
1. ก่อนเริ่มต้น
Codelab นี้ออกแบบมาเพื่อต่อยอดจากผลลัพธ์สุดท้ายของ Codelab ก่อนหน้าในชุดนี้สำหรับการตรวจจับสแปมความคิดเห็นโดยใช้ TensorFlow.js
ในโค้ดแล็บล่าสุด คุณได้สร้างหน้าเว็บที่ทำงานได้อย่างสมบูรณ์สำหรับวิดีโอบล็อกสมมติ คุณสามารถกรองความคิดเห็นเพื่อหาสแปมก่อนที่จะส่งไปยังเซิร์ฟเวอร์เพื่อจัดเก็บหรือส่งไปยังไคลเอ็นต์อื่นๆ ที่เชื่อมต่อได้ โดยใช้โมเดลการตรวจจับสแปมความคิดเห็นที่ฝึกไว้ล่วงหน้าซึ่งขับเคลื่อนโดย TensorFlow.js ในเบราว์เซอร์
ผลลัพธ์สุดท้ายของโค้ดแล็บนั้นแสดงอยู่ด้านล่าง
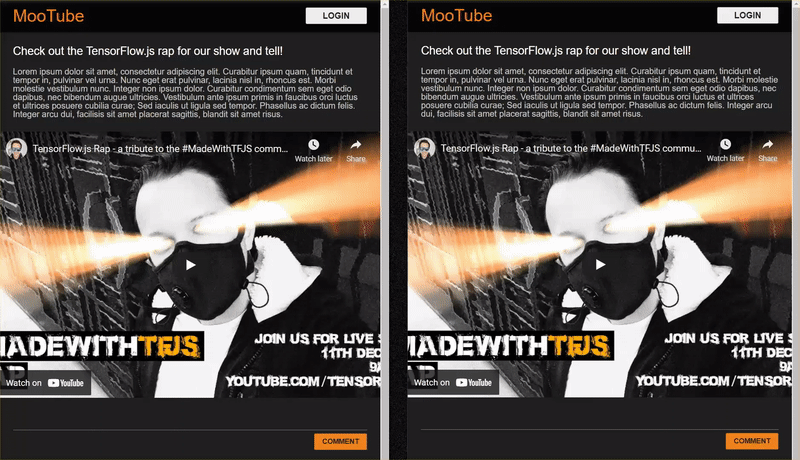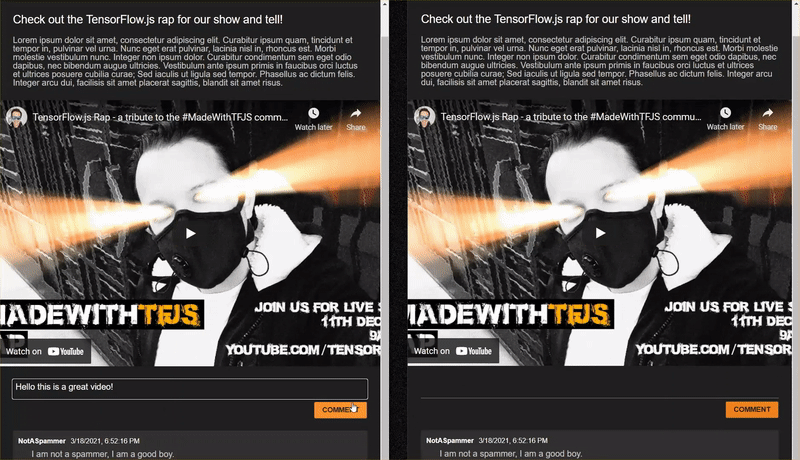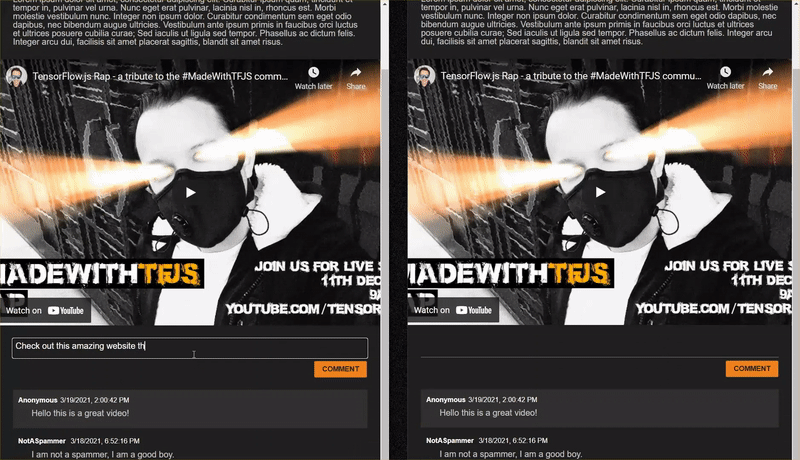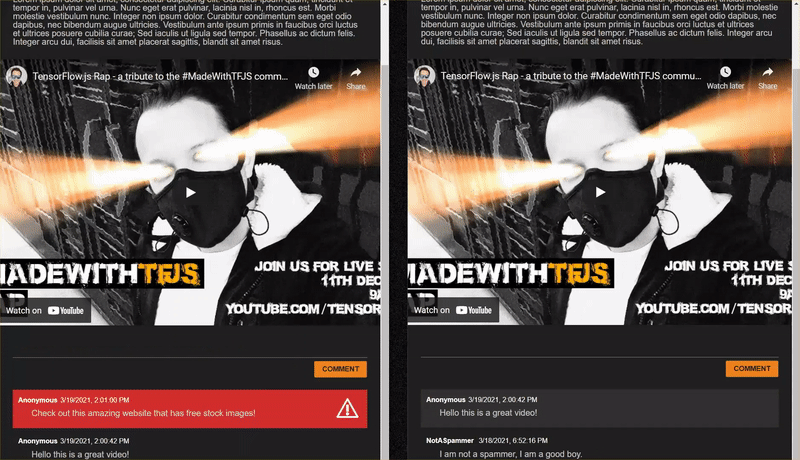
แม้ว่าวิธีนี้จะใช้ได้ดีมาก แต่ก็ยังมีกรณีที่ระบบตรวจไม่พบ คุณฝึกโมเดลใหม่เพื่อรองรับสถานการณ์ที่โมเดลจัดการไม่ได้
Codelab นี้มุ่งเน้นการใช้การประมวลผลภาษาธรรมชาติ (ศิลปะแห่งการทำความเข้าใจภาษามนุษย์ด้วยคอมพิวเตอร์) และแสดงวิธีแก้ไขเว็บแอปที่มีอยู่ซึ่งคุณสร้างขึ้น (ขอแนะนำให้คุณทำ Codelab ตามลำดับ) เพื่อแก้ปัญหาจริงเรื่องสแปมความคิดเห็น ซึ่งนักพัฒนาเว็บจำนวนมากจะต้องพบเจออย่างแน่นอนเมื่อทำงานกับเว็บแอปยอดนิยมที่มีจำนวนเพิ่มขึ้นเรื่อยๆ ในปัจจุบัน
ใน Codelab นี้ คุณจะได้ก้าวไปอีกขั้นด้วยการฝึกโมเดล ML อีกครั้งเพื่อพิจารณาการเปลี่ยนแปลงเนื้อหาข้อความสแปมที่อาจเกิดขึ้นเมื่อเวลาผ่านไป โดยอิงตามเทรนด์ปัจจุบันหรือหัวข้อสนทนายอดนิยม ซึ่งจะช่วยให้คุณอัปเดตโมเดลอยู่เสมอและพิจารณาการเปลี่ยนแปลงดังกล่าวได้
ข้อกำหนดเบื้องต้น
- ทำ Codelab แรกในชุดนี้เสร็จแล้ว
- มีความรู้พื้นฐานเกี่ยวกับเทคโนโลยีเว็บ ซึ่งรวมถึง HTML, CSS และ JavaScript
สิ่งที่คุณจะสร้าง
คุณจะนำเว็บไซต์ที่สร้างไว้ก่อนหน้านี้มาใช้ซ้ำสำหรับวิดีโอบล็อกสมมติที่มีส่วนความคิดเห็นแบบเรียลไทม์ และอัปเกรดให้โหลดโมเดลตรวจจับสแปมเวอร์ชันที่ฝึกเองโดยใช้ TensorFlow.js เพื่อให้ทำงานได้ดีขึ้นในกรณีที่พบได้ยากซึ่งก่อนหน้านี้อาจทำงานไม่สำเร็จ แน่นอนว่าในฐานะนักพัฒนาเว็บและวิศวกร คุณสามารถเปลี่ยน UX สมมตินี้เพื่อนำไปใช้ซ้ำในเว็บไซต์ใดก็ได้ที่คุณอาจกำลังทำงานในบทบาทประจำวัน และปรับโซลูชันให้เหมาะกับกรณีการใช้งานของไคลเอ็นต์ ไม่ว่าจะเป็นบล็อก ฟอรัม หรือ CMS รูปแบบใดรูปแบบหนึ่ง เช่น Drupal เป็นต้น
มาเริ่มแฮ็กกันเลย...
