
1. Antes de comenzar
Este codelab está diseñado para basarse en el resultado final del codelab anterior de esta serie para la detección de comentarios spam con TensorFlow.js.
En el último codelab, creaste una página web completamente funcional para un blog de video ficticio. Pudiste filtrar los comentarios spam antes de que se enviaran al servidor para su almacenamiento o a otros clientes conectados con un modelo previamente entrenado de detección de comentarios spam potenciado por TensorFlow.js en el navegador.
A continuación, se muestra el resultado final de ese codelab:
Si bien esto funcionó muy bien, hay casos extremos que se deben explorar y que no se pudieron detectar. Puedes volver a entrenar el modelo para que tenga en cuenta las situaciones que no pudo controlar.
Este codelab se enfoca en el uso del procesamiento de lenguaje natural (el arte de comprender el lenguaje humano con una computadora) y te muestra cómo modificar una app web existente que creaste (se recomienda realizar los codelabs en orden) para abordar el problema muy real del spam en los comentarios, con el que seguramente se encontrarán muchos desarrolladores web a medida que trabajen en una de las cada vez más populares apps web que existen hoy en día.
En este codelab, irás un paso más allá y reentrenarás tu modelo de AA para tener en cuenta los cambios en el contenido de los mensajes de spam que pueden evolucionar con el tiempo, en función de las tendencias actuales o los temas de discusión populares, lo que te permitirá mantener el modelo actualizado y tener en cuenta esos cambios.
Requisitos previos
- Completaste el primer codelab de esta serie.
- Conocimientos básicos de tecnologías web, incluidos HTML, CSS y JavaScript
Qué compilarás
Reutilizarás el sitio web creado anteriormente para un blog de video ficticio con una sección de comentarios en tiempo real y lo actualizarás para cargar una versión entrenada de forma personalizada del modelo de detección de spam con TensorFlow.js, de modo que funcione mejor en los casos extremos en los que antes habría fallado. Por supuesto, como ingenieros y desarrolladores web, podrían cambiar esta UX hipotética para reutilizarla en cualquier sitio web en el que trabajen en sus roles cotidianos y adaptar la solución para que se ajuste a cualquier caso de uso del cliente, ya sea un blog, un foro o algún tipo de CMS, como Drupal, por ejemplo.
Comencemos a hackear…
Qué aprenderás
Harás lo siguiente:
- Identifica los casos extremos en los que fallaba el modelo previamente entrenado
- Vuelve a entrenar el modelo de clasificación de spam que se creó con Model Maker.
- Exporta este modelo basado en Python al formato de TensorFlow.js para usarlo en navegadores.
- Actualiza el modelo alojado y su diccionario con el modelo recién entrenado y verifica los resultados
En este lab, se supone que tienes conocimientos de HTML5, CSS y JavaScript. También ejecutarás código de Python a través de un notebook de "co lab" para volver a entrenar el modelo que se creó con Model Maker, pero no es necesario que tengas experiencia con Python para hacerlo.
2. Cómo prepararse para programar
Una vez más, usarás Glitch.com para alojar y modificar la aplicación web. Si aún no completaste el codelab de requisitos previos, puedes clonar el resultado final aquí como punto de partida. Si tienes preguntas sobre cómo funciona el código, te recomendamos que completes el codelab anterior en el que se explica cómo crear esta app web funcional antes de continuar.
En Glitch, simplemente haz clic en el botón remix this para crear una bifurcación y un nuevo conjunto de archivos que puedes editar.
3. Descubre casos límite en la solución a priori
Si abres el sitio web completo que acabas de clonar y tratas de escribir algunos comentarios, notarás que, la mayoría de las veces, funciona según lo previsto, ya que bloquea los comentarios que suenan a spam como se espera y permite las respuestas legítimas.
Sin embargo, si te pones creativo y tratas de formular las cosas para romper el modelo, es probable que lo logres en algún momento. Con un poco de prueba y error, puedes crear manualmente ejemplos como los que se muestran a continuación. Intenta pegar estos datos en la app web existente, consulta la consola y observa las probabilidades que se muestran para determinar si el comentario es spam:
Comentarios legítimos publicados sin problemas (negativos verdaderos):
- “Guau, me encanta ese video. Es un trabajo increíble”. Probabilidad de spam: 47.91854%
- "Me encantaron estas demostraciones. ¿Tienes más detalles?" Probabilidad de spam: 47.15898%
- "¿A qué sitio web puedo ir para obtener más información?" Probabilidad de spam: 15.32495%
Esto es genial. Las probabilidades de todo lo anterior son bastante bajas y superan con éxito el SPAM_THRESHOLD predeterminado de un 75% de probabilidad mínima antes de que se tome una acción (definido en el código script.js del codelab anterior).
