
1. Başlamadan önce
AlphaGo ve AlphaStar'ın inanılmaz başarısı, makine öğrenimini kullanarak insanüstü seviyede oyun aracıları oluşturmanın potansiyelini gösterdi. Güçlü oyun aracıları oluşturmak için gereken becerileri kazanmak amacıyla küçük bir makine öğrenimi destekli oyun geliştirmek eğlenceli bir alıştırmadır.
Bu codelab'de, aşağıdakileri kullanarak nasıl masa oyunu oluşturacağınızı öğreneceksiniz:
- Güçlendirmeli öğrenme ile oyun aracısı eğitmek için TensorFlow Agent
- Modeli sunmak için TensorFlow Serving
- Platformlar arası bir masa oyunu uygulaması oluşturmak için Flutter
Ön koşullar
- Dart ile Flutter geliştirme hakkında temel bilgiler
- Eğitim ve dağıtım gibi TensorFlow ile makine öğrenimi hakkında temel bilgiler
- Python, terminaller ve Docker hakkında temel bilgiler
Neler öğreneceksiniz?
- TensorFlow Agents'ı kullanarak bir Non-Player Character (NPC) aracını eğitme
- Eğitilmiş modeli TensorFlow Serving kullanarak sunma
- Platformlar arası Flutter masa oyunu oluşturma
İhtiyacınız olanlar
- Flutter SDK'sı
- Flutter için Android ve iOS kurulumu
- Flutter için masaüstü kurulumu
- Flutter için web kurulumu
- Flutter ve Dart için Visual Studio Code (VS Code) kurulumu
- Docker
- Bash
- Python 3.7+
2. The Plane Strike Game
Bu codelab'de oluşturacağınız oyunun adı "Plane Strike". Bu oyun, "Battleship" adlı masa oyununa benzeyen, iki oyunculu küçük bir masa oyunudur. Kurallar çok basittir:
- İnsan oyuncu, makine öğrenimiyle eğitilmiş bir NPC ajanıyla oynar. İnsan oyuncu, temsilcinin tahtasındaki herhangi bir hücreye dokunarak oyunu başlatabilir.
- Oyunun başında, insan oyuncu ve temsilcinin kendi tahtalarında birer "uçak" nesnesi (aşağıdaki animasyonda insan oyuncunun tahtasında görebileceğiniz gibi "uçak" oluşturan 8 yeşil hücre) bulunur. Bu "uçaklar" rastgele yerleştirilir, yalnızca tahtanın sahipleri tarafından görülebilir ve rakiplerinden gizlenir.
- İnsan oyuncu ve aracı, birbirlerinin tahtasındaki bir hücreye sırayla saldırır. İnsan oyuncu, temsilcinin tahtasındaki herhangi bir hücreye dokunabilir. Temsilci ise makine öğrenimi modelinin tahminine göre otomatik olarak seçim yapar. Deneme yapılan hücre, "uçak" hücresi ("vuruş") ise kırmızıya, değilse sarıya ("kaçırma") döner.
- 8 kırmızı hücreye ilk ulaşan oyuncu oyunu kazanır. Ardından oyun, yeni kartlarla yeniden başlatılır.
Oyunun örnek oynanışını aşağıda bulabilirsiniz:

