
1. Başlamadan önce
Bu codelab, TensorFlow.js kullanarak spam yorum tespiti için bu serideki önceki codelab'in nihai sonucunu temel alacak şekilde tasarlanmıştır.
Son codelab'de, kurgusal bir video blogu için tam işlevli bir web sayfası oluşturmuştunuz. Tarayıcıda TensorFlow.js tarafından desteklenen, önceden eğitilmiş bir yorum spam yakalama modeli kullanarak yorumları depolama için sunucuya veya diğer bağlı istemcilere gönderilmeden önce spam olarak filtreleyebiliyordunuz.
Bu codelab'in nihai sonucu aşağıda gösterilmiştir:

Bu yöntem çok iyi çalışsa da algılayamadığı uç durumlar vardır. Modeli, ele alamadığı durumları hesaba katacak şekilde yeniden eğitebilirsiniz.
Bu codelab'de doğal dil işlemeyi (bilgisayar kullanarak insan dilini anlama sanatı) kullanmaya odaklanılır ve oluşturduğunuz mevcut bir web uygulamasını nasıl değiştireceğiniz gösterilir (codelab'leri sırayla yapmanız şiddetle tavsiye edilir). Bu sayede, günümüzde giderek artan sayıda popüler web uygulamasından birinde çalışırken birçok web geliştiricinin kesinlikle karşılaşacağı yorum spam'i sorununu çözebilirsiniz.
Bu codelab'de, makine öğrenimi modelinizi yeniden eğiterek bir adım daha ileri gideceksiniz. Bu sayede, modelin güncel kalmasını ve bu tür değişiklikleri hesaba katmasını sağlayarak spam mesaj içeriklerinde zaman içinde gelişebilecek değişiklikleri hesaba katabilirsiniz.
Ön koşullar
- Bu serideki ilk codelab'i tamamlamış olmanız gerekir.
- HTML, CSS ve JavaScript gibi web teknolojileri hakkında temel bilgi
Ne oluşturacaksınız?
Daha önce oluşturulan web sitesini, gerçek zamanlı yorum bölümü olan kurgusal bir video blog için yeniden kullanacak ve TensorFlow.js kullanarak spam yakalama modelinin özel olarak eğitilmiş bir sürümünü yükleyecek şekilde yükselteceksiniz. Böylece, daha önce başarısız olacağı uç durumlarda daha iyi performans gösterecek. Elbette web geliştiriciler ve mühendisler olarak bu varsayımsal kullanıcı deneyimini, günlük rollerinizde üzerinde çalıştığınız herhangi bir web sitesinde yeniden kullanmak üzere değiştirebilir ve çözümü herhangi bir müşteri kullanım alanına uyacak şekilde uyarlayabilirsiniz. Örneğin, bu bir blog, forum veya Drupal gibi bir içerik yönetim sistemi olabilir.
Haydi, hacklemeye başlayalım...
Neler öğreneceksiniz?
Bu kurstan sonra:
- Önceden eğitilmiş modelin başarısız olduğu uç durumları belirleme
- Model Oluşturucu kullanılarak oluşturulan spam sınıflandırma modelini yeniden eğitme
- Bu Python tabanlı modeli tarayıcılarda kullanılmak üzere TensorFlow.js biçimine aktarın.
- Barındırılan modeli ve sözlüğünü yeni eğitilen modelle güncelleyin ve sonuçları kontrol edin.
Bu laboratuvarda HTML5, CSS ve JavaScript hakkında bilgi sahibi olduğunuz varsayılır. Ayrıca, Model Maker kullanılarak oluşturulan modeli yeniden eğitmek için "co lab" not defteri aracılığıyla bazı Python kodlarını çalıştıracaksınız. Ancak bunu yapmak için Python hakkında bilgi sahibi olmanız gerekmez.
2. Kod yazmaya hazırlanma
Web uygulamasını barındırmak ve değiştirmek için yine Glitch.com'u kullanacaksınız. Ön koşul codelab'ini henüz tamamlamadıysanız başlangıç noktası olarak son sonucu buradan klonlayabilirsiniz. Kodun işleyişiyle ilgili sorularınız varsa devam etmeden önce bu çalışan web uygulamasının nasıl oluşturulacağını açıklayan önceki codelab'i tamamlamanız önemle tavsiye edilir.
Glitch'te, remix this (Bunu remiksle) düğmesini tıklayarak çatallayın ve düzenleyebileceğiniz yeni bir dosya grubu oluşturun.
3. Önceki çözümdeki uç durumları keşfetme
Klonladığınız web sitesini açıp yorum yazmaya çalıştığınızda, çoğu zaman beklendiği gibi çalıştığını, spam gibi görünen yorumları engellediğini ve meşru yanıtları kabul ettiğini görürsünüz.
Ancak yaratıcı davranıp modeli bozacak şekilde ifadeler kullanmaya çalışırsanız bir noktada başarılı olabilirsiniz. Deneme yanılma yöntemiyle, aşağıda gösterilenlere benzer örnekleri manuel olarak oluşturabilirsiniz. Bunları mevcut web uygulamasına yapıştırmayı deneyin, konsolu kontrol edin ve yorumun spam olup olmadığına dair geri dönen olasılıklara bakın:
Sorunsuz bir şekilde yayınlanan meşru yorumlar (gerçek negatifler):
- "Vay canına, bu videoya bayıldım. Harika bir iş çıkarmışsın." Spam Olasılığı: %47,91854
- "Bu demoları çok beğendim. Başka ayrıntı var mı?" Spam Olasılığı: %47,15898
- "Daha fazla bilgi edinmek için hangi web sitesine gidebilirim?" Spam Olasılığı: %15,32495
Bu harika bir sonuç. Yukarıdakilerin tümünün olasılığı oldukça düşük ve işlem yapılmadan önce varsayılan minimum olasılık olan% 75'i (önceki codelab'deki script.js kodunda tanımlanmıştır) başarıyla geçiyor.SPAM_THRESHOLD
Şimdi de spam olmamalarına rağmen spam olarak işaretlenen, biraz daha sert yorumlar yazmayı deneyelim...
