
1. לפני שמתחילים
הפריצות המדהימות של AlphaGo ושל AlphaStar הדגימו את הפוטנציאל של שימוש בלמידת מכונה כדי ליצור סוכני משחק ברמה על-אנושית. זוהי דרך מהנה ללמוד את הכישורים שנדרשים ליצירת סוכני משחק חזקים, באמצעות בנייה של משחק קטן שמבוסס על למידת מכונה.
ב-Codelab הזה תלמדו איך ליצור משחק לוח באמצעות:
- סוכן TensorFlow לאימון סוכן משחקים באמצעות למידת חיזוק
- TensorFlow Serving להכניס את המודל לשימוש בסביבת הייצור
- Flutter ליצירת אפליקציה של משחק לוח בפלטפורמות שונות
דרישות מוקדמות
- ידע בסיסי בפיתוח Flutter עם Dart
- ידע בסיסי בלמידת מכונה עם TensorFlow, כמו אימון לעומת פריסה
- ידע בסיסי ב-Python, במסופים וב-Docker
מה תלמדו
- איך מאמנים סוכן של דמות לא שחקנית (NPC) באמצעות TensorFlow Agents
- הדרכה: איך להכניס לשימוש בסביבת הייצור את המודל המאומן באמצעות TensorFlow Serving
- איך יוצרים משחק לוח ב-Flutter שפועל בפלטפורמות שונות
הדרישות
- Flutter SDK
- הגדרה של Android ו-iOS ל-Flutter
- הגדרה של מחשב ל-Flutter
- הגדרה של אינטרנט ל-Flutter
- הגדרה של Visual Studio Code (VS Code) ל-Flutter ול-Dart
- Docker
- Bash
- Python 3.7 ואילך
2. משחק המטוסים
המשחק שתיצרו ב-Codelab הזה נקרא Plane Strike. זהו משחק לוח קטן לשני שחקנים שמזכיר את משחק הלוח Battleship (צי מלחמה). הכללים פשוטים מאוד:
- השחקן האנושי משחק נגד סוכן NPC שאומן באמצעות למידת מכונה. השחקן האנושי יכול להתחיל את המשחק בהקשה על כל תא בלוח של הסוכן.
- בתחילת המשחק, לשחקן האנושי ולסוכן יש כל אחד אובייקט'מטוס' (8 תאים ירוקים שיוצרים'מטוס', כפי שאפשר לראות בלוח של השחקן האנושי באנימציה שלמטה) בלוח שלהם. המטוסים האלה מוצבים באופן אקראי וגלויים רק לבעלי הלוח ומוסתרים מהיריבים שלהם.
- השחקן האנושי והסוכן מתחלפים בתורות כדי לתקוף תא אחד בלוח של כל אחד מהם. השחקן האנושי יכול להקיש על כל תא בלוח של הסוכן, והסוכן יבצע את הבחירה באופן אוטומטי על סמך התחזית של מודל למידת מכונה. התא שנבחר הופך לאדום אם הוא תא 'מטוס' (פגיעה), אחרת הוא הופך לצהוב (החטאה).
- השחקן שמגיע ראשון ל-8 תאים אדומים מנצח במשחק. לאחר מכן המשחק מופעל מחדש עם לוחות חדשים.
הנה דוגמה למשחק:

3. הגדרת סביבת הפיתוח של Flutter
כדי להשלים את ה-codelab הזה, צריך שני רכיבי תוכנה לפיתוח ב-Flutter: Flutter SDK ועורך.
אפשר להריץ את ה-codelab באמצעות כל אחד מהמכשירים הבאים:
- סימולטור iOS (נדרשת התקנה של כלי Xcode).
- אמולטור Android (נדרשת הגדרה ב-Android Studio).
- דפדפן (חובה להשתמש ב-Chrome לצורך ניפוי באגים).
- כאפליקציה למחשב Windows, Linux או macOS. צריך לפתח בפלטפורמה שבה מתכננים לפרוס. לכן, אם רוצים לפתח אפליקציה למחשב שולחני עם Windows, צריך לפתח ב-Windows כדי לגשת לשרשרת הבנייה המתאימה. יש דרישות ספציפיות למערכות הפעלה שמוסברות בפירוט במאמר docs.flutter.dev/desktop.
4. להגדרה
כדי להוריד את הקוד של ה-Codelab הזה:
- עוברים אל מאגר GitHub של ה-Codelab הזה.
- לוחצים על Code > Download zip (קוד > הורדת קובץ zip) כדי להוריד את כל הקוד של ה-Codelab הזה.

