
۱. قبل از شروع
استفاده از مدل TensorFlow.js در چند سال گذشته به صورت تصاعدی افزایش یافته است و بسیاری از توسعهدهندگان جاوا اسکریپت اکنون به دنبال استفاده از مدلهای پیشرفته موجود و آموزش مجدد آنها برای کار با دادههای سفارشی هستند که مختص صنعت آنها است. عمل استفاده از یک مدل موجود (که اغلب به عنوان مدل پایه شناخته میشود) و استفاده از آن در یک دامنه مشابه اما متفاوت، به عنوان یادگیری انتقالی شناخته میشود.
یادگیری انتقالی مزایای زیادی نسبت به شروع از یک مدل کاملاً خالی دارد. شما میتوانید از دانشی که قبلاً از یک مدل آموزشدیده قبلی آموختهاید، دوباره استفاده کنید و به نمونههای کمتری از مورد جدیدی که میخواهید طبقهبندی کنید، نیاز دارید. همچنین، آموزش اغلب به طور قابل توجهی سریعتر است زیرا فقط باید چند لایه آخر معماری مدل را به جای کل شبکه آموزش مجدد دهید. به همین دلیل، یادگیری انتقالی برای محیط مرورگر وب که منابع ممکن است بر اساس دستگاه اجرا متفاوت باشند، بسیار مناسب است، اما همچنین دسترسی مستقیم به حسگرها برای کسب آسان دادهها دارد.
این آزمایشگاه کد به شما نشان میدهد که چگونه یک برنامه وب را از یک بوم خالی بسازید و وبسایت محبوب " ماشین قابل آموزش " گوگل را بازسازی کنید. این وبسایت به شما امکان میدهد یک برنامه وب کاربردی ایجاد کنید که هر کاربری میتواند از آن برای تشخیص یک شیء سفارشی تنها با چند تصویر نمونه از وبکم خود استفاده کند. این وبسایت عمداً مینیمال نگه داشته شده است تا بتوانید بر جنبههای یادگیری ماشینی این آزمایشگاه کد تمرکز کنید. با این حال، مانند وبسایت اصلی ماشین قابل آموزش، فضای زیادی برای اعمال تجربه توسعهدهنده وب فعلی شما برای بهبود تجربه کاربری وجود دارد.
پیشنیازها
این آزمایشگاه کد برای توسعهدهندگان وبی نوشته شده است که تا حدودی با مدلهای پیشساخته TensorFlow.js و استفاده اولیه از API آشنا هستند و میخواهند یادگیری انتقالی را در TensorFlow.js آغاز کنند.
- آشنایی اولیه با TensorFlow.js، HTML5، CSS و جاوا اسکریپت برای این آزمایش فرض شده است.
اگر در Tensorflow.js تازهکار هستید، ابتدا این دوره رایگان «از صفر تا صد» را در نظر بگیرید که فرض را بر این میگذارد که هیچ پیشزمینهای با یادگیری ماشین یا TensorFlow.js ندارید و هر آنچه را که باید بدانید در گامهای کوچکتر به شما آموزش میدهد.
آنچه یاد خواهید گرفت
- TensorFlow.js چیست و چرا باید از آن در برنامه وب بعدی خود استفاده کنید؟
- چگونه یک صفحه وب ساده شده HTML/CSS/JS بسازیم که تجربه کاربری Teachable Machine را تکرار کند.
- نحوه استفاده از TensorFlow.js برای بارگذاری یک مدل پایه از پیش آموزش دیده، به ویژه MobileNet، برای تولید ویژگیهای تصویری که میتوانند در یادگیری انتقالی استفاده شوند.
- نحوه جمعآوری دادهها از وبکم کاربر برای چندین کلاس داده که میخواهید تشخیص دهید.
- چگونه یک پرسپترون چندلایه ایجاد و تعریف کنیم که ویژگیهای تصویر را دریافت کرده و یاد میگیرد اشیاء جدید را با استفاده از آنها طبقهبندی کند.
بریم سراغ هک...
آنچه نیاز دارید
- برای دنبال کردن، داشتن یک حساب کاربری Glitch.com ترجیح داده میشود، یا میتوانید از یک محیط وبسرویس که در ویرایش و اجرای آن راحت هستید، استفاده کنید.
۲. TensorFlow.js چیست؟

TensorFlow.js یک کتابخانه یادگیری ماشین متنباز است که میتواند در هر جایی که جاوااسکریپت میتواند اجرا شود، اجرا شود. این کتابخانه بر اساس کتابخانه اصلی TensorFlow نوشته شده در پایتون است و هدف آن ایجاد مجدد این تجربه توسعهدهنده و مجموعه APIها برای اکوسیستم جاوااسکریپت است.
کجاها میشه ازش استفاده کرد؟
با توجه به قابلیت حمل جاوا اسکریپت، اکنون میتوانید به یک زبان بنویسید و یادگیری ماشین را در تمام پلتفرمهای زیر به راحتی انجام دهید:
- سمت کلاینت در مرورگر وب با استفاده از جاوا اسکریپت معمولی
- سمت سرور و حتی دستگاههای اینترنت اشیا مانند رزبری پای با استفاده از Node.js
- برنامههای دسکتاپ با استفاده از الکترون
- اپلیکیشنهای موبایل نیتیو با استفاده از React Native
TensorFlow.js همچنین از چندین backend در هر یک از این محیطها پشتیبانی میکند (محیطهای مبتنی بر سختافزار واقعی که میتواند در آنها اجرا شود، مانند CPU یا WebGL. به عنوان مثال، "backend" در این زمینه به معنای محیط سمت سرور نیست - backend برای اجرا میتواند به عنوان مثال سمت کلاینت در WebGL باشد) تا سازگاری را تضمین کند و همچنین سرعت اجرا را حفظ کند. در حال حاضر TensorFlow.js از موارد زیر پشتیبانی میکند:
- اجرای WebGL روی کارت گرافیک دستگاه (GPU) - این سریعترین راه برای اجرای مدلهای بزرگتر (با حجم بیش از ۳ مگابایت) با شتابدهی GPU است.
- اجرای Web Assembly (WASM) روی CPU - برای بهبود عملکرد CPU در دستگاهها، از جمله تلفنهای همراه نسل قدیمیتر، به عنوان مثال. این برای مدلهای کوچکتر (با اندازه کمتر از ۳ مگابایت) مناسبتر است که در واقع میتوانند به دلیل سربار آپلود محتوا به پردازنده گرافیکی، با WASM سریعتر از WebGL روی CPU اجرا شوند.
- اجرای CPU - در صورتی که هیچ یک از محیطهای دیگر در دسترس نباشند، پشتیبان خواهد بود. این کندترین از بین این سه است، اما همیشه برای شما وجود دارد.
توجه: اگر میدانید روی چه دستگاهی اجرا خواهید کرد، میتوانید یکی از این backendها را به صورت اجباری انتخاب کنید، یا اگر این مورد را مشخص نکنید، میتوانید به سادگی اجازه دهید TensorFlow.js برای شما تصمیم بگیرد.
قدرتهای برتر سمت کلاینت
اجرای TensorFlow.js در مرورگر وب روی دستگاه کلاینت میتواند مزایای متعددی داشته باشد که ارزش بررسی دارند.
حریم خصوصی
شما میتوانید دادهها را روی دستگاه کلاینت، بدون ارسال دادهها به یک وب سرور شخص ثالث، هم آموزش دهید و هم طبقهبندی کنید. ممکن است مواقعی وجود داشته باشد که این امر مستلزم رعایت قوانین محلی، مانند GDPR، یا هنگام پردازش هرگونه دادهای باشد که کاربر ممکن است بخواهد روی دستگاه خود نگه دارد و به شخص ثالث ارسال نکند.
سرعت
از آنجایی که نیازی به ارسال دادهها به یک سرور از راه دور ندارید، استنتاج (عمل طبقهبندی دادهها) میتواند سریعتر انجام شود. حتی بهتر از آن، در صورت اجازه کاربر، به حسگرهای دستگاه مانند دوربین، میکروفون، GPS، شتابسنج و موارد دیگر دسترسی مستقیم خواهید داشت.
دسترسی و مقیاس
با یک کلیک، هر کسی در جهان میتواند روی لینکی که برایش ارسال میکنید کلیک کند، صفحه وب را در مرورگر خود باز کند و از آنچه ساختهاید استفاده کند. برای استفاده از سیستم یادگیری ماشین، نیازی به تنظیمات پیچیده سمت سرور لینوکس با درایورهای CUDA و موارد دیگر نیست.
هزینه
نبود سرور به این معنی است که تنها چیزی که باید برای آن هزینه کنید، یک CDN برای میزبانی فایلهای HTML، CSS، JS و مدل شماست. هزینه CDN بسیار ارزانتر از روشن نگه داشتن یک سرور (احتمالاً با کارت گرافیک متصل) به صورت 24 ساعته و 7 روز هفته است.
ویژگیهای سمت سرور
استفاده از پیادهسازی TensorFlow.js در Node.js، ویژگیهای زیر را فعال میکند.
پشتیبانی کامل از CUDA
در سمت سرور، برای شتابدهی کارت گرافیک، باید درایورهای NVIDIA CUDA را نصب کنید تا TensorFlow بتواند با کارت گرافیک کار کند (برخلاف مرورگر که از WebGL استفاده میکند - نیازی به نصب نیست). با این حال، با پشتیبانی کامل CUDA میتوانید از تواناییهای سطح پایینتر کارت گرافیک به طور کامل استفاده کنید که منجر به زمان آموزش و استنتاج سریعتر میشود. عملکرد با پیادهسازی TensorFlow پایتون برابری میکند زیرا هر دو از یک backend ++C مشترک استفاده میکنند.
اندازه مدل
برای مدلهای پیشرفته حاصل از تحقیقات، ممکن است با مدلهای بسیار بزرگی، شاید در حد چند گیگابایت، کار کنید. این مدلها در حال حاضر به دلیل محدودیتهای استفاده از حافظه در هر تب مرورگر، در مرورگر وب قابل اجرا نیستند. برای اجرای این مدلهای بزرگتر، میتوانید از Node.js روی سرور خود با مشخصات سختافزاری مورد نیاز برای اجرای کارآمد چنین مدلی استفاده کنید.
اینترنت اشیا
Node.js روی کامپیوترهای تک برد محبوبی مانند Raspberry Pi پشتیبانی میشود، که به نوبه خود به این معنی است که میتوانید مدلهای TensorFlow.js را روی چنین دستگاههایی نیز اجرا کنید.