สิ่งที่คุณจะได้เรียนรู้
คุณจะได้รับสิ่งต่อไปนี้
- ระบุกรณีขอบที่โมเดลที่ผ่านการฝึกมาก่อนทำงานไม่สำเร็จ
- ฝึกโมเดลการแยกประเภทสแปมที่สร้างขึ้นโดยใช้ Model Maker อีกครั้ง
- ส่งออกโมเดลที่ใช้ Python นี้ไปยังรูปแบบ TensorFlow.js เพื่อใช้ในเบราว์เซอร์
- อัปเดตโมเดลที่โฮสต์และพจนานุกรมด้วยโมเดลที่ฝึกใหม่ แล้วตรวจสอบผลลัพธ์
เราถือว่าคุณมีความคุ้นเคยกับ HTML5, CSS และ JavaScript สำหรับ Lab นี้ นอกจากนี้ คุณยังจะรันโค้ด Python บางส่วนผ่าน Notebook ของ "Co Lab" เพื่อฝึกโมเดลที่สร้างขึ้นโดยใช้ Model Maker อีกครั้ง แต่ไม่จำเป็นต้องมีความคุ้นเคยกับ Python เพื่อดำเนินการนี้
2. เตรียมพร้อมเขียนโค้ด
คุณจะใช้ Glitch.com เพื่อโฮสต์และแก้ไขเว็บแอปพลิเคชันอีกครั้ง หากยังไม่ได้ทำ codelab ข้อกำหนดเบื้องต้น คุณสามารถโคลนผลลัพธ์สุดท้ายได้ที่นี่เพื่อใช้เป็นจุดเริ่มต้น หากมีข้อสงสัยเกี่ยวกับวิธีการทำงานของโค้ด เราขอแนะนำให้คุณทำ Codelab ก่อนหน้าให้เสร็จ ซึ่งจะอธิบายวิธีสร้างเว็บแอปที่ใช้งานได้นี้ก่อนดำเนินการต่อ
ใน Glitch เพียงคลิกปุ่มรีมิกซ์สิ่งนี้เพื่อแยกและสร้างชุดไฟล์ใหม่ที่คุณแก้ไขได้
3. ค้นพบกรณีข้อยกเว้นในโซลูชันก่อนหน้า
หากคุณเปิดเว็บไซต์ที่สร้างเสร็จแล้วซึ่งเพิ่งโคลนมาและลองพิมพ์ความคิดเห็น คุณจะเห็นว่าส่วนใหญ่แล้วระบบจะทำงานตามที่ตั้งใจไว้ โดยจะบล็อกความคิดเห็นที่ดูเหมือนสแปมตามที่คาดไว้ และอนุญาตให้แสดงความคิดเห็นที่ถูกต้อง
อย่างไรก็ตาม หากคุณใช้กลเม็ดและพยายามเรียบเรียงคำเพื่อทำให้โมเดลทำงานผิดปกติ คุณอาจทำสำเร็จในที่สุด คุณสร้างตัวอย่างด้วยตนเองได้โดยการลองผิดลองถูกเล็กน้อย เช่น ตัวอย่างที่แสดงด้านล่าง ลองวางโค้ดเหล่านี้ลงในเว็บแอปที่มีอยู่ ตรวจสอบคอนโซล และดูความน่าจะเป็นที่ส่งกลับมาหากความคิดเห็นเป็นสแปม
ความคิดเห็นที่ถูกต้องซึ่งโพสต์โดยไม่มีปัญหา (ผลลบลวง):
- "ว้าว ฉันชอบวิดีโอนี้มากเลย ผลงานสุดยอด" ความน่าจะเป็นที่จะเป็นสแปม: 47.91854%
- "ชอบเดโมเหล่านี้มาก มีรายละเอียดเพิ่มเติมไหม" ความน่าจะเป็นที่จะเป็นสแปม: 47.15898%
- "ฉันจะไปที่เว็บไซต์ใดเพื่อดูข้อมูลเพิ่มเติมได้บ้าง" ความน่าจะเป็นที่จะเป็นสแปม: 15.32495%
ยอดเยี่ยมมาก ความน่าจะเป็นสำหรับทั้งหมดข้างต้นค่อนข้างต่ำและผ่านเกณฑ์ความน่าจะเป็นขั้นต่ำเริ่มต้นที่ 75% ก่อนที่จะมีการดำเนินการ (กำหนดไว้ในโค้ด script.js จาก Codelab ก่อนหน้า)SPAM_THRESHOLD
ทีนี้มาลองเขียนความคิดเห็นที่ดูรุนแรงขึ้นซึ่งอาจถูกทำเครื่องหมายว่าเป็นสแปมแม้ว่าจะไม่ใช่ก็ตาม...
ความคิดเห็นที่ถูกต้องถูกทำเครื่องหมายว่าเป็นสแปม (ผลบวกลวง):
- "มีใครลิงก์เว็บไซต์ของหน้ากากที่เขาสวมได้ไหม" ความน่าจะเป็นที่จะเป็นสแปม: 98.46466%
- "ฉันซื้อเพลงนี้ใน Spotify ได้ไหม โปรดแจ้งให้เราทราบด้วย" ความน่าจะเป็นที่จะเป็นสแปม: 94.40953%
- "มีใครติดต่อฉันเพื่อแจ้งรายละเอียดเกี่ยวกับวิธีดาวน์โหลด TensorFlow.js ได้ไหม" ความน่าจะเป็นที่จะเป็นสแปม: 83.20084%
ขออภัย ดูเหมือนว่าระบบจะทำเครื่องหมายความคิดเห็นที่ถูกต้องเหล่านี้ว่าเป็นสแปมในขณะที่ควรจะอนุญาต คุณจะแก้ไขปัญหานี้ได้อย่างไร
ตัวเลือกง่ายๆ อย่างหนึ่งคือการเพิ่ม SPAM_THRESHOLD เพื่อให้มีความเชื่อมั่นมากกว่า 98.5% ในกรณีดังกล่าว ระบบจะโพสต์ความคิดเห็นที่จัดประเภทผิดเหล่านี้ เมื่อคำนึงถึงสิ่งนี้แล้ว เรามาดูผลลัพธ์อื่นๆ ที่เป็นไปได้ด้านล่างกันต่อ
ความคิดเห็นที่เป็นสแปมซึ่งทำเครื่องหมายว่าเป็นสแปม (ผลบวกจริง):
- "เจ๋งเลย แต่ลองดูลิงก์ดาวน์โหลดในเว็บไซต์ของฉันที่เจ๋งกว่านี้สิ" ความน่าจะเป็นที่จะเป็นสแปม: 99.77873%
- "ฉันรู้จักคนที่สามารถจัดหายาให้คุณได้ โปรดดูรายละเอียดในโปรไฟล์ของฉัน" ความน่าจะเป็นที่จะเป็นสแปม: 98.46955%
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอที่น่าทึ่งยิ่งกว่าเดิม http://example.com" ความน่าจะเป็นที่จะเป็นสแปม: 96.26383%
โอเค การตั้งค่านี้ทำงานได้ตามที่คาดไว้ด้วยเกณฑ์ 75% เดิม แต่เนื่องจากในขั้นตอนก่อนหน้าคุณได้เปลี่ยน SPAM_THRESHOLD ให้มีความมั่นใจมากกว่า 98.5% ซึ่งหมายความว่าตัวอย่าง 2 รายการที่นี่จะผ่านเข้ามาได้ ดังนั้นเกณฑ์อาจสูงเกินไป หรือ 96% อาจจะดีกว่า แต่หากคุณทำเช่นนั้น ความคิดเห็นรายการใดรายการหนึ่งในส่วนก่อนหน้า (ผลบวกลวง) จะถูกทำเครื่องหมายว่าเป็นสแปมแม้ว่าจะเป็นความคิดเห็นที่ถูกต้องก็ตาม เนื่องจากได้รับการจัดประเภทที่ 98.46466%
ในกรณีนี้ วิธีที่ดีที่สุดคือการรวบรวมความคิดเห็นที่เป็นสแปมจริงทั้งหมดเหล่านี้ และฝึกโมเดลใหม่สำหรับความล้มเหลวข้างต้น การตั้งค่าเกณฑ์เป็น 96% จะยังคงจับผลบวกจริงทั้งหมดได้ และคุณจะกำจัดผลบวกลวง 2 รายการข้างต้นได้ ไม่เลวเลยสำหรับการเปลี่ยนตัวเลขเพียงตัวเดียว
มาดูกันต่อ...