Ahora intentemos escribir comentarios más provocativos que se marquen como spam, aunque no lo sean…
Comentarios legítimos marcados como spam (falsos positivos):
- "¿Alguien puede compartir el vínculo al sitio web de la máscara que usa?" Probabilidad de spam: 98.46466%
- "¿Puedo comprar esta canción en Spotify? Alguien que me lo diga". Probabilidad de spam: 94.40953%
- "¿Alguien puede comunicarse conmigo para brindarme detalles sobre cómo descargar TensorFlow.js?" Probabilidad de spam: 83.20084%
¡Ay, no! Parece que estos comentarios legítimos se marcan como spam cuando deberían permitirse. ¿Cómo puedes solucionarlo?
Una opción simple es aumentar el SPAM_THRESHOLD para tener una confianza superior al 98.5%. En ese caso, se publicarían los comentarios clasificados de forma incorrecta. Con eso en mente, continuemos con los otros resultados posibles a continuación…
Comentarios spam marcados como spam (verdaderos positivos):
- "Esto es genial, pero mira los vínculos de descarga de mi sitio web, que son mejores". Probabilidad de spam: 99.77873%
- "Conozco a personas que pueden conseguirte medicamentos. Consulta mi perfil para obtener más información" Probabilidad de spam: 98.46955%
- "Visita mi perfil para descargar videos aún más increíbles y mejores. http://example.com" Probabilidad de spam: 96.26383%
De acuerdo, esto funciona como se espera con nuestro umbral original del 75%, pero, dado que en el paso anterior cambiaste SPAM_THRESHOLD para que tenga una confianza superior al 98.5%, esto significaría que se permitirían 2 ejemplos aquí, por lo que tal vez el umbral sea demasiado alto. ¿Quizás un 96% sea mejor? Sin embargo, si lo haces, uno de los comentarios de la sección anterior (falsos positivos) se marcará como spam cuando sea legítimo, ya que se calificó en un 98.46466%.
En este caso, probablemente sea mejor capturar todos estos comentarios de spam reales y, simplemente, volver a entrenar el modelo para los errores anteriores. Si estableces el umbral en el 96%, se seguirán capturando todos los verdaderos positivos y se eliminarán 2 de los falsos positivos anteriores. No está mal para cambiar un solo número.
Continuemos…
Comentarios spam que se permitieron publicar (falsos negativos):
- “Visita mi perfil para descargar videos aún más increíbles”. Probabilidad de spam: 7.54926%
- "Obtén un descuento en nuestras clases de entrenamiento en el gimnasio. ¡Consulta el perfil!" Probabilidad de spam: 17.49849%
- "¡Ay, las acciones de GOOG se dispararon! ¡Consíguelo antes de que sea demasiado tarde!" Probabilidad de spam: 20.42894%
En el caso de estos comentarios, no puedes hacer nada simplemente cambiando el valor de SPAM_THRESHOLD. Disminuir el umbral de spam del 96% a un 9% aproximadamente hará que los comentarios genuinos se marquen como spam. Uno de ellos tiene una calificación del 58% a pesar de ser legítimo. La única forma de abordar este tipo de comentarios sería volver a entrenar el modelo con esos casos extremos incluidos en los datos de entrenamiento para que aprenda a ajustar su visión del mundo sobre lo que es spam o no.
Si bien la única opción que queda ahora es volver a entrenar el modelo, también viste cómo puedes ajustar el umbral de cuándo decides llamar spam a algo para mejorar también el rendimiento. Como humano, el 75% parece bastante seguro, pero para este modelo, debías aumentar la confianza a cerca del 81.5% para ser más eficaz con las entradas de ejemplo.
No existe un valor mágico que funcione bien en todos los modelos, y este valor de umbral debe establecerse para cada modelo después de experimentar con datos del mundo real para determinar qué funciona bien.
En algunas situaciones, tener un falso positivo (o negativo) podría tener consecuencias graves (p.ej., en la industria médica), por lo que puedes ajustar tu umbral para que sea muy alto y solicitar más revisiones manuales para los que no cumplan con el umbral. Esta es tu elección como desarrollador y requiere cierta experimentación.
4. Vuelve a entrenar el modelo de detección de comentarios spam
En la sección anterior, identificaste varios casos extremos en los que fallaba el modelo y la única opción era volver a entrenarlo para tener en cuenta estas situaciones. En un sistema de producción, puedes encontrarlos con el tiempo a medida que las personas marcan manualmente un comentario como spam que se dejó pasar o los moderadores que revisan los comentarios marcados se dan cuenta de que algunos no son spam y podrían marcar esos comentarios para volver a entrenar el modelo. Suponiendo que recopilaste muchos datos nuevos para estos casos extremos (para obtener mejores resultados, deberías tener algunas variaciones de estas oraciones nuevas si puedes), ahora te mostraremos cómo volver a entrenar el modelo teniendo en cuenta esos casos extremos.
Resumen del modelo prediseñado
El modelo prediseñado que usaste fue creado por un tercero a través de Model Maker y utiliza un modelo de "embedding de palabras promedio" para funcionar.