Meşru yorumların spam olarak işaretlenmesi (yanlış pozitifler):
- "Can someone link the website for the mask he is wearing?" (Giydiği maskenin web sitesini paylaşabilir misiniz?) Spam Olasılığı: %98,46466
- "Bu şarkıyı Spotify'da satın alabilir miyim? Lütfen biri bana bilgi versin." Spam Olasılığı: %94,40953
- "TensorFlow.js'yi indirme hakkında ayrıntılı bilgi için benimle iletişime geçebilir misiniz?" Spam Olasılığı: %83,20084
Olamaz! Bu meşru yorumlar, izin verilmesi gerekirken spam olarak işaretleniyor. Bu sorunu nasıl düzeltebilirsiniz?
Basit bir seçenek, SPAM_THRESHOLD değerini% 98,5'in üzerine çıkarmaktır. Bu durumda, yanlış sınıflandırılmış yorumlar yayınlanır. Bunu göz önünde bulundurarak, aşağıdaki diğer olası sonuçlarla devam edelim...
Spam olarak işaretlenen spam yorumlar (gerçek pozitifler):
- "Bu güzel ama web sitemdeki daha iyi olan indirme bağlantılarına göz atın!" Spam Olasılığı: %99,77873
- "I know some people who can get you some medicines just see my pr0file for details" (Bazı kişilerin size ilaç getirebileceğini biliyorum. Ayrıntılar için profilime bakın.) Spam olma olasılığı: %98,46955
- "Daha da iyi olan daha da fazla harika video indirmek için profilime göz atın: http://example.com" Spam Olma İhtimali: %96,26383
Tamam, bu durum orijinal% 75 eşiğimizle beklendiği gibi çalışıyor ancak önceki adımda SPAM_THRESHOLD değerini% 98,5'in üzerinde olacak şekilde değiştirdiğiniz için buradaki 2 örnek geçirilmiş olur.Bu nedenle eşik çok yüksek olabilir. Belki% 96 daha iyidir? Ancak bunu yaparsanız önceki bölümdeki yorumlardan biri (yanlış pozitifler), %98,46466 oranında değerlendirildiği için meşru olmasına rağmen spam olarak işaretlenir.
Bu durumda, tüm bu gerçek spam yorumları yakalamak ve yukarıdaki hatalar için yeniden eğitim vermek muhtemelen en iyisidir. Eşiği% 96 olarak ayarladığınızda tüm doğru pozitifler yakalanmaya devam eder ve yukarıdaki yanlış pozitiflerden 2'si ortadan kaldırılır. Tek bir sayıyı değiştirmek için çok da kötü değil.
Devam edelim...
Yayınlanmasına izin verilen spam yorumlar (yanlış negatifler):
- "Daha da iyi olan daha da fazla harika video indirmek için profilime göz atın!" Spam Olasılığı: %7,54926
- "Spor salonu eğitim sınıflarımızda indirimden yararlanmak için profile göz atın!" Spam Olasılığı: %17,49849
- "omg GOOG stock just shot right up! Çok geç olmadan alın." Spam Olasılığı: %20,42894
Bu yorumlar için SPAM_THRESHOLD değerini daha da değiştirerek yapabileceğiniz bir şey yoktur. Spam eşiğinin% 96'dan% 9'a düşürülmesi, gerçek yorumların spam olarak işaretlenmesine neden olacaktır. Bunlardan biri, meşru olmasına rağmen% 58 puan almıştır. Bu tür yorumlarla başa çıkmanın tek yolu, modeli eğitim verilerine bu tür uç durumlar dahil edilerek yeniden eğitmek ve böylece modelin, spam olup olmadığına dair dünya görüşünü ayarlamayı öğrenmesini sağlamaktır.
Şu anda kalan tek seçenek modeli yeniden eğitmek olsa da, performansı artırmak için bir öğeye ne zaman spam diyeceğinize karar verirken eşiği nasıl hassaslaştırabileceğinizi de gördünüz. İnsanlar için% 75 oldukça yüksek bir oran olsa da bu modelde örnek girişlerle daha etkili olmak için oranı% 81,5'e yakın bir değere yükseltmeniz gerekiyordu.
Farklı modellerde iyi sonuç veren tek bir sihirli değer yoktur. Bu eşik değer, iyi sonuç veren değerleri belirlemek için gerçek dünya verileriyle denemeler yapıldıktan sonra model bazında ayarlanmalıdır.
Yanlış pozitif (veya negatif) sonuçların ciddi sonuçlara yol açabileceği bazı durumlar (ör.tıp sektöründe) olabilir. Bu nedenle, eşiğinizi çok yüksek olacak şekilde ayarlayabilir ve eşiği karşılamayanlar için daha fazla manuel inceleme isteyebilirsiniz. Bu, geliştirici olarak sizin seçiminizdir ve biraz deneme yapmanız gerekir.
4. Spam yorum tespit modelini yeniden eğitme
Önceki bölümde, modelin yalnızca bu durumları hesaba katmak için yeniden eğitilmesi gereken bir dizi uç durum belirlediniz. Üretim sisteminde, zaman içinde bu tür yorumlarla karşılaşabilirsiniz. Bunun nedeni, kullanıcıların spam olarak işaretlediği yorumların manuel olarak filtreden geçirilmesi veya işaretlenen yorumları inceleyen moderatörlerin, bazı yorumların aslında spam olmadığını fark edip bu yorumları yeniden eğitme için işaretlemesidir. Bu uç durumlar için bir dizi yeni veri topladığınızı varsayarsak (en iyi sonuçlar için mümkünse bu yeni cümlelerin bazı varyasyonlarını kullanmanız gerekir) şimdi bu uç durumları göz önünde bulundurarak modeli nasıl yeniden eğiteceğinizi göstereceğiz.
