
1. Прежде чем начать
Удивительный прорыв AlphaGo и AlphaStar продемонстрировал потенциал использования машинного обучения для создания игровых агентов сверхчеловеческого уровня. Создание небольшой игры на основе машинного обучения — это увлекательное занятие, позволяющее приобрести навыки, необходимые для создания мощных игровых агентов.
В этом практическом занятии вы научитесь создавать настольную игру, используя следующие инструменты:
- TensorFlow Agent для обучения игрового агента с использованием обучения с подкреплением.
- TensorFlow Serving используется для обслуживания модели.
- Flutter для создания кроссплатформенного приложения настольной игры.
Предварительные требования
- Базовые знания разработки на Flutter с использованием Dart.
- Базовые знания машинного обучения с использованием TensorFlow, например, различий между обучением и развертыванием.
- Базовые знания Python, работы с терминалом и Docker.
Что вы узнаете
- Как обучить агента, представляющего собой неигрового персонажа (NPC), с помощью TensorFlow Agents
- Как запустить обученную модель с помощью TensorFlow Serving
- Как создать кроссплатформенную настольную игру на Flutter
Что вам понадобится
- Flutter SDK
- Настройка Flutter для Android и iOS
- Настройка рабочего стола для Flutter
- Настройка веб-сайта для Flutter
- Настройка Visual Studio Code (VS Code) для Flutter и Dart
- Docker
- Баш
- Python 3.7+
2. Игра «Авиаудар»
Игра, которую вы создадите в этом практическом занятии, называется «Plane Strike» — это небольшая настольная игра для двух игроков, похожая на настольную игру «Battleship» . Правила очень просты:
- Игрок-человек противостоит агенту-NPC, обученному с помощью машинного обучения. Игрок-человек может начать игру, коснувшись любой клетки на игровом поле агента.
- В начале игры у игрока-человека и агента на своих игровых полях есть по одному объекту «плоскость» (8 зеленых клеток, образующих «плоскость», как показано на игровом поле игрока-человека в анимации ниже); эти «плоскости» размещаются случайным образом и видны только владельцам игровых полей, скрыты от их противников.
- Игрок-человек и агент по очереди наносят удары по одной клетке на доске друг друга. Игрок-человек может нажимать на любую клетку на доске агента, а агент автоматически делает выбор на основе предсказания модели машинного обучения. Если это клетка типа «плоскость», удар становится красным; в противном случае он становится желтым («промах»).
- Побеждает тот, кто первым соберет 8 красных клеток; затем игра начинается заново с новыми досками.
Вот пример игрового процесса:

3. Настройте среду разработки Flutter.
Для разработки на Flutter вам понадобятся два программных компонента для выполнения этого практического задания — Flutter SDK и редактор .
Вы можете выполнить это задание, используя любое из следующих устройств:
- Симулятор iOS (требуется установка инструментов Xcode).
- Эмулятор Android (требуется настройка в Android Studio).
- Для работы требуется браузер (для отладки необходим Chrome).
- Если вы разрабатываете настольное приложение для Windows , Linux или macOS , вам необходимо работать на той платформе, на которой вы планируете его развернуть. Таким образом, если вы хотите разработать настольное приложение для Windows, вам необходимо использовать Windows для доступа к соответствующей цепочке сборки. Существуют специфические требования к операционной системе, которые подробно описаны в документации docs.flutter.dev/desktop .
4. Подготовка к работе
Чтобы скачать код для этого практического занятия:
- Перейдите в репозиторий GitHub , содержащий этот практический урок.
- Нажмите «Код» > «Скачать zip-архив» , чтобы загрузить весь код для этого практического занятия.

- Распакуйте загруженный zip-файл, чтобы получить корневую папку
codelabs-mainсо всеми необходимыми ресурсами.
Для выполнения этого практического задания вам понадобятся только файлы из подкаталога tfagents-flutter/ в репозитории, который содержит несколько папок:
- В папках
step0–step6содержится исходный код, на основе которого вы будете строить каждый шаг в этом практическом занятии. - В папке
finishedсодержится готовый код для тестового приложения. - Каждая папка содержит подпапку
backbend, в которой находится код бэкэнда, и подпапкуfrontend, в которой находится код фронтенда Flutter.
5. Загрузите зависимости для проекта.
Бэкенд
Откройте терминал и перейдите в подпапку tfagents-flutter . Выполните следующую команду:
pip install -r requirements.txt
Внешний интерфейс
- В VS Code нажмите «Файл» > «Открыть папку» , а затем выберите папку
step0из исходного кода, который вы скачали ранее. - Откройте файл
step0/frontend/lib/main.dart. Если появится диалоговое окно VS Code с запросом на загрузку необходимых пакетов для стартового приложения, нажмите «Получить пакеты» . - Если вы не видите это диалоговое окно, откройте терминал и выполните команду
flutter pub getв папкеstep0/frontend.