ความคิดเห็นที่เป็นสแปมซึ่งได้รับอนุญาตให้โพสต์ (ผลลบลวง)
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอที่น่าทึ่งยิ่งกว่าเดิมได้เลย" ความน่าจะเป็นที่จะเป็นสแปม: 7.54926%
- "รับส่วนลดสำหรับคลาสฝึกที่ยิมของเรา ดูโปรไฟล์เลย" ความน่าจะเป็นที่จะเป็นสแปม: 17.49849%
- "โอ้โห หุ้น GOOG พุ่งขึ้นไปเลย รีบรับก่อนจะสายเกินไป" ความน่าจะเป็นที่จะเป็นสแปม: 20.42894%
สำหรับความคิดเห็นเหล่านี้ คุณไม่สามารถทำอะไรได้เพียงแค่เปลี่ยนค่า SPAM_THRESHOLD เพิ่มเติม การลดเกณฑ์สำหรับสแปมจาก 96% เป็นประมาณ 9% จะทำให้ระบบทำเครื่องหมายความคิดเห็นที่ถูกต้องว่าเป็นสแปม โดยความคิดเห็นหนึ่งมีคะแนน 58% แม้ว่าจะเป็นความคิดเห็นที่ถูกต้องก็ตาม วิธีเดียวที่จะจัดการกับความคิดเห็นเช่นนี้ได้คือการฝึกโมเดลใหม่โดยรวมกรณีที่พบได้ยากดังกล่าวไว้ในข้อมูลฝึกฝน เพื่อให้โมเดลเรียนรู้ที่จะปรับมุมมองของโลกสำหรับสิ่งที่ถือว่าเป็นสแปมหรือไม่
แม้ว่าตอนนี้จะมีเพียงตัวเลือกเดียวคือการฝึกโมเดลใหม่ แต่คุณก็เห็นแล้วว่าคุณจะปรับเกณฑ์เมื่อตัดสินใจว่าสิ่งใดเป็นจดหมายขยะเพื่อปรับปรุงประสิทธิภาพได้เช่นกัน ในฐานะมนุษย์ ความมั่นใจที่ 75% ดูเหมือนจะค่อนข้างสูง แต่สำหรับโมเดลนี้ คุณต้องเพิ่มความมั่นใจให้ใกล้เคียง 81.5% มากขึ้นเพื่อให้มีประสิทธิภาพมากขึ้นด้วยอินพุตตัวอย่าง
ไม่มีค่าใดค่าหนึ่งที่ใช้ได้ดีกับโมเดลต่างๆ และคุณต้องตั้งค่าเกณฑ์นี้ตามโมเดลแต่ละรายการหลังจากทดสอบกับข้อมูลจริงเพื่อดูว่าค่าใดใช้ได้ดี
ในบางสถานการณ์ การตรวจพบผลบวก (หรือลบ) ที่ไม่ถูกต้องอาจส่งผลร้ายแรง (เช่น ในอุตสาหกรรมการแพทย์) ดังนั้นคุณอาจปรับเกณฑ์ให้สูงมากและขอรับการตรวจสอบด้วยตนเองเพิ่มเติมสำหรับรายการที่ไม่เป็นไปตามเกณฑ์ คุณเป็นผู้เลือกในฐานะนักพัฒนาแอป และต้องทำการทดลองบางอย่าง
4. ฝึกโมเดลการตรวจจับสแปมความคิดเห็นใหม่
ในส่วนก่อนหน้า คุณได้ระบุกรณีขอบจำนวนหนึ่งที่โมเดลทำงานล้มเหลว ซึ่งตัวเลือกเดียวคือการฝึกโมเดลซ้ำเพื่อพิจารณาสถานการณ์เหล่านี้ ในระบบการผลิต คุณอาจพบข้อมูลเหล่านี้เมื่อเวลาผ่านไป เนื่องจากผู้ใช้แจ้งว่าความคิดเห็นเป็นสแปมด้วยตนเอง ซึ่งระบบอนุญาตให้แสดง หรือผู้ดูแลตรวจสอบความคิดเห็นที่ถูกแจ้งว่าไม่เหมาะสมและพบว่าบางความคิดเห็นไม่ใช่สแปมจริงๆ และอาจทำเครื่องหมายความคิดเห็นดังกล่าวเพื่อฝึกโมเดลใหม่ สมมติว่าคุณได้รวบรวมข้อมูลใหม่จำนวนมากสำหรับกรณีที่พบได้ยากเหล่านี้ (คุณควรมีประโยคใหม่ๆ เหล่านี้หลายรูปแบบเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด) ตอนนี้เราจะแสดงวิธีฝึกโมเดลซ้ำโดยคำนึงถึงกรณีที่พบได้ยากเหล่านั้น
สรุปโมเดลที่สร้างไว้ล่วงหน้า
โมเดลที่สร้างไว้ล่วงหน้าซึ่งคุณใช้เป็นโมเดลที่บุคคลที่สามสร้างขึ้นผ่าน Model Maker ซึ่งใช้โมเดล "การฝังคำเฉลี่ย" ในการทำงาน
เนื่องจากสร้างโมเดลด้วย Model Maker คุณจึงต้องเปลี่ยนไปใช้ Python ชั่วคราวเพื่อฝึกโมเดลซ้ำ จากนั้นส่งออกโมเดลที่สร้างไปยังรูปแบบ TensorFlow.js เพื่อให้คุณใช้ในเบราว์เซอร์ได้ โชคดีที่ Model Maker ทำให้การใช้โมเดลของตนเป็นเรื่องง่ายมาก ดังนั้นคุณจึงทำตามได้ง่ายๆ และเราจะแนะนำขั้นตอนต่างๆ ให้คุณเอง ไม่ต้องกังวลหากคุณไม่เคยใช้ Python มาก่อน
Colab
เนื่องจากคุณไม่จำเป็นต้องกังวลเกี่ยวกับการตั้งค่าเซิร์ฟเวอร์ Linux ที่ติดตั้งยูทิลิตี Python ต่างๆ ใน Codelab นี้ คุณจึงสามารถเรียกใช้โค้ดผ่านเว็บเบราว์เซอร์ได้โดยใช้ "Colab Notebook" Notebook เหล่านี้เชื่อมต่อกับ "แบ็กเอนด์" ได้ ซึ่งก็คือเซิร์ฟเวอร์ที่มีการติดตั้งสิ่งต่างๆ ไว้ล่วงหน้า จากนั้นคุณจะเรียกใช้โค้ดใดก็ได้ภายในเว็บเบราว์เซอร์และดูผลลัพธ์ได้ ซึ่งมีประโยชน์มากสำหรับการสร้างต้นแบบอย่างรวดเร็วหรือใช้ในบทแนะนำแบบนี้