Hazır model özeti
Kullandığınız hazır model, çalışmak için "ortalama kelime yerleştirme" modelini kullanan ve Model Maker aracılığıyla üçüncü tarafça oluşturulmuş bir modeldir.
Model, Model Maker ile oluşturulduğu için modeli yeniden eğitmek üzere kısa süreliğine Python'a geçmeniz ve ardından oluşturulan modeli tarayıcıda kullanabilmek için TensorFlow.js biçiminde dışa aktarmanız gerekir. Neyse ki Model Maker, modellerini kullanmayı çok kolay hale getiriyor. Bu nedenle, bu adımları takip etmek oldukça kolay olacak. Süreç boyunca size rehberlik edeceğiz. Daha önce Python kullanmadıysanız endişelenmeyin.
Colab'ler
Bu codelab'de çeşitli Python yardımcı programlarının yüklü olduğu bir Linux sunucusu oluşturmakla çok fazla ilgilenmediğiniz için kodu web tarayıcısı üzerinden "Colab not defteri" kullanarak yürütebilirsiniz. Bu not defterleri, "arka uç" olarak adlandırılan bir sunucuya bağlanabilir. Arka uç, önceden yüklenmiş bazı öğeler içeren ve web tarayıcısında rastgele kod yürütüp sonuçları görebileceğiniz bir sunucudur. Bu özellik, hızlı prototip oluşturma veya bu gibi eğitimlerde kullanma açısından çok faydalıdır.
colab.research.google.com adresine gittiğinizde aşağıdaki gibi bir karşılama ekranı görürsünüz:

Şimdi pop-up pencerenin sağ alt kısmındaki New Notebook (Yeni Not Defteri) düğmesini tıklayın. Aşağıdaki gibi boş bir Colab not defteri görmeniz gerekir:

Mükemmel! Bir sonraki adım, yazacağınız Python kodunu çalıştırabilmeniz için ön uç Colab'ı bir arka uç sunucusuna bağlamaktır. Bunu yapmak için sağ üstte Bağlan'ı tıklayın ve Barındırılan çalışma zamanına bağlan'ı seçin.
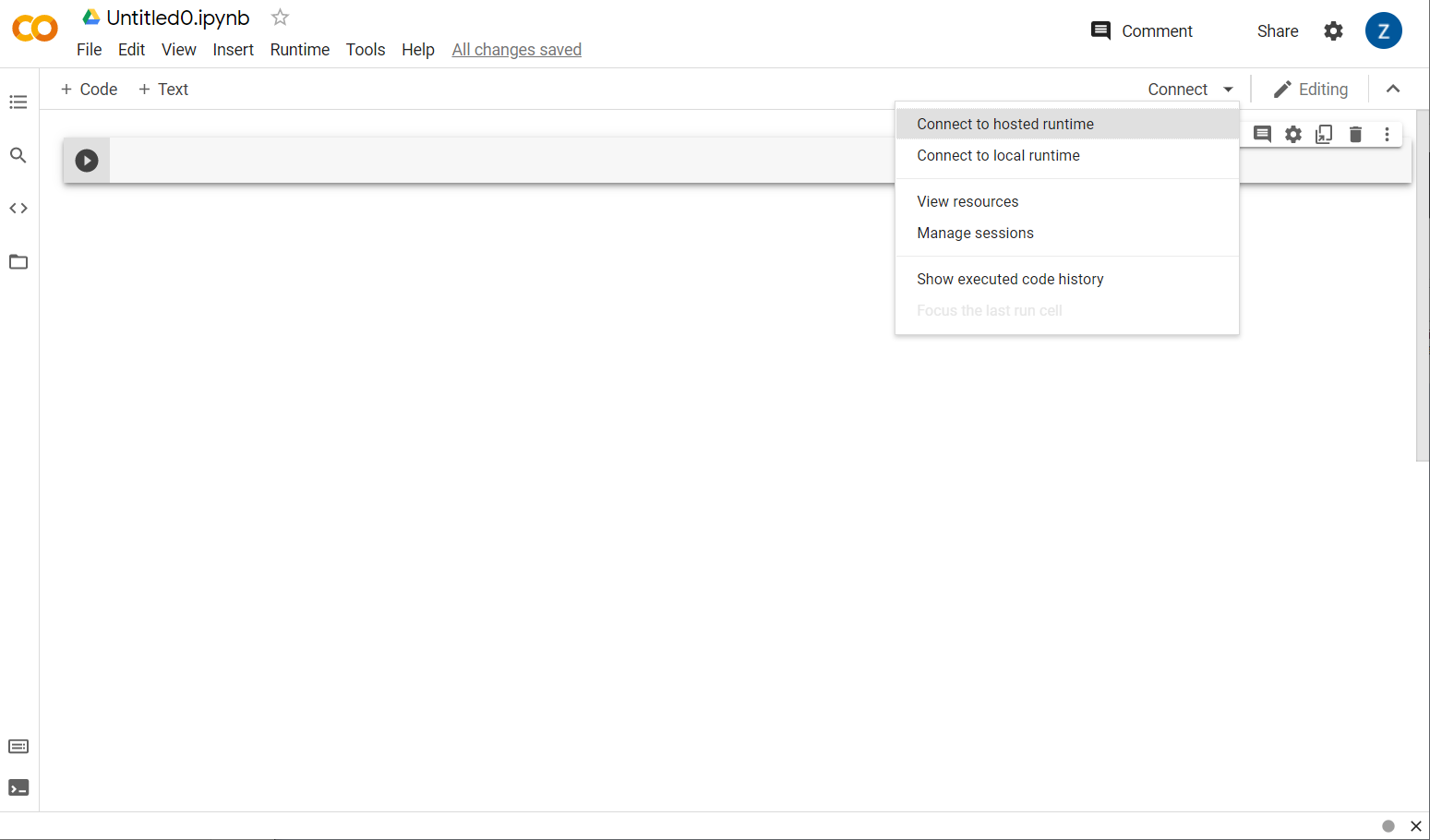
Bağlantı oluşturulduktan sonra, RAM ve Disk simgelerinin aşağıdaki gibi göründüğünü görürsünüz:

Tebrikler! Artık Model Maker modelini yeniden eğitmek için Python'da kod yazmaya başlayabilirsiniz. Aşağıdaki adımları izlemeniz yeterlidir.