Como el modelo se compiló con Model Maker, deberás cambiar brevemente a Python para volver a entrenarlo y, luego, exportar el modelo creado al formato de TensorFlow.js para que puedas usarlo en el navegador. Afortunadamente, Model Maker facilita mucho el uso de sus modelos, por lo que debería ser bastante fácil seguir el proceso, y te guiaremos en cada paso, así que no te preocupes si nunca usaste Python.
Colabs
Como en este codelab no te preocupa demasiado configurar un servidor Linux con todas las utilidades de Python instaladas, puedes ejecutar código simplemente a través del navegador web con un "notebook de Colab". Estos notebooks se pueden conectar a un "backend", que es simplemente un servidor con algunos elementos preinstalados, desde el cual puedes ejecutar código arbitrario dentro del navegador web y ver los resultados. Esto es muy útil para crear prototipos rápidos o para usar en instructivos como este.
Solo tienes que ir a colab.research.google.com y verás una pantalla de bienvenida como la que se muestra a continuación:
Ahora haz clic en el botón New Notebook en la esquina inferior derecha de la ventana emergente y deberías ver un Colab en blanco como este:
¡Genial! El siguiente paso es conectar el Colab de frontend a algún servidor de backend para que puedas ejecutar el código de Python que escribirás. Para ello, haz clic en Conectar en la esquina superior derecha y selecciona Conectar con el tiempo de ejecución alojado.
Una vez que se conecte, deberías ver los íconos de RAM y disco en su lugar, como se muestra a continuación:
¡Bien hecho! Ahora puedes comenzar a escribir código en Python para volver a entrenar el modelo de Model Maker. Simplemente, siga los pasos que se indican a continuación.
Paso 1
En la primera celda que está vacía, copia el siguiente código. Se instalará TensorFlow Lite Model Maker con el administrador de paquetes de Python llamado "pip" (es similar a npm, que la mayoría de los lectores de este codelab tal vez conozcan mejor del ecosistema de JS):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Sin embargo, si pegas código en la celda, no se ejecutará. A continuación, coloca el cursor del mouse sobre la celda gris en la que pegaste el código anterior y aparecerá un pequeño ícono de "reproducción" a la izquierda de la celda, como se destaca a continuación:
 Haz clic en el botón de reproducción para ejecutar el código que acabas de escribir en la celda.
Haz clic en el botón de reproducción para ejecutar el código que acabas de escribir en la celda.
Ahora verás que se está instalando Model Maker:
Una vez que se complete la ejecución de esta celda, como se muestra, continúa con el siguiente paso.
Paso 2
A continuación, agrega una celda de código nueva como se muestra para que puedas pegar más código después de la primera celda y ejecutarlo por separado:
La siguiente celda que se ejecute tendrá varias importaciones que deberá usar el código del resto del notebook. Copia y pega lo siguiente en la nueva celda creada:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Es algo bastante estándar, incluso si no conoces Python. Solo importas algunas utilidades y las funciones de Model Maker necesarias para el clasificador de spam. También comprobará si estás ejecutando TensorFlow 2.x, que es un requisito para usar Model Maker.
Por último, al igual que antes, ejecuta la celda presionando el ícono de "reproducir" cuando coloques el cursor sobre ella y, luego, agrega una celda de código nueva para el siguiente paso.
Paso 3
A continuación, descargarás los datos de un servidor remoto a tu dispositivo y configurarás la variable training_data para que sea la ruta del archivo local resultante descargado:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker puede entrenar modelos a partir de archivos CSV sencillos como el que se descargó. Solo necesitas especificar qué columnas contienen el texto y cuáles contienen las etiquetas. Verás cómo hacerlo en el paso 5. Si lo deseas, puedes descargar el archivo CSV directamente para ver su contenido.
Los más observadores notarán que el nombre de este archivo es jm_blog_comments_extras.csv. Este archivo es simplemente los datos de entrenamiento originales que usamos para generar el primer modelo de comentarios spam combinado con los nuevos datos de casos potenciales que descubriste, por lo que todo está en un solo archivo. Además de las oraciones nuevas de las que deseas aprender, también necesitas los datos de entrenamiento originales que se usaron para entrenar el modelo.
Opcional: Si descargas este archivo CSV y revisas las últimas líneas, verás ejemplos de casos extremos que no funcionaban correctamente antes. Se acaban de agregar al final de los datos de entrenamiento existentes que el modelo prediseñado usó para entrenarse.
Ejecuta esta celda y, luego, cuando termine de ejecutarse, agrega una celda nueva y ve al paso 4.
Paso 4
Cuando usas Model Maker, no creas modelos desde cero. Por lo general, usas modelos existentes que luego personalizas según tus necesidades.
Model Maker proporciona varias incorporaciones de modelos aprendidas previamente que puedes usar, pero la más simple y rápida para comenzar es average_word_vec, que es la que usaste en el codelab anterior para compilar tu sitio web. Este es el código:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Ejecútalo una vez que lo hayas pegado en la celda nueva.
