
১. শুরু করার আগে
গত কয়েক বছরে TensorFlow.js মডেলের ব্যবহার দ্রুতগতিতে বৃদ্ধি পেয়েছে এবং অনেক জাভাস্ক্রিপ্ট ডেভেলপার এখন বিদ্যমান অত্যাধুনিক মডেলগুলোকে নিয়ে সেগুলোকে তাদের নিজ নিজ ক্ষেত্রের জন্য অনন্য কাস্টম ডেটার সাথে কাজ করার জন্য পুনরায় প্রশিক্ষণ দিতে চাইছেন। একটি বিদ্যমান মডেলকে (যা প্রায়শই বেস মডেল হিসাবে পরিচিত) নিয়ে সেটিকে একই রকম কিন্তু ভিন্ন কোনো ডোমেইনে ব্যবহার করার এই প্রক্রিয়াটি ট্রান্সফার লার্নিং নামে পরিচিত।
একেবারে নতুন একটি মডেল থেকে শুরু করার তুলনায় ট্রান্সফার লার্নিং-এর অনেক সুবিধা রয়েছে। আপনি পূর্বে প্রশিক্ষিত কোনো মডেল থেকে অর্জিত জ্ঞান পুনরায় ব্যবহার করতে পারেন এবং যে নতুন বস্তুটি আপনি শ্রেণিবদ্ধ করতে চান, তার কম সংখ্যক উদাহরণের প্রয়োজন হয়। এছাড়াও, পুরো নেটওয়ার্কের পরিবর্তে মডেল আর্কিটেকচারের শুধুমাত্র শেষ কয়েকটি স্তরকে পুনরায় প্রশিক্ষণ দিতে হয় বলে প্রশিক্ষণ প্রক্রিয়াটি প্রায়শই উল্লেখযোগ্যভাবে দ্রুত হয়। এই কারণে, ট্রান্সফার লার্নিং ওয়েব ব্রাউজার পরিবেশের জন্য খুবই উপযুক্ত, যেখানে ডিভাইসটির উপর ভিত্তি করে রিসোর্স ভিন্ন হতে পারে, কিন্তু সহজে ডেটা সংগ্রহের জন্য সেন্সরগুলিতে সরাসরি অ্যাক্সেসও থাকে।
এই কোডল্যাবটি আপনাকে দেখাবে কীভাবে গুগলের জনপ্রিয় " টিচেবল মেশিন " ওয়েবসাইটটির আদলে একেবারে শূন্য থেকে একটি ওয়েব অ্যাপ তৈরি করতে হয়। এই ওয়েবসাইটটি আপনাকে একটি কার্যকরী ওয়েব অ্যাপ তৈরি করার সুযোগ দেয়, যা ব্যবহার করে যেকোনো ব্যবহারকারী তাদের ওয়েবক্যাম থেকে তোলা কয়েকটি উদাহরণ ছবির সাহায্যে নিজেদের পছন্দমতো কোনো বস্তু শনাক্ত করতে পারে। ওয়েবসাইটটি ইচ্ছাকৃতভাবে সংক্ষিপ্ত রাখা হয়েছে, যাতে আপনি এই কোডল্যাবের মেশিন লার্নিং অংশগুলোর উপর মনোযোগ দিতে পারেন। তবে, মূল টিচেবল মেশিন ওয়েবসাইটের মতোই, ইউজার এক্সপেরিয়েন্স (UX) উন্নত করার জন্য আপনার বিদ্যমান ওয়েব ডেভেলপার অভিজ্ঞতা প্রয়োগ করার যথেষ্ট সুযোগ রয়েছে।
পূর্বশর্ত
এই কোডল্যাবটি এমন ওয়েব ডেভেলপারদের জন্য লেখা হয়েছে, যারা TensorFlow.js-এর আগে থেকে তৈরি মডেল এবং বেসিক API ব্যবহারে কিছুটা পরিচিত এবং TensorFlow.js-এ ট্রান্সফার লার্নিং শুরু করতে চান।
- এই ল্যাবের জন্য TensorFlow.js, HTML5, CSS, এবং JavaScript সম্পর্কে প্রাথমিক ধারণা থাকা আবশ্যক।
আপনি যদি Tensorflow.js-এ নতুন হন, তাহলে প্রথমে এই বিনামূল্যের 'জিরো টু হিরো' কোর্সটি করার কথা বিবেচনা করতে পারেন , যেখানে মেশিন লার্নিং বা TensorFlow.js সম্পর্কে কোনো পূর্বজ্ঞান নেই বলেই ধরে নেওয়া হয় এবং আপনার যা কিছু জানা প্রয়োজন, তা ছোট ছোট ধাপে শেখানো হয়।
আপনি যা শিখবেন
- TensorFlow.js কী এবং কেন আপনার পরবর্তী ওয়েব অ্যাপে এটি ব্যবহার করা উচিত।
- কীভাবে একটি সরলীকৃত HTML/CSS/JS ওয়েবপেজ তৈরি করা যায় যা Teachable Machine-এর ব্যবহারকারীর অভিজ্ঞতাকে অনুকরণ করে।
- ট্রান্সফার লার্নিং-এ ব্যবহারযোগ্য ইমেজ ফিচার তৈরি করার জন্য কীভাবে TensorFlow.js ব্যবহার করে একটি প্রি-ট্রেইনড বেস মডেল, বিশেষত MobileNet, লোড করা যায়।
- ব্যবহারকারীর ওয়েবক্যাম থেকে একাধিক শ্রেণীর ডেটা শনাক্ত করার জন্য কীভাবে তথ্য সংগ্রহ করবেন।
- কীভাবে একটি মাল্টি-লেয়ার পারসেপট্রন তৈরি ও সংজ্ঞায়িত করা যায়, যা ছবির বৈশিষ্ট্য গ্রহণ করে এবং সেগুলো ব্যবহার করে নতুন বস্তু শ্রেণীবদ্ধ করতে শেখে।
চলুন হ্যাকিং শুরু করা যাক...
আপনার যা যা লাগবে
- অনুসরণ করার জন্য একটি Glitch.com অ্যাকাউন্ট থাকা বাঞ্ছনীয়, অথবা আপনি এমন একটি ওয়েব সার্ভিং এনভায়রনমেন্ট ব্যবহার করতে পারেন যা আপনি নিজে সম্পাদনা ও পরিচালনা করতে স্বাচ্ছন্দ্যবোধ করেন।
২. TensorFlow.js বলতে কী বোঝায়?

TensorFlow.js হলো একটি ওপেন সোর্স মেশিন লার্নিং লাইব্রেরি যা জাভাস্ক্রিপ্ট যেখানে চলে, সেখানেই চালানো যায়। এটি পাইথনে লেখা মূল TensorFlow লাইব্রেরির উপর ভিত্তি করে তৈরি এবং এর লক্ষ্য হলো জাভাস্ক্রিপ্ট ইকোসিস্টেমের জন্য সেই ডেভেলপার অভিজ্ঞতা ও এপিআই-এর সেটটি পুনরায় তৈরি করা।
এটি কোথায় ব্যবহার করা যেতে পারে?
জাভাস্ক্রিপ্টের বহনযোগ্যতার কারণে, আপনি এখন একটিমাত্র ভাষায় কোড লিখে নিম্নলিখিত সমস্ত প্ল্যাটফর্মে সহজেই মেশিন লার্নিং করতে পারবেন:
- ওয়েব ব্রাউজারে ক্লায়েন্ট সাইডে ভ্যানিলা জাভাস্ক্রিপ্ট ব্যবহার করে
- সার্ভার সাইডে এবং এমনকি রাস্পবেরি পাই-এর মতো IoT ডিভাইসেও Node.js ব্যবহার করা হয়।
- ইলেকট্রন ব্যবহার করে ডেস্কটপ অ্যাপ
- React Native ব্যবহার করে নেটিভ মোবাইল অ্যাপ
সামঞ্জস্যতা নিশ্চিত করতে এবং সবকিছু দ্রুত চালু রাখতে, TensorFlow.js এই প্রতিটি পরিবেশের (যেমন সিপিইউ বা ওয়েবজিএল-এর মতো প্রকৃত হার্ডওয়্যার-ভিত্তিক পরিবেশ, যেখানে এটি চলতে পারে। এই প্রসঙ্গে "ব্যাকএন্ড" বলতে সার্ভার-সাইড পরিবেশ বোঝায় না - এক্সিকিউশনের জন্য ব্যাকএন্ডটি ক্লায়েন্ট-সাইডে ওয়েবজিএল-এও হতে পারে) মধ্যে একাধিক ব্যাকএন্ড সমর্থন করে। বর্তমানে TensorFlow.js যা সমর্থন করে:
- ডিভাইসের গ্রাফিক্স কার্ডে (GPU) WebGL এক্সিকিউশন – GPU অ্যাক্সিলারেশনের মাধ্যমে বড় মডেল (আকারে ৩ মেগাবাইটের বেশি) চালানোর এটিই দ্রুততম উপায়।
- সিপিইউ-তে ওয়েব অ্যাসেম্বলি (WASM) এক্সিকিউশন – উদাহরণস্বরূপ, পুরোনো প্রজন্মের মোবাইল ফোন সহ বিভিন্ন ডিভাইসে সিপিইউ-এর পারফরম্যান্স উন্নত করার জন্য। এটি ছোট মডেলগুলির (আকারে ৩ মেগাবাইটের কম) জন্য বেশি উপযোগী, যেগুলো গ্রাফিক্স প্রসেসরে কন্টেন্ট আপলোড করার ওভারহেডের কারণে WebGL-এর চেয়ে WASM ব্যবহার করে সিপিইউ-তে প্রকৃতপক্ষে আরও দ্রুত এক্সিকিউট হতে পারে।
- সিপিইউ এক্সিকিউশন - অন্য কোনো এনভায়রনমেন্ট উপলব্ধ না থাকলে এটিই বিকল্প ব্যবস্থা। এই তিনটির মধ্যে এটি সবচেয়ে ধীরগতির, কিন্তু এটি আপনার জন্য সর্বদা প্রস্তুত থাকে।
দ্রষ্টব্য: আপনি কোন ডিভাইসে এটি চালাবেন তা জানা থাকলে, এই ব্যাকএন্ডগুলির মধ্যে একটিকে বাধ্যতামূলকভাবে ব্যবহার করার বিকল্প বেছে নিতে পারেন, অথবা এটি নির্দিষ্ট না করলে TensorFlow.js-কেই আপনার জন্য সিদ্ধান্ত নিতে দিতে পারেন।
ক্লায়েন্ট সাইডের সুপার পাওয়ার
ক্লায়েন্ট মেশিনের ওয়েব ব্রাউজারে TensorFlow.js চালানোর ফলে বেশ কিছু সুবিধা পাওয়া যেতে পারে, যা বিবেচনা করার মতো।
গোপনীয়তা
আপনি কোনো তৃতীয় পক্ষের ওয়েব সার্ভারে ডেটা না পাঠিয়েই ক্লায়েন্ট মেশিনে ডেটা প্রশিক্ষণ এবং শ্রেণীবদ্ধকরণ উভয়ই করতে পারেন। এমন কিছু পরিস্থিতি আসতে পারে যেখানে স্থানীয় আইন, যেমন উদাহরণস্বরূপ GDPR, মেনে চলার জন্য এটি একটি আবশ্যিক শর্ত হতে পারে, অথবা যখন ব্যবহারকারী এমন কোনো ডেটা প্রসেস করতে চান যা তিনি নিজের মেশিনে রাখতে চান এবং কোনো তৃতীয় পক্ষের কাছে পাঠাতে চান না।
গতি
যেহেতু আপনাকে কোনো রিমোট সার্ভারে ডেটা পাঠাতে হচ্ছে না, তাই ইনফারেন্স (ডেটা শ্রেণীবদ্ধ করার প্রক্রিয়া) আরও দ্রুত হতে পারে। আরও ভালো ব্যাপার হলো, ব্যবহারকারী অনুমতি দিলে আপনি ডিভাইসটির ক্যামেরা, মাইক্রোফোন, জিপিএস, অ্যাক্সেলেরোমিটার এবং আরও অনেক সেন্সরে সরাসরি অ্যাক্সেস পাবেন।
প্রসার এবং পরিধি
বিশ্বের যে কেউ এক ক্লিকেই আপনার পাঠানো লিঙ্কে ক্লিক করে, তাদের ব্রাউজারে ওয়েব পেজটি খুলতে এবং আপনার তৈরি করা জিনিসটি ব্যবহার করতে পারে। মেশিন লার্নিং সিস্টেমটি ব্যবহার করার জন্য CUDA ড্রাইভার এবং আরও অনেক কিছু সহ একটি জটিল সার্ভার-সাইড লিনাক্স সেটআপের কোনো প্রয়োজন নেই।
খরচ
সার্ভার না থাকার অর্থ হলো, আপনাকে শুধুমাত্র আপনার HTML, CSS, JS, এবং মডেল ফাইলগুলো হোস্ট করার জন্য একটি CDN-এর খরচ করতে হবে। একটি সার্ভারকে (সম্ভবত একটি গ্রাফিক্স কার্ডসহ) ২৪/৭ চালু রাখার চেয়ে একটি CDN-এর খরচ অনেক কম।
সার্ভার সাইডের বৈশিষ্ট্য
TensorFlow.js-এর Node.js সংস্করণ ব্যবহার করলে নিম্নলিখিত বৈশিষ্ট্যগুলো সক্ষম হয়।
সম্পূর্ণ CUDA সমর্থন
সার্ভার সাইডে, গ্রাফিক্স কার্ড অ্যাক্সিলারেশনের জন্য, আপনাকে অবশ্যই NVIDIA CUDA ড্রাইভার ইনস্টল করতে হবে যাতে TensorFlow গ্রাফিক্স কার্ডের সাথে কাজ করতে পারে (ব্রাউজারের মতো নয়, যেখানে WebGL ব্যবহৃত হয় - কোনো ইনস্টলের প্রয়োজন নেই)। তবে, সম্পূর্ণ CUDA সাপোর্টের মাধ্যমে আপনি গ্রাফিক্স কার্ডের নিম্ন-স্তরের ক্ষমতাগুলোকে পুরোপুরি কাজে লাগাতে পারবেন, যার ফলে ট্রেনিং এবং ইনফারেন্সের সময় দ্রুততর হয়। এর পারফরম্যান্স পাইথন TensorFlow ইমপ্লিমেন্টেশনের সমতুল্য, কারণ উভয়েরই একই C++ ব্যাকএন্ড রয়েছে।
মডেলের আকার
গবেষণার অত্যাধুনিক মডেলগুলোর জন্য, আপনাকে খুব বড় মডেল নিয়ে কাজ করতে হতে পারে, যা আকারে গিগাবাইট পর্যন্ত হতে পারে। প্রতি ব্রাউজার ট্যাবে মেমরি ব্যবহারের সীমাবদ্ধতার কারণে এই মডেলগুলো বর্তমানে ওয়েব ব্রাউজারে চালানো যায় না। এই ধরনের বড় মডেলগুলো দক্ষতার সাথে চালানোর জন্য প্রয়োজনীয় হার্ডওয়্যার স্পেসিফিকেশনসহ আপনার নিজের সার্ভারে Node.js ব্যবহার করতে পারেন।
আইওটি
রাস্পবেরি পাই-এর মতো জনপ্রিয় সিঙ্গেল বোর্ড কম্পিউটারে নোড.জেএস সমর্থিত, যার ফলে আপনি এই ধরনের ডিভাইসেও টেনসরফ্লো.জেএস মডেল চালাতে পারবেন।
গতি
নোড.জেএস জাভাস্ক্রিপ্টে লেখা, যার ফলে এটি জাস্ট-ইন-টাইম কম্পাইলেশনের সুবিধা পায়। এর মানে হলো, নোড.জেএস ব্যবহার করার সময় আপনি প্রায়শই পারফরম্যান্সে উন্নতি দেখতে পাবেন, কারণ এটি রানটাইমে অপ্টিমাইজ করা হয়, বিশেষ করে আপনার করা যেকোনো প্রিপ্রসেসিংয়ের জন্য। এর একটি চমৎকার উদাহরণ এই কেস স্টাডিতে দেখা যায়, যেখানে দেখানো হয়েছে কীভাবে হাগিং ফেস তাদের ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং মডেলের পারফরম্যান্স দ্বিগুণ বাড়াতে নোড.জেএস ব্যবহার করেছে।
এখন যেহেতু আপনি TensorFlow.js-এর মূল বিষয়গুলো, এটি কোথায় চালানো যায় এবং এর কিছু সুবিধা সম্পর্কে জেনেছেন, চলুন এটি দিয়ে দরকারি কিছু কাজ করা শুরু করা যাক!