1. adım
Şu anda boş olan ilk hücreye aşağıdaki kodu kopyalayın. Bu komut, "pip" adlı Python paket yöneticisini kullanarak TensorFlow Lite Model Maker'ı sizin için yükler (bu, bu codelab'i okuyanların çoğunun JS ekosisteminden daha aşina olabileceği npm'ye benzer):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Ancak kodu hücreye yapıştırmak kodu yürütmez. Ardından, fare imlecinizi yukarıdaki kodu yapıştırdığınız gri hücrenin üzerine getirin. Hücrenin solunda, aşağıda vurgulandığı gibi küçük bir "oynat" simgesi görünür:
 Hücreye yeni yazılan kodu çalıştırmak için oynat düğmesini tıklayın.
Hücreye yeni yazılan kodu çalıştırmak için oynat düğmesini tıklayın.
Model Oluşturucu'nun yüklendiğini görürsünüz:
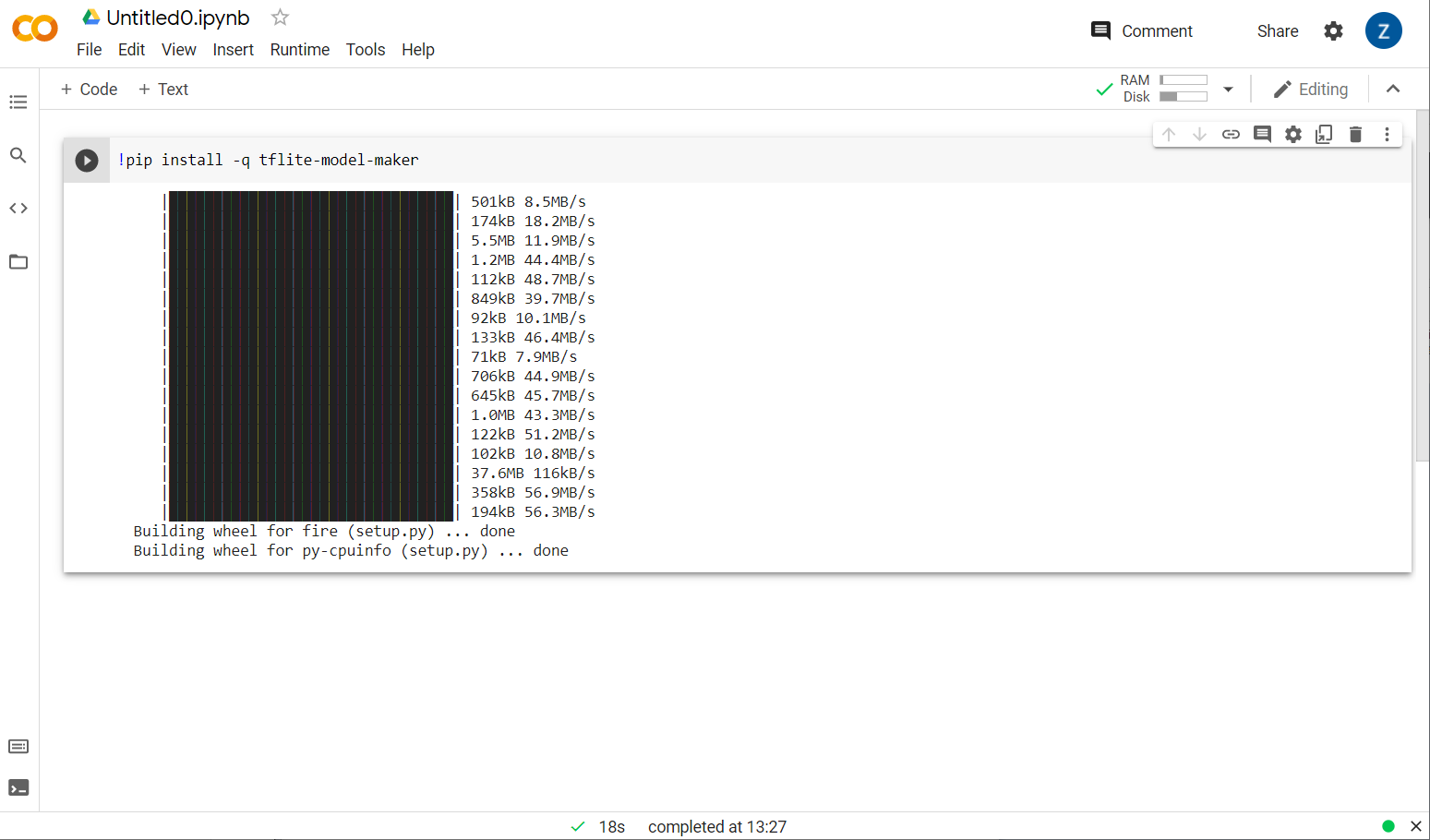
Bu hücrenin yürütülmesi gösterildiği gibi tamamlandıktan sonra aşağıdaki sonraki adıma geçin.
