
1. قبل البدء
تم تصميم هذا الدرس التطبيقي حول الترميز استنادًا إلى النتيجة النهائية للدرس التطبيقي السابق في هذه السلسلة لرصد التعليقات غير المرغوب فيها باستخدام TensorFlow.js.
في الدرس التطبيقي السابق، أنشأت صفحة ويب تعمل بكامل طاقتها لمدوّنة فيديو وهمية. كان بإمكانك فلترة التعليقات غير المرغوب فيها قبل إرسالها إلى الخادم لتخزينها أو إلى العملاء الآخرين المرتبطين، وذلك باستخدام نموذج مدرَّب مسبقًا لرصد التعليقات غير المرغوب فيها يستند إلى TensorFlow.js في المتصفّح.
تظهر النتيجة النهائية لهذا الدرس العملي أدناه:
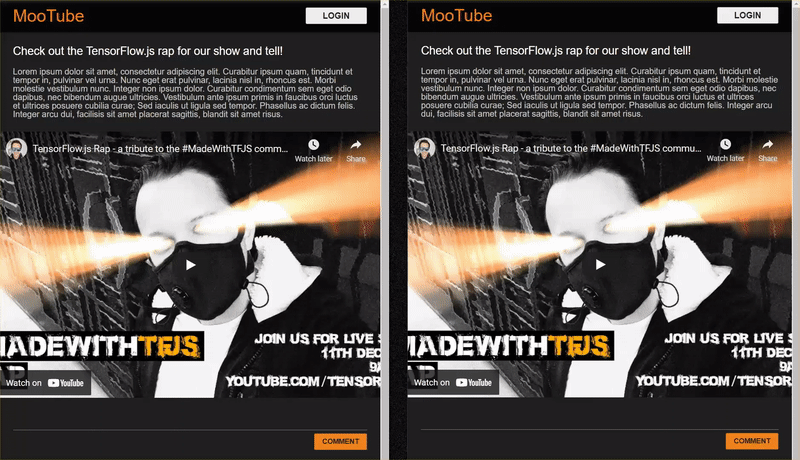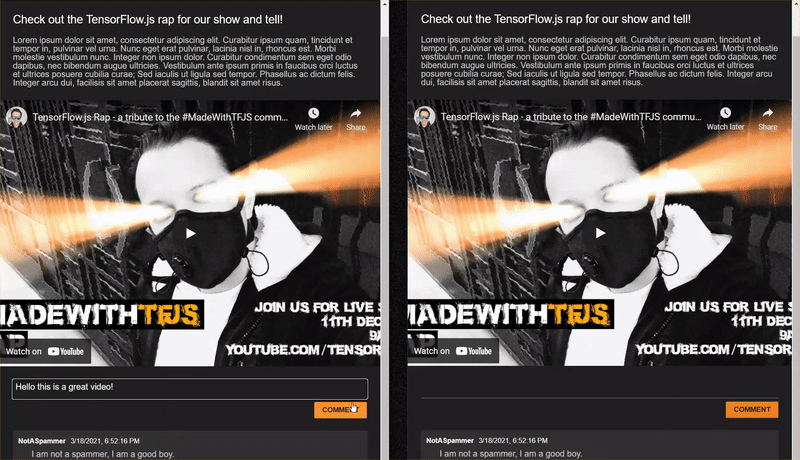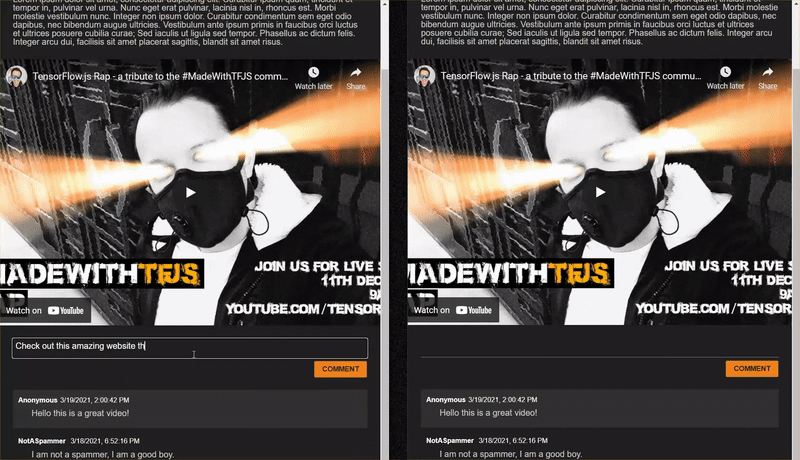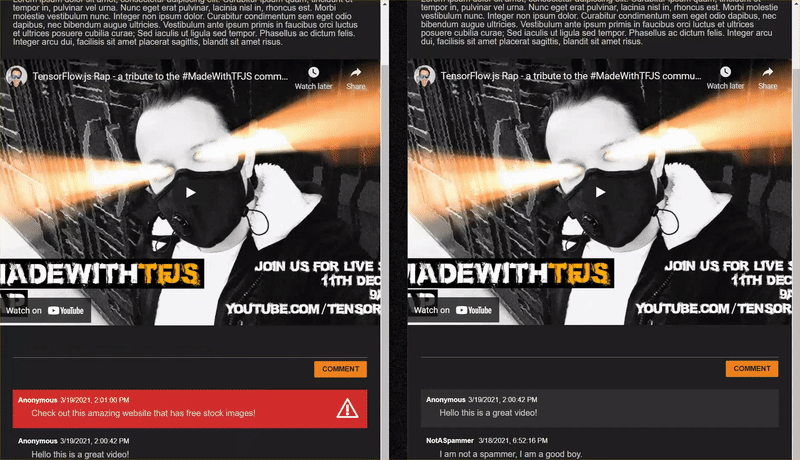
على الرغم من أنّ هذه الطريقة كانت فعّالة جدًا، هناك حالات قصوى لم تتمكّن من رصدها. يمكنك إعادة تدريب النموذج للتعامل مع الحالات التي لم يتمكّن من معالجتها.
