
1. Prima di iniziare
L'incredibile svolta di AlphaGo e AlphaStar ha dimostrato il potenziale dell'utilizzo del machine learning per creare agenti di gioco di livello sovrumano. È un esercizio divertente per creare un piccolo gioco basato sull'ML per acquisire le competenze necessarie per creare agenti di gioco efficaci.
In questo codelab imparerai a creare un gioco da tavolo utilizzando:
- TensorFlow Agent per addestrare un agente di gioco con il reinforcement learning
- TensorFlow Serving per erogare il modello
- Flutter per creare un'app di gioco da tavolo multipiattaforma
Prerequisiti
- Conoscenza di base dello sviluppo Flutter con Dart
- Conoscenza di base del machine learning con TensorFlow, ad esempio addestramento e deployment
- Conoscenza di base di Python, terminali e Docker
Obiettivi didattici
- Come addestrare un agente Non-Player Character (NPC) utilizzando TensorFlow Agents
- Come erogare il modello addestrato utilizzando TensorFlow Serving
- Come creare un gioco da tavolo multipiattaforma con Flutter
Che cosa ti serve
- SDK Flutter
- Configurazione di Android e iOS per Flutter
- Configurazione desktop per Flutter
- Configurazione web per Flutter
- Configurazione di Visual Studio Code (VS Code) per Flutter e Dart
- Docker
- Bash
- Python 3.7+
2. The Plane Strike Game
Il gioco che creerai in questo codelab si chiama "Plane Strike", un piccolo gioco da tavolo per 2 giocatori che assomiglia al gioco da tavolo "Battaglia navale". Le regole sono molto semplici:
- Il giocatore umano gioca contro un agente NPC addestrato tramite machine learning. Il giocatore umano può iniziare la partita toccando una qualsiasi cella della scacchiera dell'agente.
- All'inizio della partita, il giocatore umano e l'agente hanno ciascuno un oggetto "aereo" (8 celle verdi che formano un "aereo" come puoi vedere nel tabellone del giocatore umano nell'animazione qui sotto) sui propri tabelloni; questi "aerei" sono posizionati in modo casuale e sono visibili solo ai proprietari del tabellone e nascosti agli avversari.
- Il giocatore umano e l'agente colpiscono a turno una cella della scacchiera dell'altro. Il giocatore umano può toccare qualsiasi cella nella scacchiera dell'agente, mentre l'agente effettuerà automaticamente la scelta in base alla previsione di un modello di machine learning. La cella tentata diventa rossa se è una cella "aereo" ("colpito"); altrimenti diventa gialla ("mancato").
- Chi per primo raggiunge 8 celle rosse vince la partita, che viene poi riavviata con nuove griglie.
Ecco un esempio di gameplay del gioco:

3. Configura l'ambiente di sviluppo Flutter
Per lo sviluppo di Flutter, per completare questo codelab ti serviranno due software: l'SDK Flutter e un editor.
Puoi eseguire il codelab utilizzando uno qualsiasi di questi dispositivi:
- Il simulatore iOS (richiede l'installazione degli strumenti Xcode).
- L'emulatore Android (richiede la configurazione in Android Studio).
- Un browser (Chrome è necessario per il debug).
- Come applicazione desktop Windows, Linux o macOS. Devi sviluppare sulla piattaforma in cui prevedi di eseguire il deployment. Pertanto, se vuoi sviluppare un'app desktop Windows, devi svilupparla su Windows per accedere alla catena di build appropriata. Esistono requisiti specifici del sistema operativo trattati in dettaglio su docs.flutter.dev/desktop.
4. Configurazione
Per scaricare il codice per questo codelab:
- Vai al repository GitHub per questo codelab.
- Fai clic su Code > Download zip per scaricare tutto il codice di questo codelab.

- Decomprimi il file ZIP scaricato per estrarre una cartella principale
codelabs-maincon tutte le risorse necessarie.
Per questo codelab, ti servono solo i file nella sottodirectory tfagents-flutter/ del repository, che contiene più cartelle:
- Le cartelle da
step0astep6contengono il codice di avvio su cui si basa ogni passaggio di questo codelab. - La cartella
finishedcontiene il codice completato per l'app di esempio finita. - Ogni cartella contiene una sottocartella
backbend, che include il codice di backend, e una sottocartellafrontend, che include il codice frontend Flutter
5. Scarica le dipendenze per il progetto
Backend
Apri il terminale e vai alla sottocartella tfagents-flutter. Esegui questo comando:
pip install -r requirements.txt
Frontend
- In VS Code, fai clic su File > Apri cartella e poi seleziona la cartella
step0dal codice sorgente che hai scaricato in precedenza. - Apri il file
step0/frontend/lib/main.dart. Se viene visualizzata una finestra di dialogo di VS Code che ti chiede di scaricare i pacchetti richiesti per l'app di base, fai clic su Scarica pacchetti. - Se non vedi questa finestra di dialogo, apri il terminale ed esegui il comando
flutter pub getnella cartellastep0/frontend.