เพียงไปที่ colab.research.google.com คุณก็จะเห็นหน้าจอต้อนรับดังที่แสดง
ตอนนี้ให้คลิกปุ่ม Notebook ใหม่ที่ด้านขวาล่างของหน้าต่างป๊อปอัป แล้วคุณจะเห็น Colab ว่างเปล่าดังนี้
เยี่ยมเลย ขั้นตอนถัดไปคือการเชื่อมต่อ Colab ส่วนหน้ากับเซิร์ฟเวอร์แบ็กเอนด์เพื่อให้คุณเรียกใช้โค้ด Python ที่จะเขียนได้ โดยคลิกเชื่อมต่อที่ด้านขวาบน แล้วเลือกเชื่อมต่อกับรันไทม์ที่โฮสต์
เมื่อเชื่อมต่อแล้ว คุณควรเห็นไอคอน RAM และดิสก์ปรากฏขึ้นแทนที่ ดังนี้
เยี่ยมมาก ตอนนี้คุณเริ่มเขียนโค้ดใน Python เพื่อฝึกโมเดล Model Maker ซ้ำได้แล้ว โปรดดำเนินการตามขั้นตอนด้านล่าง
ขั้นตอนที่ 1
คัดลอกโค้ดด้านล่างในเซลล์แรกที่ว่างอยู่ ระบบจะติดตั้ง TensorFlow Lite Model Maker ให้คุณโดยใช้เครื่องมือจัดการแพ็กเกจของ Python ที่ชื่อว่า "pip" (คล้ายกับ npm ซึ่งผู้อ่านส่วนใหญ่ของ Codelab นี้อาจคุ้นเคยมากกว่าจากระบบนิเวศ JS)
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
แต่การวางโค้ดลงในเซลล์จะไม่เป็นการเรียกใช้โค้ด จากนั้นวางเมาส์เหนือเซลล์สีเทาที่คุณวางโค้ดด้านบน ไอคอน "เล่น" ขนาดเล็กจะปรากฏขึ้นทางด้านซ้ายของเซลล์ตามที่ไฮไลต์ไว้ด้านล่าง
 คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ในเซลล์
คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ในเซลล์
ตอนนี้คุณจะเห็นว่าระบบกำลังติดตั้ง Model Maker
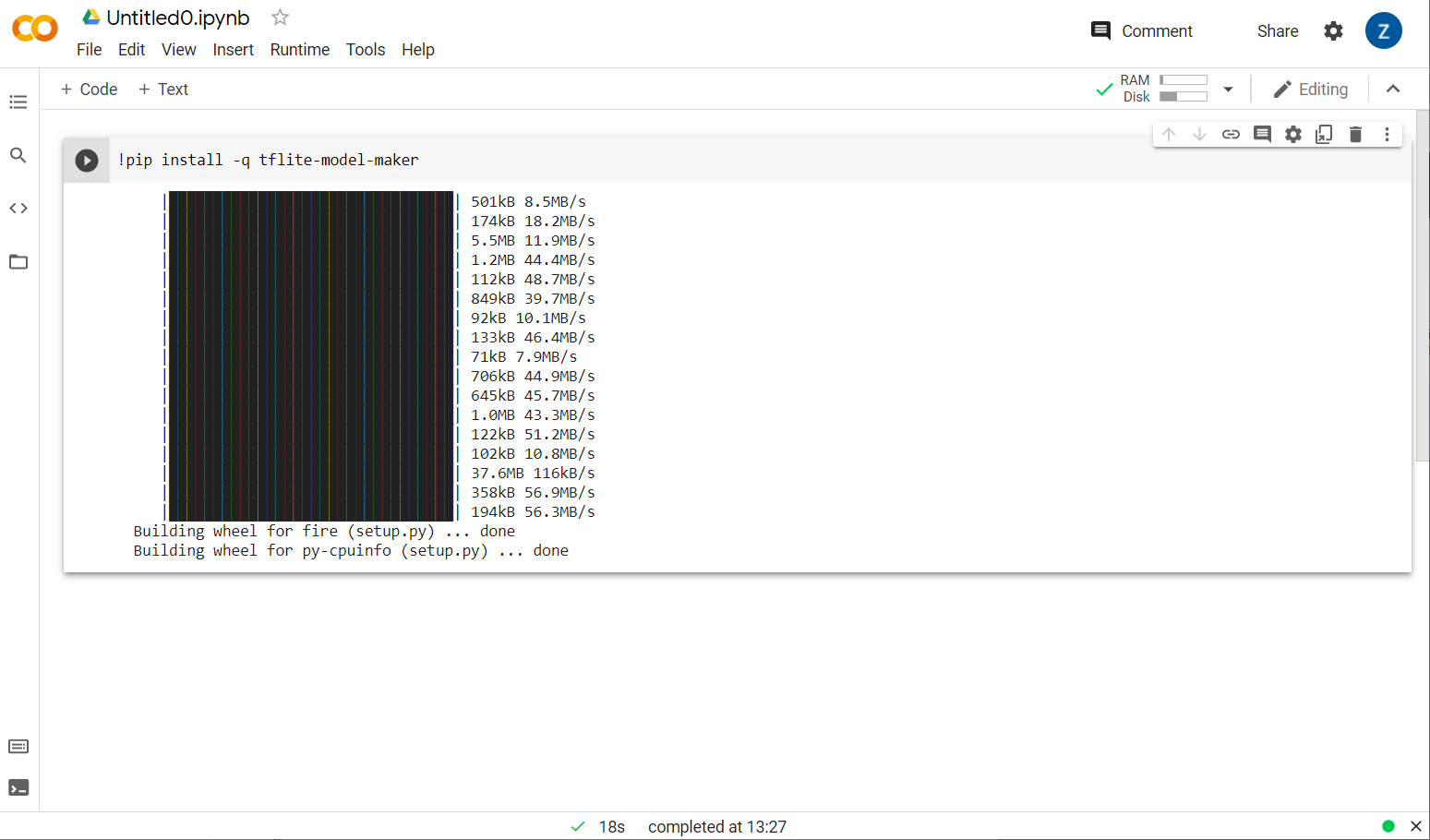
เมื่อการดำเนินการในเซลล์นี้เสร็จสมบูรณ์ตามที่แสดง ให้ไปที่ขั้นตอนถัดไปด้านล่าง
ขั้นตอนที่ 2
จากนั้นเพิ่มเซลล์โค้ดใหม่ตามที่แสดงเพื่อให้คุณวางโค้ดเพิ่มเติมหลังจากเซลล์แรกและเรียกใช้แยกกันได้
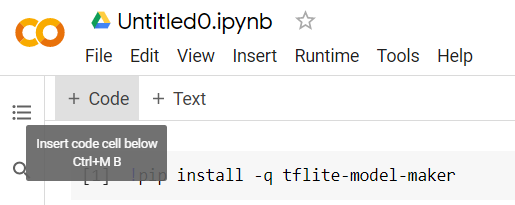
เซลล์ถัดไปที่จะดำเนินการจะมีจำนวนการนำเข้าที่โค้ดในส่วนที่เหลือของ Notebook จะต้องใช้ คัดลอกและวางข้อความด้านล่างในเซลล์ใหม่ที่สร้างขึ้น
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
ซึ่งเป็นเรื่องปกติ แม้ว่าคุณจะไม่คุ้นเคยกับ Python ก็ตาม คุณเพียงแค่นำเข้ายูทิลิตีและฟังก์ชัน Model Maker บางอย่างที่จำเป็นสำหรับเครื่องมือคัดแยกสแปม นอกจากนี้ยังจะตรวจสอบว่าคุณใช้ TensorFlow 2.x หรือไม่ ซึ่งเป็นข้อกำหนดในการใช้ Model Maker
สุดท้ายนี้ ให้เรียกใช้เซลล์โดยกดไอคอน "เล่น" เมื่อวางเมาส์เหนือเซลล์ แล้วเพิ่มเซลล์โค้ดใหม่สำหรับขั้นตอนถัดไป
ขั้นตอนที่ 3
จากนั้นคุณจะดาวน์โหลดข้อมูลจากเซิร์ฟเวอร์ระยะไกลไปยังอุปกรณ์ และตั้งค่าตัวแปร training_data ให้เป็นเส้นทางของไฟล์ในเครื่องที่ดาวน์โหลดมา
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker สามารถฝึกโมเดลจากไฟล์ CSV อย่างง่าย เช่น ไฟล์ที่ดาวน์โหลด คุณเพียงแค่ต้องระบุว่าคอลัมน์ใดมีข้อความและคอลัมน์ใดมีป้ายกำกับ คุณจะเห็นวิธีทำในขั้นตอนที่ 5 คุณสามารถดาวน์โหลดไฟล์ CSV ด้วยตนเองเพื่อดูเนื้อหาได้หากต้องการ
ผู้ที่สังเกตอย่างละเอียดจะเห็นว่าชื่อไฟล์นี้คือ jm_blog_comments_extras.csv ซึ่งเป็นเพียงข้อมูลฝึกฝนเดิมที่เราใช้สร้างโมเดลสแปมความคิดเห็นแรกรวมกับข้อมูลกรณีที่พบได้ยากใหม่ที่คุณค้นพบ ดังนั้นข้อมูลทั้งหมดจึงอยู่ในไฟล์เดียว คุณต้องมีข้อมูลฝึกฝนเดิมที่ใช้ฝึกโมเดลด้วย นอกเหนือจากประโยคใหม่ที่คุณต้องการเรียนรู้
ไม่บังคับ: หากดาวน์โหลดไฟล์ CSV นี้และตรวจสอบ 2-3 บรรทัดสุดท้าย คุณจะเห็นตัวอย่างสำหรับกรณีข้อยกเว้นที่ทำงานไม่ถูกต้องก่อนหน้านี้ โดยระบบเพิ่งเพิ่มข้อมูลดังกล่าวไว้ที่ส่วนท้ายของข้อมูลฝึกฝนที่มีอยู่ ซึ่งโมเดลที่สร้างไว้ล่วงหน้าใช้เพื่อฝึกตัวเอง
เรียกใช้เซลล์นี้ เมื่อเรียกใช้เสร็จแล้ว ให้เพิ่มเซลล์ใหม่และไปที่ขั้นตอนที่ 4
ขั้นตอนที่ 4