يركّز هذا الدرس التطبيقي حول الترميز على استخدام معالجة اللغات الطبيعية (فن فهم اللغة البشرية باستخدام الكمبيوتر) ويوضّح لك كيفية تعديل تطبيق الويب حالي أنشأته (ننصحك بشدة بإكمال الدروس التطبيقية حول الترميز بالترتيب) لمعالجة مشكلة حقيقية جدًا وهي التعليقات غير المرغوب فيها، والتي سيواجهها العديد من مطوّري الويب بالتأكيد أثناء عملهم على أحد تطبيقات الويب الشائعة المتزايدة باستمرار والمتوفرة اليوم.
في هذا الدرس التطبيقي حول الترميز، ستتخذ خطوة إضافية من خلال إعادة تدريب نموذج تعلُّم الآلة لمراعاة التغييرات في محتوى الرسائل غير المرغوب فيها التي قد تتطوّر بمرور الوقت، استنادًا إلى المؤشرات الحالية أو المواضيع الشائعة التي يتم مناقشتها، ما يتيح لك إبقاء النموذج محدّثًا ومراعاة هذه التغييرات.
المتطلبات الأساسية
- أكملت أول درس تطبيقي حول الترميز في هذه السلسلة.
- معرفة أساسية بتكنولوجيات الويب، بما في ذلك HTML وCSS وJavaScript
ما ستنشئه
ستعيد استخدام الموقع الإلكتروني الذي تم إنشاؤه سابقًا لمدوّنة فيديو وهمية تتضمّن قسمًا للتعليقات في الوقت الفعلي، وستعمل على ترقيته لتحميل نسخة مدرَّبة مخصّصة من نموذج رصد الرسائل غير المرغوب فيها باستخدام TensorFlow.js، ما يؤدي إلى تحسين أدائه في الحالات القصوى التي كان سيفشل فيها سابقًا. بالطبع، بصفتك مطوّر على الويب أو مهندسًا، يمكنك تغيير تجربة المستخدم الافتراضية هذه لإعادة استخدامها على أي موقع إلكتروني تعمل عليه في مهامك اليومية وتكييف الحلّ ليناسب أي حالة استخدام للعميل، سواء كان مدوّنة أو منتدى أو أي شكل من أشكال نظام إدارة المحتوى (CMS)، مثل Drupal على سبيل المثال.
لنبدأ عملية الاختراق...
ما ستتعلمه
عليك إجراء ما يلي:
- تحديد الحالات الهامشية التي لم يتمكّن النموذج المدرَّب مسبقًا من التعامل معها
- أعِد تدريب "نموذج تصنيف الرسائل غير المرغوب فيها" الذي تم إنشاؤه باستخدام Model Maker.
- صدِّر هذا النموذج المستند إلى Python إلى تنسيق TensorFlow.js لاستخدامه في المتصفّحات.
- تعديل النموذج المستضاف وقاموسه باستخدام النموذج الذي تم تدريبه حديثًا والتحقّق من النتائج
يُفترض أن تكون على دراية بلغات HTML5 وCSS وJavaScript في هذا الدرس التطبيقي. ستنفّذ أيضًا بعض رموز Python البرمجية من خلال دفتر ملاحظات "التعاون" لإعادة تدريب النموذج الذي تم إنشاؤه باستخدام Model Maker، ولكن لا يلزم أن تكون على دراية بلغة Python لتنفيذ ذلك.
2. الاستعداد للترميز
ستستخدم Glitch.com مرة أخرى لاستضافة تطبيق الويب وتعديله. إذا لم تكن قد أكملت درس تطبيقي حول الترميز المسبق، يمكنك استنساخ النتيجة النهائية هنا كنقطة بداية. إذا كانت لديك أسئلة حول طريقة عمل الرمز، ننصحك بشدة بإكمال الدرس التطبيقي السابق حول الترميز الذي يشرح كيفية إنشاء تطبيق ويب يعمل قبل المتابعة.
على Glitch، ما عليك سوى النقر على الزر remix this لإنشاء نسخة معدَّلة منه وإنشاء مجموعة جديدة من الملفات يمكنك تعديلها.
3- اكتشاف الحالات الحدّية في الحل السابق
إذا فتحت الموقع الإلكتروني المكتمل الذي نسخته للتو وحاولت كتابة بعض التعليقات، ستلاحظ أنّه يعمل في معظم الأحيان على النحو المنشود، إذ يحظر التعليقات التي تبدو غير مرغوب فيها كما هو متوقع، ويسمح بالردود المشروعة.
ومع ذلك، إذا كنت ماهرًا وحاولت صياغة الجمل بطريقة تؤدي إلى تعطيل النموذج، من المحتمل أن تنجح في ذلك في مرحلة ما. يمكنك إنشاء أمثلة يدويًا مثل تلك الموضّحة أدناه من خلال بعض المحاولات. جرِّب لصق هذه البيانات في تطبيق الويب الحالي، وتحقَّق من وحدة التحكّم، واطّلِع على الاحتمالات التي تظهر لمعرفة ما إذا كان التعليق غير مرغوب فيه:
التعليقات المشروعة المنشورة بدون أي مشاكل (النتائج السلبية الصحيحة):
- "رائع، أحببت هذا الفيديو، عمل مذهل". احتمالية أن تكون الرسالة غير مرغوب فيها: 47.91854%
- "أعجبتني هذه العروض التوضيحية كثيرًا. هل لديك أي تفاصيل أخرى؟" احتمالية أن تكون الرسالة غير مرغوب فيها: 47.15898%
- "ما هو الموقع الإلكتروني الذي يمكنني الانتقال إليه لمعرفة المزيد؟" احتمالية أن يكون المحتوى غير مرغوب فيه: %15.32495
هذا أمر رائع، فاحتمالات حدوث كل ما سبق منخفضة جدًا، وقد تم تجاوز الحدّ الأدنى التلقائي البالغ 75% من الاحتمالية بنجاح قبل اتّخاذ أي إجراء (محدّد في الرمز script.js من الدرس التطبيقي حول الترميز السابق).SPAM_THRESHOLD
لنحاول الآن كتابة بعض التعليقات الحادة التي يتم وضع علامة عليها كمحتوى غير مرغوب فيه على الرغم من أنّها ليست كذلك...