Información sobre la
num_words
parámetro
Esta es la cantidad de palabras que deseas que use el modelo. Es posible que pienses que “cuanto más, mejor”, pero, en general, hay un punto óptimo en función de la frecuencia con la que se utiliza cada palabra. Si usas todas las palabras de todo el corpus, es posible que el modelo intente aprender y equilibrar los pesos de las palabras que se usan solo una vez, lo que no es muy útil. En cualquier corpus de texto, encontrarás que muchas palabras solo se usan una o dos veces, y, por lo general, no vale la pena incluirlas en tu modelo, ya que tienen un impacto insignificante en la opinión general. Por lo tanto, puedes ajustar tu modelo en función de la cantidad de palabras que desees usando el parámetro num_words. Un número menor aquí generará un modelo más pequeño y rápido, pero podría ser menos preciso, ya que reconoce menos palabras. Un número más grande aquí generará un modelo más grande y potencialmente más lento. Encontrar el punto óptimo es clave y depende de ti como ingeniero de aprendizaje automático descubrir qué funciona mejor para tu caso de uso.
Información sobre la
wordvec_dim
parámetro
El parámetro wordvec_dim es la cantidad de dimensiones que deseas usar para el vector de cada palabra. Estas dimensiones son, esencialmente, las diferentes características (creadas por el algoritmo de aprendizaje automático durante el entrenamiento) con las que se puede medir cualquier palabra determinada y que el programa usará para intentar asociar de la mejor manera posible las palabras que sean similares de alguna manera significativa.
Por ejemplo, si tuvieras una dimensión para indicar qué tan "médica" es una palabra, una palabra como "píldoras" podría obtener una puntuación alta en esta dimensión y asociarse con otras palabras con puntuación alta, como "radiografía", pero "gato" obtendría una puntuación baja en esta dimensión. Puede resultar que una "dimensión médica" sea útil para determinar el spam cuando se combina con otras dimensiones potenciales que puede decidir usar y que son significativas.
En el caso de las palabras que obtienen una puntuación alta en la "dimensión médica", podría ser útil una segunda dimensión que correlacione las palabras con el cuerpo humano. Palabras como "pierna", "brazo" y "cuello" pueden obtener una puntuación alta aquí y también bastante alta en la dimensión médica.
Luego, el modelo puede usar estas dimensiones para detectar palabras que es más probable que estén asociadas con el spam. Quizás los correos electrónicos de spam tengan más probabilidades de contener palabras que se relacionen con la medicina y las partes del cuerpo humano.
La regla general que se determina a partir de la investigación es que la raíz cuarta de la cantidad de palabras funciona bien para este parámetro. Por lo tanto, si uso 2,000 palabras, un buen punto de partida para esto es 7 dimensiones. Si cambias la cantidad de palabras que usas, también puedes cambiar esto.
Información sobre la
seq_len
parámetro
Por lo general, los modelos son muy rígidos en lo que respecta a los valores de entrada. Para un modelo de lenguaje, esto significa que el modelo puede clasificar oraciones de una longitud estática específica. Esto se determina con el parámetro seq_len, que significa "longitud de la secuencia". Cuando conviertes palabras en números (o tokens), una oración se convierte en una secuencia de esos tokens. Por lo tanto, tu modelo se entrenará (en este caso) para clasificar y reconocer oraciones que tengan 20 tokens. Si la oración es más larga, se truncará. Si es más corta, se rellenará, al igual que en el primer codelab de esta serie.
Paso 5: Carga los datos de entrenamiento
Antes, descargaste el archivo CSV. Ahora, es el momento de usar un cargador de datos para convertir esto en datos de entrenamiento que el modelo puede reconocer.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Si abres el archivo CSV en un editor, verás que cada línea solo tiene dos valores, que se describen con texto en la primera línea del archivo. Por lo general, cada entrada se considera una "columna". Verás que el descriptor de la primera columna es commenttext y que la primera entrada de cada línea es el texto del comentario.
De manera similar, el descriptor de la segunda columna es spam, y observarás que la segunda entrada de cada línea es TRUE o FALSE para indicar si ese texto se considera comentario spam o no. Las otras propiedades establecen la especificación del modelo que creaste en el paso 4, junto con un carácter delimitador, que en este caso es una coma cuando el archivo está separado por comas. También puedes establecer un parámetro de aleatorización para reorganizar aleatoriamente los datos de entrenamiento, de modo que los elementos que podrían haber sido similares o recopilados juntos se distribuyan aleatoriamente en todo el conjunto de datos.
Luego, usarás data.split() para dividir los datos en datos de entrenamiento y de prueba. El .9 indica que el 90% del conjunto de datos se usará para el entrenamiento y el resto para las pruebas.