6. Шаг 0: Запустите стартовое приложение
- Откройте файл
step0/frontend/lib/main.dartв VS Code, убедитесь, что эмулятор Android или симулятор iOS правильно настроен и отображается в строке состояния.
Например, вот что вы увидите, когда используете Pixel 5 с эмулятором Android:

Вот что вы увидите при использовании iPhone 13 с симулятором iOS:

- Нажмите
 Начать отладку .
Начать отладку .
Запустите и изучите приложение.
Приложение должно запускаться на вашем эмуляторе Android или симуляторе iOS. Пользовательский интерфейс довольно прост. Есть 2 игровых поля; игрок может коснуться любой клетки на верхнем поле агента, указывая позицию для удара. Вы будете обучать умного агента автоматически предсказывать, куда нанести удар, основываясь на поле игрока.
Внутри приложения Flutter текущая игровая доска игрока отправляется на бэкэнд, который запускает модель обучения с подкреплением и возвращает прогнозируемую позицию клетки для следующего удара. После получения ответа фронтенд отображает результат в пользовательском интерфейсе.


Если вы сейчас щелкнете по любой ячейке на доске агента, ничего не произойдет, потому что приложение еще не может взаимодействовать с бэкэндом.
7. Шаг 1: Создайте среду Python для агентов TensorFlow.
Основная цель этой практической работы — разработать агента, который учится, взаимодействуя с окружающей средой. Хотя игра Plane Strike относительно проста, и для NPC-агента можно вручную создавать правила, вы используете обучение с подкреплением для тренировки агента, чтобы освоить необходимые навыки и в будущем легко создавать агентов для других игр.
В стандартном алгоритме обучения с подкреплением (Reinforcement Learning, RL) агент получает наблюдение на каждом шаге времени и выбирает действие. Действие применяется к среде, и среда возвращает вознаграждение и новое наблюдение. Агент обучает стратегию выбора действий, максимизирующих сумму вознаграждений, также известную как доход. Играя в игру много-много раз, агент способен изучить закономерности и отточить свои навыки, чтобы освоить игру. Чтобы сформулировать игру «Удар самолёта» как задачу RL, представьте состояние доски как наблюдение, позицию удара как действие, а сигнал попадания/промаха как вознаграждение.

Для обучения NPC-агента используется библиотека TensorFlow Agents, представляющая собой надежную, масштабируемую и простую в использовании библиотеку для обучения с подкреплением в TensorFlow.
TF Agents отлично подходит для обучения с подкреплением, поскольку поставляется с обширным набором практических заданий, примеров и подробной документацией, которые помогут вам начать работу. Вы можете использовать TF Agents для решения реалистичных и сложных задач обучения с подкреплением, обеспечивая масштабируемость и позволяя быстро разрабатывать новые алгоритмы. Вы можете легко переключаться между различными агентами и алгоритмами для экспериментов. Кроме того, он хорошо протестирован и прост в настройке.
В OpenAI Gym , Mujuco и других подобных платформах реализовано множество готовых игровых сред, которые TF Agents могут легко использовать. Но поскольку игра Plane Strike — это полностью пользовательская игра, вам сначала нужно будет создать новую среду с нуля.
Для реализации среды Python для TF Agents необходимо реализовать следующие методы:
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
Наиболее важной является функция _step() , которая принимает действие и возвращает новый объект time_step . В случае игры Plane Strike у вас есть игровое поле; когда появляется новая позиция для удара, на основе состояния игрового поля среда определяет:
- Как должна выглядеть игровая доска дальше (должна ли клетка изменить свой цвет на красный или желтый, учитывая местоположение скрытой плоскости?)
- Какую награду должен получить игрок за эту позицию (награду за попадание или штраф за промах)?
- Игра должна быть завершена (кто-нибудь выиграл?)
- Добавьте следующий код в функцию
_step()в файле_planestrike_py_environment.py:
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. Шаг 2: Обучение игрового агента с помощью TensorFlow Agents
С помощью среды TF Agents вы можете обучить игрового агента. Для этой практической работы вы используете агента REINFORCE. REINFORCE — это алгоритм градиента политики в обучении с подкреплением. Его основная идея заключается в корректировке параметров нейронной сети политики на основе сигналов вознаграждения, собранных во время игры, чтобы сеть политики могла максимизировать отдачу в будущих играх.
- Сначала необходимо создать среды обучения и оценки. Добавьте следующий код в функцию
train_agent()в файлеstep2/backend/training.py:
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- Далее вам нужно создать агента обучения с подкреплением, которого вы будете обучать. В этом практическом задании вы используете агента REINFORCE, который является агентом, основанным на политиках. Добавьте этот код сразу под кодом выше:
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- Наконец, обучите агента в цикле обучения. В цикле вы сначала собираете несколько эпизодов игрового процесса в буфер, а затем обучаете агента с использованием данных из буфера. Добавьте этот код в функцию
train_agent()в файлеstep2/backend/training.py:
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- Теперь вы можете начать обучение. В терминале перейдите в папку
step2/backendна вашем компьютере и выполните следующую команду:
python training.py
Обучение занимает от 8 до 12 часов, в зависимости от конфигурации вашего оборудования (вам не обязательно проходить весь процесс обучения самостоятельно, так как на step3 предоставляется предварительно обученная модель). Тем временем вы можете отслеживать прогресс с помощью TensorBoard . Откройте новое окно терминала, перейдите в папку step2/backend на вашем компьютере и выполните команду:
tensorboard --logdir tf_agents_log/
Папка tf_agents_log содержит журнал обучения. Пример выполнения обучения выглядит следующим образом:


Как видно, средняя продолжительность эпизода уменьшается, а средняя отдача увеличивается по мере обучения. Интуитивно понятно, что если агент умнее и делает более точные прогнозы, продолжительность игры сокращается, и агент получает больше вознаграждений. Это логично, поскольку агент хочет завершить игру за меньшее количество шагов, чтобы минимизировать существенное снижение вознаграждения на более поздних этапах.
После завершения обучения обученная модель экспортируется в папку policy_model .
9. Шаг 3: Разверните обученную модель с помощью TensorFlow Serving.
Теперь, когда вы обучили игрового агента, вы можете развернуть его с помощью TensorFlow Serving.
- В терминале перейдите в папку
step3/backendна вашем компьютере и запустите TensorFlow Serving с помощью Docker:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
Docker автоматически сначала загружает образ TensorFlow Serving, что занимает минуту. После этого TensorFlow Serving должен запуститься. В логе должен отображаться следующий фрагмент кода:
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
Вы можете отправить тестовый запрос на конечную точку, чтобы убедиться, что она работает должным образом:
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
Конечная точка вернет прогнозируемую позицию 45 , которая находится в точке (5, 5) в центре доски (для любопытных, можно попытаться понять, почему центр доски является хорошим предположением для позиции первого удара).
{
"predictions": [45]
}
Вот и всё! Вы успешно создали бэкэнд для прогнозирования следующей позиции атаки для агента NPC.
10. Шаг 4: Создайте приложение Flutter для Android и iOS
Бэкенд готов. Вы можете начать отправлять запросы к нему для получения прогнозов позиций по страйкам из Flutter-приложения.
- Во-первых, вам нужно определить класс, который будет оборачивать отправляемые входные данные. Добавьте следующий код в файл
step4/frontend/lib/game_agent.dart:
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
Теперь вы можете отправить запрос в TensorFlow Serving для выполнения прогнозов.
- Добавьте этот код в функцию
predict()в файлеstep4/frontend/lib/game_agent.dart:
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
После получения ответа от бэкэнда приложение обновляет пользовательский интерфейс игры, чтобы отразить ход игры.
- Добавьте следующий код в функцию
_gridItemTapped()в файлеstep4/frontend/lib/main.dart:
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
Запустите его
- Нажмите Начните отладку , а затем дождитесь загрузки приложения.
- Нажмите на любую ячейку на игровом поле агента, чтобы начать игру.

