
1. 始める前に
AlphaGo と AlphaStar の驚くべきブレークスルーにより、機械学習を使用して超人的なレベルのゲーム エージェントを構築できる可能性が示されました。小さな ML 搭載ゲームを構築して、強力なゲーム エージェントの作成に必要なスキルを習得するのは楽しい演習です。
この Codelab では、以下を使用してボードゲームを作成する方法を学びます。
- 強化学習でゲーム エージェントをトレーニングする TensorFlow エージェント
- TensorFlow Serving を使用してモデルを提供する
- Flutter でクロス プラットフォームのボードゲーム アプリを作成する
前提条件
- Dart を使った Flutter の開発に関する基本的な知識
- TensorFlow を使用した機械学習に関する基本的な知識(トレーニングとデプロイなど)
- Python、ターミナル、Docker に関する基本的な知識
学習内容
- TensorFlow Agents を使用してノンプレイヤー キャラクター(NPC)エージェントをトレーニングする方法
- TensorFlow Serving を使用してトレーニング済みモデルを提供する
- クロス プラットフォームの Flutter ボードゲームを作成する方法
必要なもの
- Flutter SDK
- Flutter を使用するための Android と iOS の設定
- Flutter を使用するためのデスクトップの設定
- Flutter を使用するためのウェブの設定
- Flutter と Dart を使用するための Visual Studio Code(VS Code)の設定
- Docker
- Bash
- Python 3.7+
2. 飛行機攻撃ゲーム
この Codelab で作成するゲームは「Plane Strike」という、ボードゲーム「Battleship」に似た 2 人用の小さなボードゲームです。ルールは非常にシンプルです。
- 人間のプレーヤーは、ML でトレーニングされた NPC エージェントと対戦します。人間プレーヤーは、エージェントのボードの任意のセルをタップしてゲームを開始できます。
- ゲームの開始時に、人間プレーヤーとエージェントはそれぞれ自分のボードに「飛行機」オブジェクト(下の動画の人間プレーヤーのボードにあるように「飛行機」を形成する 8 つの緑色のセル)を持っています。これらの「飛行機」はランダムに配置され、ボードの所有者にのみ表示され、対戦相手には表示されません。
- 人間プレーヤーとエージェントは、互いのボードの 1 つのセルを交互に攻撃します。人間はエージェントのボードの任意のセルをタップできますが、エージェントは機械学習モデルの予測に基づいて自動的に選択を行います。試行したセルが「飛行機」セル(「ヒット」)の場合は赤に、それ以外の場合は黄色(「ミス」)に変わります。
- 赤色のセルを 8 個先に獲得したプレイヤーがゲームに勝利し、その後、新しい盤面でゲームが再開されます。
ゲームのゲームプレイの例を次に示します。