เมื่อใช้ Model Maker คุณไม่จำเป็นต้องสร้างโมเดลตั้งแต่ต้น โดยทั่วไปแล้ว คุณจะใช้โมเดลที่มีอยู่แล้ว จากนั้นปรับแต่งให้ตรงกับความต้องการ
Model Maker มีการฝังโมเดลที่เรียนรู้ไว้ล่วงหน้าหลายรายการที่คุณใช้ได้ แต่รายการที่ง่ายและรวดเร็วที่สุดในการเริ่มต้นคือ average_word_vec ซึ่งเป็นรายการที่คุณใช้ใน Codelab ก่อนหน้านี้เพื่อสร้างเว็บไซต์ รหัสมีดังนี้
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
เรียกใช้คำสั่งนั้นเมื่อวางลงในเซลล์ใหม่แล้ว
ทำความเข้าใจ
num_words
พารามิเตอร์
นี่คือจำนวนคำที่คุณต้องการให้โมเดลใช้ คุณอาจคิดว่ายิ่งมีคำมากก็ยิ่งดี แต่โดยทั่วไปแล้วจะมีจุดที่เหมาะสมซึ่งขึ้นอยู่กับความถี่ในการใช้คำแต่ละคำ หากใช้ทุกคำในคลังทั้งหมด คุณอาจพบว่าโมเดลพยายามเรียนรู้และปรับสมดุลน้ำหนักของคำที่ใช้เพียงครั้งเดียว ซึ่งไม่ค่อยมีประโยชน์ คุณจะเห็นในคลังข้อความใดก็ตามว่าคำหลายคำใช้เพียงครั้งเดียวหรือสองครั้งเท่านั้น และโดยทั่วไปแล้วไม่คุ้มค่าที่จะใช้คำเหล่านั้นในโมเดลเนื่องจากมีผลกระทบต่อความรู้สึกโดยรวมเพียงเล็กน้อย คุณจึงปรับแต่งโมเดลตามจำนวนคำที่ต้องการได้โดยใช้พารามิเตอร์ num_words ตัวเลขที่น้อยลงจะทำให้โมเดลมีขนาดเล็กลงและทำงานได้เร็วขึ้น แต่อาจมีความแม่นยำน้อยลงเนื่องจากจดจำคำได้น้อยลง จำนวนที่มากขึ้นที่นี่จะทำให้โมเดลมีขนาดใหญ่ขึ้นและอาจช้าลง การค้นหาจุดที่เหมาะสมเป็นสิ่งสำคัญ และขึ้นอยู่กับคุณในฐานะวิศวกรแมชชีนเลิร์นนิงที่จะพิจารณาว่าอะไรเหมาะกับกรณีการใช้งานของคุณมากที่สุด
ทำความเข้าใจ
wordvec_dim
พารามิเตอร์
พารามิเตอร์ wordvec_dim คือจำนวนมิติข้อมูลที่คุณต้องการใช้สำหรับเวกเตอร์ของแต่ละคำ มิติข้อมูลเหล่านี้เป็นลักษณะต่างๆ (สร้างขึ้นโดยอัลกอริทึมแมชชีนเลิร์นนิงเมื่อฝึก) ที่สามารถใช้วัดคำใดๆ ก็ได้ ซึ่งโปรแกรมจะใช้เพื่อพยายามเชื่อมโยงคำที่มีความคล้ายคลึงกันในลักษณะที่มีความหมายมากที่สุด
เช่น หากคุณมีมิติข้อมูลสำหรับความ "ทางการแพทย์" ของคำ คำอย่าง "ยา" อาจได้คะแนนสูงในมิติข้อมูลนี้ และเชื่อมโยงกับคำอื่นๆ ที่ได้คะแนนสูง เช่น "เอกซเรย์" แต่คำว่า "แมว" จะได้คะแนนต่ำในมิติข้อมูลนี้ ปรากฏว่า "มิติข้อมูลทางการแพทย์" มีประโยชน์ในการระบุสแปมเมื่อใช้ร่วมกับมิติข้อมูลอื่นๆ ที่อาจใช้ได้ซึ่งมีความสําคัญ
ในกรณีของคำที่ได้คะแนนสูงใน "มิติข้อมูลทางการแพทย์" ระบบอาจพิจารณาว่ามิติข้อมูลที่ 2 ซึ่งเชื่อมโยงคำกับร่างกายมนุษย์อาจมีประโยชน์ คำอย่าง "ขา" "แขน" "คอ" อาจได้คะแนนสูงในที่นี้และได้คะแนนสูงพอสมควรในมิติข้อมูลทางการแพทย์ด้วย
โมเดลสามารถใช้มิติข้อมูลเหล่านี้เพื่อตรวจหาคำที่มีแนวโน้มที่จะเชื่อมโยงกับสแปมได้ อีเมลสแปมอาจมีคำที่เกี่ยวข้องกับทั้งการแพทย์และอวัยวะของร่างกายมนุษย์
กฎทั่วไปที่ได้จากการวิจัยคือรากที่ 4 ของจำนวนคำจะใช้ได้ดีกับพารามิเตอร์นี้ ดังนั้นหากฉันใช้คำ 2, 000 คำ จุดเริ่มต้นที่ดีสำหรับเรื่องนี้คือ 7 มิติ หากเปลี่ยนจำนวนคำที่ใช้ คุณก็เปลี่ยนค่านี้ได้เช่นกัน
ทำความเข้าใจ
seq_len
พารามิเตอร์
โดยทั่วไปแล้ว โมเดลจะมีความเข้มงวดมากเมื่อพูดถึงค่าอินพุต สำหรับโมเดลภาษา หมายความว่าโมเดลภาษาสามารถจัดประเภทประโยคที่มีความยาวคงที่เฉพาะเจาะจงได้ ซึ่งกำหนดโดยพารามิเตอร์ seq_len ซึ่งหมายถึง "ความยาวของลำดับ" เมื่อแปลงคำเป็นตัวเลข (หรือโทเค็น) ประโยคจะกลายเป็นลำดับของโทเค็นเหล่านี้ ดังนั้นโมเดลจะได้รับการฝึก (ในกรณีนี้) เพื่อจัดประเภทและจดจำประโยคที่มีโทเค็น 20 รายการ หากประโยคยาวกว่านี้ ระบบจะตัดประโยค หากสั้นกว่านั้น ระบบจะเพิ่มช่องว่างให้เหมือนกับในโค้ดแล็บแรกในชุดนี้
ขั้นตอนที่ 5 - โหลดข้อมูลฝึกฝน
ก่อนหน้านี้คุณได้ดาวน์โหลดไฟล์ CSV แล้ว ตอนนี้ได้เวลาใช้โปรแกรมโหลดข้อมูลเพื่อเปลี่ยนข้อมูลนี้ให้เป็นข้อมูลฝึกฝนที่โมเดลรู้จักแล้ว