3. Flutter geliştirme ortamınızı kurma
Flutter geliştirme için bu codelab'i tamamlamak üzere iki yazılıma ihtiyacınız vardır: Flutter SDK ve bir düzenleyici.
Codelab'i aşağıdaki cihazlardan herhangi birini kullanarak çalıştırabilirsiniz:
- iOS simülatörü (Xcode araçlarının yüklenmesi gerekir).
- Android Emulator (Android Studio'da kurulum gerektirir).
- Tarayıcı (hata ayıklama için Chrome gereklidir).
- Windows, Linux veya macOS masaüstü uygulaması olarak. Dağıtmayı planladığınız platformda geliştirme yapmanız gerekir. Bu nedenle, bir Windows masaüstü uygulaması geliştirmek istiyorsanız uygun derleme zincirine erişmek için Windows'ta geliştirme yapmanız gerekir. docs.flutter.dev/desktop adresinde ayrıntılı olarak ele alınan işletim sistemine özel gereksinimler vardır.
4. Hazırlanın
Bu codelab'in kodunu indirmek için:
- Bu codelab'in GitHub deposuna gidin.
- Bu codelab'in tüm kodunu indirmek için Code > Download zip'i (Kod > Zip dosyasını indir) tıklayın.
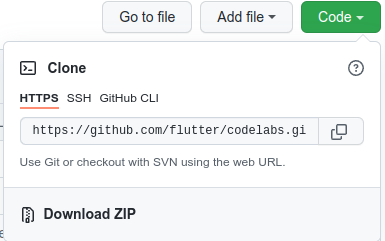
- İndirilen ZIP dosyasını açarak ihtiyacınız olan tüm kaynakları içeren bir
codelabs-mainkök klasörü oluşturun.
Bu codelab için depodaki tfagents-flutter/ alt dizinindeki dosyalar yeterlidir. Bu alt dizinde birden fazla klasör bulunur:
step0ilestep6klasörleri, bu codelab'deki her adımda temel alacağınız başlangıç kodunu içerir.finishedklasöründe, tamamlanmış örnek uygulamanın kodu yer alır.- Her klasörde, arka uç kodunu içeren bir
backbendalt klasörü ve Flutter ön uç kodunu içeren birfrontendalt klasörü bulunur.
5. Projenin bağımlılıklarını indirme
Arka uç
Terminalinizi açın ve tfagents-flutter alt klasörüne gidin. Aşağıdaki komutu çalıştırın:
pip install -r requirements.txt
Ön uç
- VS Code'da File > Open folder'ı (Dosya > Klasörü aç) tıklayın ve daha önce indirdiğiniz kaynak kodundan
step0klasörünü seçin. step0/frontend/lib/main.dartdosyasını açın. Başlangıç uygulaması için gerekli paketleri indirmenizi isteyen bir VS Code iletişim kutusu görürseniz Get packages (Paketleri al) seçeneğini tıklayın.- Bu iletişim kutusunu görmüyorsanız terminalinizi açın ve
flutter pub getkomutunustep0/frontendklasöründe çalıştırın.

6. 0. adım: Başlangıç uygulamasını çalıştırın
- VS Code'da
step0/frontend/lib/main.dartdosyasını açın, Android Emulator veya iOS Simulator'ın doğru şekilde ayarlandığından ve durum çubuğunda göründüğünden emin olun.
Örneğin, Pixel 5'i Android Emulator ile kullandığınızda gördüğünüz ekranı aşağıda bulabilirsiniz:

iOS Simülasyon Aracı ile iPhone 13'ü kullandığınızda görecekleriniz:

 Hata ayıklamayı başlat'ı tıklayın.
Hata ayıklamayı başlat'ı tıklayın.
Uygulamayı çalıştırıp keşfetme
Uygulama, Android Emulator veya iOS Simulator'da başlatılmalıdır. Kullanıcı arayüzü oldukça basittir. 2 oyun tahtası vardır. İnsan oyuncu, üstteki temsilcinin tahtasında herhangi bir hücreye vuruş pozisyonu olarak dokunabilir. Akıllı bir temsilciyi, insan oyuncunun tahtasına göre nereye vuracağını otomatik olarak tahmin edecek şekilde eğitirsiniz.
Flutter uygulaması, arka planda insan oyuncunun mevcut tahtasını arka uca gönderir. Arka uçta, pekiştirmeli öğrenme modeli çalıştırılır ve bir sonraki hamle için tahmin edilen hücre konumu döndürülür. Ön uç, yanıtı aldıktan sonra sonucu kullanıcı arayüzünde gösterir.