التعليقات الصالحة التي تم تصنيفها كرسائل غير مرغوب فيها (إيجابيات خاطئة):
- "هل يمكن لأحد أن يشارك رابط الموقع الإلكتروني الخاص بالقناع الذي يرتديه؟" الاحتمالية بأن تكون الرسالة غير مرغوب فيها: 98.46466%
- "هل يمكنني شراء هذه الأغنية على Spotify؟ أرجو أن يخبرني أحد بذلك". محتوى غير مرغوب فيه محتمل: %94.40953
- "هل يمكن لأحد التواصل معي لتقديم تفاصيل حول كيفية تنزيل TensorFlow.js؟" احتمالية أن تكون الرسالة غير مرغوب فيها: 83.20084%
يا للهول! يبدو أنّه يتم تصنيف هذه التعليقات الشرعية على أنّها غير مرغوب فيها، مع أنّه يجب السماح بها. كيف يمكن حلّ هذه المشكلة؟
أحد الخيارات البسيطة هو زيادة SPAM_THRESHOLD لتكون نسبة الثقة أعلى من% 98.5. في هذه الحالة، سيتم نشر هذه التعليقات المصنّفة بشكل خاطئ. مع أخذ ذلك في الاعتبار، لنتابع مع النتائج المحتملة الأخرى أدناه...
التعليقات غير المرغوب فيها التي تم وضع علامة عليها باعتبارها غير مرغوب فيها (موجب صحيح):
- "هذا رائع، ولكن يمكنك الاطّلاع على روابط التنزيل الأفضل على موقعي الإلكتروني". محتوى غير مرغوب فيه محتمل: 99.77873%
- "أعرف بعض الأشخاص الذين يمكنهم توفير بعض الأدوية لك، يمكنك الاطّلاع على ملفي الشخصي لمعرفة التفاصيل" احتمال أن تكون الرسالة غير مرغوب فيها: 98.46955%
- "يمكنك الاطّلاع على ملفي الشخصي لتنزيل المزيد من الفيديوهات الرائعة التي هي أفضل من ذلك! http://example.com" احتمال أن تكون رسالة غير مرغوب فيها: 96.26383%
حسنًا، هذا يعمل على النحو المتوقّع مع الحدّ الأصلي البالغ% 75، ولكن بما أنّك غيّرت في الخطوة السابقة SPAM_THRESHOLD ليكون أكثر من% 98.5، هذا يعني أنّه سيتم السماح بمثالَين هنا، لذا قد يكون الحدّ مرتفعًا جدًا. هل نسبة% 96 أفضل؟ ولكن في حال إجراء ذلك، سيتم وضع علامة "محتوى غير مرغوب فيه" على أحد التعليقات في القسم السابق (موجب خاطئ) على الرغم من أنّه صالح، وذلك لأنّ تقييمه بلغ %98.46466.
في هذه الحالة، من الأفضل على الأرجح تسجيل كل هذه التعليقات غير المرغوب فيها وإعادة التدريب ببساطة على حالات الفشل المذكورة أعلاه. من خلال ضبط الحدّ الأدنى على% 96، سيتم تسجيل جميع النتائج الإيجابية الصحيحة، وستتم إزالة نتيجتَين من النتائج الإيجابية الخاطئة أعلاه. هذا ليس سيئًا بالنسبة إلى تغيير رقم واحد فقط.
لنواصل...
التعليقات غير المرغوب فيها التي تم السماح بنشرها (نتائج سلبية خاطئة):
- "يمكنك الاطّلاع على ملفي الشخصي لتنزيل المزيد من الفيديوهات الرائعة التي ستنال إعجابك". احتمالية أن يكون المحتوى غير مرغوب فيه: 7.54926%
- "احصل على خصم على دروس التدريب في النادي الرياضي، اطّلِع على الملف الشخصي!" احتمالية أن يكون المحتوى غير مرغوب فيه: 17.49849%
- "يا إلهي، لقد ارتفع سعر سهم GOOG بشكل كبير! احصل على العرض قبل فوات الأوان". الاحتمالية غير المرغوب فيها: 20.42894%
بالنسبة إلى هذه التعليقات، لا يمكنك اتّخاذ أي إجراء من خلال تغيير قيمة SPAM_THRESHOLD بشكل أكبر. سيؤدي خفض الحد الأدنى للمحتوى غير المرغوب فيه من% 96 إلى% 9 تقريبًا إلى وضع علامة "غير مرغوب فيه" على التعليقات الصالحة، إذ حصل أحدها على تقييم% 58 على الرغم من أنّه صالح. الطريقة الوحيدة للتعامل مع هذه الأنواع من التعليقات هي إعادة تدريب النموذج مع تضمين هذه الحالات القصوى في بيانات التدريب ليتعلّم كيفية تعديل نظرته إلى العالم بشأن المحتوى غير المرغوب فيه.
مع أنّ الخيار الوحيد المتبقي الآن هو إعادة تدريب النموذج، رأيت أيضًا كيف يمكنك تحسين أداء النموذج من خلال تحسين الحدّ الذي تحدّده لتصنيف المحتوى كرسائل غير مرغوب فيها. بصفتك إنسانًا، قد يبدو لك أنّ نسبة% 75 هي نسبة ثقة عالية، ولكن بالنسبة إلى هذا النموذج، كان عليك زيادة النسبة إلى% 81.5 تقريبًا لتكون أكثر فعالية مع أمثلة الإدخالات.