سرعت
Node.js با جاوا اسکریپت نوشته شده است، به این معنی که از کامپایل درجا (just in time compilation) بهره میبرد. این بدان معناست که هنگام استفاده از Node.js اغلب شاهد افزایش عملکرد خواهید بود، زیرا در زمان اجرا بهینه میشود، به خصوص برای هرگونه پیشپردازشی که ممکن است انجام دهید. یک مثال عالی از این مورد را میتوان در این مطالعه موردی مشاهده کرد که نشان میدهد چگونه Hugging Face از Node.js برای افزایش دو برابری عملکرد مدل پردازش زبان طبیعی خود استفاده کرده است.
حالا که اصول اولیه TensorFlow.js، محل اجرا و برخی از مزایای آن را فهمیدید، بیایید شروع به انجام کارهای مفید با آن کنیم!
۳. انتقال یادگیری
یادگیری انتقالی دقیقاً چیست؟
یادگیری انتقالی شامل استفاده از دانشی است که قبلاً آموخته شده است تا به یادگیری یک چیز متفاوت اما مشابه کمک کند.
ما انسانها همیشه این کار را انجام میدهیم. شما یک عمر تجربه در مغز خود دارید که میتوانید از آنها برای تشخیص چیزهای جدیدی که قبلاً هرگز ندیدهاید استفاده کنید. برای مثال، این درخت بید را در نظر بگیرید:

بسته به اینکه کجای دنیا هستید، این احتمال وجود دارد که قبلاً این نوع درخت را ندیده باشید.
با این حال اگر از شما بخواهم که به من بگویید آیا در تصویر جدید زیر درخت بیدی وجود دارد یا خیر، احتمالاً میتوانید خیلی سریع آنها را تشخیص دهید، حتی اگر در زاویه متفاوتی باشند و کمی با تصویر اصلی که به شما نشان دادم متفاوت باشند.

شما در حال حاضر تعدادی نورون در مغز خود دارید که میدانند چگونه اشیاء درختمانند را شناسایی کنند، و نورونهای دیگری که در یافتن خطوط مستقیم بلند مهارت دارند. میتوانید از این دانش برای طبقهبندی سریع یک درخت بید، که یک شیء درختمانند است و شاخههای عمودی مستقیم و بلند زیادی دارد، استفاده مجدد کنید.
به طور مشابه، اگر یک مدل یادگیری ماشینی دارید که قبلاً در یک دامنه، مانند تشخیص تصاویر، آموزش دیده است، میتوانید از آن برای انجام یک کار متفاوت اما مرتبط استفاده مجدد کنید.
شما میتوانید همین کار را با یک مدل پیشرفته مانند MobileNet انجام دهید، که یک مدل تحقیقاتی بسیار محبوب است که میتواند تشخیص تصویر را روی ۱۰۰۰ نوع شیء مختلف انجام دهد. از سگها گرفته تا ماشینها، این مدل بر روی یک مجموعه داده عظیم به نام ImageNet آموزش دیده است که میلیونها تصویر برچسبگذاری شده دارد.
در این انیمیشن، میتوانید تعداد بسیار زیاد لایههای موجود در مدل MobileNet V1 را مشاهده کنید:
این مدل در طول آموزش خود یاد گرفت که چگونه ویژگیهای مشترک مهم برای همه آن ۱۰۰۰ شیء را استخراج کند و بسیاری از ویژگیهای سطح پایینتری که برای شناسایی چنین اشیاء استفاده میکند، میتوانند برای تشخیص اشیاء جدیدی که قبلاً هرگز ندیده است نیز مفید باشند. از این گذشته، همه چیز در نهایت فقط ترکیبی از خطوط، بافتها و شکلها است.
بیایید نگاهی به معماری سنتی شبکه عصبی کانولوشن (CNN) (شبیه به MobileNet) بیندازیم و ببینیم که چگونه یادگیری انتقالی میتواند از این شبکه آموزشدیده برای یادگیری چیزهای جدید استفاده کند. تصویر زیر معماری مدل معمولی یک CNN را نشان میدهد که در این مورد برای تشخیص ارقام دستنویس از ۰ تا ۹ آموزش دیده است:
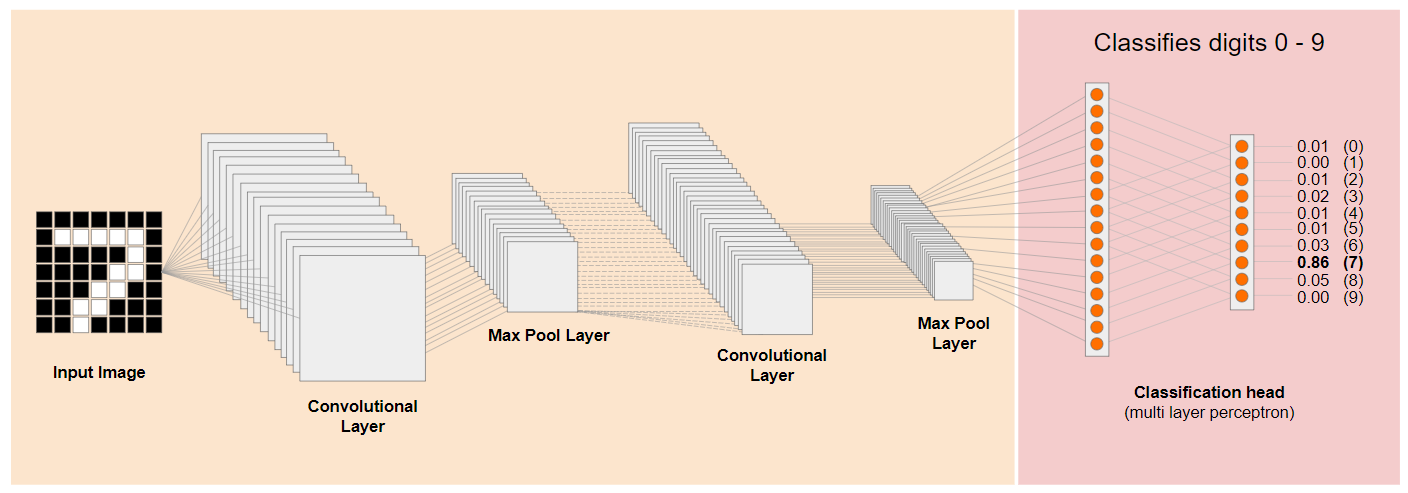
اگر بتوانید لایههای سطح پایینتر از پیش آموزشدیده یک مدل آموزشدیده موجود، مانند این نشان داده شده در سمت چپ، را از لایههای طبقهبندی نزدیک به انتهای مدل نشان داده شده در سمت راست (که گاهی اوقات به عنوان سر طبقهبندی مدل نامیده میشود) جدا کنید، میتوانید از لایههای سطح پایینتر برای تولید ویژگیهای خروجی برای هر تصویر داده شده بر اساس دادههای اصلی که بر روی آن آموزش داده شده است، استفاده کنید. در اینجا همان شبکه با سر طبقهبندی حذف شده است:
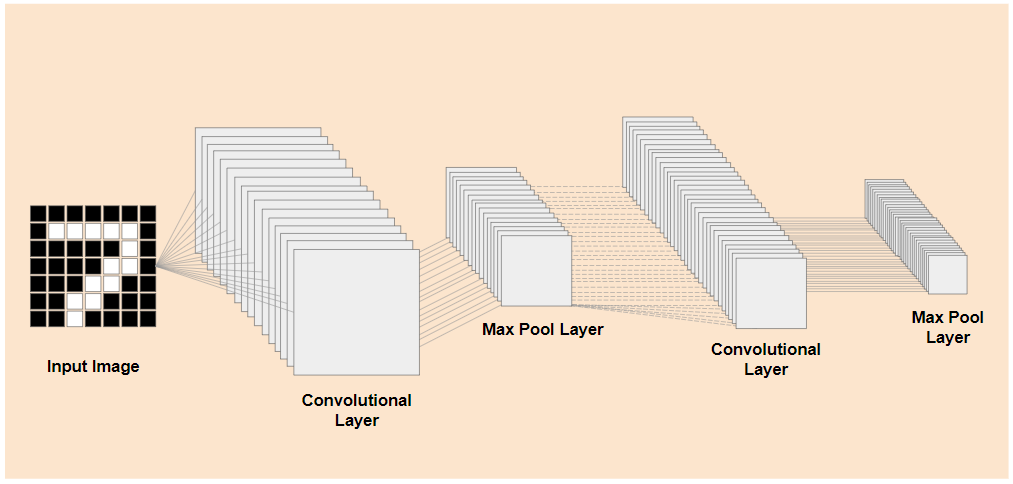
با فرض اینکه چیز جدیدی که سعی در تشخیص آن دارید میتواند از چنین ویژگیهای خروجی که مدل قبلی آموخته است نیز استفاده کند، احتمال زیادی وجود دارد که بتوان از آنها برای هدف جدیدی استفاده مجدد کرد.
در نمودار بالا، این مدل فرضی روی ارقام آموزش داده شده است، بنابراین شاید آنچه در مورد ارقام آموخته شده است، بتواند در مورد حروفی مانند a، b و c نیز اعمال شود.
بنابراین اکنون میتوانید یک سر طبقهبندی جدید اضافه کنید که سعی میکند a، b یا c را پیشبینی کند، همانطور که نشان داده شده است:
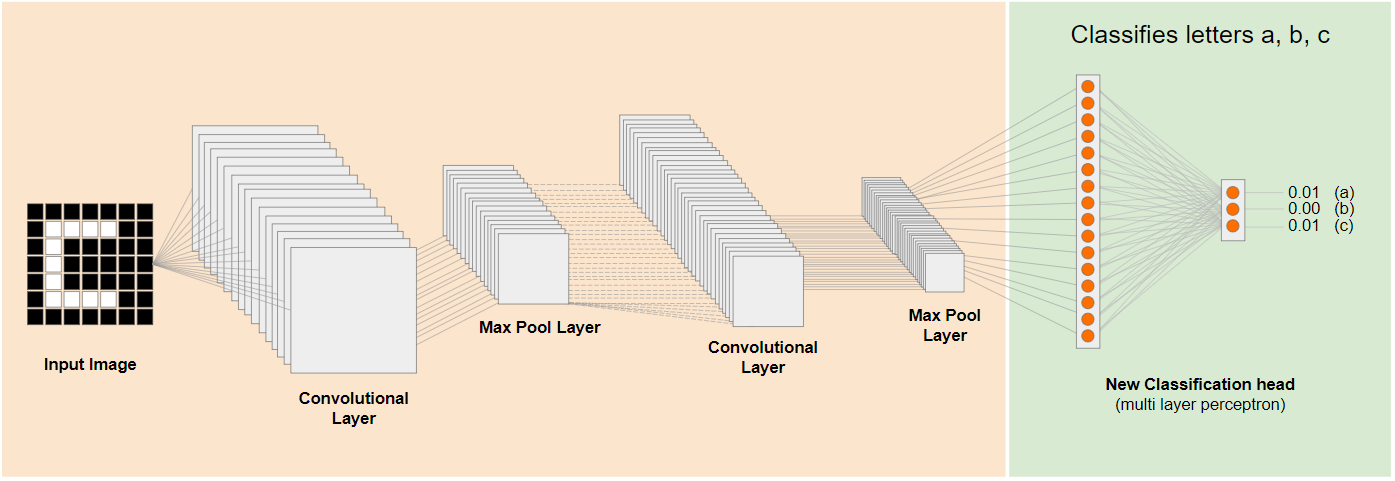
در اینجا لایههای سطح پایینتر ثابت مانده و آموزش داده نمیشوند، فقط سر طبقهبندی جدید خود را بهروزرسانی میکند تا از ویژگیهای ارائه شده از مدل خرد شده از پیش آموزش دیده در سمت چپ یاد بگیرد.