3. Flutter の開発環境をセットアップする
Flutter 開発では、この Codelab を完了するために、Flutter SDK とエディタの 2 つのソフトウェアが必要です。
この Codelab は、次のいずれかのデバイスを使って実行できます。
- iOS シミュレータ(Xcode ツールのインストールが必要)
- Android Emulator(Android Studio でセットアップが必要)
- ブラウザ(デバッグには Chrome が必要)
- Windows、Linux、macOS のデスクトップ アプリケーション。開発はデプロイする予定のプラットフォームで行う必要があります。たとえば、Windows のデスクトップ アプリを開発する場合は、適切なビルドチェーンにアクセスできるように Windows で開発する必要があります。オペレーティング システム固有の要件については、docs.flutter.dev/desktop に詳しい説明があります。
4. セットアップする
この Codelab のコードをダウンロードするには:
- この Codelab の GitHub リポジトリに移動します。
- [Code] > [Download zip] をクリックして、この Codelab のすべてのコードをダウンロードします。
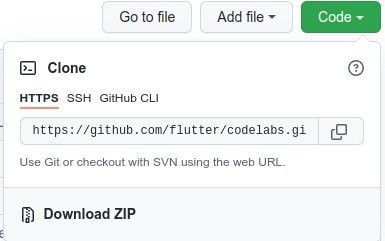
- ダウンロードした zip ファイルを解凍して、
codelabs-mainルートフォルダを展開します。このフォルダに必要なリソースがすべて含まれています。
この Codelab では、リポジトリの tfagents-flutter/ サブディレクトリ内のファイルのみが必要です。このサブディレクトリには複数のフォルダが含まれています。
step0フォルダからstep6フォルダには、この Codelab の各ステップで構築するスターター コードが含まれています。finishedフォルダには、完成したサンプルアプリの完全なコードが含まれています。- 各フォルダには、バックエンド コードを含む
backbendサブフォルダと、Flutter フロントエンド コードを含むfrontendサブフォルダが含まれています。
5. プロジェクトの依存関係をダウンロードする
バックエンド
ターミナルを開き、tfagents-flutter サブフォルダに移動します。以下のコマンドを実行します。
pip install -r requirements.txt
フロントエンド
- VS Code で、[File] > [Open folder] をクリックし、先ほどダウンロードしたソースコードの
step0フォルダを選択します。 step0/frontend/lib/main.dartファイルを開きます。スターター アプリに必要なパッケージのダウンロードを求める VS Code ダイアログが表示されたら、[Get packages] をクリックします。- このダイアログが表示されない場合は、ターミナルを開いて
step0/frontendフォルダでflutter pub getコマンドを実行します。

6. ステップ 0: スターター アプリを実行する
- VS Code で
step0/frontend/lib/main.dartファイルを開き、Android Emulator または iOS Simulator が正しくセットアップされ、ステータスバーに表示されていることを確認します。
たとえば、Android Emulator で Google Pixel 5 を使用する場合は次のようになります。

iOS シミュレータで iPhone 13 を使用する場合は次のようになります。

- [
 Start debugging] をクリックします。
Start debugging] をクリックします。
アプリを実行して操作する
Android Emulator または iOS シミュレータでアプリを起動します。UI は非常にシンプルです。ゲームボードは 2 つあります。人間プレーヤーは、上部にあるエージェントのボードの任意のセルをタップして、ストライクの位置を指定できます。人間のプレーヤーのボードに基づいて、どこを攻撃するかを自動的に予測するようにスマート エージェントをトレーニングします。
内部的には、Flutter アプリは人間のプレーヤーの現在の盤面をバックエンドに送信します。バックエンドは強化学習モデルを実行し、次に打つと予測されるセルの位置を返します。フロントエンドは、レスポンスを受信すると、結果を UI に表示します。