Şu anda temsilcinin panosundaki herhangi bir hücreyi tıklarsanız uygulama henüz arka uçla iletişim kuramadığı için hiçbir şey olmaz.
7. 1. adım: TensorFlow Agents Python ortamı oluşturun
Bu codelab'in temel amacı, bir ortamla etkileşim kurarak öğrenen bir aracı tasarlamaktır. Plane Strike oyunu nispeten basit olsa ve NPC aracısı için kurallar elle oluşturulabilse de, bir aracı eğitmek için pekiştirmeli öğrenmeyi kullanırsınız. Böylece becerileri öğrenir ve gelecekte diğer oyunlar için kolayca aracı oluşturabilirsiniz.
Standart pekiştirmeli öğrenme (RL) ayarında, aracı her zaman adımında bir gözlem alır ve bir işlem seçer. İşlem ortama uygulanır ve ortam bir ödül ile yeni bir gözlem döndürür. Aracı, ödüllerin toplamını (getiri olarak da bilinir) en üst düzeye çıkaracak işlemleri seçmek için bir politika eğitir. Oyunu defalarca oynayan ajan, kalıpları öğrenip becerilerini geliştirerek oyunda ustalaşır. Plane Strike oyununu bir RL problemi olarak formüle etmek için tahtanın durumunu gözlem, vuruş pozisyonunu eylem ve isabet/kaçırma sinyalini ödül olarak düşünebilirsiniz.

NPC aracısını eğitmek için TensorFlow'da güvenilir, ölçeklenebilir ve kullanımı kolay bir pekiştirmeli öğrenme kitaplığı olan TensorFlow Agents'ı kullanırsınız.
TF Agents, pekiştirmeli öğrenme için idealdir. Çünkü başlamanıza yardımcı olacak kapsamlı bir codelab, örnek ve ayrıntılı doküman setiyle birlikte gelir. TF Agents'ı kullanarak gerçekçi ve karmaşık pekiştirmeli öğrenme sorunlarını ölçeklenebilirlikle çözebilir ve yeni pekiştirmeli öğrenme algoritmalarını hızlı bir şekilde geliştirebilirsiniz. Deneme yapmak için farklı aracıları ve algoritmaları kolayca değiştirebilirsiniz. Ayrıca iyi bir şekilde test edilmiştir ve yapılandırması kolaydır.
TF Agents'ın kolayca kullanabileceği, OpenAI Gym (ör. Atari oyunları), Mujuco vb. gibi birçok önceden oluşturulmuş oyun ortamı vardır. Ancak Plane Strike oyunu tamamen özel bir oyun olduğundan önce sıfırdan yeni bir ortam uygulamanız gerekir.
TF Agents Python ortamı uygulamak için aşağıdaki yöntemleri uygulamanız gerekir:
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
En önemlisi, bir işlem alan ve yeni bir time_step nesnesi döndüren _step() işlevidir. Plane Strike oyununda bir oyun tahtanız vardır. Yeni bir saldırı konumu geldiğinde, oyun tahtasının durumuna göre ortam şunları belirler:
- Oyun tahtası bir sonraki adımda nasıl görünmeli? (Gizli uçağın konumu göz önüne alındığında hücrenin rengi kırmızıya mı yoksa sarıya mı dönmeli?)
- Oyuncu bu pozisyon için hangi ödülü almalı (vuruş ödülü mü yoksa kaçırma cezası mı?)
- Oyun sonlandırılmalı mı? (Kazanan oldu mu?)
_step()işlevine aşağıdaki kodu ekleyin:_planestrike_py_environment.py
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. 2. adım: Oyun aracısını TensorFlow Agents ile eğitme
TF Agents ortamı hazır olduğunda oyun aracını eğitebilirsiniz. Bu codelab'de bir REINFORCE aracısı kullanacaksınız. REINFORCE, RL'deki bir politika gradyanı algoritmasıdır. Temel fikri, oyun sırasında toplanan ödül sinyallerine göre politika nöral ağı parametrelerini ayarlayarak politika ağının gelecekteki oyunlarda getiriyi en üst düzeye çıkarmasını sağlamaktır.
- İlk olarak eğitim ve değerlendirme ortamlarını oluşturmanız gerekir.
step2/backend/training.pydosyasındakitrain_agent()işlevine aşağıdaki kodu ekleyin:
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- Ardından, eğitilecek bir pekiştirmeli öğrenme aracısı oluşturmanız gerekir. Bu codelab'de, politikaya dayalı bir temsilci olan REINFORCE temsilcisini kullanacaksınız. Bu kodu, yukarıdaki kodun hemen altına ekleyin:
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- Son olarak, temsilciyi eğitim döngüsünde eğitin. Döngüde önce birkaç oyun oynama bölümünü arabelleğe toplarsınız, ardından arabelleğe alınan verilerle aracıyı eğitirsiniz.
step2/backend/training.pydosyasındakitrain_agent()işlevine aşağıdaki kodu ekleyin:
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- Artık eğitime başlayabilirsiniz. Terminalinizde, bilgisayarınızdaki
step2/backendklasörüne gidin ve şu komutu çalıştırın:
python training.py
Donanım yapılandırmalarınıza bağlı olarak eğitimin tamamlanması 8-12 saat sürer (step3 içinde önceden eğitilmiş bir model sağlandığından eğitimin tamamını kendiniz bitirmeniz gerekmez). Bu süre zarfında, TensorBoard ile ilerlemeyi izleyebilirsiniz. Yeni bir terminal açın, bilgisayarınızda step2/backend klasörüne gidin ve şu komutu çalıştırın:
tensorboard --logdir tf_agents_log/
tf_agents_log, eğitim günlüğünü içeren klasördür. Örnek bir eğitim çalıştırması aşağıdaki gibi görünür:
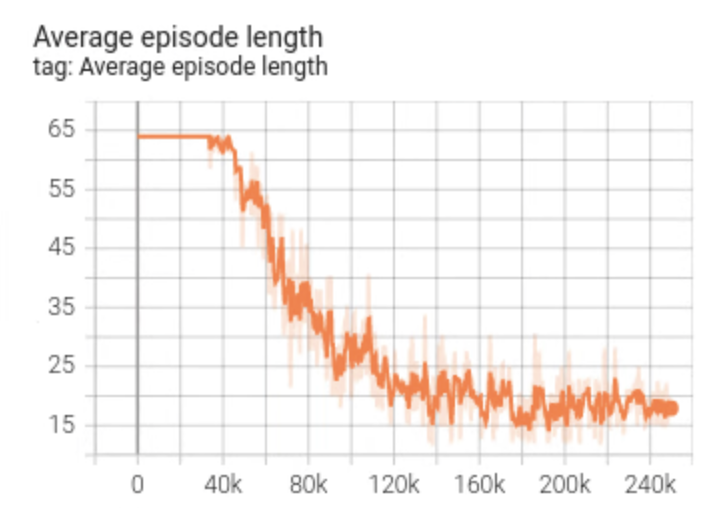