2. Adım
Ardından, ilk hücreden sonra biraz daha kod yapıştırıp ayrı ayrı çalıştırabilmek için gösterildiği gibi yeni bir kod hücresi ekleyin:
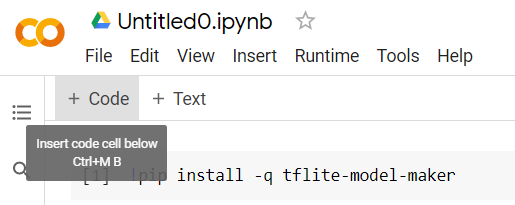
Çalıştırılacak bir sonraki hücrede, not defterinin geri kalanındaki kodun kullanması gereken bir dizi içe aktarma işlemi bulunur. Aşağıdaki kodu kopyalayıp oluşturulan yeni hücreye yapıştırın:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Python'a aşina olmasanız bile oldukça standart bir işlemdir. Yalnızca bazı yardımcı programları ve spam sınıflandırıcı için gereken Model Oluşturucu işlevlerini içe aktarıyorsunuz. Bu işlem, Model Maker'ı kullanmak için gerekli olan TensorFlow 2.x'in çalıştırılıp çalıştırılmadığını da kontrol eder.
Son olarak, hücrenin üzerine geldiğinizde "oynat" simgesine basarak hücreyi çalıştırın ve bir sonraki adım için yeni bir kod hücresi ekleyin.
3. adım
Ardından, verileri uzak bir sunucudan cihazınıza indirir ve training_data değişkenini indirilen yerel dosyanın yolu olarak ayarlarsınız:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Oluşturucu, indirilen dosya gibi basit CSV dosyalarından modelleri eğitebilir. Yalnızca hangi sütunların metni, hangi sütunların etiketleri içerdiğini belirtmeniz gerekir. Bunu nasıl yapacağınızı 5. adımda öğreneceksiniz. İsterseniz CSV dosyasını doğrudan indirerek içeriğini görebilirsiniz.
Bu dosyayı dikkatli bir şekilde incelediğinizde dosyanın adının jm_blog_comments_extras.csv olduğunu fark edeceksiniz. Bu dosya, ilk spam yorum modelini oluşturmak için kullandığımız orijinal eğitim verilerinin, keşfettiğiniz yeni uç durum verileriyle birleştirilmiş halidir. Modeli eğitmek için kullanılan orijinal eğitim verilerinin yanı sıra öğrenmek istediğiniz yeni cümlelere de ihtiyacınız vardır.
İsteğe bağlı: Bu CSV dosyasını indirip son birkaç satırı kontrol ederseniz daha önce doğru çalışmayan uç durumlarla ilgili örnekleri görürsünüz. Bu veriler, hazır modelin kendini eğitmek için kullandığı mevcut eğitim verilerinin sonuna eklenir.
Bu hücreyi çalıştırın. Çalıştırma işlemi tamamlandıktan sonra yeni bir hücre ekleyin ve 4. adıma geçin.
4. Adım
Model Oluşturucu'yu kullanırken modelleri sıfırdan oluşturmazsınız. Genellikle, ihtiyaçlarınıza göre özelleştireceğiniz mevcut modelleri kullanırsınız.
Model Maker, kullanabileceğiniz çeşitli önceden öğrenilmiş model yerleştirmeleri sunar. Ancak başlamak için en basit ve en hızlı olanı, web sitenizi oluşturmak için önceki codelab'de kullandığınız average_word_vec'dır. Kod:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Yeni hücreye yapıştırdıktan sonra kodu çalıştırın.
Anlama
num_words
parameter
Modelin kullanmasını istediğiniz kelime sayısıdır. Ne kadar çok olursa o kadar iyi olduğunu düşünebilirsiniz ancak genellikle her kelimenin kullanım sıklığına bağlı olarak ideal bir nokta vardır. Tüm derlemdeki her kelimeyi kullanırsanız model, yalnızca bir kez kullanılan kelimelerin ağırlıklarını öğrenmeye ve dengelemeye çalışabilir. Bu durum pek faydalı değildir. Herhangi bir metin korpusunda birçok kelimenin yalnızca bir veya iki kez kullanıldığını görürsünüz. Bu kelimeler, genel duygu üzerinde ihmal edilebilir bir etkiye sahip olduklarından modelinizde kullanılmaları genellikle faydalı değildir. Bu nedenle, num_words parametresini kullanarak modelinizi istediğiniz kelime sayısına göre ayarlayabilirsiniz. Buradaki daha küçük bir sayı, daha küçük ve daha hızlı bir model oluşturur ancak daha az kelime tanıdığı için doğruluğu daha düşük olabilir. Buradaki daha büyük bir sayı, daha büyük ve muhtemelen daha yavaş bir modele yol açar. İdeal noktayı bulmak çok önemlidir ve kullanım alanınız için en iyi yaklaşımı belirlemek makine öğrenimi mühendisi olarak sizin görevinizdir.
Anlama
wordvec_dim
parameter
wordvec_dim parametresi, her kelimenin vektörü için kullanmak istediğiniz boyut sayısıdır. Bu boyutlar, temelde herhangi bir kelimenin ölçülebileceği farklı özelliklerdir (eğitim sırasında makine öğrenimi algoritması tarafından oluşturulur). Program, anlamlı bir şekilde benzer olan kelimeleri en iyi şekilde ilişkilendirmeye çalışmak için bu özellikleri kullanır.