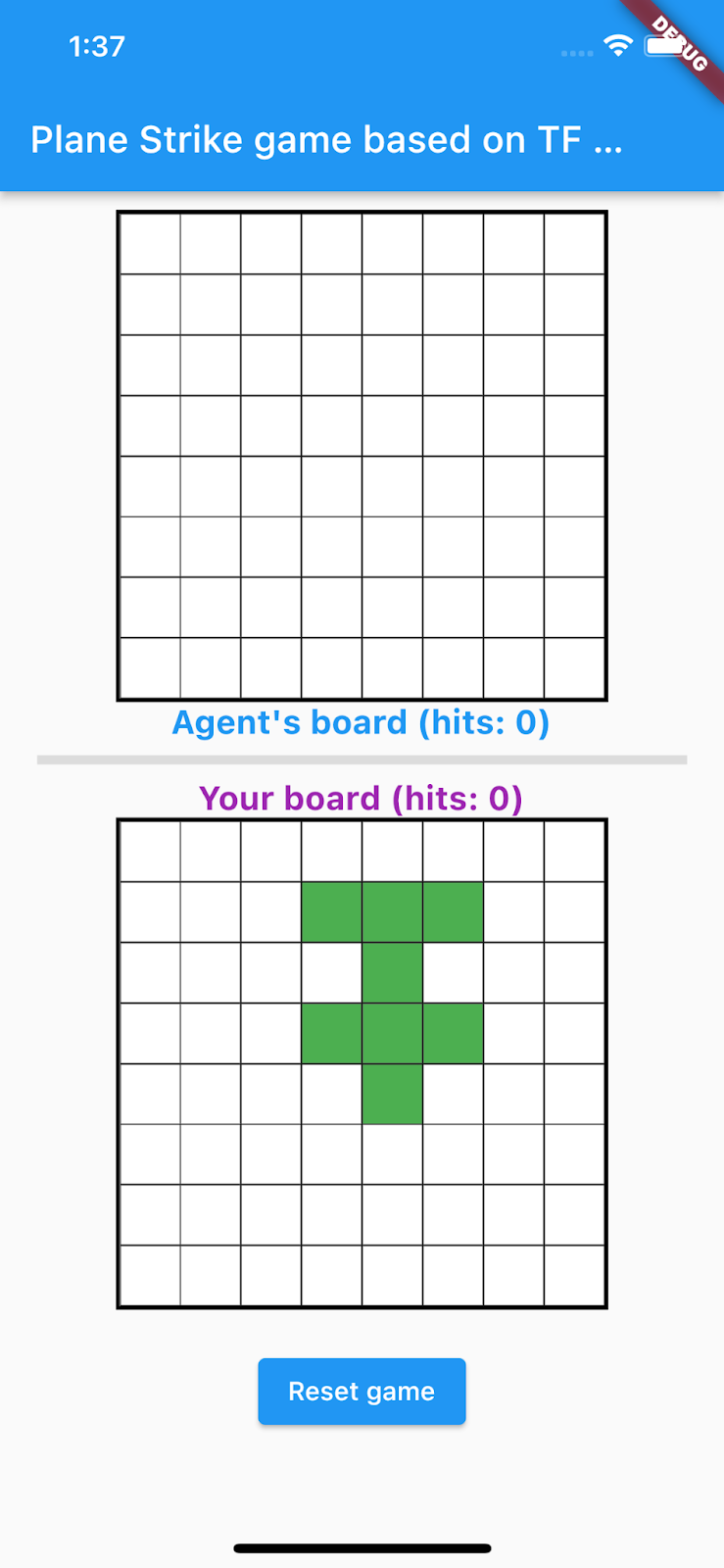
現時点では、アプリがまだバックエンドと通信できないため、エージェントのボードのセルをクリックしても何も起こりません。
7. ステップ 1: TensorFlow Agents Python 環境を作成する
この Codelab の主な目標は、環境とのやり取りを通じて学習するエージェントを設計することです。Plane Strike ゲームは比較的シンプルで、NPC エージェントのルールを手作業で作成することもできますが、強化学習を使用してエージェントをトレーニングすることで、スキルを習得し、将来的に他のゲームのエージェントを簡単に構築できるようになります。
標準的な強化学習(RL)の設定では、エージェントは各タイムステップで観測データを受け取り、行動を選択します。アクションが環境に適用され、環境から報酬と新しい観測データが返されます。エージェントは、報酬の合計(収益)を最大化するアクションを選択するポリシーをトレーニングします。エージェントは、ゲームを何度もプレイすることでパターンを学習し、スキルを磨いてゲームをマスターできます。Plane Strike ゲームを RL 問題として定式化するには、盤面を観測、攻撃位置をアクション、ヒット/ミス信号を報酬と考える必要があります。

