
1. Einführung
In diesem Codelab erfahren Sie, wie Sie GKE Dynamic Slicing verwenden, um die Nutzung von Cloud TPU-Ressourcen zu optimieren. Mit Dynamic Slicing können Sie die Bereitstellung von TPU-Rohressourcen von der Arbeitslastplanung entkoppeln.
Insbesondere werden zwei wichtige Muster untersucht:
- Sub-Slicing: Aufteilen eines großen bereitgestellten TPU-Blocks in kleinere, isolierte Slices für kleinere Arbeitslasten.
- Super-Slicing: Mehrere bereitgestellte TPU-Blöcke werden zu einem größeren virtuellen Slice für Arbeitslasten im großen Maßstab zusammengefügt.
Sie wenden diese Muster an, um eine leistungsstarke Disaggregated Serving-Architektur (Prefill-/Decode-Disaggregation) für ein Large Language Model (Qwen 397B) mit Kueue, LeaderWorkerSet (LWS) und der Gateway API bereitzustellen.
Architektur
Hier ist die allgemeine Architektur des Setups für dynamisches TPU-Slicing und disaggregierte Bereitstellung:
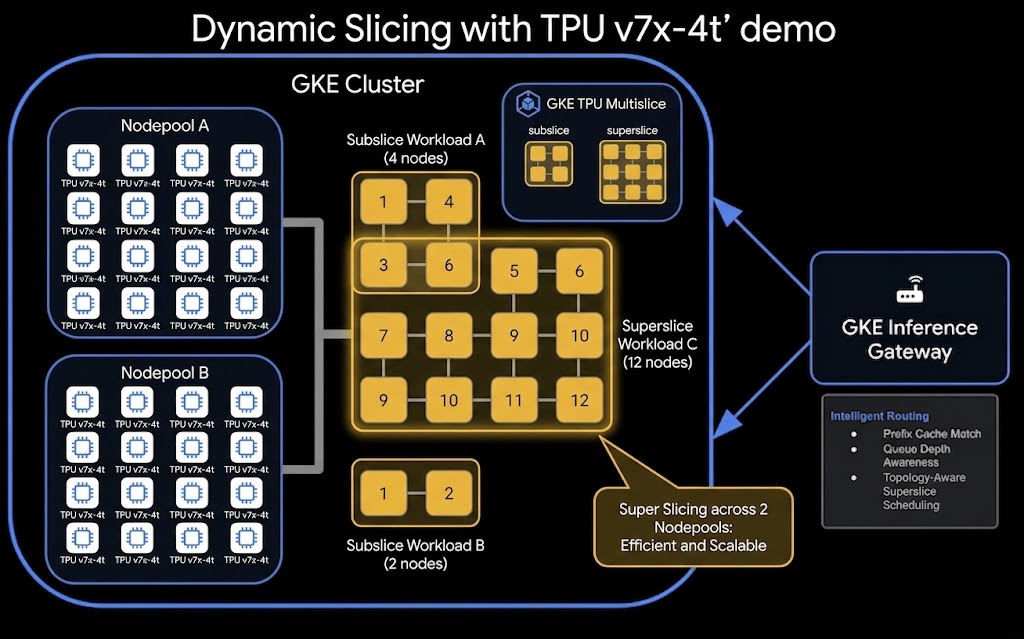
Aufgaben
- Stellen Sie einen GKE-Cluster mit aktiviertem GKE Slice Controller bereit.
- GKE-TPU-Knotenpools erstellen, die für die inkrementelle Bereitstellung konfiguriert sind
- Kueue und LeaderWorkerSet bereitstellen, um TPU-Arbeitslasten zu verwalten.
- Führen Sie eine Subslicing-Arbeitslast aus, um den JAX-TPU-Zugriff auf kleineren Slices zu prüfen.
- Führen Sie eine Superslicing-Arbeitslast aus, um den JAX-TPU-Zugriff über mehrere kombinierte Knotenpools hinweg zu prüfen.
- Stellen Sie eine Disaggregated Serving-Konfiguration bereit, in der die Prefill- und Decode-Phasen auf separaten, dynamisch zugewiesenen TPU-Slices ausgeführt werden, die von einem LLM-Router koordiniert werden.
Voraussetzungen
- Ein Webbrowser wie Chrome.
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- WICHTIG: Zugriff auf eine Cloud TPU7x-Reservierung (Ironwood) im Modus „Alle Kapazitäten“.
2. Hinweis
Google Cloud-Projekt erstellen oder auswählen
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Demo-Repository klonen
Klonen Sie das Repository mit den Manifesten und Hilfsskripts für dieses Codelab:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Umgebung konfigurieren
Bevor Sie Ressourcen bereitstellen, müssen Sie Ihre Umgebungsvariablen konfigurieren. Ein Hilfsskript 01_setup_env.sh wird bereitgestellt, um eine env.sh-Datei zu generieren.