Örneğin, bir kelimenin ne kadar "tıbbi" olduğuna dair bir boyutunuz varsa "hap" gibi bir kelime bu boyutta yüksek puan alabilir ve "röntgen" gibi yüksek puanlı diğer kelimelerle ilişkilendirilebilir ancak "kedi" bu boyutta düşük puan alır. "Tıbbi boyut"un, spam'i belirlemek için yararlı olduğu ve kullanmaya karar verebileceği diğer önemli boyutlarla birleştirildiğinde spam'i belirlemek için yararlı olduğu ortaya çıkabilir.
"Tıbbi boyut"ta yüksek puan alan kelimeler için, kelimeleri insan vücuduyla ilişkilendiren ikinci bir boyutun faydalı olabileceği anlaşılıyor. "Bacak", "kol", "boyun" gibi kelimeler burada yüksek puan alabilir ve tıbbi boyutta da oldukça yüksek puan alabilir.
Model, bu boyutları kullanarak spam ile ilişkilendirilme olasılığı daha yüksek olan kelimeleri algılayabilir. Spam e-postalar, hem tıbbi hem de insan vücudunun bölümlerini ifade eden kelimeler içerebilir.
Araştırmalardan elde edilen genel kural, kelime sayısının dördüncü kökünün bu parametre için iyi sonuç verdiğidir. Bu nedenle, 2.000 kelime kullanıyorsam 7 boyut iyi bir başlangıç noktasıdır. Kullanılan kelime sayısını değiştirirseniz bunu da değiştirebilirsiniz.
Anlama
seq_len
parameter
Modeller, giriş değerleri konusunda genellikle çok katıdır. Bir dil modeli için bu, dil modelinin belirli ve statik bir uzunluktaki cümleleri sınıflandırabileceği anlamına gelir. Bu, seq_len parametresiyle belirlenir. Bu parametre, "dizi uzunluğu" anlamına gelir. Kelimeleri sayılara (veya jetonlara) dönüştürdüğünüzde cümle, bu jetonların bir dizisi haline gelir. Bu nedenle modeliniz (bu örnekte) 20 jeton içeren cümleleri sınıflandıracak ve tanıyacak şekilde eğitilir. Cümle bundan daha uzunsa kısaltılır. Daha kısaysa bu serideki ilk codelab'de olduğu gibi doldurulur.
5. adım: Eğitim verilerini yükleyin
Daha önce CSV dosyasını indirmiş olmanız gerekir. Şimdi de bu verileri, modelin tanıyabileceği eğitim verilerine dönüştürmek için bir veri yükleyici kullanma zamanı.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
CSV dosyasını bir düzenleyicide açarsanız her satırda yalnızca iki değer olduğunu ve bunların dosyanın ilk satırında metinle açıklandığını görürsünüz. Genellikle her giriş "sütun" olarak kabul edilir. İlk sütunun tanımlayıcısının commenttext olduğunu ve her satırdaki ilk girişin yorum metni olduğunu görürsünüz.
Benzer şekilde, ikinci sütunun tanımlayıcısı spam'dır ve her satırdaki ikinci girişin, metnin spam yorum olarak kabul edilip edilmediğini belirtmek için DOĞRU veya YANLIŞ olduğunu görürsünüz. Diğer özellikler, 4. adımda oluşturduğunuz model spesifikasyonunu ve bir sınırlayıcı karakteri (bu durumda dosya virgülle ayrılmış olduğundan virgül) ayarlar. Ayrıca, benzer olabilecek veya birlikte toplanmış öğelerin veri kümesine rastgele dağıtılması için eğitim verilerini rastgele yeniden düzenleyen bir karıştırma parametresi de ayarlarsınız.
Ardından, verileri eğitim ve test verileri olarak bölmek için data.split() simgesini kullanırsınız. .9, veri kümesinin% 90'ının eğitim, geri kalanının ise test için kullanılacağını gösterir.
6. adım: Modeli oluşturun
Modeli oluşturmak için kod ekleyeceğimiz başka bir hücre ekleyin:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Bu işlem, Model Oluşturucu ile bir metin sınıflandırıcı modeli oluşturur. Ayrıca, kullanmak istediğiniz eğitim verilerini (4. adımda tanımlanmıştır), model spesifikasyonunu (4. adımda da ayarlanmıştır) ve dönem sayısını (bu örnekte 50) belirtirsiniz.
Makine öğreniminin temel ilkesi, bunun bir tür kalıp eşleştirme olduğudur. Başlangıçta, kelimeler için önceden eğitilmiş ağırlıkları yükler ve bunları, gruplandırıldığında hangilerinin spam'i, hangilerinin ise spam olmayanları gösterdiğine dair bir "tahmin" ile birlikte gruplandırmaya çalışır. Model, aşağıda gösterildiği gibi henüz yeni başladığı için ilk seferde bu oran muhtemelen 50:50'ye yakın olacaktır:

Ardından, bunun sonuçlarını ölçer, tahminini değiştirmek için modelin ağırlıklarını değiştirir ve tekrar dener. Bu bir dönemdir. Bu nedenle, epochs=50 belirtildiğinde, gösterildiği gibi bu "döngü" 50 kez tekrarlanır:

Bu nedenle, 50. döneme ulaştığınızda model çok daha yüksek bir doğruluk düzeyi bildirir. Bu örnekte %99,1 gösteriliyor.
7. adım: Modeli dışa aktarın
Eğitiminiz tamamlandıktan sonra modeli dışa aktarabilirsiniz. TensorFlow, bir modeli kendi biçiminde eğitir ve bu modelin bir web sayfasında kullanılabilmesi için TensorFlow.js biçimine dönüştürülmesi gerekir. Aşağıdaki kodu yeni bir hücreye yapıştırıp çalıştırın:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Bu kodu çalıştırdıktan sonra Colab'in sol tarafındaki küçük klasör simgesini tıklarsanız yukarıda dışa aktardığınız klasöre (kök dizinde; bir üst düzeye gitmeniz gerekebilir) gidebilir ve dışa aktarılan dosyaların zip paketini ModelFiles.zip içinde bulabilirsiniz.