NPC エージェントをトレーニングするには、TensorFlow 用の信頼性が高く、スケーラブルで使いやすい強化学習ライブラリである TensorFlow エージェントを活用します。
TF Agents は、すぐに使用できる豊富な Codelab、サンプル、詳細なドキュメントが付属しているため、強化学習に最適です。TF Agents を使用すると、スケーラビリティを備えた現実的で複雑な RL 問題を解決し、新しい RL アルゴリズムを迅速に開発できます。テスト用にさまざまなエージェントとアルゴリズムを簡単に切り替えることができます。また、十分にテストされており、構成も簡単です。
OpenAI Gym(Atari ゲームなど)、Mujuco などに実装されている事前構築済みのゲーム環境は、TF Agents で簡単に活用できます。ただし、Plane Strike ゲームは完全なカスタムゲームであるため、まず新しい環境をゼロから実装する必要があります。
TF Agents Python 環境を実装するには、次のメソッドを実装する必要があります。
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
最も重要なのは _step() 関数です。この関数はアクションを受け取り、新しい time_step オブジェクトを返します。Plane Strike ゲームの場合、ゲーム盤があります。新しいストライク位置が入力されると、ゲーム盤の状態に基づいて、環境は次のことを判断します。
- 次のゲーム盤の様子(隠された飛行機の位置を考慮して、セルの色を赤または黄色に変更すべきか?)
- その位置に当たった場合、プレーヤーはどのような報酬を受け取るべきですか(ヒット報酬かミス ペナルティか)?
- ゲームを終了すべきか(勝者はいるか?)
_planestrike_py_environment.pyファイルの_step()関数に次のコードを追加します。
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. ステップ 2: TensorFlow Agents を使用してゲーム エージェントをトレーニングする
TF Agents 環境が整ったら、ゲーム エージェントをトレーニングできます。この Codelab では、REINFORCE エージェントを使用します。REINFORCE は、RL のポリシー グラデーション アルゴリズムです。基本的な考え方は、ゲームプレイ中に収集された報酬シグナルに基づいてポリシー ニューラル ネットワークのパラメータを調整し、ポリシー ネットワークが将来のプレイでリターンを最大化できるようにすることです。
- まず、トレーニング環境と評価環境をインスタンス化する必要があります。次のコードを
step2/backend/training.pyファイルのtrain_agent()関数に追加します。
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- 次に、トレーニングする強化学習エージェントを作成する必要があります。この Codelab では、ポリシーベースのエージェントである REINFORCE エージェントを使用します。上記のコードのすぐ下に、次のコードを追加します。
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- 最後に、トレーニング ループでエージェントをトレーニングします。ループでは、まずゲームプレイのエピソードをバッファに収集し、次にバッファリングされたデータでエージェントをトレーニングします。次のコードを
step2/backend/training.pyファイルのtrain_agent()関数に追加します。
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- これでトレーニングを開始できます。ターミナルで、パソコンの
step2/backendフォルダに移動して、次のコマンドを実行します。
python training.py
トレーニングの完了には、ハードウェア構成に応じて 8 ~ 12 時間かかります(step3 に事前トレーニング済みモデルが用意されているため、トレーニング全体を自分で完了する必要はありません)。その間、TensorBoard で進行状況をモニタリングできます。新しいターミナルを開き、パソコンの step2/backend フォルダに移動して、次のコマンドを実行します。
tensorboard --logdir tf_agents_log/
tf_agents_log は、トレーニング ログを含むフォルダです。トレーニング実行の例を次に示します。