لا توجد قيمة سحرية واحدة تعمل بشكل جيد مع مختلف النماذج، ويجب ضبط قيمة الحدّ هذه على أساس كل نموذج على حدة بعد تجربة بيانات من العالم الحقيقي لمعرفة ما هو الأفضل.
قد تكون هناك بعض الحالات التي قد يؤدي فيها الحصول على نتيجة إيجابية (أو سلبية) خاطئة إلى عواقب وخيمة (مثل المجال الطبي)، لذا يمكنك تعديل الحدّ الأدنى ليكون مرتفعًا جدًا وطلب المزيد من المراجعات اليدوية لتلك التي لا تستوفي الحدّ الأدنى. هذا هو اختيارك كمطوِّر ويتطلّب بعض التجارب.
4. إعادة تدريب نموذج رصد التعليقات غير المرغوب فيها
في القسم السابق، حدّدت عددًا من الحالات الحدّية التي لم ينجح النموذج في التعامل معها، ولم يكن هناك خيار سوى إعادة تدريب النموذج للتعامل مع هذه الحالات. في نظام الإنتاج، يمكنك العثور على هذه التعليقات بمرور الوقت عندما يبلغ المستخدمون يدويًا عن تعليق على أنّه غير مرغوب فيه، أو عندما يدرك المشرفون الذين يراجعون التعليقات التي تم الإبلاغ عنها أنّ بعضها ليس غير مرغوب فيه فعلاً ويمكنهم وضع علامة على هذه التعليقات لإعادة التدريب. بافتراض أنّك جمعت مجموعة من البيانات الجديدة لحالات الاستخدام غير الشائعة هذه (للحصول على أفضل النتائج، يجب أن تتضمّن بعض الاختلافات في هذه الجُمل الجديدة إذا أمكن)، سنوضّح لك الآن كيفية إعادة تدريب النموذج مع أخذ حالات الاستخدام غير الشائعة هذه في الاعتبار.
ملخّص النموذج الجاهز
النموذج الجاهز الذي استخدمته هو نموذج أنشأته جهة خارجية من خلال أداة إنشاء النماذج، ويستخدم نموذج "تضمين الكلمات المتوسط" ليعمل.
بما أنّ النموذج تم إنشاؤه باستخدام Model Maker، عليك التبديل مؤقتًا إلى Python لإعادة تدريب النموذج، ثم تصدير النموذج الذي تم إنشاؤه إلى تنسيق TensorFlow.js حتى تتمكّن من استخدامه في المتصفّح. لحسن الحظ، يسهّل Model Maker استخدام نماذجهم، لذا من المفترض أن يكون من السهل جدًا اتّباع الخطوات، وسنرشدك خلال العملية، لذا لا تقلق إذا لم يسبق لك استخدام Python.
Colabs
بما أنّك لا تهتم كثيرًا في هذا الدرس التطبيقي حول الترميز بإعداد خادم Linux مع تثبيت جميع أدوات Python المختلفة، يمكنك ببساطة تنفيذ الرمز من خلال متصفح الويب باستخدام "دفتر ملاحظات Colab". يمكن ربط هذه الدفاتر بـ "نظام خلفي"، وهو ببساطة خادم يتضمّن بعض البرامج المثبّتة مسبقًا، ويمكنك من خلاله تنفيذ أي رمز برمجي داخل متصفّح الويب والاطّلاع على النتائج. هذه الميزة مفيدة جدًا لإنشاء نماذج أولية سريعة أو لاستخدامها في برامج تعليمية مثل هذه.
ما عليك سوى الانتقال إلى colab.research.google.com وستظهر لك شاشة ترحيب كما هو موضّح:

انقر الآن على الزر دفتر ملاحظات جديد في أسفل يسار النافذة المنبثقة، وسيظهر لك مستند Colab فارغ على النحو التالي:
رائع! الخطوة التالية هي ربط واجهة Colab الأمامية بخادم خلفي لتتمكّن من تنفيذ رمز Python الذي ستكتبه. يمكنك إجراء ذلك من خلال النقر على ربط في أعلى يسار الصفحة واختيار الربط بوقت التشغيل المستضاف.

بعد الربط، من المفترض أن تظهر رموز ذاكرة الوصول العشوائي (RAM) والقرص في مكانها، كما يلي:
أحسنت! يمكنك الآن البدء بكتابة الرموز في Python لإعادة تدريب نموذج Model Maker. ما عليك سوى اتباع الخطوات التالية.
الخطوة 1
في الخلية الأولى الفارغة حاليًا، انسخ الرمز أدناه. سيتم تثبيت أداة TensorFlow Lite Model Maker لك باستخدام أداة إدارة الحِزم في Python التي تُسمى "pip" (وهي تشبه npm التي قد يكون معظم قارئي هذا الدرس التطبيقي حول الترميز على دراية بها من نظام JS المتكامل):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
ومع ذلك، لن يؤدي لصق الرمز في الخلية إلى تنفيذه. بعد ذلك، مرِّر مؤشر الماوس فوق الخلية الرمادية التي لصقت فيها الرمز أعلاه، وسيظهر رمز "تشغيل" صغير على يسار الخلية كما هو موضّح أدناه:
 انقر على زر التشغيل لتنفيذ الرمز الذي تم إدخاله للتو في الخلية.
انقر على زر التشغيل لتنفيذ الرمز الذي تم إدخاله للتو في الخلية.
سيظهر لك الآن أنّه يتم تثبيت أداة Model Maker:
بعد اكتمال تنفيذ هذه الخلية كما هو موضّح، انتقِل إلى الخطوة التالية أدناه.