عمل انجام این کار به عنوان یادگیری انتقالی شناخته میشود و کاری است که Teachable Machine در پشت صحنه انجام میدهد.
همچنین میتوانید ببینید که با آموزش دادن پرسپترون چندلایه در انتهای شبکه، این شبکه بسیار سریعتر از زمانی که مجبور باشید کل شبکه را از ابتدا آموزش دهید، آموزش میبیند.
اما چگونه میتوانید به بخشهای فرعی یک مدل دسترسی پیدا کنید؟ برای فهمیدن این موضوع به بخش بعدی بروید.
۴. هاب TensorFlow - مدلهای پایه
یک مدل پایه مناسب برای استفاده پیدا کنید
برای مدلهای تحقیقاتی پیشرفتهتر و محبوبتر مانند MobileNet، میتوانید به TensorFlow hub بروید و سپس مدلهای مناسب برای TensorFlow.js که از معماری MobileNet v3 استفاده میکنند را فیلتر کنید تا نتایجی مانند آنچه در اینجا نشان داده شده است را پیدا کنید:
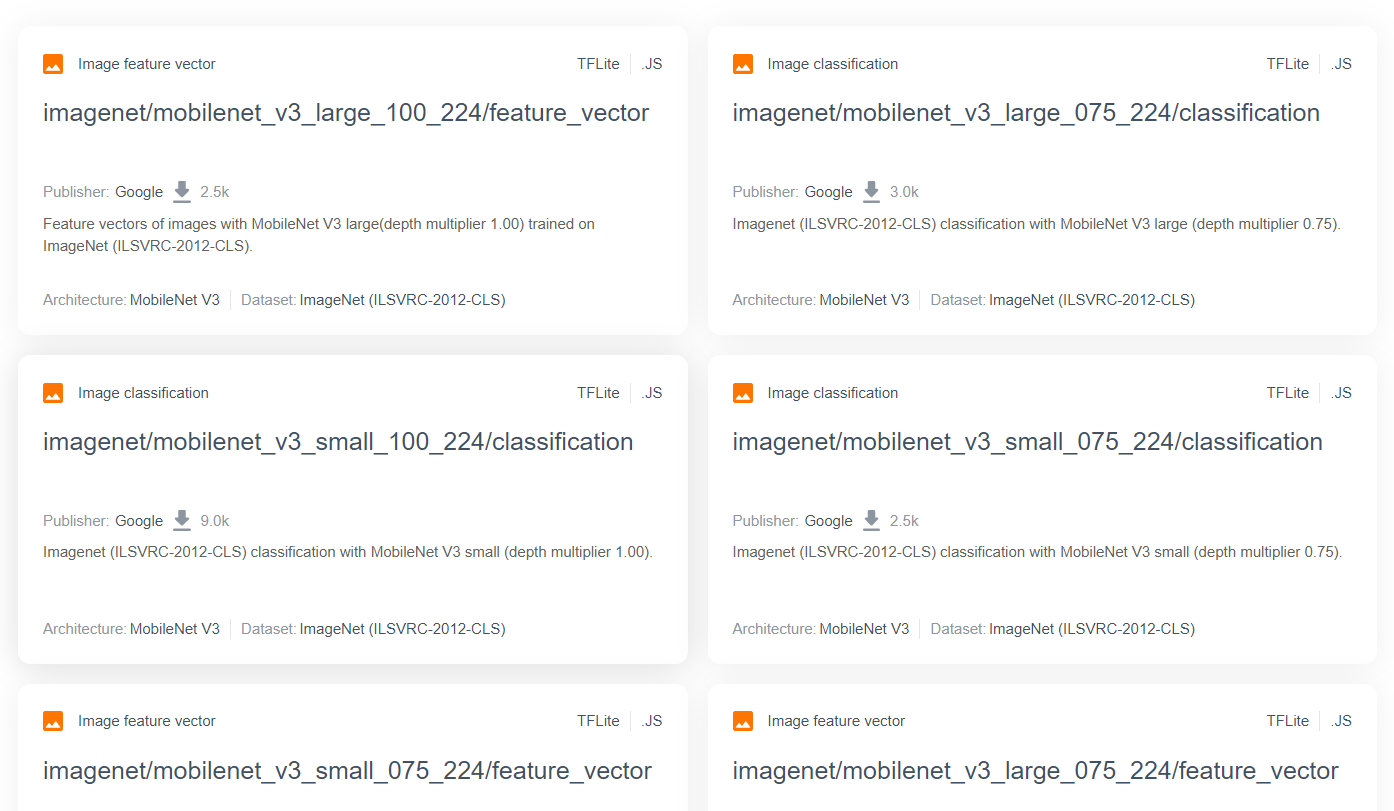
توجه داشته باشید که برخی از این نتایج از نوع «طبقهبندی تصویر» هستند (جزئیات آن در بالا سمت چپ هر نتیجه کارت مدل آمده است) و برخی دیگر از نوع «بردار ویژگی تصویر» هستند.
این نتایج بردار ویژگی تصویر اساساً نسخههای از پیش خرد شده MobileNet هستند که میتوانید به جای طبقهبندی نهایی، برای دریافت بردارهای ویژگی تصویر از آنها استفاده کنید.
مدلهایی از این دست اغلب «مدلهای پایه» نامیده میشوند که میتوانید از آنها برای انجام یادگیری انتقالی به همان روشی که در بخش قبل نشان داده شد، با اضافه کردن یک سر طبقهبندی جدید و آموزش آن با دادههای خود، استفاده کنید.
نکته بعدی که باید بررسی شود این است که برای یک مدل پایه مورد نظر، فرمت TensorFlow.js که مدل با آن منتشر میشود، چیست. اگر صفحه مربوط به یکی از این مدلهای بردار ویژگی MobileNet v3 را باز کنید، میتوانید از مستندات JS ببینید که به شکل یک مدل گراف بر اساس قطعه کد نمونه در مستندات است که از tf.loadGraphModel() استفاده میکند.

همچنین لازم به ذکر است که اگر مدلی را در قالب لایهها به جای قالب گراف پیدا کردید، میتوانید انتخاب کنید که کدام لایهها برای آموزش فریز و کدام یک را آزاد کنید. این میتواند هنگام ایجاد مدل برای یک کار جدید، که اغلب به عنوان "مدل انتقال" شناخته میشود، بسیار قدرتمند باشد. با این حال، در حال حاضر، از نوع مدل گراف پیشفرض برای این آموزش استفاده خواهید کرد که اکثر مدلهای TF Hub به این صورت مستقر میشوند. برای کسب اطلاعات بیشتر در مورد کار با مدلهای لایهها، دوره آموزشی TensorFlow.js را از صفر تا صد بررسی کنید.
مزایای یادگیری انتقالی
مزایای استفاده از یادگیری انتقالی به جای آموزش کل معماری مدل از ابتدا چیست؟
اول، زمان آموزش یک مزیت کلیدی برای استفاده از رویکرد یادگیری انتقالی است، زیرا شما از قبل یک مدل پایه آموزش دیده برای ساخت بر اساس آن دارید.
دوم اینکه، به دلیل آموزشی که قبلاً انجام شده است، میتوانید نمونههای بسیار کمتری از چیز جدیدی که سعی در طبقهبندی آن دارید را نشان دهید.
اگر زمان و منابع محدودی برای جمعآوری دادههای نمونه از چیزی که میخواهید طبقهبندی کنید دارید و نیاز دارید قبل از جمعآوری دادههای آموزشی بیشتر برای تقویت آن، به سرعت یک نمونه اولیه بسازید، این واقعاً عالی است.
با توجه به نیاز به دادههای کمتر و سرعت آموزش یک شبکه کوچکتر، یادگیری انتقالی به منابع کمتری نیاز دارد. این امر آن را برای محیط مرورگر بسیار مناسب میکند و آموزش کامل مدل را به جای ساعتها، روزها یا هفتهها، تنها چند ده ثانیه در یک دستگاه مدرن به طول میانجامد.
بسیار خب! حالا که با مفهوم یادگیری انتقالی آشنا شدید، وقت آن رسیده که نسخه خودتان از ماشین قابل آموزش را بسازید. بیایید شروع کنیم!
۵. برای کدنویسی آماده شوید
آنچه نیاز دارید
- یک مرورگر وب مدرن.
- آشنایی اولیه با HTML، CSS، جاوا اسکریپت و ابزارهای توسعه کروم (مشاهده خروجی کنسول).
بریم سراغ کدنویسی
قالبهای آماده برای شروع کار برای Glitch.com یا Codepen.io ایجاد شدهاند. میتوانید به سادگی و تنها با یک کلیک، هر یک از این قالبها را به عنوان حالت پایه خود برای این آزمایشگاه کد کپی کنید.
در Glitch، روی دکمهی « remix this» کلیک کنید تا آن را منشعب کرده و مجموعهای جدید از فایلهای قابل ویرایش ایجاد کنید.
روش دیگر، در Codepen، روی « fork» در پایین سمت راست صفحه کلیک کنید.