Führen Sie das Setupscript aus:
./01_setup_env.sh
Sie werden aufgefordert, mehrere Werte einzugeben. Drücken Sie die EINGABETASTE, um die Standardwerte zu übernehmen. Achten Sie jedoch darauf, dass Sie den korrekten Reservierungsnamen und Reservierungsblock angeben, die Ihnen von Ihrem Kursleiter mitgeteilt wurden:
- GCP-Projekt-ID: Ihre aktuelle Projekt-ID.
- GCP-Projektnummer: Ihre Projektnummer.
- GKE-Clustername:
tpu-serving-cluster(Standard). - Zone des TPU-Knotenpools:
us-central1-ai1a(Standard). - Kubernetes-Namespace:
llm-d-pd-disaggregation(Standard). - Name der Cloud TPU-Reservierung: [Geben Sie den angegebenen Reservierungsnamen ein]
- Name des Cloud TPU-Reservierungsblocks:
block-0(Standard). - Name des GCS-Buckets für Gewichte:
model-weights(Standard). - TPU-Maschinentyp:
tpu7x-standard-4t(Standard). - Hugging Face-Token: [Geben Sie bei Bedarf Ihr HF-Token ein oder drücken Sie die EINGABETASTE, wenn Sie vorab geladene Gewichte verwenden.]
Nachdem Sie das Skript ausgeführt haben, wenden Sie die Variablen auf Ihre aktuelle Sitzung an:
source env.sh
4. APIs und AI Zone-Funktionen aktivieren
Nachdem Sie Ihre Umgebung konfiguriert haben, müssen Sie die erforderlichen Google Cloud APIs und die Funktion zur Sichtbarkeit der AI Zone aktivieren. Ein Hilfsskript 02_enable_apis_and_features.sh wird bereitgestellt.
Führen Sie das Script aus:
./02_enable_apis_and_features.sh
Mit diesem Skript wird Folgendes ausgeführt:
- Aktiviert die APIs für GKE, Compute, IAM, Resource Manager, Filestore und Network Services.
- Aktiviert die
ai-zones-visibility-Vorschaufunktion für GKE Dynamic Slicing.
5. GKE-Cluster und TPU-Knotenpools bereitstellen
In diesem Schritt stellen Sie die zugrunde liegende Netzwerkinfrastruktur, den GKE-Cluster und die TPU-Knotenpools bereit.
Die TPU-Knotenpools werden mit inkrementeller Bereitstellung (mit --placement-policy=superslice-policy und --reservation-affinity=specific) konfiguriert. Dabei wird jeder Knotenpool einem 16-Knoten-„Cube“ (Unterblock) der rohen TPU-Kapazität zugeordnet.
Führen Sie das Bereitstellungsskript aus:
./03_create_cluster_and_nodes.sh
Mit diesem Skript wird Folgendes ausgeführt:
- VPC-Netzwerk und Subnetze erstellen: Richtet ein Haupt-VPC-Netzwerk mit einer großen MTU (8896) ein, das für TPU-Traffic optimiert ist, sowie ein TPU-Subnetz und ein Proxy-only-Subnetz, das für GKE Gateway erforderlich ist.
- GKE-Cluster erstellen: Stellt einen Standard-GKE-Cluster mit aktiviertem Slice Controller (
--enable-slice-controller) bereit. - Arbeitslastrichtlinie erstellen: Definiert eine Ressourcenrichtlinie mit dem Namen
superslice-policyvom TypHIGH_THROUGHPUTmit einer Topologie von4x4x4. - GKE-TPU-Knotenpools erstellen: Stellt zwei Knotenpools (
tpu7-pool-1undtpu7-pool-2) mit jeweils 16 Knoten vom Typtpu7x-standard-4tbereit. Sie stellen zwei separate 16-Knoten-Cubes dar.
Knoten überprüfen
Prüfen Sie nach Abschluss des Skripts, ob alle 32 TPU-Knoten bereitgestellt und registriert wurden:
kubectl get nodes -l google.com/tpu=present
In der Liste sollten 32 Knoten angezeigt werden.
6. Orchestration Tools installieren
Für das dynamische Slicing sind mehrere Kubernetes-Controller erforderlich, um Jobs und die Slice-Zuweisung zu koordinieren. Sie installieren:
- JobSet: Zum Verwalten einer Gruppe von Jobs (für Superslicing erforderlich).
- Kueue: Für Warteschlangen, Ressourcenverwaltung und Topology Aware Scheduling (TAS).