الخطوة 2
بعد ذلك، أضِف خلية رمز جديدة كما هو موضّح حتى تتمكّن من لصق المزيد من الرموز بعد الخلية الأولى وتنفيذها بشكل منفصل:

ستتضمّن الخلية التالية التي سيتم تنفيذها عددًا من عمليات الاستيراد التي سيحتاج الرمز البرمجي في بقية دفتر الملاحظات إلى استخدامها. انسخ ما يلي والصقه في الخلية الجديدة التي تم إنشاؤها:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
هذه أمور أساسية، حتى لو لم تكن على دراية بلغة Python. أنت بصدد استيراد بعض برامج الخدمات ووظائف Model Maker اللازمة لمصنِّف الرسائل غير المرغوب فيها. سيتحقّق هذا الأمر أيضًا مما إذا كنت تستخدم TensorFlow 2.x، وهو شرط لاستخدام Model Maker.
أخيرًا، كما فعلنا سابقًا، نفِّذ الخلية من خلال النقر على رمز "التشغيل" عند تمرير مؤشر الماوس فوق الخلية، ثم أضِف خلية رمز برمجي جديدة للخطوة التالية.
الخطوة 3
بعد ذلك، ستنزّل البيانات من خادم بعيد إلى جهازك، وتضبط المتغيّر training_data ليكون مسار الملف المحلي الذي تم تنزيله:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
يمكن لـ Model Maker تدريب النماذج من ملفات CSV بسيطة مثل الملف الذي تم تنزيله. ما عليك سوى تحديد الأعمدة التي تحتوي على النص والأعمدة التي تحتوي على التصنيفات. ستتعرّف على كيفية إجراء ذلك في الخطوة 5. يمكنك تنزيل ملف CSV مباشرةً للاطّلاع على محتواه إذا أردت ذلك.
سيلاحظ المستخدمون الحريصون أنّ اسم هذا الملف هو jm_blog_comments_extras.csv. هذا الملف هو ببساطة بيانات التدريب الأصلية التي استخدمناها لإنشاء نموذج رصد التعليقات غير المرغوب فيها الأول مدمجة مع بيانات الحالات القصوى الجديدة التي عثرت عليها، لذا فهي كلها في ملف واحد. تحتاج أيضًا إلى بيانات التدريب الأصلية المستخدَمة لتدريب النموذج بالإضافة إلى الجُمل الجديدة التي تريد التعلّم منها.
اختياري: إذا نزّلت ملف CSV هذا وتحقّقت من الأسطر القليلة الأخيرة، ستظهر لك أمثلة على حالات هامشية لم تكن تعمل بشكل صحيح من قبل. تمت إضافتها للتو إلى نهاية بيانات التدريب الحالية التي استخدمها النموذج المُعدّ مسبقًا لتدريب نفسه.
نفِّذ هذه الخلية، ثم أضِف خلية جديدة بعد الانتهاء من التنفيذ، وانتقِل إلى الخطوة 4.
الخطوة الرابعة
عند استخدام Model Maker، لن تحتاج إلى إنشاء نماذج من البداية. بشكل عام، يمكنك استخدام نماذج حالية وتخصيصها لتلبية احتياجاتك.
توفّر أداة Model Maker العديد من تضمينات النماذج المدرَّبة مسبقًا التي يمكنك استخدامها، ولكنّ أبسطها وأسرعها للبدء هي average_word_vec، وهي ما استخدمته في الدرس التطبيقي السابق حول الترميز لإنشاء موقعك الإلكتروني. إليك الرمز:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
يمكنك تنفيذ ذلك بعد لصقه في الخلية الجديدة.
فهم
num_words
المَعلمة
هذا هو عدد الكلمات التي تريد أن يستخدمها النموذج. قد تعتقد أنّ المزيد أفضل، ولكن هناك عادةً نقطة مثالية استنادًا إلى عدد مرات استخدام كل كلمة. إذا استخدمت كل كلمة في مجموعة النصوص بأكملها، قد ينتهي بك الأمر إلى محاولة النموذج تعلُّم أوزان الكلمات التي تُستخدم مرة واحدة فقط وتحقيق التوازن بينها، وهذا ليس مفيدًا جدًا. ستجد في أي مكنَز لغوي أنّ العديد من الكلمات لا تُستخدم إلا مرة واحدة أو مرتين، وبشكل عام لا يستحق استخدامها في نموذجك لأنّ تأثيرها ضئيل على المشاعر العامة. وبالتالي، يمكنك ضبط النموذج على عدد الكلمات التي تريدها باستخدام المَعلمة num_words. سيؤدي استخدام عدد أقل هنا إلى إنشاء نموذج أصغر وأسرع، ولكن قد يكون أقل دقة لأنّه يتعرّف على عدد أقل من الكلمات. سيؤدي استخدام رقم أكبر هنا إلى الحصول على نموذج أكبر حجمًا وأبطأ على الأرجح. يُعدّ العثور على النقطة المثالية أمرًا أساسيًا، ويعود إليك كمهندس تعلُّم آلي تحديد ما هو الأفضل لحالة الاستخدام.
فهم
wordvec_dim
المَعلمة
المَعلمة wordvec_dim هي عدد السمات التي تريد استخدامها لمتّجه كل كلمة. هذه السمات هي في الأساس الخصائص المختلفة (التي تنشئها خوارزمية التعلّم الآلي أثناء التدريب) التي يمكن قياس أي كلمة معيّنة بها، وسيستخدمها البرنامج لمحاولة ربط الكلمات المتشابهة بأفضل طريقة ممكنة.
على سبيل المثال، إذا كانت لديك سمة تحدّد مدى "طبية" كلمة معيّنة، قد تحصل كلمة مثل "حبوب" على درجة عالية في هذه السمة، ويتم ربطها بكلمات أخرى ذات درجة عالية مثل "أشعة سينية"، ولكن ستحصل كلمة "قطة" على درجة منخفضة في هذه السمة. قد تبيّن أنّ "البُعد الطبي" مفيد في تحديد المحتوى غير المرغوب فيه عند دمجه مع أبعاد محتملة أخرى قد يقرّر استخدامها وتكون مهمة.