این اسکلت بسیار ساده فایلهای زیر را در اختیار شما قرار میدهد:
- صفحه HTML (index.html)
- فایل استایل (style.css)
- فایلی برای نوشتن کد جاوا اسکریپت ما (script.js)
برای راحتی شما، یک فایل ایمپورت (import) برای کتابخانه TensorFlow.js به فایل HTML اضافه شده است که به شکل زیر است:
فهرست.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
جایگزین: از ویرایشگر وب دلخواه خود استفاده کنید یا به صورت محلی کار کنید
اگر میخواهید کد را دانلود کنید و به صورت محلی یا در یک ویرایشگر آنلاین دیگر کار کنید، کافیست ۳ فایل ذکر شده در بالا را در یک دایرکتوری ایجاد کنید و کد را از الگوی Glitch ما در هر یک از آنها کپی و جایگذاری کنید.
۶. کدهای HTML پیشفرض برنامه
از کجا شروع کنم؟
همه نمونههای اولیه به برخی چارچوبهای HTML اولیه نیاز دارند که میتوانید یافتههای خود را روی آنها رندر کنید. اکنون آن را تنظیم کنید. قرار است موارد زیر را اضافه کنید:
- یک عنوان برای صفحه.
- مقداری متن توصیفی.
- یک پاراگراف وضعیت.
- ویدیویی برای نگه داشتن فید وبکم پس از آماده شدن.
- چندین دکمه برای شروع دوربین، جمعآوری دادهها یا تنظیم مجدد تجربه.
- ایمپورتهای مربوط به فایلهای TensorFlow.js و JS که بعداً کدنویسی خواهید کرد.
فایل index.html را باز کنید و کد زیر را برای تنظیم ویژگیهای فوق، روی کد موجود قرار دهید:
فهرست.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transfer Learning - TensorFlow.js</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<h1>Make your own "Teachable Machine" using Transfer Learning with MobileNet v3 in TensorFlow.js using saved graph model from TFHub.</h1>
<p id="status">Awaiting TF.js load</p>
<video id="webcam" autoplay muted></video>
<button id="enableCam">Enable Webcam</button>
<button class="dataCollector" data-1hot="0" data-name="Class 1">Gather Class 1 Data</button>
<button class="dataCollector" data-1hot="1" data-name="Class 2">Gather Class 2 Data</button>
<button id="train">Train & Predict!</button>
<button id="reset">Reset</button>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.11.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
تجزیهاش کن
بیایید برخی از کد HTML بالا را تجزیه کنیم تا برخی از نکات کلیدی که اضافه کردهاید را برجسته کنیم.
- شما یک تگ
<h1>برای عنوان صفحه به همراه یک تگ<p>با شناسه 'status' اضافه کردهاید، که در آن اطلاعات را چاپ خواهید کرد، زیرا از بخشهای مختلف سیستم برای مشاهده خروجیها استفاده میکنید. - شما یک عنصر
<video>با شناسهی 'webcam' اضافه کردید که بعداً جریان وبکم خود را در آن رندر خواهید کرد. - شما ۵ عنصر
<button>اضافه کردید. اولی، با شناسه 'enableCam'، دوربین را فعال میکند. دو دکمه بعدی دارای کلاس 'dataCollector' هستند که به شما امکان میدهد تصاویر نمونه را برای اشیاء مورد نظر خود جمعآوری کنید. کدی که بعداً مینویسید به گونهای طراحی میشود که بتوانید هر تعداد از این دکمهها را اضافه کنید و آنها به طور خودکار طبق برنامه عمل خواهند کرد.
توجه داشته باشید که این دکمهها همچنین دارای یک ویژگی خاص تعریفشده توسط کاربر به نام data-1hot هستند که یک مقدار صحیح از 0 برای کلاس اول شروع میشود. این شاخص عددی است که شما برای نمایش دادههای یک کلاس خاص استفاده خواهید کرد. از این شاخص برای رمزگذاری صحیح کلاسهای خروجی با نمایش عددی به جای رشته استفاده میشود، زیرا مدلهای یادگیری ماشین فقط میتوانند با اعداد کار کنند.
همچنین یک ویژگی data-name وجود دارد که شامل نام قابل خواندن برای انسان است که میخواهید برای این کلاس استفاده کنید، که به شما امکان میدهد به جای یک مقدار اندیس عددی از کدگذاری داغ ۱، نام معنادارتری را به کاربر ارائه دهید.
در نهایت، شما یک دکمه آموزش و تنظیم مجدد دارید تا پس از جمعآوری دادهها، فرآیند آموزش را شروع کنید یا برنامه را به ترتیب تنظیم مجدد کنید.
- همچنین دو
<script>import اضافه کردهاید. یکی برای TensorFlow.js و دیگری برای script.js که به زودی تعریف خواهید کرد.
۷. سبک اضافه کنید
پیشفرضهای عنصر
برای عناصر HTML که اضافه کردهاید، استایلهایی اضافه کنید تا مطمئن شوید که به درستی رندر میشوند. در اینجا چند استایل وجود دارد که به درستی به موقعیت و اندازه عناصر اضافه میشوند. چیز خیلی خاصی نیست. مطمئناً میتوانید بعداً به این موارد اضافه کنید تا یک تجربه کاربری حتی بهتر ایجاد کنید، همانطور که در ویدیوی ماشین آموزشی دیدید.
استایل.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
clear: both;
display: block;
margin: 10px;
background: #000000;
width: 640px;
height: 480px;
}
button {
padding: 10px;
float: left;
margin: 5px 3px 5px 10px;
}
.removed {
display: none;
}
#status {
font-size:150%;
}
عالی! این تمام چیزی است که نیاز دارید. اگر همین الان خروجی را پیشنمایش کنید، باید چیزی شبیه به این باشد:
۸. جاوا اسکریپت: ثابتها و شنوندههای کلیدی
تعریف ثابتهای کلیدی
ابتدا، چند ثابت کلیدی که در طول برنامه استفاده خواهید کرد را اضافه کنید. با جایگزینی محتویات script.js با این ثابتها شروع کنید:
اسکریپت.js
const STATUS = document.getElementById('status');
const VIDEO = document.getElementById('webcam');
const ENABLE_CAM_BUTTON = document.getElementById('enableCam');
const RESET_BUTTON = document.getElementById('reset');
const TRAIN_BUTTON = document.getElementById('train');
const MOBILE_NET_INPUT_WIDTH = 224;
const MOBILE_NET_INPUT_HEIGHT = 224;
const STOP_DATA_GATHER = -1;
const CLASS_NAMES = [];
بیایید بررسی کنیم که اینها برای چه هستند:
-
STATUSصرفاً ارجاعی به تگ پاراگرافی که قرار است بهروزرسانیهای وضعیت را در آن بنویسید، در خود نگه میدارد. -
VIDEOارجاعی به عنصر ویدیوی HTML دارد که فید وبکم را رندر میکند. -
ENABLE_CAM_BUTTON،RESET_BUTTONوTRAIN_BUTTONارجاعات DOM به تمام دکمههای کلید را از صفحه HTML میگیرند. -
MOBILE_NET_INPUT_WIDTHوMOBILE_NET_INPUT_HEIGHTبه ترتیب عرض و ارتفاع ورودی مورد انتظار مدل MobileNet را تعریف میکنند. با ذخیره این مقدار در یک ثابت نزدیک به بالای فایل مانند این، اگر تصمیم بگیرید بعداً از نسخه دیگری استفاده کنید، بهروزرسانی مقادیر یکباره آسانتر میشود، به جای اینکه مجبور باشید آنها را در مکانهای مختلف جایگزین کنید. -
STOP_DATA_GATHERروی -۱ تنظیم شده است. این یک مقدار وضعیت ذخیره میکند تا بدانید چه زمانی کاربر کلیک روی دکمهای برای جمعآوری دادهها از فید وبکم را متوقف کرده است. با دادن نامی معنادارتر به این عدد، خوانایی کد در آینده بیشتر میشود. -
CLASS_NAMESبه عنوان یک جستجو عمل میکند و نامهای قابل خواندن توسط انسان را برای پیشبینیهای کلاس ممکن نگه میدارد. این آرایه بعداً پر خواهد شد.
بسیار خب، حالا که به عناصر کلیدی ارجاع دادهاید، وقت آن رسیده که برخی از شنوندههای رویداد را به آنها مرتبط کنید.
اضافه کردن شنوندههای رویداد کلیدی
با اضافه کردن کنترلکنندههای رویداد کلیک به دکمههای کلید، همانطور که نشان داده شده است، شروع کنید:
اسکریپت.js
ENABLE_CAM_BUTTON.addEventListener('click', enableCam);
TRAIN_BUTTON.addEventListener('click', trainAndPredict);
RESET_BUTTON.addEventListener('click', reset);
function enableCam() {
// TODO: Fill this out later in the codelab!
}
function trainAndPredict() {
// TODO: Fill this out later in the codelab!
}
function reset() {
// TODO: Fill this out later in the codelab!
}
ENABLE_CAM_BUTTON - هنگام کلیک، تابع enableCam را فراخوانی میکند.
TRAIN_BUTTON - هنگام کلیک، trainAndPredict را فراخوانی میکند.
RESET_BUTTON - هنگام کلیک، تنظیم مجدد را فراخوانی میکند.
در نهایت در این بخش میتوانید تمام دکمههایی که کلاس 'dataCollector' دارند را با استفاده از document.querySelectorAll() پیدا کنید. این تابع آرایهای از عناصر یافت شده از سند که با موارد زیر مطابقت دارند را برمیگرداند:
اسکریپت.js
let dataCollectorButtons = document.querySelectorAll('button.dataCollector');
for (let i = 0; i < dataCollectorButtons.length; i++) {
dataCollectorButtons[i].addEventListener('mousedown', gatherDataForClass);
dataCollectorButtons[i].addEventListener('mouseup', gatherDataForClass);
// Populate the human readable names for classes.
CLASS_NAMES.push(dataCollectorButtons[i].getAttribute('data-name'));
}
function gatherDataForClass() {
// TODO: Fill this out later in the codelab!
}
توضیح کد:
سپس روی دکمههای پیدا شده جستجو میکنید و به هر کدام دو شنونده رویداد اختصاص میدهید. یکی برای 'mousedown' و یکی برای 'mouseup'. این به شما امکان میدهد تا زمانی که دکمه فشرده میشود، نمونهها را ضبط کنید، که برای جمعآوری دادهها مفید است.
هر دو رویداد یک تابع gatherDataForClass را فراخوانی میکنند که بعداً تعریف خواهید کرد.
در این مرحله، میتوانید نامهای کلاس قابل خواندن توسط انسان را نیز از ویژگی دکمه HTML به نام data-name به آرایه CLASS_NAMES منتقل کنید.