৩. স্থানান্তর শিক্ষা
ট্রান্সফার লার্নিং বলতে ঠিক কী বোঝায়?
স্থানান্তর শিখন বলতে বোঝায় পূর্বে অর্জিত জ্ঞানকে কাজে লাগিয়ে ভিন্ন কিন্তু অনুরূপ কোনো বিষয় শেখা।
আমরা মানুষরা এটা প্রতিনিয়ত করে থাকি। আপনার মস্তিষ্কে সারাজীবনের অভিজ্ঞতা জমা থাকে, যা ব্যবহার করে আপনি আগে কখনো না দেখা নতুন জিনিস চিনতে পারেন। উদাহরণস্বরূপ এই উইলো গাছটির কথাই ধরুন:

আপনি বিশ্বের কোথায় আছেন তার উপর নির্ভর করে, এমন সম্ভাবনা থাকতে পারে যে আপনি আগে এই ধরণের গাছ দেখেননি।
তবুও যদি আমি আপনাকে নীচের নতুন ছবিটিতে কোনো উইলো গাছ আছে কিনা বলতে বলি, আপনি সম্ভবত খুব দ্রুতই সেগুলো চিহ্নিত করতে পারবেন, যদিও সেগুলো একটি ভিন্ন কোণ থেকে তোলা এবং আমি আপনাকে দেখানো আসল ছবিটির থেকে কিছুটা আলাদা।

আপনার মস্তিষ্কে ইতিমধ্যেই এমন অনেক নিউরন রয়েছে যা গাছের মতো বস্তু শনাক্ত করতে জানে, এবং অন্য নিউরনগুলো লম্বা সরলরেখা খুঁজে বের করতে পারদর্শী। আপনি সেই জ্ঞানকে পুনরায় ব্যবহার করে দ্রুত একটি উইলো গাছকে শ্রেণীবদ্ধ করতে পারেন, যা একটি গাছের মতো বস্তু এবং যার অনেকগুলো লম্বা, সোজা, উল্লম্ব শাখা রয়েছে।
একইভাবে, যদি আপনার কাছে ছবি শনাক্তকরণের মতো কোনো একটি ক্ষেত্রে আগে থেকেই প্রশিক্ষিত একটি মেশিন লার্নিং মডেল থাকে, তবে আপনি সেটিকে ভিন্ন কিন্তু সম্পর্কিত কোনো কাজ সম্পাদনের জন্য পুনরায় ব্যবহার করতে পারেন।
আপনি MobileNet-এর মতো একটি উন্নত মডেল দিয়েও একই কাজ করতে পারেন, যা একটি অত্যন্ত জনপ্রিয় গবেষণা মডেল এবং এটি ১০০০ বিভিন্ন ধরণের বস্তুর ছবি শনাক্ত করতে পারে। কুকুর থেকে শুরু করে গাড়ি পর্যন্ত, এটিকে ImageNet নামে পরিচিত একটি বিশাল ডেটাসেটের উপর প্রশিক্ষণ দেওয়া হয়েছিল, যেখানে লক্ষ লক্ষ লেবেলযুক্ত ছবি রয়েছে।
এই অ্যানিমেশনে, আপনি দেখতে পারেন যে এই MobileNet V1 মডেলটিতে কত বিপুল সংখ্যক লেয়ার রয়েছে:
এর প্রশিক্ষণের সময়, এই মডেলটি ঐ ১০০০টি বস্তুর সবগুলোর জন্য গুরুত্বপূর্ণ সাধারণ বৈশিষ্ট্যগুলো বের করতে শিখেছে, এবং এই ধরনের বস্তু শনাক্ত করতে এটি যে নিম্ন-স্তরের বৈশিষ্ট্যগুলো ব্যবহার করে, তার অনেকগুলোই আগে কখনো না দেখা নতুন বস্তু শনাক্ত করতেও কাজে লাগতে পারে। সর্বোপরি, সবকিছুই শেষ পর্যন্ত রেখা, গঠন এবং আকৃতির একটি সংমিশ্রণ মাত্র।
চলুন একটি প্রচলিত কনভল্যুশনাল নিউরাল নেটওয়ার্ক (CNN) আর্কিটেকচার (মোবাইলনেটের মতো) দেখি এবং ট্রান্সফার লার্নিং কীভাবে এই প্রশিক্ষিত নেটওয়ার্ককে কাজে লাগিয়ে নতুন কিছু শিখতে পারে তা জেনে নিই। নিচের ছবিতে একটি CNN-এর সাধারণ মডেল আর্কিটেকচার দেখানো হয়েছে, যেটিকে এই ক্ষেত্রে ০ থেকে ৯ পর্যন্ত হাতে লেখা সংখ্যা শনাক্ত করার জন্য প্রশিক্ষণ দেওয়া হয়েছিল:
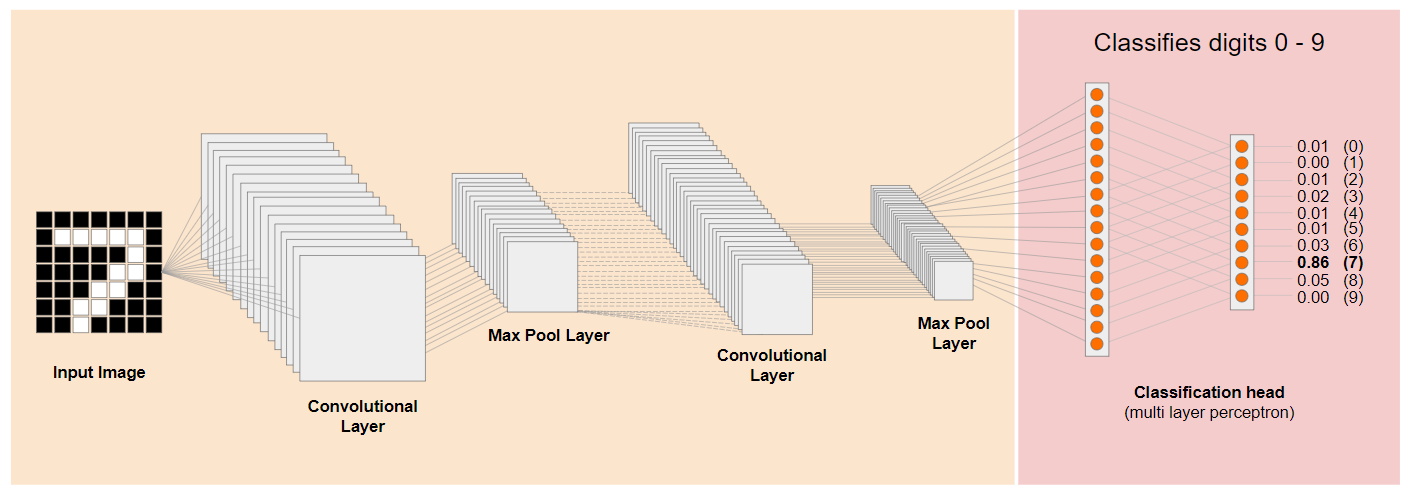
যদি আপনি বাম দিকে দেখানো এই ধরনের একটি বিদ্যমান প্রশিক্ষিত মডেলের প্রি-ট্রেইনড নিম্ন স্তরের লেয়ারগুলোকে, ডান দিকে দেখানো মডেলটির শেষের দিকের ক্লাসিফিকেশন লেয়ারগুলো (যাকে কখনও কখনও মডেলের ক্লাসিফিকেশন হেড বলা হয়) থেকে আলাদা করতে পারেন, তাহলে আপনি যে মূল ডেটার উপর ভিত্তি করে এটি প্রশিক্ষিত হয়েছিল, তার উপর নির্ভর করে যেকোনো প্রদত্ত ছবির জন্য আউটপুট ফিচার তৈরি করতে নিম্ন স্তরের লেয়ারগুলো ব্যবহার করতে পারবেন। এখানে ক্লাসিফিকেশন হেডটি বাদ দিয়ে একই নেটওয়ার্কটি দেখানো হলো:
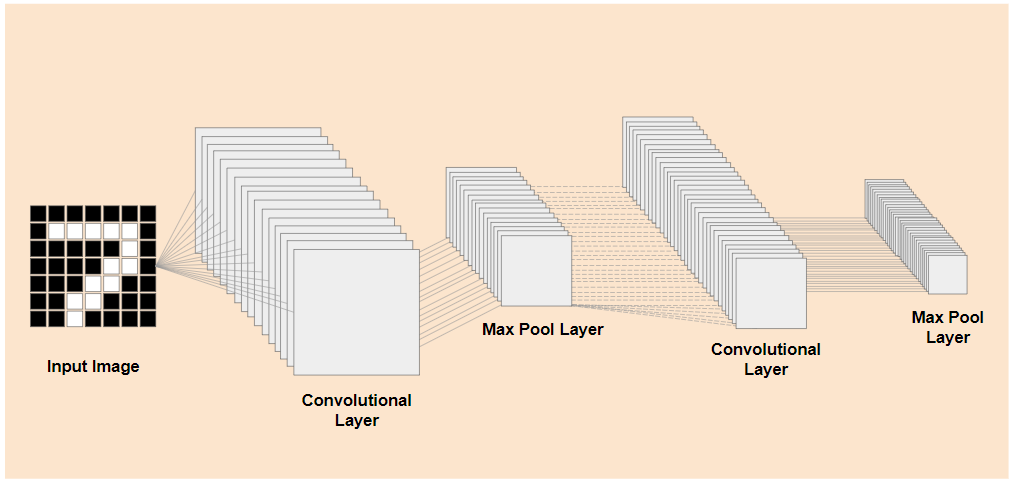
যদি ধরে নেওয়া হয় যে আপনি যে নতুন জিনিসটি শনাক্ত করার চেষ্টা করছেন, সেটিও পূর্ববর্তী মডেলের শেখা এই ধরনের আউটপুট বৈশিষ্ট্যগুলো ব্যবহার করতে পারে, তাহলে সেগুলোকে একটি নতুন উদ্দেশ্যে পুনরায় ব্যবহার করার যথেষ্ট সম্ভাবনা রয়েছে।