Paso 6: Compila el modelo
Agrega otra celda en la que agregaremos código para compilar el modelo:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Esto crea un modelo clasificador de texto con Model Maker, y debes especificar los datos de entrenamiento que deseas usar (que se definieron en el paso 4), la especificación del modelo (que también se configuró en el paso 4) y una cantidad de ciclos de entrenamiento, que, en este caso, es 50.
El principio básico del aprendizaje automático es que es una forma de coincidencia de patrones. Primero, cargará los pesos previamente entrenados para las palabras y, luego, intentará agruparlos con una “predicción” de cuáles, cuando se agrupan, indican spam y cuáles no. La primera vez, es probable que se acerque a 50:50, ya que el modelo solo se está iniciando, como se muestra a continuación:

Luego, medirá los resultados de esto y cambiará los pesos del modelo para ajustar su predicción y, luego, volverá a intentarlo. Este es un ciclo de entrenamiento. Por lo tanto, si especificas epochs=50, pasará por ese “bucle” 50 veces, como se muestra a continuación:

Por lo tanto, cuando llegues al ciclo de entrenamiento número 50, el modelo informará un nivel de exactitud mucho mayor. En este caso, se muestra un 99.1%.
Paso 7: Exporta el modelo
Una vez que finalice el entrenamiento, podrás exportar el modelo. TensorFlow entrena un modelo en su propio formato, y este debe convertirse al formato de TensorFlow.js para usarse en una página web. Simplemente pega lo siguiente en una celda nueva y ejecútalo:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Después de ejecutar este código, si haces clic en el ícono de carpeta pequeña que se encuentra a la izquierda de Colab, podrás navegar hasta la carpeta a la que exportaste anteriormente (en el directorio raíz; es posible que debas subir un nivel) y encontrar el paquete ZIP de los archivos exportados que se encuentran en ModelFiles.zip.
Descarga este archivo ZIP en tu computadora ahora, ya que usarás esos archivos como en el primer codelab:
¡Genial! La parte de Python terminó. Ahora puedes volver al mundo de JavaScript que conoces y amas. ¡Vaya!
5. Entrega del nuevo modelo de aprendizaje automático
Ya casi está todo listo para cargar el modelo. Sin embargo, antes de hacerlo, debes subir los nuevos archivos del modelo que descargaste anteriormente en el codelab para que se alojen y se puedan usar en tu código.
Primero, si aún no lo hiciste, descomprime los archivos del modelo que acabas de descargar del notebook de Colab de Model Maker que acabas de ejecutar. Deberías ver los siguientes archivos en sus diferentes carpetas:
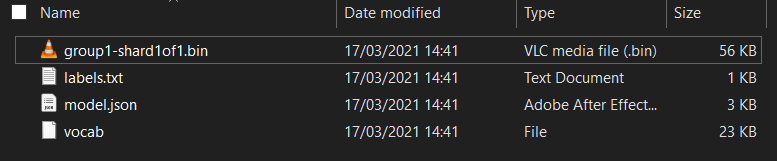
¿Qué tienes aquí?
model.json: Este es uno de los archivos que componen el modelo entrenado de TensorFlow.js. Harás referencia a este archivo específico en el código de JS.group1-shard1of1.bin: Es un archivo binario que contiene gran parte de los datos guardados para el modelo de TensorFlow.js exportado y deberá alojarse en algún lugar de tu servidor para su descarga en el mismo directorio quemodel.jsonanterior.vocab: Este extraño archivo sin extensión es algo de Model Maker que nos muestra cómo codificar palabras en las oraciones para que el modelo comprenda cómo usarlas. Profundizarás en este tema en la siguiente sección.labels.txt: Simplemente contiene los nombres de clase resultantes que predecirá el modelo. En este modelo, si abres este archivo en tu editor de texto, simplemente verás "false" y "true" que indican "no es spam" o "spam" como resultado de la predicción.
Cómo alojar los archivos del modelo de TensorFlow.js
Primero, coloca los archivos model.json y *.bin que se generaron en un servidor web para que puedas acceder a ellos a través de tu página web.
Borrar los archivos de modelos existentes
Como crearás sobre el resultado final del primer codelab de esta serie, primero debes borrar los archivos de modelo existentes que se subieron. Si usas Glitch.com, simplemente revisa el panel de archivos a la izquierda para ver model.json y group1-shard1of1.bin, haz clic en el menú desplegable de 3 puntos de cada archivo y selecciona Borrar como se muestra a continuación:
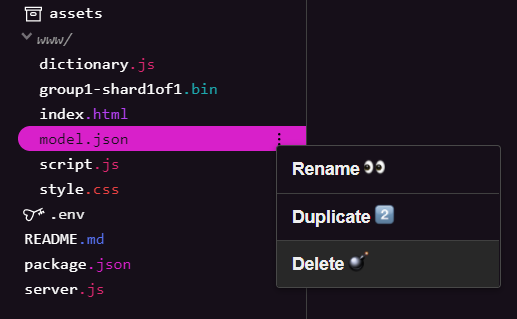
Cómo subir archivos nuevos a Glitch
¡Genial! Ahora sube los nuevos:
- Abre la carpeta assets en el panel izquierdo de tu proyecto de Glitch y borra los recursos antiguos que se hayan subido si tienen los mismos nombres.