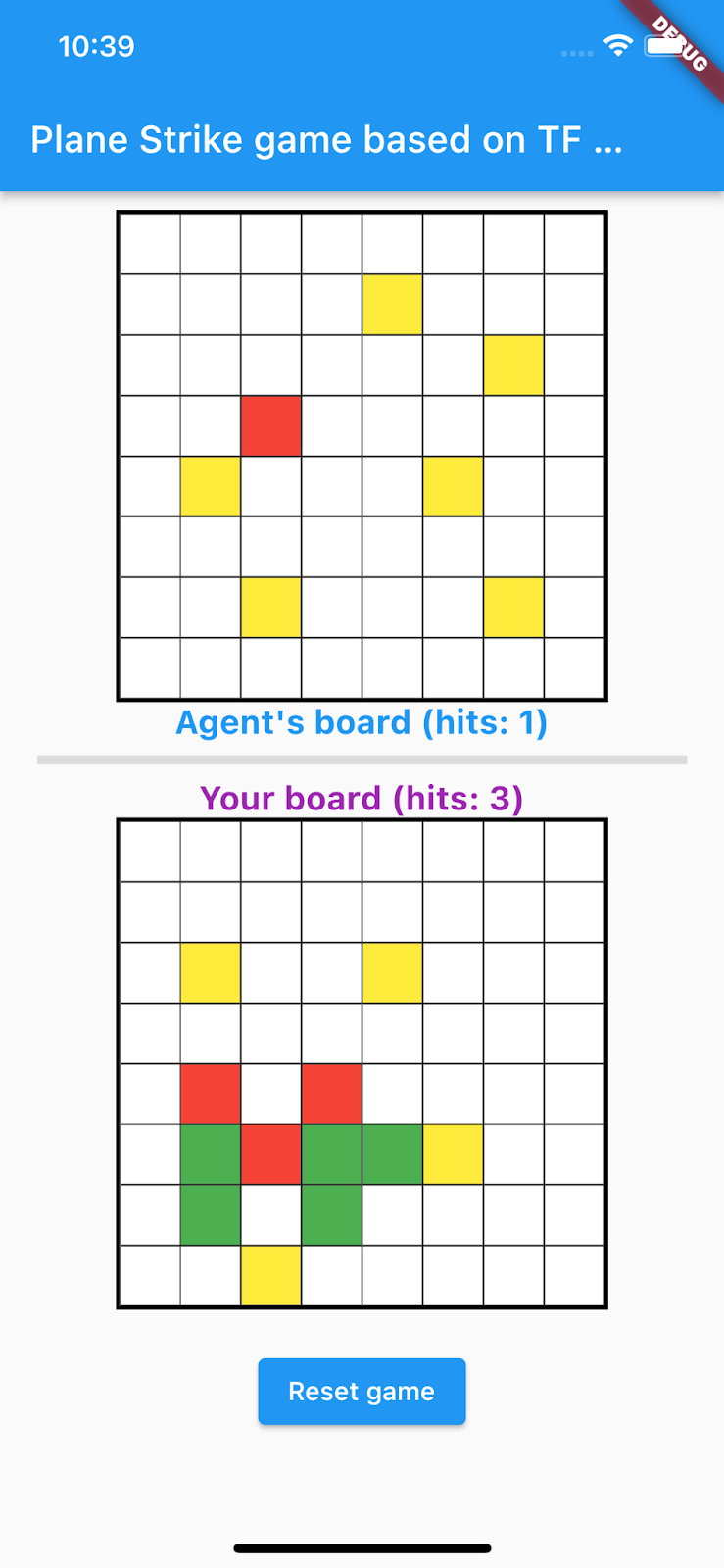
11. Шаг 5: Включите приложение Flutter для настольных платформ.
Помимо Android и iOS, Flutter также поддерживает настольные платформы, включая Linux, Mac и Windows.
Linux
- Убедитесь, что целевое устройство настроено на
 в строке состояния VSCode.
в строке состояния VSCode. - Нажмите Начните отладку , а затем дождитесь загрузки приложения.
- Чтобы начать игру, щелкните по любой ячейке на доске агента.

Мак
- Для Mac необходимо настроить соответствующие права доступа, поскольку приложение будет отправлять HTTP-запросы на серверную часть. Более подробную информацию см. в разделах «Права доступа» и «Песочница приложений» .
Добавьте следующий код в файлы step4/frontend/macOS/Runner/DebugProfile.entitlements и step4/frontend/macOS/Runner/Release.entitlements соответственно:
<key>com.apple.security.network.client</key>
<true/>
- Убедитесь, что целевое устройство настроено на
 в строке состояния VSCode.
в строке состояния VSCode. - Нажмите Начните отладку , а затем дождитесь загрузки приложения.
- Чтобы начать игру, щелкните по любой ячейке на доске агента.

Windows
- Убедитесь, что целевое устройство настроено на
 в строке состояния VSCode.
в строке состояния VSCode. - Нажмите Начните отладку , а затем дождитесь загрузки приложения.
- Чтобы начать игру, щелкните по любой ячейке на доске агента.

12. Шаг 6: Включите приложение Flutter для веб-платформы
Ещё один вариант — добавить поддержку веб-разработки в приложение Flutter. По умолчанию веб-платформа автоматически включена для приложений Flutter, поэтому всё, что вам нужно сделать, это запустить его.
- Убедитесь, что целевое устройство настроено на
 в строке состояния VSCode.
в строке состояния VSCode. - Нажмите Начните отладку , а затем дождитесь загрузки приложения в браузере Chrome.
- Чтобы начать игру, щелкните по любой ячейке на доске агента.

13. Поздравляем!
Вы создали приложение для настольной игры с агентом, работающим на основе машинного обучения, чтобы играть против человека!