উপরের ডায়াগ্রামে, এই কাল্পনিক মডেলটিকে সংখ্যার উপর প্রশিক্ষণ দেওয়া হয়েছিল, তাই হয়তো সংখ্যা সম্পর্কে যা শেখা হয়েছে তা a, b, এবং c-এর মতো অক্ষরের ক্ষেত্রেও প্রয়োগ করা যেতে পারে।
সুতরাং এখন আপনি একটি নতুন ক্লাসিফিকেশন হেড যোগ করতে পারেন যা এর পরিবর্তে a, b, বা c ভবিষ্যদ্বাণী করার চেষ্টা করে, যেমনটি দেখানো হয়েছে:
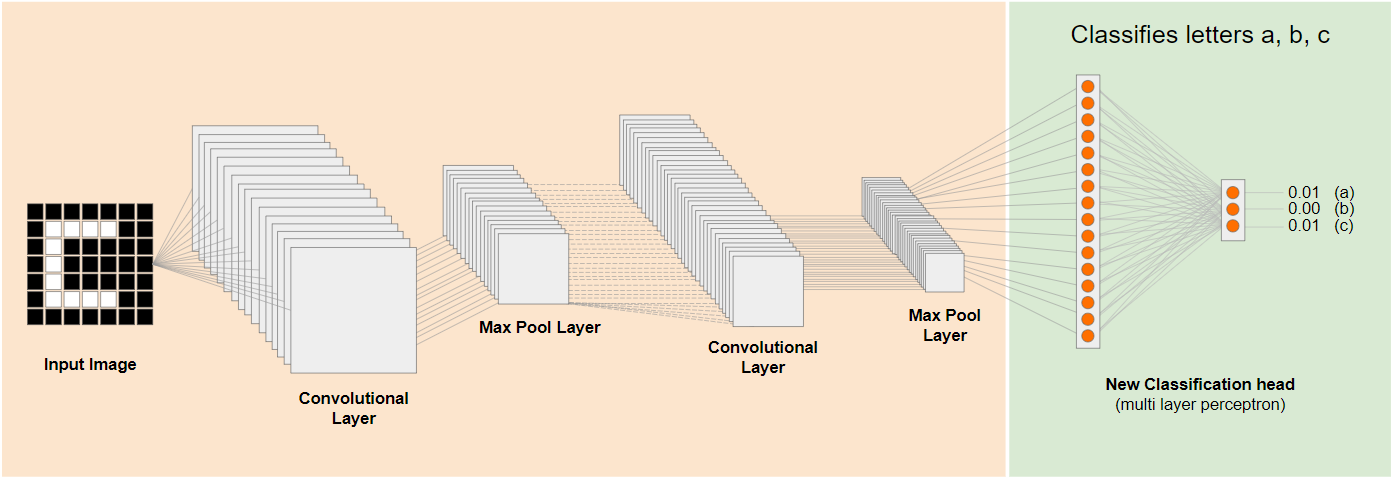
এখানে নিম্ন স্তরের লেয়ারগুলো স্থির রাখা হয়েছে এবং সেগুলোকে প্রশিক্ষণ দেওয়া হয়নি, শুধুমাত্র নতুন ক্লাসিফিকেশন হেডটি বামদিকের পূর্ব-প্রশিক্ষিত খণ্ডিত মডেল থেকে প্রাপ্ত বৈশিষ্ট্যগুলো ব্যবহার করে নিজেকে আপডেট করবে।
এই কাজটি করার প্রক্রিয়াটি ট্রান্সফার লার্নিং নামে পরিচিত এবং টিচেবল মেশিন নেপথ্যে ঠিক এই কাজটিই করে থাকে।
আপনি এটাও দেখতে পারেন যে, নেটওয়ার্কের একেবারে শেষে শুধু মাল্টি-লেয়ার পারসেপট্রনটিকে প্রশিক্ষণ দিলে, পুরো নেটওয়ার্কটিকে শুরু থেকে প্রশিক্ষণ দেওয়ার চেয়ে এটি অনেক দ্রুত প্রশিক্ষিত হয়।
কিন্তু একটি মডেলের উপাংশগুলো আপনি কীভাবে পেতে পারেন? জানতে পরবর্তী বিভাগে যান।
৪. টেনসরফ্লো হাব - বেস মডেল
ব্যবহারের জন্য একটি উপযুক্ত বেস মডেল খুঁজুন
MobileNet-এর মতো আরও উন্নত ও জনপ্রিয় গবেষণা মডেলগুলোর জন্য, আপনি TensorFlow hub- এ যেতে পারেন এবং তারপরে MobileNet v3 আর্কিটেকচার ব্যবহার করে TensorFlow.js-এর জন্য উপযুক্ত মডেলগুলো ফিল্টার করে এখানে দেখানো ফলাফলগুলোর মতো ফলাফল খুঁজে পেতে পারেন:
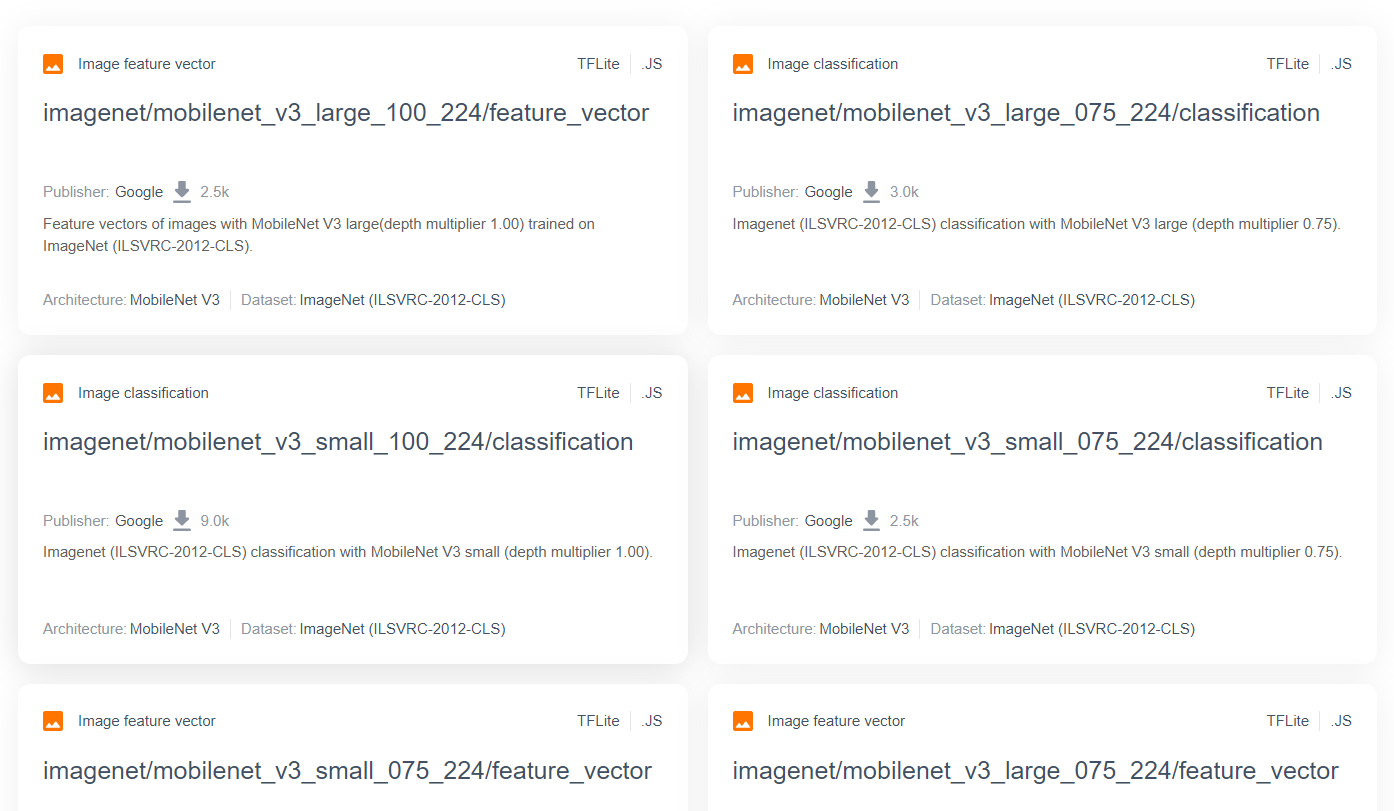
উল্লেখ্য যে, এই ফলাফলগুলোর মধ্যে কয়েকটি 'ইমেজ ক্লাসিফিকেশন' ধরনের (যা প্রতিটি মডেল কার্ড ফলাফলের উপরের বাম দিকে বিস্তারিতভাবে বর্ণনা করা হয়েছে), এবং অন্যগুলো 'ইমেজ ফিচার ভেক্টর' ধরনের।
এই ইমেজ ফিচার ভেক্টর ফলাফলগুলো মূলত MobileNet-এর পূর্ব-বিভক্ত সংস্করণ, যা আপনি চূড়ান্ত ক্লাসিফিকেশনের পরিবর্তে ইমেজ ফিচার ভেক্টরগুলো পেতে ব্যবহার করতে পারেন।
এই ধরনের মডেলগুলোকে প্রায়শই "বেস মডেল" বলা হয়, যা ব্যবহার করে আপনি পূর্ববর্তী বিভাগে দেখানো পদ্ধতিতেই ট্রান্সফার লার্নিং করতে পারেন। এর জন্য আপনাকে একটি নতুন ক্লাসিফিকেশন হেড যোগ করে আপনার নিজের ডেটা দিয়ে সেটিকে প্রশিক্ষণ দিতে হবে।
এর পরের যে বিষয়টি পরীক্ষা করতে হবে তা হলো, আপনার পছন্দের কোনো নির্দিষ্ট বেস মডেল TensorFlow.js-এর কোন ফরম্যাটে প্রকাশিত হয়েছে। আপনি যদি এই ফিচার ভেক্টর MobileNet v3 মডেলগুলোর কোনো একটির পৃষ্ঠা খোলেন, তাহলে JS ডকুমেন্টেশন থেকে দেখতে পাবেন যে এটি একটি গ্রাফ মডেলের আকারে রয়েছে। এটি ডকুমেন্টেশনের উদাহরণ কোড স্নিপেটের উপর ভিত্তি করে তৈরি, যেখানে tf.loadGraphModel() ব্যবহৃত হয়েছে।
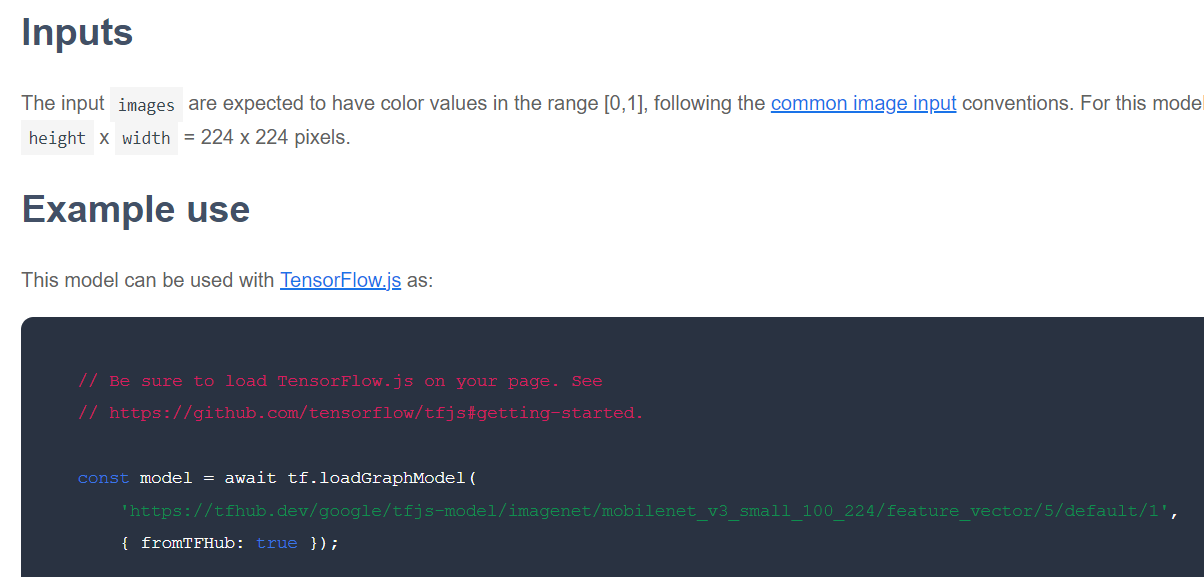
এটিও মনে রাখা উচিত যে, আপনি যদি গ্রাফ ফরম্যাটের পরিবর্তে লেয়ার ফরম্যাটে কোনো মডেল খুঁজে পান, তাহলে প্রশিক্ষণের জন্য কোন লেয়ারগুলো ফ্রিজ করবেন এবং কোনগুলো আনফ্রিজ করবেন তা বেছে নিতে পারেন। নতুন কোনো কাজের জন্য মডেল তৈরি করার সময় এটি খুব শক্তিশালী হতে পারে, যাকে প্রায়শই "ট্রান্সফার মডেল" বলা হয়। তবে আপাতত, এই টিউটোরিয়ালের জন্য আপনি ডিফল্ট গ্রাফ মডেল টাইপ ব্যবহার করবেন, যা বেশিরভাগ TF Hub মডেলে ডেপ্লয় করা হয়। লেয়ার মডেল নিয়ে কাজ করার বিষয়ে আরও জানতে, জিরো টু হিরো TensorFlow.js কোর্সটি দেখুন।
স্থানান্তর শিক্ষার সুবিধা
সম্পূর্ণ মডেল আর্কিটেকচারটি একেবারে শুরু থেকে প্রশিক্ষণ দেওয়ার পরিবর্তে ট্রান্সফার লার্নিং ব্যবহার করার সুবিধাগুলো কী কী?