6. Passaggio 0: esegui l'app di base
- Apri il file
step0/frontend/lib/main.dartin VS Code, assicurati che l'emulatore Android o il simulatore iOS sia configurato correttamente e che venga visualizzato nella barra di stato.
Ad esempio, ecco cosa vedi quando utilizzi Pixel 5 con l'emulatore Android:

Ecco cosa vedi quando utilizzi iPhone 13 con iOS Simulator:

- Fai clic su
 Avvia debug.
Avvia debug.
Eseguire ed esplorare l'app
L'app dovrebbe avviarsi sull'emulatore Android o sul simulatore iOS. L'interfaccia utente è piuttosto semplice. Ci sono due tabelloni di gioco: un giocatore umano può toccare qualsiasi cella del tabellone dell'agente in alto come posizione di attacco. Addestrerai un agente intelligente a prevedere automaticamente dove colpire in base alla scacchiera del giocatore umano.
Sotto il cofano, l'app Flutter invia la scacchiera attuale del giocatore umano al backend, che esegue un modello di apprendimento per rinforzo e restituisce una posizione della cella prevista da colpire successivamente. Dopo aver ricevuto la risposta, il frontend mostrerà il risultato nell'UI.


Se fai clic su una cella nella scheda dell'agente, non succede nulla perché l'app non può ancora comunicare con il backend.
7. Passaggio 1: crea un ambiente Python TensorFlow Agents
L'obiettivo principale di questo codelab è progettare un agente che impari interagendo con un ambiente. Anche se il gioco Plane Strike è relativamente semplice ed è possibile creare manualmente le regole per l'agente NPC, utilizzi il reinforcement learning per addestrare un agente in modo da acquisire le competenze e poter creare facilmente agenti per altri giochi in futuro.
Nell'impostazione standard di apprendimento per rinforzo (RL), l'agente riceve un'osservazione a ogni passo temporale e sceglie un'azione. L'azione viene applicata all'ambiente e l'ambiente restituisce una ricompensa e una nuova osservazione. L'agente addestra una policy per scegliere le azioni per massimizzare la somma dei premi, nota anche come rendimento. Giocando molte volte, l'agente è in grado di imparare gli schemi e affinare le sue abilità per padroneggiare il gioco. Per formulare il gioco Plane Strike come problema di RL, considera lo stato del tabellone come l'osservazione, una posizione di attacco come l'azione e il segnale di colpo/mancato come la ricompensa.
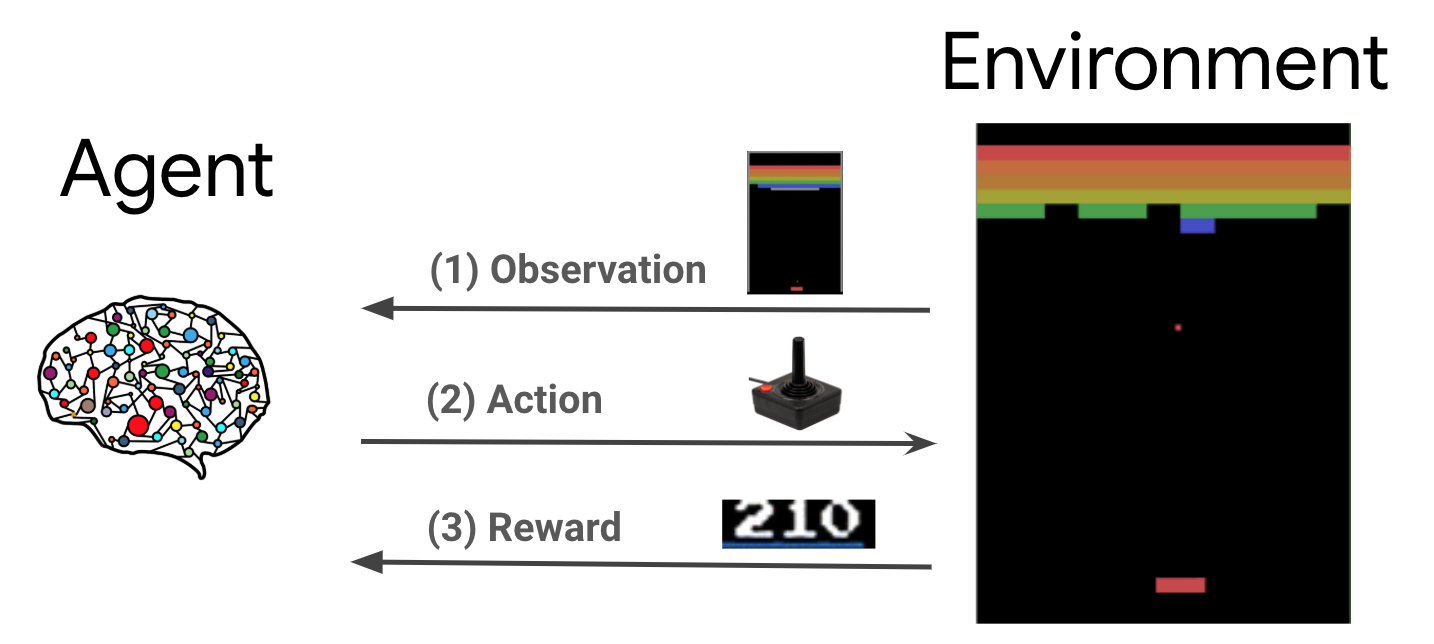
Per addestrare l'agente NPC, utilizzi TensorFlow Agents, una libreria di apprendimento per rinforzo affidabile, scalabile e facile da usare per TensorFlow.
TF Agents è ideale per l'apprendimento per rinforzo perché include un'ampia gamma di codelab, esempi e documentazione completa per iniziare. Puoi utilizzare TF Agents per risolvere problemi di RL realistici e complessi con scalabilità e sviluppare rapidamente nuovi algoritmi di RL. Puoi passare facilmente da un agente all'altro e da un algoritmo all'altro per fare esperimenti. Inoltre, è ben testato e facile da configurare.