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
หากเปิดไฟล์ CSV ในโปรแกรมแก้ไข คุณจะเห็นว่าแต่ละบรรทัดมีค่าเพียง 2 ค่า และค่าเหล่านี้จะอธิบายด้วยข้อความในบรรทัดแรกของไฟล์ โดยปกติแล้ว ระบบจะถือว่าแต่ละรายการเป็น "คอลัมน์" คุณจะเห็นว่าตัวอธิบายสำหรับคอลัมน์แรกคือ commenttext และรายการแรกในแต่ละบรรทัดคือข้อความของความคิดเห็น
ในทำนองเดียวกัน ตัวอธิบายสำหรับคอลัมน์ที่ 2 คือ spam และคุณจะเห็นว่ารายการที่ 2 ในแต่ละบรรทัดคือ TRUE หรือ FALSE เพื่อระบุว่าข้อความนั้นถือเป็นสแปมความคิดเห็นหรือไม่ พร็อพเพอร์ตี้อื่นๆ จะตั้งค่าข้อกำหนดของโมเดลที่คุณสร้างในขั้นตอนที่ 4 พร้อมกับอักขระคั่น ซึ่งในกรณีนี้คือคอมมาเนื่องจากไฟล์คั่นด้วยคอมมา นอกจากนี้ คุณยังตั้งค่าพารามิเตอร์การสับเปลี่ยนเพื่อจัดเรียงข้อมูลฝึกฝนแบบสุ่มได้ด้วย เพื่อให้รายการที่อาจคล้ายกันหรือรวบรวมไว้ด้วยกันกระจายออกไปแบบสุ่มทั่วทั้งชุดข้อมูล
จากนั้นคุณจะใช้ data.split() เพื่อแยกข้อมูลเป็นข้อมูลการฝึกและข้อมูลการทดสอบ .9 หมายความว่าจะใช้ชุดข้อมูล 90% สำหรับการฝึก และที่เหลือสำหรับการทดสอบ
ขั้นตอนที่ 6 - สร้างโมเดล
เพิ่มอีกเซลล์หนึ่งซึ่งเราจะเพิ่มโค้ดเพื่อสร้างโมเดล
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
ซึ่งจะสร้างโมเดลตัวแยกประเภทข้อความด้วย Model Maker และคุณจะระบุข้อมูลการฝึกที่ต้องการใช้ (ซึ่งกำหนดไว้ในขั้นตอนที่ 4) ข้อกำหนดของโมเดล (ซึ่งตั้งค่าไว้ในขั้นตอนที่ 4 เช่นกัน) และจำนวน Epoch ในกรณีนี้คือ 50
หลักการพื้นฐานของแมชชีนเลิร์นนิงคือการจับคู่รูปแบบ ในตอนแรก โมเดลจะโหลดค่าที่ฝึกไว้ล่วงหน้าสำหรับคำต่างๆ และพยายามจัดกลุ่มคำเหล่านั้นเข้าด้วยกันพร้อมกับ "การคาดการณ์" ว่าคำใดบ้างที่เมื่อจัดกลุ่มเข้าด้วยกันแล้วจะระบุว่าเป็นสแปม และคำใดบ้างที่ไม่ใช่ ในครั้งแรก สัดส่วนน่าจะใกล้เคียง 50:50 เนื่องจากโมเดลเพิ่งเริ่มต้นใช้งานดังที่แสดงด้านล่าง

จากนั้นจะวัดผลลัพธ์ของการดำเนินการนี้ และเปลี่ยนน้ำหนักของโมเดลเพื่อปรับแต่งการคาดการณ์ แล้วลองอีกครั้ง นี่คือยุค ดังนั้น การระบุ epochs=50 จะทำให้ระบบวนลูปดังกล่าว 50 ครั้ง ดังที่แสดง

ดังนั้นเมื่อคุณไปถึง Epoch ที่ 50 โมเดลจะรายงานความแม่นยำในระดับที่สูงขึ้นมาก ในกรณีนี้แสดง 99.1%
ขั้นตอนที่ 7 - ส่งออกโมเดล
เมื่อฝึกเสร็จแล้ว คุณจะส่งออกโมเดลได้ TensorFlow ฝึกโมเดลในรูปแบบของตัวเอง และต้องแปลงเป็นรูปแบบ TensorFlow.js เพื่อใช้ในหน้าเว็บ เพียงวางโค้ดต่อไปนี้ในเซลล์ใหม่แล้วเรียกใช้
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
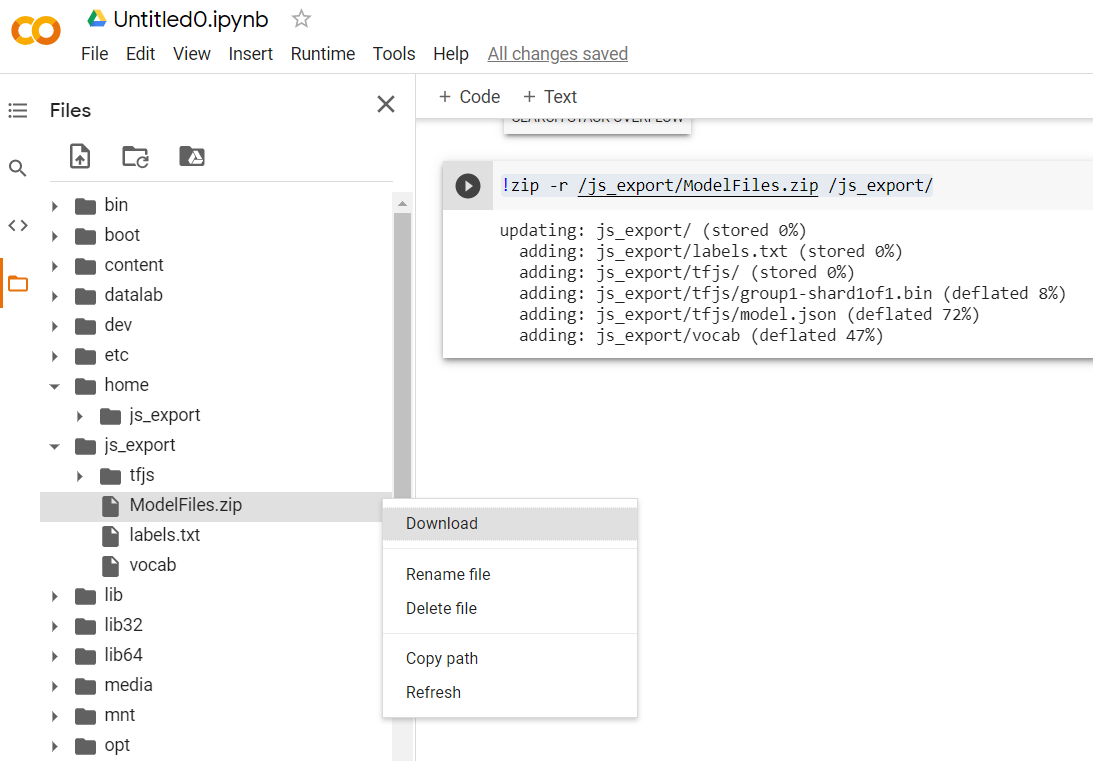
!zip -r /js_export/ModelFiles.zip /js_export/
หลังจากเรียกใช้โค้ดนี้แล้ว หากคลิกไอคอนโฟลเดอร์ขนาดเล็กทางด้านซ้ายของ Colab คุณจะไปยังโฟลเดอร์ที่ส่งออกไว้ข้างต้นได้ (ในไดเรกทอรีราก - คุณอาจต้องขึ้นไป 1 ระดับ) และค้นหาแพ็กเกจ ZIP ของไฟล์ที่ส่งออกซึ่งอยู่ใน ModelFiles.zip
ดาวน์โหลดไฟล์ ZIP นี้ลงในคอมพิวเตอร์ตอนนี้เลย เนื่องจากคุณจะต้องใช้ไฟล์เหล่านั้นเหมือนใน Codelab แรก
เยี่ยมเลย ตอนนี้คุณกลับไปใช้ JavaScript ที่คุณคุ้นเคยและชื่นชอบได้แล้ว ในที่สุด
5. การแสดงโมเดลแมชชีนเลิร์นนิงใหม่
ตอนนี้คุณก็พร้อมที่จะโหลดโมเดลแล้ว อย่างไรก็ตาม ก่อนที่จะทำเช่นนั้นได้ คุณต้องอัปโหลดไฟล์โมเดลใหม่ที่ดาวน์โหลดไว้ก่อนหน้านี้ใน Codelab เพื่อให้ระบบโฮสต์และใช้งานได้ภายในโค้ดของคุณ
ก่อนอื่น หากยังไม่ได้ดำเนินการ ให้คลายซิปไฟล์สำหรับโมเดลที่เพิ่งดาวน์โหลดจากสมุดบันทึก Colab ของ Model Maker ที่คุณเพิ่งเรียกใช้ คุณควรเห็นไฟล์ต่อไปนี้ในโฟลเดอร์ต่างๆ
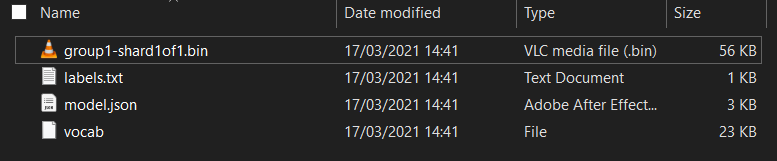