- Haz clic en Subir un recurso y selecciona
group1-shard1of1.binpara subirlo a esta carpeta. Una vez que se suba, debería verse de la siguiente manera:
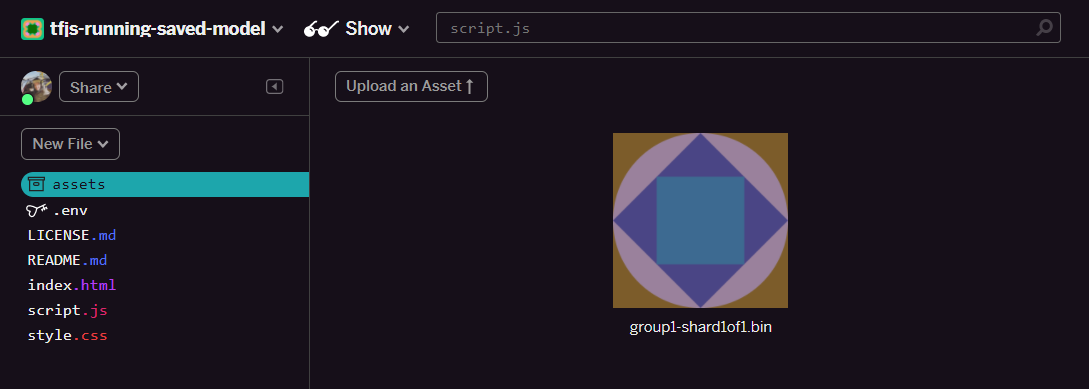
- ¡Genial! Ahora haz lo mismo con el archivo model.json, de modo que haya 2 archivos en tu carpeta de recursos, como se muestra a continuación:
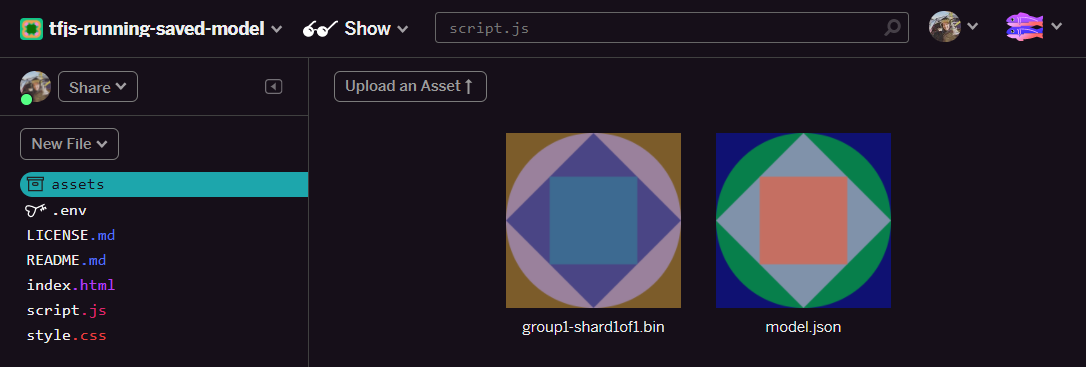
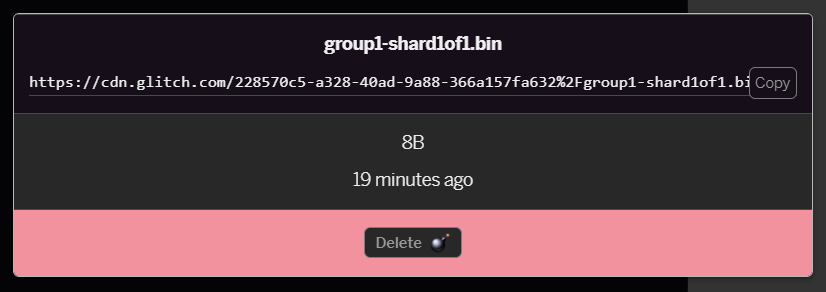
- Si haces clic en el archivo
group1-shard1of1.binque acabas de subir, podrás copiar la URL a su ubicación. Copia esta ruta de acceso ahora como se muestra a continuación:
- Ahora, en la parte inferior izquierda de la pantalla, haz clic en Herramientas > Terminal. Espera a que se cargue la ventana de terminal.
- Una vez cargado, escribe lo siguiente y, luego, presiona Intro para cambiar el directorio a la carpeta
www:
terminal:
cd www
- A continuación, usa
wgetpara descargar los 2 archivos que acabas de subir. Para ello, reemplaza las URLs que se muestran a continuación por las que generaste para los archivos en la carpeta de recursos de Glitch (consulta la carpeta de recursos para ver la URL personalizada de cada archivo).