در مرحله بعد، چند متغیر برای ذخیره موارد کلیدی که بعداً استفاده خواهند شد، اضافه کنید.
اسکریپت.js
let mobilenet = undefined;
let gatherDataState = STOP_DATA_GATHER;
let videoPlaying = false;
let trainingDataInputs = [];
let trainingDataOutputs = [];
let examplesCount = [];
let predict = false;
بیایید از میان آنها عبور کنیم.
ابتدا، شما یک متغیر به نام mobilenet دارید که مدل بارگذاری شده mobilenet را در آن ذخیره میکند. در ابتدا این متغیر را روی undefined تنظیم کنید.
در مرحله بعد، متغیری به نام gatherDataState دارید. اگر دکمه 'dataCollector' فشرده شود، این متغیر به شناسه داغ شماره ۱ آن دکمه، همانطور که در HTML تعریف شده است، تغییر میکند، بنابراین میدانید که در آن لحظه در حال جمعآوری چه کلاس دادهای هستید. در ابتدا، این متغیر روی STOP_DATA_GATHER تنظیم شده است تا حلقه جمعآوری دادهای که بعداً مینویسید، وقتی هیچ دکمهای فشرده نمیشود، هیچ دادهای جمعآوری نکند.
videoPlaying پیگیری میکند که آیا جریان وبکم با موفقیت بارگیری و پخش شده و برای استفاده در دسترس است یا خیر. در ابتدا، این مقدار روی false تنظیم شده است زیرا وبکم تا زمانی که ENABLE_CAM_BUTTON.
در مرحله بعد، دو آرایه به trainingDataInputs و trainingDataOutputs تعریف کنید. این آرایهها مقادیر دادههای آموزشی جمعآوریشده را ذخیره میکنند، زیرا شما روی دکمههای 'dataCollector' برای ویژگیهای ورودی تولید شده توسط مدل پایه MobileNet و کلاس خروجی نمونهبرداری شده کلیک میکنید.
سپس یک آرایه نهایی examplesCount, تعریف میشود تا تعداد مثالهای موجود برای هر کلاس را پس از شروع اضافه کردن آنها، پیگیری کند.
در نهایت، شما یک متغیر به نام predict دارید که حلقه پیشبینی شما را کنترل میکند. این متغیر در ابتدا روی false تنظیم شده است. هیچ پیشبینی نمیتواند انجام شود تا زمانی که بعداً روی true تنظیم شود.
حالا که همه متغیرهای کلیدی تعریف شدهاند، بیایید مدل پایه MobileNet v3 که از قبل تکهتکه شده و به جای طبقهبندی، بردارهای ویژگی تصویر را ارائه میدهد، بارگذاری کنیم.
۹. مدل پایه MobileNet را بارگذاری کنید
ابتدا، یک تابع جدید به نام loadMobileNetFeatureModel همانطور که در زیر نشان داده شده است تعریف کنید. این باید یک تابع async باشد زیرا عمل بارگذاری یک مدل ناهمزمان است:
اسکریپت.js
/**
* Loads the MobileNet model and warms it up so ready for use.
**/
async function loadMobileNetFeatureModel() {
const URL =
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/feature_vector/5/default/1';
mobilenet = await tf.loadGraphModel(URL, {fromTFHub: true});
STATUS.innerText = 'MobileNet v3 loaded successfully!';
// Warm up the model by passing zeros through it once.
tf.tidy(function () {
let answer = mobilenet.predict(tf.zeros([1, MOBILE_NET_INPUT_HEIGHT, MOBILE_NET_INPUT_WIDTH, 3]));
console.log(answer.shape);
});
}
// Call the function immediately to start loading.
loadMobileNetFeatureModel();
در این کد، URL محل قرارگیری مدل برای بارگذاری را از مستندات TFHub تعریف میکنید.
سپس میتوانید مدل را با استفاده از await tf.loadGraphModel() بارگذاری کنید، و به یاد داشته باشید که هنگام بارگذاری مدل از این وبسایت گوگل، ویژگی ویژه fromTFHub را روی true تنظیم کنید. این یک مورد خاص فقط برای استفاده از مدلهای میزبانی شده در TF Hub است که در آن باید این ویژگی اضافی تنظیم شود.
پس از اتمام بارگذاری، میتوانید innerText عنصر STATUS را با یک پیام تنظیم کنید تا بتوانید به صورت بصری ببینید که به درستی بارگذاری شده است و آماده شروع جمعآوری دادهها هستید.
تنها کاری که اکنون باقی مانده است گرم کردن مدل است. در مدلهای بزرگتری مانند این، اولین باری که از مدل استفاده میکنید، تنظیم همه چیز میتواند کمی طول بکشد. بنابراین، عبور دادن صفرها از مدل برای جلوگیری از هرگونه انتظار در آینده که زمانبندی ممکن است حیاتیتر باشد، مفید است.
میتوانید از tf.zeros() که در tf.tidy() قرار گرفته است استفاده کنید تا مطمئن شوید که تانسورها به درستی حذف میشوند، با اندازه دسته ۱ و ارتفاع و عرض صحیحی که در ابتدا در ثابتهای خود تعریف کردهاید. در نهایت، کانالهای رنگی را نیز مشخص میکنید که در این حالت ۳ است زیرا مدل انتظار تصاویر RGB را دارد.
در مرحله بعد، شکل حاصل از تانسور برگردانده شده را با استفاده از answer.shape() ثبت کنید تا به شما در درک اندازه ویژگیهای تصویری که این مدل تولید میکند، کمک کند.
پس از تعریف این تابع، میتوانید بلافاصله آن را فراخوانی کنید تا دانلود مدل در هنگام بارگذاری صفحه آغاز شود.
اگر همین الان پیشنمایش زنده خود را مشاهده کنید، پس از چند لحظه، متن وضعیت را از «منتظر بارگذاری TF.js» به «MobileNet v3 با موفقیت بارگذاری شد!» تغییر خواهید داد، همانطور که در زیر نشان داده شده است. قبل از ادامه، مطمئن شوید که این گزینه کار میکند.
همچنین میتوانید خروجی کنسول را بررسی کنید تا اندازه چاپشده ویژگیهای خروجی که این مدل تولید میکند را ببینید. پس از اجرای صفرها در مدل MobileNet، شکلی به شکل [1, 1024] چاپشده را خواهید دید. اولین مورد فقط اندازه دستهای 1 است و میتوانید ببینید که در واقع 1024 ویژگی را برمیگرداند که میتوانند برای کمک به طبقهبندی اشیاء جدید مورد استفاده قرار گیرند.
۱۰. سر مدل جدید را تعریف کنید
اکنون زمان آن رسیده است که مدل سر خود را تعریف کنید، که اساساً یک پرسپترون چند لایه بسیار مینیمال است.
اسکریپت.js
let model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1024], units: 128, activation: 'relu'}));
model.add(tf.layers.dense({units: CLASS_NAMES.length, activation: 'softmax'}));
model.summary();
// Compile the model with the defined optimizer and specify a loss function to use.
model.compile({
// Adam changes the learning rate over time which is useful.
optimizer: 'adam',
// Use the correct loss function. If 2 classes of data, must use binaryCrossentropy.
// Else categoricalCrossentropy is used if more than 2 classes.
loss: (CLASS_NAMES.length === 2) ? 'binaryCrossentropy': 'categoricalCrossentropy',
// As this is a classification problem you can record accuracy in the logs too!
metrics: ['accuracy']
});
بیایید این کد را بررسی کنیم. شما با تعریف یک مدل tf.sequential شروع میکنید که لایههای مدل را به آن اضافه خواهید کرد.
در مرحله بعد، یک لایه متراکم به عنوان لایه ورودی به این مدل اضافه کنید. این لایه دارای شکل ورودی 1024 است زیرا خروجیهای ویژگیهای MobileNet v3 به این اندازه هستند. شما این را در مرحله قبل پس از عبور از مدل کشف کردید. این لایه دارای ۱۲۸ نورون است که از تابع فعالسازی ReLU استفاده میکنند.
اگر در مورد توابع فعالسازی و لایههای مدل تازهکار هستید، برای درک عملکرد این ویژگیها در پشت صحنه، دورهای را که در ابتدای این کارگاه توضیح داده شده است، در نظر بگیرید .
لایه بعدی که باید اضافه شود، لایه خروجی است. تعداد نورونها باید برابر با تعداد کلاسهایی باشد که میخواهید پیشبینی کنید. برای انجام این کار میتوانید از CLASS_NAMES.length برای یافتن تعداد کلاسهایی که قصد طبقهبندی آنها را دارید استفاده کنید، که برابر با تعداد دکمههای جمعآوری داده موجود در رابط کاربری است. از آنجایی که این یک مسئله طبقهبندی است، از فعالسازی softmax در این لایه خروجی استفاده میکنید که باید هنگام تلاش برای ایجاد مدلی برای حل مسائل طبقهبندی به جای رگرسیون استفاده شود.