Esistono molti ambienti di gioco predefiniti implementati in OpenAI Gym (ad es. giochi Atari), Mujuco e così via, che TF Agents può sfruttare facilmente. Tuttavia, poiché il gioco Plane Strike è un gioco personalizzato completo, devi prima implementare un nuovo ambiente da zero.
Per implementare un ambiente Python TF Agents, devi implementare i seguenti metodi:
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
La più importante è la funzione _step(), che accetta un'azione e restituisce un nuovo oggetto time_step. Nel caso del gioco Plane Strike, hai un tabellone di gioco; quando arriva una nuova posizione di attacco, in base alla condizione del tabellone di gioco, l'ambiente determina:
- Come dovrebbe apparire la griglia di gioco successiva (la cella dovrebbe cambiare colore in rosso o giallo, data la posizione nascosta dell'aereo?)
- Quale premio deve ricevere il giocatore per quella posizione (premio per il successo o penalità per l'errore)?
- Se la partita deve terminare (qualcuno ha vinto?)
- Aggiungi il seguente codice alla funzione
_step()nel file_planestrike_py_environment.py:
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. Passaggio 2: addestra l'agente di gioco con TensorFlow Agents
Con l'ambiente TF Agents configurato, puoi addestrare l'agente di gioco. Per questo codelab, utilizzi un agente REINFORCE. REINFORCE è un algoritmo di policy gradient nel reinforcement learning. L'idea di base è quella di modificare i parametri della rete neurale delle norme in base ai segnali di ricompensa raccolti durante il gameplay, in modo che la rete delle norme possa massimizzare il rendimento nelle partite future.
- Innanzitutto, devi creare un'istanza degli ambienti di addestramento e valutazione. Aggiungi questo codice alla funzione
train_agent()nel filestep2/backend/training.py:
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- Successivamente, devi creare un agente di apprendimento per rinforzo che verrà addestrato. In questo codelab, utilizzi l'agente REINFORCE, che è un agente basato su policy. Aggiungi questo codice subito sotto il codice precedente:
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- Infine, addestra l'agente nel ciclo di addestramento. Nel ciclo, prima raccogli alcuni episodi di partite in un buffer, poi addestri l'agente con i dati memorizzati nel buffer. Aggiungi questo codice alla funzione
train_agent()nel filestep2/backend/training.py:
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- Ora puoi iniziare l'addestramento. Nel terminale, vai alla cartella
step2/backendsul computer ed esegui:
python training.py
L'addestramento richiede 8-12 ore, a seconda delle configurazioni hardware (non devi completare l'intero addestramento da solo, poiché in step3 viene fornito un modello preaddestrato). Nel frattempo, puoi monitorare l'avanzamento con TensorBoard. Apri un nuovo terminale, vai alla cartella step2/backend sul computer ed esegui:
tensorboard --logdir tf_agents_log/
tf_agents_log è la cartella che contiene il log di addestramento. Un esempio di sessione di addestramento è riportato di seguito:


Puoi notare che la durata media degli episodi diminuisce e il rendimento medio aumenta man mano che l'addestramento procede. Intuitivamente, puoi capire che se l'agente è più intelligente e fa previsioni migliori, la durata della partita si riduce e l'agente raccoglie più premi. Ciò ha senso, dato che l'agente vuole finire il gioco in meno passaggi per ridurre al minimo lo sconto elevato della ricompensa nei passaggi successivi.
Al termine dell'addestramento, il modello addestrato viene esportato nella cartella policy_model.
9. Passaggio 3: esegui il deployment del modello addestrato con TensorFlow Serving
Ora che hai addestrato l'agente di gioco, puoi eseguirne il deployment con TensorFlow Serving.
- Nel terminale, vai alla cartella
step3/backendsul computer e avvia TensorFlow Serving con Docker:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
Docker scarica automaticamente l'immagine TensorFlow Serving, il che richiede un minuto. Dopodiché, TensorFlow Serving dovrebbe avviarsi. Il log dovrebbe avere l'aspetto di questo snippet di codice:
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
Puoi inviare una richiesta di esempio all'endpoint per assicurarti che funzioni come previsto:
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
L'endpoint restituirà una posizione prevista 45, ovvero (5, 5) al centro del tabellone (per i più curiosi, potete provare a capire perché il centro del tabellone è una buona ipotesi per la prima posizione di attacco).
{
"predictions": [45]
}
È tutto. Hai creato correttamente un backend per prevedere la posizione del prossimo attacco per l'agente NPC.
10. Passaggio 4: crea l'app Flutter per Android e iOS
Il backend è pronto. Puoi iniziare a inviare richieste per recuperare le previsioni della posizione di strike dall'app Flutter.
- Innanzitutto, devi definire una classe che contenga gli input da inviare. Aggiungi questo codice al file
step4/frontend/lib/game_agent.dart:
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
Ora puoi inviare la richiesta a TensorFlow Serving per fare previsioni.
- Aggiungi questo codice alla funzione
predict()nel filestep4/frontend/lib/game_agent.dart:
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
Una volta che l'app riceve la risposta dal backend, aggiorna la UI del gioco per riflettere i progressi.
- Aggiungi questo codice alla funzione
_gridItemTapped()nel filestep4/frontend/lib/main.dart:
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
Esegui
- Fai clic su Avvia debug e attendi il caricamento dell'app.
- Tocca una cella qualsiasi nel tabellone dell'agente per iniziare la partita.


11. Passaggio 5: attiva l'app Flutter per le piattaforme desktop
Oltre ad Android e iOS, Flutter supporta anche piattaforme desktop, tra cui Linux, Mac e Windows.
Linux
- Assicurati che il dispositivo di destinazione sia impostato su
 nella barra di stato di VSCode.
nella barra di stato di VSCode. - Fai clic su Avvia debug e attendi il caricamento dell'app.
- Fai clic su una cella qualsiasi nel tabellone dell'agente per iniziare la partita.

Mac
- Per Mac, devi configurare i diritti appropriati, poiché l'app invierà richieste HTTP al backend. Per ulteriori dettagli, consulta Diritti e sandbox dell'app.
Aggiungi questo codice a step4/frontend/macOS/Runner/DebugProfile.entitlements e step4/frontend/macOS/Runner/Release.entitlements rispettivamente:
<key>com.apple.security.network.client</key>
<true/>
- Assicurati che il dispositivo di destinazione sia impostato su
 nella barra di stato di VSCode.
nella barra di stato di VSCode. - Fai clic su Avvia debug e attendi il caricamento dell'app.
- Fai clic su una cella qualsiasi nel tabellone dell'agente per iniziare la partita.

Windows
- Assicurati che il dispositivo di destinazione sia impostato su
 nella barra di stato di VSCode.
nella barra di stato di VSCode. - Fai clic su Avvia debug e attendi il caricamento dell'app.
- Fai clic su una cella qualsiasi nel tabellone dell'agente per iniziare la partita.

12. Passaggio 6: attiva l'app Flutter per la piattaforma web
Un'altra cosa che puoi fare è aggiungere il supporto web all'app Flutter. Per impostazione predefinita, la piattaforma web è attivata automaticamente per le app Flutter, quindi devi solo avviarla.
- Assicurati che il dispositivo di destinazione sia impostato su
 nella barra di stato di VSCode.
nella barra di stato di VSCode. - Fai clic su Avvia debug e poi attendi che l'app venga caricata nel browser Chrome.
- Fai clic su una cella qualsiasi nel tabellone dell'agente per iniziare la partita.

13. Complimenti
Hai creato un'app di gioco da tavolo con un agente basato sull'ML per giocare contro il giocatore umano.