คุณมีอะไรที่นี่
model.json- นี่คือไฟล์หนึ่งที่ประกอบกันเป็นโมเดล TensorFlow.js ที่ฝึกแล้ว คุณจะอ้างอิงไฟล์นี้ในโค้ด JSgroup1-shard1of1.bin- นี่คือไฟล์ไบนารีที่มีข้อมูลที่บันทึกไว้จำนวนมากสำหรับโมเดล TensorFlow.js ที่ส่งออก และจะต้องโฮสต์ไว้ที่ใดที่หนึ่งในเซิร์ฟเวอร์เพื่อให้ดาวน์โหลดในไดเรกทอรีเดียวกับmodel.jsonด้านบนvocab- ไฟล์แปลกๆ ที่ไม่มีนามสกุลนี้มาจาก Model Maker ซึ่งแสดงให้เราเห็นวิธีเข้ารหัสคำในประโยคเพื่อให้โมเดลเข้าใจวิธีใช้คำเหล่านั้น คุณจะเจาะลึกเรื่องนี้มากขึ้นในส่วนถัดไปlabels.txt- มีเพียงชื่อคลาสผลลัพธ์ที่โมเดลจะคาดการณ์ สำหรับโมเดลนี้ หากคุณเปิดไฟล์นี้ในโปรแกรมแก้ไขข้อความ จะมีเพียง "false" และ "true" ที่ระบุว่า "ไม่ใช่สแปม" หรือ "สแปม" เป็นเอาต์พุตการคาดการณ์
โฮสต์ไฟล์โมเดล TensorFlow.js
ก่อนอื่น ให้นำไฟล์ model.json และ *.bin ที่สร้างขึ้นไปไว้ในเว็บเซิร์ฟเวอร์เพื่อให้คุณเข้าถึงไฟล์ดังกล่าวผ่านหน้าเว็บได้
ลบไฟล์โมเดลที่มีอยู่
เนื่องจากคุณกำลังสร้างต่อจากผลลัพธ์สุดท้ายของ Codelab แรกในชุดนี้ คุณจึงต้องลบไฟล์โมเดลที่มีอยู่ซึ่งอัปโหลดไว้ก่อน หากใช้ Glitch.com ให้ตรวจสอบแผงไฟล์ทางด้านซ้ายเพื่อดู model.json และ group1-shard1of1.bin จากนั้นคลิกเมนูแบบเลื่อนลง 3 จุดสำหรับแต่ละไฟล์ แล้วเลือกลบตามที่แสดง
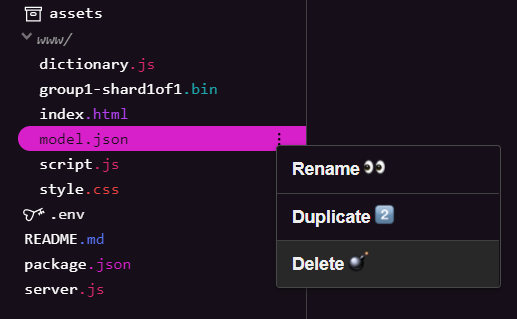
การอัปโหลดไฟล์ใหม่ไปยัง Glitch
เยี่ยมเลย ตอนนี้ให้อัปโหลดไฟล์ใหม่
- เปิดโฟลเดอร์ชิ้นงานในแผงด้านซ้ายของโปรเจ็กต์ Glitch แล้วลบชิ้นงานเก่าที่อัปโหลดไปแล้วหากมีชื่อเดียวกัน
- คลิกอัปโหลดชิ้นงาน แล้วเลือก
group1-shard1of1.binที่จะอัปโหลดลงในโฟลเดอร์นี้ เมื่ออัปโหลดแล้ว ควรมีลักษณะดังนี้
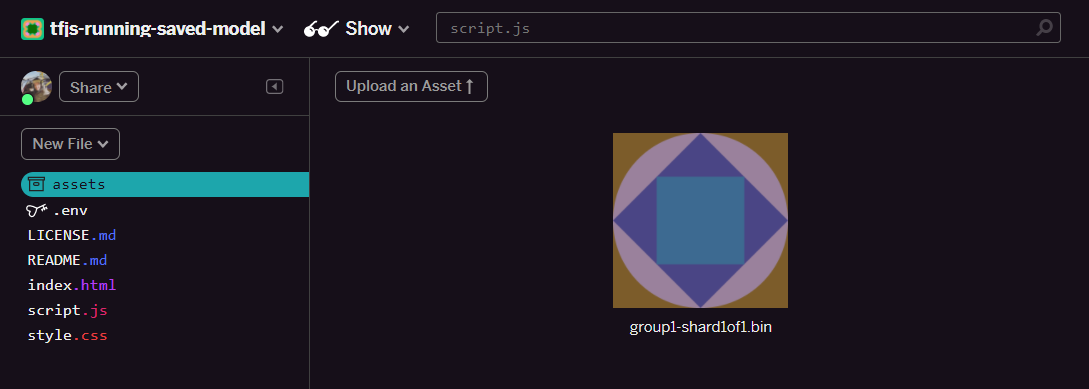
- เยี่ยมเลย ตอนนี้ให้ทำเช่นเดียวกันกับไฟล์ model.json ด้วย ดังนั้นควรมี 2 ไฟล์ในโฟลเดอร์ชิ้นงานของคุณดังนี้
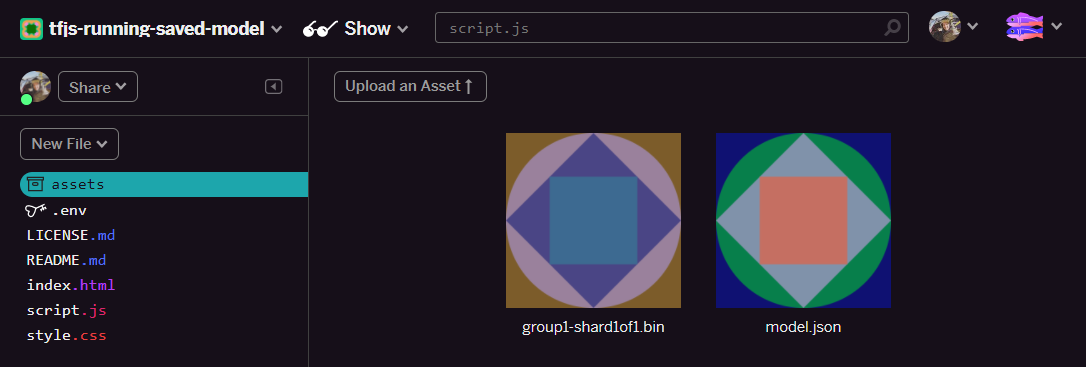
- หากคลิกไฟล์
group1-shard1of1.binที่เพิ่งอัปโหลด คุณจะคัดลอก URL ไปยังตำแหน่งของไฟล์ได้ คัดลอกเส้นทางนี้ตอนนี้ตามที่แสดง
- ตอนนี้ที่ด้านล่างซ้ายของหน้าจอ ให้คลิกเครื่องมือ > เทอร์มินัล รอให้หน้าต่างเทอร์มินัลโหลด
- เมื่อโหลดแล้ว ให้พิมพ์คำสั่งต่อไปนี้ แล้วกด Enter เพื่อเปลี่ยนไดเรกทอรีเป็นโฟลเดอร์
www
terminal:
cd www
- จากนั้นใช้
wgetเพื่อดาวน์โหลดไฟล์ 2 ไฟล์ที่เพิ่งอัปโหลดโดยแทนที่ URL ด้านล่างด้วย URL ที่คุณสร้างขึ้นสำหรับไฟล์ในโฟลเดอร์เนื้อหาบน Glitch (ตรวจสอบโฟลเดอร์เนื้อหาสำหรับ URL ที่กำหนดเองของแต่ละไฟล์)
โปรดสังเกตช่องว่างระหว่าง URL ทั้ง 2 รายการ และ URL ที่คุณจะต้องใช้จะแตกต่างจาก URL ที่แสดง แต่จะมีลักษณะคล้ายกัน
เทอร์มินัล
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
ยอดเยี่ยม! ตอนนี้คุณได้ทำสำเนาไฟล์ที่อัปโหลดไปยังโฟลเดอร์ www แล้ว
อย่างไรก็ตาม ขณะนี้ไฟล์จะดาวน์โหลดโดยมีชื่อแปลกๆ หากคุณพิมพ์ ls ในเทอร์มินัลแล้วกด Enter คุณจะเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

- ใช้คำสั่ง
mvเพื่อเปลี่ยนชื่อไฟล์ พิมพ์ข้อความต่อไปนี้ลงในคอนโซล แล้วกด Enter หลังแต่ละบรรทัด
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- สุดท้าย ให้รีเฟรชโปรเจ็กต์ Glitch โดยพิมพ์
refreshในเทอร์มินัล แล้วกด Enter
terminal:
refresh
เมื่อรีเฟรชแล้ว คุณควรเห็น model.json และ group1-shard1of1.bin ในโฟลเดอร์ www ของอินเทอร์เฟซผู้ใช้
เยี่ยมเลย ขั้นตอนสุดท้ายคือการอัปเดตไฟล์ dictionary.js
- แปลงไฟล์คำศัพท์ที่ดาวน์โหลดใหม่เป็นรูปแบบ JS ที่ถูกต้องด้วยตนเองผ่านโปรแกรมแก้ไขข้อความ หรือใช้เครื่องมือนี้ แล้วบันทึกเอาต์พุตที่ได้เป็น
