
Po wykonaniu tego kodu, jeśli klikniesz małą ikonę folderu po lewej stronie Colabu, możesz przejść do folderu, do którego wyeksportowano pliki (w katalogu głównym – może być konieczne przejście o jeden poziom wyżej) i znaleźć pakiet ZIP wyeksportowanych plików w ModelFiles.zip.
Pobierz teraz ten plik ZIP na komputer, ponieważ będziesz używać tych plików tak samo jak w pierwszym ćwiczeniu:
Świetnie. Część dotycząca Pythona dobiegła końca. Możesz teraz wrócić do JavaScriptu, który znasz i lubisz. Uff...
5. Udostępnianie nowego modelu uczenia maszynowego
Możesz już prawie wczytać model. Zanim to zrobisz, musisz przesłać nowe pliki modelu pobrane wcześniej w ramach codelabu, aby były hostowane i można było ich używać w kodzie.
Najpierw, jeśli jeszcze tego nie zrobiono, rozpakuj pliki modelu pobrane z notatnika Colab Model Maker, który został właśnie uruchomiony. W różnych folderach powinny znajdować się te pliki:
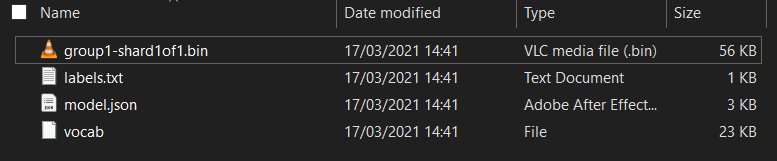
Co tu masz?
model.json– to jeden z plików, z których składa się wytrenowany model TensorFlow.js. W kodzie JavaScript odwołasz się do tego konkretnego pliku.group1-shard1of1.bin– jest to plik binarny zawierający większość zapisanych danych wyeksportowanego modelu TensorFlow.js. Musi być hostowany na serwerze w tym samym katalogu co plikmodel.jsonpowyżej, aby można było go pobrać.vocab– ten dziwny plik bez rozszerzenia pochodzi z Model Maker i pokazuje, jak kodować słowa w zdaniach, aby model wiedział, jak ich używać. Więcej informacji na ten temat znajdziesz w następnej sekcji.labels.txt– zawiera nazwy klas, które model będzie przewidywać. W tym modelu, jeśli otworzysz ten plik w edytorze tekstu, zobaczysz po prostu „false” i „true”, co oznacza odpowiednio „nie spam” i „spam” jako wynik prognozy.
Hostowanie plików modelu TensorFlow.js
Najpierw umieść wygenerowane pliki model.json i *.bin na serwerze WWW, aby mieć do nich dostęp ze strony internetowej.
Usuń istniejące pliki modelu
Ponieważ będziesz korzystać z wyniku pierwszego ćwiczenia z tej serii, musisz najpierw usunąć przesłane pliki modelu. Jeśli korzystasz z Glitch.com, po prostu sprawdź panel plików po lewej stronie, aby znaleźć ikony model.json i group1-shard1of1.bin. Kliknij menu z 3 kropkami przy każdym pliku i wybierz Usuń, jak pokazano poniżej:
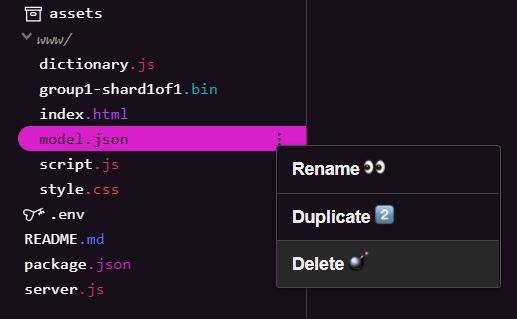
Przesyłanie nowych plików do Glitcha
Świetnie. Teraz prześlij nowe:
- Otwórz folder assets w panelu po lewej stronie projektu Glitch i usuń wszystkie stare przesłane komponenty, jeśli mają takie same nazwy.