প্রথমত, ট্রান্সফার লার্নিং পদ্ধতি ব্যবহারের একটি প্রধান সুবিধা হলো এর প্রশিক্ষণের সময় কম লাগে, কারণ আপনার কাছে আগে থেকেই একটি প্রশিক্ষিত ভিত্তি মডেল থাকে যার উপর ভিত্তি করে কাজ করা যায়।
দ্বিতীয়ত, ইতিমধ্যে সম্পন্ন হওয়া প্রশিক্ষণের কারণে, আপনি যে নতুন জিনিসটিকে শ্রেণীবদ্ধ করার চেষ্টা করছেন তার অনেক কম উদাহরণ দেখিয়েও কাজ চালিয়ে নিতে পারেন।
আপনি যে জিনিসটিকে শ্রেণীবদ্ধ করতে চান তার উদাহরণ ডেটা সংগ্রহ করার জন্য যদি আপনার কাছে সীমিত সময় ও সংস্থান থাকে এবং এটিকে আরও শক্তিশালী করার জন্য অতিরিক্ত প্রশিক্ষণ ডেটা সংগ্রহ করার আগে দ্রুত একটি প্রোটোটাইপ তৈরি করার প্রয়োজন হয়, তবে এটি সত্যিই দারুণ একটি উপায়।
কম ডেটার প্রয়োজন এবং ছোট নেটওয়ার্ক প্রশিক্ষণের গতির কারণে, ট্রান্সফার লার্নিং কম রিসোর্স-নির্ভর। এই কারণে এটি ব্রাউজার পরিবেশের জন্য খুবই উপযুক্ত, কারণ একটি সম্পূর্ণ মডেল প্রশিক্ষণের জন্য যেখানে ঘন্টা, দিন বা সপ্তাহ লেগে যায়, সেখানে একটি আধুনিক মেশিনে এর জন্য মাত্র কয়েক দশ সেকেন্ড সময় লাগে।
বেশ! এখন যেহেতু আপনি ট্রান্সফার লার্নিং-এর মূল বিষয়টি জেনে গেছেন, এবার আপনার নিজস্ব টিচেবল মেশিন তৈরি করার পালা। চলুন শুরু করা যাক!
৫. কোড করার জন্য প্রস্তুত হন
আপনার যা যা লাগবে
- একটি আধুনিক ওয়েব ব্রাউজার।
- HTML, CSS, JavaScript এবং Chrome DevTools (কনসোল আউটপুট দেখার ক্ষমতা) সম্পর্কে প্রাথমিক জ্ঞান।
চলুন কোডিং শুরু করা যাক।
Glitch.com বা Codepen.io-এর জন্য কাজ শুরু করার উপযোগী বয়লারপ্লেট টেমপ্লেট তৈরি করা হয়েছে। আপনি মাত্র এক ক্লিকে এই কোড ল্যাবের জন্য যেকোনো একটি টেমপ্লেটকে আপনার ভিত্তি হিসেবে ক্লোন করতে পারেন।
Glitch-এ, এটিকে ফোর্ক করতে এবং সম্পাদনাযোগ্য নতুন ফাইল সেট তৈরি করতে " remix this" বোতামে ক্লিক করুন।
বিকল্পভাবে, কোডপেনে স্ক্রিনের নিচের ডানদিকে থাকা ' ফর্ক' বোতামে ক্লিক করুন।
এই অত্যন্ত সরল কাঠামোটি আপনাকে নিম্নলিখিত ফাইলগুলি প্রদান করে:
- এইচটিএমএল পৃষ্ঠা (index.html)
- স্টাইলশিট (style.css)
- আমাদের জাভাস্ক্রিপ্ট কোড লেখার ফাইল (script.js)
আপনার সুবিধার জন্য, HTML ফাইলে TensorFlow.js লাইব্রেরির একটি অতিরিক্ত ইম্পোর্ট যোগ করা হয়েছে। এটি দেখতে এইরকম:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
বিকল্প: আপনার পছন্দের ওয়েব এডিটর ব্যবহার করুন অথবা স্থানীয়ভাবে কাজ করুন।
যদি আপনি কোডটি ডাউনলোড করে আপনার কম্পিউটারে বা অন্য কোনো অনলাইন এডিটরে কাজ করতে চান, তাহলে একই ডিরেক্টরিতে উপরে উল্লিখিত ৩টি ফাইল তৈরি করুন এবং আমাদের গ্লিচ বয়লারপ্লেট থেকে কোডটি কপি করে সেগুলোর প্রতিটিতে পেস্ট করুন।
৬. অ্যাপের এইচটিএমএল বয়লারপ্লেট
কোথা থেকে শুরু করব?
সমস্ত প্রোটোটাইপের জন্য কিছু প্রাথমিক HTML কাঠামো প্রয়োজন, যার উপর আপনি আপনার প্রাপ্ত ফলাফলগুলো রেন্ডার করতে পারবেন। এখনই সেটি তৈরি করুন। আপনি যা যোগ করতে চলেছেন:
- পৃষ্ঠাটির জন্য একটি শিরোনাম।
- কিছু বর্ণনামূলক লেখা।
- একটি স্থিতিসূচক অনুচ্ছেদ।
- ওয়েবক্যাম ফিড প্রস্তুত হয়ে গেলে তা ধরে রাখার জন্য একটি ভিডিও।
- ক্যামেরা চালু করতে, ডেটা সংগ্রহ করতে বা অভিজ্ঞতাটি রিসেট করতে একাধিক বাটন রয়েছে।
- TensorFlow.js এবং পরবর্তীতে কোড করবেন এমন JS ফাইলগুলোর জন্য ইম্পোর্ট।
উপরোক্ত বৈশিষ্ট্যগুলো সেট আপ করতে index.html খুলুন এবং বিদ্যমান কোডের উপর নিম্নলিখিত কোডটি পেস্ট করুন:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
ভেঙে ফেলুন
আপনার যোগ করা কিছু গুরুত্বপূর্ণ বিষয় তুলে ধরতে চলুন উপরের HTML কোডটি বিশ্লেষণ করা যাক।
- আপনি পেজের শিরোনামের জন্য একটি
<h1>ট্যাগ এবং 'status' আইডি সহ একটি<p>ট্যাগ যোগ করেছেন, যেখানে আপনি সিস্টেমের বিভিন্ন অংশ ব্যবহার করে আউটপুট দেখার সময় তথ্য প্রিন্ট করবেন। - আপনি 'webcam' আইডি সহ একটি
<video>এলিমেন্ট যোগ করেছেন, যেখানে আপনি পরবর্তীতে আপনার ওয়েবক্যাম স্ট্রিম রেন্ডার করবেন। - আপনি ৫টি
<button>এলিমেন্ট যোগ করেছেন। প্রথমটি, যার আইডি 'enableCam', ক্যামেরা চালু করে। পরবর্তী দুটি বাটনের ক্লাস হলো 'dataCollector', যা আপনাকে শনাক্ত করতে চাওয়া বস্তুগুলোর জন্য উদাহরণ ছবি সংগ্রহ করতে দেয়। পরবর্তীতে আপনি যে কোড লিখবেন তা এমনভাবে ডিজাইন করা হবে যাতে আপনি এই বাটনগুলোর যেকোনো সংখ্যক যোগ করতে পারেন এবং সেগুলো স্বয়ংক্রিয়ভাবে উদ্দেশ্য অনুযায়ী কাজ করবে।
উল্লেখ্য যে, এই বাটনগুলোতে data-1hot নামে একটি বিশেষ ইউজার-ডিফাইন্ড অ্যাট্রিবিউটও রয়েছে, যার পূর্ণসংখ্যা মান প্রথম ক্লাসের জন্য ০ থেকে শুরু হয়। এটি হলো সেই সাংখ্যিক সূচক যা আপনি একটি নির্দিষ্ট ক্লাসের ডেটা উপস্থাপন করতে ব্যবহার করবেন। এই সূচকটি আউটপুট ক্লাসগুলোকে স্ট্রিং-এর পরিবর্তে সাংখ্যিক উপস্থাপনার মাধ্যমে সঠিকভাবে এনকোড করতে ব্যবহৃত হবে, কারণ এমএল মডেলগুলো শুধুমাত্র সংখ্যা নিয়েই কাজ করতে পারে।
এছাড়াও একটি data-name অ্যাট্রিবিউট আছে, যেখানে এই ক্লাসের জন্য আপনার পছন্দসই পাঠযোগ্য নামটি থাকে। এর ফলে আপনি 1 hot এনকোডিং-এর সাংখ্যিক ইনডেক্স মানের পরিবর্তে ব্যবহারকারীকে একটি আরও অর্থপূর্ণ নাম দিতে পারেন।
অবশেষে, ডেটা সংগ্রহ হয়ে গেলে প্রশিক্ষণ প্রক্রিয়াটি শুরু করার জন্য অথবা অ্যাপটি রিসেট করার জন্য একটি ট্রেন এবং রিসেট বাটন রয়েছে।
- আপনি দুটি
<script>ইম্পোর্টও যোগ করেছেন। একটি TensorFlow.js-এর জন্য, এবং অন্যটি script.js-এর জন্য, যা আপনি শীঘ্রই সংজ্ঞায়িত করবেন।
৭. স্টাইল যোগ করুন
উপাদানের ডিফল্ট
আপনি এইমাত্র যে HTML এলিমেন্টগুলো যোগ করেছেন, সেগুলো যেন সঠিকভাবে রেন্ডার হয়, তা নিশ্চিত করতে সেগুলোতে স্টাইল যোগ করুন। এখানে কিছু স্টাইল দেওয়া হলো যা এলিমেন্টগুলোর অবস্থান ও আকার সঠিকভাবে নির্ধারণ করে। খুব বিশেষ কিছু নয়। আপনি অবশ্যই পরে এর সাথে আরও কিছু যোগ করে একটি আরও ভালো ইউজার এক্সপেরিয়েন্স (UX) তৈরি করতে পারেন, যেমনটা আপনি টিচেবল মেশিন ভিডিওতে দেখেছেন।
স্টাইল.সিএসএস
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
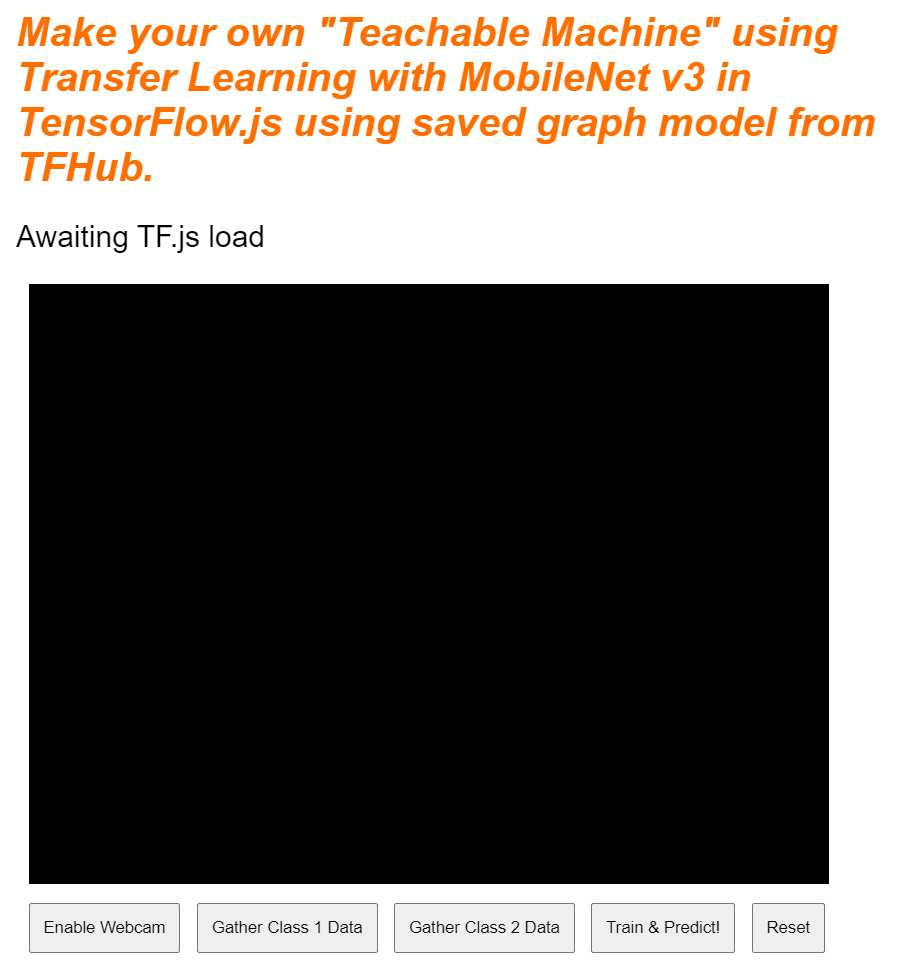
চমৎকার! আপনার শুধু এটুকুই প্রয়োজন। আপনি যদি এখনই আউটপুটটি প্রিভিউ করেন, তাহলে এটি দেখতে অনেকটা এইরকম হবে:
৮. জাভাস্ক্রিপ্ট: গুরুত্বপূর্ণ ধ্রুবক এবং লিসেনার
মূল ধ্রুবকগুলি সংজ্ঞায়িত করুন
প্রথমে, কিছু গুরুত্বপূর্ণ কনস্ট্যান্ট যোগ করুন যা আপনি পুরো অ্যাপ জুড়ে ব্যবহার করবেন। script.js ফাইলের বিষয়বস্তু এই কনস্ট্যান্টগুলো দিয়ে প্রতিস্থাপন করে শুরু করুন:
স্ক্রিপ্ট.জেএস
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
চলুন জেনে নেওয়া যাক এগুলো কীসের জন্য:
-
STATUSকেবল সেই প্যারাগ্রাফ ট্যাগের একটি রেফারেন্স ধারণ করে, যেখানে আপনি স্ট্যাটাস আপডেট লিখবেন। -
VIDEOHTML ভিডিও এলিমেন্টের একটি রেফারেন্স থাকে, যা ওয়েবক্যাম ফিডটি রেন্ডার করবে। -
ENABLE_CAM_BUTTON,RESET_BUTTONএবংTRAIN_BUTTONএইচটিএমএল পেজ থেকে সমস্ত মূল বাটনগুলোর ডম (DOM) রেফারেন্স গ্রহণ করে। -
MOBILE_NET_INPUT_WIDTHএবংMOBILE_NET_INPUT_HEIGHTযথাক্রমে MobileNet মডেলের প্রত্যাশিত ইনপুট প্রস্থ এবং উচ্চতা নির্ধারণ করে। ফাইলের উপরের দিকে এইভাবে একটি কনস্ট্যান্টে এটি সংরক্ষণ করার ফলে, আপনি যদি পরে একটি ভিন্ন সংস্করণ ব্যবহার করার সিদ্ধান্ত নেন, তবে বিভিন্ন জায়গায় এটি প্রতিস্থাপন করার পরিবর্তে একবার মানগুলি আপডেট করা সহজ হয়। -
STOP_DATA_GATHERমান -1 সেট করা আছে। এটি একটি অবস্থার মান সংরক্ষণ করে, যার ফলে আপনি জানতে পারেন কখন ব্যবহারকারী ওয়েবক্যাম ফিড থেকে ডেটা সংগ্রহের জন্য বোতামে ক্লিক করা বন্ধ করেছে। এই সংখ্যাটিকে একটি আরও অর্থপূর্ণ নাম দিলে, পরবর্তীতে কোডটি আরও সহজে পাঠযোগ্য হয়। -
CLASS_NAMESএকটি লুকআপ অ্যারে হিসেবে কাজ করে এবং সম্ভাব্য ক্লাস প্রেডিকশনগুলোর পাঠযোগ্য নাম ধারণ করে। এই অ্যারেটি পরবর্তীতে পূরণ করা হবে।
ঠিক আছে, এখন যেহেতু আপনার কাছে মূল উপাদানগুলোর রেফারেন্স আছে, সেগুলোর সাথে কিছু ইভেন্ট লিসেনার যুক্ত করার সময় এসেছে।
মূল ইভেন্ট লিসেনার যোগ করুন
দেখানো অনুযায়ী কী বাটনগুলিতে ক্লিক ইভেন্ট হ্যান্ডলার যোগ করে শুরু করুন:
স্ক্রিপ্ট.জেএস
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON - ক্লিক করা হলে enableCam ফাংশনটি চালু হয়।
TRAIN_BUTTON - ক্লিক করা হলে trainAndPredict কল করে।
RESET_BUTTON - ক্লিক করলে রিসেট চালু হয়।
অবশেষে এই বিভাগে আপনি document.querySelectorAll() ব্যবহার করে 'dataCollector' ক্লাসযুক্ত সমস্ত বাটন খুঁজে পেতে পারেন। এটি ডকুমেন্ট থেকে খুঁজে পাওয়া মিলে যাওয়া উপাদানগুলোর একটি অ্যারে রিটার্ন করে:
স্ক্রিপ্ট.জেএস
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
কোডের ব্যাখ্যা:
এরপর আপনি খুঁজে পাওয়া বাটনগুলোর প্রত্যেকটির সাথে দুটি ইভেন্ট লিসেনার যুক্ত করবেন। একটি 'মাউসডাউন'-এর জন্য এবং অন্যটি 'মাউসআপ'-এর জন্য। এর ফলে বাটনটি যতক্ষণ চাপা থাকবে, ততক্ষণ স্যাম্পল রেকর্ড করা যাবে, যা ডেটা সংগ্রহের জন্য বেশ উপযোগী।
উভয় ইভেন্টই একটি gatherDataForClass ফাংশনকে কল করে, যা আপনি পরে সংজ্ঞায়িত করবেন।
এই পর্যায়ে, আপনি HTML বাটন অ্যাট্রিবিউটের data-name থেকে খুঁজে পাওয়া পাঠযোগ্য ক্লাস নেমগুলো CLASS_NAMES অ্যারেতে পুশ করতে পারেন।
এরপরে, পরবর্তীতে ব্যবহৃত হবে এমন গুরুত্বপূর্ণ বিষয়গুলো সংরক্ষণ করার জন্য কিছু ভেরিয়েবল যোগ করুন।
স্ক্রিপ্ট.জেএস
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
চলুন সেগুলো আলোচনা করা যাক।
প্রথমে, লোড করা মোবাইলনেট মডেলটি সংরক্ষণ করার জন্য আপনার কাছে mobilenet নামে একটি ভ্যারিয়েবল আছে। প্রাথমিকভাবে এটিকে 'undefined' সেট করুন।
এরপরে, আপনার কাছে gatherDataState নামে একটি ভ্যারিয়েবল আছে। যদি একটি 'dataCollector' বাটন চাপা হয়, তাহলে এটি HTML-এ সংজ্ঞায়িত সেই বাটনের ১ হট আইডি-তে পরিবর্তিত হয়ে যায়, ফলে আপনি জানতে পারেন যে সেই মুহূর্তে আপনি কোন শ্রেণীর ডেটা সংগ্রহ করছেন। প্রাথমিকভাবে, এটি STOP_DATA_GATHER এ সেট করা থাকে, যাতে পরে লেখা আপনার ডেটা সংগ্রহের লুপটি কোনো বাটন চাপা না থাকলে কোনো ডেটা সংগ্রহ না করে।
videoPlaying ওয়েবক্যাম স্ট্রিমটি সফলভাবে লোড ও প্লে হচ্ছে কিনা এবং ব্যবহারের জন্য উপলব্ধ আছে কিনা তার হিসাব রাখে। প্রাথমিকভাবে, এটি false সেট করা থাকে, কারণ আপনি ENABLE_CAM_BUTTON.
এরপর, trainingDataInputs এবং trainingDataOutputs নামে দুটি অ্যারে সংজ্ঞায়িত করুন। আপনি যখন MobileNet বেস মডেল দ্বারা তৈরি ইনপুট ফিচার এবং যথাক্রমে স্যাম্পল করা আউটপুট ক্লাসের জন্য 'dataCollector' বোতামে ক্লিক করেন, তখন সংগৃহীত প্রশিক্ষণ ডেটার মানগুলো এই অ্যারেগুলোতে জমা হয়।
এরপর, আপনি উদাহরণ যোগ করা শুরু করলে প্রতিটি ক্লাসে কতগুলো উদাহরণ রয়েছে তার হিসাব রাখার জন্য examplesCount, একটি চূড়ান্ত অ্যারে সংজ্ঞায়িত করা হয়।
সবশেষে, আপনার কাছে predict নামে একটি ভ্যারিয়েবল আছে যা আপনার প্রেডিকশন লুপ নিয়ন্ত্রণ করে। এটি প্রাথমিকভাবে false সেট করা থাকে। পরবর্তীতে এটিকে true সেট না করা পর্যন্ত কোনো প্রেডিকশন হতে পারে না।
এখন যেহেতু সমস্ত মূল ভেরিয়েবল সংজ্ঞায়িত করা হয়েছে, চলুন আগে থেকে সংক্ষিপ্ত করা MobileNet v3 বেস মডেলটি লোড করি, যা ক্লাসিফিকেশনের পরিবর্তে ইমেজ ফিচার ভেক্টর সরবরাহ করে।
৯. মোবাইলনেট বেস মডেল লোড করুন
প্রথমে, নিচে দেখানো অনুযায়ী loadMobileNetFeatureModel নামে একটি নতুন ফাংশন সংজ্ঞায়িত করুন। এটি অবশ্যই একটি async ফাংশন হতে হবে, কারণ একটি মডেল লোড করার কাজটি অ্যাসিঙ্ক্রোনাস:
স্ক্রিপ্ট.জেএস
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
এই কোডে আপনি TFHub ডকুমেন্টেশন থেকে লোড করার জন্য মডেলটির URL নির্ধারণ করেন।
এরপর আপনি await tf.loadGraphModel() ব্যবহার করে মডেলটি লোড করতে পারেন। তবে মনে রাখবেন, যেহেতু আপনি এই গুগল ওয়েবসাইট থেকে একটি মডেল লোড করছেন, তাই fromTFHub নামক বিশেষ প্রপার্টিটির মান true সেট করতে হবে। এটি শুধুমাত্র TF Hub-এ হোস্ট করা মডেল ব্যবহারের একটি বিশেষ ক্ষেত্র, যেখানে এই অতিরিক্ত প্রপার্টিটি সেট করতে হয়।
লোডিং সম্পূর্ণ হয়ে গেলে আপনি STATUS এলিমেন্টের innerText এ একটি বার্তা সেট করতে পারেন, যাতে আপনি চোখে দেখে বুঝতে পারেন যে এটি সঠিকভাবে লোড হয়েছে এবং আপনি ডেটা সংগ্রহ শুরু করার জন্য প্রস্তুত।
এখন শুধু মডেলটিকে ওয়ার্ম আপ করা বাকি। এই ধরনের বড় মডেলের ক্ষেত্রে, প্রথমবার ব্যবহারের সময় সবকিছু সেট আপ হতে কিছুটা সময় লাগতে পারে। তাই, ভবিষ্যতে যেখানে টাইমিং আরও গুরুত্বপূর্ণ হতে পারে, সেখানে অপেক্ষা এড়ানোর জন্য মডেলের মধ্যে দিয়ে জিরো পাস করে দেওয়া সহায়ক হয়।
টেনসরগুলো যাতে সঠিকভাবে ডিসপোজ হয়, তা নিশ্চিত করতে আপনি tf.tidy() এর মধ্যে tf.zeros() ব্যবহার করতে পারেন। এক্ষেত্রে ব্যাচ সাইজ হবে ১ এবং শুরুতে আপনার কনস্ট্যান্টে সংজ্ঞায়িত করা সঠিক উচ্চতা ও প্রস্থ ব্যবহৃত হবে। সবশেষে, আপনাকে কালার চ্যানেলগুলোও নির্দিষ্ট করতে হবে, যা এই ক্ষেত্রে ৩, কারণ মডেলটি RGB ইমেজ আশা করে।
এরপরে, এই মডেল দ্বারা উৎপাদিত ইমেজ ফিচারগুলোর আকার বুঝতে, answer.shape() ব্যবহার করে প্রাপ্ত টেনসরের আকৃতিটি লগ করুন।