トレーニングが進むにつれて、エピソードの平均長が減少し、平均収益が増加していることがわかります。エージェントがより賢く、より正確な予測を行うほど、ゲームの長さが短くなり、エージェントがより多くの報酬を獲得することは直感的に理解できます。エージェントは、後のステップで大きな報酬割引を最小限に抑えるために、より少ないステップでゲームを終了したいと考えているため、これは理にかなっています。
トレーニングが完了すると、トレーニング済みのモデルが policy_model フォルダにエクスポートされます。
9. ステップ 3: TensorFlow Serving を使用してトレーニング済みモデルをデプロイする
ゲーム エージェントをトレーニングしたので、TensorFlow Serving を使用してデプロイできます。
- ターミナルで、パソコンの
step3/backendフォルダに移動し、Docker を使用して TensorFlow Serving を起動します。
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
Docker は、まず TensorFlow Serving のイメージを自動的にダウンロードします。これには 1 分ほどかかります。その後、TensorFlow Serving が起動します。次のようなログが出力されます。
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
エンドポイントにサンプル リクエストを送信して、想定どおりに動作することを確認できます。
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
エンドポイントは予測された位置 45 を返します。これは、ボードの中央にある (5, 5) です(興味のある方は、ボードの中央が最初の攻撃位置として適切な理由を考えてみてください)。
{
"predictions": [45]
}
これで、これで、NPC エージェントの次の攻撃位置を予測するバックエンドが正常に構築されました。
10. ステップ 4: Android と iOS 向けの Flutter アプリを作成する
バックエンドの準備が完了しました。リクエストの送信を開始して、Flutter アプリからストライク ポジションの予測を取得できます。
- まず、送信する入力をラップするクラスを定義する必要があります。次のコードを
step4/frontend/lib/game_agent.dartファイルに追加します。
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
これで、TensorFlow Serving にリクエストを送信して予測を行うことができます。
- 次のコードを
step4/frontend/lib/game_agent.dartファイルのpredict()関数に追加します。
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
アプリがバックエンドからレスポンスを受け取ったら、ゲームの進行状況を反映するようにゲーム UI を更新します。
- 次のコードを
step4/frontend/lib/main.dartファイルの_gridItemTapped()関数に追加します。
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
実行
- [ Start debugging] をクリックして、アプリが読み込まれるまで待ちます。
- エージェントのボードの任意のセルをタップしてゲームを開始します。


11. ステップ 5: パソコンのプラットフォームで Flutter アプリを有効にする
Flutter では、Android と iOS だけでなく、Linux、Mac、Windows といったパソコンのプラットフォームもサポートしています。
Linux
- VSCode のステータスバーで、対象デバイスが
 に設定されていることを確認します。
に設定されていることを確認します。 - [ Start debugging] をクリックして、アプリが読み込まれるまで待ちます。
- エージェントのボードの任意のセルをクリックしてゲームを開始します。

Mac
- Mac の場合、アプリがバックエンドに HTTP リクエストを送信するため、適切なエンタイトルメントを設定する必要があります。詳しくは、Entitlements and the App Sandbox をご覧ください。
次のコードを step4/frontend/macOS/Runner/DebugProfile.entitlements と step4/frontend/macOS/Runner/Release.entitlements にそれぞれ追加します。
<key>com.apple.security.network.client</key>
<true/>
- VSCode のステータスバーで、対象デバイスが
 に設定されていることを確認します。
に設定されていることを確認します。 - [ Start debugging] をクリックして、アプリが読み込まれるまで待ちます。
- エージェントのボードの任意のセルをクリックしてゲームを開始します。

Windows
- VSCode のステータスバーで、対象デバイスが
 に設定されていることを確認します。
に設定されていることを確認します。 - [ Start debugging] をクリックして、アプリが読み込まれるまで待ちます。
- エージェントのボードの任意のセルをクリックしてゲームを開始します。

12. ステップ 6: ウェブ プラットフォームで Flutter アプリを有効にする
Flutter アプリにウェブのサポートを追加することもできます。ウェブ プラットフォームは、デフォルトで Flutter アプリ向けに自動的に有効になっているため、あとはリリースするだけです。
- VSCode のステータスバーで、対象デバイスが
 に設定されていることを確認します。
に設定されていることを確認します。 - [ Start debugging] をクリックして、アプリが Chrome ブラウザに読み込まれるのを待ちます。
- エージェントのボードの任意のセルをクリックしてゲームを開始します。

13. 完了
ML を活用したエージェントを使用して人間と対戦するボードゲーム アプリを構築しました。