dictionary.jsภายในโฟลเดอร์wwwหากมีไฟล์dictionary.jsอยู่แล้ว คุณก็เพียงแค่คัดลอกและวางเนื้อหาใหม่ทับลงไป แล้วบันทึกไฟล์
ไชโย คุณอัปเดตไฟล์ที่เปลี่ยนแปลงทั้งหมดเรียบร้อยแล้ว และหากตอนนี้คุณลองใช้เว็บไซต์ คุณจะเห็นว่าโมเดลที่ฝึกใหม่ควรจะสามารถจัดการกับกรณีที่พบได้ยากซึ่งค้นพบและเรียนรู้ได้ดังที่แสดง
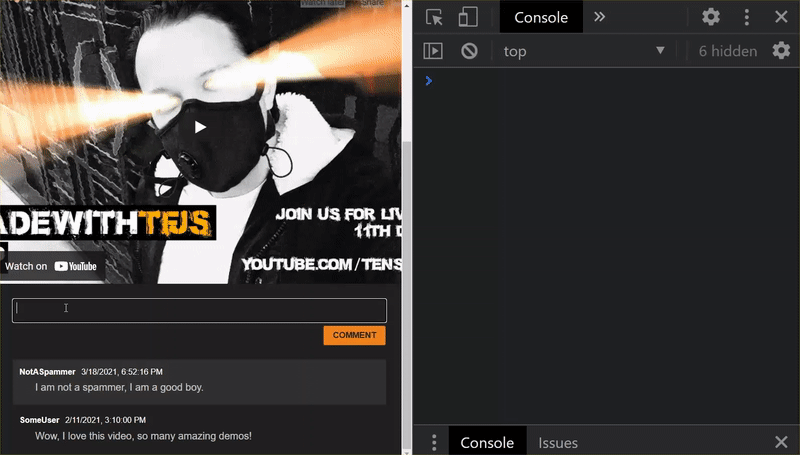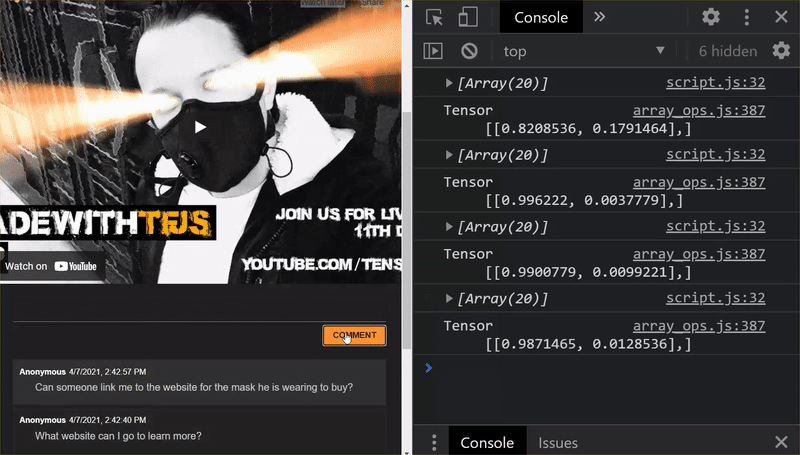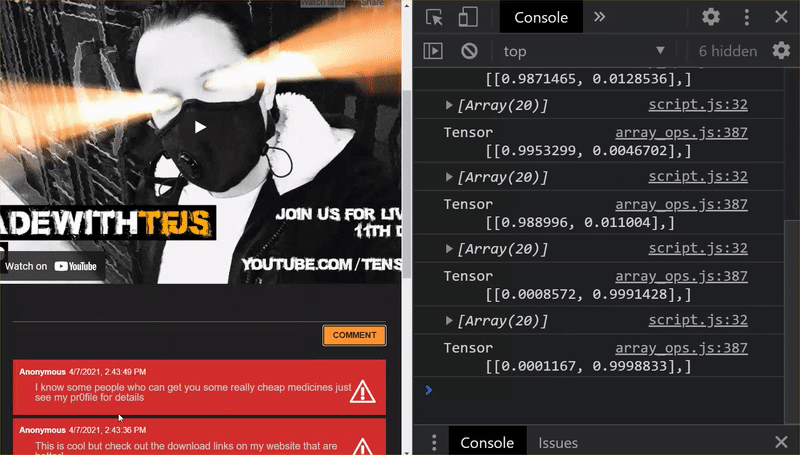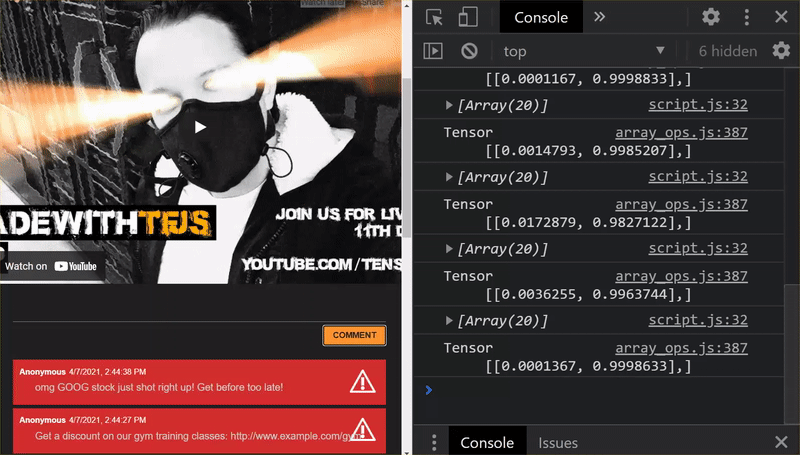
ดังที่คุณเห็น อีเมล 6 ฉบับแรกได้รับการจัดประเภทอย่างถูกต้องว่าไม่ใช่จดหมายขยะ และอีเมล 6 ฉบับที่ 2 ได้รับการระบุว่าเป็นจดหมายขยะทั้งหมด เยี่ยมเลย
มาลองใช้รูปแบบต่างๆ เพื่อดูว่าโมเดลทำงานได้ดีหรือไม่ เดิมทีมีประโยคที่ไม่ผ่าน เช่น
"omg GOOG stock just shot right up! รีบรับสิทธิ์ก่อนจะสายเกินไป"
ตอนนี้ระบบจัดประเภทอีเมลนี้เป็นจดหมายขยะอย่างถูกต้องแล้ว แต่จะเกิดอะไรขึ้นหากคุณเปลี่ยนเป็น
"หุ้น XYZ เพิ่งมีมูลค่าเพิ่มขึ้น อย่าลืมซื้อก่อนที่จะสายเกินไป"
ในที่นี้ คุณจะได้รับการคาดการณ์ว่ามีแนวโน้มที่จะเป็นสแปม 98% ซึ่งถูกต้องแม้ว่าคุณจะเปลี่ยนสัญลักษณ์หุ้นและคำเล็กน้อยก็ตาม
แน่นอนว่าหากคุณพยายามที่จะทำลายโมเดลใหม่นี้ คุณจะทำได้ และเราจะต้องรวบรวมข้อมูลฝึกฝนเพิ่มเติมเพื่อให้มีโอกาสที่ดีที่สุดในการจับภาพรูปแบบที่ไม่ซ้ำกันมากขึ้นสำหรับสถานการณ์ทั่วไปที่คุณมีแนวโน้มที่จะพบทางออนไลน์ ใน Codelab ในอนาคต เราจะแสดงวิธีปรับปรุงโมเดลอย่างต่อเนื่องด้วยข้อมูลสดเมื่อมีการแจ้งว่าไม่เหมาะสม
6. ยินดีด้วย
ขอแสดงความยินดี คุณสามารถฝึกโมเดลแมชชีนเลิร์นนิงที่มีอยู่ใหม่เพื่ออัปเดตให้ทำงานกับกรณีขอบที่คุณพบ และนำการเปลี่ยนแปลงเหล่านั้นไปใช้กับเบราว์เซอร์ด้วย TensorFlow.js สำหรับแอปพลิเคชันในโลกแห่งความเป็นจริง
สรุป
ใน Codelab นี้ คุณจะได้ทำสิ่งต่อไปนี้
- พบกรณีที่พบได้ยากซึ่งใช้ไม่ได้เมื่อใช้โมเดลสแปมความคิดเห็นที่สร้างไว้ล่วงหน้า
- ฝึกโมเดล Model Maker ใหม่เพื่อพิจารณากรณีที่พบได้ยากที่คุณค้นพบ
- ส่งออกโมเดลที่ฝึกใหม่ไปยังรูปแบบ TensorFlow.js
- อัปเดตเว็บแอปให้ใช้ไฟล์ใหม่
สิ่งต่อไปที่ควรทำ
การอัปเดตนี้จึงทำงานได้ดี แต่เช่นเดียวกับเว็บแอปอื่นๆ การเปลี่ยนแปลงจะเกิดขึ้นเมื่อเวลาผ่านไป จะดีกว่ามากหากแอปปรับปรุงตัวเองอย่างต่อเนื่องเมื่อเวลาผ่านไป แทนที่เราจะต้องดำเนินการนี้ด้วยตนเองทุกครั้ง คุณคิดว่าคุณจะทำให้ขั้นตอนเหล่านี้เป็นแบบอัตโนมัติเพื่อฝึกโมเดลใหม่โดยอัตโนมัติหลังจากที่มีความคิดเห็นใหม่ 100 รายการที่ทำเครื่องหมายว่าแยกประเภทไม่ถูกต้องได้อย่างไร เพียงสวมหมวกวิศวกรเว็บตามปกติ คุณก็อาจคิดออกว่าจะสร้างไปป์ไลน์เพื่อดำเนินการนี้โดยอัตโนมัติได้อย่างไร หากยังไม่มี ไม่ต้องกังวล โปรดรอติดตาม Codelab ถัดไปในซีรีส์นี้ที่จะแสดงวิธีให้คุณ
แชร์ผลงานของคุณกับเรา
คุณสามารถขยายผลงานที่สร้างในวันนี้ไปใช้ในกรณีการใช้งานอื่นๆ ที่สร้างสรรค์ได้ด้วย และเราขอแนะนำให้คุณคิดนอกกรอบและสร้างสรรค์ต่อไป
อย่าลืมแท็กเราบนโซเชียลมีเดียโดยใช้แฮชแท็ก #MadeWithTFJS เพื่อให้โปรเจ็กต์ของคุณมีโอกาสได้แสดงในบล็อก TensorFlow หรือแม้แต่กิจกรรมในอนาคต เราอยากเห็นผลงานของคุณ
Codelab ของ TensorFlow.js เพิ่มเติมเพื่อเจาะลึก
- ใช้ Firebase Hosting เพื่อทำให้ใช้งานได้และโฮสต์โมเดล TensorFlow.js ในวงกว้าง
- สร้างเว็บแคมอัจฉริยะโดยใช้โมเดลการตรวจจับวัตถุที่สร้างไว้ล่วงหน้าด้วย TensorFlow.js
เว็บไซต์ที่ควรดู
- เว็บไซต์ทางการของ TensorFlow.js
- โมเดล TensorFlow.js ที่สร้างไว้ล่วงหน้า
- TensorFlow.js API
- TensorFlow.js Show & Tell - รับแรงบันดาลใจและดูสิ่งที่ผู้อื่นสร้าง