এই ফাংশনটি সংজ্ঞায়িত করার পর, পেজ লোড হওয়ার সাথে সাথেই মডেল ডাউনলোড শুরু করার জন্য আপনি এটিকে কল করতে পারেন।
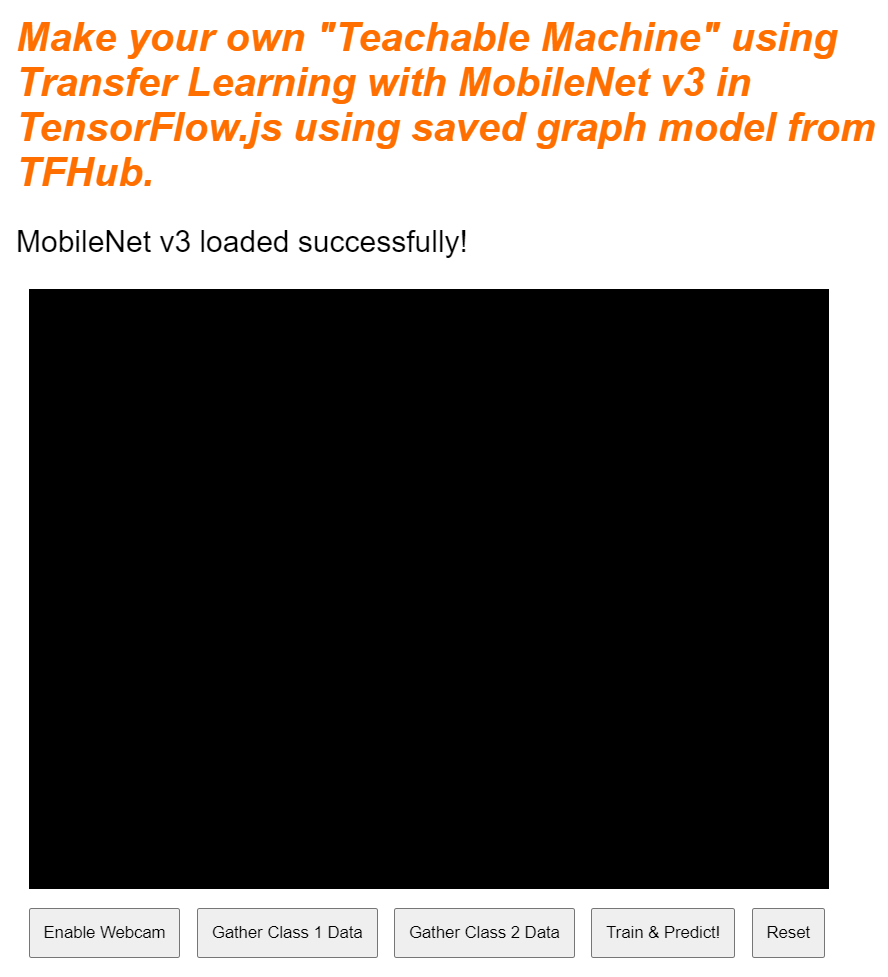
আপনি যদি এখনই আপনার লাইভ প্রিভিউ দেখেন, তাহলে কিছুক্ষণ পরেই দেখবেন স্ট্যাটাস টেক্সটটি "Awaiting TF.js load" থেকে পরিবর্তিত হয়ে "MobileNet v3 loaded successfully!" হয়ে গেছে, যেমনটি নিচে দেখানো হয়েছে। চালিয়ে যাওয়ার আগে এটি সঠিকভাবে কাজ করছে কিনা তা নিশ্চিত করুন।
এই মডেলটি যে আউটপুট ফিচারগুলো তৈরি করে, সেগুলোর প্রিন্ট করা আকার দেখতে আপনি কনসোল আউটপুটও দেখতে পারেন। MobileNet মডেলে শূন্য চালানোর পর, আপনি [1, 1024] আকারের একটি আউটপুট দেখতে পাবেন। প্রথম আইটেমটি হলো ব্যাচ সাইজ 1, এবং আপনি দেখতে পাবেন যে এটি আসলে 1024টি ফিচার রিটার্ন করে, যা পরবর্তীতে নতুন অবজেক্টগুলোকে শ্রেণীবদ্ধ করতে আপনাকে সাহায্য করতে ব্যবহার করা যেতে পারে।
১০. নতুন মডেলের মাথাটি সংজ্ঞায়িত করুন
এখন আপনার মডেল হেডটি সংজ্ঞায়িত করার সময় এসেছে, যা মূলত একটি অত্যন্ত ন্যূনতম বহুস্তরীয় পারসেপট্রন।
স্ক্রিপ্ট.জেএস
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
চলুন এই কোডটি বিশ্লেষণ করা যাক। প্রথমে আপনাকে একটি tf.sequential মডেল সংজ্ঞায়িত করতে হবে, যেটিতে আপনি মডেল লেয়ারগুলো যুক্ত করবেন।
এরপর, এই মডেলের ইনপুট লেয়ার হিসেবে একটি ডেন্স লেয়ার যোগ করুন। এর ইনপুট শেপ হলো 1024 কারণ MobileNet v3 ফিচারগুলোর আউটপুট এই আকারের হয়ে থাকে। আগের ধাপে মডেলের মধ্য দিয়ে এক (ones) পাস করার পর আপনি এটি জানতে পেরেছেন। এই লেয়ারটিতে ১২৮টি নিউরন রয়েছে, যেগুলো ReLU অ্যাক্টিভেশন ফাংশন ব্যবহার করে।
আপনি যদি অ্যাক্টিভেশন ফাংশন এবং মডেল লেয়ারের সাথে নতুন পরিচিত হন, তবে এই প্রোপার্টিগুলো নেপথ্যে কী কাজ করে তা বোঝার জন্য এই কর্মশালার শুরুতে বিস্তারিতভাবে বর্ণিত কোর্সটি করার কথা বিবেচনা করতে পারেন ।
এর পরের স্তরটি হলো আউটপুট লেয়ার। নিউরনের সংখ্যা আপনার ভবিষ্যদ্বাণী করতে চাওয়া ক্লাসের সংখ্যার সমান হওয়া উচিত। এটি করার জন্য, আপনি CLASS_NAMES.length ব্যবহার করে খুঁজে বের করতে পারেন যে আপনি কতগুলি ক্লাস শ্রেণীবদ্ধ করার পরিকল্পনা করছেন, যা ইউজার ইন্টারফেসে থাকা ডেটা গ্যাদার বাটনের সংখ্যার সমান। যেহেতু এটি একটি ক্লাসিফিকেশন সমস্যা, তাই এই আউটপুট লেয়ারে softmax অ্যাক্টিভেশন ব্যবহার করতে হবে, যা রিগ্রেশনের পরিবর্তে ক্লাসিফিকেশন সমস্যা সমাধানের জন্য মডেল তৈরি করার সময় অবশ্যই ব্যবহার করতে হবে।
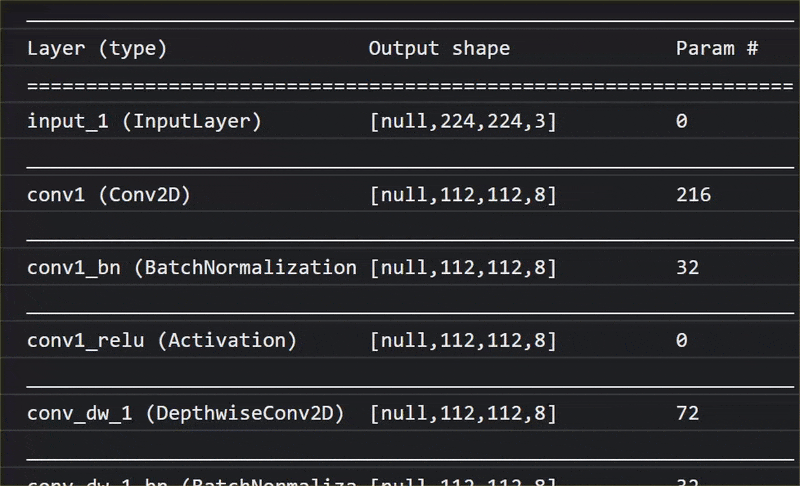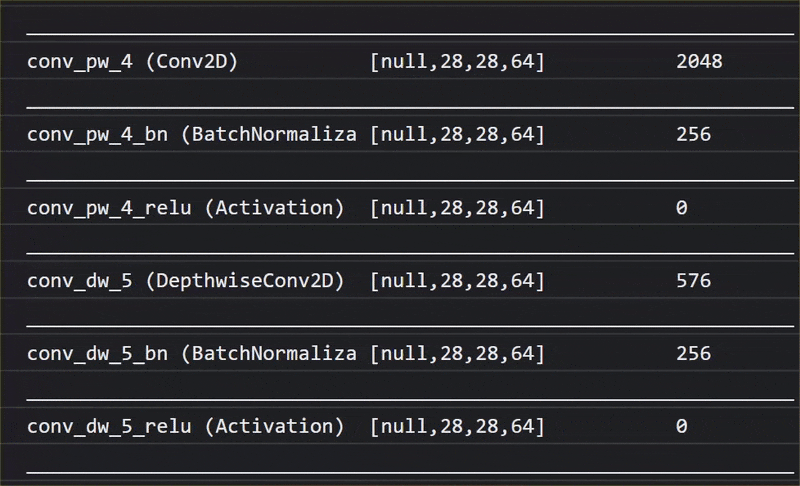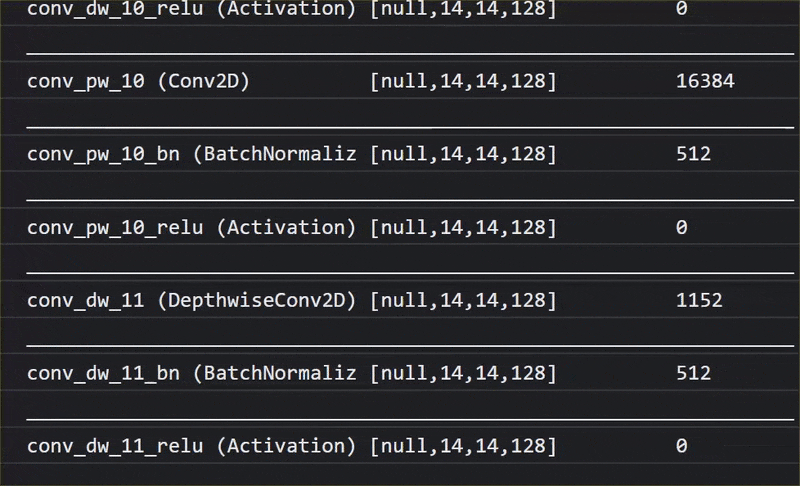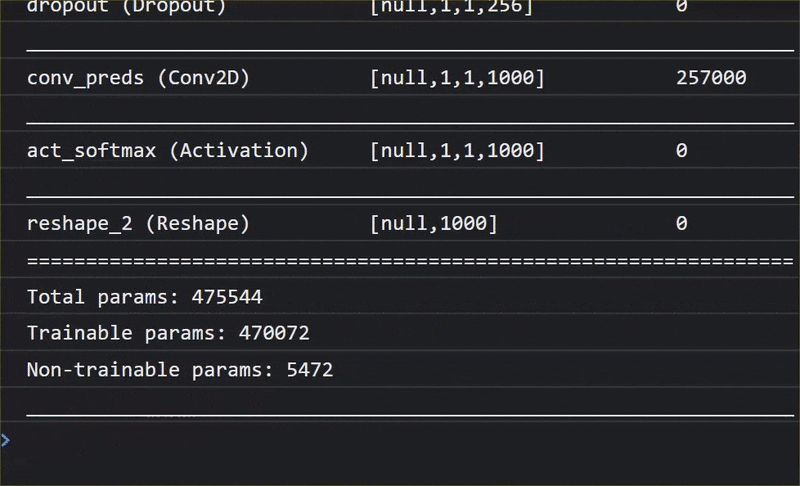
এখন নতুন সংজ্ঞায়িত মডেলটির একটি সংক্ষিপ্ত বিবরণ কনসোলে প্রিন্ট করতে model.summary() ব্যবহার করুন।
অবশেষে, মডেলটি কম্পাইল করুন যাতে এটি প্রশিক্ষণের জন্য প্রস্তুত হয়। এখানে অপটিমাইজারটি ‘অ্যাডাম’ ( adam এ সেট করা হয়েছে, এবং যদি CLASS_NAMES.length এর মান 2 হয় তবে লস হবে binaryCrossentropy , অথবা যদি শ্রেণীবিন্যাস করার জন্য ৩ বা তার বেশি শ্রেণী থাকে তবে এটি categoricalCrossentropy ব্যবহার করবে। অ্যাকুরেসি মেট্রিক্সও অনুরোধ করা হয়েছে যাতে পরবর্তীতে ডিবাগিংয়ের উদ্দেশ্যে লগগুলিতে সেগুলি পর্যবেক্ষণ করা যায়।
কনসোলে আপনি এইরকম কিছু দেখতে পাবেন:
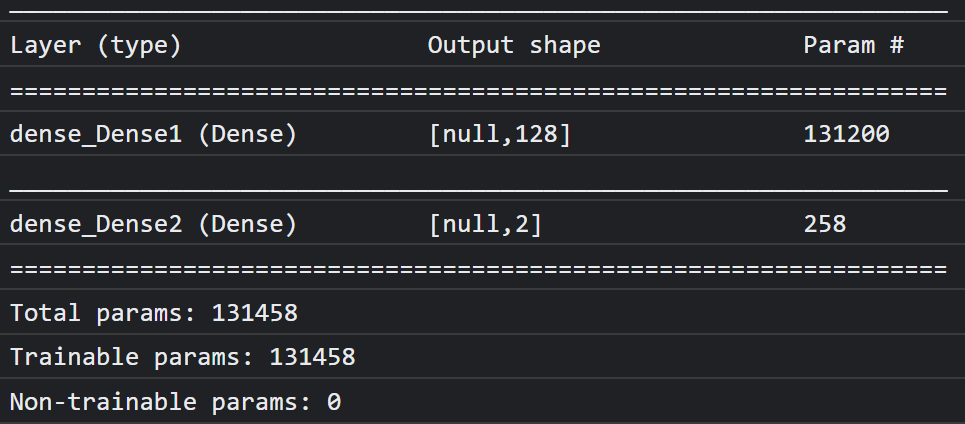
উল্লেখ্য যে, এতে ১ লক্ষ ৩০ হাজারেরও বেশি প্রশিক্ষণযোগ্য প্যারামিটার রয়েছে। কিন্তু যেহেতু এটি সাধারণ নিউরনের একটি সরল ডেন্স লেয়ার, তাই এটি বেশ দ্রুত প্রশিক্ষিত হবে।
প্রকল্পটি সম্পন্ন হওয়ার পর একটি করণীয় কাজ হিসেবে, আপনি প্রথম লেয়ারের নিউরনের সংখ্যা পরিবর্তন করে দেখতে পারেন যে, ভালো পারফরম্যান্স পাওয়ার জন্য সংখ্যাটি কতটা কমানো যায়। মেশিন লার্নিং-এর ক্ষেত্রে প্রায়শই রিসোর্স ব্যবহার এবং গতির মধ্যে সেরা ভারসাম্য খুঁজে বের করার জন্য সর্বোত্তম প্যারামিটার মানগুলো পরীক্ষা-নিরীক্ষার প্রয়োজন হয়।
১১. ওয়েবক্যাম চালু করুন।
এখন আপনার পূর্বে সংজ্ঞায়িত করা enableCam() ফাংশনটিকে বিস্তারিত করার সময় এসেছে। নিচে দেখানো অনুযায়ী hasGetUserMedia() নামে একটি নতুন ফাংশন যোগ করুন এবং তারপর পূর্বে সংজ্ঞায়িত enableCam() ফাংশনের বিষয়বস্তু নিচের সংশ্লিষ্ট কোড দিয়ে প্রতিস্থাপন করুন।
স্ক্রিপ্ট.জেএস
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
প্রথমে, hasGetUserMedia() নামে একটি ফাংশন তৈরি করুন, যা ব্রাউজারের মূল এপিআই প্রোপার্টিগুলোর অস্তিত্ব যাচাই করার মাধ্যমে ব্রাউজারটি getUserMedia() সমর্থন করে কিনা তা পরীক্ষা করবে।
enableCam() ` ফাংশনের মধ্যে, এটি সমর্থিত কিনা তা পরীক্ষা করার জন্য উপরে সংজ্ঞায়িত ` hasGetUserMedia() ফাংশনটি ব্যবহার করুন। যদি এটি সমর্থিত না হয়, তাহলে কনসোলে একটি সতর্কবার্তা প্রিন্ট করুন।
যদি এটি সমর্থন করে, তাহলে আপনার getUserMedia() কলের জন্য কিছু সীমাবদ্ধতা নির্ধারণ করুন, যেমন আপনি শুধু ভিডিও স্ট্রিমটি চান, এবং ভিডিওটির width 640 পিক্সেল ও height 480 পিক্সেল হোক। কেন? কারণ, এর চেয়ে বড় ভিডিও নেওয়ার কোনো মানে হয় না, যেহেতু MobileNet মডেলে দেওয়ার জন্য এটিকে ২২৪ বাই ২২৪ পিক্সেলে রিসাইজ করতে হবে। এর চেয়ে ছোট রেজোলিউশনের অনুরোধ করে আপনি কিছু কম্পিউটিং রিসোর্স বাঁচাতে পারেন। বেশিরভাগ ক্যামেরাই এই আকারের রেজোলিউশন সমর্থন করে।
এরপর, উপরে বর্ণিত constraints সহ navigator.mediaDevices.getUserMedia() কল করুন এবং stream ফেরত আসা পর্যন্ত অপেক্ষা করুন। stream ফেরত এলে, আপনি আপনার VIDEO এলিমেন্টের srcObject ভ্যালু হিসেবে এটি সেট করে stream প্লে করতে পারবেন।
stream কখন লোড হয়েছে এবং সফলভাবে প্লে হচ্ছে তা জানার জন্য আপনার VIDEO এলিমেন্টে একটি ইভেন্টলিসেনারও যোগ করা উচিত।
স্টিম লোড হয়ে গেলে, আপনি videoPlaying true সেট করতে পারেন এবং ENABLE_CAM_BUTTON এর ক্লাস " removed "-এ সেট করে সেটিকে পুনরায় ক্লিক করা থেকে বিরত রাখতে পারেন।
এখন আপনার কোডটি রান করুন, ‘enable camera’ বাটনটিতে ক্লিক করুন এবং ওয়েবক্যাম ব্যবহারের অনুমতি দিন। আপনি যদি প্রথমবারের মতো এটি করে থাকেন, তাহলে দেখানো ছবির মতো করে পেজের ভিডিও এলিমেন্টে নিজেকে রেন্ডার হতে দেখবেন:

আচ্ছা, এখন dataCollector বাটনের ক্লিকগুলো পরিচালনা করার জন্য একটি ফাংশন যোগ করার সময় হয়েছে।
১২. ডেটা সংগ্রহ বাটনের ইভেন্ট হ্যান্ডলার
এখন আপনার gatherDataForClass(). কোডল্যাবের শুরুতে আপনি dataCollector বাটনগুলোর জন্য ইভেন্ট হ্যান্ডলার ফাংশন হিসেবে এটিই নির্ধারণ করেছিলেন।
স্ক্রিপ্ট.জেএস