- מבטלים את הדחיסה של קובץ ה-ZIP שהורדתם כדי לפתוח תיקיית בסיס
codelabs-mainעם כל המשאבים שאתם צריכים.
ב-codelab הזה, צריך רק את הקבצים בספריית המשנה tfagents-flutter/ במאגר, שמכילה כמה תיקיות:
- התיקיות
step0עדstep6מכילות את קוד לתחילת הדרך שעליו תבנו בכל שלב ב-Codelab הזה. - התיקייה
finishedמכילה את הקוד המלא של האפליקציה לדוגמה. - כל תיקייה מכילה תיקיית משנה
backbend, שכוללת את קוד ה-Backend, ותיקיית משנהfrontend, שכוללת את קוד ה-Frontend של Flutter
5. הורדת התלות של הפרויקט
בק-אנד
פותחים את הטרמינל ועוברים לתיקיית המשנה tfagents-flutter. מריצים את הפקודה הבאה:
pip install -r requirements.txt
קצה קדמי
- ב-VS Code, לוחצים על File > Open folder (קובץ > פתיחת תיקייה) ואז בוחרים את התיקייה
step0מקוד המקור שהורדתם קודם. - פותחים את הקובץ
step0/frontend/lib/main.dart. אם מופיעה תיבת דו-שיח ב-VS Code עם הנחיה להוריד את החבילות הנדרשות לאפליקציה לתחילת הדרך, לוחצים על Get packages (קבלת חבילות). - אם תיבת הדו-שיח הזו לא מופיעה, פותחים את הטרמינל ומריצים את הפקודה
flutter pub getבתיקייהstep0/frontend.

6. שלב 0: הפעלת אפליקציה לתחילת הדרך
- פותחים את קובץ
step0/frontend/lib/main.dartב-VS Code ומוודאים שאמולטור Android או הסימולטור של iOS מוגדרים כראוי ומופיעים בשורת הסטטוס.
לדוגמה, כך נראה השימוש ב-Pixel 5 עם אמולטור Android:

כך נראה השימוש ב-iPhone 13 עם סימולטור iOS:

- לוחצים על
 התחלת ניפוי באגים.
התחלת ניפוי באגים.
הפעלה של האפליקציה וסקירת התכונות שלה
האפליקציה אמורה להיפתח באמולטור Android או בסימולטור iOS. ממשק המשתמש די פשוט. יש 2 לוחות משחק. שחקן אנושי יכול להקיש על כל תא בלוח של הסוכן בחלק העליון כמיקום פגיעה. תאמנו סוכן חכם שינבא באופן אוטומטי את המקום לתקיפה על סמך הלוח של השחקן האנושי.
מתחת לפני השטח, אפליקציית Flutter תשלח את הלוח הנוכחי של השחקן האנושי אל ה-Backend, שבו פועל מודל של למידת חיזוק, והמודל יחזיר את מיקום התא החזוי שצריך להכות בו בהמשך. אחרי קבלת התשובה, התוצאה תוצג בממשק המשתמש של חזית האתר.