- Kliknij prześlij komponent i wybierz
group1-shard1of1.bin, który chcesz przesłać do tego folderu. Po przesłaniu powinien wyglądać tak:
- Świetnie. Teraz zrób to samo z plikiem model.json. W folderze assets powinny znajdować się 2 pliki:
- Jeśli klikniesz
group1-shard1of1.binprzesłany plik, możesz skopiować adres URL do jego lokalizacji. Skopiuj teraz tę ścieżkę, jak pokazano poniżej:
- Teraz w lewym dolnym rogu ekranu kliknij Narzędzia > Terminal. Poczekaj, aż okno terminala się wczyta.
- Po załadowaniu wpisz to polecenie, a następnie naciśnij Enter, aby przejść do folderu
www:
terminal:
cd www
- Następnie użyj
wget, aby pobrać 2 przesłane pliki, zastępując poniższe adresy URL adresami URL wygenerowanymi dla plików w folderze zasobów na platformie Glitch (sprawdź folder zasobów, aby znaleźć niestandardowy adres URL każdego pliku).
Zwróć uwagę na spację między dwoma adresami URL. Adresy URL, których będziesz używać, będą inne niż te, które są pokazane, ale będą wyglądać podobnie:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Świetnie! Kopia plików przesłanych do folderu www została utworzona.
Obecnie jednak będą pobierane z dziwnymi nazwami. Jeśli w terminalu wpiszesz ls i naciśniesz Enter, zobaczysz coś takiego:

- Zmień nazwy plików za pomocą polecenia
mv. Wpisz w konsoli te polecenia i po każdym z nich naciśnij Enter:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Na koniec odśwież projekt Glitch, wpisując w terminalu
refreshi naciskając Enter:
terminal:
refresh
Po odświeżeniu w folderze www w interfejsie powinny pojawić się ikony model.json i group1-shard1of1.bin:
Świetnie. Ostatnim krokiem jest zaktualizowanie dictionary.js.
- Przekonwertuj nowy pobrany plik słownictwa na prawidłowy format JS ręcznie w edytorze tekstu lub za pomocą tego narzędzia i zapisz wynikowy plik jako
dictionary.jsw folderzewww. Jeśli masz już plikdictionary.js, możesz po prostu skopiować i wkleić do niego nową zawartość, a następnie zapisać plik.
Super! Wszystkie zmienione pliki zostały zaktualizowane. Jeśli teraz spróbujesz użyć witryny, zauważysz, że ponownie wytrenowany model powinien uwzględniać odkryte i wykorzystane przypadki brzegowe, jak pokazano poniżej:
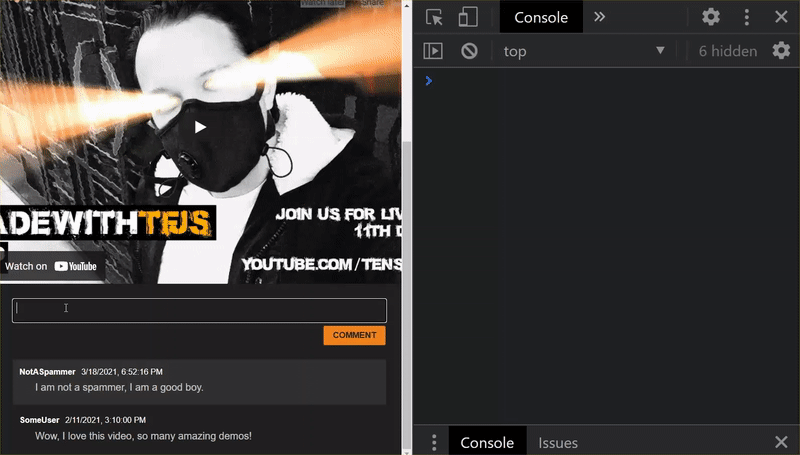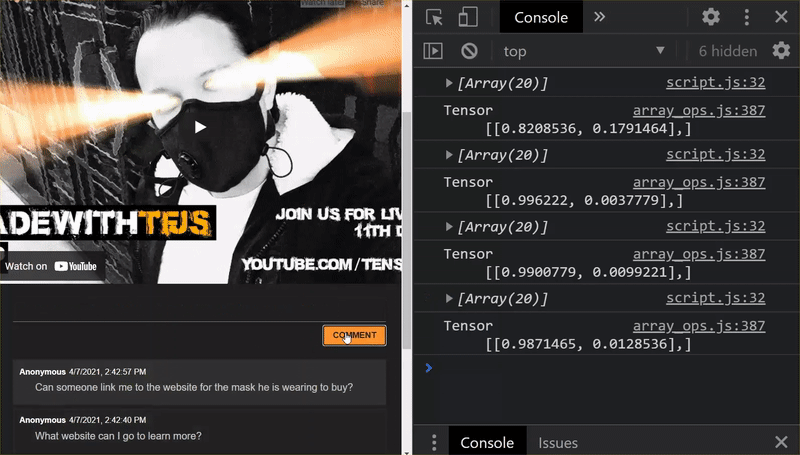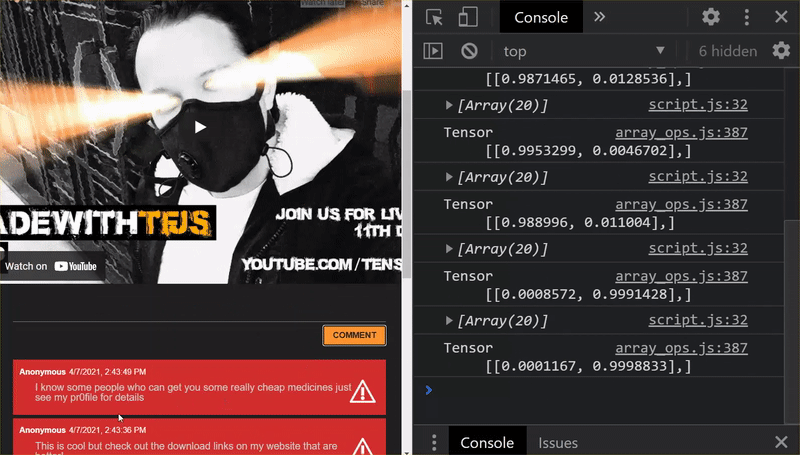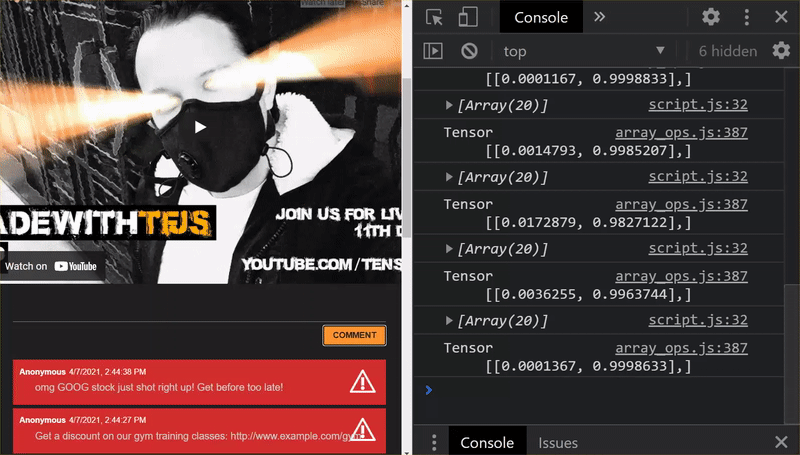
Jak widać, pierwsze 6 wiadomości zostało prawidłowo zaklasyfikowanych jako nie spam, a druga grupa 6 wiadomości została oznaczona jako spam. Super!