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
প্রথমে, বর্তমানে ক্লিক করা বাটনের data-1hot অ্যাট্রিবিউটটি পরীক্ষা করুন। এর জন্য, প্যারামিটার হিসেবে অ্যাট্রিবিউটের নাম (এই ক্ষেত্রে data-1hot ) দিয়ে this.getAttribute() ফাংশনটি কল করুন। যেহেতু এটি একটি স্ট্রিং, তাই আপনি parseInt() ব্যবহার করে এটিকে একটি ইন্টিজারে রূপান্তর করতে পারেন এবং এই ফলাফলটি classNumber.
Next, set the gatherDataState variable accordingly. If the current gatherDataState is equal to STOP_DATA_GATHER (which you set to be -1), then that means you are not currently gathering any data and it was a mousedown event that fired. Set the gatherDataState to be the classNumber you just found.
Otherwise, it means that you are currently gathering data and the event that fired was a mouseup event, and you now want to stop gathering data for that class. Just set it back to the STOP_DATA_GATHER state to end the data gathering loop you will define shortly.
Finally, kick off the call to dataGatherLoop(), which actually performs the recording of class data.
13. Data collection
Now, define the dataGatherLoop() function. This function is responsible for sampling images from the webcam video, passing them through the MobileNet model, and capturing the outputs of that model (the 1024 feature vectors).
It then stores them along with the gatherDataState ID of the button that is currently being pressed so you know what class this data represents.
Let's walk through it:
স্ক্রিপ্ট.জেএস
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
You are only going to continue this function's execution if videoPlaying is true, meaning that the webcam is active, and gatherDataState is not equal to STOP_DATA_GATHER and a button for class data gathering is currently being pressed.
Next, wrap your code in a tf.tidy() to dispose of any created tensors in the code that follows. The result of this tf.tidy() code execution is stored in a variable called imageFeatures .
You can now grab a frame of the webcam VIDEO using tf.browser.fromPixels() . The resulting tensor containing the image data is stored in a variable called videoFrameAsTensor .
Next, resize the videoFrameAsTensor variable to be of the correct shape for the MobileNet model's input. Use a tf.image.resizeBilinear() call with the tensor you want to reshape as the first parameter, and then a shape that defines the new height and width as defined by the constants you already created earlier. Finally, set align corners to true by passing the third parameter to avoid any alignment issues when resizing. The result of this resize is stored in a variable called resizedTensorFrame .
Note that this primitive resize stretches the image, as your webcam image is 640 by 480 pixels in size, and the model needs a square image of 224 by 224 pixels.
For the purposes of this demo this should work fine. However, once you complete this codelab, you may want to try and crop a square from this image instead for even better results for any production system you may create later.
Next, normalize the image data. Image data is always in the range of 0 to 255 when using tf.browser.frompixels() , so you can simply divide resizedTensorFrame by 255 to ensure all values are between 0 and 1 instead, which is what the MobileNet model expects as inputs.
Finally, in the tf.tidy() section of the code, push this normalized tensor through the loaded model by calling mobilenet.predict() , to which you pass the expanded version of the normalizedTensorFrame using expandDims() so that it is a batch of 1, as the model expects a batch of inputs for processing.
Once the result comes back, you can then immediately call squeeze() on that returned result to squash it back down to a 1D tensor, which you then return and assign to the imageFeatures variable that captures the result from tf.tidy() .
Now that you have the imageFeatures from the MobileNet model, you can record those by pushing them onto the trainingDataInputs array that you defined previously.
You can also record what this input represents by pushing the current gatherDataState to the trainingDataOutputs array too.
Note that the gatherDataState variable would have been set to the current class's numerical ID you are recording data for when the button was clicked in the previously defined gatherDataForClass() function.
At this point you can also increment the number of examples you have for a given class. To do this, first check if the index within the examplesCount array has been initialized before or not. If it is undefined, set it to 0 to initialize the counter for a given class's numerical ID, and then you can increment the examplesCount for the current gatherDataState .
Now update the STATUS element's text on the web page to show the current counts for each class as they're captured. To do this, loop through the CLASS_NAMES array, and print the human readable name combined with the data count at the same index in examplesCount .
Finally, call window.requestAnimationFrame() with dataGatherLoop passed as a parameter, to recursively call this function again. This will continue to sample frames from the video until the button's mouseup is detected, and gatherDataState is set to STOP_DATA_GATHER, at which point the data gather loop will end.
If you run your code now, you should be able to click the enable camera button, await the webcam to load, and then click and hold each of the data gather buttons to gather examples for each class of data. Here you see me gather data for my mobile phone and my hand respectively.