- LeaderWorkerSet (LWS): Zum Verwalten replizierter TPU-Bereitstellungen mit mehreren Knoten (erforderlich für die LLM-Bereitstellung).
- GKE Slice Controller (Nutzerbereich): Stellt eine Verbindung zwischen Kueue und dem TPU Cluster Director her, um die physischen Slices dynamisch zu verwalten.
Führen Sie das Installationsskript aus:
./04_install_kueue_lws_slice_controller.sh
Prüfen Sie, ob der Slice Controller erfolgreich ausgeführt wird:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Kueue-Ressourcen konfigurieren
Jetzt müssen Sie die Kueue-Ressourcen definieren, die Ihre TPU-Hardwaretopologie darstellen, und die Zulassungsprüfungen konfigurieren.
Führen Sie dazu das Bereitstellungsskript aus:
./05_deploy_kueue_resources.sh
Wichtige bereitgestellte Ressourcen:
- Topologie (
slice-topology): Definiert die hierarchischen Ebenen der TPU-Partitionen (von Block bis Hostname), die Kueue bei der Planung berücksichtigen soll. - ResourceFlavor (
slice-rf): Ordnet dieslice-topologydemtpu7x-Beschleuniger zu. - AdmissionCheck (
ac): Konfiguriert Kueue für die Verwendung des GKE Slice Controller (accelerator.gke.io/slice) zum dynamischen Bereitstellen von Slices, wenn ein Job zugelassen wird. - ClusterQueue (
cq) und LocalQueue (lq): Richtet die Warteschlangen ein, an die Arbeitslasten gesendet werden. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): Definiert Prioritätsstufen, um die Präemption und die prioritätsbasierte Planung zu ermöglichen.
Ressourcen überprüfen:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. TPU-Zugriff mit Subslicing bereitstellen und überprüfen
Mit Sub-Slicing können Sie mehrere kleinere Arbeitslasten in einem einzelnen bereitgestellten TPU-Block ausführen. In diesem Schritt senden Sie eine Arbeitslast, die eine 2x2x2-Topologie (8 Chips / 2 VMs) anfordert, an einen Cluster, der aus 4x4x4-Blöcken (64 Chips / 16 VMs) besteht.
Stellen Sie die Arbeitslast für das Unterslicing bereit:
./06_deploy_simple_subslicing.sh
Dieses Skript wendet kueue-jobset-simple-subslicing.yaml an.
Funktionsweise:
- Die JobSet-Spezifikation enthält die Annotation
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Es konfiguriert
replicas: 6undparallelism: 2(Vervollständigungen: 2). Das bedeutet, dass Kueue 6 unabhängige Jobs plant, die jeweils aus 2 Pods bestehen. - Jeder Pod fordert
google.com/tpu: "4"(1 TPU-VM) an. - Kueue und der GKE Slice Controller teilen den 32-Knoten-Cluster dynamisch auf, um sechs
2x2x2-Slices zuzuweisen.
JAX-Ausführung prüfen
Beobachten Sie die Pods, bis sie ausgeführt werden:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Prüfen Sie die Logs eines der Pods, um zu bestätigen, dass JAX die acht TPU-Geräte (Kerne) in seinem Sub-Slice erfolgreich erkannt hat:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Die Ausgabe sollte Folgendes anzeigen: Total TPU devices (cores): 8
9. TPU-Zugriff mit Superslicing bereitstellen und überprüfen
Superslicing ist eine leistungsstarke GKE-Funktion, mit der sich eine einzelne Arbeitslast über mehrere physische TPU-Blöcke (oft als Cubes oder Topologien wie 4x4x4 bezeichnet) erstrecken kann. Durch das Zusammenfügen dieser Blöcke können Sie einen größeren virtuellen Slice für umfangreiche Trainings- oder Bereitstellungsarbeitslasten erstellen. In diesem Schritt stellen Sie ein JobSet bereit, das eine 4x4x8-Topologie (128 Chips / 32 VMs) anfordert. Da ein einzelner 4x4x4-Block nur 64 Chips enthält, überschreitet diese Arbeitslast die Größe eines einzelnen Blocks. GKE muss die Knotenpools tpu7-pool-1 und tpu7-pool-2 dynamisch zusammenfügen, um die Anfrage zu erfüllen.
Superslicing-Arbeitslast bereitstellen:
./07_deploy_simple_superslicing.sh
In diesem Skript wird kueue-jobset-simple-superslicing.yaml angewendet.
Funktionsweise:
- Die JobSet-Vorlage enthält die Annotation
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Es konfiguriert
parallelism: 32undcompletions: 32. - Jeder Pod fragt
google.com/tpu: "4"an. - Da für eine
4x4x8-Topologie alle 32 Knoten erforderlich sind, konfiguriert der Slice-Controller das OCS-Netzwerk (Optical Circuit Switching) dynamisch, um die beiden 16‑Knoten-Pools zu einem einzelnen 32‑Knoten-ICI-Mesh zu verbinden.