Ten en cuenta el espacio entre las dos URLs y que las URLs que deberás usar serán diferentes de las que se muestran, pero se verán similares:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Exactamente Ahora tienes una copia de los archivos subidos a la carpeta www.
Sin embargo, por el momento, se descargarán con nombres extraños. Si escribes ls en la terminal y presionas Intro, verás algo como lo siguiente:

- Usa el comando
mvpara cambiar el nombre de los archivos. Escribe lo siguiente en la consola y presiona Intro después de cada línea:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Por último, actualiza el proyecto de Glitch escribiendo
refreshen la terminal y presionando Intro:
terminal:
refresh
Después de actualizar, deberías ver model.json y group1-shard1of1.bin en la carpeta www de la interfaz de usuario:
¡Genial! El último paso es actualizar el archivo dictionary.js.
- Convierte tu nuevo archivo de vocabulario descargado al formato JS correcto de forma manual con tu editor de texto o con esta herramienta, y guarda el resultado como
dictionary.jsen tu carpetawww. Si ya tienes un archivodictionary.js, puedes copiar y pegar el contenido nuevo y guardar el archivo.
¡Muy bien! Actualizaste correctamente todos los archivos modificados y, si ahora intentas usar el sitio web, notarás que el modelo reentrenado debería poder tener en cuenta los casos extremos descubiertos y aprendidos, como se muestra a continuación:
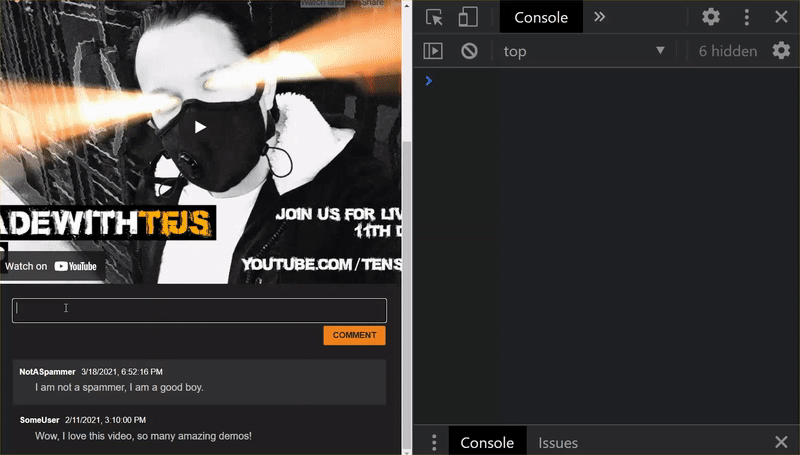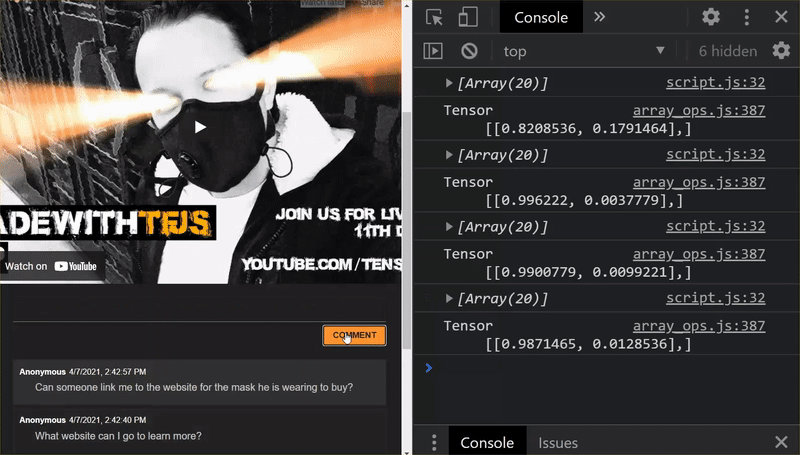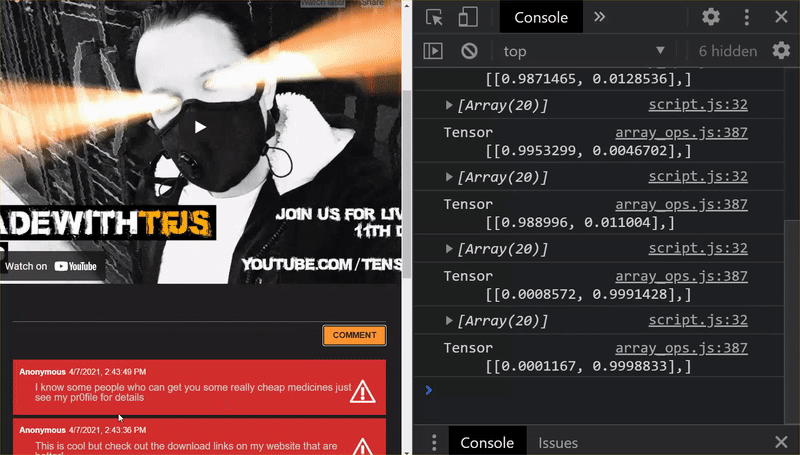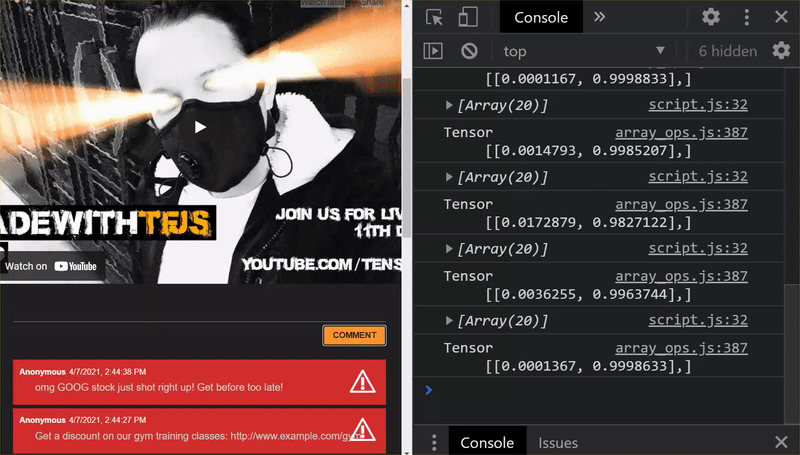
Como puedes ver, los primeros 6 ahora se clasifican correctamente como no spam, y los 6 del segundo lote se identifican como spam. ¡Perfecto!
También probemos algunas variaciones para ver si se generalizó bien. Originalmente, había una oración incorrecta, como la siguiente:
"OMG, las acciones de GOOG acaban de subir muchísimo. ¡Consíguelo antes de que sea demasiado tarde!"
Ahora se clasifica correctamente como spam, pero ¿qué sucede si lo cambias a lo siguiente?
"Entonces, las acciones de XYZ acaban de aumentar su valor. Compra algunos antes de que sea demasiado tarde."
Aquí obtienes una predicción de un 98% de probabilidades de que sea spam, lo cual es correcto, incluso si cambiaste el símbolo bursátil y la redacción ligeramente.