אם תלחצו עכשיו על תא כלשהו בלוח של הסוכן, לא יקרה כלום כי האפליקציה עדיין לא יכולה לתקשר עם ה-Backend.
7. שלב 1: יצירת סביבת Python של TensorFlow Agents
המטרה העיקרית של ה-Codelab הזה היא לתכנן סוכן שלומד באמצעות אינטראקציה עם סביבה. המשחק Plane Strike הוא פשוט יחסית, ואפשר ליצור כללים באופן ידני עבור סוכן ה-NPC. עם זאת, אתם משתמשים בלמידת חיזוק כדי לאמן סוכן, כך שתוכלו לרכוש את הכישורים ולבנות בקלות סוכנים למשחקים אחרים בעתיד.
בהגדרת למידת חיזוק (RL) רגילה, הסוכן מקבל תצפית בכל פעימה ובוחר פעולה. הפעולה מוחלת על הסביבה, והסביבה מחזירה תגמול ותצפית חדשה. הסוכן מאמן מדיניות לבחירת פעולות כדי למקסם את סכום התגמולים, שנקרא גם החזר. הסוכן משחק במשחק הרבה מאוד פעמים, לומד את התבניות ומשפר את הכישורים שלו עד שהוא שולט במשחק. כדי להגדיר את המשחק Plane Strike כבעיה של RL, אפשר לחשוב על מצב הלוח כעל התצפית, על מיקום הפגיעה כעל הפעולה ועל האות של פגיעה או החטאה כעל התגמול.
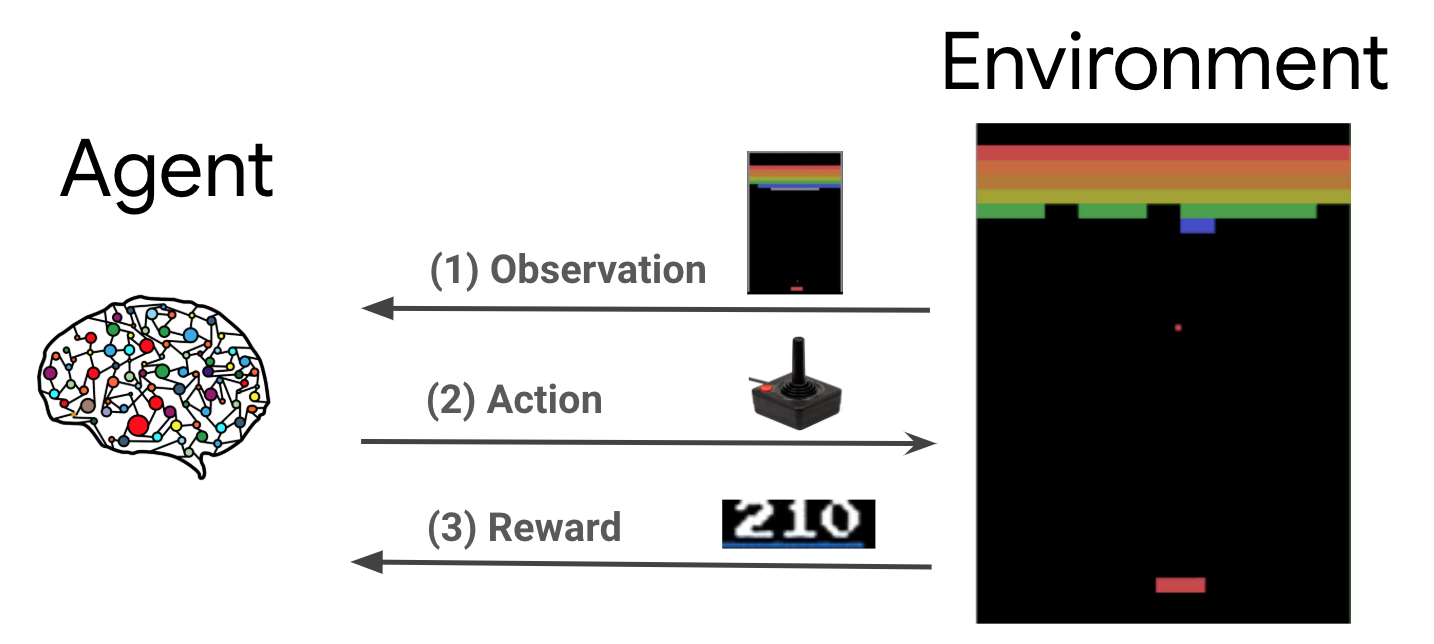
כדי לאמן את סוכן ה-NPC, משתמשים ב-TensorFlow Agents, שהיא ספרייה אמינה, ניתנת להרחבה וקלה לשימוש של למידת חיזוק ל-TensorFlow.
TF Agents הוא כלי מצוין ללמידת חיזוק, כי הוא כולל מגוון רחב של סדנאות קוד, דוגמאות ומאמרי עזרה מפורטים שיעזרו לכם להתחיל. אפשר להשתמש ב-TF Agents כדי לפתור בעיות מורכבות וריאליסטיות של RL עם יכולת הרחבה, ולפתח במהירות אלגוריתמים חדשים של RL. אתם יכולים להחליף בקלות בין סוכנים ואלגוריתמים שונים כדי להתנסות. הוא גם נבדק היטב וקל להגדרה.
יש הרבה סביבות משחק מוכנות מראש שמיושמות ב-OpenAI Gym (למשל, משחקי Atari), ב-Mujuco וכו', ש-TF Agents יכולה להשתמש בהן בקלות. אבל מכיוון שהמשחק Plane Strike הוא משחק מותאם אישית מלא, צריך קודם להטמיע סביבה חדשה מאפס.
כדי להטמיע סביבת Python של TF Agents, צריך להטמיע את השיטות הבאות:
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
הפונקציה הכי חשובה היא _step(), שמקבלת פעולה ומחזירה אובייקט time_step חדש. במקרה של המשחק Plane Strike, יש לוח משחק. כשמגיעה עמדת תקיפה חדשה, המערכת מבינה על סמך מצב לוח המשחק:
- איך לוח המשחק צריך להיראות בהמשך (האם התא צריך לשנות את הצבע שלו לאדום או לצהוב, בהתחשב במיקום המטוס המוסתר?)
- איזה תגמול צריך השחקן לקבל על המיקום הזה (תגמול על פגיעה או קנס על החמצה?)
- האם המשחק צריך להסתיים (האם מישהו ניצח?)
- מוסיפים את הקוד הבא לפונקציה
_step()בקובץ_planestrike_py_environment.py:
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. שלב 2: מאמנים את סוכן המשחק באמצעות TensorFlow Agents
אחרי שיוצרים את סביבת TF Agents, אפשר לאמן את סוכן המשחק. ב-Codelab הזה משתמשים בסוכן REINFORCE. REINFORCE הוא אלגוריתם של שיפוע מדיניות ב-RL. הרעיון הבסיסי הוא להתאים את הפרמטרים של רשת הנוירונים של המדיניות על סמך אותות התגמול שנאספים במהלך המשחק, כדי שרשת המדיניות תוכל למקסם את התגמול במשחקים עתידיים.
- קודם כול, צריך ליצור מופע של סביבות האימון וההערכה. מוסיפים את הקוד הזה לפונקציה
train_agent()בקובץstep2/backend/training.py:
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- עכשיו צריך ליצור סוכן ללמידת חיזוק שיוכשר. ב-Codelab הזה משתמשים בסוכן REINFORCE, שהוא סוכן מבוסס-מדיניות. מוסיפים את הקוד הזה מיד מתחת לקוד שלמעלה:
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- לסיום, מאמנים את הסוכן בלולאת האימון. בלולאה, קודם אוספים כמה פרקים של משחקים לתוך מאגר זמני, ואז מאמנים את הסוכן באמצעות הנתונים שבמאגר הזמני. מוסיפים את הקוד הזה לפונקציה
train_agent()בקובץstep2/backend/training.py:
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- עכשיו אפשר להתחיל את האימון. במסוף, עוברים לתיקייה
step2/backendבמחשב ומריצים את הפקודה:
python training.py
תהליך האימון נמשך 8-12 שעות, בהתאם להגדרות החומרה (לא צריך לסיים את כל האימון לבד, כי מודל שאומן מראש מסופק ב-step3). בינתיים, אפשר לעקוב אחרי ההתקדמות באמצעות TensorBoard. פותחים טרמינל חדש, עוברים לתיקייה step2/backend במחשב ומריצים:
tensorboard --logdir tf_agents_log/
tf_agents_log היא התיקייה שמכילה את יומן האימון. דוגמה להרצת אימון:


אפשר לראות שככל שהאימון מתקדם, אורך הפרק הממוצע יורד והתשואה הממוצעת עולה. באופן אינטואיטיבי, אפשר להבין שאם הסוכן חכם יותר ומבצע חיזויים טובים יותר, משך המשחק מתקצר והסוכן אוסף יותר תגמולים. זה הגיוני כי הסוכן רוצה לסיים את המשחק בפחות שלבים כדי למזער את ההנחות הגדולות על התגמולים בשלבים המאוחרים.
אחרי שהאימון מסתיים, המודל המאומן מיוצא לתיקייה policy_model.
9. שלב 3: פריסת המודל שאומן באמצעות TensorFlow Serving
אחרי שמאמנים את סוכן המשחק, אפשר לפרוס אותו באמצעות TensorFlow Serving.
- בטרמינל, עוברים לתיקייה
step3/backendבמחשב ומפעילים את TensorFlow Serving באמצעות Docker:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
מערכת Docker מורידה קודם באופן אוטומטי את תמונת TensorFlow Serving, וזה לוקח דקה. לאחר מכן, TensorFlow Serving אמור להתחיל לפעול. היומן צריך להיראות כמו קטע הקוד הבא:
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
כדי לוודא שנקודת הקצה פועלת כמו שצריך, אפשר לשלוח אליה בקשת לדוגמה:
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
נקודת הקצה תחזיר מיקום משוער 45, שהוא (5, 5) במרכז הלוח (למי שסקרן, אפשר לנסות להבין למה מרכז הלוח הוא ניחוש טוב למיקום המכה הראשונה).
{
"predictions": [45]
}
זהו! יצרת בהצלחה קצה עורפי לחיזוי מיקום המכה הבאה של סוכן ה-NPC..
10. שלב 4: יצירת אפליקציית Flutter ל-Android ול-iOS
הקצה העורפי מוכן. אפשר להתחיל לשלוח אליו בקשות כדי לאחזר תחזיות לגבי מיקום הכדור מאפליקציית Flutter.
- קודם כול צריך להגדיר מחלקה שעוטפת את נתוני הקלט לשליחה. מוסיפים את הקוד הזה לקובץ
step4/frontend/lib/game_agent.dart:
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
עכשיו אפשר לשלוח את הבקשה אל TensorFlow Serving כדי לקבל תחזיות.
- מוסיפים את הקוד הזה לפונקציה
predict()בקובץstep4/frontend/lib/game_agent.dart:
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
אחרי שהאפליקציה מקבלת את התשובה מהקצה העורפי, מעדכנים את ממשק המשתמש של המשחק כדי לשקף את ההתקדמות במשחק.
- מוסיפים את הקוד הזה לפונקציה
_gridItemTapped()בקובץstep4/frontend/lib/main.dart:
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
מפעילים פתרונות חכמים
- לוחצים על התחלת ניפוי באגים ומחכים שהאפליקציה תיטען.
- מקישים על תא כלשהו בלוח של הסוכן כדי להתחיל את המשחק.
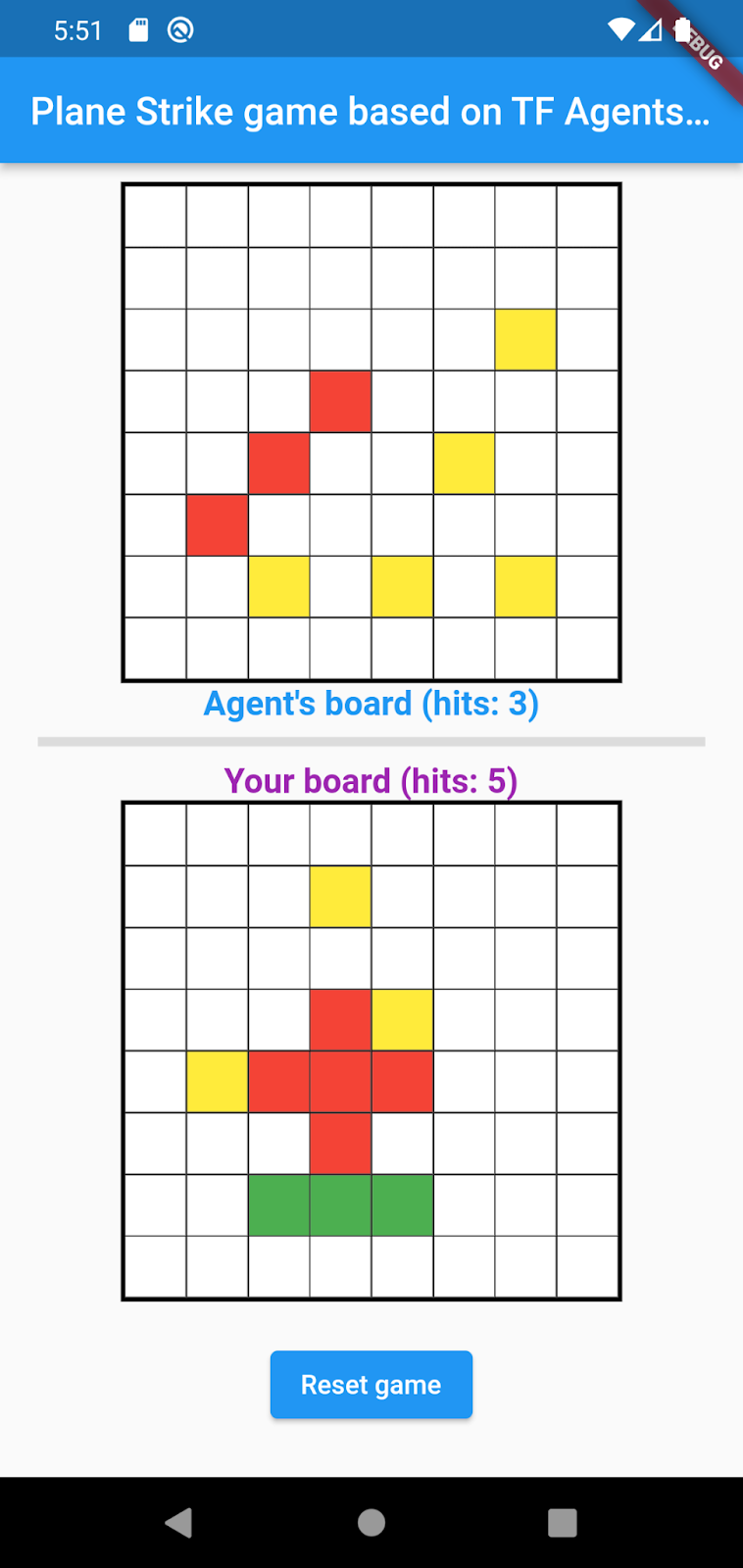