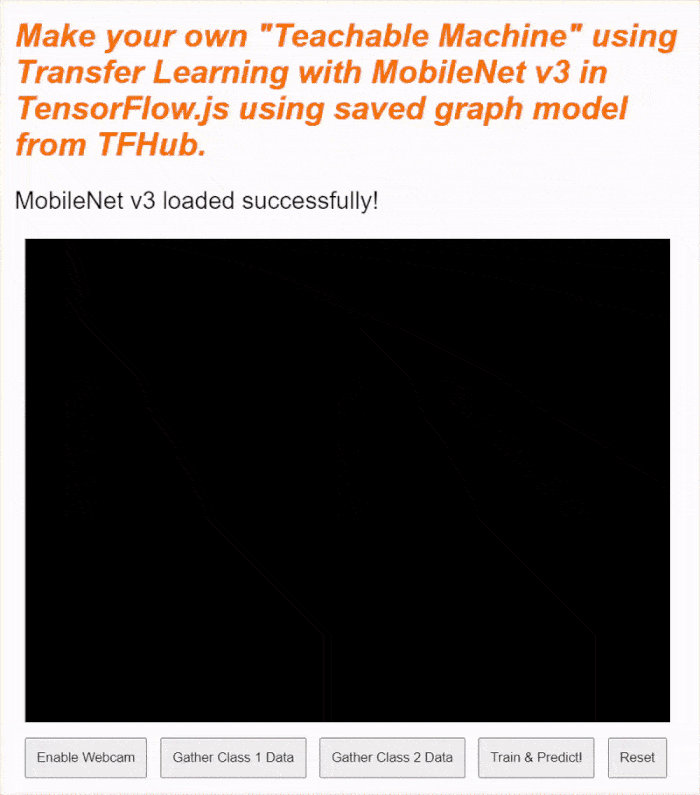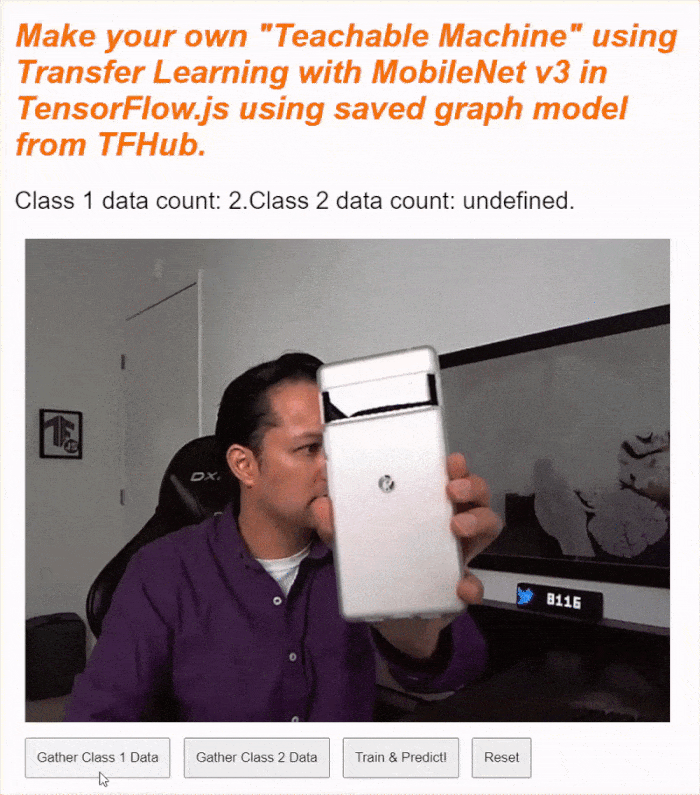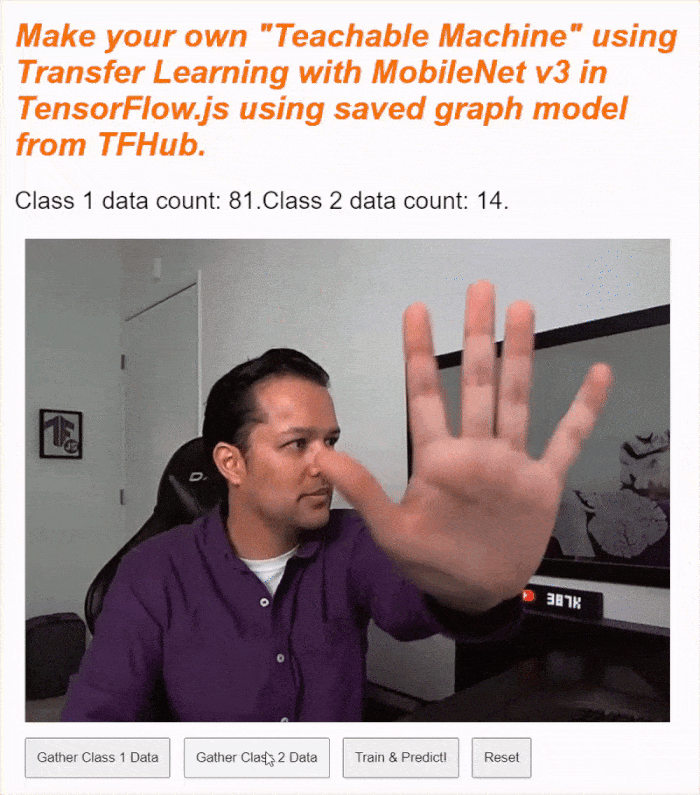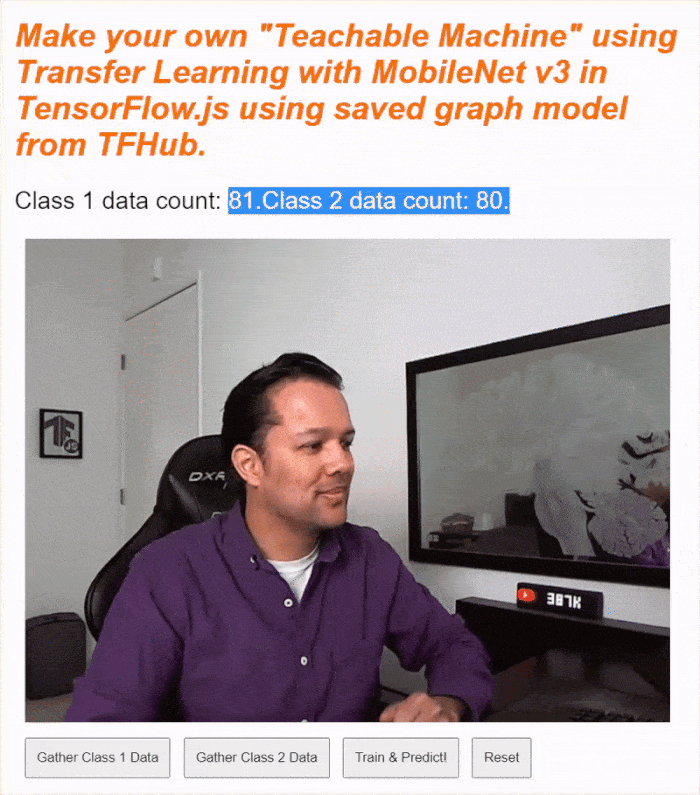
You should see the status text updated as it stores all the tensors in memory as shown in the screen capture above.
14. Train and predict
The next step is to implement code for your currently empty trainAndPredict() function, which is where the transfer learning takes place. Let's take a look at the code:
স্ক্রিপ্ট.জেএস
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
First, ensure you stop any current predictions from taking place by setting predict to false .
Next, shuffle your input and output arrays using tf.util.shuffleCombo() to ensure the order does not cause issues in training.
Convert your output array, trainingDataOutputs, to be a tensor1d of type int32 so it is ready to be used in a one hot encoding . This is stored in a variable named outputsAsTensor .
Use the tf.oneHot() function with this outputsAsTensor variable along with the max number of classes to encode, which is just the CLASS_NAMES.length . Your one hot encoded outputs are now stored in a new tensor called oneHotOutputs .
Note that currently trainingDataInputs is an array of recorded tensors. In order to use these for training you will need to convert the array of tensors to become a regular 2D tensor.
To do that there is a great function within the TensorFlow.js library called tf.stack() ,
which takes an array of tensors and stacks them together to produce a higher dimensional tensor as an output. In this case a tensor 2D is returned, that's a batch of 1 dimensional inputs that are each 1024 in length containing the features recorded, which is what you need for training.
Next, await model.fit() to train the custom model head. Here you pass your inputsAsTensor variable along with the oneHotOutputs to represent the training data to use for example inputs and target outputs respectively. In the configuration object for the 3rd parameter, set shuffle to true , use batchSize of 5 , with epochs set to 10 , and then specify a callback for onEpochEnd to the logProgress function that you will define shortly.
Finally, you can dispose of the created tensors as the model is now trained. You can then set predict back to true to allow predictions to take place again, and then call the predictLoop() function to start predicting live webcam images.
You can also define the logProcess() function to log the state of training, which is used in model.fit() above and that prints results to console after each round of training.
You're almost there! Time to add the predictLoop() function to make predictions.
Core prediction loop
Here you implement the main prediction loop that samples frames from a webcam and continuously predicts what is in each frame with real time results in the browser.
Let's check the code:
স্ক্রিপ্ট.জেএস
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
First, check that predict is true, so that predictions are only made after a model is trained and is available to use.
Next, you can get the image features for the current image just like you did in the dataGatherLoop() function. Essentially, you grab a frame from the webcam using tf.browser.from pixels() , normalise it, resize it to be 224 by 224 pixels in size, and then pass that data through the MobileNet model to get the resulting image features.
Now, however, you can use your newly trained model head to actually perform a prediction by passing the resulting imageFeatures just found through the trained model's predict() function. You can then squeeze the resulting tensor to make it 1 dimensional again and assign it to a variable called prediction .
With this prediction you can find the index that has the highest value using argMax() , and then convert this resulting tensor to an array using arraySync() to get at the underlying data in JavaScript to discover the position of the highest valued element. This value is stored in the variable called highestIndex .
You can also get the actual prediction confidence scores in the same way by calling arraySync() on the prediction tensor directly.
You now have everything you need to update the STATUS text with the prediction data. To get the human readable string for the class you can just look up the highestIndex in the CLASS_NAMES array, and then grab the confidence value from the predictionArray . To make it more readable as a percentage, just multiply by 100 and math.floor() the result.
Finally, you can use window.requestAnimationFrame() to call predictionLoop() all over again once ready, to get real time classification on your video stream. This continues until predict is set to false if you choose to train a new model with new data.
Which brings you to the final piece of the puzzle. Implementing the reset button.
15. Implement the reset button
Almost complete! The final piece of the puzzle is to implement a reset button to start over. The code for your currently empty reset() function is below. Go ahead and update it as follows:
স্ক্রিপ্ট.জেএস
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
First, stop any running prediction loops by setting predict to false . Next, delete all contents in the examplesCount array by setting its length to 0, which is a handy way to clear all contents from an array.
Now go through all the current recorded trainingDataInputs and ensure you dispose() of each tensor contained within it to free up memory again, as Tensors are not cleaned up by the JavaScript garbage collector.
Once that is done you can now safely set the array length to 0 on both the trainingDataInputs and trainingDataOutputs arrays to clear those too.
Finally set the STATUS text to something sensible, and print out the tensors left in memory as a sanity check.
Note that there will be a few hundred tensors still in memory as both the MobileNet model and the multi-layer perceptron you defined are not disposed of. You will need to reuse them with new training data if you decide to train again after this reset.
16. Let's try it out
It's time to test out your very own version of Teachable Machine!
Head to the live preview, enable the webcam, gather at least 30 samples for class 1 for some object in your room, and then do the same for class 2 for a different object, click train, and check the console log to see progress. It should train pretty fast:

Once trained, show the objects to the camera to get live predictions that will be printed to the status text area on the web page near the top. If you are having trouble, check my completed working code to see if you missed copying over anything.
17. Congratulations
Congratulations! You have just completed your very first transfer learning example using TensorFlow.js live in the browser.
Try it out, test it on a variety of objects, you may notice some things are harder to recognize than others, especially if they are similar to something else. You may need to add more classes or training data to be able to tell them apart.
পুনরালোচনা
In this codelab you learned:
- What transfer learning is, and its advantages over training a full model.
- How to get models for re-use from TensorFlow Hub.
- How to set up a web app suitable for transfer learning.
- How to load and use a base model to generate image features.
- How to train a new prediction head that can recognize custom objects from webcam imagery.
- How to use the resulting models to classify data in real time.
এরপর কী?
Now that you have a working base to start from, what creative ideas can you come up with to extend this machine learning model boilerplate for a real world use case you may be working on? Maybe you could revolutionize the industry that you currently work in to help folk at your company train models to classify things that are important in their day-to-day work? The possibilities are endless.
To go further, consider taking this full course for free , which shows you how to combine the 2 models you currently have in this codelab into 1 single model for efficiency.
Also if you are curious more around the theory behind the original teachable machine application check out this tutorial .
আপনি যা তৈরি করেন তা আমাদের সাথে শেয়ার করুন
আপনি আজ যা তৈরি করেছেন তা সহজেই অন্যান্য সৃজনশীল কাজেও ব্যবহার করতে পারেন এবং আমরা আপনাকে গতানুগতিক চিন্তাধারার বাইরে ভাবতে ও নতুন কিছু উদ্ভাবন চালিয়ে যেতে উৎসাহিত করি।
আপনার প্রজেক্টটি আমাদের টেনসরফ্লো ব্লগে বা ভবিষ্যতের কোনো অনুষ্ঠানে প্রদর্শিত হওয়ার সুযোগ পেতে, #MadeWithTFJS হ্যাশট্যাগটি ব্যবহার করে সোশ্যাল মিডিয়ায় আমাদের ট্যাগ করতে ভুলবেন না। আপনি কী তৈরি করেন তা দেখার জন্য আমরা অধীর আগ্রহে অপেক্ষা করছি।
যাচাই করার জন্য ওয়েবসাইটগুলি
- TensorFlow.js অফিসিয়াল ওয়েবসাইট
- TensorFlow.js-এর পূর্ব-নির্মিত মডেল
- TensorFlow.js API
- TensorFlow.js Show & Tell — get inspired and see what others have made.