Eğitim ilerledikçe ortalama bölüm uzunluğunun azaldığını ve ortalama geri dönüşün arttığını görebilirsiniz. Ajan daha akıllıysa ve daha iyi tahminler yapıyorsa oyun süresinin kısalacağını ve ajanın daha fazla ödül toplayacağını sezgisel olarak anlayabilirsiniz. Bu, temsilcinin oyunu daha az adımda bitirerek sonraki adımlarda büyük ödül indirimini en aza indirmek istemesi nedeniyle mantıklıdır.
Eğitim tamamlandıktan sonra eğitilen model policy_model klasörüne aktarılır.
9. 3. adım: Eğitilmiş modeli TensorFlow Serving ile dağıtın
Oyun temsilcisini eğittiğinize göre artık TensorFlow Serving ile dağıtabilirsiniz.
- Terminalinizde, bilgisayarınızdaki
step3/backendklasörüne gidin ve Docker ile TensorFlow Serving'i başlatın:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
Docker, önce TensorFlow Serving görüntüsünü otomatik olarak indirir. Bu işlem bir dakika sürer. Ardından TensorFlow Serving başlatılmalıdır. Günlük, aşağıdaki kod snippet'i gibi görünmelidir:
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
Beklendiği gibi çalıştığından emin olmak için uç noktaya örnek bir istek gönderebilirsiniz:
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
Uç nokta, tahmin edilen bir konum 45 döndürür. Bu konum, tahtanın merkezinde (5, 5) olur (Merak edenler için tahtanın merkezinin ilk vuruş konumu için neden iyi bir tahmin olduğunu bulmaya çalışabilirsiniz).
{
"predictions": [45]
}
İşte bu kadar. NPC aracısının bir sonraki vuruş pozisyonunu tahmin etmek için başarıyla bir arka uç oluşturdunuz.
10. 4. adım: Android ve iOS için Flutter uygulamasını oluşturun
Arka uç hazır. Flutter uygulamasından vuruş pozisyonu tahminlerini almak için bu uygulamaya istek göndermeye başlayabilirsiniz.
- İlk olarak, gönderilecek girişleri sarmalayan bir sınıf tanımlamanız gerekir.
step4/frontend/lib/game_agent.dartdosyasına şu kodu ekleyin:
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
Artık tahmin yapmak için isteği TensorFlow Serving'e gönderebilirsiniz.
step4/frontend/lib/game_agent.dartdosyasındakipredict()işlevine aşağıdaki kodu ekleyin:
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
Uygulama, arka uçtan yanıtı aldıktan sonra oyunun ilerleme durumunu yansıtacak şekilde oyunun kullanıcı arayüzünü güncellersiniz.
step4/frontend/lib/main.dartdosyasındaki_gridItemTapped()işlevine aşağıdaki kodu ekleyin:
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
Uygulayın
- Hata ayıklamayı başlat'ı tıklayın ve uygulamanın yüklenmesini bekleyin.
- Oyunu başlatmak için temsilcinin tahtasındaki herhangi bir hücreye dokunun.
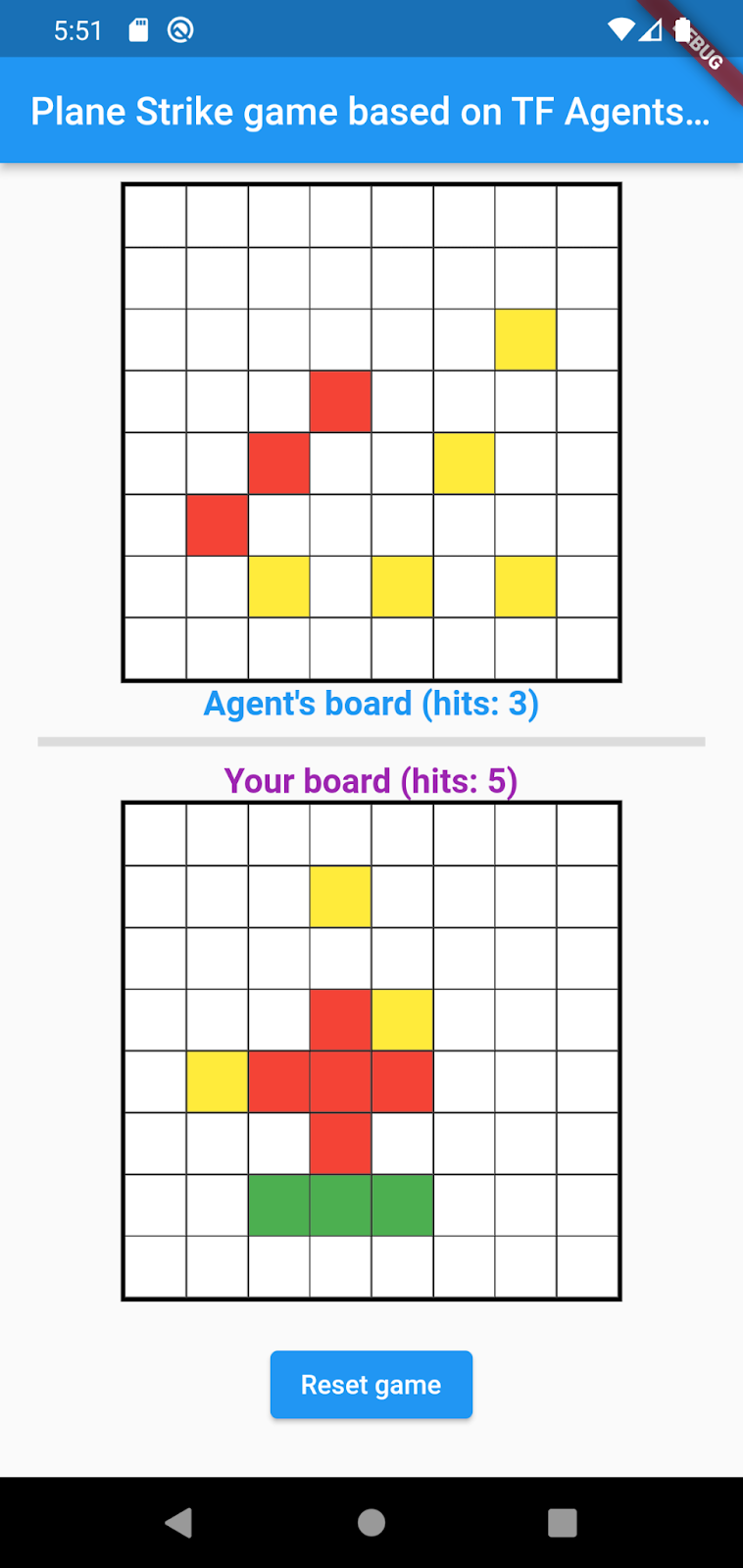