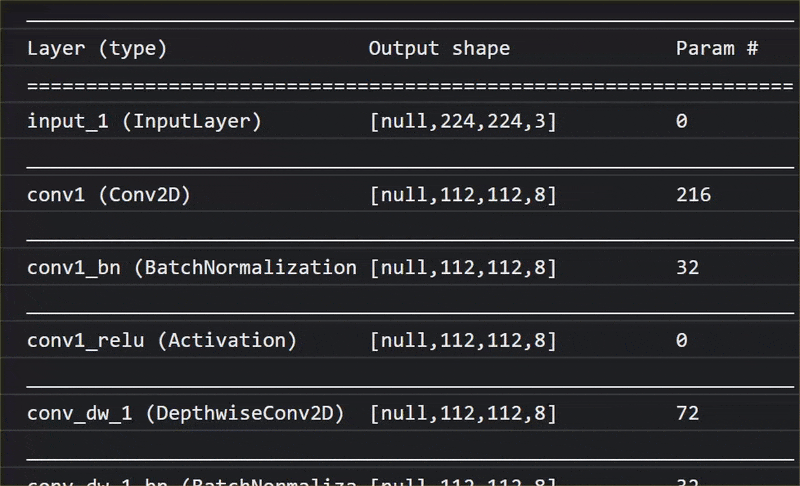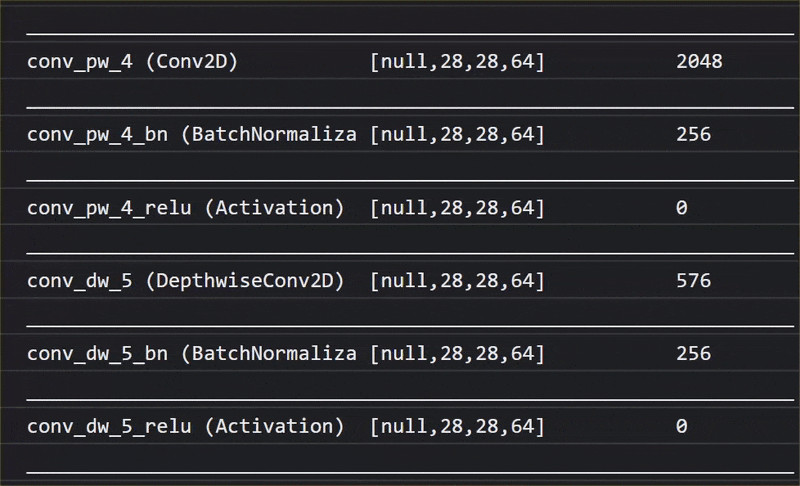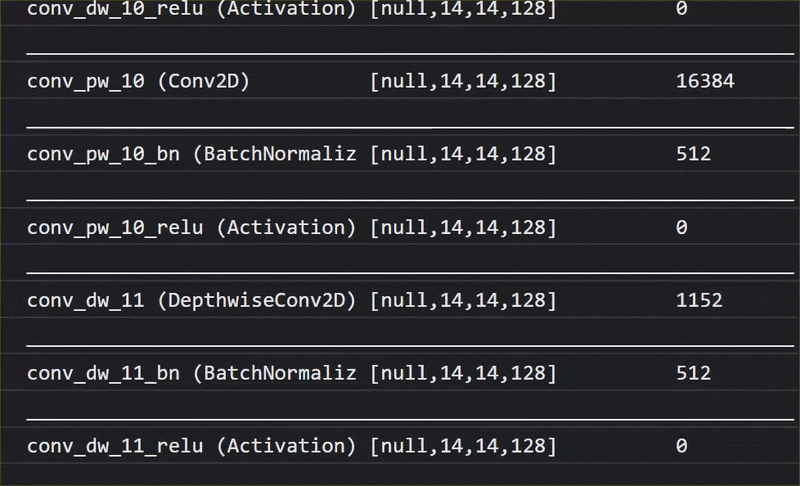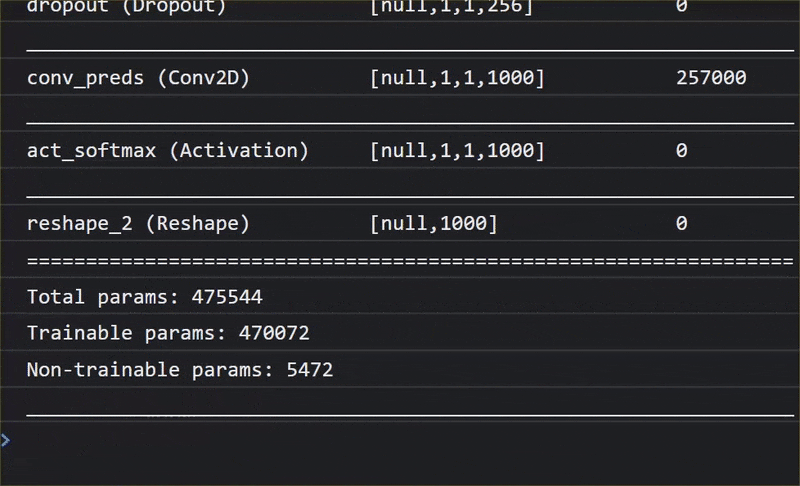
حالا یک model.summary() چاپ کنید تا نمای کلی مدل تازه تعریف شده را در کنسول چاپ کند.
در نهایت، مدل را کامپایل کنید تا آماده آموزش شود. در اینجا بهینهساز روی adam تنظیم شده است و اگر CLASS_NAMES.length برابر با 2 باشد، تابع loss از نوع binaryCrossentropy خواهد بود، یا اگر ۳ یا بیشتر کلاس برای طبقهبندی وجود داشته باشد، از categoricalCrossentropy استفاده خواهد کرد. معیارهای دقت نیز درخواست میشوند تا بتوان آنها را بعداً برای اهداف اشکالزدایی در لاگها مشاهده کرد.
در کنسول باید چیزی شبیه به این را ببینید:
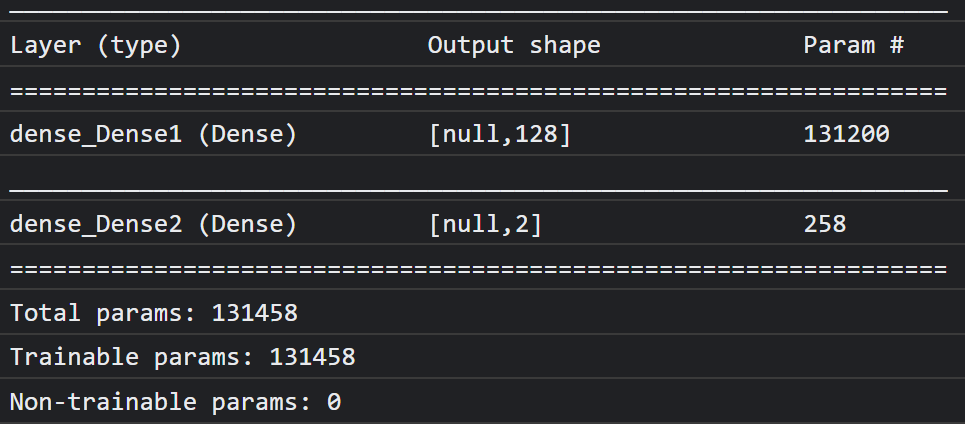
توجه داشته باشید که این بیش از ۱۳۰ هزار پارامتر قابل آموزش دارد. اما از آنجایی که این یک لایه متراکم ساده از نورونهای معمولی است، خیلی سریع آموزش خواهد دید.
به عنوان فعالیتی که پس از تکمیل پروژه باید انجام دهید، میتوانید تعداد نورونها را در لایه اول تغییر دهید تا ببینید چقدر میتوانید آن را کم کنید و در عین حال عملکرد مناسبی داشته باشید. اغلب با یادگیری ماشین، سطحی از آزمون و خطا برای یافتن مقادیر بهینه پارامترها وجود دارد تا بهترین تعادل بین استفاده از منابع و سرعت را به شما ارائه دهد.
۱۱. وبکم را فعال کنید
اکنون زمان آن رسیده است که تابع enableCam() را که قبلاً تعریف کردهاید، تکمیل کنید. یک تابع جدید به نام hasGetUserMedia() مطابق شکل زیر اضافه کنید و سپس محتویات تابع enableCam() که قبلاً تعریف شده بود را با کد مربوطه در زیر جایگزین کنید.
اسکریپت.js
function hasGetUserMedia() {
return !!(navigator.mediaDevices && navigator.mediaDevices.getUserMedia);
}
function enableCam() {
if (hasGetUserMedia()) {
// getUsermedia parameters.
const constraints = {
video: true,
width: 640,
height: 480
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
VIDEO.srcObject = stream;
VIDEO.addEventListener('loadeddata', function() {
videoPlaying = true;
ENABLE_CAM_BUTTON.classList.add('removed');
});
});
} else {
console.warn('getUserMedia() is not supported by your browser');
}
}
ابتدا، یک تابع با نام hasGetUserMedia() ایجاد کنید تا با بررسی وجود ویژگیهای کلیدی APIهای مرورگر، بررسی کند که آیا مرورگر getUserMedia() پشتیبانی میکند یا خیر.
در تابع enableCam() از تابع hasGetUserMedia() که در بالا تعریف کردید استفاده کنید تا بررسی کنید که آیا پشتیبانی میشود یا خیر. اگر پشتیبانی نمیشود، یک هشدار در کنسول چاپ کنید.
اگر از آن پشتیبانی میکند، برای فراخوانی getUserMedia() خود محدودیتهایی تعریف کنید، مثلاً اینکه فقط میخواهید جریان ویدیو را ببینید و اینکه ترجیح میدهید width ویدیو 640 پیکسل و height آن 480 پیکسل باشد. چرا؟ خب، گرفتن ویدیویی بزرگتر از این فایدهای ندارد زیرا برای ارسال به مدل MobileNet باید به ۲۲۴ در ۲۲۴ پیکسل تغییر اندازه داده شود. همچنین میتوانید با درخواست وضوح کمتر، در منابع محاسباتی صرفهجویی کنید. اکثر دوربینها از وضوحی با این اندازه پشتیبانی میکنند.
در مرحله بعد، تابع navigator.mediaDevices.getUserMedia() را با constraints ذکر شده در بالا فراخوانی کنید و سپس منتظر بمانید تا stream (stream) بازگردانده شود. پس از بازگرداندن stream ، میتوانید با تنظیم عنصر VIDEO به عنوان مقدار srcObject ، آن را برای پخش stream آماده کنید.
همچنین باید یک eventListener به عنصر VIDEO اضافه کنید تا بدانید چه زمانی stream بارگذاری شده و با موفقیت پخش میشود.
پس از بارگذاری استیم، میتوانید videoPlaying روی true تنظیم کنید و ENABLE_CAM_BUTTON را حذف کنید تا با تنظیم کلاس آن به " removed "، دیگر نتوانید روی آن کلیک کنید.
حالا کد خود را اجرا کنید، روی دکمه فعال کردن دوربین کلیک کنید و اجازه دسترسی به وبکم را بدهید. اگر اولین بار است که این کار را انجام میدهید، باید همانطور که نشان داده شده است، خود را در عنصر ویدیو در صفحه رندر شده ببینید:

بسیار خوب، حالا وقت آن رسیده که یک تابع برای مدیریت کلیکهای دکمه dataCollector اضافه کنیم.
۱۲. کنترلکننده رویداد دکمه جمعآوری دادهها
حالا وقت آن رسیده که تابع خالی فعلی خود به نام gatherDataForClass(). این همان چیزی است که شما در ابتدای codelab به عنوان تابع مدیریت رویداد برای دکمههای dataCollector اختصاص دادهاید.
اسکریپت.js
/**
* Handle Data Gather for button mouseup/mousedown.