Bu zip dosyasını şimdi bilgisayarınıza indirin. Bu dosyaları ilk codelab'deki gibi kullanacaksınız:

Mükemmel! Python kısmı sona erdi. Artık bildiğiniz ve sevdiğiniz JavaScript dünyasına geri dönebilirsiniz. Bora
5. Yeni makine öğrenimi modeline hizmet sunma
Artık modeli yüklemeye neredeyse hazırsınız. Ancak bunu yapabilmeniz için daha önce codelab'de indirilen yeni model dosyalarını, kodunuzda barındırılacak ve kullanılacak şekilde yüklemeniz gerekir.
İlk olarak, henüz yapmadıysanız az önce çalıştırdığınız Model Maker Colab not defterinden yeni indirdiğiniz model dosyalarını açın. Çeşitli klasörlerinde aşağıdaki dosyaları görmeniz gerekir:

Burada ne var?
model.json: Bu, eğitilmiş TensorFlow.js modelini oluşturan dosyalardan biridir. JS kodunda bu dosyaya referans vereceksiniz.group1-shard1of1.bin: Bu, dışa aktarılan TensorFlow.js modeli için kaydedilen verilerin çoğunu içeren bir ikili program dosyasıdır ve yukarıdakimodel.jsonile aynı dizinde indirilmek üzere sunucunuzda bir yerde barındırılması gerekir.vocab: Uzantısı olmayan bu garip dosya, Model Maker'dan alınmıştır. Cümlelerdeki kelimelerin nasıl kodlanacağını göstererek modelin bunları nasıl kullanacağını anlamasını sağlar. Bu konuyu bir sonraki bölümde daha ayrıntılı olarak ele alacağız.labels.txt: Bu, modelin tahmin edeceği sonuç sınıf adlarını içerir. Bu modelde, dosyayı metin düzenleyicinizde açtığınızda tahmin çıktısı olarak "spam değil" veya "spam" anlamına gelen "false" ve "true" listelenir.
TensorFlow.js model dosyalarını barındırma
Öncelikle, web sayfanız üzerinden erişebilmek için oluşturulan model.json ve *.bin dosyalarını bir web sunucusuna yerleştirin.
Mevcut model dosyalarını silme
Bu serideki ilk codelab'in nihai sonucunu temel aldığınız için öncelikle yüklenen mevcut model dosyalarını silmeniz gerekir. Glitch.com kullanıyorsanız soldaki dosyalar panelinde model.json ve group1-shard1of1.bin simgelerini bulun, her dosya için 3 noktalı menü açılır listesini tıklayın ve gösterildiği gibi sil'i seçin:

Glitch'e yeni dosya yükleme
Mükemmel! Şimdi yenilerini yükleyin:
- Glitch projenizin sol panelinde assets (öğeler) klasörünü açın ve aynı ada sahipse yüklenen eski öğeleri silin.
- Öğe yükle'yi tıklayın ve bu klasöre yüklenecek
group1-shard1of1.binöğesini seçin. Yüklenen dosya aşağıdaki gibi görünmelidir:
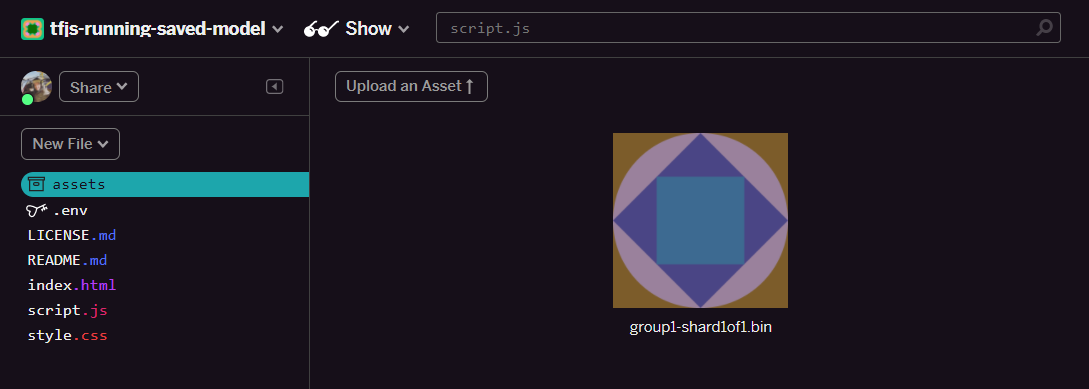
- Mükemmel! Şimdi de model.json dosyası için aynı işlemi yapın. Böylece, öğeler klasörünüzde aşağıdaki gibi 2 dosya olmalıdır:

- Yeni yüklediğiniz
group1-shard1of1.bindosyasını tıkladığınızda dosyanın bulunduğu konumun URL'sini kopyalayabilirsiniz. Bu yolu şimdi gösterildiği gibi kopyalayın:

- Ekranın sol alt kısmında Araçlar > Terminal'i tıklayın. Terminal penceresinin yüklenmesini bekleyin.
- Yüklendikten sonra aşağıdakileri yazın ve dizini
wwwklasörüne değiştirmek için Enter tuşuna basın:
terminal:
cd www
- Ardından, aşağıdaki URL'leri Glitch'teki öğeler klasöründeki dosyalar için oluşturduğunuz URL'lerle değiştirerek (her dosyanın özel URL'si için öğeler klasörünü kontrol edin) yeni yüklenen 2 dosyayı indirmek için
wgetsimgesini kullanın.