في حالة الكلمات التي تحقّق نتائج عالية في "البُعد الطبي"، قد يكون من المفيد استخدام بُعد ثانٍ يربط الكلمات بجسم الإنسان. قد تحصل كلمات مثل "ساق" و"ذراع" و"رقبة" على درجة عالية هنا، بالإضافة إلى درجة عالية إلى حد ما في البُعد الطبي أيضًا.
يمكن للنموذج استخدام هذه السمات لتحديد الكلمات التي يُرجّح ارتباطها بالمحتوى غير المرغوب فيه. ربما تحتوي الرسائل الإلكترونية غير المرغوب فيها على كلمات طبية وأخرى متعلقة بأجزاء من جسم الإنسان.
تشير القاعدة الأساسية التي تم تحديدها من خلال البحث إلى أنّ الجذر الرابع لعدد الكلمات مناسب لهذه المَعلَمة. لذا، إذا كنت أستخدم 2, 000 كلمة، فإنّ نقطة البداية الجيدة لذلك هي 7 سمات. إذا غيّرت عدد الكلمات المستخدَمة، يمكنك أيضًا تغيير هذا الإعداد.
فهم
seq_len
المَعلمة
تكون النماذج بشكل عام صارمة جدًا عندما يتعلق الأمر بقيم الإدخال. بالنسبة إلى نموذج اللغة، يعني ذلك أنّ نموذج اللغة يمكنه تصنيف الجُمل ذات الطول الثابت والمحدّد. يتم تحديد ذلك من خلال المَعلمة seq_len، حيث يشير ذلك إلى "طول التسلسل". عند تحويل الكلمات إلى أرقام (أو رموز مميزة)، تصبح الجملة سلسلة من هذه الرموز المميزة. وبالتالي، سيتم تدريب النموذج (في هذه الحالة) على تصنيف الجُمل التي تحتوي على 20 رمزًا مميزًا والتعرّف عليها. إذا كانت الجملة أطول من ذلك، سيتم اقتطاعها. إذا كان طولها أقصر، سيتم إضافة مساحة متروكة إليها، تمامًا كما في أول درس تطبيقي حول الترميز في هذه السلسلة.
الخطوة 5: تحميل بيانات التدريب
سبق لك تنزيل ملف CSV. حان الوقت الآن لاستخدام أداة تحميل البيانات لتحويل هذا إلى بيانات تدريب يمكن للنموذج التعرّف عليها.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
إذا فتحت ملف CSV في محرر، ستلاحظ أنّ كل سطر يحتوي على قيمتين فقط، ويتم وصف هاتين القيمتين بنص في السطر الأول من الملف. ويُعتبر كل إدخال عادةً "عمودًا". سيظهر لك أنّ واصف العمود الأول هو commenttext، وأنّ الإدخال الأول في كل سطر هو نص التعليق.
وبالمثل، فإنّ واصف العمود الثاني هو spam، وستلاحظ أنّ الإدخال الثاني في كل سطر هو TRUE أو FALSE للإشارة إلى ما إذا كان هذا النص يُعدّ تعليقات غير مرغوب فيها أم لا. تضبط الخصائص الأخرى مواصفات النموذج التي أنشأتها في الخطوة 4، بالإضافة إلى محدِّد، وهو الفاصلة في هذه الحالة لأنّ الملف مفصول بفاصلة. يمكنك أيضًا ضبط مَعلمة ترتيب عشوائي لإعادة ترتيب بيانات التدريب بشكلٍ عشوائي، وذلك لتوزيع العناصر التي ربما كانت متشابهة أو تم جمعها معًا بشكلٍ عشوائي في جميع أنحاء مجموعة البيانات.
ستستخدم بعد ذلك data.split() لتقسيم البيانات إلى بيانات تدريب واختبار. يشير الرقم 0 .9 إلى أنّه سيتم استخدام% 90 من مجموعة البيانات للتدريب، وسيتم استخدام الباقي للاختبار.
الخطوة 6: إنشاء النموذج
أضِف خلية أخرى سنضيف فيها رمزًا برمجيًا لإنشاء النموذج:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
يؤدي ذلك إلى إنشاء نموذج مصنِّف للنصوص باستخدام "أداة إنشاء النماذج"، وتحديد بيانات التدريب التي تريد استخدامها (التي تم تحديدها في الخطوة 4)، ومواصفات النموذج (التي تم إعدادها أيضًا في الخطوة 4)، وعدد الفترات، وفي هذه الحالة 50 فترة.
المبدأ الأساسي لتعلُّم الآلة هو أنّه شكل من أشكال مطابقة الأنماط. في البداية، سيتم تحميل الأوزان المُدرَّبة مسبقًا للكلمات، ومحاولة تجميعها معًا باستخدام "توقّع" الكلمات التي تشير عند تجميعها إلى محتوى غير مرغوب فيه، والكلمات التي لا تشير إلى ذلك. في المرة الأولى، من المرجّح أن تكون النسبة قريبة من 50:50، لأنّ النموذج يكون في بداية عمله كما هو موضّح أدناه:

بعد ذلك، سيقيس النتائج ويغيّر أوزان النموذج لتعديل توقّعه، ثم سيحاول مرة أخرى. هذه حقبة. لذا، من خلال تحديد epochs=50، سيتم تكرار هذه "الحلقة" 50 مرة كما هو موضّح:

لذلك، بحلول الوقت الذي تصل فيه إلى الحقبة الخمسين، سيُظهر النموذج مستوى دقة أعلى بكثير. في هذه الحالة، تبلغ النسبة 99.1%.