11. 5. adım: Masaüstü platformları için Flutter uygulamasını etkinleştirin
Android ve iOS'e ek olarak Flutter; Linux, Mac ve Windows gibi masaüstü platformlarını da destekler.
Linux
- Hedef cihazın VSCode'un durum çubuğunda
 olarak ayarlandığından emin olun.
olarak ayarlandığından emin olun. - Hata ayıklamayı başlat'ı tıklayın ve uygulamanın yüklenmesini bekleyin.
- Oyunu başlatmak için temsilcinin tahtasındaki herhangi bir hücreyi tıklayın.

Mac
- Mac'te, uygulama arka uca HTTP istekleri göndereceğinden uygun yetkileri ayarlamanız gerekir. Daha fazla bilgi için lütfen Haklar ve Uygulama Korumalı Alanı başlıklı makaleyi inceleyin.
Bu kodu sırasıyla step4/frontend/macOS/Runner/DebugProfile.entitlements ve step4/frontend/macOS/Runner/Release.entitlements dosyalarına ekleyin:
<key>com.apple.security.network.client</key>
<true/>
- Hedef cihazın VSCode'un durum çubuğunda
 olarak ayarlandığından emin olun.
olarak ayarlandığından emin olun. - Hata ayıklamayı başlat'ı tıklayın ve uygulamanın yüklenmesini bekleyin.
- Oyunu başlatmak için temsilcinin tahtasındaki herhangi bir hücreyi tıklayın.

Windows
- VSCode'un durum çubuğunda hedef cihazın
 olarak ayarlandığından emin olun.
olarak ayarlandığından emin olun. - Hata ayıklamayı başlat'ı tıklayın ve uygulamanın yüklenmesini bekleyin.
- Oyunu başlatmak için temsilcinin tahtasındaki herhangi bir hücreyi tıklayın.

12. 6. adım: Web platformu için Flutter uygulamasını etkinleştirin
Yapabileceğiniz bir diğer işlem de Flutter uygulamasına web desteği eklemektir. Web platformu, varsayılan olarak Flutter uygulamaları için otomatik olarak etkinleştirilir. Bu nedenle, tek yapmanız gereken platformu başlatmaktır.
- Hedef cihazın VSCode'un durum çubuğunda
 olarak ayarlandığından emin olun.
olarak ayarlandığından emin olun. - Hata ayıklamayı başlat'ı tıklayın ve uygulamanın Chrome tarayıcıda yüklenmesini bekleyin.
- Oyunu başlatmak için temsilcinin tahtasındaki herhangi bir hücreyi tıklayın.

13. Tebrikler
İnsan oyuncuya karşı oynamak için makine öğrenimi destekli bir aracı içeren bir masa oyunu uygulaması geliştirdiniz.