11. שלב 5: הפעלת אפליקציית Flutter לפלטפורמות למחשב
בנוסף ל-Android ול-iOS, Flutter תומכת גם בפלטפורמות למחשבים, כולל Linux, Mac ו-Windows.
Linux
- מוודאים שמכשיר היעד מוגדר ל-
 בסרגל הסטטוס של VSCode.
בסרגל הסטטוס של VSCode. - לוחצים על התחלת ניפוי באגים ומחכים שהאפליקציה תיטען.
- כדי להתחיל את המשחק, לוחצים על תא כלשהו בלוח של הסוכן.
Mac
- ב-Mac, צריך להגדיר הרשאות מתאימות כי האפליקציה תשלח בקשות HTTP לשרת העורפי. פרטים נוספים מופיעים במאמר בנושא הרשאות וארגז החול של האפליקציה.
מוסיפים את הקוד הזה ל-step4/frontend/macOS/Runner/DebugProfile.entitlements ול-step4/frontend/macOS/Runner/Release.entitlements בהתאמה:
<key>com.apple.security.network.client</key>
<true/>
- מוודאים שמכשיר היעד מוגדר ל-
 בסרגל הסטטוס של VSCode.
בסרגל הסטטוס של VSCode. - לוחצים על התחלת ניפוי באגים ומחכים שהאפליקציה תיטען.
- כדי להתחיל את המשחק, לוחצים על תא כלשהו בלוח של הסוכן.

Windows
- מוודאים שמכשיר היעד מוגדר ל-
 בסרגל הסטטוס של VSCode.
בסרגל הסטטוס של VSCode. - לוחצים על התחלת ניפוי באגים ומחכים שהאפליקציה תיטען.
- כדי להתחיל את המשחק, לוחצים על תא כלשהו בלוח של הסוכן.

12. שלב 6: הפעלת אפליקציית Flutter לפלטפורמת האינטרנט
אפשר גם להוסיף תמיכה באינטרנט לאפליקציה שנוצרה ב-Flutter. כברירת מחדל, פלטפורמת האינטרנט מופעלת אוטומטית באפליקציות שנוצרו ב-Flutter, כך שכל מה שצריך לעשות הוא להפעיל אותה.
- מוודאים שמכשיר היעד מוגדר ל-
 בסרגל הסטטוס של VSCode.
בסרגל הסטטוס של VSCode. - לוחצים על התחלת ניפוי באגים ומחכים שהאפליקציה תיטען בדפדפן Chrome.
- כדי להתחיל את המשחק, לוחצים על תא כלשהו בלוח של הסוכן.

13. מזל טוב
יצרתם אפליקציה של משחק לוח עם סוכן מבוסס-ML שמשחק נגד השחקן האנושי.