الخطوة 7: تصدير النموذج
بعد الانتهاء من التدريب، يمكنك تصدير النموذج. يدرّب TensorFlow نموذجًا بتنسيقه الخاص، ويجب تحويله إلى تنسيق TensorFlow.js لاستخدامه على صفحة ويب. ما عليك سوى لصق ما يلي في خلية جديدة وتنفيذه:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
بعد تنفيذ هذا الرمز، إذا نقرت على رمز المجلد الصغير على يمين Colab، يمكنك الانتقال إلى المجلد الذي تم التصدير إليه أعلاه (في الدليل الجذر - قد تحتاج إلى الانتقال إلى مستوى أعلى) والعثور على حزمة zip الخاصة بالملفات التي تم تصديرها والمضمّنة في ModelFiles.zip.
نزِّل ملف zip هذا على جهاز الكمبيوتر الآن لأنّك ستستخدم هذه الملفات كما في الدرس العملي الأول:

رائع! انتهى الجزء المتعلّق بلغة Python، ويمكنك الآن الرجوع إلى JavaScript التي تعرفها وتحبّها. أخيرًا!
5- عرض نموذج تعلُّم الآلة الجديد
أنت الآن على وشك الانتهاء من تحميل النموذج. قبل أن تتمكّن من ذلك، عليك تحميل ملفات النموذج الجديد التي تم تنزيلها سابقًا في الدرس التطبيقي حول الترميز حتى تتم استضافتها واستخدامها في الرمز البرمجي.
أولاً، إذا لم يسبق لك إجراء ذلك، عليك فك ضغط ملفات النموذج التي نزّلتها للتو من ورقة ملاحظات Model Maker Colab التي نفّذتها للتو. من المفترض أن تظهر لك الملفات التالية ضمن مجلداته المختلفة:

ماذا لديك هنا؟
-
model.json: هذا أحد الملفات التي يتكوّن منها نموذج TensorFlow.js المدرَّب. ستشير إلى هذا الملف المحدّد في رمز JavaScript. group1-shard1of1.bin: هذا ملف ثنائي يحتوي على معظم البيانات المحفوظة لنموذج TensorFlow.js الذي تم تصديره، ويجب استضافته في مكان ما على الخادم لتنزيله في الدليل نفسه كما هو موضح فيmodel.jsonأعلاه.-
vocab: هذا الملف الغريب الذي لا يحتوي على أي امتداد هو ملف من Model Maker يوضّح لنا كيفية ترميز الكلمات في الجمل لكي يفهم النموذج كيفية استخدامها. سنتناول هذا الموضوع بمزيد من التفصيل في القسم التالي. labels.txt: يحتوي هذا الملف ببساطة على أسماء الفئات الناتجة التي سيتوقّعها النموذج. بالنسبة إلى هذا النموذج، إذا فتحت هذا الملف في محرّر النصوص، سيحتوي ببساطة على القيمتَين "false" و "true" المدرجتَين للإشارة إلى "ليس محتوى غير مرغوب فيه" أو "محتوى غير مرغوب فيه" كنتيجة للتوقّع.
استضافة ملفات نموذج TensorFlow.js
ضَع أولاً ملفَي model.json و*.bin اللذين تم إنشاؤهما على خادم ويب لتتمكّن من الوصول إليهما من خلال صفحة الويب.
حذف ملفات النماذج الحالية
بما أنّك ستستند إلى النتيجة النهائية للدرس التطبيقي الأول في هذه السلسلة، عليك أولاً حذف ملفات النموذج الحالية التي تم تحميلها. إذا كنت تستخدم Glitch.com، ما عليك سوى التحقّق من لوحة الملفات على يمين الشاشة بحثًا عن model.json وgroup1-shard1of1.bin، ثم النقر على القائمة المنسدلة التي تضمّ 3 نقاط لكل ملف واختيار حذف كما هو موضّح:

تحميل ملفات جديدة إلى Glitch
رائع! حمِّل الآن الصور الجديدة:
- افتح مجلد assets (مواد العرض) في اللوحة اليمنى من مشروعك على Glitch واحذف أي مواد عرض قديمة تم تحميلها إذا كانت تحمل الأسماء نفسها.
- انقر على تحميل مادة عرض واختَر
group1-shard1of1.binلتحميلها في هذا المجلد. يُفترض أن يظهر الآن على النحو التالي بعد تحميله:

- رائع! كرِّر الخطوات نفسها مع ملف model.json أيضًا، وبالتالي يجب أن يتضمّن مجلد "الأصول" ملفَين كما يلي:

- إذا نقرت على ملف
group1-shard1of1.binالذي حمّلته للتو، سيصبح بإمكانك نسخ عنوان URL الخاص بموقعه. انسخ هذا المسار الآن كما هو موضّح:

- الآن في أسفل يسار الشاشة، انقر على الأدوات > الطرفية. انتظِر إلى أن يتم تحميل نافذة المحطة الطرفية.
- بعد التحميل، اكتب ما يلي ثم اضغط على Enter لتغيير الدليل إلى المجلد
www:
terminal:
cd www
- بعد ذلك، استخدِم
wgetلتنزيل الملفَين اللذين تم تحميلهما للتو من خلال استبدال عناوين URL أدناه بعناوين URL التي أنشأتها للملفات في مجلد "الأصول" على Glitch (راجِع مجلد "الأصول" للاطّلاع على عنوان URL المخصّص لكل ملف).
يُرجى الانتباه إلى المسافة بين عنوانَي URL وإلى أنّ عناوين URL التي عليك استخدامها ستكون مختلفة عن تلك المعروضة ولكنّها ستكون متشابهة:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
ممتاز! لقد أنشأت الآن نسخة من الملفات التي تم تحميلها إلى المجلد www.
ومع ذلك، سيتم تنزيلها حاليًا بأسماء غريبة. إذا كتبت ls في الوحدة الطرفية وضغطت على مفتاح Enter، سيظهر لك ما يلي:

- استخدِم الأمر
mvلإعادة تسمية الملفات. اكتب ما يلي في وحدة التحكّم واضغط على Enter بعد كل سطر:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- أخيرًا، أعِد تحميل مشروع Glitch من خلال كتابة
refreshفي نافذة المحطة الطرفية والضغط على مفتاح Enter:
terminal:
refresh
بعد إعادة التحميل، من المفترض أن يظهر لك الرمزان model.json وgroup1-shard1of1.bin في المجلد www بواجهة المستخدم:

رائع! الخطوة الأخيرة هي تعديل ملف dictionary.js.