**/
function gatherDataForClass() {
let classNumber = parseInt(this.getAttribute('data-1hot'));
gatherDataState = (gatherDataState === STOP_DATA_GATHER) ? classNumber : STOP_DATA_GATHER;
dataGatherLoop();
}
ابتدا، با فراخوانی this.getAttribute() به همراه نام ویژگی، که در این مورد data-1hot data-1hot به عنوان پارامتر است، ویژگی data-1hot را روی دکمهای که در حال حاضر کلیک شده است، بررسی کنید. از آنجایی که این یک رشته است، میتوانید parseInt() برای تبدیل آن به یک عدد صحیح استفاده کنید و این نتیجه را به متغیری به نام classNumber.
Next, set the gatherDataState variable accordingly. If the current gatherDataState is equal to STOP_DATA_GATHER (which you set to be -1), then that means you are not currently gathering any data and it was a mousedown event that fired. Set the gatherDataState to be the classNumber you just found.
Otherwise, it means that you are currently gathering data and the event that fired was a mouseup event, and you now want to stop gathering data for that class. Just set it back to the STOP_DATA_GATHER state to end the data gathering loop you will define shortly.
Finally, kick off the call to dataGatherLoop(), which actually performs the recording of class data.
13. Data collection
Now, define the dataGatherLoop() function. This function is responsible for sampling images from the webcam video, passing them through the MobileNet model, and capturing the outputs of that model (the 1024 feature vectors).
It then stores them along with the gatherDataState ID of the button that is currently being pressed so you know what class this data represents.
Let's walk through it:
script.js
function dataGatherLoop() {
if (videoPlaying && gatherDataState !== STOP_DATA_GATHER) {
let imageFeatures = tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor, [MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let normalizedTensorFrame = resizedTensorFrame.div(255);
return mobilenet.predict(normalizedTensorFrame.expandDims()).squeeze();
});
trainingDataInputs.push(imageFeatures);
trainingDataOutputs.push(gatherDataState);
// Intialize array index element if currently undefined.
if (examplesCount[gatherDataState] === undefined) {
examplesCount[gatherDataState] = 0;
}
examplesCount[gatherDataState]++;
STATUS.innerText = '';
for (let n = 0; n < CLASS_NAMES.length; n++) {
STATUS.innerText += CLASS_NAMES[n] + ' data count: ' + examplesCount[n] + '. ';
}
window.requestAnimationFrame(dataGatherLoop);
}
}
You are only going to continue this function's execution if videoPlaying is true, meaning that the webcam is active, and gatherDataState is not equal to STOP_DATA_GATHER and a button for class data gathering is currently being pressed.
Next, wrap your code in a tf.tidy() to dispose of any created tensors in the code that follows. The result of this tf.tidy() code execution is stored in a variable called imageFeatures .
You can now grab a frame of the webcam VIDEO using tf.browser.fromPixels() . The resulting tensor containing the image data is stored in a variable called videoFrameAsTensor .
Next, resize the videoFrameAsTensor variable to be of the correct shape for the MobileNet model's input. Use a tf.image.resizeBilinear() call with the tensor you want to reshape as the first parameter, and then a shape that defines the new height and width as defined by the constants you already created earlier. Finally, set align corners to true by passing the third parameter to avoid any alignment issues when resizing. The result of this resize is stored in a variable called resizedTensorFrame .
Note that this primitive resize stretches the image, as your webcam image is 640 by 480 pixels in size, and the model needs a square image of 224 by 224 pixels.
For the purposes of this demo this should work fine. However, once you complete this codelab, you may want to try and crop a square from this image instead for even better results for any production system you may create later.
Next, normalize the image data. Image data is always in the range of 0 to 255 when using tf.browser.frompixels() , so you can simply divide resizedTensorFrame by 255 to ensure all values are between 0 and 1 instead, which is what the MobileNet model expects as inputs.
Finally, in the tf.tidy() section of the code, push this normalized tensor through the loaded model by calling mobilenet.predict() , to which you pass the expanded version of the normalizedTensorFrame using expandDims() so that it is a batch of 1, as the model expects a batch of inputs for processing.
Once the result comes back, you can then immediately call squeeze() on that returned result to squash it back down to a 1D tensor, which you then return and assign to the imageFeatures variable that captures the result from tf.tidy() .
Now that you have the imageFeatures from the MobileNet model, you can record those by pushing them onto the trainingDataInputs array that you defined previously.
You can also record what this input represents by pushing the current gatherDataState to the trainingDataOutputs array too.
Note that the gatherDataState variable would have been set to the current class's numerical ID you are recording data for when the button was clicked in the previously defined gatherDataForClass() function.
At this point you can also increment the number of examples you have for a given class. To do this, first check if the index within the examplesCount array has been initialized before or not. If it is undefined, set it to 0 to initialize the counter for a given class's numerical ID, and then you can increment the examplesCount for the current gatherDataState .
Now update the STATUS element's text on the web page to show the current counts for each class as they're captured. To do this, loop through the CLASS_NAMES array, and print the human readable name combined with the data count at the same index in examplesCount .
Finally, call window.requestAnimationFrame() with dataGatherLoop passed as a parameter, to recursively call this function again. This will continue to sample frames from the video until the button's mouseup is detected, and gatherDataState is set to STOP_DATA_GATHER, at which point the data gather loop will end.
If you run your code now, you should be able to click the enable camera button, await the webcam to load, and then click and hold each of the data gather buttons to gather examples for each class of data. Here you see me gather data for my mobile phone and my hand respectively.
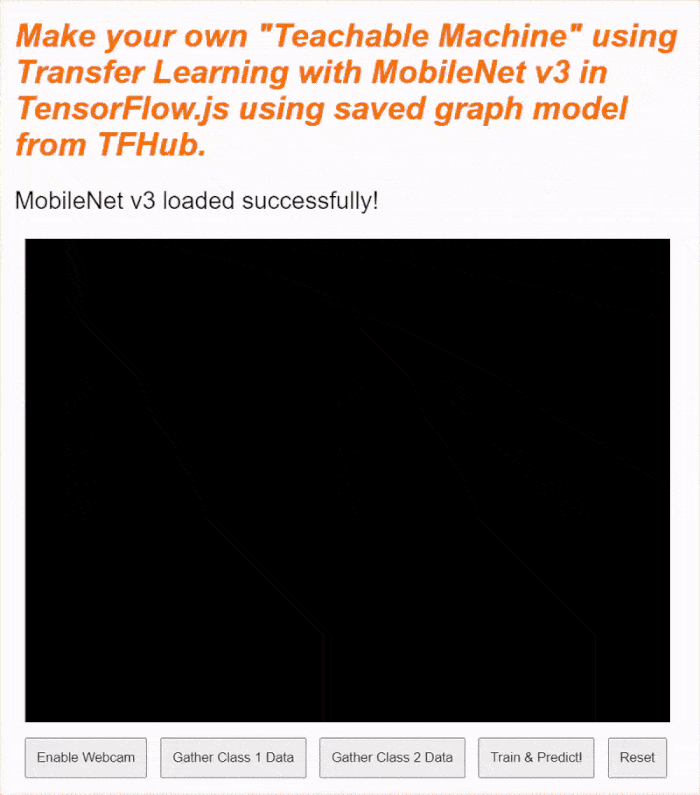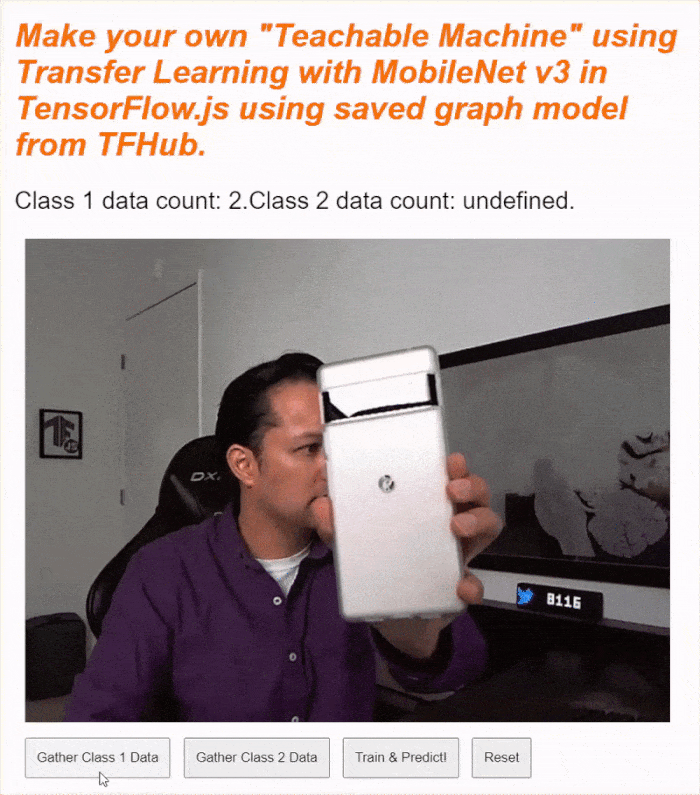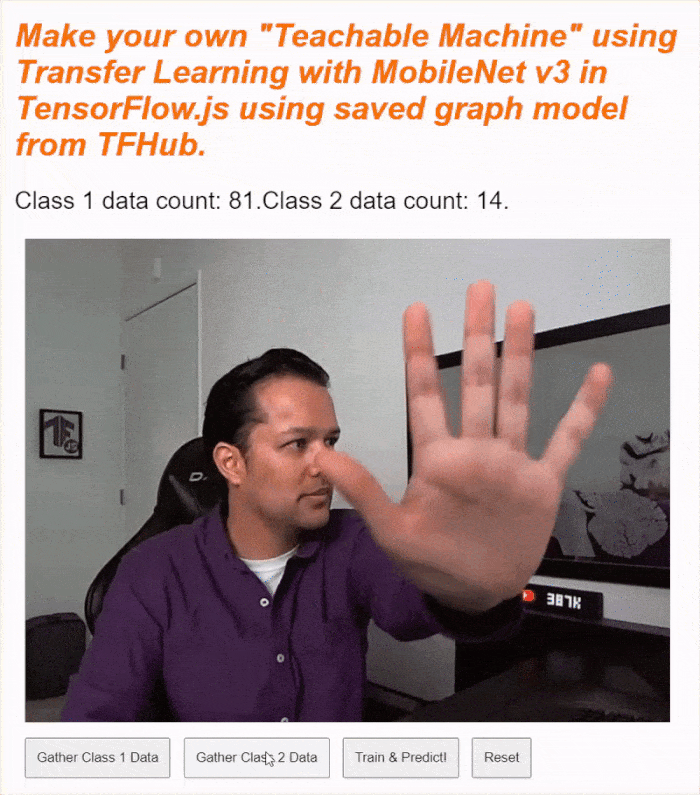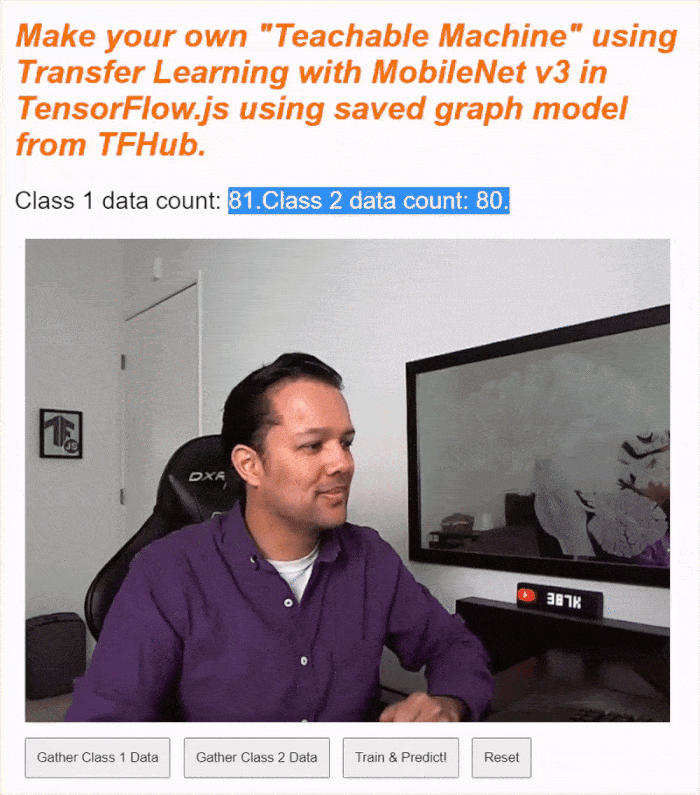
You should see the status text updated as it stores all the tensors in memory as shown in the screen capture above.