İki URL arasındaki boşluğa ve kullanmanız gereken URL'lerin gösterilenlerden farklı olacağını ancak benzer görüneceğini unutmayın:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Süper! Artık www klasörüne yüklenen dosyaların kopyasını oluşturdunuz.
Ancak şu anda bu dosyalar tuhaf adlarla indiriliyor. Terminalde ls yazıp Enter tuşuna bastığınızda aşağıdakine benzer bir sonuç görürsünüz:

mvkomutunu kullanarak dosyaları yeniden adlandırın. Aşağıdakileri konsola yazın ve her satırdan sonra Enter tuşuna basın:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Son olarak, terminale
refreshyazıp Enter tuşuna basarak Glitch projesini yenileyin:
terminal:
refresh
Yeniledikten sonra kullanıcı arayüzünün www klasöründe model.json ve group1-shard1of1.bin simgelerini görmeniz gerekir:
Mükemmel! Son adım, dictionary.js dosyasını güncellemektir.
- Yeni indirdiğiniz kelime dosyası, metin düzenleyiciniz aracılığıyla manuel olarak veya bu aracı kullanarak doğru JS biçimine dönüştürün ve sonuçtaki çıktıyı
wwwklasörünüzdedictionary.jsolarak kaydedin. Zaten birdictionary.jsdosyanız varsa yeni içerikleri kopyalayıp bu dosyanın üzerine yapıştırabilir ve dosyayı kaydedebilirsiniz.
Harika! Değiştirilen tüm dosyaları başarıyla güncellediniz. Web sitesini kullanmaya çalıştığınızda, yeniden eğitilen modelin, keşfedilen ve öğrenilen uç durumları nasıl hesaba katabildiğini göreceksiniz.

Gördüğünüz gibi, ilk 6 ileti artık doğru şekilde "spam değil" olarak sınıflandırılıyor ve ikinci 6 ileti de spam olarak tanımlanıyor. Mükemmel!
İyice genelleştirilip genelleştirilmediğini görmek için bazı varyasyonları da deneyelim. Başlangıçta şu gibi başarısız bir cümle vardı:
"omg GOOG stock just shot right up! Çok geç olmadan alın!"
Bu ileti artık doğru şekilde spam olarak sınıflandırılıyor ancak aşağıdaki gibi değiştirirseniz ne olur?
"Yani XYZ hissesinin değeri arttı! Çok geç olmadan satın alın."
Burada, hisse senedi sembolünü ve kelimeleri biraz değiştirmenize rağmen% 98 spam olma olasılığı tahminini doğru bir şekilde alırsınız.
Elbette bu yeni modeli gerçekten bozmaya çalışırsanız bunu başarabilirsiniz. Bu durumda, internette karşılaşmanız muhtemel olan yaygın durumlar için daha fazla benzersiz varyasyon yakalama şansını artırmak amacıyla daha fazla eğitim verisi toplamanız gerekir. Gelecekteki bir codelab'de, canlı veriler işaretlendikçe modelinizi sürekli olarak nasıl iyileştireceğinizi göstereceğiz.
6. Tebrikler!
Tebrikler. Mevcut bir makine öğrenimi modelini yeniden eğiterek bulduğunuz uç durumlara göre çalışacak şekilde güncellediniz ve bu değişiklikleri gerçek dünya uygulaması için TensorFlow.js ile tarayıcıya dağıttınız.
Özet
Bu codelab'de:
- Hazır spam yorum modelini kullanırken çalışmayan uç durumlar keşfedildi.
- Keşfettiğiniz uç durumları dikkate almak için Model Maker modelini yeniden eğittik.
- Yeni eğitilen modeli TensorFlow.js biçiminde dışa aktarma
- Web uygulamanızı yeni dosyaları kullanacak şekilde güncellediyseniz
Yapabilecekleriniz
Bu güncelleme harika çalışıyor ancak diğer web uygulamalarında olduğu gibi zaman içinde değişiklikler yapılacak. Uygulamanın her seferinde manuel olarak yapmamız yerine zaman içinde sürekli olarak kendini geliştirmesi çok daha iyi olurdu. Örneğin, 100 yeni yorumun yanlış sınıflandırılmış olarak işaretlenmesinin ardından modeli otomatik olarak yeniden eğitmek için bu adımları nasıl otomatikleştirebileceğinizi düşünebilir misiniz? Normal web mühendisliği şapkanızı takarak bunu otomatik olarak yapacak bir ardışık düzen oluşturmayı muhtemelen çözebilirsiniz. Değilse endişelenmeyin. Nasıl yapılacağını gösteren serideki bir sonraki codelab'i takip edin.
Ürettiklerinizi bizimle paylaşma
Bugün oluşturduğunuz içerikleri diğer yaratıcı kullanım alanlarında da kolayca kullanabilirsiniz. Yaratıcılığınızı konuşturmaya ve denemeye devam etmenizi öneririz.
Projenizin TensorFlow blogunda veya gelecekteki etkinliklerde yer alma şansı için sosyal medyada #MadeWithTFJS hashtag'ini kullanarak bizi etiketlemeyi unutmayın. Ürettiklerinizi görmeyi çok isteriz.
Daha ayrıntılı bilgi için diğer TensorFlow.js Codelab'leri
- TensorFlow.js modelini büyük ölçekte dağıtmak ve barındırmak için Firebase Hosting'i kullanın.
- TensorFlow.js ile önceden hazırlanmış bir nesne algılama modelini kullanarak akıllı bir web kamerası oluşturma
Göz atabileceğiniz web siteleri
- TensorFlow.js resmi web sitesi
- TensorFlow.js önceden hazırlanmış modelleri
- TensorFlow.js API'si
- TensorFlow.js Show & Tell: İlham alın ve diğer kullanıcıların neler yaptığını görün.