- حوِّل ملف المفردات الذي تم تنزيله حديثًا إلى تنسيق JS الصحيح إما يدويًا باستخدام محرِّر النصوص أو باستخدام هذه الأداة، واحفظ الناتج في
dictionary.jsضمن المجلدwww. إذا كان لديك ملفdictionary.js، يمكنك ببساطة نسخ المحتوى الجديد ولصقه فوقه وحفظ الملف.
رائع! لقد عدّلت بنجاح جميع الملفات التي تم تغييرها، وإذا حاولت الآن استخدام الموقع الإلكتروني، ستلاحظ كيف يمكن للنموذج الذي تمّت إعادة تدريبه أن يفسّر الحالات الحدّية التي تمّ اكتشافها والاستفادة منها كما هو موضّح:

كما تلاحظ، تم تصنيف أول 6 رسائل بشكل صحيح على أنّها ليست رسائل غير مرغوب فيها، وتم تحديد جميع الرسائل الست الثانية على أنّها رسائل غير مرغوب فيها. ممتاز.
لنجرّب بعض الاختلافات أيضًا لمعرفة ما إذا كان قد تم تعميمها بشكل جيد. في الأصل، كانت هناك جملة غير صحيحة، مثل:
"يا إلهي، لقد ارتفع سعر سهم GOOG بشكل كبير! احصل على العرض قبل فوات الأوان!"
تم الآن تصنيف هذا المحتوى بشكل صحيح على أنّه محتوى غير مرغوب فيه، ولكن ماذا يحدث إذا غيّرته إلى:
"إذًا، ارتفعت قيمة سهم XYZ للتو. اشترِ بعضًا منها قبل فوات الأوان!"
في هذه الحالة، ستحصل على توقّع بنسبة% 98 بأنّ الرسالة غير مرغوب فيها، وهذا التوقّع صحيح على الرغم من أنّك غيّرت رمز السهم والصيغة قليلاً.
بالطبع، إذا حاولت اختراق هذا النموذج الجديد، ستتمكّن من ذلك، وسيعتمد الأمر على جمع المزيد من بيانات التدريب للحصول على أفضل فرصة لالتقاط المزيد من الاختلافات الفريدة للحالات الشائعة التي من المحتمل أن تواجهها على الإنترنت. في درس تطبيقي حول الترميز مستقبلي، سنوضّح لك كيفية تحسين نموذجك باستمرار باستخدام البيانات المباشرة عند الإبلاغ عنها.
6. تهانينا!
تهانينا، لقد تمكّنت من إعادة تدريب نموذج حالي لتعلُّم الآلة من أجل تعديله ليعمل مع الحالات الحدّية التي عثرت عليها، ونشرت هذه التغييرات على المتصفّح باستخدام TensorFlow.js لتطبيقها في العالم الحقيقي.
ملخّص
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على ما يلي:
- اكتشاف حالات قصوى لم تكن تعمل عند استخدام نموذج التعليقات غير المرغوب فيها الجاهز
- أعدنا تدريب نموذج Model Maker ليأخذ في الاعتبار الحالات القصوى التي اكتشفتها
- تصدير النموذج المدرَّب الجديد إلى تنسيق TensorFlow.js
- تعديل تطبيق الويب لاستخدام الملفات الجديدة
ما هي الخطوات التالية؟
إذًا، هذا التحديث يعمل بشكل رائع، ولكن كما هو الحال مع أي تطبيق ويب، ستحدث تغييرات بمرور الوقت. سيكون من الأفضل بكثير أن يحسّن التطبيق نفسه باستمرار بمرور الوقت بدلاً من أن نضطر إلى إجراء ذلك يدويًا في كل مرة. هل يمكنك التفكير في كيفية أتمتة هذه الخطوات لإعادة تدريب نموذج تلقائيًا بعد أن تتلقّى، مثلاً، 100 تعليق جديد تم تصنيفه بشكل غير صحيح؟ إذا كنت مهندس ويب عاديًا، يمكنك على الأرجح معرفة كيفية إنشاء مسار لتنفيذ ذلك تلقائيًا. إذا لم يكن لديك حساب، لا تقلق، ترقَّب إصدار codelab التالي في السلسلة الذي سيوضّح لك كيفية إنشاء حساب.
مشاركة المحتوى الذي تصنعه معنا
يمكنك بسهولة توسيع نطاق استخدام ما صنعته اليوم ليشمل حالات إبداعية أخرى أيضًا، ونشجّعك على التفكير بأسلوب جديد ومواصلة الابتكار.
لا تنسَ الإشارة إلينا على وسائل التواصل الاجتماعي باستخدام الهاشتاغ #MadeWithTFJS للحصول على فرصة عرض مشروعك على مدونة TensorFlow أو حتى في الفعاليات المستقبلية. نتشوّق لرؤية ابتكاراتك.
المزيد من الدروس التطبيقية حول الترميز في TensorFlow.js للتعمّق أكثر
- استخدام ميزة "استضافة Firebase" لتفعيل نموذج TensorFlow.js واستضافته على نطاق واسع
- إنشاء كاميرا ويب ذكية باستخدام نموذج جاهز لرصد الأهداف باستخدام TensorFlow.js
مواقع إلكترونية ننصحك بالاطّلاع عليها
- الموقع الإلكتروني الرسمي لـ TensorFlow.js
- نماذج TensorFlow.js الجاهزة
- TensorFlow.js API
- TensorFlow.js Show & Tell: استلهِم الأفكار واطّلِع على ما أنشأه الآخرون.