14. Train and predict
The next step is to implement code for your currently empty trainAndPredict() function, which is where the transfer learning takes place. Let's take a look at the code:
script.js
async function trainAndPredict() {
predict = false;
tf.util.shuffleCombo(trainingDataInputs, trainingDataOutputs);
let outputsAsTensor = tf.tensor1d(trainingDataOutputs, 'int32');
let oneHotOutputs = tf.oneHot(outputsAsTensor, CLASS_NAMES.length);
let inputsAsTensor = tf.stack(trainingDataInputs);
let results = await model.fit(inputsAsTensor, oneHotOutputs, {shuffle: true, batchSize: 5, epochs: 10,
callbacks: {onEpochEnd: logProgress} });
outputsAsTensor.dispose();
oneHotOutputs.dispose();
inputsAsTensor.dispose();
predict = true;
predictLoop();
}
function logProgress(epoch, logs) {
console.log('Data for epoch ' + epoch, logs);
}
First, ensure you stop any current predictions from taking place by setting predict to false .
Next, shuffle your input and output arrays using tf.util.shuffleCombo() to ensure the order does not cause issues in training.
Convert your output array, trainingDataOutputs, to be a tensor1d of type int32 so it is ready to be used in a one hot encoding . This is stored in a variable named outputsAsTensor .
Use the tf.oneHot() function with this outputsAsTensor variable along with the max number of classes to encode, which is just the CLASS_NAMES.length . Your one hot encoded outputs are now stored in a new tensor called oneHotOutputs .
Note that currently trainingDataInputs is an array of recorded tensors. In order to use these for training you will need to convert the array of tensors to become a regular 2D tensor.
To do that there is a great function within the TensorFlow.js library called tf.stack() ,
which takes an array of tensors and stacks them together to produce a higher dimensional tensor as an output. In this case a tensor 2D is returned, that's a batch of 1 dimensional inputs that are each 1024 in length containing the features recorded, which is what you need for training.
Next, await model.fit() to train the custom model head. Here you pass your inputsAsTensor variable along with the oneHotOutputs to represent the training data to use for example inputs and target outputs respectively. In the configuration object for the 3rd parameter, set shuffle to true , use batchSize of 5 , with epochs set to 10 , and then specify a callback for onEpochEnd to the logProgress function that you will define shortly.
Finally, you can dispose of the created tensors as the model is now trained. You can then set predict back to true to allow predictions to take place again, and then call the predictLoop() function to start predicting live webcam images.
You can also define the logProcess() function to log the state of training, which is used in model.fit() above and that prints results to console after each round of training.
You're almost there! Time to add the predictLoop() function to make predictions.
Core prediction loop
Here you implement the main prediction loop that samples frames from a webcam and continuously predicts what is in each frame with real time results in the browser.
Let's check the code:
script.js
function predictLoop() {
if (predict) {
tf.tidy(function() {
let videoFrameAsTensor = tf.browser.fromPixels(VIDEO).div(255);
let resizedTensorFrame = tf.image.resizeBilinear(videoFrameAsTensor,[MOBILE_NET_INPUT_HEIGHT,
MOBILE_NET_INPUT_WIDTH], true);
let imageFeatures = mobilenet.predict(resizedTensorFrame.expandDims());
let prediction = model.predict(imageFeatures).squeeze();
let highestIndex = prediction.argMax().arraySync();
let predictionArray = prediction.arraySync();
STATUS.innerText = 'Prediction: ' + CLASS_NAMES[highestIndex] + ' with ' + Math.floor(predictionArray[highestIndex] * 100) + '% confidence';
});
window.requestAnimationFrame(predictLoop);
}
}
First, check that predict is true, so that predictions are only made after a model is trained and is available to use.
Next, you can get the image features for the current image just like you did in the dataGatherLoop() function. Essentially, you grab a frame from the webcam using tf.browser.from pixels() , normalise it, resize it to be 224 by 224 pixels in size, and then pass that data through the MobileNet model to get the resulting image features.
Now, however, you can use your newly trained model head to actually perform a prediction by passing the resulting imageFeatures just found through the trained model's predict() function. You can then squeeze the resulting tensor to make it 1 dimensional again and assign it to a variable called prediction .
With this prediction you can find the index that has the highest value using argMax() , and then convert this resulting tensor to an array using arraySync() to get at the underlying data in JavaScript to discover the position of the highest valued element. This value is stored in the variable called highestIndex .
You can also get the actual prediction confidence scores in the same way by calling arraySync() on the prediction tensor directly.
You now have everything you need to update the STATUS text with the prediction data. To get the human readable string for the class you can just look up the highestIndex in the CLASS_NAMES array, and then grab the confidence value from the predictionArray . To make it more readable as a percentage, just multiply by 100 and math.floor() the result.
Finally, you can use window.requestAnimationFrame() to call predictionLoop() all over again once ready, to get real time classification on your video stream. This continues until predict is set to false if you choose to train a new model with new data.
Which brings you to the final piece of the puzzle. Implementing the reset button.
15. Implement the reset button
Almost complete! The final piece of the puzzle is to implement a reset button to start over. The code for your currently empty reset() function is below. Go ahead and update it as follows:
script.js
/**
* Purge data and start over. Note this does not dispose of the loaded
* MobileNet model and MLP head tensors as you will need to reuse
* them to train a new model.
**/
function reset() {
predict = false;
examplesCount.length = 0;
for (let i = 0; i < trainingDataInputs.length; i++) {
trainingDataInputs[i].dispose();
}
trainingDataInputs.length = 0;
trainingDataOutputs.length = 0;
STATUS.innerText = 'No data collected';
console.log('Tensors in memory: ' + tf.memory().numTensors);
}
First, stop any running prediction loops by setting predict to false . Next, delete all contents in the examplesCount array by setting its length to 0, which is a handy way to clear all contents from an array.
Now go through all the current recorded trainingDataInputs and ensure you dispose() of each tensor contained within it to free up memory again, as Tensors are not cleaned up by the JavaScript garbage collector.
Once that is done you can now safely set the array length to 0 on both the trainingDataInputs and trainingDataOutputs arrays to clear those too.
Finally set the STATUS text to something sensible, and print out the tensors left in memory as a sanity check.
Note that there will be a few hundred tensors still in memory as both the MobileNet model and the multi-layer perceptron you defined are not disposed of. You will need to reuse them with new training data if you decide to train again after this reset.
16. Let's try it out
It's time to test out your very own version of Teachable Machine!
Head to the live preview, enable the webcam, gather at least 30 samples for class 1 for some object in your room, and then do the same for class 2 for a different object, click train, and check the console log to see progress. It should train pretty fast:

Once trained, show the objects to the camera to get live predictions that will be printed to the status text area on the web page near the top. If you are having trouble, check my completed working code to see if you missed copying over anything.
17. Congratulations
Congratulations! You have just completed your very first transfer learning example using TensorFlow.js live in the browser.
Try it out, test it on a variety of objects, you may notice some things are harder to recognize than others, especially if they are similar to something else. You may need to add more classes or training data to be able to tell them apart.
خلاصه
In this codelab you learned:
- What transfer learning is, and its advantages over training a full model.
- How to get models for re-use from TensorFlow Hub.
- How to set up a web app suitable for transfer learning.
- How to load and use a base model to generate image features.
- How to train a new prediction head that can recognize custom objects from webcam imagery.
- How to use the resulting models to classify data in real time.
بعدش چی؟
Now that you have a working base to start from, what creative ideas can you come up with to extend this machine learning model boilerplate for a real world use case you may be working on? Maybe you could revolutionize the industry that you currently work in to help folk at your company train models to classify things that are important in their day-to-day work? The possibilities are endless.
To go further, consider taking this full course for free , which shows you how to combine the 2 models you currently have in this codelab into 1 single model for efficiency.
Also if you are curious more around the theory behind the original teachable machine application check out this tutorial .
آنچه را که میسازید با ما به اشتراک بگذارید
شما به راحتی میتوانید آنچه را که امروز ساختهاید برای موارد استفاده خلاقانه دیگر نیز گسترش دهید و ما شما را تشویق میکنیم که خارج از چارچوب فکر کنید و به هک کردن ادامه دهید.
فراموش نکنید که برای نمایش پروژهتان در وبلاگ TensorFlow یا حتی رویدادهای آینده، ما را در شبکههای اجتماعی با استفاده از هشتگ #MadeWithTFJS تگ کنید. ما دوست داریم ببینیم چه چیزی میسازید.
وبسایتهایی برای بررسی
- وبسایت رسمی TensorFlow.js
- مدلهای از پیش ساخته شده TensorFlow.js
- API تنسورفلو.جیاس
- TensorFlow.js Show & Tell — get inspired and see what others have made.