Prüfen Sie, ob die JobSet-Pods erfolgreich ausgeführt werden und JAX alle 128 Geräte erkennt:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Prüfen Sie die Logs eines der Pods:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Sie sollten eine JAX-Ausgabe mit der globalen Anzahl von Geräten sehen: Global device count: 128
10. Disaggregated Serving (Prefill/Decode) bereitstellen
Jetzt stellen Sie den End-to-End-LLM-Serving-Stack mit Prefill/Decode Disaggregation bereit.
Beim Standard-Serving werden Vorfüllen (Verarbeiten des Prompts) und Decodieren (Generieren von Tokens) auf denselben TPUs ausgeführt. Da das Vorfüllen rechengebunden und das Decodieren speicherbandbreitenbeschränkt ist, kommt es zu Konflikten. Beim disaggregierten Serving werden sie auf separaten TPU-Slices ausgeführt und der KV-Cache wird über das Netzwerk übertragen.
LLM-D und Gateway einrichten
Richten Sie die Namespaces, Hugging Face-Secrets und das GKE Gateway ein:
./08_setup_llm_d.sh
LLM-D-Router bereitstellen
Stellen Sie den Router bereit, der Clientanfragen empfängt und das Routing zwischen Prefill- und Decode-Slices koordiniert:
./09_deploy_llm_d_router.sh
Prefill- und Decode-Arbeitslasten bereitstellen
Stellen Sie die vLLM-Modellserver auf dynamisch zugewiesenen TPU-Slices bereit:
./10_deploy_subslicing_pd_workload.sh
Ergebnis:
- Stellt
kueue-vllm-prefill-model-streamerbereit (LWS fordert einen2x2x2-TPU-Slice an). - Stellt
kueue-vllm-decode-model-streamerbereit (LWS fordert einen2x2x2-TPU-Slice an). - Im Prefill-Slice werden die Modellgewichte von Qwen 397B geladen. Er fungiert als
kv_producer. - Der decodierte Slice fungiert als
kv_consumer. - Sie kommunizieren über
TPUConnectorHMA, um KV-Caches zu übertragen.
Warten Sie, bis sowohl der Prefill- als auch der Decode-Pod ausgeführt werden:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Bereitstellung überprüfen
Nachdem die Router-, Vorabfüll- und Decodierungs-Workloads ausgeführt wurden, können Sie die Serving API prüfen.
Führen Sie das Überprüfungsskript aus:
./11_verify_serving.sh
Funktionsweise:
- Das Script ruft die interne IP-Adresse des GKE-Gateways ab.
- Es wird ein temporärer Pod (
curl-debug-comp) gestartet, um eine Vervollständigungsanfrage anhttp://${GATEWAY_IP}/v1/completionszu senden. - Es wird ein weiterer Pod (
curl-debug-chat) gestartet, um eine Chatanfrage anhttp://${GATEWAY_IP}/v1/chat/completionszu senden.
Sie sollten eine erfolgreiche JSON-Antwort vom Qwen-Modell sehen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren für Ihr Google Cloud-Konto zu vermeiden.
Führen Sie das Teardown-Skript aus:
./12_teardown_cleanup.sh
Mit diesem Skript wird Folgendes ausgeführt:
- Löscht GKE-Knotenpools (
tpu7-pool-1,tpu7-pool-2). - Löscht den GKE-Cluster (
tpu-serving-cluster). - Löscht Ressourcenrichtlinien (
superslice-policy). - Löscht VPC-Netzwerke (
qwen-serving-main).
Wenn Sie für dieses Codelab ein eigenes Projekt erstellt haben, können Sie das gesamte Projekt löschen:
gcloud projects delete ${PROJECT_ID}
13. Glückwunsch
Glückwunsch! Sie haben GKE Dynamic Slicing erfolgreich ausprobiert und eine disaggregierte LLM-Bereitstellungsarchitektur bereitgestellt.
Das haben Sie gelernt
- So aktivieren Sie den GKE Slice Controller und konfigurieren Knotenpools für inkrementelle Bereitstellung.
- Kueue zum Anfordern bestimmter TPU-Topologien verwenden
- Wie Sub-Slicing einen großen TPU-Block für kleinere, unabhängige JAX-Arbeitslasten aufteilt.
- Wie durch Super-Slicing mehrere Knotenpools zu einem einzelnen größeren virtuellen TPU-Slice zusammengefügt werden.
- Disaggregiertes Bereitstellen von Prefill/Decode mit LWS, Gateway API und vLLM bereitstellen.