Por supuesto, si realmente intentas romper este nuevo modelo, podrás hacerlo, y se tratará de recopilar aún más datos de entrenamiento para tener la mejor oportunidad de capturar más variaciones únicas para las situaciones comunes que es probable que encuentres en línea. En un futuro codelab, te mostraremos cómo mejorar continuamente tu modelo con datos en tiempo real a medida que se marquen.
6. ¡Felicitaciones!
Felicitaciones. Lograste volver a entrenar un modelo de aprendizaje automático existente para que se actualice y funcione en los casos extremos que encontraste, y luego implementaste esos cambios en el navegador con TensorFlow.js para una aplicación del mundo real.
Resumen
En este codelab, lograste lo siguiente:
- Se descubrieron casos extremos que no funcionaban cuando se usaba el modelo de comentarios spam prediseñado.
- Se volvió a entrenar el modelo de Model Maker para tener en cuenta los casos extremos que descubriste.
- Se exportó el nuevo modelo entrenado al formato de TensorFlow.js
- Actualizaste tu app web para usar los archivos nuevos.
¿Qué sigue?
Por lo tanto, esta actualización funciona muy bien, pero, como con cualquier app web, los cambios se producirán con el tiempo. Sería mucho mejor si la app se mejorara continuamente con el tiempo en lugar de que tuviéramos que hacerlo manualmente cada vez. ¿Puedes pensar cómo podrías haber automatizado estos pasos para volver a entrenar automáticamente un modelo después de tener, por ejemplo, 100 comentarios nuevos marcados como clasificados de forma incorrecta? Si te pones tu sombrero de ingeniero web habitual, probablemente puedas crear una canalización para hacerlo automáticamente. Si no es así, no te preocupes. En el próximo codelab de la serie, te mostraremos cómo hacerlo.
Comparte tus creaciones con nosotros
También puedes extender fácilmente lo que creaste hoy para otros casos de uso creativos, y te recomendamos que pienses de manera innovadora y sigas hackeando.
Recuerda etiquetarnos en las redes sociales con el hashtag #MadeWithTFJS para tener la oportunidad de que se incluya tu proyecto en el blog de TensorFlow o, incluso, en futuros eventos. Nos encantaría ver tus creaciones.
Más Codelabs de TensorFlow.js para aprender más
- Usa Firebase Hosting para implementar y alojar un modelo de TensorFlow.js a gran escala.
- Crea una cámara web inteligente con un modelo de detección de objetos prediseñado con TensorFlow.js
Sitios web que puedes revisar
- Sitio web oficial de TensorFlow.js
- Modelos prediseñados de TensorFlow.js
- API de TensorFlow.js
- TensorFlow.js Show & Tell: Inspírate y mira lo que crearon otros.