Wypróbujmy też kilka wariantów, aby sprawdzić, czy model dobrze uogólnia. Pierwotnie było to zdanie:
„omg akcje GOOG właśnie poszybowały w górę! Skorzystaj z niej, zanim będzie za późno!
Teraz jest ona prawidłowo klasyfikowana jako spam, ale co się stanie, jeśli zmienisz ją na:
„Akcje XYZ właśnie zyskały na wartości! Kup je, zanim będzie za późno!"
W tym przypadku otrzymasz prognozę, że istnieje 98% prawdopodobieństwo, że jest to spam. Jest to prawidłowa prognoza, mimo że zmieniono symbol akcji i nieco zmodyfikowano treść.
Oczywiście, jeśli naprawdę spróbujesz „złamać” ten nowy model, możesz to zrobić. W takim przypadku konieczne będzie zebranie jeszcze większej ilości danych treningowych, aby zwiększyć szansę na wychwycenie bardziej unikalnych odmian w typowych sytuacjach, które mogą wystąpić w internecie. W przyszłym laboratorium pokażemy, jak stale ulepszać model za pomocą danych na żywo, gdy są one oznaczane.
6. Gratulacje!
Gratulacje! Udało Ci się ponownie wytrenować istniejący model uczenia maszynowego, aby dostosować go do znalezionych przypadków brzegowych, i wdrożyć te zmiany w przeglądarce za pomocą TensorFlow.js na potrzeby rzeczywistej aplikacji.
Podsumowanie
W tych ćwiczeniach z programowania:
- Odkrywanie przypadków granicznych, które nie działały w przypadku gotowego modelu do wykrywania spamu w komentarzach
- ponowne wytrenowanie modelu Model Maker z uwzględnieniem odkrytych przez Ciebie przypadków granicznych;
- Wyeksportowano nowy wytrenowany model do formatu TensorFlow.js.
- zaktualizować aplikację internetową, aby korzystała z nowych plików;
Co dalej?
Ta aktualizacja działa świetnie, ale jak w przypadku każdej aplikacji internetowej, z czasem zajdą w niej zmiany. Byłoby o wiele lepiej, gdyby aplikacja z czasem sama się ulepszała, zamiast wymagać od nas ręcznego wykonywania tych czynności. Czy możesz podać przykład, jak zautomatyzować te kroki, aby automatycznie ponownie wytrenować model po uzyskaniu np. 100 nowych komentarzy oznaczonych jako nieprawidłowo sklasyfikowane? Jeśli masz doświadczenie w inżynierii internetowej, prawdopodobnie wiesz, jak utworzyć potok, który będzie to robić automatycznie. Jeśli nie, nie martw się. W kolejnym codelabie z tej serii pokażemy Ci, jak to zrobić.
Udostępnianie nam swoich treści
Możesz łatwo rozszerzyć to, co udało Ci się dziś stworzyć, na inne kreatywne zastosowania. Zachęcamy Cię do nieszablonowego myślenia i dalszego eksperymentowania.
Nie zapomnij oznaczyć nas w mediach społecznościowych, używając hashtagu #MadeWithTFJS. Dzięki temu Twój projekt może zostać wyróżniony na blogu TensorFlow lub podczas przyszłych wydarzeń. Chętnie zobaczymy, co stworzysz.
Więcej ćwiczeń z TensorFlow.js
- Używaj Hostingu Firebase do wdrażania i hostowania modelu TensorFlow.js na dużą skalę.
- Tworzenie inteligentnej kamery internetowej z użyciem gotowego modelu wykrywania obiektów w TensorFlow.js
Witryny, które warto sprawdzić
- Oficjalna strona TensorFlow.js
- Gotowe modele TensorFlow.js
- Interfejs API TensorFlow.js
- TensorFlow.js Show & Tell – zainspiruj się i zobacz, co stworzyli inni.